Epidata 3.1 使用教程之快速入门篇(90分钟速成)
十步搞定EpiData3.1

《十步搞定EpiData3.1》EpiData3.1是由丹麦软件工程师Jens uritsen.等专门为流行病学调查而设计开发的数据处理软件,是WHO向各国基层卫生工作者唯一推荐的工作软件。
初次接触该软件往往很难得心应手,网络上的操作手册往往把简单的事情搞复杂。
其实只要做好以下十步,即可搞定EpiData3.1。
一.在“开始”—“程序”中打开EpiData软件。
二.点击菜单栏“文件”,在其下拉菜单中点击“生成调查表文件”,输入原始资料。
三.非指标性内容直接输入。
四.指标性内容输入:1.文字性指标:将光标移至指标名称后,点击菜单栏“编辑”,在其下拉菜单中点击“字段编辑器”,打开“字段编辑器”对话框,点击“文本”,选择长度(字数乘以2)后点击“插入”。
2.数量性指标:将光标移至指标名称后,点击菜单栏“编辑”。
在其下拉菜单中点击“字段编辑器”,打开“字段编辑器”对话框,点击“数字”,选择小数点前后位数后点击“插入”。
3.其它如日期、逻辑(是/否)等内容亦必须在“字段编辑器”中选择、插入。
五.点击菜单栏“文件”,在其下拉菜单中点击“存盘”或“另存为”,在弹出的对话框中选择路径后,在所在的位置中新建文件夹并命名,选择该文件夹点击“打开”、“保存”。
六.点击菜单栏中“rec文件”,在其下拉菜单中点击“生成rec文件”,在弹出的对话框中保持默认值不变直接点击“确定”,随后弹出的“文件标记”对话框可以填写输入者的姓名,或者直接点击“确定”即可跳过。
在随后弹出的“信息”对话框中点击“确定”。
七.点击菜单栏中“数据导入/导出”,在其下拉菜单中点击“数据录入/编辑”,在弹出的对话框中保持默认值不变直接点击“打开”。
八.用向下方向键移动光标依次输入指标内容,当最后一个指标内容输入完成后点击向下方向键,在弹出的“确认”对话框中点击“是”保存。
九.重复第七—八步继续输入下一组数据,直至所有数据输入完成后,关闭当前窗口,资料输入任务全部完成。
epidata使用方法

2018/10/30
epidata 软件使用
9
2.1.2 定义变量名(Field Names)
输入的信息要保存在变量中因此需要定义变量名。 一个数据库中录入变量的名称可以根据QES文件 的内容自动创建。 EpiData中命名变量的方式有两种: 1)将第一个单词作为变量名(First word in question is field name) 2)根据规则自动定义变量名(Automatic field names) 执行“文件→选项”命令打开“生成REC文件” (File→Options→Create data file)选项卡。 (1)QES文件字体设置:变量名称的字体及其大 小可以在QES文件显示(Show data form)中设置. 。
2018/10/30
epidata 软件使用
3
2 数据库创建过程
在使用EpiData软件之前,先对该软件中用到的三种 基本的文件类型进行简单介绍: ①.QES文件:调查表文件即数据库结构文件,决定 数据库结构。 ②.REC文件:数据库文件,主要用于存放数据。 ③.CHK文件:核对文件,存放控制数据录入的核对 规则,起质量控制作用。 EpiData由数据库结构文件(.qes),来决定数据库 结构,然后根据该数据库结构文件生成数据文件 (.rec)。
2018/10/30 epidata 软件使用 4
一个最简单的创建数据库的工作至少要包括以下两步: 1、建立调查表文件——根据调查表制作数据库结构文 件即调查表文件(.qes) 2、生成数据库文件——根据调查表文件生成数据库文 件(.rec)。 理论上说,有了数据库文件就可以进行数据录入了,但 是在实际工作中,往往需要对数据录入进行质量控制, 比如对某些字段设置合法值、跳转等等。这些质量 控制工作需要专门的核对文件来完成(.chk)。 因此,在数据库创建过程一般还包括: 3、编写核对程序——即生成数据核对文件(.chk). 在EpiData软件中,在其主界面的上形象的标示出了数 据库创建过程:
问卷录入工具epidata软件使用方法教程

精品课件
1.建立调查表文件
1.5 变量类型-变量编码
变量标签{变量名}变量编码
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
计算机程序包 在流行病学中的应用
公共卫生学院
精品课件
精品课件
精品课件
精品课件
精品课件
EpiData
❖ 免费的数据录入和数据管理软件 ❖ 小而精: 62.9M---0.9M ❖ 开发者:丹麦欧登塞 (Odense, Denmark)的一个
非盈利组织,即The EpiData Association (http://www.epidata.dk) ❖ 创始者:Jens uritsen. MD. Ph.d.
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品课件
精品Байду номын сангаас件
精品课件
精品课件
精品课件
精品课件
1、建立调查表文件
精品课件
2、创建数据库
精品课件
3、建立核查文件
Epidata3.1的安装及使用
Epidata3.1的安装及使用
Epidata软件的安装及使用
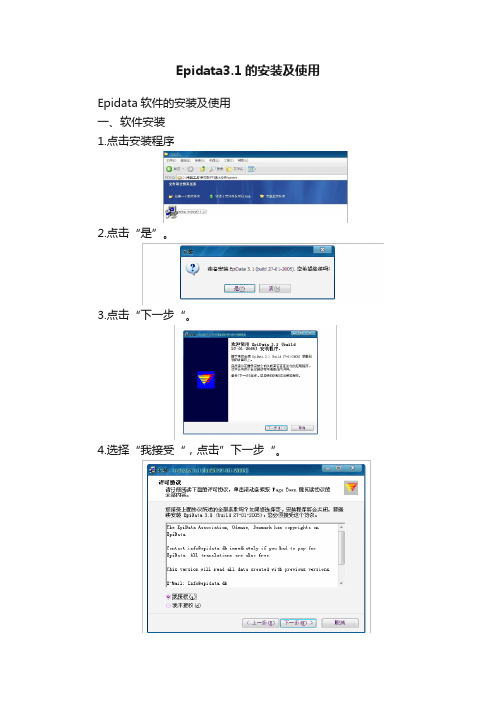
一、软件安装
1.点击安装程序
2.点击“是”。
3.点击“下一步“。
4.选择“我接受“,点击”下一步“。
5.选择程序的安装位置(默认为C:\Program Files\EpiData)
6.点击“下一步“。
7.点击“下一步“。
8.点击“安装“
9.点击“下一步“。
10.点击“结束“,完成安装。
二、软件使用准备工作
1.“开始“菜单,点击安装生成的图标即可。
2.软件第一次打开的初始页面如下,勾选“下次不再显示此页“,点击”
关闭“。
3.设置软件的字体、字号,以防乱码。
1)点击“文件“下拉菜单的”选项“。
2)点击“qes文件显示“,点击”字体选择“。
3)下面对话框内,字体选择“宋体“,字形选择”常规“,大小选择”小五“,点击确定。
4)下面对话框内,点击“确定“。
4.设置“生成变量名“的选项
1)点击“文件“下拉菜单的”选项“。
2)点击“生成rec文件“,将默认的”以调查表第一个词命名“改为“使用{}内的内容自动添加字段名”,点击“确定”即可。
5.设置相关文件默认打开程序
1)点击“文件“下拉菜单的”选项“。
2)点击“相关文件“,点击“相关文件类型”。
3)跳出的对话框,点击“确定”即可。
epidata录入数据操作过程及演示

e p i d a t a录入数据操作
过程及演示
Company Document number:WTUT-WT88Y-W8BBGB-BWYTT-19998
Epidata录入数据基础与操作过程笔记
一、基础知识
EpiData的三种文件类型
♣QES文件(调查表文件):定义调查表(问卷)的结构;
♣REC文件(数据文件):存放数据以及已经定义好的编码;
♣CHK文件(核查文件):定义了数据输入时字段的有效性规则。
QES文件字段定义
•字符型:用下划线_
•数字型:用#号,每位一#,##.#
•逻辑型:用Y或N,<Y>、<N>
•日期型:<mm/dd/yyyy>
<dd/mm/yyyy>
•字段名框在{ }之中
二、操作过程
Ps:注意空格,以及标签“编号”“学校”等的设置。
也可将“问卷问题”设置到里面。
可以将设置的CHK文件复制到其他问题中,另外1>a41指:对于a1题目,如果结果为1,则直接跳入到a41题。
数据录入1
数据录入2
将数据录入界面关掉。
导出到spss数据
如图,桌面上出现的spss文件,将其打开。
会有一个空的spss文件和output文件同时打开。
然后再后者中runAll,这样会在spss数据文件中导入所输入的4条数据记录,如下所示。
最后的文件夹中共有六个不同类型的六个同名文件。
EpiData使用说明

位出错
2013-7-4 30
(二)双份录入与核查
2013-7-4
31
六、数据导出
EpiData软件产生的数据文件以“REC”作 为扩展名,一般不能被其它软件程序直接调 用,但可以导出为其他多种数据格式:
2013-7-4
当前最高版本3.1
可不必安装,直接copy并运行安装目
录下epidata.exe
2013-7-4
6
(三)在数据管理方面的优点
规则简单
数据文件生成与录入界面设计方便 具备双份录入核查功能 具有多种常用数据库的输出接口 Free
7
2013-7-4
(四)应用方面的局限性
变量名不能为中文
记录数最好不超过300000条
录入界面不超过999行
2013-7-4
8
(五)EpiData的三种文件类型
QES文件(调查表文件):定义调查表(
问卷)的结构 ;
REC文件(数据文件):存放数据以及已
经定义好的编码;
CHK文件(核查文件):定义了数据输入
时字段的有效性规则。
2013-7-4 9
变量描述文本如:年龄
2013-7-4
字段定义如:##代表两位整数
14
生成字段名设置选项
2013-7-4
15
自动生成字段名的几条规则
2013-7-4
另外有: 变量名第一个字符一定为字母(A-Z) 变量名不能是中文 变量名最多10个字符
16
举例
---------------------------------------------------------------------问题 产生的字段名 使用规则 ---------------------------------------------------------------------State your {nation}ality NATION Rule 1 Al{l} you l{i}ke is i{ce}cream LICE Rule 1 What is your name ISYOURNA Rule 2 3.question: N3QUESTI Rule 4 ----------------------------------------------------------------------
Epidata3.1软件实战全集【推荐】

Epidata3.1软件实战全集【推荐】在我们进行问卷或者量表调查时,测试完毕后,需要将纸质数据录入成电子表格,这一步往往会消耗大量的人力。
Epidata软件就是专门进行数据录入的软件,其效率比你在Excel中录入数据快10倍,而且可以在录入过程中进行质量控制,录入后进行错误比对,确实是科研一大利器!需要软件者,消息联系后台!EpiData 是一个免费的数据录入和数据管理软件。
开发者是丹麦欧登塞(Odense,Denmark)的一个非盈利组织即TheEpiData Association。
程序设计者为Jens M. Lauritsen,Michael Bruus 和MarkMyatt。
Epidata数据录入包含三种类型文件,分别为:1、调查表文件:后缀为.QES,根据规则定义调查表的结构,包括变量名、变量类型和长度等,建立录入表格的框架。
2、数据文件:后缀为.REC,包含录入的数据信息以及定义好的编码。
3、核查文件:后缀为.CHK,用于定义数据录入的有效性规则。
下面我们分别进行讲述!Epidata软件应用之.qes文件构建一、打开文件,新建一个空白文件,如图操作。
二、将你现有的调查表Word文件复制,贴如空白文档。
如下图。
必要说明:1.{}:大括号用于指定变量名,如地区{A4},就是说地区这个变量录入后,显示变量名为A4;2.数值型数据录入采用#表示,如身高168.5cm,可以表示为###.#;3.字符型数据录入采用_(下划线)表示,一个下划线为半个字符;4.日期型数据,有多种录入形式,一般采用<yyyy/mm/dd>格式较多;5.调查表编号:<IDNUM>,添加后可以自动进行编码。
上述2-4步可以菜单-编辑-字段编辑器,弹出下图,进行窗口式操作!三、设置完毕,点击保存按钮,即可以生成.QES文件,意即我们将调查表设计完毕!Epidata3.1之建立Rec文件一、点击生成REC文件按钮,点击生成REC文件,弹出下下图。
Epidata的使用

四、数据录入
• “打开”的图标或“数据导入/导出”—“数 据录入/编辑”,如下图
• 打开.rec文件。 • 录入时字符达到设置时位数时会自动跳转。
2015-6-4 22
4.1 在变量间转换
• 激活下一个变量,使用Enter、Tab、↓键、或 用鼠标直接点击目标变量。
• 如果变量允许录入的字符数全部录满,则光标 会自动移到下一个变量。 • 按Shift+Tab 键,或↑键,回到上一个变量。
2015-6-4 9
一、*.QES制作步骤
2015-6-4
10
定义变量或者字段的类型、长度
第1步:编辑->字段编辑器或单击 第2步:选择合适的字段,字段长度,插入 第3步:数据表预览的三种方式: 菜单(生成数据文件) 工作流程栏(生成数据文件) 快捷按钮
2015-6-4
11
设置QES文件以及REC文件的显示格式
