实验一 Clementine12.0数据挖掘分析方法与应用
第5章 Clementine使用简介

第5章 Clementine使用简介5.1Clementine 概述Clementine数据挖掘平台是一个可视化的、强大的数据分析平台。
用户可以通过该平台进行与商业数据操作相关的操作。
数据流区域:它是Clementine窗口中最大的区域,这个区域的作用是建立数据流,或对数据进行操作。
选项板区域:它是在Clementine的底部,每个选项卡包含一组相关的可以用来加载到数据流区域的节点组成。
它包括:数据源、记录选项、字段选项、图形、建模和输出。
管理器:它位于Clementine的右上方,包括流、输出和模型三个管理器。
项目区域:它位于Clementine的右下方,主要对数据挖掘项目进行管理。
并且,它提供CRISP-DM和类两种视图。
另外,Clementine还包括类似于其他windows软件的菜单栏、工具栏和状态栏。
Clementine非常容易操作,包含很多经典数据挖掘算法和一些较新的数据挖掘算法通常,大多数数据挖掘工程都会经历以下过程:检查数据以确定哪些属性可能与相关状态的预测或识别有关。
保留这些属性(如果已存在),或者在必要时导出这些属性并将其添加到数据中。
使用结果数据训练规则和神经网络。
使用独立测试数据测试经过训练的系统。
Clementine的工作就是与数据打交道。
最简单的就是“三步走”的工作步骤。
首先,把数据读入Clementine中,然后通过一系列的操作来处理数据,最后把数据存入目的文件。
Clementine数据挖掘的许多特色都集成在可视化操作界面中。
可以运用这个接口来绘制与商业有关的数据操作。
每个操作都会用相应的图标或节点来显示,这些节点连接在一起,形成数据流,代表数据在操作间的流动。
Clementine用户界面包括6个区域。
数据流区域(Stream canvas):数据流区域是Clementine窗口中最大的区域,在这个区域可以建立数据流,也可以对数据流进行操作。
每次在Clementine中可以多个数据流同时进行工作,或者是同一个数据流区域有多个数据流,或者打开一个数据流文件。
实验二 Clementine12购物篮分析(关联规则)

实验二Clementine12购物篮分析(关联规则)一、[实验目的]设计关联规则分析模型,通过模型演示如何对购物篮分析,并根据细分结果对采取不同的营销策略。
体验以数据驱动的模型计算给科学决策带来的先进性。
二、[知识要点]1、购物蓝分析概念;2、管来呢规则算法原理;3、购物蓝分析工具;4、Clementine12.0关联规则分析流程。
三、[实验要求和内容]1、初步了解使用工作流的方式构建分析模型;2、理解智能数据分析流程,主要是CRISP-DM工业标准流程;3、理解关联规则模型原理;4、设计关联规则分流;5、运行该流,并将结果可视化展示;6、得出模型分析结论7、运行结果进行相关营销策略设计。
四、[实验条件]Clementine12.0挖掘软件。
五、[实验步骤]1、启动Clementine12.0软件;2、在工作区设计管来呢规则挖掘流;3、执行模型,分析计算结果;4、撰写实验报告。
六、[思考与练习]1、为什么要进行关联规则分析?它是如何支持客户营销的?实验内容与步骤一、前言“啤酒与尿布”的故事是营销届的神话,“啤酒”和“尿布”两个看上去没有关系的商品摆放在一起进行销售、并获得了很好的销售收益,这种现象就是卖场中商品之间的关联性,研究“啤酒与尿布”关联的方法就是购物篮分析,购物篮分析曾经是沃尔玛秘而不宣的独门武器,购物篮分析可以帮助我们在门店的销售过程中找到具有关联关系的商品,并以此获得销售收益的增长!“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。
父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。
基于SPSS Clementine的关联规则分析在中医药数据挖掘中的应用优势和局限

中医学 是 一 门对 临 床经 验 有较 高 要求 的学 科 ,
一
,
它包 含 了决 策 树 、 支 持 向量 机 、 贝 叶斯 网络 等分
其本身具有整体性 、 系统性 、 复杂性等特点。 名老中
医作 为 中医药 学 术 的带 头 人 , 其学 术 思 想 和临 证 经 验 是 中 医学 的重 要 组成 部 分 , 也 是不 可 多得 的宝 贵
Vo l _39 No .6 1 2 .2 01 6
基于 S P S S C l e me n t i n e的关联规则分析在 中医药数 据挖掘 中的 应 用 优 势 和 局 限
王玲 玲 ,付 桃 芳 ,杜 俊 英 , 梁 宜 1 , 2 A ,方剑 乔
( 1 .浙江 中医药大学第三临床医学院 ,浙江 杭州 3 1 0 0 5 3 ;2 .浙江 中医药大学附属第三 医院,浙江 杭州 3 1 0 0 0 5 )
基金项 目:全国名老中医药专 家传承工作室建设项 目( 国中医药人教发【 2 0 1 3 】 4 7号 ) ; 浙江省名老中医专 家传承工作室 建设项 目( GZ S 2 0 1 2 0 1 4) ; 浙江省 中医药科技计 划项 目( 2 0 1 4 Z A0 5 9 )
收 稿 日期 :2 0 1 6 — 0 9 — 2 5
摘要 :C l e m e n t i n e 是数据挖掘 的常用工具之一 , 在如今 中医学领 域数据挖掘方 面也 运用相 当广泛 , 其 中它 的关 联规则分析也是应用最多的挖掘方法之一 。 本文综述了 目前 S P S S C l e m e n t i n e 关联规则分析方法在 中医药研究 中运
用的概况 , 主要是对名老 中医经验传承 、 中医病机 、 症 状与 中药 、 医案研究 和针 灸处 方研究等方 面的关联规 律挖掘 ,
数据挖掘技术与应用实验报告

