数据清洗需求设计V1.1
数据中心逻辑架构设计
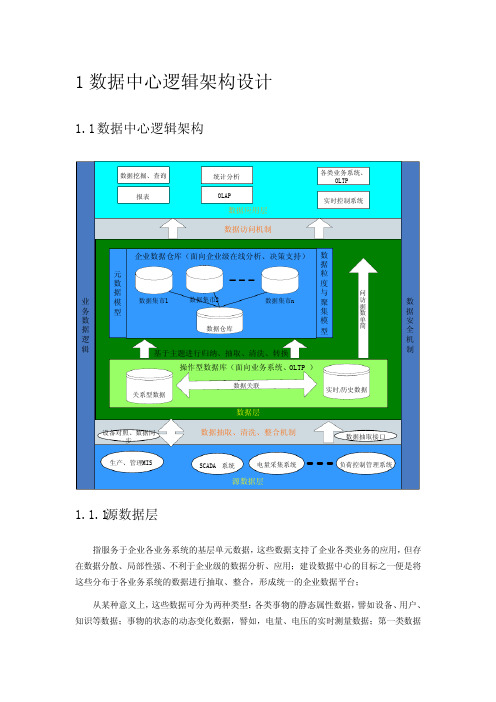
1数据中心逻辑架构设计1.1数据中心逻辑架构数据抽取、清洗、整合机制数据层企业数据仓库(面向企业级在线分析、决策支持)操作型数据库(面向业务系统、OLTP )源数据层电量采集系统负荷控制管理系统SCADA 系统数据抽取接口设备对照、数据同步生产、管理MIS关系型数据数据集市1实时/历史数据数据关联数据集市2数据集市n简单数据访问业务数据逻辑数据安全机制数据应用层报表数据挖掘、查询OLAP统计分析各类业务系统、OLTP 实时控制系统数据访问机制基于主题进行归纳、抽取、清洗、转换数据仓库元数据模型数据粒度与聚集模型1.1.1源数据层指服务于企业各业务系统的基层单元数据,这些数据支持了企业各类业务的应用,但存在数据分散、局部性强、不利于企业级的数据分析、应用;建设数据中心的目标之一便是将这些分布于各业务系统的数据进行抽取、整合,形成统一的企业数据平台;从某种意义上,这些数据可分为两种类型:各类事物的静态属性数据,譬如设备、用户、知识等数据;事物的状态的动态变化数据,譬如,电量、电压的实时测量数据;第一类数据的特点是在局部区域内是保持相对稳定的,人们更多关心的是这些数据的关联;第二类数据具有很强的“时间本性”,它们或明确或潜在的都具有“时间标签”的属性,人们更多关注的是它们在某一时刻的值。
1.1.2数据层或者说是企业数据平台、数据中心,通过对企业数据的整体规划、抽取、加工、整合,将存在于各独立系统的数据组织为一个有机的整体,使纷杂无序的数据成为企业有用信息,同时,使基于企业级的数据深层挖掘、分析成为可能;数据层负责对企业数据进行收集、加工、标准化并将之进行科学的存贮,同时,需要为上层应用提供安全、高效、方便的访问接口;如上所述,我们可以将现实世界的数据抽象为两类,基于这两类数据特征,分别采用关系型数据库譬如Oracle和实时数据库譬如eDNA进行管理,两类数据以数据的逻辑关系进行关联;为便于数据的挖掘、分析,在面向业务系统的操作型数据库上建立一组基于业务主题的数据仓库、集市,可以提高数据分析的性能;进一步讲,操作型数据面向具体业务系统、联机事务处理(OLTP)等应用,而数据仓库(Data Warehouse)、数据集市(DataMarts)为企业决策支持、联机分析处理(OLAP)等深层数据挖掘提供基础。
(完整版)数据清洗规则

