信息论无失真信源编码
信息论:第5章 无失真信源编码定理

(7)码的N次扩展码
假定某码C,它把信源 S {s1 , s2 ,, sq }中的符号
s i 一一变换成码C中的码字 Wi ,则码C的N次扩展 码是所有N个码字组成的码字序列的集合。
24
例如:若码 C {W1 ,W2 ,,Wq } 满足:si Wi ( xi1 , xi 2 ,, xil ), si S , xil X 则码C的N次扩展码集合 B {B1 , B2 , , Bq } ,其中:
为了解决这两个问题,就要引入信源编码和信 道编码。
2
一般来说,抗干扰能力与信息传输率二者相互矛盾。 然而编码定理已从理论上证明,至少存在某种最佳 的编码能够解决上述矛盾,做到既可靠又有效地传 输信息。 信源虽然多种多样,但无论是哪种类型的信源, 信源符号之间总存在相关性和分布的不均匀性,使 得信源存在冗余度。
q r
N
l
(5.2)
36
25
(8)惟一可译码
若任意一串有限长的码符号序列只能被惟一地 译成所对应的信源符号序列,则此码称为惟一可译 码(或称单义可译码)。否则就称为非惟一可译码 或非单义可译码。
若要使某一码为惟一可译码,则对于任意给定 的有限长的码符号序列,只能被惟一地分割成一个 个的码字。
26
例如:对于二元码 C1 {1, 01, 00},当任意给定一串 码字序列,例如“10001101”,只可唯一地划分为 1,00,01,1,01,因此是惟一可译码; 而对另一个二元码 C 2 {0,10, 01},当码字序列 为“01001”时,可划分为0,10,01或01,0,01,所以是 非惟一可译的。
i
N
Bi {Wi1 ,Wi2 ,,WiN }; i1 ,, i N 1,, q; i 1,, q N
信息论常用无失真信源编码设计(含MATLAB程序)

《信息论基础》题目:常用无失真信源编码程序设计目录1. 引言 (2)2. 香农编码 (2)2.1 编码步骤 (3)2.2 程序设计 (3)2.3 运行结果 (3)3. 费诺编码 (4)3.1 编码步骤 (5)3.2 程序设计 (5)3.3 运行结果 (5)4. 哈夫曼编码 (6)4.1 编码步骤 (7)4.2 程序设计 (7)4.3 运行结果 (8)5. 结论 (9)6. 参考文献 (10)7. 附录 (11)7.1 香农编码Matlab程序 (11)7.2 费诺编码Matlab程序 (12)7.3 哈夫曼编码Matlab程序 (14)1. 引言信息论(Information Theory)是运用概率论与数理统计的方法研究信息、信息熵、通信系统、数据传输、密码学、数据压缩等问题的应用数学学科。
信息系统就是广义的通信系统,泛指某种信息从一处传送到另一处所需的全部设备所构成的系统。
信息论是关于信息的理论,应有自己明确的研究对象和适用范围[1]。
信息论将信息的传递作为一种统计现象来考虑,给出了估算通信信道容量的方法。
信息传输和信息压缩是信息论研究中的两大领域。
这两个方面又由信息传输定理、信源-信道隔离定理相互联系。
信源编码是一种以提高通信有效性为目的而对信源符号进行的变换,或者说为了减少或消除信源冗余度而进行的信源符号变换。
具体说,就是针对信源输出符号序列的统计特性来寻找某种方法,把信源输出符号序列变换为最短的码字序列,使后者的各码元所载荷的平均信息量最大,同时又能保证无失真地恢复原来的符号序列[2]。
在通信中,传送信源信息只需要具有信源极限熵大小的信息率,但在实际的通信系统中用来传送信息的信息率远大于信源极限熵。
为了能够得到或接近信源熵的最小信息率,必须解决编码的问题,而编码分为信源编码和信道编码,其中的信源编码又分为无失真信源编码和限失真信源编码。
由于无失真信源编码只适用于离散信源,所以本次作业讨论无失真离散信源的三种简单编码,即香农(Shannon)编码、费诺(Fano) 编码和哈夫曼(Huffman) 编码[3]。
无失真的信源编码

[例]有一单符号离散无记忆信源
对该信源编二进制香农码。其编码过程如表所示。 二进制香农编码
