1019大数据笔记记录
牛津通识读本读书摘录读书感想读书笔记

《牛津通识读本:大数据》大数据的三个视角●一是计算视角:从计算视角来看,大数据是一个难以获取、难以组织与管理、难以处理和分析的技术难题(以及因此而引发的各类思维层难题),也正是因为这样的难题驱动,加之人们对大数据在优政、兴业、科研、惠民等不同领域的价值期望,促使相关科研人员进行技术攻关和发明创造,进而推进了相关理论和技术的发展。
●二是科研视角:从科学研究的角度来看,大数据成为继实验、理论、模拟之后用于科学研究的“第四范式”(此处的“范式”指的是从事某一科学的科学家群体所共同遵从的世界观和行为方式)。
●三是商业视角:从商业应用的角度来看,大数据能够带来利润。
一般而言,只要找到一个合适的应用场景,并为这个应用场景找到一个合适的解决方案,知道数据的来源并且能够获取,而且有技术支撑(研发能力),更重要的是能够找到融资支持(经过可行性分析、盈亏平衡分析等之后),就有可能最终成功应用并获得收益。
这在彰显大数据商业价值的同时,也会促使同行去挖掘更多的大数据价值。
实现大数据价值的四个维度(ABCD)1算法(Algorithm):大数据价值的实现路径涵盖了数据采集与汇聚、数据存储与管理、数据处理与分析、应用系统开发与运维,每一个环节都需要依赖不同的算法进行,如数据采集算法、数据汇聚算法、数据治理算法、数据处理和分析算法等。
2商业应用(Business):大数据应用一般体现在描述性分析、预测性分析或者决策性分析等,任何一种应用都是围绕某个具体场景展开的,因此大数据价值得以实现的一个重要前提,是找到一个合适的应用场景,该应用场景既直击需求痛点并有投资回报预期,又有数据积淀和IT建设基础。
大数据在这个场景的应用,能够进一步内生和富集更多数据并因而形成数据闭环,就能进一步体现和实现大数据价值。
3算力(Computing Power):所谓算力,指的是设备的计算能力,显然,对于大数据应用而言,更精准(复杂)的算法以及更高效的计算需求都需要强大的算力支撑,因此算力是大数据价值实现的基本保障。
洛飞超短笔记汇总

洛飞超短笔记汇总洛飞,一位资深科技博主,以其短小精悍的笔记闻名于业界。
他的笔记内容涵盖了广泛的科技领域,包括人工智能、大数据、区块链等各个热门话题。
在这篇文章中,我们将对洛飞的超短笔记进行汇总和梳理,为您带来一场关于科技前沿的精彩聚集。
一、人工智能领域1. 机器学习算法的发展- 传统算法 vs. 深度学习:全连接网络、卷积神经网络、循环神经网络,掀起了机器学习的新风潮。
- 半监督学习:利用带标签数据和未标签数据相结合,提高了模型性能。
- 强化学习:通过试错来优化模型,实现智能决策。
2. 自然语言处理(NLP)的进展- 语音识别:深度学习技术的应用提高了语音识别的准确性和交互性。
- 文本分类:基于深度学习的模型,实现更准确的文本分类和情感分析。
- 机器翻译:神经网络机器翻译(NMT)的使用,实现了更准确、流畅的语言翻译。
二、大数据领域1. 数据存储与计算- 分布式文件系统:HDFS、Ceph等,实现了大规模数据的存储和处理。
- 数据仓库技术:Hive、Presto等,提供了高效的数据查询和分析能力。
- 分布式计算框架:Hadoop、Spark等,加速了大规模数据处理和分析的速度。
2. 数据挖掘与分析- 关联规则挖掘:通过挖掘数据集中的关联规则,发现隐藏在数据中的有用信息。
- 聚类分析:将数据集划分为不同的群组,揭示数据内在的分布特征。
- 预测与分类:通过构建预测模型,实现对未来事件的预测和分类。
三、区块链领域1. 去中心化的特点- 去中心化网络:区块链网络通过节点之间的共识机制,实现了信息的去中心化传输和存储。
- 区块链账本:通过区块的链接和加密算法,保证了数据的安全性和不可篡改性。
2. 智能合约与DApp- 智能合约:在区块链上编码的合约,能够自动执行和验证合约中的条款和条件。
- DApp(去中心化应用):基于区块链技术构建的应用程序,具有去中心化和安全性的优势。
四、网络安全领域1. 数据加密与隐私保护- 对称加密算法:使用相同的密钥进行加密和解密,实现数据的机密性。
大数据时代读书笔记

大数据时代读书笔记Newly compiled on November 23, 2020大数据时代维克托·迈尔·舍恩伯格首先作者抛出了大数据时代处理数据理念上的三大转变:●要全体不要抽样。
首先,要分析与某事物相关的所有数据,而不是依靠分析少量的数据样本。
全数据模式,样本=总体。
●要效率不要绝对精确。
其次,我们乐于接受数据的纷繁复杂,而不再追求精确性。
●要相关不要因果。
最后,我们的思想发生了转变,不再探求难以捉摸的因果关系,转而关注事物的相关关系。
接着,从万事万物数据化和数据交叉复用的巨大价值两个方面,讲述驱动大数据战车在材质和智力方面向前滚动的最根本动力;最后,作者冷静描绘了大数据帝国前夜的脆弱和不安,包括产业生态环境、数据安全隐私、信息公正公开等问题。
●大数据的核心就是预测●大数据是指不用随机分析法这样的捷径,而采用所有数据的方法。
●大数据的精髓在于我们分析信息时的三个转变,这些转变将改变我们理解和组建社会的方法。
✧第一个转变就是,在大数据时代,我们可以分析更多的数据,有时候甚至可以处理和某个特别现象相关的所有数据,而不再依赖于随机采样。
✧第二个改变就是,研究数据如此之多,以至于我们不再热衷于追求精确度。
✧第三个转变因前两个转变而促成,即我们不再热衷于寻找因果关系。
●让数据发声,我们会注意到很多以前从来没有意识到的联系的存在●数据化意味着我们要从一切太阳底下的事物中汲取信息,甚至包括很多我们以前认为和“信息”根本搭不上边的事情。
●大数据时代开启了一场寻宝游戏,而人们对于数据的看法以及对于由因果关系向相关关系转化时释放出的潜在价值的态度,正是主宰这场游戏的关键。
第一部分大数据时代的思维变革●大数据与三个重大的思维转变有关,这三个转变是相互联系和相互作用的。
●要想获得大规模数据带来的好处,混乱应该是一种标准途径,而不应该是竭力避免的。
●知道“是什么”就够了,没必要知道“为什么”。
大数据时代读书笔记

大数据时代——读书笔记一、引论1.大数据时代的三个转变:1.可以分析更多的数据,处理和某个现象相关的所有数据,而不是随机采样2.不热衷于精确度3.不热衷与寻找因果关系2.习惯:用来决策的信息必须是少量而精确的。
实际:数据量变大,数据处理速度变快,数据不在精确3.危险:不是隐私的泄露而是未来行动的预判二、大数据时代的思维变革1.原因:没有意识到处理大规模数据的能力,假设信息匮乏,发展一些使用少量信息的技术(随机采样)1.1086年末日审判书英国对人的记载2.约翰·格朗特:统计学,采样分析精确性随着采样随机性上升而大幅上升,与样本数量关系不大3.1890年,穿孔卡片制表机,人口普查4.随机采样有固有的缺陷1.采样过程中存在偏差2.采样不适合考察子类别3.只能得出实现设计好的问题的结果4.忽视了细节考察2.全数据模式:样本=总体1.通过异常量判断信用卡诈骗2.大数据分析:不用随机抽样,而是采用所有数据。
不是绝对意义而是相对意义。
(Xroom信用卡诈骗,日本相扑比赛)3.多样性的价值(社区外联系很多》社区内联系很多)3. 混杂性而非精确性1. 葡萄树温度测量:数据变多,虽然可能有错误数据,但总体而言会更加精确。
2. 包容错误有更大好处3. word语法检查:语料库》算法发展4. google翻译:让计算机自己估算对应关系,寻找成千上万对译结论:大数据的简单算法好过小数据的复杂算法5. 大数据让我们不执著于也无法执着于精确6. MIT的通货紧缩软件:即时的大数据7. 标签:不精确8. 想要获得大规模数据的好处,混乱是一种标准途经9. 新的数据库:大部分数据是非结构化的,无法被利用10. Hadoop:与mapreduce系统相对的开源式分布系统,输出结果不精确,但是非常快结论:相比于依赖小数据和精确性的时代,大数据因为更强调数据的完整性和混杂性,帮助我们进一步接近事情的真相。
“部分”和”确切“的吸引力是可以理解的。
大数据管理与应用专业笔记