数据挖掘技术与应用 实 验 报 告专业:_______________________班级:_______________________学号:_______________________姓名:_______________________2012-2013学年 第二学期经济与管理学院实验名称:SPSS Clementine 软件安装、功能演练指导教师: 实验日期: 成绩:实验目的1、熟悉SPSS Clementine 软件安装、功能和操作特点。
2、了解SPSS Clementine 软件的各选项面板和操作方法。
3、熟练掌握SPSS Clementine 工作流程。
实验内容1、打开SPSS Clementine 软件,逐一操作各选项,熟悉软件功能。
2、打开一有数据库、或新建数据文件,读入SPSS Clementine,并使用各种输出节点,熟悉数据输入输出。
(要求:至少做access数据库文件、excel文件、txt文件、可变文件的导入、导出)实验步骤一 实验前准备:1.下载SPSS Clementine 软件安装包和一个虚拟光驱。
2.选择任意盘区安装虚拟光驱,并把下载的安装包的文件(后缀名bin)添加到虚拟光驱上,然后双击运行。
3.运行安装完成后,把虚拟光驱中CYGiSO文件中的lservrc文件和PlatformSPSSLic7.dll文件复制替换到安装完成后的bin文件中,完成破解,获得永久免费使用权。
4.运行中文破解程序,对SPSS Clementine 软件进行汉化。
二 实验操作:从 Windows 的“开始”菜单中选择:所有程序/SPSS 1、启动 Clementine:Clementine 12.0/SPSS Clementine client 12.02、Clementine窗口当第一次启动 Clementine 时,工作区将以默认视图打开。
中中,这将是用来工作的主要区域。
间的区域称作流工作区。
Clementine上机操作实验指导

数据流的基本操作
向数据流区域添节点
双击选项板区中待添加的节点; 左键按住待添加节点,将其拖入数据流区域内; 先选中选项板区中待添加的节点,然后将鼠标放入数据
流区域,在鼠标变为十字形时单击数据流区域的任何空 白处。
向数据流区域删节点
左键单击待删除的节点,按键盘上的delete键删除; 右键单击待删除的节点,在快捷菜单中选择delete。
管理器窗口
管理器窗口中共包含了“流”、“输出”、“模 型”三个栏。
工程管理区
工程管理区含有两个选项栏,一个是“CRISPDM”,一个是“类”。
数据流的基本操作
生成数据流的基本过程
向数据流区域增添新的节点; 将这些节点连接到数据流中; 设定数据节点或数据流的功能; 运行数据流。
调节因子η
点击“执行”按钮,即可在管理器窗口的“模型” 标签下显示生成的K-Means模型节点。
右键单击管理器窗口“模型”标签下生成的K-Means模型节点,在快 捷菜单中选择“浏览”,打开“K-Means”对话框,在“模型”标签 下会显示划分出来的三个聚类,点击“全部展开”,则可以显示每个 簇的一些统计信息
SmallSampleComma.txt
字段实例化 将ID字段的类型修改为
无类型
字段方向
输入:输入或者预测字 段
输出:输出或者被预测 字段字段
两者:既是输入又是输 出,只在关联规则中用 到
无:建模过程中不使用 该字段
分区:将数据拆分为训 练、测试(验证)部分
字段方向设置只有在建 模时才起作用
如果数据是列界定的(字段未被分隔,但是 始于相同的位置并有固定长度),应该使用固 定文本文件导入固定文件节点
实验四 Clementine数据挖掘

实验四 数据挖掘实验指导一、目的掌握数据挖掘工具Clementine 的基本方法与操作。
二、任务利用Clementine 对药物数据进行简单的数据挖掘操作,熟悉数据挖掘的基本步骤。
三、要求了解数据挖掘的基本步骤,完成针对给定数据的决策树挖掘/关联规则分析/聚类分析,并写出实验报告。
四、实验内容利用Clementine 对Drug.txt 中药物研究数据进行决策树、关联规则分析,观察挖掘的结果,比较这些方法挖掘结果的异同,根据观察的结果写出实验报告。
注:药物研究数据来源于对治疗同一疾病病人的处方,这些病人服用不同药物,取得了相同效果。
其中所含数据项如下:Age: 年龄 Sex: 性别(M\F) Drug: 病人所服药物种类(A/B/C/X/Y) BP: 血压(High\Normal\Low)Cholesterol: 胆固醇(Normal\High) Na: 唾液中钠元素含量 K: 唾液中钾元素含量 希望通过数据挖掘发现这些处方中隐藏的规律,给出不同临床特征病人更适合服务哪种药物的建议,为未来医生填写处方提供参考。
五、实验环境1、 硬件:P4/256MB 台式计算机2、 软件:Windows 2000 Professional/SQL Server 2000/Clementine 8.1及以上3、 数据:Drugs 数据 (文件Drug.txt) 六、步骤(一) 启动clementine双击桌面数据挖掘工具“clementine 8.1” 图标或C:\Clementine 8.1\bin\Clementine.exe ,即可启动该挖掘工具,界面如图4-1所示。
主工作区结果输出区(二)数据挖掘操作1.挖掘流(stream)操作(1)新建:File菜单→New Stream命令(2)保存/另存:File菜单→Save Stream /Save Stream As…命令→指定保存位置、文件名称→保存按钮(3)打开:File菜单→Open Stream…命令→指定要打开流的位置、文件名称→打开按钮2.挖掘步骤(1)建立连接数据源1)在挖掘工具区选项卡“Sources”中将“Var. File”节点拖入到主工作区。
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
SPSS_Clementine典型案例分析

最后,在数据流中增加一个“条形图”节点。 双击该节点,在“字段”下拉列表中选择 “name”字段,点击“执行(E)”,得出 结果如图所示。在图中所显示的就是我们要 重点关注的数据。
24.4小结
本章通过使用Apriori模型、GRI模型、可视化网 络图、决策树、神经网络等来说明如何使用 Clementine在数据库中发现知识。Clementine系 统中提供了很多种模型,对于这些模型的使用, 要考虑到实际情况来酌情进行使用。 本章所展示的只是Clementine系统的一部分应 用。随着社会的不断发展,数据库技术的不断进 步。Clementine将会越来越多的被重视、使用。
数据挖掘原理与SPSS Clementine应用宝典
本章包括:
市场购物篮分析 利用决策树模型挖掘商业信息 利用神经网络对数据进行欺诈探测
24.1市场购物篮分析
本节的例子采用Clementine系统自带的 数据 集BASKETS1n。该数据集是超市的“购物 篮” (一次购物内容的集合)数据和购买者个人 的背景数据,目标是发现购买物品之间的关 联分析。
24.3.4 建模
将一个“类型”节点添加到当前数据流中。对 数据集中的数据进行设置。
在数据流上添加一个“神经网络”节点。执 行此数据流。神经网络经过训练后,会产生 一个模型。将产生的模型加入到数据流流中。 然后在数据流中再增加一个“散点图”节点, 对“散点图”节点进行设置。设置完成之后, 执行。
在数据流区域中添加一个“选择”节点,对 该节点进行设置。 以农场大小、主要作物类型、土壤质量等为 自变量建立一个回归模型来估计一个农场的 收入是多少。
为了发现那些偏离估计值的农场,先生成一个字段――diff, 代表估计值与实际值偏离的百分数。在数据流中再增加一 个“导出”节点 进行设置。 在数据流中增加一个“直方图”节点。对“直方图”节点进 行设置。。
SPSS_Clementine_数据挖掘入门

