XPath 表达式
xpath attribute 用法

xpath attribute 用法XPath attribute 用于选择 XML 或 HTML 文档中具有特定属性的元素。
使用 attribute 语法可以根据元素的属性名和属性值来选择元素。
下面是一些有关 XPath attribute 用法的详细说明。
1.选择具有特定属性的元素:使用 attribute 语法可以选择具有特定属性的元素。
例如,以下XPath 表达式可以选择具有 "class" 属性的所有元素:2.选择具有特定属性值的元素:可以使用 attribute 语法来选择具有特定属性值的元素。
以下是一些示例 XPath 表达式:3.使用逻辑运算符选择多个属性:可以使用逻辑运算符(如 "and" 和 "or")结合多个属性来选择元素。
以下是一些示例 XPath 表达式:4.选择具有某个属性名的元素:可以使用 attribute 语法选择具有特定属性名的元素。
以下是一个示例 XPath 表达式:5.使用通配符选择属性值:可以使用通配符来选择属性值的一部分。
例如,以下 XPath 表达式可以选择属性 "class" 值以 "header" 开头的所有元素:以上仅是一些关于 XPath attribute 用法的基本说明。
XPath 还提供了更多的功能,如选择特定属性不存在的元素(使用 "not" 运算符)、根据属性值的部分匹配选择元素等等。
使用 XPath attribute 可以方便地选择和定位文档中具有特定属性的元素,从而更好地解析和处理 XML 或 HTML 文档中的数据。
xpath中用于选取所用节点的表达式_解释说明

xpath中用于选取所用节点的表达式解释说明1. 引言1.1 概述在现代的Web开发和数据抓取工作中,XPath作为一种强大的查询语言,被广泛应用于从XML或HTML文档中选择和提取特定节点或数据。
XPath的灵活性和表达能力使得它成为了Web开发者和数据分析人员必备的工具之一。
1.2 文章结构本文将重点介绍XPath中用于选取所需节点的表达式。
首先,我们将简要概述什么是XPath以及其在Web开发和数据抓取中的应用。
然后,我们将深入探讨XPath的语法规则,包括常用表达式和特殊选择器。
最后,我们总结文章内容并给出相关结论。
1.3 目的本文旨在帮助读者全面理解XPath中用于选取节点的表达式,并通过实例演示其使用方法。
无论你是一个刚入门的Web开发者还是一个有经验的数据分析师,通过阅读本文,你将对XPath在项目中如何选取特定节点有更清晰准确的认识,并能够更加高效地应用它来满足自己技术需求。
2. Xpath中用于选取节点的表达式2.1 什么是XPathXPath是一种用于在XML文档中定位节点的语言。
它通过路径表达式来选取节点或者计算节点集合。
XPath由W3C组织定义,被广泛应用于XML文档的解析和处理。
2.2 XPath语法概述XPath语法基于路径表达式和运算符,用来选择或过滤XML文档中的节点。
路径表达式可以描述从根节点到目标节点的路径,也可以描述相对于当前节点的路径。
XPath语法主要包括以下几种类型:- 标签名称:使用标签名称可以选择具有该名称的所有节点。
- 路径:使用"/"符号表示从根节点开始的全路径,使用"//"符号表示匹配任意位置的多层嵌套节点。
- 谓语:谓语用来筛选满足特定条件的指定类型节点。
- 运算符:包括比较运算符、逻辑运算符和数值运算符等。
2.3 常用的XPath表达式在XPath中有许多常用的表达式可用于选取特定类型的节点。
以下是其中最常见的几种:- 选取元素节点:通过元素名进行匹配,例如`//elementname`。
XPath 表达式
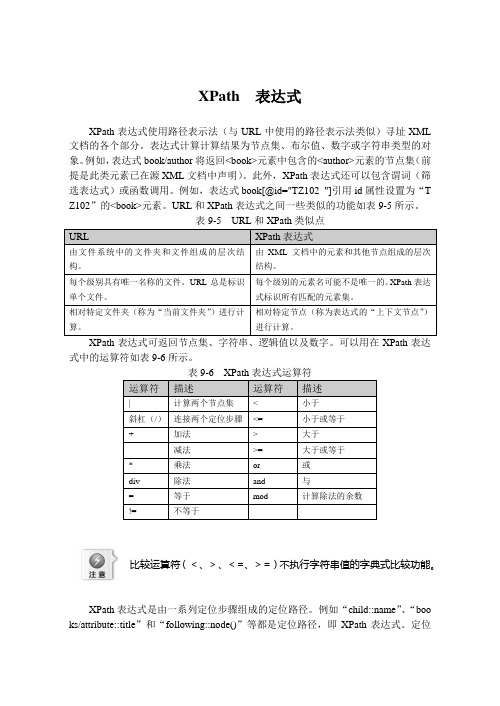
XPath 表达式XPath表达式使用路径表示法(与URL中使用的路径表示法类似)寻址XML 文档的各个部分。
表达式计算计算结果为节点集、布尔值、数字或字符串类型的对象。
例如,表达式book/author将返回<book>元素中包含的<author>元素的节点集(前提是此类元素已在源XML文档中声明)。
此外,XPath表达式还可以包含谓词(筛选表达式)或函数调用。
例如,表达式book[@id="TZ102 "]引用id属性设置为“T Z102”的<book>元素。
URL和XPath表达式之间一些类似的功能如表9-5所示。
XPath表达式可返回节点集、字符串、逻辑值以及数字。
可以用在XPath表达式中的运算符如表9-6所示。
表9-6 XPath表达式运算符比较运算符(<、>、<=、>=)不执行字符串值的字典式比较功能。
XPath表达式是由一系列定位步骤组成的定位路径。
例如“child::name”、“boo ks/attribute::title”和“following::node()”等都是定位路径,即XPath表达式。
定位步骤的基本语法如下所示:轴用来确定在上下文环境中的搜索(或匹配)方向(或范围)。
节点测试用来确定匹配节点类型;谓词必须使用中括号([ ])扩住,它用来对符合节点类型的节点进行进一步筛选。
据上节的XML 文档示例,下面就列举几个常用的定位步骤:(1)/选择文档的根节点。
例如,XSLT 中的根模板的标记匹配模式就是“/”,表示元素匹配从根节点开始搜索。
(2)child::*因为child 轴的主要节点类型是元素,所以该定位步骤表示的是选择上下文节点的所有子元素节点。
例如,将id 为TZ102的book 元素节点作为上下文节点,使用该定位路径将选择子元素节点name 和publisher 。
(3)child::text()使用轴child 和节点测试text()来选择上下文节点的所有子文本节点。
xpath中用于选取所用n节点的表达式

