汉语词频统计
现代汉语中和制汉语词的量化考察

现代汉语中和制汉语词的量化考察
制汉语词是指由两个以上汉字构成的词语。
现代汉语中,制汉语词的量化主要是通过词频统计、辞书收录和语料库分析等方法进行考察。
1. 词频统计:利用大规模的语料库进行统计分析,统计某个汉字组合出现的频率,通过频率高低来判断词语的常用程度。
一般而言,频率较高的词语往往是制汉语词。
2. 辞书收录:各种汉语词典的编纂者会根据实际语料和语言规律,选取制汉语词作为词典的词条。
辞书编纂者在选择时一般会参考频率高低、使用范围、文化价值等因素。
3. 语料库分析:通过对大规模语料库的分析,可以获得文字材料冗杂、样本大、覆盖面广的特点,从而更全面和准确地了解汉字组合的使用情况。
通过对语料库中频次较高的词语进行分析,可以判断词语是否为制汉语词。
在实际研究中,一般会综合以上方法进行考察,以获得更加准确全面的结论。
同时,随着技术的发展,人工智能和自然语言处理的应用也可以提供更精确和有效的制汉语词量化考察结果。
antconc词频统计原理

antconc词频统计原理AntConc词频统计原理AntConc是一款基于Windows操作系统的文本分析工具,主要用于统计文本中词语的频率和分布情况。
它的核心功能是词频统计,即统计文本中每个词语出现的次数,并按照出现次数进行排序和展示。
在实际应用中,词频统计是文本分析的基础工作,可以帮助研究者快速了解文本的特征和趋势,从而进行更深入的分析和研究。
AntConc的词频统计原理是基于一个简单的算法实现的。
首先,它会将输入的文本按照空格或其他分隔符进行分词,将文本拆分成一个个单词。
然后,它会遍历所有单词,统计每个单词出现的次数,并保存在一个词频统计表中。
最后,根据词频统计表中的数据,AntConc会按照词频的高低进行排序,并将结果展示给用户。
词频统计的原理虽然简单,但是在实际应用中有着广泛的应用价值。
首先,通过词频统计,我们可以了解文本中哪些词语出现的频率较高,从而推断出文本的主题和关键词。
例如,在新闻报道中,出现频率较高的词语往往与报道的主题密切相关。
其次,词频统计还可以帮助我们分析文本的情感倾向。
通过统计文本中积极和消极情感词语的频率,我们可以判断文本的情感倾向是正面还是负面。
此外,词频统计还可以帮助我们分析文本的语言特点和风格。
不同作者或不同领域的文本往往有着不同的词语使用习惯,通过词频统计,我们可以发现这些差异。
在使用AntConc进行词频统计时,我们还可以根据需求进行一些参数设置。
例如,我们可以选择忽略某些常见词语,如“的”、“是”、“在”等,以减少噪音干扰。
我们还可以设置词语的最小频数和最大频数,以过滤掉出现次数过低或过高的词语。
另外,AntConc还提供了词语共现分析、词语关键词提取等功能,可以帮助我们更全面地理解文本的特征和结构。
AntConc词频统计原理简单而实用,通过统计文本中词语的频率和分布情况,我们可以快速了解文本的特征和趋势,为后续的文本分析和研究提供基础支持。
无论是对于学术研究、情感分析还是语言风格分析,词频统计都是一个必不可少的工具,AntConc的词频统计功能可以帮助我们更高效地进行相关工作。
附录一现代汉语语料库词频统计资料库说明
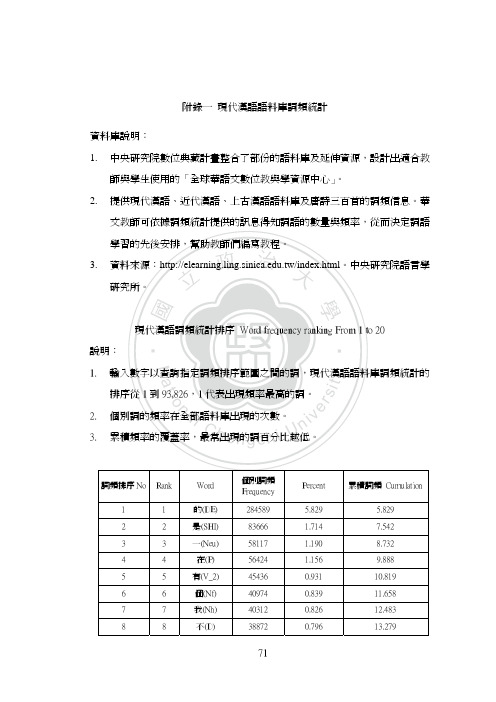
4. 見檔率:「頻率」的計算,是以某一單字於某一語料單元中出現的頻次除以 該單元的總字數,再換成百分比而構成。「見檔率」的計算,則以某一首字 於某一語料單元中的「見檔次」(即含有該首字的檔案的數目)除以該語料 單元的總檔數,再換成百分比而得出。
是3
9 9755 1.483% 50634 7.697% 319 99.69%
不4
4 8359 1.271% 58993 8.968% 317 99.06%
人5
2 7107 1.080% 66100 10.05% 319 99.69%
在6
6 6931 1.054% 73031 11.10% 319 99.69%
75
附錄三 初級學習者「的地不分」之偏誤例句
1) 嚴格的說,我也沒有很用力的大他,只是為了管教起見,輕輕的打他一下。 2) 在那個時候,小黃很明顯的不高興。 3) 在電影裏,小慧的夫婚夫,也就是開小巴的阿文在一場車禍中意外的喪生
了。 4) 請你們要仔細的聽,免得你們等一下不懂。 5) 電腦對人類有很大的貢獻,所以我們絕對要徹底的瞭解電腦的結構。 6) 繼續的讀下去了 7) 我們應該好好的保護它 8) 從那天起我才能正式的由學校的老師慢慢的教導 9) 都很積極的學中文 10) 就算是再困難再難懂也要努力的去突破 11) 雖然沒有像台灣的學生那麼的吃香 12) 有一回,母親心血來潮的問我 13) 這時母親疑惑的看著我: 14) 加上老师有声有色的讲述后 15) 深深的烙印在他們的心中 16) 辛苦的照顧她的小孩時 17) 媽媽是那麼細心、辛苦的照顧我 18) 辛勤的在田裡工作時 19) 小女孩卻高高興興的吃飯 20) 媽媽會毫不留情的拿起橡皮擦「嚄嚄」兩下 21) 儘管我們力竭聲嘶的吶喊 22) 就這樣含淚吞苦的寫了一年半多 23) 而我也可以毫無困難的寫出來時 24) 現在我終於可以很大聲很驕傲的說「我是個十足十會中文的台灣人了!」
中文词频统计系统设计分析

中文词频统计系统设计分析摘要随着互联网时代的到来,网络信息呈极速增长态势,互联网让人们的生活更加“碎片化”,有用信息的获取变更越来越不容易,中文词频统计系统有效解决这一难题,帮助人们从一堆杂乱无章的文本数据中快速准确获取有价值的信息。
本文通过分析中文词频统计的关键技术,即中文分词技术,并经过对比分析几种常用的中文分词工具后,最终通过开源的IK Analyzer完成中文词频统计系统的实现。
关键词:中文词频统计关键技术综述;中文词频统计系统设计前言目前我们正处于一个互联网时代,而信息量的高速增长带来的复杂性,需要我们对其进行有效处理。
如何利用计算机来进行有效地信息处理就产生了中文信息处理技术。
中文信息处理是计算机对中文的音、形、义等信息进行处理和加工的过程,它是自然语言处理的一个分支,是一门与计算机科学、语言学、数学等多种学科相关联的综合性学科。
从20世纪80年代开始,中文信息处理进入了快速发展阶段,具体研究内容只要包括对字、词、句、段、篇、章的输入输出、压缩存储、检索传输、分析理解和智能生成等方面的技术。
随着网络信息的极速增长,有用信息的获取变得越来越不容易,中文词频统计系统的诞生为人们解决这一难题,帮助人们从一堆杂乱无章的中文文本数据中获取高频词或关键词,有助于准确把握文章的要义,从而深入了解其核心思想,获得有用的信息。
1. 中文词频统计关键技术1.1 中文分词技术中文分词是中文词频统计首要解决的问题,也是中文词频统计的关键技术。
中文文本信息与英文文本信息存在一个明显差别,即在英文文本中,单词与单词之间有空格分隔;而中文文本中,词与词之间不存在天然分隔符,同时中文词语没有清晰的定义。
这些文本信息区别,要求在对中文文本信息进行处理前,必须将成段的文本分隔成更小的词汇单元,这个过程即是中文分词。
中文自动分词是指使用自计算机自动对中文文本进行词语的切分,即像英文那样使得中文句子中的词之间有空格以标识,达到被计算机自动识别语义的效果。
汉字的使用频率

