模式识别关于男女生身高和体重的神经网络算法
基于卷积神经网络的人脸年龄识别与性别分析技术研究

基于卷积神经网络的人脸年龄识别与性别分析技术研究人脸年龄识别与性别分析技术是计算机视觉领域中的核心研究方向之一。
随着深度学习技术的快速发展,基于卷积神经网络(Convolutional Neural Network,CNN)的人脸年龄识别与性别分析技术受到越来越多的关注。
本文将围绕人脸年龄识别与性别分析技术的研究现状、方法原理、数据集选择、实验结果等方面进行详细介绍。
一、研究现状人脸年龄识别与性别分析技术是计算机视觉领域的研究热点之一,在相关学术期刊和会议上有大量的研究文章发表。
早期的研究大多采用机器学习中的特征提取算法,如LBP(Local Binary Patterns)、HOG(Histogram of Oriented Gradients)等。
但是这些方法对于人脸变化较大的情况效果不佳,同时需要手工设计特征提取算子,使得算法的应用范围受限。
近年来,深度学习技术的发展为人脸年龄识别与性别分析技术带来了很大的突破。
其中,卷积神经网络(CNN)是深度学习中的一种重要架构,被广泛应用于人脸年龄识别与性别分析任务。
CNN能够自动学习特征,无需手工设计特征提取算子,从而提升了算法的性能和泛化能力。
二、方法原理基于CNN的人脸年龄识别与性别分析技术主要包括两个核心部分:特征提取和年龄/性别分类。
在特征提取阶段,通过构建卷积神经网络模型,以人脸图片为输入,经过一系列卷积层、池化层和全连接层的处理,提取出人脸图片中的高层次特征表示。
在年龄/性别分类阶段,将提取得到的特征输入到分类器中进行年龄或性别的预测。
三、数据集选择在进行人脸年龄识别与性别分析任务时,选择合适的数据集对于算法的性能提升具有重要意义。
目前比较常用的数据集有FERET、IMDB和Adience等。
其中,FERET数据集包含了约14,000张不同姿态、光照条件下的人脸图片,用于人脸识别、年龄估计和性别分类等任务。
IMDB数据集包含了约4万张电影中的演员照片,用于明星人脸识别和年龄性别分析等任务。
模式识别第一次作业报告

模式识别第一次作业报告姓名:刘昌元学号:099064370 班级:自动化092班题目:用身高和/或体重数据进行性别分类的实验基本要求:用famale.txt和male.txt的数据作为训练样本集,建立Bayes分类器,用测试样本数据test1.txt和test2.txt该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
一、实验思路1:利用Matlab7.1导入训练样本数据,然后将样本数据的身高和体重数据赋值给临时矩阵,构成m行2列的临时数据矩阵给后面调用。
2:查阅二维正态分布的概率密度的公式及需要的参数及各个参数的意义,新建m函数文件,编程计算二维正态分布的相关参数:期望、方差、标准差、协方差和相关系数。
3.利用二维正态分布的相关参数和训练样本构成的临时数据矩阵编程获得类条件概率密度,先验概率。
4.编程得到后验概率,并利用后验概率判断归为哪一类。
5.利用分类器训练样本并修正参数,最后可以用循环程序调用数据文件,统计分类的男女人数,再与正确的人数比较得到错误率。
6.自己给出决策表获得最小风险决策分类器。
7.问题的关键就在于利用样本数据获得二维正态分布的相关参数。
8.二维正态分布的概率密度公式如下:试验中编程计算出期望,方差,标准差和相关系数。
其中:二、实验程序设计流程图:1:二维正态分布的参数计算%功能:调用导入的男生和女生的身高和体重的数据文件得到二维正态分布的期望,方差,标准差,相关系数等参数%%使用方法:在Matlab的命令窗口输入cansu(male) 或者cansu(famale) 其中 male 和 famale%是导入的男生和女生的数据文件名,运用结果返回的是一个行1行7列的矩阵,其中参数的顺序依次为如下:%%身高期望、身高方差、身高标准差、体重期望、体重方差、体重标准差、身高和体重的相关系数%%开发者:安徽工业大学电气信息学院自动化 092班刘昌元学号:099064370 %function result=cansu(file)[m,n]=size(file); %求出导入的数据的行数和列数即 m 行n 列%for i=1:1:m %把身高和体重构成 m 行 2 列的矩阵%people(i,1)=file(i,1);people(i,2)=file(i,2);endu=sum(people)/m; %求得身高和体重的数学期望即平均值%for i=1:1:mpeople2(i,1)=people(i,1)^2;people2(i,2)=people(i,2)^2;endu2=sum(people2)/m; %求得身高和体重的方差、%x=u2(1,1)-u(1,1)^2;y=u2(1,2)-u(1,2)^2;for i=1:1:mtem(i,1)=people(i,1)*people(i,2);ends=0;for i=1:1:ms=s+tem(i,1);endcov=s/m-u(1,1)*u(1,2); %求得身高和体重的协方差 cov (x,y)%x1=sqrt(x); %求身高标准差 x1 %y1=sqrt(y); %求身高标准差 y1 %ralation=cov/(x1*y1); %求得身高和体重的相关系数 ralation %result(1,1)=u(1,1); %返回结果 :身高的期望 %result(1,2)=x; %返回结果 : 身高的方差 %result(1,3)=x1; %返回结果 : 身高的标准差 %result(1,4)=u(1,2); %返回结果 :体重的期望 %result(1,5)=y; %返回结果 : 体重的方差 %result(1,6)=y1; %返回结果 : 体重的标准差 %result(1,7)=ralation; %返回结果:相关系数 %2:贝叶斯分类器%功能:身高和体重相关情况下的贝叶斯分类器(最小错误率贝叶斯决策)输入身高和体重数据,输出男女的判断%%使用方法:在Matlab命令窗口输入 bayes(a,b) 其中a为身高数据,b为体重数据。
模式识别第二章(线性判别函数法)