一、什么是XPath?XPath(XML Path Language)是一种用来确定XML文档中的特定部分的语言。
它是一种在XML文档中选取节点的能力。
二、 XPath的语法1. 选取节点:XPath使用路径表达式来选取XML文档中的节点或者元素。
要选取XML文档中的某个节点,可以使用路径表达式来表明。
2. 路径表达式:路径表达式是XPath中最重要的内容之一,由一个或多个步组成,用来定位XML文档中的节点或者元素。
路径表达式的基本语法为 nodename,表示选取此节点的所有子节点。
3. 谓语:谓语用来查找某个特定的节点或者含有某个特定值的节点。
4. 选取节点:XPath中用星号 * 来选取所有元素节点,用符号来选取属性。
三、 XPath的常用表达式1. 选取所有节点:选取XML文档中所有的节点,可以使用双斜杠 // 表示。
//title 表示选取XML文档中的所有 title 节点。
2. 选取特定节点:选取XML文档中指定的节点或者元素,可以使用节点名称来表示。
/bookstore/book 表示选取 bookstore 下的所有 book 节点。
3. 选取节点的属性:选取节点的属性可以使用符号, //book[id] 表示选取所有具有id属性的book节点。
4. 谓语:使用谓语可以筛选出符合条件的节点,//book[price>35.00] 表示选取价格大于35.00的所有book节点。
四、使用XPath的场景在实际开发中,XPath可以用于各种场景,包括但不限于:1. Web自动化测试:在自动化测试中,XPath可以用来定位网页元素,进行页面操作和验证。
2. 数据抓取:XPath可以用来定位和抓取网页中所需的数据,进行数据分析和处理。
3. XML文档处理:XPath可以用来处理XML文档,提取所需的信息,进行数据处理和转换。
五、XPath的局限性在使用XPath的过程中,也需要注意一些局限性,包括但不限于:1. 性能:使用XPath可能会影响性能,尤其是在大规模的文档上。
XPATH表达式写法

XPATH表达式写法Xpath表达式写法先看错误⽰例复制⽽来的页⾯上选择元素右键检查(元素)在元素代码上复制xpath⽽来的⽰例上图中⼆三⾏⽰例:绝对路径-不准:以/开头从根节点开始显⽰所找元素在DOM树中路径, div[2] div块,2是序号,从1开始不是从0开始的,前端开发如果改变了dom树顺序或新增了div内容,此路径就找不到原元素了不推荐使⽤相对路径-推荐使⽤Xpath格式如下:1.基本⽤法: //标签名[@属性名=值]2.叠加⽤法⽀持逻辑运算and/or://标签名[@属性名=值 and @属性名=值]//标签名[@属性名=值 or @属性名=值]//*[@id="virus-2020"] *为通配符实操:F12 /element选中元素,⾼亮元素所在标签⾏后,ctrl+F5打开搜索框,按⾼亮⾏中内容去搜索,时刻注意搜索框中结果个数,当结果唯⼀了就不⽤累加组合条件了, 结果多个时⽀持点击⼩箭头上下翻动再次找出我要找的再往上累加条件。
所选组合条件优先⽤id name3.xpath复杂写法1-拼爹拼祖宗如下图定位百度⾸页的登陆按钮:// a[@name="tj_login" ] 会得到两条结果如下图框出来的,其他属性都⼀样。
解决⽅法:拼爹甚⾄拼爷//div[@id="u1"]/a[@name="tj_login" ]第⼆个写为/,代表下⼀层是上⼀层的⼉⼦//div[@id="u1"]//a[@name="tj_login" ] 第⼀个//代表以整个DOM树为相对路径,第⼆个//代表其上层写的div为相对路径或理解为下层为上层的⼦、孙都可以,建议都⽤//。
//代表相对路径/代表绝对路径4.xpath复杂写法2-包含://标签名[contains(@属性名/text(),”要包含的内容”)]场景如:定位链接,链接中带有动态ID,可⽤模糊匹配如下图想定位“作业”,但不是每个学员登陆都显⽰的是22期的作业,即对应的链接中的id不⼀致,但前半段是⼀⾄的,即⽤://a[contains(@href, “/Course/homework/courseid/”)] (勿掉引号)5.xpath复杂写法3-元素⽂本匹配: //标签名[text()=” “]如上图则写为: //a[text()=”作业”]⽂本和属性都⽀持精准匹配+部分匹配,所以⽂本的部分匹配为://标签名[contains(text(),”要包含的内容”)]6.以上五种⽅法可以随意组合叠加原则:xpath定位可能不⽌⼀种表达⽅式但尽量不要⽤会变的东西来定位//标签名[@属性=值 and text()=值 and contains(@属性/text(), 值)]我踩过的坑:⽤class来找时如果class有多个值⼀次只能找⼀个值,所以要⽤contains只取其中⼀个来匹配。
xpath表达式

