Java读取pdf文件方法
JAVA 提取PDF中文本、图片
Java 提取PDF中文本和图片PDF常携带大量且还原度高的信息内容,有时为了获得一些必要的数据我们需要从PDF 中读取文本和图片信息。
下面这篇文章将介绍通过Java实现提取PDF的文本和图片。
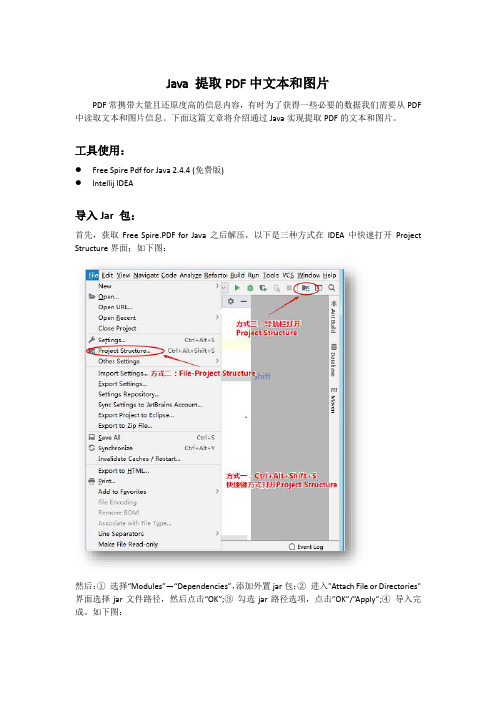
工具使用:●Free Spire Pdf for Java 2.4.4 (免费版)●Intellij IDEA导入Jar 包:首先,获取Free Spire.PDF for Java之后解压,以下是三种方式在IDEA中快速打开Project Structure界面;如下图:然后:①选择“Modules”—“Dependencies”,添加外置jar包;②进入"Attach File or Directories"界面选择jar文件路径,然后点击“OK”;③勾选jar路径选项,点击”OK”/”Apply”;④导入完成。
如下图:测试源文档参考如下:Java 代码示例参考:【示例 1】提取PDF 中文本内容步骤一:添加命名空间; import com.spire.pdf.*; import java.io.FileWriter ;步骤二:创建PDF实例和加载PDF源文件;//创建PDF实例PdfDocument doc = new PdfDocument();//加载PDF源文件doc.loadFromFile("data/PDF_3.pdf");步骤三:使用StringBuilder方法定义一个字符缓冲区实例,for循环遍历整个PDF文档;// 遍历PDF文档StringBuilder buffer = new StringBuilder();for(int i = 1; i<doc.getPages().getCount(); i++){PdfPageBase page = doc.getPages().get(i);buffer.append(page.extractText());}步骤四:定义一个writer实例将数据写到缓冲区,使用write()将缓冲区的数据写入text.txt 文件并保存。
java itext acrofields字段用法

java itext acrofields字段用法iText是一种用于处理PDF文件的Java库,它允许开发人员在创建、修改和读取PDF文件时进行灵活的操作。
iText的AcroFields类提供了一种方便的方式来操作PDF表单中的字段,包括填充字段值、获取字段属性和校验字段。
AcroFields字段用法分为以下几个方面:1. 填充字段值:在PDF表单中,经常需要将特定的值填充到字段中,比如姓名、地址、日期等。
使用iText的AcroFields类,我们可以通过以下步骤来填充字段值:1.1 创建一个PdfReader对象,用于读取PDF文件。
```javaPdfReader reader = new PdfReader("input.pdf");```1.2 创建一个PdfStamper对象,用于写入数据到PDF文件中。
```javaPdfStamper stamper = new PdfStamper(reader, new FileOutputStream("output.pdf"));```1.3 获取AcroFields对象,并使用setValue方法填充字段值。
```javaAcroFields fields = stamper.getAcroFields();fields.setField("name", "John Doe");fields.setField("address", "123 Street, City");```1.4 关闭PdfStamper对象,确保已经保存填充的字段值到PDF文件中。
```javastamper.close();```2. 获取字段属性:除了填充字段值,有时候也需要获取字段的一些属性信息,比如字段的类型、默认值、是否只读等。
使用iText的AcroFields类,我们可以通过以下方法获取字段的属性:```javaAcroFields fields = reader.getAcroFields();String type = fields.getFieldType("name");String defaultValue = fields.getField("name");boolean readOnly = fields.getFieldFlag("name", PdfFormField.FF_READ_ONLY);```getFieldType方法返回字段的类型,可以是文本、按钮、选择框等。
Java读取文件内容的六种方法