xi x1 x2 x3 x4 x5 x6 p(xi) 0.25 0.25 0.20 0.15 0.10 0.05 pa(xj) 0.000 0.250 0.500 0.700 0.85 0.95 ki 2 2 3 3 4 5 码字 00 01 100 101 1101 11110 0.000 =(0.000)2 0.250 =(0.010)2 0.500 =(0.100)2 0.700 =(0.101)2 0.85 =(0.1101)2 0.95 =(0.11110)2
7/13/2013 4/31
信源编码概述
信源的原始信号绝大多数是模拟信号,因此,信源编码的 第一个任务是模拟和数字的变换,即:A/D,D/A。 抽样率取决于原始信号的带宽:fc = 2 w,w为信号带宽。 抽样点的比特数取决于经编译码后的信号质量要求: SNR = 6 L(dB),L为量化位数 但是,由于传输信道带宽的限制,又由于原始信源的信号 具有很强的相关性,则信源编码不是简单的A/D,D/A, 而是要进行压缩。为通信传输而进行信源编码,主要就是 压缩编码。 信源编码要考虑的因素:
只含(n-2)个符号的缩减信源S2。
重复上述步骤,直至缩减信源只剩两个符号为止,此时所剩两个符 号的概率之和必为1。然后从最后一级缩减信源开始,依编码路径向
前返回,就得到各信源符号所对应的码字。
7/13/2013 16/31
[例] 设单符号离散无记忆信源如下,要求对信源编二进制哈夫曼码。
7/13/2013
7/13/2013
2/31
信源编码:提高通信有效性。通常通过压缩信源的
信息论基础与应用-李梅-第五章 无失真信源编码解析

二次扩展码码字 w j ( j 1, 2,...,16)
w1 w1w1 00 w 2 w1w2 001 w3 w1w3 0001 w16 w4 w4 111111
第五章:无失真信源编码
一、信源编码的相关概念
4. 关于编码的一些术语
编码器输出的码符号序列 wi称为码字;长度 li 称为码 字长度,简称码长;全体码字的集合C称为码。 若码符号集合为X={0,1},则所得的码字都是二元序 列,称为二元码。
将信源符号集中的每个信源符号
si 固定的映射成某
一个码字 wi ,这样的码称为分组码。
码字与信源符号一一对应
2) 不同的信源符号序列对应不同的码字序列
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续2)
例1:
1) 奇异码
s1 s2 s3 s4
0 11 00 Байду номын сангаас1
译码 11
s2 s4
奇异码一定不是唯一可译码
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续3)
译码 0 0 0 1 1 0 1 1
s1s2 s3 s4
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续5)
4)
唯一可译码 1 1 0 1 0 0 1 0 0 0 0
s1 s2
1 10
1 0
1
s2 / s3 ?
s3 100 s4 1000
为非即时码
第五章:无失真信源编码
一、信源编码的相关概念
信息论与编码第2

第2章 无失真信源编码原理
某些简单的离散平稳信源先后发出的一个个符号是统计 独立的。也就是说,在信源输出的随机序列X=X1X2…XN中, 各随机变量Xi(i=1,2,…,N)之间是无依赖的、统计独立的,这 样的信源称为离散无记忆信源。该信源在不同时刻发出的各 符号之间也是无依赖的、统计独立的。离散无记忆信源输出 的随机变量X所描述的信源称为离散无记忆信源的N次扩展 信源。可见,N次扩展信源是由离散无记忆信源输出N长的 随机序列构成的信源。一般情况下,信源在不同时刻发出的 各符号之间是相互依赖的,也就是在信源输出的平稳随机序 列X=X1X2…XN中,各随机变量Xi之间是相互依赖的。
第2章 无失真信源编码原理
