阿里大数据架构
阿里大数据产品最新特性介绍

智能生态市场
• 一键部署
• 版本控制
• 蓝绿部署
• 弹性扩缩
PAI-AutoLearning
自动学习 • 零门槛使用 • 迁移学习框架 • 一站式解决 • 初级算法工程师
PAI-Studio
可视化建模 • 200种算法组件 • 拖拽方式构建实验 • 支持百亿特征样本 • 中级算法工程师
PAI-DSW
PAI-DSW
NoteBook建模 • 内置Jupyter开发环
境
• 深度优化TensorFlow • 神经网络可视化编辑 • 高级算法工程师
大数据“淘宝”平 台
• 链接技术与业务 • 解决方案 • 算法&模型 • 业务应用API • 智能生态圈
计算框架(MR / MPI / PS / Graph / SQL / Tensorflow)
数据资源(MaxCompute / OSS / HDFS / NAS)
目录
content
01 PAI产品简介 02 自定义算法上传 03 智能生态市场 04 AutoML2.0 05 AutoLearning自动学习
2、自定义算法上传
用户业务(推荐系统 金融风控 疾病预测 新闻分类)
PAI-EAS 模型在线服务
认证
提供ApsaraClouder技能认证课程,通过认证提升开发 者专业技术,并为开发者的能力提供官方认定。为智能 生态市场的整体开发水平提供保障。
论坛
为大数据智能的相关用户及兴趣爱好者提供交流共享的 平台,在知识问答中,交流切磋,学习提高。
市场
用户
开发
论坛
智能生态市场
3、数加智能生态市场
3、数加智能生态市场
ห้องสมุดไป่ตู้
阿里大数据架构

阿里大数据架构阿里大数据架构1.引言本文档旨在介绍阿里大数据架构的设计和部署。
阿里大数据架构是基于云计算和大数据技术的解决方案,用于处理海量数据和实时分析。
本文将从整体架构设计、数据存储、数据处理和数据分析等方面进行详细说明。
2.整体架构设计2.1 架构目标2.2 架构图示2.3 架构组件说明3.数据存储3.1 数据库选择与设计3.2 存储系统配置和部署3.3 数据备份与恢复策略4.数据处理4.1 数据采集与清洗4.2 数据传输与转换4.3 数据分区与分片4.4 数据压缩与解压缩5.数据分析5.1 数据建模与查询5.2 数据可视化与报表5.3 数据挖掘与机器学习5.4 数据安全与权限控制附件:附件1、架构图示附件2、数据库设计文档附件3、数据处理脚本示例附件4、数据分析报告样例法律名词及注释:1.云计算:指将计算资源通过互联网通过按需共享的方式提供给用户,并根据用户的实际需求进行弹性分配和管理的一种计算模式。
云计算具备资源池化、按需供给、分布式部署、灵活扩展等特点。
2.大数据:大数据是指以传统数据处理软件无法处理的数据规模、数据类型、数据速度和数据处理能力为特征的数据集合。
大数据一般具备“4V”特点,即数据量大(Volume)、数据类型多样(Variety)、数据流速快(Velocity)和数据价值高(Value)。
3.数据备份与恢复策略:指为保护数据安全和防止数据丢失,采取的数据备份与恢复措施。
常用的策略包括定期备份、增量备份、冷备份、热备份等。
4.数据采集与清洗:指将原始数据从不同来源收集到数据平台,并对数据进行清洗和预处理,以保证数据质量和可用性。
5.数据传输与转换:指将数据从一个系统或存储介质转移到另一个系统或存储介质,并在转移过程中对数据进行格式转换和结构调整,以适应目标系统的需求。
6.数据建模与查询:指对原始数据进行数据模型设计和数据查询操作,以实现数据分析和业务需求。
7.数据可视化与报表:指通过图表、图形和报表等方式将数据可视化展示,并向用户提供直观和容易理解的数据报告。
阿里巴巴大数据之路——数据技术篇

阿⾥巴巴⼤数据之路——数据技术篇⼀、整体架构 从下⾄上依次分为数据采集层、数据计算层、数据服务层、数据应⽤层 数据采集层:以DataX为代表的数据同步⼯具和同步中⼼ 数据计算层:以MaxComputer为代表的离线数据存储和计算平台 数据服务层:以RDS为代表的数据库服务(接⼝或者视图形式的数据服务) 数据应⽤层:包含流量分析平台等数据应⽤⼯具⼆、数据采集(离线数据同步) 数据采集主要分为⽇志采集和数据库采集。
⽇志采集暂略(参考书籍原⽂)。
我们主要运⽤的是数据库采集(数据库同步)。
通常情况下,我们需要规定原业务系统表增加两个字段:创建时间、更新时间(或者⾄少⼀个字段:更新时间) 数据同步主要可以分为三⼤类:直连同步、数据⽂件同步、数据库⽇志解析同步 1.直连同步 通过规范好的接⼝和动态连接库的⽅式直接连接业务库,例如通过ODBC/JDBC进⾏直连 当然直接连接业务库的话会对业务库产⽣较⼤压⼒,如果有主备策略可以从备库进⾏抽取,此⽅式不适合直接从业务库到数仓的情景 2.数据⽂件同步 从源系统⽣成数据⽂本⽂件,利⽤FTP等传输⽅式传输⾄⽬标系统,完成数据的同步 为了防⽌丢包等情况,⼀般会附加⼀个校验⽂件,校验⽂件包含数据量、⽂件⼤⼩等信息 为了安全起见还可以加密压缩传输,到⽬标库再解压解密,提⾼安全性 3.数据库⽇志同步 主流数据库都⽀持⽇志⽂件进⾏数据恢复(⽇志信息丰富,格式稳定),例如Oracle的归档⽇志 (数据库相关⽇志介绍,参考:) 4.阿⾥数据仓库同步⽅式 1)批量数据同步 要实现各种各样数据源与数仓的数据同步,需要实现数据的统⼀,统⼀的⽅式是将所有数据类型都转化为中间状态,也就是字符串类型。
以此来实现数据格式的统⼀。
产品——阿⾥DataX:多⽅向⾼⾃由度异构数据交换服务产品,产品解决的主要问题:实现跨平台的、跨数据库、不同系统之间的数据同步及交互。
产品简介: 开源地址: 更多的介绍将会通过新开随笔进⾏介绍!(当然还有其他主流的数据同步⼯具例如kettle等!) 2)实时数据同步 实时数据同步强调的是实时性,基本原理是通过数据库的⽇志(MySQL的bin-log,Oracle的归档⽇志等)实现数据的增量同步传输。
《阿里大数据架构》PPT课件

