centos修改默认字符编码为GBK(服务器端java GBK字符乱码)
Godaddy的 VPS GBK乱码简单解决办法

Godaddy的 VPS GBK乱码简单解决办法
用户在使用空间时,会出现 GBK乱码,用户可以试着用以下的处理办法。
1>进入控制面板(我的是简单控制面板)
SERVER ADMINISTRATION—>MANAGE FILES—>Browse entire server
2>进入 /etc/httpd/conf/ 目录
选中httpd.conf 点右边的小眼睛 view 把代码复制下来放到一个 txt上,复制完毕后把系统上的 httpd.conf rename 什么名字都行,
例如 httpd.conf.11.back
现在修改txt 上的代码找到 AddDefaultCharset UTF-8 在前面加个
#AddDefaultCharset UTF-8
这样系统的默认字符集就取消了,所有编码都按程序的编码自动识别
3>修改完毕后把txt 文件另存为httpd.conf
4>然后把修改后的httpd.conf 通过 Manage Files — > new file 上传到
/etc/httpd/conf
5>最后restart server 一分钟后,VPS GBK乱码就搞定了。
Linux怎么设置中文语言?centos中文乱码的解决办法

Linux怎么设置中⽂语⾔?centos中⽂乱码的解决办法
怎么设置Linux系统中⽂语⾔?是很多⼩伙伴在开始使⽤Linux的时候,都会遇到⼀个问题,就是终端输⼊命令回显的时候中⽂显⽰乱码。
出现这个情况⼀般是由于没有安装中⽂语⾔包,或者设置的默认语⾔有问题导致的。
今天我们就以centos为例,操作Linux怎么查看语⾔,设置修改语⾔的⽅法,详细请看下⽂介绍。
⼀、Linux怎么查看设置系统语⾔包
1、查看当前系统语⾔
登陆linux系统打开操作终端之后,输⼊ echo $LANG可以查看当前使⽤的系统语⾔。
如
2、查看安装的语⾔包
查看是否有中⽂语⾔包可以在终端输⼊ locale命令,如有zh cn 表⽰已经安装了中⽂语⾔
3、如果没有中⽂语⾔呢
可以通过⽹上下载安装中⽂语⾔包yum groupinstall chinese-support(不能联⽹的通过其他电脑下载,上传上去吧)
⼆、如何修改系统语⾔为中⽂
1、临时更换语⾔
如果只是临时更换linux系统的语⾔环境,可以通过输⼊设置 LANG=语⾔名称,如中⽂是
Zn_CN.UTF-8(注意我这⾥本来就是中⽂的,我临时设置为英⽂
2、修改系统默认语⾔
以上⽅法是通过修改设置系统默认的语⾔配置
如Vi /etc/sysconfig/i18n (注意改好之后重启⼀下系统)
三、其他注意事项
如果按照以上⽅法设置修改设置中⽂语⾔还是不⾏的话,注意您的链接终端选择的编码。
如xshell为例,把终端的编码选择中⽂,或者UTF8即可
设置好之后,再次查看之前的乱码⽂件就能看到显⽰为中⽂了
以上就是centos中⽂乱码的解决办法,希望⼤家喜欢,请继续关注。
java中文乱码常见解决方式

java中⽂乱码常见解决⽅式说明项⽬出现中⽂乱码现象、常见编码解决⽅法如下。
项⽬乱码项⽬⼯作空间在 Windows -> Prefenrences -> General -> Workspace 中进⾏设置在创建项⽬⼯作空间的时候、优先设置编码,在该⼯作空间下创建的项⽬默认遵循⼯作框架配置项⽬编码在 Project -> Resource中设置创建项⽬的时候、设置编码,则项⽬下⽂件都将会和项⽬统⼀页⾯⽂件编码⽂件右键 Properties -> Resource⽂件头编码⽂件头⼀般是HTML、JSP标签头部添加编码JSP:<%@ page language="java" import="java.util.*" pageEncoding="UTF-8"%>HTML:添加在<head>标签⾥⾯<meta http-equiv="Content-Type" content="text/html; charset=utf-8">编辑器编码设置NotePad++编辑器打开⼀个⽂件时候乱码在 菜单 -> 格式记事本存储时,保存为UTF-8格式服务器乱码SpringMVC在web.xml添加<filter><description>字符集过滤器</description><filter-name>encodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><init-param><description>字符集编码</description><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param></filter><filter-mapping><filter-name>encodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>Tomcat编码Tomcat 的 conf/server.conf设置编码、设置为:<Connector port="8080" protocol="HTTP/1.1"connectionTimeout="20000"URIEncoding="UTF-8"redirectPort="8443" />添加:URIEncoding="UTF-8" 