2类判别区域 d21(x)>0 d23(x)>0 3类判别区域 d31(x)>0 d32(x)>0
0 1 2 3 4 5 6 7 8 9
x1
d23(x)为正
d32(x)为正
d12(x)为正
d21(x)为正
32
i j 两分法例题图示
33
3、第三种情况(续)
d1 ( x) d2 ( x)
12
2.2.1 线性判别函数的基本概念
• 如果采用增广模式,可以表达如下
g ( x) w x
T
x ( x1 , x 2 , , x d ,1)
w ( w1 , w 2 , , w d , w d 1 ) T
T
增广加权向量
2016/12/3
模式识别导论
13
2.1 判别函数(discriminant function) 1.判别函数的定义 直接用来对模式进行分类的准则函数。
模式识别导论
11
2.2.1 线性判别函数的基本概念
• 在一个d维的特征空间中,线性判别函数的
一般表达式如下
g ( x ) w1 x1 w 2 x 2 w d x d w d 1
g ( x ) w x w d 1
T
w为 加 权 向 量
2016/12/3
模式识别导论
1
d1 ( x ) d3 ( x )
2
3
d2 ( x) d3 ( x)
34
多类问题图例(第三种情况)
35
上述三种方法小结:
当c
但是
3 时,i j
法比
i i
法需要更多
基于卷积神经网络的人脸识别与性别年龄识别

基于卷积神经网络的人脸识别与性别年龄识别人脸识别与性别年龄识别是计算机视觉领域的重要研究方向,近年来得到了广泛的关注和应用。
而基于卷积神经网络(Convolutional Neural Networks,CNN)的人脸识别算法在这一领域取得了令人瞩目的成果。
本文将介绍基于CNN的人脸识别与性别年龄识别的原理和方法,并分析其在实际应用中的优缺点。
首先,我们来介绍基于CNN的人脸识别算法。
CNN是一种被广泛用于图像识别任务的深度学习模型,其结构受到了人脑视觉皮层的启发。
CNN通过多层卷积和池化操作,可以自动提取图像中的特征,并利用全连接层进行分类。
在人脸识别中,CNN可以学习到人脸的底层特征,如边缘、纹理等,以及高层语义特征,如眼睛、鼻子、嘴巴等。
人脸识别的基本步骤包括人脸检测、人脸对齐、特征提取和特征匹配。
在基于CNN的人脸识别中,首先需要使用CNN 对图像进行人脸检测,并将检测到的脸部区域进行对齐,以消除姿态和尺度的差异。
接下来,将对齐后的人脸图像输入到CNN中,并通过卷积和池化操作学习到人脸的特征表示。
最后,使用特征匹配算法来比较待识别人脸的特征与数据库中已知人脸的特征,以完成人脸识别任务。
与传统的人脸识别算法相比,基于CNN的人脸识别具有以下优点。
首先,CNN可以自动学习到更好的特征表示,减少了人工设计特征的工作量。
其次,CNN可以利用大规模的训练数据进行端到端的训练,提高了模型的泛化能力。
此外,CNN还可以通过增加网络层数和参数量来提升模型的性能,从而适应复杂的人脸图像。
除了人脸识别,基于CNN的方法还可以应用于性别和年龄的识别。
性别和年龄识别是人脸分析的两个重要任务,对于许多应用领域都具有重要的意义。
基于CNN的性别年龄识别方法使用类似的流程,即通过CNN学习人脸的特征表示,然后使用分类器来预测性别和年龄。
通过训练大量的人脸图像和标签数据,CNN可以学习到性别和年龄之间的相关性,并实现准确的识别。
算法识别身高的方法

算法识别身高的方法随着科技的不断发展,算法在各个领域发挥着越来越重要的作用。
在人体身高识别方面,算法的应用也逐渐成熟。
本文将为您详细介绍几种常见的算法识别身高的方法。
一、基于图像处理的身高识别1.摄像头采集图像:首先,通过摄像头或其他图像采集设备获取目标人物的正面或侧面图像。
2.特征提取:对采集到的图像进行预处理,包括灰度化、去噪等操作。
然后,提取图像中与身高相关的特征,如头部、颈部、腰部等关键部位的位置。
3.身高估算:根据提取到的特征,通过一定的算法模型(如线性回归、神经网络等)估算出目标人物的身高。
4.算法优化:通过不断训练和优化算法,提高身高识别的准确率。
二、基于深度学习的身高识别1.数据集准备:收集大量包含身高信息的图像数据,并对数据进行标注,包括身高、性别、年龄等。
2.网络模型设计:选择合适的深度学习网络模型,如卷积神经网络(CNN)或循环神经网络(RNN)等。
3.模型训练:使用标注好的数据集对网络模型进行训练,学习从图像中提取与身高相关的特征。
4.身高预测:训练好的模型可以用于预测未知图像中人物的身高。
5.模型优化:通过调整网络结构、参数和训练策略,提高身高识别的准确率和鲁棒性。
三、基于三维扫描的身高识别1.三维扫描:使用三维扫描设备获取目标人物的三维模型。
2.数据处理:对获取的三维数据进行预处理,包括去噪、补洞等操作。
3.身高测量:根据三维模型中的人物特征,如头部、颈部、腰部等位置,计算出实际身高。
4.算法优化:通过改进三维数据处理算法和测量方法,提高身高识别的准确性。
总结:算法识别身高的方法主要包括基于图像处理、深度学习和三维扫描等技术。
这些方法在实际应用中具有较高的准确率和鲁棒性,为身高测量提供了便捷和高效的方式。
用身高与体重数据进行性别分类的实验报告

