标准差与估计标准差
标准差和标准差估计值

标准差和标准差估计值标准差是统计学中常用的一种测量数据分散程度的方法,它能够反映一组数据的离散程度。
在实际应用中,我们经常需要对总体的标准差进行估计,这就引入了标准差的估计值。
本文将对标准差和标准差估计值进行详细介绍,希望能够帮助读者更好地理解和运用这两个概念。
首先,我们来了解一下标准差的概念。
标准差是一组数据离散程度的度量,它的大小反映了数据的波动程度。
标准差越大,说明数据的离散程度越大;标准差越小,说明数据的离散程度越小。
标准差的计算公式如下:\[ \sigma = \sqrt{\frac{\sum_{i=1}^{n}(x_i \overline{x})^2}{n}} \]其中,\( \sigma \) 表示标准差,\( x_i \) 表示第 i 个数据点,\( \overline{x} \) 表示数据的平均值,n 表示数据的个数。
通过这个公式,我们可以计算出一组数据的标准差,从而了解数据的离散程度。
接下来,我们将介绍标准差的估计值。
在实际应用中,我们往往无法获得总体的全部数据,而是通过抽样得到一部分数据。
因此,我们需要对总体的标准差进行估计。
常用的标准差估计值有样本标准差和无偏估计标准差。
样本标准差是通过样本数据计算得到的标准差,它的计算公式如下:\[ s = \sqrt{\frac{\sum_{i=1}^{n}(x_i \overline{x})^2}{n-1}} \]其中,s 表示样本标准差,\( x_i \) 表示第 i 个样本数据点,\( \overline{x} \) 表示样本数据的平均值,n 表示样本数据的个数。
样本标准差通常会略微高估总体标准差,因此在实际应用中,我们常常使用无偏估计标准差。
无偏估计标准差是对总体标准差的无偏估计,它的计算公式如下:\[ s = \sqrt{\frac{\sum_{i=1}^{n}(x_i \overline{x})^2}{n-1}} \]无偏估计标准差通过对样本标准差进行修正,消除了样本标准差高估总体标准差的影响,因此在实际应用中更加准确可靠。
用样本的均值标准差估计总体的均值标准差

与总体标准差的关系:样本标准差是总体标准差的估计值,当样本量足够大时,样本 标准差接近总体标准差。
样本量大小的影响:样本量越大,样本标准差越接近总体标准差,估计的准确性越高。
总体标准差的估计
定义:总体标准差是总体各单位标 志值与总体均值的离差平方的算术 平均数的平方根。
样本量增加对估计的影响
降低估计误差:样本量越大,估计的准确性越高,误差范围越小。 提高估计精度:样本量增加有助于更准确地估计总体参数。 降低抽样风险:样本量增加可以降低由于抽样误差导致的风险。 更稳定的结果:样本量越大,估计结果越稳定,不易受到个别异常值的影响。
Part Five
样本变异系数对估 计的影响
变异系数与总体标准差的关系
变异系数的定义:变异系数是标准差与均 值的比值,用于衡量数据的相对波动性。
变异系数对估计总体标准差的影响:样本 变异系数越小,对总体标准差的估计越准 确。
样本量对变异系数的影响:样本量越大, 变异系数越小,对总体标准差的估计越准 确。
变异系数与总体标准差的关系:总体标 准差越大,变异系数也越大,样本变异 系数对估计总体标准差的影响也越大。
样本均值和标准差对总 体均值和标准差的估计
XX,a click to unlimited possibilities
汇报人:XX
目录
01 添 加 目 录 项 标 题 03 样 本 标 准 差 和 总 体
标准差的估计
05 样 本 变 异 系 数 对 估 计的影响
02 样 本 均 值 和 总 体 均 值的估计
不准确。
Part Six
样本分布对估计的 影响
正态分布对估计的影响
标准误差和估计标准误差

标准误差和估计标准误差
标准误差和估计标准误差是统计学中常用的两个概念,用于衡量样本均值或估计量与
总体参数之间的差异。
我们来介绍一下标准误差。
标准误差表示样本均值或估计量在多次抽样中的变动情况。
它是通过计算样本观测值与样本均值之间的离差来衡量样本的离散程度。
标准误差的计算
公式如下:
标准误差 = 标准差/ √样本容量
标准差是用来描述样本数据总体分布与样本均值之间的差异程度的度量。
样本容量是
指样本中观测值的数量。
接下来,我们介绍一下估计标准误差。
估计标准误差是用于衡量估计量的不确定性。
在统计推断中,我们通常使用样本统计量来估计总体参数。
估计标准误差反映了用样本统
计量进行估计时的不确定性程度。
估计标准误差的计算方法与标准误差类似,只是标准差
的计算方式略有不同,具体计算公式如下:
估计标准误差= √((1-样本相关系数^2) * 总体方差 / 样本容量)
需要注意的是,标准误差和估计标准误差都是用来衡量样本数据和总体参数之间的差异,其中标准误差是通过样本数据来计算的,而估计标准误差是通过样本统计量来进行估
计的。
它们在统计模型的拟合性和参数估计的精度评估中起到重要的作用。
标准差的无偏估计