若信源只输出一个消息(符号),则用一维随机变量来描 述。然而,很多实际信源输出的消息往往是由一系列符号序 列所组成的。例如,将中文自然语言文字作为信源,这时中 文信源的样本空间是所有汉字与标点符号的集合。由这些汉 字和标点符号组成的序列即构成中文句子和文章。因此,从 时间上看,中文信源输出的消息是时间上离散的符号序列, 其中每个符号的出现是不确定的、随机的,由此构成了不同 的中文消息。又例如,对离散化的平面灰度图像信源来说, 从XY平面空间上来看每幅画面是一系列空间离散的灰度值 符号,而空间每一点的符号(灰度值)又都是随机的,由此 形成了不同的图像消息。
第2章 无失真信源编码原理
2.1.2 信源的数学模型 根据信源输出信息所对应的不同的随机过程可以导出不
同的信源模型。例如,根据随机过程具有的随机变量前后独 立与否可分为独立随机信源(或称无记忆信源)和不独立随机 信源(或称有记忆信源);根据随机过程平稳与否可分为平稳 (稳恒)信源和非平稳(非稳恒)信源。与特殊的随机过程相对 应又有特殊的信源模型,例如,与高斯过程相对应的高斯信 源,与马尔可夫过程相对应的马尔可夫信源等,其中,马尔 可夫信源是有记忆信源中最简单且最具代表性的一种。信源 的类型不同其对应的模型也不同,限于篇幅,这里只介绍基 本离散信源的数学模型及其无记忆扩展信源的数学模型。
信息论与编码第5章(2)

2.48
3
011
a4
0.17
0.57
2.56
3
100
a5
0.15
0.74
2.743101 Nhomakorabeaa6
0.10
0.89
3.34
4
1110
a7
0.01
0.99
6.66
7
1111110
10
香农编码
• 由上表可以看出,一共有5个三位的代码组,各代 码组之间至少有一位数字不相同,故是唯一可译码。 还可以判断出,这7个代码组都属于即时码。
相等。如编二进制码就分成两组,编m进制码就分成 m组。 给每一组分配一位码元。 将每一分组再按同样原则划分,重复步骤2和3,直至概 率不再可分为止。
13
费诺编码
xi
符号概 率
x1
0.32
0
编码 0
码字 00
码长 2
x2
0.22
1
01
2
x3
0.18
0
10
2
x4
0.16
1
0
110
3
x5
0.08
1
0
的码字总是0、00、000、0…0的式样; ✓ 码字集合是唯一的,且为即时码; ✓ 先有码长再有码字; ✓ 对于一些信源,编码效率不高,冗余度稍大,因此
其实用性受到较大限制。
12
费诺编码
费诺编码属于概率匹配编码 。
编码步骤如下: 将概率按从大到小的顺序排列,令
p(x1)≥ p(x2)≥…≥ p(xn) 按编码进制数将概率分组,使每组概率尽可能接近或
15
哈夫曼编码
哈夫曼编码也是用码树来分配各符号的码字。 哈夫曼(Huffman)编码是一种效率比较高的变长无失
第三章-无失真信源编码(2)
序列 x1x1 x1x2 x2x1 x2x2
序列概率 9/16 3/16 3/16 1/16
即时码 0 10 110 111
这个码的码字平均长度
lN
9 1
3 2
3 3
1 3 27
码元/ 信源序列
16 16 16 16 16
单个符号的平均码长
l
l
N
lN
27
码元 / 符号
N 2 32
编码效率
c
H(X)
例1:设有一简单DMS信源:
U
p
u1 1 2
u2 1 22
u3 1 23
u4 u5 u6 u7
111
1
24 25 26 26
用码元表X={0,1}对U的单个符号进行编码(N=1),即对U
的单个符号进行2进制编码。
解:用X的两个码元对U的7个符号进行编码,单 个对应的定长码长:
l lN log q log 7 2.8 码元 / 符号 N log r log 2
j 1
log r
1 qN
r l j
ln 2
P(a j ) ln
j 1
P(aj )
1 qN
r l j
ln 2 j1 P(a j )( P(a j ) 1)
(ln z z 1)
qN
qN
rlj P(a j )
j 1
j 1
ln 2
11 0 (Kraft不等式和概率完备性质) ln 2
(2)根据信源的自信息量来选取与之对应的码长:
【说明】
霍夫曼编码是真正意义上的最佳编码,对给定的信源,平 均码长达到最小,编码效率最高,费诺编码次之,香农编码 效率最低。
