梯度下降法理论及部分代码实现
matlab梯度算法

matlab梯度算法Matlab梯度算法在数学和计算机科学中,梯度是指一个多元函数在某一点上的变化率或斜率。
梯度算法是一种优化算法,用于找到函数的最小值或最大值。
在Matlab中,有多种方法可以使用梯度算法来优化函数,包括梯度下降和共轭梯度法。
本文将详细介绍Matlab中的梯度算法,并逐步讲解其原理和应用。
I. 梯度下降法梯度下降法是一种基于迭代的优化算法,通过计算函数的梯度来更新参数的值,以逐步接近函数的最小值。
在Matlab中,可以使用"gradientDescent"函数来实现梯度下降法。
1. 实现梯度下降法首先,我们需要定义一个优化目标函数,例如:f(x) = x^2 + 2x + 1。
然后,定义其梯度函数为g(x) = 2x + 2。
接下来,我们可以使用以下代码来计算梯度下降:matlab定义优化目标函数f = (x) x^2 + 2*x + 1;定义梯度函数g = (x) 2*x + 2;初始化参数x0 = 0;设置学习率和迭代次数alpha = 0.01;iterations = 100;梯度下降法for i = 1:iterationsx0 = x0 - alpha * g(x0);end打印最优解disp(['Optimal solution: ', num2str(x0)]);在这个例子中,我们使用了学习率(alpha)为0.01,迭代次数(iterations)为100。
通过不断更新参数x0的值,最终得到了最优解。
2. 梯度下降法的原理梯度下降法的核心思想是利用函数在当前点的梯度信息来更新参数的值,以便能够向着函数的最小值前进。
具体来说,算法的步骤如下:a. 初始化参数的值:选择一个初始参数的值作为起始点。
b. 计算梯度:计算函数在当前点的梯度,即求解函数关于参数的偏导数。
c. 更新参数:根据当前点的梯度和学习率,通过减去梯度的乘积来更新参数的值。
梯度下降法实验报告

梯度下降法实验报告梯度下降法是一种优化算法,常用于机器学习中的参数优化问题。
本次实验旨在通过使用梯度下降法求解线性回归模型的参数,加深对算法的理解和实践。
实验过程分为以下几步:1. 数据准备为了方便起见,我们从sklearn库中导入波士顿房价数据集,共506条样本,13个特征和1个目标值即房价。
2. 模型搭建我们使用线性回归模型来进行预测,其公式为 y = Wx+b,其中y为预测值,W和b为要求解的模型参数,x为输入的特征向量。
在此之前,我们需要对数据进行归一化处理,保证各维度特征之间的比较公平。
3. 损失函数设计我们使用均方误差(mean squared error,MSE)作为模型的损失函数,其公式为:$\frac{1}{n}\sum_{i=1}^{n}{(y_i-\hat{y}_i)^2}$,其中$n$为样本数,$y_i$为真实值,$\hat{y}_i$为预测值。
我们的目标是最小化损失函数。
4. 梯度计算通过对损失函数求导,可以得到每个参数的梯度值,即损失函数对参数的变化率。
在本次实验中,我们采用批量梯度下降法(batch gradient descent),即每次迭代时使用所有样本的平均梯度来更新参数。
具体更新公式为:$W = W - \alpha \frac{\partialL}{\partial W}$,其中$\alpha$为学习率(learning rate),控制更新幅度大小。
5. 参数求解按照迭代次数,反复进行梯度计算和参数更新,直到模型收敛(即损失函数不再明显降低)。
下面是完整的实验代码:```import numpy as npfrom sklearn.datasets import load_bostonfrom sklearn.preprocessing import StandardScaler# 数据准备data = load_boston()x = data.datay = data.target# 归一化处理scaler = StandardScaler()x = scaler.fit_transform(x)# 模型搭建W = np.zeros(x.shape[1]) # 初始化权重b = np.zeros(1) # 初始化偏置learning_rate = 0.001 # 学习率num_epochs = 1000 # 迭代次数# 损失函数设计def mse_loss(y_true, y_pred):return np.mean((y_true - y_pred) ** 2)# 梯度计算def grad(x, y_true, y_pred):dw = np.dot(x.T, y_pred - y_true) / len(x)db = np.mean(y_pred - y_true)return dw, db# 模型训练for epoch in range(num_epochs):y_pred = np.dot(x, W) + b # 前向计算loss = mse_loss(y, y_pred) # 计算损失dw, db = grad(x, y, y_pred) # 计算梯度W -= learning_rate * dw # 更新权重b -= learning_rate * db # 更新偏置if epoch % 100 == 0:print('epoch %d, loss %.4f' % (epoch, loss))# 测试模型x_test = np.array([[0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2, 1.3]])x_test = scaler.transform(x_test)y_test = np.dot(x_test, W) + bprint('predicted value:', y_test)```运行结果如下:```epoch 0, loss 592.1469epoch 100, loss 28.8471epoch 200, loss 25.0884epoch 300, loss 22.4019epoch 400, loss 20.1854epoch 500, loss 18.3634epoch 600, loss 16.8751epoch 700, loss 15.6636epoch 800, loss 14.6823epoch 900, loss 13.8919predicted value: [[23.32270733]]```从运行结果中可以看出,经过1000次迭代后,模型的损失值稳定在较低水平,预测值也接近真实值。
梯度下降法(例题待完成)

梯度下降法(例题待完成)梯度下降法:梯度:在微积分中,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
⽐如函1.梯度:数f( x, y ), 分别对x ,y求偏导数,求得的梯度向量就是(∂f/∂x, ∂f/∂y)T,简称grad f( x, y )或者▽f( x, y )。
对于在点(x0,y0)的具体梯度向量就是(∂f/∂x0, ∂f/∂y0)T或者▽f(x0,y0),如果是3个参数的向量梯度,就是(∂f/∂x, ∂f/∂y,∂f/∂z)T,以此类推。
这个梯度向量的意义从⼏何意义上讲,就是函数变化增加最快的地⽅。
具体来说,对于函数f ( x, y ),在点(x0,y0)沿着梯度向量的⽅向就是f( x, y )增加最快的地⽅。
或者说,沿着梯度向量的⽅向,更加容易找到函数的最⼤值。
反过来说,沿着梯度向量相反的⽅向,也就是 -(∂f/∂x0, ∂f/∂y0)T的⽅向,梯度减少最快,也就是更加容易找到函数的最⼩值。
2.梯度算法原理:3.例题:求f(x1,x2)=(1-x1)^2+100*(x2-x1^2)^2的最⼩值。
(暂时还不会做)参考算法1(别的题⽬的):%求解的初值的函数值Max x = x;maxfx = feval_r(f,x);dist = dist0;%迭代计算求最优解for k = 1: MaxIterg = feval_r(grad,x); %求梯度g = grm(g); %求在x处的梯度⽅向x=x-dist*g;%求新的x0fx = feval_r(f,x);%求新的fx0if fxmaxx=x;maxfx=fx;endendendJoshua Black 2017/09/22 10:09:19clc;clear;f1=inline('x(1)^2+4*x(2)^2','x');%⽬标函数grad=inline('[2*x(1),8*x(2)]','x');%⽬标函数的梯度函数x0=[1 1];%x0为搜索初始值MaxIter=100;%MaxIter为最⼤迭代次数dist0=0.1;%dist0为初始步长[xo,fo]=Opt_Steepest(f1,grad,x0,dist0,MaxIter);%xo为最优值点,fo为函数在点xo处的函数值disp(xo);disp(fo);参考算法2(俱乐部部长分享的c++语句):。
《统计学习方法》梯度下降的两种应用场景

