词法分析器的设计与实现
词法分析器原理

词法分析器原理词法分析器(Lexical Analyzer)是编译器中的重要组成部分,用于将输入的源代码分解为一个个词法单元(Token),为语法分析器(Syntax Analyzer)提供分析的基础。
本文将介绍词法分析器的原理和工作流程。
一、概述词法分析器通过扫描源代码字符流,并识别出其中的合法词法单元。
它将源代码转化为一个个标识符、关键字、常数、运算符等基本构件,以供后续阶段进行进一步的处理和分析。
二、工作原理1. 自动机词法分析器通常使用有限自动机(Finite Automaton)来实现。
有限自动机由一系列状态组成,每个状态所接受的输入决定了自动机的状态转移。
利用状态转移规则,自动机可以根据输入字符逐步分析源代码并产生相应的词法单元。
2. 正则表达式为了方便描述词法分析器对输入的词法单元进行匹配,可以使用正则表达式。
正则表达式是一种描述字符模式的工具,它可以定义一类字符串的集合。
词法分析器将正则表达式与状态机相结合,通过模式匹配的方式识别输入字符流中的词法单元。
3. 词法规则词法分析器通过预先定义的词法规则来描述源代码中的不同词法单元。
例如,某个编程语言的词法规则可能包含关键字、标识符、数字、字符串等。
词法规则的定义中常常使用正则表达式来指定某个词法单元的模式。
4. 符号表为了方便后续的语义处理和编译过程,词法分析器通常会维护一个符号表(Symbol Table)。
符号表记录了源代码中出现的标识符、常量等信息,以供后续的语法分析和语义分析使用。
三、工作流程词法分析器的工作流程可以分为以下几个步骤:1. 读取源代码字符流,并初始化状态机。
2. 通过状态转移规则,逐个输入字符进行状态转移,直到达到某个终止状态。
3. 判断当前状态是否为某个词法单元的终止状态,如果是,产生相应的词法单元,并将其记录在符号表中。
4. 继续读取源代码字符流,重复以上过程,直到扫描完整个源代码。
五、总结词法分析器作为编译器的重要组成部分,负责将源代码分解为一个个词法单元,并提供给语法分析器进行进一步的处理。
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
一个简单的词法分析器

实验一词法分析程序设计与实现一、实验目的:加深对词法分析器的工作过程的理解;加强对词法分析方法的掌握;能够采用一种编程语言实现简单的词法分析程序;能够使用自己编写的分析程序对简单的程序段进行词法分析。
二、实验内容:自定义一种程序设计语言,或者选择已有的一种高级语言(C语言),编制它的词法分析程序。
词法分析程序的实现可以采用任何一种编程工具。
三、实验要求:1. 对单词的构词规则有明确的定义;2. 编写的分析程序能够正确识别源程序中的单词符号;3. 识别出的单词以<种别码,值>的形式保存在符号表中;4. 词法分析中源程序的输入以.c格式,分析后的符号表保存在.txt文件中。
5. *对于源程序中的词法错误,能够做出简单的错误处理,给出简单的错误提示,保证顺利完成整个源程序的词法分析;6. 实验报告要求用自动机或者文法的形式对词法定义做出详细说明,说明词法分析程序的工作过程,说明错误处理的实现*。
四、实验学时:12学时五、实验步骤:1. 定义目标语言的可用符号表和构词规则;2. 依次读入源程序符号,对源程序进行单词切分和识别,直到源程序结束;3. 对正确的单词,按照它的种别以<种别码,值>的形式保存在符号表中;4. *对不正确的单词,做出错误处理*。
词法分析(Lexical Analysis) 是编译的第一阶段。
词法分析器的主要任务是读入源程序的输入字符、将他们组成词素,生成并输出一个词法单元序列,每个词法单元对应一个词素。
这个词法单元序列被输出到语法分析器进行语法分析。
知识储备词法单元:由一个词法单元名和一个可选的属性值组成。
词法单元名是一个表示某种词法单位的抽象符号,比如一个特定的关键字,或者代表一个标识符的输入字符序列。
词法单元名字是由语法分析器处理的输入符号。
模式:描述了一个词法单元的词素可能具有的形式。
词素:源程序中的一个字符序列,它和某个词法单元的模式匹配,并被词法分析器识别为该词法单元的一个实例。
词法分析器的实现与设计

题目:词法分析器的设计与实现一、引言................................ 错误!未定义书签。
二、词法分析器的设计 (3)2.1词的内部定义 (3)2.2词法分析器的任务及功能 (3)32.2.2 功能: (4)2.3单词符号对应的种别码: (4)三、词法分析器的实现 (5)3.1主程序示意图: (5)3.2函数定义说明 (6)3.3程序设计实现及功能说明 (6)错误!未定义书签。
77四、词法分析程序的C语言源代码: (7)五、结果分析: (12)摘要:词法分析是中文信息处理中的一项基础性工作。
词法分析结果的好坏将直接影响中文信息处理上层应用的效果。
通过权威的评测和实际应用表明,IRLAS是一个高精度、高质量的、高可靠性的词法分析系统。
众所周知,切分歧义和未登录词识别是中文分词中的两大难点。