2015-6-4
26
2015-6-4
27
追加(append)
• 两种不同方式: 1) 新生成的数据文件 和第一个原始文件 的结构相同。第二 个数据文件中只有 和第一个文件中相 同的变量才追加。 2) 新生成文件中包含 第一个文件和第二 个文件中所有的变 量。
2015-6-4 28
合并(merge)
操作:文件->选项 用于设置字体、大小、背景、变量名的命 名方法等
2015-6-4
12
二、生成数据REC文件
两种方式: 1、菜单:REC文件->生成REC文件 工作流程栏: 2、生成REC文件 生成的文件“*.rec”与调查表文件 “*.qes”在同一个目录
2015-6-4 13
Epidata的使用(周荣军)

个人编码(附件5、6):001-999 学校编码(附件7、8):小学1、初中2、高中3 学生编码(附件8) :01-99 场所调查机构类型编码(附件9):医疗卫生机构1、 机关2、事业单位3、企业4 单位编码(附件9):1-9
九、数据录入要求
(一)、单选题 录入调查对象所选择的选项数字1-5。如果调查对象 没有选择,录入0。 (二)、多选题 1、每一个选项均需要完成数据录入。如果调查对象 选了相应选项则录入1,没选则录入2。 2、如果该题没有回答,所有选项均录入0。
横向连接主要两种方式: ① 只有两个文件中都存在的记录连接起来。 ② 如两个数据文件中的记录不匹配,可导致连接后变量值的缺失。为 此,两个文件中必须有相同字段。
(五)查看和删除记录
菜单
录入界面
移到第一条记录
移到最后一条记录 移到前一条记录 移到后一条记录 开始录入新记录 删除记录或恢复删除的记录
一、 Epidata 简介
Epidata 是什么? Epidata软件是用于数据录入、数据核 对、数据管理、数据报告的自由软件。 为什么使用Epidata? 识别错误(数据录入质控、数据双录入 后的一致性检验)是该软件区别于其它 软件最大的一个功能。
一、 Epidata 简介
EpiData的三种基本文件类型:
一致性 检验结 果界面
(六)数据处理—数据一览表
点 击
(七)数据导出
点击
选 择 文 件 类 型
八、健康促进县(区)基线调查问 卷录入规则
(一)问卷编码规则 省(附件4-9):45 县(附件4-9):右江区1、鹿寨县2、荔浦县6 村(附件4):1、2,如果抽中的村大于2个的则依次 编号3、4 成人问卷类型编码(附件5、6):居民1、教师2、 医务人员3、机关公务员4、事业单位职工5、企业职 工6
EpiData使用手册

EpiData使用手册预览说明:预览图片所展示的格式为文档的源格式展示,下载源文件没有水印,内容可编辑和复制目录一、EpiData2.0软件的安装 (3)1.EpiData2.0软件介绍 (3)2.EpiData2.0软件的组成 (3)3.EpiData2.0软件的安装 (3)4.EpiData2.0软件汉化文件的安装 (5)5.数据文件Data的安装 (5)6.EpiData2.0软件的启动 (5)二、EpiData2.0软件的功能 (6)1.工具条 (6)2.快捷键 (7)3.调查表文件(.qes)的制作 (7)3.1EpiData编辑器 (7)3.2字段选取清单 (8)3.3变量符号编写器 (8)3.4数据表格式预览 (9)3.5变量命名法 (9)3.6自动变量命名规则 (10)3.7第一单词作为变量名 (11)3.8变量标记 (11)3.9自动缩进 (12)3.10字段输入框对齐 (12)4.创建.REC数据文件和修改数据结构 (13)4.1 如何创建.rec数据文件 (13)4.2 数据文件的修改 (13)5. .REC数据文件的追加与合并 (15)5.1 数据文件的追加 (15)5.2数据文件的合并 (16)6. EpiData中的字段类型 (17)6.1 自动编码变量 (17)6.2 数值型变量 (17)6.3 字符型变量 (17)6.4 大写字符型变量 (17)6.5 布尔变量 (17)6.6 日期型变量 (17)6.7 今天型日期字段 (18)6.8Soundex型变量 (18)6.9 隔位符 (18)7. 编辑.CHK核查文件及核查文件命令和函数 (19) 7.1 增加/更改核对命令 (20)7.2 使用编辑器产生核查文件 (23)7.3 核查文件的核对命令 (24)7.4 操作符和函数 (38)8. 数据的录入 (43)8.1字段间移动 (43)8.2 记录间移动 (44)8.3 查找记录 (44)8.4 过滤器 (45)8.5 数据双录入和有效性检查 (45)8.6 关于数据文件 (46)9. 数据输出 (47)9.1 数据备份 (47)9.2数据文件转成dBase III格式 (47)9.3 数据文件转成Excel格式 (48)9.4 数据文件转成Stata文件 (48)9.5 将数据转成文本文件 (48)三、EpiData 2.0软件与EpiInfo的兼容性 (49)1.在数据文件中的不同 (49)2.检查文件中的区别 (49)四、结束语 (50)EpiData2.0软件使用指南一、EpiData2.0软件的安装1. EpiData2.0软件介绍:EpiData 软件是在EpiInfo 6.0软件基础上开发研制的。
epidata中文教程
再后面的@###:@表示一种对齐方式,先不用管它,后面会讲到;
###是用来定义前面那个 DrugNum 字段的属性的,#代表一位数字,###就代表 3 位数字,也就是说药物编 号最大也就能输入 999 了,不能再大了;
总结第 1 句的含义:定义了一个字段“药物编号”,字段名是 DrugNum,用于记录 3 位数字形式的数据。(刚
图 1-1 建立调查表文件
这个调查表怎么写呢?看下面的这个例子:
说明: 第 1 句中
1、药物编号({DrugNum}):@#### 2、患者姓名缩写({Pname}):@_____ 3、就诊日期({date}):@<yyyy/mm/dd> 4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________ 5、性别({sex}):# ①男 ②女
图 3-5 (Range 和 Legal 这两个命令的作用就是这个) 还记得上一个图中那个“编辑”按钮吗?我们点击它看看里面是什么:
图 3-6 CHK 文件的“编辑”
EPIDATA教程

EPIDATA使用方法简介一、建立新QES文件第一种:在菜单中,点击“文件”(File)→“生成调查表文件QES文件”。
第二种:在工作栏的工作流程中,点击“1. 打开文件”(1.Define Data)→“建立新QES文件”。
第三种:在按钮栏中,点击,这时窗口中会在工作区显示一个空白的文档,你可以在此文档中键入调查表内容和框架,编辑完成后,将调查表文件保存,文件的扩展名统一为.QES。
二、调查表书写生成1.“文件”(File)→“选项”(Option)→“生成REC文件”(Create data file)→ 在“如何生成字段名”(How to generate field names)中选择字段的命名方式。
2.1 如果选择:以调查表第一个词命名、更新问题为实际文件名效果。
2 如果只选择:以调查表第一个词命名,字段名为汉字显示。
3 如果只选择:使用{ }内的内容自动添加字段名,则显示{ }的内容。
【①在普通文本中优先选择“{ }”括进的文本。
如果问题是{my}first{field}?那末字段名将为MYFIELD;如果问题是“姓名{name}?”,产生的字段名为name。
4 ②通用常见单词不予考虑(即What?Who?If?etc.)。
What did you do?产生的字段名为YOUDO。
5 ③如果字段前没有“问题”文本,字段名就取前一个字段名再加上一个数字。
如果前一个字段名是dMY字段,那末下一个字段(如果没有“问题”文本)就是dMY1。
如果前一个字段是dV31,则下一个字段名就是dV32。
如果不存在前一个字段名则使用隐含字段名FIELD1。
6 ④如果第一个字符是数字则在第一个字符前插入一个字母N。
例如3 little mice?产生的字段名为N3LITTLE。
】3. 数值型字段:##,###.##… ;仅接受数字和空格,不输按空格处理,分析时作缺失值处理,以“.”显示。
数字位数由“#”个数决定,小数位数由小数点右边的“#”个数确定。
epidata3.1教程(英文版)
EpiData Help fileVersion 3.1 Data entry and data documentationhttp://www.epidata.dkJens M. Lauritsen & Michael Bruus The EpiData Association, Odense DenmarkVersion of : November 26th 2004About EpiData v3.1Program design by:Jens M. Lauritsen & Michael Bruus.EpiData is released as freeware by the non-profit organisation “The EpiData Association” Odense, Denmark (In danish: EpiData foreningen). Previous releases by County of Funen, Denmark and Brixton Health, UK. Programming by: Michael Bruus, Denmark.Translation:EpiData has been translated to several languages. See http://www.epidata.dk for a list of names, web servers and institutions of those who made the translations.Suggested citation:Lauritsen JM & Bruus M. EpiData (version 3.1). A comprehensive tool for validated entry and documentation of data. The EpiData Association, Odense Denmark, 2004.Previous versions: We wish to emphasise that Mark Myatt contributed with great inspiration, specifications and ideas to version 1 and 2 of EpiData – initiation of the EpiData effort would not have been possible without Marks contribution. See also history document on www.epidata.dk First version of EpiData released as Lauritsen JM, Bruus M., Myatt MA, EpiData, version 1.0-1.5. A tool for validated entry and documentation of data. County of Funen Denmark and Brixton Health UK. 2001.EpiData is free.EpiData is distributed as freeware. You are welcome to give a copy to a colleague. All documentation documents are released with permission to copy, distribute, and / or modify the documents under the terms of the GNU (/copyleft/fdl.html) Free Documentation License Version 1.1 or any later version published by the Free Software Foundation with no invariant sections, no back-cover texts. Front pages must be kept as is when documents are translated with the addition of name and organisation of translator.If anyone finds that EpiData is sold or restricted in use by some regulations please notify us immediately atinfo@epidata.dk It