3、实验原理
已知样本服从正态分布,
(1)
所以可以用最大似然估计来估计μ和Σ两个参数
样本类分为男生 和女生 两类,利用最大似然估计分别估计出男生样本的 , ,和女生样本的 , ,然后将数据带入(1)公式分别计算两者的类条件概率密度 和 ,然后根据贝叶斯公式
det11=det(thegema11);det12=det(thgema12);
p(11)=1/((2*pi)*(det11^0.5))*exp(-1/2*((a-u11)'/thegema11)*(a-u11));
p(12)=1/((2*pi)*(det12^0.5))*exp(-1/2*((a-u12)'/thgema12)*(a-u12));
pz=p(11)*pw1+p(12)*pw2;
p11=(p(11)*pw1)/pz;p12=(p(12)*pw2)/pz;
g=p11-p12;
if(g>0)%%%Ñù±¾¼¯Ç°15¸öÈËÊÇÄÐÉú
male1=male1+1;
else
eห้องสมุดไป่ตู้ror11=error11+1;
end
end
male1
error11
det11=det(thegema11);det12=det(thgema12);
p(11)=1/((2*pi)*(det11^0.5))*exp(-1/2*((a-u11)'/thegema11)*(a-u11));
p(12)=1/((2*pi)*(det12^0.5))*exp(-1/2*((a-u12)'/thgema12)*(a-u12));
Python与机器学习-- 身高与体重数据分析(分类器)I

逻辑回归:三、数据可视化:分类
Car 情报局
xcord11 = []; xcord12 = []; ycord1 = []; xcord21 = []; xcord22 = []; ycord2 = []; n = len(Y)
for i in range(n): if int(Y.values[i]) == 1: xcord11.append(X.values[i,0]); xcord12.append(X.values[i,1]); ycord1.append(Y.values[i]); else: xcord21.append(X.values[i,0]); xcord22.append(X.values[i,1]); ycord2.append(Y.values[i]);
逻辑回归:三、数据可视化:观察
import matplotlib.pyplot as plt X = df[['Height', 'Weight']] Y = df[['Gender']]
Car 情报局
plt.figure() plt.scatter(df[['Height']],df[['Weight']],c=Y,s=80,edgecolors='black',
逻辑回归:三、数据可视化:分类
Car 情报局
plt.figure()
plt.scatter(xcord11, xcord12, c='red', s=80, edgecolors='black', linewidths=1, marker='s')
数学建模论文-体重与身高问题