大数据管理与应用专业笔记一、概述大数据管理与应用专业是当前信息管理领域中备受瞩目的专业方向之一。
随着信息技术的飞速发展和互联网的普及,海量数据的产生和应用已经成为了现代社会不可忽视的问题。
大数据管理与应用专业应运而生,旨在培养具备大数据处理与管理能力的专业人才,以满足社会对于数据管理和应用的需求。
二、专业课程1.大数据原理与技术本课程主要介绍大数据的基本概念、原理和技术,包括大数据的特征、存储与处理技术、大数据分析与挖掘技术等内容。
学生通过学习,可以对大数据的基本概念有所了解,了解大数据的存储和处理技术,掌握大数据分析与挖掘的基本方法。
2. 数据管理系统本课程主要介绍数据管理系统的结构、原理和技术,包括数据库系统、数据仓库、数据挖掘等内容。
学生通过学习,可以了解不同类型数据管理系统的特点以及其在大数据环境中的运行原理和技术。
3. 大数据编程与开发本课程主要介绍大数据编程和开发的相关技术,包括Hadoop生态系统、Spark、Flink 等大数据框架的编程与开发技术。
学生通过学习,可以掌握大数据编程和开发的基本原理和方法,提高对大数据处理和应用的技术能力。
4. 大数据应用案例分析本课程主要介绍大数据在不同领域的应用案例,包括金融、医疗、电商等行业的大数据应用案例分析。
学生通过学习,可以深入了解大数据在实际领域中的应用,并掌握大数据分析和挖掘技术在不同行业中的应用方法。
三、专业能力培养1. 数据管理能力学生通过学习数据管理系统和大数据原理与技术,掌握数据管理系统的搭建、维护和优化能力,具备数据清洗、整合、存储和分析的能力。
2. 数据分析能力学生通过学习大数据应用案例分析和大数据编程与开发,掌握大数据分析工具和技术,具备对大数据进行分析和挖掘的能力,可以从海量数据中提取有效信息。
3. 专业实践能力学生通过实习和课程设计,实际应用所学的知识和技能,具备在实际工作中处理大数据和应用大数据技术的能力,解决大数据管理与应用中的实际问题。
大数据与会计笔记

大数据与会计笔记在当今数字化时代,大数据的浪潮汹涌而来,深刻地影响着各个领域,会计行业也不例外。
大数据为会计工作带来了前所未有的机遇和挑战,也促使会计从业者不断更新知识和技能,以适应这一变革。
大数据是什么呢?简单来说,就是海量、多样、高速和价值密度低的数据集合。
这些数据来源广泛,包括企业内部的财务数据、业务数据,以及来自外部的市场数据、行业数据等等。
它们的规模之大、增长速度之快,超出了传统数据处理技术的能力范围。
对于会计工作而言,大数据的影响首先体现在数据的采集和处理上。
以往,会计人员主要依靠企业内部的结构化财务数据进行核算和分析。
但现在,随着大数据技术的应用,非结构化数据如文本、图像、音频等也能被纳入到会计信息系统中。
这意味着会计人员需要掌握新的数据采集和处理技术,能够从海量的、杂乱无章的数据中提取有价值的信息。
大数据也改变了会计的分析方法。
传统的会计分析往往侧重于财务指标的计算和比较,而大数据时代则更注重数据的相关性分析和预测。
通过运用数据挖掘、机器学习等技术,会计人员可以发现隐藏在数据背后的规律和趋势,为企业的决策提供更准确、更及时的支持。
例如,通过分析客户的购买行为和偏好数据,企业可以制定更有针对性的营销策略,提高销售业绩;通过分析供应链数据,企业可以优化采购和库存管理,降低成本。
同时,大数据对会计信息的质量和安全性提出了更高的要求。
海量的数据意味着出错的可能性增加,数据的准确性和完整性需要得到更严格的保障。
此外,数据的安全性也至关重要,一旦数据泄露,将给企业带来巨大的损失。
因此,会计人员需要加强对数据质量的把控和数据安全的防护,建立完善的数据管理制度。
在大数据背景下,会计职能也在发生转变。
传统的会计主要侧重于核算和监督,而现在则更倾向于决策支持和战略规划。
会计人员不再仅仅是数据的记录者,更是数据的分析师和决策者的参谋。
他们需要运用大数据技术,为企业提供深入的财务分析和风险评估,帮助企业制定合理的发展战略。
23课的课堂笔记

23课的课堂笔记
23课堂笔记:
本次课程主要讲解了大数据处理中的一些基本概念和技术,以下是我所记录的一些重点内容:
1. 大数据指的是数据量过大、类型繁多、处理速度要求高的数
据集合。
其特点包括三个V:Volume(数据规模大)、Variety(数据类型多样)和Velocity(数据处理速度快)。
2. 大数据处理的技术包括分布式存储和计算、MapReduce编程
模型、Hadoop生态系统等。
其中,Hadoop是一个开源的大数据处理
框架,包含了HDFS分布式文件系统和MapReduce计算模型。
3. 在大数据处理中,常用的数据存储格式包括文本格式、序列
化格式和列式存储格式。
其中,列式存储格式在处理大规模数据时具有较好的性能表现。
4. 数据清洗和预处理在大数据处理中也非常重要。
常用的数据
清洗工具包括OpenRefine、DataWrangler等。
5. 大数据可视化是将大数据处理结果以图形化界面展现出来的
过程。
常用的大数据可视化工具包括Tableau、D3.js等。
总的来说,本次课程让我了解到了大数据处理的基本概念和技术,对我今后的工作和学习都有很大的启发作用。
大数据管理与应用专业笔记

大数据管理与应用专业笔记一、大数据概述1.1 定义大数据是指由传统数据库工具难以捕捉、管理和处理的超大规模数据集。
这些数据通常具有高速增长、多样化、低价值密度和低密度特点,这些特点决定了传统数据库方法已不再适用于其管理和处理。
1.2 特点大数据主要具有四个特点:数据量大、数据类型多样、数据价值密度低、数据密度低。
这决定了大数据的管理和应用需要采用新型的技术和方法。
1.3 应用大数据在各个行业都有着广泛的应用,如金融、电商、医疗、交通、能源等。
大数据的管理与应用已成为各个行业竞争的核心。
二、大数据技术2.1 存储技术大数据存储技术是大数据管理的关键技术之一。
Hadoop、Spark、NoSQL数据库等存储技术成为了大数据存储的主要技术工具。
2.2 处理技术大数据的处理技术是大数据应用的重要组成部分,MapReduce、Storm、Flink等大数据处理技术为大数据处理提供了强大的支持。
2.3 分析技术大数据分析技术是大数据应用的关键环节,机器学习、数据挖掘、文本分析等技术为大数据分析提供了有效的手段。
2.4 可视化技术大数据的可视化技术有助于以直观直觉的方式表达大数据的信息,Tableau、D3.js等可视化技术为大数据分析与应用提供了重要的支持。
三、大数据管理3.1 数据采集大数据管理从数据采集开始,包括结构化数据、非结构化数据、半结构化数据等。
数据采集质量直接影响着后续数据分析与应用的结果。
3.2 数据存储大数据存储包括数据存储系统的选择、存储结构的优化、数据备份与恢复等环节,其目的是为了保证大数据的安全和高效的管理。
3.3 数据清洗与预处理大数据管理首先要进行数据清洗与预处理操作,以保障数据的质量,包括去重、去噪、缺失值处理等操作。
3.4 数据分析与挖掘数据分析与挖掘是大数据管理的核心环节,有助于发现数据中的潜在规律,指导决策和优化业务流程。
四、大数据应用4.1 金融大数据在金融领域的应用已经十分普遍,包括风险控制、信用评估、市场预测等方面,大数据的应用加速了金融行业的数字化进程。
《大数据时代》读书笔记