标准差的无偏估计标准差是一组数据离散程度的度量,它衡量了数据点与其平均值的偏离程度。
在统计学中,我们经常需要对总体的标准差进行估计,而其中的一个重要概念就是无偏估计。
本文将对标准差的无偏估计进行详细介绍,并探讨其在实际应用中的重要性。
首先,我们来了解一下标准差的定义。
标准差是一组数据离散程度的度量,它是方差的平方根。
方差是每个数据点与平均值的差的平方的平均值,而标准差则是方差的平方根。
标准差越大,代表数据点越分散;标准差越小,代表数据点越集中。
在实际应用中,我们通常无法得知总体的标准差,因此需要通过样本来估计总体的标准差。
而样本的标准差通常是对总体标准差的一个估计值。
然而,样本标准差的计算方法会导致其估计值偏小,这就引出了无偏估计的概念。
无偏估计是指估计量的期望值等于被估计参数的真实值。
在样本标准差的情况下,我们知道样本标准差的计算公式中分母是n-1而不是n。
这是因为在计算样本方差时,我们用样本均值代替总体均值,而样本均值本身也是通过样本数据计算得到的,因此引入了一个自由度的损失,需要通过n-1来进行修正,从而得到无偏估计。
无偏估计的重要性在于,它能够更准确地估计总体参数,避免了由于样本误差而导致的估计偏差。
在统计推断和实际应用中,我们通常希望得到对总体参数更准确的估计,这就需要使用无偏估计来进行估计。
总之,标准差的无偏估计是统计学中一个重要的概念,它能够帮助我们更准确地估计总体的标准差,避免了由于样本误差而导致的估计偏差。
在实际应用中,我们应该充分理解无偏估计的原理,并合理地应用到实际问题中,以确保我们得到的估计结果更加准确可靠。
标准差估计值计算公式

标准差估计值计算公式
标准差计算公式是标准差σ=方差开平方。
标准差,中文环境中又常称均方差,是离均差平方的算术平均数的平方根,用σ表示。
在概率统计中最常使用作为统计分布程度上的测量。
标准差是方差的算术平方根。
标准差能反映一个数据集的离散程度。
方差和标准差是测算离散趋势最重要、最常用的指标。
方差是各变量值与其均值离差平方的平均数,它是测算数值型数据离散程度的最重要的`方法。
标准差为方差的算术平方根,用s表示。
标准差可以当做不确定性的一种测量。
比如在物理科学中,搞重复性测量时,测量数值子集的标准差代表这些测量的精确度。
当要同意测量值与否合乎预测值,测量值的标准差占据决定性关键角色:如果测量平均值与预测值差距太远,则指出测量值与预测值互相矛盾。
标准差的有关介绍及标准差计算公式标准差标准差

标准差的有关介绍及标准差计算公式标准差标准差标准差的有关介绍及标准差计算公式标准差标准差(Standard Deviation) 也称均方差(mean square error)各数据偏离平均数的距离(离均差)的平均数,它是离均差平方和平均后的方根。
用& sigma;表示。
因此标准差是方差的算术平方根。
例如:如果有n个数据X1 ,X2 ,X3……Xn ,数据的平均数为X,标准差c :标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B72、71、69、68、67。
这两组的平均数都是70,但A组的标准差为18.71分,B组组的分数为73、的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
标准差也被称为标准偏差,或者实验标准差。
关于这个函数在EXCEL中的STDEV函数有详细描述,EXCEL中文版里面就是用的“标准偏差”字样。
但我国的中文教材等通常还是使用的是“标准差”。
在EXCEL中STDEV函数就是下面评论所说的另外一种标准差,也就是总体标准差。
在繁体中文的一些地方可能叫做“母体标准差”在R统计软件中标准差的程序为:sum((x-mean(x)F2)/(length(x)-1) 因为有两个定义,用在不同的场合:如是总体,标准差公式根号内除以n,如是样本,标准差公式根号内除以(n-1),因为我们大量接触的是样本,所以普遍使用根号内除以(n-1),外汇术语:标准差指统计上用于衡量一组数值中某一数值与其平均值差异程度的指标。
标准差被用来评估价格可能的变化或波动程度。
标准差越大,价格波动的范围就越广,股票等金融工具表现的波动就越大。
阐述及应用简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。
一个较大的标准差,代表大部分的数值和其平均值之间差异较大; 一个较小的标准差,代表这些数值较接近平均值。
标准差的有关介绍及标准差计算公式标准差标准差

标准差的有关介绍及标准差计算公式标准差标准差标准差的有关介绍及标准差计算公式标准差标准差(Standard Deviation) 也称均方差(mean square error)各数据偏离平均数的距离(离均差)的平均数,它是离均差平方和平均后的方根。
用σ表示。
因此标准差是方差的算术平方根。
例如:如果有n个数据X1 ,X2 ,X3 ......Xn ,数据的平均数为X,标准差σ: 标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B72、71、69、68、67。
这两组的平均数都是70,但A组的标准差为18.71分,B组组的分数为73、的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
标准差也被称为标准偏差,或者实验标准差。
关于这个函数在EXCEL中的STDEVP函数有详细描述,EXCEL中文版里面就是用的“标准偏差”字样。
但我国的中文教材等通常还是使用的是“标准差”。
在EXCEL中STDEVP函数就是下面评论所说的另外一种标准差,也就是总体标准差。
在繁体中文的一些地方可能叫做“母体标准差”在R统计软件中标准差的程序为: sum((x-mean(x))^2)/(length(x)-1)因为有两个定义,用在不同的场合:如是总体,标准差公式根号内除以n,如是样本,标准差公式根号内除以(n-1),因为我们大量接触的是样本,所以普遍使用根号内除以(n-1),外汇术语:标准差指统计上用于衡量一组数值中某一数值与其平均值差异程度的指标。
标准差被用来评估价格可能的变化或波动程度。
标准差越大,价格波动的范围就越广,股票等金融工具表现的波动就越大。
阐述及应用简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。
一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
估计标准误差公式