xpath表达式XPath(XML路径语言)是一门在XML文档中查找信息的语言,它基于 XPointer 和在XML文档中使用路径表达式来查找节点。
XPath主要共四种类型的表达式:路径表达式、运算表达式、谓词表达式和函数表达式。
1. 路径表达式路径表达式是XPath中最基本的表达式类型。
它是一系列按特定顺序构造的标记,每个标记描述了一种“如何”或“何时”走下一步。
例如:/HTML/BODY/H1/P,这种表达式表示从HTML节点开始,然后匹配(即走向)包含在其中的BODY节点,再匹配H1节点,最后匹配P节点,我们就可以轻松地访问XML文档中的元素,属性和文本。
2. 运算表达式运算表达式包括算术运算符、比较运算符和逻辑运算符。
它们可用于将两个值(或变量)进行运算并产生结果。
例如,使用 XPATH 表达式 //BODY[2]可以比较值 2 与 BODY 元素内容,以确定是否存在第二个 BODY 元素。
3. 谓词表达式谓词表达式有助于筛选XML文档中的元素。
它们可以将给定的XML 值与另一个给定的值进行比较,以确定它们是否符合我们的需要。
如果一个指定的谓词为True,则结果集将包含相应的结果。
例如,/HTML/BODY/H1/P[id='doc1']将会精确地只返回ID属性等于 doc1 的P元素。
4. 函数表达式函数表达式用于将字符串处理为需要的格式,并进行一些特殊处理。
常用函数表达式有:string()-用于将传入参数转换成字符串;translate()-用于替换一个字符串中的字符;contains()-用于检查一个字符串中是否包含另一个字符串;concat()-用于连接两个或多个字符串;count()-用于获取列表长度;sum()-用于求和;and、not、or-用于实现布尔逻辑;substring()-可以裁剪一个字符串;substring-after()-用于提取字符串的结尾;substring-before()-用于提取字符串的开头;position()-可以返回当前节点在节点列表中的位置;last()-用于获取节点列表中最后一个元素;name()-返回当前节点的指定名称;text()-可以返回当前节点的所有文本;parent()-返回无当前元素的父元素等。
xpath提取链接写法

xpath提取链接写法XPath是一种在XML文档中查找信息的语言,它可以在XML文档中定位到特定的元素,并提取出其中的链接。
XPath在网页抓取、数据提取等领域有着广泛的应用。
下面将介绍一些常用的XPath提取链接的写法。
一、提取所有链接如果要提取一个XML文档中所有的链接,可以使用以下XPath表达式:```//a/@href|//link/@href```这个表达式会匹配所有的`<a>`和`<link>`元素,并提取其中的`href`属性值,即链接地址。
需要注意的是,如果文档中有其他类型的链接元素,例如`<img>`元素的`src`属性,也可以使用同样的XPath 表达式来提取。
二、提取指定元素的链接如果要提取XML文档中某个特定元素的链接,可以使用以下XPath表达式:```python//element_name[@attribute='value']/@href```这个表达式会匹配所有符合指定元素名和属性的链接元素,并提取其中的`href`属性值。
例如,如果要提取所有名为`<div>`的元素的链接地址,可以使用以下XPath表达式:```css//div[@id='div_id']/@href```三、提取HTML页面中链接如果要提取HTML页面中的链接,可以使用以下XPath表达式:```css//a/@href|//link/@href|//img[@src='']/@src```这个表达式会匹配所有的`<a>`,`<link>`和`<img>`元素,并提取其中的`href`和`src`属性值。
需要注意的是,如果要提取其他类型的链接元素,例如`<area>`元素的`href`属性,也可以使用同样的XPath 表达式来提取。
四、提取特定标签内部的链接如果要提取HTML页面中某个特定标签内部的链接,可以使用以下XPath表达式:```css//tag_name[text()='search_string']/@href```这个表达式会匹配所有符合指定标签名和文本内容的链接元素,并提取其中的`href`属性值。
calibre结构检测xpath表达式

calibre结构检测xpath表达式摘要:1.引言2.calibre 结构检测简介3.XPath 表达式的基本概念4.使用XPath 表达式进行calibre 结构检测5.总结正文:calibre 结构检测是电子书处理软件calibre 的一个功能,它可以帮助用户检测电子书中的特定元素,例如章节、标题等。
XPath 表达式是一种用于描述XML 或HTML 文档中节点和属性的语言,通过使用XPath 表达式,用户可以准确地定位到文档中的特定元素。
在calibre 中,我们可以利用XPath 表达式进行结构检测。
首先,需要了解一些基本的XPath 表达式概念。
XPath 表达式由路径和筛选器组成。
路径用于描述从根节点到目标节点的路径,而筛选器则用于筛选满足特定条件的节点。
例如,假设我们有一个HTML 文档,其中包含以下代码:```<html><head><title>示例文档</title></head><body><h1>欢迎来到示例网站</h1><p>这是一个段落。
</p></body></html>```我们可以使用以下XPath 表达式来定位到文档的标题(title)元素:```//title```这里的路径表达式为“//”,表示从文档的根节点(html)开始。
筛选器为空,表示选择所有满足条件的节点。
在calibre 中,我们可以使用XPath 表达式进行结构检测。
例如,假设我们有一个包含章节标题和段落文本的电子书文件,我们可以使用以下表达式来检测所有的章节标题:```//h[@level="1"]```这里的路径表达式为“//”,表示从电子书的根节点开始。
筛选器`@level="1"`表示只选择级别为1 的标题元素。
带命名空间的xpath表达式