读书笔记1:《大数据时代》生活、工作和思维的大变革 【英】维克托·迈尔—舍恩伯格 肯尼斯·库克耶著 大数据标志着人类在寻求量化和理解世界的道路上前进了一大步。
过去不可计量、储存、分析和共享的不少东西都被数据化了。
拥有大量的数据和更多不那末精确的数据为我们理解世界打开了一扇大门。
社会所以抛却了寻觅因果关系的传统偏好,开始挖掘相关系数的好处。
“大数据”的本质是思维、商业和管理领域前所未有的大变革。
由此,必然会带来教学方式的改变。
大数据与三个重大的思维转变相关,这三个转变是相互联系和相互作用的。
首先,要分析与某事物相关的所有数据,而不是依靠分析少量的数据样本。
●其次,我们乐于接受数据的纷繁复杂,而再也不追求精确性。
●最后,我们的思想发生了转变,再也不探求难以捉摸的因果关系,转而注重事物的相关关系。
数据创新就像一个奇妙的钻石矿,当它的首要价值被发掘后仍能持续赋予。
它的真实价值就像飘荡在海洋中的冰山,第一眼只能看到冰山的一角,而绝绝大部份都隐藏在表面之下。
当世界开始迈向大数据时代,社会也将经历类似的地壳运动。
在改变人类基本的生活与思量方式的同时,大数据早已在推动人类信息管理准则的重新定位。
无非,不同于印刷革命,我们没有几个世纪的时间去适合,我们也许只有几年时间。
大数据,给我们带来了机遇、风险和挑战。
它们持续对我们管理世界的方法提出挑战,我们要意识到新技术的风险,促动其发展,然后然后斩获成果。
大数据标志着真正的“信息社会”终于到来了。
我们能够获得比以前更多的信息并实行分析。
在我们诠释世界时,能够利用更多的数据,甚至是全部数据。
这需要我们采取非传统的方法,特殊是要改变我们理想中构成实用信息的因素。
我们“做新、做多、做好、做快”的水平能释放出无限价值,产生新的赢家和输家。
绝大部份的信息价值来自于二级用途,即潜在价值,而不是我们所习惯认为的基本用途。
结果,对于绝大部份数据来说,尽可能多地采集、等待信息增值并且让其他更适合挖掘价值的人来分析它才是明智之举(前提是这人能够分享开辟出的利润)。
大数据实习报告工作记录

大数据实习报告工作记录在过去的三个月里,我有幸成为一家大数据公司的实习生,这段经历让我收获颇丰。
我主要参与了公司的一个项目,负责数据解析入库和爬虫采集入库等工作。
以下是我在实习期间的工作记录和一些心得体会。
一开始,我对大数据领域知之甚少,因此在实习初期遇到了不少困难。
我花费了大量时间去学习相关知识,包括数据解析、数据存储、数据挖掘等。
在项目过程中,我负责的数据解析入库工作让我对数据处理有了更深入的了解。
我学会了如何将原始数据进行清洗、转换和解析,使其成为可用于分析和挖掘的格式。
此外,我还学习了如何使用各种数据存储技术,如关系型数据库和非关系型数据库,来存储和管理大量数据。
在爬虫采集入库方面,我负责开发和维护爬虫程序,从互联网上获取所需的数据并将其存储到数据库中。
我学会了使用Python编写爬虫程序,使用Scrapy框架来构建爬虫项目。
在实际操作中,我遇到了一些挑战,如如何解决爬虫在访问网站时遇到的反爬虫机制、如何处理异步加载的数据等。
通过查阅资料和不断实践,我逐渐找到了解决这些问题的方法。
除了参与项目工作,我还养成了记笔记和写博客的习惯。
每天下班后,我会将当天学到的知识和遇到的问题记录下来,以便日后回顾和总结。
同时,我开始在CSDN上发表博客,分享自己的学习经验和心得。
通过写博客,我不仅巩固了自己的知识,还吸引了其他读者的关注和讨论,从而拓宽了视野。
在实习期间,我还有机会参加了一些面试。
通过面试,我更加明确了自己的职业目标和发展方向。
我意识到,在大数据领域,除了掌握相关技术技能,还需要具备良好的沟通能力和团队协作能力。
因此,我开始注重培养这些软技能,参加了一些培训和讲座。
总的来说,这段实习经历让我对大数据领域有了更深入的了解,也让我明白了自己的不足之处。
我会继续努力学习和提升自己,为未来的职业生涯做好准备。
同时,我也希望我的经验和心得能够对其他有意进入大数据领域的人有所帮助。
《人工智能与大数据时代》的读书笔记

《人工智能与大数据时代》的读书笔记一、引言随着科技的飞速发展,人工智能和大数据已经成为当今社会的两大热门话题。
它们在各个领域的应用越来越广泛,深刻影响着我们的生活方式和工作方式。
在这本书中,作者详细阐述了人工智能与大数据之间的关系,以及它们如何相互促进,共同推动社会的进步和发展。
二、人工智能与大数据的概述人工智能人工智能是一种模拟人类智能的技术,通过计算机程序和算法实现。
它涵盖了机器学习、深度学习、自然语言处理、计算机视觉等多个领域。
人工智能的应用范围非常广泛,包括自动驾驶、智能家居、医疗诊断、金融风控等。
大数据大数据是指数据量巨大、复杂度高、处理难度大的数据集合。
它包括结构化数据、半结构化数据和非结构化数据等多种类型。
大数据的应用范围也非常广泛,包括商业分析、智能制造、智慧城市、医疗健康等。
三、人工智能与大数据的关系数据驱动的人工智能人工智能的发展离不开数据。
通过大量数据的训练和学习,机器可以逐渐掌握各种知识和技能,实现智能化。
因此,大数据是人工智能的基础和驱动力。
人工智能驱动的大数据大数据的处理和分析需要借助人工智能技术。
通过机器学习和深度学习等技术,可以对海量数据进行高效处理和分析,挖掘出有价值的信息和知识。
因此,人工智能是大数据处理和分析的关键技术。
四、人工智能与大数据在各领域的应用商业领域在商业领域,人工智能和大数据的应用非常广泛。
例如,通过大数据分析,企业可以了解消费者的购买习惯和需求,制定更加精准的营销策略。
同时,人工智能技术也可以帮助企业提高生产效率和管理效率,降低成本。
医疗领域在医疗领域,人工智能和大数据的应用也日益增多。
例如,通过大数据分析,医生可以更加准确地诊断疾病和治疗方案。
同时,人工智能技术也可以帮助医生进行病情监测和治疗建议,提高治疗效果和患者满意度。
智慧城市领域在智慧城市领域,人工智能和大数据的应用也发挥着重要作用。
例如,通过大数据分析,城市管理者可以了解城市运行状况和公共需求,制定更加科学合理的城市规划和管理方案。
大数据管理与应用专业笔记

大数据管理与应用专业笔记一、大数据概述1. 大数据的定义:大数据是指数据量大、更新快、类型多、使用范围广的数据集合,通常包括结构化数据、半结构化数据和非结构化数据。
2. 大数据的特点:(1)数据量大:传统的数据管理工具无法满足处理大数据的需求。
(2)多样性:大数据来源多元,包括文本、图像、视频、音频等多种形式的数据。
(3)实时性:大数据的产生和更新速度快,需要实时处理和分析。
(4)价值密度低:大数据中有大量的无效信息,需要通过分析挖掘出有价值的信息。
二、大数据管理1. 大数据的采集:大数据管理的第一步是对数据进行采集,包括数据来源的选择、数据的抓取和存储等步骤。
2. 大数据的存储:大数据存储通常采用分布式存储技术,包括Hadoop、Spark等,以及云端存储等方式。
3. 大数据的处理:大数据的处理包括数据清洗、数据预处理、数据分析等环节,需要借助大数据处理平台和工具来完成。
4. 大数据的挖掘:通过数据挖掘技术,可以从大数据中发现隐藏的规律、趋势和价值信息,为企业决策和应用提供支持。
三、大数据应用1. 企业管理决策:大数据在企业管理决策中发挥重要作用,包括市场营销、客户管理、供应链管理等方面。
2. 金融行业:大数据在风控、反欺诈、智能投顾等方面有广泛应用。
3. 医疗健康:大数据在医疗领域的应用包括疾病预测、个性化治疗、医疗资源优化等方面。
4. 智能制造:大数据在工业生产中的应用包括设备故障预测、生产优化、智能物流等。
四、大数据管理与应用的挑战1. 数据安全和隐私保护:大数据中包含大量的个人隐私和敏感信息,如何有效保护数据安全和隐私是一个重大挑战。
2. 数据质量:大数据中存在大量的噪声和无效信息,如何保证数据的质量和准确性是一个重要挑战。
3. 处理能力和效率:大数据处理和分析需要强大的计算和存储资源,如何提高处理效率和节约成本是一个挑战。
4. 法律法规的合规性:大数据的管理和应用需要符合相关的法律法规,如何保证合规性也是一个挑战。
《大数据时代》读书笔记