理解词法分析在编译程序中的作用,加深对有穷自动机模型的理解,掌握词法分析程序的实现方法和技术,用c语言对一个简单语言的子集编制一个一遍扫描的编译程序,以加深对编译原理的理解,掌握编译程序的实现方法和技术。
Abstract:lexical analysis is a basic task in Chinese information processing. The results of lexical analysis will directly affect the effectiveness of the application of Chinese information processing. The evaluation and practical application show that IRLAS is a high precision, high quality and high reliability lexical analysis system. It is well known that segmentation ambiguity and unknown word recognition are the two major difficulties in Chinese word segmentation. The understanding of lexical analyse the program at compile, deepen of finite automata model for understanding, master lexical analysis program implementation method and technology, using C language subset of a simple language compilation of a scanned again compiler, to deepen to compile the principle solution, master compiler implementation method and technology.关键词:词法分析器?扫描器?单词符号?预处理Keywords: lexical analyzer word symbol pretreatment scanner一、引言运用C语言设计词法分析器,由指定文件读入预分析的源程序,经过词法分析器的分析,将结果写入指定文件。
词法分析器实验报告

词法分析器实验报告词法分析器实验报告一、引言词法分析器是编译器中的重要组成部分,它负责将源代码分解成一个个的词法单元,为之后的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,以深入理解其工作原理和实现过程。
二、实验目标本实验的目标是设计和实现一个能够对C语言代码进行词法分析的程序。
该程序能够将源代码分解成关键字、标识符、常量、运算符等各种词法单元,并输出其对应的词法类别。
三、实验方法1. 设计词法规则:根据C语言的词法规则,设计相应的正则表达式来描述各种词法单元的模式。
2. 实现词法分析器:利用编程语言(如Python)实现词法分析器,将源代码作为输入,根据词法规则将其分解成各种词法单元,并输出其类别。
3. 测试和调试:编写测试用例,对词法分析器进行测试和调试,确保其能够正确地识别和输出各种词法单元。
四、实验过程1. 设计词法规则:根据C语言的词法规则,我们需要设计正则表达式来描述各种词法单元的模式。
例如,关键字可以使用'|'操作符将所有关键字列举出来,标识符可以使用[a-zA-Z_][a-zA-Z0-9_]*的模式来匹配,常量可以使用[0-9]+的模式来匹配等等。
2. 实现词法分析器:我们选择使用Python来实现词法分析器。
首先,我们需要读取源代码文件,并将其按行分解。
然后,针对每一行的代码,我们使用正则表达式进行匹配,以识别各种词法单元。
最后,我们将识别出的词法单元输出到一个结果文件中。
3. 测试和调试:我们编写了一系列的测试用例,包括各种不同的C语言代码片段,以测试词法分析器的正确性和鲁棒性。
通过逐个测试用例的运行结果,我们可以发现和解决词法分析器中的问题,并进行相应的调试。
五、实验结果经过多次测试和调试,我们的词法分析器能够正确地将C语言代码分解成各种词法单元,并输出其对应的类别。
例如,对于输入的代码片段:```cint main() {int a = 10;printf("Hello, world!\n");return 0;}```我们的词法分析器将输出以下结果:```关键字:int标识符:main运算符:(运算符:)运算符:{关键字:int标识符:a运算符:=常量:10运算符:;标识符:printf运算符:(常量:"Hello, world!\n"运算符:)运算符:;关键字:return常量:0运算符:;```可以看到,词法分析器能够正确地将代码分解成各种词法单元,并输出其对应的类别。
一个词法分析器构造过程模拟器的设计与实现

计 算机 应 用与软件
Co p trAp lc to n ot r m u e p iainsa d S fwa e
V0. 8 No 1 12 .
