南京信息工程大学数据库作业
2022年南京信息工程大学数据科学与大数据技术专业《操作系统》科目期末试卷A(有答案)

2022年南京信息工程大学数据科学与大数据技术专业《操作系统》科目期末试卷A(有答案)一、选择题1、操作系统提供给编程人员的接口是()。
A.库函数B.高级语言C.系统调用D.子程序2、与早期的操作系统相比,采用微内核结构的操作系统具有很多优点,但是这些优点不,包括()。
A.提高了系统的可扩展性B.提高了操作系统的运行效率C.增强了系统的可靠性D.使操作系统的可移植性更好3、若某单处理器多进程系统中有多个就绪进程,则下列关于处理器调度的叙述中,错误的是()。
A.在进程结束时能进行处理器调度B.创建新进程后能进行处理器调度C.在进程处于临界区时不能进行处理器调度D.在系统调用完成并返回用户态时能进行处理器调度4、下列关于进程和线程的叙述中,正确的是()A.不管系统是否支持线程,进程都是资源分配的基本单位,B.线程是资源分配的基本单位,进程是调度的基本单位C.系统级线程和用户级线程的切换都需要内核的支持D.同一进程中的各个线程拥有各自不同的地址空间5、一个进程的读磁盘操作完成后,操作系统针对该进程必做的是(),A.修改进程状态为就绪态B.降低进程优先级C.给进程分配用户内存空间D.增加进程时间片大小6、下列关于SPOOLing技术的叙述中,错误的是()A.需要外存的文持B.需要多道程序设计技术的支持C.可以让多个作业共享一台独占设备D.由用户作业控制设备与输入/输出之间的数据传送7、某文件占10个磁盘块,现要把该文件磁盘块逐个读入主存缓冲区,并送用户区进行分析。
假设一个缓冲区与一个磁盘块人小相同,把一个磁盘块读入缓冲区的时间为100μs,将缓冲区的数据传送到用户区的时间是50μs.CPU对一块数据进行分析的时间为50us。
在单缓冲区和双缓冲区结构ド,读入并分析完该文件的时间分别是()。
Α.1500μs,1000μsB.1550μs,1100μsC.1550μs,1550μsD.2000μs,2000μs8、若某文件系统索引节点(inode)中有直接地址项和间接地址项,则下列选项中,与单个文件长度无关的因素是().A.索引节点的总数B.间接地址索引的级数C.地址项的个数D.文件块大小9、下列选项中,不能改善磁盘设备I/O性能的是()。
南京信息工程大学试卷《数据库系统》课程试卷

南京信息工程大学试卷2014 - 2015 学年 第 2 学期 《数据库系统》 课程试卷( B 卷) 本试卷共 4 页;考试时间 120 分钟;任课教师 顾韵华 ;出卷时间 2015 年 6 月 计算机与软件 学院 计算机科学与技术 专业 2013 年级 班 学号 姓名 得分一、单项选择题( 每小题 1 分,共 15 分 )1. (1) 属于信息世界的模型,实际上是从现实世界到机器世界的一个中间层次。
A .数据模型B .概念模型C .非关系模型D .关系模型2. 具有数据冗余度小、数据共享以及较高数据独立性等特征的系统是 (2) 。
A. 文件系统B. 管理系统C. 数据库系统D. 高级程序3. 数据库系统的物理独立性是指 (3) 。
A. 不会因为数据结构的变化而影响到数据库管理系统B. 不会因为某些存储结构的变化而影响其他的存储结构C. 不会因为存储策略的变化而影响存储结构D. 不会因为数据存储结构的变化而影响应用程序4. 在一个关系中如果有这样的属性或属性组,其值能惟一地标识关系中的每一个元组,且不包含多余属性,则称该属性或属性组为 (4) 。
A. 候选码B. 数据项C. 主属性D. 外码5. 下列关系代数表达式中,哪些等式成立? (5)(1))())((2121R R F F F F ∧=σσσ (2)R S S R =(3) )()(T S R T S R =(4)))(())((1221R R F F F F σσσσ=A. 全部B.(2)和(3)C. 没有D.(1)和(4)6. 自然连接是构成新关系的有效方法。
通常对关系R 和S 进行自然连接运算时,要求R 和S 含有一个或多个共同 (6) 。
A. 记录B. 行C.属性D. 元组7. 将SPB 中商品编号为"10010001"的商品单价字段值改为100的SQL 语句是 (7) 。
A. UPDATE SPB SET 单价=100 WHERE 商品编号="10010001"B. UPDATE SPB SET 单价=100 WHERE 商品编号='10010001'C. UPDATE SPB SET 单价=100D. UPDATE SPB SET 单价=100 HA VING 商品编号="10010001"8. 设有关系R,按条件f对关系R进行选择,正确的是(8) 。
南京信息工程大学试卷《数据库系统》课程试卷(2)

南京信息工程大学试卷2014 - 2015 学年第 1 学期数据库系统课程试卷( B卷 ) 本试卷共5页;考试时间120 分钟;任课教师马瑞;出卷时间2014年12月系专业年级班学号姓名得分一、单选题 (本题共22小题,1-17每选项1分,18-22每选项2分,共27分)1、在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
在这几个阶段中,数据独立性最高的是()阶段。
A.数据库系统B.文件系统C.人工管理D.数据项管理2、以下所列数据库系统组成中,正确的是()A.计算机、文件、文件管理系统、程序B.计算机、文件、程序设计语言、程序C.计算机、文件、报表处理程序、网络通信程序D.支持数据库系统的计算机软硬件环境、数据库文件、数据库管理系统、数据库应用程序和数据库管理员3、数据库系统的数据独立性体现在()A.不会因为数据的变化而影响到应用程序B.不会因为系统数据存储结构与数据逻辑结构的变化而影响应用程序C.不会因为存储策略的变化而影响存储结构D.不会因为某些存储结构的变化而影响其他的存储结构4、要保证数据库逻辑数据独立性,需要修改的是()A.模式B.模式与内模式的映射C.模式与外模式的映射D.内模式5、E-R方法的三要素是()A.实体、属性、实体集 B.实体、码、属性C.实体、属性、联系D.实体、域、联系6、下面的选项不是关系数据库基本特征的是()A.不同的列应有的不同的数据类型B.不同的列应有不同的列名C.与行的次序无关D.与列的次序无关7、有关系R(A,B,C)和S(A,B,C),它们分别有13个元组和20个元组,则R-S运算最多有()元组A.20 B.13 C.33 D.78、SQL语言具有()功能A.关系规范化、数据操纵、数据控制B.数据定义、数据操纵、数据控制第1页,共5页C.数据定义、关系规范化、数据控制D.数据定义、关系规范化、数据操纵9、对视图的描述错误的是()A、是一张虚拟的表B、在存储视图时存储的是视图的定义C、在存储视图时存储的是视图中的数据D、可以像查询表一样来查询视图10、在数据库的表定义中,限制成绩属性列的取值在0-100的范围内,属于数据的()约束。
南京信息工程大学试卷《数据库系统》课程试卷(3)