信息论与编码第4章无失真信源编码

0
2
1
w1 0 1 2 0 1 2
01
2w2
w3 w4
0
1
2
w5
w6 w7 w8
w9 w10 w11
0级节点 1级节点 2级节点
3级节点
25
4.3 变长编码
码树编码方法
(1)树根编码的起点; (2)每一个中间节点树枝的个数编码的进制数; (3)树的节点编码或编码的一部分; (4)树的终止节点(端点、树叶)码; (5)树的节数码长; (6)码位于多级节点变长码; (7)码位于同一级节点码等长码;
设离散无记忆信源X的熵为H(X), 若对长为N的信源符号序 列进行等长编码,码长为L , 码元符号个数为m. 则对任意的
>0, >0, 只要
L log m H ( 率小于。
反之,当
L log m H ( X ) 2
N
时, 则译码差错概率一定是有限值(不可能实现无失真编 码), 而当N足够大时, 译码错误概率近似等于1。
概率分布 0.5 0.25 0.125 0.125
码1:C1 码2:C2 码3:C3
00
0
0
码4:C4 1
码5:C5 1
01
11
10
10
01
10
00
00
100
001
11
11
01
1000
0001
等长码 非唯一 非 唯 唯一可译 及时码 可译 一可译
11
4.1 无失真信源编码的概念
关系 即时码一定是唯一可译码 唯一可译码一定是非奇异码 定长的非奇异码一定是唯一可译码 非定长的非奇异码不一定是唯一可译码
一般地,平均码长: L 3.322 (N ) N
第5章无失真信源编码定理12

第5章无失真信源编码定理●通信的实质是信息的传输。
高效率、高质量地传送信息又是信息传输的基本问题。
●信源信息通过信道传送给信宿,需要解决两个问题:第一,在不失真或允许一定失真条件下,如何用尽可能少的符号来传送信源信息,以提高信息传输率。
第二,在信道受干扰的情况下,如何增强信号的抗干扰能力,提高信息传输的可靠性同时又使得信息传输率最大。
●为了解决以上两个问题,引入了信源编码和信道编码。
●提高抗干扰能力(降低失真或错误概率)往往是增加剩余度以降低信息传输率为代价的;反之,要提高信息传输率往往通过压缩信源的剩余度来实现,常常又会使抗干扰能力减弱。
●上面两者是有矛盾的,然而在信息论的编码定理中,已从理论上证明,至少存在某种最佳的编码或信息处理方法,能够解决上述矛盾,做到既可靠又有效地传输信息。
●第5章着重讨论对离散信源进行无失真信源编码的要求、方法及理论极限,得出极为重要的极限定理——香农第一定理。
5.1编码器●编码实质上是对信源的原始符号按一定的数学规则进行的一种变换。
●图5.1就是一个编码器,它的输入是信源符号集S={s 1,s 2,…,s q }。
同时存在另一符号集X={x 1,x 2, …,x r },一般元素x j 是适合信道传输的,称为码符号(或称为码元)。
编码器是将信源符号集中的符号s i (或者长为N 的信源符号序列a i )变换成由x j(j=1,2, …,r )组成的长度为l i的一一对应序列。
●这种码符号序列W i 称为码字。
长度l i称为码字长度或简称码长。
所有这些码字的集合C 称为码。
●编码就是从信源符号到码符号的一种映射,若要实现无失真编码,必须这种映射是一一对应的、可逆的。
编码器S :{s 1,s 2,…s q }X :{x 1,x 2,…x r }C :{w 1,w 2,…w q }(w i 是由l i 个x j (x j 属于X ))组成的序列,并于s i 一一对应一些码的定义●二元码:若码符号集为X={0,1},所得码字都是一些二元序列,则称为二元码。
信息论:第8章 无失真的信源编码讲解

9
8.1 霍夫曼码
香农编码 • 香农编码严格意义上来说不是最佳码。 • 香农编码是采用信源符号的累计概率分布函数来
分配码字。
10
香农编码方法如下: (1)将信源消息符号按其出现的概率大小依次排列:
• 一般情况下,按照香农编码方法编出来的码,其平 均码长不是最短的,也即不是紧致码(最佳码)。只有 当信源符号的概率分布使不等式左边的等号成立时, 编码效率才达到最高。