估计标准误差公式在统计学中,估计标准误差是一种用来衡量统计估计值的精确度的指标。
它可以帮助我们了解估计值与真实值之间的偏差程度,进而评估统计模型的准确性。
在本文中,我们将介绍估计标准误差的计算公式及其应用。
估计标准误差通常用来衡量样本统计量与总体参数之间的偏差。
在实际应用中,我们往往无法得知总体参数的真实数值,只能通过样本统计量来进行估计。
而估计标准误差则可以帮助我们评估样本统计量的稳定性和准确性。
估计标准误差的计算公式如下:\[SE = \frac{s}{\sqrt{n}}\]其中,SE代表估计标准误差,s代表样本标准差,n代表样本容量。
这个公式告诉我们,估计标准误差与样本标准差成正比,与样本容量的平方根成反比。
也就是说,样本标准差越大,估计标准误差就越大;而样本容量越大,估计标准误差就越小。
在实际应用中,我们可以利用估计标准误差来计算置信区间。
置信区间是用来估计总体参数的范围,一般情况下,我们希望总体参数落在置信区间内的概率较高。
而估计标准误差可以帮助我们确定置信区间的宽度,进而评估统计估计值的精确度。
除了计算置信区间,估计标准误差还可以用来进行假设检验。
在假设检验中,我们通常会计算统计量的标准误差,进而判断样本统计量与总体参数之间的偏差是否显著。
如果统计量的偏差超过了一定的标准误差范围,我们就可以拒绝原假设,认为样本统计量与总体参数存在显著差异。
总的来说,估计标准误差是统计学中一项重要的指标,它可以帮助我们评估统计估计值的精确度,进而进行置信区间估计和假设检验。
通过合理地利用估计标准误差,我们可以更加准确地进行统计推断,为决策提供科学依据。
在实际应用中,我们需要注意估计标准误差的计算方法和应用条件,避免在统计推断中出现错误的结论。
同时,我们也可以通过增加样本容量和提高数据质量来降低估计标准误差,提高统计估计值的精确度。
希望本文对您有所帮助,谢谢阅读!。
(整理)标准差与估计标准差

2-3 變異的計算及解析由基礎課程裡我們可以知道:表示變異的方法有很多,其最常使用的是“標準差”;關於標準差的計算又分兩個觀念:(真)標準差σ與估計標準差σˆ。
為了解釋這兩個觀念的差異,我們先看下例數據:下例數據有經過分組,每組抽測5個數據(即S/S 或n = 5的意思)。
分組的原因不外乎量產、或長期研究等, 需要分批量測而形成母體與樣本的關係。
(1)(真)標準差σ:若將所有Raw Data 視為一個母體、混合不分組,則=STDEV( )所計算出來的標準差即為所求,即工程師最熟悉的算法。
--------------------------------------------------------------使用時機:a.) 想了解母體真正的變異的時候;b.) 想敏銳地抓出上圖/組間變異的異常的時候。
---------------------------------目的:了解整個母體的總變異。
優點:可以充分反映整個母體的異常(含上圖/組間變異、及下圖/組內變異的異常…尤其是組間變異的異常)。
缺點:數據量要夠大(避免誤差過大)、且上圖不能有異常(避免組間變異顯著),否則計算出來的σ不具代表性。
(2) 估計標準差σˆ:大部分的工程師沒聽說過估計標準差。
Raw Data 若經過分組(分組與抽樣皆要隨機),我們可以利用樣本的變異、去估算整個母體的變異;但是要特別注意組間變σ)已經被假設成常態分配;以白話來說:想像管制異(X圖-上圖的每個組平均X是一顆綠豆,當這些綠豆被一把撒到管制圖-上圖的時候,這些綠豆皆自動定位到常態分配該有的位置上,因此整個上圖的假設都是常態分配,若真有異常、也早已被視而不見。
故以估計標準差σˆ來看問題,祇能解析下圖/組內變異的異常(即管理面的異常:如某單一人/機抽樣技術不穩定的問題、某單一作業機台不穩定的問題、某個別材料品質不穩定的問題等⎡一般因⎦…主要還是抽樣技術不穩定的問題)。
标准差的有关介绍及标准差计算公式标准差标准差
标准差的有关介绍及标准差计算公式标准差标准差标准差的有关介绍及标准差计算公式标准差标准差(Standard Deviation) 也称均方差(mean square error)各数据偏离平均数的距离(离均差)的平均数,它是离均差平方和平均后的方根。
用σ表示。
因此标准差是方差的算术平方根。
例如:如果有n个数据X1 ,X2 ,X3 ......Xn ,数据的平均数为X,标准差σ: 标准差能反映一个数据集的离散程度。
平均数相同的,标准差未必相同。
例如,A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45,B72、71、69、68、67。
这两组的平均数都是70,但A组的标准差为18.71分,B组组的分数为73、的标准差为2.37分(此数据时在R统计软件中运行获得),说明A组学生之间的差距要比B组学生之间的差距大得多。
标准差也被称为标准偏差,或者实验标准差。
关于这个函数在EXCEL中的STDEVP函数有详细描述,EXCEL中文版里面就是用的“标准偏差”字样。
但我国的中文教材等通常还是使用的是“标准差”。
在EXCEL中STDEVP函数就是下面评论所说的另外一种标准差,也就是总体标准差。
在繁体中文的一些地方可能叫做“母体标准差”在R统计软件中标准差的程序为: sum((x-mean(x))^2)/(length(x)-1)因为有两个定义,用在不同的场合:如是总体,标准差公式根号内除以n,如是样本,标准差公式根号内除以(n-1),因为我们大量接触的是样本,所以普遍使用根号内除以(n-1),外汇术语:标准差指统计上用于衡量一组数值中某一数值与其平均值差异程度的指标。
标准差被用来评估价格可能的变化或波动程度。
标准差越大,价格波动的范围就越广,股票等金融工具表现的波动就越大。
阐述及应用简单来说,标准差是一组数值自平均值分散开来的程度的一种测量观念。
一个较大的标准差,代表大部分的数值和其平均值之间差异较大;一个较小的标准差,代表这些数值较接近平均值。
总体标准差σ的五种估计及估计精密度
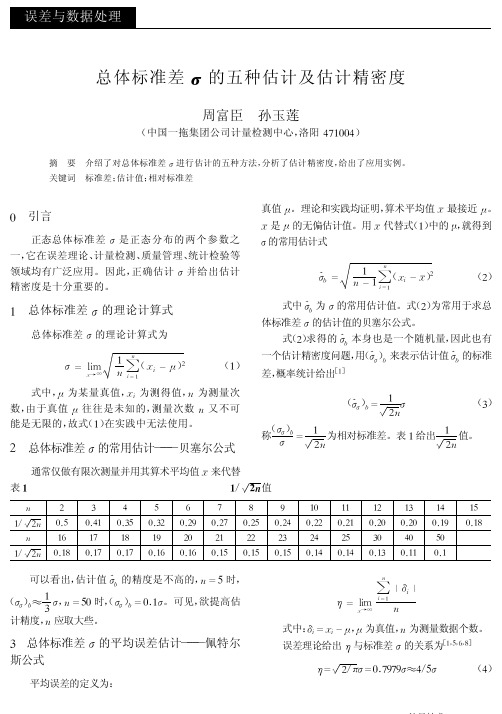
总体标准差!的五种估计及估计精密度周富臣孙玉莲(中国一拖集团公司计量检测中心,洛阳471004)摘要介绍了对总体标准差O 进行估计的五种方法,分析了估计精密度,给出了应用实例。
关键词标准差;估计值;相对标准差引言正态总体标准差O 是正态分布的两个参数之一,它在误差理论、计量检测、质量管理、统计检验等领域均有广泛应用。
因此,正确估计O 并给出估计精密度是十分重要的。
1总体标准差O 的理论计算式总体标准差O 的理论计算式为O =li m一17Z 7=1( _I )。
2(1)式中,I 为某量真值,为测得值,7为测量次数,由于真值I 往往是未知的,测量次数7又不可能是无限的,故式(1)在实践中无法使用。
2总体标准差O 的常用估计———贝塞尔公式通常仅做有限次测量并用其算术平均值 来代替真值I 。
理论和实践均证明,算术平均值 最接近I 。
是I 的无偏估计值。
用 代替式(1)中的!,就得到"的常用估计式^O b =17_1Z 7=1( _ )。
2(2)式中^O b 为O 的常用估计值。
式(2)为常用于求总体标准差O 的估计值的贝塞尔公式。
式(2)求得的^O b 本身也是一个随机量,因此也有一个估计精密度问题,用(^O O )b 来表示估计值^O b 的标准差,概率统计给出[1](^O O )b =12。
7O (3)称(O O )bO =12。
7为相对标准差。
表1给出12。
7值。
表!!/"。
!值7234567891011121314151/2。
70.50.410.350.320.290.270.250.240.220.210.200.200.190.187161718192021222324253040501/2。
70.180.170.170.160.160.150.150.150.140.140.130.110.1可以看出,估计值^O b 的精度是不高的,7=5时,(O O )b 。
13O ,7=50时,(O O )b =0.1O 。
标准差的无偏估计

