基于Fisher的分类器设计
Fisher准则线性分类器设计

F i s h e r准则线性分类器设计内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)一 、基于F i s h e r 准则线性分类器设计1、 实验内容: 已知有两类数据1ω和2ω二者的概率已知1)(ωp =,2)(ωp =。
1ω中数据点的坐标对应一一如下:数据:x =y =z =2ω数据点的对应的三维坐标为x2 =y2 =z2 =数据的样本点分布如下图:1)请把数据作为样本,根据Fisher选择投影方向W的原则,使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,求出评价投影方向W的函数,并在图形表示出来。
取极大值的*w。
用matlab完并在实验报告中表示出来,并求使)J(wF成Fisher线性分类器的设计,程序的语句要求有注释。
2)根据上述的结果并判断(1,,),,,,,,,,,(,,),属于哪个类别,并画出数据分类相应的结果图,要求画出其在W上的投影。
3)回答如下问题,分析一下W的比例因子对于Fisher判别函数没有影响的原因。
2、实验代码x1 =[];x2 =[];x3 =[];%将x1、x2、x3变为行向量x1=x1(:);x2=x2(:);x3=x3(:);%计算第一类的样本均值向量m1m1(1)=mean(x1);m1(2)=mean(x2);m1(3)=mean(x3);%计算第一类样本类内离散度矩阵S1S1=zeros(3,3);for i=1:36S1=S1+[-m1(1)+x1(i) -m1(2)+x2(i) -m1(3)+x3(i)]'*[-m1(1)+x1(i) -m1(2)+x2(i) -m1(3)+x3(i)];end%w2的数据点坐标x4 =[];x5 =[];x6 =[];x4=x4(:);x5=x5(:);x6=x6(:);%计算第二类的样本均值向量m2m2(1)=mean(x4);m2(2)=mean(x5);m2(3)=mean(x6);%计算第二类样本类内离散度矩阵S2S2=zeros(3,3);for i=1:36S2=S2+[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)]'*[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)];end%总类内离散度矩阵SwSw=zeros(3,3);Sw=S1+S2;%样本类间离散度矩阵SbSb=zeros(3,3);Sb=(m1-m2)'*(m1-m2);%最优解WW=Sw^-1*(m1-m2)'%将W变为单位向量以方便计算投影W=W/sqrt(sum(W.^2));%计算一维Y空间中的各类样本均值M1及M2for i=1:36y(i)=W'*[x1(i) x2(i) x3(i)]';endM1=mean(y);for i=1:36y(i)=W'*[x4(i) x5(i) x6(i)]';endM2=mean(y);%利用当P(w1)与P(w2)已知时的公式计算W0p1=;p2=;W0=-(M1+M2)/2+(log(p2/p1))/(36+36-2);%计算将样本投影到最佳方向上以后的新坐标X1=[x1*W(1)+x2*W(2)+x3*W(3)]';X2=[x4*W(1)+x5*W(2)+x6*W(3)]'; %得到投影长度XX1=[W(1)*X1;W(2)*X1;W(3)*X1];XX2=[W(1)*X2;W(2)*X2;W(3)*X2]; %得到新坐标%绘制样本点figure(1);plot3(x1,x2,x3,'r*'); %第一类hold onplot3(x4,x5,x6,'gp') ; %第二类legend('第一类点','第二类点');title('Fisher线性判别曲线');W1=5*W;%画出最佳方向line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','g'); %判别已给点的分类a1=[1,,]';a2=[,,]';a3=[,,]';a4=[,,]';a5=[,,]';A=[a1 a2 a3 a4 a5];n=size(A,2);%下面代码在改变样本时可不修改%绘制待测数据投影到最佳方向上的点for k=1:nA1=A(:,k)'*W;A11=W*A1;%得到待测数据投影y=W'*A(:,k)+W0; %计算后与0相比以判断类别,大于0为第一类,小于0为第二类if y>0plot3(A(1,k),A(2,k),A(3,k),'ro'); %点为"rp"对应第一类plot3(A11(1),A11(2),A11(3),'ro'); %投影为"r+"对应ro类elseplot3(A(1,k),A(2,k),A(3,k),'ch'); %点为"bh"对应ch类plot3(A11(1),A11(2),A11(3),'ch'); %投影为"b*"对应ch类endend%画出最佳方向line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','m');view([,30]);axis([-2,3,-1,3,,]);grid onhold off3、实验结果根据求出最佳投影方向,然后按照此方向,将待测数据进行投影。
基于混淆矩阵和Fisher准则构造层次化分类器(

基于混淆矩阵和Fisher准则构造层次化分类器*张静+, 宋锐, 郁文贤, 夏胜平, 胡卫东(国防科学技术大学ATR重点实验室,湖南长沙410073)Construction of Hierarchical Classifiers Based on the Confusion Matrix and Fisher’s PrincipleZHANG Jing+, SONG Rui, YU Wen-Xian, XIA Sheng-Ping, HU Wei-Dong(State Laboratory of Automatic Target Recognition, National University of Defense Technology, Changsha 410073, China)+ Corresponding author: Phn: +86-10-66356573, Fax: +86-10-64836117, E-mail: ben_bbzj@Received 2004-03-31; Accepted 2004-10-09Zhang J, Song R, Yu WX, Xia SP, Hu WD. Construction of hierarchical classifiers based on the confusion matrix and Fisher’s principle. Journal of Software, 2005,16(9):1560-1567. DOI: 10.1360/jos161560Abstract: Determination of the hierarchical relationship and the objective patterns of sub-classifiers is a primary problem in the construction of a hierarchical classifier. In this paper, a method focusing on the similarities between patterns is proposed to generate a hierarchical structure automatically. Firstly, a similarity measurement utilizing the confusion matrix is advanced to avoid the drawbacks of the traditional measurements, such as high computation costs and invalidity of preliminary conditions. Then abiding by Fisher’s Principle, a Patterns’ Similarity Rel ationship Analyzing Machine (PSRAM), which is integrated with the supervised and unsupervised pattern recombination methods, is designed to adaptively construct the structure of a hierarchical classifier. Various tests are testified that the proposed method is effective and practical, and it can prominently improve the performance and robustness of the hierarchical classifier.Key words: hierarchical classifier; similarity measurement; patterns’ similarity relationship analysis machine; Fisher’s principle;adaptive pattern combination摘要: 构造层次化分类器的首要环节是确定各个子分类器的层属关系及其内部组成.从模式间的相似关系入手,实现了一种自动产生层次化分类器结构的方法.为了描述模式间的相似关系,首先提出利用混淆矩阵度量相似性的思路与方法,避免了现有常用度量方法计算量大、假设条件难以成立的不足.进而遵循Fisher准则,设计并实现了模式相似关系分析机(patterns’ similarity relationship analyzing machine,简称PSRAM),将有师指派和无师自组两种常用的模式重组方法有机结合起来,自适应地产生层次化分类器结构.大量测试证实,该方法有效、实用,可以显著地提高分类器的识别性能和稳健性.关键词: 层次化分类器;相似性度量;模式相似关系分析机;Fisher准则;自适应模式组合中图法分类号: TP18文献标识码: A层次化分类器由一系列子分类器按照一定的组织结构和层属关系共同构成.它将复杂的多模式识别问题分解成多个不同层次上、相对简单的针对较少模式的识别问题,从而达到降低分类难度、分而治之的目的[1-3].设计层次化分类器,首先需要解决多模式的重新组合问题,确定各个子分类器的层属关系及其内部组成[1,2].目前常用的方法可分为两种思路:有师指派,即领域专家根据背景知识确定模式重组方案;无师自组,即通过不同的聚类算法产生模式组合关系.然而,前者常存在结构单调、主观性强等缺陷,而后者则存在不可控因素多、性能不稳定等不足,需要将两种思想有机地结合起来,建立合理的层次化分类器结构[1,2].*作者简介: 张静(1977-),女,河北唐山人,博士,助理研究员,主要研究领域为机器学习,雷达目标识别,建模与仿真,武器装备论证;宋锐(1975-),男,博士,讲师,主要研究领域为雷达目标识别,系统集成;郁文贤(1964-),男,博士,教授,博士生导师,主要研究领域为智能信号处理,目标识别,信息融合;夏胜平(1969-),男,博士,副教授,主要研究领域为雷达目标识别,机器学习,智能信号处理;胡卫东(1967-),男,博士,教授,主要研究领域为信息融合,目标识别,智能信号处理,系统集成.Fisher 准则[4]指出,当模式样本具有最小类内距离和最大类间距离时,将具有最佳的分类效果.着眼于设计合理的层次化分类器结构,提高重聚类后的类内一致性和类间可分性,本文提出并实现了一种基于模式间相似关系(similarity relationship,简称SR)自适应地构造分类器层次结构的方法,以模式在判决域中表现出的相似性为切入点,基于Fisher 准则产生模式组合的依据和准则.该方法有效地综合了有师和无师方法,具有原理简单、可实施性强、稳定性高的优点.本文第1节首先分析了多种常用的模式间相似性度量方法及其不足,然后设计了一种利用混淆矩阵对相似性进行度量的方法.第2节在对有师和无师两类模式重组方法的优缺点进行分析的基础上,基于上述度量,采用模块化思想设计了模式相似关系分析机PSRAM(patterns ’ similarity relationship analyzing machine),自适应建立层次化分类器的组织结构.第3节通过多个雷达目标识别场景中的大量实测数据,对本文提出的方法与常规层次化方法进行了综合测试和比较分析,验证了本文所提出方法的有效性、实用性和稳定性.第4节对本文工作进行了总结说明.1 模式间相似性的度量1.1 常用的模式间相似性度量方法在模式识别中,各个类型之间通常具有不同程度的相似性,这决定了识别问题的难度和判决结果的质量.当相似的模式种类少且相似程度低时,模式之间的可分性较好,有利于识别问题的完成;而当相似的模式种类多且相似程度高时,模式之间的可分性差,进行识别的难度就高.因此,需要建立对模式间相似性进行度量的方法和准则,掌握具体问题背景下各个模式之间的相似程度,从而指导分类器的构造过程.相似性属于抽象概念,难以直接定量求取.现有的方法主要从下面3个角度[1,2,4]对其进行描述:基于特征空间几何距离的方法,如离差矩阵W S ,B S ,T S 及其变换[]B WS S Tr 1-,W B S S 等;基于模式概率分布的方法,如Bhattacharyya 判据B J 、Chernoff判据C J 、散度判据D J 等,以及基于后验概率的方法,如Shannon 熵可分性判据H J 和计算更为简便的广义熵判据等.上述各种判据能够从不同角度描述模式之间的相似性,在理论分析与实际应用中发挥了一定作用.但是在实际应用中,度量模式间相似性的方法应同时达到前提条件的可满足性和计算方法的可实施性这两个要求,而上述方法却不具备这样的性质[5].例如,当样本数量多、特征空间维数高时,基于特征空间距离测度的判据运算代价相当大,且难以完全避免特征相关所造成的影响;基于模式概率分布的判据要求模式概率分布已知,这一前提条件在实际问题中往往难以满足,通常只能建立在假设条件基础上;基于后验概率的判据,遵循熵的基本原则,更适合于刻画整个聚类问题的不确定性,而并非两两模式之间的相似性.