发展空质间量成本
– 技术搭台,业务唱戏 架构搭台,应用唱戏
• 架构永远在随着业务的发展而变更 更多多迁用数–户据 拥抱变
化!
更多功能 提高 收益
精选PPT
3
B2B架构演化过程
WebMacro pojo jdbc
Velocity Ejb
17
网站镜像部署图(国际站)
中供用户
网站运营
海外卖家
精选PPT
18
用户请求处理
Apache
Load Balance (F5, Alteon)
Apache
Jboss
Jboss
Apache
Jboss
Apache
Static Resource
精选PPT
Database Search Engine Cache Storage
基于pojo的Biz层
CompanyObj
业务逻辑方法 数据访问方法
业务层
基于POJO的biz层
数据存储 Oracle数据库
LDAP
精选PPT
BizObj
业务逻辑方法 数据访问方法
MemberObj
业务逻辑方法 数据访问方法
OfferObj
业务逻辑方法 数据访问方法
8
石器时代-中世纪原因
• 表现层仅仅使用模板技术,缺乏MVC框架, 导致大量的servlet配置
19
互联网的挑战
• 流量随着用户量而增加 • 业务的变更频繁 • 用户行为的收集 • 产品角色的细分及调整 • 7 X 24的高可用性
精选PPT
20
单击此处编辑流版量标题激样增式
阿里集团大数据建设OneData体系

层次结构
数
据 化
表数据分布 情况
表关联使用 情况
CDM核心架构
汇总事实表 明细事实表 明细维表
维度
Star Scheme
指标
规范化
设计方法-DWD模型设计
识别业务过 程
选择事实表 的类型
确定粒度及 选定维度
添加度量
冗余维度
流量 维度冗余事实表带来的好处与弊端 DWD层关联相关数据和组合相似数据的原则 DWD层事实宽表垂直划分和水平切割
定位
OneData体系架构
名词术语(一)
名词
解释
数据域
数据域是业务板块中有一定规模且相对独立的数据业务范围。 面向业务分析,将业务过程或者维度进行抽象的集合。 为保障整个体系的生命力,数据域是需要抽象提炼、并且长期维护 和更新的,但不轻易变动。在划分数据域时,既能涵盖当前所有的 业务需求,又能在新业务进入时无影响的被包含进已有的数据域和 扩展新的数据域。
逻辑结构 业务板块
核心架构
举例 电商业务
数据域
交易域
业务过程
维度
支付
订单
修饰类型
时间 周期
修饰词
原子指标
最近1天
支付方式 花呗
支付金额 pay_amt
派生指标
度量 属性
最近1天通过花呗 支付的支付金额 pay_amt_1d_009
支付金额 pay_amt
订单ID 创建时间
……
1.数据域:是指一个或多个业务过程或者维度的集合 2.原子指标:基于某一业务过程下的度量。例如:支付+金额=支付金额; 3.派生指标=原子指标+时间修饰+其他修饰词+原子指标;属性是用来刻画某个实体对象维度的数据形态;事实叫做度量,如购买数量 4.修饰:指针对原子指标的业务场景限定抽象。例如:最近N天
《阿里大数据架构》课件