标准差的无偏估计标准差是描述数据离散程度的重要统计量,它衡量了数据集合中各个数据点与均值的偏离程度。
然而,在实际应用中,我们往往无法得到整个总体的数据,而只能通过样本来估计总体的标准差。
因此,对于样本标准差的估计就显得至关重要。
本文将介绍标准差的无偏估计方法,帮助读者更好地理解和应用统计学中的相关概念。
首先,让我们回顾一下标准差的定义。
标准差是方差的平方根,而方差则是各数据点与均值的差的平方的平均数。
在统计学中,我们通常用σ表示总体标准差,用s表示样本标准差。
而在对总体标准差进行估计时,我们需要使用无偏估计方法,以减小估计值与真实值之间的偏差。
无偏估计是指在一组估计值的平均数等于被估计参数的真实值的估计方法。
对于标准差的无偏估计,我们通常使用修正样本标准差来进行估计。
修正样本标准差的计算公式为:s = sqrt(Σ(xi x̄)² / (n-1))。
其中,s表示修正样本标准差,xi表示第i个数据点,x̄表示样本均值,n表示样本容量。
可以看出,修正样本标准差的计算方法与样本标准差的计算方法相似,只是在分母上除以了n-1而不是n。
这是因为在样本标准差的计算中,我们使用了样本均值来代替总体均值,从而引入了估计误差,而将分母调整为n-1可以减小这种估计误差,使得修正样本标准差成为总体标准差的无偏估计。
需要注意的是,修正样本标准差的无偏性是建立在样本是来自正态分布总体的基础上的。
对于非正态分布的样本,修正样本标准差可能并不是总体标准差的无偏估计。
因此,在实际应用中,我们需要根据具体情况来选择合适的估计方法。
除了修正样本标准差外,还有其他无偏估计方法,比如贝塞尔校正。
贝塞尔校正是一种常用的无偏估计方法,它通过在计算样本方差时将分母调整为n-1来减小估计误差。
贝塞尔校正的优点是简单易行,适用范围广泛,因此在实际应用中得到了广泛的应用。
总之,标准差的无偏估计是统计学中的重要概念,它帮助我们更准确地估计总体标准差,从而更好地理解和分析数据。
统计学的标准差计算