汉字的使用频率汉字的使用频率汉字的数量非常庞大,总数大约九万左右。
但常用字才三千多个,即使是常用字,使用频率的差别也很悬殊。
国家标准GB2312-80《信息交换用汉字编码字符集*基本集》就是根据这种事实制订的。
一级字库为常用字,3755个,二级字库为不常用字,3008个,一、二级字库共有汉字6763个。
一级字库的字,使用频率合计达99.7%。
即在现代汉语材料中的每一万个汉字中,这些字就会出现9970次以上,其余的所有汉字也不足30次。
而最常用的1000个汉字,使用频率在90%以上.根据国家出版局抽样统计,汉字中最常用字560个,常用字807个,次常用字1033个。
三者合计2400个,占一般书刊用字的99%,所以小学生如果认识2400个常用字就能阅读一般书刊。
我国古代的周兴嗣能在一夜之间将1000个不同的常用字编成四言的押韵体《千字文》,既表达了一定的意义,又通俗易懂,和辙押韵,成为历代的识字课本。
最常用的140个汉字(按使用频率从高到低的右序排列):的一是了我不人在他有这个上们来到时大地为子中你说生国年着就那和要她出也得里后自以会家可下而过天去能对小多然于心学么之都好看起发当没成只如事把还用第样道想作种开美总从无情己面最女但现前些所同日手又行意动方期它头经长儿回位分爱老因很给名法间斯知世什两次使身者被高已亲其进此话常与活正感(这140个汉字的使用频率之和为50%)其中:最常用的5个汉字:的一是了我(这5个汉字的使用频率之和为10%)最常用的17个汉字:的一是了我不人在他有这个上们来到时(这17个汉字的使用频率之和为20%)最常用的42个汉字:的一是了我不人在他有这个上们来到时大地为子中你说生国年着就那和要她出也得里后自以会(这42个汉字的使用频率之和为30%)最常用的79个汉字:的一是了我不人在他有这个上们来到时大地为子中你说生国年着就那和要她出也得里后自以会家可下而过天去能对小多然于心学么之都好看起发当没成只如事把还用第样道想作种开(这42个汉字的使用频率之和为30%)使用频率排名141-232的汉字(这92个汉字的频率之和为10%)见明问力理尔点文几定本公特做外孩相西果走将月十实向声车全信重三机工物气每并别真打太新比才便夫再书部水像眼等体却加电主界门利海受听表德少克代员许稜先口由死安写性马光白或住难望教命花结乐色使用频率排名233-380的汉字(148个汉字,使用频率之和10%) 更拉东神记处让母父应直字场平报友关放至张认接告入笑内英军候民岁往何度山觉路带万男边风解叫任金快原吃妈变通师立象数四失满战远格士音轻目条呢病始达深完今提求清王化空业思切怎非找片罗钱紶吗语元喜曾离飞科言干流欢约各即指合反题必该论交终林请医晚制球决窢传画保读运及则房早院量苦火布品近坐产答星精视五连司巴382-500 (5.43%)奇管类未朋且婚台夜青北队久乎越观落尽形影红爸百令周吧识步希亚术留市半热送兴造谈容极随演收首根讲整式取照办强石古华諣拿计您装似足双妻尼转诉米称丽客南领节衣站黑刻统断福城故历惊脸选包紧争另建维绝树系伤示愿持千史谁准联妇纪基买志静阿诗独复痛消社算501-631算义竟确酒需单治卡幸兰念举仅钟怕共毛句息功官待究跟穿室易游程号居考突皮哪费倒价图具刚脑永歌响商礼细专黄块脚味灵改据般破引食仍存众注笔甚某沉血备习校默务土微娘须试怀料调广蜖苏显赛查密议底列富梦错座参八除跑亮假印设线温虽掉京初养香停际致阳纸李纳验助激够严证帝饭忘趣支632-1000春集丈木研班普导顿睡展跳获艺六波察群皇段急庭创区奥器谢弟店否害草排背止组州朝封睛板角况曲馆育忙质河续哥呼若推境遇雨标姐充围案伦护冷警贝著雪索剧啊船险烟依斗值帮汉慢佛肯闻唱沙局伯族低玩资屋击速顾泪洲团圣旁堂兵七露园牛哭旅街劳型烈姑陈莫鱼异抱宝权鲁简态级票怪寻杀律胜份汽右洋范床舞秘午登楼贵吸责例追较职属渐左录丝牙党继托赶章智冲叶胡吉卖坚喝肉遗救修松临藏担戏善卫药悲敢靠伊村戴词森耳差短祖云规窗散迷油旧适乡架恩投弹铁博雷府压超负勒杂醒洗采毫嘴毕九冰既状乱景席珍童顶派素脱农疑练野按犯拍征坏骨余承置臓彩灯巨琴免环姆暗换技翻束增忍餐洛塞缺忆判欧层付阵玛批岛项狗休懂武革良恶恋委拥娜妙探呀营退摇弄桌熟诺宣银势奖宫忽套康供优课鸟喊降夏困刘罪亡鞋健模败伴守挥鲜财孤枪禁恐伙杰迹妹藸遍盖副坦牌江顺秋萨菜划授归浪听凡预奶雄升碃编典袋莱含盛济蒙棋端腿招释介烧误。
现代汉语语料库词频表CorpusWordlist

101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154
词语
出现次数 744863 130191 118823 118527 83958 81119 65146 53556 52912 52728 47908 46965 44947 42332 41116 40849 38084 35429 34323 33991 31512 30936 30123 29749 29265 29039 28769 28404 28038 26823 25715 24807 23823 23749 22029 21744 21148 21041 20907 20210 19915 19539 18963 18950 18805 18698
155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 却 主要 再 由于 我国 最 关系 作用 不同 中国 才 人们 出 但是 现在 则 需要 所以 因此 如果 已经 一定 们 各 重要 象 一些 情况 吧 二 次 月 便 知道 时候 做 必须 成 人民 四 走 出来 活动 同 方面 条 高 吗
语料库常用统计方法

语料库常用统计方法在当今信息爆炸的时代,语料库作为一种大规模的语言数据集,对于语言学研究、自然语言处理、翻译研究等领域都具有重要意义。
而要从海量的语料中提取有价值的信息,就需要运用各种统计方法。
接下来,让我们一起深入了解一些语料库常用的统计方法。
一、词频统计词频统计是语料库分析中最基础也最常见的方法之一。
简单来说,就是计算某个词在语料库中出现的次数。
通过词频统计,我们可以了解到哪些词在特定的语料中使用最为频繁,哪些词相对较少出现。
例如,在一个关于科技新闻的语料库中,“人工智能”“大数据”等词可能会有较高的词频,而在一个文学作品的语料库中,“情感”“风景”等词可能更常见。
词频统计不仅能帮助我们快速把握语料的主题和重点,还能为词汇的重要性排序提供依据。
为了进行词频统计,首先需要对语料进行预处理,包括分词、去除标点符号和停用词(如“的”“了”“啊”等常见但对语义影响不大的词)。
然后,通过编程语言(如 Python)中的相关库(如 collections 库)或者专门的语料库分析工具(如 AntConc),可以轻松实现词频的计算和排序。
二、词汇多样性统计词汇多样性是衡量语言丰富程度的一个重要指标。
常见的词汇多样性统计方法包括类符/形符比(TypeToken Ratio,简称 TTR)和标准化类符/形符比(Standardized TypeToken Ratio)。
类符指的是语料库中不同的单词,形符则是单词出现的总次数。
TTR 就是类符数量除以形符数量。
例如,一个包含100 个单词的文本,其中不同的单词有 50 个,那么 TTR 就是 05。
然而,TTR 会受到文本长度的影响,文本越长,TTR 往往越低。
为了克服这一问题,标准化类符/形符比通过对文本进行分段计算 TTR,然后取平均值来得到更稳定和可靠的结果。
词汇多样性统计对于比较不同作者、不同文体、不同语言的文本特点具有重要意义。
一般来说,文学作品的词汇多样性往往高于科技文献,而高水平的作者通常能够在作品中展现出更高的词汇多样性。
4.6双字词词频统计

4.6双字词词频统计双字(连续)词同现频率统计的任务是:统计给定语料中有多少个不同的字对( Character pair),每个字对各出现多少次。
例如“发展中国家的”这个汉字串中就有“发展”、“展中中国”“国家”、“家的”共5个字对,每个字对各出现了一次。
字对不一定是双字词,例如“展中”、“家的”不是词,“中国”虽然是词,但在这个汉字串中不是词。
用任一字对在语料中的出现次数,除以所有字对出现的总次数,就可以得到这个字对的频率,即双字同现频率。
如果语料规模充分大并且分布均匀,就可以根据双字同现频率和单字频率来估计其中某个汉字的条件概率。
例如,用字对“中国”的频率除以汉字“国”的频率,可以得到条件概率P(Z1=中|Z2=国),即,当后一字已确定为“国”字时,前字为“中”的可能性有多大类似地,也可以得到条件概率P(Z2=国|Z1=中),即,当前一字已确定为“中”时,后一字为“国”的可能性有多大。
如果考察汉字的条件概率时需要看更长些的上下文,就需要做三字同现、四字同现…的频率统计双字字频统计一般是为了计算单字出现的条件概率或者双字的相关性计算中必然要用到单字出现的概率,因此做双字字频统计往往同时统计单字频率,除非单字频率已经统计过。
对一个文件进行双字字频统计,仍然是循环地读出文件中的每一个汉字,登记其出现次然后查它和前面一个汉字是否在双字字表中出现过:如果已经出现,同现次数加1;否则在双字字表中插入这对汉字,并置同现次数为1。
4.6.1双字字表结构的三种方案双字字表的数据结构是一个更需要仔细斟酌的问题。
国标码汉字6763个,那么所有可能的双字有6763×6763=45738169种。
如果全部放在内存中,每种用2个字节表示同现次数,大约需要占用87兆内存。
日前的微机一般是16兆或32兆内存,面且不是全部内存都能使用。
一般的微机上用的是 WINDOWS系统,允许多个程序同时运行;如果一个程序占用太多内存,别的程序就无法运行了。
语料库——精选推荐