目录SPSS Clementine数据挖掘入门(1) (2)客户端基本界面 (3)项目区 (3)工具栏 (3)源工具(Sources) (3)记录操作(Record Ops)和字段操作(Field Ops) (4)图形(Graphs) (4)输出(Output) (4)模型(Model) (4)数据流设计区 (4)管理区 (5)Outputs (5)Models (5)SPSS Clementine数据挖掘入门(2) (6)1.定义数据源 (6)2.理解数据 (8)3.准备数据 (9)4.建模 (13)5.模型评估 (14)6.部署模型 (15)SPSS Clementine数据挖掘入门(3) (17)分类 (20)决策树 (20)Naïve Bayes (23)神经网络 (24)回归 (26)聚类 (27)序列聚类 (30)关联 (31)SPSS Clementine数据挖掘入门(1)SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
分类工具spss Clementine的介绍
分类工具spss Clementine 的介绍数据挖掘的工具平台有很多,常见的有Spss Clementine 、Weka 、Matlab 等。
本研究采用的是Spss Clementine 12.0汉化版,下面简单介绍Clementine 工具。
Clementine 软件充分利用了计算机系统的运算能力和图形展示能力,将方法、应用与工具紧密地结合在一起,是解决数据挖掘的理想工具。
它不但集成了诸多计算机学科中机器学习的优秀算法,同时也综合了一些行之有效的数学统计分析方法,成为内容最为全面,功能最为强大、使用最为方便的数据挖掘工具。
由于其界面友好、操作简便,十分适合普通人员快速实现对数据的挖掘,使其大受用户欢迎,已经连续多年雄踞数据挖掘工具之首[96]。
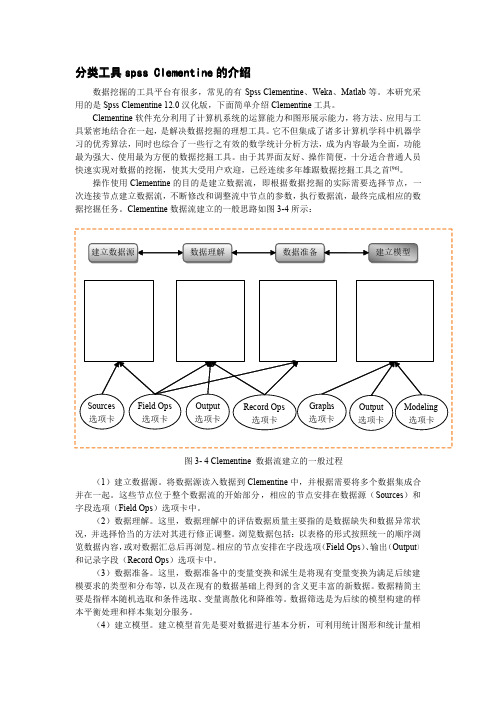
操作使用Clementine 的目的是建立数据流,即根据数据挖掘的实际需要选择节点,一次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成相应的数据挖掘任务。
Clementine 数据流建立的一般思路如图3-4所示:(1)建立数据源。
将数据源读入数据到Clementine 中,并根据需要将多个数据集成合并在一起。
这些节点位于整个数据流的开始部分,相应的节点安排在数据源(Sources )和字段选项(Field Ops )选项卡中。
(2)数据理解。
这里,数据理解中的评估数据质量主要指的是数据缺失和数据异常状况,并选择恰当的方法对其进行修正调整。
浏览数据包括:以表格的形式按照统一的顺序浏览数据内容,或对数据汇总后再浏览。
相应的节点安排在字段选项(Field Ops )、输出(Output )和记录字段(Record Ops )选项卡中。
(3)数据准备。
这里,数据准备中的变量变换和派生是将现有变量变换为满足后续建模要求的类型和分布等,以及在现有的数据基础上得到的含义更丰富的新数据。
数据精简主要是指样本随机选取和条件选取、变量离散化和降维等。
clementine的中文教程