属性请求响应编码设置请求、响应编码//设置获取请求的编码request.setCharacterEncoding("utf-8")//设置服务器端的编码response.setCharacterEncoding("utf-8");//通知浏览器服务器发送的数据格式response.setContentType("text/html;charset=utf-8");字符串编码String oldStr = "编码设置";String newStr = new String(oldStr.getBytes(), "UTF-8");System.out.println("UTF-8编码:" + newStr);JDBC 连接指定编码url=jdbc:mysql://127.0.0.1/database?characterEncoding=UTF-8数据库设置编码编码可选:mysql> set character_set_client=utf8;mysql> set character_set_connection=utf8;mysql> set character_set_database=utf8;mysql> set character_set_results=utf8;mysql> set character_set_server=utf8;mysql> set character_set_system=utf8;mysql> set collation_connection=utf8;mysql> set collation_database=utf8;mysql> set collation_server=utf8;数据库表设置编码创建表的时候、指定编码:DEFAULT CHARSET=UTF8;CREATE TABLE `type` (`id` int(10) unsigned NOT NULL auto_increment,`type_name` varchar(50) character set utf8 NOT NULL default '', PRIMARY KEY (`id`)) DEFAULT CHARSET=UTF8;补充如果出现乱码现象、可对应⽂章修改。
JAVA中文字符乱码解决详解

JAVA中⽂字符乱码解决详解⾸先要了解JAVA处理字符的原理。
JAVA使⽤UNICODE来存储字符数据,处理字符时通常有三个步骤:– 按指定的字符编码形式,从源输⼊流中读取字符数据– 以UNICODE编码形式将字符数据存储在内存中– 按指定的字符编码形式,将字符数据编码并写⼊⽬的输出流中。
所以JAVA处理字符时总是经过了两次编码转换,⼀次是从指定编码转换为UNICODE编码,⼀次是从UNICODE编码转换为指定编码。
如果在读⼊时⽤错误的形式解码字符,则内存存储的是错误的UNICODE字符。
⽽从最初⽂件中读出的字符数据,到最终在屏幕终端显⽰这些字符,期间经过了应⽤程序的多次转换。
如果中间某次字符处理,⽤错误的编码⽅式解码了从输⼊流读取的字符数据,或⽤错误的编码⽅式将字符写⼊输出流,则下⼀个字符数据的接收者就会编解码出错,从⽽导致最终显⽰乱码。
这⼀点,是我们分析字符编码问题以及解决问题的指导思想。
好,现在我们开始⼀只只的解决这些乱码怪兽。
⼀、在JAVA⽂件中硬编码中⽂字符,在eclipse中运⾏,控制台输出了乱码。
例如,我们在JAVA⽂件中写⼊以下代码:String text = “⼤家好”;System.out.println(text);如果我们是在eclipse⾥编译运⾏,可能看到的结果是类似这样的乱码:。
那么,这是为什么呢?我们先来看看整个字符的转换过程。
1. 在eclipse窗⼝中输⼊中⽂字符,并保存成UTF-8的JAVA⽂件。
这⾥发⽣了多次字符编码转换。
不过因为我们相信eclipse的正确性,所以我们不⽤分析其中的过程,只需要相信保存下的JAVA⽂件确实是UTF-8格式。
2. 在eclipse中编译运⾏此JAVA⽂件。
这⾥有必要详细分析⼀下编译和运⾏时的字符编码转换。
– 编译:我们⽤javac编译JAVA⽂件时,javac不会智能到猜出你所要编译的⽂件是什么编码类型的,所以它需要指定读取⽂件所⽤的编码类型。
java中文乱码解决方法

java中文乱码解决方法Java是一种强大的编程语言,它可以为不同的计算机平台提供稳定可靠的软件开发环境,它也在处理文本文件上有着独特的优势。
但在使用Java处理中文文件时,乱码就成为了一个重大问题,如果不能很好地处理乱码,会影响到Java应用软件的正常使用。
本文给出了3种常用的Java中文乱码解决方案,以帮助相关开发人员快速解决乱码问题。
首先,使用正确的字符集编码将文件保存为指定的编码格式,这可以有效防止中文乱码的出现。
首先,应确保将文本文件保存为国际标准字符集UNIX UTF-8编码。
这是一种任何平台及系统都能够正确执行的字符集,比如Windows系统可以使用ANSI编码,但是在Linux 中会出现乱码问题。
其次,在字符编码方面应尽量使用UTF-8,它可以支持多种字符集,可以为用户提供更丰富的文本文件内容。
此外,为了完全解决Java中文乱码问题,开发者可以利用相关的API来设置不同的编码格式。
例如,开发者可以使用System.setProperty()方法来指定程序的编码格式,即指定文件使用的字符集。
以下是一个简单的示例代码:System.setProperty(file.encoding UTF-8另外,Java还提供了更加强大的控制功能。