is strictly prohibited to charge anything for the use or delivery of EpiData. Exceptions for this can be supplementary materials in printing made at the cost of printing or for postage of disks or CD’s. But the program as such cannot be sold. This includes translations. No-one can charge any fee for delivery of a translated version. If you are in doubt do not hesitate to contact us. Give reference for the download site or postal adress of those asking for payments for delivery of EpiData. Procedures in EpiData cannot be patented.Visit www.epidata.dk for information on updates, known bugs and further documentation.Some useful internet pages on Biostatistics, Epidemiology, Public Health, Epi Info etc.:Data types and analysis: /faculty/gerstman/Epi InfoTools for tabulated data: Epi Info home page: /epo/epi/Epi Info.htmStatistical routines: /training/stata/Epidemiology Sources: /epidem/epidem.htmlEpidemiology lectures: /~super1/EpiDemiology – further: /epitools/ Including analysis in RS Bennett, Mark Myatt, D Jolley and A Radalowicz. Data Management for Surveys and Trials - A Practical Primer using EpiData. Available from: http://www.epidata.dk/documentation.phpFreeware for calculations and diagrams: See http://www.epidata.dk/documentation.phpDisclaimer The EpiData software program was developed and tested to ensure fail-safe entering and documentation of data. We made every possible effort in producing a fail-safe program, but cannot in any circumstance be held responsible for errors, loss of data, work time or other losses incurred by or in relation to the program.About EpiData v3.1 (2)EpiData is free (2)New features (7)Introduction (8)Overview – short tour of EpiData (9)1. Define Data (9)2. Make datafile (9)3. Add/Revise Checks - at Entry of Data (9)4. Enter Data (9)5. Document Data (10)6. Export for analysis and securing data (11)How to analyse data after entry (11)History of EpiData: (12)The EpiData Association (12)Thanks for the support and testing (12)Contributions and funding (13)Credit card payments (13)Bank transfer (13)Financial review (13)Support (14)EpiData mail news (14)Features in EpiData (15)EpiData future Development plan: (15)Compatibility with Epi Info (16)Editor (17)Auto indention (17)Aligning entry fields (17)The Field Pick List (17)Code Writer (18)Preview Data Form (18)Field names (19)First word as field name (20)Automatic field names (20)Variable labels (21)Create data file (22)Revise Data File (23)Rename fields (24)Check file (24)Add / Revise Checks (25)Range / Legal (26)Ignoremissing (26)Jumps (27)Must Enter (27)Repeat (27)Value labels (28)Edit all checks for current field (29)Copying checks (30)Clear Checks (30)Check file structure (30)Example of a check file (31)User defined check functions (33)List of check commands (33)AFTER ENTRY (33)AFTER FILE (33)AFTER RECORD (34)AUTOJUMP (34)AUTOSAVE (34)AUTOSEARCH (35)BACKUP (35)BEEP (36)BEFORE ENTRY (36)BEFORE FILE (36)BEFORE RECORD (37)CLEAR (37)CLEAR COMMENT LEGAL (37)COLOR (37)COMMENTS (*) (37)COMMENT LEGAL (38)CONFIRM (40)CONFIRMFIELD (40)COPYTOCLIPBOARD (40)DEFINE (40)EXECUTE (41)EXIT (42)GOTO (42)HELP (42)HIDE, UNHIDE (43)INCLUDE (43)IF..THEN (44)JUMPS (44)KEY (45)LABEL (46)LABELBLOCK (46)LET (47)MISSINGVALUE (47)MUSTENTER (48)NOENTER (48)QUIT (48)RANGE (48)RELATE (49)REPEAT (49)SHOWLASTRECORD (49)TOPOFSCREEN (49)TYPE (50)TYPE COMMENT (50)TYPE STATUSBAR (51)UNHIDE (51)WRITENOTE (52)Operators and functions (53)Operators (53)Arithmetic operators (53)Logical operators (53)Relational operators (53)Arithmetic functions (54)ABS(X): FLOAT (54)ARCTAN(X: FLOAT): FLOAT (54)COS(X: FLOAT): FLOAT (54)EXP(X: FLOAT): FLOAT (54)FLOAT(X): FLOAT (54)FRAC(X: FLOAT): FLOAT (54)INT(X: FLOAT): FLOAT (54)INTEGER(X): INTEGER (54)LN(X: FLOAT): FLOAT (54)LOG10(X: FLOAT): FLOAT (54)PI: FLOAT (54)POWER(BASE, EXPONENT: FLOAT): FLOAT (54)ROUND(X: FLOAT): INTEGER (54)SIN(X: FLOAT): FLOAT (54)SQR(X: FLOAT): FLOAT (55)SQRT(X: FLOAT): FLOAT (55)STRING(X): STRING (55)TRUNC(X: FLOAT):INTEGER (55)String functions (56)UPPER(S: STRING): STRING (56)LOWER(S: STRING): STRING (56)COPY(S: STRING; INDEX, COUNT: INTEGER): STRING (56)POS(SUBSTR: STRING; S: STRING): INTEGER (56)LENGTH(S: STRING): INTEGER (56)STRING(X): STRING (56)SOUNDEX(S: STRING): STRING (56)Date and time functions (57)DATE(D:INTEGER,M:INTEGER,Y:INTEGER): DATE (57)DAY(D: DATE): INTEGER (57)DAYOFWEEK(D: DATE):INTEGER (57)MONTH(D: DATE): INTEGER (57)NOW: DATE (57)NUM2TIME(D: DATE): FLOAT (57)TIME2NUM(F: FLOAT): DATE (57)TODAY: DATE (57)WEEKNUM(D: DATE):INTEGER (57)YEAR(D: DATE): INTEGER (57)About dates (57)How to calculate age on a given specific date ? (59)About time (59)Other functions (60)ISBLANK(FIELD NAME): BOOLEAN (60)RECORDCOUNT: INTEGER (60)RECORDNUMBER: INTEGER (60)Enter Data (61)Navigation between fields (61)Navigation between records (61)Navigation between related files (62)Finding records (62)Finding fields and relatefields (62)Filter (63)Append / Merge Data files (64)Append (64)Merge Data files (64)Document data file (66)Data entry notes (66)Data file label (66)List data (67)Codebook – basic tabulation (67)Logical Consistency Check (68)Double entry and validation (69)Validate duplicate data files (69)Double entry (69)Count records by field (70)Export data (72)Backup of data (72)Export to text file (72)Export to dBase III format (73)Export to Excel (73)Export to SPSS (74)Export to SAS (74)Export to Stata (74)Select lettecase for fieldnames (75)Export to new EpiData data file (75)Import data (76)Import text files (76)Import dBase files (76)Import Stata files (77)Other tools and functions (78)Make QES file from data file (78)Recode data file (78)Converting a two digit year to a four digit year (78)Pack data file (79)Compress data file (79)Print data entry form (79)Options (80)Editor options (80)Show data form options (80)Create data file options (80)Documentation options (80)Advanced options (80)Sounds (81)File associations (81)The .INI file (81)Toolbars (81)Short-cut keys / mouse (82)Program parameters (84)Internationalisation (85)Field types in EpiData (85)ID Number (86)Numeric fields (86)Text fields and encrypted fields (86)Upper-case text fields (86)Boolean fields (yes/no fields) (87)Date fields (87)Today’s date fields (87)Soundex fields (87)Tabulator code (89)Appendices (90)Contributions and further acknowledgement (90)Acknowledgements (90)EpiData house example. – extended explanation (91)Datafile structure (94)EpiData International Versions (97)Principles of translation and local adaptation (97)Who can translate EpiData texts (98)New features in v3.1Double entry of data and feedback if different from first time. Implementation of user defined extensions to the check file language New check commands and functions implemented as: SHOWLASTRECORDLOG10BACKUP creating zip-files or encrypted zip-filesSee http://www.epidata.dk/revision.htm for an updated list of changesIntroductionEpiData is a program for DataEntry and documentation of data.Use EpiData when you have collected data on paper and you want to do statistical analyses or tabulation of data. Basic frequency tables and lists of data can be made, but other than that EpiData is focused on dataentry and documentation of data.During dataentry calculation of summary scales or restrictions to values can be defined. You can choose an item from a list and save the corresponding numerical code (1 = No 2= Yes), the text lists are exported as "value labels" for statistical programs. Dates are easily entered, e.g. 2301 will be formatted as 23/01/2001 if entered in year 2001 in a "dd/mm/yyyy" field.EpiData is suitable for simple datasets where you have one source of data (e.g. one questionnaire or one laboratory registration form) as well as datasets with many or branching dataforms. The principle is rooted in the simplicity of the dos program Epi Info version 6, which has many users around the world. EpiData implements the Epi Info version 6 file structure and principles in a windows setting with focus on documentation.The idea is that you write simple text lines and the program converts this to a dataentry form. Once the dataentry form is ready it is easy to define which data can be entered in the different data fields. EpiData will not interfere with your computer setup.It is an essential principle of EpiData not to interfere with the setup of your computer. EpiData consists of one program file and help files. (In technical terms: EpiData comes as a few files and does not depend on, install or replace any DLL files in your system directory. Options are saved in an ini file). A standard "setup.exe" file helps you get the program into your computer. But you can copy the exe file alone to any other place on your computer and it will still work.LimitationsNo limit on number of observations in theory. In practice it should be less than about 2-300.000. (tested with 250.000). Search with index in 80.000 records < 1 sec on Pentium I 200Mhz). All fields (variables) must fit within 999 lines of text.EpiData cannot handle several users working in the same file. It is a single user system. But there is no problem in placing datafiles on a shared network drive. As long as each operator works with the data at a time when no other operator uses the data.The length of explaining texts for numerical or string codes is 80, the length of the codes as such is 30 characters.Overview – short tour of EpiData.How to work with EpiDataThe EpiData screen has a “standard” windows layout with one menu line and two toolbars. The "Work Process toolbar" guides you from "1. Define data" to “6. Export data” for analysis.1. Define DataDefine data by writing three types of information for each variable:A.. Name of input field (variable, e.g. v1 or exposure).B.. Text describing the variable. (e.g. sex or "day of birth")C.. An input definition, e.g. ## for two digit numerical.Other field types are boolean (yes-no) or Soundex. Variable names can take two forms: a . v1sex (8 first characters in sentence) b . v1 (first word of sentence). 2. Make datafile.After writing the defintion you can preview yourdataform or create a datafile.3. Add/Revise Checks - at Entry of DataA strong part of EpiData is the possibility to specify rules and calculations during dataentry. • Restrict dataentry to certain values and give text descriptions to the numerical codes entered. • Specify sequence of dataentry E.g. fill out certain questions for males only, (jumps)• Apply calculations during dataentry. E.g. age at visit based on date of visit and date of birth. Summation of scales and index.• Help messages and extended definitions, e.g. if.. then ...endif.