stata操作教程
STATA基本操作入门

8.相关系数
• 如果要显示PL,PF两个变量的相关系数 • 方法:pwcorr pl pf
整理PP数
• 方法:pwcorr pl pf pk
整理PPT课件
15
8.1 相关系数
• 如果要显示PL,PF,PK三个变量之间的相关 系数,并显示显著性水平
• 保存该图:输入graph save scatter2
整理PPT课件
22
9.6 图像合并展示
• 将线性拟合和二次拟合这两个图像在一起 展示
• 方法:输入graph combine scatter1.gph scatter2.gph
整理PPT课件
23
此课件下载可自行编辑修改,此课件供参考! 部分内容来源于网络,如有侵权请与我联系删除!感谢你的观看!
整理PPT课件
18
9.3 画图:散点图
整理PPT课件
19
9.3.1 散点图改进
• 定义新变量值n来表示第n个观测值: • 方法:gen n=_n (_n表示第n个观测值) • 使散点图显示对应的观测值: • 方法:scatter tc q,mlabel(n) mlabpos(6)
整理PPT课件
20
• 展示变量q的样本容量,平均值,标准差, 最小值,最大值
整理PPT课件
9
6.2查看变量的统计特征
• 如果要查看满足q≥10000的子样本的统计指 标。方法:输入summarize q if q >=10000
• 或者su q if q >=10000
整理PPT课件
10
6.3 查看变量的统计特征
Properties: 性质窗口,
显示当前数
据文件和变 量的性质
stata 第一讲

****** Stata软件分析与应用 *******--------------------*-> 课程纲要*--------------------/*第一部分:Stata 基本操作1.Stata简介2.数据处理3.初步绘图第二部分:Stata的计量应用1.普通最小二乘法(OLS)2.广义最小二乘法(GLS)3.工具变量法与GMM4.时间序列分析5.面板数据模型第三部分:课堂报告(考核形式)选择一个经济学问题,利用stata实现,讲解相关经济学原理和操作过程,并提交书面报告。
* 教材:* 基础教材:王群勇. STATA在统计与计量分析中的应用. 南开大学出版社Hamilton Lawrence. Statistics with Stata. Cengage Learning.(中文版:郭志刚译. 应用Stata做统计分析. 重庆大学出版社)王天夫. STATA实用教程. 中国人民大学出版社* 高级应用教材:陈强. 高级计量经济学及STATA应用. 高等教育出版社.王志刚. 面板数据模型及其在经济分析中的应用. 经济科学出版社* 万能教材:help菜单The stata journal* 预备知识:计量经济学、数理统计、宏观经济学、微观经济学* ::第一部分::* Stata 基本操作* =====================* 第一讲 Stata简介* =====================* Stata 是何方神圣?Stata 统计软件包是目前世界上最著名的统计软件之一,国外将Stata与SAS、SPSS 一起被并称为三大权威统计软件。
它同时具有数据管理软件、统计分析软件、图表绘制软件、矩阵计算软件和程序语言编制的特点,几乎可以完成全部复杂的统计和计量分析工作。
*--------------------*-> Stata有何优点?*--------------------* 短小精悍、功能强大它最新的第12版的安装文件不到200M,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的计量分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。
Stata教程

Stata教程基本操作好东西~~~(三)五.语句结构及⼏条常⽤命令语句1.注释语句:在语句前加*,则该语句不被当作命令执⾏2.命令语句:基本结构为: command [varlist] [if exp] [in range] [,options][if exp]选项指当表达式exp为真时执⾏该命令; [in range]指明命令对什么范围内的观测执⾏,如 in 5 指命令执⾏的范围是第5个观测, in -5指命令执⾏的范围是倒数第5个观测, in 5/12指命令执⾏的范围是从第5到第12个观测。
1) 列表——list例: list in 5/12 if varname i ==2即列出第5到12个观测中变量varname i值为2的观测。
list varname i- varname j即列出变量varname i到varname j逻辑符号==:等于>=:⼤于等于<=:⼩于等于!:不等于&:并且|:或2) ⽣成新变量——generategenerate newvar= exp改变⼀个变量的变量名——renamerename oldvar newvar改变⼀个已经存在的变量的内容——replacereplace oldvar=exp3) 删除变量和观测——drop从内存中删掉所有数据 drop _all删掉变量 drop varname(s)删掉第1到3个观测 drop in 1/34) 保留变量和观测——keep5) 保存修改——save注意对数据库作了修改后,需及时重新保存,否则关闭数据集时会丢失所做改动。
保存命令为 savefilename,replace6) 描述性统计量sum varname(s)得到变量的均值、标准差、最⼤值和最⼩值。
tab varname得到变量各种取值的频数,所占百分⽐以及累积百分⽐。
tab1 varname(s)得到各变量各种取值的频数,所占百分⽐以及累积百分⽐。
stata17 中文操作手册