带命名空间的XPath表达式1. 什么是XPathXPath是一种在XML文档中定位节点的语言,它可以用来选择XML 文档中的元素和属性。
XPath有自己的数据模型,依赖于节点和数值的概念,XPath可以在XML文档中查找信息,是一个用于遍历和查询XML文档的标准。
2. 命名空间的概念在XML文档中,命名空间用来避免元素和属性名的冲突。
命名空间是一种将元素和属性的名字与其所属的XML文档区分开来的机制,它通过给元素和属性名字加上一个前缀来创建一个唯一的标识符。
命名空间的作用是使得不同XML文档中具有相同名字的元素和属性可以被区分开来。
3. 带命名空间的XPath表达式在XPath中,如果要选取带有命名空间的节点,需要使用带有命名空间的XPath表达式。
带命名空间的XPath表达式的格式如下:```xml/ns1:element/ns2:subelement```其中,`ns1`和`ns2`是命名空间的前缀,`element`和`subelement`分别是带有命名空间的元素和子元素的名字。
在使用带命名空间的XPath表达式时,需要先声明相应的命名空间,然后在XPath表达式中使用命名空间的前缀来选择相应的节点。
4. 示例假设有如下的XML文档:```xml<root xmlns:ns1="" xmlns:ns2=""><ns1:element><ns2:subelement>Value</ns2:subelement></ns1:element></root>```要选择`<ns2:subelement>`节点中的值,可以使用如下的带命名空间的XPath表达式:```xml/root/ns1:element/ns2:subelement/text()```在这个XPath表达式中,`ns1`和`ns2`是命名空间的前缀,`element`和`subelement`分别是带有命名空间的元素和子元素的名字。
selenium xpath表达式

Selenium中的XPath表达式是一种在HTML或XML文档中查找信息的方法,它基于文档的树结构,并提供浏览树的能力。
Selenium WebDriver支持使用XPath表达式来定位和查找网页中的元素。
XPath表达式的语法相对灵活,可以根据元素和属性的不同来编写。
以下是一些常用的XPath表达式:1. 查找所有div元素:`//div`2. 查找所有a元素:`//a`3. 查找第一个div元素:`//div[1]`4. 查找所有class为"example"的元素:`//div[@class="example"]`5. 查找所有id为"example"的元素:`//div[@id="example"]`6. 查找所有h1元素的前一个兄弟元素:`//h1[1]/preceding-sibling::h1`在使用XPath表达式时,可以根据需要灵活组合不同的语法和属性。
需要注意的是,XPath表达式是基于HTML/XML文档的树结构,因此在编写表达式时,要熟悉HTML/XML 文档的组织结构。
对于Selenium WebDriver中的XPath表达式,可以参考以下几点:1. XPath表达式通常以`//`开头,表示匹配任意节点。
2. 属性通常使用`[@属性名]`表示,例如`//div[@class='example']`表示查找所有class为"example"的div元素。
3. 索引表示法用于查找具有特定属性的第一个或最后一个元素,例如`//div[1]`表示查找第一个div元素。
4. 多个属性可以使用`and`和`or`进行组合,例如`//div[@class='example' and @id='another-example']`表示查找class为"example"且id为"another-example"的div元素。
xpath child语法

xpath child语法
XPath是一种用于在XML文档中定位节点的查询语言。
在XPath 中,child轴用于选取当前节点的所有子节点。
其基本语法如下:
/parent::node/child::node.
其中,parent::node表示父节点,child::node表示子节点。
这个语法表示选取父节点下的所有子节点。
另外,child轴还可以简写为斜杠(/),因此上面的表达式也可以写成:
/parent::node/node.
这样就更加简洁明了了。
需要注意的是,child轴只会选取当前节点的直接子节点,不会包括后代节点。
如果想要选取所有后代节点,可以使用双斜杠(//)来代替单斜杠。
除了基本的child轴语法,还可以结合节点名称、通配符、谓语等进行更复杂的节点选择操作。
例如:
/parent::node/child::node[@attribute='value']
这个表达式表示选取父节点下具有特定属性值的子节点。
总的来说,child轴是XPath中非常重要的一部分,能够帮助我们准确定位到所需的子节点,是XPath查询中经常会用到的语法之一。
xpath的用法

xpath的用法
XPath是一种路径表达式语言,用于在XML文档中查找和选取节点。
以下是XPath的用法:
1. 选择节点:
XPath使用路径表达式来选择节点,可以通过节点名称、属性或者位置来进行选择,例如:选择所有的节点://*
选择名称为book的节点://book
选择拥有属性category并且属性值为web的节点:
//@category[.='web']
选择第二个book节点://book[2]
2. 调用函数:
XPath使用函数来操作节点,例如获取节点内容、统计节点数量等等。
一些常用的函数包括:text()用于获取节点文字内容,count()用于统计节点数量,concat()用于合并字符串,substring()用于获取子串等等。
例如:获取第二个book节点的title内容:
//book[2]/title/text()
统计所有book节点数量:count(//book)
3. 进一步筛选节点:
XPath还提供了一些进一步筛选节点的方法,包括比较运算符、逻辑运算符以及通配符。
例如:选择所有价格大于10的book节点:
//book[price>10]
选择第一个同时拥有title和author子节点的book节点:
//book[title and author][1]
选择所有拥有author子孙节点并且作者姓氏为Smith的节点:
//*[author//last='Smith']
通过使用上述方法,我们可以轻松选取XML文档中的节点并进行操作。
xpath表达式