《统计学习⽅法》梯度下降的两种应⽤场景这⼏天在看《统计学习⽅法》这本书,发现梯度下降法在感知机等机器学习算法中有很重要的应⽤,所以就特别查了些资料。
⼀.介绍梯度下降法(gradient descent)是求解⽆约束最优化问题的⼀种常⽤⽅法,有实现简单的优点。
梯度下降法是迭代算法,每⼀步需要求解⽬标函数的梯度向量。
⼆.应⽤场景1.给定许多组数据(x i, y i),x i (向量)为输⼊,y i为输出。
设计⼀个线性函数y=h(x)去拟合这些数据。
2.感知机:感知机(perceptron)为⼆类分类的线性分类模型。
输⼊为实例的特征向量,输出为实例的类别,取+1 和 -1 ⼆值。
下⾯分别对这两种应⽤场景进⾏分析。
1.对于第⼀种场景:既然是线性函数,在此不妨设为 h(x) = w0*x0 + w1*x1。
此时我们遇到的问题就是如何确定w0和w1这两个参数,即w=(w0,w1)这个向量。
既然是拟合,则拟合效果可以⽤平⽅损失函数:E(w)=∑ [ h(x)- y ] ^2 / 2 来衡量。
其中w是权重⼆维向量,x是输⼊⼆维向量,x和y都是训练集的数据,即已知。
⾄于后⾯除于2只是为了之后的推导过程中对E求导时候可以消除系数,暂时可以不管。
因此该问题变成了求E(w)最⼩值的⽆约束最优化问题2.对于第⼆种场景:假设输⼊空间(特征向量)为x,输出空间为y = {+1, -1},由输⼊空间到输出空间的如下函数f(x) = sign(w · x + b) w∈R n其中 w 叫做权值或者权值向量, b叫做偏振。
w · x 表⽰向量w和x的点积感知机sign(w · x + b)的损失函数为 L(w, b) = -∑y i(w · x i + b) x ∈M, M为误分类点集合。
因此该问题变成了求L(w, b)最⼩值的⽆约束最优化问题三.梯度下降⽅法梯度其实就是⾼数求导⽅法,对E这个公式针对每个维数(w0,w1)求偏导后的向量▽E(w)=(∂E/∂w0,∂E/∂w1)1. 对于第⼀种场景对E这个公式针对每个维数(w0,w1)求偏导后的向量▽E(w)=(∂E/∂w0,∂E/∂w1)梯度为最陡峭上升的⽅向,对应的梯度下降的训练法则为: w=w-η▽E(w) 这⾥的η代表学习速率,决定梯度下降搜索中的步长。
神经网络中BP算法的原理与Python实现源码解析

神经⽹络中BP算法的原理与Python实现源码解析最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能⼒有限,若有明显错误,还请指正。
什么是梯度下降和链式求导法则假设我们有⼀个函数 J(w),如下图所⽰。
梯度下降⽰意图现在,我们要求当 w 等于什么的时候,J(w) 能够取到最⼩值。
从图中我们知道最⼩值在初始位置的左边,也就意味着如果想要使 J(w) 最⼩,w的值需要减⼩。
⽽初始位置的切线的斜率a > 0(也即该位置对应的导数⼤于0),w = w – a 就能够让 w 的值减⼩,循环求导更新w直到 J(w) 取得最⼩值。
如果函数J(w)包含多个变量,那么就要分别对不同变量求偏导来更新不同变量的值。
所谓的链式求导法则,就是求复合函数的导数:链式求导法则放个例题,会更加明⽩⼀点:链式求导的例⼦神经⽹络的结构神经⽹络由三部分组成,分别是最左边的输⼊层,隐藏层(实际应⽤中远远不⽌⼀层)和最右边的输出层。
层与层之间⽤线连接在⼀起,每条连接线都有⼀个对应的权重值 w,除了输⼊层,⼀般来说每个神经元还有对应的偏置 b。
神经⽹络的结构图除了输⼊层的神经元,每个神经元都会有加权求和得到的输⼊值 z 和将 z 通过 Sigmoid 函数(也即是激活函数)⾮线性转化后的输出值 a,他们之间的计算公式如下神经元输出值 a 的计算公式其中,公式⾥⾯的变量l和j表⽰的是第 l 层的第 j 个神经元,ij 则表⽰从第 i 个神经元到第 j 个神经元之间的连线,w 表⽰的是权重,b 表⽰的是偏置,后⾯这些符号的含义⼤体上与这⾥描述的相似,所以不会再说明。
下⾯的 Gif 动图可以更加清楚每个神经元输⼊输出值的计算⽅式(注意,这⾥的动图并没有加上偏置,但使⽤中都会加上)动图显⽰计算神经元输出值使⽤激活函数的原因是因为线性模型(⽆法处理线性不可分的情况)的表达能⼒不够,所以这⾥通常需要加⼊ Sigmoid 函数来加⼊⾮线性因素得到神经元的输出值。
三元函数梯度下降matlab代码

三元函数梯度下降 Matlab 代码一、引言在数学和计算机科学领域,梯度下降是一种常用的优化算法,用于最小化一个函数的值。
对于多元函数,我们可以使用梯度下降算法来求解函数的最小值点。
在本篇文章中,我将着重讨论三元函数的梯度下降,并共享针对该算法的 Matlab 代码实现。
二、梯度下降算法简介梯度下降是一种迭代优化算法,其基本思想是通过不断沿着函数梯度的相反方向更新参数,直到达到函数的最小值点。
对于三元函数,我们需要求解的是函数在三维空间中的最小值点,而梯度下降算法就能很好地实现这一目标。
三、三元函数的梯度下降 Matlab 代码实现我们首先定义一个三元函数,例如 f(x, y, z) = x^2 + y^2 + z^2,然后编写Matlab 代码来实现梯度下降算法。
以下是一个简单的示例:```matlab% 定义三元函数function f = three_variable_function(x, y, z)f = x^2 + y^2 + z^2;end% 梯度下降算法实现function [min_point, min_value] = gradient_descent() learning_rate = 0.1; % 学习率max_iterations = 1000; % 最大迭代次数precision = 0.0001; % 收敛精度x = 3; % 初值y = 4;z = 5;for i = 1:max_iterationsgrad_x = 2*x; % 计算梯度grad_y = 2*y;grad_z = 2*z;x = x - learning_rate * grad_x; % 参数更新y = y - learning_rate * grad_y;z = z - learning_rate * grad_z;f_val = three_variable_function(x, y, z); % 计算函数值 if abs(f_val) < precision % 判断收敛break;endendmin_point = [x, y, z]; % 最小值点min_value = f_val; % 最小值end```以上代码中,我们首先定义了一个简单的三元函数three_variable_function,并在 gradient_descent 函数中实现了梯度下降算法,最终得到了函数的最小值点和最小值。
deeplearning tutorial (2) 原理简介+代码详解