针对上述问题,本文利用混淆矩阵,设计了一种简捷、实用的度量模式间相似性的方法. 1.2 基于混淆矩阵度量模式间相似性 1.2.1 混淆矩阵混淆矩阵是模式识别领域中一种常用的表达形式.它描绘样本数据的真实属性与识别结果类型之间的关系,是评价分类器性能的一种常用方法.假设对于N 类模式的分类任务,识别数据集D 包括0T 个样本,每类模式分别含有i T 个数据)...,,1(N i =.采用某种识别算法构造分类器C ,ij cm 表示第i 类模式被分类器C 判断成第j 类模式的数据占第i 类模式样本总数的百分率,则可得到N N ⨯维混淆矩阵),(D C CM :⎪⎪⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛=NN NiN N iN ii i i N iN i cm cm cm cm cm cm cm cm cm cm cm cm cm cm cm cm D C CM ....................................),(2121222221112211(1)混淆矩阵中元素的行下标对应目标的真实属性,列下标对应分类器产生的识别属性.对角线元素表示各模式能够被分类器C 正确识别的百分率,而非对角线元素则表示发生错误判断的百分率.通过混淆矩阵,可以获得分类器的正确识别率和错误识别率: 各模式正确识别率:N i cm R ii i ...,,1,==(2)平均正确识别率:()01T T cm R Ni i ii A ∑=⨯=(3)各模式错误识别率:i ii Nij j ij i R cm cm W -=-==∑≠=11,1 (4)平均错误识别率:()A Ni Nij j i ij A R T T cm W -=⨯=∑∑=≠=101,1(5)1.2.2 基于混淆矩阵的模式间相似性度量利用混淆矩阵,除了可以获得分类器正确/错误识别率等指标以外,还可以发现那些容易发生错误判断的模式类型.然而,由式(2)~式(5)可知,错误识别率均可以通过正确识别率得到.这意味着,人们通常仅利用了混淆矩阵中的N 个对角线元素,却忽视了)1(-N N 个非对角线元素,损失了其中所蕴含的反映模式之间相似性的丰富信息.在模式识别过程中,如果某两种模式之间比较相似,那么它们的样本就容易被判定为对方类型.假设模式i 与模式j 的相似性强,而与模式k 的相似性弱,那么相对于ik c 和ki c 而言,ij c 和ji c 的取值将会较大,而ik c 和ki c 则较小甚至为.0由此,可以推出下面的结论:结论. 混淆矩阵行向量i C (N i ...,,1=)代表了模式i 的对象在进行分类时对各模式的倾向性.进而,分析行向量i C 与j C 之间的关系,能够发现模式i 和模式j 在判决倾向性上所表现出来的一致性及相悖性.这从本质上看,是模式i 和j 之间相似性的表现和延伸.因此,可以从混淆矩阵入手,建立某种度量,描述不同模式间相似性的强弱.i C 和j C 之间的距离测度和矢量夹角,分别表示了它们之间的空间距离和相关性[6],均可被用来度量模式之间的相似性.若二者相距近,则相似性;强若相距远则表明相似性弱.若二者的夹角小,也意味着相似性强;若夹角大则说明相似性弱.本文以2L 范数为例来说明如何基于混淆矩阵进行度量.由2L 测度的定义[6],可以得到混淆矩阵),(D C CM 的2L 测度矩阵2LM .2LM 为N N ⨯方阵,其元素ij lm 与ij cm ,N j i ...,,1,=具有如下关系:⎪⎩⎪⎨⎧≠-=-==∑=j i cm cm C C j i lm Nk jk ik j i ij 122,)()(,(6)可见,2LM 矩阵为一个对角线元素为0的对称矩阵.因此,为了便于计算,只需分析其上三角部分的元素,而将其下三角元素置为0,则得到相似性度量矩阵(similarity measurement matrix,简称SMM),记为2TM .ij lm 取值越小,说明模式i 与模式j 的相似性越强,识别过程中这两类模式之间也就越容易发生错误判断;反之,ij lm 取值越大,模式i 与模式j 的相似性就越弱,也就越不容易产生错误判断.2 模式相似关系分析机PSRAM确定各层子分类器的层属关系及其内部组成,是层次化分类器设计的重点和难点.只有合理的层次化结构,才能提高模式重新聚类后的类内一致性和类间可分性,有效达到分而治之的目的,降低分类器构造和维护中的风险与代价. 2.1 常用层次化结构确定方法的不足确定层次化分类器的组织结构,即对多种模式类型进行重新组合和聚类,既可以按照有师指派方式产生,也可以根据无师自组的方式进行[2].有师指派是指领域专家根据相关背景知识,将多个类型分别组合成不同的群体[3],比如在舰船目标识别中可以根据吨位(大/中/小型)将模式进行重组.无师自组则采用无师聚类的思想设计分类器,由一定量的实验样本数据自动产生组合方案[5].可见,有师指派是一种针对问题应用领域进行分析的方法,而无师自组则主要是一种着眼于模式特征域的手段,在实际中这两种方式都具有广泛的应用.通常,模式识别是基于特征空间进行的[2].如果仅根据其应用领域的情况,主观地指定聚类/组合方案,而不考虑模式的特征分布,往往是不够合理的.有师指派产生层次化分类结构就存在这种主观性强、结构单一的问题.而无师自组的方式,由于其运算处理过程自动完成,存在一定的不可控性和较强的不稳定性.为此,需要将两种方法结合起来,使层次化分类器的结构既包含先验信息的指导,也能反映出不同模式在特征空间中的分布情况.鉴于此,我们设计了一个模式相似关系分析机PSRAM,自适应地确定层次化分类器的结构. 2.2 模式相似关系分析机PSRAM图1为PSRAM 的原理框图.图中实线框表示分析机中各个组成模块,虚线框表示各个处理环节所产生的输出结果.相似程度描述器D 也称为预分类器,它是一个计算快捷、易于实现的单分类器,如基本Bayes 分类器等.预分类器对样本数据进行识别,产生分类的混淆矩阵,从中获取模式相似性指标(如平均正确率A R 、错误率A W 等)以及相似性度量矩阵SMM.预分类器并不需要达到很高的正确识别率.这是因为,一方面,它只需刻画模式间的基本相似性而无须完成最终的识别任务;另一方面,若达到较高的识别性能,通常需要较多数量的样本和较为复杂的算法,这将增加运算的代价.模式相似性指标用于控制是否启动相似性分析器A .若该指标,如A R ,超过一定门限,则表明简单的分类器即可达到较高的正确率,故不必建立层次化的分类结构;如果A R 不足某个标准,则表明当前的预分类器和样本数据可能尚不足以描述模式之间的相似性,需要对预分类器进行调整或者增加样本数量.在这两种情况下,均不应启动分析器A .只有当A R 处于特定范围时,才通过触发开关开启分析器A ,将相似性度量矩阵传递给它.在相似性分析器A 中,可以采用多种方法对SMM 进行处理.由第1.2.2节可知,SMM 中的各个元素将不同模式在判决域中所具有的多维分类倾向性之间的关系映射成一维距离量.因此,许多基本的模式识别方法可以直接用来对这个简单的一维物理量进行分析.例如,基于最近邻的方法[4]根据lm ij 的不同取值采用基本k 均值法即可将距离近的类型组合在一起;基于图论的方法[7]将各个模式类型定义为图中的节点,lm ij 定义为各个节点间的连接长度,从连接图中获得相应的分割;基于规则的方法[8]制定若干准则,判断模式之间是否相似,从而形成组合方案P .本文以基于规则的分析方法为例进行讨论. 2.3 模式组合规则首先,按照式(7)对相似性度量矩阵2TM 进行归一化处理,得到矩阵U TM .,max ,t lm tm ij ij U =其中,)(max ,,max j i j i lm t =(7)然后,设定相似门限α和相异门限β,这通常由实际样本情况和经验共同决定. 进而,按照如下规则对模式进行自适应重组:规则1. 若α≤ij U tm ,,则模式i 与模式j 相似,将二者进行组合,记为可组合模式集},{j i m C C G =. 规则2. 若β≥ij U tm ,,则模式i 与模式j 相异,不易发生混淆,记为不可组合模式集},{j i nC C G ='. 规则3. 对于两个可组合模式集1m G ,2m G ,若∅≠21m m G G ,则将二者合并.规则4. 对于βα<<ij U tm ,的模式i ,j ,由于二者较为相似,需要根据已有可组合模式集G 和不可组合模式集G ',确定它们的“归属”.规则4.1. 若βα<<ij U tm ,,且同时存在一个可组合模式集},{k i C C G =和一个不可组合模式集},{k j C C G =',则模式j 不可添加进可组合模式集G 中.规则4.2. 若βα<<ik U ij U tm tm ,,,,且同时存在可组合模式集},{1k j C C G =,},{2h i C C G =,只有当h j U tm ,, h k U tm ,均小于β时方可进行组合.至此,经过PSRAM 的处理,产生了基于相似性的自适应模式重组聚类方案.根据这种组合关系,可对各个聚类分别设计子分类器,建立起层次化的分类结构.由于子分类器的任务相对简化,计算代价有所降低,故可以采用算法相对复杂但准确性更高的方法,如大规模神经网络[9]、支撑向量机SVM [10]、遗传算法[5]等.3 实验分析3.1 实验数据说明本文采用从某现役对海警戒雷达上实际测量得到的8类舰船目标的视频回波序列作为实验数据.不同类型的舰船目标由于吨位、结构、材质不同,其雷达回波具有一定的规律性[11,12].但由于受到目标位置、姿态、运动状态、气象及海面状况等多种因素的影响,同一类型目标的雷达回波常表现出较大的差异性,而不同类型目标的回波也可能具有很强的相似性[12].对于这种复杂的多类目标雷达回波,采用单一结构的分类器很难达到良好的分类性能和稳健的泛化能力,必须采用层次化识别方法,将复杂问题分解为多个简单子问题[5,11].Fig.1 Block diagram of PSRAM 图1 模式相似关系分析机原理框图通常,这8种目标可以按照其吨位不同,划分成大型、中型、小型3大类,也可以根据其用途划分成军用、民用两大类,如图2所示,其中,基于吨位和用途的组合方案分别用T P 和U P 代表.不同吨位目标的雷达回波强度、稳定性等均有所差别[11];而不同用途的目标通常在船体结构上具有一定的差异,这将导致其回波具有不同的散射特性[12].因此,基于上述两种层次化关系构造的分类器能够在一定程度上满足识别需要[5].然而,在针对雷达回波数据进行目标识别时,基于目标吨位或用途,而不是目标的雷达散射特性来完成层次化聚类,带有较强的主观性和片面性,不够合理.特别是在复杂的实际场景中,模式之间的相似性可能会发生变化,出现新的模式重组合方式,而并非如图2所示的固定结构.表1为实验数据清单,其中每个样本都是由基于雷达目标回波数据所提取的23维特征矢量[5,12]构成的.其中,场景1和场景2为同一部雷达的不同观察区域,训练集/测试集数据分别用于训练/测试分类器,二者互相独立.Table 1 Experimental data list表1 实验数据清单3.2 实验过程及结果分析3.2.1 基于场景1数据进行的实验针对训练集1,首先利用一个双隐层BP 神经网络[13]作为相似性分析机中的预分类器D ,得到混淆矩阵,CM 见表2.采用2L 测度建立相似性度量矩阵,经归一化后得到U TM ,见表3.Table 2 Confusion matrix CM in scenario 1 (⨯10-3) 表2 场景1条件下目标混淆矩阵CM (⨯10-3)Table 3 The SMM TM 2U 表3 相似性度量矩阵TM U在相似性分析器中,采用基于规则的方法,经过一定选择和调整[5],取相似门限,8000.0=α相异门限8300.0=β.将表3中低于α的元素以粗体表示,低于β的元素所带上标表示其升序排序的序号.由规则1,(类型A ,类型C ,0.746),(类型B ,类型D ,0.799)满足相似性的要求,分别记为可组合模式集},{1C A G =和},{2D B G =.由规则2,得到不可组合模式集},{D A ,},{G E 等. 不存在能够根据规则3合并的可组合模式集.由规则4,(类型B ,类型C ,0.806),(类型A ,类型B ,0.811),(类型B ,类型E ,0.816),(类型C ,类型H ,0.827),(类型C ,类型D ,0.829)的相似程度较高,需要进一步确定它们与1G ,2G 的关系.由规则4.1,类型H 不可添加进1G ,类型E 不可添加进2G .由规则4.2,类型B 与A ,C 较为相似,但是由于它与类型D 的相似性最高,而D 与A 的相似程度却不满足要求,不可添加进组合1G ;故1G 与2G 不能进行合并.至此,由PSRAM 得到的模式重组聚类方案为[1G ,2G ,类型E ,F ,G ,H ].由于E ,F ,G ,H 相互之间以及它们与1G ,2G 之Fig.2 Classes combination schemes with a prioriinformation间均存在着较强的差异性,故可将其看作某种模式集组合的不同表现形态,记为3G .进行这样的处理,同时可以达到平衡训练样本数量、提高分类器学习质量的效果.综上所述,在场景1条件下得到的目标自组织聚类方案1P 将8种目标类型归属到3个集合,命名为I 类目标[类型A ,类型C ]、II 类目标[类型B ,类型D ]和III 类目标[类型E ,类型F ,类型G ,类型H ],如图3(a)所示.采用基于吨位、用途和相似关系的聚类方案T P ,U P 和1P ,利用训练集1分别构造3个层次化分类器,并使用测试集1进行测试.为了便于比较,3种层次化分类器中的各个子分类器均采用相同结构的BP 神经网络.为确保实验结果的稳定性和可靠性,我们对在3种不同初始条件下训练得到分类器进行测试.表4列出了测试的平均正确识别率,并将各个类型在3种层次化方案下识别率最高者加粗显示.Table 4 Correct recognition rates by hierarchical classifiers with different schemes in scenario 1表4 场景1下基于不同组织结构的层次化分类结果Class Correct recognition rates (%)Scheme P T (tonnage)Scheme P U (usage)Scheme P 1 (similarity)A 80 82 90B 78 81 89C 82 80 89D 83 78 91E 83 86 97F 98 94 97G 98 93 99 H989097由表4可见,基于1P 结构的层次化分类器,除了对类型F 和H 的最终识别率略低于方案T P 以外,对其余6种类型的正确识别率较之其他两种方案均有较大幅度的提高,有的甚至超过10%,如类型A,B,E 等.