语言学的研究必须以语言事实作为根据,必须详尽地、大量地占有材料,才有可能在理论上得出比较可靠的结论。
传统的语言材料的搜集、整理和加工完全是靠手工进行的,这是一种枯燥无味、费力费时的工作。
计算机出现后,人们可以把这些工作交给计算机去作,大大地减轻了人们的劳动。
后来,在这种工作中逐渐创造了一整套完整的理论和方法,形成了一门新的学科——语料库语言学(corpus linguistics),并成为了自然语言处理的一个分支学科。
语料库语言学主要研究机器可读自然语言文本的采集、存储、检索、统计、语法标注、句法语义分析,以及具有上述功能的语料库在语言定量分析、词典编纂、作品风格分析、自然语言理解和机器翻译等领域中的应用。
多年来,机器翻译和自然语言理解的研究中, 分析语言的主要方法是句法语义分析。
因此,在很长一段时间内,许多系统都是基于规则的,而根据当前计算机的理论和技术的水平很难把语言学的各种事实和理解语言所需的广泛的背景知识用规则的形式充分地表达出来,这样,这些基于规则的机器翻译和自然语言理解系统只能在极其受限的某些子语言(sub-language)中获得一定的成功。
为了摆脱困境,自然语言处理的研究者者们开始对大规模的非受限的自然语言进行调查和统计,以便采用一种基于统计的模型来处理大量的非受限语言。
不言而喻,语料库语言学将有可能在大量语言材料的基础上来检验传统的理论语言学基于手工搜集材料的方法所得出的各种结论,从而使我们对于自然语言的各种复杂现象获得更为深刻全面的认识。
本文首先简要介绍国外语料库的发展情况,然后,比较详细地介绍中国语料库的发展情况和主要的成绩,使我们对于语料库研究得到一个鸟瞰式的认识。
一、国外语料库概况现在,美国Brown大学建立了BROWN语料库(布朗语料库),英国Lancaster大学与挪威Oslo大学与Bergen大学联合建立了LOB 语料库。
欧美各国学者利用这两个语料库开展了大规模的研究,其中最引人注目的是对语料库进行语法标注的研究。
汉语词频统计

第二章 汉语词语的信息处理
第一节 汉语词语的词频统计
授课时间:2006年10月9日 授课人: 徐艳华
内容提要:
词频统计的方法与意义 词表的建立 词库的建立 汉语统计的难题
一、词频统计的方法与意义
1、词频与频率 词频: 即词语的频度,是指每个词 语在一定语料中出现的次数。 频率:每个词语的频度与总频度和 之比。
三、言语统计的特殊性
(1)抽样问题。词频统计和字频统计一样, 统计结果的准确性在很大程度上依赖于所 选择的语料是否科学,频率误差多半是由 于选材的不合理。 一是选材的比例。 二是均匀分布。 三是抽样量的问题。
(2)真实文本的问题。言语统计要保持 统计语料的完整性和真实性。
(3)一般频度词表的内容: 词的频度,即该词在语料中出现的次数; 相对频度,即该词在统计出来的全部词中 所占的百分比; 累积频度,即对所列各员出现次数的累加 数; 分布范围及分布频度,即按不同风格或不 同标准分别统计的篇章数及出现次数。 (4)最新统计方法和科学技术的运用,比如 语料库的使用。
1、词的分级 在词频统计的基础上,词语信息处理的工作 就是词的分级工作,即把频度相等的词归 为一级,频度最高者为第一级,依次排列, 最低者(出现一次的)为最末一级。这样, 我们就可以将汉语的词分成通用词、常用 词、一级词或二级词,并相应地建立成现 代汉语常用词表、词库,现代汉语通用词 表、词库。
同音字“频度语音差异优势说”研究——基于现代汉语常用汉字的字频统计分析

2020年7月JuL ,2020第35卷第7期Vol. 35 No. 7北部湾大学学报JOURNAL OF BEIBU GULF UNIVERSITYDOI : 10. 19703/j. bbgu. 2096—7276. 2020. 07. 0071同)频度语"'异优势说*研-——基于现代汉语常用汉字的字频统计分析董国华%广东海洋大学文学与新闻传播学院,广东湛江524088)[摘 要]同音字数量众多是汉字的一大特点,在3 000个常用字中的同音率高达65.19%,这无疑给汉 字的日常使用和信息化处理带来困扰。
影响汉字使用频度(字频)的因素复杂多样,在读音不同的同义字组中,同音字数少的字理论上会比同音字数多的字使用频度更高,可简称为“频度语音差异优势说”。
在3 000个常 用汉字中随机挑选36组同义字组,通过统计字组的同音字个数,分析其在1925年、1946年、1989年和1992年的四个重要常用字表的位次变化,有18组字组的字频变化符合这一现象,比例占50% o 研究表明,同义字组中 的单字同音字数是影响字频的重要因素,同音字数量较少的字使用频率星现逐渐增加的趋势,字频的变化也受到语体色彩、方言差异和使用习惯等因素的综合影响。
[关键词]同音字;同义字组;常用汉字;字频;统计分析[中图分类号]H124.3[文献标识码]A [文章编号]2096-7276( 2020) 07-0071 -10一、汉语同音字与“频度语音差异优势说”(一)现代汉语同音字的性质和特点同音字,一般指声、韵、调都相同但意义不同的字。
由于现代汉语普通话大约有1 300个有意义的音节,作为表意文字的汉字(或称意音文字)却大大高于我们的音节数,在这种情况下,就出现 了只有极少数的一个音节代表一个汉字的情况, 绝大部分的情况是一个音节表示多个汉字的读音。
简而言之,现代汉语语音系统简单,以单音节为表现形式,然而“语音是利用发音器官的各种变化形成的,这种变化主要是舌头、唇和小舌的变化,而人能做出的这种能感知出来的变化种类是非常有限的*[1](同时,人类耳朵所能感受到的 音节也是有限的,但是,我们所要表达的意思却比我们本身能发出的声音要多得多。
对外汉语教材等级词频统计模块构建——一种辅助对外汉语教材词汇难度评量的工具

在深入分析 《 纲》中 80 大 0 0词 的基 本 特 征 规 律 、存 储 特 征 及
句子长度和句子结构 复杂性增加 ,句 中出现 的词数量 随之增
多 ,除 了检 索 过 程 中 词汇 歧义 问题 将 越 发 突 出外 , 检 索 次 数 词
第 1 9卷
现 代教 育 技 术
M o e d c t n l e h oo y d m E u a i a c n l g o T
V01 9 .1 N o. 0 720 9
20 09年第 7 期
对外汉语 教材等级词频统计模块 构建
— —
一
种辅助对外汉语教材词汇难度评量 的工具
梁 少丽 宋继华
( 京 师 范 大 学 信 息 科 学 与 技 术 学 院 , E 10 7 ) 北 京 08 5
【 摘要 】在对外汉语教材 的编著过程 中,用词频度和难度直接影 响教材编著的质量。根据 《 汉语水平词汇与汉字等级大纲》 ( 以下简称 《 大纲》 0 0多等级用词 目、词性、难度等级三个属性,设计并实现对外汉语教材编著系统难度等级词频统计模 )8 0 块 ,并在 2 教材语料基础上 ,进行实验 。实验证 明,在速度上取得 了较 为 良好的效果 。 0万 【 关键词 】对外汉语 教材编著系统 ;词频检索统计;汉语词汇等级 ;键树 【 中图分类号 】G 00 7 4 .5 【 文献标 识码 】A 【 论文编号】10 - 8 9 2 0 )0 _ o 8 一O 0 9- 0 7(0 9 7 - O 6 4 - _
要还是通过词汇难度划分来实现的, 因此 , 本文将借鉴此思路,
自然语言处理算法之词频统计

自然语言处理算法之词频统计自然语言处理(Natural Language Processing,NLP)是计算机科学与人工智能领域中的一个重要分支,旨在使计算机能够理解和处理人类语言。
在NLP中,词频统计是一种常见的算法,用于分析文本中的词汇使用情况。
本文将探讨词频统计算法的原理、应用以及可能的改进方法。
一、词频统计算法的原理词频统计算法的原理很简单:通过计算文本中每个词出现的频率,来衡量该词在文本中的重要性。
词频统计算法通常包括以下几个步骤:1. 分词:将文本划分为一个个单词或短语。
分词是NLP中的一个重要任务,可以使用各种方法,如基于规则的分词、统计分词和基于机器学习的分词等。
2. 统计词频:统计每个词在文本中出现的次数。
可以使用哈希表或字典等数据结构来存储词频信息。
3. 排序:按照词频从高到低对词进行排序。
排序可以使用快速排序、归并排序等常见的排序算法。
4. 输出结果:将排序后的词及其对应的词频输出。
可以选择输出前N个词,或者输出所有词。
二、词频统计算法的应用词频统计算法在文本挖掘、信息检索、自动摘要等领域有着广泛的应用。
以下是一些常见的应用场景:1. 关键词提取:通过词频统计,可以找出文本中出现频率最高的词,从而提取出文本的关键词。
关键词提取在搜索引擎、文本分类等任务中非常有用。
2. 文本摘要:通过词频统计,可以找出文本中出现频率较高的词,从而生成文本的摘要。
文本摘要在新闻报道、文献综述等场景中有着重要的应用价值。
3. 语言模型:通过词频统计,可以估计一个词在给定上下文中出现的概率,从而构建语言模型。
语言模型在机器翻译、语音识别等任务中起着关键作用。
三、词频统计算法的改进方法尽管词频统计算法简单易懂,但它也存在一些局限性。
例如,它无法处理词义消歧、停用词过滤和词序信息等问题。
为了改进词频统计算法,可以考虑以下几个方向:1. TF-IDF算法:TF-IDF(Term Frequency-Inverse Document Frequency)是一种常用的文本特征表示方法。
汉语常用八千高频词频率表