Xpath文件表达式简单说,xpath就是选择XML文件中节点的方法。
所谓节点(node),就是XML文件的最小构成单位,一共分成7种。
- element(元素节点)- attribute(属性节点)- text(文本节点)- namespace(名称空间节点)- processing-instruction(处理命令节点)- root(根节点)xpath可以用来选择这7种节点。
不过,下面的笔记只涉及最常用的第一种element(元素节点),因此可以将下文中的节点和元素视为同义词。
一、xpath表达式的基本格式xpath通过“路径表达式”(Path Expression)来选择节点。
在形式上,“路径表达式”与传统的文件系统非常类似。
#斜杠(/)作为路径内部的分割符。
#同一个节点有绝对路径和相对路径两种写法。
#绝对路径(absolute path)必须用“/”起首,后面紧跟根节点,比如/step/step/...。
#相对路径(relative path)则是除了绝对路径以外的其他写法,比如step/step,也就是不使用“/”起首。
# “.”表示当前节点。
# “..”表示当前节点的父节点二、选择节点的基本规则- nodename(节点名称):表示选择该节点的所有子节点-“/”:表示选择根节点-“//”:表示选择任意位置的某个节点-“@”:表示选择某个属性三、选择节点的实例先看一个XML实例文档。
<?xml version="1.0" encoding="ISO-8859-1"?><bookstore><book><title lang="eng">Harry Potter</title> <price>29."99</price></book><book><title lang="eng">Learning XML</title> <price>39."95</price></book></bookstore>[例1]bookstore:选取bookstore元素的所有子节点。
xpath 表达式

xpath 表达式XPath是一种用于在XML文档中定位和选择节点的语言。
它可以让开发人员轻松地遍历XML文档,并根据需要提取或修改数据。
XPath 表达式是XPath语言中最重要的部分,它是一种描述节点位置和选择节点的方式。
XPath表达式可以用于各种编程语言中的XPath解析器,如Java、Python和PHP。
它们可以用于从XML文档中提取数据、验证XML文档和转换XML文档格式,等等。
下面是一些常见的XPath表达式:1. 选择所有元素“//”表示选择文档中所有的元素。
例如: //book这将选择文档中所有的book元素。
2. 选择指定元素“/”表示选择文档中直接子元素。
例如: /bookstore/book这将选择文档中bookstore元素的所有子元素中所有的book元素。
3. 选择元素属性“@”表示选择元素的属性。
例如: //book[@category='web']这将选择文档中所有category属性为web的book元素。
4. 选择元素的子元素“/”表示选择元素的直接子元素。
例如: //bookstore/book/title这将选择文档中bookstore元素的所有子元素中所有的title元素。
5. 选择元素的父元素“..”表示选择元素的父元素。
例如: //bookstore/book/title/..这将选择文档中bookstore元素的所有子元素中所有的title元素的父元素。
以上是一些常见的XPath表达式,开发人员可以根据实际需要来灵活运用XPath表达式来定位和选择XML文档中的节点。
xpath表达式

xpath表达式XPath表达式(也称为XPath语言)是一种用于在XML(可扩展标记语言)文档中提取信息的表达式语言。
XPath语言允许您使用路径表达式来指定XML文档中的节点或属性。
它可以是非常有用的工具,用于解析XML文档,搜索特定的元素或属性,检索或更新信息,最终实现自动化工作。
XPath表达式的语法XPath使用一种路径表达式语法来指定XML文档中每个节点或属性。
XPath表达式包括几种不同的操作,用于在XML文档中搜索和提取特定元素。
XPath中,每个节点类型都有自己的用法。
下面是XPath表达式语法中典型操作的例子:子节点: //子节点名称 [@属性名]元素: //元素名称 [@属性名]文本: //文本()属性: //属性名称XPath表达式的用法XPath表达式可以用来搜索和提取XML文档中特定的元素或属性。
它可以用来按顺序检索XML文档中的信息,从而获得特定的节点或属性。
它还可以检索XML文档中特定的元素,然后更新或删除它们。
XPath表达式可以用于检索和更新XML文档的部分或整个内容。
XPath还可以用于使用XSLT(可扩展样式表语言转换)转换XML文档,或者将XML文档转换为其他文件格式。
XPath表达式的实践XPath表达式可以用于XML的任何应用程序开发,但是这是比较复杂的,因此它不适合初学者使用。
XPath语言的主要用途是搜索XML 文档中的特定元素,以及提取信息并将它们格式化为其他形式。
在编写XPath表达式之前,需要熟悉XML文档的结构。
可以使用像XPath文本编辑器(XPath-TED)这样的工具来查看XML文档中的每个节点,例如属性,子节点,文本和元素。
通常,XPath表达式可以组合在一起,以实现更复杂的任务和类型的检索。
例如,可以使用XPath表达式搜索XML文档中的所有图像,然后将这些图像拼接在一起以形成网页图像。
XPath表达式可以用于搜索特定的属性,并从XML文档中获取所需的信息。
xpath实验报告