南京信息工程大学试卷2014 - 2015 学年第 1 学期《数据库系统》课程试卷( B 卷) 本试卷共 4 页;考试时间 120 分钟;任课教师顾韵华;出卷时间 2015 年 1 月计算机与软件学院计算机科学与技术专业2012 年级班学号姓名得分一、单项选择题( 每小题 1 分,共 20 分 )1. 在数据管理技术的发展过程中,经历了人工管理阶段、文件系统阶段和数据库系统阶段。
在这几个阶段中,数据独立性最高的是(1) 阶段。
A. 数据库系统B. 文件系统C. 人工管理D. 数据项管理2. 关系模式要求其任何属性(2) 。
A. 可再分B. 不可再分C. 命名在该关系模式中可以不惟一D. 以上都不是3. 下面关于关系性质的叙述中,不.正确的是(3) 。
A. 关系中元组的次序不重要B. 关系中列的次序不重要C. 关系中元组不可以重复D. 关系不可以为空关系4. 候选码中的属性可以有(4) 。
A. 0个B. 1个C. 1个或多个D. 多个5. 关系模型中3NF是指(5) 。
A. 满足2NF且不存在传递依赖现象B. 满足2NF且不存在部分依赖现象C. 满足2NF且不存在非主属性D. 满足2NF且不存在组合属性6. 数据库中,数据的物理独立性是指(6) 。
A. 数据库与数据库管理系统的相互独立B. 用户程序与DBMS的相互独立C. 用户的应用程序与存储在磁盘上的数据库中的数据是相互独立的D. 应用程序与数据库中数据的逻辑结构相互独立7. 下面两个关系中,职工号和设备号分别为“职工”关系和“设备”关系的码:职工(职工号,职工名,部门号,职务,工资)设备(设备号,职工号,设备名,数量)两个关系的属性中,存在外码为(7) 。
A. 职工关系的“职工号”B. 职工关系的“设备号”C. 设备关系的“职工号”D. 设备关系的“设备号”8. 在数据库设计的需求分析阶段,业务流程一般采用的表示方法是(8) 。
A. E-R图B. 数据流图C. 程序结构图D. 程序框图9. 关系R 和S 进行自然连接时,要求R 和S 含有一个或多个公共 (9) 。
南京信息工程大学滨江学院期末复习之数据库ER图设计
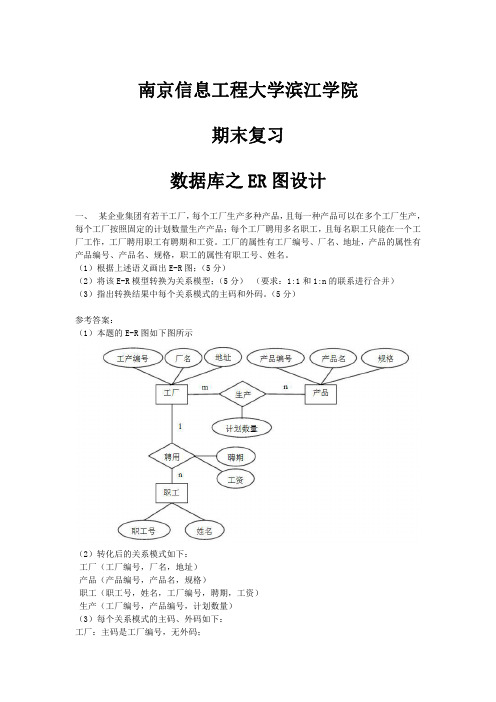
(2)转化后的工厂关系模式、产品关系模式、生产关系模式各1分,有一个属性不正 确均不给分,职工关系模式 2 分。
(3)工厂:主码是工产编号(0.5 分),无外码(0.5 分); 产品:主码是产品编号(0.5 分),无外码(0.5 分); 职工:主码职工号(0.5 分),外码是工厂编号(0.5 分); 生产:主码是(工产编号,产品编号)(1 分), 外码是工产编号(0.5 分)、产品编号(0.5 分)。
学生的属性有学号、学生姓名;教师的属性有教师编号,教师姓名;课程的属性有课程号、
课程名。
要求:根系的类型;
解答:
学号 姓名
m
学生
选修
课程号
n
课程
n
课程名
成绩
讲授
(3)每个关系模式的主码、外码如下: 工厂:主码是工产编号; 产品:主码是产品编号; 职工:职工号,外码是工厂编号; 生产:主码是(工产编号,产品编号), 外码是工产编号、产品编号。
评分标准: (1)三个实体型工厂、产品、职工各 1 分,属性漏写、错写不给分;两个联系各 1 分, 名称一定要表达联系含义,联系类型错误不给分,属性漏写不给分。
管理信息系统_南京信息工程大学4中国大学mooc课后章节答案期末考试题库2023年

管理信息系统_南京信息工程大学4中国大学mooc课后章节答案期末考试题库2023年1.管理信息系统的发展与使用将()。
答案:以上全部2.信息()。
答案:是形成知识的基础3.()是管理信息系统环境中最重要的因素之一,决定着管理信息系统应用的目标和规模。
答案:组织规模4.数据库管理系统能实现对数据库中数据的查询、插入、修改和删除,这类功能称为()。
答案:.数据操纵5.IP地址是()。
答案:网络号加主机号6.域名是()。
答案:用文字表示的IP地址7.BSP是指()答案:企业系统规划法8.数据字典建立应从()阶段开始。
答案:系统分析9.数据流()。
答案:也可以用来表示数据文件的存储操作10.某种代码由3位字符组成,每位可选择8种字符,则代码的总数是()。
答案:51211.管理业务流程图可用来描述()。
答案:作业顺序12.UML 是一种面向对象的统一建模语言。
它包含若干种图,其中,用例图展示了外部 actor与系统所提供的用例之间的连接,UML 中的外部 actor 是指()。
答案:人员或外部系统13.G to G电子政务即政府与政府之间的电子政务,它是指政府内部、政府上下级之间、不同地区和不同职能部门之间实现的电子政务活动。
以下属于G to G电子政务有()。
答案:电子公文系统14.下列哪一项不是数据库三大模型之一()答案:概要模型15.()是新系统开发工作的最后一个阶段,是将类似于设计图的新系统方案转换成可执行的应用软件系统。
答案:系统实施16.管理控制属于()答案:中期计划范围17.从管理决策问题的性质来看,在运行控制层上的决策大多属于()的问题。
答案:结构化18.将软件作为服务的云计算服务类型是()。
答案:SaaS19.系统分析报告的主要作用是()。
答案:系统设计的依据20.系统分析人员的要求是()。
答案:精通本行业管理,并熟悉计算机21.信息量的多少是由消除对事物认识的“不确定程度”来决定的。
答案:正确22.在电子商务环境下,MIS还应该支持跨组织的管理,实现整个供应链的优化和业务模式的改进。
2021年南京信息工程大学数据科学与大数据技术专业《计算机组成原理》科目期末试卷A(有答案)