同时,与表2中的对角线元素相比可知,基于吨位及用途的层次化分类器与单一型分类器相比,识别性能不仅没有改善,反而表现出一定程度的下降;而基于相似性的自适应层次化分类器则表现出较为稳定和较高幅度的提高.这说明,不合理的层次化分类结构可能会导致识别性能的下降.上述结果不仅说明了合理设计层次化分类器结构的重要性,同时也证实了本文所提出方法的有效性和稳健性. 3.2.2 基于场景2进行的实验针对训练数据集2,首先按照相同的方法获取基于相似性的层次化分类方案2P ,如图3(b)所示;然后分别根据T P ,U P 以及方案2P 训练层次化分类器,每层中的各个子分类器仍然采用具有相同结构的BP 神经网络,在不同初始条件下训练3次,分别对测试数据集2进行测试,平均正确识别率见表5.Table 5 Correct recognition rates by hierarchical classifiers with different schemes in scenario 2表5 场景2下基于不同组织结构的层次化分类结果Class Correct recognition rates (%)Scheme P T (tonnage)Scheme P U (usage)Scheme P 2 (similarity) (%)A 80 81 87B 82 76 80 C818083Fig.3 Adaptive combination schemes for variousscenarios(a) Scheme for scenario 1(a) 场景1自适应聚类方案(b) Scheme for scenario 2 (b) 场景2自适应聚类方案D 80 76 95E 81 82 97F 97 85 98G 96 87 98H 96 87 98由图3和表5可以看到:(1) 场景2中基于目标相似性产生的自组织聚类方案2P有较大差别,可见,P与场景1下的方案1始终使用同一种层次化结构处理多种复杂场景是不够合理的;(2) 基于方案2P得到的层次化分类器,综合识别率仍远高于基于吨位和用途所设计的分类器,表现出稳定的优越性,更进一步地验证了本文的方法的可行性和有效性;(3) 通过本组实验再次说明了层次化分类器的综合性能是由各层子分类器的组织结构及实际效能共同决定的,必须对其进行合理设计.4 结束语通过本文的理论分析和综合测试,可以得到以下结论:1. 层次化分类器的合理设计意义重大,基于模式间相似性自适应地构造分类器组织关系,能够增加模式重新聚类后的类内一致性和类间可分性,从而提高分类器构造效率,降低维护系统的难度.2. 本文的方法以各类目标在特征空间与识别空间中的表现形态为切入点,采用简便、可行的手段获取关于目标相似性与差异性的度量指标,从而实现满足Fisher准则的层次化聚类方案.其识别正确率、可靠性和泛化能力均优于常规的层次化方法.3. 针对实际应用中复杂场景下的目标识别问题,聚合各模式类型时不能在所有场合中都仅采用一种固定形式,应根据具体情况进行相应的调整.最后,指出使用本文的方法时需要注意的问题:1. 在PSRAM中,若模式间相似性不强,即相似程度描述器D得到的模式相似性综合指标在允许范围之内,则无须进行层次化分类,以避免分类器结构复杂化所带来的负面影响.若分析器A提示无法有效地进行自适应聚类重组,则需要根据其他知识确定层次关系的组织结构.2. 为了准确、可靠地获取不同模式之间的相似性,在相似程度描述器D和相似性分析器中,可以采用不同的方法进行多次实验,以确保获取模式间相似性的有效度量,从而建立稳定的层次化组织结构.References:[1] Ruda H, Snorrason M, Shue D. Framework for automatic target recognition optimization. No.R96451, Cambridge: Charles River Analytics, 1997.[2] Jain AK, Duin RPW, Mao JC. Statistical pattern recognition: A review. 1999. /jain99statistical.html[3] Song R, Ji H, Xia SP, Hu WD, Yu WX. Hierarchical modular structure for automatic target recognition systems. In: Shen J, Pankanti S, Wang RS, eds.Proc. of the SPIE, Vol 4554, Object Detection, Classification and Tracking Technologies. Bellingham: SPIE, 2001. 57-61.[4] Sun JX, et al. Modern Pattern Recognition. Changsha: National University of Defense Technology Press, 2002 (in Chinese).[5] Zhang J. Research and implementation of flexible radar target recognition [Ph.D. Thesis]. Changsha: National University of Defense Technology, 2004(in Chinese with English abstract).[6] Logan JD. Applied Mathematics. 2nd ed., Hoboken: Wiley-Interscience, 1996.[7] Rosen KH. Discrete Mathematics and Its Applications. 5th ed., Berkshire: McGraw-Hill Science/Engineering/Math, 2003.[8] Chen WW. Intelligent Decision Making. Beijing: Publishing House of Electronics Industry, 1998 (in Chinese).[9] Ripley BD. Pattern Recognition and Neural Networks. London: Cambridge University Press, 1996.[10] Vapnik VN. The Nature of Statistical Learning Theory. New York: Springer-Verlag, 1995.[11] Yu WX. Intelligent recognition approaches and their applications in the radar ship target recognition system [Ph.D. Thesis]. Changsha: NationalUniversity of Defense Technology, 1992 (in Chinese).[12] Zhang J, Song R, Yu WX, Xia SP, Hu WD. Visual effects based feature extraction for dynamic radar target echo series. In: Yuan BZ, et al., eds. Proc. ofthe 7th Int’l Conf. on Signal Processing (ICSP 2004). Beijing: Publishing House of Electronics Industry, 2004. 2111-2115.[13] Song R, Zhang J, Xia SP, Yu WX. An adaptive classification method of bp-nn group based classification system and its application. ACTA ElectronicaSinica, 2001,29(12A):1950-1953 (in Chinese with English abstract).附中文参考文献:[4] 孙即祥,等.现代模式识别.长沙:国防科技大学出版社,2002.[5] 张静.柔性雷达目标识别技术研究与实现[博士学位论文].长沙:国防科学技术大学,2004.[8] 陈文伟.智能决策技术.北京:电子工业出版社,1998.[11] 郁文贤.智能化识别方法及其在舰船雷达目标识别系统中的应用[博士学位论文].长沙:国防科技大学,1992.[13] 宋锐,张静,夏胜平,郁文贤.一种基于BP神经网络群的自适应分类方法及其应用.电子学报,2001,29(12A):1950-1953.。
使用Fisher线性判别方法的提取分类器

文, 用 , … 分别表示 个个体分类器 , , … } 。
1 问题 形 式化 描述 及个 体分 类器 训练
对分 类问题而 言 , 问题 域为 类 对象 , 类别标 签分别为
,
, , 。每—个样本可以表示成一个 d 的权重特征向 J …, , 维
个体 分类器 训练指从 数据集 中训练 获得这 个分 类器 的过
p tr En iern n pia o s 2 1 4 ( 4 :3 - 3 . ue g e ig a d Ap l t n . 0 0。6 I ) 1 2 1 4 n ci
Ab t a t I r e o ei n t e aii ewe n n e ld ca s ir n mp o e f c n tb l y o o i e , n a p o c sr c : n od r t l mi ae rl t t b t e e s mb e ls i e a d i r v e e t a d sa i t f c mbn r a p r a h vy f s f i
e ta t ca sfes xr ci ng l si r ba e o Fih r i e r ic i n n a lss s o o e I c n e uc ca sfe s c wih ih i e in, i sd n s e ln a ds rmi a t nay i i pr p s d.t a r d e l s i r pa e i t hg dm nso
Fisher分类器(算法及程序)
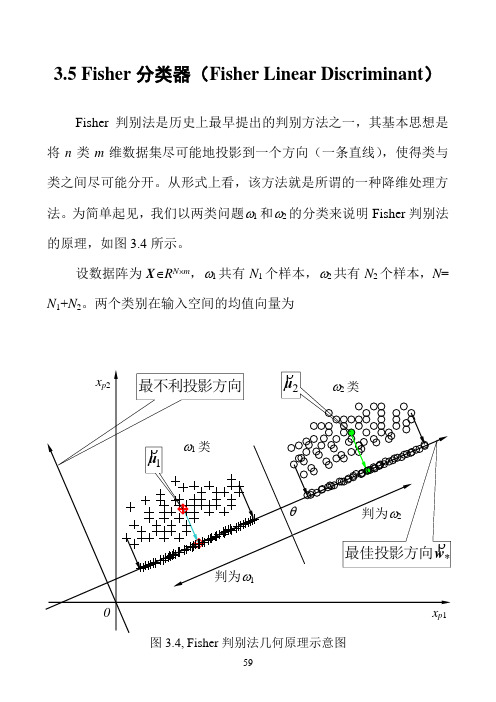
3.5 Fisher分类器(Fisher Linear Discriminant)Fisher判别法是历史上最早提出的判别方法之一,其基本思想是将n类m维数据集尽可能地投影到一个方向(一条直线),使得类与类之间尽可能分开。
从形式上看,该方法就是所谓的一种降维处理方法。
为简单起见,我们以两类问题ω1和ω2的分类来说明Fisher判别法的原理,如图3.4所示。
设数据阵为X∈R N⨯m,ω1共有N1个样本,ω2共有N2个样本,N= N1+N2。
两个类别在输入空间的均值向量为图3.4, Fisher判别法几何原理示意图)37.3(11212211⎪⎪⎩⎪⎪⎨⎧∈=∈=∑∑∈∈m pmp R N R N p pϖϖx x x μx μρρρρρρ设有一个投影方向()mT m R w w w ∈=,,,21Λρw ,这两个均值向量在该方向的投影为)38.3(1~1~1222111121⎪⎪⎩⎪⎪⎨⎧∈==∈==∑∑∈∈R N R N p p pT T p T T ϖϖx x x w μw μx w μw μρρρρρρρρρρρρ在w ρ方向,两均值之差为())39.3(~~2121μμw μμρρρρρ-=-=∇T类似地,样本总均值向量在该方向的投影为)40.3(1~11R NNp pT T ∈==∑=x w μw μρρρρρ定义类间散度(Between-class scatter)平方和SS B 为()()()()()()()()()[])41.3(~~~~~~222111222211221222211w S w w μμμμμμμμw μw μw μw μw μμμμμμρρρρρρρρρρρρρρρρρρρρρρρρρρB T T T T T T T T j j j B N N N N N N N SS =--+--=-+-=-=-+-=∑=其中()()()()()())42.3(21222111∑=--=--+--=j Tj j j TT B N N N μμμμμμμμμμμμS ρρρρρρρρρρρρ定义类ωj 的类内散度(Within-class scatter)平方和为()())43.3(~22∑∑∈∈-=-=jjNp jT p T N p jp T Wj x x SS μw w μw ρρρρρρρ两个类的总的类内散度误差平方和为()()())44.3(2121221wS w w μμw μw w ρρρρρρρρρρρρW T j Np T jp j p T j N p jT p T j wj W j jx x x SS SS =⎥⎥⎦⎤⎢⎢⎣⎡--=-==∑∑∑∑∑=∈=∈=其中,()())45.3(21∑∑=∈--=j N p Tjp j p W jx x μμS ρρρρ我们的目的是使类间散度平方和SS B 与类内散度平方和SS w 的比值为最大,即())46.3(max wS w w S w w ρρρρρW T B T WBSS SS J ==图3.5a, Fisher判别法—类间散度平方和(分子)的几何意义图3.5b, Fisher判别法—类内散度平方和(分母)的几何意义图3.5给出了类间散度平方和S B 与类内散度平方和S E 的几何意义。
Fisher分类器(算法及程序)
3.5 Fisher分类器(Fisher Linear Discriminant)Fisher判别法是历史上最早提出的判别方法之一,其基本思想是将n类m维数据集尽可能地投影到一个方向(一条直线),使得类与类之间尽可能分开。