deeplearning tutorial (2) 原理简介+代码详解【原创实用版】目录一、Deep Learning 简介二、Deep Learning 原理1.神经网络2.梯度下降3.反向传播三、Deep Learning 模型1.卷积神经网络(CNN)2.循环神经网络(RNN)3.生成对抗网络(GAN)四、Deep Learning 应用实例五、Deep Learning 代码详解1.TensorFlow 安装与使用2.神经网络构建与训练3.卷积神经网络(CNN)实例4.循环神经网络(RNN)实例5.生成对抗网络(GAN)实例正文一、Deep Learning 简介Deep Learning 是一种机器学习方法,其主要目标是让计算机模仿人脑的工作方式,通过多层次的抽象表示来理解和处理复杂的数据。
Deep Learning 在图像识别、语音识别、自然语言处理等领域取得了显著的成果,成为当前人工智能领域的研究热点。
二、Deep Learning 原理1.神经网络神经网络是 Deep Learning 的基本构成单元,它由多个神经元组成,每个神经元接收一组输入信号,根据权重和偏置计算输出信号,并将输出信号传递给其他神经元。
神经网络通过不断调整权重和偏置,使得模型能够逐渐逼近目标函数。
2.梯度下降梯度下降是一种优化算法,用于求解神经网络的权重和偏置。
梯度下降算法通过计算目标函数关于权重和偏置的梯度,不断更新权重和偏置,使得模型的预测误差逐渐减小。
3.反向传播反向传播是神经网络中计算梯度的一种方法。
在训练过程中,神经网络根据实际输出和预期输出的误差,按照梯度下降算法计算梯度,然后沿着梯度反向更新权重和偏置,使得模型的预测误差逐渐减小。
三、Deep Learning 模型1.卷积神经网络(CNN)卷积神经网络是一种特殊的神经网络,广泛应用于图像识别领域。
CNN 通过卷积层、池化层和全连接层等操作,对图像进行特征提取和分类,取得了在图像识别领域的突破性成果。
python使用梯度下降和牛顿法寻找Rosenbrock函数最小值实例

python使⽤梯度下降和⽜顿法寻找Rosenbrock函数最⼩值实例Rosenbrock函数的定义如下:其函数图像如下:我分别使⽤梯度下降法和⽜顿法做了寻找Rosenbrock函数的实验。
梯度下降梯度下降的更新公式:图中蓝⾊的点为起点,橙⾊的曲线(实际上是折线)是寻找最⼩值点的轨迹,终点(最⼩值点)为 (1,1)(1,1)。
梯度下降⽤了约5000次才找到最⼩值点。
我选择的迭代步长α=0.002α=0.002,αα没有办法取的太⼤,当为0.003时就会发⽣振荡:⽜顿法⽜顿法的更新公式:Hessian矩阵中的每⼀个⼆阶偏导我是⽤⼿算算出来的。
⽜顿法只迭代了约5次就找到了函数的最⼩值点。
下⾯贴出两个实验的代码。
梯度下降:import numpy as npimport matplotlib.pyplot as pltfrom matplotlib import tickerdef f(x, y):return (1 - x) ** 2 + 100 * (y - x * x) ** 2def H(x, y):return np.matrix([[1200 * x * x - 400 * y + 2, -400 * x],[-400 * x, 200]])def grad(x, y):return np.matrix([[2 * x - 2 + 400 * x * (x * x - y)],[200 * (y - x * x)]])def delta_grad(x, y):g = grad(x, y)alpha = 0.002delta = alpha * greturn delta# ----- 绘制等⾼线 -----# 数据数⽬n = 256# 定义x, yx = np.linspace(-1, 1.1, n)y = np.linspace(-0.1, 1.1, n)# ⽣成⽹格数据X, Y = np.meshgrid(x, y)plt.figure()# 填充等⾼线的颜⾊, 8是等⾼线分为⼏部分plt.contourf(X, Y, f(X, Y), 5, alpha=0, cmap=plt.cm.hot)# 绘制等⾼线C = plt.contour(X, Y, f(X, Y), 8, locator=ticker.LogLocator(), colors='black', linewidth=0.01) # 绘制等⾼线数据plt.clabel(C, inline=True, fontsize=10)# ---------------------x = np.matrix([[-0.2],[0.4]])tol = 0.00001xv = [x[0, 0]]yv = [x[1, 0]]plt.plot(x[0, 0], x[1, 0], marker='o')for t in range(6000):delta = delta_grad(x[0, 0], x[1, 0])if abs(delta[0, 0]) < tol and abs(delta[1, 0]) < tol:breakx = x - deltaxv.append(x[0, 0])yv.append(x[1, 0])plt.plot(xv, yv, label='track')# plt.plot(xv, yv, label='track', marker='o')plt.xlabel('x')plt.ylabel('y')plt.title('Gradient for Rosenbrock Function')plt.legend()plt.show()⽜顿法:import numpy as npimport matplotlib.pyplot as pltfrom matplotlib import tickerdef f(x, y):return (1 - x) ** 2 + 100 * (y - x * x) ** 2def H(x, y):return np.matrix([[1200 * x * x - 400 * y + 2, -400 * x],[-400 * x, 200]])def grad(x, y):return np.matrix([[2 * x - 2 + 400 * x * (x * x - y)],[200 * (y - x * x)]])def delta_newton(x, y):alpha = 1.0delta = alpha * H(x, y).I * grad(x, y)return delta# ----- 绘制等⾼线 -----# 数据数⽬n = 256# 定义x, yx = np.linspace(-1, 1.1, n)y = np.linspace(-1, 1.1, n)# ⽣成⽹格数据X, Y = np.meshgrid(x, y)plt.figure()# 填充等⾼线的颜⾊, 8是等⾼线分为⼏部分plt.contourf(X, Y, f(X, Y), 5, alpha=0, cmap=plt.cm.hot)# 绘制等⾼线C = plt.contour(X, Y, f(X, Y), 8, locator=ticker.LogLocator(), colors='black', linewidth=0.01) # 绘制等⾼线数据plt.clabel(C, inline=True, fontsize=10)# ---------------------x = np.matrix([[-0.3],[0.4]])tol = 0.00001xv = [x[0, 0]]yv = [x[1, 0]]plt.plot(x[0, 0], x[1, 0], marker='o')for t in range(100):delta = delta_newton(x[0, 0], x[1, 0])if abs(delta[0, 0]) < tol and abs(delta[1, 0]) < tol:breakx = x - deltaxv.append(x[0, 0])yv.append(x[1, 0])plt.plot(xv, yv, label='track')# plt.plot(xv, yv, label='track', marker='o')plt.xlabel('x')plt.ylabel('y')plt.title('Newton\'s Method for Rosenbrock Function')plt.legend()plt.show()以上这篇python使⽤梯度下降和⽜顿法寻找Rosenbrock函数最⼩值实例就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
深度学习面试题04:随机梯度下降法、批量梯度下降法、小批量梯度下降