一,Clementine数据挖掘的基本思想数据挖掘(Data Mining)是从大量的,不完全的,有噪声的,模糊的,随机的实际应用数 据中,提取隐含在其中的,人们事先不知道的,但又是潜在有用的信息和知识的过程,它是一 种深层次的数据分析方法.随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法. 它结合了人工智能(AI)和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些 高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于 自己所要解决的问题. Clementine为我们提供了大量的人工智能,统计分析的模型(神经网络,关联分析,聚类分 析,因子分析等) ,并用基于图形化的界面为我们认识,了解,熟悉这个软件提供了方便.除了 这些Clementine还拥有优良的数据挖掘设计思想, 正是因为有了这个工作思想, 我们每一步的工 作也变得很清晰. (如图一所示)图一CRISP-DM process model如图可知,CRISP-DM Model包含了六个步骤,并用箭头指示了步骤间的执行顺序.这些顺 序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行.通 过对这些步骤的执行,我们也涵盖了数据挖掘的关键部分. Business understanding:商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段 里我们需要明确商业目标,评估商业环境,确定挖掘目标以及产生一个项目计划. Data understanding:数据是我们挖掘过程的"原材料",在数据理解过程中我们要知道都有些什么数据,这些 数据的特征是什么,可以通过对数据的描述性分析得到数据的特点. Date preparation:在数据准备阶段我们需要对数据作出选择,清洗,重建,合并等工作. 选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作. Modeling:建模过程也是数据挖掘中一个比较重要的过程.我们需要根据分析目的选出适 合的模型工具,通过样本建立模型并对模型进行评估. Evaluation: 并不是每一次建模都能与我们的目的吻合, 评价阶段旨在对建模结果进行评估, 对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义. Deployment:这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督,维持, 产生最终报表,重新评估模型等过程.二,Clementine的基本操作方法1,操作界面的介绍图二 Clementine操作界面 1.1数据流程区 Clementine在进行数据挖掘时是基于数据流程形式,从读入数据到最后的结果显示都是由 流程图的形式显示在数据流程区内.数据的流向通过箭头表示,每一个结点都定义了对数据的 不同操作,将各种操作组合在一起便形成了一条通向目标的路径. 数据流程区是整个操作界面中最大的部分,整个建模过程以及对模型的操作都将在这个区 域内执行.我们可以通过File-new stream新建一个空白的数据流,也可以打开已有的数据流. 所有在一个运行期内打开的数据流都将保存在管理器的Stream栏下. 1.2选项面板 选项面板横跨于Clementine操作界面的下部, 它被分为Favorites, Sources, Record Ops, Fields Ops,Graphs,Modeling,Output七个栏,其中每个栏目包含了具有相关功能的结点. 结点是数据流的基本组成部分,每一个结点拥有不同的数据处理功能.设置不同的栏是为了将 不同功能的结点分组,下面我们介绍各个栏的作用. Sources:该栏包含了能读入数据到Clementine的结点.例如Var. File结点读取自由格式的文 本文件到Clementine,SPSS File读取spss文件到Clementine. Record Ops: 该栏包含的结点能对数据记录进行操作. 例如筛选出满足条件的记录 (select) , 将来自不同数据源的数据合并在一起(merge) ,向数据文件中添加记录(append)等. Fields Ops:该栏包含了能对字段进行操作的结点.例如过滤字段(filter)能让被过滤的字段不作为模型的输入,derive结点能根据用户定义生成新的字段,同时我们还可以定义字段的数 据格式. Graphs:该栏包含了纵多的图形结点,这些结点用于在建模前或建模后将数据由图形形式 输出. Modeling:该栏包含了各种已封装好的模型,例如神经网络(Neural Net) ,决策树(C5.0) 等. 这些模型能完成预测 (Neural Net, Regression, Logistic ) 分类 , (C5.0, C&R Tree, Kohonen, K-means,Twostep) ,关联分析(Apriori,GRI,Sequece)等功能. Output:该栏提供了许多能输出数据,模型结果的结点,用户不仅可以直接在Clementine 中查看输出结果,也可以输出到其他应用程序中查看,例如SPSS和Excel.Favorites:该栏放置了用户经常使用的结点,方便用户操作.用户可以自定义其Favorites 栏,操作方法为:选中菜单栏的Tools,在下拉菜单中选择Favorites,在弹出的Palette Manager 中选中要放入Favorites栏中的结点. 图三 Favorites栏的设置 1.3管理器管理器中共包含了Streams,Outputs,Models三个栏.其中Streams中放置了运行期内打开的 所有数据流,可以通过右键单击数据流名对数据流进行保存,设置属性等操作.Outputs中包含 了运行数据流时所有的输出结果,可以通过双击结果名查看输出的结果.Models中包含了模型 的运行结果,我们可以右键单击该模型从弹出的Browse中查看模型结果,也可以将模型结果加入到数据流中.图四 管理器窗口中对stream的设置 1.4项目窗口的介绍 项目窗口含有两个选项栏,一个是CRISP-DM,一个是Classes.CRISP-DM的设置是基于CRISP-DM Model的思想,它方便用户存放在挖掘各个阶段形成的 文件.由右键单击阶段名,可以选择生成该阶段要拥有的文件,也可以打开已存在的文件将其 放入该阶段.这样做的好处是使用户对数据挖掘过程一目了然,也有利于对它进行修改.图五 将各阶段的文件归类 Classes窗口具有同CRISP-DM窗口相似的作用,它的分类不是基于挖掘的各个过程,而是 基于存储的文件类型.例如数据流文件,结点文件,图表文件等.2,数据流基本操作的介绍2.1生成数据流的基本过程数据流是由一系列的结点组成,当数据通过每个结点时,结点对它进行定义好的操作.我 们在建立数据流是通常遵循以下四步: ①,向数据流程区增添新的结点; ②,将这些结点连接到数据流中; ③,设定数据结点或数据流的功能; ④,运行数据流. 2.2向数据流程区添/删结点 当向数据流程区添加新的结点时,我们有下面三种方法遵循: ①,双击结点面板中待添加的结点; ②,左键按住待添加结点,将其拖到数据流程区内; ③,选中结点面板中待添加的结点,将鼠标放入数据流程区,在鼠标变为十字形时单击数 据流程区. 通过上面三种方法我们都将发现选中的结点出现在了数据流程区内. 当我们不再需要数据流程区内的某个结点时,可以通过以下两种方法来删除: ①左键单击待删除的结点,用delete删除; ②右键单击待删除的结点,在出现的菜单中选择delete. 2.3将结点连接到数据流中 上面我们介绍了将结点添加到数据流程区的方法,然而要使结点真正发挥作用,我们需要 把结点连接到数据流中.以下有三种可将结点连接到数据流中的方法: ①,双击结点 左键选中数据流中要连接新结点的结点(起始结点) ,双击结点面板中要连 接入数据流的结点(目标结点) ,这样便将数据流中的结点与新结点相连接了; 图六 双击目标结点以加入数据流 ②,通过鼠标滑轮连接在工作区内选择两个待连接的结点,用左键选中连接的起始结点,按住鼠标滑轮将其拖曳 到目标结点放开,连接便自动生成. (如果鼠标没有滑轮也选用alt键代替) 图七 由滑轮连接两结点 ③,手动连接 右键单击待连接的起始结点,从弹出的菜单栏中选择Connect.选中Connect后鼠标和起始 结点都出现了连接的标记,用鼠标单击数据流程区内要连接的目标结点,连接便生成.图八 选择菜单栏中的connect 图九 点击要连入的结点 注意:①,第一种连接方法是将选项面板中的结点与数据流相连接,后两种方法是将已在 数据流程区中的结点加入到数据流中 ②,数据读取结点(如SPSS File)不能有前向结点,即在 连接时它只能作为起始结点而不能作为目标结点. 2.4绕过数据流中的结点 当我们暂时不需要数据流中的某个结点时我们可以绕过该结点.在绕过它时,如果该结点 既有输入结点又有输出结点那么它的输入节点和输出结点便直接相连;如果该结点没有输出结 点,那么绕过该结点时与这个结点相连的所有连接便被取消.方法:用鼠标滑轮双击需要绕过的结点或者选择按住alt键,通过用鼠标左键双击该结点来 完成.图十 绕过数据流中的结点 2.5将结点加入已存在的连接中 当我们需要在两个已连接的结点中再加入一个结点时,我们可以采用这种方法将原来的连 接变成两个新的连接.方法:用鼠标滑轮单击欲插入新结点的两结点间的连线,按住它并把他拖到新结点时放手, 新的连接便生成. (在鼠标没有滑轮时亦可用alt键代替) 图十一 将连线拖向新结点图十二 生成两个新的连接 2.6删除连接 当某个连接不再需要时,我们可以通过以下三种方法将它删除: ①,选择待删除的连接,单击右键,从弹出菜单中选择Delete Connection; ②,选择待删除连接的结点,按F3键,删除了所有连接到该结点上的连接;③,选择待删除连接的结点,从主菜单中选择Edit Node Disconnect. 图十三 用右键删除连接 2.7数据流的执行 数据流结构构建好后要通过执行数据流数据才能从读入开始流向各个数据结点.执行数据 流的方法有以下三种:①,选择菜单栏中的按钮,数据流区域内的所有数据流将被执行;②,先选择要输出的数据流,再选择菜单栏中的按钮,被选的数据流将被执行; ③,选择要执行的数据流中的输出结点,单击鼠标右键,在弹出的菜单栏中选择Execute选项,执行被选中的数据流.图十四 执行数据流的方法三,模型建立在这部分我们将介绍五种分析方法的建立过程, 它们分别是因子分析, 关联分析, 聚类分析, 决策树分析和神经网络.为了方便大家练习,我们将采用Clementine自带的示例,这些示例在 demos文件夹中均可找到,它们的数据文件也在demos文件夹中.在模型建立过程中我们将介绍 各个结点的作用.1,因子分析(factor. str)示例factor.str是对孩童的玩具使用情况的描述,它一共有76个字段.过多的字段不仅增添了 分析的复杂性,而且字段之间还可能存在一定的相关性,于是我们无需使用全部字段来描述样 本信息.下面我们将介绍用Clementine进行因子分析的步骤: Step一:读入数据Source栏中的结点提供了读入数据的功能,由于玩具的信息存储为toy_train.sav,所以我们 需要使用SPSS File结点来读入数据.双击SPSS File结点使之添加到数据流程区内,双击添加到数据流程区里的SPSS File结点,由此来设置该结点的属性. 在属性设置时,单击Import file栏右侧的按钮,选择要加载到数据流中进行分析的文件,这 里选择toy_train.sav.单击Annotations页,在name栏中选择custom选项并在其右侧的文本框中输 入自定义的结点名称.这里我们按照原示例输入toy_train. Step二:设置字段属性进行因子分析时我们需要了解字段间的相关性,但并不是所有字段都需要进行相关性 分析,比如"序号"字段,所以需要我们将要进行因子分析的字段挑选出来.Field Ops栏中 的Type结点具有设置各字段数据类型,选择字段在机器学习中的的输入/输出属性等功能, 我们利用该结点选择要进行因子分析的字段.首先,将Type结点加入到数据流中,双击该 结点对其进行属性设置: 由上图可看出数据文件中所有的字段名显示在了Field栏中,Type表示了每个字段的数 据类型. 我们不需要为每个字段设定数据类型, 只需从Values栏中的下拉菜单中选择<Read> 项,然后选择Read Value键,软件将自动读入数据和数据类型;Missing栏是在数据有缺失 时选择是否用Blank填充该字段;Check栏选择是否判断该字段数据的合理性;而Direction 栏在机器学习模型的建立中具有相当重要的作用,通过对它的设置我们可将字段设为输入/ 输出/输入且输出/非输入亦非输出四种类型.在这里我们将前19个字段的Direction设置为 none,这表明在因子分析我们不将这前19个字段列入考虑,从第20个字段起我们将以后字 段的direction设置为In,对这些字段进行因子分析. Step三:对数据进行因子分析 因子分析模型在Modeling栏中用PCA/Factor表示.在分析过程中模型需要有大于或等 于两个的字段输入,上一步的Type结点中我们已经设置好了将作为模型输入的字段,这里 我们将PCA/Factor结点连接在Type结点之后不修改它的属性,默认采用主成分分析方法.在建立好这条数据流后我们便可以将它执行.右键单击PCA/Factor结点,在弹出的菜 单栏中选择Execute执行命令.执行结束后,模型结果放在管理器的Models栏中,其标记为 名称为PCA/Factor的黄色结点.右键单击该结果结点,从弹出的菜单中选择Browse选项查看输出结果.由结果可知参 与因子分析的字段被归结为了五个因子变量,其各个样本在这五个因子变量里的得分也在 结果中显示. Step四:显示经过因子分析后的数据表 模型的结果结点也可以加入到数据流中对数据进行操作.我们在数据流程区内选中 Type结点,然后双击管理器Models栏中的PCA/Factor结点,该结点便加入到数据流中. 为了显示经过因子分析后的数据我们可以采用Table结点,该结点将数据由数据表的形式输 出. 4.1为因子变量命名 在将PCA/Factor(结果)结点连接到Table结点之前,用户可以设置不需要显示的字段, 也可以更改因子变量名,为了达到这个目的我们可以添加Field Ops栏中的filter结点.在对filter结点进行属性设置时,Filter项显示了字段的过滤与否,如果需要将某个字段过滤,只需用鼠标单击Filter栏中的箭头,当箭头出现红“×”时该字段便被过滤。
Clementine在用户频繁访问路径挖掘中的应用