Java读取⽂件内容的六种⽅法1.Scanner第⼀种⽅式是Scanner,从JDK1.5开始提供的API,特点是可以按⾏读取、按分割符去读取⽂件数据,既可以读取String类型,也可以读取Int类型、Long类型等基础数据类型的数据。
@Testvoid testReadFile1() throws IOException {//⽂件内容:Hello World|Hello ZimugString fileName = "D:\\data\\test\\newFile4.txt";try (Scanner sc = new Scanner(new FileReader(fileName))) {while (sc.hasNextLine()) { //按⾏读取字符串String line = sc.nextLine();System.out.println(line);}}try (Scanner sc = new Scanner(new FileReader(fileName))) {eDelimiter("\\|"); //分隔符while (sc.hasNext()) { //按分隔符读取字符串String str = sc.next();System.out.println(str);}}//sc.hasNextInt() 、hasNextFloat() 、基础数据类型等等等等。
//⽂件内容:1|2fileName = "D:\\data\\test\\newFile5.txt";try (Scanner sc = new Scanner(new FileReader(fileName))) {eDelimiter("\\|"); //分隔符while (sc.hasNextInt()) { //按分隔符读取Intint intValue = sc.nextInt();System.out.println(intValue);}}}上⾯的⽅法输出结果如下:Hello World|Hello ZimugHello WorldHello Zimug122.Files.lines (Java 8)如果你是需要按⾏去处理数据⽂件的内容,这种⽅式是我推荐⼤家去使⽤的⼀种⽅式,代码简洁,使⽤java 8的Stream流将⽂件读取与⽂件处理有机融合。
java根据内容坐标给pdf填充内容的方法

java根据内容坐标给pdf填充内容的方法PDF文件作为一种常用的文档格式,已经被广泛应用于各种领域。
然而,对于一些需要编辑PDF文件的情况,如需要在PDF文件中根据内容坐标填充内容,现有的PDF处理库可能无法满足需求。
本文将介绍一种基于Java的PDF处理方法,可以实现根据内容坐标给PDF填充内容的功能。
一、PDF文件读取首先,我们需要使用Java中的PDF库来读取PDF文件,获取需要填充内容的区域信息。
常见的PDF库有iText、Apache PDFBox等。
在本方法中,我们使用iText库作为示例。
具体实现过程如下:1. 创建一个PdfReader对象,指定需要读取的PDF文件路径。
```javaPdfReader reader = new PdfReader("path/to/pdf/file.pdf");```2. 遍历PDF文档中的每一页,获取每个页面的信息。
```javafor (int page = 1; page <= reader.getNumberOfPages();page++) {// 获取当前页面的信息Document document = new Document(reader, PageSize.A4);PdfWriter writer = PdfWriter.getInstance(document,new FileOutputStream("output/page_" + page + ".pdf"));document.open();// 获取当前页面的内容信息...}```二、内容坐标计算在获取PDF文件中的内容信息后,我们需要根据内容坐标计算填充内容的区域位置。
通常来说,PDF文件中的内容坐标是以像素为单位进行计算的。
因此,我们需要根据实际需求,将像素坐标转换为页面坐标或屏幕坐标。
具体实现过程如下:1. 根据内容坐标计算填充区域的起始位置和结束位置。
java解析pdf的原理

java解析的原理
Java解析PDF的原理是通过使用PDF解析库来读取PDF文件的内容,提取其中的文本、图像和图形等信息,并进行解析和处理。
Java解析PDF的原理是通过解析PDF文件的结构和内容,将其中的文本、图像和图形等信息提取出来,并转换成Java可用的格式进行处理和展示。
在这个过程中,需要使用PDF解析库来辅助完成解析操作。
具体的解析过程如下:
1. 打开PDF文件:使用Java的文件操作库打开PDF文件,并读取其中的内容。
2. 解析文件结构:PDF文件采用的是二进制格式,需要解析其文件结构。
PDF文件由多个对象组成,包括页面、字体、图像等。
3. 解析字体信息:PDF文件中的文本通常使用字体进行描述。
解析器会读取PDF 文件中的字体信息,并将其保存为Java可用的格式。
4. 解析页面信息:PDF文件由多个页面组成,每个页面包含了文本、图像和图形等元素。
解析器会读取并保存每个页面的信息。
5. 提取文本内容:解析器通过解析页面信息,提取文本内容。
根据PDF文件中的字体信息,将文本内容转换成可读的格式。
6. 提取图像信息:PDF文件中可能含有嵌入的图像。
解析器会读取图像的信息,并将其保存为Java可用的格式,如BufferedImage。
7. 处理图形信息:PDF文件中的图形通常是由矢量图形描述的。
解析器会读取图形的绘制指令,将其转换成Java中的图形绘制指令。
8. 关闭文件:解析器读取完PDF文件的内容后,会关闭文件以释放相关资源。
java 读取pdf中条码方法

java 读取pdf中条码方法在Java中读取PDF中的条码是一项相对复杂的工作,需要借助特定的库和技术来实现。
下面是一个基本的步骤指南,帮助你了解如何使用Java读取PDF中的条码。
首先,你需要选择一个适合处理PDF和条码的Java库。
一些常用的库包括Apache PDFBox和ZXing(也称为Zebra Crossing)。
这些库提供了丰富的功能,可以帮助你解析PDF文件并识别其中的条码。
1. 添加依赖库:将所选库添加到你的Java项目中。
如果你使用的是Maven项目,可以在pom.xml文件中添加相应的依赖项。
2. 读取PDF文件:使用所选库提供的API,读取包含条码的PDF文件。
你可以使用PDFBox的PDDocument类来打开和读取PDF 文件。
3. 提取条码图像:一旦你加载了PDF文件,你需要从文件中提取包含条码的图像。
这通常涉及到遍历PDF页面,查找包含条码的区域,并提取相应的图像数据。
4. 条码识别:将提取的条码图像传递给条码识别引擎进行解析。
你可以使用ZXing库提供的BarcodeReader类来执行此操作。
5. 处理识别结果:一旦条码被识别,你可以根据需要处理识别的数据。
例如,你可以将条码数据存储在变量中,或者将其转换为特定的格式以便进一步处理。
需要注意的是,读取PDF中的条码是一项技术挑战,尤其是在处理不同类型的条码和复杂的PDF布局时。
此外,不同的条码类型可能需要不同的识别算法和库。
因此,在实际应用中,你可能需要根据具体需求调整和优化上述步骤。
此外,为了提高条码识别的准确性和可靠性,你可能还需要考虑一些额外的因素,如图像质量、条码损坏程度、背景噪声等。
对于这些情况,你可能需要进行一些预处理步骤(如去噪、二值化、缩放等),以提高识别过程的性能。
总结起来,使用Java读取PDF中的条码需要一定的技术知识和经验。
通过选择合适的库、遵循基本步骤并处理各种挑战,你应该能够成功地从PDF中提取和识别条码。
java分批次读取大文件的三种方法