词条词次频率的73835 5.6174%了28881 2.1973%是21831 4.6619%一50672 1.5727%不18107 1.3776%我16970 1.2911%在14656 1.1150%有125910.9579%他122060.9286%个110420.8401%这103750.7893%着102530.7801%就101070.7689%你96940.7375%和91380.6952%说90970.6921%上83070.6320%人76820.5845%地73940.5625%也69990.5325%里64740.4925%我们61630.4689%来60920.4635%到58480.4449%都53730.4088%还53180.4046%大52940.4028%去52770.4015%把49010.3729%又48650.3701%看46820.3562%要44130.3357%她42360.3223%那40440.3077%好40260.3063%小38210.2907%主义37820.2877%能37260.2835%国36510.2778%很36370.2767%年36330.2764%十36150.2750%得35630.2711%他们34180.2600%什么33940.2582%没30730.2338%两30720.2337%三29650.2256%中29120.2216%用29090.2213%走28990.2206%从28100.2138%天26810.2040%种26560.2021%二25970.1976%出25710.1956%自己25700.1955%几25120.1911%人民24660.1876%到24270.1847%它23990.1825%起来23250.1769%对23120.1759%呢23070.1755%一22290.1696%会21610.1644%多21390.1627%而21070.1603%吧20730.1577%家19920.1516%革命19630.1494%时候19600.1491%叫19570.1489%向18940.1441%只18870.1436%工作18780.1429%这样18720.1424%四18610.1416%没有18440.1403%社会18410.1401%给18390.1399%五18270.1390%同志18250.1389%想18190.1384%做17990.1369%可以17870.1360%水17850.1358%第17650.1343%话17610.1340%头16830.1280%象16710.1275%手16420.1249%们16250.1236%才16140.1228%使16110.1226%知道16030.1220%您15930.1212%成15900.1210%次15890.1209%时15660.1191%打15480.1178%最15450.1175%事15390.1171%老15330.1166%吃15260.1161%为15070.1147%再14850.1131%在14630.1113%问题14490.1102%这个14470.1101%高14470.1101%起14450.1099%上14430.1098%出来14410.1096%怎么14410.1096%下14360.1093%九14320.1090%听15150.1077%党14120.1074%回14040.1068%百13910.1058%新13820.1051%被13580.1033%等13540.1030%现在13480.1026%各13440.1016%想13350.1008%可是13250.0998%已经13120.0997%声13110.0985%吗12940.0984%全12930.0974%心12800.0959%前12600.0957%生产12580.0951%你们12500.0938%后12330.0930%过12220.0930%问12220.0926%见12170.0911%更11970.0886%山11640.0883%下11610.0864%住11360.0859%开11290.0857%月11260.0857%发展11260.0847%却11130.0839%阶级11030.0838%啊11020.0837%这些11000.0820%点11000.0811%敌人10780.0810%但是10660.0809%谁10650.0810%每10630.0809%跟10590.0806%写10540.0802%拿10460.0796%人们10370.0796%万10370.0789%出10360.0789%边10330.0788%身10260.0786%孩子10250.0781%地10200.0780%但10180.0776%呀10150.0775%思想10140.0772%因为10110.0772%六10070.0769%条10050.0766%八10010.0765%所10010.0762%研究9990.0762%世界9980.0760%一定9980.0759%笑9960.0759%给9890.0758%经济9870.0752%开9850.0751%坐9800.0749%以9800.0746%科学9790.0746%过9780.0745%为9770.0744%些9750.0743%找9740.0742%让9690.0741%国家9670.0737%啦9620.0736%与9560.0732%放9490.0727%过9450.0722%下9330.0719%许多9230.0710%看见9210.0702%道9110.0701%路9020.0693%东西8990.0686%于8950.0684%以后8950.6810%跑8950.0681%七8820.0679%正8630.0672%门8630.0657%群众8630.0657%进行8610.0655%斗争8600.0654%带8550.0651%上8520.0648%作8470.0644%者8450.0643%外8360.0636%站8250.0628%性8190.0623%真8180.0622%内8100.0616%可8100.0616%由8070.0614%在8020.0610%一样7960.0606%工人7930.0603%便7930.0603%河7880.0600%如果7840.0597%钱7800.0593%脸7780.0592%快7770.0591%比7730.0588%大家7700.0586%讲7690.0585%多769 1.0585%千7670.0584%生活7630.0581%为了7620.0580%死7570.0576%军7520.0572%回7510.0571%提7420.0565%只7400.0563%受7390.0562%劳动7330.0558%这么7330.0558%一些7290.0555%长7270.0553%可7240.0551%妈妈7190.0547%块7180.0546%所以7160.0545%主席7100.0540%眼睛7070.0538%或7050.0536%今天7010.0533%日7000.0533%已6920.0527%地方6910.0526%下来6880.0523%船6850.0521%车6820.0519%学习6790.0517%起6780.0516%先6780.0516%历史6780.0516%一切6760.0514%远6740.0513%进6690.0509%一点6670.0508%等6660.0507%早6650.0506%买6650.0506%半6630.0504%要6630.0504%而且6620.0504%时间6600.0502%同6590.0501%这里6580.0501%机6520.0496%运动6510.0495%送6480.0493%先生6470.0492%需要6450.0491%赶6440.0490%必须6440.0490%解放6390.0486%位6370.0485%能够6360.0484%为什么6360.0484% ]方面6360.0484%学习6310.0480%政治6310.0480%发6290.0479%无6270.0477%关系6230.0474%满6210.0473%爱6190.0471%大6170.0469%太6170.0469%别6170.0469%树6160.0469%没6130.0466%得6120.0466%完6100.0464%并6080.0463%怕6030.0459%拉6020.0458%句6010.0457%似的5990.0456%技术5990.0456%情况5980.0455%建设5980.0455%领导5930.0451%咱们5930.0451%红5920.0450%应该5920.0450%进5880.0447%员5870.0447%穿5850.0445%它们5850.0445%之5800.0441%主要5800.0441%那5800.0441%还是5760.0438%风5760.0438%觉得5740.0437%胜利5740.0437%眼5700.0434%少5680.0432%书5680.0432%重要5630.0428%共产党5600.0426%由于5570.0424%告诉5520.0420%民族5490.0418%那么5470.0416%对5400.0411%化5390.0410%低5380.0409%对于5350.0407%组织5320.0405%流5300.0403%件5270.0401%可能5260.0400%民主5260.0400%办5210.0396%真5160.0391%好5140.0390%伟大5120.0386%妈5070.0385%战争5060.0383%实际5030.0381%完全5010.0379%下去4980.0379%变4980.0379%望4980.0378%当4970.0378%部4970.0378%方法4970.0377%力4960.0377%一会儿4950.0375%不同4930.0373%请4900.0372%开始4890.0372%海4890.0372%区4890.0372%声音4880.0371%南4850.0369%多4810.0366%过来 4770.0363%事情 4760.0362%不过 4760.0362%无产阶级4760.0362%特别4750.0361%一般4740.0361%厂4730.0360%认识4710.0358%工业4710.0358%面4700.0358%好象4660.0355%解决4650.0354%白4640.0353%睡4640.0353%动4620.0352%帝4620.0352%脚4610.0351%离4600.0350%屋4600.0350%北4590.0349%得4580.0348%青年4580.0348%字4560.0347%饭4560.0347%要求4560.0347%哪4550.0346%反对4550.0346%岁4530.0345%如4520.0344%么4520.0344%谈4510.0343%提高4500.0342%马4490.0342%气4480.0341%鱼4480.0341%发现4460.0339%部分4460.0339%跳4450.0339%干部4450.0339%有的4440.0338%长4440.0338%嘴4430.0337%作用4430.0337%花4410.0336%办法4400.0335%步4400.0335%虽然4390.0334%朋友4370.0333%错误4350.0331%抗4330.0329%紧4320.0329%这儿4300.0327%爸爸4290.0326%母亲4280.0326%资本4270.0325%将4250.0323%並4250.0323%学生4240.0323%知识4230.0322%造4230.0322%汽车4230.0321%同时4220.0321%村4220.0321%行4220.0320%忽然4200.0319%雨4190.0318%分4180.0317%光4170.0317%怎样4160.0315%算4140.0315%书记4140.0315%桥4140.0314%搞4130.0314%资产4130.0312%往4100.0312%卖4100.0311%黑4090.0310%那样4080.0310%赶4080.0309%张4060.0309%夜4060.0307%到4030.0307%响4030.0307%现代4030.0305%处4010.0305%将4010.0304%米4000.0304%人家4000.0304%基础4000.0304%或者3990.0303%其他3980.0302%轻3970.0302%飞3970.0302%条件3970.0302%文化3970.0302%政府3970.0301%极3960.0301%成为3950.0301%层3950.0299%决定3930.0299%父亲3930.0229%啊3920.0298%过3900.0297%之间3900.0297%地区3900.0297%基本3900.0297%抓3890.0296%慢3870.0294%当3870.0294%刚3870.0294%正确3870.0294%其3860.0294%正在3840.0292%非常3840.0292%原来3840.0292%参加3840.0292%加3840.0292%片3840.0292%任务3840.0292%准备3830.0291%只要3830.0291%深3830.0291%室3830.0291%经验3830.0291%总3820.0291%一下3820.0291%力量3820.0291%中央3820.0291%喊3810.0290%精神3810.0290%因此3800.0289%教育3780.0288%敢3750.0285%旧3750.0285%东3750.0285%那些3740.0285%口3730.0284%住3720.0283%铁3710.0282%人类3710.0282%当时3690.0281%根据3690.0281%活动3670.0279%那里3660.0279%理论3660.0279%一起3650.0278%当然 3640.0288%高兴3630.0276%多少3620.0275%姑娘3620.0275%法3610.0275%不断3610.0275%多么3600.0274%信3590.0273%唱3590.0273%那个3570.0272%接3550.0270%转3550.0270%发生3540.0269%利用3530.0269%较3530.0269%太阳3510.0267%回3510.0267%批评3510.0267%出现3490.0266%近3470.0264%得到3470.0264%西3450.0263%困难3440.0262%点3440.0262%制度3440.0262%论3430.0261%钟3420.0260%灯3420.0260%哭3420.0260%最后3410.0259%坏3400.0259%口3400.0259%变成3400.0259%火3400.0259%喝3400.0259%就是3390.0258%热3390.0258%事业3390.0258%后来3380.0257%然后3380.0257%社3380.0257%继续3360.0256%建立3360.0256%意见3350.0255%容易3350.0255%快3350.0255%路线3350.0255%队3330.0253%认为3320.0253%老师3310.0252%雪3310.0252%反3300.0251%跟3290.0250%明白3290.0250%分之3290.0250%代表3290.0250%指3280.0250%够3280.0250%要是3280.0250%计算3280.0250%装3270.0249%战士3270.0249%一直3260.0248%城3260.0248%呀3250.0247%留3240.0247%知3230.0246%分3230.0246%全3220.0245%晚上3220.0245%实现3220.0245%希望3210.0244%随3200.0244%忙3200.0244%会议3200.0244%弄3190.0243%农业3190.0243%入3180.0242%往3180.0242%各种3180.0242%左3160.0240%停3150.0240%文艺3150.0240%增加3130.0238%草3120.0237%实践3120.0237%只有3110.0237%战斗3110.0237%女3100.0236%衣服3090.0235%不要3080.0234%感到3070.0234%于是3070.0234%该3070.0234%连…都…3070.0234%任何3060.0233%时期3060.0233%帮助3050.0232%纸3050.0232%並且3040.0231%另3040.0231%爬3040.0231%反动3030.0231%文章3020.0230%线3020.0230%飞机3020.0230%化学3000.0228%别2990.0228%江2990.0228%突然2980.0227%岸2970.0226%抬2970.0226%总2970.0226%冷2960.0225%学校2960.0225%回答2950.0224%影响2950.0224%十分2940.0224%听见2940.0224%市2940.0224%使用2940.0224%了解2930.0223%注意2930.0223%此2930.0223%变化2930.0223%嗯2930.0223%人员2920.0222%皮2910.0221%相2900.0221%计划2900.0221%农民2900.0221%常常2890.0220%身体2890.0220%存在2890.0220%速度2890.0220%自动2890.0220%落2880.0219%过去2870.0218%那么2870.0218%钢2870.0218%部队2860.0218%产生2860.0218%伸2850.0217%声2850.0217%创造2820.0215%面前2810.0214%里面2810.0214%倒2810.0214%祖国2810.0214%经过2810.0214%哪儿2810.0214%管2810.0214%有些2800.0213%清楚2790.0212%所有2790.0212%矛盾2790.0212%段2780.0212%冲2780.0212%现象2780.0212%出去2770.0211%座2760.0210%病2760.0210%及2760.0210%清2750.0209%接着2750.0209%下2750.0209%生2740.0209%活2740.0209%愿意2740.0209%县2730.0208%方向2730.0208%某2730.0208%过程2730.0208%常2720.0207%点2720.0207%哪里2720.0207%把2720.0207%经过2720.0207%越越2720.0206%掉2710.0206%底2710.0206%里2710.0206%枪2710.0206%床2710.0206%样子2710.0205%摇2700.0205%省2700.0205%机器2700.0205%抱2700.0205%布2690.0205%只是2690.0204%形成2680.0204%制2680.0204%动物2680.0203%前进2670.0202%意思2660.0202%以及2660.0202%哪2660.0202%文学2650.0202%直2640.0201%取得2640.0201%别人2630.0200%完成2630.0200%阵2630.0200%重2620.0199%成2620.0199%电影2620.0199%难2610.0199%马上2610.0199%着2610.0199%坚持2610.0199%具有2610.0188%群2600.0188%有一点2600.0198%刚才2600.0198%亮2590.0197%不但2590.0197%材料2590.0197%国民党2590.0197%也许2580.0196%换2580.0196%立刻2580.0196%统治2560.0195%整个2550.0194%规律2550.0194%学2550.0194%系统2540.0193%收2560.0193%画2560.0193%急2520.0192%根2520.0192%喜欢2520.0192%然而2520.0192%仿佛2520.0192%表现2520.0192%中间2510.0191%洗2510.0191%甚至2510.0191%斤2510.0191%水平2510.0191%类2510.0191%烧2500.0190%自然2500.0190%酒2500.0190%挂2490.0189%同2480.0189%腿2480.0189%牛2480.0189%年轻2470.0188%似乎2470.0188%以前2460.0187%破2460.0187%一就2460.0187%嘛2460.0187%团结2460.0187%广大2460.0187%歌2450.0186%关于2450.0186%石油2450.0186%右2440.0186%种2440.0186%严重2430.0185%屋子2430.0185%地球2430.0185%上面2420.0184%她们2410.0183%物质2400.0183%永远2390.0182%团2390.0182%时代2380.0181%台2380.0181%土地2380.0181%总是2370.0180%努力2370.0180%统一2370.0180%委员2360.0180%通过2360.0180%联系2360.0180%改造2360.0180%短2350.0179%比较2350.0179%瞧2350.0179%侵略2350.0179%量2350.0179%工程2340.0178%组2340.0178%规定2340.0178%倒2330.0177%应当2330.0177%房子2330.0177%鸡2320.0177%摸2320.0177%大量2320.0177%爷爷2320.0177%靠2310.0176%全部2310.0176%政策2310.0176%读2300.0175%推2290.0174%间2290.0174%对2290.0174%烟2280.0174%领导2280.0174%回来2280.0174%听说2280.0174%碗2270.0173%级2270.0173%大会2270.0173%数学2270.0173%石2260.0172%女人2260.0172%空气2260.0172%哩2250.0171%真正2250.0171%发动2250.0171%原则2250.0171%吹2240.0170%首先2240.0170%太太2240.0170%了2230.0170%朝2230.0170%窗2230.0170%所2230.0170%来2220.0169%湖2220.0169%认真2220.0169%道路2220.0169%总理2220.0169%则2210.0168%相信2200.0167%班2200.0167%顶2200.0167%作为2190.0167%倍2190.0167%平原2190.0167%公里2190.0167%记2180.0166%前面2180.0166%懂2180.0166%乱2180.0166%表示2170.0165%态度2170.0165%不仅2170.0165%共产主义2170.0165%分子2170.0165%哲学2170.0165%哥哥2170.0165%支2160.0164%之后2160.0164%仍然2160.0164%取2160.0164%几乎2160.0164%生命2160.0164%黄2160.0164%队伍2160.0164%菜2160.0164%电影2160.0164%个人2160.0164%院2150.0164%之后2150.0164%强2150.0164%木2140.0163%街2140.0163%巨大2140.0163%会2140.0163%将来2130.0162%土2130.0162%交2130.0162%玻璃2130.0162%派2120.0161%师2120.0161%种2120.0161%派2120.0161%定2110.0161%要2110.0161%界2110.0161%艺术2110.0161%油2110.0161%积极2110.0161%目前2110.0161%竟2100.0160%称2100.0160%旁边2090.0159%业2090.0159%更加2080.0158%肯2080.0158%环境2080.0158%教师2080.0158%哎2080.0158%破坏2070.0158%占2070.0158%肉2060.0157%封建2060.0157%整2050.0156%碰2050.0156%明天2050.0156%制造2050.0156%利益2050.0156%事实2040.0155%即2040.0155%唯物2040.0155%未2030.0154%翻2030.0154%儿子2030.0154%错2030.0154%女儿2030.0154%应2020.0154%其中2020.0154%能力2020.0154%药2020.0154%叫做2020.0154%反映2020.0154%终于2010.0153%城市2010.0153%结合2010.0153%含2010.0153%气候2010.0153%母2010.0153%师傅2010.0153%传2000.0152%除了2000.0152%日子2000.0152%元2000.0152%鞋2000.0152%说明2000.0152%杀1990.0151%细1990.0151%如何1990.0151%部门1990.0151%既1980.0151%躺1980.0151%项1980.0151%妇女1980.0151%副1970.0150%棉1970.0150%门口1970.0150%服务1970.0150%集中1970.0150%纤维1970.0150%摆1960.0149%以为1960.0149%俩1960.0149%哦1960.0149%压1950.0148%消息1950.0148%古1950.0148%丰富1940.0148%机关1940.0148%产品1940.0148%举1930.0147%周围1930.0147%比1930.0147%后面1930.0147%答应1930.0147%中心1930.0147%生物1930.0147%指出1930.0147%实行1930.0147%军队1930.0147%双1920.0146%大概1920.0146%机会1910.0145%上去1910.0145%上来1910.0145%曾1910.0145%回1910.0145%迅速1910.0145%引起1910.0145%忘1910.0145%修1910.0145%洲1910.0145%有时1900.0145%照1900.0145%只好1900.0145%篇1900.0145%苦1900.0145%角1890.0144%指导1890.0144%本1890.0144%形式1890.0144%报1880.0143%改1880.0143%实在1880.0143%建1880.0143%国际1880.0143%晚1870.0142%内容1870.0142%成立1870.0142%长期1870.0142%加强1870.0142%方针1870.0142%圆1860.0142%改变1860.0142%闹1860.0142%管理1860.0142%达到1860.0142%小时1860.0142%坚决1860.0142%简直1850.0141%洞1850.0141%简单1850.0141%毛1850.0141%意义1840.0140%按照184 1.0140%特点184 1.0140%颗184 1.0140%至1830.0139%间1830.0139%亿1830.0139%比较1820.0139%那儿1820.0139%军事1820.0139%指挥1810.0138%剥削1810.0138%久1800.0137%进来1800.0137%保护1800.0137%采取1800.0137%具体1790.0136%哥1790.0136%起义1790.0136%热情1780.0135%墙1780.0135%抽1780.0135%地方1780.0135%主任1770.0135%羊1770.0135%约1770.0135%大夫1770.0135%以来1770.0135%执行1770.0135%擦1760.0134%试1760.0134%野1760.0134%以上1760.0134%名1750.0133%曾经1750.0133%结束1750.0133%道1750.0133%工厂1750.0133%战线1750.0133%例如1750.0133%举行1750.0133%老人1740.0132%样1740.0132%正1740.0132%彻底1740.0132%机械1740.0132%其实1730.0132%今年1730.0132%老1730.0132%真理1730.0132%老爷1730.0132%建筑1720.0131%昨天1720.0131%专政1720.0131%掉1710.0130%决1710.0130%难道1710.0130%骂1710.0130%合作1710.0130%熟1700.0129%负责1700.0129%去年1700.0129%棵1700.0129%外国1700.0129%所谓1700.0129%共同1700.0129%理想1690.0129%不久1690.0129%云1690.0129%休息1690.0129%合1690.0129%温度1690.0129%反1690.0129%退1680.0128%通1680.0128%拍1680.0128%掌握1680.0128%自由1680.0128%处理1680.0128%资料1680.0128%武装1680.0128%金属1680.0128%法制1680.0128%立1670.0127%犯1670.0127%铁路1670.0127%内部1670.0127%商品1670.0127%走1660.0126%站1660.0126%追1660.0126%旁1660.0126%地面1660.0126%企业1660.0126%鸟1650.0126%控制1650.0126%经常1640.0125%发表1640.0125%火车1640.0125%公社1640.0125%阶段1640.0125%就是1640.0124%检查1630.0124%断1630.0124%因1630.0124%左右1630.0124%替1630.0123%幸福1620.0123%不是吗1620.0123%钻1610.0123%大学1610.0123%进步1610.0123%保证1610.0123%农村1610.0123%意识1610.0122%每1600.0122%头发1600.0122%刀1600.0122%狗1600.0122%关1600.0121%电话1590.0121%奇怪1590.0121%静1590.0120%外面1580.0120%单位1580.0120%怎么样1580.0120%现1580.0120%矿1580.0120%设计1580.0120%不管1570.0119%剩1570.0119%双1570.0119%局1570.0119%目的1570.0119%宣传1570.0119%设备1570.0119%吨1570.0119%从来1560.0119%进去1560.0119%按1560.0119%介绍1560.0119%兵1560.0119%身子1560.0119%讨论1560.0119%客观1560.0119%党员1560.0119%价值1560.0119%进攻1560.0119%来1550.0118%感情1550.0118%桌1550.0118%股1550.0118%猛1550.0118%集体1550.0118%馆1550.0118%劲1540.0117%一块儿1540.0117%生长1540.0117%根本1540.0117%应用1540.0117%睡觉1530.0116%煤1530.0116%减少1530.0116%达1530.0116%叔叔1530.0116%挤1520.0116%粮食1520.0116%一边一边1520.0116%经1520.0116%工具1520.0116%规模1520.0116%大娘1520.0116%倒1520.0116%小姐1520.0116%重新1510.0115%故事1510.0115%美丽1510.0115%原因1510.0115%包括1510.0115%直接1510.0115%回头1510.0115%危险1500.0114%缺点1500.0114%另外1500.0114%票1500.0114%厚1500.0114%地位1500.0114%借1490.0113%叶1490.0113%互相1490.0113%结果1490.0113%充分1490.0113%高度1490.0113%害虫1490.0113%英雄1480.0113%责任1480.0113%记得1480.0113%咱1480.0113%物1480.0113%帮1470.0112%咬1470.0112%成功1470.0112%哼1470.0112%本来1460.0111%初1460.0111%直1460.0111%下午1460.0111%代替1460.0111%器1460.0111%教1450.0110%懂得1450.0110%越来越1450.0110%根1450.0110%国民1450.0110%电子1450.0110%道1440.0110%腰1440.0110%下面1440.0110%渐渐1440.0110%战1440.0110%式1440.0110%吸1440.0110%实验1440.0110%炼1440.0110%采用1440.0110%空1430.0109%盖1430.0109%店1430.0109%逐渐1430.0109%调查1430.0109%少数1430.0109%联合1430.0109%决心1420.0108%枝1420.0108%好好儿1420.0108%家1410.0107%养1410.0107%等1410.0107%试验1410.0107%道理1400.0107%本1400.0107%光1400.0107%感觉1400.0107%茶1400.0107%失败1400.0107%分析1400.0107%交通1400.0107%发明1400.0107%套1390.0106%干1390.0106%房1390.0106%堆1390.0106%大约1390.0106%有关1390.0106%资源1390.0106%戏1390.0106%观点1390.0106%名字1380.0105%露1380.0105%春天1380.0105%阵地1380.0105%证明1380.0105%扩大1380.0105%信1380.0105%质量1380.0105%根据地1380.0105%大嫂1380.0105%救1370.0104%行1370.0104%戴1370.0104%家庭1370.0104%弟弟1370.0104%世纪1370.0104%植物1370.0104%分布1370.0104%辆1360.0104%份1360.0104%至于1360.0104%围1360.0104%挖1360.0104%挑1360.0104%井1360.0104%通过1360.0104%性质1360.0104%主观1360.0104%面积1360.0104%即使1350.0103%到处1350.0103%绿1350.0103%激动1350.0103%一阵子1350.0103%人物1350.0103%共1350.0103%范围1350.0103%治1340.0102%金1340.0102%代1340.0102%医生1340.0102%骑1340.0102%包1340.0102%战略1340.0102%无论1330.0101%必要1330.0101%形1330.0101%权1330.0101%事物1330.0101%号1320.0100%根本1320.0100%拖1320.0100%田1320.0100%仔细1320.0100%成绩1320.0100%眼光1320.0100%颜色1320.0100%进入1320.0100%往往1320.0100%钢铁1320.0100%少爷1310.0100%回击1310.0100%引1310.0100%领1310.0100%搬1310.0100%指示1310.0100%石头1310.0100%消灭1310.0100%挺1310.0100%数1310.0100%办公1310.0100%敌1310.0100%画1310.0100%货1310.0100%经理1310.0100%合成1310.0100%高原1310.0100%关心1300.0099%艰苦1300.0099%男1300.0099%度1300.0099%局长1300.0099%宇宙1300.0099%紧张1290.0098%眼前1290.0098%离1290.0098%武器1290.0098%压迫1290.0098%天气1290.0098%报告1290.0098%底下1290.0098%升1290.0098%标准1290.0098%显得1280.0097%同样1280.0097%如此1280.0097%选1280.0097%青1280.0097%象1280.0097%原1270.0097%泥1270.0097%赶快1270.0097%饿1270.0097%眼1270.0097%产量1270.0097%涌1270.0097%接受1260.0096%天空1260.0096%总结1260.0096%求1260.0096%有些1260.0096%同学1260.0096%工农1260.0096%眼泪1260.0096%人口1260.0096%工夫1250.0095%最近1250.0095%扑1250.0095%报告1250.0095%沟1250.0095%巩固1250.0095%脱1240.0094%玩1240.0094%早晨1240.0094%硬1240.0094%贴1240.0094%冒1240.0094%阳光1240.0094%从前1240.0094%地主1240.0094%批判1240.0094%据1240.0094%沿1240.0094%顶1240.0094%亲自1230.0094%丢1230.0094%耳朵1230.0094%片1230.0094%插1230.0094%支持1230.0094%超过1230.0094%尾巴1230.0094%零1230.0094%结构1230.0094%该1230.0094%战役1230.0094%到底1220.0093%丝1220.0093%附近1220.0093%打击1220.0093%排1220.0093%效果1220.0093%和平1210.0092%吓1210.0092%隔1210.0092%肚子1210.0092%要1210.0092%落后1210.0092%沙1210.0092%粉碎1210.0092%往1210.0092%领袖1210.0092%获得1210.0092%心情1200.0091%睁1200.0091%同意1200.0091%行动1200.0091%普通1200.0091%代表1200.0091%宽1200.0091%1200.0091%不是…,而是表面1200.0091%网1200.0091%作品1200.0091%政权1200.0091%着急1190.0091%一下子1190.0091%背1190.0091%春1190.0091%从此1190.0091%带1190.0091%板1190.0091%血1190.0091%愿1180.0090%进一步1180.0090%传统1180.0090%小孩儿1180.0090%向1180.0090%圈1180.0090%课1180.0090%召开1180.0090%图1180.0090%院子1180.0090%闪1170.0089%抢1170.0089%结果1170.0089%遍1170.0089%化1170.0089%独立1170.0089%痛1170.0089%报纸1170.0089%改革1170.0089%加工1170.0089%食物1170.0089%老板1170.0089%制1170.0089%棉花1170.0089%爸1170.0089%醒1160.0088%平1160.0088%花1160.0088%桌子1160.0088%摔1160.0088%党委1160.0088%林1160.0088%名1160.0088%权利1160.0088%集团1160.0088%从…出发1160.0088%作物1160.0088%骆驼1160.0088%充满1150.0088%衣1150.0088%体1150.0088%镇1150.0088%味1140.0087%属于1140.0087%对1140.0087%程度1140.0087%帐1140.0087%年代1140.0087%笔1140.0087%编1140.0087%球1140.0087%端1140.0087%刚刚1130.0086%提供1130.0086%假1130.0086%客人1130.0086%教学1130.0086%微笑1130.0086%平均1130.0086%塑料1130.0086%阿1130.0086%老太太1130.0086%专门1120.0085%粗1120.0085%穷1120.0085%发挥1120.0085%场1120.0085%印1120.0085%医院1120.0085%美1120.0085%依靠1120.0085%小伙子1120.0085%老头儿1120.0085%挨1110.0084%躲1110.0084%敲1110.0084%累1110.0084%恢复1110.0084%滚1110.0084%熟悉1110.0084%可怜1110.0084%作风1110.0084%纪念1110.0084%广泛1110.0084%读书1110.0084%运输1110.0084%公司1110.0084%商量1110.0084%分子1110.0084%直到1100.0084%尤其1100.0084%确定1100.0084%仍1100.0084%全面1100.0084%比如1100.0084%著作1100.0084%观1100.0084%王1100.0084%之一1100.0084%重大1100.0084%究竟1090.0083%欢迎1090.0083%保持1090.0083%部1090.0083%啥1090.0083%楼1090.0083%车间1090.0083%劝1090.0083%如1090.0083%普遍1090.0083%兴奋1080.0082%深刻1080.0082%冬天1080.0082%包1080.0082%中学1080.0082%影1080.0082%上级1080.0082%架1080.0082%幅1080.0082%东北1080.0082%原料1080.0082%汗1080.0082%制定1080.0082%增长1080.0082%鬼子1080.0082%厉害1070.0081%运用1070.0081%亩1070.0081%开展1070.0081%因而1070.0081%小心1070.0081%蹲1070.0081%族1070.0081%村子1070.0081%忘记1060.0081%湿1060.0081%考虑1060.0081%掏1060.0081%习惯1060.0081%观察1060.0081%逃1060.0081%意志1060.0081%来1060.0081%就1060.0081%哈哈1060.0081%严肃1050.0080%果然1050.0080%帽子1050.0080%刮1050.0080%藏1050.0080%鼻子1050.0080%先进1050.0080%秘密1050.0080%奋斗1050.0080%瓶1050.0080%两1050.0080%大伙儿1050.0080%可1050.0080%转1040.0079%因素1040.0079%姓1040.0079%赶紧1040.0079%位置1040.0079%偷1040.0079%秒1040.0079%古代1040.0079%洋1040.0079%海洋1040.0079%奶奶1040.0079%共和1030.0078%牺牲1030.0078%射1030.0078%蓝1030.0078%解1030.0078%尖1030.0078%场1030.0078%庄稼1030.0078%家伙1030.0078%活1030.0078%噢1030.0078%队长1030.0078%差不多1020.0078%不错1020.0078%张1020.0078%干净1020.0078%相当1020.0078%靠1020.0078%放心1020.0078%允许1020.0078%形势1020.0078%渡1020.0078%一致1010.0077%扔1010.0077%情形1010.0077%加以1010.0077%横1010.0077%立即1010.0077%工1010.0077%自然1010.0077%争取1010.0077%余1010.0077%生气1010.0077%措施1010.0077%放大1010.0077%岛1010.0077%透1000.0076%顿1000.0076%展开1000.0076%遇到1000.0076%气1000.0076%里边1000.0076%克服1000.0076%黑暗1000.0076%着1000.0076%妹妹1000.0076%演员1000.0076%科研1000.0076%少年1000.0076%燃烧1000.0076%重量1000.0076%既然990.0075%以外990.0075%担心990.0075%当作990.0075%990.0075%一面…,一面踏990.0075%碎990.0075%特殊990.0075%生990.0075%运990.0075%有利990.0075%米990.0075%冻990.0075%号召990.0075%头980.0075%随便980.0075%教训980.0075%一带980.0075%香980.0075%强烈980.0075%念980.0075%封980.0075%产980.0075%可以980.0075%沙漠980.0075%悄悄980.0075%织980.0075%虫980.0075%照970.0074%连忙970.0074%杯970.0074%撞970.0074%争970.0074%贡献970.0074%势力970.0074%强大970.0074%品970.0074%教授970.0074%作战970.0074%谢谢970.0074%娘970.0074%聪明960.0073%现实960.0073%可爱960.0073%光荣960.0073%毕业960.0073%令960.0073%逐步960.0073%尽管950.0072%尽950.0072%准950.0072%自950.0072%排950.0072%脑子950.0072%场950.0072%户950.0072%铜950.0072%调整950.0072%山脉950.0072%专 940.0072%培养940.0072%园940.0072%战场940.0072%力气940.0072%著名940.0072%部长940.0072%博物940.0072%政委940.0072%弯930.0071%痛苦930.0071%老实930.0071%非930.0071%观众930.0071%脑袋930.0071%密切930.0071%游930.0071%干嘛930.0071%嫂子930.0071%俺930.0071%情绪920.0070%承认920.0070%不用920.0070%本920.0070%小学920.0070%期920.0070%明确920.0070%物体920.0070%足910.0069%停止910.0069%坚定910.0069%握910.0069%数910.0069%沉重910.0069%冰910.0069%爆发910.0069%品种910.0069%爹910.0069%将军910.0069%闭900.0069%年纪900.0069%老百姓900.0069%故意900.0069%般900.0069%星900.0069%坑900.0069%距离900.0069%大小900.0069%出发900.0069%病900.0069%保卫900.0069%叶子900.0069%辩证900.0069%批900.0069%梦900.0069%夏天900.0069%疼900.0069%那边900.0069%发育900.0069%捉890.0068%兴趣890.0068%趟890.0068%。
汉字字频表