stata17 中文操作手册Stata 17 中文操作手册Stata是一款广泛应用于数据分析和统计建模的统计软件,它能够帮助用户进行各种数据处理和分析任务。
本操作手册将带领您了解如何在Stata 17中进行常见的数据操作、统计分析和图表制作等操作。
请按照以下步骤进行操作:1. 数据导入和保存在Stata 17中,您可以使用"import"命令将外部数据文件导入Stata工作环境。
例如,您可以使用"import excel"命令导入Excel文件,使用"import delimited"命令导入CSV文件。
导入后,您可以使用"save"命令将数据保存为Stata格式的文件,以便以后使用。
2. 数据清理与转换在进行数据分析之前,您可能需要对数据进行清理和转换。
Stata提供了一系列命令来实现这些操作。
例如,使用"drop"命令可以删除数据集中的某些变量或观测值,使用"rename"命令可以重新命名变量,使用"generate"命令可以创建新的变量。
3. 描述性统计分析Stata 17提供了大量的命令和功能来进行描述性统计分析。
例如,使用"summarize"命令可以计算变量的均值、标准差、最大值和最小值等统计量,使用"tabulate"命令可以生成交叉表并计算频数和百分比等。
4. 统计推断在进行统计推断时,Stata 17提供了各种命令来进行假设检验和参数估计。
例如,使用"ttest"命令可以进行单样本或双样本均值差异的t 检验,使用"regress"命令可以进行线性回归分析。
5. 绘图功能Stata 17具备强大的绘图功能,能够绘制各种类型的图表以可视化数据。
例如,使用"histogram"命令可以绘制直方图,使用"scatter"命令可以绘制散点图,使用"line"命令可以绘制折线图。
STATA实用教程

STATA实用教程STATA是一种统计分析软件,广泛应用于数据分析、统计建模、数据可视化等领域。
它具有强大的数据处理能力和丰富的统计功能,能够快速、准确地处理大规模的数据集。
下面是一些STATA实用教程,帮助初学者快速上手该软件。
1.STATA基本操作STATA的基本操作包括数据导入和导出、数据集处理、变量管理等。
首先要学会使用STATA命令行界面和菜单栏来进行操作,了解STATA常用的命令和语法,掌握STATA常用的数据结构,如数据集、变量类型等。
同时,还需要学会使用STATA的帮助文档和网络资源,解决自己在使用过程中遇到的问题。
2.数据的描述性统计STATA可以进行各种描述性统计,例如计算均值、中位数、标准差、四分位数等,了解数据的分布情况。
可以利用summarize、describe等命令来进行描述性统计,还可以使用tabulate、histogram等命令进行变量的频数统计和画出直方图。
3.数据清洗和转换在实际应用中,数据往往需要进行清洗和转换。
STATA提供了一系列的命令,用于数据的清洗和转换。
比如,drop、keep命令可以删除不需要的变量或观察值;rename、recode命令可以对变量进行重命名和重新编码;reshape、merge命令可以进行数据重塑和合并等操作。
4.统计分析STATA提供了许多常用的统计方法和模型,可以进行统计分析。
例如,t检验、方差分析、线性回归、Logistic回归、生存分析、聚类分析等。
用户可以使用STATA内置的命令来进行统计分析,也可以使用STATA扩展包来进行更加复杂的分析。
5.高级数据处理STATA还提供了一些高级数据处理方法,如面板数据分析、时间序列分析、密度估计、非参数统计等。
这些方法对于处理复杂的数据结构和模型非常有用。
通过学习STATA的面板数据命令如xtreg、xtsum等,可以进行面板数据分析;通过学习STATA的时间序列命令如arima、xtdes等,可以进行时间序列分析。
STATA使用教程