统计学的标准差计算标准差是统计学中常用的一种测量数据离散程度的方法,它可以帮助我们了解数据的分布情况,对数据的稳定性和可靠性进行评估。
在实际应用中,标准差的计算方法有多种,我们可以根据具体情况选择适合的方法进行计算。
下面我们将详细介绍标准差的计算方法及其在统计学中的应用。
首先,我们来了解一下标准差的定义。
标准差是一组数据的离散程度的度量,它衡量的是数据点与其均值之间的平均距离。
标准差越大,说明数据点相对于均值的离散程度越大;标准差越小,说明数据点相对于均值的离散程度越小。
因此,标准差可以帮助我们判断数据的分布情况,对数据进行比较和分析。
接下来,我们将介绍标准差的计算方法。
标准差的计算方法有两种,分别是总体标准差的计算方法和样本标准差的计算方法。
总体标准差是用来描述整个数据集的离散程度,而样本标准差是用来描述从总体中抽取的样本数据的离散程度。
总体标准差的计算方法如下:1. 首先计算所有数据点与均值的差值。
2. 然后将这些差值的平方求和。
3. 最后将平方和除以数据点的个数,再取平方根即可得到总体标准差。
样本标准差的计算方法与总体标准差类似,不同之处在于在计算平方和时需要除以数据点的个数减一。
这是因为在计算样本标准差时,我们使用样本数据来估计总体数据的离散程度,因此需要对计算结果进行修正。
在实际应用中,我们可以根据数据的特点和需求选择合适的标准差计算方法。
如果我们需要描述整个数据集的离散程度,可以选择总体标准差的计算方法;如果我们需要描述从总体中抽取的样本数据的离散程度,可以选择样本标准差的计算方法。
除了了解标准差的计算方法,我们还需要掌握标准差在统计学中的应用。
标准差可以帮助我们进行数据的比较和分析,例如在质量控制中,我们可以使用标准差来评估产品质量的稳定性;在金融领域,我们可以使用标准差来衡量投资组合的风险;在医学研究中,我们可以使用标准差来评估治疗效果的稳定性等等。
总之,标准差是统计学中非常重要的概念,它可以帮助我们了解数据的分布情况,对数据的稳定性和可靠性进行评估。
标准差概念

标准差概念标准差是统计学中一项重要的概念,用于衡量一组数据或概率分布的离散程度。
它是方差的平方根,代表了数据点离平均值的平均距离。
标准差的计算可分为两种情况,分别是针对总体和样本。
对于总体而言,标准差的计算公式如下:σ = √(Σ(xi - μ)² / N)其中,σ表示标准差,Σ表示求和符号,xi表示第i个数据点,μ表示总体的平均值,N表示总体中的数据点个数。
对于样本而言,标准差的计算公式稍有不同:s = √(Σ(xi - x)² / (n-1))其中,s表示样本的标准差,n表示样本的数据点个数,x表示样本的平均值。
需要注意的是,在样本的计算公式中,除以的是n-1而不是n。
这是因为在样本的计算中,标准差需要通过样本估计总体的离散程度,所以需要使用除以n-1的修正系数。
标准差衡量了数据或概率分布的离散程度,它越大代表数据点离平均值越远,离散程度越高。
相反,标准差越小代表数据点离平均值越近,离散程度越低。
标准差的应用非常广泛。
首先,在统计学和概率论中,标准差是常用的统计量之一,常用于描述数据的分散程度。
例如,在市场分析中,标准差可以衡量某种商品价格的波动程度,进而帮助投资者进行风险管理。
在财务分析中,标准差可以用来评估投资组合的风险。
此外,在研究自然科学中,标准差也常用于测量实验结果的可靠性和一致性。
其次,标准差在工程学和质量控制领域也有广泛应用。
通过计算数据的标准差,可以判断生产过程是否稳定,从而评估生产质量。
例如,汽车制造商常用标准差来衡量汽车零件的尺寸精度,以确保零件的一致性和质量。
标准差还在工程设计中用来评估设计参数的稳定性和精确性。
此外,在社会科学研究中,标准差也被广泛应用于测量变量的离散程度和差异性。
例如,教育研究中经常用标准差来评估学生成绩的差异。
另外,在心理学研究中,标准差可用于评估调查问卷中各项指标的变异程度,从而判断调查结论的稳定性和可靠性。
总之,标准差是一项重要的统计概念,广泛应用于各个领域。
用极差给出标准差的估计值

用极差给出标准差的估计值极差(range)是统计学中一种常用的度量数据的离散程度的指标,它是最大值和最小值的差。
通常情况下,极差可以用来初步估计数据的离散程度,但它并不是一个很精确的测度。
因为它只考虑了最大值和最小值,而没有考虑其他数据的分布情况。
标准差(standard deviation)是一个更精确的测度数据离散程度的统计指标。
它是各个数据与平均数的偏离程度的平方的平均数的平方根。
标准差较大的数据集表明数据分布较为分散,标准差较小的数据集表明数据分布较为集中。
标准差可以更准确地描述数据的分布情况,因此在实际应用中更为常用。
在某些情况下,我们可以利用极差来初步估计标准差的值。
极差是最大值和最小值的差,而标准差是数据与平均值的偏离程度的平方的平均数的平方根。
根据这两者的定义,我们可以得出一个初步的关系:当极差较大时,标准差可能也较大;当极差较小时,标准差可能也较小。
但这只是一个初步的估计,因为极差只考虑了最大值和最小值,没有考虑其他数据的分布情况。
在实际应用中,我们可以通过一定的比例关系来利用极差来估计标准差。
比如,我们可以假设标准差大约等于极差的四分之一。
这只是一个大致的估计,实际情况中可能会有偏差。
但在某些情况下,这样的估计也能够提供一定程度上的参考价值。
举个例子,假设我们有一组数据,它们的极差是20。
按照上面的估计方法,我们可以初步估计标准差大约是20的四分之一,即5。
这样的估计可能并不十分准确,但它可以给我们一个大致的印象:数据的离散程度不是很大,数据的分布相对较为集中。
当然,在实际应用中,我们也可以使用更加精确的方法来估计标准差。
例如,我们可以通过计算数据的方差来得到更为精确的标准差估计值。
方差是数据与平均值的偏离程度的平方的平均数,它能够更准确地反映数据的分布情况。
总的来说,极差可以在一定程度上反映数据的离散程度,但它并不是一个很精确的测度。
在某些情况下,我们可以利用极差来初步估计标准差的值。
估计值的标准误差