2021年南京信息工程大学数据科学与大数据技术专业《计算机组成原理》科目期末试卷A(有答案)一、选择题1、主存按字节编址,地址从0A4000H到0CBFFFH,共有()字节;若用存储容量为32K×8位的存储芯片构成该主存,至少需要()片。
A.80K,2B.96K,2C.160K,5 C.192K,52、有效容量为128KB的Cache,每块16B,8路组相联。
字节地址为1234567H的单元调入该Cache,其tag应为()。
A.1234HB.2468HC.048DHD.12345H3、下列编码中,能检测出所有长度小于或等于校验位(检测位)长度的突发错的校验码是()。
A.循环冗余校验码B.海明码C.奇校验码D.偶校验码4、在定点机中执行算术运算时会产生溢出,其根本原因是()。
A.主存容量不够B.运算结果无法表示C.操作数地址过大D.栈溢出5、在浮点机中,判断原码规格化的形式的原则是()。
A.尾数的符号位与第一数位不同B.尾数的第一数位为1,数符任意C.尾数的符号位与第一位相同D.阶符与数符不同6、下列关于多总线结构的叙述中,错误的是()。
A.靠近CPU的总线速度较快B.存储器总线可支持突发传送方式C.总线之间需通过桥接器相连D.PCI-Expressx16采用并行传输方式7、在集中式总线控制中,响应时间最快的是()。
A.链式查询B.计数器定时查询C.独立请求D.分组链式查询8、下列描述中,正确的是()。
A.控制器能理解、解释并执行所有指令以及存储结果B.所有数据运算都在CPU的控制器中完成C.ALU可存放运算结果D.输入、输出装置以及外界的辅助存储器称为外部设备9、()可区分存储单元中在放的是指令还是数据。
A.存储器B.运算C.用户D.控制器10、单周期处理器中所有指令的指令周期为一个时钟周期。
下列关于单周期处理器的叙述中,错误的是()。
A.可以采用单总线结构数据通路B.处理器时钟频率较低C.在指令执行过程中控制信号不变D.每条指令的CPI为111、某计算机采用微程序控制器,共有32条指令,公共的取指令微程序包含2条微指令,各指令对应的微程序平均由4条微指令组成,采用断定法(下地址字,段法)确定下条微指令地址,则微指令中下地址字段的位数至少是()。
南京信息工程大学数据库总复习

基本的E-R模型
实体、属性、联系、实体联系图、二元联系类别 (1:1,1:n,m:n)、多元联系、同一实体集的联系、联系 的角色、联系的属性、弱实体集。 E-R模型向关系模型的转换
基本规则(实体、联系的转换) 特殊情况处理(弱实体集)第五章 关系规范化理论 Nhomakorabea
•
关系模式中可能存在的异常
数据冗余、插入异常、删除异常、更新复杂
第1章 绪论
1. 基本概念:数据、数据处理、数据管理、数 据库、数据库系统、数据库管理系统、实体、 属性 2. 数据库系统的组成和特点
3. 数据库系统的三级模式结构和二级映像
4. 数据模型概念
5. E-R模型三要素,实体间的联系,E-R图
6. (逻辑)数据模型三要素,三类逻辑模型
第二章 关系数据模型
― ODBC(Open DataBase Connectivity,开放数据库连接) ― JDBC(Java DataBase Connectivity,Java数据库连接)
JDBC体系结构
由4部分构成:
• Java应用程序
• JDBC驱动程序管理器 • JDBC驱动程序 • 数据库
第八章 数据库保护
数据库安全性
•
含义、用户标识与鉴别、访问控制(授权管理语句)
数据库完整性
•
含义、数据库完整性机制(定义、检查、违约处理) 事务并发执行的三个问题 事务的ACID性质
含义、数据库备份 、数据库恢复
数据库并发控制
• •
数据库恢复
•
题型:
一、单项选择
二、填空
三、名词解释 四、简答与计算题 五、应用题
数据查询(单表查询)
南京信息工程大学滨江学院数据库填空重点

填空题
1、数据库完整性:参照完整性、实体完整性、用户定义完整性
2、存取控制方法:自动与强制
3、数据库设计的基本步骤:需求分析、概念/逻辑/物理结构分析、数据库实施、数据库运行和维护。
4、必须使用游标的SQL语句:
查询为多条记录的select语句
current形式的update和delete 语句
5、使用游标的步骤:说明、打开、推进、关闭
6、存储过程的优点:运行效率高、降低了客户机和服务器之间的通信量、方便实施企业规划
7、ODBC的构成:
用户应用程序、驱动应用程序管理器、数据库驱动程序、数据源
ODBC的作用:
可移植性好,可同时访问不同数据库,共享数据资源
8、查询优化的方法:代数查找、物理查找
9、数据库管理技术的三个阶段:人工管理、文件系统、数据库系统
10、数据库管理系统的功能有:数据定义、操纵、控制功能,数据库的建立和维护功能。
11、数据模型分为:层次模型、网状模型、关系模型和面向对象模型四类。
12、聚簇索引是指索引项顺序与表中数据记录的物理顺序一致。
13、自然连接是一种特殊的等值连接。
14、关系代数运算中,基本的运算是①、②、③、④和⑤。
答案:①并②差③笛卡尔积④投影⑤选择
16、游标是系统为用户开设的一个(),存放SQL语句的执行结果答案:数据缓冲区
17、有两种基本类型的锁,它们是①和
②。
答案:①共享锁②排它锁。
南京信息工程大学vfpA卷滨江