《大数据时代》读书笔记《大数据时代》读书笔记导语:生活在信息时代的我们,读一读大数据时代,会改变一些我们对这个世界的看法。
《大数据时代》读书笔记一世界的本质就是数据,当你掌握了数据,你便掌控了世界—你可以轻而易举地通过数据中的相关关系预测事物的发展,将一切不利因素扼杀于摇篮之中—这远胜于"防患于未然"。
《大数据时代》一书,让我们在观念上有了三大转变:要全体不要抽样,要效率不要绝对精确,要相关不要因果。
全书介绍了 "大数据"时代三种大的变革:思维变革,商业变革和管理变革。
在这些巨大变革如洪水一般的"冲击"之下,现代社会的运作方式必将有重大的改变,若不顺应这种变革的潮流,就像古中国固步自封,最终被坚船利炮打开国门而自己还用着长钩铁戟抗争一样,不可避免被掠夺,被落于世界进程之后,所以我们必须转变我们的思想。
"我们不再热衷于寻找因果关系,而应该寻找事物间的相关关系",我想这句话是本书的核心思想。
大数据时代,信息与数据已成为了一切的本源,我们生活在各种数据构成的海洋之中,如果从另一种视角看,就好像无数条"看不见的线"将我们与这些数据联系到一起,这是我们以前从未有过、从未想过的。
大数据改变了我们以前的通过因果关系了解世界的方法,而提供了几种新的途径,因为,在大数据时代,我们可以分析更多数据,有时甚至可以处理和某个特别现象相关的所有数据,也就是:样本=总体;而且,当研究数据如此之多时,我们已不热衷于"精确",而是"混乱",若不接受"混乱",那么有95%的非结构化数据无法利用,这将无法使我们构建完整的数据世界,在分析更多、更全面的数据之后,我们就可以从这些数据之中发掘它们的相关关系,即以"是什么"而不是"为什么"的角度看待数据,不用管其从何而来,只要分析其如何影响其他事物既可,即"让数据自己发声",这些,彻底推翻了人类以前探索数据的方法,展现了一个全新的世界。
第19章大数据架构设计理论与实践学习笔记

第19章大数据架构设计理论与实践学习笔记一、传统数据处理系统存在的问题数据库无法支撑日益增长的用户请求的负载,导致数据库服务器无法及时响应用户请求,导致出现超时错误。
1、在web服务器和数据库中间加入异步处理队列;2、对数据库进行分区;3、读写分离;4、分库分表技术。
以上都无法彻底解决问题,依旧存在这样那样的问题,导致数据不一致,需要研究大数据架构设计。
二、大数据系统架构1、大数据处理系统面临的挑战(1)处理结构化和非结构化数据;(2)大数据的复杂性和不确定性;(3)数据异构和决策异构2、大数据处理系统结构设计的特征(1)鲁棒性和容错性;(2)低延迟读取和更新能力;(3)横向扩容;(4)通用性;(5)延展性;(6)即席查询能力;(7)最少维护能力;(8)可调试性。
三、Lambda架构1、Lambda架构Lambda是用于同时处理离线和实时数据,可容错、可扩展的分布式系统架构。
有批处理层、加速层、服务层。
同时以流计算和批处理计算合并视图。
Lambda架构的批处理层采用不可变存储模型,不断地往主数据集后追加新的数据。
2、Lambda架构的优缺点(1)优点容错性好、查询灵活度高、易伸缩、易扩展。
(2)缺点全场景覆盖,编码开销;离线训练益处不大;重新部署和迁移成本很高。
四、Kappa架构1、Lambda架构只通过流计算产生视图,删除了批处理层,将数据通道以消息队列的方式代替。
实时层、服务层和数据层。
2、Lambda架构的优缺点(1)优点:将实时和离线代码统一起来,方便维护而且统一了数据口径的问题,避免了Lambda架构中与离线数据合并的问题;查询历史数据的时候只需要重放存储的历史数据即可。
(2)缺点:消息中间件缓存的数据量和回溯数据有性能瓶颈。
通常算法需要过去180天的数据,如果都存在消息中间件,无疑有非常大的压力。
同时,一次性回溯订正180天级别的数据,对实时计算的资源消耗也非常大。
在实时数据处理时,遇到大量不同的实时流进行关联时,非常依赖实时计算系统的能力,很可能因为数据流先后顺序问题,导致数据丢失。
大数据读书笔记3000字

大数据读书笔记3000字随时随地注意收集客户数据、需求数据、产品数据、市场数据、资源数据等,经过整理,把它变成公司的数据资产;然后是要有据,信息与数据最大的不同,就是数据是能够度量或者确定的信息,不能“毛估估”,收集数据要精细化,要准确,下面是小编整理的关于的大数据读书笔记。
从徐子沛的《大数据》中得到的感悟数据,对于我们现代社社会来说,已经是再熟悉不过了。
大量化、多样化、快速化和大价值。
这四个v就是大数据的基本特征。
每天我们都不得不和数据打交道,比如我们平常所说得“眼观六路,耳听八方,”就是生活中一个很好的的收集数据的例子。
还有,在我们平时的学习中,我们对于一些学习上的数据的整理等等。
可以说,数据已经成为了我们的影子一样,无时无刻的在我们的身边活动。
拿到《大数据》这本书时,吸引我的不是书评的内容,而是书的封面上的一句话“除了上帝,任何人都可以用数据说话。
”也就是说,上帝可以不用数据来说话,但是,作为一个平常人,我们做事,言论等都必须用数据来说话。
用数据论来证我们的观点正确性。
那么数据真的就是那么重要吗?其实不然,数据果真有那么的重要。
作者在书中大量应用世界头号强国美国的例子来说明美国是如何利用数据以及数据在美国人的利用下,是如何造福美国人的。
使得美国人走上了民主、发展的道路。
书中还引用了大量的利用数据的案例,以及利用数据会有什么样的后果。
当然,作者在书中也很明确的表达了自己观点,也就是数据要被人利用,利用的好了,造福人类,否则,祸害无穷。
毫无疑问,我们正处在一个真正意义的大数据时代。
但是,大数据浪潮的来龙去脉如何?数据技术变革何以能推动政府信息的公开、透明和社会公正?又何以给我们带来无限的商机,既便利又危及我们每个人的生活?《大数据》给了我们一个很好的答案。
在拿到徐子沛《大数据》时,与其说这是个新概念,还不如说就是一个现实。
信息技术的迅速发展和普遍应用,存储能力的膨胀,网络传输的便捷,必然产生巨大的数据量。
大数据时代的读书笔记

大数据时代的读书笔记大数据时代的读书笔记篇1大数据时代的读书笔记一、背景介绍随着信息技术的飞速发展,大数据已经成为当今社会的一个重要议题。
本书《大数据时代》从多个角度深入探讨了大数据对各行各业的影响,以及在大数据时代下我们所面临的机遇和挑战。
二、深入分析本书强调了大数据的四大特征:海量化、多样化、高速化和价值化。
海量化指的是数据量的快速增长,多样化则是指数据类型的多样化,高速化则是指数据处理的速度和效率,价值化则是指如何在海量数据中提取出有价值的信息。
作者指出,大数据的四大特征对传统的数据处理和分析方法提出了挑战。
传统的数据处理方法主要依赖于手工操作和少量数据的分析,而在大数据时代,这些方法已经无法满足需求。
相反,我们需要使用更为先进的数据处理和分析技术,如云计算、人工智能等,来应对大数据带来的挑战。
此外,本书还介绍了大数据在医疗、金融、物流、社交媒体等多个领域的应用。
作者指出,大数据的应用可以带来许多优势,如提高效率、优化决策、提高客户满意度等。
但是,大数据的应用也面临着一些挑战,如数据安全和隐私保护等问题。
三、个人观点在阅读本书的过程中,我对大数据的应用有了更深入的理解。
我认为,大数据的应用可以带来许多机遇,但同时也需要我们注意数据安全和隐私保护等问题。
此外,我认为在大数据时代下,我们需要不断学习和掌握新的数据处理和分析技术,以应对大数据带来的挑战。
四、总结与展望本书对大数据时代进行了深入的探讨,为读者提供了有益的启示。
在未来,随着技术的不断进步和数据的不断增长,大数据的应用将会越来越广泛。
我相信,在大数据时代下,我们能够更好地应对挑战,抓住机遇,推动社会的进步和发展。
大数据时代的读书笔记为本网站原创作品,不得擅自转载!大数据时代的读书笔记篇2大数据时代的阅读笔记应由本人根据自身实际情况书写,以下仅供参考,请您根据自身实际情况撰写。
在大数据时代,我们面临着一系列的挑战和机遇。
*主要探讨了大数据时代的特点、挑战和机遇,以及如何应对这些挑战和机遇。
读书笔记——《大数据》·涂子沛