2
阿里云实时计算引擎
阿里云实时计算引擎是一种实时数据分析和计算平台,提供实时数据处理和实时 智能服务。
3
TensorFlow在阿里的应用
阿里巴巴广泛使用TensorFlow进行机器学习和深度学习,在智能推荐和图像识 别等领域取得了重要成果。
大数据平台管理
阿里巴巴大数据 平台管理的架构
阿里巴巴建立了一套完善 的大数据平台管理架构, 实现了数据的集中管理和 资源的统一调度。
Storm流式计算引擎
Storm是一种分布式的实时流 式计算引擎,用于处理和分析 高速数据流。
Flink在流处理中的应用
阿里巴巴使用Flink进行实时流 处理,通过流计算实现业务实 时监控和分析。
实时智能架构
1
实时智能分析的概念和应用场景
实时智能分析是基于实时数据进行智能挖掘和分析,用于实时推荐、智能广告等 应用。
2 阿里巴巴大数据安全架构设计
阿里巴巴通过建立严格的安全架构和流程,确保数据在收集、存储和处理过程中的安全。
3 阿里云数据加密解决方案
阿里云提供多种数据加密解决方案,保护数据的机密性和完整性,防止数据泄露和篡改。
流处理架构
流处理的定义和应用场景
流处理是一种实时处理数据的 方式,广泛应用于实时推荐、 欺诈检测和实时分析等场景。
数据的写入和读取。
阿里云OSS存储
阿里云对象存储(OSS)是一种安全 可靠、高扩展性的云存储服务,用于 存储和管理大规模的非结构化数据。
HBase列式数据库
HBase是一种分布式、可扩展的列式 数据库,用于存储和查询大规模结构 化数据。
数据安全
1 数据安全的重要性
在大数据时代,数据安全是保护个人隐私和企业利益的关键,需要采取有效的安全措施。
阿里巴巴的组织结构图
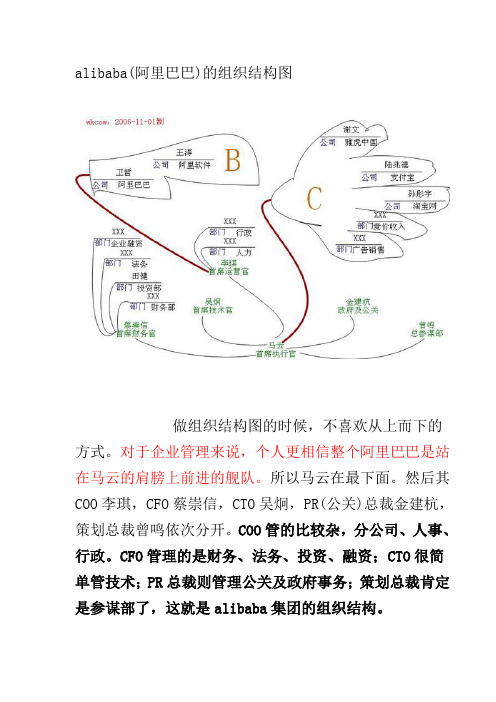
alibaba(阿里巴巴)的组织结构图做组织结构图的时候,不喜欢从上而下的方式。
对于企业管理来说,个人更相信整个阿里巴巴是站在马云的肩膀上前进的舰队。
所以马云在最下面。
然后其COO李琪,CFO蔡崇信,CTO吴炯,PR(公关)总裁金建杭,策划总裁曾鸣依次分开。
COO管的比较杂,分公司、人事、行政。
CFO管理的是财务、法务、投资、融资;CTO很简单管技术;PR总裁则管理公关及政府事务;策划总裁肯定是参谋部了,这就是alibaba集团的组织结构。
对于alibaba的事业群来说,B事业群的阿里巴巴由卫哲负责,刀身,目前效益最好。
阿里软件则由王涛负责,刀尖,还没见血。
加起来是一把刀,而他们的COO李琪就是这个刀的操盘手;C事业群由谢文管理雅虎中国(还掌管竞价收入、广告销售两个部门)、孙彤宇掌管淘宝网和及陆兆禧管理支付宝,组合起来画成了一个拳头。
拳头的大拇指自然是雅虎中国了,占用资源最多,但产出效益最少,这就是他为什么最短的原因;无名指和小手指则是竞价排名和广告收入两个部门,这两个部门目前都归雅虎中国管理,作用不大,本文由世纪淘商城()整理分享!版权归原作者所有!但却不能舍弃;食指是支付宝,使用相当多,而且点钱非常管用;中指是淘宝网,虽然市场占有率最高,但正反两种意思,淘宝目前正处于这种困境,收费则被骂,不收费则自己窝火。
对于这样的舰队组合来说,一句话概括起来是马云的拳头、李琪的刀。
对于这把刀来说,目前是alibaba主要的收入来源。
而对于拳头来说,是alibaba需要打出效益或者赢得突破的地方。
这就是我理解的阿里巴巴。
阿里巴巴对集团架构进行了大规模调整,分别组建了针对个人和企业用户两个事业群。
相应人员的组织架构也进行了重新梳理,原事业部提升为子公司,原事业部总经理提升为子公司总裁。
在新的集团组织结构中,马云任首席执行官(CEO阿里巴巴对集团架构进行了大规模调整,分别组建了针对个人和企业用户两个事业群。
相应人员的组织架构也进行了重新梳理,原事业部提升为子公司,原事业部总经理提升为子公司总裁。
阿里中台(大中台小前台)架构详解

2. 只支持一个业务的能力不能称为中台
如果只能支持一个业务的,只能称为一个业务后台,而中台是为效率而生,它 的特性就是整合多种功能在一起,能够同时支持多个业务发展的中间件。
前 台
项目A
业 支付 务 中心
中 台
搜索 中心
项目B
商品 中心
用户 中心
项目C
营销 中心
交易 中心
业务中台
业务中台在前文中反复提及,就是把各 个项目的共通业务进行下沉,整合成通 用的服务平台
美军的“特种部队(小前台)+航母舰群 (大中台)”模式
02
Ilkka Paananen
前台
皇室战争 部落冲突 海岛奇兵 卡通农场
中台
支付系统 数据分析
系统用户 基础设施
开发工具 游戏引擎
想了解更多关于美军“ Team of Teams”的组织设计,可参考书蜜021《赋能》
游骑兵排 ranger platoon
项目A前台
提供配置
项目A管理 后台
项目B前台
项目B管理 后台
阿里巴巴提出来“大中台,小前台”的战略
小前台
淘宝
天猫
支付 宝
聚划 算
阿里 妈妈
阿里 菜鸟
盒马 生鲜
用户
商品
交易
评价
搜索
营销
中心
中心
中心
中心
中心
中心
大中台
Aliware
什么是“大中台,小前台”战略?
“小前台大中台”的理论来自美军的作战理论。
业务中台化——产品形态
了解/评估过程
业务身份标识
能力地图
需求结构化
业务清单
1、能力裂变
大数据系统体系架构(含图示)