[ 摘要] 利用 Ce et e l ni 工具 实现 用户频繁访 问路径 的挖掘 , m n 包括数据预处理、 数据格 式转化 、 挖掘分析等 3个过程 。基 于
工具的挖掘 , 可大大缩减数据预 处理和序列挖掘 的时间。研 究证 明, 实现 用户频繁访 问路 径的 Ce et e l ni 挖掘 是一种行 之有 m n
[ yw rs We -o iig Ke o d ] b lgm nn ;We -o rpoes g f q e trvl ah l niem nn b l pe rcsi ; r u n ae p t;Ce t iig g n e t me n
We b日志挖掘 也被 称为 We 用记 录挖 掘 , b使 是
服务提供 前 摄 的 、 于 知 识 的 、 可 视 化 _ 的决 策 基 并 3
数 量庞 大而 且 存 在 大 量 噪 声 的原 始 We 日志 b 数据 , 格 式 上 和 内容 上 并 不 适 合 直 接 进 行 挖 掘 , 从 需要 经 过清 洗 、 滤 、 组 、 式 转 化 等 步 骤 , 化 过 重 格 转 成适 合挖 掘 的数 据格 式 , 以上统 称 为 We b日志 预处 理 。在整个 系统 处理 中, b日志预 处理 是 最苛 刻 、 We 最复杂 、 最耗 费时 间的工 作 。23的学者认 为 花 费在 /
(ntueo d a I om t n C ieeA ae yo eia Si cs B in 0 05, hn ) Istt f i Mei l n r ai , hns cd m f dc c ne , e ig10 0 C ia c f o M l e j
[ src] l et ecnb sdi a iig frqetr epts ic dn a rpoes g dt Abtat Ce ni a eue dt mnn eun a l ah,nl igdtpercsi , a m n n a of tv u a n a
数据挖掘Clementine应用实务(上)

