微信文章抓取工具详细使用方法
抓取公众号文章标题

抓取公众号文章标题在如今的移动互联网时代,越来越多的信息在社交媒体上发布,其中微信公众号是一个非常重要的平台。
许多企业、个人和媒体都拥有自己的公众号,通过发布文章来传递信息和提升品牌影响力。
然而,由于微信公众号的存在,一些消息源并没有被收录在传统搜索引擎上,使得我们需要手动打开微信才能查看这些信息。
因此,如何从微信公众号中抓取文章标题就成为了一个非常值得探讨的问题。
抓取公众号文章标题的方法1. 使用开源爬虫框架Scrapy是一个Python开源的爬虫框架,非常适合用于抓取公众号文章标题。
为了使用Scrapy抓取微信公众号文章标题,需要先安装Scrapy,并学会使用XPath或CSS选择器来定位HTML元素。
Scrapy的底层是Twisted,支持异步网络,能够快速高效地抓取数据,具有很好的扩展性。
同时,Scrapy还有一个优秀的框架和社区,可以解决很多爬虫相关问题。
2. 使用微信公众平台接口如果您是微信公众号的管理员或拥有微信开放平台的账号,可以使用微信公众平台提供的开放接口来获取公众号文章。
通过调用微信公众平台接口,获取文章标题等信息,可以快速高效地实现数据抓取,并且数据的准确性和实时性也有保障。
需要注意的是,这种方式需要一定的开发技能和开发成本,同时需要获得微信平台的授权。
3. 使用第三方公众号抓取工具目前,市面上出现了很多第三方公众号抓取工具,可以帮助我们快速抓取公众号文章标题。
一般来说,这种工具的操作简单方便,同时还提供了一些数据分析和展示功能,如Word、Excel导出等。
需要注意的是,使用第三方工具存在安全风险,需要仔细选择和使用。
抓取公众号文章标题的注意事项无论采用哪种方式获取公众号文章标题,都需要了解一些注意事项,以确保数据的准确和安全。
1. 不要太频繁地请求微信公众平台有一定的访问限制,如果您过于频繁地请求,可能会被封禁。
因此,尽量控制请求的频率,以免影响整个平台的正常运行。
2. 遵守微信公众平台的规则微信公众平台有一些规则限制,如限制转载、不允许发布攻击性内容等,如果您在抓取公众号文章标题过程中违反了这些规则,有可能被封禁或拒绝访问。
微信文章采集器使用方法详解
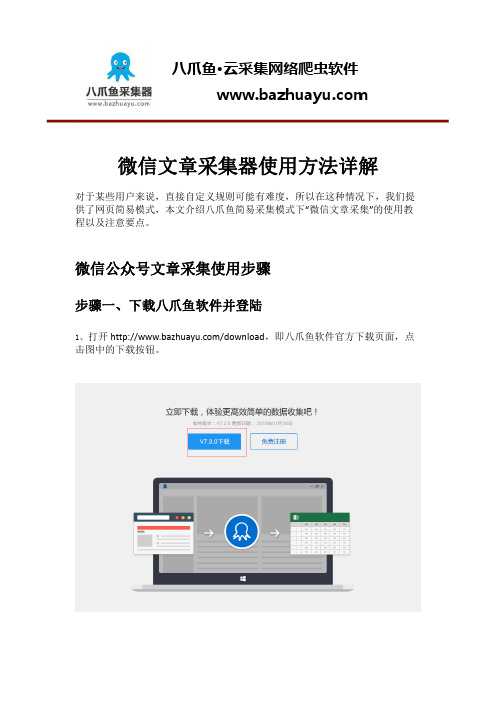
微信文章采集器使用方法详解对于某些用户来说,直接自定义规则可能有难度,所以在这种情况下,我们提供了网页简易模式,本文介绍八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
采集数目:可根据自身需求选填(当前默认)注意事项:URL列表中建议不超过2万条步骤三、保存并运行微信文章爬虫规则1、设置好爬虫规则之后点击保存。
微信公众号内容采集方法详解

微信已成为大多数人每天生活工作的一部分,所以会花不少的时间浏览微信公众号的文章内容,里面的精品以及爆款文章不少,如果想把这些文章都采集下来,怎么办在手机上一篇一篇下载有不方便,这是不得不用一下科学高效的采集方法了。
下面介绍一个微信公众号内容采集的神奇方法。
很多时候,我们有采集网页文章正文的需求。
本文以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法。
文章正文里一般包括文本和图片两种。
本文仅演示采集正文中本文的方法,图文采集会在另一篇教程中讲到。
本文将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)。
以下为“自定义数据合并方式”详解教程,大家可先了解一下:/tutorialdetail-1/zdyhb_7.html采集网站:/使用功能点:分页列表信息采集 1)进入主界面,选择“自定义模式”微信公众号文章正文采集步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” 微信公众号文章正文采集步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”微信公众号文章正文采集步骤32)选择“循环点击单个元素”,以创建一个翻页循环微信公众号文章正文采集步骤4由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”微信公众号文章正文采集步骤5注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
网络文字抓取工具使用方法

网络文字抓取工具使用方法网页文字是网页中常见的一种内容,有些朋友在浏览网页的时候,可能会有批量采集网页内容的需求,比如你在浏览今日头条文章的时候,看到了某个栏目有很多高质量的文章,想批量采集下来,下面本文以采集今日头条为例,介绍网络文字抓取工具的使用方法。
采集网站:使用功能点:●Ajax滚动加载设置●列表内容提取步骤1:创建采集任务 1)进入主界面选择,选择“自定义模式”今日头条网络文字抓取工具使用步骤12)将上面网址的网址复制粘贴到网站输入框中,点击“保存网址”今日头条网络文字抓取工具使用步骤23)保存网址后,页面将在八爪鱼采集器中打开,红色方框中的信息是这次演示要采集的内容,即为今日头条最新发布的热点新闻。
今日头条网络文字抓取工具使用步骤3步骤2:设置ajax页面加载时间●设置打开网页步骤的ajax滚动加载时间●找到翻页按钮,设置翻页循环●设置翻页步骤ajax下拉加载时间1)网页打开后,需要进行以下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载完成向下滚动”,设置滚动次数,每次滚动间隔时间,一般设置2秒,这个页面的滚动方式,选择直接滚动到底部;最后点击确定今日头条网络文字抓取工具使用步骤4注意:今日头条的网站属于瀑布流网站,没有翻页按钮,这里的滚动次数设置将影响采集的数据量。
今日头条网络文字抓取工具使用步骤5步骤3:采集新闻内容创建数据提取列表1)如图,移动鼠标选中评论列表的方框,右键点击,方框底色会变成绿色然后点击“选中子元素”今日头条网络文字抓取工具使用步骤6注意:点击右上角的“流程”按钮,即可展现出可视化流程图。
2)然后点击“选中全部”,将页面中需要需要采集的信息添加到列表中今日头条网络文字抓取工具使用步骤7注意:在提示框中的字段上会出现一个“X”标识,点击即可删除该字段。
今日头条网络文字抓取工具使用步骤8 3)点击“采集以下数据”今日头条网络文字抓取工具使用步骤94)修改采集字段名称,点击下方红色方框中的“保存并开始采集”今日头条网络文字抓取工具使用步骤10步骤4:数据采集及导出1)根据采集的情况选择合适的采集方式,这里选择“启动本地采集”今日头条网络文字抓取工具使用步骤11说明:本地采集占用当前电脑资源进行采集,如果存在采集时间要求或当前电脑无法长时间进行采集可以使用云采集功能,云采集在网络中进行采集,无需当前电脑支持,电脑可以关机,可以设置多个云节点分摊任务,10个节点相当于10台电脑分配任务帮你采集,速度降低为原来的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导出操作。
用微信如何提取图片文字