(完整版)数据清洗规则引言概述:数据清洗是数据分析的重要步骤之一,它涉及到对原始数据进行预处理,以确保数据的准确性、一致性和完整性。
本文将详细介绍数据清洗规则的完整版,包括数据去重、缺失值处理、异常值处理、数据类型转换和数据格式规范。
正文内容:1. 数据去重1.1 基于唯一标识符进行去重1.2 基于多个字段的组合进行去重1.3 基于时间戳进行去重1.4 基于规则进行去重1.5 基于模型进行去重2. 缺失值处理2.1 删除含有缺失值的记录2.2 使用平均值、中位数或众数填充缺失值2.3 使用插值法填充缺失值2.4 使用机器学习算法预测缺失值2.5 使用数据关联规则填充缺失值3. 异常值处理3.1 基于统计学方法检测异常值3.2 基于规则进行异常值检测3.3 使用聚类算法检测异常值3.4 使用离群点检测算法检测异常值3.5 使用机器学习算法检测异常值4. 数据类型转换4.1 将字符型数据转换为数值型数据4.2 将数值型数据转换为字符型数据4.3 将日期型数据转换为数值型数据4.4 将数值型数据转换为日期型数据4.5 将类别型数据转换为数值型数据5. 数据格式规范5.1 统一日期格式5.2 统一数值格式5.3 统一字符格式5.4 统一文本格式5.5 统一类别格式总结:数据清洗是数据分析的重要步骤,通过数据去重、缺失值处理、异常值处理、数据类型转换和数据格式规范等规则,可以确保数据的准确性、一致性和完整性。
在进行数据清洗时,需要根据具体情况选择合适的方法和算法,并结合领域知识和业务需求进行处理。
通过合理的数据清洗规则,可以为后续的数据分析和建模提供可靠的基础。
MS1500 配置手册 V1.1

《用户使用手册》
目录
1 产品介绍 ................................................................................................................................... 6 1.1 产品特性 ........................................................................................................................................ 6 1.2 术语 ................................................................................................................................................ 6 1.3 RAID 级别简要介绍 ................................................................................
数据科学入门数据清洗可视化和建模

数据科学入门数据清洗可视化和建模数据科学入门:数据清洗、可视化和建模数据科学在当前信息时代中扮演着重要的角色,它依靠数据的收集、清洗、可视化和模型构建等步骤来提取有价值的信息。
在本文中,我将介绍数据科学的入门技巧,特别是数据清洗、可视化和建模方面的知识。
一、数据清洗数据清洗是数据科学的第一步,它涉及到去除数据集中的噪音、处理缺失值、标准化数据等操作。
清洗后的数据集将为后续的分析和建模工作提供基础。
1.1 去除噪音在数据收集的过程中,由于各种原因可能会引入一些噪音数据,这些数据对后续分析的结果产生不良影响。
因此,我们需要使用合适的算法和方法来识别和清除这些噪音数据。
1.2 处理缺失值数据集中常常会存在缺失值,这些缺失值可能是由于数据采集过程中的技术问题或是部分样本信息确实所导致。
我们可以通过插值、删除等方法来处理缺失值,以确保数据集的完整性和准确性。
1.3 数据标准化不同特征之间的数值范围可能存在巨大差距,这可能会影响到后续的分析结果。
因此,数据标准化是将数据转化为相同尺度的一种技术手段,常见的方法有min-max标准化和Z-score标准化等。
二、数据可视化数据可视化是将数据以图形化的方式展现出来,帮助我们更好地理解数据、发现数据的规律和趋势。
通过数据可视化,我们可以更直观地分析数据、提取数据的潜在信息。
2.1 散点图散点图是一种常见的数据可视化方式,通过在二维坐标系中展示不同特征之间的关系,我们可以发现变量之间的相关性或者离群点等突出的特征。
2.2 柱状图柱状图用来展示离散数据,通常由横纵坐标和柱子的高度组成,它可以帮助我们比较不同类别或不同时间点的数据差异。
2.3 折线图折线图一般用来展示序列数据,通过将数据点用线段连接起来,我们可以看到数据随时间或其他变量的变化趋势。
三、数据建模数据建模是数据科学的核心环节,它通过数学模型和算法来揭示数据之间的关系,构建预测模型或分类模型。
3.1 监督学习监督学习是一种通过已知输入和其对应的输出来建立模型的方法。
《数据清洗技术》课件