深度学习⾯试题04:随机梯度下降法、批量梯度下降法、⼩批量梯度下降⽬录在《深度学习⾯试题03改进版梯度下降法Adagrad、RMSprop、Momentum、Adam》中讲到了多种改进的梯度下降公式。
⽽这篇⽂章和03篇描述的不是⼀个事情,我们从⼀个例⼦说起,就知道改良的GD算法和本节介绍的GD算法的不同点了。
举例:以房屋⾯积预测房屋价格假设函数可以设置为每⼀个预测值都与真实值存在⼀个差距,差距的平⽅和就可以作为⼀个代价函数。
因此代价函数为:如下图所⽰(为⽅便观察,做了⼀个截断)代码为:from matplotlib import pyplot as pltimport numpy as npfrom mpl_toolkits.mplot3d import Axes3Dfig = plt.figure()ax = Axes3D(fig)w = np.arange(-5, 8, .25)b = np.arange(-15, 15, .25)x = np.array([1,2,3,4])y = np.array([3.2,4.7,7.3,8.5])w, b = np.meshgrid(w, b)R = 0for i in range(len(x)):R += (w*x[i]+b-y[i])**2R /= len(x)a = R<50R = ~a*50+R*a# ax.plot_surface(w, b, R, rstride=1, cstride=1, cmap='rainbow', )ax.plot_wireframe(w, b, R)plt.title("cost(w,b) = 1/N * Σ(w*x_i+b-y_i)^2")X = np.array([1.85,3.5]) # [ 0 3 6 9 12 15 18 21]Y = np.array([1.3,3.5]) # [ 1 4 7 10 13 16 19 22]R = 0for i in range(len(x)):R += (X*x[i]+Y-y[i])**2R /= len(x)Z = Rax.scatter(X, Y, Z, c='r', label='顺序点')for i in range(len(X)):ax.text(X[i], Y[i], Z[i], "({:.2f},{:.2f},{:.2f})".format(X[i], Y[i], Z[i]), color='red',fontsize=15)plt.xlabel("w")plt.ylabel("b")plt.show()View Code当使⽤梯度下降法求解时,假设初始化(w,b)=(3.5,3.5)代价函数关于w和b的偏导数为:重点来了:Adagrad、RMSprop、Adam等算法都是建⽴在偏导数之上的,他们并不关⼼上式中N的取值,N取1,取100,还是取N,Adagrad、RMSprop、Adam等算法都可以运⾏。
matlab 梯度下降法编程

梯度下降法是一种常用的优化算法,可用于求解最优化问题。
在MATLAB 中,我们可以通过编写梯度下降法的程序来解决各种复杂的优化问题。
本文将深入介绍 MATLAB 中梯度下降法的编程方法,并根据其深度和广度要求,逐步探讨梯度下降法的原理、实现步骤、优化调节和应用场景,帮助读者全面理解和掌握这一优化算法。
1. 梯度下降法的原理梯度下降法是一种迭代优化算法,其基本原理是不断沿着目标函数的负梯度方向更新参数,直至达到局部最小值或全局最小值。
在MATLAB 中,我们可以利用数值计算和矩阵运算来实现梯度下降法,通过不断迭代来更新参数并逐步逼近最优解。
2. 梯度下降法的实现步骤在 MATLAB 中实现梯度下降法主要包括以下步骤:定义目标函数、计算目标函数的梯度、选择学习率和迭代次数、初始化参数、通过循环迭代更新参数直至收敛。
通过编写 MATLAB 程序来实现这些步骤,我们可以轻松地对各种复杂的优化问题进行求解。
3. 优化调节和应用场景在实际应用中,梯度下降法的效果受到学习率和迭代次数的影响,因此需要进行适当的优化调节。
在 MATLAB 中,我们可以通过调节学习率和设置合理的停止准则来提高梯度下降法的收敛速度和稳定性。
梯度下降法在机器学习、神经网络训练、参数优化等领域有着广泛的应用场景,通过 MATLAB 编程可以快速应用于实际问题中。
总结回顾通过本文的介绍,我们全面了解了 MATLAB 中梯度下降法的编程方法。
从梯度下降法的原理到实现步骤,再到优化调节和应用场景,我们逐步深入地探讨了这一优化算法。
在实际编程中,我们需要注意学习率和迭代次数的选择,并结合具体问题进行调节优化。
梯度下降法在各种优化问题中具有广泛的应用,通过 MATLAB 编程可以轻松应用于实际场景中。
个人观点和理解我个人认为,掌握 MATLAB 中梯度下降法的编程方法对于解决各种复杂的优化问题非常重要。
通过编写梯度下降法的程序,我们可以深入理解优化算法的原理,并在实际问题中灵活应用。
梯度下降算法代码

梯度下降算法代码
梯度下降算法是机器学习中常用的优化算法。
它的原理是通过不断迭代,不断调整模型参数,不断降低目标函数的值,从而找到最优解。
下面是梯度下降算法的代码实现:
```
import numpy as np
def gradient_descent(X, y, theta, alpha, num_iters): m = y.size
J_history = np.zeros(num_iters)
for i in range(num_iters):
h = np.dot(X, theta)
theta = theta - (alpha / m) * np.dot(X.T, h - y)
J_history[i] = compute_cost(X, y, theta)
return theta, J_history
def compute_cost(X, y, theta):
m = y.size
h = np.dot(X, theta)
J = 1 / (2 * m) * np.sum((h - y) ** 2)
return J
```
其中,X是输入数据矩阵,y是输出数据矩阵,theta是模型参数矩阵,alpha是学习率,num_iters是迭代次数。
在每次迭代中,首先计算模型的预测值h,然后根据预测值和真实值之间的误差,更新模型的参数theta。
最后,计算目标函数的值并保存在J_history数组中。
该函数返回最终的模型参数theta和目标函数的值
J_history。
使用该函数可以优化线性回归模型、逻辑回归模型等。
梯度下降法matlab代码