最小 数据集 :上升 到立法 高度的 开路先 锋
摘录:所谓的“管理信息系统”,也就是实现某一特定业务管理功能的软件。 概括:本节讲述了“最小数据集”的起源、出现、发展过程,然后讲述了信息管理系统 的兴起和普及。 心得:“最小数据集”的概念起源于美国的医疗领域,由于实用性,被迅速推广。随着 时间的推移,“最小数据集”演变成了一般的概念,在不少领域甚至被上升到了立法的高度。 “管理信息系统”的兴起将“最小数据集”的应用推上了新的高点,而“最小数据集”为信 息管理系统的开发和设计起了重要的铺垫作用。信息管理系统在美国大幅度地增加,提高了 政府的办事效率。
心得:奥巴马政府的基石是法治和透明,这也是奥巴马竞选过程中对选民的承诺,因为 奥巴马深知,他的根本任务是改变华盛顿的运行方式,致力于建设一个前所未有的开放政府, 重建公众对政府机关的信任。13489 号总统令放松了总统文件的管制,破除了布什总统对公
1 / 21
众查阅总统文件权利的限制。第一份总统令就拿前总统“开刀”,表明了奥巴马建立开放透 明政府的决心;首份总统备忘案《透明和开放的政府》则是对建立开放透明政府的执政理念 的强调;总统备忘案《 信息自由法》,法案开篇引用了美国著名大法官路易斯·布兰代斯的 名言“阳光 是最好的防腐剂”,是对建立开放透明政府的承诺和表达。三份文件的签署对于 美国政府的开放、透明和纪律有着重大意义,《信息自由法 》在信息技术领域印发了一顾新 的浪潮,起到引出本书主题的作用。
2021年大数据时代读书笔记