Jn 2 1 a .0 l
一
个 词 法分 析 器 构 造 过 程 模 拟 器 的设 计 与 实现
Tk n , 编 译 程 序 的 基 础 , 是 编 译 程序 的重 要 组 成 部 分 。 词 oe ) 是 也
即具 体 规则 下 的 D A的 构 造 过 程 , 文 设 计 实 现 了一 个 词 法 分 F 本 析构造过程模拟器。
1 设计 原 理
1 1 正则 表达 式 .
正 则 表 达式 是 一 种 符 号 表 示 法 , 为 了 用 有 限 的 描 述 来 详 是 细说 明 ( 能 ) 限 的 语 言 。 也 就 是 说 正 则 表 达 式 是 针 对 某 个 可 无
孙文明 郭德贵 朱兆龙 吴姚睿
( 吉林大学计算机科学与技术学院 吉林 长春 10 1 ) 30 2
摘
词法分 析器 是编译器 的第一个 组成部分 , 是后续部分的基础 , 同时, 词法分析也广 泛应用在很多软件 中 所 以理 解 词 法 分 析器 的构造原理 比较重要。设计 并实现 的模拟器 能够 以表格和 图形 的方 式展 示词法分 析器 的构造过 程 并 可 以形 象 模 拟 词 法 分 析
Ab ta t s r c L x c l n l z ri te f s c mp n n f o i r a d i as h a e o e s b e u n a t M e n e i a a ay e h i t o o e t c mp l , n s lot e b s ft u s q e t r s r oa e h p s a whie,lxc la l ss l e ia nay i
词法分析程序的设计与实现

词法分析程序的设计与实现方法1:采用C作为实现语言,手工编制一.文法及状态转换图1.语言说明:C语言有以下记号及单词:(1)标识符:以字母开头的、后跟字母或数字组成的符号串。
(2)关键字:标识符集合的子集,该语言定义的关键字有32个,即auto,break,case,char,const,continue,default,do,double,else,enum, extern,float,for,goto,if,int,long,register,return,short,signed,static, sizeof,struct,switch,typedef ,union,unsigned ,void, volatile和while。
(3)无符号数:即常数。
(4)关系运算符:<,<=,==,>,>=,!=。
(5)逻辑运算符:&&、||、!。
(6)赋值号:=。
(7)标点符号:+、++、-、--、*、:、;、(、)、?、/、%、#、&、|、“”、,、.、{}、[]、_、^等(8)注释标记:以“/*”开始,以“*/”结束。
(9)单词符号间的分隔符:空格。
2.记号的正规文法:仅给出各种单词符号的文法产生式(1)标识符的文法id->letter ridrid->ε|letter rid|digit rid(2)无符号整数的文法digits->digit remainderremainder->ε|digit remainder(3)无符号数的文法num->digit num1num1->digit num1|. num2|E num4|εnum2->digit num3num3->digit num3|E num4|εnum4->+digits|-digits|digit num5digits->digit num5num5->digit num5|ε(4)关系运算符的文法relop-> <|<=|==|>|>=|!=(5)赋值号的文法assign_op->=(6)标点符号的文法special_symbol->+|-|*|%|#|^|(|)|{|}|[|]|:|;|”|?|/|,|.& (7)逻辑运算符的文法logic->&&| || | !(8)注释头符号的文法note->/starstar->*3.状态转换图其中,状态0是初始状态,若此时读入的符号是字母,则转换到状态1,进入标识符识别过程;如果读入的是数字,则转换到状态2,进入无符号数识别过程;……;若读入的符号是/,转换到状态11,再读入下一个符号,如果读入的符号是*,则转换到状态12,进入注释处理状态;如果在状态0读入的符号不是语言所定义的单词符号的开始字符,则转换到状态13,进入错误处理状态。
词法分析器生成器的设计与实现

有限 自动机理论是描述词法规则的基本理论 F J N A可 以看作一种特殊 的有 限 自动机 , 从某种意
义上 说 它是 带有 原始 内部 存 储 的 机 器 的抽 象 模 型 H 。一 个 N A可 以表 示 成 一 个 五元 组 : J F N=( , , S∑
定的算法( 规则) 把正规式转换为 N A 。 F
2 1 把 正规 式转换 为 N A N 的方 法描 述 . F
输 入 : 表 ∑的正规 式 r 字母 。
输出: 接受 L r的 N A N () F 。 方法 : 首先分析 r把它分解成子表达式 , , 然后使用下面的规则 1 和 2 , r ) ) 为 中的每个基本符号( 8
1 基 本 概 念
1 1 正 规 式 .