南京信息工程大学滨江学院2008 ─ 2009学年第二学期数据库技术与应用课程试卷( A 卷)注意:1、本试卷共页; 2、考试时间 120 分钟;出卷时间:2009 年 6月3、姓名、学号等必须写在指定地方;4、本考卷适用专业年级:会计08 任课教师:林美华专业年级2006 班级学号姓名一、选择题 (每小题 1 分,共 20 分)1、根据提供的数据独立性、数据共享性、数据完整性、数据存取方式等水平的高低,计算机数据管理技术的发展可以分为三个阶段,其中不包括下列的。
A.人工管理阶段B.计算机管理阶段C.文件系统阶段D.数据库系统阶段2、根据关系模型的有关理论,下列说法中正确的是_____。
A.二维表中的每一列可以有多个字段名B.二维表中允许出现完全相同的行C.二维表中行的顺序、列的顺序均可以任意交换D.二维表中行的顺序、列的顺序不可以任意交换3、下列不属于关系运算的是_____。
A.选择运算B.合并运算C.投影运算D.联结运算4、在Visual FoxPro 中,表结构中的逻辑型、通用型、日期型字段的宽度由系统自动给出,它们的宽度分别为_____。
A. 1、4、8B. 4、4、10C. 1、10、8D. 2、8、85、当打开一张空表(无任何记录的表)时RECNO()、BOF()和EOF()函数的值分别为_____。
A. 0、.T.和.T.B. 0、.T.和.F.C. 1、.T.和.T.D. 1、.T.和.F.6、建立事件循环的命令是__________。
A. READ EVENTSB. CLEAR EVENTSC. DO WHILE ENDDOD. FOR…ENDFOR7、在利用报表设计器创建报表时,默认情况下显示的三个带区为_____。
A.标题、细节和总结B.页标头、细节和页注脚C.组标头、细节和组注脚D.报表标题、细节和页注脚8、在Visual FoxPro 系统中,下列命名中不能作为变量名的是_____________ 。
南京信息工程大学数据库期中试题及答案

一、概念简答56 分1、数据模型数据模型是信息模型(概念模型)的数据化,从计算机角度出发,提供表示和组织数据的方法。
2、内模式内模式(Internal Schema,也称存储模式),一个数据库只有一个内模式,它是数据物理结构和存储方式的描述,是数据在数据库内部的表示方式。
3、元组在关系模型中,元组定义是:表中的一行即为一个元组。
从集合论角度,元组定义是:给定一组域D1,D2,…Dn(可相同),D1,D2…Dn 上的笛卡尔积为:D1×D2 × … × Dn={(d1,d2,…,dn)|di=1,2,…,n},其中每一个元素(d1,d2,…,dn)称为一个n 元组(n-tuple)或简称元组(Tuple),di 叫作元组(d1,d2,…,dn)的第i 个分量component。
4、关系模式关系的描述称为关系模式(Relation Schema)。
它可以形式化地表示为R(U,D,DOM,F)其中R 为关系名,U 为组成该关系的属性名集合,D 为属性组U 中属性所来自的域,DOM 为属性向域的映像集合,F 为属性间数据的依赖关系集合。
5、关系代数关系代数Relational Algebra:以集合为,定义一组运算,由已知关系经过一列运算,得到需要的查询结果。
关系代数是过程化的查询语言。
6、关系演算关系演算就是用谓词来描述关系的构成(查询的结果)。
按照谓词变元的不同分为元组关系演算和域关系演算,分别简称为元组演算和域演算。
二、判断是非25 分1、数据模型的三要素是数据结构、数据操纵和参照完整性约束。
(F)数据结构,数据操作,数据完整性约束2、关系语言是高度过程化的语言。
(F)关系数据语言是高度非过程化的语言3、关系代数、元组关系演算和域关系演算三种语言在表达能力上完全等价。
(F)关系代数,元祖关系演算和域关系演算都是抽象的查询语言,它们在表达能力上是等价的。
4、关系代数是非过程化的查询语言。
2022年南京信息工程大学软件工程专业《数据库原理》科目期末试卷A(有答案)

2022年南京信息工程大学软件工程专业《数据库原理》科目期末试卷A(有答案)一、填空题1、DBMS的完整性控制机制应具备三个功能:定义功能,即______;检查功能,即______;最后若发现用户的操作请求使数据违背了完整性约束条件,则采取一定的动作来保证数据的完整性。
2、设有关系模式R(A,B,C)和S(E,A,F),若R.A是R的主码,S.A是S的外码,则S.A的值或者等于R中某个元组的主码值,或者______取空值,这是规则,它是通过______和______约束来实现的。
3、关系数据库中基于数学的两类运算是______________和______________。
4、设某数据库中有商品表(商品号,商品名,商品类别,价格)。
现要创建一个视图,该视图包含全部商品类别及每类商品的平均价格。
请补全如下语句: CREATE VIEW V1(商品类别,平均价格)AS SELECT商品类别,_____FROM商品表GROUP BY商品类别;5、以子模式为框架的数据库是______________;以模式为框架的数据库是______________;以物理模式为框架的数据库是______________。
6、数据库系统是利用存储在外存上其他地方的______来重建被破坏的数据库。
方法主要有两种:______和______。
7、有两种基本类型的锁,它们是______和______。
8、SQL Server中数据完整性包括______、______和______。
9、在SQL Server 2000中,某数据库用户User在此数据库中具有对T 表数据的查询和更改权限。
现要收回User对T表的数据更改权,下述是实现该功能的语句,请补全语句。
_____UPDATE ON T FROM User;10、____________和____________一起组成了安全性子系统。
二、判断题11、并发执行的所有事务均遵守两段锁协议,则对这些事务的任何并发调度策略都是可串行化的。
南京信息工程大学滨江学院数据库填空题汇总

南京信息工程大学滨江学院数据库填空题汇总二、填空题1.数据库处理技术经历了____人工管理______、____文件系统______、____数据库系统______三个发展阶段。
3.在实体中能作为码的属性称为__主属性_,否则称为非主属性7.把保存____关系定义____的关系称为对应数据库的元关系,一个数据库的元关系由____DBMS____自动建立。
8.在对象数据模型中,每个对象不仅要包含描述实体的___状态_____特征,而且要包含描述实体的____行为____特征。
9.在___列级_____完整性约束中,每个约束只能涉及到1个属性,在____表级____完整性约束中,每个约束可以涉及到多个属性。
10.在SQL中,主码约束的关键字为______primarykey______,外码约束的关键字为_____foreignkey_______。
11.在SQL中,单值约束的关键字为____unique______,检查约束的关键字为_____check_____。
12.在SQL中,createtable、altertable和droptable命令分别为在数据库中____建立____、____修改____和____删除____基本表结构的命令。
13.在SQL中,根据基本表建立一个视图时,包括建立了该视图的___结构_____和___内容____两个方面。
14.层次模型是一棵__树__结构,关系模型是一个_二维表格__结构。
15.数据库管理系统的功能有数据定义功能,数据操纵功能,数据控制功能,数据库的建立和维护功能。
16.数据模型的分为层次模型、网状模型、关系模型和面向对象模型四类。
3、将多对多17.关系的完整性分为实体完整性、参照完整性和用户定义完整性。
6、WHERE子句作用于基本表或视图,从中选择满足条件的元组。
HAVING短语作用于组,从中选择满足条件的组。
18.集函数只能用于SELECT子句和HAVING短语之中,而绝对不能出现在WHERE子句中。
南京信息工程大学高级数据库期末复习资料