大数据系统体系架构(含图示)目录• 1 大数据体系架构图• 2 数据采集层• 3 数据计算层• 4 数据服务层• 5 数据应用层1 大数据体系架构图2 数据采集层1.阿里的的日志采集包括两大体系: Aplus.JS是Web端的日志采集技术方案,UserTrack是APP端的日志采集技术方案;2.在采集技术基础上,阿里用面向各个场景的埋点规范,来满足通用浏览、点击、特殊交互、APP事件、H5及APP里的H5和Native日志数据打通等多种业务场景;3.同时建立了一套高性能、高可靠性的数据传输体系,完成数据从生产业务端到大数据系统的传输;4.在传输方面,采用TimeTunnel(TT),它既包括数据库的增量数据传输,也包括日志数据的传输;作为数据传输服务的基础架构,既支持实时流式计算,也支持各种时间窗口的批量计算;5.另外,通过数据同步工具(DataX和同步中心,其中同步中心是基于DataX易用性封装的)直连异构数据库(备库)来抽取各种时间窗口的数据;3 数据计算层1.数据只有被整合和计算,才能被用于洞察商业规律,挖掘潜在信息,从而实现大数据价值,达到赋能于商业和创造价值的目的;2.阿里的数据计算层包括两大体系:数据存储及计算云平台(离线计算平台 MaxCompute和实时计算平台StreamCompute )和数据整合及管理体系(“OneData ”);3.从数据计算频率角度来看,阿里数据仓库可以分为离线数据仓库和实时数据仓库。
离线数据仓库主要是指传统的数据仓库概念,数据计算频率主要以天(或小时、周和月)为单位,例如每天凌晨处理上一天的数据;但是随着业务的发展特别是交易过程的缩短,用户对数据产出的实时性要求逐渐提高,所以阿里的实时数据仓库应运而生,“双11 ”实时数据直播大屏,就是实时数据仓库的一种典型应用;4.阿里的数据仓库的数据加工链路遵循分层理念,包括操作数据层( Operational DataStore, ODS)、明细数据层( Data Warehouse Detail , DWD)、汇总数据层( Data Warehouse Summary, DWS )和应用数据层( Application Data Store, ADS )。
阿里大数据架构

阿里大数据架构1、引言1.1 范围和目的1.2 定义、缩写和缩略语1.3 参考文档2、概述2.1 项目背景2.2 目标和目标2.3 主要功能2.4 读者指南3、技术架构3.1 架构概述3.2 数据存储架构3.2.1 数据库选择和设计3.2.2 数据同步和复制3.3 大数据处理架构3.3.1 批处理3.3.2 实时处理3.3.3 流式处理3.4 安全架构3.4.1 访问控制3.4.2 数据隐私3.4.3 安全审计4、数据管理4.1 数据收集4.1.1 数据源选择4.1.2 数据采集策略4.2 数据处理4.2.1 数据清洗和预处理 4.2.2 数据转换和集成 4.3 数据存储4.3.1 数据分区和分布 4.3.2 数据备份和恢复4.4 数据查询与分析4.4.1 数据查询语言和工具4.4.2 数据分析和挖掘5、系统架构5.1 服务器架构5.1.1 硬件规格和配置5.1.2 服务器部署和管理 5.2 网络架构5.2.1 网络拓扑5.2.2 网络安全性要求5.3 高可用性和容错5.3.1 故障恢复策略5.3.2 自动化监控和报警6、性能优化6.1 数据库性能优化6.1.1 索引优化6.1.2 查询优化6.2 基础设施性能优化6.2.1 硬件性能调优6.2.2 网络性能优化6.3 算法和应用优化6.3.1 算法改进6.3.2 应用优化策略7、扩展和维护7.1 扩展性考虑7.1.1 水平扩展7.1.2 垂直扩展7.2 系统维护7.2.1 日常监控7.2.2 系统维护计划8、附件:技术规范、示例代码等注:法律名词及注释1、数据隐私:指个人或组织在收集、处理、存储和传输数据时的保护政策和措施。
数据隐私通常包括对个人身份信息、敏感数据和其他保密信息的保护。
2、安全审计:指对系统、网络或应用程序的安全性进行定期检查和评估,以确保其符合安全标准和合规要求。
安全审计可以通过日志分析、漏洞扫描和渗透测试等方法进行。
3、批处理:指按照预定的脚本或流程,对一批数据进行集中处理和计算的过程。
阿里云大数据产品体系介绍