它可以为用户提供一种可以自行设置和识别字符集的文件编码类。
例如,使用InputStreamReader和OutputStreamWriter类,开发者可以指定输入和输出的字符集,以进行不同的输入和输出操作,从而得到更加准确的结果,避免出现乱码问题。
以下是一个使用InputStreamReader 和OutputStreamWriter设置字符集的简单示例:InputStreamReader isr = new InputStreamReader(inputStream, UTF-8OutputStreamWriter osw = newOutputStreamWriter(outputStream, UTF-8最后,用户还可以使用相关的第三方软件来解决Java中文乱码问题,这些软件专门设计用于解决文本文件字符集编码的问题,可以自动识别文件的编码格式,并将其转换成指定的编码格式。
解决java命令行乱码的问题

解决java命令⾏乱码的问题虚拟机参数加上-Dfile.encoding=GBK -Ddefault.client.encoding=GBK nguage=zh -Duser.region=CN补充:java执⾏cmd命令,返回结果中⽂乱码问题解决public static void main(String[] args) {try {// 执⾏ping命令Process process = Runtime.getRuntime().exec("cmd /c e:&dir");BufferedReader br = new BufferedReader( new InputStreamReader( process.getInputStream(), Charset.forName("GBK") ) );String line = null;while ((line = br.readLine()) != null) {System.out.println(line);}} catch (IOException e) {e.printStackTrace();}}我的代码package net.bigwrok;import java.io.BufferedReader;import java.io.InputStreamReader;import java.nio.charset.Charset;public class Test2_net {public static void main(String[] args) {BufferedReader br = null;try {Process p = Runtime.getRuntime().exec("ping 127.0.0.1");br = new BufferedReader(new InputStreamReader(p.getInputStream(),Charset.forName("GBK")));String line = null;StringBuilder sb=new StringBuilder();while ((line = br.readLine()) != null) {sb.append(line+"\n");}System.out.println(sb.toString());} catch (Exception e) {e.printStackTrace();} finally {if (br != null) {try {br.close();} catch (Exception e) {e.printStackTrace();}}}}}结果以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
java中文乱码解决方法

java中文乱码解决方法1、解决文件中文乱码:1.1、修改文件字符编码:由于不同系统,比如Unix下用GBK格式编辑的文件,在Windows中就会乱码,此时可以使用Notepad++(记事本插件),将文件编码转换为系统默认的utf-8,8为Unicode编码。
1.2、修改系统语言及字符编码:此外,也可以通过改变操作系统的语言及字符编码,这种方法我们可以在控制面板-区域和语言的地方进行修改,再次点击其中的管理,在点击详细设置,这时候就可以看到字符集,将其设置为utf-8。
2、解决程序中文乱码:2.1、使用unicod-8格式编码:在这种情况下,一定要注意程序代码的编码格式,一定要以utf-8格式进行编码,而不是GBK,否则一样会出现乱码。
2.2、设置字符集:有时候,可以在程序中设置语言字符集,例如:response.setContentType("text/html;charset=utf-8");用于普通的JSP页面编码设置,也可以在web.xml中设置characterEncoding3、修改Tomcat的默认编码:可以修改tomcat的server.xml文件,将其默认编码为utf-8,在相应的位置加上URIEncoding="utf-8"。
4、前端乱码解决方法:也可以到浏览器中去修改编码,比如:Firefox浏览器中,可以按Ctrl + U,Chrome可以按Ctrl + U,IE下可以第一个菜单栏中点击View,然后选择Encoding,转换为相应的编码即可。
5、对数据库使用正确的编码:在不同的数据库中当我们有gbk的字符编码的时候,一定要创建数据库时候指定好字符编码,让数据库与整个程序保持一致,如果仅仅程序有编码时,数据库没有则容易出现乱码。