2021年大数据时代读书笔记大数据时代成为炙手可热的话题。
笔者在这说明信息和数据,只是试图首先说明信息、数据的关系和不同,也试图说明,为什么信息时代转变为了大数据时代?大数据时代带给了我们什么?下面是为大家精心整理了一些关于《大数据时代》读书笔记,欢迎查阅。
《大数据时代》读书笔记1《大数据时代》这本书主要描述的是大数据时代到临人们生活、工作与思维各方面所遇到的重大变革。
引言提出了大数据将给生活、工作于思维带来重大的变革。
一个例子是2019年H1N1流行病毒背景下谷歌通过检测检索词条,处理了4.5亿个不同的数据模型,通过预测并与2019年、2019年美国疾控中心记录的实际流感病例进行对比后,确定了45条检索词条组合,并将其用于一个特定的数学模型后,预测的结果与官方数据的相关系数高达97%。
按照传统的信息返回流程,通告新流感病毒病例将有一到两周的延迟。
对于飞速传播的疾病,信息滞后两周是致命的。
而谷歌运用大数据技术,以前所未有的方式,通过海量数据分析得出流感所传播的范围,为世界预测流感提供了一种更快捷的预测工具。
此外,我联想到原淘宝董事长马云通过大量数据分析得出2019年经济疲弱,为其商家提前做好迎接经济危机提供了时间缓冲。
关于大数据在商业领域的应用,Farecast公司是一个成功的典型范例。
该公司由奥伦·埃齐奥尼创办,利用机票的销售数据来预测未来的机票价格,旨在帮助用户在购买机票方面做出预测,并对机票价格走势预测的可信度标示出来供消费者查考。
Farecast系统利用近十万亿条价格记录预测的准确度达75%,使得使用Farecast票价预测工具购买机票的旅客,平均每张机票节约50美元。
而处理如此多的数据离开了大数据技术将无法进行。
也正是由于我们进入了一个前所未有的信息化时代,人们拥有了如此多的数据,才提供给我们利用大数据的分析处理手段,创造新的价值。
也许有人以为我们大数据时代的还未来临。
其实大数据技术早已渗透到我们中间,它被应用在垃圾邮件的过滤,新浪微博技术平台,谷歌翻译以及输入文字的自动纠错等。
大数据学习笔记——HDFS写入过程源码分析(1)
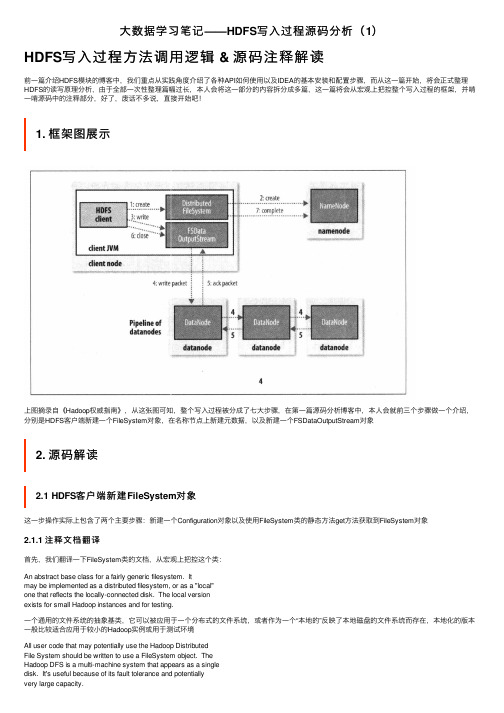
⼤数据学习笔记——HDFS写⼊过程源码分析(1)HDFS写⼊过程⽅法调⽤逻辑 & 源码注释解读前⼀篇介绍HDFS模块的博客中,我们重点从实践⾓度介绍了各种API如何使⽤以及IDEA的基本安装和配置步骤,⽽从这⼀篇开始,将会正式整理HDFS的读写原理分析,由于全部⼀次性整理篇幅过长,本⼈会将这⼀部分的内容拆分成多篇,这⼀篇将会从宏观上把控整个写⼊过程的框架,并啃⼀啃源码中的注释部分,好了,废话不多说,直接开始吧!1. 框架图展⽰上图摘录⾃《Hadoop权威指南》,从这张图可知,整个写⼊过程被分成了七⼤步骤,在第⼀篇源码分析博客中,本⼈会就前三个步骤做⼀个介绍,分别是HDFS客户端新建⼀个FileSystem对象,在名称节点上新建元数据,以及新建⼀个FSDataOutputStream对象2. 源码解读2.1 HDFS客户端新建FileSystem对象这⼀步操作实际上包含了两个主要步骤:新建⼀个Configuration对象以及使⽤FileSystem类的静态⽅法get⽅法获取到FileSystem对象2.1.1 注释⽂档翻译⾸先,我们翻译⼀下FileSystem类的⽂档,从宏观上把控这个类:An abstract base class for a fairly generic filesystem. Itmay be implemented as a distributed filesystem, or as a "local"one that reflects the locally-connected disk. The local versionexists for small Hadoop instances and for testing.⼀个通⽤的⽂件系统的抽象基类,它可以被应⽤于⼀个分布式的⽂件系统,或者作为⼀个“本地的”反映了本地磁盘的⽂件系统⽽存在,本地化的版本⼀般⽐较适合应⽤于较⼩的Hadoop实例或⽤于测试环境All user code that may potentially use the Hadoop DistributedFile System should be written to use a FileSystem object. TheHadoop DFS is a multi-machine system that appears as a singledisk. It's useful because of its fault tolerance and potentiallyvery large capacity.所有的可能会使⽤到HDFS的⽤户代码在进⾏编写时都应该使⽤FileSystem对象,HDFS⽂件系统是⼀个跨机器的系统,并且是⼀个单独的磁盘(即根⽬录)的形式出现的,这样的⽅式⾮常有⽤,是因为它的容错机制和海量的容量2.1.2 新建Configuration对象我们将断点打到下图为⽌,进⾏调试,来看看新建Configuration对象时究竟发⽣了些什么关键代码如下:static{//print deprecation warning if hadoop-site.xml is found in classpathClassLoader cL = Thread.currentThread().getContextClassLoader();if (cL == null) {cL = Configuration.class.getClassLoader();}if(cL.getResource("hadoop-site.xml")!=null) {LOG.warn("DEPRECATED: hadoop-site.xml found in the classpath. " +"Usage of hadoop-site.xml is deprecated. Instead use core-site.xml, "+ "mapred-site.xml and hdfs-site.xml to override properties of " +"core-default.xml, mapred-default.xml and hdfs-default.xml " +"respectively");}addDefaultResource("core-default.xml");addDefaultResource("core-site.xml");}由此可见,Configuration对象会加⼊两个默认的配置⽂件,core-default.xml以及core-site.xml2.1.3 获取FileSystem对象现在我们将断点打到下图位置:经过⽅法的层层调⽤,我们最终找到了FileSystem对象是通过调⽤getInternal⽅法得到的⾸先在getInternal⽅法中调⽤了createFileSystem⽅法进⼊createFileSystem⽅法,关键的来了!private static FileSystem createFileSystem(URI uri, Configuration conf) throws IOException {Class<?> clazz = getFileSystemClass(uri.getScheme(), conf);FileSystem fs = (FileSystem)ReflectionUtils.newInstance(clazz, conf);fs.initialize(uri, conf);return fs;}原来,FileSystem实例是通过反射的⽅式获得的,具体实现是通过调⽤反射⼯具类ReflectionUtils的newInstance⽅法并将class对象以及Configuration 对象作为参数传⼊最终得到了FileSystem实例2.2 在名称节点上新建元数据2.2.1 注释⽂档翻译此步骤⼀共涉及到这⼏个类,DistributedFileSystem,DFSClient以及DFSOutputStreamDistributedFileSystem类Implementation of the abstract FileSystem for the DFS system.This object is the way end-user code interacts with a HadoopDistributedFileSystem.在分布式⽂件系统上,抽象的FileSystem类的实现⼦类,这个对象是末端的⽤户代码⽤来与Hadoop分布式⽂件系统进⾏交互的⼀种⽅式DFSClient类DFSClient can connect to a Hadoop Filesystem andperform basic file tasks. It uses the ClientProtocolto communicate with a NameNode daemon, and connectsdirectly to DataNodes to read/write block data.Hadoop DFS users should obtain an instance ofDistributedFileSystem, which uses DFSClient to handlefilesystem tasks.DFSClient类可以连接到Hadoop⽂件系统并执⾏基本的⽂件任务,它使⽤ClientProtocal来与⼀个NameNode进程通讯,并且直接连接到DataNodes上来读取或者写⼊块数据,HDFS的使⽤者应该要获得⼀个DistributedFileSystem的实例,使⽤DFSClient来处理⽂件系统任务DFSOutputStream类DFSOutputStream creates files from a stream of bytes.DFSOutputStream从字节流中创建⽂件The client application writes data that is cached internally bythis stream. Data is broken up into packets, each packet istypically 64K in size. A packet comprises of chunks. Each chunkis typically 512 bytes and has an associated checksum with it.客户端写被这个流缓存在内部的数据,数据被切分成packets的单位,每⼀个packet⼤⼩是64K,⼀个packet是由chunks组成的,每⼀个chunk为512字节⼤⼩并且伴随⼀个校验和When a client application fills up the currentPacket, it isenqueued into dataQueue. The DataStreamer thread picks uppackets from the dataQueue, sends it to the first datanode inthe pipeline and moves it from the dataQueue to the ackQueue.The ResponseProcessor receives acks from the datanodes. When asuccessful ack for a packet is received from all datanodes, theResponseProcessor removes the corresponding packet from theackQueue.当⼀个客户端进程填满了当前的包时,它就会被排⼊数据队列(dataQueue),DataStreamer线程从数据队列中获取包并在管线将它发送到第⼀个datanode中去,然后把它从数据队列移动⾄确认队列(ackQueue),响应处理器(ResponseProcessor)从datanodes中接收确认回执,当⼀个包成功确认的回执被从所有的datanodes接收到时,响应处理器就会从确认队列中移除相应的数据包In case of error, all outstanding packets are moved fromackQueue. A new pipeline is setup by eliminating the baddatanode from the original pipeline. The DataStreamer nowstarts sending packets from the dataQueue.如果出现错误,所有未完成的包都会从确认队列中移除(同时会将packet移动到数据队列的末尾),通过从原始的管线中消除坏掉的datanode,⼀个新的管线被重新架设起来,DataStreamer开始从数据队列中发送数据包2.2.2 新建元数据源码解读先将断点打到下图位置,然后debug第⼀步调试,我们⾸先进⼊到的是FileSystem类,经过create⽅法的层层调⽤,最终我们找到了出⼝public FSDataOutputStream create(Path f,boolean overwrite,int bufferSize,short replication,long blockSize,Progressable progress) throws IOException {return this.create(f, FsPermission.getFileDefault().applyUMask(FsPermission.getUMask(getConf())), overwrite, bufferSize,replication, blockSize, progress);}继续调试,我们发现FSDataOutputStream是⼀个包装类,它是通过调⽤DistributedFileSystem类的create⽅法返回的,⽽查看代码可知,这个包装类所包装的,正是DFSOutputStream于是乎,第⼆个出⼝也被我们找到了@Overridepublic FSDataOutputStream create(final Path f, final FsPermission permission,final EnumSet<CreateFlag> cflags, final int bufferSize,final short replication, final long blockSize, final Progressable progress,final ChecksumOpt checksumOpt) throws IOException {statistics.incrementWriteOps(1);Path absF = fixRelativePart(f);return new FileSystemLinkResolver<FSDataOutputStream>() {@Overridepublic FSDataOutputStream doCall(final Path p)throws IOException, UnresolvedLinkException {final DFSOutputStream dfsos = dfs.create(getPathName(p), permission,cflags, replication, blockSize, progress, bufferSize,checksumOpt);return dfs.createWrappedOutputStream(dfsos, statistics);}继续调试,我们发现这个DFSOutputStream是从DFSClient类的create⽅法中返回过来的public DFSOutputStream create(String src,FsPermission permission,EnumSet<CreateFlag> flag,boolean createParent,short replication,long blockSize,Progressable progress,int buffersize,ChecksumOpt checksumOpt,InetSocketAddress[] favoredNodes) throws IOException {checkOpen();if (permission == null) {permission = FsPermission.getFileDefault();}FsPermission masked = permission.applyUMask(dfsClientConf.uMask);if(LOG.isDebugEnabled()) {LOG.debug(src + ": masked=" + masked);}final DFSOutputStream result = DFSOutputStream.newStreamForCreate(this,src, masked, flag, createParent, replication, blockSize, progress,buffersize, dfsClientConf.createChecksum(checksumOpt),getFavoredNodesStr(favoredNodes));beginFileLease(result.getFileId(), result);return result;}查看已标记了的关键代码,我们⼜发现,DFSClient类中的DFSOutputStream实例对象是通过调⽤DFSOutputStream类的的newStreamForCreate⽅法产⽣的,于是乎,我们单步进⼊这个⽅法,⼀探究竟,终于,我们找到了新建元数据的关键代码static DFSOutputStream newStreamForCreate(DFSClient dfsClient, String src,FsPermission masked, EnumSet<CreateFlag> flag, boolean createParent,short replication, long blockSize, Progressable progress, int buffersize,DataChecksum checksum, String[] favoredNodes) throws IOException {TraceScope scope =dfsClient.getPathTraceScope("newStreamForCreate", src);try {HdfsFileStatus stat = null;// Retry the create if we get a RetryStartFileException