xpath实验报告XPath实验报告引言:XPath是一种用于在XML文档中定位和选择节点的语言,它提供了一种简洁而强大的方式来解析和操作XML数据。
在本实验中,我们将探索XPath的基本语法和功能,并利用XPath来解析和提取XML数据。
一、XPath的基本语法和表达式XPath使用路径表达式来定位和选择节点。
路径表达式由一系列的节点和操作符组成,用于描述节点之间的关系和位置。
以下是XPath的基本语法和表达式:1. 节点选择:- 选择所有节点://*- 选择指定节点:/节点名称- 选择当前节点:.- 选择父节点:..- 选择属性节点:@属性名称2. 谓语:- 使用谓语来过滤节点:[条件]- 谓语可以是比较运算符、逻辑运算符或函数调用3. 轴:- 轴用于指定节点之间的关系和方向:轴名称::节点名称- 常用的轴有子节点轴(child)、父节点轴(parent)、兄弟节点轴(following-sibling)等二、XPath的实验应用在实验中,我们将使用XPath来解析一个示例XML文档,并提取其中的数据。
XML文档示例:```<books><book><title>Harry Potter and the Philosopher's Stone</title><author>J.K. Rowling</author><year>1997</year></book><book><title>The Great Gatsby</title><author>F. Scott Fitzgerald</author><year>1925</year></book></books>```1. 选择所有书籍的标题:XPath表达式://book/title结果:Harry Potter and the Philosopher's Stone, The Great Gatsby2. 选择所有作者为J.K. Rowling的书籍:XPath表达式://book[author='J.K. Rowling']结果:Harry Potter and the Philosopher's Stone3. 选择所有年份早于2000年的书籍标题:XPath表达式://book[year<2000]/title结果:Harry Potter and the Philosopher's Stone4. 选择第一本书的作者:XPath表达式://book[1]/author结果:J.K. Rowling5. 选择最后一本书的标题:XPath表达式://book[last()]/title结果:The Great Gatsby三、XPath的优缺点XPath作为一种强大的XML解析语言,具有以下优点:1. 简洁而灵活:XPath使用简洁的语法和表达式来描述节点之间的关系,可以灵活地定位和选择节点。
xpath表达式的例子

xpath表达式的例子XPath表达式是一种在XML文档中定位元素的语言。
通过使用XPath表达式,我们可以轻松地查找和选择XML文档中的特定节点,从而实现对数据的有效处理和提取。
以下是一些XPath表达式的示例:1. 选择所有节点:XPath表达式:"//*"这个表达式可以选择XML文档中的所有节点,不论是元素、属性还是文本节点。
2. 选择特定元素节点:XPath表达式:"//元素名"通过替换“元素名”为实际的元素名称,这个表达式可以选择XML文档中所有具有指定元素名的元素节点。
3. 选择具有特定属性的元素节点:XPath表达式:"//元素名[@属性名='属性值']"这个表达式根据给定的属性名和属性值选择具有特定属性的元素节点。
可以根据实际的属性名和属性值进行替换。
4. 选择具有特定父节点的子节点:XPath表达式:"//父节点名/子节点名"这个表达式可以选择具有特定父节点的子节点。
通过替换“父节点名”和“子节点名”为实际的父节点名称和子节点名称,可以准确选择对应的子节点。
5. 选择具有特定文本内容的节点:XPath表达式:"//节点名[text()='文本内容']"这个表达式可以选择文本内容与给定文本相匹配的节点。
通过替换“节点名”和“文本内容”为实际的节点名称和文本内容,可以选择具有特定文本内容的节点。
XPath表达式是一种强大的工具,用于在XML文档中快速准确地定位所需的节点。
通过灵活运用XPath表达式,我们能够高效地处理XML数据,提取所需的信息。
xpath的not的搭配用法