12 数据仓库、KDD、数据挖掘的关系
许多人对于数据仓库和数据挖掘时常混淆,不知如何分辨。其实,数据仓库是数据库技术的一 个新主题,在数据库技术日ቤተ መጻሕፍቲ ባይዱ普及的情况下,利用计算机系统帮助我们操作、计算和思考,随着操作 方式改变,决策方式也跟着改变。另外,决策支持系统和主管信息系统也日渐普遍,它们操作数据 的方式不尽相同,因而有必要把操作性数据库和数据仓库分隔开来,利用不同数据库系统与技术操 作,才能达到系统优化。由于关系数据库、平行处理及分布式数据库技术的进步,不论是主从式架 构或主机型架构的数据库系统,数据仓库技术皆可以利用原有操作或已有的系统,进而提供一个稳 固的基础以支持全公司的决策支持系统(DSS)。
关于数据挖掘……
乐观的说法……Berry和 Linoff(1997)
分析报告给你后见之明 统计分析给你先机 数据挖掘(DataMining)给你洞察 这三者都是在已有的数据上作分析,在概念上应该并无优劣,差别只是手上的数据大小与性质。 所以,方法不同才有定义的不同。
负面的定义……FriedmanJ(1997)
11 何谓数据挖掘
数据挖掘是指寻找隐藏 在数 据 中 的 信 息 (如 趋 势 (Trend)、特 征 (Pattern)及 相 关 性 (Relation ship))的过程,也就是从数据中发掘信息或知识 KDD(KnowledgeDiscoveryinDatabases),也有人称 为“数 据 考 古学”(DataArchaeology)、“数 据 模 式 分 析”(DataPatternAnalysis)或 “功 能 相 依 分 析” (FunctionalDependencyAnalysis),目前,许多研究人员把它视为结合数据库系统与机器学习技术的 重要领域,许多产业界人士也认为此领域是一项增加各企业潜能的重要指标。此领域蓬勃发展的原 因:现代的企业经常搜集大量数据,包括市场、客户、供货商、竞争对手以及未来趋势等重要信息, 但是信息超载与无结构化使得企业决策部门无法有效利用现存的信息,甚至使决策行为产生混乱与 误用。如果能通过数据挖掘技术,从大容量的数据库中,发掘出不同的信息与知识作为决策支持之 用,必能产生企业的竞争优势。
Clementine12.0操作

分割,如将样本分为训练集合测试集。
图形(Graphs)选项卡中的Plot节点和Multiplot节点。 Plot节点指定X和Y轴的变量(每个坐标轴只能指定一个变量),描画相应的散点图; Multiplot节点指定X和Y轴的变量,Y轴变量可以是多个,描画相应的折线图。
2015/10/8
9
总体介绍
41
建模指导-回归
智慧数据 财富未来
第二步:创建流
2015/10/8
42
建模指导-回归 第三步:设置参数
智慧数据 财富未来
2015/10/8
43
建模指导-回归
智慧数据 财富未来
2015/10/8
44
建模指导-回归 第四步:生成模型
智慧数据 财富未来
2015/10/8
45
建模指导-回归
智慧数据 财富未来
13
建模指导-分类
智慧数据 财富未来
输入项:购买量、保养情况、车门数、 座位数、底盘、安全性
输出项:汽车类别
2015/10/8
14
建模指导-分类 第一步:导入数据
智慧数据 财富未来
2015/10/8
15
建模指导-分类
智慧数据 财富未来
第二步:创建流
2015/10/8
16
建模指导-分类 第三步:设置参数
3.设置节点参数。
节点是用来处理数据的,需要对某些节点针对数据处理的方式设置参数。双击相应节点,或者右击 相应节点,选择弹出菜单中的Edit即可。
4.执行数据流。
当数据流建立完成后,若要得到数据分析结果,则需要执行数据流。选择主菜单Tools->Execute,
或右击会得结果的节点,选择弹出菜单中的Execute。
《基于Clementine的数据挖掘》课件—05决策树2

模型的对比分析
选择通用指标评价:如误差、收益率、提升度等 Analysis节点:用于评价单个模型
区分预测置信度和倾向性得分。通常倾向性得 分高于0.5,则可判断其预测类别为Yes。决 策树中仅根据预测置信度无法判断预测类别
在逻辑回归中,一般置信水平越高,预测正确 率会越高,但通常不分析置信水平和预测正确 率的关系,原因是分析结果是一个模型
随着值增大,得到子树序列。它们的复杂度 依次降低,但代价复杂度的变化情况并不确定
CART:剪枝算法
剪枝过程 选择k个子树中代价复杂度最低的子树,也可 以允许考虑误差项
放大因子
R(Topt ) min k R (Tk ) m SE(R(Tk ))
SE(R(Tk ))
R(Tk )(1 R(Tk )) N'
收益(Gains):模型对数据规律提炼的能力 利润(Profit):财务角度反映模型价值 角度:每条推理规则、决策树整体
效益评价:收益评价(单个节点)
收益:对具有某类特征的数据,输入和输出变量 取值规律的提炼的能力 针对用户关心的“目标”类别。例:流失yes
收益评价指标 【收益:n】:节点中样本属目标类别的样本量 【响应(%)】:节点中样本属目标类别的样本 量占本节点样本的百分比(置信程度) 【收益(%)】:节点中样本属目标类别的样本 量占目标类别总样本的百分比(适用广泛性)
决策树得到是模型集合,为评价哪些模型更好 ,应分析置信水平和预测正确率的关系
模型的对比分析
Analysis节点: 给出各种情况下的置信水平 预测正确(错误)的规则的平均置信度 置信度到达怎样水平时,预测正确率将达 到怎样的程度
Analysis节点:用于不同模型的对比评价
参附注射液治疗冠心病临床用药方案实效研究