(For an example getfirst.chk from Http:///www.epidata.dk -examples page).4. Enter DataOpen the file and enter, add orsearch data. Colors for fieldsand background can beconfigured. Here whitebackground and yellow field.The blue explanatory text tothe right of the input fields isadded by EpiData after entry ofdata based on labels in checkfile. Body mass index and ageare calculated automatically.Files saved:A. Dataform definition file.E.g. first.qes B.Actual datafile containing the data. E.g. first.rec .C. A file with the defined checks. E.g. first.chkD. Supplementary files, e.g. first.not with notes taken during dataentry or first.log withdocumentation.5. Document DataAfter creating the datafile you can document file structure. An example (part of first.rec) is: DATAFILE:C:\data\first.recFilelabel:My first test datafile is an exampleFilesize:612bytesLast revision:28.Jan200112:14Number of fields:7Number of records:0Checks applied:Yes(Last revision28.Jan200112:02)Fields in datafile: Variable label Fieldtype Width Checks Value labels---------------------------------------------------------------------------------------1id ID-number62v1sex Integer1sex1:Male2:Female9:Unknown 3v2Height(meter)Fixed number4:2Legal:0.0-2.30,96v4Date of birth Date(dmy)10(other fields omitted)And after dataentry lists values for some or all records:Observation1id1v1Male v2 1.92v412/12/1945s1denmark s2Copenhagent128/10/2000A "codebook" can include raw frequency tables. (example not based on first.rec file)v2-------------------------------------------------------------------------Sextype:Integervalue labels:sexrange/legal:1-2,2missing:0/25range:[1,2]unique values:2tabulation:Freq.Pct.Value Label1144.01Male1456.02Femalev3------------------------------------------------------------------------Temptype:Floating pointrange/legal:36.00-40.00missing:0/25range:[36.00,37.50]unique values:12mean:36,84std.dev:0,376. Export for analysis and securing data.The backup routine will copy all files associated with a given datafile to a selected user defined backup directory/folder. You can also export the data to a number of data formats for analysis.How to analyse data after entryEpiData Data Entry is made for entry / checking / management / documentation of data only. It is not a data analysis system – although basic crude tables can be made (codebook).Follow the development of an analysis programme on www.epidata.dk. A testversion of Analysis has been available since October 2004. The programme is nearing release and many basic functions are available. See Http://www.epidata.dk/testing.php (and later also download pages).The format of data files produced by EpiData is the same as Epi Info v6.xx, as well as the principles of the analysis programme. Exceptions to Epi Info file compatibility are described on page 16You can use Epi Info for Dos to analyse EpiData data files directly or export data to a comma separated text file, a dBase III file, an Excel file, a Stata data file () or a command file which can be read by SPSS or SAS. You can also convert your data using StatTransfer(), DBMS/Copy or Epi Info’s Export module ().Several add-on programs are available for analysis of data in Epi Info format (e.g. survival analysis or regression analysis). Visit for more information.History of EpiData:The initiative to make EpiData was taken by Jens uritsen. MD. Ph.d. from Denmark. Initially as part of the “Initiative for Accident Prevention” at Funen County - but why develop a new data entry programme ?Epi Info version 6 has all that we need in terms of control of data entry and simplicity. But with development of windows like programs most users find it hard to cope with the "dos" mode of working in Epi Info developed during 1990-1995.Commercially available programs are not focused on documentation, simplicity of use and validation of double entered data.On the Epi Info discussion list there were some discussions on strategies around 1997-1998, when the Epi Info team at CDC in USA decided to make an updated Epi Info version 2000. The updated Epi Info applies a different strategy in using a completely new way of working and the Access database format instead of simple text files (ascii).Since Mark Myatt had similar viewpoints on development strategies he was contacted by Jensuritsen towards the end of 1999 and agreed to join the EpiData development team which at that point also included a skilled pascal programmer Michael Bruus, who is doing the actual programming.The ambition of EpiData is to create a simple to use independent application, which will not interfere with or require any special database system drivers (dll based routines) shared with or interfering with other applications.The ambition is also to finance development by contributions from institutions, individuals and other contributors such that the program can be delivered as freeware.Previous versions: We wish to emphasise that Mark Myatt contributed with great inspiration, specifications and ideas to version 1 and 2 of EpiData – initiation of the EpiData effort would not have been possible without Marks contribution. See also history document on www.epidata.dk First version of EpiData released as Lauritsen JM, Bruus M., Myatt MA, EpiData, version 1.0-1.5. A tool for validated entry and documentation of data. County of Funen Denmark and Brixton Health UK. 2001.The EpiData AssociationEpiData is released for public use by the EpiData association, which has the purpose of enhancing dataquality and tools for public health and other field work by dissemination of the Epidata program. The purpose is also to gain external funding such that all costs for EpiData are paid for. Thereby allowing for continued dissemination of EpiData as freeware. The EpiData association has no personnel employed. Persons involved are having jobs elsewhere and are doing the work in freetime or on paid leave for larger tasks or part of the development.It is expected that more groups will be formed as part of the continued EpiData development, each responsible for one part. Contact info@epidata.dk for further information.Thanks