从形式上看,该方法就是所谓的一种降维处理方法。
为简单起见,我们以两类问题ω1和ω2的分类来说明Fisher判别法的原理,如图3.4所示。
设数据阵为X∈R N⨯m,ω1共有N1个样本,ω2共有N2个样本,N= N1+N2。
两个类别在输入空间的均值向量为图3.4, Fisher判别法几何原理示意图)37.3(11212211⎪⎪⎩⎪⎪⎨⎧∈=∈=∑∑∈∈m pmp R N R N p pϖϖx x x μx μρρρρρρ设有一个投影方向()mT m R w w w ∈=,,,21Λρw ,这两个均值向量在该方向的投影为)38.3(1~1~1222111121⎪⎪⎩⎪⎪⎨⎧∈==∈==∑∑∈∈R N R N p p pT T p T T ϖϖx x x w μw μx w μw μρρρρρρρρρρρρ在w ρ方向,两均值之差为())39.3(~~2121μμw μμρρρρρ-=-=∇T类似地,样本总均值向量在该方向的投影为)40.3(1~11R NNp pT T ∈==∑=x w μw μρρρρρ定义类间散度(Between-class scatter)平方和SS B 为()()()()()()()()()[])41.3(~~~~~~222111222211221222211w S w w μμμμμμμμw μw μw μw μw μμμμμμρρρρρρρρρρρρρρρρρρρρρρρρρρB T T T T T T T T j j j B N N N N N N N SS =--+--=-+-=-=-+-=∑=其中()()()()()())42.3(21222111∑=--=--+--=j Tj j j TT B N N N μμμμμμμμμμμμS ρρρρρρρρρρρρ定义类ωj 的类内散度(Within-class scatter)平方和为()())43.3(~22∑∑∈∈-=-=jjNp jT p T N p jp T Wj x x SS μw w μw ρρρρρρρ两个类的总的类内散度误差平方和为()()())44.3(2121221wS w w μμw μw w ρρρρρρρρρρρρW T j Np T jp j p T j N p jT p T j wj W j jx x x SS SS =⎥⎥⎦⎤⎢⎢⎣⎡--=-==∑∑∑∑∑=∈=∈=其中,()())45.3(21∑∑=∈--=j N p Tjp j p W jx x μμS ρρρρ我们的目的是使类间散度平方和SS B 与类内散度平方和SS w 的比值为最大,即())46.3(max wS w w S w w ρρρρρW T B T WBSS SS J ==图3.5a, Fisher判别法—类间散度平方和(分子)的几何意义图3.5b, Fisher判别法—类内散度平方和(分母)的几何意义图3.5给出了类间散度平方和S B 与类内散度平方和S E 的几何意义。
Fisher分类器设计
Fisher分类器设计班级:自092 姓名:刘昌元学号:099064370 一、实验目的:1:根据fisher准则设计线性分类器2:由fisher分类器训练样本数据3:由fisher分类器测试样本观察出错率并与贝叶斯分类器的出错率比较判断两种分类器的性能优劣4:将测试数据和决策面画在一张图上直观显示是三、实验所用函数:类均值向量:∑=∈ixj j i x N M χ1类内离散度矩阵:Ti j i ixj j iM x M x S ))((--∑∈=χ总类内离散度矩阵:21S S S w +=类间离散度矩阵:T b M M M M S ))((2121--= 最有投影方向:)(211*M M S W w -=-决策函数:0)(w x w x G T +=阈值:)(21210M w M w w T T+-= 四、实验结果:1:得到参数:最有投影向量和阈值2:利用分类器输入身高和体重数据得到性别分类(实验结果如下)w=[ 0.0012; 0.0003] threshold =0.2318classify(165,56) 结果为“女” classify(178,70) 结果为“男”3:fisher准则分类器的出错率统计:测试test1:实际个数分类个数出错率男生84.0000 31.0000 0.6310女生40.0000 93.0000 1.3250测试test2:4:bayes分类器测试出错统计:测试test1:测试test2:结论:很显然bayes分类器比fisher分类器准确率高的多。
4:分类面决策图:五、程序:程序1:求最有投影方向和阈值%程序功能:应用fisher分类方法,使用训练数据获得阈值和最佳变换向量(投影方向)% function fisher(boys,girls) %调用男生和女生的训练样本数据%A=boys.';B=girls.';[k1,l1]=size(A);[k2,l2]=size(B);M1=sum(boys);M1=M1.';M1=M1/l1; %求男生身高与体重的均值%M2=sum(girls);M2=M2.';M2=M2/l2; %求女生身高与体重的均值%S1=zeros(k1,k1);S2=zeros(k2,k2);for i=1:l1S1=S1+(A(:,i)-M1)*((A(:,i)-M1).'); %求类内离散度矩阵S1%endfor i=1:l2S2=S2+(B(:,i)-M2)*((B(:,i)-M2).'); %求类内离散度矩阵S2%endfor i=1:2for j=1:2Sw(i,j)=S1(i,j)+S2(i,j); %求总类内离散度矩阵Sw%endendw=inv(Sw)*(M1-M2) %求最有投影方向%wT=w.';for i=1:l1Y1(i)=wT(1,1)*A(1,i)+wT(1,2)*A(2,i); %由分类函数g(x)=wT*x求男生身高和体重的阈值%endfor i=1:l2Y2(i)=wT(1,1)*B(1,i)+wT(1,2)*B(2,i); %由分类函数g(x)=wT*x求女生身高和体重的阈值%endm1=sum(Y1)/l1; %阈值平均%m2=sum(Y2)/l2; %阈值平均%threshold=(l1*m1+l2*m2)/(l1+l2) %求fisher决策面的阈值%程序2:构成fisher判别器%函数功能:应用Fisher准则构成的分类器判断一个身高体重二维数据的性别%函数使用方法:输入classify(hight,weight)其中hight和weight分别是身高和体重的数据function value=classify(hight,weight)w=[0.0012;0.0003];threshold=0.2318;tem=[hight;weight]; %将输入的身高和体重数据构成列向量%result=(w.')*tem; %根据fisher判别式求判别值%if result>threshold %判别值和决策面阈值比较%value=1;elsevalue=0;end程序3:%功能:调用Fisher分类器统计出错率%开发者:安徽工业大学自动化092班刘昌元function result=Error(file)[m,n]=size(file);Boy=0;Girl=0;boy=0;girl=0;for i=1:mif(file(i,3)==0)Girl=Girl+1;elseBoy=Boy+1;endA(i,1)=file(i,1);A(i,2)=file(i,2);endw=[0.0012;0.0003];threshold =0.2318;for i=1:mclassify(A(i,1),A(i,2));if(ans==0)girl=girl+1;elseboy=boy+1;endendtem1=abs(Boy-boy)/Boy;tem2=abs(Girl-girl)/Girl;result(1,1)=Boy;result(1,2)=boy;result(1,3)=tem1;result(2,1)=Girl;result(2,2)=girl;result(2,3)=tem2;程序4:%程序:画图%功能:将训练样本boy.txt和girl.txt中的数据和线性决策面以及贝叶斯决策面画到一幅图上function graphics(boys,girls)w=[0.0012;0.0003];threshold =0.2318;A=boys.';B=girls.';[m1,n1]=size(A);[m2,n2]=size(B);for i=1:n1x=A(1,i);y=A(2,i);plot(x,y,'R.');hold onendfor i=1:n2x=B(1,i);y=B(2,i);plot(x,y,'G.');hold onenda1=min(A(1,:));a2=max(A(1,:));b1=min(B(1,:));b2=max(B(1,:));a3=min(A(2,:));a4=max(A(2,:));b3=min(B(2,:));b4=max(B(2,:));if a1<b1a=a1;elsea=b1;endif a2>b2b=a2;elseb=b2;endif a3<b3c=a3;elsec=b3;endif a4>b4。
基于边际Fisher准则和迁移学习的小样本集分类器设计算法

第42卷第9期自动化学报Vol.42,No.9 2016年9月ACTA AUTOMATICA SINICA September,2016基于边际Fisher准则和迁移学习的小样本集分类器设计算法舒醒1于慧敏1,2郑伟伟1谢奕1胡浩基1唐慧明1摘要如何利用大量已有的同构标记数据(源域)设计小样本训练数据(目标域)的分类器是一个具有很强应用意义的研究问题.由于不同域的数据特征分布有差异,直接使用源域数据对目标域样本进行分类的效果并不理想.针对上述问题,本文提出了一种基于迁移学习的分类器设计算法.首先,本文利用内积度量的边际Fisher准则对源域进行特征映射,提高源域中类内紧凑性和类间区分性.其次,为了筛选合理的训练样本对,本文提出一种去除边界奇异点的算法来选择源域密集区域样本点,与目标域中的标记样本点组成训练样本对.在核化空间上,本文学习了目标域特征到源域特征的非线性转换,将目标域映射到源域.最后,利用邻近算法(k-nearest neighbor,kNN)分类器对映射后的目标域样本进行分类.本文不仅改进了边际Fisher准则方法,并且将基于自适应样本对筛选的迁移学习应用到小样本数据的分类器设计中,提高域间适应性.在通用数据集上的实验结果表明,本文提出的方法能够有效提高小样本训练域的分类器性能.关键词小样本集分类器,迁移学习,边际Fisher准则,kNN分类器,域间转换引用格式舒醒,于慧敏,郑伟伟,谢奕,胡浩基,唐慧明.基于边际Fisher准则和迁移学习的小样本集分类器设计算法.自动化学报,2016,42(9):1313−1321DOI10.16383/j.aas.2016.c150560Classifier-designing Algorithm on a Small Dataset Based onMargin Fisher Criterion and Transfer LearningSHU Xing1YU Hui-Min1,2ZHENG Wei-Wei1XIE Yi1HU Hao-Ji1TANG Hui-Ming1Abstract It has great practical significance to design a classifier on a small dataset(target domain)with the help of a large dataset(source domain).Since feature distribution varies on different datasets,the classifiers trained on the source domain cannot perform well on a target domain.To solve the problem,we propose a novel classifier-designing algorithm based on transfer learning theory.Firstly,to improve the compass of the same category and separateness of different categories in the source domain,this paper utilizes the extended margin Fisher criterion where the distance is measured by the inner product between data.Secondly,to select good sample pairs for transfer learning,this paper presents an algorithm to get rid of marginal singular points by selecting high-density samples in the source domain.The non-linear feature transformation mapping the target domain to the source domain is learned in the kernel space.Finally,k-nearest neighbor(kNN)classifiers are trained for classifipared with the existing works,this paper not only extends the margin Fisher criterion,but also applies the transfer learning theory based on the algorithm of selecting training sample pairs to design classifiers of a small dataset.We experimentally demonstrate the superiority of our method to effectively improve the performance of classifiers on the general datasets.Key words Classifiers on a small dataset,transfer learning,margin Fisher criterion,k-nearest neighbor(kNN)classifiers, domain transformationCitation Shu Xing,Yu Hui-Min,Zheng Wei-Wei,Xie Yi,Hu Hao-Ji,Tang Hui-Ming.Classifier-designing algorithm on a small dataset based on margin Fisher criterion and transfer learning.Acta Automatica Sinica,2016,42(9):1313−1321收稿日期2015-09-09录用日期2015-12-11Manuscript received September9,2015;accepted December11, 2015国家自然科学基金(61471321),教育部–中国移动科研基金(MCM20150503),国家自然科学基金(61202400),浙江省自然科学基金(LQ12F02014)资助Supported by National Natural Science Foundation of China (61471321),Ministry of Education–China Mobile Research Fund(MCM20150503),National Natural Science Foundation of China(61202400),and Natural Science Foundation of Zhejiang Province(LQ12F02014)本文责任编委胡清华Recommended by Associate Editor HU Qing-Hua1.