通过本课件,我们将深入探讨数据清洗的重要性、步骤、技术、工具以及各 种数据类型的清洗方法。让我们一起来了解数据世界的美妙!
什么是数据清洗?
数据清洗是指处理和修复数据集中的错误、不一致以及缺失值的过程。它是数据分析中必不可少的一步,确保 数据的准确性和可信度。
数据清洗的重要性
1 删除异常值
删除与大多数数据明显不同的异常值。
2 修正异常值
通过更合理的值替换异常值。
3 离群值检测
使用统计方法或机器学习算法检测离群值。
1 数据准确性
2 决策依据
清洗数据可以消除错误和 不一致,提高数据准确性。
清洗后的数据可被用于决 策制定及业务分析。
3 模型建立
清洗后的数据有助于构建 准确、可靠的预测模型。
数据清洗的步骤
1
数据收集和输入
收集原始数据并转化为可用的数据格式。
数据预处理
2
处理缺失值、异常值以及重复数据。
3
数据探索和可视化
通和归一化
将数据转化为统一的比例和范围。
数据转换
转换数据格式以适应分析需求。
异常值处理
识别和处理与其他数据明显不同的异常值。
数据筛选和过滤
根据特定条件筛选出所需的数据。
数据清洗的工具
1 开源工具
例如Python的pandas和OpenRefine。
2 商业工具
例如SAS Data Quality和IBM InfoSphere DataStage。
3 可视化工具
例如Tableau和Power BI。
缺失值的处理方法
1 删除缺失值
删除包含缺失值的行或列。
2 插值填充
(完整版)数据清洗规则

(完整版)数据清洗规则在数据分析和数据挖掘领域,数据清洗是非常重要的一个环节。
数据清洗规则的制定能够有效地提高数据质量,进而提高分析结果的准确性和可信度。
本文将详细介绍数据清洗规则的完整版,匡助读者更好地理解和应用数据清洗规则。
一、数据去重规则1.1 根据惟一标识进行去重:在数据清洗过程中,首先需要根据惟一标识字段进行去重操作,以确保数据的惟一性。
1.2 去除重复值:对于重复浮现的数据记录,需要进行去重操作,保留其中一条记录,避免数据冗余。
1.3 去除空值:在去重过程中,需要注意将空值数据记录进行清除,避免对后续分析造成影响。
二、数据格式规范化规则2.1 统一日期格式:对于日期字段,需要统一格式,避免不同格式造成的数据混乱。
2.2 统一文本格式:对于文本字段,需要进行大小写统一、去除特殊符号等操作,以提高数据的一致性。
2.3 格式转换:对于数值字段,需要将不同单位的数据进行统一转换,确保数据的可比性。
三、数据缺失值处理规则3.1 缺失值填充:对于缺失值较少的字段,可以采用均值、中位数、众数等方法进行填充,保持数据完整性。
3.2 缺失值删除:对于缺失值较多或者无法填充的字段,可以考虑将其删除,避免对后续分析造成干扰。
3.3 缺失值预测:对于一些重要字段的缺失值,可以利用机器学习算法进行预测填充,提高数据的完整性和准确性。
四、数据异常值处理规则4.1 异常值识别:通过统计分析和可视化手段,识别数据中的异常值,包括极端值、离群值等。
4.2 异常值处理:对于异常值,可以采取删除、替换、平滑等方法进行处理,保证数据的准确性和稳定性。
4.3 异常值监控:建立异常值监控机制,定期检测和处理数据中的异常值,确保数据质量的稳定性和可靠性。
五、数据一致性检查规则5.1 数据一致性检查:对于不同数据源的数据进行比对和检查,确保数据的一致性和准确性。
5.2 数据关联性检查:对于关联字段进行数据关联性检查,确保数据之间的逻辑关系和一致性。
(完整版)数据清洗规则