for the support and testingDuring the period from end of 1999 to january 2001 it was not known whether EpiData was just my cracy idea or a sustainable idea. Since then it has gained wide acceptance, not the least shown by the many Epi Info centers around the world having engaged in translation of menu’s and documents. Also the many persons having spent hours on testing and commenting are worth mentioning.Without this support the development of EpiData would not have continued.uritsenDated : see front page.Contributions and fundingContributions and donationsEpiData has been made on a very small budget and is supplied as free-ware to the international community. EpiData is from version 2.0 and above released by the non-profit organisation “The EpiData Association” Odense, Denmark (In danish: EpiData foreningen). The association receives NO baseline budget from anyone.If you like EpiData please consider giving a donation for further development. If you need a proof of payment please mail us at info@epidata.dkFurther funding is needed to facilitate the development after version 1.5 (e.g. refining of programming, enhancing speed, maintenance of website, to pay for absence from paid work to do EpiData or other developmental and promotional efforts for EpiData).CREDIT CARD PAYMENTS.A credit card payment should be possible directly on the website www.epidata.dk from mid or end december 2001. (Awaits official approval).BANK TRANSFER.You can also send a contribution to this bank account by direct bank-to-bank transfer (not cheque): Bank Name: Laan & Spar BankBank Address: Hoejbro Plads 9-11, Postboks 2117,DK1014 København K, DenmarkAccount number: 0400 401 0550861Account holder: EpiDataSWIFT code: LOSADKKDue to transaction costs the contribution should be at least $25 / £20 / Euro25 or equivalent. Any less and it all goes to the banks! From some banks the transaction cost is around $18 / £14 / Euro18 others as low as $3 / £2 / Euro3. Ask your bank to transfer contributions directly to the bank mentioned above not through a different danish bank first. Ask for transfer in $/ £/ Euro (€) this should minimise transaction costs. The transaction costs are the same for small and large contributions. A mechanism of combined transaction is therefore worked upon.FINANCIAL REVIEWThe Danish Society of Public Health (Research and general public health association for public health interested professionals in Denmark) monitors use of the contributions and has full insight into the spending of donations.SupportThe current document works as the technical manual for EpiData. Use this document for printing of a manual. See also:a. Steve Bennett, Mark Myatt, Damien Jolley, and Andrzej Radalowicz. Data Management forSurveys and Trials - A Practical Primer using EpiData. Available from:b. EpiTour guide provided as windows help file and pdf file.Other manuals and examples exist. See www.epidata.dk for updated lists of materials.Unfortunately we do not have the resources to provide personal support in general. But we always try to help people out of a situation. In particular if data are threatened to be lost or malfunctioning.In general EpiData questions can be sent to the Epi Info discussion list (subscribe from/epo/epi/Epi Info.htm). Remember that the list is for all Epi Info users so include the key word EpiData in the title of your message.If you find errors or bugs when using the program or have suggestions for improvements you may contact us at:Info@EpiData.dkA list of known bugs is maintained at www.EpiData.dk as well as at the discussion forum at the same adress..Bug reports should include the following information:Description of problem. Was it consistent? Did it appear with different data files / structures or only with a particular one? Could you make the error appear on a different PC? Which operating system were you using? How much free disk space? Which version of EpiData? Which e-mail address to contact you if we have suggestions.Basic principles of formation of data-entry forms, entering data, building of check rules etc. follows what can be read in the Epi Info v6.xx manual (see /Epi Info/ei6.htm ).EpiData mail newsTo receive major news on EpiData development sign on at www.epidata.dk/php/maillist.php or use the link on the help menu which will take you to the same link if you have a direct internet connection.Users who signed on will receive information on major updates and changes arising from major bug reports. We might also ask users to participate in decisions on what to include in upcoming versions or to test future versions of EpiData.Your e-mail address will not be used for other purposes nor will it be given to anyone else.Features in EpiDataA complete version and development list is maintained at the http://www.epidata.dk site. Version 3.1 of EpiData includes the following features:An editor where multiple questionnaire definition (.QES) files may be created or modified including find / replace, copy to / from clipboard, and undo functions.A easy-to-use field alignment functionA test-data form function allowing questionnaires to be previewed without creating a data file Creation of data files based on .QES filesAutomatic naming of variables based on the text before the variableBasic entry validationCheck rulesBeep /sounds emitted on errorCreate new data records and view / modify existing recordsExport of data files to comma separated text files, dBase III, Excel, Stata, SPSS and SAS filesImport of data from text files, dBase III/IV and Stata filesData file compatibility with Epi Info