19
8.1.1 二元霍夫曼码
1952年霍夫曼提出了一种构造最佳码的方法。它是一 种最佳的逐个符号的编码方法。其编码步骤如下: (1) 将信源消息符号按其出现的概率大小依次排列
上式。
36
注意: 对于r元码时,不一定能找到一个使式 q (r 1) r 成立。在不满足上式时,可假设一些信源符号: sq1 , sq2 ,..., sqt 作为虚拟的信源,并令它们对应 的概率为零,即:pq1 pq2 ... pqt 0
而使 q t (r 1) r 能成立,这样处理后得到
21
例8.1:
对离散无记忆信源 进行霍夫曼编码。
S p(si
)
s1 0.4
s2 0.2
s3 0.2
s4 0.1
s5 0.1
解:编码过程如表所示,
1)将信源符号按概率大小由大至小排序。
2)从概率最小的两个信源符号和开始1”,上面的信源符号(大概率)为“0”。若两 支路概率相等,仍为下面的信源符号为“1” 上面的 信源符号为“0”。
可变长无失真信源编码定理

可变长无失真信源编码定理一、概述可变长无失真信源编码定理是信息论的核心概念之一,它是由美国数学家香农(Claude Shannon)于1948年首次提出。
该定理主要探讨了信源编码的极限性能,为无失真编码提供了理论基础。
可变长无失真信源编码定理不仅在理论上有重要意义,而且在数据压缩、网络传输和存储系统等领域有着广泛的应用价值。
二、定理内容可变长无失真信源编码定理的主要内容是:对于任意给定的离散无记忆信源,存在一种可变长编码方式,使得编码后的平均码长小于或等于信源的熵,从而实现无失真编码。
换句话说,如果信源的熵为H,那么存在一种编码方式,使得编码后的平均码长L满足L ≤ H。
三、证明过程证明可变长无失真信源编码定理的过程较为复杂,涉及到概率论和信息论的基本知识。
以下是证明过程的大致步骤:1.定义信源的熵:信源的熵是信源输出随机变量的不确定性度量,定义为所有可能符号的概率加权和。
如果信源有n个符号,每个符号出现的概率为p1, p2, ..., pn,则信源的熵H定义为H = - Σ (pi * log2(pi)),其中i=1,2,...,n。
2.构造一个可变长度编码表:根据信源的概率分布,构造一个可变长度编码表,使得出现概率较大的符号对应较短的码字,反之亦然。
假设码字长度按照字典序排列,第i个码字的长度为log2(1/pi),其中i=1,2,...,n。
3.计算平均码长:根据可变长度编码表,计算所有可能符号的平均码长。
平均码长等于所有码字长度的概率加权和,即L = Σ(log2(1/pi) * pi),其中i=1,2,...,n。
4.证明平均码长小于或等于信源熵:利用不等式性质和概率分布的性质,推导出平均码长L满足L ≤H。
关键在于利用概率分布的不均匀性,通过调整码字长度来最小化平均码长。
5.构造一个解码函数:为了实现无失真解码,需要构造一个解码函数,使得每个码字能够唯一地还原为原始符号。
解码函数可以采用查表法或类似算法实现。
信息论与编码理论第6章无失真信源编码

LN N
Hr (U )
1 N
离散无记忆信源X的N次扩展信源XN的熵等于信 源X的熵的N倍,即
其中: LN 是N次扩展信源的平均 码长
H(XN)=NH(X)
变长信源编码定理的含义
H (U ) LN H (U ) 1 log r N log r N
以r=2,N=1为例,则 H (U ) L H (U ) 1 这说明,总可以找到一种唯一可译码,它的平均
u4 11 01 11 0001 1000
对码1,如果S=u2u4u1,则X=011100
符号 码1
6.1.2 码的分类
等长码:所有码子长度相同(码1)
u1 00 u2 01 u3 10 u4 11
变长码:码子的长度不同 (码2、码3、码4、码5)0
码2 码3 码4 码5
0
0
1
1
10 11 01 10
0.125
4
H (U ) p(xi ) log p(xi ) 1.75 i1
n
L p(ui )li 0.5 1 0.25 2 0.125 3 0.125 3 1.75 i 1
4
H (U )