用微信如何提取图片文字
当你遇到一篇精美的文章很想摘抄下来保存在Word文档里该怎么办呢?手动输入吗?如果只有几十个字开可以,那如果是几百个字呢?其实可以用微信里的小程序把文章拍下来,然后直接转换为文字。
1.先把手机连接网络然后打开微信选择发现里的小程序。
2.点击右上角的搜索输入文字识别,找到对应的小程序。
3.点击进入主页这里有两个选择:照片/拍照、票证识别;这时点击照片/拍照。
4.这时会出现选择图片和拍照,=根据自己的情况选择,以拍照识别为例。
5.拍下需要识别的文章,拍摄完成后点击右上角的“ ”。
6.看一下照片是否清晰,然后选择右上角的完成。
7.等待一会就会出现识别的结果,有需要的可以选择翻译、复制、转发。
用微信就可以提取图片中的文字,不需要任何的APP,希望可以帮助到大家。
Python如何爬取微信公众号文章和评论(基于Fiddler抓包分析)

Python如何爬取微信公众号⽂章和评论(基于Fiddler抓包分析)背景说明感觉微信公众号算得是⽐较难爬的平台之⼀,不过⼀番折腾之后还是⼩有收获的。
没有⽤Scrapy(估计爬太快也有反爬限制),但后⾯会开始整理写⼀些实战出来。
简单介绍下本次的开发环境:python3requestspsycopg2 (操作postgres数据库)抓包分析本次实战对抓取的公众号没有限制,但不同公众号每次抓取之前都要进⾏分析。
打开Fiddler,将⼿机配置好相关代理,为避免⼲扰过多,这⾥给Fiddler加个过滤规则,只需要指定微信域名就好:Fiddler配置Filter规则平时关注的公众号也⽐较多,本次实战以“36氪”公众号为例,继续往下看:“36氪”公众号公众号右上⾓ -> 全部消息在公众号主页,右上⾓有三个实⼼圆点,点击进⼊消息界⾯,下滑找到并点击“全部消息”,往下请求加载⼏次历史⽂章,然后回到Fiddler界⾯,不出意外的话应该可以看到这⼏次请求,可以看到返回的数据是json格式的,同时⽂章数据是以json字符串的形式定义在general_msg_list字段中:公众号⽂章列表抓包请求分析⽂章列表接⼝把请求URL和Cookie贴上来进⾏分析:https:///mp/profile_ext?action=getmsg&__biz=MzI2NDk5NzA0Mw==&f=json&offset=10&count=10&is_ok=1&scene=126&uin=777&key=777&pass_ticket=QhOypNwH5dAr5w6UgMjyBrTSOdMEUT86vWc73GANoziWFl8xJd1hIMbMZ82KgCpN& Cookie: pgv_pvid=2027337976; pgv_info=ssid=s3015512850; rewardsn=; wxtokenkey=777; wxuin=2089823341; devicetype=android-26; version=26070237; lang=zh_CN;pass_ticket=NDndxxaZ7p6Z9PYulWpLqMbI0i3ULFeCPIHBFu1sf5pX2IhkGfyxZ6b9JieSYR 下⾯把重要的参数说明⼀下,没提到的说明就不那么重要了:__biz:相当于是当前公众号的id(唯⼀固定标志)offset:⽂章数据接⼝请求偏移量标志(从0开始),每次返回的json数据中会有下⼀次请求的offset,注意这⾥并不是按某些规则递增的count:每次请求的数据量(亲测最多可以是10)pass_ticket:可以理解是请求票据,⽽且隔⼀段时间后(⼤概⼏个⼩时)就会过期,这也是为什么微信公众号⽐较难按固定规则进⾏抓取的原因appmsg_token:同样理解为⾮固定有过期策略的票据Cookie:使⽤的时候可以把整段贴上去,但最少仅需要wap_sid2这部分是不是感觉有点⿇烦,毕竟不是要搞⼤规模专业的爬⾍,所以单就⼀个公众号这么分析下来,还是可以往下继续的,贴上截取的⼀段json数据,⽤于设计⽂章数据表:{"ret": 0,"errmsg": "ok","msg_count": 10,"can_msg_continue": 1,"general_msg_list": "{\"list\":[{\"comm_msg_info\":{\"id\":1000005700,\"type\":49,\"datetime\":1535100943,\"fakeid\":\"3264997043\",\"status\":2,\"content\":\"\"},\"app_msg_ext_info\":{\"title\":\"⾦融危机⼜⼗年:钱荒之下,⼆⼿基⾦迎来⾼光时刻\",\"digest\":\"退出"next_offset": 20,"video_count": 1,"use_video_tab": 1,"real_type": 0}可以简单抽取想要的数据,这⾥将⽂章表结构定义如下,顺便贴上建表的SQL语句:⽂章数据表-- ------------------------------ Table structure for tb_article-- ----------------------------DROP TABLE IF EXISTS "public"."tb_article";CREATE TABLE "public"."tb_article" ("id" serial4 PRIMARY KEY,"msg_id" int8 NOT NULL,"title" varchar(200) COLLATE "pg_catalog"."default" NOT NULL,"author" varchar(20) COLLATE "pg_catalog"."default","cover" varchar(500) COLLATE "pg_catalog"."default","digest" varchar(200) COLLATE "pg_catalog"."default","source_url" varchar(800) COLLATE "pg_catalog"."default","content_url" varchar(600) COLLATE "pg_catalog"."default" NOT NULL,"post_time" timestamp(6),"create_time" timestamp(6) NOT NULL);COMMENT ON COLUMN "public"."tb_article"."id" IS '⾃增主键';COMMENT ON COLUMN "public"."tb_article"."msg_id" IS '消息id (唯⼀)';COMMENT ON COLUMN "public"."tb_article"."title" IS '标题';COMMENT ON COLUMN "public"."tb_article"."author" IS '作者';COMMENT ON COLUMN "public"."tb_article"."cover" IS '封⾯图';COMMENT ON COLUMN "public"."tb_article"."digest" IS '关键字';COMMENT ON COLUMN "public"."tb_article"."source_url" IS '原⽂地址';COMMENT ON COLUMN "public"."tb_article"."content_url" IS '⽂章地址';COMMENT ON COLUMN "public"."tb_article"."post_time" IS '发布时间';COMMENT ON COLUMN "public"."tb_article"."create_time" IS '⼊库时间';COMMENT ON TABLE "public"."tb_article" IS '公众号⽂章表';-- ------------------------------ Indexes structure for table tb_article-- ----------------------------CREATE UNIQUE INDEX "unique_msg_id" ON "public"."tb_article" USING btree ("msg_id" "pg_catalog"."int8_ops" ASC NULLS LAST);附请求⽂章接⼝并解析数据保存到数据库的相关代码:class WxMps(object):"""微信公众号⽂章、评论抓取爬⾍"""def __init__(self, _biz, _pass_ticket, _app_msg_token, _cookie, _offset=0):self.offset = _offset = _biz # 公众号标志self.msg_token = _app_msg_token # 票据(⾮固定)self.pass_ticket = _pass_ticket # 票据(⾮固定)self.headers = {'Cookie': _cookie, # Cookie(⾮固定)'User-Agent': 'Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 '}wx_mps = 'wxmps' # 这⾥数据库、⽤户、密码⼀致(需替换成实际的)self.postgres = pgs.Pgs(host='localhost', port='5432', db_name=wx_mps, user=wx_mps, password=wx_mps)def start(self):"""请求获取公众号的⽂章接⼝"""offset = self.offsetwhile True:api = 'https:///mp/profile_ext?action=getmsg&__biz={0}&f=json&offset={1}' \'&count=10&is_ok=1&scene=124&uin=777&key=777&pass_ticket={2}&wxtoken=&appmsg_token' \'={3}&x5=1&f=json'.format(, offset, self.pass_ticket, self.msg_token)resp = requests.get(api, headers=self.headers).json()ret, status = resp.get('ret'), resp.get('errmsg') # 状态信息if ret == 0 or status == 'ok':print('Crawl article: ' + api)offset = resp['next_offset'] # 下⼀次请求偏移量general_msg_list = resp['general_msg_list']msg_list = json.loads(general_msg_list)['list'] # 获取⽂章列表for msg in msg_list:comm_msg_info = msg['comm_msg_info'] # 该数据是本次推送多篇⽂章公共的msg_id = comm_msg_info['id'] # ⽂章idpost_time = datetime.fromtimestamp(comm_msg_info['datetime']) # 发布时间# msg_type = comm_msg_info['type'] # ⽂章类型# msg_data = json.dumps(comm_msg_info, ensure_ascii=False) # msg原数据app_msg_ext_info = msg.get('app_msg_ext_info') # article原数据if app_msg_ext_info:# 本次推送的⾸条⽂章self._parse_articles(app_msg_ext_info, msg_id, post_time)# 本次推送的其余⽂章multi_app_msg_item_list = app_msg_ext_info.get('multi_app_msg_item_list')if multi_app_msg_item_list:for item in multi_app_msg_item_list:msg_id = item['fileid'] # ⽂章idif msg_id == 0:msg_id = int(time.time() * 1000) # 设置唯⼀id,解决部分⽂章id=0出现唯⼀索引冲突的情况self._parse_articles(item, msg_id, post_time)print('next offset is %d' % offset)else:print('Before break , Current offset is %d' % offset)breakdef _parse_articles(self, info, msg_id, post_time):"""解析嵌套⽂章数据并保存⼊库"""title = info.get('title') # 标题cover = info.get('cover') # 封⾯图author = info.get('author') # 作者digest = info.get('digest') # 关键字source_url = info.get('source_url') # 原⽂地址content_url = info.get('content_url') # 微信地址# ext_data = json.dumps(info, ensure_ascii=False) # 原始数据self.postgres.handler(self._save_article(), (msg_id, title, author, cover, digest,source_url, content_url, post_time,datetime.now()), fetch=True)@staticmethoddef _save_article():sql = 'insert into tb_article(msg_id,title,author,cover,digest,source_url,content_url,post_time,create_time) ' \'values(%s,%s,%s,%s,%s,%s,%s,%s,%s)'return sqlif __name__ == '__main__':biz = 'MzI2NDk5NzA0Mw==' # "36氪"pass_ticket = 'NDndxxaZ7p6Z9PYulWpLqMbI0i3ULFeCPIHBFu1sf5pX2IhkGfyxZ6b9JieSYRUy'app_msg_token = '971_Z0lVNQBcGsWColSubRO9H13ZjrPhjuljyxLtiQ~~'cookie = 'wap_sid2=CO3YwOQHEogBQnN4VTNhNmxQWmc3UHI2U3kteWhUeVExZHFVMnN0QXlsbzVJRUJKc1pkdVFUU2Y5UzhSVEtOZmt1VVlYTkR4SEllQ2huejlTTThJWndMQzZfYUw2SldLVGVMQUthUjc3QWdVMUdoaGN0Nml2SU05cXR1dTN2RkhRUVd # 以上信息不同公众号每次抓取都需要借助抓包⼯具做修改wxMps = WxMps(biz, pass_ticket, app_msg_token, cookie)wxMps.start() # 开始爬取⽂章分析⽂章评论接⼝获取评论的思路⼤致是⼀样的,只是会更加⿇烦⼀点。
网络赚钱利器:文章采集神器分享

网络赚钱利器:文章采集神器分享哈喽,各位亲爱的伙伴们,大家好,今天给大家分享一个超级腻害、实用的神器:文章采集器。
为什么要给大家分享这款神器呢?因为我们现在做互联网,在互联网赚钱,写文章是家常便饭,比如你自己本身就是做自媒体、微信公众号、网站编辑,站长类等工作,你每天都需要大量的文章去维持更新。
还有你像你的客户介绍产品,大多数也需要写软文文案等等这款神器就是分享给那些需要写文章的人的,你可以用这款神器根据关键词采集文章,然后可以借鉴这些文章的思想,完成文章的撰写,对于做网站推广和优化的朋友来说更是一款不可多得的使用工具;可以大大提高你的工作效率;解决没文章没素材的烦恼,助你网络赚钱一臂之力!接下来正式分享这款采集器:水淼万能文章采集器是一款简单有效功能强大的文章采集软件。
你只需要可输入关键词,即可采集各大搜索引擎网页和新闻,也可以采集指定网站文章,非常方便快捷;本次小编为大家带来的是水淼万能文章采集器绿色免费破解版,双击即可打开使用,软件已经完美破解无需注册码激活即可免费使用,喜欢的小伙伴们欢迎下载。
文章采集来源主要来自以下搜索引擎:百度网页、百度新闻、搜狗网页、搜狗新闻、微信、360网页、360新闻、今日头条、一点资讯、必应网页、必应新闻、雅虎、谷歌网页、谷歌新闻功能特点一、依托于万能正文识别智能算法,可实现任何网页正文自动提取准确率95%以上。
二、只需输入关键词,就能采集到百度新闻和网页、搜狗新闻和网页、360新闻和网页、谷歌新闻和网页、必应新闻和网页、雅虎;可批量关键词全自动采集。
三、可定向采集指定网站栏目列表下的所有文章,智能化匹配,无需编写复杂规则。
四、文章转译功能,可对采集好的文章,将其翻译到英文再翻译回中文,实现翻译伪原创,支持谷歌和有道翻译。
五、史上最简单最智能文章采集器,支持全功能试用,效果如何一试就知!使用说明1、下载并解压好文件,双击“水淼·万能文章采集器Crack.exe”打开,你会发现软件还是免费破解的哦。
网页内容抓取工具使用教程