浙江大学信息与电子工程学院杭州3100272.浙江大学CAD&CG国家重点实验室杭州3100271.College of Information Science and Electronic Engineering,在模式识别和计算机视觉领域中,物体分类识别方法已经得到广泛的研究,现存的算法也比较成熟.但是在一个标记样本很少的数据库上,这些传统的方法并不能得到较高的识别准确度,这是因为几乎所有的监督学习算法[1−2]都需要大量的标记样本作为训练数据.近年来,基于一个大量标记的同构数据集上的物体识别模型,设计一种基于迁移学习的分类器算法来提高新的只有少量标记样本的数据集上的识别准确度是一个越来越受关注的研究方向,其中大样Zhejiang University,Hangzhou310027 2.The State Key Lab-oratory of CAD&CG,Zhejiang University,Hangzhou3100271314自动化学报42卷本和小样本数据集分别被称作源域和目标域[3],其主要原因是获取大量标记样本是一个昂贵、极其耗费人力和时间的过程,同时不可避免人为标记错误的情况[4].借助于源域来优化目标域的分类模型能很好地解决上述问题.但是源域训练得到的分类器直接应用在目标域中并不能得到理想的效果,这是因为不同域的特征分布有差异.导致域间差异的因素有很多,比如相机参数、光线、视角、分辨率、背景和姿态等[3,5−6],如图1所示.因此,我们可以将源域作为目标域的先验知识,利用域间的相关性,通过迁移学习的方法来提高目标域的分类准确率[6−8].图1源域(上)与目标域(下)是存在差异的(与源域相比,目标域中的背景更复杂,分辨率更低,视角更多样)Fig.1There exist differences between source domain(top)and target domain (bottom)(Compared with the source domain,the target domain contains more complex backgrounds,the lower solution,and more camera angles.)利用大样本数据学习小样本数据分类器问题的算法从采用的参数模型的角度主要可以分为三类:基于支持向量机(Support vector machine,SVM)的算法、基于深度学习的算法和基于域间特征转换的算法.基于SVM 的算法,比如文献[9−13],通过改变在源域上训练得到的支持向量机中的参数或者目标函数来适应目标域.基于SVM 的算法最大的缺点是不能够将算法扩展到目标域中标记样本未出现过的新类别的情况.基于深度学习的算法是将在大量已知标记样本集上训练得到的神经网络应用到一个相对少量标记的数据域上.文献[14]是基于ILSVRC2012数据库上训练好的CNNs (Cellular neural netwarks),利用目标域上的标记样本重新训练了全连接层.文献[15]是基于在ILSVRC13数据库上训练得到的OverFeat 网络模型,利用目标域中的少量标记样本以及OverFeat 学习出来的特征,训练出适应目标域的分类器.基于深度学习的算法的局限性是需要海量训练数据来保证分类准确度.基于域间特征转换的算法也有很多,比如文献[3,16−19]等.文献[18]提出了一种将源域和目标域中的高维特征映射到低维特征空间中,实现域间迁移的学习算法.基于域间特征转换的算法刚好可以克服掉基于SVM 的算法的最大缺点,例如文献[16]提出的ARC-t 算法.但是ARC-t (Asymmet-ric regularized cross-domain transformation)算法对源域中类别的可分离性以及学习特征空间转换中训练点的选择缺乏充分的考虑.综上,为了充分利用源域的标记同构数据和保证目标域中不同类映射到源域后尽可能相互不重叠,本文提出了一种新的基于域间特征转换的迁移学习方法.首先,针对源域的样本,本文基于边际Fisher 准则,提出了特征向量点积作为距离度量标准,尽可能最大化类间分离性和最小化类内紧凑性,这个过程将直接影响后面的转换学习的效果.其次,本文设计了一种去除边缘奇异点的算法,基于K-medoids 思想从源域中选取合理的样本点,学习与目标域标记样本间的特征转换,实现目标域到源域的映射.本文采用该去除奇异点算法的原因有两个:1)由于源域中每个类别中样本点的分散性,必然在边界附近存在部分奇异点,所以采用K-medoids 思想能够避免将目标域相应类别映射到源域的边界附近;2)k-means 算法同样可以达到以上效果,但是该算法计算类的中心点时会受到奇异点的影响,并不能将目标域映射到源域中样本密集分布区域.由于线性的特征转换有时在特征空间上不能令不同类别可区分,所以为实现特征的非线性转换,本文利用了核化特征,最后训练邻近算法(k-nearest neighbor,kNN)分类器并在通用数据库上计算物体分类识别准确度.本文的结构如下:第1节介绍本文所提算法涉及的相关工作;第2节详细阐述本文提出的基于边际Fisher 准则和迁移学习的分类器设计算法;第3节是实验,给出了本文算法的具体实现过程,并把本文算法与近年来一些具有代表性的基于迁移学习的小样本分类器设计算法进行了性能对比;第4节是论文总结及后续研究方向.1相关工作在近年来,利用大样本数据集来提高小样本集分类器性能的问题吸引了越来越多的关注.国内外很多学者针对该问题做了许多研究工作,也提出了很多思路[6].目前提出的方法从目标域是否进行特征映射的角度主要分为以下两类:一类是在保持源域和目标域在特征分布空间不变的前提下,在目标域上通过调节分类器的适应性参数来达到提高小样本数据分类准确率的目的;另一类是在保持目标域中的特征分布不变的前提下,将目标域上的点在特征空间中映射到源域中,直接利用在源域中训练好的分类器.在第一类方法中,文献[9]提出一种自适应SVM 算法,通过增加扰动函数和目标域中的标记样本来更新源域中训练好的分类器f A (x ),即9期舒醒等:基于边际Fisher 准则和迁移学习的小样本集分类器设计算法1315目标域上的分类器为f T (x )=f A (x )+δf (x ),其中δf (x )是扰动函数.文献[11]中将转换SVMs 应用到了适应性学习中.同时,很多工作是基于第二类的思想进行研究的.文献[20]提出的算法是基于测地流核的特征迁移学习算法实现的.在文献[21]中,Long 等学习了一种能够直接使源域和目标域间的特征分布相匹配的域间不变核,从而达到域间迁移学习的目的.文献[22]通过一种自动域间适应的特征学习算法来适应不同图片数据域的特征差异性.在文献[3]中,Saenko 等提出了一种基于信息论矩阵学习[23]的特征转换算法(Symm 算法),在特征空间上将目标域映射到源域,通过源域上的分类器对目标域进行分类.在文献[16]中,Kulis 等提出了一种叫做ARC-t 的算法,该算法的核心是一种基于域间特征核化非线性转换的模型并训练出kNN 分类器.与本文相关的工作还有文献[24−25],它们提出了边际Fisher 分析算法(Marginal Fisher analysis,MFA),该算法是使用欧氏距离作为度量标准并基于边际Fisher 准则来设计特征映射,不仅对数据分布没有严格的要求,而且能更好地表达出类内紧凑性和类外分离性,有助于将不同类别更好地区分开.为了提高域间适应性,虽然基于信息论矩阵学习的算法和ARC-t 算法能够将目标域在特征空间中映射到源域中,但是存在两个明显的问题:1)源域内不同类如果在特征空间中相互交错,不具有很好的类别差异性,那么目标域中的类别映射到源域也不能保证相互之间是可区分的.2)在特征转换训练过程中,源域中的训练样本是随机选取并与目标域中的标记样本组成训练对,如果该过程选取的点是在源域对应类别的边界上,那么目标域样本也会被映射到源域的边界区域,这样势必会影响类别间的分类.综上考虑,首先我们需要将源域中的样本点降维到类间可分离的特征空间中,使得在该空间中,源域的不同类别相互可区分.另外,为了保证目标域的映射结果具有较高的分类准确度以及训练样本对的选择要避免边缘区域的样本点,本文算法的设计正是基于上述考虑.2基于边际Fisher 准则和迁移学习的小样本集分类器设计算法为了利用大量已有的同构标记数据提高小样本集的分类器性能,本文提出了基于边际Fisher 准则和迁移学习的小样本数据的分类器设计算法.该算法的思路是首先为了提高源域的类内紧凑性和类间区分性,本文根据内积度量的边际Fisher 准则优化源域特征分布,其次利用筛选算法得到的训练样本对学习目标域到源域的非线性特征转换的迁移学习算法,将目标域映射到源域,提高域间适应性,最后利用在源域上训练得到的kNN 分类器对目标域的样本进行分类.本文的分类器设计算法流程图见图2.图2基于边际Fisher 准则和迁移学习的小样本数据分类器设计算法流程图Fig.2The flow diagram of classifier-designing algorithm on a small dataset based on margin Fisher criterion andtransfer learning1316自动化学报42卷首先,我们考虑到了源域内特征分布,利用内积度量的边际Fisher 准则对源域进行特征映射,提高源域中类内紧凑性和类间区分性.其次,在目标域到源域的特征转换的学习过程中,为了筛选合理的训练样本对,本文提出一种去除边界奇异点的算法来选择源域密集区域样本点,与目标域中的标记样本点组成训练样本对.并在核化空间上,本文学习了目标域特征到源域特征的非线性转换,将目标域映射到源域.最后,利用kNN 分类器对映射后的目标域样本进行分类.与其他小样本集分类器的算法相比,本文算法考虑了域间转换的学习过程的细节.以下是本文提出算法的具体描述.2.1内积度量的边际Fisher 准则为了提高类内紧凑性和类间可分性,本文首先利用根据边际Fisher 准则将源域的特征映射到新的特征空间中.本文对原始MFA [26]方法进行了改进.改进后的边际Fisher 准则与原始MFA 方法的区别在于:本文方法的距离度量方式是内积,而不是欧几里得距离.这是为了优化算法的求解过程,同时与后面的迁移学习算法中的距离度量方式保持一致,以保证算法求解的一致性.边际Fisher 准则是基于图嵌入的框架,设计出描述类内紧凑性的本征图和类间区分性的惩罚图,如图3所示.图3边际Fisher 准则的图结构:本征图和惩罚图Fig.3The graph structure of margin Fisher criterion:intinsic graph and penalty graph在本征图G c 中,同类点间的邻近关系是由每一个样本与k 1个与其同类并近邻的样本点的距离之和描述.在惩罚图G p 中,类间边界点邻近关系是由边界奇异点与k 2个与其异类并近邻的边界点的距离之和描述.因此本征图G c 中类内紧凑性S c 可以表示为S c = ii ∈N k 1(j )or j ∈N k 1(i )(M T x i )T M T x j =ii ∈N k 1(j )or j ∈N k 1(i )x T i MM Tx j =tr MT ii ∈N k 1(j )or j ∈N k 1(i )x T i x jM(1)其中,M 代表特征变换矩阵,N k 1(i )表示k 1个与样本x i 同类并与x i 近邻的样本点的索引集.惩罚图G p 中的类间分离性S p 可以表示为S p = i(i,j )∈P k 2(c i )or (i,j )∈N k 2(c j )(M T x i )T M T x j =i(i,j )∈P k 2(c i )or (i,j )∈N k 2(c j )x T i MM Tx j =trMT i(i,j )∈P k 2(c i )or (i,j )∈N k 2(c j )x T i x j M(2)其中,P k 2(c i )表示(i,j ),i ∈πc i ,j /∈πc i 中k 2个最邻近的边界样本对集.根据边界Fisher 准则,最小化类内紧凑性和最大化类间分离性,则特征变换矩阵M 可以利用图嵌入结构得到:M =arg minMS c S p(3)本文算法创新点之一就是本文通过改进传统的边界Fisher 准则并将其与域间迁移学习相结合,这样更加充分地利用了源域的标记样本信息.