梯度下降法matlab代码梯度下降法matlab代码是一种基于梯度下降的机器学习算法,它的核心思想是:在每次迭代中,以当前参数值计算损失函数的梯度,根据梯度更新参数值,使得参数值不断趋向于使损失函数最小值。
它是目前最流行的机器学习优化方法之一,可用于解决回归、分类等问题。
梯度下降法matlab代码的具体实现步骤如下:1.加载数据:首先,根据实际情况,加载所需要的数据集,并将其分割成训练集和测试集。
2.初始化参数:接下来,需要初始化模型参数,可以采用随机初始化法,也可以采用其他方法(如高斯分布)。
3.计算损失函数:接下来,需要计算损失函数,可以采用常见的损失函数,如均方误差(MSE)、交叉熵(CE)等。
4.计算梯度:然后,需要计算损失函数的梯度,以便进行参数更新。
5.更新参数:根据上一步计算的梯度,计算各参数的更新值,并将其应用于模型参数中,以进行参数更新。
6.重复步骤3-5:重复步骤3-5,直到模型收敛或超过预定的迭代次数。
最后,通过上述步骤,即可得到梯度下降法matlab代码的实现步骤,从而解决机器学习中的优化问题。
以下是梯度下降法matlab代码的示例:% 加载数据 load('data.mat'); % 初始化参数w=rand(size(X,2),1); b=rand(); % 设定学习率alpha=0.01; % 设定迭代次数 epochs=1000; % 训练 fori=1:epochs % 计算损失函数 Y_hat=X*w+b; loss=mean((Y-Y_hat).^2); % 计算梯度grad_w=mean(-2*X.*(Y-Y_hat)); grad_b=mean(-2*(Y-Y_hat)); % 更新参数 w=w-alpha*grad_w; b=b-alpha*grad_b; end。
深度学习必备:随机梯度下降(SGD)优化算法及可视化
深度学习必备:随机梯度下降(SGD)优化算法及可视化补充在前:实际上在我使⽤LSTM为流量基线建模时候,发现有效的激活函数是elu、relu、linear、prelu、leaky_relu、softplus,对应的梯度算法是adam、mom、rmsprop、sgd,效果最好的组合是:prelu+rmsprop。
我的代码如下:# Simple example using recurrent neural network to predict time series valuesfrom__future__import division, print_function, absolute_importimport tflearnfrom yers.normalization import batch_normalizationimport numpy as npimport tensorflow as tfimport mathimport jsonimport matplotlibe('Agg')import matplotlib.pyplot as pltstep_radians = 0.01steps_of_history = 20steps_in_future = 1index = 0def get_data(x):seq = []next_val = []for i in range(0, len(x) - steps_of_history, steps_in_future):seq.append(x[i: i + steps_of_history])next_val.append(x[i + steps_of_history])seq = np.reshape(seq, [-1, steps_of_history, 1])next_val = np.reshape(next_val, [-1, 1])print(np.shape(seq))trainX = np.array(seq)trainY = np.array(next_val)return trainX, trainYdef myRNN(x, activator, optimizer, domain=""):trainX, trainY = get_data(x)tf.reset_default_graph()# Network buildingnet = tflearn.input_data(shape=[None, steps_of_history, 1])net = tflearn.lstm(net, 32, dropout=0.8, bias=True)net = tflearn.fully_connected(net, 1, activation=activator)net = tflearn.regression(net, optimizer=optimizer, loss='mean_square')# customize==>#sgd = tflearn.SGD(learning_rate=0.1, lr_decay=0.96, decay_step=100)#network = tflearn.regression(net, optimizer=sgd, loss='mean_square')model = tflearn.DNN(net)"""net = tflearn.input_data(shape=[None, steps_of_history, 1])net = tflearn.simple_rnn(net, n_units=32, return_seq=False)net = tflearn.fully_connected(net, 1, activation='linear')net = tflearn.regression(net, optimizer='sgd', loss='mean_square', learning_rate=0.1)# Trainingmodel = tflearn.DNN(net, clip_gradients=0.0, tensorboard_verbose=0)"""model.fit(trainX, trainY, n_epoch=100, validation_set=0.1, batch_size=128)# Testing#x = np.sin(np.arange(20*math.pi, 24*math.pi, step_radians))seq = []Y = []for i in range(0, len(x) - steps_of_history, steps_in_future):seq.append(x[i: i + steps_of_history])Y.append(x[i + steps_of_history])seq = np.reshape(seq, [-1, steps_of_history, 1])testX = np.array(seq)# Predict the future valuespredictY = model.predict(testX)print(predictY)# Plot the resultsplt.figure(figsize=(20,4))plt.suptitle('Prediction')plt.title('History='+str(steps_of_history)+', Future='+str(steps_in_future))plt.plot(Y, 'r-', label='Actual')plt.plot(predictY, 'gx', label='Predicted')plt.legend()if domain:plt.savefig('pku_'+activator+"_"+optimizer+"_"+domain+".png")else:plt.savefig('pku_'+activator+"_"+optimizer+".png")def main():out_data = {}with open("out_data.json") as f:out_data = json.load(f)#x = out_data[""]#myRNN(x, activator="prelu", optimizer="rmsprop", domain="")# I find that prelu and rmsprop is best choicex = out_data[""]activators = ['linear', 'tanh', 'sigmoid', 'softmax', 'softplus', 'softsign', 'relu', 'relu6', 'leaky_relu', 'prelu', 'elu']optimizers = ['sgd', 'rmsprop', 'adam', 'momentum', 'adagrad', 'ftrl', 'adadelta']for activator in activators:for optimizer in optimizers:print ("Running for : "+ activator + " & " + optimizer)myRNN(x, activator, optimizer)main()梯度下降算法是机器学习中使⽤⾮常⼴泛的优化算法,也是众多机器学习算法中最常⽤的优化⽅法。
逻辑回归梯度下降代码

逻辑回归梯度下降代码逻辑回归是用于分类的一种常见算法。
在逻辑回归中,希望找到一条拟合数据的分界线或决策边界,将数据分成两部分(可能是两个或多个类别)。
在本文中,我们将详细地介绍逻辑回归,以及如何使用梯度下降算法实现逻辑回归。
本文中的代码将使用 Python语言编写。
1. 数据集我们将使用一个简单的数据集来实现逻辑回归算法。
数据集包含两个特征 x1 和 x2,以及一个二元分类标签 y(0 或 1)。
我们将在代码中使用 Numpy 库读取和处理数据。
以下是数据集的前几行:```X_0 X_1 Y0.7 0.6 10.2 0.3 00.3 0.5 00.6 0.8 10.1 0.9 0```我们需要将数据集分成训练集和测试集。
在这里,我们将 20% 的数据用于测试,80% 的数据用于训练。
我们还需要对数据进行标准化,使得数据在不同特征上有相同的尺度。
这可以通过将每个特征减去其平均值,并除以其标准差来实现。
以下是完整的数据预处理代码:# 加载数据集data = np.loadtxt(open("data.csv"), delimiter=",", skiprows=1)2. 梯度下降算法在逻辑回归中,我们需要找到一组权重参数,使得模型能够最好地拟合数据。
学习这些参数的过程就是训练模型。
梯度下降算法是逐步更新权重参数的优化方法,以最小化成本函数。
在逻辑回归中,成本函数定义为:$$J(w) = -\frac{1}{m} \sum_{i=1}^{m} \left( y^{(i)} \log (h_w(x^{(i)})) + (1 - y^{(i)}) \log (1 - h_w(x^{(i)})) \right)$$其中,$w$ 是权重向量,$x^{(i)}$ 是第 $i$ 个训练样本,$y^{(i)}$ 是对应的标签,$h_w(x^{(i)})$ 是模型的预测值。
$m$ 是训练样本数。
机器学习:随机梯度下降法(线性回归中的应用)