网页内容抓取工具使用教程目前市面上有很多种网页内容抓取工具,各有优缺点。
而八爪鱼是行业内的佼佼者,不用写代码,也更为适合0基础的小白用户。
但对于部分没有时间学习的用户来说,直接用自定义模式做规则可能有难度,考虑到这种情况,八爪鱼提供了网页简易模式,简易模式下放了许多现成的爬虫采集规则,涵盖国内大部分主流网站,在急需采集相关网站时可以直接使用,大大的方便了用户,节省了做规则的时间和精力。
所以本文介绍网页内容抓取工具—八爪鱼简易采集模式下“微信文章采集”的使用教程以及注意要点。
微信文章采集下来有很多作用,比如可以将自己行业中最近一个月之内发布的内容采集下来,然后分析文章标题和内容的一个方向与趋势。
微信公众号文章采集使用步骤步骤一、下载八爪鱼软件并登陆1、打开/download,即八爪鱼软件官方下载页面,点击图中的下载按钮。
2、软件下载好了之后,双击安装,安装完毕之后打开软件,输入八爪鱼用户名密码,然后点击登陆步骤二、设置微信文章爬虫规则任务1、进入登陆界面之后就可以看到主页上的网站简易采集了,选择立即使用即可。
2、进去之后便可以看到目前网页简易模式里面内置的所有主流网站了,需要采集微信公众号内容的,这里选择搜狗即可。
3、找到搜狗公众号这条爬虫规则,点击即可使用。
4、搜狗公众号简易采集模式任务界面介绍查看详情:点开可以看到示例网址任务名:自定义任务名,默认为搜狗公众号任务组:给任务划分一个保存任务的组,如果不设置会有一个默认组公众号URL列表填写注意事项:提供要采集的网页网址,即搜狗微信中相关公众号的链接。
多个公众号输入多个网址即可。
采集数目:输入希望采集的数据条数示例数据:这个规则采集的所有字段信息。
5、微信文章爬虫规则设置示例例如要采集相关旅游、美食的公众号文章在设置里如下图所示:任务名:自定义任务名,也可以不设置按照默认的就行任务组:自定义任务组,也可以不设置按照默认的就行商品评论URL列表:/weixin?type=1&s_from=input&query=电影&ie=utf8&_sug_=n&_sug_type_=/weixin?type=1&s_from=input&query=美食&ie=utf8&_sug_=n&_sug_type_=一行一个,使用回车(Enter)进行换行。
如何一键采集复制微信公众号自媒体的文章图文?

如何一键采集复制微信公众号自媒体的文章图文?
通常我们在转载其他公众号的文章的时候会采用直接复制的方法,在电脑端打开文章全选复制,简单快捷,但是经常出现格式错误或者样式错位,如果图文内容元素较多的话出错几率很高。
倘若使用微信图文采集功能就能很好的解决这个问题,具体操作如下:
一、获取文章链接
电脑端用户可直接全选复制浏览器地址栏中的文章链接。
手机端用户可点击右上角菜单按钮,选择复制链接,将该链接发送到电脑上。
二、点击采集文章按钮
编辑器采集文章功能入口有两个:
1. 编辑菜单右上角的采集文章按钮;
2. 右侧功能按钮底部的采集文章按钮。
三、粘贴文章链接点击采集
采集完成后即可对文章进行编辑与修改。
微信爬虫如何采集数据

微信爬虫如何采集数据微信公众号已经成为我们日常获取信息的一个非常重要的方式,很多人也希望能把优质的信息抓取出来,却苦于不会使用爬虫软件。
下面教大家一个不用会打代码也能轻松采集数据的软件工具:八爪鱼是如何采集微信文章信息的抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”微信爬虫采集数据步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址” 微信爬虫采集数据步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”微信爬虫采集数据步骤32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮微信爬虫采集数据步骤43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”微信爬虫采集数据步骤54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”微信爬虫采集数据步骤6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”微信爬虫采集数据步骤72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”微信爬虫采集数据步骤83)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
字段选择完成后,选择“采集以下数据”微信爬虫采集数据步骤94)由于我们还想要采集每篇文章的URL,因而还需要提取一个字段。
使用fiddler抓取微信公众号文章的阅读数、点赞数、评论数

使⽤fiddler抓取微信公众号⽂章的阅读数、点赞数、评论数1 设置fiddler⽀持https打开fiddler,在菜单栏中依次选择 [Tools]->[Options]->[HTTPS],勾上如下图的选项:单击Actions,选择Export Root Certificate to Desktop(导出证书到桌⾯)选项:安装证书:在桌⾯上找到FiddlerRoot.cer⽂件,双击进⾏安装直到导⼊成功。
2 配置fiddler抓取规则在菜单栏中依次选择 [Rules]->[Customize Rules] 弹出Fiddler ScriptEditor界⾯找到OnBeforeRequest⽅法和OnBeforeResponse⽅法修改OnBeforeRequest⽅法内容如下:static function OnBeforeRequest(oSession: Session) {//加在⽅法末尾if (oSession.fullUrl.Contains("")){var fso;var file;fso = new ActiveXObject("Scripting.FileSystemObject");//⽂件保存路径,可⾃定义file = fso.OpenTextFile("c:\\Sessions.txt",8 ,true, true);file.writeLine("Request url: " + oSession.url);file.writeLine("Request header:" + "\n" + oSession.oRequest.headers);file.writeLine("Request body: " + oSession.GetRequestBodyAsString());file.writeLine("\n");file.close();}}修改OnBeforeResponse⽅法内容如下:static function OnBeforeResponse(oSession: Session) {//加在⽅法末尾if (oSession.HostnameIs("") && oSession.uriContains("https:///mp/getappmsgext")){var filename = "C:/fiddler-token.log";var curDate = new Date();var logContent = "[" + curDate.toLocaleString() + "] " + oSession.PathAndQuery + "\r\n"+oSession.GetResponseBodyAsString()+"\r\n";var sw : System.IO.StreamWriter;if (System.IO.File.Exists(filename)){sw = System.IO.File.AppendText(filename);sw.Write(logContent);}else{sw = System.IO.File.CreateText(filename);sw.Write(logContent);}sw.Close();sw.Dispose();}}修改后保存⽂件。
网站抓取工具