估计值的标准误差
估计值的标准误差(Standard Error of Estimate)是指在通过样本数据估计总体参数时所引入的误差的标准差。
它用于衡量估计值与真实值之间的差异程度。
标准误差的计算取决于所使用的估计方法和模型类型。
在统计学中,常见的标准误差计算方法有:
1. 对于回归分析中的线性回归模型,标准误差可以通过计算残差的标准差来获得。
残差是观测值与回归线之间的差异,标准差表示了残差的平均偏离量。
2. 对于抽样方法(如样本平均值、样本比例)获得的估计值,标准误差可以通过计算样本标准差和样本容量的函数关系来获得。
样本标准差反映了样本数据的离散程度,样本容量越大,标准误差越小。
标准误差是一个重要的统计指标,它可以用来评估估计值的可靠性。
当标准误差较小时,说明估计值的可靠性较高;当标准误差较大时,表示估计值的可靠性较低。
标准差和标准误差

标准差和标准误差首先,让我们来了解一下标准差的概念。
标准差是一组数据平均值与每个数据之间的差异的平方的平均数的平方根。
标准差越大,代表数据的离散程度越高,数据点偏离平均值的程度也越大。
标准差的计算公式为,标准差= sqrt [ Σ ( Xi X )^2 / N ],其中Xi 为每个数据点,X 为数据的平均值,N 为数据的个数。
标准差的单位与原始数据的单位相同,它可以帮助我们了解数据的分布情况,以及数据点偏离平均值的程度。
接下来,让我们来了解一下标准误差的概念。
标准误差是用来衡量样本均值与总体均值之间的差异的一种度量。
标准误差越小,代表样本均值与总体均值之间的差异越小,样本的代表性就越好。
标准误差的计算公式为,标准误差 = 标准差 / sqrt ( n ),其中n 为样本的大小。
标准误差的单位与样本均值的单位相同,它可以帮助我们判断样本均值的可靠性,以及对总体均值的估计精度。
在实际应用中,标准差和标准误差经常被用来进行数据分析和统计推断。
比如在医学研究中,我们可以用标准差来衡量药物对疾病的疗效,用标准误差来估计样本均值对总体均值的估计精度。
在市场调研中,我们可以用标准差来衡量产品销售额的波动程度,用标准误差来判断样本调研结果对总体市场情况的可靠性。
总之,标准差和标准误差都是用来衡量数据的离散程度和变异程度的重要指标。
它们的应用范围非常广泛,可以帮助我们更好地理解数据,做出准确的分析和判断。
因此,对于数据分析工作者和统计学研究人员来说,掌握标准差和标准误差的计算方法和应用场景是非常重要的。
希望本文能够帮助您更好地理解标准差和标准误差的含义和作用。
标准差与估计标准差

2-3 變異的計算及解析由基礎課程裡我們可以知道:表示變異的方法有很多,其最常使用的是“標準差”;關於標準差的計算又分兩個觀念:(真)標準差σ與估計標準差σˆ。
為了解釋這兩個觀念的差異,我們先看下例數據:下例數據有經過分組,每組抽測5個數據(即S/S 或n = 5的意思)。
分組的原因不外乎量產、或長期研究等, 需要分批量測而形成母體與樣本的關係。
(1)(真)標準差σ:若將所有Raw Data 視為一個母體、混合不分組,則=STDEV( )所計算出來的標準差即為所求,即工程師最熟悉的算法。
--------------------------------------------------------------使用時機:a.) 想了解母體真正的變異的時候;b.) 想敏銳地抓出上圖/組間變異的異常的時候。
---------------------------------目的:了解整個母體的總變異。
優點:可以充分反映整個母體的異常(含上圖/組間變異、及下圖/組內變異的異常…尤其是組間變異的異常)。
缺點:數據量要夠大(避免誤差過大)、且上圖不能有異常(避免組間變異顯著),否則計算出來的 不具代表性。
(2) 估計標準差σˆ:大部分的工程師沒聽說過估計標準差。
Raw Data 若經過分組(分組與抽樣皆要隨機),我們可以利用樣本的變異、去估算整個母體的變異;但是要特別注意組間變σ)已經被假設成常態分配;以白話來說:想像管制異(X圖-上圖的每個組平均X是一顆綠豆,當這些綠豆被一把撒到管制圖-上圖的時候,這些綠豆皆自動定位到常態分配該有的位置上,因此整個上圖的假設都是常態分配,若真有異常、也早已被視而不見。
故以估計標準差σˆ來看問題,祇能解析下圖/組內變異的異常(即管理面的異常:如某單一人/機抽樣技術不穩定的問題、某單一作業機台不穩定的問題、某個別材料品質不穩定的問題等 一般因 …主要還是抽樣技術不穩定的問題)。
标准差和样本标准差的关系