v6.xxA work process toolbar to help structure the creation of data and check filesCreate a questionnaire (.QES) file from data (.REC) fileBackup of data filePrint Data FormData file labels, variable labels and value labelsRevise structure of data file with revised .QES fileCase-wise data listing and enhanced data documentation functionsIndexing of data files for fast searchingDouble-entry and validationFacilities to implement hierarchical coding schemes.Functions to handle different languages in menus, dialogs, etc.Relational data entryMerge / append data filesBatch consistency check of data filesBatch recoding of data filesImplementation of user defined extensions to the check file languageEPIDATA FUTURE DEVELOPMENT PLAN:Depending on the number of bugs reported in EpiData 3.1 a bug fix release might come out in first quarter of 2005, but other than that we are in a phase of preparing for the next possible extension of EpiData.The development could include:a. Analysis module compatible with EpiDatab. Implementation of user configurable menu and user specified extensions and external programs.c. Implementation of a module for transaction logging during dataentry. A request by data authoritiesin some countries.d. A version for the Linux platforme. Listing and reporting of data based on menu files and additions.But the above will not take place unless further funding is secured. The basic principle is to get funding and donations for development and release such that EpiData can be given away at no cost.Compatibility with Epi InfoEpiData is, in its ideas and principles of operation, based upon the MSDOS program EpiInfo v6.xx created for the WHO by the CDC. visit /epiinfo.htm for more information.In the development of EpiData it has been a basic principle that data files created in EpiData should be compatible with Epi Info and vice versa. However, some differences do exist because some field types are available in EpiData that are not available in Epi Info and vice-versa.EpiData and Epi Info v6 are sufficiently similar that many EpiInfo v6.xx projects will work in EpiData with little or no modification. This is particularly true if only basic checks (i.e. ranges, legal values, repeats, must enter, skip patterns) are used in the EpiInfo v6.xx project.Differences between EpiData and Epi Info data filesUsing Epi Info data files in EpiDataEpiData does not support the following field types:•Phonenumber fields•Phone extension number fields•Colour codes for background and single entry fields (ignored by EpiData) Using EpiData data files in EpiInfoEpiInfo does not support the following EpiData field types:•European style today’s date <Today-dmy>•Reversed dates <yyyy/mm/dd> and <Today-ymd>•Soundex fields•Tabulator (@) codes•Colour codes for background, entry fields, etc. are not saved by EpiData For a full list of field types supported by EpiData, see Field types description.CHECK language•IF … THEN structures that specify more than one condition (i.e. IF … THEN structures that use Boolean operators such as AND / OR) must use round brackets to enclose eachconditional expression (e.g. IF (a=2) AND (b>3) THEN ...). EpiData uses a slightly differentsyntax in some calculations and expression.•The EpiData check language has now been extended to include many functions not allowed in the Epi Info v6 check file language.•The HELP command uses a slightly different syntax.•Colour codes and screen coordinates in some commands (e.g. TYPE, HELP) are ignored by EpiData.•Date constants must be ten digit European dates in EpiData, e.g. ”10/02/2001”•Codefield and codes are NOT supported by EpiData. But the same feature can be implemented by use of COMMENT LEGAL and TYPE COMMMENT, see the bacterialistexample on the EpiData homepage.•QUIT, COPYTOCLIPBOARD, SHOWLASTRECORD and user-defined check-commands are not supported by Epi Info.Screen co-ordinates in some commands (e.g. TYPE, HELP) are ignored by EpiData.EpiData uses a slightly different syntax in some calculations and expression.。
Epidata_3.1_使用教程之快速入门篇(90分钟速成)
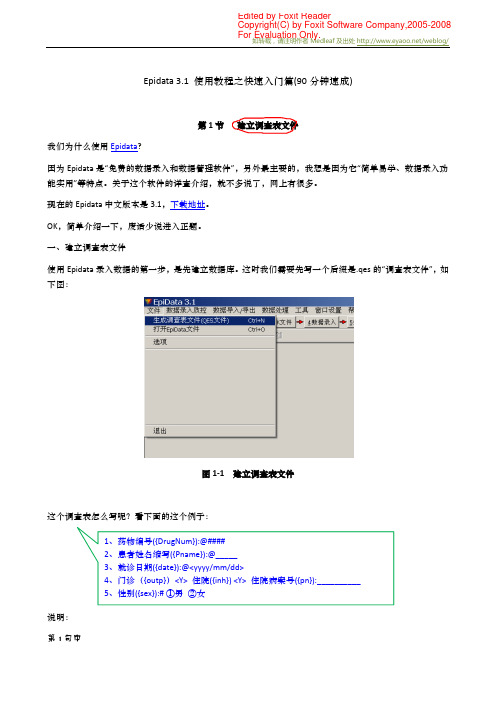
第 1 节 建立调查表文件 我们为什么使用 Epidata? 因为 Epidata 是“免费的数据录入和数据管理软件”,另外最主要的,我想是因为它“简单易学、数据录入功 能实用”等特点。关于这个软件的详查介绍,就不多说了,网上有很多。 现在的 Epidata 中文版本是 3.1,下载地址。 OK,简单介绍一下,废话少说进入正题。 一、建立调查表文件 使用 Epidata 录入数据的第一步,是先建立数据库。这时我们需要先写一个后缀是.qes 的“调查表文件”,如 下图:
图 1-1 建立调查表文件
这个调查表怎么写呢?看下面的这个例子:
说明: 第 1 句中
1、药物编号({DrugNum}):@#### 2、患者姓名缩写({Pname}):@_____ 3、就诊日期({date}):@<yyyy/mm/dd> 4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________ 5、性别({sex}):# ①男 ②女
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
如转载,请注明作者 Medleaf 及出处 /weblog/
“药物编号”只是起到提示作用,在由.qes 文件生成数据库文件时不编译,就是说在数据库里面它还是显示 “药物编号”;
后面括号{}里的“DrugNum”,是字段名,当然这个字段(或者说变量)记录的就是药物编号了,用{}定义字 段名是 Epidata 字段命名的一种方式(还有另一种,这里就不说了),当然如果不加的话也可以,Epidata 会根据系统的设臵自动生成字段名(象这种:n1aa,n2,n3ae 等等);
图 2-1 QES 文件编辑窗口 然后点击“生成 REC 文件”,如下图:
图 2-2 由 QES 文件生成 REC 文件
一般不用管它,你的.qes 文件在什么位臵,就把.rec 放到什么文件夹中,所以下面基本上都是一路“确定” 下去了:
如转载,请注明作者 Medleaf 及出处 /weblog/
图 4-1 设臵跳转命令 在上图中我们可以看到,如果在 sample.chk 那个选项卡中编辑 Jumps 命令的话,格式是: Y>sex 解释:如果录入的值等于 Y 则将跳转到字段 sex。对于这个字段,由于是布尔型变量,录入 0 或者 1,系 统自动将其转换为 N 或 Y,所以这个字段的 Jumps 命令中,条件取值是 Y 而不是 1。 如果进行文本格式的编辑(见上图中右下角的编辑窗口),Jumps 的命令格式是: outp /这个是字段名 JUMPS /Jumps 命令开始 Y sex /跳转条件,可以有多个,每个条件占 1 行 END /Jumps 命令结束 END / outp 字段的 CHK 命令结束 上面这种情况,是一个跳转命令,如果有多个跳转怎么办? 在 CHK 选项卡中设臵的话,是用英文的“,”分隔不同的跳转命令,如 Y>sex,N>inh。
图 3-2 选择要建立 CHK 文件的数据库文件 点击打开后,出现编写 CHK 文件的页面:
图 3-3 CHK 文件编辑器 简单的解释一下: Epidata 的 CHK 文件,命令有很多,这个编辑窗口,仅列出了比较常用的几个,其它更为复杂的功能,需 要点击“编辑”按钮,以文本编辑方式打开 CHK 文件来编写 CHK 命令。这些命令的使用,大家可以参考《Epidata 3.0 使用手册》。
开始有些费劲,呵呵,以后就越来越轻松了!