目录大数据产品框架数据计算平台数据加工与分析服务与应用引擎大数据应用场景记录 统计大规模计算GB计算复杂程度数据量TBPB网站独立数据 集市论坛小型电商小型EDW BI/DWMPP淘宝支付宝 CRMERPHPC语言识别影音识别图像识别关系网络图像比对 行为DNA刷脸精准广告大数仓消费预测征信搜索排序EB深度学习大数据产品框架应用加速器分析引擎 推荐引擎 兴趣画像分类预测规则引擎 标签管理ID-Mapping计算引擎数据加工和分析工具离线计算 流计算 数据开发 ETL 开发调度系统机器学习分析型数据库数据可视化工具数据采集CDP (离线)数据服务和应用引擎数据管理数据 地图数据 质量智能 监控阿里云大数据集成服务平台是阿里巴巴集团统一的大数据平台,提供一站式的大数据开发、管理、分析挖掘、共享交换解决方案,可用于构建PB 级别的数据仓库,实现超大规模数据集成,对数据进行资产化管理,通过对数据价值的深度挖掘,实现业务的数据化运营。
目录大数据产品框架数据计算平台数据加工与分析服务与应用引擎大数据离线计算服务 MaxCompute离线计算流计算分析型数据库大数据计算服务(MaxCompute ,原ODPS)是由阿里巴巴自主研发的大数据产品,支持针对海量数据(结构化、非结构化)的离线存储和计算、分布式数据流处理服务,并可以提供海量数据仓库的解决方案以及针对大数据的分析建模服务,应用于数据分析、挖掘、商业智能等领域。
存储易用安全计算●支持TB 、PB 级别数据存储 ●支持结构化、非结构化数据存储●集群规模可灵活扩展,支持同城、异地多数据中心模式●支持海量数据离线计算●支持分布式数据流式处理服务 ●支持SQL 、MR 、Graph(BSP)、StreamSQL 、MPI 编程框架 ●提供丰富的机器学习算法库●支持以RESTful API 、SDK 、CLT 等方式提供服务●不必关心文件存储格式以及分布式技术细节●经受了阿里巴巴实践检验●数据存储多份拷贝 ●所有计算在沙箱中运行MaxCompute 的优势和能力高效处理海量数据1、跨集群技术突破,集群规模可以根据需要灵活扩展,支持同城、异地多数据中心模式2、单一集群规模可以达到10000+服务器(保持80%线性扩展)3、不保证线性增长的情况下,单个集群部署可以支持100万服务器以上4、对用户数、应用数无限制,多租户支持500+部门5、100万以上作业及2万以上并发作业安全性1、所有计算在沙箱中运行2、多种权限管理方式、灵活数据访问控制策略3、数据存储多份拷贝易用性1、开箱即用2、支持SQL、MR、Graph、流计算等多种计算框架3、提供丰富的机器学习算法库4、ODPS支持完善的多租户机制,多用户可分享集群资源自主可控经过实践验证1、阿里巴巴自主研发2、整套平台经受了阿里巴巴超大规模数据应用的实践验证离线计算流计算分析型数据库离线计算流计算分析型数据库自主可控•使用Hadoop组件开发受制于开源社区,最多只能维护一个分支•开源社区组件太多,版本问题,打包问题,升级维护成本太高Hadoop核心技术架构发展缓慢•一些技术阿里要比开源社区更早实现(如分布式文件系统多master实现等)没有一个Hadoop发行版可以满足阿里巴巴的业务场景•如异地多数据中心、数据安全性等要求Hadoop社区分化严重,发展状况有隐忧当前Yahoo、Facebook等公司使用的都是自己的私有版本流计算 StreamCompute离线计算流计算分析型数据库●阿里云流计算(StreamCompute)是一个通用的流式计算平台,提供实时的流式数据分析及计算服务●整个数据处理链路是进行压缩的,链路是即时的,完全以业务为中心,数据驱动解决用户实际问题实时ETL 监控预警实时报表实时在线系统对用户行为或相关事件进行实时监测和分析,基于风控规则进行预警用户行为预警、app crash预警、服务器攻击预警数据的实时清洗、归并、结构化数仓的补充和优化实时计算相关指标反馈及时调整决策内容投放、无线智能推送、实时个性化推荐等双11、双12等活动直播大屏对外数据产品:数据魔方、生意参谋等低延时高效流数据处理,根据不同业务场景的时效性需要,从数据写入到计算出结果秒级别的延迟高可靠●底层的体系架构充分考虑了单节点失效后的故障恢复等问题,可以保证数据在处理过程中的不重不丢, Exactly-Once 语义保证●通过定期记录的checkpoint数据,自动恢复当前计算状态,保证数据计算结果的准确性可扩展计算能力和集群能力具有良好的可扩展性,用户可以通过简单的增加Worker节点数量的方式进行水平扩展,可以支持每天PB级别的数据流量开发方便●SQL支持度高:标准SQL,语义明确,门槛低,只需要关心计算逻辑,开发维护成本低●完善的元数据管理:SQL天然对元数据友好,SQL优化支持离线计算流计算分析型数据库功能特性BI分析的发展方向离线计算流计算分析型数据库分析型数据库概述离线计算流计算分析型数据库分析型数据库(Analytic DB),是一套实时OLAP(Realtime-OLAP)系统。
阿里巴巴组织架构和主要职能部门

阿里巴巴组织架构和主要职能部门
阿里巴巴是中国最大的电子商务公司之一,拥有丰富的组织架构和多样的职能部门。
以下是阿里巴巴组织架构和主要职能部门的介绍: 1. 阿里巴巴集团:阿里巴巴集团是阿里巴巴的母公司,负责整
个集团的管理和战略决策。
2. 电商事业群:电商事业群是阿里巴巴的核心部门,负责淘宝、天猫、聚划算等电商平台的运营和管理。
3. 云计算事业群:云计算事业群是阿里巴巴的新兴业务,包括
阿里云、云数据库、云存储等云计算服务。
4. 数字媒体与娱乐事业群:数字媒体与娱乐事业群是阿里巴巴
的文化娱乐业务,包括优酷、土豆、UC浏览器等媒体和娱乐平台。
5. 创新事业群:创新事业群是阿里巴巴的创新业务,包括阿里
健康、菜鸟网络、阿里影业等新兴领域。
6. 公共事务部:公共事务部是阿里巴巴的公共关系和社会责任
部门,负责与政府和公众的交流和合作。
7. 技术委员会:技术委员会是阿里巴巴的技术中枢,负责技术
研发和创新。
8. 人力资源部:人力资源部是阿里巴巴的人力资源管理部门,
负责员工招聘、培训和福利等工作。
总之,阿里巴巴的组织架构和职能部门非常庞大,涵盖了电商、云计算、文化娱乐、创新业务、公共关系、技术研发和人力资源等多个领域。
这些部门的协同配合,推动了阿里巴巴的快速发展和成功。
阿里 大数据权限管理框架 -回复