STATA使用教程第一章:介绍 StataStata 是一款统计分析软件,广泛应用于经济学、社会科学、健康科学和医学研究等领域。
本章将介绍 Stata 软件的基本特点、适用范围和主要功能。
1.1 Stata 的特点Stata 是一款功能强大、易于使用的统计软件。
不同于其他统计软件,Stata 具有灵活性高、数据处理效率好的优点。
它支持多种数据文件格式,可以处理大规模的数据集,并且具有丰富的数据处理、统计分析和图形展示功能。
1.2 Stata 的适用范围Stata 软件适用于各类研究领域,涵盖了经济学、社会科学、医学、健康科学等多个领域。
它广泛应用于定量分析、回归分析、面板数据分析、时间序列分析等领域,可用于统计推断、数据可视化和模型建立等任务。
1.3 Stata 的主要功能Stata 软件提供了丰富的功能模块,包括数据导入导出、数据清洗、数据管理、描述性统计、推断统计、回归分析、面板数据分析、时间序列分析、图形展示等。
这些功能模块为用户提供了全面且灵活的数据分析工具。
第二章:Stata 数据处理数据处理是统计分析的前置工作,本章将介绍 Stata 软件的数据导入导出、数据清洗和数据管理等功能。
2.1 数据导入导出Stata 支持导入多种文件格式的数据,如文本文件、Excel 文件和 SAS 数据集等。
用户可以使用内置命令或者图形界面进行导入操作,导入后的数据可以存储为 Stata 数据文件(.dta 格式),方便后续的数据处理和分析。
2.2 数据清洗数据清洗是数据处理的重要环节,Stata 提供了多种数据清洗命令,如缺失值处理、异常值处理和数据类型转换等。
用户可以根据实际情况选择合适的数据清洗操作,确保数据的准确性和完整性。
2.3 数据管理数据管理是有效进行数据处理的关键,Stata 提供了许多数据管理命令,如数据排序、数据合并、数据分割和数据标记等。
这些命令可以帮助用户高效地对数据进行管理和组织,提高数据处理效率。
stata教程

stata教程Stata 是一种广泛应用于统计分析的软件,拥有强大的数据处理和建模能力。
本教程将介绍 Stata 的一些基础操作和常用命令,帮助您快速上手使用该软件。
1. 安装和启动 Stata在开始使用Stata 之前,您需要先安装该软件。
安装完成后,双击图标启动 Stata。
2. 导入数据使用 Stata 进行统计分析的第一步是导入数据。
可以通过命令 `use` 来加载已有的 Stata 数据集,或者使用 `import` 命令导入其它格式的数据文件。
3. 数据处理Stata 提供了许多数据处理的命令,比如 `drop` 可以删除某些变量或观察值,`rename` 可以修改变量名,`generate` 可以创建新变量等。
4. 描述性统计描述性统计是对数据的基本概况进行分析,可以使用命令`summarize` 来获取平均值、标准差等统计量,使用 `tabulate`命令生成频数表,还可以通过 `graph` 命令绘制直方图或散点图等图形。
5. 假设检验假设检验用于验证某个统计假设是否成立。
Stata 提供了多种假设检验的命令,比如 `ttest` 可以进行单样本或独立样本 t 检验,`anova` 可以进行方差分析等。
6. 回归分析回归分析是一种常用的建模方法,可以用于研究变量之间的关系。
在Stata 中,可以使用`regress` 命令进行简单线性回归,使用 `logit` 命令进行逻辑回归等。
7. 图形输出Stata 可以生成各种类型的图形输出,比如线图、散点图、柱状图等。
可以使用`graph export` 命令将图形导出为图片文件,方便在报告中使用。
8. 编写批处理脚本如果需要重复执行一组命令,可以将这些命令写入批处理脚本。
Stata 支持编写批处理脚本来自动化数据处理和分析的过程。
以上是关于 Stata 的基础教程,希望能帮助您快速入门并熟练使用该软件进行数据分析。
更多高级功能和命令,请参考Stata 官方文档或相关教程。
STATA统计分析软件使用教程

STATA统计分析软件使用教程引言STATA统计分析软件是一款功能强大、使用广泛的统计分析软件,广泛应用于经济学、社会学、医学和其他社会科学领域的研究中。
本教程将介绍STATA的基本操作和常用功能,并提供实例演示,帮助读者快速上手使用。
第一章:STATA入门1.1 安装与启动首先,下载并安装STATA软件。
完成安装后,点击软件图标启动STATA。
1.2 界面介绍STATA的界面分为主窗口、命令窗口和结果窗口。
主窗口用于数据显示,命令窗口用于输入分析命令,结果窗口用于显示分析结果。
1.3 数据导入与保存使用命令`use filename`导入数据,使用命令`save filename`保存当前数据。
1.4 基本命令介绍常用的基本命令,如`describe`用于显示数据的基本信息、`summarize`用于计算变量的统计描述等。
第二章:数据处理与变量管理2.1 数据选择与筛选通过命令`keep`和`drop`选择和删除数据的特定变量和观察值。
2.2 数据排序与重编码使用命令`sort`对数据进行排序,使用命令`recode`对变量进行重编码。
2.3 缺失值处理介绍如何检测和处理数据中的缺失值,包括使用命令`missing`和`recode`等。
第三章:数据分析3.1 描述性统计介绍如何使用STATA计算和展示数据的描述性统计量,如均值、标准差、最大值等。
3.2 统计检验介绍如何进行常见的统计检验,如t检验、方差分析、卡方检验等。
3.3 回归分析介绍如何进行回归分析,包括一元线性回归、多元线性回归和逻辑回归等。
3.4 生存分析介绍如何进行生存分析,包括Kaplan-Meier生存曲线和Cox比例风险模型等。
第四章:图形绘制与结果解释4.1 图形绘制基础介绍如何使用STATA进行常见的数据可视化,如散点图、柱状图、折线图等。
4.2 图形选项与高级绘图介绍如何通过调整图形选项和使用高级绘图命令,进一步美化和定制图形。
Stata教程(免费)