本文的实验分别对集成了原始MFA 的算法(实验部分的mmf-Euclid 算法)和集成了改进后的边际Fisher 准则算法(实验部分的mmf 算法)进行了实验.我们通过对比实验结果可以验证,集成了改进后的边际Fisher 准则的算法比集成了原始MFA 的算法更有效地提高分类器的准确率.2.2自适应训练样本筛选和域间迁移学习针对域间特征分布的差异性以及相关性,本文通过信息矩阵学习的方式,学习出目标域到源域的映射矩阵.源域A 和目标源B 的类别数均为c ,其中A 有n A 个样本点,设为X =[x 1,x 2,···,x n A ],B 中有n B 个样本点,设为Y =[y 1,y 2,···,y n B ]2.2.1训练样本对自适应筛选训练样本对的选择会直接影响到训练结果的好坏.在文献[16]提出的ARC-t 算法,对于样本对的选择是随机选取的.但是事实上,如果样本对恰好选择到源域中的奇异点,那么目标域就会被映射到对应类别的边界区域,类间差异性就会变得不明显,如图4所示.为了避免源域中奇异点对于学习特征转换的影响,特征映射学习的训练样本对(x i ,y j )不能随机选9期舒醒等:基于边际Fisher 准则和迁移学习的小样本集分类器设计算法1317取.本文其中一个主要的创新点是考虑到域间特征转换学习的效果与训练样本对的质量是紧密相关的,我们提出了一种通过去除边缘奇异点筛选出训练样本对的算法,算法详细过程如下:图4圆形虚线内是源域的同类样本的密集区,源域的其他样本点被称为奇异点Fig.4The concentrated region of samples belonging tothe same category in the source domain is surrounded by the round dashed line,while the other samples in thesource domain are called singular points1)计算每一个样本点x i 与同类其余样本点间的距离,记为S ij ,在本文中,距离统一都用点积作为度量标准,即S ij =x T i y j ,i =j ;2)计算S i = ne j =1S ij ,其中n e 是类别e 中样本数,S i 表示样本点x i 与同类其余样本点间的距离之和;3)针对每个i (1≤i ≤n e )对S i 按降序进行排序,倒数k 3个样本点会被认为是奇异点,其余样本点组成样本候选集;4)从上述候选集中随机均匀选出k A 个样本点,该集合记为T (A ),这些点将与B 域中的k B 个标记样本点(记为T (B ))组成样本对.随机选取是为了避免将B 域中的样本过分地映射到A 域的中心位置,而是均匀地映射到A 域的较密集区域.至此,域转换学习中所用到的训练样本对的选择结束.算法最后得到的样本对将作为域间特征转换的训练样本对.图5域间特征转换示意图(灰色表示源域,黑色表示目标域)Fig.5The diagrammatic sketch of featurestransformation between the target domain and source domain (The gray points represent the target domain,while the balck ones represent the source domain.)2.2.2域间迁移学习样本间相似性函数可表示为sim W (x ,y )=x T Wyy (4)其中,x ∈A ,y ∈B ,维数分别为d A 和d B ,本文讨论的是维数相同的情况.根据样本间的约束关系,可计算出B 到A 的线性转换W .为避免过拟合,将W 正则化,记为γ(W ),该优化问题可以表示为min Wγ(W )s .t .f i (X TW Y )≥0,1≤i ≤c(5)其中,f i (X T W Y )是域间的约束条件.为了简化算法,可以选择对W 使用LogDet 正则化.正则化函数γ(W )可以写成W 的奇异值之和的形式,即如果σ1,σ2,···,σp 是W 的奇异值,那么γ(W )可以写成γ(W )= pj =1γj (σj )的形式,γj 是一个标量函数.但是这个方法有一个很大的局限性就是使用LogDet 正则化需要W 是正定矩阵,为避免这个限制条件,本文提出用样本之间特征向量的点乘来表示样本间的相似性函数[16],该问题的目标函数可以用内积的形式表示.设内积K A =X T X ,K B =Y T Y ,该问题的最优解W =XK −1/2A LK −1/2B Y T ,其中L 是一个n A ×n B 的矩阵[12].那么,该问题的约束函数可以表示为f i (X T W Y )=f i (X T XK −12A LK −12B Y T Y )=f i (K 12A LK 12B )(6)因此算法的计算过程中只涉及特征向量内积的计算问题.考虑到类内相似性和类间差异性,建立对应的约束条件.假设(x i ,l Ai )是源域A 中的标记样本,其中l Ai 是x i 的标签;(y j ,l B j)是目标域B 中的标记样本,其中l Bj 是y j 的标签.从A 和B 中分别选出相应的样本对,则将约束条件变成:f ij (x i Wy y j )=x T i Wyy j −l,l A i =l Bj f ij (x i Wy y j )=u −x T i Wyy j ,l A i =l Bj (7)其中,l 和u 分别是两个样本点相似性的上限和下限参数.对于同一类别的样本对来说,相似性应该更大;对于不同类别的样本对来说,相似性应该更小.综上,域间迁移学习的过程可以表述如下.设σ1,σ2,···,σp 是W 的奇异值,γj 是一个标量函数,本文采用γj (σj )=σ2j /2的标量函数,那么γ(W )=12W 2F 就是一个弗罗贝尼乌斯范数形1318自动化学报42卷式.则该迁移学习问题的求解可以用以下形式描述:min Wpj=1γj(σj)s.t.xi∈T(A)x T i Wy yj−l≥0,l Ai=l Bju−x Ti Wy yj≥0,l Ai=l Bj(8)其中,x i=Mx x i,y j=My y j.由于该问题是一个严格凸优化问题,该凸优化问题的松弛系数记为λ,则该问题可进一步表示为min Wpj=1γj(σj)+λijf ij(x TiWy yj)s.t.x Ti ∈T(A),xj∈T(B)(9)线性转换有时并不能很好地表达出域间的映射关系,而非线性转换则能较好地表达,所以算法可以引入特征的核化空间.该算法的核化就是将算法中出现特征向量内积的地方用相应的核化函数表示.当引入原始核函数k(x,y)=φ(x)Tφ(y),核化之后f i(φ(x),φ(y))=φ(x)T Wφ(y),则W表示的是在希尔伯特(Hilbert)空间中的一个算子,维度与φ(x)和φ(y)的维度相关.因此,如果引入的原始核函数为径向基函数(Radial basis function,RBF)核,则W的维数就是无穷大.尽管不能显式计算W,但是仍然可以根据文献[23]中的核化算法将W递归展开成如下形式:W=I+i,j σijφ(x i)φ(yj)T(10)其中,(x i,y j)为约束训练样本对,σij为Breg-man投影系数(Bregman projection parameter).此时我们可定义一个新的核函数 k(x,y)=φ(x)T Wφ(y).则核化之后的相似性函数可以用新引入的核化函数表示,即f i(φ(x),φ(y))= k(x,y),因此算法中出现特征向量内积的地方用相应的核函数表示,算法的核化就完成了.该凸优化问题有很多方法可以求解,本文采用Bregman迭代算法进行求解,可以很快得到收敛解,具体求解过程可以参考文献[27].3实验结果本文提出的算法采用Matlab编程实现.3.1数据库实验所用数据库[3]包含了三个子数据域,分别是webcam,amazon和dslr.在这三个域中分别有31个物体类别,涵盖了生活中常见的物体,例如椅子、背包、键盘等.这三个数据域相互之间是有差异的.首先,webcam域中的图片是带有闪关灯的网络摄像头拍摄得到的,具有姿态各异,低分辨率(640×480),背景变化等的特点,每一类别中有5个不一样的对象且每个对象平均有3个不同的视角, webcam域共有795张图片.其次,amazon域中的图片是从网上收集的,具有画面单一、物体居中、白色背景等特点,每一类别中平均有90张图片,共计2813张图片.最后,dslr域中的图片是由数码单镜头反光(Single lens reflex,SLR)相机在自然环境中拍摄得到的,具有背景多样,高分辨率4288×2848,自然光线的特点,每一类别中有5个不同对象,每个对象平均有3个不同的视角.dslr域共有498张图片.图6webcam,amazon和dslr中椅子类别中的样例图Fig.6The samples image of chair in three domain:webcam,amazon,dslr3.2本文算法的具体实现和参数本文提出算法(记为mmf)实验的具体实现方案如下.如果每个算法采用的图像特征不是统一的,那么很难对这些算法做比较.为了能更好地与前人取得的成果做对比,本实验中所用到的图像特征均采用文献[3]中提供的SURF(Speeded up robust features)特征,将所有图片灰度化并提取其SURF 特征,最后被量化成800维的特征.为保证各对比算法实验结果的可比性,所有算法中的参数K A和K B均保持一致.从A中选取K A个样本点(当A 域为amazon时,取K A=20,当A域为webcam 或dslr时,取K A=15),与B域中随机选择的3个样本点组成样本对,取K B=3.首先训练出映射矩阵M,本文借鉴了对比方法中采用的核函数,利用的是高斯RBF核函数,其中σ=1,λ=103.通过迭代学习出域间的转换W,本实验采用kNN分类器,其中k=1,通过20次的随机实验,最终取所有9期舒醒等:基于边际Fisher准则和迁移学习的小样本集分类器设计算法1319实验的分类准确率的平均值作为本实验的平均分类准确率.具体的实验参数设置如表1所示.表1本文算法的实验参数设置Table1The experiment parameters set of our methodA→B k1k2k A k Bσa→w2217002031a→d2217002031w→a206801531w→d206801531d→a174201531d→w174201531 3.3实验结果及分析本文方法与近年来具有代表性的一些相关研究成果进行了实验对比.基于深度学习的算法需要源域是目标域的父集[15]并且需要海量训练数据保证其准确率.考虑到本文实验所用的数据库没有其对应的大样本库且其最小的数据域的样本仅有498个,我们没有加入基于深度学习的算法对比.对比实验中的基于SVM的算法和基于域间特征转换的算法描述如下:1)kNN-ab是在A域中的标记样本上训练出kNN分类器,直接将B域中的测试数据用在该kNN分类器上计算分类的准确率.2)kNN-bb是将B域中的标记样本和A域中的标记样本作为训练样本训练出kNN分类器.其余样本作为测试样本计算分类准确率.3)symm是Saenko等提出的算法[3].该算法主要通过信息论矩阵学习实现域间转换并训练出kNN 分类器来提高目标域上的分类准确率.4)ARC-t是Kulis等提出的算法[16].该算法是利用域间的非线性转换的学习解决域间差异性问题,结合源域训练的kNN分类器对目标域样本进行分类.5)gfk是文献[20]中提出的算法,是通过基于测地流核(Geodesicflow kernel)的迁移学习来训练目标域上的kNN分类器.6)svm-s是利用A域中的标记样本训练出的SVM分类器.7)hfa是文献[28]提出的,该方法提出了一种新的边缘最大化的特征表示和svm损失函数相结合的算法,最终通过SVM分类器达到提高目标域的分类准确度的目的.表2给出了本文算法和其他算法的对比结果.其中mmf-Euclid是集成了原始MFA的分类器算法,mmf是集成了本文改进后的边际Fisher准则的分类器算法.从实验结果可以看出,mmf的分类准确度要比mmf-Euclid更高,因此本文采用改进后的边际Fisher准则比原始MFA更有助于提高本文的分类器算法的准确率.与kNN-ab和kNN-bb的实验结果相比较,本文提出的算法通过将目标域的样本映射到源域的学习过程而不是简单地融合了两个域的标记样本数据,有效提高了目标域上的分类准确率.从基于SVM的算法和基于域间特征转换的算法的对比实验结果中,我们可以看出本文的算法充分考虑了源域和目标域的特征分布及其差异性,通过对源域和目标域的特征映射的学习过程使得目标域的分类准确率上有提高,并且在平均的识别准确率上是最高的.最后,我们不仅验证了本文提出的算法能够获得高准确率,而且在图7中还验证了该算法的性能随着目标域可用标记样本数的增大而提升.源域中的训练样本数为20,目标域中可用标记的样本数从1到5变化.从图7可以看到这5种方法都是递增的趋势,本文的方法在整体上要比其他方法好.综上,与其他算法相比,本文提出的小样本集的分类器设计算法能够更充分考虑到了源域中不同类间的可分离性、同类间的紧凑性、域间特征分布的表2在三个数据域上的分类准确率(%)(加粗字体表示最佳性能,缩写:a:amazom,w:webcam,d:dslr) Table2Accuracy rates in the three domains(%)(The bold font represents the best performance,abbreviation:a:amazom,w:webcam,d:dslr.)A→B kNN-ab kNN-bb symm[3]ARCt[16]gfk[20]svm-s hfa[28]mmf-Euclid mmfa→w9.6±1.051.0±0.851.0±1.455.7±0.957.8±1.034.5±0.861.5±0.949.3±0.855.5±0.7 a→d 4.9±1.147.9±0.947.9±1.450.2±0.750.5±0.835.3±0.652.4±1.050.6±0.957.6±0.9 w→a10.5±0.640.1±0.543.7±0.743.4±0.544.1±0.434.9±0.444.5±0.742.9±0.644.6±0.8 w→d23.2±0.854.1±0.969.8±1.071.3±0.868.5±0.565.8±0.852.7±1.170.1±0.771.5±0.6 d→a11.3±0.535.6±0.742.7±0.542.5±0.545.7±0.833.8±0.445.4±0.941.4±0.742.6±0.6 d→w37.6±0.854.0±0.763.4±0.965.3±0.566.4±0.568.1±0.662.4±0.868.5±1.069.5±0.7平均准确率12.2±0.837.8±0.855.6±1.056.9±0.757.7±0.745.4±0.653.2±0.955.4±0.858.6±0.8。