标准差和样本标准差的关系
标准差和样本标准差是统计学中常用的两个概念,它们之间
有着密切的关系。
标准差是一种度量数据集中值的离散程度的统
计量,它可以反映数据的分散程度。
样本标准差是根据样本数据
计算出来的标准差,它可以反映样本数据的分散程度。
标准差和样本标准差之间的关系是,样本标准差是根据样本
数据计算出来的标准差,它可以反映样本数据的分散程度,而标
准差是一种度量数据集中值的离散程度的统计量,它可以反映数
据的分散程度。
因此,样本标准差是根据样本数据计算出来的标
准差,它可以反映样本数据的分散程度,而标准差是一种度量数
据集中值的离散程度的统计量,它可以反映数据的分散程度。
样本标准差和标准差之间的关系是,样本标准差是根据样本
数据计算出来的标准差,它可以反映样本数据的分散程度,而标
准差是一种度量数据集中值的离散程度的统计量,它可以反映数
据的分散程度。
因此,样本标准差可以用来估计总体标准差,但
是由于样本数据的分布可能不同,样本标准差的估计值可能会有
偏差。
总之,标准差和样本标准差之间有着密切的关系,样本标准
差可以用来估计总体标准差,但是由于样本数据的分布可能不同,样本标准差的估计值可能会有偏差。
因此,在使用样本标准差估
计总体标准差时,应该根据样本数据的分布情况进行调整,以减少偏差。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2-3 變異的計算及解析由基礎課程裡我們可以知道:表示變異的方法有很多,其最常使用的是“標準差”;關於標準差的計算又分兩個觀念:(真)標準差σ與估計標準差σˆ。
為了解釋這兩個觀念的差異,我們先看下例數據:下例數據有經過分組,每組抽測5個數據(即S/S 或n = 5的意思)。
分組的原因不外乎量產、或長期研究等, 需要分批量測而形成母體與樣本的關係。
(1)(真)標準差σ:若將所有Raw Data 視為一個母體、混合不分組,則=STDEV( )所計算出來的標準差即為所求,即工程師最熟悉的算法。
--------------------------------------------------------------使用時機:a.) 想了解母體真正的變異的時候;b.) 想敏銳地抓出上圖/組間變異的異常的時候。
---------------------------------目的:了解整個母體的總變異。
優點:可以充分反映整個母體的異常(含上圖/組間變異、及下圖/組內變異的異常…尤其是組間變異的異常)。
缺點:數據量要夠大(避免誤差過大)、且上圖不能有異常(避免組間變異顯著),否則計算出來的 不具代表性。
(2) 估計標準差σˆ:大部分的工程師沒聽說過估計標準差。
Raw Data 若經過分組(分組與抽樣皆要隨機),我們可以利用樣本的變異、去估算整個母體的變異;但是要特別注意組間變σ)已經被假設成常態分配;以白話來說:想像管制異(X圖-上圖的每個組平均X是一顆綠豆,當這些綠豆被一把撒到管制圖-上圖的時候,這些綠豆皆自動定位到常態分配該有的位置上,因此整個上圖的假設都是常態分配,若真有異常、也早已被視而不見。
故以估計標準差σˆ來看問題,祇能解析下圖/組內變異的異常(即管理面的異常:如某單一人/機抽樣技術不穩定的問題、某單一作業機台不穩定的問題、某個別材料品質不穩定的問題等 一般因 …主要還是抽樣技術不穩定的問題)。
此時的計算,都是由下圖/組內變異的平均來倒推,以估算整個母體變異的期望值:σˆ=s/c4 =R/d2 (註),其中c4、d2是查表值( 附表),隨著n (即S/S)而變,n愈大估計值就會愈接近母體。
註:樣本s、R、MR與母體σ之間的關係,令母體與樣本均為常態分配,不需執行冗繁的計算,可以直接以查表方式整理如下:E(s)= c4σ,D(s)= c3σ,其中c4、c3是查表值(附表)E(R)= d2σ,D(R)= d3σ,其中d2、d3是查表值( 附表)--------------------------------------------------------------------------------------------使用時機:當組間變異過於顯著,無法正確評估製程之實力時。
(註)註:理想上σˆ=σ;實務上通常σˆ<σ:σˆ代表著統計經驗對一特性在常態分配時的理想預測;也許是因為製程真的較差、也許是因為管制圖的管理分組做得並不好,造成上圖/組間變異變得比常態分配預期的還要大。
-----------------------------------------------------------------目的:估算整個母體的總變異的期望值。
優點:因為計算的是期望值,當數據量不大時、較(真)標準差具代表性。
缺點:只能反映下圖/組內變異的異常,而組內變異的異常通常只能反映管理問題,所以較適合量產使用。
t检验是对各回归系数的显著性所进行的检验,(--这个太不全面了,这是指在多元回归分析中,检验回归系数是否为0的时候,先用F检验,考虑整体回归系数,再对每个系数是否为零进行t检验。
t检验还可以用来检验样本为来自一元正态分布的总体的期望,即均值;和检验样本为来自二元正态分布的总体的期望是否相等)目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。
计算公式:t统计量:自由度:v=n - 1适用条件:(1) 已知一个总体均数;(2) 可得到一个样本均数及该样本标准误;(3) 样本来自正态或近似正态总体。
例1 难产儿出生体重n=35, =3.42, S =0.40,一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否?解:1.建立假设、确定检验水准αH0:μ = μ0 (无效假设,null hypothesis)H1:(备择假设,alternative hypothesis,)双侧检验,检验水准:α=0.052.计算检验统计量,v=n-1=35-1=343.查相应界值表,确定P值,下结论查附表1,t0.05 / 2.34 = 2.032,t < t0.05 / 2.34,P >0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义什么是T检验T检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