第一章 Stata 概貌§1.1 Stata的功能、特点和背景Stata是一个用于分析和管理数据的功能强大又小巧玲珑的实用统计分析软件,由美国计算机资源中心(Computer Resource Center)研制。
从1985至1998的十四年时间里,已连续推出1.1,1.2,1.3,1.4,1.5,……及2.0,2.1,3.0,3.1,4.0,5.0,6.0等多个版本,通过不断更新和扩充,内容日趋完善。
它同时具有数据管理软件、统计分析软件、绘图软件、矩阵计算软件和程序语言的特点,又在许多方面别具一格。
Stata融汇了上述程序的优点,克服了各自的缺点,使其功能更加强大,操作更加灵活、简单,易学易用,越来越受到人们的重视和欢迎。
Stata的突出特点是只占用很少的磁盘空间,输出结果简洁,所选方法先进,内容较齐全,制作的图形十分精美,可直接被图形处理软件或字处理软件如WORD等直接调用。
一、 Stata的数据管理能力1.Stata的数据管理空间受计算机的操作系统和计算机扩展内存的影响。
对640k内存的微机,3.1版本的Stata可以管理2400个记录×99个变量,并随计算机扩展内存的增加而增加;对4.0的WINDOWS版本,Stata可以管理4800个记录×99个变量;对WINDOWS 95下的5.0版本,可根据计算机的配置情况设置变量数和记录数,如32M扩展内存的计算机,可处理2千万个数据。
变量数和记录数可以互相交易(trade),即减少记录数可以增加变量数,减少变量数可以增加记录数。
2.可以将分组变量转换成指示变量(哑变量),将字符串变量映射成数字代码。
3.可以对数据文件进行横向和纵向链接,可以将行数据转为列数据,或反之。
4.可以恢复、修改执行过的命令。
5.可以利用数值函数或字符串函数产生新变量。
6.可以从键盘或磁盘读入数据。
二、 Stata的统计功能Stata的统计功能很强,除了传统的统计分析方法外,还收集了近20年发展起来的新方法,如Cox比例风险回归,指数与Weibull回归,多类结果与有序结果的logistic回归,Poisson回归、负二项回归及广义负二项回归,随机效应模型等。
stata处理数据步骤 -回复

stata处理数据步骤-回复Stata是一种统计分析软件,广泛应用于社会科学研究、经济学、生物统计等领域。
它提供了一个强大的数据管理和分析平台,能够帮助研究人员快速、准确地处理和分析数据。
在本文中,我们将一步一步回答如何使用Stata进行数据处理的步骤。
第一步:导入数据在Stata中,要导入数据,可以选择多种文件格式,如Excel、CSV、SPSS 等。
将数据导入Stata的方法有很多种,其中最常用的方法是使用"import"命令。
以下是导入数据的基本步骤:1. 打开Stata软件,并新建一个.do文件(扩展名为.do,用于保存数据处理的步骤)。
2. 在.do文件中输入以下命令来导入数据:import excel using "文件路径\文件名.xlsx", sheet("工作表名称")这里,"文件路径"是指数据文件的保存路径,"文件名.xlsx"是数据文件的文件名,"工作表名称"是数据文件中的工作表名称。
如果数据文件是CSV 格式,则将命令中的"excel"改为"csv"。
3. 运行该.do文件,Stata将加载数据文件并将其存储在工作区中。
可以使用以下命令查看导入的数据:browse这个命令可以在Stata界面中显示数据文件的前几行。
第二步:查看数据在导入数据后,我们需要查看数据的结构和内容,以便于后续的数据清理和分析。
以下是查看数据的几种基本方法:1. 使用"describe"命令来查看数据的基本信息,包括变量的名称、类型和标签等:describe2. 使用"browse"命令来查看数据文件的前几行,以了解数据的内容:browse3. 使用"list"命令来查看数据文件的全部内容,以便于查找和筛选数据:list第三步:数据清理在对数据进行分析之前,我们通常需要进行数据清理,以确保数据的一致性和准确性。
Stata软件操作教程