总之,我们在解决Java中文乱码的问题是要以系统- web页面-程序-数据库为关键点进行检查,以确保编码的一致性。
【免费下载】Java乱码问题解决方案

Java乱码问题解决方案.txt生活是一张千疮百孔的网,它把所有激情的水都漏光了。
寂寞就是你说话时没人在听,有人在听时你却没话说了!Java乱码问题解决方案Java乱码问题一直是困扰初学者的一个难题,下面就根据笔者的经验来给大家一个解决方案。
我写了一个Demo的web应用,解决了乱码问题,点击下载1 问题来源Java的乱码问题,根源在于操作系统、数据库(MySQL)、Web服务器(Tomcat)、页面(JSP)中的编码不一致造成的。
例如,mysql的编码是latin1,而页面上字符的编码是GBK,则就会出现乱码问题。
2 解决方案了解了乱码产生的原因,下面就来看一下如何解决乱码。
事实上,只要保证各个环节的编码一致,就不会产生乱码,所以只要将所有的环节,设置的编码为UTF-8,就不会出现乱码了(为了支持国际化,建议统一设置成UTF-8)。
3 mysql数据库编码的设置(以MySQL 5.0.41为例)查看数据库支持的编码:show character set;这样可以查看mysql数据库支持的所有编码,其中可以看到有支持utf8编码。
mysql> show character set ;+----------+-----------------------------+---------------------+--------+| Charset | Description | Default collation | Maxlen |+----------+-----------------------------+---------------------+--------+| big5 | Big5 Traditional Chinese | big5_chinese_ci | 2 || dec8 | DEC West European | dec8_swedish_ci | 1 || cp850 | DOS West European | cp850_general_ci | 1 || hp8 | HP West European | hp8_english_ci | 1 || koi8r | KOI8-R Relcom Russian | koi8r_general_ci | 1 || latin1 | cp1252 West European | latin1_swedish_ci | 1 | | latin2 | ISO 8859-2 Central European | latin2_general_ci | 1 | | swe7 | 7bit Swedish | swe7_swedish_ci | 1 | | ascii | US ASCII | ascii_general_ci | 1 | | ujis | EUC-JP Japanese | ujis_japanese_ci | 3 | | sjis | Shift-JIS Japanese | sjis_japanese_ci | 2 | | hebrew | ISO 8859-8 Hebrew | hebrew_general_ci | 1 | | tis620 | TIS620 Thai | tis620_thai_ci | 1 | | euckr | EUC-KR Korean | euckr_korean_ci | 2 | | koi8u | KOI8-U Ukrainian | koi8u_general_ci | 1 | | gb2312 | GB2312 Simplified Chinese | gb2312_chinese_ci | 2 | | greek | ISO 8859-7 Greek | greek_general_ci | 1 | | cp1250 | Windows Central European | cp1250_general_ci | 1 | | gbk | GBK Simplified Chinese | gbk_chinese_ci | 2 | | latin5 | ISO 8859-9 Turkish | latin5_turkish_ci | 1 | | armscii8 | ARMSCII-8 Armenian | armscii8_general_ci | 1 | | utf8 | UTF-8 Unicode | utf8_general_ci | 3 || ucs2 | UCS-2 Unicode | ucs2_general_ci | 2 | | cp866 | DOS Russian | cp866_general_ci | 1 | | keybcs2 | DOS Kamenicky Czech-Slovak | keybcs2_general_ci | 1 | | macce | Mac Central European | macce_general_ci | 1 || macroman | Mac West European | macroman_general_ci | 1 | | cp852 | DOS Central European | cp852_general_ci | 1 | | latin7 | ISO 8859-13 Baltic | latin7_general_ci | 1 | | cp1251 | Windows Cyrillic | cp1251_general_ci | 1 | | cp1256 | Windows Arabic | cp1256_general_ci | 1 | | cp1257 | Windows Baltic | cp1257_general_ci | 1 | | binary | Binary pseudo charset | binary | 1 | | geostd8 | GEOSTD8 Georgian | geostd8_general_ci | 1 | | cp932 | SJIS for Windows Japanese | cp932_japanese_ci | 2 | | eucjpms | UJIS for Windows Japanese | eucjpms_japanese_ci | 3 | +----------+-----------------------------+---------------------+--------+ 36 rows in set (0.00 sec)查看数据库默认的编码: show variables like '%character%'; mysql> show variables like '%character%';+--------------------------+---------------------------------------+| Variable_name | Value |+--------------------------+---------------------------------------+| character_set_client | latin1 || character_set_connection | latin1 || character_set_database | latin1 || character_set_filesystem | binary || character_set_results | latin1 || character_set_server | latin1 || character_set_system | utf8 || character_sets_dir | E:\mysql-5.0.41-win32\share\charsets\ |+--------------------------+---------------------------------------+8 rows in set (0.00 sec)可以看到,mysql数据库中,此时有关字符串的设置的参数,其中“character_set_server”为创建数据库是默认的编码,现在需要将其修改为utf8。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策在Java Web项目的开发过程中,中文乱码问题是一种经常遇到的问题,这是因为Java 中默认使用的是Unicode编码,而在Web开发中,常常会涉及到数据通过HTTP协议传输,由于HTTP默认使用的是ISO-8859-1编码,因此就会出现中文乱码的问题。
中文乱码问题主要有以下几种形式:1.数据库中的中文显示为乱码;4.页面跳转后的中文显示为乱码。
为了解决这些中文乱码问题,开发人员可以采取以下对策:1.设置服务器的默认字符集为UTF-8在Tomcat配置文件server.xml里面,找到Connector节点下添加URIEncoding="UTF-8"即可设置默认字符集为UTF-8。
如下:<Connector port="8080" protocol="HTTP/1.1" connectionTimeout="20000" redirectPort="8443" URIEncoding="UTF-8" />2.设置response的头信息在Java中,可以通过设置response的Content-Type头信息来指定编码方式。
常用的编码方式有UTF-8和GBK。
具体如下:response.setContentType("text/html;charset=UTF-8");3.设置JSP页面的page指令在JSP页面中,可以通过设置page指令来指定编码方式。
例如:<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8"%>4.修改MySQL字符集如下:ALTER DATABASE database_name DEFAULT CHARACTER SET utf8;5.修改Hibernate的配置文件在Hibernate的配置文件hibernate.cfg.xml中,一般会配置如下:<property name="eUnicode">true</property>6.修改Web.xml配置文件<?xml version="1.0" encoding="UTF-8"?>7.在表单中添加字符集编码8.避免字符串转换在Java中,字符串转换时,需要指定编码方式。
Linux系统修改默认语言环境为zh_CN.UTF-8字符集,解决中文乱码问题

Linux系统修改默认语⾔环境为zh_CN.UTF-8字符集,解决中⽂乱码问题原因:简单的说是因为服务器没有安装zh_CN.UTF-8 字符集,导致不⽀持中⽂!解决办法环境:CentOS7. ⽆GUI安装。