up to a maximum// number of timesboolean shouldRetry = true;int retryCount = CREATE_RETRY_COUNT;while (shouldRetry) {shouldRetry = false;try {stat = node.create(src, masked, dfsClient.clientName,new EnumSetWritable<CreateFlag>(flag), createParent, replication,blockSize, SUPPORTED_CRYPTO_VERSIONS);break;} catch (RemoteException re) {IOException e = re.unwrapRemoteException(AccessControlException.class,DSQuotaExceededException.class,FileAlreadyExistsException.class,FileNotFoundException.class,ParentNotDirectoryException.class,NSQuotaExceededException.class,RetryStartFileException.class,SafeModeException.class,UnresolvedPathException.class,SnapshotAccessControlException.class,UnknownCryptoProtocolVersionException.class);if (e instanceof RetryStartFileException) {if (retryCount > 0) {shouldRetry = true;retryCount--;} else {throw new IOException("Too many retries because of encryption" +" zone operations", e);}} else {throw e;}}}Preconditions.checkNotNull(stat, "HdfsFileStatus should not be null!");final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,flag, progress, checksum, favoredNodes);out.start();return out;} finally {scope.close();}}查看关键代码,我们发现这个stat对象是调⽤namenode的create⽅法产⽣的,⽽ctrl + 左键点击namenode后发现namenode正是之前注释⾥⾯提到的ClientProtocal的⼀个实例对象,⽽ClientProtocal是⼀个接⼝,它的⼀个实现⼦类名字叫做ClientNamenodeProtocalTranslatorPB就是我们想要的,我们找寻这个类的⽅法,最终发现了create⽅法⽽返回值是通过调⽤rpcProxy的create⽅法实现的,这⾥⽤到的是Google的Protobuf序列化技术@Overridepublic HdfsFileStatus create(String src, FsPermission masked,String clientName, EnumSetWritable<CreateFlag> flag,boolean createParent, short replication, long blockSize,CryptoProtocolVersion[] supportedVersions)throws AccessControlException, AlreadyBeingCreatedException,DSQuotaExceededException, FileAlreadyExistsException,FileNotFoundException, NSQuotaExceededException,ParentNotDirectoryException, SafeModeException, UnresolvedLinkException,IOException {CreateRequestProto.Builder builder = CreateRequestProto.newBuilder().setSrc(src).setMasked(PBHelper.convert(masked)).setClientName(clientName).setCreateFlag(PBHelper.convertCreateFlag(flag)).setCreateParent(createParent).setReplication(replication).setBlockSize(blockSize);builder.addAllCryptoProtocolVersion(PBHelper.convert(supportedVersions));CreateRequestProto req = builder.build();try {CreateResponseProto res = rpcProxy.create(null, req);return res.hasFs() ? PBHelper.convert(res.getFs()) : null;} catch (ServiceException e) {throw ProtobufHelper.getRemoteException(e);}}2.3 新建FSDataOutputStream对象之前讲解的是新建元数据的代码,⽽事实上,整个过程并未结束,还需要新建⼀个DFSOutputStream对象才⾏,同样在之前的newStreamForCreate ⽅法中,我们发现了以下⼏⾏代码,最终返回的是这个out对象,并且在返回之前,调⽤了out对象的start⽅法final DFSOutputStream out = new DFSOutputStream(dfsClient, src, stat,flag, progress, checksum, favoredNodes);out.start();return out;点进start⽅法,发现调⽤的是streamer对象的start⽅法private synchronized void start() {streamer.start();}点进streamer对象,发现它是DataStreamer类的⼀个实例,并且DataStreamer类是DFSOutputSteam的⼀个内部类,在这个类中,有⼀个⽅法叫做run⽅法,数据写⼊的关键代码就在这个run⽅法中实现@Overridepublic void run() {long lastPacket = Time.monotonicNow();TraceScope scope = NullScope.INSTANCE;while (!streamerClosed && dfsClient.clientRunning) {// if the Responder encountered an error, shutdown Responderif (hasError && response != null) {try {response.close();response.join();response = null;} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}}DFSPacket one;try {// process datanode IO errors if anyboolean doSleep = false;if (hasError && (errorIndex >= 0 || restartingNodeIndex.get() >= 0)) {doSleep = processDatanodeError();}synchronized (dataQueue) {// wait for a packet to be sent.long now = Time.monotonicNow();while ((!streamerClosed && !hasError && dfsClient.clientRunning&& dataQueue.size() == 0 &&(stage != BlockConstructionStage.DATA_STREAMING ||stage == BlockConstructionStage.DATA_STREAMING &&now - lastPacket < dfsClient.getConf().socketTimeout/2)) || doSleep ) { long timeout = dfsClient.getConf().socketTimeout/2 - (now-lastPacket); timeout = timeout <= 0 ? 1000 : timeout;timeout = (stage == BlockConstructionStage.DATA_STREAMING)?timeout : 1000;try {dataQueue.wait(timeout);} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}doSleep = false;now = Time.monotonicNow();}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}// get packet to be sent.if (dataQueue.isEmpty()) {one = createHeartbeatPacket();assert one != null;} else {one = dataQueue.getFirst(); // regular data packetlong parents[] = one.getTraceParents();if (parents.length > 0) {scope = Trace.startSpan("dataStreamer", new TraceInfo(0, parents[0]));// TODO: use setParents API once it's available from HTrace 3.2// scope = Trace.startSpan("dataStreamer", Sampler.ALWAYS);// scope.getSpan().setParents(parents);}}}// get new block from namenode.if (stage == BlockConstructionStage.PIPELINE_SETUP_CREATE) {if(DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("Allocating new block");}setPipeline(nextBlockOutputStream());initDataStreaming();} else if (stage == BlockConstructionStage.PIPELINE_SETUP_APPEND) { if(DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("Append to block " + block);}setupPipelineForAppendOrRecovery();initDataStreaming();}long lastByteOffsetInBlock = one.getLastByteOffsetBlock();if (lastByteOffsetInBlock > blockSize) {throw new IOException("BlockSize " + blockSize +" is smaller than data size. " +" Offset of packet in block " +lastByteOffsetInBlock +" Aborting file " + src);}if (one.isLastPacketInBlock()) {// wait for all data packets have been successfully ackedsynchronized (dataQueue) {while (!streamerClosed && !hasError &&ackQueue.size() != 0 && dfsClient.clientRunning) {try {// wait for acks to arrive from datanodesdataQueue.wait(1000);} catch (InterruptedException e) {DFSClient.LOG.warn("Caught exception ", e);}}}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}stage = BlockConstructionStage.PIPELINE_CLOSE;}// send the packetSpan span = null;synchronized (dataQueue) {// move packet from dataQueue to ackQueueif (!one.isHeartbeatPacket()) {span = scope.detach();one.setTraceSpan(span);dataQueue.removeFirst();ackQueue.addLast(one);dataQueue.notifyAll();}}if (DFSClient.LOG.isDebugEnabled()) {DFSClient.LOG.debug("DataStreamer block " + block +" sending packet " + one);}// write out data to remote datanodeTraceScope writeScope = Trace.startSpan("writeTo", span);try {one.writeTo(blockStream);blockStream.flush();} catch (IOException e) {// HDFS-3398 treat primary DN is down since client is unable to // write to primary DN. If a failed or restarting node has already // been recorded by the responder, the following call will have no // effect. Pipeline recovery can handle only one node error at a // time. If the primary node fails again during the recovery, it// will be taken out then.tryMarkPrimaryDatanodeFailed();throw e;} finally {writeScope.close();}lastPacket = Time.monotonicNow();// update bytesSentlong tmpBytesSent = one.getLastByteOffsetBlock();if (bytesSent < tmpBytesSent) {bytesSent = tmpBytesSent;}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}// Is this block full?if (one.isLastPacketInBlock()) {// wait for the close packet has been ackedsynchronized (dataQueue) {while (!streamerClosed && !hasError &&ackQueue.size() != 0 && dfsClient.clientRunning) {dataQueue.wait(1000);// wait for acks to arrive from datanodes }}if (streamerClosed || hasError || !dfsClient.clientRunning) {continue;}endBlock();}if (progress != null) { progress.progress(); }// This is used by unit test to trigger race conditions.if (artificialSlowdown != 0 && dfsClient.clientRunning) {Thread.sleep(artificialSlowdown);}} catch (Throwable e) {// Log warning if there was a real error.if (restartingNodeIndex.get() == -1) {DFSClient.LOG.warn("DataStreamer Exception", e);}if (e instanceof IOException) {setLastException((IOException)e);} else {setLastException(new IOException("DataStreamer Exception: ",e)); }hasError = true;if (errorIndex == -1 && restartingNodeIndex.get() == -1) {// Not a datanode issuestreamerClosed = true;}} finally {scope.close();}}closeInternal();}private void closeInternal() {closeResponder(); // close and joincloseStream();streamerClosed = true;setClosed();synchronized (dataQueue) {dataQueue.notifyAll();}}。
大数据管理与应用专业笔记