java分批次读取⼤⽂件的三种⽅法1. java 读取⼤⽂件的困难java 读取⽂件的⼀般操作是将⽂件数据全部读取到内存中,然后再对数据进⾏操作。
例如Path path = Paths.get("file path");byte[] data = Files.readAllBytes(path);这对于⼩⽂件是没有问题的,但是对于稍⼤⼀些的⽂件就会抛出异常Exception in thread "main" ng.OutOfMemoryError: Required array size too largeat java.nio.file.Files.readAllBytes(Files.java:3156)从错误定位看出,Files.readAllBytes ⽅法最⼤⽀持 Integer.MAX_VALUE - 8 ⼤⼩的⽂件,也即最⼤2GB的⽂件。
⼀旦超过了这个限度,java 原⽣的⽅法就不能直接使⽤了。
2. 分次读取⼤⽂件既然不能直接全部读取⼤⽂件到内存中,那么就应该把⽂件分成多个⼦区域分多次读取。
这就会有多种⽅法可以使⽤。
(1) ⽂件字节流对⽂件建⽴ java.io.BufferedInputStream ,每次调⽤ read() ⽅法时会接连取出⽂件中长度为 arraySize 的数据到 array 中。
这种⽅法可⾏但是效率不⾼。
import java.io.BufferedInputStream;import java.io.FileInputStream;import java.io.IOException;/*** Created by zfh on 16-4-19.*/public class StreamFileReader {private BufferedInputStream fileIn;private long fileLength;private int arraySize;private byte[] array;public StreamFileReader(String fileName, int arraySize) throws IOException {this.fileIn = new BufferedInputStream(new FileInputStream(fileName), arraySize);this.fileLength = fileIn.available();this.arraySize = arraySize;}public int read() throws IOException {byte[] tmpArray = new byte[arraySize];int bytes = fileIn.read(tmpArray);// 暂存到字节数组中if (bytes != -1) {array = new byte[bytes];// 字节数组长度为已读取长度System.arraycopy(tmpArray, 0, array, 0, bytes);// 复制已读取数据return bytes;}return -1;}public void close() throws IOException {fileIn.close();array = null;}public byte[] getArray() {return array;}public long getFileLength() {return fileLength;}public static void main(String[] args) throws IOException {StreamFileReader reader = new StreamFileReader("/home/zfh/movie.mkv", 65536);long start = System.nanoTime();while (reader.read() != -1) ;long end = System.nanoTime();reader.close();System.out.println("StreamFileReader: " + (end - start));}}(2) ⽂件通道对⽂件建⽴ java.nio.channels.FileChannel ,每次调⽤ read() ⽅法时会先将⽂件数据读取到分配的长度为 arraySize 的 java.nio.ByteBuffer 中,再从中将已经读取到的⽂件数据转化到 array 中。
java pdf读取的几种方法

在Java中,有几种主要的方法可以用来读取PDF文件:1.Apache PDFBox: Apache PDFBox是一个开源的Java库,用于处理PDF文档。
你可以使用它来读取、创建、修改PDF文件等。
它支持各种功能,例如提取文本、图像,添加水印,加密和解密PDF文件等。
2.iText: iText是一个用于处理PDF文件的商业库。
它提供了许多功能,如创建PDF文件、添加文本、图像、表格,以及读取、修改和加密PDF文件等。
3.jPDFBox: jPDFBox是另一个Java库,用于处理PDF文件。
它的功能包括读取PDF文件的内容,提取图像,添加书签等。
4.Batik: Apache Batik是一个用于处理PDF文件的工具集,它是ApacheXML Graphics Project的一部分。
除了处理PDF文件,Batik还支持SVG 文件。
5.Poppler: Poppler是一个用于渲染PDF文档的库。
Poppler基于Qt和Glib,并且是免费的。
Poppler可以用于显示PDF文件,也可以用于提取文本和图像。
Poppler通常与Evince一起使用,Evince是一个开源的PDF 阅读器。
6.PDFBox-Android: PDFBox-Android是Apache PDFBox的一个分支,专门为Android平台设计。
它支持大部分的PDFBox功能,并且针对Android进行了优化。
以上这些库都有自己的优缺点,你可以根据你的具体需求来选择适合你的库。
例如,如果你需要加密和解密PDF文件,那么iText可能更适合你。
如果你只需要读取PDF文件的内容,那么Poppler可能是一个更好的选择。
Java读取文本文件的各种方法