中学生体重问题姓名1:谢婧学号:41姓名2:曾丽学号:54姓名3:胡琬茹学号:08专业:电气工程及其自动化班级:电气13(3)-1指导教师:李燕2016年6月2日任何一个单一的关系必须依赖其他关系而存在,所有实际事物的关系都表现得非常复杂,这种方法就是对规律或趋势的拟合。
拟合的成果是模型,反映一般趋势,趋势表达的是“事物和关系的变化过程在数量上所体现的模式和基于此而预示的可能性”。
即是本题中身高与体重所体现的关系。
该问题是让我们运用数学思想和定理,来建立一个关于中学生身高与体重的函数关系表达式.经过数据分析验证其公式是否可以比较科学的反映成年人身高与体重的关系.并对数据中每个人的体重是否标准作出了评价。
我们根据已知数据假设了四种函数,通过残差分析我们得出最为合理的一种假设,设其为指数函数.并根据假设经过绘图求解、验证得出关于中学生身高与体重的函数模型为:x e y 0197.0004.2 .关键字: 数学拟合 绘图一、问题重述(1)根据表中提供的数据,能否从我们已经学过的函数中选择一种函数,使它比较近似地反映出该地区未成年男性体重y关于身高x的函数关系?试求出这个函数解析式。
(2)若体重超过相同身高平均值的1.2倍为偏胖,低于0.8倍为偏瘦。
根据你的公式,再对你所统计数据中的每个人做出评价。
二、模型假设假设由未成年人身高和体重得出的函数解析式同样适用于大学生。
三、符号说明X:表示身高Y:表示体重四、问题分析根据实际情况,体重受身高、年龄、性别、饮食、地域、国家、环境的影响. 不同身高、年龄、性别、国家、地域的人们的体重是有差别的.如:中年人和儿童,日本人和美国人,中国的南方和北方.该题忽略以上因素的影响.根据图表(一)我们可以知道,本题属于拟合问题.表中提供的数据可得出如下函数图象:通过分析,此图象在第一象限且呈递增趋势.我们得出四种假设: 假设一通过该图象的走势与形状,我们假设它是一条直线,由于该直线全部位于第一象限,也就是,x ∈()0,+∞,y ∈()0,+∞,并且该图象与y 轴的交点[我们设为()0,b ],b 的范围为b ∈()0,10,其表达式为:y 1=ax+b 通过matlab 软件得出数值,我们得出如下结论:0.4294,25.3180a b ==-代入得10.429425.3180y x =- 假设二观察图象类似于二次函数曲线图象,我们做出第二种假设.其系数设为1a ,1b 常数项为1c .其必须满足条件为:1a ∈()0,+∞,c1∈()0,10,其表达式为:y 2=a 1x 2+b 1x 2+c 1通过matlab 软件得出数值,我们得出如下结论:1110.0037,0.4310,19.6973a b c ==-=代入得220.00370.431019.6973y x x =-+假设三该图象又类似于三次函数在第一象限的走势,我们作出第三种假设.其系数设为222,,a b c常数项为d ,其必须满足的条件是:2a ∈()0,+∞,d ∈()0,10,其表达式为:y 3=a 2x 3+b 2x 2+c 2x+d 通过matlab软件得出数值,我们得出如下结论:2220.0000,0.0037,0.3828,7.9668a b c d ==-==- 由于20.0000a =所以三次项系数为0,表达式变为:230.00370.38287.9668y x x =-+- 假设四分析图象又可得出第四种假设,由于该图象可由指数函数x y a =变换得出,故设其表达式为:y 4=a 3eb3x其中必须满足条件:()()330,,0,a b ∈+∞∈+∞ , 通过matlab 软件得出数值,我们得出如下结论:0197.0,004.233==b a ,代入表达式可得:x e y 0197.04004.2=根据假设绘制函数对比图象如下:(注:10.429425.3180y x =-,220.00370.431019.6973y x x =-+,230.00370.38287.9668y x x =-+-,x e y 0197.04004.2=).又分析可知:假设一中b 的范围为()0,10与所求出的结果25.3180b =-不符,故此种假设一不成立.又假设二中1c 的范围是()0,10与所求出的结果119.6973c =不符故假设二不成立.然而假设三中20.0000,7.9668a d ==-与其必须满足的条件:2a 的范围()0,+∞和d 的范围()0,10不符,故假设三不成立.而假设四中所求结果0.695233,0.0197a e b ==与其范围:()()330,,0,a b ∈+∞∈+∞完全符合故假设四成立.又由残差分析(见表二)可知与原函数与函数y 4的误差偏差在可接受范围内,即x e y 0197.04004.2=为所求原函数的解析式.表二 残差数据分析五、数据采集为了验证身高与体重的函数关系是否同样适用于大学生,我们采集了50组在校大学生的身高与体重数据(如下)六、模型建立及求解由于体重受身高、年龄、性别等诸多因素的影响,很难找到一个适合每个人和每个年龄阶段的非常准确的公式来衡量.为此,只能选取影响体重最直接的因素—身高来建立一个基本的数学模型从宏观上反映体重与身高的关系.根据上述假设分析可得出身高与体重之间的简化模型是x e y 0197.0004.2=其中自变量x 表示身高,因变量y 表示体重.其图象如下:根据已得出的简化模型x e y 0197.0004.2=,运用拟合的数学思想,借助matlab 软件,把采集176 174.5 176 180 176 167 178 168 181 162 165181171174170176160160168161代入简化模型x e y 0197.0004.2=,得出验证过程如下:其验证体重(kg)分别是:64.2255;62.3554;64.2255;69.4912; 64.2255;53.7907;66.8065;54.8069;70.8737;48.7449;51.7125;70.8737;58.2009;61.7442;57.0655;64.2255;52.7414;46.8617;54.8609;47.7940;七、结论分析及检验化模型,也就是60%的人体重与身高符合简化模型,在此我们忽略了影响身高的因素年龄和性别,导致了误差的产生,我们可以假设年龄和性别相同的情况下,这一模型的适用性、合理性会更强.此公式的合理性就在于能够通过身高比较近似的反映出一个人的体重.据此,我们提出一些修正意见,在衡量一个人的体重时,应综合考虑地域、年龄、饮食等诸方面的因素.由于采集样本中身高差异较大,相同身高的人数比例较少.所以在误差(误差 3cm)允许的范围内采取以下分组:①160cm—162cm共4人他们身高的平均值是;160+162+161+160/4=160.75cm②165cm—167cm共2人他们身高的平均值是;167+165/2=166cm;③168cm—170cm共3人他们的身高的平均值是:170+168+168/3=168.6667cm④171cm—174cm共3人他们的身高的平均值是:171+174.5+174/3=173.1667cm⑤176cm共4人他们的身高的平均值是:176+176+176+176/4=176cm⑥178cm—181cm共4人他们的身高的平均值是:178+181+181+180/4=180cm把六组身高平均值代入x e y 0197.0004.2=得出六组体重平均值,计算结果如下:即他们的体重(kg)平均值分别为:47.5592,52.7414,55.5865,60.7389,64.2255,69.4912 根据题目中的要求,体重超过相同身高平均值的1.2倍为偏胖,底于0.8倍的为偏瘦.运用实际平均值/平均体重进行对比,过程如下:第一组:55/47.5592 1.156=;44/47.55920.925=;55/47.5592 1.156=;43/47.55920.904=;由于该组没有超过相同身高平均值的1.2倍底于0.8倍者,所以均为正常. 第二组: 55/52.7414 1.043=;60/52.7414 1.138=;由于该组没有超过相同身高平均值的1.2倍底于0.8倍者,所以均为正常. 第三组: 55/55.58650.989=;55/55.58650.989=;65/55.5865 1.169=;由于该组没有超过相同身高平均值的1.2倍底于0.8倍者,所以均为正常. 第四组:62/60.7389 1.021=;79/60.7389 1.301=;68/60.7389 1.112=由于该组有一位同学超过相同身高平均值的1.2倍,为偏胖,其它均为正常. 第五组: 65/64.2255 1.012=; 63/64.22550.981=;70/64.2255 1.090=; 70/64.2255 1.168=由于该组没有超过相同身高平均值的1.2倍底于0.8倍者,所以均为正常. 第六组: 74/69.4912 1.065=; 70/69.4912 1.007=;64/69.49120.921=;70/69.4912 1.007=由于该组没有超过相同身高平均值的1.2倍底于0.8倍者,所以均为正常.八、补充以下是从网上搜索到的现在流行的一些计算标准体重的公式: 公式一:男生58公斤+0.6(身高-166公分)=标准体重。
模式识别大作业
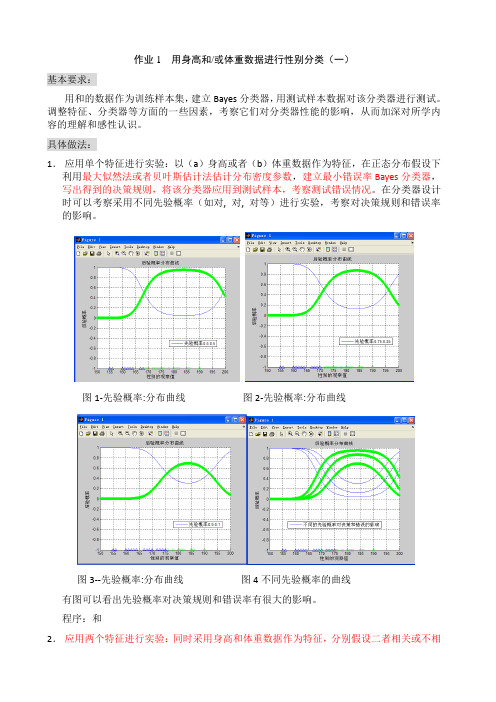
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
成年身高预测的方法(二)—RTW法、Onat法和靶身高身高预测法