南京信息⼯程⼤学⾼级数据库期末复习资料⼀、Concept explaining1. ordered indexBased on a sorted ordering of the values2. hash indexA hash index organizes the search keys, with their associated pointers, into a hash filestructure.3.search keyAn attribute or set of attributes used to look up records in a file is called a search key.4. TransactionA transaction is a unit of program execution that accesses and possibly updates variousdata items5.conflict serializableWe say that a schedule S is conflict serializable if it is conflict equivalent to a serial schedule6.data warehouseA data ware house is a repository of information gathered from multiple sources, storedunder a unified schema, at a single site.7.data miningDate mining refers loosely to the process of semi-automatically analyzing large databases to find useful patterns.8.distributed database systemIn a distributed database system the database is stored on several computers9.local transactionA local transaction is one that accesses data only from sites global transaction10.global transactionA global transaction is one that either accesses data in a site different form the oneat which the transaction was initiated, or accesses data in several different sites11.homogeneous distributed databaseIn a homogeneous distributed database system, all sites have indentical database-management system software, are aware of one another, and agree to cooperate in processing users’requests12.heterogeneous distributed databaseA distribute database has to be constructed by linking together multiple already-existingdatabase systems, each with its own schema and possibly running different database-management software⼆、Fill blanks1.A clustering index is an index whose search key also defines the sequentialorder of the file.2.To ensure integrity of the data,we require that the database system maintain thefollowing properties of the transactions: Atomicity,Consistency , Isolation , Durability .3. Transactions access data using two operations, write(X), which transfers the data itemX from the local buffer of the transaction that executed the write back to the database .4. Ensuring durability is the responsibility of a software component of the databasesystem called the recovery-management component .5. If a schedule S can be transformed into a schedule S’by a series of swaps ofnonconficting instructions, we say that S and S’are conflict equivalent .6. A recoverable schedule is one where,for each pair of transactions Ti and Tj such thatTj reads a data item previously written by Ti,the commit operation of Ti appears before the commit operation of Tj .7. A cascadeless schedule is ne where,for each pair of transactions Ti and Tj such thatTj reads a data item previously written by Ti,the commit operation of Ti appears before the read operation of Tj .8.There are main two main modes: shared and exclusive in which a dataitem may be locked.9.There are two types of errors: Logical error and System error that maycause a transaction to fail.10.According to relative speed, capacity,and resilience to failure, storage media canbe classified volatile storage and nonvolatile storage .11.Block movements between disk and main memory art initiated through the following twooperations,output(B) transfers the buffer block B to the the disk , and replaces the appropriate physical block there.12.The deferred-database modification technique ensures transaction atomicity byrecording all database modifications in the log .13.Server system can be broadly categorized as transaction servers and dataservers .14.Transaction-server systems,also called query-server systems, provide an interface towhich clients can send requests to preform an action,in response to which they execute the action and send back results to the client.15.Data-server systems allow client to interact with the servers .16.The processes that form part of the database system include lock manager process,,database writer process, log writer process, checkpoint process, process monitor process.17.There are two main measures of performance of a database system: (1)throughput, thenumber of tasks that can be completed in a given time interval, and (2)response time, the amount of time it takes to complete a single task from the time it is submitted.18.Running a given task in less time by increasing the degree of parallelism is calledspeedup.19.Handling larger tasks by increasing the degree of parallelism is called scaleup.20.There are several reasons for building distributed database systems, includingsharing data , Autonomy , and Availability.21.Consider a relation r that is to be stored in the database. There are two approachesto storing this relation in the distributed database: replication and global fragmentation.22.There are two different schemes for fragmenting a relation: account.23.Data transparency includes three main forms: fragmentation, and transparency.24.A distributed system may suffer from the same types of failure that a centralized systemdoes. The basic failure types are failure of a site , loss of message, failure of a communication link and Network partition .三、Answer questions1. How to avoid starvation of transactions?A: We can avoid starvation of transactions by granting locks in the following manner:Whena transaction Ti requests a lock on a data item Q in a particular mode M,theconcurrency-control manager grants the lock provided that(1)There is no other transaction holding a lock on Q in a mode that conflicts with M(2)There is no other transaction that is waiting for a lock on Q and that made its lockrequest before Ti2. Explains two-phase locking protocol, strict two-phase locking protocol and rigoroustwo-phase locking protocol.A:The two-phase locking protocol allows a traction to lock a new data item only if that traction has not yet unlocked any data item.Cascading rollbacks can be avoided by a modification of two-phase locking called the strict two-phase locking protocol.This protocol requires not only that locking be two phase,but also taht all exclusive-mode locks taken by a traction be held until that traction commits. Another variant of two-phase locking is the rigorous two-phase locking protocol,which requires that all locks be held until the traction commits.3.There are three different logs, please recovery the database with immediate-modificationtechnique,write the final results of A,B and C values of these cases respectively.Fig.1 Three different logA:A---$950B---$2050C---$6004.Suppose you were in charge of the database operations of a company whose main job isto process transactions. Suppose the company is growing rapidly each year, and has outgrown its current computer system. When you are choosing a new parallel computer,what measure is most relevant-speedup, batch scaleup, or transaction scaleup? Why?A:With increasing scale of operations, we expect that the number oftransactions submitted per unit time increases. On the other hand,wewouldn’texpect most of the individual transactions to grow longer, nor would we requirethat a given transaction should execute more quickly now than it did before.Hence transaction scale-up is the most relevant measure in this scenario5.Consider a bank that has a collection of sites, each running a database system. Supposethe only way the databases interact is by electronic transfer of money between one another.Would such a system qualify as a distributed database? Why?A:In a distributed system, all the sites typically run the same databasemanagement software, and they share a global schema. Each site provides anenvironment for execution of both global transactions initiated at remote sitesand local transactions. The system described in the question does not havethese properties, and hence it cannot qualify as a distributed database.四、Application1. Given the set of key values as follows.(10,15,21,37,44,51,59,63,72,85,91,97)Assume that the tree is initially empty and values are added inasending order. Please finish following operation:(1)Construct a B+-tree for four pointers.(2)Insert 26 and 32 values into the above B+-tree.(3)Delete 63 value2. Suppose that we are using extendable hashing on a file that contains records with the followingsearch-key values:2,3,5,7,11,17,19,23,29,31The hash function is h(x)=x mod 8 and buckets can hold three records.1Construct a extendable hash structure2Delete 113Insert 153. Consider the following two transactions:T1: read(A);read(B);if A=0 then B:=B+!;write(B);T2: read(B);read(A);if B=0 then A:=A+!;write(A).Let the consistency requirement be A=0 or B=0, with A=B=0 the initial values.(1)Show a concurrent execution of T1 and T2 that produces a nonserializable schedule.(2)Is there a concurrent execution of T1 and T2 that produces a serializable schedule, Why?A(1)(2)There is no parallel execution resulting in a serializable schedule. Frompart a. we know that a serializable schedule results in A = 0 ∨B = 0. Supposewe start with T1 read(A). Then when the schedule ends, no matterwhen we run the steps of T2, B = 1. Now suppose we start executing T2prior to completion of T1. Then T2 read(B) will give B a value of 0. Sowhen T2 completes, A = 1. Thus B = 1 ∧A = 1 →¬(A = 0 ∨B = 0).Similarly for starting with T2 read(B).4.Is the expression r i∝r j necessarily equal to r j∝r i for the relations of Figure 1.Why? Under what conditions does r i∝r j = r j∝r i hold?In general, ri rj = rj ri. This can be easily seen fromExercise 22.11, in which r s = s r. r s was given in 22.11,whileBy definition, ri rj = ΠRi (ri rj) and rj ri= ΠRj (ri rj), whereRi and Rj are the schemas of ri and rj respectively. For ΠRi (ri rj) to bealways equal to ΠRj (ri rj), the schemas Ri and Rj must be the same.5. Consider the relationsEmployee(name, address, salary, plant_number)Machine(machine_number, type, plant_number)Assume that the employee relation is fragmented horizontally by plant_number, and that each fragment is stored locally at its corresponding plant site. Assume that the machine relation is stored in its entirety at the Armonk site. Describe a good strategy for processing each of the following queries.a)Find all employees at the plant that contains machine number 1130.b)Find all machines at the Almaden plant.c)Find employee∞machine.A:a)i. Perform Πplant number (σmachine number=1130 (machine)) at Armonk.ii. Send the query Πname (employee) to all site(s) which are in the resultof the previous query.iii. Those sites compute the answers.iv. Union the answers at the destination site.b)i. Perform σplant number = x (machine) at Armonk, where x is the plantnumber for Almaden.ii. Send the answers to the destination site.c)Strategy :i. Group machine at Armonk by plant number.ii. Send the groups to the sites with the corresponding plant number.iii. Perform a local join between the local data and the received data.iv. Union the results at the destination site.6.Consider the relationsstud_grade(stud_id, stud_name, course_id, grade)Answer the following question with SQL:(1)how to browse the stucture information of the table.describe stud_grade(2)select all information of the table.select * from stud_grade(3)add column with the follow information: course_name, varchar2 (18)alter table stud_grade add course_name varchar2 (18);(4)insert the follow information: (‘0401020209’,’Zhang San’,’001’, ‘C++ Programming’, 92) insert into stud_grade values (‘0401020209’,’Zhang San’,’001’, ‘C++ Programming’, 92);(5)create a index with the name is stud_course_id_idx on course_id.create index name stud_course_id_idx on course_id(6)create a sequence: start with 50,increment by 2.create sequence stud_seq start with 50 increment by 2(7)select all information with the grade between 60 and 80.select * from stud_grade where grade between 60 and 80(8)delete the information with the stud_id is '0401020201'.Delete from stud_grade where stud_id = '0401020201'。
数据库大作业(全·参考答案)