参附注射液治疗冠心病临床用药方案实效研究目的:了解参附注射液治疗冠心病的临床应用情况,为参附注射液治疗冠心病的规范用药方案和最佳用药组合提供参考。
方法:采集全国20家大型三甲医院信息系统(hospital information system ,HIS)中使用过参附注射液的冠心病患者信息,运用基本统计方法对参附注射液的用法用量、用药疗程进行分析,运用关联规则对合并用药等信息进行统计分析,并对常用组合与其他组合进行对比。
结果:参附注射液治疗冠心病为静脉给药,单次给药剂量多为60 mL;疗程一般3~7 d;最常用组合为参附注射液+氢氯吡格雷+阿司匹林+硝酸异山梨酯。
结论:参附注射液在临床应用中绝大多数符合药品说明书,治疗冠心病的用药方案有一定规律。
标签:参附注射液;临床用药方案;实效研究参附注射液是由红参、附片组成的中药制剂,药品说明书中记载其具有益气温阳,回阳救逆,益气固脱的功效。
主要用于治疗各型休克及心脏疾病,是冠心病治疗的临床常用药物。
为了解参附注射液临床治疗冠心病的实际运用情况,本研究在对全国20家大型三甲医院的信息系统(hospital information system,HIS)中使用过参附注射液的全人群进行分析的基础上[1],进一步分析冠心病住院患者信息,运用关联规则的方法对参附注射液治疗冠心病的用法用量、用药疗程及合并用药等信息进行统计分析,以期得到参附注射液治疗冠心病的用药规律及合并用药方案,为规范使用参附注射液治疗冠心病提供参考。
1 材料与方法1.1 数据来源本研究选取来自全国20家三甲综合医院HIS数据库中使用过参附注射液并诊断为冠心病患者信息,共计3 150人。
1.2 数据标准化及规范化处理本研究的数据来源于多家医院,各医院在同一项目中所采用的标准不尽相同,为便于分析,需对数据进行规范化。
将数据库中记录为商品名称的化学药物转化为化学通用名称,再将同种化学药物合并;对于中成药,将同种药物成分但剂型不同者合并,其他中成药保留原始名称,对合并用药的分析均基于标准化后的数据。
中药面膜治疗寻常型痤疮的用药规律