正规式是按照一组定义规则 , 由较简单 的正规式构成 的, 每个正规式 r 表示一个语 言 L r。如 : ()
I D=( 划线 I 下 字母 )・( 划 线 l 下 字母 f 字 ) 数
其中 , I表示“ 关系 , ” “” 或” “・ 表示 “ 连接 ” 系 , ” 关 “ 表示 出现零次或多次 。当然 , 正则表 达式还有 “ : +”表示出现一次或多次 ; ? 表示出现零次或一次 ……等等运算符 , “” 有兴趣 的可以在参考文献 [ ] 1
查 一下 , 里就 不详 细描 述 了。 这
形式语言的理论告诉我们 : 正则表达式可以转换成为一张转换图 ( 有限状态机 ) 。正则表达式有三 种最基本 的关系 J“ :连接” 关系 : A・ ;或” c= B “ 关系 : Al ; ” 系: A C= B “ 关 C= 。另外 的关系都可 以
词法分析器的设计与实现

词法分析器的设计与实现
1.定义词法规则:根据编程语言的语法规范,定义不同的词法规则,
如关键字、标识符、操作符、常量等。
每个词法规则由一个正则表达式或
有限自动机来描述。
2.构建有限自动机:根据词法规则,构建一个有限自动机(DFA)来
识别词法单元。
有限自动机是一种形式化模型,用于在输入字符序列上进
行状态转换。
3.实现状态转换函数:根据有限自动机的定义,实现状态转换函数。
状态转换函数接受一个输入字符,并返回当前状态和输出的词法单元。
4.实现输入缓冲区:为了方便词法分析器的实现,通常需要实现一个
输入缓冲区,用于存储源代码,并提供一些读取字符的函数。
5. 实现词法分析器:将前面实现的状态转换函数和输入缓冲区结合
起来,实现一个完整的词法分析器。
词法分析器可以使用迭代器模式,每
次调用next(函数来获取下一个词法单元。
6.处理错误情况:在词法分析过程中,可能会遇到一些错误情况,如
未定义的词法单元、不符合语法规范的词法单元等。
词法分析器需要能够
检测并处理这些错误情况。
7.构建测试用例:为了验证词法分析器的正确性,需要构建测试用例,包括各种不同的源代码片段,并验证分析结果是否符合预期。
8.进行性能优化:词法分析是编译器中的一个耗时操作,因此可以进
行一些性能优化,如使用缓存机制、减少状态转换次数等。
以上是词法分析器的设计与实现的一般步骤,具体实现过程可能因编程语言和编译器的不同而有所差异。
词法分析器实验报告

词法分析器实验报告一、实验目的本实验旨在通过构建一个简单的词法分析器来加深对编译原理中词法分析的理解,并掌握基本的词法分析算法和程序设计技巧。
二、实验环境操作系统:Windows 10编程语言:C/C++开发环境:Visual Studio 2019三、实验内容1. 设计并实现一个词法分析器,要求具备以下功能:(1)能够识别并区分关键字、标识符、字符常量、字符串常量、整型常量和浮点型常量等基本单词;(2)能够跳过注释、空格、制表符和换行符等无用字符;(3)能够给出错误提示并指明错误所在位置。
2. 对设计的词法分析器进行测试,并记录测试结果,分析测试结果的正确性和效率。
四、实验方法1. 分析待处理的源程序,并确定需要识别的词法单元;2. 设计状态转换图或状态转换表,并将其转化为程序代码;3. 开发测试程序,对所设计的词法分析器进行测试。
五、实验结果1. 实现的词法分析器程序可以正确识别出源程序中的各个单词,并能够跳过无用字符;2. 在测试过程中发现了一些错误,比如未能正确识别一些特殊情况下的单词,或者给出了错误的错误提示等。
经过修改后,程序可以正确识别这些情况,并给出正确的错误提示信息;3. 程序的效率较高,能够在短时间内对源程序进行词法分析。
六、实验体会通过本次实验,我对编译原理中词法分析的概念、算法和程序设计技巧有了更加深入的了解和掌握。
在实践中,我遇到了许多问题,比如如何设计状态转换图,如何正确识别一些特殊的单词等。
这些问题一一解决后,我对词法分析有了更加深刻的理解。
通过本次实验,我还深刻体会到了编译器设计过程中的思维方式和技术要求。
编译器是计算机科学中的一项重要技术,对于提高程序运行效率、保证程序安全性、增强程序可读性和扩展程序功能等都有重要作用。
因此,编译原理作为计算机科学的重要组成部分,对于我以后的学习和研究具有重要意义。
词法分析器的实现与设计

词法分析器的实现与设计
1. 确定待分析的源代码的字符集和词法规则:首先,确定源代码所
使用的字符集,例如ASCII或Unicode。
然后,根据编程语言的语法规则,确定各种词法单元(如关键字、标识符、操作符、常量等)的识别规则。
2.设计识别词法单元的算法:根据词法规则,设计算法来识别每个词
法单元。
通常,这涉及到使用正则表达式或有限自动机(DFA)来进行模
式匹配。
3. 实现词法分析器:使用选定的编程语言实现词法分析器。
词法分