网站抓取工具如何使用如今,大量的信息和数据发布在各式各样的网站上,面对这些数据,有些朋友或公司就有采集下来的需求,那么网站抓取工具如何使用呢?下面就为大家介绍一款简单实用,功能强大的抓取工具—八爪鱼的使用方法,下面以抓取采集微信文章信息为例子,通俗的讲解网站抓取工具的使用方法。
抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”网站抓取工具详细使用步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”网站抓取工具详细使用步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”网站抓取工具详细使用步骤32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮网站抓取工具详细使用步骤43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 网站抓取工具详细使用步骤54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”网站抓取工具详细使用步骤6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”网站抓取工具详细使用步骤72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”网站抓取工具详细使用步骤8 3)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
微信热门文章采集方法以及详细步骤

微信热门文章采集方法以及详细步骤本文将以搜狗微信文章为例,介绍使用八爪鱼采集网页文章正文的方法。
文章正文里一般包括文本和图片两种。
本文将采集文章正文中的文本+图片URL。
将采集以下字段:文章标题、时间、来源和正文(正文中的所有文本,将合并到一个excel单元格中,将使用到“自定义数据合并方式”功能,请大家注意)。
同时,采集文章正文中的文本+图片URL,将用到“判断条件”,“判断条件”的使用,有很多需要注意的地方。
以下两个教程,大家可先熟悉一下。
“自定义数据合并方式”详解教程:“判断条件”详解教程:采集网站:使用功能点:●分页列表信息采集●Xpath●AJAX点击和翻页●判断条件●AJAX滚动步骤1:创建采集任务1)进入主界面,选择“自定义模式”微信热门文章采集方法步骤12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”微信热门文章采集方法步骤2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
网页打开后,默认显示“热门”文章。
下拉页面,找到并点击“加载更多内容”按钮,在操作提示框中,选择“更多操作”微信热门文章采集方法步骤32)选择“循环点击单个元素”,以创建一个翻页循环微信热门文章采集方法步骤4由于此网页涉及Ajax技术,我们需要进行一些高级选项的设置。
选中“点击元素”步骤,打开“高级选项”,勾选“Ajax加载数据”,设置时间为“2秒”微信热门文章采集方法步骤5注:AJAX即延时加载、异步更新的一种脚本技术,通过在后台与服务器进行少量数据交换,可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
表现特征:a、点击网页中某个选项时,大部分网站的网址不会改变;b、网页不是完全加载,只是局部进行了数据加载,有所变化。
验证方式:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或者转圈状态。
观察网页,我们发现,通过5次点击“加载更多内容”,页面加载到最底部,一共显示100篇文章。
新媒体人,微信公众号有哪些好的采集文章工具?

新媒体人,微信公众号有哪些好的采集文章工具?展开全文经常写公众号的媒体人,除了花时间在创作和找素材上,还要费时间做图文编辑、排版,是不是觉得很吃力了?今天想跟大家推荐一款小工具,它可以一秒提高你的公众号排版效率。
壹伴,一款安装在浏览器里面的插件。
它不仅只有强大的排版功能,还可以群发前违规检测、数据分析、采集文章、还提供了超多的,无版权图片,给你使用。
一键排版,让排版变得有趣又简单。
文本标记功能,让排版程序,准确识别文章中的不同元素。
如在段落前加上“#”符号,标题为一级标题。
在段落前加上“##”符号,标记为二级标题。
通过类似的方式,标题引用、加粗等内容。
样式中心有好看的格子纹理背景、常用的标题、分割线、正文、引用、图片、顶部签名、底部签名。
如果不满足于壹伴样式中心的样式,还可以采集其他公众号文章的样式,具体怎么操作,接下来会详细介绍。
壹伴的采集功能必须拿出来好好讲一讲,如果你之前还没接触过这个功能,只能说之前的工作你已经浪费了大量时间。
采集的意思就是复制收藏文章、样式或者图片,采集具体怎么操作?1、采集文章如何复制采集其他文章,壹伴的采集文章有三个入口。
一:在微信公众平台编辑页的右下角,出现采集文章的按钮,将公众号文章的的链接复制粘贴在输入框即可。
二:公众号文章用默认浏览器打开后,右侧会出现壹伴图文工具箱,点击采集图文,即可采集当前文章到微信后台的素材管理,去素材库的图文消息可以找到哦!三:阅读浏览器页面的文章时,点击鼠标右键,选中壹伴小插件,随后再次点击【采集文章素材】,采集的文章同样在素材库内。
2、采集样式在不同公众号文章中看到喜欢的样式如何收藏在微信公众后台呢?壹伴的采集样式功能,直接将样式保存在收藏内,需要时插入即可。
也有两种采集方法哦!方法一:在微信编辑页面导入样式,复制喜欢的样式在空白框内,点击收藏。
方法二:用默认浏览器打开微信文章后,点击壹伴图文工具箱的采集样式按钮,选中样式,然后收藏。
通过微信公众平台获取公众号文章的方法示例