阿里大数据权限管理框架-回复什么是阿里大数据权限管理框架?阿里大数据权限管理框架是一套由阿里云推出的大数据权限管理解决方案。
它提供了一个集中式的、统一管理大数据平台权限的框架,旨在简化权限管理流程,提高权限管理的效率和安全性。
为什么需要大数据权限管理框架?随着大数据技术的快速发展,越来越多的企业和组织开始使用大数据平台来分析和利用海量数据。
然而,大数据平台的权限管理往往面临一些困难和挑战。
首先,大数据平台通常由多个组件和应用程序组成,每个组件都有自己的权限管理方式,这使得权限管理变得复杂且难以统一。
其次,大数据平台中的数据往往分布在不同的存储系统和计算框架中,权限管理需要涵盖到这些不同的数据源和计算模型。
最后,由于大数据平台涉及的数据量庞大且数据敏感性高,需要保证权限管理的安全性和可靠性。
阿里大数据权限管理框架的主要特点阿里大数据权限管理框架具有以下主要特点:1. 集中式管理:通过统一的权限管理中心,可以集中管理大数据平台上的权限。
管理员可以在一个地方查看和管理所有的权限,无需逐个配置各个组件和应用程序的权限。
2. 统一安全认证:阿里大数据权限管理框架提供了统一的安全认证入口,用户只需登录一次,即可访问所有需要权限认证的组件和数据源。
这不仅提高了用户的使用体验,还加强了权限管理的安全性。
3. 权限继承和细粒度控制:框架支持权限的继承和细粒度的控制。
管理员可以在角色和用户层级上进行权限的继承,从而简化权限管理的过程。
同时,管理员还可以根据需求对权限进行细粒度的控制,以满足不同用户的具体需求。
4. 弹性适配和扩展:框架提供了弹性适配和扩展的能力,可以根据实际需求定制和扩展权限管理策略。
无论是新增组件、数据源,还是调整现有权限策略,都可以通过框架来实现。
5. 监控和审计:框架提供了权限的监控和审计功能,管理员可以查看权限的使用情况和访问日志,及时发现和解决潜在的安全问题。
阿里大数据权限管理框架的工作原理阿里大数据权限管理框架的工作原理可以分为以下几个步骤:1. 集成:将各个组件和应用程序的权限管理机制集成到权限管理中心。
阿里巴巴全域数据建设方案

阿里巴巴全域数据建设方案一、引言随着数字化时代的到来,数据成为企业发展的核心资源。
阿里巴巴作为全球领先的互联网企业,拥有大量的数据资源。
为了充分利用这些数据,提升企业的竞争力和创新能力,阿里巴巴需要建设一个全域数据平台。
本文将详细介绍阿里巴巴全域数据建设方案,包括架构设计、数据采集与整合、数据存储与管理、数据分析与应用等方面。
二、架构设计1. 数据采集与整合层:通过各种方式(包括API接口、数据抓取、传感器等)采集数据,并将其整合到一个统一的数据湖中,实现数据的标准化和集中管理。
2. 数据存储与管理层:采用分布式存储技术,将数据存储在云端,并进行数据备份和容灾处理,确保数据的安全性和可靠性。
3. 数据处理与分析层:利用大数据处理技术(如Hadoop、Spark等),对数据进行清洗、转换和计算,提取有价值的信息,并进行数据挖掘和机器学习等分析。
4. 数据应用与服务层:将分析结果应用于企业的各个业务领域,包括市场营销、供应链管理、客户服务等,提供个性化的数据服务和决策支持。
三、数据采集与整合1. 多渠道数据采集:通过API接口、数据抓取、传感器等方式,从各个渠道(包括线上、线下)采集数据,包括用户行为数据、销售数据、供应链数据等。
2. 数据清洗和转换:对采集到的数据进行清洗和转换,去除重复数据和错误数据,将数据转换为统一的格式和结构,以便后续的处理和分析。
3. 数据标准化和集成:根据业务需求,对数据进行标准化处理,确保不同数据源之间的一致性和可比性。
同时,将不同数据源的数据进行整合,形成一个统一的数据视图。
四、数据存储与管理1. 云端存储:将数据存储在云端,利用云计算资源弹性扩展的特性,满足数据规模不断增长的需求。
同时,云端存储还可以提供高可用性和容灾能力,确保数据的安全性和可靠性。
2. 数据备份和恢复:定期对数据进行备份,以防止数据丢失和损坏。
同时,建立完善的数据恢复机制,以便在数据出现故障时能够快速恢复数据。
阿里 大数据权限管理框架