大数据管理与应用专业笔记第一章:大数据概述1.1 大数据概念大数据是指规模巨大、复杂性高、多样性的数据集合,其处理和分析传统的数据管理技术无法胜任。
大数据能够包含结构化数据、半结构化数据和非结构化数据,来自多个来源,包括传感器数据、社交媒体、文本数据、音频和视频等。
在当今数字化时代,大数据已成为重要的资源和竞争优势,对各行各业产生了深远的影响。
1.2 大数据特点大数据具有“四V”特点,即Volume(数据量大)、Velocity(数据处理速度快)、Variety(数据多样化)、Value(价值密度低)。
这些特点对大数据管理与应用提出了挑战,也为其带来了巨大的机遇。
第二章:大数据管理技术2.1 数据采集与存储大数据管理的第一步是数据的采集与存储。
数据采集涉及到从各种来源收集数据,包括传感器、互联网、移动设备等。
数据存储则需要考虑如何有效地存储大规模的数据,包括分布式存储、云存储、NoSQL数据库等技术。
2.2 数据清洗与预处理大数据往往包含大量的冗余信息、噪声和错误数据,需要进行数据清洗与预处理,以提高数据质量和准确性。
数据清洗与预处理包括数据去重、缺失值处理、异常值检测等过程。
2.3 数据分析与挖掘数据分析与挖掘是大数据处理的核心环节,包括数据的建模、模式识别、预测分析、文本挖掘、图像处理等。
传统的数据分析技术已不能满足大数据分析的需求,需要引入并行计算、分布式计算、机器学习等技术。
第三章:大数据应用3.1 金融风控大数据在金融领域有着广泛的应用,通过对大规模数据的分析,可以实现风险评估、欺诈检测、信用评分等。
金融机构可以利用大数据技术更好地管理风险,降低不良贷款率。
3.2 医疗健康大数据在医疗健康领域的应用包括疾病预测、个性化治疗、医疗资源配置等。
通过对大量病例数据的分析,可以为临床决策提供数据支持,提高诊断精度和治疗效果。
3.3 智慧城市大数据技术可以帮助城市管理部门更好地监控城市运行状态,提高城市管理效率,解决交通拥堵、环境污染等城市化问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、大数据,云计算,AI概述
1、背景及来源
大数据的背景:20世纪开始,政府和各行业(如医疗、通信、交通、金融等)信息化的发展,积累了海量数据。
而且目前数据增长速度越来越快。
如何实现对海量数据的存储、查询、分析,使之产生商业价值,是目前面临的主要挑战。
2、大数据的定义
目前没有统一的大数据的定义。
Gartner:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
麦肯锡:大数据指的是大小超出常规的数据库工具获取、存储、管理和分析能力的数据集。
但它同时强调,并不是说一定要超过特定TB 值的数据集才能算是大数据。
维基百科:大数据是指无法在一定时间内用常规软件工具对其内容进行抓取、管理和处理的数据集合.
总结成一句话、大数据实际上不是一项单一的技术,而是一个概念,一套技术,一个生态圈。
3、大数据的4大特征
第一个特征:数据量大(Volume).
第二个特征:数据类型繁多(Variety)
第三个特征:价值密度低(Value)
第四个特征是速度快、时效高(Velocity)。
4、大数据生态圈
框架:Hadoop、Spark
集群管理:MapReduce、Yarn、Mesos
开发语言:Java、Python、Scala、Pig、Hive、SparkSQL。
数据库:NoSQL、HBase、Cassandra、Impala。
文件系统:HDFS、Ceph。
搜索系统:Elastic Search
采集系统:Flume、Sqoop、Kafka
流式处理:Spark Streaming、Storm
发行版:HortonWorks、Cloudera、MapR
集群管理:Ambari、大数据管理平台
机器学习:Spark MLLib、Mahout
5、大数据应用
大数据的应用已经深入到各行各业各领域,如金融(银行、证券、P2P)、互联网、通信、交通、医疗、环保等等!
6、大数据应用:案例分享
案例:无线通信大数据平台VMAX
数据量:以深圳市南山区为例,一天大概2T的数据。
功能:无线网络质量监控、布网规划和优化
技术:Hadoop+SPARK+HBASE+Kafka+…
硬件配置:联想服务器(Linux环境,30台,每台40核,256G内存,12个4T外挂盘)
过程:开发+优化升级+运维
7、大数据应用:思维的转变
第一个思维变革:利用所有的数据,而不再仅仅依靠部分数据,即不是随机样本,而是全体数据。
第二个思维变革:我们唯有接受不精确性,才有机会打开一扇新的世界之窗,即不是精确性,而是混杂性。
第三个思维变革:不是所有的事情都必须知道现象背后的原因,而是要让数据自己“发声”,即不是因果关系,而是相关关系。
8、大数据应用:面临的问题
存储和计算问题
成本问题
数据质量问题
数据安全问题
9、大数据应用中的一些坑
大数据不是万能良方,发挥不出价值就只是一片坟墓
第一:数据它首先是成本,其次才是价值,要让价值作为一个取舍对象。
而不是为了建一个数据中心而建一个数据中心。
第二:千万不要试图用我们的理念去束缚计算机,要把大数据和人工智能用来解决企业问题的时候,我们要抓住的是企业真正要解决的目标是什么,然后我们要去尊重计算机的方法。
第三:不要用自己的人类语言套计算机身上,计算机在提供可预测性的时候,不一定提供可解释性,在提供可解释性的时候,不一定给出非常好的预测建议。
10、大数据应用:一些建议
注重数据的积累。
重视大数据技术。
重视大数据人才的培养。
时刻注意数据安全和法律合规风险。
二、大数据与云计算。
1、云计算(CloudComputing)的定义
云计算(CloudComputing):是基于互联网的相关服务的增加、使用和交付模式,通常涉及通过互联网来提供动态易扩展且经常是虚拟化的资源。
云计算是分布式计算(Distributed Computing)、并行计算(Parallel Computing)、效用计算(Utility Computing)、网络存储(Network Storage Technologies)、虚拟化(Virtualization)、负载均衡(Load Balance)、热备份冗余(High Available)等传统计算机和网络技术发展融合的产物。
2、云计算的特点
(1) 超大规模
(2) 虚拟化
(3) 高可靠性
(4) 通用性
(5) 高可扩展性
(6) 按需服务
(7) 价格廉价
(8) 潜在的危险性
3、云计算的服务形式
IaaS:基础设施即服务
PaaS:平台即服务
SaaS:软件即服务
4、目前已有的云计算平台
IaaS:AWS、Azure、GCP等;
Paas:GCP、IBM、Oracle、Azure等;
DELL、EMC、Oracle、Teradata和惠普等提供大数据系统一体机服务;
国内有:阿里云、腾讯云、平安云、华为云等。
5、为什么要用云计算?
大数据基础架构的特征,必须要支持节点的横向扩展,既然实现了通过横向扩展的架构来提高性能,就没必要在每个节点上花费太多的钱。
大数据的高可用性是通过软件设计和架构设计实现的,而不是通过传统的高性能、高可用性的高端硬件设备来实现的。
6、大数据与云计算:今后的趋势如何?
未来的趋势是:云计算平台作为存储和计算的底层,支撑着上层的大数据处理,而大数据的发展为云计算的落地找到而更多的实际应用。
大数据和云计算的融合是今后的重大趋势,两者相辅相成。
三、大数据与AI
1、定义
人工智能(Artificial Intelligence),简称AI。
意为机器对人脑认知思维功能的模拟。
2、大数据与AI的关系。
数据是AI发展的粮食和催化剂,如今的人工智能不如说是数据智能,人工智能其实就是用大量的数据作导向,让需要机器来做判别的问题最终转化为数据问题。
3、AI、机器学习、深度学习的关系
AI≠机器学习≠深度学习。