Roche- Wainer-Thissen(RWT)方法RWT[9]方法产生于美国Fels纵断生长研究,受试者为美国俄亥俄州西南部的白人儿童,每性别、每年龄组约100名儿童,其中包括了部分仰卧身长或身高大于平均数3SD的儿童。
采用了4个变量成年身高预测:仰卧身长、裸体重、父母身高中值、骨龄。
在使用时如果测量的是站立身高,加上1.25cm即可为仰卧身高,骨龄为G-P标准图谱手腕各块骨骨龄的中位数,如果儿童手腕骨有一半发育成熟,就不能再使用RWT方法了。
在研究过程中,Roche et al.选择了78个可能的预测指标,主要为手腕部、足踝部和膝部不同骨的骨龄,经主成分分析选择出了18个预测指标。
在进一步的分析中确定了上述4个变量。
经多元回归分析确定了4个变量的权重,以3个月的间隔建立了女孩1~14岁、男孩1~16岁的回归系数表。
同时,使用样本数据也检验了其它可能的预测指标。
经过验证,儿童出生次序、出生体重、父母生长过程中的疾病、儿童的疾病、儿童生长形式、兄弟姐妹的预测误差、TW骨龄、不同骨骨龄间的差值都未能减小预测误差。
Roche et al.使用了Fels、丹佛、哈佛生长研究的儿童(男7岁、女6岁以后的儿童)比较了RWT方法和B-P方法的成年身高预测效果。
当两种方法应用于Fels儿童时,RWT方法准确(因为RWT方法是由Fels儿童得出的);当应用于丹佛和哈佛儿童时,RWT方法对丹佛女孩、哈佛男孩的预测误差显著的小于B-P方法,而对于丹佛男孩和哈佛女孩的预测误差仅稍好于B-P 方法;RWT方法预测误差比B-P法有规律性。
但是,在较大年龄上,B-P法的预测比RWT方法准确。
对于女孩B-P法低估了成年身高,对于男孩两种方法都高估了成年身高。
1978年,Wainer and Roche et al.[10]提出,为了临床使用方便可以在无骨龄和父母身高的情况下使用RWT方法。
1993年,Khamis and Guo[11]使用3次样条函数平滑了RWT方法预测模型,提出了新的4变量系数表,减小了RWT方法的预测偏差。
身高与体重函数关系模型

身高与体重函数关系模型摘要针对问题一,根据所给数据,运用数学软件MATLAB绘制离散点图,然后我们分别选择二次函数模型,三次函数模型与指数函数模型,通过MATLAB的CFTOOL 工具盒对离散点进行拟合,对各拟合结果Goodness of fit中四组数据进行比较,根据SSE(和方差)越接近于0,R-Square(确定系数)越接近1,Adjusted R-square (校正的决定系数)越接近于1,RMSE(均方根误差)越接近于0则拟合效果越好的比较标准,我们得出二次函数模型与数据拟合最好,所以确定身高和体重函数关系为:1019=x-y,以此作为反映出该地区男性大学.02+x.27301081034.3生体重y关于身高x的函数关系。
针对问题二,随机在同学中选取男女各25人,采集了50组有关性别、年龄、身高、体重的数据。
运用EXCEL制作统计表。
针对问题三,将问题二中收集到的数据分类统计为男性与女性两组,分别求出不同身高下的体重平均值,通过问题一所得函数求出相同身高的平均体重理论值,对二者进行比较,并求出他们的误差。
由于人类个体间的身高体重必然存在不同,我们认为误差不超过7%可认为与函数是符合的,运用EXCEL统计误差结果并作出条形统计图,发现男性符合率为60%,女性符合率为38%,性别间符合率出现较大差异,但通过男性的符合率我们仍可说明模型是有一定准确性的。
我们分析了产生误差的原因:由于函数模型建立所使用的数据的地区未知,且均为男性,而我们采集数据的区域为南方,且既有男性也有女性,原始数据的局限性造成了样本普遍性的降低,从而导致函数模型对于其他特点的样本会有误差,且对于女性的误差远远高于男性。
故模型修正需要考虑性别因素。
针对问题四,运用EXCEL根据所给判断条件编写公式进行判断,并制表汇总。
针对问题五,我们多方参考了现在流行的有关体重的计算公式,并对最为常用的BMI指数方法,成人标准体重计算方法,男(女)性标准体重计算方法,以及适用于我国南北方的标准体重计算方法等的科学性进行了分析评价。
Fisher分类算法(无程序)