《数据库原理与应用》综合设计任务书前言《数据库原理与应用》课程的重点知识模块包括:1)数据库设计、2)用SQL实现建库、建表、查询、更新、和创建视图、3)存储过程和触发器设计。
针对这三个应用能力,用一个案例作为背景,布置三次大作业。
在校大学生都能理解“图书管理系统”的应用场合和业务流程。
因此,以图书管理系统作为案例来布置作业,可以降低业务分析难度,让学生将主要精力放在知识消化与技术应用上。
本文档包括四个部分。
第一部分描述系统的需求,第二部分提出E-R模型设计和关系模型设计的任务;第三部分提出在SQL Server中,用SQL语句来建库、建表、查询、更新数据、创建视图的任务;第四部分,根据应用需求、安全需求和数据完整性要求,提出设计存储过程和触发器的任务。
每个任务之前,都给出了完成任务所需要掌握的关键知识点,学生可以在对这些知识点进行复习的基础上完成任务,每个任务是一次大作业。
第一部分案例的需求描述本部分描述“图书管理系统”的需求,学生通过阅读本部分内容,了解系统的功能要求、运行环境,对系统所需的数据有总体认识,作为三次作业的基础。
1.2 需求分析1)功能需求图1-1:功能需求示意图教师信息管理:用于教师基本资料的增删改查。
图书信息管理:用于图书基本信息的增删改查,分类统计图书册数和价值。
借书登记:记录借书时间、所借图书、借书人、办理人。
还书登记:记录还书时间、所还图书、还书人、办理人。
催还:查询借阅逾期的借书信息,给借书人发电子邮件,给借书人的部门打电话。
2)运行环境要求图1-2:运行环境拓扑图系统采用C/S模式,有两台PC和一台服务器,联成一个局域网。
PC上安装图书管理软件的客户端,服务器上安装DBMS,服务器也可由两台PC中的一台来代替。
第二部分作业1——E-R模型与关系模型设计(满分8分)本部分的任务是:在需求分析的基础上,进行E-R图设计,然后将E-R模型转换为关系模型。
任务:1)根据需求描述,绘制E-R图。
南京信息工程大学滨江学院数据库模拟题