默认安装英⽂。
⾸先查询语⾔环境:# locale# locale -a 可以查看⽀持的字符集。
# locale -a |grep -i cn1.临时修改:# export LANG=zh_CN.UTF-82.永久修改:# vim /etc/locale.confor# localectl set-locale LANG=zh_CN.UTF8更改为zh_CN.UTF-8,重启。
# reboot---------------------下⾯可忽略:3.发现重启之后 .locale 和 locale.conf 都是 en_US.UTF-8.4.centos7 在开机初始化时,locale.conf 来⾃ /etc/profile.d/lang.sh 的加载。
5.打开 lang.sh脚本。
即使修改成zh_CN.UTF-8之后,加载脚本时仍然会初始化为en_US.UTF-8.6.修改之后,重启。
更改时区:ln -sf localtime /usr/share/zoneinfo/Asia/Shanghai参考:环境:Ubuntu 141.安装基本的软件包(第2步安装 zh_CN 中⽂字符集时要⽤到)sudo apt-get update //系统更新软件包列表sudo apt-get install -y language-pack-zh-hanssudo apt-get install -y language-pack-zh-hant (安装zh_HK和zh_TW)2. 在/etc/profile或/etc/bash.bashrc⽂件添加如下内容# cat /etc/profile |grep -i cnexport LANG="zh_CN.UTF-8"export LANGUAGE="zh_CN.UTF-8"export LC_ALL="zh_CN.UTF-8"3.source /etc/profile 查看是否⽣效# localeLANG=zh_CN.UTF-8LANGUAGE=zh_CN.UTF-8LC_CTYPE="zh_CN.UTF-8"LC_NUMERIC="zh_CN.UTF-8"LC_TIME="zh_CN.UTF-8"LC_COLLATE="zh_CN.UTF-8"LC_MONETARY="zh_CN.UTF-8"LC_MESSAGES="zh_CN.UTF-8"LC_PAPER="zh_CN.UTF-8"LC_NAME="zh_CN.UTF-8"LC_ADDRESS="zh_CN.UTF-8"LC_TELEPHONE="zh_CN.UTF-8"LC_MEASUREMENT="zh_CN.UTF-8"LC_IDENTIFICATION="zh_CN.UTF-8"LC_ALL=zh_CN.UTF-8。
SUSE-was修改GBK字符集

export LANG=“zh_CN.GBK”
3. 进入etc,找到bash.bashrc文件,打开,在文件末尾添加如下两行
export LANG=“zh_CN.GBK”
4. 重启服务器,打开终端,输入“echo $LANG”命令,查看系统编码,如下图,若显示为
由于前置应用服务器编码为GBK,则需要将操作系统的编码改为GBK,方法如下:
1. 修改/etc/sysconfig/language文件,按照下面修改变量的
RC_LANG=“zh_CN.GBK”
RC_LC_ALL=“zh_CN.GBK”
ROOT_USES_LANG=“yes”
2. 进入etc,找到profile文件,打开,在文件末尾添加如下两行
文件中的
genericJvmArguments="-Dfile.encoding=GBK -Ddefault.client.encoding=GBK"
-Dfile.encoding=GBK -Ddefault.client.encoding=GBK
-Dfile.encoding=GBK -Ddefault.client.encoding=GBK
设置参数以支持中文字符集
路径:服务器——应用程序服务器——server1——进程定义——ava 虚拟机:
通用JVM参数=-Dfile.encoding=GBK -Ddefault.client.encoding=GBK
修改的具体配置文件路径例子如下,如修改错误启动WAS失败可以修改回来。
\usr\IBM\WebSphere\AppServer\profiles\AppSrv01\config\cells\loushangaixNode01Cell\nodes\loushangaixNode01\servers\server1.xml
CentOS中文乱码问题的解决方法

CentOS中文乱码问题的解决方法在使用CentOS系统时,如果出现各种中文乱码情况的时候,我们该如何解决这种问题呢。
本文将介绍一些常见乱码和解决方案。
一、CentOS系统访问 ,发现中文乱码于是用以前的方式:# yum -y install fonts-chineseCentOS系统安装后,还是不能显示中文字体。
我使用gedit 编辑源码,其中文注释也为乱码。
后来,终于找到以下方法可以解决,需要两个中文支持的包:fonts-chinese-3.02-12.el5.noarch.rpmfonts-ISO8859-2-75dpi-1.0-17.1.noarch.rpm一个是中文字体,一个是字体显示包。