汉字字频表汉字字频表汉字字、词、常用短句频度统计是中文信息化重要内容之一,统计的准确率很大程度上取决于所选择的汉字语料和语料产生时代以及语料总量;本文报告作者从 467,355,735字当代语料中对GB13000.1字符集20902字和近60000条简体词语进行了流通频度统计,可以说这是当前最具使用价值的汉字字、词频度统计。
[separator]一、语料构成总字数:467,355,735字。
⒈ 1999年至2003年4月报刊文摘、政经时事、科学技术:375,689,126字,占80.4%。
2、现代文学:91,666,609字,占19.6%。
二、字频概况⒈ 在以上语料中,总共用到的汉字为10647个,扣除繁体字1038个,共用简体字9609个,在GB 13000.1字符集20902字中有10255个未曾出现。
⒉ 与1988年国家语委公布的字频表比较,与青月亮流通字频表比较,字频有较大的涨落,表1为30个高频字的频度比较。
表1:30个高频字的频度比较表1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 的 一 是 了 不 在 有 人 上 这 大 我 国 来 们 和 个 他 中 说 到 地 为 35.929 14.585 11.843 11.559 11.121 9.1168.6288.1667.3237.1496.9056.3756.0995.8445.7625.5675.2905.2865.2664.6534.4794.3024.225 35.929 50.562.473.98594.2 102.8 110.9 118.3 125.4 132.3 138.7 144.8 150.6 156.4 162 167.3 172.5 177.8 182.5 186.9 191.2 195.5 的 一 在 国 是 中 和 有 了 人 不 为 大 年 用 上 作 发 个 以 地 会 要 36.52610.912 8.600 8.364 8.251 8.075 7.949 7.756 7.397 7.193 6.598 6.250 6.033 4.863 4.836 4.645 4.637 4.522 4.514 4.421 4.408 4.349 4.311 36.526 47.438 56.038 64.403 72.655 80.730 88.679 96.436 103.833 111.027 117.626 123.876 129.910 134.774 139.610 144.255 148.893 153.415 157.929 162.351 166.760 171.109 175.421 的 一 了 是 在 人 不 有 中 大 国 上 他 这 为 我 和 个 年 来 到 出 会 31.9095 12.8531 9.23691 9.22364 9.03071 8.96561 8.58411 7.96150 6.49679 6.16388 5.75413 5.65598 5.23414 5.22631 5.20342 4.83986 4.82400 4.72296 4.63624 4.49203 4.35898 4.16824 4.10603 31.9095 44.7627 53.9996 63.2232 72.2539 81.2195 89.8037 97.7652 104.262 110.425 116.180 121.836 127.070 132.296 137.499 142.339 147.163 151.886 156.522 161.015 165.373 169.542 173.64824 25 26 27 28 29 30 以 子 小 就 时 全 可 4.1484.1054.0494.0433.9483.9183.879 199.6 203.7 207.8 211.8 215.8 219.7 223.6 生 出 这 学 成 行 对 3.914 3.898 3.895 3.859 3.826 3.734 3.699 179.335 183.234 187.129 190.989 194.816 198.550 202.249 时 地 要 以 市 生 发 4.03592 3.91603 3.79890 3.76444 3.74665 3.71942 3.61892 177.684 181.600 185.399 189.163 192.910 196.629 200.248从上表进行分析:其中:“的、一、了、是、在、人、不、有、中、大、国、上、这、和、以、个、为、地”这18个字,三家统计均在前30出现,位置略有不同。
中文词频分布与齐夫定律的汉语适用性初探