Stata软件操作教程第15章:面板数据分析面板数据是指在时间上具有一定连续性的多个个体观测值,例如不同地区连续多年的经济数据、同一个企业在多个时间点的财务数据等。
面板数据具有时间序列和截面两个维度,因此在分析面板数据时需要考虑个体间的相关性和时间序列的影响。
在Stata中,面板数据的操作和分析可以使用如下的一些命令:1. 导入面板数据:使用`use`命令导入面板数据文件,例如`use filename, clear`,其中filename为数据文件名。
2. 面板数据的描述性统计:使用`summarize`命令计算面板数据的平均值、标准差等描述性统计量。
例如,`summarize varname, detail`计算变量varname的描述性统计量。
3. 面板数据的时间序列图:使用`tsline`命令绘制面板数据的时间序列图。
例如,`tsline varname`绘制变量varname的时间序列图。
4. 固定效应模型(Fixed Effects Model):使用`xtreg`命令估计固定效应模型,该模型考虑了个体间的固定效应。
例如,`xtreg dependent var independent var, fe`估计固定效应模型。
5. 随机效应模型(Random Effects Model):使用`xtreg`命令估计随机效应模型,该模型考虑了个体间的随机效应。
例如,`xtreg dependent var independent var, re`估计随机效应模型。
6. 混合效应模型(Mixed Effects Model):使用`xtmixed`命令估计混合效应模型,该模型既考虑了个体间的固定效应,又考虑了个体间的随机效应。
例如,`xtmixed dependent var independent var ,groupvar:`估计混合效应模型。
7. 模型检验和诊断:使用`xttest0`命令进行固定效应模型的F检验;使用`xtserial`命令进行个体效应的序列相关性检验;使用`xtgee`命令进行广义估计方程的估计和推断。
stata入门操作

3.4 三种操作的相互关系, 在不记得命令时可以采用菜单操作方式得到命令,
-2-
如不记得列示数据的命令,选择 data>>describe data>>list data 在结果窗口和命令回顾窗口都出现 list,此即命令名。 击活命令回顾窗口,点右键选择 save review content 即可得到程序操作的命令。
姓名
性别
年龄
寝室号
班级
电子邮件
手机号
家乡省份
预期薪水
自己是否有 PC
室友是否有 PC
提示:使用 input 时,如果需录入中文名,用命令 str#表示后面的变量为字复型变量,#表示
有多少个字符。
input id str8 name str2 sex age dom class str30 email mobile str10 province salary
windowing preference (3)点击右上角的 X 号退出。
建议安装路径为: D: /stata8 。这是因为我们通常会将数据和程序存储于安装目录 下,如果安装c 盘,一旦计算机出现意外故障,很可能导致我们存储在上面的数据无法 恢复。
3.录入数据
3.1 菜单式操作:
任务:录入五个学生的学号和姓名
4.1 菜单式 Help>>stata command…
4.2 命令式 • help contents • help search • search anything you want • search search
4.3 几个主要的网站 (1) STATA公司官方网站 (2) STATA 资源链接 /links/resources.html (3) STATA出版社 (4) STATA电子杂志/ 获得文章的摘要/archives.html 获得程序net from / (5) STATA 技术公告版
使用Stata进行统计分析和数据可视化的教程