)
第 2 句:
与第 1 句不同的是,患者姓名缩写肯定是字母了,这里用下横杠“_”来定义。下横杠“_”是用来定义字符串 的,一个字母用一个“_”表示(如果是汉字,要占两个“_”)。这一句的含义就是:定义了一个字段“患者姓 名缩写”,字段名是 Pname,用于记录字符形式的数据。 (以后就轻松了:-)
第 1 节 建立调查表文件 我们为什么使用 Epidata? 因为 Epidata 是“免费的数据录入和数据管理软件”,另外最主要的,我想是因为它“简单易学、数据录入功 能实用”等特点。关于这个软件的详查介绍,就不多说了,网上有很多。 现在的 Epidata 中文版本是 3.1,下载地址。 OK,简单介绍一下,废话少说进入正题。 一、建立调查表文件 使用 Epidata 录入数据的第一步,是先建立数据库。这时我们需要先写一个后缀是.qes 的“调查表文件”,如 下图:
如转载,请注明作者 Medleaf 及出处 /weblog/
图 3-4 CHK 文件编辑器的选项卡 上图中对 CHK 选项卡中的 5 个项目作了简单的说明,下面逐一进行介绍: 1、字段的允许数值范围与允许数值 对应的 CHK 命令为:Range 和 Legal “控制”作用:在录入时,如果录入的数值不在这两个命令定义的允许数值(范围)内,系统将报错,需重 新录入“合格”的数值。 这是 CHK 文件中常用的两个命令,其作用稍有不同,Range 限定的是字段数值的“允许范围”,比如我们可 以键入“1-8”,代表该字段的数值是从 1 到 8 且连续的 8 个数值;而 Legal 则限定字段的允许数值,对上面 这种情况,用 Legal 命令的话,我们需要键入“1,2,3,4,5,6,7,8”, 如果实际情况是既有连续的数值,又有不 连续的,那这两个命令可以一起用,比如键入“1-5,7,8”,表示这个字段共允许 7 个数值,包括 1 到 5 连续 5 个 数,还有“7”和“8”这两个数。如果录入时输入了 6,系统会报错,提示“非法录入”,同时还提示应该 输入的允许数值(范围)。如下图:
如转载,请注明作者 Medleaf 及出处 /weblog/
第 4 节 数据录入的控制(2) 2、跳转 对应的 CHK 命令:Jumps “控制”作用:在录入时,如果录入的值符合条件,则跳转到条件中设定的字段处进行录入。 这个一个很常用的 CHK 命令,格式也很简单,如下图:
第 3 句:
<yyyy/mm/dd>是定义日期格式的字段的,写法是固定的,很简单吧?这一句将“就诊日期”的字段名设为 “date”,字段属性设臵为 4 位年 2 位月和 2 位日形式的日期数据。
第 4 句:
<Y>代表另外一种格式的数据:布尔逻辑变量,它的值只能是 Y 或 N(在录入时也可输入 1 或 0,系统自动 将其变成 Y 或 N);对于一名患 者,一般情况下只有门诊病人或住院病人两种情况,非此即彼,所以设臵 为布尔逻辑变量。这一句的含义:定义门诊与住院两种情况,如果是住院病人,还要填写住 院病案号。
,所以也可写成:1 男 2 女 3
事实上,上述例子,基本上把 Epidata 中的所有常用的变量类型都用上了。
作为练习,把上面那 5 句拷贝到 Epidata 的编辑区,保存为.qes 后缀的调查表文件,即建库文件,。
第 2 节 生成数据库文件
二、生成数据库文件(.rec)文件 把第 1 节中那 5 句 COPY 到 epidata 中,如下图:
图 1-1 建立调查表文件
这个调查表怎么写呢?看下面的这个例子:
说明: 第 1 句中
1、药物编号({DrugNum}):@#### 2、患者姓名缩写({Pname}):@_____ 3、就诊日期({date}):@<yyyy/mm/dd> 4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________ 5、性别({sex}):# ①男 ②女
Edited by Foxit Reader Copyright(C) by Foxit Software Company,2005-2008 For Evaluation Only.
如转载,请注明作者 Medleaf 及出处 /weblog/
Epidata 3.1 使用教程之快速入门篇(90 分钟速成)
图 2-3 生成 REC 文件 最后出来的这个文件标记,一般是不用设的(具体它有什么作用我还真没仔细研究过),最后一个“确定” 点了以后,你的数据库文件(以.rec 格式保存)就生成了。
图 2-4 生成 REC 文件过程中的文件标记 好啦,来看看我们的成果吧! 点击 Epidata 工具栏中的“数据录入”菜单,选择“数据录入”菜单,如下图:
图 2-5 打开数据库文件 找到先前生成的那个 sample.rec 文件,然后打开,呈现在我们面前的就是数据录入的界面了:
如转载,请注明作者 Medleaf 及出处 /weblog/
图 2-6 数据录入界面
第 3 节 数据录入的控制(1)
前两节我们了解了如何编写调查表文件,如何用这个文件生成数据库及数据录入界面的显示。 这一节,我们看看数据录入的控制。 问题提出:为什么需要“控制”? 还是先前的那个例子,
如转载,请注明作者 Medleaf 及出处 /weblog/
为了实现这些“控制”过程,我们需要建一个与.rec 文件同名但后缀为.chk 的文件。在启动 epidata 后,在工 具栏上就能看到建立 CHK 文件的按钮。
图 3-1 建立 CHK 文件 选择我们先前生成的 sample.rec 文件:
图 3-5 (Range 和 Legal 这两个命令的作用就是这个) 还记得上一个图中那个“编辑”按钮吗?我们点击它看看里面是什么:
如转载,请注明作者 Med3-6 CHK 文件的“编辑” 这是对当前字段的 CHK 命令进行文本方式的编辑(其实 Epidata 的文件基本都是文本格式,只不过文件的 后缀不是.txt 罢了)。在里面我们可以看到,一个合格的 CHK 命令是字段名加 CHK 命令,以 END 结尾。 Range 命令的用法是 RANGE 1 5 (它定义了允许的数值范围是 1 到 5) Legal 的用法是: LEGAL 7 8 END (注意:很多 CHK 命令都以 END 结尾,比如这个 LEGAL,但 RANGE 不需要) 对于 LEGAL 命令,每个允许的数值要占一行。 事实上,对于这两个命令,我们不需要以文本方式编辑,直接在图 3-4 中的选项卡中填上数值范围或数值 就可以了(以英文“,”分隔每个单独的数值),而对于选项卡中没有的命令,我们必需用编辑文本自己编 写。 好了,这两个命令我们已经简单的了解了用法,下面我们看看跳转命令 Jumps 怎么用。
再后面的@###:@表示一种对齐方式,先不用管它,后面会讲到;
###是用来定义前面那个 DrugNum 字段的属性的,#代表一位数字,###就代表 3 位数字,也就是说药物编 号最大也就能输入 999 了,不能再大了;
总结第 1 句的含义:定义了一个字段“药物编号”,字段名是 DrugNum,用于记录 3 位数字形式的数据。(刚
1、药物编号({DrugNum}):@#### 2、患者姓名缩写({Pname}):@_____ 3、就诊日期({date}):@<yyyy/mm/dd> 4、门诊({outp})<Y> 住院({inh}) <Y> 住院病案号({pn}):__________ 5、性别({sex}):# ①男 ②女 其中编号为 4 的那一行,有“门诊”“住院”和“住院病案号”三项,这三项中最多只有两项需要我们来录入数 据,因为门诊和住院这两种情况是相斥的,一个病人如果是门诊病人,那就不是住院病人,病案号当然也 没有了。 所以,为了提高数据录入的效率,我们需要对录入过程进行控制:对于上面的这种情况,我们的预期控制 效果是: 在录完就诊日期后,光标到“门诊”项,这时,如果这个病人是门诊病人,那么我们录入 1 或者 Y(因为这 个变量是布尔型,其值只有 1 或 Y,0 或 N,键入其它的值都是无效的)之后,光标不是到“住院”项,而是 跳转到“性别”,因为门诊病人没有病案号。 当然,对数据录入的控制还远不只这些,还包括字段允许值的设定、是否必须录入、是否允许重复数值等。