中文词频分布与齐夫定律的汉语适用性初探本文试图通过对汉语语料的词频统计与分析,证明齐夫定律的汉语适用性,以期对中文词频分布机理的探索有所裨益。
标签:词频齐夫定律汉语适用性词语频次的观念古已有之,人们也很早就发现了语言中词语使用频次的差异。
但那时人们对词语使用频次特征的把握,仍处于感性阶段。
19世纪以来,随着语言学的发展,以及对诸如音素、语素和词等各种语言单位认识的提高,人们开始有了较为明确的“基本词汇”的概念。
在飞速发展的语言学理论的指导下,出于文学风格和速记研究的需要,人们开始对这些语言成分进行计量分析,统计出这些语言成分在一定的篇章范围内出现的频次,试图总结出这些语言成分的使用频次的规律,以更好地认识语言以及对语言和文献进行分析。
这些工作中代表性的成果就是各种频率词典的出现。
1898年,德国语言学家F.W.Kaeding在5000名速记人员和800名合作者的帮助下,历时七年,手工统计了以报刊为主要语料来源的资料,所统计的总词汇量达10,910,777条,而其中频次在4以上的词共有79716个,这些统计结果被编纂成了世界上第一部频率词典“Haufigkeits Worterbuch der Deutschen Sprache”(《德语频率词典》),这也被普遍认为是第一次现代意义上的以统计调查方法完成的词汇研究工作。
到了20世纪初,美国教育学家兼心理学家 E.L.Thorndike先后编写了Teacher’s Word Book of 20,000 Words(《教师二万词词书》)和Teacher’s Word Book of 30,000 Words(《教师三万词词书》),对英语的词汇作了大量的频率统计工作。
此后各种语言的频率词典大量涌现,形式也多种多样。
而随着不同语言中有关词频资料的大量积累,词语频次的特征也不断被揭示,人们开始从理论上思考词频差异的现象,并尝试总结出词频现象的规律来。
由于频率词典实际上就是一种词表,而其中词的出现频次与词的等级是最基本的两个数据,规定了一个词在词表中的地位和性质,因此人们首先着重研究的就是这两个基本数据之间的相互关系,以揭示词的序号的分布规律。
中文常用词 频率 统计