在命令行安装:# rpm -ivh XXXXCentOS系统安装完成后,重新启动即可。
二、终端、gedit 显示乱码# vim /etc/sysconfig/i18n将:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改原内容为:LANG="zh_CN.GB18030"LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"SUPPORTED="zh_CN.UTF-8:zh_CN:zh:en_US.UTF-8:en_US:en"SYSFONT="lat0-sun16"用yum 安装中文字体# yum install fonts-chinese.noarchsystem -> logout 注销重新登录CentOS系统时,你会发现,所有界面已从英文变成中文。
三、在ssh ,telnet 终端中文显示乱码解决办法#vim /etc/sysconfig/i18n将原内容:LANG="en_US.UTF-8"SYSFONT="latarcyrheb-sun16"修改为:LANG="zh_CN.GB18030" (只需修改本行也是可以的)LANGUAGE="zh_CN.GB18030:zh_CN.GB2312:zh_CN"SUPPORTED="zh_CN.UTF-8:zh_CN:zh:en_US.UTF-8:en_US:en"SYSFONT="lat0-sun16"用yum 安装中文字体# yum install fonts-chinese.noarch断开ssh ,重新连四、在CentOS系统 5.3 中使用中文输入法命令行输入:# yum install scim# yum install scim-pinyin重启动X(按Ctrl+Alt+Backpace)或注销(logout)。
CentOS下中文文件名显示乱码问题

CentOS下中⽂⽂件名显⽰乱码问题
在windows上使⽤ftp上传⽂件到Linux上,中⽂名称在Linux系统中显⽰为乱码。
虽然将Linux的env设置了LANG=en_US.UTF-8,并且本地的Shell客户端编码也设置成UTF-8,但在Shell中(或通过http访问),仍是乱码……
原因在于,Windows 的⽂件名中⽂编码默认为GBK,压缩或者上传后,⽂件名还会是GBK编码,⽽Linux中默认⽂件名编码为UTF8,由于编码不⼀致所以导致了⽂件名乱码的问题,解决这个问题需要对⽂件名进⾏转码。
yum install convmv
convmv -f gbk -t utf-8 -r --notest /home/wwwroot
常⽤参数:
-r 递归处理⼦⽂件夹
–notest 真正进⾏操作,默认情况下是不对⽂件进⾏真实操作
–list 显⽰所有⽀持的编码
–unescap 可以做⼀下转义,⽐如把%20变成空格
-i 交互模式(询问每⼀个转换,防⽌误操作)
linux下有许多⽅便的⼩⼯具来转换编码:
⽂本内容转换 iconv
⽂件名转换 convmv
mp3标签转换 python-mutagen
以上所述是⼩编给⼤家介绍的CentOS 下中⽂⽂件名显⽰乱码问题,希望对⼤家有所帮助,如果⼤家有任何疑问请给我留⾔,⼩编会及时回复⼤家的。
在此也⾮常感谢⼤家对⽹站的⽀持!。
CentOS部署MRTG出现中文乱码

出现中文乱码ServerName:行 151:AllowOverride AllServerTokens Prod重启服务,并将服务设置成开机运行:systemctl start httpdsystemctl enable httpd加入防火firewall-cmd --add-service=http --permanent重启防火墙配置:firewall-cmd --reload面查看搭建是否成功:w/h t m l/"width:font-size: 40px;bold; text-align: center;">ApachePage</div></body></html>SNMP搭建安装yumsnmp net-snmp-utils mrtg修改为后续MRTGvi /etc/SNMP/snmpd.conf取消默认的名:# 行 41: 增加注释#com2secUser default public设置本地团体名和允许被SNMP客户端团体名为# 行及变更# 将需要访问的网络命名为mynetwork# 更新团体名,期间建议private图1 第一次生成MRTG详细流量文件可能出现的部分信息Trouble Shooting图2 详情页面出现乱码码。
再查看标签,显示charset=“gb2312”也正常。
笔者进一步想到Web容编码设置:vi /etc/httpd/conf/变更AddDefaultCharset OFFUTF-8,此时Apache以网页源代码中声明的编码格后,重启查看详细页面,所示。
网页显示出中文,但SecureCRT连接编辑文件时访问,通过查看网页代码以及将软件编码设置成UTF-8所示。
图4 查看网页代码及设置成UTF-8后仍显示乱码图3 重启httpd 服务并查看详细页面显示正常图5 成功解决乱码问题vi /etc/vimrc# 新增set encoding=utf-8set fileencoding=utf-8,gbk最后终于成功解决了在secureCRT 网页源文件乱码问题,所示。
如何解决centos u盘乱码问题
如何解决centos u盘乱码问题?