p(xi ) log p(xi )
i1
100%
L log2 r
1.75log2 2
变长码的几个衡量指标
平均码长:每个信源符号 平均需用的码元数
n
L p(ui )li i 1
编码效率: H (U )
L log2 r
信息传输率:平均每个 码元携带的信息量
R H (U ) L
码集
{0, 1}
码元数
r=2(二元码)
码长
1
2
3
3
信息论-无失真信源编码-信源编码

码符号集
{b1,L br}
信源编码器(3)
原信源的N次扩展码:
将N个信源符号编成一个码字。相当于对原信 源的N次扩展源的信源符号进行编码。
§信§离单2散源击.2.平1此编1.稳处1自有码添记自条加信器忆标信件息信(题和息自源3的互信)熵信息息
例
信源X={0,1}的二次扩展源X2的 符号集为:{00,01,10,11}。对 X2编码,即为原信源X的二次扩 展码。
1 (01) 1 (1)
分组码(10)
一些结论
r 在码树中,n阶节点的个数最多为 n
例:2进码树中,r阶节点数目最多为 2r
非奇异码字总能与码树建立一一对应的关系
定长码
1.无失真编码条件 2.信源序列分组定理 3.定长码信源编码定理
无失真编码条件(1)
对于定长码, 只要非奇异就唯一可译。这就要求码字的数 目不少于被编码的信源序列的个数 单信源符号编码:
北京邮电大学信息论
第5章
无失真信源编码
Source coding theorem
• Example 2: Suppose that we have a horse race with eight horses taking part. Assume that the (p1ro, 1b,a1b, i1lit,ie1s,o1f w, 1in,n1in)g for the eight horses are
NG 2 N ( H ( X ) )
信源序列分组定理(10)
利用概率估计的上界 1 NG max p(x) NG 2N[H ( X ) ]
x
NG (1 )2N[H ( X ) ]
(1 )2N [H ( X ) ] NG 2N [H ( X ) ]
信息论导论第六章信源编码

第6章 信源编码
从数学意义上,信源编码就是信源符号序列到码 字之间的映射。 无失真信源编码 选择适合信道传输的码集,现在一般选二进 制数 寻求一种将信源符号序列变换为码字的系统 方法,这种方法要保证符号序列与码字之间的 一一对应关系
信源编码
衡量编码方法优劣的主要指标中,码长和易实现 性最受重视。
i 1 i 1 i 1
nN
nN
nN
H(X N ) NH(X) K H(X N ) 1 NH(X) 1
K 1 H(X) H(X) N N 1 任意给定 ,只要NN
信源编码
三、无失真信源编码 1、香农码
香农码直接基于最优码码长的界,是一种采用异 前置码实现的无失真不等长编码。
信源编码
例2
X x1 x 2 x 3 P(X) 0.5 0.3 0.2
分别对该信源和其二次扩展信源编香农码,并计 算编码效率。 (1)对信源编码
log P(x1 ) log 2 1 k1 1 log P(x 2 ) log 0.3 1.74 取k 2 2
码B 码C 0 01 0 10
x 3 0.15 x 4 0.05
011 110 0111 111
码A不是单义可译码,它有二义性;码B和码C是 单义可译码;码B是延时码,它需等到对应与下一 个符号的码字开头0才能确定本码字的结束,存在 译码延时;码C是即时码。
信源编码
码C的特点——任何一个码字都不是其它码字的前 缀,因此将该码称为异前置码。 异前置码可以用树图来构造。 一个三元码树图 从树根开始到每一个终节 点的联枝代表一个码字, 相应的异前置码
x1
x2
0.5
信息论与编码理论-第4章无失真信源编码-习题解答-20071202
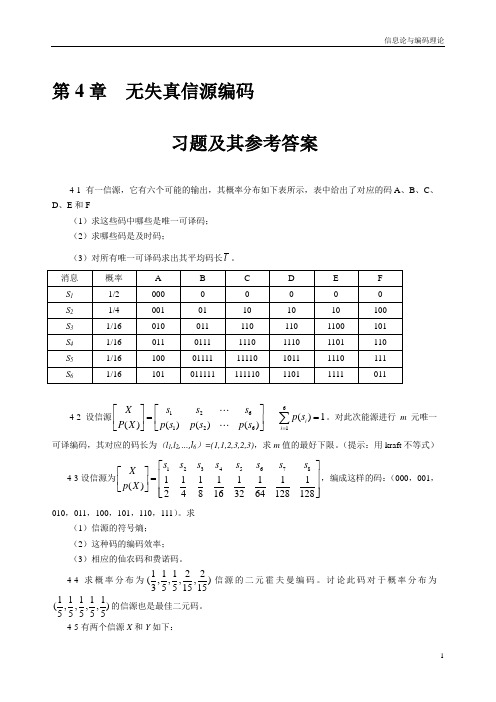
第4章无失真信源编码习题及其参考答案4-1 有一信源,它有六个可能的输出,其概率分布如下表所示,表中给出了对应的码A、B、C、D、E和F(1)求这些码中哪些是唯一可译码;(2)求哪些码是及时码;(3)对所有唯一可译码求出其平均码长l。