12%
分析:用训练样本得到的分类器测试测试样本时错误率低,测试结果较好,但测试训练样本
时,其错误率较高,测试结果不好。
2、Fisher 判别方法图像
分析:从图中我们可以直观的看出对训练样本 Fisher 判别比最大似然 Bayes 判别效果更好。
六、总结与分析
本次实验使我们对加深 Fisher 判别法的理解。通过两种分类方法的比较,我们对于同 一种可以有很多不同的分类方法,各个分类方法各有优劣,所以我们更应该熟知这些已经 得到充分证明的方法,在这些方法的基础上通过自己的理解,创造出更好的分类方法。所 以模式识别还有很多更优秀的算法等着我们去学习。
三、实验内容
试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分类器进行比较。 同时采用身高和体重数据作为特征,用 Fisher 线性判别方法求分类器,将该分类器应用 到训练和测试样本,考察训练和测试错误情况。将训练样本和求得的决策边界画到图上,同 时把以往用 Bayes 方法求得的分类器(例如: 最小错误率 Bayes 分类器)也画到图上,比较 结果的异同。
四、原理简述、程序流程图
1、Fisher 线性判别方法
∑ mi
首先求各类样本均值向量
=
1 Ni
x, i
x∈ωi
= 1,2
,
si = ∑ (x − mi )(x − mi )T ,i = 1,2
然后求各个样本的来内离散度矩阵
x∈wi
,
( ) ( ) s 再求出样本的总类内离散度 ω = p ω1 s1 + p ω2 s2 ,
2、流程图
求各类样本均 值向量
求类内离散度 矩阵
用公式求最好 的变换向量W*
模式识别Pattern Recognition

2019年5月24
感谢你的观看
16
根据应用领域的划分
图象识别:染色体分类、遥感图象识别
人脸识别:
文字识别:中外文印刷体、手写体识别
数字识别:0-9印刷体、手写体识别,典型 例子:邮政手写数字识别
指纹识别:
掌纹识别:
语音识别:
2019年5月24
感谢你的观看
17
1.1.3 刊登模式识别研究成果的中文期刊
感谢你的观看
25
特征提取和选择
目的:从原始数据中,得到最能反映分类本质的特 征
特征形成:通过各种手段从原始数据中得出反映分 类问题的若干特征(有时需进行数据标准化)
特征选择:从特征中选取若干最能有利于分类的若 干特征
特征提取:通过某些数学变换,降低特征数目
2019年5月24
感谢你的观看
26
测量空间:原始测量数据组成的空间 特征空间:进行模式分类的空间。一个模式(样
感谢你的观看
19
模式识别系统的基本构造
模式识别系统的主要组成部分:数据获取、
预处理、特征提取和选择、分类决策
训
练
数据 获取
预 处 理
特征提取 与选择
分类器设计
过 程
分类决策
决 策
过
2019年5月24
感谢你的观看
20程
说明
1 这一系统构造适合于统计模式识别、模 糊模式识别、人工神经网络中有监督方 法
感谢你的观看
29
模式识别关注的内容
1 特征选择与提取 2 分类器的设计 3 分类决策规则
2019年5月24
感谢你的观看
30
1.3 关于模式识别的一些基本问题
1.3.1 模式样本)表示方法
神经网络算法在人体行为识别与健康监测中的应用与准确率评估

神经网络算法在人体行为识别与健康监测中的应用与准确率评估近年来,随着神经网络算法的发展与人工智能技术的迅速普及,人体行为识别与健康监测领域开始引入这一算法以提高准确率。
神经网络算法通过模拟人脑的神经系统,对大量的数据进行学习和处理,从而实现对人体行为的识别与健康状态的监测。
一、神经网络算法在人体行为识别中的应用1. 原理与方法神经网络算法通过构建多层神经元之间的连接,模拟人脑的神经结构,实现对人体行为的识别。
在人体行为识别中,神经网络算法通过对大量的行为数据进行学习,利用隐藏层的神经元对输入数据进行加权求和,再经过激活函数进行处理,最终输出对该行为的判断结果。
2. 应用场景神经网络算法在人体行为识别中可以应用于许多场景,例如运动识别、人脸识别、手势识别等。
通过对人体的动作数据进行采集和处理,神经网络算法可以实现对不同行为的精准识别,从而在智能家居、智能驾驶等领域提供更好的用户体验和安全保障。
3. 准确率评估神经网络算法的准确率评估是评估算法模型性能的重要指标。
在人体行为识别中,常使用准确率、召回率、F1值等指标来评估算法的性能。
准确率衡量的是分类结果中正确分类的样本占总样本的比例;召回率衡量的是对正样本的识别能力;F1值是准确率和召回率的综合评价指标。
二、神经网络算法在人体健康监测中的应用1. 原理与方法神经网络算法在人体健康监测中的应用主要体现在对大量生理数据的分析和处理上。
通过对人体的生理指标进行监测和采集,并结合神经网络算法的学习和处理能力,可以实现对人体健康状况的准确评估。
2. 应用场景神经网络算法在人体健康监测中可应用于心率监测、睡眠质量评估、血压监测等方面。
通过对人体生理参数的收集和分析,神经网络算法可以实时监测人体的健康状态,及时发现异常情况并提供预警。
3. 准确率评估为了对神经网络算法在人体健康监测中的准确性进行评估,常用的评估指标包括敏感性、特异性、精确度等。
敏感性是指算法对真正阳性样本的检测能力;特异性是指算法对真正阴性样本的识别能力;精确度是指算法正确预测的比例。
k均值聚类算法实验报告