一、选择题1.数据模型是___B___。
A、现实世界数据内容的抽象;B、现实世界数据特征的抽象;C、现实世界数据库结构的抽象;D、现实世界数据库物理存储的抽象;2.在数据库的三级模式结构中,设计数据库模式结构时应首先确定的是__D____。
A、数据库的物理结构;B、数据库的层次结构;C、数据库的规模;D、数据库的逻辑模式;3.实体和属性的关系是___B___。
A、一个属性对应于若干实体;B、一个实体可以由若干属性来刻画;C、一个属性包含有若干实体;D、一个实体可以由一个属性来刻画;4.元组(Tuple)所对应的是___A___。
A、表的一行;B、表的一列;C、表的一个元素;D、位于表顶端的一行元素;5.同一个关系模型的任意两个元组值____A__。
A、不能全同B、可全同C、必须全同D、以上都不是6.数据库管理系统的英文缩写是B。
A、DBB、DBMSC、DBSD、DBA7.数据库管理系统的核心部分是B。
A、数据模型B、数据库C、数据库管理系统D、计算机硬件8.下列关于“数据库系统(DBS)”的叙述中,正确的一条说法是A。
A、DBS是指在计算机系统中引入数据库后的系统B、DBS是帮助用户建立、使用和管理数据库的一种计算机软件C、DBS是用户建立的若个文件的集合D、DBS是一种新颖的关系数据库管理系统9.提供数据定义语言DDL(Data Description/Definition Language)的功能是B。
A、实现对数据库的检索、插入、修改、删除B、描述数据库的结构,为用户建立数据库提供手段C、用于数据的安全性控制、完整性控制、并控制和通信控制D、提供数据的初始装入、数据转储、数据恢复、数据库重新组织10.数据库具有三级结构,也称为三级模式,其中的模式(也称逻辑模式或概念模指的是B。
A、用户使用数据视图B、是所有用户的公共数据视图C、对对整个数据物理结构和存储结构的特征的描述D、一种局部数据视图11.数据库三级模式体系结构的划分,有利于保持数据库的A。
南京信息工程大学数据库110必须至少用连接谓词或JOIN子句表达1120必须至少用子查询表示
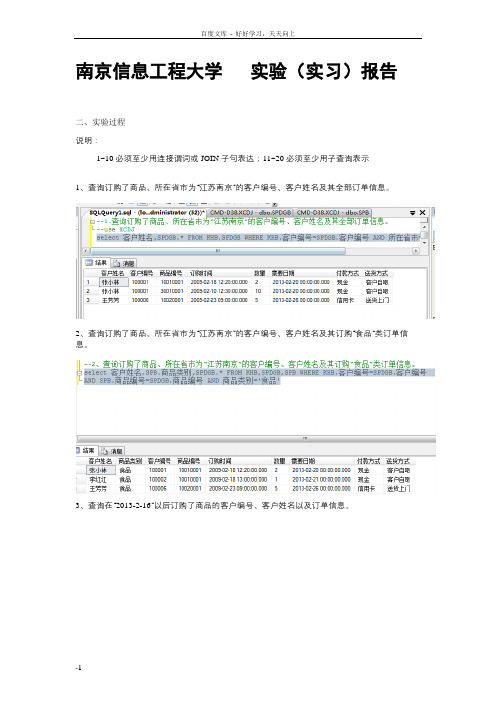
南京信息工程大学实验(实习)报告二、实验过程说明:1~10必须至少用连接谓词或JOIN子句表达;11~20必须至少用子查询表示1、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其全部订单信息。
2、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其订购“食品”类订单信息。
3、查询在“2013-2-16”以后订购了商品的客户编号、客户姓名以及订单信息。
4、查询在“2013-2-16”以后订购了“食品”类商品的客户编号、客户姓名及其订单信息。
5、查询订购了单价在50元以上(含)、并且订购数量在2个以上(含)的客户编号、客户姓名及其订购商品信息。
6、**查询订购了同一编号的商品超过一次的客户编号、客户姓名及其相应商品编号。
7、**查询41岁以下的客户编号、客户姓名及其订单信息。
8、统计各个女客户的客户姓名及其订单数量。
9、统计姓“张”的客户姓名及其订单数量。
10、统计订购的食品类订单数量在2个及其以上的客户姓名及其食品类订单数量。
11、查询所在省市为“江苏南京”的客户的订单信息。
12、查询订购了“营养菜谱”产品的客户编号、客户姓名和相应订单信息。
13、查询订购了张小林订购过的商品的客户编号和客户姓名。
14、查询订购了库存量在50及以上的商品的客户编号和客户姓名。
15、查询订购数量比张小林所有订单数量都小的订单信息。
**16、查询年龄小于所有客户平均年龄的客户的订单信息。
17、查询库存量超过平均库存量的商品信息。
18、查询订购了商品名称中包含“球”的订单信息。
19、查询订购了食品类商品的客户编号和客户姓名。
20、查询具有相同出生日期的客户信息。
三、实验总结我在做之时,有标题加“*”的,就是自己想破脑袋都没有做出来的,自己会做的,我倒没有感觉到什么,就是自己不会做的反而让自己有更大的收获,比如DATEDIFF(YY,KHB.出生日期,GETDATE())的应用,又比如查找相同的类别(例:商品编号),语句还可以这样用:SELECT商品编号FROM SPDGB GROUP BY商品编号Having COUNT(商品编号)>1,我自己以前还以为当使用COUNT(商品编号)>1时,必须在SELECT之后用COUNT(商品编号),看来我自己的举一反三能力有待提高啊。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
南京信息工程大学数据库系统实验(实习)报告实验(实习)名称数据库系统实验2 实验(实习)日期2018-4-12 得分指导教师顾韵华系计软院专业计科年级2016级班次计科三班姓名徐文庆学号20161308109一、实验目的1.掌握SELECT语句的基本语法2.掌握查询条件表示方法3.掌握数据汇总的方法4.掌握GROUP BY、ORDER BY、HA VING子句的作用和使用方法二、实验内容在SPDG数据库中,用SQL语句实现如下查询:说明:1~10必须至少用连接谓词或JOIN子句表达。
1、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其全部订单信息。
2、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其订购“食品”类订单信息。
3、查询在“2013-2-17”以后订购了商品的客户编号、客户姓名以及订单信息。
4、查询在“2013-2-17”以后订购了“食品”类商品的客户编号、客户姓名及其订单信息。
5、查询订购了单价在50元以上(含)、并且订购数量在2个以上(含)的客户编号、客户姓名及其订购商品信息。
6、查询订购了同一编号的商品超过一次的客户编号、客户姓名及其相应商品编号。
7、查询22岁以下的客户编号、客户姓名及其订单信息。
8、统计各个女客户的客户姓名及其订单数量。
9、统计姓“张”的客户姓名及其订单数量。
10、统计订购的食品类订单数量在2个及其以上的客户姓名及其食品类订单数量。
说明:11~20必须至少用子查询表达。
11、查询所在省市为“江苏南京”的客户的订单信息。
12、计算所有订购了商品的客户的平均年龄。
13、查询订购了“新新文化用品制造厂”产品的客户编号、客户姓名和相应订单信息。
14、查询订购了“食品”类商品的“江苏南京”的客户的最小年龄。
15、查询订购了“食品”类商品的“江苏南京”的年龄最小的客户信息。
16、查询“张小林”订购过的商品信息。
17、查询订购了“张小林”订购过的商品的客户编号和客户姓名。
18、查询“食品”类商品被哪些省市的客户订购。
19、查询订购了库存量在50及以上的商品的客户编号和客户姓名。
20、查询订购数量比“张小林”所有订单数量都小的订单信息。
说明:21~25必须至少用子查询表达。
21、查询年龄小于所有客户平均年龄的客户的订单信息。
22、查询库存量超过平均库存量的商品信息。
23、查询订购了商品名称中包含“球”的订单信息。
24、查询订购了“食品”类商品的客户编号和客户姓名。
25、查询具有相同出生日期的客户信息(注意:测试时添加一个与已有客户出生日期相同的客户)。
说明:26~30请综合运用SQL语言各种表达能力来完成。