Java读取⽂本⽂件的各种⽅法⽬录1、⽅法⽅法⼀、使⽤BufferedReader类⽅法⼆、使⽤ FileReader 类⽅法三、使⽤ Scanner 类⽅法四、读取列表中的整个⽂件2、语法⽅法五、将⽂本⽂件读取为字符串前⾔:有多种写⼊和读取⽂本⽂件的⽅法。
这在处理许多应⽤程序时是必需的。
在Java 中有多种⽅法可以读取纯⽂本⽂件,例如你可以使⽤FileReader、BufferedReader或Scanner来读取⽂本⽂件。
每个实⽤程序都提供了⼀些特殊的东西,例如BufferedReader 为快速读取提供数据缓冲,⽽Scanner 提供解析能⼒。
1、⽅法使⽤BufferedReader 类使⽤Scanner 类使⽤⽂件阅读器类读取列表中的整个⽂件将⽂本⽂件读取为字符串我们还可以同时使⽤BufferReader 和Scanner在Java 中逐⾏读取⽂本⽂件。
然后Java SE 8引⼊了另⼀个Stream类java.util.stream.Stream,它提供了⼀种惰性且更有效的⽅式来读取⽂件。
让我们更深⼊地讨论上述每个⽅法,最重要的是通过⼀个⼲净的Java 程序实现它们。
⽅法⼀、使⽤BufferedReader类此⽅法从字符输⼊流中读取⽂本。
它确实缓冲以有效读取字符、数组和⾏。
可以指定缓冲区⼤⼩,也可以使⽤默认⼤⼩。
对于⼤多数⽤途,默认值⾜够⼤。
通常,Reader 发出的每个读取请求都会导致对底层字符或字节流发出相应的读取请求。
因此,建议将BufferedReader 包装在任何 read() 操作可能代价⾼昂的Reader 周围,例如FileReaders和InputStreamReaders,如下所⽰:BufferedReader in = new BufferedReader(Reader in, int size);例⼦:import java.io.*;public class HY {public static void main(String[] args) throws Exception{File file = new File("C:\\Users\\pankaj\\Desktop\\test.txt");BufferedReader br= new BufferedReader(new FileReader(file));String st;while ((st = br.readLine()) != null)System.out.println(st);}}输出:如果你想学习编程可以参考海拥的博客⽅法⼆、使⽤ FileReader 类读取字符⽂件的便利类。
Java 读取PDF文件包中的文件
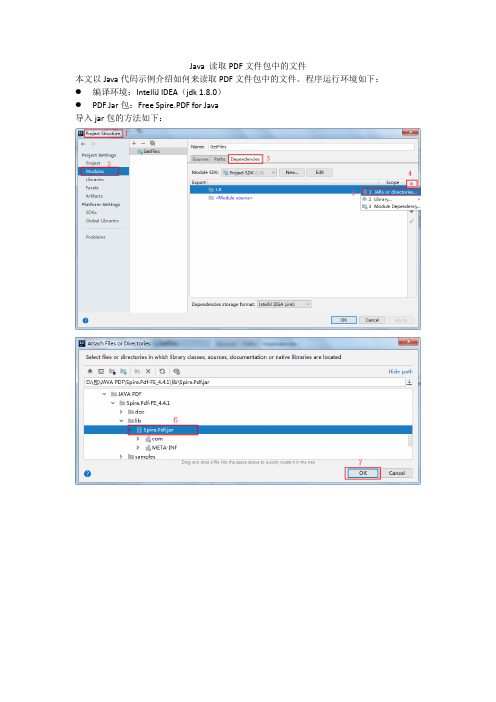
Java 读取PDF文件包中的文件本文以Java代码示例介绍如何来读取PDF文件包中的文件。
程序运行环境如下:●编译环境:IntelliJ IDEA(jdk 1.8.0)●PDF Jar包:Free Spire.PDF for Java导入jar包的方法如下:Java代码import com.spire.pdf.*;import com.spire.pdf.attachments.PdfAttachment;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;public class GetFiles {public static void main(String[] args) throws IOException { //创建PdfDocument实例PdfDocument pdf = new PdfDocument();//加载PDF文档pdf.loadFromFile("test.pdf");//判断该PDF是否为PDF文件包boolean value = pdf.isPortfolio();//如果是文件包,则读取所有文件到指定文件夹路径if (value){//System.out.println("此文档是PDF文件包");//遍历文档中的附件for(int i = 0; i< pdf.getAttachments().getCount();i++){PdfAttachment attachment = pdf.getAttachments().get(i);//提取附件String fileName = attachment.getFileName();OutputStream fos = new FileOutputStream("ExtractedFiles/" + fileName);fos.write(attachment.getData());}pdf.dispose();}else{System.out.println("此文档不是PDF文件包");}}}完成代码后,执行程序,读取文件包中的文件,如下:。
java从pdf中获取页码的方法(一)