4-2 设信源61261126()1()()()()iis s sXp sp s p s p sP X=⎡⎤⎡⎤==⎢⎥⎢⎥⎣⎦⎣⎦∑。
对此次能源进行m元唯一可译编码,其对应的码长为(l1,l2,…,l6)=(1,1,2,3,2,3),求m值的最好下限。
(提示:用kraft不等式)4-3设信源为1234567811111111()248163264128128s s s s s s s sXp X⎡⎤⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦⎢⎥⎣⎦,编成这样的码:(000,001,010,011,100,101,110,111)。
求(1)信源的符号熵;(2)这种码的编码效率;(3)相应的仙农码和费诺码。
4-4求概率分布为11122(,,,,)3551515信源的二元霍夫曼编码。
讨论此码对于概率分布为11111(,,,,)55555的信源也是最佳二元码。
4-5有两个信源X和Y如下:121234567()0.200.190.180.170.150.100.01X s s s s s s s p X ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦123456789()0.490.140.140.070.070.040.020.020.01Y s s s s s s s s s p Y ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦(1)用二元霍夫曼编码、仙农编码以及费诺编码对信源X 和Y 进行编码,并计算其平均码长和编码效率;(2)从X ,Y 两种不同信源来比较三种编码方法的优缺点。
4-6设二元霍夫曼码为(00,01,10,11)和(0,10,110,111),求出可以编得这样 霍夫曼码的信源的所有概率分布。
4-7设信源为12345678()0.40.20.10.10.050.050.050.05X s s s s s s s s p X ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦,求其三元霍夫曼编码。
信息论与编码第4章无失真信源编码

THANKS
感谢观看
编码性能的评价指标
压缩比
压缩比是指编码后数据量与原始数据量之比,是衡量 编码效率的重要指标。
编码复杂度
编码复杂度是指实现编码算法所需的计算量和存储量 ,是衡量编码性能的重要指标。
重建精度
重建精度是指解码后数据的准确度,是衡量编码性能 的重要指标。
编码效率与性能的关系
01
编码效率与压缩比成正比,压缩比越高,编码效率越高。
游程编码
对连续出现的相同符号进 行编码,如哈夫曼编码等 。
算术编码
将输入信号映射到一个实 数轴上的区间,通过该区 间的起始和长度表示码字 ,如格雷码等。
编码的数学模型
信源
产生随机变量的集合 ,表示各种可能的信 息符号。
编码器
将输入信号映射到码 字的转换设备,其输 出为码字序列。
解码器
将接收到的码字还原 成原始信号的设备。
拓展应用领域
无失真信源编码技术的应用领域正在不断拓 展,未来研究将致力于将其应用于更多领域 ,如多媒体处理、物联网、云计算等。
融合其他技术
将无失真信源编码技术与其他相关技术进行 融合,以实现更高效、更实用的信息处理系 统。例如,将无失真信源编码与图像处理、 语音处理等技术相结合,提高信息传输和处
理的效率和质量。
03
行程编码的缺点包 括
压缩比有限、对于离散无记忆信 源效果不佳。
03
CATALOGUE
无失真信源编码的效率与性能
编码效率的定义与计算
定义
编码效率是指编码后信息量与原始信 息量之比,通常用比特率(bit per symbol)或比特率(bit per source symbol)来表示。
计算
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
信息,例如霍夫曼编码。