阿里大数据权限管理框架什么是阿里大数据权限管理框架?阿里大数据权限管理框架是阿里巴巴集团开发的一种权限管理工具,专为大数据场景下的数据安全和权限控制而设计。
在大数据时代,数据安全和权限控制成为企业不可忽视的重要问题。
阿里大数据权限管理框架致力于提供全面的数据安全解决方案,保护企业数据不被未经授权的人员访问和使用。
大数据时代的挑战随着互联网的迅猛发展和技术的不断进步,企业面临着海量数据的存储和处理需求。
然而,与此同时,数据安全和权限控制问题也日益突出。
企业需要确保数据不被未经授权的人员访问和使用,同时也需要在合规和监管方面满足各类要求。
传统的权限管理方法往往无法满足大数据场景下的需求。
传统的权限管理工具主要依赖于文件系统的权限控制机制,无法应对复杂的大数据环境和海量的数据。
此外,传统的权限管理方法也无法提供细粒度的权限控制,即无法对不同用户、不同数据进行个性化的权限控制。
阿里大数据权限管理框架的特点阿里大数据权限管理框架正是出于对传统权限管理工具的不足之处的认识和需求,针对大数据场景下的数据安全和权限控制问题进行了全面的优化与改进。
该框架具有以下几个显著的特点:1. 高效的权限验证和控制:阿里大数据权限管理框架采用了分布式架构和并行计算技术,能够高效地处理海量的数据权限验证和控制请求。
即使在大规模数据处理的场景下,也能够保持低延迟和高吞吐量。
2. 细粒度的权限控制:阿里大数据权限管理框架支持细粒度的权限控制,可以为不同用户、不同数据设置个性化的权限。
通过灵活的权限管理策略和数据标签系统,可以实现对数据的细粒度精确控制。
3. 多层次的权限管理体系:阿里大数据权限管理框架提供了多层次的权限管理体系,可以根据实际需求对权限分级授权。
管理员可以根据角色和职责设置相应的权限,从而确保合理的权限分配和管理。
4. 高度可伸缩性和扩展性:阿里大数据权限管理框架采用了开放式架构和可插拔的模块设计,可以灵活地扩展和集成其他安全产品和技术。
阿里 大数据权限管理框架 -回复

阿里大数据权限管理框架-回复阿里大数据权限管理框架是一个针对大数据平台的权限管理系统,它集成了强大的权限控制功能,可以帮助企业有效管理和保护数据的访问权限。
本文将深入探讨阿里大数据权限管理框架的原理、特性和实施步骤,以及它对企业数据安全的重要性和价值。
一、阿里大数据权限管理框架的原理和特性1.1 原理阿里大数据权限管理框架的原理是基于角色的访问控制(Role-Based Access Control, RBAC)模型。
RBAC模型将权限分配给角色,然后将角色分配给用户,实现对不同用户进行不同级别权限的控制。
通过这种模型,可以减少权限管理的复杂性,提高数据安全性和管理效率。
1.2 特性阿里大数据权限管理框架具有以下特性:- 统一管理:框架可以集中管理企业所有的数据权限,包括大数据平台上的所有数据资源、集群和用户。
- 灵活易用:用户可以根据具体需求进行权限配置和管理,同时也支持动态的权限调整和扩展。
- 多级权限控制:框架支持对不同层级的数据进行权限控制,包括数据库、表、列等。
- 权限继承:框架支持权限的继承和继承链的管理,可以简化权限管理的流程。
- 审计和监控:框架可以对权限的使用情况进行审计和监控,提供实时的数据访问日志和报告。
二、阿里大数据权限管理框架的实施步骤2.1 环境准备在部署阿里大数据权限管理框架之前,需要满足以下条件:- 安装和配置大数据平台,包括Hadoop、Hive、HBase等组件。
- 部署安全网关,用于实现数据流的安全传输和访问控制。
- 配置身份认证和授权服务,如LDAP或Active Directory。
2.2 框架部署部署阿里大数据权限管理框架的具体步骤如下:1. 部署集中式权限管理服务器:在大数据平台上,搭建一个集中式权限管理服务器,用于管理和分配权限。
2. 配置权限策略:根据企业的具体需求,制定权限策略,包括角色定义、权限分配和审计规则等。
3. 集成身份认证和授权服务:将权限管理框架与企业的身份认证和授权服务进行集成,实现统一认证和授权。
阿里云计算与大数据