机器学习:随机梯度下降法(线性回归中的应⽤)⼀、指导思想 # 只针对线性回归中的使⽤算法的最优模型的功能:预测新的样本对应的值;什么是最优的模型:能最⼤程度的拟合住数据集中的样本数据;怎么才算最⼤程度的拟合:让数据集中的所有样本点,在特征空间中距离线性模型的距离的和最⼩;(以线性模型为例说明)怎么得到最优模型:求出最优模型对应的参数;怎么求解最优模型的参数:通过数学⽅法,得到⽬标函数(此函数计算数据集中的所有样本点,在特征空间中到该线性模型的距离,也就是损失函数),通过批量梯度下降法和随机梯度下降法对⽬标函数进⾏优化,得到⽬标函数最⼩值时对应的参数;梯度下降法的⽬的:求解最优模型对应的参数;(并不是为了求⽬标函数的最⼩值,这⼀点有助于理解随机梯度下降法)⼆、批量梯度下降法基础 1)批量梯度下降法的特点1. 运算量⼤:批量梯度下降法中的每⼀项计算:,要计算所有样本(共 m 个);2. 批量梯度下降法的梯度是损失函数减⼩最快的⽅向,也就是说,对应相同的 theta 变化量,损失函数在梯度⽅向上的变化量最⼤; 2)批量梯度下降法的思路思路:计算损失函数的梯度,按梯度的⽅向,逐步减⼩损失函数的变量 theta,对应的损失函数也不断减⼩,直到损失函数的的变化量满⾜精度要求;梯度计算:变形公式如下梯度是优化的⽅向,损失函数的变量theta 的变化量 = 学习率 X 当前梯度值三、随机梯度下降法(Batch Gradient Descent) 1)基础理解思路:随机抽取 n (⼀般 n = 总样本数 / 3)个样本,在每个样本的梯度⽅向上逐步优化(每随机抽取⼀个样本就对 theta 做⼀次递减优化)变量 theta;分析:批量梯度下降法的优化,是整体数据集的梯度⽅向逐步循环递减变量 theta ,随机梯度下降法,是数据集中的⼀个随机的样本的梯度⽅向,优化变量 theta;特点⼀:直接优化变量 theta,⽽不需要计算 theta 对应的⽬标函数值;特点⼆:不是按整体数据集的梯度⽅向优化,⽽是按随机抽取的某个样本的梯度⽅向进⾏优化; 2)优化⽅向的公式新的搜索⽅向计算公式(也即是优化的⽅向):;此处称为搜索⽅向,⽽不是梯度的计算公式,因为此公式已经不是梯度公式,⽽表⽰优化损失函数的⽅向;随机梯度下降法的搜索路径:特点:1. 每⼀次搜索的⽅向,不能保证是损失函数减⼩的⽅向;2. 每⼀次搜索的⽅向,不能保证是损失函数减⼩最快的⽅向;3. 其优化⽅向具有不可预知性;意义:1. 实验结论表明,即使随机梯度下降法的优化⽅向具有不可预知性,通过此⽅法依然可以差不多来到损失函数最⼩值的附近,虽然不像批量梯度下降法那样,⼀定可以来到损失函数最⼩值位置,但是,如果样本数量很⼤时,有时可以⽤⼀定的模型精度,换取优化模型所⽤的时间;实现技巧:确定学习率(η:eta)的取值,很重要;1. 原因:在随机梯度下降法优化损失函数的过程中,如果η⼀直取固定值,可能会出现,已经优化到损失函数最⼩值位置了,但由于随机的过程不够好,η⼜是各固定值,导致优化时慢慢的⼜跳出最⼩值位置;2. ⽅案:优化过程中让η逐渐递减(随着梯度下降法循环次数的增加,η值越来越⼩); 3)η的确定过程⼀:如果η = 1 / i_iters;(i_iters:当前循环次数)1. 问题:随着循环次数(i_iters)的增加,η的变化率差别太⼤;⼆:如果η = 1 / (i_iters + b);(b:为常量)1. 解决了η的变化率差异过⼤再次变形:η = a / (i_iters + b);(a、b:为常量)1. 分⼦改为 a ,增加η取值的灵活度;1. a、b:为随机梯度下降法的超参数;2. 本次学习不对 a、b 调参,选⽤经验上⽐较适合的值:a = 5、b = 50;学习率的特点 # 学习率随着循环次数的增加,逐渐递减; # 这种逐渐递减的思想,是模拟在搜索领域的重要思路:模拟退⽕思想; # 模拟退⽕思想:在退⽕过程中的冷却函数,温度与冷却时间的关系;⼀般根据模拟退⽕思想,学习率还可以表⽰:η = t0 / (i_iters + t1) 4)循环次数的确定原则1. 将每个样本都随机抽取到;2. 将每个样本⾄少抽取 n 次,也就是总的循环次数⼀般为:len(X_b) * n;具体操作1. 将变形后的数据集 X_b 的 index 做随机乱序处理,得到新的数据集 X_b_new ;2. 根据乱序后的 index 逐个抽取 X_b_new 中的样本,循环 n 遍;四、实现随机梯度下降法优化⽅向:,结果是⼀个列向量; # array . dot(m) == array . meta 取值:η = a / (i_iters + b)优化结束条件1. 批量梯度下降法:1)达到设定的循环次数;2)找到损失函数的最⼩值2. 随机梯度下降法:达到设定的循环次数随机梯度下降法中不能使⽤精度来结束优化:因为随机梯度下降法的优化⽅向,不⼀定全都是损失函数减⼩的⽅向; 1)代码实现随机梯度下降法模拟数据import numpy as npimport matplotlib.pyplot as pltm = 100000x = np.random.normal(size=m)X = x.reshape(-1, 1)y = 4. * x + 3. + np.random.normal(0, 3, size=m)批量梯度下降法def J(theta, X_b, y):try:return np.sum((y - X_b.dot(theta)) ** 2) / len(y)except:return float('inf')def dJ(theta, X_b, y):return X_b.T.dot(X_b.dot(theta) - y) * 2. / len(y)def gradient_descent(X_b, y, initial_theta, eta, n_iters=10**4, epsilon=10**-8):theta = initial_thetacur_iter = 0while cur_iter < n_iters:gradient = dJ(theta, X_b, y)last_theta = thetatheta = theta - eta * gradientif (abs(J(theta, X_b, y) - J(last_theta, X_b, y)) < epsilon):breakcur_iter += 1return theta# cur_iter:循环次数# initial_theta:theta的初始化值%%timeX_b = np.hstack([np.ones((len(X), 1)), X])initial_theta = np.zeros(X_b.shape[1])eta = 0.01theta = gradient_descent(X_b, y, initial_theta, eta)# 输出:Wall time: 898 mstheta# 输出:array([3.00280663, 3.9936598 ])随机梯度下降法1)通过每⼀次随机抽取的样本,计算 theta 的优化⽅向def dJ_sgd(theta, X_b_i, y_i):return X_b_i.T.dot(X_b_i.dot(theta) - y_i) * 2# X_b_i:是 X_b 中的⼀⾏数据,也就是⼀个随机样本,不在是全部的数据集# y_i:对应的随机抽取的样本的真值2)随机优化过程def sgd(X_b, y, initial_theta, n_iters):# 计算学习率 etat0 = 5t1 = 50# 定义求解学习率的函数def learning_rate(t):return t0 / (t + t1)theta = initial_thetafor cur_iter in range(n_iters):rand_i = np.random.randint(len(X_b))gradient = dJ_sgd(theta, X_b[rand_i], y[rand_i])theta = theta - learning_rate(cur_iter) * gradientreturn theta# 此处的形参中不需要设置 eta 值了,eta 值随着循环的进⾏,在函数内部求取# cur_iter:当前循环次数# rand_i:从 [0, len(X_b)) 中随机抽取的⼀个数# gradient:⼀次循环中,随机样本的优化⽅向# learning_rate(cur_iter) * gradient:⼀次循环的 theta 的变化量3)给初始化数值,预测数据%%timeX_b = np.hstack([np.ones((len(X), 1)), X])initial_theta = np.zeros(X_b.shape[1])theta = sgd(X_b, y, initial_theta, n_iters=len(X_b)//3)# 输出:Wall time: 287 ms4)查看最终优化结果theta# 输出:array([2.9648937 , 3.94467405]) 2)封装与调⽤⾃⼰的代码封装:已规范循环次数(代码中的红⾊字样)1def fit_sgd(self, X_train, y_train, n_iters=5, t0=5, t1=50):2"""根据训练数据集X_train, y_train, 使⽤梯度下降法训练Linear Regression模型"""3assert X_train.shape[0] == y_train.shape[0], \4"the size of X_train must be equal to the size of y_train"5assert n_iters >= 167def dJ_sgd(theta, X_b_i, y_i):8return X_b_i * (X_b_i.dot(theta) - y_i) * 2.910def sgd(X_b, y, initial_theta, n_iters, t0=5, t1=50):1112def learning_rate(t):13return t0 / (t + t1)1415 theta = initial_theta16 m = len(X_b)1718for cur_iter in range(n_iters):19 indexes = np.random.permutation(m)20 X_b_new = X_b[indexes]21 y_new = y[indexes]22for i in range(m):23 gradient = dJ_sgd(theta, X_b_new[i], y_new[i])24 theta = theta - learning_rate(cur_iter * m + i) * gradient2526return theta2728 X_b = np.hstack([np.ones((len(X_train), 1)), X_train])29 initial_theta = np.random.randn(X_b.shape[1])30 self._theta = sgd(X_b, y_train, initial_theta, n_iters, t0, t1)3132 self.intercept_ = self._theta[0]33 self.coef_ = self._theta[1:]3435return self# n_iters:对所有数据集循环的遍数;调⽤⾃⼰封装的代码1. 获取原始数据import numpy as npimport matplotlib.pyplot as pltfrom sklearn import datasetsboston = datasets.load_boston()X = boston.datay = boston.targetX = X[y < 50.0]y = y[y < 50.0]2. 数据分割from ALG.data_split import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, seed=666)3. 数据归⼀化from sklearn.preprocessing import StandardScalerstandardScaler = StandardScaler()standardScaler.fit(X_train)X_train_standard = standardScaler.transform(X_train)X_test_standard = standardScaler.transform(X_test)# 数据归⼀化,主要是将训练数据集(X_train)和测试数据集(X_test)归⼀化;4. 使⽤线性回归算法:LinearRegressionfrom LR.LinearRegression import LinearRegressionlin_reg = LinearRegression()%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=2)lin_reg.score(X_test_standard, y_test)# 输出:Wall time: 10 ms0.7865171620468298# 问题:通过score()函数得到的 R^2 值,也就是准确度过⼩# 原因:对所有的 X_train_standard 循环优化的遍数太少:n_iters=25. 循环遍数改为 50:n_iters=50%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=50)lin_reg.score(X_test_standard, y_test)# 输出:Wall time: 143 ms0.80857287165738356. 循环遍数改为 100:n_iters = 100%time lin_reg.fit_sgd(X_train_standard, y_train, n_iters=100)lin_reg.score(X_test_standard, y_test)# 输出:Wall time: 502 ms0.81259543683252957. 总结:随着循环遍数的增加,模型的准确度也随着增加; 3)调⽤ scikit-learn 中的算法模型SGDRegressor:该算法虽是名为随机梯度下降法的回归器,但其只能解决线性模型,因为,其被封装在了 linear_model 线性回归模块中;学习scikit-learn中的算法的过程:掉包 - 构建实例对象 - 拟合 - 验证训练模型的效果(查看准确度)实现过程:前期的数据处理与步骤(2)相同from sklearn.linear_model import SGDRegressorsgd_reg = SGDRegressor()%time sgd_reg.fit(X_train_standard, y_train)sgd_reg.score(X_test_standard, y_test)# 输出:Wall time: 16 ms0.8065416815240762# 准确度为0.8065 左右,此时循环遍数使⽤默认的 5 遍:max_iter = 5修改循环遍数:max_iter = 100sgd_reg = SGDRegressor(max_iter=100)%time sgd_reg.fit(X_train_standard, y_train)sgd_reg.score(X_test_standard, y_test)# 输出:Wall time: 8 ms0.813372455938393 4)总结与⾃⼰写的算法相⽐,scikit-learn中的算法的实现过程更加复杂,性能更优:1. 通过计算时间就可以看出:n_iters=100时,⾃⼰的算法需要 502ms,scikit-learn中的算法需要 8ms;2. ⾃⼰所学的封装好的算法,只是为了帮助理解算法的原来,⽽scikit-learn中使⽤了很多优化的⽅案。
python梯度下降法计算平方根