virtualBox linux centos 挂载u盘解决乱码
linux 挂载u盘
环境:虚拟机virtualBox5.2.8 linux centos6.5 64bit
第一步:插入u盘
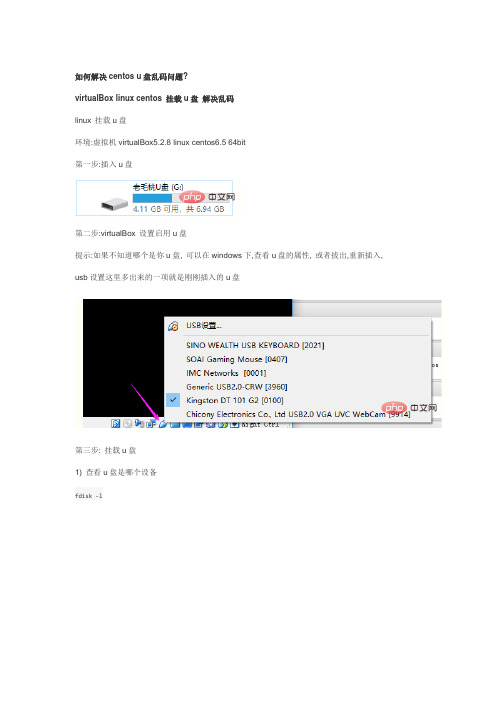
第二步:virtualBox 设置启用u盘
提示:如果不知道哪个是你u盘, 可以在windows下,查看u盘的属性, 或者拔出,重新插入, usb设置这里多出来的一项就是刚刚插入的u盘
第三步: 挂载u盘
1) 查看u盘是哪个设备
fdisk -l
找到其u盘设备的'Device Boot'项,记住,我这里是/dev/sdc1
2) 挂载u盘
创建挂载点
mkdir /mnt/upan
挂载u盘
mount -o iocharset=utf8 /dev/sdc1 /mnt/upan
说明: -o 表示选项, 如果不设置编码, 等下挂载完,查看u盘文件名中文会有乱码连接工具, 也设置utf8编码我用的xshell
第四步:可以使用u盘了
如果要卸载挂载umount 挂载点例:
umount /mnt/upan
/END。
javadoc错误:编码gbk的不可映射字符

在使用eclipse进行javadoc的导出时提示编码gbk的不可映射字符应该就是中文注释eclipse不认需要在调用javadocexe的时候传递编码集告诉它采用什么编码去生成javadoc文档
javadoc错误:编码 gbk的不可映射字符
在使用Eclipse进行doc的导出时,提示“编码 GBK 的不可映射字符”,应该就是中文注释Eclipse不认,需要在调用javadoc.exe的 时候传递编码集告诉它采用什么编码去生成javadoc文档。 打开eclipse,project –> Export –> javadoc 一项一项的选你要输出javadoc的项目,最后一步中VM设置行中加入以下代码 -encoding utf-8 -charset utf-8”问题,而且html字符编码都设为了UTF-8,问题彻底解决。