T检验是用于小样本(样本容量小于30)的两个平均值差异程度的检验方法。
它是用T分布理论来推断差异发生的概率,从而判定两个平均数的差异是否显著。
T检验是戈斯特为了观测酿酒质量而发明的。
戈斯特在位于都柏林的健力士酿酒厂担任统计学家,基于Claude Guinness聘用从牛津大学和剑桥大学出来的最好的毕业生以将生物化学及统计学应用到健力士工业程序的创新政策。
戈特特于1908年在Biometrika上公布T检验,但因其老板认为其为商业机密而被迫使用笔名(学生)。
实际上,戈斯特的真实身份不只是其它统计学家不知道,连其老板也不知道。
T检验的适用条件:正态分布资料单个样本的t检验目的:比较样本均数所代表的未知总体均数μ和已知总体均数μ0。
计算公式:t统计量:自由度:v=n - 1适用条件:(1) 已知一个总体均数;(2) 可得到一个样本均数及该样本标准误;(3) 样本来自正态或近似正态总体。
例1 难产儿出生体重n=35, =3.42, S =0.40,一般婴儿出生体重μ0=3.30(大规模调查获得),问相同否?解:1.建立假设、确定检验水准αH0:μ = μ0(无效假设,null hypothesis)H1:(备择假设,alternative hypothesis,)双侧检验,检验水准:α=0.052.计算检验统计量,v=n-1=35-1=343.查相应界值表,确定P值,下结论查附表1,t0.05 / 2.34= 2.032,t< t0.05 / 2.34,P >0.05,按α=0.05水准,不拒绝H0,两者的差别无统计学意义配对样本t检验配对设计:将受试对象的某些重要特征按相近的原则配成对子,目的是消除混杂因素的影响,一对观察对象之间除了处理因素/研究因素之外,其它因素基本齐同,每对中的两个个体随机给予两种处理。
∙两种同质对象分别接受两种不同的处理,如性别、年龄、体重、病情程度相同配成对。
∙同一受试对象或同一样本的两个部分,分别接受两种不同的处理∙自身对比。
即同一受试对象处理前后的结果进行比较。
目的:判断不同的处理是否有差别计算公式及意义:t 统计量:自由度:v=对子数-1适用条件:配对资料T检验的步骤1、建立虚无假设H0:μ1= μ2,即先假定两个总体平均数之间没有显著差异;2、计算统计量T值,对于不同类型的问题选用不同的统计量计算方法;1)如果要评断一个总体中的小样本平均数与总体平均值之间的差异程度,其统计量T值的计算公式为:2)如果要评断两组样本平均数之间的差异程度,其统计量T值的计算公式为:3、根据自由度df=n-1,查T值表,找出规定的T理论值并进行比较。
理论值差异的显著水平为0.01级或0.05级。
不同自由度的显著水平理论值记为T(d f)0.01和T(df)0.054、比较计算得到的t值和理论T值,推断发生的概率,依据下表给出的T 值与差异显著性关系表作出判断。
T值与差异显著性关系表T P值差异显著程度差异非常显著差异显著T< T(df)0.05 P> 0.05 差异不显著5、根据是以上分析,结合具体情况,作出结论。
T检验举例说明例如,T检验可用于比较药物治疗组与安慰剂治疗组病人的测量差别。
理论上,即使样本量很小时,也可以进行T检验。
(如样本量为10,一些学者声称甚至更小的样本也行),只要每组中变量呈正态分布,两组方差不会明显不同。
如上所述,可以通过观察数据的分布或进行正态性检验估计数据的正态假设。
方差齐性的假设可进行F检验,或进行更有效的Levene's检验。
如果不满足这些条件,只好使用非参数检验代替T检验进行两组间均值的比较。
T检验中的P值是接受两均值存在差异这个假设可能犯错的概率。
在统计学上,当两组观察对象总体中的确不存在差别时,这个概率与我们拒绝了该假设有关。
一些学者认为如果差异具有特定的方向性,我们只要考虑单侧概率分布,将所得到t-检验的P值分为两半。
另一些学者则认为无论何种情况下都要报告标准的双侧T检验概率。
1、数据的排列为了进行独立样本T检验,需要一个自(分组)变量(如性别:男女)与一个因变量(如测量值)。
根据自变量的特定值,比较各组中因变量的均值。
用T检验比较下列男、女儿童身高的均值。
性别身高对象1 对象2 对象3 对象4 对象5 男性男性男性女性女性111110109102104 男性身高均数= 110女性身高均数= 1032、T检验图在T检验中用箱式图可以直观地看出均值与方差的比较,见下图:这些图示能够很快地估计并且直观地表现出分组变量与因变量关联的强度。
3、多组间的比较科研实践中,经常需要进行两组以上比较,或含有多个自变量并控制各个自变量单独效应后的各组间的比较,(如性别、药物类型与剂量),此时,需要用方差分析进行数据分析,方差分析被认为是T检验的推广。
在较为复杂的设计时,方差分析具有许多t-检验所不具备的优点。
(进行多次的T检验进行比较设计中不同格子均值时)。
T检验注意事项∙要有严密的抽样设计随机、均衡、可比∙选用的检验方法必须符合其适用条件(注意:t检验的前提是资料服从正态分布)∙单侧检验和双侧检验单侧检验的界值小于双侧检验的界值,因此更容易拒绝,犯第Ⅰ错误的可能性大。
∙假设检验的结论不能绝对化∙不能拒绝H0,有可能是样本数量不够拒绝H0,有可能犯第Ⅰ类错误∙正确理解P值与差别有无统计学意义P越小,不是说明实际差别越大,而是说越有理由拒绝H0 ,越有理由说明两者有差异,差别有无统计学意义和有无专业上的实际意义并不完全相同∙假设检验和可信区间的关系∙结论具有一致性∙差异:提供的信息不同区间估计给出总体均值可能取值范围,但不给出确切的概率值,假设检验可以给出H0成立与否的概率学习教育统计中,对自由度的概念不甚了解,故求助于baidu。