通过微信公众平台获取公众号⽂章的⽅法⽰例我之前⾃⼰维护了⼀个公众号,但因为个⼈关系很久没有更新了,今天上来缅怀⼀下,却偶然发现了⼀个获取微信公众号⽂章的⽅法。
之前获取⽅法有很多,通过搜狗、清博、⽹页端、客户端等等都还可以,这个可能并没有其他的优秀,但是操作简单,很容易理解。
so、⾸先需要有⼀个微信公众平台的账号登陆之后,进⼊⾸页,点击新建群发。
选择⾃建图⽂:似乎像是公众号运营教学了进⼊编辑页⾯之后,点击超链接弹出选择框,我们在框中输⼊对应的公众号名字,即可出现对应的⽂章列表是不是很惊奇,可以打开控制台,查看⼀下请求的接⼝打开response,⾥⾯就是我们需要的⽂章链接确定了数据以后,我们需要分析⼀下这个接⼝。
感觉很简单,⼀个GET请求,携带⼀些参数。
fakeid是公众号的独有ID,所以想通过名字直接获取⽂章列表,还需要先获取⼀下fakeid。
当我们输⼊公众号名字后,点击搜索。
可以看到触发了搜索接⼝,返回了fakeid。
这个接⼝所需参数也不多。
接下来,我们可以⽤代码来模拟以上的操作了。
但是还需要使⽤现有Cookie避免登陆。
⽬前Cookie的有效期,我还没有测试。
可能需要及时更新Cookie。
测试代码:import requestsimport jsonCookie = '请换上⾃⼰的Cookie,获取⽅法:直接复制下来'url = "https:///cgi-bin/appmsg"headers = {"Cookie": Cookie,"User-Agent": 'Mozilla/5.0 (Linux; Android 10; YAL-AL00 Build/HUAWEIYAL-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/70.0.3538.64 HuaweiBrowser/10.0.1.335 Mobile Safari/537.36' }keyword = 'pythonlx' # 公众号名字:可⾃定义token = '你的token' # 获取⽅法:如上述直接复制下来search_url = 'https:///cgi-bin/searchbiz?action=search_biz&begin=0&count=5&query={}&token={}&lang=zh_CN&f=json&ajax=1'.format(keyword,token)doc = requests.get(search_url,headers=headers).textjstext = json.loads(doc)fakeid = jstext['list'][0]['fakeid']data = {"token": token,"lang": "zh_CN","f": "json","ajax": "1","action": "list_ex","begin": 0,"count": "5","query": "","fakeid": fakeid,"type": "9",}json_test = requests.get(url, headers=headers, params=data).textjson_test = json.loads(json_test)print(json_test)这样就能获取最新的10篇⽂章了,如果想要获取更多的历史⽂章,可以修改data中的"begin"参数,0是第⼀页,5是第⼆页,10是第三页(以此类推)但是如果想要⼤规模抓取的话:请给⾃⼰安排⼀个稳定的代理,降低爬⾍的速度,准备多个账号,来减少被封禁的可能性。
自媒体文章采集器使用方法

自媒体文章采集器使用方法在这个自媒体时代,人人都是撰稿人。
而要写的一手好文章,除非天资聪颖,各种妙语信手拈来,否则前期的资料积累是必不可少的。
参考其他人的文章,去其糟粕留其精华归吾所用。
可谓提升自己文章之捷径。
而又应如何快速大量的获取到他人文章呢?这时网页采集器就必不可少了!让我们能快速搜集各个平台上的自媒体文章。
以下是一个使用八爪鱼采集网站文章的完整示例,示例中采集的是在搜狗微信这个网站上,搜索关键词“八爪鱼大数据”后出现的结果文章的标题、文章关键词、文章部分内容展示、所属公众号、发布时间、文章URL等字段数据。
采集网站:/步骤1:创建采集任务1)进入主界面,选择“自定义模式”自媒体文章采集器使用步骤图12)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”自媒体文章采集器使用步骤图2步骤2:创建翻页循环1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”自媒体文章采集器使用步骤图32)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮自媒体文章采集器使用步骤图43)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮”自媒体文章采集器使用步骤图54)页面中出现了“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”自媒体文章采集器使用步骤图6步骤3:创建列表循环并提取数据1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”自媒体文章采集器使用步骤图72)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”自媒体文章采集器使用步骤图83)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
Python网络爬虫中的微博微信与QQ数据抓取

Python网络爬虫中的微博微信与QQ数据抓取数据在当今的信息时代扮演着至关重要的角色,越来越多的人开始关注和利用这些宝贵的数据。
在网络爬虫领域,Python作为一种强大而灵活的编程语言,广泛应用于数据抓取和处理。
本文将介绍Python 网络爬虫中如何抓取微博、微信和QQ等平台的数据。
一、微博数据抓取1.1 登录微博平台为了抓取微博数据,首先需要登录到微博平台。
可以使用Python的模拟登录技术,模拟浏览器行为,通过输入用户名和密码进行登录。
1.2 抓取微博用户信息登录成功后,可以通过微博的API接口获取微博用户的信息,包括用户的基本信息、关注列表、粉丝列表、微博内容等。
通过请求API 的方式,可以将用户信息以JSON格式返回,并进一步解析和存储。
1.3 抓取微博话题和热门微博除了抓取用户信息,还可以抓取微博中的话题和热门微博。
通过解析微博页面的HTML结构,提取相关的信息,例如话题的名称、热门微博的内容和评论等。
二、微信数据抓取2.1 获取微信公众号信息对于微信数据的抓取,首先需要获取微信公众号的信息。
可以通过微信公众平台的API接口获取公众号的基本信息,包括公众号的名称、认证状态、文章数量等。
2.2 抓取微信文章内容登录微信公众平台后,可以通过API接口抓取微信文章的内容。
可以根据关键词搜索,获取与关键词相关的文章,进一步解析和提取文章的标题、作者、发布时间、内容等信息。
2.3 自动回复和发布文章利用Python的机器学习和自然语言处理技术,可以实现微信公众号的自动回复和文章的智能发布。
通过训练机器学习模型,可以根据用户的提问和关键词等进行智能回复,提高用户体验。
三、QQ数据抓取3.1 登录QQ空间QQ空间是一个用户交流和分享的社交平台,也是一个抓取数据的重要来源。
通过模拟登录QQ空间,可以获取用户的基本信息、好友列表、说说、日志、相册等数据。
3.2 抓取QQ说说和日志在QQ空间中,说说和日志是用户最常用的功能之一。
python爬取微信公众号文章的方法