java从pdf中获取页码的方法(一)Java从PDF中获取页码的方法在Java开发中,有时候我们需要从PDF文件中获取页码信息,以便进行相应的处理。
本文将详细介绍几种常用的方法来实现这一功能。
方法一:使用iText库iText是一个广泛使用的用于处理PDF文件的Java库。
下面是使用iText库来获取PDF文件页码的步骤:1.导入iText库:import ;import ;2.加载PDF文件:String filePath = "path/to/pdf/";PdfReader reader = new PdfReader(filePath);3.获取总页数:int totalPages = ();("总页数:" + totalPages);4.获取指定页的页码:PageInfo pageInfo = (pageNumber);int pageLabel = ();("第" + pageNumber + "页的页码:" + pageLabel);5.关闭PDF文件:();方法二:使用Apache PDFBox库Apache PDFBox是一个开源的用于处理PDF文件的Java库,下面是使用PDFBox库来获取PDF文件页码的步骤:1.导入PDFBox库:import ;2.加载PDF文件:String filePath = "path/to/pdf/";PDDocument document = (new File(filePath));3.获取总页数:int totalPages = ();("总页数:" + totalPages);4.获取指定页的页码:int pageLabel = ((pageNumber - 1));("第" + pageNumber + "页的页码:" + pageLabel);5.关闭PDF文件:();方法三:使用库是一个基于JavaScript的开源PDF查看器库,它可以在浏览器中解析和渲染PDF文件。
pdf java 解析

要使用Java解析PDF文件,可以使用一些流行的库,如Apache PDFBox或iText。
这些库提供了用于读取、编辑和创建PDF文件的功能。
以下是使用Apache PDFBox库解析PDF文件的基本步骤:1. 添加PDFBox库依赖项到您的项目中。
如果您使用的是Maven,请在pom.xml文件中添加以下依赖项:```maven<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.26</version></dependency>```2. 导入必要的库和类。
3. 使用PDDocument类打开PDF文件。
4. 访问PDF文档中的内容,如页面、文本、图像等。
您可以使用各种API方法来实现此目的。
5. 关闭PDDocument对象以释放资源。
下面是一个简单的示例代码,演示如何使用PDFBox库读取PDF 文件中的文本:```javaimport org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.text.PDFTextStripper;public class PDFParser {public static void main(String[] args) {try {PDDocument document = PDDocument.load(new File("example.pdf"));PDFTextStripper stripper = new PDFTextStripper();String text = stripper.getText(document);System.out.println(text);document.close();} catch (Exception e) {e.printStackTrace();}}}```此代码将打开名为“exa mple.pdf”的PDF文件,提取文本并将其打印到控制台,然后关闭文档对象以释放资源。
使用Java在macOS系统中进行PDF文件操作

使用Java在macOS系统中进行PDF文件操作在日常工作和学习中,我们经常会遇到需要对PDF文件进行操作的情况,比如合并多个PDF文件、提取特定页面、加密解密等。
而在macOS系统中,使用Java语言进行PDF文件操作是一种常见且高效的方式。
本文将介绍如何利用Java在macOS系统中进行PDF文件操作,包括读取、创建、编辑和保存PDF文件。
1. 准备工作在开始之前,我们需要准备好以下工具和环境:macOS系统:确保你的电脑上安装了macOS操作系统。
Java开发环境:安装并配置好Java开发环境,确保可以编译和运行Java程序。
PDF文件库:选择适合的Java PDF文件库,比如iText、Apache PDFBox等。
2. 读取PDF文件首先,我们来看看如何使用Java在macOS系统中读取PDF文件。
通过选择合适的PDF文件库,我们可以轻松实现对PDF文件的读取操作。
下面是一个简单的示例代码:示例代码star:编程语言:javaimport org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.text.PDFTextStripper;import java.io.File;import java.io.IOException;public class ReadPDF {public static void main(String[] args) {try {PDDocument document = PDDocument.load(new File("example.pdf"));PDFTextStripper pdfStripper = new PDFTextStripper();String text = pdfStripper.getText(document);System.out.println(text);document.close();} catch (IOException e) {e.printStackTrace();}}}示例代码end上面的代码使用了Apache PDFBox库来读取名为example.pdf的PDF文件,并将其内容输出到控制台。
Java基于PDFbox实现读取处理PDF文件