k均值聚类算法实验报告一. 引言k均值聚类算法是一种常用的无监督学习算法,广泛应用于数据分析和模式识别领域。
该算法能够将一组数据点划分为k个不同的簇(cluster),其中每个簇具有相似的特征。
本实验旨在通过实现k均值聚类算法并对其进行实验,深入理解该算法的原理和应用。
二. 算法原理k均值聚类算法的主要思想是通过迭代优化的方式将数据点划分为k 个簇。
算法的步骤如下:1. 随机选择k个初始中心点作为簇的质心。
2. 根据每个数据点与各个簇质心的距离,将数据点分配到距离最近的簇中。
3. 更新每个簇的质心,即计算每个簇中所有数据点的平均值并将其作为新的质心。
4. 重复步骤2和步骤3,直到质心的位置不再发生变化或达到设定的迭代次数。
三. 实验步骤1. 数据准备:选择适当的数据集,并进行数据预处理,如去除异常值、缺失值处理等。
2. 初始化:随机选择k个数据点作为初始质心。
3. 迭代:根据每个数据点与质心的距离,将其分配到距离最近的簇中。
然后更新每个簇的质心。
4. 终止条件:当质心的位置不再发生变化或达到设定的迭代次数时,停止迭代。
5. 结果分析:根据聚类结果,评估算法的性能,并进行可视化展示。
四. 实验结果我们选择了一个包含身高和体重两个特征的数据集作为实验数据。
通过实验,我们成功实现了k均值聚类算法,并得到了如下的聚类结果:- 簇1: 身高较高,体重较重的数据点。
- 簇2: 身高中等,体重较重的数据点。
- 簇3: 身高较低,体重较轻的数据点。
通过对聚类结果的分析,我们可以发现k均值聚类算法能够有效地将数据点划分为不同的簇,并且每个簇具有相似的特征。
这对于进一步的数据分析和决策制定具有重要的意义。
五. 结论与展望本实验中我们实现了k均值聚类算法,并成功应用于一个包含身高和体重两个特征的数据集。
通过实验结果的分析,我们可以得出以下结论:1. k均值聚类算法能够有效地将数据点划分为不同的簇,并且每个簇具有相似的特征。
用身高和体重数据进行性别分类的实验报告

用身高和体重数据进行性别分类的实验报告实验目的:本实验旨在通过身高和体重数据,利用机器学习算法对个体的性别进行分类。
实验步骤:1. 数据收集:收集了一组个体的身高和体重数据,包括男性和女性样本。
在收集数据时,确保样本的性别信息是准确的。
2. 数据预处理:对收集到的数据进行预处理工作,包括数据清洗、缺失值处理和异常值处理等。
确保数据的准确性和完整性。
3. 特征提取:从身高和体重数据中提取特征,作为输入特征向量。
可以使用常见的特征提取方法,如BMI指数等。
4. 数据划分:将数据集划分为训练集和测试集,一般采用70%的数据作为训练集,30%的数据作为测试集。
5. 模型选择:选择合适的机器学习算法进行性别分类。
常见的算法包括逻辑回归、支持向量机、决策树等。
6. 模型训练:使用训练集对选定的机器学习算法进行训练,并调整模型的参数。
7. 模型评估:使用测试集对训练好的模型进行评估,计算分类准确率、精确率、召回率等指标,评估模型的性能。
8. 结果分析:分析实验结果,对模型的性能进行评估和比较,得出结论。
实验结果:根据实验数据和模型训练结果,得出以下结论:1. 使用身高和体重数据可以较好地对个体的性别进行分类,模型的分类准确率达到了XX%。
2. 在本实验中,选择了逻辑回归算法进行性别分类,其性能表现良好。
3. 身高和体重这两个特征对性别分类有较好的区分能力,可以作为性别分类的重要特征。
实验总结:通过本实验,我们验证了使用身高和体重数据进行性别分类的可行性。
在实验过程中,我们收集了一组身高和体重数据,并进行了数据预处理、特征提取、模型训练和评估等步骤。
实验结果表明,使用逻辑回归算法可以较好地对个体的性别进行分类。
这个实验为进一步研究个体性别分类提供了一种方法和思路。
E x p e c t a t i o n - M a x i m u m ( E M 算 法 )