xpath的not的搭配用法
XPath中的not操作符可以用来对一个表达式的结果进行否定。
它的语法为“not(expression)”,其中expression是一个XPath表达式,not会对expression的结果进行取反。
not操作符通常用于筛选出不满足某些条件的节点或属性。
例如,如果我们想要选出所有不含有class属性的div节点,可以使用如下XPath表达式:
//div[not(@class)]
这个表达式的意思是选出所有div节点,但要排除掉含有class 属性的节点。
not操作符还可以和其他操作符搭配使用,例如与and或or结合使用。
例如,如果我们想要选出所有class属性不为“red”且不为“green”的div节点,可以使用如下XPath表达式:
//div[not(@class='red') and not(@class='green')] 这个表达式的意思是选出所有div节点,但要排除掉class属性为“red”或“green”的节点。
总之,not操作符是XPath中非常常用的一个操作符,它可以帮助我们更灵活地筛选出符合要求的节点或属性。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
XML 文档对象模型(DOM)能够以编程方式读取、处理和修改XML 文档。
XPath 表达式XPath 表达式使用路径表示法(与URL 中使用的路径表示法类似)寻址XML 文档的各个部分。
表达式计算为生成子元素集、布尔值、数字或字符串类型的对象。
URL与XPath 表达式比较URL: 由文件系统中的文件夹和文件组成的层次结构。
每个级别具有唯一名称的文件。
URL 总是标识单个文件。
相对特定文件夹(称为“当前文件夹”)进行计算。
XPath: 由XML 文档中的元素和其他元素组成的层次结构。
每个级别的元素名可能不是唯一的。
XPath 表达式标识所有匹配的元素集。
相对特定元素(称为表达式的“上下文”)进行计算。
基本XPath 表达式(判断是谁的集合!!)1.当前上下文以句点和正斜杠(./) 作为前缀的表达式明确使用当前上下文作为上下文。
例如,以下表达式引用当前上下文中的所有<author> 元素:./author注意,此表达式等效于以下表达式:author2.文档根以正斜杠(/) 为前缀的表达式使用文档树的根作为上下文。
例如,以下表达式引用此文档根的<bookstore> 元素:/bookstore3.根元素使用正斜杠后接星号(/*) 的表达式将使用根元素作为上下文。
例如,以下表达式查找文档的根元素:/*4.递归下降用双正斜杠(//) 的表达式指示可以包括零个或多个层次结构级别的搜索。
如果此运算符出现在模式的开头,上下文相对于文档的根。
例如,以下表达式引用当前文档中任意位置的所有<author> 元素://author.// 前缀指示上下文从层次结构中当前上下文所指示的级别开始。
5.特定元素以元素名开头的表达式引用特定元素的查询,从当前上下文节点开始。
例如,以下表达式引用当前上下文节点中<images> 元素内的<background.jpg> 元素:images/background.jpg以下表达式引用当前上下文节点中<bookstore> 元素内的<book> 元素的集合:bookstore/book以下表达式引用当前上下文节点中的所有<> 元素:XPath 表达式是使用下表中所示的运算符和特殊字符构造的。
运算符和特殊字符:/ 子运算符;选择左侧集合的直接子级。
此路径运算符出现在模式开头时,表示应从根节点选择该子级。
// 递归下降;在任意深度搜索指定元素。
此路径运算符出现在模式开头时,表示应从根节点递归下降。
. 指示当前上下文。
.. 当前上下文节点的父级。
* 通配符;选择所有元素,与元素名无关。
@ 属性;属性名的前缀。
@* 属性通配符;选择所有属性,与名称无关。
: 命名空间分隔符;将命名空间前缀与元素名或属性名分隔。
( ) 为运算分组,明确设置优先级。
[ ] 应用筛选模式。
[ ] 下标运算符;用于在集合中编制索引。
+ 执行加法。
- 执行减法。
div 根据IEEE 754 执行浮点除法。
* 执行乘法。
mod 从截断除法返回余数。
优先级字符用途1 ( ) 分组2 [ ] 筛选器3 / // 路径运算分组运算符()仅适用于顶级路径表达式。
例如:(//author/degree | //author/name) 是有效的分组运算//author/(degree | name) 不是有效的分组运算筛选模式运算符[] 的优先级高于路径运算符(/ 和//)。
例如://comment()[3]选择相对于文档中任意位置comment的父级索引等于3的所有comment,可以返回多个备注(//comment())[3]选择相对于父级的所有comment集中的第三个comment,只能返回一个备注。
author/first-name当前上下文节点的<author> 元素中的所有<first-name> 元素。
bookstore//title<bookstore> 元素中更深的一级或多级(任意子代)的所有<title> 元素。
注意,此表达式与以下模式bookstore/*/title 不同。
bookstore/*/title属于<bookstore> 元素的孙级的所有<title> 元素。
bookstore//book/excerpt//emph<book> 元素的<excerpt> 子级中的任意位置和<bookstore> 元素中的任意位置的所有<emph> 元素:.//title当前上下文中更深的一级或多级的所有<title> 元素。
注意,本质上只有这种情况需要句点表示法。
通配符通过使用通配符* 集合,不使用元素名即可引用元素。
* 集合引用作为当前上下文的子级的所有元素,与名称无关。
例如:author/*<author> 元素的所有元素子级。
book/*/last-name所有作为<book> 元素的孙级的<last–name> 元素。
*/*当前上下文的所有孙级元素。
my:bookmy 命名空间中的<book> 元素。
my:*my 命名空间中的所有元素。
属性XPath 使用@ 符号表示属性名。
属性和子元素应公平对待,两种类型之间的功能应尽可能相当。
例如:@style当前元素上下文的style 属性。
price/@exchange当前上下文中<price> 元素的exchange 属性。
book/@style所有<book> 元素的style 属性。
@*当前上下文节点的所有属性。
@my:*my 命名空间中的所有属性。
不包括my 命名空间中的元素的未限定属性。
注意:属性不能包含子元素,所以,如果对属性应用路径运算符,将出现语法错误。
此外,不能对属性应用索引,因为根据定义,不为属性定义任何顺序。
price/@exchange/total比较运算符:and 逻辑与or 逻辑或not() 非= 相等!= 不相等< 小于<= 小于或等于> 大于<= 大于或等于| 集运算;返回两个节点集的联合例如:author[last-name = "Bob"]至少包含一个值为Bob 的<last-name> 元素的所有<author> 元素。
author[last-name[1] = "Bob"]第一个<last-name> 子元素的值为Bob 的所有<author> 元素。
author/degree[@from != "Harvard"]包含from 属性不等于"Harvard" 的<degree> 元素的所有<author> 元素。
author[last-name = /editor/last-name]包含与根元素下<editor> 元素中的<last-name> 元素相同的<last-name> 元素的所有<author> 元素。
author[. = "Matthew Bob"]所有字符串值为Matthew Bob 的<author> 元素。
集运算Union (|) 运算符|(即union)运算符返回两个操作数的联合,操作数必须是节点集。
例如,//author | //publisher 返回的节点集结合了所有//author 节点和所有//publisher 节点。
例如:first-name | last-name包含当前上下文中的<first-name> 和<last-name> 元素的节点集。
(bookstore/book | bookstore/magazine)包含<bookstore> 元素中的<book> 或<magazine> 元素的节点集。
book | book/author包含<book> 元素中的所有<book> 元素和所有<author> 元素的节点集。
(book | magazine)/price包含<book> 或<magazine> 元素的所有<price> 元素的节点集。
筛选器和筛选模式通过将筛选子句[pattern] 添加到集合中,可以对任何集合应用约束和分支。
筛选器类似于SQL WHERE 子句。
筛选器中包含的模式称为“筛选模式”。
例如:book[excerpt]至少包含一个<excerpt> 元素的所有<book> 元素。
book[excerpt]/title至少包含一个<excerpt> 元素的<book> 元素内的所有<title> 元素。
book[excerpt]/author[degree]至少包含一个<degree> 元素并且在至少包含一个<excerpt> 元素的<book> 元素内的所有<author> 元素。
book[author/degree]至少包含一个<author> 元素并且该元素至少包含一个<degree> 子元素的<book> 所有元素。
book[excerpt][title]至少包含一个<excerpt> 元素以及至少包含一个<title> 元素的<book> 所有元素。