Java基于PDFbox实现读取处理PDF⽂件⽬录前⾔pdfbox介绍开发环境PDFbox依赖快速开始结语前⾔嗨,⼤家好,2022年春节已经接近尾声,各地都陆陆续续开⼯了。
近期有朋友做⼀个⼩项⽬正好使⽤Java读取PDF⽂件信息。
因此记录⼀下相关过程。
pdfbox介绍PDFbox是⼀个开源的、基于Java的、⽀持PDF⽂档⽣成的⼯具库,它可以⽤于创建新的PDF⽂档,修改现有的PDF⽂档,还可以从PDF⽂档中提取所需的内容。
Apache PDFBox还包含了数个命令⾏⼯具。
PDF⽂件的数据时⼀系列基本对象的集合:数组,布尔型,字典,数字,字符串和⼆进制流。
开发环境本次Java基于PDFbox读取处理PDF⽂件的版本信息如下:JDK1.8SpringBoot 2.3.0.RELEASEPDFbox 1.8.13PDFbox依赖在初次使⽤PDFbox的时候需要引⼊PDFbox依赖。
本次使⽤的依赖包如下:<dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>1.8.13</version></dependency>快速开始本⽰例是将指定⽬录下的PDF⽂件中的信息读取出来,存储到新的指定路径的txt⽂本⽂件当中。
class PdfTest {public static void main(String[] args) throws Exception {String filePath ="C:\\Users\\Admin\\Desktop\\cxy1.pdf";List<String> list = getFiles(basePath);for (String filePath : list) {long ltime = System.currentTimeMillis();String substring = filePath.substring(stIndexOf("\\") + 1, stIndexOf("."));String project = "()";String textFromPdf = getTextFromPdf(filePath);String s = writterTxt(textFromPdf, substring + "--", ltime, basePath);StringBuffer stringBuffer = readerText(s, project);writterTxt(stringBuffer.toString(), substring + "-", ltime, basePath);}System.out.println("******************** end ************************");}public static List<String> getFiles(String path) {List<String> files = new ArrayList<String>();File file = new File(path);File[] tempList = file.listFiles();for (int i = 0; i < tempList.length; i++) {if (tempList[i].isFile()) {if (tempList[i].toString().contains(".pdf") || tempList[i].toString().contains(".PDF")) { files.add(tempList[i].toString());}//⽂件名,不包含路径//String fileName = tempList[i].getName();}if (tempList[i].isDirectory()) {//这⾥就不递归了,}}return files;}public static String getTextFromPdf(String filePath) throws Exception {String result = null;FileInputStream is = null;PDDocument document = null;try {is = new FileInputStream(filePath);PDFParser parser = new PDFParser(is);parser.parse();document = parser.getPDDocument();PDFTextStripper stripper = new PDFTextStripper();result = stripper.getText(document);} catch (FileNotFoundException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();} finally {if (is != null) {try {is.close();} catch (IOException e) {e.printStackTrace();}}if (document != null) {try {document.close();} catch (IOException e) {e.printStackTrace();}}}Map<String, String> map = new HashMap<String, String>();return result;}public static String writterTxt(String data, String text, long l, String basePath) {String fileName = null;try {if (text == null) {fileName = basePath + "javaio-" + l + ".txt";} else {fileName = basePath + text + l + ".txt";}File file = new File(fileName);//if file doesnt exists, then create itif (!file.exists()) {file.createNewFile();}//true = append fileOutputStream outputStream = new FileOutputStream(file);// FileWriter fileWritter = new FileWriter(file.getName(), true);// fileWritter.write(data);// fileWritter.close();OutputStreamWriter outputStreamWriter = new OutputStreamWriter(outputStream); outputStreamWriter.write(data);outputStreamWriter.close();outputStream.close();System.out.println("Done");} catch (IOException e) {e.printStackTrace();}return fileName;}public static StringBuffer readerText(String name, String project) {// 使⽤ArrayList来存储每⾏读取到的字符串StringBuffer stringBuffer = new StringBuffer();try {FileReader fr = new FileReader(name);BufferedReader bf = new BufferedReader(fr);String str;// 按⾏读取字符串while ((str = bf.readLine()) != null) {str = replaceAll(str);if (str.contains("D、") || str.contains("D.")) {stringBuffer.append(str);stringBuffer.append("\n");stringBuffer.append("参考: \n");stringBuffer.append("参考: \n");stringBuffer.append("\n\n\n\n");} else if (str.contains("A、") || str.contains("A.")) {stringBuffer.deleteCharAt(stringBuffer.length() - 1);stringBuffer.append("。
Java 添加、下载、获取PDF附件信息(基于Spire.Cloud.SDK for Java)

Java 添加、下载、读取PDF附件信息(基于Spire.Cloud.SDK for Java)Spire.Cloud.SDK for Java提供了PdfAttachmentsApi接口添加附件addAttachment()、下载附件downloadAttachment()、获取附件信息getAttachmentsInfo(),本文将通过Java代码示例介绍具体实现方法。
详细内容参考以下步骤:一、导入jar文件。
(有2种方式)(推荐)方式1. 创建Maven项目程序,通过maven仓库下载导入。
以IDEA为例,新建Maven项目,在pom.xml文件中配置maven仓库路径,并指定spire.cloud.sdk的依赖,如下:<repositories><repository><id>com.e-iceblue</id><name>cloud</name><url>/repository/maven-public/</url></repository></repositories><dependencies><dependency><groupId> cloud </groupId><artifactId>spire.cloud.sdk</artifactId><version>3.5.0</version></dependency><dependency><groupId> com.google.code.gson</groupId><artifactId>gson</artifactId><version>2.8.1</version></dependency><dependency><groupId> com.squareup.okhttp</groupId><artifactId>logging-interceptor</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okhttp </groupId><artifactId>okhttp</artifactId><version>2.7.5</version></dependency><dependency><groupId> com.squareup.okio </groupId><artifactId>okio</artifactId><version>1.6.0</version></dependency><dependency><groupId> io.gsonfire</groupId><artifactId>gson-fire</artifactId><version>1.8.0</version></dependency><dependency><groupId>io.swagger</groupId><artifactId>swagger-annotations</artifactId><version>1.5.18</version></dependency><dependency><groupId> org.threeten </groupId><artifactId>threetenbp</artifactId><version>1.3.5</version></dependency></dependencies>完成配置后,点击“Import Changes” 即可导入所有需要的jar文件。
xpdf读取pdf文件并根据pdf内容修改文件名称