它相对简单,是 本章的重点。
信息有一定的差别,例如JPEG 、MPEG
■无失真信源编码:解码之后可以得到原始 jlll ■有失真信源编码:解码之后的信息与原始 jlll
■其中X 称为码符号集,X 中的元素“称为码元或者 码符号。
输岀符号叱•称为码字,植字的集合C 称 为代码组或者码。
码字比•的长度厶称为码字长度, 简称码长。
■要实现无失真编码,编码器的映射必须是一一对 应、可逆的。
码的分类
5.1编码器
编码器
C=(W1,W2,…,W 几
■信源编码器表示为: X=(QK2,…对
■例如:
S=(ACD) r A B C D C=(OOJOJl)r
00,01,10,11
r X=(o ,l)
S=(A ,CQ) AB C D C=(0,001,lip
* 0,01,001,111
X=(0J)
■根据码长
□固定长度码(定长码):所有码字的长度相同。
□可变长度码(变长码):码字长短不一。
■码字是否相同
□非奇异码:所有码字都不相同。
□奇异码:存在相同的码字。
5.2分组码
■象稱蛊轟凋11映射
■通常在接收端收到的码字之间并没有明显的间隔, 表现为皿叫…巴的形式,把这种形式称为g阶扩展码。
例如前面的两个例子,ACD编码成另 001011/0001111的形式,均为3阶扩展码。
■码字之间缺少间隔,给译码造成了一定的困难□定长码:不存在困难,001011必定译码成为ACD □变长码:存在困难,0001111可以译码成为ACD(0 001 111),也可以译码成为AABD(0 0 01 lll)o
唯一可译性
■定义524 —个分组码若对于任意有限的整 数N,其N 阶扩展码均为非奇异的,则称之 为唯一可译码。
■含义:无论码由多少个码字组成,总是能 够正确译码,不存在二义性。
10110 010 ^BACB 10110 0 Ol^ABAD
■无需知道下一个码字的码符号,即可译码, 这样的唯一可译码成为即时码。
■命题521 —个唯一可译码成为即时码的充 要条件是其中任何一个码字都不是其他码 字的前缀。
即时码
5.3定长码
■编码速率: ~1T,其中/是码字长度,厂是码符号的个数,N代表N次扩展信源。
■编码效率:rj=H(S)R其中H(S)是扩展之前信源的爛。
■例如:S={ABC},等概率出现,N=2,SN={AA,・・・,CC},对SN进行二元编码,则心2,编码方式如下,则上4。
■那么,S"的编码速率为R=(41og2)/2=2, S"的编码效率为
7=H(S)//?=log3/2=0.7925
5.4变长码
■匹配编码:根据概率进行编码,概率大的所给的代码短,概率小的所给的代码长。
例如哈夫曼编码。
■变换编码:将信号从一个空间变换到另一个空间,在新的空间里对信号进行编码。
例如JPEG
■识别编码:主要用于印刷或奢打字机等有标准形状的符号的编码。
0 2 4 6 8 10 12 14 16 18 20
5.4.2两个不等式
■定理5.4.1即时码爭在的充要条件是茁a
Z = 1
克拉夫特(Kraft)不等式。
■定理5.4.2唯一可译码存在的充要条件是
q
y
麦克米伦(McMillanS不等式。
5.4.3唯一可译码判别准则
■命题541 —种码是唯一可译码的充要条件是S], S”…中没有一个含有So中的码字。
5.4.4码平均长度 /八一…]…么 ....................
0 g 。
对唯一可译桐,则这个码的平 q 厶二£卩(训
i=l
■定义5.4.2对应一给定的信源和一给定的码符号
集,若有一种唯一可译码,其平均长度小于所有 其他
[;]
■定义5.4.1设信源
编码后的码字分别为W]W?…巴,各码字相应的码 长分别为仏••丿 均长度为
的唯一可译码,则称这种码为紧致码,或最佳码。
精品课件
V
1 •
•r
精品课件
V
1 •
•r
5.4.5变长码的编码方法:霍夫曼编码
■ {^5.4.4
$1$3$5
10 11 01 001 000
L = 2 x 0.4 + 2x 0.2 + 2x 0.2 + 3x0.1+3x0.! =
2.2
■定理5.4.6霍夫曼码是紧致码。