中文常用词频率统计
中文常用词频率统计是一种对中文文本中词语出现频率进行统计分析的方法。
通过对大量中文文本进行处理,可以得出不同词语在语料库中出现的频率,从而揭示出中文中常用词的使用规律和特点。
这种统计方法可以帮助语言学家、研究人员和语言工程师更好地理解和分析中文语言的特征。
在进行中文常用词频率统计时,首先需要准备一个包含大量中文文本的语料库,这些文本可以来自于书籍、新闻、社交媒体等各种来源。
然后,利用计算机程序对这些文本进行分词处理,将文本中的词语进行切分和统计。
接着,可以利用统计软件或编程语言进行频率统计,得出各个词语在语料库中出现的次数,进而计算出它们的频率。
通过中文常用词频率统计,我们可以发现一些常用词汇在不同语境下的使用频率,比如“的”、“是”、“了”等常见的虚词在中文文本中出现频率较高,而一些专业术语或生僻词汇则可能出现频率较低。
这种统计分析有助于我们理解中文语言的特点,同时也可以为自然语言处理、机器翻译、信息检索等领域的研究提供重要的数据支持。
除了对整体语料库进行频率统计,中文常用词频率统计也可以
针对特定主题或领域的文本进行分析,比如医学领域、金融领域等,从而更好地理解不同领域中的常用词语特点。
这种分析方法对于语
言学研究和应用具有重要意义,可以帮助我们更好地理解和利用中
文语言。
中英文词频统计(MATLAB)