python梯度下降法计算平方根Python梯度下降法是一种常用的数学最优化算法,可以通过不断调整参数来最小化损失函数。
在本文中,我们将介绍如何使用Python梯度下降法来计算平方根。
首先,我们需要定义一个函数来计算平方根,例如:def sqrt(x):return x ** 0.5接下来,我们需要定义一个损失函数,用于评估我们预测的平方根与实际平方根之间的差距。
在这种情况下,我们可以使用均方误差(MSE)作为损失函数,如下所示:def mse(y_pred, y_true):return sum([(y_pred[i] - y_true[i])**2 for i inrange(len(y_pred))]) / len(y_pred)然后,我们需要实现一个梯度下降算法,用于更新参数以最小化损失函数。
在这种情况下,我们只有一个参数,即平方根的值。
因此,我们可以使用以下代码来实现梯度下降:def gradient_descent(x, y_true, learning_rate,n_iterations):# 初始化参数theta = 1.0# 迭代更新参数for i in range(n_iterations):# 预测值y_pred = sqrt(x) * theta# 计算误差error = y_pred - y_true# 计算梯度gradient = sum(error * sqrt(x)) / len(x)# 更新参数theta -= learning_rate * gradientreturn theta最后,我们可以使用以下代码来测试我们的模型:import random# 生成随机数据x = [random.uniform(0, 100) for i in range(100)]y_true = [sqrt(xi) for xi in x]# 训练模型theta = gradient_descent(x, y_true, learning_rate=0.01, n_iterations=1000)# 打印结果print('Predicted theta:', theta)print('True theta:', 1.0)我们可以看到,使用Python梯度下降法计算平方根的结果非常接近1.0,这是我们预期的结果。
nesterov加速梯度下降法代码

《Nesterov加速梯度下降法代码》1. 引言Nesterov加速梯度下降法是一种优化算法,它在梯度下降法的基础上进行了改进,能够更快地收敛到全局最优解。
在本文中,我将详细介绍Nesterov加速梯度下降法的原理和代码实现方法,并共享我的个人观点和理解。
2. Nesterov加速梯度下降法原理Nesterov加速梯度下降法是一种动量加速算法,它利用历史梯度信息来更新参数值,以减少参数更新时的波动。
其公式如下:\[\theta_{t+1} = \theta_t - \alpha \nabla f(\theta_t + \beta v_t)\] 其中,\(\theta_t\)表示第t次迭代的参数值,\(\alpha\)表示学习率,\(\nabla f(\theta_t)\)表示损失函数在\(\theta_t\)处的梯度,\(\beta\)表示动量系数,\(v_t\)表示上一次迭代的动量。
3. Nesterov加速梯度下降法代码实现下面是Nesterov加速梯度下降法的Python代码实现:```pythonimport numpy as npdef nesterov_gradient_descent(theta, alpha, beta,num_iterations, gradient_func):v = np.zeros_like(theta)for t in range(num_iterations):gradient = gradient_func(theta + beta*v)v = beta*v - alpha*gradienttheta = theta + vreturn theta```4. 个人观点和理解我认为Nesterov加速梯度下降法在实际应用中具有很大的潜力。
它通过引入动量项,能够在参数更新过程中更好地利用历史梯度信息,从而更快地收敛到全局最优解。
Nesterov加速梯度下降法的代码实现非常简洁,易于理解和使用,对于解决实际问题具有很大的帮助。
三元梯度下降法python

三元梯度下降法python梯度下降法是一种常用的优化算法,用于求解函数的最小值或最大值,下面是一个使用Python 实现三元梯度下降法的示例代码:```pythonfrom sympy import symbols, diffdef gradient_descent():x = symbols('x')y = symbols('y')z = symbols('z')w = x**2 + y**2 + z**2 + 2*x + 4*y - 6*z# 初始点x1 = 20y1 = 20z1 = 20alpha = 0.03# 对w求偏导dx = diff(w, x).subs({x: x1, y: y1, z: z1})dy = diff(w, y).subs({x: x1, y: y1, z: z1})dz = diff(w, z).subs({x: x1, y: y1, z: z1})last_result = (w.subs({x: x1, y: y1, z: z1}))# 先上升一步以进行后面的收敛判断x1 -= alpha * dxy1 -= alpha * dyz1 -= alpha * dzthis_result = (w.subs({x: x1, y: y1, z: z1}))# 当两次结果之差小于一个给定的阈值时,算法收敛while abs(this_result - last_result) > 0.0001:last_result = (w.subs({x: x1, y: y1, z: z1}))dx = diff(w, x).subs({x: x1, y: y1, z: z1})dy = diff(w, y).subs({x: x1, y: y1, z: z1})dz = diff(w, z).subs({x: x1, y: y1, z: z1})x1 -= alpha * dxy1 -= alpha * dyz1 -= alpha * dzthis_result = (w.subs({x: x1, y: y1, z: z1}))print('极值点:', (x1, y1, z1))print('极值:', this_result)gradient_descent()```在上述代码中,定义了一个名为`gradient_descent`的函数,在函数内部首先定义了符号变量`x`、`y`和`z`,以及目标函数`w`。
python opencv tenengrad梯度方法