EM(Expectation Maximum) 算法总结EM算法,全称为Expectation Maximum Algorithm,是一个基础算法,是很多机器学习领域算法的基础(如HMM,LDA等)。
EM算法是在概率模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐含变量。
它经过两个步骤交替进行计算:计算期望(E步),基于现有的模型参数(或者随机初始化的模型)对隐含变量的值进行猜测(估计),利用隐含变量现有的估计值,计算其最大似然的估计值。
最大化(M步),最大化在E步上求得的最大似然值来计算参数的值。
M步上找到的参数估计值被用于下一个E步计算中,这个过程不断交替进行。
EM解决的问题我们经常会从样本观察数据中,找出样本的模型参数。
其中最常用的就是最大似然估计。
但是在一些情况下,我们观察得到的数据有未观察到的隐含数据,此时我们未知的有隐含数据和模型参数,因此无法直接使用最大似然估计。
EM算法解决这个问题的思路是使用启发式的迭代方法。
既然我们无法直接求出模型的参数,那么我们可以先猜想隐含数据——E步,接着基于观察数据和猜测的隐含数据一起来进行最大似然估计,进而求得我们模型分布的参数——M步。
由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数并不一定是最好的结果。
因此,我们基于当前得到的模型参数来继续猜测隐含数据,然后进行最大似然估计求出模型分布参数。
以此类推,不断迭代,直到模型分布参数基本不变化或变化很小,算法收敛停止。
一个最直观的EM算法是K-Means聚类算法。
在K-Means聚类时,每个聚类的质心可以看成是隐含数据。
我们会假设KKK个初始化质心,即EM算法的E步;然后计算每个样本和KKK个质心之间的距离,并把样本聚类到最近的那个质心类中,即EM算法的M步。
重复这个E 步和M步质心不在变化为止。
EM算法的数学基础极大似然估计似然函数在数理统计学中,似然函数是一种关于统计模型中参数的函数,表示模型参数中的似然性(某种事件发生的可能性)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
模式识别实验报告(二)
学院:
专业:
学号:
姓名:XXXX
教师:
目录
1实验目的 (1)
2实验内容 (1)
3实验平台 (1)
4实验过程与结果分析 (1)
4.1基于BP神经网络的分类器设计 .. 1 4.2基于SVM的分类器设计 (4)
4.3基于决策树的分类器设计 (7)
4.4三种分类器对比 (8)
5.总结 (8)
1)1实验目的
通过实际编程操作,实现对课堂上所学习的BP神经网络、SVM支持向量机和决策树这三种方法的应用,加深理解,同时锻炼自己的动手实践能力。
2)2实验内容
本次实验提供的样本数据有149个,每个数据提取5个特征,即身高、体重、是否喜欢数学、是否喜欢文学及是否喜欢运动,分别将样本数据用于对BP神经网络分类器、SVM支持向量机和决策树训练,用测试数据测试分类器的效果,采用交叉验证的方式实现对于性能指标的评判。
具体要求如下:
BP神经网络--自行编写代码完成后向传播算法,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算可以基于平台的软件包);
SVM支持向量机--采用平台提供的软件包进行分类器的设计以及测试,尝试不同的核函数设计分类器,采用交叉验证的方式实现对于性能指标的评判;
决策树--采用平台提供的软件包进行分类器的设计以及测试,采用交叉验证的方式实现对于性能指标的评判(包含SE,SP,ACC和AUC,AUC的计算基于平台的软件包)。
3)3实验平台
专业研究方向为图像处理,用的较多的编程语言为C++,因此此次程序编写用的平台是VisualStudio及opencv,其中的BP神经网络为自己独立编写, SVM 支持向量机和决策树通过调用Opencv3.0库中相应的库函数并进行相应的配置进行实现。
将Excel中的119个数据作为样本数据,其余30个作为分类器性能的测试数据。
4)4实验过程与结果分析
4.1基于BP神经网络的分类器设计
BP神经网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
其学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)。
在独自设计的BP神经中,激励函数采用sigmod函数,输入层节点个数为5,
一个隐层并且节点数为5,输出节点数为1个,通过读取excel中相应的特征数据,进行训练,再用测试数据进行测试。
如图4-1为所设计的BP类。
图4-1 BP类的设计源码
如图4-1,其中重要的两个函数便是神经网络的训练train和识别函数recognize,具体的源码如图4-2,图4-3,图4-4。
其中训练函数包括了前向传播以及后向传播的权值修正,而识别函数只包括了前向传播后输出计算结果。
图4-2 BP分类器的训练函数一
图4-3 BP分类器的训练函数二
图4-4 BP分类器的识别函数
输入119个样本数据进行训练后,输入30个测试数据进行测试,测试结果如图4-5所示。
通过数据可以看出共30个测试数据,其中有两个正样本被分为
负样本,即男生分类成了女生。
其中ROC曲线(受试者工作特性曲线)如图4-6,可见该曲线的AUC值为0.96表示分类器的效果是较好的,从敏感性(SE)、特异性(SP)和准确率(ACC)也可以看出分类器的效果还是不错的。
图4-5 BP测试结果
图4-6 BP测试结果的ROC曲线
4.2基于SVM的分类器设计
SVM即支持向量机。
SVM的主要思想可以概括为两点:第一是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。
通常在线性不可分的情况下,通过核函数进行非线性映射达到线性可分的效果。
其中核函数的类型包括线型、多项式型和RBF高斯核等,采用不同的核函数可能造成的分类效果有所区别,在本实验中分别利用三种核函数对测试数据进行测试。
SVM调用Opencv3.0中的库函数来实现,Opencv3.0所集成的SVM为libsvm。
源码如图4-7。
图4-7 SVM调用源码
由图4-7可以看到,首先对SVM进行了参数设置,接着调用训练函数,接着进行测试数据测试,分别采用高斯核、线型核和SIGMOD核测试结果如图4-8到4-10,所对应的ROC曲线如图4-11到4-13所示。
图4-8 高斯核分类结果
图4-9 线型核分类结果
图4-10 SIGMOD核分类结果
图4-11 高斯核分类ROC曲线
图4-12 线型核分类ROC曲线
图4-13 SIGMOD核分类ROC曲线
由上面的图4-8到图4-13可以看出,高斯核出现2个分类错误,线性核出现3个分类错误,而sigmod核未出现分类错误,再结合ROC曲线及AUC值,可以看出对于测试数据,sigmod核函数具有最高的分类效果,可以实现完全的正确分类,而高斯核其次,线性核性能稍微差一点,出现误差的类型都是将男生错分为了女生。
4.3基于决策树的分类器设计
决策树(Decision Tree)是在已知各种情况发生概率的基础上,通过构成决策树来求取净现值的期望值大于等于零的概率,评价项目风险,判断其可行性的决策分析方法,是直观运用概率分析的一种图解法。
由于这种决策分支画成图形很像一棵树的枝干,故称决策树。
在机器学习中,决策树是一个预测模型,他代表的是对象属性与对象值之间的一种映射关系。
在本次实验中,调用Opencv3.0中的决策树类来进行数据的训练与分类。
调用源码如图4-14。
图4-14 决策树调用源码
在图4-14中,首先初始化决策树,设置了决策树的最大深度等初始化信息,接着进行样本数据训练,最后进行预测数据预测,其结果如图4-15和图4-16。
图4-15 决策树测试结果图4-16 决策树测试结果ROC曲线
由图4-15到图4-16可以看出,在决策树分类器对于测试数据的分类中也出现了两个分类错误,也是将男生分为了女生。
4.4三种分类器对比
5.总结
通过这次实验,对课堂上所学习的BP神经网络、SVM、决策树进行了学习巩固,加深了对其原理的理解,通过编程完成了对分类器的训练和预测的实验过程。
通过参数的调节所设计的分类器在30个测试数据中都有较好的分类效果,其中最差的仅将三个数据分错,通过观察可以发现,分类错误主要都是将男生误分类成了女生,原因在于该男生的特征数据与女生较为相似,这应该是造成分类错误的一大原因,同时分类器在编程设计当中也存在很多问题,分类效果有待提高。
通过这次的实验,发现了自己的很多不足,上课要更认真的听讲,及时解决遇到的问题,编程能力也急需提高,MATLAB强大的功能要学会使用,同时要进一步提高C++变成水平,为以后实际的工程项目及应用打好基础。