中英⽂词频统计(MATLAB)中英⽂词频统计(MATLAB)1. 英⽂词频统计英⽂词频统计很简单,只需借助split断句,再统计即可。
完整MATLAB代码:function wordcount%思路:中⽂词频统计涉及到对“词语”的判断,需要导⼊词典或编写判断规则,很复杂。
%最简单的办法是直接统计英⽂词频,并由空格直接划分词语。
然后再翻译即可得到中⽂词频。
%从官⽅⽹站上下载的pdf,转成reportfulltext.txt,存到workspace进⾏操作全⽂共25003个字符。
clc;clear;report=fileread('reportfulltext.txt'); %读⼊全⽂report=regexprep(report,'\W',' '); %不是字符的,都转换为空格。
主要是去除标点符号report=lower(report); %变成⼩写words=regexp(report,' ','split')'; %根据空格分隔为单词cell%⾄此每个单词都拿出来了rank = tabulate(words); %rank是三列向量,包括名称,出现次数和百分⽐ans=sortrows(rank,-2); %只根据第⼆列进⾏排序 -2表⽰降序xlswrite('results',ans);%输出为excel⽂件end2. 中⽂词频统计中⽂词频统计相对复杂⼀些。
关键在于:使⽤合适的语料库从长到短,匹配词语。
⽐如句中出现了“计算机”三字词,我们应该将三个字视为⼀个词,⽽不能把“计算”当做⼀个词。
function wordcountchineseclc;clear;report=fileread('reportchinese.txt'); %读⼊中⽂报告,事先已放在⼯作区%% dictionary.mat是⼀个我事先准备好的列向量%其中dict是14636*1的字典列向量,从⽹上下载的官⽅语料库转换得到的load dictionary.mat;Maxlen=max(cellfun(@length,dict)); %最⼤词长,结果是10%% 按标点初步分词cut='[\,\。
中文词频分析

中⽂词频分析中⽂词频统计1. 下载⼀长篇中⽂⼩说。
三体2. 从⽂件读取待分析⽂本。
3. 安装并使⽤jieba进⾏中⽂分词。
4. 更新词库,加⼊所分析对象的专业词汇。
import reimport collectionsimport numpy as npimport jiebafrom wordcloud import WordCloud # 词云展⽰库from PIL import Image # 图像处理库import matplotlib.pyplot as plt # 图像展⽰库f=open("三体全集.txt","r",encoding='UTF-8')text=""for str in f.readlines():text=text+str.strip()f.close()stop_word=[]stop_word=open("停⽤词.txt","r",encoding='UTF-8').read().split("\n")f.close()object_list=[]jieba.load_userdict("三体词库.txt") #加载⾃定义词text_list=jieba.lcut(text)for i in text_list:if len(i)!=1:if i not in stop_word:object_list.append(i)word_counts = collections.Counter(object_list) # 对分词做词频统计word_counts_top10 = word_counts.most_common(20) # 获取前10最⾼频的词print (word_counts_top10) # 输出检查wl_split=' '.join(object_list)mywc = WordCloud().generate(wl_split)plt.imshow(mywc)plt.axis("off")plt.show()5. ⽣成词频统计6. 排序7. 排除语法型词汇,代词、冠词、连词等停⽤词。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2、汉语词频的统计方法
词频统计就是抽样一定数量的语料,计算
其中各个不同词语的出现次数,这是词频 统计工程最主要的方法。 词频统计的目的在于根据量的描述,对词 的属性给出质的评价,即依靠定量分析得 出定性分析。词频统计结果一般是做出各 种频度表,供不同专业人员使用。 用计算机统计词语使用频度的特点是速度 快,准确率高,统计量大,而且能提供多 种参数。
第二章 汉语词语的信息处理
第一节 汉语词语的词频统计
授课时间:2006年10月9日 授课人: 徐艳华
内容提要:
词频统计的方法与意义 词表的建立 词库的建立 汉语统计的难题
一、词频统计的方法与意义
1、词频与频率 词频: 即词语的频度,是指每个词 语在一定语料中出现的次数。 频率:每个词语的频度与总频度和 之比。
3、词库的建立
词库(词语数据库)是语言信息处理最 基本的资源。词库实际上就是机器可读 的电子词典。把一部人用词典如《现代 汉语词典》录入到计算机里,计算机当 然也是可以阅读的。但这里所谓的“可 以阅读”,还含有便于查找词语的各种 信息的意思。因此最好是把词库划分为 若干个相关的表。
词用计算机进行 词频统计发展很快。我国第一个最 大的词频统计工程是北京航空航天 大学在“六五”期间完成的。这次 大规模的词频统计为建立我国常用 词库具有重大意义。
我国第二个大规模的词频统计工程是由
新华社等单位于“七五”期间完成的。 1990年,新华社等单位公布了新闻语料 词频统计结果,共选147,955条词条作 为统计底表,词条出现的总次数达7, 455,171次。北京语言学院也对200万 字语料的词频进行了统计,出版了《现 代汉语频率词典》(1986),收词 31159条,这是中国正式出版的第一部汉 语频率词典。
三、言语统计的特殊性
(1)抽样问题。词频统计和字频统计一样, 统计结果的准确性在很大程度上依赖于所 选择的语料是否科学,频率误差多半是由 于选材的不合理。 一是选材的比例。 二是均匀分布。 三是抽样量的问题。
(2)真实文本的问题。言语统计要保持 统计语料的完整性和真实性。
(3)一般频度词表的内容: 词的频度,即该词在语料中出现的次数; 相对频度,即该词在统计出来的全部词中 所占的百分比; 累积频度,即对所列各员出现次数的累加 数; 分布范围及分布频度,即按不同风格或不 同标准分别统计的篇章数及出现次数。 (4)最新统计方法和科学技术的运用,比如 语料库的使用。
词表:就是通过词频统计给词语分级后,
建立的一种语言基本词语的集合。 词表的构成 (1)词条,用1-7个汉字的代表的词 语; (2)拼音,标注词语的拼音及声调; (3)标记,标注词语的分级标记。
词表的分类
通用词表
所谓现代汉语通用词,是指社会生活 各个方面、各行各业都通用的现代汉 语词汇。它是相对于流通性较窄的专 业词汇而言,它有常用性、全民性。 专业词表
4、词频统计的意义
词频统计对语言教学、语言信息处理、 语言工程都具有重要意义。 是语言教学中的课文编制的基本依据。 我们正在进行“中学文言文词频的统 计”。 在语言信息处理中为词语的分级,词 表、词库的建立提供一个基本依据。 为一定的语言工程奠定初步的基础
二、词的分级与词表、词库的建立
3、词频统计的发展
词频统计已有悠久的历史。早在公元9世纪,
评注《圣经》的希伯来学者就已经知道利 用频度来计算不同版本经典中的用词情况, 但大规模使用频度来进行词汇统计的,是 德国人F.w.Kaeding,Kaeding于1989年出 版的《德国词频词典》共抽样10 ,910 , 777词次的语料,截取频度在4次以上不同 的词一共79716个。
四、汉语统计的难题
(1)字形信息与语音信息有不同 处理技术要求。拼音文字没有这个 问题,只要用打字键盘直接往计算 机内输入就行了。 (2)词的划分问题。 (3)如何区分同音词。
1、词的分级 在词频统计的基础上,词语信息处理的工作 就是词的分级工作,即把频度相等的词归 为一级,频度最高者为第一级,依次排列, 最低者(出现一次的)为最末一级。这样, 我们就可以将汉语的词分成通用词、常用 词、一级词或二级词,并相应地建立成现 代汉语常用词表、词库,现代汉语通用词 表、词库。
2、词表的建立
分词一般只需要访问这个表; 词性表:存放词条的若干个词性标 记及其频度,可供词性标注时使用; 义项表:存放词条的若干个义项及 其频度,可供义项标注时使用; 句法分析时,这几个表都要用到。
建立词库的意义
对现代汉语词汇进行科学描述; 建立各种信息处理系统的必要手
段; 为人工和机器分词建立一个标准 底本,为分词提供方便和约束。