python爬取微信公众号⽂章的⽅法最近在学习Python3⽹络爬⾍开发实践(崔庆才著)刚好也学习到他使⽤代理爬取公众号⽂章这⾥,但是照着他的代码写,出现了⼀些问题。
在这⾥我⽤到了这本书的前⾯讲的⼀些内容进⾏了完善。
(作者写这个代码已经是半年前的事了,但腾讯的⽹站在这半年前进⾏了更新)下⾯我直接上代码:TIMEOUT = 20from requests import Request, Session, PreparedRequestimport requestsfrom selenium import webdriverfrom mon.exceptions import NoSuchElementExceptionfrom bs4 import BeautifulSoup as bsimport pymysql# 要爬取的内容keyword = '美⼥图⽚'options = webdriver.ChromeOptions()# 设置中⽂options.add_argument('lang=zh_CN.UTF-8')# 更换头部options.add_argument('user-agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"')browser = webdriver.Chrome(chrome_options=options)REDIS_HOST = '192.168.1.248'REDIS_PORT = 6379REDIS_PASSWORD = '*****'REDIS_KEY = 'requests'PROXY_POOL_URL = 'http://127.0.0.1:8080/random'MAX_FAILED_TIME = 5MYSQL_HOST = 'localhost'MYSQL_PORT = 3306MYSQL_USER = 'moxiao'MYSQL_PASSWORD = '******'class mysqlConn():def __init__(self, host=MYSQL_HOST, username=MYSQL_USER, password=MYSQL_PASSWORD, port=MYSQL_PORT):"""mysql 初始化:param host::param username::param password::param port:"""try:self.db = pymysql.Connection(host=host, user=username, password=password,database='weixin_data', port=port)self.cursor = self.db.cursor()except pymysql.MySQLError as e:print(e.args)def insert(self, table, data):keys = ', '.join(data.keys())values = ', '.join(['%s'] * len(data))sql = 'insert into %s (%s) values (%s)' % (table, keys, values)try:self.cursor.execute(sql, tuple(data.values()))mit()except pymysql.MySQLError as e:print(e.args)self.db.rollback()class WeixinRequest(Request):def __init__(self, url, callback, method="GET", headers=None, need_proxy=False, fail_time=0, timeout=TIMEOUT):super(WeixinRequest, self).__init__(url=url, method=method, headers=headers)self.callback = callbackself.need_proxy = need_proxyself.fail_time = fail_timeself.timeout = timeoutdef prepare(self):p = PreparedRequest()p.prepare(method=self.method,url=self.url,headers=self.headers,)return pclass WeixinResponse():def __init__(self, text):self.text = textdef set_status_code(self, status_code):self.status_code = status_codeimport picklefrom redis import StrictRedisclass RedisQueue():def __init__(self):"""初始化redis"""self.db = StrictRedis(host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASSWORD, db=3) def add(self, request):"""向队列添加序列化后的Request:param request:请求对象:return:添加结果"""if isinstance(request, WeixinRequest):return self.db.rpush(REDIS_KEY, pickle.dumps(request))return Falsedef pop(self):"""取出下⼀个request并反序列化:return: Request 或者 None"""if self.db.llen(REDIS_KEY):return pickle.loads(self.db.lpop(REDIS_KEY))return Falsedef empty(self):return self.db.llen(REDIS_KEY) == 0def del_all(self):return self.db.delete(REDIS_KEY)def get_proxy(self):"""从代理池获取代理IP:return:"""try:response = requests.get(PROXY_POOL_URL)if response.status_code == 200:print('get Proxy', response.text)return response.textexcept requests.ConnectionError:return Nonefrom urllib.parse import urlencodefrom requests import ReadTimeout, ConnectionErrorfrom pyquery import PyQuery as pqVALD_STATUES = [200]class Spider():base_url = '/weixin?'# 这⾥的page可以修改,即第⼏页,我本来想获取所有的个数再除以10 这样就能爬完了,但是我只是测试所以这⾥并没有做# 但如果需要做可以加到schedule⽅法的while循环内的最下⾯即self.params['page']+=1params = {'type': 2, 's_from': 'input', 'query': keyword, 'page': 1, 'ie': 'utf8', '_sug_': 'n','_sug_type_': ''}headers = {'Host': '','Connection': 'keep-alive','Cache-Control': 'max-age=0','Upgrade-Insecure-Requests': '1','User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8','Accept-Encoding': 'gzip, deflate','Accept-Language': 'zh-CN,zh;q=0.9','Referer': 'http: // /','Cookie': '你的cookie'} # TODO 不可能把我的给你撒session = Session()queue = RedisQueue()queue.del_all()mysql = mysqlConn()def start(self):"""初始化⼯作:return:"""# 全局更新headers# 如果你试过⽤这个⽅法修改headers,那么就知道这个在这⾥好像没什么⽤,我在这⾥浪费了⾄少两个⼩时self.session.headers.update(self.headers)start_url = self.base_url + urlencode(self.params)# 这⾥我将need_proxy=False设为了False 即并没有使⽤代理 ps:我也就是测试⼀下# 真正修改了headers是在这⾥weixin_request = WeixinRequest(url=start_url, callback=self.parse_index, headers=self.headers, need_proxy=False)# 调度第⼀个请求self.queue.add(weixin_request)def schedule(self):"""调度请求:return:"""while not self.queue.empty():weixin_request = self.queue.pop()callback = weixin_request.callbackprint('Schedule', weixin_request.url)response = self.request(weixin_request)if response and response.status_code in VALD_STATUES:results = list(callback(response))if results:for result in results:print('New Result', result)if isinstance(result, WeixinRequest):# 将新的⽂章详情的url也加⼊队列self.queue.add(result)if isinstance(result, dict):# 