26、查询有一个或一个以上订单总金额大于30的所有客户的编号、姓名。
27、计算所有订购了商品的客户的平均年龄。
28、查询每类商品被订购的总数量并由大到小排序。
29、查询每个客户姓名及其订购商品的总数量并由大到小排序(考虑有重名的情况)。
30、查询每个客户姓名及其订购商品的总金额并由大到小排序(考虑有重名的情况)。
三、实验过程与结果1、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其全部订单信息。
•设计的SQL语句如下:SELECT 客户姓名,b.*FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE 所在省市='江苏南京'•语句执行结果如下:2、查询订购了商品、所在省市为“江苏南京”的客户编号、客户姓名及其订购“食品”类订单信息。
•设计的SQL语句:SELECT KHB.客户姓名,SPDGB.*FROM KHB JOIN SPB JOIN SPDGB ON SPDGB.商品编号=SPB.商品编号 ON KHB.客户编号=SPDGB.客户编号WHERE 所在省市='江苏南京'AND 商品类别='食品'•语句执行结果如下:3、查询在“2013-2-17”以后订购了商品的客户编号、客户姓名以及订单信息。
•设计的SQL语句:SELECT 客户姓名,b.*FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE 订购时间>'2013-2-17'•语句执行结果如下:4、查询在“2013-2-17”以后订购了“食品”类商品的客户编号、客户姓名及其订单信息。
•设计的SQL语句:SELECT KHB.客户姓名,SPDGB.*FROM KHB JOIN SPB JOIN SPDGB ON SPDGB.商品编号=SPB.商品编号 ON KHB.客户编号=SPDGB.客户编号WHERE 订购时间>'2013-2-17'AND 商品类别='食品'•语句执行结果如下:5、查询订购了单价在50元以上(含)、并且订购数量在2个以上(含)的客户编号、客户姓名及其订购商品信息。
•设计的SQL语句:SELECT KHB.客户姓名,KHB.客户编号,SPB.*FROM KHB JOIN SPB JOIN SPDGB ON SPDGB.商品编号=SPB.商品编号 ON KHB.客户编号=SPDGB.客户编号WHERE 单价>=50 AND 数量>=2•语句执行结果如下:6、查询订购了同一编号的商品超过一次的客户编号、客户姓名及其相应商品编号。
•在SPDGB中添加信息:•设计的SQL语句:SELECT DISTINCT KHB.客户姓名,SPDGB.客户编号,SPB.商品编号FROM KHB JOIN SPDGB JOIN SPB ON SPB.商品编号=SPDGB.商品编号ON KHB.客户编号=SPDGB.客户编号WHERE SPDGB.客户编号 IN(SELECT 客户编号FROM SPDGBGROUP BY 客户编号,商品编号HAVING COUNT(商品编号)>=2)AND SPDGB.商品编号 IN(SELECT 商品编号FROM SPDGBGROUP BY 商品编号,客户编号HAVING COUNT(商品编号)>=2)•语句执行结果如下:7、查询22岁以下的客户编号、客户姓名及其订单信息。
•在KHB中添加信息:•在SPDGB中添加信息:•设计的SQL语句:SELECT a.客户编号,客户姓名,b.*FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE YEAR(GETDATE())-YEAR(出生日期)<22•语句执行结果如下:8、统计各个女客户的客户姓名及其订单数量。
•设计的SQL语句:SELECT 客户姓名,COUNT (商品编号) AS 订单数量FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE 性别='女'GROUP BY 客户姓名•语句执行结果如下:9、统计姓“张”的客户姓名及其订单数量。
•设计的SQL语句:SELECT 客户姓名,COUNT (商品编号) AS 订单数量FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE 客户姓名 LIKE '张%'GROUP BY 客户姓名•语句执行结果如下:10、统计订购的食品类订单数量在2个及其以上的客户姓名及其食品类订单数量。
•在SPDGB中添加信息:•设计的SQL语句:SELECT DISTINCT 客户姓名,COUNT(*) AS '食品类订单数量'FROM KHB JOIN SPDGB JOIN SPB ON SPB.商品编号=SPDGB.商品编号ON KHB.客户编号=SPDGB.客户编号WHERE 商品类别='食品'GROUP BY 客户姓名HAVING COUNT(SPDGB.商品编号)>=2•语句执行结果如下:11、查询所在省市为“江苏南京”的客户的订单信息。
•设计的SQL语句:SELECT b.*FROM KHB a INNER JOIN SPDGB b ON a.客户编号=b.客户编号WHERE b.客户编号 IN(SELECT b.客户编号FROM SPDGBWHERE 所在省市='江苏南京')•语句执行结果如下:12、计算所有订购了商品的客户的平均年龄。
•设计的SQL语句:SELECT AVG(YEAR(GETDATE())-YEAR(出生日期)) AS '平均年龄'FROM KHBWHERE 客户编号 IN(SELECT DISTINCT 客户编号FROM SPDGB)•语句执行结果如下:13、查询订购了“新新文化用品制造厂”产品的客户编号、客户姓名和相应订单信息。
•设计的SQL语句:SELECT DISTINCT 客户姓名,SPDGB.*FROM KHB JOIN SPDGB JOIN SPB ON SPB.商品编号=SPDGB.商品编号ON KHB.客户编号=SPDGB.客户编号WHERE 生产商 IN(SELECT 生产商FROM SPBWHERE 生产商='新新文化用品制造厂')•语句执行结果如下:14、查询订购了“食品”类商品的“江苏南京”的客户的最小年龄。
•设计的SQL语句:SELECT MIN(YEAR(GETDATE())-YEAR(出生日期)) AS '最小年龄'FROM KHB JOIN SPDGB ON KHB.客户编号=SPDGB.客户编号WHERE 所在省市='江苏南京' AND SPDGB.商品编号 IN(SELECT SPDGB.商品编号FROM SPDGB JOIN SPB ON SPDGB.商品编号=SPB.商品编号WHERE 商品类别='食品')•语句执行结果如下:15、查询订购了“食品”类商品的“江苏南京”的年龄最小的客户信息。
•设计的SQL语句:SELECT KHB.*FROM KHB JOIN SPDGB JOIN SPB ON SPB.商品编号=SPDGB.商品编号ON KHB.客户编号=SPDGB.客户编号WHERE 所在省市='江苏南京' AND 商品类别='食品' ANDYEAR(GETDATE())-YEAR(出生日期)=(SELECT MIN(YEAR(GETDATE())-YEAR(出生日期)) AS '最小年龄'FROM KHB)•语句执行结果如下:16、查询“张小林”订购过的商品信息。