阿里云计算与大数据章节一、引言
1.1 本文档的目的与范围
1.2 读者对象
1.3 文档参考资料
章节二、阿里云计算概述
2.1 阿里云计算的定义
2.2 阿里云计算的优势
2.3 阿里云计算的应用场景
章节三、阿里云大数据平台介绍
3.1 阿里云大数据平台的定义
3.2 阿里云大数据平台的组成部分
3.3 阿里云大数据平台的特性
章节四、阿里云计算与大数据技术架构4.1 阿里云计算与大数据的整体技术架构4.2 阿里云计算与大数据的核心技术组件
4.3 阿里云计算与大数据的架构设计原则章节五、阿里云大数据产品与服务
5.1 阿里云数据计算与处理产品
5.2 阿里云数据存储与管理产品
5.3 阿里云数据智能分析产品
5.4 阿里云数据安全与隐私保护服务
章节六、阿里云计算与大数据应用案例6.1 电商行业的大数据应用案例
6.2 金融行业的大数据应用案例
6.3 制造业的大数据应用案例
6.4 其他行业的大数据应用案例
章节七、阿里云计算与大数据的发展趋势7.1 云计算与大数据产业的现状
7.2 阿里云计算与大数据的发展趋势预测7.3 阿里云计算与大数据的挑战与机遇本文档涉及附件:
附件一、阿里云计算与大数据平台架构图
附件二、阿里云大数据产品与服务详细介绍文档
附件三、阿里云计算与大数据应用案例汇总
本文所涉及的法律名词及注释:
1、云计算:指通过互联网提供一种共享的、可按需访问的计算
资源服务模式。
2、大数据:指处理传统技术无法处理的大规模、高速增长的各
类数据的技术和工具。
3、数据隐私保护:指保护个人数据不被未经授权的收集、存储、处理、传输和使用。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
– 无状态Web应用,基于cookie实现session,获取 线性扩展性
• 业务逻辑层使用Alibaba Service框架,并且 引入spring 框架
– Spring容器和Alibaba Service框架无缝集成
2005-工业革命(续)
表现层
基于Webx以及Service框架的Web层框架
系统架构概述
Yes, We KAO 更强,更高,更持久
课程目标和内容
• 了解什么是架构 • 了解Alibaba网站架构的历史 • 掌握Alibaba网站架构的现状 • 掌握网站架构设计的理念
什么是架构?
• 架构规定了软件的高层划分及各部分间的 交互
– 架构不是软件,但架构决策体现于软件平台和
框架之中
分布式 Session
商业逻辑层
基于Spring以及Service框架的biz层框架
数据访问层
基于Spring以及DAO设计模式的数据访问框架
分布式 Cache
数据存储
搜索引擎 Oracle数据库
LDAP
演化还在继续…
• 数据库成为瓶颈 -> 分布式数据库 • 应用耦合严重 -> SOA • Pampas平台
网站的现在
• 中文站会员数超过2000万 • 中文站Offer已经超过1.5亿 • 中文站每天的用户PV已经超过1.6亿 • 中文站每天新发Offer超过100万 • 中文站每天重发Offer超过1500万 • 国际站略少,但是增长迅猛
中文站/国际站应用部署图
网站镜像部署图(国际站)
中供用户
网站运营
SOA OPEN API 云计算
……
Perl
1999 史前 2001 石器时代 2002 中世纪 2005 工业革命 未来 星际时代?
1999-史前时代
• Perl,CGI…… • Mysql • Apache • 服务器在美国,56KModem,远程开发、测
试、部署
史前-石器时代原因
• Java服务器使用Байду номын сангаас程性能比cgi技术使用进程 好
单击此处编辑流版量标题激样增式
处理用户请求
Request Process Response Request Process Response Request Process Response
应对的挑战 • 并发(垂直)
– 用户数量的增加 – 使用资源的增加
• 响应(水平)
– 处理性能的维持
单击此处编辑业版标务题变样更式
LDAP
中世纪-工业革命原因
• Turbine的发展缓慢 • EJB配置复杂,可维护性差 • 重量级框架,业务侵入高 • 高度容器依赖,可测试性差 • CMP性能差,导致DAO和CMP并存
2005-工业革命
• 表现层使用WebX和Service 框架
– Velocity模板技术
– 自有服务框架及多种公共服务:Form Service, Template Service,Mail Service,Rundata Service, Upload Service等
实现业务逻辑 – 使用CMP实现单条记录的增加和删除
2002底-中世纪(续)
表现层 商业逻辑层
基于Webx以及Service框架的Web层框架
delegate
Façade
使用SLSB实现的业务逻辑对象Controlers
数据访问层
CMP进行单条记录的增加删除,DAO对象查找
数据存储
搜索引擎 Oracle数据库
数据访问方法
MemberObj
业务逻辑方法
数据访问方法
OfferObj
业务逻辑方法
数据访问方法
石器时代-中世纪原因
• 表现层仅仅使用模板技术,缺乏MVC框架, 导致大量的servlet配置
• 业务逻辑层和数据访问层耦合,可维护性 和可扩展性差
• 受到EJB风潮的影响
2002底-中世纪
• 表现层采用WebX
– 架节成构约本的硬人优件力劣成成本本决定了业务应用系统的实施能力和 发展空质间量成本
– 技术搭台,业务唱戏 架构搭台,应用唱戏
• 架构永远在随着业务的发展而变更 更多多迁用数–户据 拥抱变
化!
更多功能 提高
收益
B2B架构演化过程
WebMacro pojo jdbc
Velocity Ejb
WebX Spring
海外卖家
用户请求处理
Apache
Load Balance (F5, Alteon)
Apache
Apache Apache
Jboss
Jboss Jboss Static Resource
Database Search Engine Cache Storage
互联网的挑战
• 流量随着用户量而增加 • 业务的变更频繁 • 用户行为的收集 • 产品角色的细分及调整 • 7 X 24的高可用性
transaction
• Java相比Perl,可维护性好,开发效率高 • Java开始在国内流行
• 开始使用Java • 模板技术采用WebMacro • 中间层采用Servlet技术,使用POJO封装业
务逻辑和数据访问
– 使用BizObj对象封装基本业务逻辑和数据访问 方法
– 其它业务对象继承BizObj方法,实现自己的业 务逻辑和数据访问方法
专业化细分之前
• list
offer
• detail
• company
member
• personal
• no
transaction
support
专业化细分之后
• Clothing offer • Retail
• Loan
member
• Trust Pass
• Special Market
• alipay
– 模板技术Velocity – 在Turbine基础上开发了自己的服务框架和一系
列公共服务 – 通过一个delegate对象访问业务逻辑层
• 业务逻辑层使用EJB(SLSB,CMP,DAO等)
– 通过一个façade对象供表现层delegate访问 – Façade对象访问多个SLSB实现的controller对象
• 使用JDBC访问数据库 • Servlet容器使用resin,Web服务器使用
2001底-石器时代(续)
表现层
基于WebMacro的模板技术
基于pojo的Biz层
CompanyObj
业务逻辑方法 数据访问方法
业务层
基于POJO的biz层
数据存储 Oracle数据库
LDAP
BizObj
业务逻辑方法