储存到mysqlself.mysql.insert('articles', result)else:self.error(weixin_request)else:self.error(weixin_request)def request(self, weixin_request):"""执⾏请求:param weixin_request:请求:return: 响应"""if not '/s?src' in weixin_request.url:try:if weixin_request.need_proxy:proxy = self.queue.get_proxy()if proxy:proxies = {'http': 'http://' + proxy,'https': 'https://' + proxyreturn self.session.send(weixin_request.prepare(),timeout=weixin_request.timeout, allow_redirects=False, proxies=proxies)return self.session.send(weixin_request.prepare(), timeout=weixin_request.timeout, allow_redirects=False)except (ConnectionError, ReadTimeout) as e:print(e.args)return Falseelse:print('-' * 20)browser.get(weixin_request.url)try:browser.find_element_by_class_name('rich_media_area_primary_inner')wr = WeixinResponse(browser.page_source)wr.set_status_code(200)return wrexcept NoSuchElementException:wr = WeixinResponse('')wr.set_status_code(403)return wrdef parse_index(self, response):"""解析索引页:param response: 响应:return: 新的响应"""doc = pq(response.text)items = doc('.news-box .news-list li .txt-box h3 a').items()for item in items:url = item.attr('href')weixin_request = WeixinRequest(url=url, callback=self.parse_detail)yield weixin_requestdef parse_detail(self, response):"""解析详情页:param response: 响应:return: 微信公众号⽂章"""doc = pq(response.text)profile_inner = doc('.profile_inner')data = {'title': doc('.rich_media_title').text(),'content': doc('.rich_media_content').text(),'date': doc('#publish_time').text(),# 'nickname':doc('#js_profile_qrcode > div > strong').text(),'nickname': profile_inner.find('.profile_nickname').text(),'wechat':[ns for ns in profile_inner.find('.profile_meta').find('.profile_meta_value').items()][0].text()}# 储存图⽚print('#' * 30)soup = bs(response.text)wn = soup.find_all('img')for img in wn:if img.has_attr('_width') and img.has_attr('data-src'):print(img.attrs['data-src'])yield datadef error(self, weixin_request):"""错误处理:param weixin_request:请求:return:"""weixin_request.fail_time = weixin_request.fail_time + 1print('Request Failed', weixin_request.fail_time, 'Times', weixin_request.url)if weixin_request.fail_time < MAX_FAILED_TIME:self.queue.add(weixin_request)def run(self):self.start()self.schedule()if __name__ == '__main__':spider = Spider()spider.run()2018-10-6更新:今天测试之后使⽤了cookie并不能登录这个⽹站了,也许是腾讯使⽤了新的安全验证,具体也⽆从得知,但使⽤浏览器访问没有问题以上就是本⽂的全部内容,希望对⼤家的学习有所帮助,也希望⼤家多多⽀持。
微信8.0新增扫描仪功能,长按屏幕2秒,一键提取纸上文字
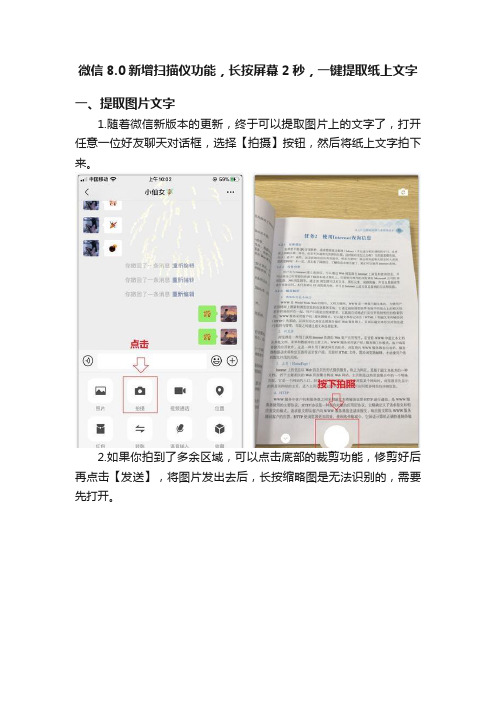
微信8.0新增扫描仪功能,长按屏幕2秒,一键提取纸上文字
一、提取图片文字
1.随着微信新版本的更新,终于可以提取图片上的文字了,打开任意一位好友聊天对话框,选择【拍摄】按钮,然后将纸上文字拍下来。
2.如果你拍到了多余区域,可以点击底部的裁剪功能,修剪好后再点击【发送】,将图片发出去后,长按缩略图是无法识别的,需要先打开。
3.查看大图时,长按屏幕2秒,在底部就可以看到【提取文字】功能,点击就能立马识别,涂抹或全选文字,支持一键转发、复制、收藏。
二、识别纸质表格
1.微信自带的这个小程序,不仅能识别文档,还能提取表格,打开后点击【立即识别】,然后切换到【表格】,将纸质表格拍下来。
2.拍下后拖动蓝色矩形框,调整识别区域,接着再点击底部的【立即识别】,就可以将表格内容提取出来了,我们还可以选择【导出Excel】。
3.按照步骤,进入客服会话窗口,发送获取链接,你将会收到一条预览链接,直接点击就可以查看Excel电子表格,还可以选择【在电
脑上打开】。
三、拍照翻译文档
1.打开微信首页,右上角有个“+”号按钮,下方有5个功能,平时我们用到最多的就是【扫一扫】,很多人只会扫描二维码付款、加好友。
2.其实在底部有3个扫描功能,切换到最后一个【翻译】,它可以将中文与英文相互翻译,比如我将英语文档拍下来,瞬间被翻译成中
文。
3.下面我再将镜头对准中文,点击快门键拍下来,随后文档就翻译成英文了,点击底部的下载按钮,可以将翻译结果保存到手机相册中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
微信文章抓取工具详细使用方法
如今越来越多的优质内容发布在微信公众号中,面对这些内容,有些朋友就有采集下来的需求,下面为大家介绍使用八爪鱼抓取工具去抓取采集微信文章信息。
抓取的内容包括:微信文章标题、微信文章关键词、微信文章部分内容展示、微信所属公众号、微信文章发布时间、微信文章URL等字段数据。
采集网站:/
步骤1:创建采集任务
1)进入主界面,选择“自定义模式”
微信文章抓取工具详细使用步骤1
2)将要采集的网址URL复制粘贴到网站输入框中,点击“保存网址”
微信文章抓取工具详细使用步骤2
步骤2:创建翻页循环
1)在页面右上角,打开“流程”,以展现出“流程设计器”和“定制当前操作”两个板块。
点击页面中的文章搜索框,在右侧的操作提示框中,选择“输入文字”
微信文章抓取工具详细使用步骤3
2)输入要搜索的文章信息,这里以搜索“八爪鱼大数据”为例,输入完成后,点击“确定”按钮
微信文章抓取工具详细使用步骤4
3)“八爪鱼大数据”会自动填充到搜索框,点击“搜文章”按钮,在操作提示框中,选择“点击该按钮” 微信文章抓取工具详细使用步骤5
4)页面中出现了
“八爪鱼大数据”的文章搜索结果。
将结果页面下拉到底部,点击“下一页”按钮,在右侧的操作提示框中,选择“循环点击下一页”
微信文章抓取工具详细使用步骤6
步骤3:创建列表循环并提取数据
1)移动鼠标,选中页面里第一篇文章的区块。
系统会识别此区块中的子元素,在操作提示框中,选择“选中子元素”
微信文章抓取工具详细使用步骤7
2)继续选中页面中第二篇文章的区块,系统会自动选中第二篇文章中的子元素,并识别出页面中的其他10组同类元素,在操作提示框中,选择“选中全部”
微信文章抓取工具详细使用步骤8
3)我们可以看到,页面中文章区块里的所有元素均被选中,变为绿色。
右侧操作提示框中,出现字段预览表,将鼠标移到表头,点击垃圾桶图标,可删除不需要的字段。
字段选择完成后,选择“采集以下数据” 微信文章抓取工具详细使用步骤9 4)由于我们还想要采集每篇文章的URL
,因而还需要提取一个字段。
点击第一篇文章的链接,再点击第二篇文章的链接,系统会自动选中页面中的一组文章链接。
在右侧操作提示框中,选择“采集以下链接地址”
微信文章抓取工具详细使用步骤10
5)字段选择完成后,选中相应的字段,可以进行字段的自定义命名。
完成后,点击左上角的“保存并启动”,启动采集任务
微信文章抓取工具详细使用步骤11
6)选择“启动本地采集”
微信文章抓取工具详细使用步骤12
步骤4:数据采集及导出
1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导出方式”,将采集好的搜狗微信文章的数据导出
微信文章抓取工具详细使用步骤13
2)这里我们选择excel作为导出为格式,数据导出后如下图
微信文章抓取工具详细使用步骤14
注意:通过此种方法采集下来的搜狗微信文章URL,具有时效性,会在短时间
内失效。
这是因为搜狗微信本身的限制所致。
相关采集教程:
京东商品信息采集
新浪微博数据采集
58同城信息采集
八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
3、云采集,关机也可以。
配置好采集任务后可关机,任务可在云端执行。
庞大云采集集群24*7不间断运行,不用担心IP被封,网络中断。
4、功能免费+增值服务,可按需选择。
免费版具备所有功能,能够满足用户的基本采集需求。
同时设置了一些增值服务(如私有云),满足高端付费企业用户的需要。