[java]view plaincopy1.package com.sunlei;2.3.import java.io.BufferedReader;4.import java.io.File;5.import java.io.IOException;6.import java.io.InputStreamReader;7.8.import javax.crypto.spec.IvParameterSpec;9.10.public class Rename {11.12./**13. * @param args14. * @throws IOException15. */16.public static void main(String[] args) {17.// TODO Auto-generated method stub18.// System.out.println("hello\n");19. File file = new File("D:\\pdf");//pdf文件夹20. String xpdfPath = "D:\\TDDOWNLOAD\\xpdfbin-win-3.03\\bin32\\pdfinfo.exe ";21.//pdfinfo.exe文件夹,注意这个exe和后面的pdf文件名有空格,所以这里有空格22. File[] fileListFiles = file.listFiles();// 取出文件夹下所有的文件23.for (int i = 0; i < fileListFiles.length; i++) {24. String cmd = xpdfPath + fileListFiles[i].getAbsolutePath();25.try {26. Process process = Runtime.getRuntime().exec(cmd);27. BufferedReader br = new BufferedReader(new InputStreamReader(28. process.getInputStream()));//获得exe执行程序返回结果29. String firstLine = br.readLine();//只需要读取第一行就行,只要标题30.// System.out.println(firstLine);31.// System.out.println(firstLine.indexOf('D')); //下面substring的时候为什么是16,是通过这个实验出来的32.if (firstLine != null) {33. String subTitle = firstLine.substring(16);34.if (!subTitle.equals("")) {35.36. subTitle = subTitle.replace(':', ' ');// 去掉文件名不合规范的37. subTitle = subTitle.replace('*', ' ');38. subTitle = subTitle.replace('/', ' ');39. subTitle = subTitle.replace('?', ' ');40. String title = subTitle + ".pdf";//加上后缀名41. File newFile;42.if (title != "untitled.pdf" && title != ".pdf") {43. newFile = new File("D:/pdf/" + title);44.// System.out.println(title);45.if (fileListFiles[i].renameTo(newFile)) {//修改文件名46. System.out.println(fileListFiles[i].getName()47. + "修改成功");48. } else {49. System.out.println(fileListFiles[i].getName()50. + "修改失败");51. }52. }53. br.close();//别忘了关闭流54. process.destroy();55. }else {56. System.out.println(fileListFiles[i].getName()57. + "因为文中没有文件title而修改失败");58. }59. }60. } catch (IOException e) {61.// TODO Auto-generated catch block62. e.printStackTrace();63. }64.65. }66.67. }68.}1:准备工作上网查资料,C++读取pdf库,java读取pdf库,最后找到了xpdf库,还好,下载地址【下载xpdf地址】,我下载的是windows版的,然后按照步骤实验了一下实验,打开压缩包,读了读readme,然后进入bin32文件夹,里面好多exe可执行文件,好吧,开始搞起拷贝一个pdf文件进去,然后cmd命令行进入bin32文件夹,[html] view plaincopypdftotext.exe 5026a001.pdf然后果然生成了一个5026a001.txt,打开一看,哇,完美转换,看来不需要配置什么东西就能执行。
JAVA中读取文件(二进制,字符)内容的几种方法总结

JAVA中读取⽂件(⼆进制,字符)内容的⼏种⽅法总结JAVA中读取⽂件内容的⽅法有很多,⽐如按字节读取⽂件内容,按字符读取⽂件内容,按⾏读取⽂件内容,随机读取⽂件内容等⽅法,本⽂就以上⽅法的具体实现给出代码,需要的可以直接复制使⽤public class ReadFromFile {/*** 以字节为单位读取⽂件,常⽤于读⼆进制⽂件,如图⽚、声⾳、影像等⽂件。
*/public static void readFileByBytes(String fileName) {File file = new File(fileName);InputStream in = null;try {System.out.println("以字节为单位读取⽂件内容,⼀次读⼀个字节:");// ⼀次读⼀个字节in = new FileInputStream(file);int tempbyte;while ((tempbyte = in.read()) != -1) {System.out.write(tempbyte);}in.close();} catch (IOException e) {e.printStackTrace();return;}try {System.out.println("以字节为单位读取⽂件内容,⼀次读多个字节:");// ⼀次读多个字节byte[] tempbytes = new byte[100];int byteread = 0;in = new FileInputStream(fileName);ReadFromFile.showAvailableBytes(in);// 读⼊多个字节到字节数组中,byteread为⼀次读⼊的字节数while ((byteread = in.read(tempbytes)) != -1) {System.out.write(tempbytes, 0, byteread);}} catch (Exception e1) {e1.printStackTrace();} finally {if (in != null) {try {in.close();} catch (IOException e1) {}}}}/*** 以字符为单位读取⽂件,常⽤于读⽂本,数字等类型的⽂件*/public static void readFileByChars(String fileName) {File file = new File(fileName);Reader reader = null;try {System.out.println("以字符为单位读取⽂件内容,⼀次读⼀个字节:");// ⼀次读⼀个字符reader = new InputStreamReader(new FileInputStream(file));int tempchar;while ((tempchar = reader.read()) != -1) {// 对于windows下,\r\n这两个字符在⼀起时,表⽰⼀个换⾏。
java获取ofd文件页数的方法