FISHER分类器(FISHER
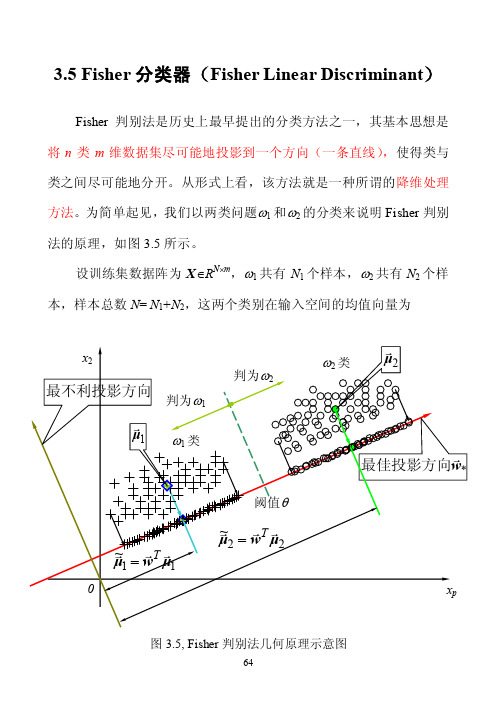
3.5 Fisher分类器(Fisher Linear Discriminant)Fisher判别法是历史上最早提出的分类方法之一,其基本思想是将n类m维数据集尽可能地投影到一个方向(一条直线),使得类与类之间尽可能地分开。
从形式上看,该方法就是一种所谓的降维处理方法。
为简单起见,我们以两类问题ω1和ω2的分类来说明Fisher判别法的原理,如图3.5所示。
设训练集数据阵为X∈R N⨯m,ω1共有N1个样本,ω2共有N2个样本,样本总数N= N1+N2,这两个类别在输入空间的均值向量为图3.5, Fisher判别法几何原理示意图)37.3(11212211⎪⎪⎩⎪⎪⎨⎧∈=∈=∑∑∈∈m p m p R N R N pp ωωx xx μx μ设有一个投影方向()mT m R w w w ∈=,...,,21w ,这两个均值向量在该方向的投影为)38.3(1~1~1222111121⎪⎪⎩⎪⎪⎨⎧∈==∈==∑∑∈∈R N R N pp p T T p T T ϖϖx xx w μw μx w μw μ(3-38)表示的是两个数。
在w方向,两均值之差为())39.3(~~2121μμw μμ -=-=∇T类似地,样本总均值向量在该方向的投影为)40.3(1~11R NNp p T T ∈==∑=x w μw μ定义类间散度(Between-class scatter )平方和SS B 为()()()()()()()()()[])41.3(~~~~~~222111222211221222211wS w w μμμμμμμμw μw μw μw μw μμμμμμ B T T T T T T T T j j j B N N N N N N N SS =--+--=-+-=-=-+-=∑=其中,类间散度阵为()()()()()())42.3(21222111∑=--=--+--=j T j j j TT B N N N μμμμμμμμμμμμS若将所有样本用所在类别的均值所代表,则类间散度平方和SS B 为这N 个均值到训练集总均值在最佳投影方向上投影之差的平方和。
基于Fisher准则的线性分类器设计

基于Fisher 准则的线性分类器设计一、 实验目的:1. 进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深刻地认识;2. 理解Fisher 准则方法确定最佳线性分界面方法的原理,以及拉格朗日乘子求解的原理。
二、 实验条件:1. PC 微机一台和MATLAB 软件。
三、 实验原理:设有一个集合包含N 个d 维样本N x x x ,,,21 ,其中1N 个属于1ω类,2N 个属于2ω类。
线性判别函数的一般形式可表示成0)(w x W x g T +=,其中T d w w W ),,(1 =。
根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:WS W WS W W J w T b T F =)(T W m m S W )(211*-=-其中:∑==i N j j i i x N m 11 2,1=i j x 为i N 类中的第j 个样本w S 为类内离散度,定义为:∑∑==--=2111))((i N j Ti j j w im x m x S b S 为类间离散度,定义为:T b m m m m S ))((2121--=上面的公式是使用Fisher 准则求最佳法线向量的解,我们称这种形式的运算为线性变换,其中)(21m m -是一个向量,1-W S 是W S 的逆矩阵,如)(21m m -是d 维,1-WS 和W S 都是d ×d 维,得到的*W 也是一个d 维的向量。
向量*W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量*W 的计算方法,但是判别函数中的另一项0w 尚未确定,一般可采用以下几种方法确定0w 如2)(21*0m m W w T +-=或者212211*0)(N N m N m N W w T ++-=或当)(1ωP 与)(2ωP 已知时可用]2)](/)(ln[2)([212121*0-+-+-=N N P P m m W w T ωω当0w 确定之后,则可按以下规则分类,10*ω∈→->x w X W T20*ω∈→-<x w X W T四、 实验内容:(以下例为模板,自己输入实验数据)已知有两类数据1ω和2ω二者的概率已知)(1ωP =0.6,)(2ωP =0.4。
基于Fisher线性判别的基因分类器的设计

基于Fisher 线性判别的基因分类器的设计2000年6月人类基因组计划正式完成对人类分布在细胞核中的23条染色体的6万到10万个基因,大约30亿个碱基的测序工作,其中我国完成对3号染色体上的3000万个碱基的测序。
基因草图是由4个字符A 、T 、C 、G 按一定顺序排列组成的长约30亿的序列,其中没有断句,也没有标点。
除了知道这四个字符代表四种碱基之外,人类对基因知之甚少。
但众多的科研工作者发现,NDA 的序列中隐藏这重大的秘密,关系到人的生老病死,对基因的研究具有重大的意义。
本文对DNA 中的四种碱基:腺嘌呤(A ),鸟嘌呤(G ),胞嘧啶(C )和胸腺嘧啶(T )在基因链中出现的频率作为输入向量的四个特征成员,用Fisher 线性分类方法对已知类别的20个基因样本进行训练和测试,表明Fisher 线性分类方法能对这些已知类别的DNA 序列达到分类的目的。
本文采用的数据来自参考文献[1],数据表1所示:显然表1中的样本共分为两类,其中0P >的为一类,在神经网络中以输出为“1”表示;0P <的为另一类,在神经网络中以输出为“0”表示。
Fisher 线性判别:Fisher 线性判别的基本思想是将d 维空间中的样本投射到一维空间中的一条直线上,将维度由多维压缩到一维。
在一维的直线上找到一个阈值点,大于该阈值点的样本分为一类,小于该阈值点的样本分为另一类。
基于以上思想,假设集合ψ包含N 个d 维样本123,,,......N x x x x 其中1N 个属于1ψ的样本,2N 个属于2ψ的样本。
若对n x 的分量做线性组合,可得到标量,1,2,3,......T n n y x n N ω==这样便得到N 个一维样本n y 的集合,可分为两个子集12,y y 。
从几何上,如果||||1ω=,则每个n y 就是对应于n x 到方向为ω的直线的投影。
ω方向的不同,将使样本投影后的可分程度不同,从而直接影响识别的效果。
基于贝叶斯算法的分类器设计与实现

基于贝叶斯算法的分类器设计与实现一、引言随着大数据时代的来临,数据分类和预测成为了各行各业中的重要任务。
其中,贝叶斯算法作为一种常用的机器学习算法,具有较好的分类效果和运算速度。
本文将探讨基于贝叶斯算法的分类器的设计与实现方法,旨在为研究者提供一种有效的分类解决方案。
二、贝叶斯分类器原理贝叶斯分类器是基于贝叶斯定理的一种分类算法。
其核心思想是通过计算后验概率,选取具有最大后验概率的类别作为分类结果。
贝叶斯分类器通过学习训练集中的样本数据,利用先验概率和条件概率来进行分类。
三、分类器设计1. 数据预处理在设计分类器之前,首先需要进行数据预处理。
数据预处理包括数据清洗、特征选择和数据转换等步骤。
其中,数据清洗可以去除异常数据和噪声数据,特征选择可以筛选出与分类任务相关的特征,数据转换可以将数据转换为分类器所需的输入格式。
2. 特征提取特征提取是分类器设计的关键步骤之一。
通过对原始数据进行特征提取,可以将数据转化为分类器所能理解的形式。
常用的特征提取方法包括词袋模型、TF-IDF权重和词嵌入等。
3. 训练模型在特征提取完成后,需要利用训练集来训练分类器模型。
贝叶斯分类器利用训练集中的样本数据计算先验概率和条件概率,并建立分类模型。
训练模型的过程包括计算类别先验概率、计算条件概率和选择最优特征等。
4. 分类预测分类预测是利用训练好的分类器模型对新样本进行分类的过程。
对于新的输入样本,分类器根据先验概率和条件概率计算后验概率,并将概率最大的类别作为分类结果输出。
四、分类器实现1. 贝叶斯公式实现贝叶斯算法的核心是贝叶斯公式。
在编程实现过程中,可以借助概率统计的库函数,计算样本的先验概率和条件概率。
同时,根据样本的特征提取结果,利用贝叶斯公式计算后验概率,并选择概率最大的类别作为分类结果。
2. 预测算法实现预测算法是分类器实现过程中的关键步骤。
贝叶斯分类器中常用的预测算法有朴素贝叶斯算法和多项式贝叶斯算法。
feisher线性判别分类器的设计实验报告()

实验二 Fisher 线性判别实验一、实验目的应用统计方法解决模式识别问题的困难之一是维数问题, 低维特征空间的分类问题一般比高维空间分类问题简单。
因此, 人们力图将特征空间进行降维, 降维的一个基本思路是将 d 维特征空间投影到一条直线上, 形成一维空间, 这在数学上比较容易实现。
问题的关键是投影之后原来线性可分的样本可能变为线性不可分。
一般对于线性可分的样本, 总能找到一个投影方向, 使得降维后样本仍然线性可分。
如何确定投影方向使得降维以后, 样本不但线性可分, 而且可分性更好(即不同类别的样本之间的距离尽可能远,同一类别的样本尽可能集中分布),就是 Fisher 线性判别所要解决的问题。
本实验通过编制程序让初学者能够体会 Fisher 线性判别的基本思路,理解线性判别的基本思想,掌握 Fisher 线性判别问题的实质。
二、实验原理Fisher 线性判别分类器(Fisher Linear Discriminant Analysis,FLDA ),此方法的基本思想是在Fisher 准则下,先求解最佳鉴别矢量,然后将高维的样本投影到最佳鉴别矢量张成的空间,使投影后的样本在低维空间有最大类间距离和最小类内距离,这样在低维空间中样本将有最佳的可分性,分类是一项非常基本和重要的任务,并有着极其广泛的应用。
分类是利用预定的已分类数据集构造出一个分类函数或分类模型(也称作分类器),并利用该模型把未分类数据映射到某一给定类别中的过程。
分类器的构造方法很多,主要包括规则归纳、决策树、贝叶斯、神经网络、粗糙集、以及支持向量机(SVM)等方法。
其中贝叶斯分类方法建立在贝叶斯统计学[v1和贝叶斯网络[s1基础上,能够有效地处理不完整数据,并且具有模型可解释、精度高等优点,而被认为是最优分类模型之一[9]。
尤其是最早的朴素贝叶斯分类器[l0l 虽然结构简单,但在很多情况下却具有相当高的分类精度,可以达到甚至超过其它成熟算法如c4.5[l ’]的分类精度,而且对噪声数据具有很强的抗干扰能力。
作业二 基于Fisher准则线性分类器设计

作业二 F i s h e r线性判别分类器一 实验目的 本实验旨在让同学进一步了解分类器的设计概念,能够根据自己的设计对线性分类器有更深刻地认识,理解Fisher 准则方法确定最佳线性分界面方法的原理,以及Lagrande 乘子求解的原理。
二 实验条件Matlab 软件三 实验原理线性判别函数的一般形式可表示成0)(w X W X g T += 其中根据Fisher 选择投影方向W 的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求,用以评价投影方向W 的函数为:)(211*m m S W W -=-上面的公式是使用Fisher 准则求最佳法线向量的解,该式比较重要。
另外,该式这种形式的运算,我们称为线性变换,其中21m m -式一个向量,1-W S 是W S 的逆矩阵,如21m m -是d 维,W S 和1-W S 都是d ×d 维,得到的*W 也是一个d 维的向量。
向量*W 就是使Fisher 准则函数)(W J F 达极大值的解,也就是按Fisher 准则将d 维X 空间投影到一维Y 空间的最佳投影方向,该向量*W 的各分量值是对原d 维特征向量求加权和的权值。