析器可以使用手写的代码实现,也可以使用工具(如Lex、Flex等)来自
动生成。
4.构建词法分析器的输入和输出接口:词法分析器通常需要从输入流
中读取源代码,并将识别出的词法单元输出到输出流中。
因此,需要设计
适当的输入和输出接口。
5.测试和调试词法分析器:编写测试用例,用不同类型的代码对词法
分析器进行测试,以确保它能正确地识别各种词法单元。
在测试过程中,
需要检查词法分析器的输出是否符合预期的结果。
6.集成到编译器中:将词法分析器集成到编译器的其他部分中,例如
语法分析器、语义分析器等。
这需要定义合适的接口,并确保各个部分之
间的协调工作。
总结起来,词法分析器的设计和实现包括选择字符集和词法规则、设
计识别算法、实现词法分析器、构建输入和输出接口、测试和调试以及集
成到编译器中。
这些步骤需要综合考虑编程语言的特点、词法规则的复杂
性和性能需求等因素。
词法分析器-计算器-设计与实现实验报告汇总

辅导教师张静成绩else if(choice2(rz[st])==1)st=number(st);else if(rz[st]=='/')st=anotation(st);else st=other(st);return st;}测试结果:8、心得通过本次的实验,使我真正的了解词法分析器的实现过程,让我更加深刻领悟词法分析器的实现原理.虽然在本次实验中遇到了各种各样的困难和错误,但在同学们的帮助下我都一一克服了,使得词法分析器能够正确的识别相应的词法和表达式。
在做实验的过程中,总是会忽略各种细节,从而导致经常修改一些很小的低级错误才能使程序正常运行,不仅浪费时间,还影响对其他地方的修改,并且在很多步骤处理上,方法不正确。
使结果不能符合要求,深刻体会到了自己在编程方面与别人的差距,在今后的学习中,我会注意改正自己在这方面的缺点,促使自己的编程水平不断进步。
编译原理是一门专业学科,对于辅导教师张静成绩实验日期实验时间1实验名称计算器的设计与实现2、实验目的掌握自上而下语法分析方法、自下而上语法分析方法3、实验要求(1)实验内容设计及实现计算表达式的计算器。
表达式中可包含+、-、*、/、(、)等运算符.(2)实验要求:对已给的一个二元式形式表达式,能够检查有无语法错误.并指定出错位置。
将表达式的语法树输出(或将语法分析过程输出).4、实验原理根据算符优先分析思想实现语法分析程序。
5、实验步骤(1)根据文法构造语法分析表。
(2)编写总控程序实现语法分析.6、算符优先分析表及语法分析程序算符优先分析表:case '(': /*当是的时候将此括号存入栈op*/op.top++;op.data[op.top]=ch;break;case ’)’:while(op.data[op。
top] != ’(’)/*括号内的转换优先级最高故先提取表达式*/{exp[t]=op.data[op。
实验一 词法分析程序的设计与实现(C语言)
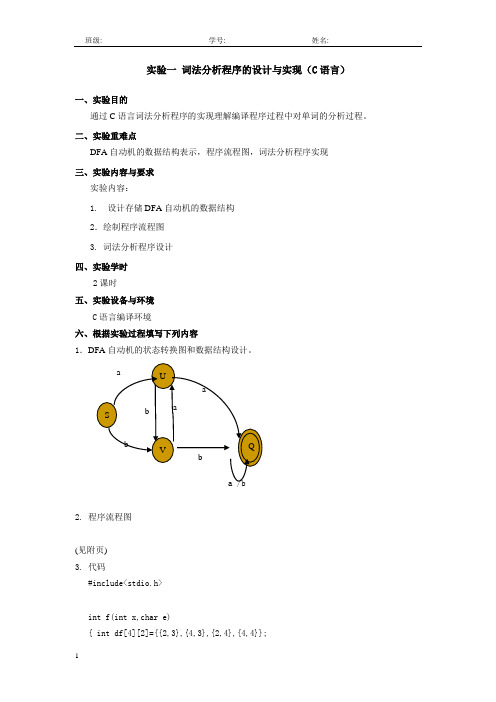
实验一 词法分析程序的设计与实现(C 语言)一、实验目的通过C 语言词法分析程序的实现理解编译程序过程中对单词的分析过程。
二、实验重难点DFA 自动机的数据结构表示,程序流程图,词法分析程序实现三、实验内容与要求实验内容:1. 设计存储DFA 自动机的数据结构2.绘制程序流程图3. 词法分析程序设计四、实验学时2课时五、实验设备与环境C 语言编译环境六、根据实验过程填写下列内容1.DFA 自动机的状态转换图和数据结构设计。
a /b2. 程序流程图(见附页)3. 代码#include<stdio.h>int f(int x,char e){ int df[4][2]={{2,3},{4,3},{2,4},{4,4}};U a a a S b Q bV bint i;if(e=='a')i=df[x][1];if(e=='b')i=df[x][2];return(i);}void main(){ int S=1,U=2,V=3,Q=4;int k=S;char c;printf("请输入字符,按#结束:\n");c=getchar();while(c!='#'){k=f(k,c);c=getchar();}if(k==Q) printf("你输入的字符串能被DFA所识别\n");else printf("你输入的字符串能被DFA所识别\n");}4.测试数据及结果分析(结果见附页)分析:从实验的结果可以看出上面程序代码基本上可以实现所给DFA的要求,但是有关实验的可读性和功能方面还有待进一步改进。
程序流程图教师评语:是否完成实验程序的预备设计? 是: 不是: 程序能否正常运行? 是: 不是: 有无测试数据及结果分析 是: 不是: 是否在本次规定时间完成所有项目? 是: 不是: 实验成绩等级: 教师签名:N0:时间:开始初始化输入句子判断是否退出标志判断是否被接受?接受不接受输出错误位置NY NY结束。