Python 中使用 OpenCV 和 Tenengrad 实现梯度方法本文介绍了如何在 Python 中使用 OpenCV 和 Tenengrad 库来实现梯度方法,包括梯度计算和梯度下降算法。
在 Python 中,可以使用 OpenCV 和 Tenengrad 库来实现梯度方法。
下面是一个简单的示例代码,演示如何使用这些库来计算梯度和进行梯度下降算法。
首先,需要安装 OpenCV 和 Tenengrad 库。
可以使用以下命令来安装它们:```pip install opencv-pythonpip install tenengrad```接下来,让我们看看如何使用这些库来计算梯度。
以下是一个计算梯度的简单示例代码:```pythonimport cv2import numpy as npimport tenengrad as tg# 定义一个函数,用于计算图像的梯度def calculate_gradient(img):# 将图像转换为灰度图像gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 计算梯度grad = tg.gradient(gray)# 将梯度转换为弧度theta = np.arctan2(grad[:, 1], grad[:, 0])# 返回梯度return theta# 读取一张图像img = cv2.imread("image.jpg")# 计算梯度gradient = calculate_gradient(img)# 显示梯度图像cv2.imshow("Gradient", gradient)cv2.waitKey(0)cv2.destroyAllWindows()```在这个示例代码中,我们使用了 OpenCV 库中的`cv2.imread()`函数来读取一张图像,然后使用 Tenengrad 库中的`tg.gradient()`函数来计算梯度。
对梯度下降算法的理解和实现
对梯度下降算法的理解和实现对梯度下降算法的理解和实现梯度下降算法是机器学习程序中⾮常常见的⼀种参数搜索算法。
其他常⽤的参数搜索⽅法还有:⽜顿法、坐标上升法等。
以线性回归为背景当我们给定⼀组数据集合D={(x(0),y(0)),(x(1),y(1)),...,(x(n),y(n))} ,其中上标为样本标记,每个x(i)为⼀个d维向量(向量默认加粗表⽰)。
我们在有了⼀定数量的样本的情况下,希望能够从样本数据中提取信息或者某种模式,从⽽实现对新的数据也能具有⼀定的预测作⽤,这就需要我们找到⼀个能表⽰这组数据集合D的函数表达式。
这样我们就从离散的点得到了连续的函数曲线,从⽽可以预测未曾见过的输⼊变量。
⼀种常见的假设是,将输⼊变量和输出变量之间的关系假设为线性关系:hθ(x)=θ0+θ1x1+...+θk x d=θx T。
其中h为 hypothesis,是我们假设的能够表⽰数据集合D的假设函数。
⽽我们同时假设,存在⼀个 true function f,使得样本集合D中的样本都是由该函数,加上⼀定的噪声产⽣的(因为我们⽆法考虑到与响应变量y相关的所有的情况,也⽆法搜集到所有的数据)。
并且很常见的,我们假设噪声服从正态分布。
机器学习的任务就是从假设函数空间H={h1,h2,...,h k} 中找到⼀个对 true function 最好的近似。
这个寻找h的过程,就是机器去学习的过程。
从直观⾓度出发,我们可以设定这样⼀个⽬标函数:希望有⼀条直线能够距离每个样本点的距离都⼗分的近,整体来看,希望距离所有样本的距离和最近,这样的⼀条直线是最有可能接近 true function 的。
形式化表达,可以表⽰为:也可称之为损失函数。
当该函数取得最⼩值时,说明当前的这个hθ是在当前数据集下对 true function 的最好的⼀个估计。
所以问题转化为⼀个最优化问题,在损失函数最⼩的情况下的θ是要求解的。
这⾥我先举⼀个直观的例⼦。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
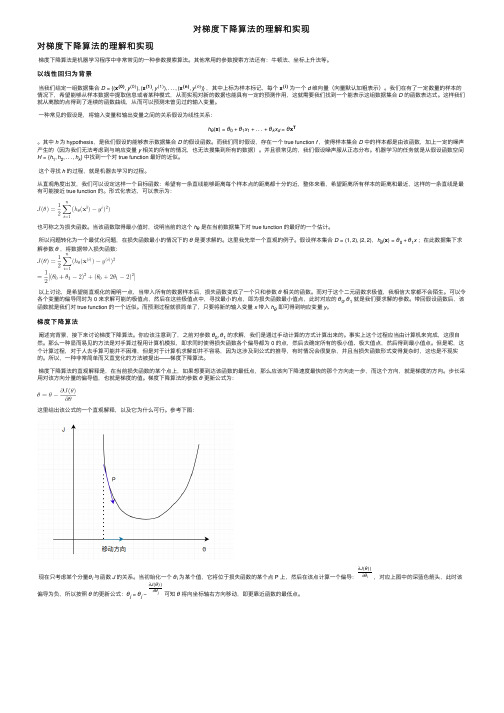
梯度下降法
梯度下降法是一种最优化算法,常用来优化参数,通常也称为最速下降法。
梯度下降法是一般分为如下两步:
1)首先对参数θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量;
2)改变θ的值,使得J(θ)按梯度下降的方向进行减少。
以一个线性回归问题为例,应用libsvm 包里的数据heart_scale.mat 数据做测试。
假设要学习这么一个函数:
+++==22110)()(x x x h x h θθθθ
那么损失函数可以定义成:
2||||2
1)(Y X J -=θθ (1) 其中X 看以看成一行一行的样本向量,那么Θ就是一列一列的了。
目标很简单,就是求损失J 最小值时候的解Θ:
先直接求导,对于求导过程,详解如下:
首先定义损失变量:
∑=-=n
j i j ij i y X r 1θ
那么损失函数就可以表示成:
∑==m i i r J 1
221 一步一步的求导:
∑=∂∂⨯=∂∂m i j
i i j r r J 1)(θθ 再求:
ij j
i X r =∂∂θ 那么把分步骤合起来就是:
∑∑==-=∂∂m i ij n k i k ik j X y X J 11
)(θθ 令导数为0,求此时的Θ,整理一下,有:
∑∑∑====m i m
i j ij n k k ik ij y X X X
111^θ 用矩阵符号将上面的细节运算抽象一下:
0=-=∂∂Y X X X J T T θθ
让导数为0,那么求得的解为:
Y X X X T T 1)(-=θ
求解矩阵的逆复杂度有点儿高,可以用梯度下降来求解:
][)()(1111Y X X X J J T i T i i i i --=∂∂-=∆-=----θγθθ
θγθθγθθ (2) 其中γ就是下降的速度,一般是一个小的数值,可以从0.01开始尝试,越大下降越快,收敛越快。
迭代终止的条件取:
εθθ<--||||1i i
部分代码如下:
w_old=zeros(size(X,2),1);%%初始化参数w
k=1;
while 1
minJ_w(k) = 1/2 * (norm(X*w_old - Y))^2; %%损失函数 公式(1)
%%norm 默认为L2标准化 w_new = w_old - gamma*(X'*X*w_old - X'*Y);%%梯度下降公式
%%公式(2)
if norm(w_new-w_old) < epsilon %%终止条件
W_best = w_new;
break ;
end
w_old = w_new;
k=k+1;
end
实验结果:。