使用Stata进行统计分析和数据可视化的教程Stata是一种常用的统计分析软件,广泛应用于社会科学、经济学和健康科学等领域的数据分析和可视化。
本文将为大家提供一个使用Stata进行统计分析和数据可视化的教程,包括数据导入、数据处理、统计分析和数据可视化等内容。
首先,我们需要了解Stata软件的基本操作。
一、Stata软件的基本操作1. 安装与启动:将Stata软件下载并安装在电脑上,然后双击桌面上的图标启动程序。
2. 导入数据:在Stata中,可以通过多种方式导入数据,如Excel表格、文本文件和数据库等。
使用命令“import excel”导入Excel表格数据,命令“import delimited”导入文本文件数据。
导入数据后,可以使用“describe”命令查看数据的结构和变量的属性。
3. 数据浏览与修改:使用“browse”命令可以打开数据集的浏览窗口,查看数据的内容。
要对数据进行修改,可以使用“generate”或“replace”命令创建或修改变量的值。
4. 数据子集选择:使用“keep”和“drop”命令选择需要分析的变量或观测。
5. 数据排序:使用“sort”命令可以按照指定的变量对数据进行排序。
二、数据处理与统计分析1. 描述统计分析:使用“summarize”命令计算变量的均值、方差、最大值、最小值等统计指标。
可以使用“tabulate”命令生成频数表和交叉表。
使用“histogram”命令生成直方图,“scatter”命令生成散点图。
2. t检验与方差分析:使用“ttest”命令进行两样本t检验,使用“oneway”命令进行方差分析。
3. 回归分析:使用“regress”命令进行线性回归分析。
可以使用“predict”命令创建预测值,并使用“estat”命令计算回归结果的统计量。
4. 面板数据分析:对于面板数据,使用“xtset”命令设置面板数据的结构,然后使用面板数据专用的命令进行分析,如“xtreg”进行面板数据的固定效应模型分析。
STATA简易操作

单击命令框按键,会出现下面的命令窗口
在窗口中 输入命令, 单击 Execute键, 即可执行 该命令。
1.点击“输入数据”按键,即可出现如下数据输入窗口。 2.将excel中的数据复制到该区域,注意:复制后会出现一个 对话框,选择将第一行设置为变量的选项。
STATA常用命令
• 1.设置面板数据 xtset year code xtset是命令 ,后接你设置的变量名称(这 里一般按照年和证券代码回归) 2. 描述性统计 tabstat c cf qa lna nwca sdebta riskt, stat(max min mean p50 sd n)
STATA常用命令
新安装的STATA的命令并不完整,有些命令需要手动安装才可使用
findit logout(findit 后接你要安装的命令)
STATA常用命令
• • • • 6.缩尾处理(进行1%的缩尾处理) winsor sdebta,gen (sdebta1)p(0.01) 7.方差膨胀因子检验(多重共线性检测) vif, uncentered
• 3. 皮尔森相关性检验(在0.1的显著性水平) pwcorr c cf qa lna nwca sdebta riskt, star(.1) bonferroni 4. 多元线性回归命令 (固定效应模型fe,随 机效应用re) xtreg c cf qa lna nwca sdebta riskt,fe 5. 添加某命令
stata入门操作总结

Stata入门操作总结
1. 导入数据:
方法一:点击文件选项,选择导入,根据数据类型选择即可。
方法二:进入数据编辑器界面,点击“文件”选择打开。
注意,该方式只能打开.dta文件,若数据量较小建议在Excel 中的打开,全选后复制,粘贴至数据编辑器中。
2. 修改变量标签:
在数据编辑器的属性窗口直接输入即可。
在命令窗口输入label variable 城市“city”,注意var后面的跟变量名称,即使是汉字也不需要加引号。
3. 检视数据:
输入命令describe(可简写为d)看数据集中变量名称、标签等。
若想看某几个变量的具体数据,则输入命令:list A B C。
也可通过逻辑关系来定义数据集子集,比如列出C变量大于等于10000的数据,则使用命令:list A C if C>=10000。
这里注意下其他表示关系的逻辑符号有“==”(等于)、“~=”(不等于,也可以用“!”)。
4. 进行假设检验:T检验(又称学生t检验)用于统计量服从正态分布,但方差未知的情况。
具体操作包括单样本t检验、独立样本t检验和配对样本t检验,分别用于检验总体方差未知、正态数据或近似正态的单样本均值是否与已知的总体均值相等,两对独立的正态数据或近似正态的样本的均值是否相等(可根据总体方差是否相等分类讨论),以及一对配对样本的均值的差是否等于某一个值。
以上是Stata入门操作总结,希望对您有所帮助。
STATA基础教程
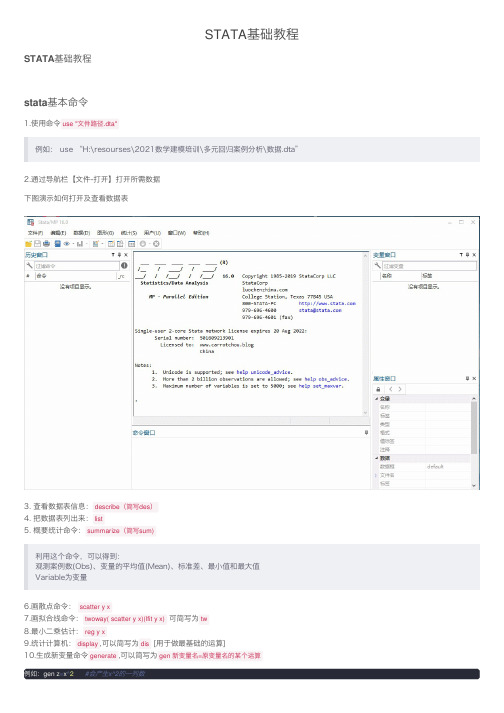
STATA基础教程STATA基础教程
stata基本命令
1.使⽤命令use "⽂件路径.dta"
例如: use “H:\resourses\2021数学建模培训\多元回归案例分析\数据.dta”
2.通过导航栏【⽂件-打开】打开所需数据
下图演⽰如何打开及查看数据表
3. 查看数据表信息:describe(简写des)
4. 把数据表列出来:list
5. 概要统计命令:summarize(简写sum)
利⽤这个命令,可以得到:
观测案例数(Obs)、变量的平均值(Mean)、标准差、最⼩值和最⼤值
Variable为变量
6.画散点命令: scatter y x
7.画拟合线命令:twoway( scatter y x)(lfit y x) 可简写为tw
8.最⼩⼆乘估计:reg y x
9.统计计算机:display,可以简写为dis [⽤于做最基础的运算]
10.⽣成新变量命令generate,可以简写为gen 新变量名=原变量名的某个运算
例如:gen z=x^2#会产⽣x^2的⼀列数
11.去除变量的命令:drop 某变量名
例如:drop z #z那⼀栏就不见了,被删除了
12.提取残差的命令:reg y x,紧跟第⼆条命令:predict e,res 边学习边补充~。
stata 教程