编译原理词法分析器实验报告

编译原理词法分析器实验报告1. 引言编译原理是计算机科学中的重要概念,它涉及将高级语言程序转换为计算机可执行的低级指令。
词法分析是编译过程中的第一个阶段,它负责将源代码分解为词法单元,为后续的语法分析做准备。
本实验旨在设计和实现一个基本的词法分析器,以了解词法分析的原理和实际应用。
2. 实验目标本实验的主要目标是实现一个基本的词法分析器,能够识别并提取源代码中的各种词法单元。
具体而言,我们将设计一个针对某种编程语言的词法分析器,能够识别关键字、标识符、算术运算符、括号、常量等。
3. 实验环境为了完成本实验,我们需要使用以下工具和环境:•一种编程语言,例如Python、Java或C++•一个文本编辑器,例如Visual Studio Code或Sublime Text•一个命令行终端4. 实验步骤4.1 定义词法规则首先,我们需要定义词法分析器的词法规则。
这些规则描述了编程语言中各种词法单元的模式。
例如,关键字可以被定义为由特定字符组成的字符串,标识符可以被定义为以字母开头并由字母和数字组成的字符串。
4.2 实现词法分析器接下来,我们将根据定义的词法规则,使用编程语言实现一个词法分析器。
在实现过程中,我们可以使用正则表达式来匹配和提取各种词法单元。
4.3 编写测试用例完成词法分析器的实现后,我们需要编写一些测试用例来验证其正确性。
测试用例应该包含各种可能的输入情况,以确保词法分析器能够正确地识别和提取词法单元。
4.4 运行测试用例最后,我们将使用编写的测试用例来运行词法分析器,并检查输出是否符合预期。
如果测试通过,说明词法分析器能够正常工作;否则,我们需要检查代码并进行调试。
5. 实验结果经过实验,我们成功地设计并实现了一个基本的词法分析器。
该词法分析器能够按照预定义的词法规则,正确地识别和提取源代码中的各种词法单元。
在运行测试用例时,词法分析器能够产生符合预期的输出,表明其具有良好的准确性和可靠性。
(完整)编译原理实验报告(词法分析器 语法分析器)

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字。
标示符。
无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号.2、程序流程图(1)主程序(2)扫描子程序3、各种单词符号对应的种别码五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符.字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include 〈stdio.h〉#include <math.h>#include <string。
h>int i,j,k;char c,s,a[20],token[20]={’0’};int letter(char s){if((s〉=97)&&(s〈=122)) return(1);else return(0);}int digit(char s){if((s〉=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else”)==0) return(3);else if(strcmp(token,"switch”)==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf(”please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!=’#’);i=1;j=0;get();while(s!=’#'){ memset(token,0,20);switch(s){case 'a':case ’b':case ’c':case ’d':case ’e’:case ’f’:case 'g’:case ’h':case 'i':case ’j':case 'k’:case ’l':case 'm’:case 'n':case ’o':case ’p':case ’q’:case 'r’:case 's’:case 't’:case ’u’:case ’v’:case ’w’:case ’x':case ’y':case ’z’:while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)”,6,token);else printf("(%d,—)",k);break;case ’0':case ’1’:case ’2':case ’3':case '4’:case '5’:case ’6':case ’7’:case ’8’:case '9’:while(digit(s)){token[j]=s;j=j+1;get();}retract();printf(”%d,%s",7,token);break;case '+':printf(”(’+',NULL)”);break;case ’-':printf("(’-',null)");break;case ’*':printf(”('*’,null)");break;case '<':get();if(s=='=’) printf(”(relop,LE)”);else{retract();printf("(relop,LT)");}break;case ’=':get();if(s=='=’)printf("(relop,EQ)");else{retract();printf(”('=',null)”);}break;case ’;':printf(”(;,null)");break;case ' ’:break;default:printf("!\n”);}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术.三、实验原理:1、算术表达式语法分析程序的算法思想首先通过关系图法构造出终结符间的左右优先函数f(a),g(a)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
if (isalnum (Char) ) AddChar TokenSt ring (Char) ;
else break ;
} BackChar (Char) ; t = J udge (Buffer) ;
token. ch = Buffer ;
ret urn t ;
} else if (isdigit (Char) )
default :token. type = ERR TO KEN ;break ;
}Hale Waihona Puke } 2 词法分析器设计注意的问题
词法分析器设计还需要注意以下问题 。 在设计程序时 ,需要为源程序设计一个符号表 , 符号表用来保存标识符信息 ,为单词语法分析和语 义分析服务 。验证了单词的合法性后 ,可以将单词 放入符号表中 ,符号表中的表项除了类型名和数值 以外还需要添加一些其他项目 。语法分析 、语义分 析时 ,从符号表中读取单词信息 ,将其他后继处理的 信息放入空白表项中保存 。 另外在处理过程中可能遇到“超前搜索”问题 。 当读入一个字符时 ,循环结束 ,不进行相关操作 。下 一次对字符操作前是要将多读入的字符回退 。 3 结语 词法分析在整个编译器设计中处于初级阶段 , 词法分析器的设计与实现相对其他几个阶段来说比 较简单 。本文中所提到的词法分析器的设计还有待 于进一步改进 。如为了实现快速的表搜索 ,可以引 入散列来设计各类需要存储的表等 。
词法分析是编译程序进行翻译的第一个阶段 , 他对程序进行线性分析 ,从字符串中分出单词 ,并检 查所分出的单词是否为合法的词类 。编译中的分词 思想在“文本格式化”及“公式排版”中应用的比较广 泛 ,是一种实用性很强的分析方法 。
词法分析顾名思义就是分词 。它以程序设计语 言编制的源程序作为输入 ,以单词序列作为输出 。 分词过程可以通过编制程序自动完成 ,我们通常称 这个分词程序为词法分析器 。词法分析器分析的源 程序可以是现有的各类程序设计语言源程序也可以 是人为给定的模型语言的源程序 。本文中的源程序 为后者 。 1 词法分析器的设计
词法分析在教学上的主要应用是对源程序进行 分词同时验证词的合法性 ,词法分析的输入是给定 的模型语言 ,输出为单词序列 。输入的源程序可以 看成是一个字符串序列 ,通过把源程序看作字符串 序列就可以采用形式语言的一些现有理论处理相关 的编译问题 。分词的输出为单词序列 ,单词是一个 有共同含义的字符集 。由于程序设计语言中通常使 用空格来分割不同的词 ,因此初学者在理解这一概 念时可以简单的把空格分隔开的字符串认为是一个 单词 。
词法分析器设计时 ,输入的源程序以文件的形 式存储在外部 。主控程序通过打开文件调用待分析 的源程序 。
我给定的模型语言如图 4 。从词的角度来看 , 它涉及的内容较为简单 ,只包括几个较为常用的词 类 ,词类的构成上也适当的作了一些简化 。对词进 行分析时 ,我们是按类型进行分析的 。不同类型的 词在后续的分析中所起的作用不同 ,相应的操作也 各有不同 ,但同种类型中的词虽然单词的构成不同 但从宏观上看它们的操作大体一致 。模型语言中的 单词可以分为“关 键 字 ”、 “标 识 符 ”、 “常 数 ”、 “分 隔 符”“ 、运算符”几类 。一般 ,关键字在程序设计语言 中人为给定 。程序设计时采用一字一码的形式处 理 。标志符为一类 ,不同的标志符通过值区别 。常