以上讨论了线性判别函数加权向量W 的确定方法,并讨论了使Fisher 准则函数极大的d 维向量*W 的计算方法,但是判别函数中的另一项0W 尚未确定,一般可采用以下几种方法确定0W 如 或者 m N N m N m N W ~~~2122110=++-= 或当1)(ωp 与2)(ωp 已知时可用当W 0确定之后,则可按以下规则分类,2010ωω∈→-<∈→->X w X W X w X W T T四 实验程序及结果分析%w1中数据点的坐标x1 =[0.2331 1.5207 0.6499 0.7757 1.0524 1.19740.2908 0.2518 0.6682 0.5622 0.9023 0.1333-0.5431 0.9407 -0.2126 0.0507 -0.0810 0.73150.3345 1.0650 -0.0247 0.1043 0.3122 0.66550.5838 1.1653 1.2653 0.8137 -0.3399 0.51520.7226 -0.2015 0.4070 -0.1717 -1.0573 -0.2099];x2 =[2.3385 2.1946 1.6730 1.6365 1.7844 2.01552.0681 2.1213 2.4797 1.5118 1.9692 1.83401.87042.2948 1.7714 2.3939 1.5648 1.93292.2027 2.4568 1.7523 1.6991 2.4883 1.72592.0466 2.0226 2.3757 1.7987 2.0828 2.07981.94492.3801 2.2373 2.1614 1.9235 2.2604];x3 =[0.5338 0.8514 1.0831 0.4164 1.1176 0.55360.6071 0.4439 0.4928 0.5901 1.0927 1.07561.0072 0.4272 0.4353 0.9869 0.4841 1.09921.0299 0.7127 1.0124 0.4576 0.8544 1.12750.7705 0.4129 1.0085 0.7676 0.8418 0.87840.9751 0.7840 0.4158 1.0315 0.7533 0.9548];%将x1、x2、x3变为行向量x1=x1(:);x2=x2(:);x3=x3(:);%计算第一类的样本均值向量m1m1(1)=mean(x1);m1(2)=mean(x2);m1(3)=mean(x3);%计算第一类样本类内离散度矩阵S1S1=zeros(3,3);for i=1:36S1=S1+[-m1(1)+x1(i) -m1(2)+x2(i) -m1(3)+x3(i)]'*[-m1(1)+x1(i)-m1(2)+x2(i) -m1(3)+x3(i)];end%w2的数据点坐标x4 =[1.4010 1.2301 2.0814 1.1655 1.3740 1.18291.7632 1.97392.4152 2.5890 2.8472 1.95391.2500 1.2864 1.26142.0071 2.1831 1.79091.3322 1.1466 1.7087 1.59202.9353 1.46642.9313 1.8349 1.8340 2.5096 2.7198 2.31482.0353 2.6030 1.2327 2.1465 1.5673 2.9414];x5 =[1.0298 0.9611 0.9154 1.4901 0.8200 0.93991.1405 1.0678 0.8050 1.2889 1.4601 1.43340.7091 1.2942 1.3744 0.9387 1.2266 1.18330.8798 0.5592 0.5150 0.9983 0.9120 0.71261.2833 1.1029 1.2680 0.7140 1.2446 1.33921.1808 0.5503 1.4708 1.1435 0.7679 1.1288];x6 =[0.6210 1.3656 0.5498 0.6708 0.8932 1.43420.9508 0.7324 0.5784 1.4943 1.0915 0.76441.2159 1.3049 1.1408 0.9398 0.6197 0.66031.3928 1.4084 0.6909 0.8400 0.5381 1.37290.7731 0.7319 1.3439 0.8142 0.9586 0.73790.7548 0.7393 0.6739 0.8651 1.3699 1.1458];x4=x4(:);x5=x5(:);x6=x6(:);%计算第二类的样本均值向量m2m2(1)=mean(x4);m2(2)=mean(x5);m2(3)=mean(x6);%计算第二类样本类内离散度矩阵S2S2=zeros(3,3);for i=1:36S2=S2+[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)]'*[-m2(1)+x4(i) -m2(2)+x5(i) -m2(3)+x6(i)];end%总类内离散度矩阵SwSw=zeros(3,3);Sw=S1+S2;%样本类间离散度矩阵SbSb=zeros(3,3);Sb=(m1-m2)'*(m1-m2);%最优解WW=Sw^-1*(m1-m2)'%将W变为单位向量以方便计算投影W=W/sqrt(sum(W.^2));%计算一维Y空间中的各类样本均值M1及M2for i=1:36y(i)=W'*[x1(i) x2(i) x3(i)]';endM1=mean(y)for i=1:36y(i)=W'*[x4(i) x5(i) x6(i)]';endM2=mean(y)%利用当P(w1)与P(w2)已知时的公式计算W0p1=0.6;p2=0.4;W0=-(M1+M2)/2+(log(p2/p1))/(36+36-2);%计算将样本投影到最佳方向上以后的新坐标X1=[x1*W(1)+x2*W(2)+x3*W(3)]';X2=[x4*W(1)+x5*W(2)+x6*W(3)]';%得到投影长度XX1=[W(1)*X1;W(2)*X1;W(3)*X1];XX2=[W(1)*X2;W(2)*X2;W(3)*X2];%得到新坐标%绘制样本点figure(1)plot3(x1,x2,x3,'r*') %第一类hold onplot3(x4,x5,x6,'bp') %第二类legend('第一类点','第二类点')title('Fisher 线性判别曲线')W1=5*W;%画出最佳方向line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','b');%判别已给点的分类a1=[1,1.5,0.6]';a2=[1.2,1.0,0.55]';a3=[2.0,0.9,0.68]';a4=[1.2,1.5,0.89]';a5=[0.23,2.33,1.43]';A=[a1 a2 a3 a4 a5]n=size(A,2);%下面代码在改变样本时都不必修改%绘制待测数据投影到最佳方向上的点for k=1:nA1=A(:,k)'*W;A11=W*A1;%得到待测数据投影y=W'*A(:,k)+W0;%计算后与0相比以判断类别,大于0为第一类,小于0为第二类 if y>0plot3(A(1,k),A(2,k),A(3,k),'go'); %点为"rp"对应第一类plot3(A11(1),A11(2),A11(3),'go'); %投影为"r+"对应go 类elseplot3(A(1,k),A(2,k),A(3,k),'m+'); %点为"bh"对应m+类plot3(A11(1),A11(2),A11(3),'m+'); %投影为"b*"对应m+类endend%画出最佳方向line([-W1(1),W1(1)],[-W1(2),W1(2)],[-W1(3),W1(3)],'color','k');view([-37.5,30]);axis([-2,3,-1,3,-0.5,1.5]);grid onhold off实验结果和数据:首先根据求出最佳投影方向,然后按照此方向,将待测数据进行投影 。
基于Fisher距离的新型脑机接口分类器

基于Fisher距离的新型脑机接口分类器
张旭秀;陈坚
【期刊名称】《大连交通大学学报》
【年(卷),期】2010(031)001
【摘要】提出基于Fisher距离测度的线性分类器符合统计学习理论框架的观点,结合主分量分析和遗传算法提出一种基于结构风险最小化(Structural Risk Minimization,简称SRM)归纳原则的分类器设计方法.通过对比遗传算法和穷举法的运算量,阐明所提出的特征提取方法在采用Fisher线性分类器分类时的优势.最后采用所提出的基于SRM归纳原则的方法对一组人脑慢皮层电位数据进行了分类仿真实验,并将结果与该组数据竞赛优胜者的结果进行了对比,性能得到了明显提高.【总页数】4页(P104-107)
【作者】张旭秀;陈坚
【作者单位】大连交通大学电气信息学院,辽宁,大连,116028;大连交通大学电气信息学院,辽宁,大连,116028
【正文语种】中文
【中图分类】R318
【相关文献】
1.基于Fisher准则和贝叶斯分类器的藏文WEB文档分类算法 [J], 安见才让
2.基于多尺度小波变换和加权Fisher线性分类器的离线签名认证 [J], 曾晓云
3.最小距离分类器的改进算法--加权最小距离分类器 [J], 任靖;李春平
4.基于边际Fisher准则和迁移学习的小样本集分类器设计算法 [J], 舒醒;于慧敏;郑伟伟;谢奕;胡浩基;唐慧明
5.基于Fisher准则的分类器在皮革正反面分类中的应用 [J], 崔扬;周泽魁
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
7
8 9 10 11 12
2
3 4 1 3 3
2
3 4 1 3 3
13
14 15 16 17 18
1
2 4 2 4 3
1
2 4 2 4 2
19
20 21 22 23 24
4
2 2 3 3 1
4
2 3 3 3 1
25
26 27 28 29 30
1
4 1 3 3 3
1
4 1 3 3 3
结果分析:从表中可以看出有2个分类结果是错的,正确率为93.3%。
T
0 1
y y , x
0
2
算法实现
◆ 流程图
算法实现
◆ 样本均值
clear,close all; N=29; %N为训练样本总个数 X = [1495.18 1957.44 3498.02 %X为训练样本 1125.17 1594.39 2937.73 1269.07 1910.72 2701.97 …… ……] m1=mean(X(1:11,:)); %求得第一类样本均值 m2=mean(X(12:29,:)); %求得第二类样本均值
y0
Fisher投影原理
Fisher分类器设计
样本在d维特征空间的一些描述量 (1)各类样本均值 m 1 m i 1,2 x N (2)样本类内离散度矩阵 S 与总类内离散度矩阵 S
i
i X i i
i
w
S ( X m )( X m )
i X wi i i
T
基于Fisher的分类器设计
主 单 讲:周润景 教授 位:电子信息工程学院
目 录
Fisher判别法简介
Fisher判别法的基本原理
分类器设计
算法实现 识别待测样本类别 结论
Fisher判别法简介
Fisher判别法作为一种分类方法是1936年由 首先提出的。 判别法是一种 线性判别法,线性判别又称线性准则,与线性准则相对应的还有非线性准则, 其中一些在变换条件下可以化为线性准则,因此对应于 维特征空间,线性判别 函数虽然最简单,但是在应用上却具有普遍意义,便于对分类问题理解与描述。 基于线性判别函数的线性分类方法,虽然使用有限样本集合来构造,从严 格意义上来讲属于统计分类方法。也就是说,对于线性分类器的检验,应建立 在样本扩充的条件下,以基于概率的尺度来评价才是有效的评价。尽管线性分 类器的设计在满足统计学的评价下并不严格与完美,但是由于其简单性与实用 性,在分类器设计中还是获得了广泛的应用。
算法实现
◆ 阈值点
本设计器采用 y w (m m ) / 2 来确定阈值点,由于它既考
* T 0 1 2
虑了样本均值之间的平均距离,又考虑了两类样本的容量大小
作阈值位置的偏移修正,因此,采用它可以使得分类误差尽可
能小。
算法实现
◆ 输出分类结果
for i=1:22 y=W*x(i,:)' %确定投影点y if y>y0 %当y>y0时,测试样本属于第一类 disp('一') hold on,plot3(x(i,1),x(i,2),x(i,3),'r+','MarkerSize',6,'LineWidth',2) else disp('二') %当y<y0时,测试样本属于第二类 hold on,plot3(x(i,1),x(i,2),x(i,3),'b+','MarkerSize',6,'LineWidth',2) end end
F
Fisher分类器设计
最好投影方向 w S (m m ) 阈值点 y m m 2 N m N m y N N m m ln( P( ) / P( )) y 2 N N 2
* 1 w 1 2
1 2 0
1
1
2
2
0
1
2
1
2
1
2
0
1
2
对于任意未知类别的样本x,计算它的投影点 y w x 决策规则为: y y , x
识别待测样本类别
数 据 编 号 原 始 分 类 预 测 分 类 数 据 编 号 原 始 分 类 预 测 分 类 数 据 编 号 原 始 分 类 预 测 分 类 数 据 编 号 原 始 分 类 预 测 分 类 数 据 编 号 原 始 分 类 预 测 分 类
1
2 3 4 5 6
3
3 1 3 4 2
3
3 1 3 4 2
w 1 2
上述两条原则,构造Fisher准则函数
(m m ) J ( w) S S
1 2 F 1 2
F
2
使得 J ( w) 为最大值的w 即为要求的投影向量 w 。 进一步化为w的显
*
函数,得到Fisher准则函为:
wSw J ( w) wSw
T b F T w
*
求解Fisher准则函数的条件极值,即可解得使J ( w)为极值的 w 。
四、总结
◆文章主要论述了分类法的内容、特点以及其分类器设计,重点
讨论了利用Fisher分类法设计分类器的全过程。在设计该种分类器过 程中,首先利用训练样本求得最佳投影方向,并确定阈值点。接着通 过分析归纳给定样本数据的分类情况,最后利用Matlab中的相关函数、 工具设计了基于分类法的分类器,并将测试数据进行了成功分类。
i
w
S ( y m ) , i 1,2
2 i yyi i
S S S
w 1
2
Fisher分类器设计
Fisher准则函数定义原则为:希望投影后,在一维空间中样本类别区 分清晰,即两类样本的距离越大越好,也就是 (m m ) 均值之差越大
1 2
越好;各类样本内部密集,即类内离散度 S S S 越小越好,根据
识别待测样本类别
◆ 选择分类方法
识别待测样本类别
种类 分类方法
第一种
第12类作为第一类,第34类作为第二类
第二种
第13类作一类,第23类作为第二类
识别待测样本类别
观察训练样本分布图可知,如果 将第 1 、 2 类分在一起作为第一类, 第 3 、 4 类分在一起作为第二类, 显然,这样很难将其分开。因此, 排除这种分类方法。选择第二、 三种分类方法。
i 1,2
S S S
w 1
2
(3)样本类间离散度矩阵
S (m m )(m m )
b 1 2 1 2
T
Fisher分类器设计
在一维上投影,则有: (1)各类样本均值 m 1 m y,2i 1,2 N (2)样本类内离散度矩阵 S 与总类内离散度矩阵 S
i
i yyi i
Fisher判别法的基本原理
Fisher 判别法基本原理是:对于 d维空间的样本,投影到一维坐标上,样 本特征将混杂在一起,难以区分。 Fisher判别法的目的,就是要找到一个最合 适的投影轴w,使两类样本在该轴上投影的交迭部分最少,从而使分类效果为 最佳。如何寻找一个投影方向,使得样本集合在该投影方向上最易区分,这就 是Fisher判别法所要解决的问题。Fisher投影原理如下所示。 Fisher准则函数的基本思路: 即向量w的方向选择应能使两类样本投影的均 值之差尽可能大些,而使类内样本的离散程度尽可能小。