stata 教程Stata是一种强大的统计分析软件,广泛应用于经济学、社会科学、生物统计学等领域。
本教程将介绍Stata的基本操作和常用功能,帮助您快速入门。
1. Stata的界面和基本操作- 打开Stata软件后,会出现一个命令行界面。
您可以直接在命令行输入Stata命令进行操作。
- 菜单栏提供了常用的功能选项,包括打开数据文件、保存结果、运行程序等。
- 数据编辑窗口可以对数据进行编辑和处理。
- 结果窗口会显示Stata命令的执行结果和输出信息。
2. 导入和导出数据- 使用`import`命令可以导入各种格式的数据文件,如CSV、Excel、SPSS等。
- 使用`export`命令可以将Stata数据文件保存为其他格式的文件。
3. 数据的描述性统计- 使用`summarize`命令可以计算数据的基本统计量,如均值、中位数、标准差等。
- 使用`tabulate`命令可以制作数据的列联表和交叉报表。
- 使用`graph`命令可以绘制数据的直方图、散点图等。
4. 数据的清洗和处理- 使用`drop`命令可以删除数据中的变量或观察。
- 使用`rename`命令可以修改变量的名称。
- 使用`generate`命令可以生成新的变量,并进行数值计算和逻辑判断。
5. 统计分析- 使用`regress`命令可以进行回归分析。
- 使用`ttest`命令可以进行单样本或双样本t检验。
- 使用`correlate`命令可以计算变量之间的相关系数。
6. 编写和运行程序- 使用`do`命令可以运行存储在.do文件中的Stata程序。
- 使用`foreach`和`forvalues`命令可以进行循环操作。
- 使用`if`和`else`命令可以进行条件判断。
这些是Stata的基本操作和常用功能,希望对您的学习和使用有所帮助。
通过实践和深入了解Stata的不同命令和功能,您将能够灵活地进行数据处理和统计分析。
Stata软件操作教程 (15)