java获取ofd文件页数的方法OFD (Open File Document) 是一种电子文件格式,主要用于电子文档的存储和交换。
在 Java 中获取 OFD 文件的页数,通常需要依赖于特定的库或者工具。
目前,Apache PDFBox 和 iText 是两个比较流行的用于处理PDF 文件的 Java 库,但它们对 OFD 格式的支持有限。
如果你确实需要处理 OFD 文件,可能需要寻找或开发一个专门用于处理OFD 格式的 Java 库。
不过,如果你只是想要一个大致的页数,你可以尝试使用 Java 的标准库来读取 OFD 文件,然后统计其中的分页标记。
但这通常是一个不太可靠的方法,因为不同的 OFD 文件可能使用了不同的分页策略或标记。
下面是一个非常基本的示例,展示如何使用 Java 的 `RandomAccessFile` 来读取 OFD 文件的一部分,并统计分页标记(这里假设分页标记是特定的字符串):```javaimport ;public class OFDPageCounter {public static void main(String[] args) throws Exception {RandomAccessFile file = newRandomAccessFile("path/to/your/ofd/", "r");byte[] buffer = new byte[1024]; // Adjust the buffer size as neededint readBytes;int pageCount = 0;String marker = "PAGE"; // Adjust this to match your OFD file's pagination markerwhile ((readBytes = (buffer)) != -1) {String data = new String(buffer, 0, readBytes, _8);if ((marker)) {pageCount++;}}("OFD file has " + pageCount + " pages.");}}```请注意,这只是一个非常简化的示例,并不一定适用于所有 OFD 文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
System.out.println("insert into ok");
byte b[] = null; //**保存从BLOB读出的字节
public OraclePreparedStatement opst = null; //**PreparedStatement用
public Connection conn = null;
public Statement stmt = null;
import oracle.jdbc.driver.OraclePreparedStatement;
import oracle.jdbc.driver.OracleResultSet;
import java.sql.Connection;
import java.sql.DriverManager;
int j = blob.putBytes(1, a); //**将字节数组写入BLOB字段
System.out.println("j:" + j);
mit();
java.io.File f2 = new java.io.File("d:/testout.doc"); //**从BLOB读出的信息写
//入该文 件,和源文件对比测试用
fin = new java.io.FileInputStream(f1);
opst = (OraclePreparedStatement) test.conn.prepareStatement(mysql);
opst.setString(1, "wordtemplate2");
opst.clearParameters();
// /**插入其它数据后,定位BLOB字段
mysql = "select filebody from filelist where filename=?";
ors.close();
Clob clob;
clob = ors.getClob("");
String str;
opst.clearParameters();
mysql = "select filebody from filelist where filename=?";
opst = (OraclePreparedStatement) test.conn.
str = clob.toString();
str = clob.getSubString(0L,(int)clob.length());
System.out.println(str);
try {
Class.forNamacleDriver");
String url = "jdbc:oracle:thin:@" + serverName + ":1521:BOHDATA";
for (; itotal < flength; itotal = i + itotal) {
i = fin.read(a, itotal, flength - itotal);
import java.sql.Statement;
import java.sql.Clob;
public class TestOpenDoc {
public OracleResultSet ors = null; //**这里rs一定要用Oracle提供的
opst.setString(1, "wordtemplate2");
opst.setInt(2, flength);
opst.executeUpdate();
test.conn.setAutoCommit(false);
byte a[] = null; //**将测试文件test.doc读入此字节数组
java.io.FileInputStream fin = null;
OracleResultSet ors = (OracleResultSet) opst.executeQuery();
if (ors.next()) {
oracle.sql.BLOB blob = ors.getBLOB(1); //**得到BLOB字段
}
fin.close();
System.out.println("read itotal::" + itotal);
//**注意Oracle的 BLOB一定要用EMPTY_BLOB()初始化
a = new byte[flength];
int i = 0;
int itotal = 0;
//* 将文件读入字节数组
String mysql =
"insert into filelist (FileName,FileSize,FileBody) values (?,?,EMPTY_BLOB())";
public TestOpenDoc() {
}
public boolean getConnect() {
//这是我的数据库所在
String serverName = "prosrv";
PDFTextStripper stripper=new PDFTextStripper();
nr = stripper.getText(doc);
nr = nr.replace(" ", "");
doc.close();
System.out.println("pdf内容:"+nr);
conn = DriverManager.getConnection(url, "appuser", "appuser");
}
catch (Exception e) {
System.out.println(e);
if (!test.getConnect()) {
System.out.println("数据库连结错误");
return ;
}
try{
java.io.FileOutputStream fout = null;
//Oracle提供的
try {
java.io.File f1 = new java.io.File("c:/test.doc");
OraclePreparedStatement opst = (OraclePreparedStatement) test.conn.
prepareStatement(mysql);
return false;
}
return true;
}
public static void main(String[] args) {
TestOpenDoc test = new TestOpenDoc();
fout = new java.io.FileOutputStream(f2);
int flength = (int) f1.length(); //**读入文件的字节长度
System.out.println("file length::" + flength);
首先从/网站上下载最新的pdfbox.jar包和fontbox.jar 两个jar包,将两个jar包放到你的classpath下面,读取代码如下:
String filePath = "E:\\tes.pdf",nr="";
PDDocument doc=PDDocument.load(filePath);