中药面膜治疗寻常型痤疮的用药规律杨璐;吕素;张丽;潘焕焕;陈茜;岳婷;卢改会【期刊名称】《中医学报》【年(卷),期】2024(39)3【摘要】目的:分析中药面膜治疗寻常型痤疮的用药规律。
方法:通过检索中国知网、万方、读秀、维普、中国生物医学文献数据库中2013年5月5日至2022年5月5日包含中药面膜治疗痤疮的处方文献,并对其进行数据挖掘。
运用Excel 2016软件建立中药数据库,采用Clementine 12.0以及SPSS 25.0软件中的聚类分析和关联规则分析方法。
结果:通过对中药面膜治疗寻常型痤疮的临床文献进行检索并整理,最终纳入符合标准的文献181篇,共涉及181首方剂,189味中药,其中高频药物(≥40次)共11味,以大黄最常见,药性以寒、微寒为主,药味以苦、微苦居多,归经以肝经最多;高频药物聚类分析可划分为3类,分别为清热类(蒲公英、野菊花、丹参、连翘、金银花、黄芩、黄连、黄柏)、消肿散结止痛类(白芷)、解毒疗疮类(大黄、苦参),其中以清热类药物使用频次最高,占比69.37%;关联规则的中药处方分析表明,支持率最高的是大黄-丹参;大黄和白芷是置信率最高的组合。
结论:治疗寻常型痤疮的中药面膜组方以苦寒之药清热解毒为主,兼有疏调气血、消瘀散结之功。
【总页数】4页(P675-678)【作者】杨璐;吕素;张丽;潘焕焕;陈茜;岳婷;卢改会【作者单位】河南中医药大学第一附属医院;河南中医药大学【正文语种】中文【中图分类】R275.933【相关文献】1.中药面膜与痤疮饮治疗寻常型痤疮82例2.中药面膜与痤疮饮治疗寻常型痤疮120例3.自身菌苗配合中药熏蒸和中药面膜治疗寻常型痤疮的临床体会4.中药内服加自拟中药面膜倒模治疗寻常型痤疮临床观察5.中药面膜治疗寻常痤疮用药规律的数据挖掘研究因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一Clementine12.0数据挖掘分析方法与应用一、[实验目的]熟悉Clementine12.0进行数据挖掘的基本操作方法与流程,对实际的问题能熟练利用Clementine12.0开展数据挖掘分析工作。
二、[知识要点]1、数据挖掘概念;2、数据挖掘流程;3、Clementine12.0进行数据挖掘的基本操作方法。
三、[实验内容与要求]1、熟悉Clementine12.0操作界面;2、理解工作流的模型构建方法;3、安装、运行Clementine12.0软件;4、构建挖掘流。
四、[实验条件]Clementine12.0软件。
五、[实验步骤]1、主要数据挖掘模式分析;2、数据挖掘流程分析;3、Clementine12.0下载与安装;4、Clementine12.0功能分析;5、Clementine12.0决策分析实例。
六、[思考与练习]1、Clementine12.0软件进行数据挖掘的主要特点是什么?2、利用Clementine12.0构建一个关联挖掘流(购物篮分析)。
实验部分一、Clementine简述Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台,Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比,Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
为了解决各种商务问题,企业需要以不同的方式来处理各种类型迥异的数据,相异的任务类型和数据类型就要求有不同的分析技术。
Clementine提供最出色、最广泛的数据挖掘技术,确保可用最恰当的分析技术来处理相应的问题,从而得到最优的结果以应对随时出现的商业问题。
即便改进业务的机会被庞杂的数据表格所掩盖,Clementine也能最大限度地执行标准的数据挖掘流程,为您找到解决商业问题的最佳答案。
为了推广数据挖掘技术,以解决越来越多的商业问题,SPSS和一个从事数据挖掘研究的全球性企业联盟制定了关于数据挖掘技术的行业标准--CRISP-DM (Cross-Industry Standard Process for Data Mining)。
与以往仅仅局限在技术层面上的数据挖掘方法论不同,CRISP-DM把数据挖掘看作一个商业过程,并将其具体的商业目标映射为数据挖掘目标。
最近一次调查显示,50%以上的数据挖掘工具采用的都是CRISP-DM的数据挖掘流程,它已经成为事实上的行业标准。
Clementine完全支持CRISP-DM标准,这不但规避了许多常规错误,而且其显著的智能预测模型有助于快速解决出现的问题。
在数据挖掘项目中使用Clementine应用模板(CATs)可以获得更优化的结果。
应用模板完全遵循CRISP-DM标准,借鉴了大量真实的数据挖掘实践经验,是经过理论和实践证明的有效技术,为项目的正确实施提供了强有力的支撑。
Clementine中的应用模板包括:(1)CRM CAT--针对客户的获取和增长,提高反馈率并减少客户流失;(2)Web CAT--点击顺序分析和访问行为分析;(3)cTelco CAT--客户保持和增加交叉销售;(4)Crime CAT--犯罪分析及其特征描述,确定事故高发区,联合研究相关犯罪行为;(5)Fraud CAT--发现金融交易和索赔中的欺诈和异常行为;(6)Microarray CAT--研究和疾病相关的基因序列并找到治愈手段。
利用Clementine,可以在如下几方面提供解决方案:(1)公共部门。
各国政府都使用数据挖掘来探索大规模数据存储,改善群众关系,侦测欺诈行为(譬如洗黑钱和逃税),检测犯罪行为和恐怖分子行为模式以及进一步扩展电子政务领域。
(2)CRM。
客户关系管理可以通过对客户类型的智能分类和客户流失的准确预测而得到提高。
Clementine 已成功帮助许多行业的企业吸引并始终保有最有价值的客户。
(3)Web 挖掘。
Clementine 包含的相关工具具有强大的顺序确定和预测算法,对于准确发现网站浏览者的行为以及提供精确满足浏览者需求的产品或信息而言,这些工具是不可或缺的。
从数据准备到构建模型,全部的数据挖掘过程均可在Clementine 内部操控。
(4)药物发现和生物信息学。
通过对由试验室自动操作获得的大量数据进行分析,数据挖掘有助于药物和基因组的研究。
聚类和分类模型帮助从化合物库中找出线索,与此同时顺序检测则有助于模式的发现。
二、Clementine数据挖掘的基本思想数据挖掘(Data Mining)是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,它是一种深层次的数据分析方法。
随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法。
它结合了人工智能(AI)和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题。
Clementine为我们提供了大量的人工智能、统计分析的模型(神经网络,关联分析,聚类分析、因子分析等),并用基于图形化的界面为我们认识、了解、熟悉这个软件提供了方便。
除了这些,Clementine还拥有优良的数据挖掘设计思想,正是因为有了这个工作思想,我们每一步的工作也变得很清晰。
Clementine 遵循CRISP-DM Model(Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程),具体如图所示。
图4.1 CRISP-DM process model如图可知,CRISP-DM Model包含了六个步骤,并用箭头指示了步骤间的执行顺序。
这些顺序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行。
通过对该步骤的执行,我们也涵盖了数据挖掘的关键部分。
1.商业理解商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段里我们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。
Clementine的可视化操作界面使得企业可以更容易地把业务知识应用到数据挖掘项目中。
此外,使用针对特定商业目标的Clementine应用模板(CATs),可以在数据挖掘工作中使用成熟的、最佳的方法。
CATs使用的样本数据可以以平面文件或者关系型数据库表的形式安装。
■ 客户关系管理(CRM)CAT*■ 电信CAT*■ 欺诈探测CAT*■ 微阵列CAT*■ 网页挖掘CAT* (需要购买Web Mining for Clementine)2.数据理解数据是我们挖掘过程的“原材料”,在数据理解过程中我们要知道都有些什么数据,这些数据的特征是什么,可以通过对数据的描述性分析得到数据的特点。
使用Clementine,可以做到:■ 使用Clementine的数据审核节点获取对数据的初步认识;■ 通过图形、统计汇总或数据质量评估快速浏览数据;■ 创建基本的图表类型,如直方图、分布图、线形图和点状图;■ 在图形面板节点中通过自动帮助方式创建比过去更多的基本图形及高级图形;■ 通过表格定制节点轻松创建复杂的交叉表;■ 编辑图表使分析结果交流变得更容易;■ 通过可视化联接技术分析数据的相关性;■ 与数据可视化互动,可在图形中选择某个区域或部分数据,然后对选择的数据部分再进行观察或在后续分析中使用这些信息;■ 在Clementine中直接使用SPSS统计分析、图形以及报表功能。
3.数据准备在数据准备阶段我们需要对数据作出选择、清洗、重建、合并等工作。
选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。
运用Clementine,可以做到:(1)访问数据–---结构化(表格) 数据■ 通过SPSS Data Access Pack访问支持ODBC的数据源,包括IBM DB2,Oracle,Microsoft SQL Server,Informix和Sybase数据库;■ 导入用分隔符分隔和固定宽度的文件,任何SPSS的文件,SAS 6, 7, 8, 和9文件;■ 在读取Excel文件时,可以限定工作表和数据范围。
–---非结构化(原文) 数据■ 使用Text Mining for Clementine自动从任何类型的文本中提取各种概念。
– ---网站数据■ 使用Web Mining for Clementine自动从网络日志中提取网站上的事件。
–----调查数据■ 直接访问存储在Dimensions数据模型或Dimensions*产品中的数据文件。
–--- 数据输出■ 可以输出为分隔符分隔,固定宽度的文件,所有主流数据库数据,Microsoft Excel,SPSS,和SAS 6,7,8和9文件;■ 使用Excel导出节点导出成XLS格式;■ 为市场调研输出数据到Dimensions中。
(2)各种数据清洗选项–移出或者替换无效数据–使用预测模型自动填充缺失值–自动侦测及处理异常值或极值(3)数据处理–--- 完整的记录和字段操作,包括:■ 字段过滤、命名、导出、分段、重新分类、值填充以及字段重排;■ 对记录进行选择、抽样(包括簇与分层抽样)、合并(内连接、完全外连接、部分外连接以及反连接)和追求;排序、聚合和平衡;■ 数据重新结构化,包括转置;■ 分段节点能够根据预测值对数字值进行最优分段;■ 使用新的字符串函数:字符串创建、取子字符串、替换、查询和匹配、空格移除以及截断;■ 使用时间区间节点为时间序列分析做准备;–--- 将数据拆分成训练、测试和验证集。
–--- 对多个变量自动进行数据转换。
■ 可视化的标准数据转换–---数据转换在Clementine中直接使用SPSS数据管理和转换功能;■ RFM评分:对客户交易进行汇总,生成与最近交易日期、交易频度以及交易金额相关的评分,并对这些评分进行组合,从而完成完整的RFM分析过程。
4.建模建模过程也是数据挖掘中一个比较重要的过程。
需要根据分析目的选出适合的模型工具,通过样本建立模型并对模型进行评估。
Clementine提供了非常广泛的数据挖掘算法以及更多高级功能,从而帮助企业从数据中得到尽可能最优的结果。