ret urn token ;
}
else
{ switch (Char)
{ case’;’:token. type = SEM ICO ;break ; case’,’:token. type = COMMA ;break ; case’+ ’:token. type = PL U S ;break ;
图 1 标识符的自动机
Ξ 收稿日期 :2008 - 01 - 22 作者简介 :张岚 (1979 —) ,女 ,硕士 ,讲师 ,编译技术 ,内蒙古呼和浩特市人 ,内蒙古财经学院讲师 。 王鑫 (1979 —) ,女 ,本科 ,助教 ,网络技术 ,内蒙古呼和浩特市人 ,内蒙古财经学院讲师 。
·223 ·
{ for ( ; ;)
{ Char = Get Char () ; if (isdigit (Char) ) AddChar TokenSt ring (Char) ;
else break ;
} BackChar (Char) ;
token. t ype = CON ST - ID ; token. value = atof (Buffer) ;
总第 168 期
内蒙古科技与经济
自动机是从识别的角度来看待单词 。通过人为 的在自动机 (本质上是一个有向图) 上找一条从起点 到终点的路径就可以确定某个单词是否为合法的单 词 。自动机的另一个特点是可以非常方便的转化为 程序 。我们可以将每类单词连接成为只有一个入口 一个出口的自动机 。连接后的自动机如下图 4 。
图 4 模型语言单词的自动机 该图已经确定化 。为了提高效率 ,还可以将图 最小化 ,即合并等价状态 ,减少状态总数 。最小化后 的状态图可以很方便的翻译为程序代码 ,而且效率 较高 。最后用直接转向法实现有限自动机 ,生成词 法分析程序 。 词法分析程序识别某类单词的部分代码如下 。 token. ch = Buffer ; for ( ; ;) { Char = Get Char () ; if (Char = = ’ n’) LineNo + + ; if ( ! isspace ( Char) ) break ; / / 如果字符不为空 结束取一个字符 } AddChar TokenSt ring (Char) ; if (isalp ha (Char) ) { for ( ; ;) { Char = Get Char () ;
第 14 期 总第 168 期 2008 年 7 月
内蒙古科技与经济 Inner Mongolia Science Technology & Economy
No. 14 , t he 168t h issue J ul. 2008
词法分析器的设计与实现Ξ
张 岚 ,王 鑫
(内蒙古财经学院 计算机信息管理学院 ,内蒙古 呼和浩特 010051)
数只给出具体的值即可 。根据以上的分析可以相应 的设计如下的存储结构 。
关键字可以设计为一个预先存储好的表格 。 标志符和常数的逻辑结构设计如下 : st ruct Token { Token - Type t char 3 ch }; 和 st ruct Token { Token - Type t double value ; }; 每个类型中的单词都有它的构成规则 。符合构 成规则的即为合法的类型 ,否则 ,为不合法 。下面给 出部分词类的正规式描述 。 < 标识符 > = < 字母 > ( < 字母 > < 数字 > ) 3 < 无符号整数 > = < 数字 > (数字) 3 < 分隔符 > = ;| ’ n’| ’’ < 运算符 > = + | - | 3 | / < 赋值运算符 > = : = 正规式是一种常用的描述单词的手段 。它简 单 、清晰 。能清楚地描述出单词的构成 。并且可以 方便的转化为单词的识别装置 ———自动机 。根据给 定的正规式得到的自动机如图 。
[ 参考文献 ]
[ 1 ] 陈火旺 ,刘春林. 程序设计语言编译原理 [ M ] . 北京 :国防工业出版社 ,2000.
[ 2 ] Alf red V ·Ano , Ravi Set hi ,J eff rey D·Ullman , 编译原理[ M ] . 机械工业出版社 ,2003.
[ 3 ] 张素琴 ,吕映芝 ,蒋维杜 ,等. 编译原理 [ M ] . 北 京 :清华大学出版社 ,2005.
摘 要 :介绍了词法分析器的概念 ,并指出词法分析器设计时 ,输入的源程序以文件的形式存储在 外部 。主控程序通过打开文件调用待分析的源程度 。
关键词 :词法分析器 ;正规式 ;自动机 中图分类号 : TP391 文献标识码 :A 文章编号 :1007 —6921 (2008) 14 —0223 —02