在Dom4j中使用xpath在使用Dom4j解析xml文档时,我们很希望有一种类似正则表达式的东西来规范查询条件,而xpath正是这样一种很便利的规则吧.以下是本人用写的一个类,摘取部分代码;Java代码String xmlName = path + "/" + userName + ".xml";// 定义需要返回的第一级菜单的名字集合List firstNames = new ArrayList();// Attribute的属性集合List attrs = new ArrayList();// 声明SAXReaderSAXReader saxReader = new SAXReader();try {Document doc = saxReader.read(xmlName);// 获得所有grade=1的Element的text的值String xpath = "/tree/item";List list = doc.selectNodes(xpath);Iterator it = list.iterator();while (it.hasNext()) {Element elt = (Element) it.next();Attribute attr = elt.attribute("grade");System.out.println(attr.getValue());if (new Integer(attr.getValue()).intValue() == 1) {attr = elt.attribute("text");attrs.add(attr.getValue());System.out.println(attr.getValue());}}} catch (DocumentException e) {e.printStackTrace();}return attrs;String xmlName = path + "/" + userName + ".xml";// 定义需要返回的第一级菜单的名字集合List firstNames = new ArrayList();// Attribute的属性集合List attrs = new ArrayList();// 声明SAXReaderSAXReader saxReader = new SAXReader();try {Document doc = saxReader.read(xmlName);// 获得所有grade=1的Element的text的值String xpath = "/tree/item";List list = doc.selectNodes(xpath);Iterator it = list.iterator();while (it.hasNext()) {Element elt = (Element) it.next();Attribute attr = elt.attribute("grade");System.out.println(attr.getValue());if (new Integer(attr.getValue()).intValue() == 1) {attr = elt.attribute("text");attrs.add(attr.getValue());System.out.println(attr.getValue());}}} catch (DocumentException e) {e.printStackTrace();}return attrs;还有一个是获取某个节点下面里的所有第一级子节点,而不是所有的节点(包括子节点和孙节点).Java代码public static List getSecondMenuNames(String textName, String path,String userName) {String xmlName = path + "/" + userName + ".xml";String name = textName;// 定义需要返回的第二级菜单的名字集合List firstNames = new ArrayList();// Attribute的属性集合List attrs = new ArrayList();// 声明SAXReaderSAXReader saxReader = new SAXReader();try {Document doc = saxReader.read(xmlName);// 这个xpath的意思是,获取text='系统管理'的一个Item下的所有Item的节点String xpath = "//item[@text='" + name + "']/child::*";List list = doc.selectNodes(xpath);Iterator it = list.iterator();while (it.hasNext()) {Element elt = (Element) it.next();Attribute attr = elt.attribute("grade");System.out.println(attr.getValue());attr = elt.attribute("text");System.out.println(attr.getValue());attrs.add(attr.getValue());}} catch (Exception e) {e.printStackTrace();}return attrs;}public static List getSecondMenuNames(String textName, String path,String userName) {String xmlName = path + "/" + userName + ".xml";String name = textName;// 定义需要返回的第二级菜单的名字集合List firstNames = new ArrayList();// Attribute的属性集合List attrs = new ArrayList();// 声明SAXReaderSAXReader saxReader = new SAXReader();try {Document doc = saxReader.read(xmlName);// 这个xpath的意思是,获取text='系统管理'的一个Item下的所有Item的节点String xpath = "//item[@text='" + name + "']/child::*";List list = doc.selectNodes(xpath);Iterator it = list.iterator();while (it.hasNext()) {Element elt = (Element) it.next();Attribute attr = elt.attribute("grade");System.out.println(attr.getValue());attr = elt.attribute("text");System.out.println(attr.getValue());attrs.add(attr.getValue());}} catch (Exception e) {e.printStackTrace();}return attrs;}注意看其中的xpath的写法,正是因为有了xpath,我们才能如此简单灵活的对xml 进行操作.刚刚使用xpath的时候可能会报一个错误:Exception in thread "main" ng.NoClassDefFoundError: org/jaxen/JaxenException这时我们应该往CLASSPATH导入一个jar包,叫jaxen-1.1.1.jar,可从网上下载.以下附上xpath的部分语法,具体可查看我的BOLG的链接,有一个叫xpath的.呵呵!<?xml version="1.0" encoding="ISO-8859-1"?><bookstore><book><title lang="eng">Harry Potter</title><price>29.99</price></book><book><title lang="eng">Learning XML</title><price>39.95</price></book></bookstore>表达式描述节点名选择所有该名称的节点集/ 选择根节点// 选择当前节点下的所有节点. 选择当前节点.. 选择父节点@ 选择属性示例表达式描述bookstore 选择所有bookstore子节点/bookstore 选择根节点bookstorebookstore/book 在bookstore的子节点中选择所有名为book的节点//book 选择xml文档中所有名为book的节点bookstore//book 选择节点bookstore下的所有名为book为节点//@lang 选择所有名为lang的属性断言在方括号中[],用来更进一步定位选择的元素表达式描述/bookstore/book[1] 选择根元素bookstore的book子元素中的第一个注意: IE5以上浏览器中第一个元素是0/bookstore/book[last()] 选择根元素bookstore的book子元素中的最后一个/bookstore/book[last()-1] 选择根元素bookstore的book子元素中的最后第二个/bookstore/book[position()<3] 选择根元素bookstore的book子元素中的前两个//title[@lang] 选择所有拥有属性lang的titile元素//title[@lang='eng'] 选择所有属性值lang为eng的title元素/bookstore/book[price>35.00] 选择根元素bookstore的book子元素中那些拥有price子元素且值大于35的/bookstore/book[price>35.00]/title 选择根元素bookstore的book子元素中那些拥有price子元素且值大于35的title子元素选择位置的节点通配符描述* 匹配所有元素@* 匹配所有属性节点node() 匹配任何类型的节点示例表达式描述/bookstore/* 选择根元素bookstore的下的所有子元素//* 选择文档中所有元素//title[@*] 选择所有拥有属性的title元素使用操作符“|”组合选择符合多个path的表达式。