在这个命令语句中,graph-command是用来定义图的
类型的命令语句,plot-command是用来定义曲线类型 的命令语句,不同的曲线之间用括号隔开,曲线有自 身的options选项,整个图形也有统一的options选项。
3.1图形制作的基本命令与相关操作
3.1.2图形制作的菜单
选项
主要内容:
1、图形制作的基本命令与相关操作 2、直方图、散点图与曲线标绘图的绘制 3、条形图、饼图与箱线图的绘制 4、图形的保存、合并与修改
3.1图形制作的基本命令与相关操作
一个完整的图形(如图3.1),主要包括以下几个部分:标
题、副标题、主体图形、坐标轴刻度与标题、图例说明、 注释语句等。这些部分的设置均可以通过命令方式进行操 作,也可以通过菜单方式进行操作。在Stata制图过程中, 最常用的操作流程即通过命令方式画出主体图形,细节的 修改则通过菜单方式进行操作。
以双变量图的选项为例,点击“Two way graph”,可
以看到如图3.3所示的对话框。
3.1图形制作的基本命令与相关操作
在这个菜单中,主要有八个选项卡对图形的绘制功能进行 设置: Plots选项卡的功能是用来选择横、纵坐标所代表的变量, 从而生成初步的图形。在这个选项卡中,只要点击Create 图标,就可以进行绘图变量的选择和设置了。 if/in选项卡的功能是筛选绘制图形部分的数据的,例如只 选择数据文件中具有某种特征的数据进行绘图而不是使用 全部数据。 Y axis选项卡的功能是设置纵轴相关内容的,主要包括坐标 轴的标题、刻度、显示样式等,与此相对应的X axis选项 卡的功能是设置横轴相关内容的。 Titles选项卡的功能是设置与标题相关的内容,主要包括标 题的设置、副标题的设置、注释文字的设置等。 Legend选项卡的功能是设置与图例相关的内容,主要包括 图例的显示与否、图例的样式、图例的位置等内容。 Overall选项卡的功能是设置与总体图形相关的内容,主要 包括整个图形的大小设置,风格设置等内容。
stata入门教程

stata入门教程Stata 快速入门 1、Stata的窗口?在最上方有一排菜单,即“File Edit Data Graphics Statistics User Window Help”。
?左上“Review”(历史窗口):此窗口记录着自启动Stata以来执行过的命令。
?右上“Variables”(变量窗口):此窗口记录着目前Stata内存中的所有变量。
?正上方“Results”(结果窗口):此窗口显示执行Stata命令后的输出结果。
?正下方“Command”(命令窗口):在此窗口输入想要执行的Stata命令。
2、将数据导入Stata?打开Stata软件后,点击Data Editor(Edit)图标(也可以点击菜单“Window”→“Data Editor”),即可打开一个类似Excel的空白表格。
?用Excel打开文件“nerlove.xls”,复制文件中的所有数据,并粘贴到Data Editor中。
?导入数据的另一方法是,点击菜单“File” →“Import”,然后导入各种格式的数据。
但这种方法有时不如直接从Excel表中粘贴数据来得方便直观。
3、变量窗口?关闭Data Editor后,即会看到右上方的“Variables”窗口出现了5个变量: ?分别为tc(total cost,总成本),q(total output, 总产量),pl(price of labor,小时工资率),pf(price of fuel,燃料价格),与pk(user cost of capital,资本的租赁价格。
4、存为dta数据文件?此时,可以点击Save图标(也可以点击菜单“File” →“Save”),将数据存为Stata格式的文件(扩展名为dta),比如nerlove.dta。
?以后就可以用Stata直接打开这个数据集了(不需要再从Excel表中粘贴过来)。
5、打开dta数据文件打开的方式有三种:1.点击Open图标(也可以点击菜单“File” →“Open”),然后寻找要打开的dta 文件的位置。
Stata软件操作教程 (11)

二、实验数据和实验内容
实验数据来源于某学校对两个班的某次英语 成绩的记录,其中score1代表一班的英语成 绩,score2代表二班的英语成绩。完整的数 据在本书附带光盘的data文件夹的 “english.dta”工作文件中。
利用english数据,进行两个正态总体的方差 和均值检验,检验两个班英语成绩的方差和 均值是否相等。
习题
1.利用usaauto.dta数据库中的数据,检验变量price的均 值是否为6300。
2.利用usaauto.dta数据库中的数据,检验变量price的标 准差是否为4000,部分数据如第1题所示。
3.利用usaauto.dta数据库中的数据,检验进口车与国产 车价格的方差是否相等,部分数据如第1题所示。(提示: 进行分类变量为foreign的两个总体方差的检验)
varname == #是将所要检验的变量的标准差的数值填入,if 是条件语句,in是范围语句,level(#)用来设置置信水平。 如果不知道样本的具体数值,只有相关统计量,也可以进 行标准差的检验,所使用到的命令语句如下:
sdtesti #obs {#mean | . } #sd #val [, level(#)] 在这个命令语句中,sdtesti是进行标准差检验的命令语句,
例如,根据长期经验和观测,某砖厂砖的抗断强度服 从正态分布,方差为1.21,从中随机抽取六块的数据存 储在数据文件brick.dta中,分析一下这批砖抗断强度பைடு நூலகம்的均值是否为32.5。进行这个分析所用到的命令语句 为:
quietly summarize
scalar z=(r(mean)-32.5)/(1.1/sqrt(6))