(完整版)数据清洗规则数据清洗是数据分析中非常重要的一步,它可以匡助我们提高数据的质量和准确性,从而为后续的数据分析工作打下坚实的基础。
本文将介绍数据清洗的完整版规则,包括数据清洗的概述以及五个部份的详细内容。
一、数据清洗的概述数据清洗是指对原始数据进行筛选、处理和转换,以消除数据中的错误、不一致和冗余,从而使数据变得更加可靠和准确。
数据清洗的目标是提高数据的质量,使其适合于后续的数据分析和挖掘工作。
二、数据清洗规则的制定1.1 数据格式的规范化在数据清洗过程中,首先需要对数据的格式进行规范化处理。
这包括统一日期、时间、货币和单位的表示方式,统一缺失值和异常值的表示方式等。
通过规范化数据格式,可以减少后续数据处理的复杂性,提高数据的可靠性和一致性。
1.2 数据缺失值的处理数据中往往存在缺失值,这会影响后续的数据分析和挖掘工作。
对于缺失值的处理,可以采取删除、插值和填充等方法。
删除缺失值可以简化数据分析的过程,但可能会导致数据的丢失。
插值方法可以根据已有数据的特征来猜测缺失值,但可能会引入不确定性。
填充方法可以使用统计指标(如均值、中位数等)来填充缺失值,但需要注意不要引入过多的偏差。
1.3 数据异常值的处理数据中的异常值可能是由于测量误差、数据录入错误或者数据采集问题等原因引起的。
对于异常值的处理,可以采取删除、替换和标记等方法。
删除异常值可以提高数据的准确性,但可能会导致数据的丢失。
替换异常值可以使用统计指标(如均值、中位数等)来替换异常值,但需要注意不要引入过多的偏差。
标记异常值可以将其标记为特殊值,以便后续的数据分析和挖掘工作。
三、数据清洗的具体步骤2.1 数据质量的评估在进行数据清洗之前,需要对原始数据的质量进行评估。
这包括检查数据的完整性、一致性、准确性和可用性等方面。
通过评估数据的质量,可以确定数据清洗的重点和方法。
2.2 数据清洗的处理方法根据数据质量评估的结果,可以选择合适的数据清洗方法。
数据治理中数据清洗的方法

数据治理中数据清洗的方法1.引言1.1 概述数据清洗是数据治理过程中的重要环节,它涉及到对数据进行筛选、转换和清除错误、不完整或无效数据的步骤。
在数据治理中,数据清洗是确保数据质量和准确性的关键步骤,因为原始数据往往存在着各种问题,如缺失值、异常值和重复数据等。
因此,本文将介绍数据治理中数据清洗的方法,包括处理缺失值、异常值和重复数据的具体技术和工具,并强调数据清洗对数据治理的重要性,展望数据清洗在未来的发展趋势。
1.2文章结构文章结构部分的内容可以如下编写:文章结构部分旨在介绍本文的整体结构安排,以便读者能够更好地理解文章内容的脉络。
本文共分为引言、正文和结论三个部分。
在引言部分中,将首先概述数据清洗的重要性和作用,介绍本文的目的与意义,并阐述文章结构。
正文部分将详细介绍数据清洗的概念与方法,包括缺失值处理、异常值处理和重复数据处理等内容,并介绍一些常用的数据清洗工具。
最后,在结论部分将总结数据清洗的重要性,强调其对数据治理的作用,并展望数据清洗在未来的发展方向。
通过本文的结构安排,读者将能够系统地了解数据治理中数据清洗的方法与工具,为实际工作提供参考与指导。
"1.3 目的":数据清洗作为数据治理中非常重要的一环,在数据分析和决策过程中起着至关重要的作用。
本文的目的是通过对数据清洗的方法进行系统的总结和介绍,帮助读者全面了解数据清洗的重要性和方法,从而提高数据质量,准确性和可信度。
同时,本文也旨在引导读者选择适合自己需求的数据清洗工具,提高数据清洗效率和准确度。
最终达到优化数据管理和应用的目的,提高数据的有效性和可利用性。
同时,本文也希望能够促进数据清洗技术的不断创新和发展,为数据治理领域的进步贡献力量。
2.正文2.1 数据清洗概述数据清洗是数据治理过程中的重要步骤,其主要目的是检测、纠正、删除或转换数据中的不准确、不完整、不一致或重复的部分,从而确保数据的质量和可靠性。
数据清洗是数据预处理的一部分,也是数据分析和挖掘的前提条件,其重要性不言而喻。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据清洗(时间序列数据TSD(time series Data)需求设计Data Cleaning ModuleDCM应该属于DAX的一个模块。
1、数据清洗的目的原始采集的数据会受到传感器、变送器、信号传输、环境干扰(电磁、潮湿、高热)、人为造假等各种因素的影响,数据中会包含一些受到“污染”的数据。
如果直接利用这些数据进行控制、绘图、制表、数据分析、数据挖掘,则不可避免的会影响分析过程和结果,总的来说:低质量的数据无法获得高质量的分析结果。
任何规模的数据在分析以前,有必要对原始数据进行预处理,以使其达到必要的质量,这个过程我们称之为数据清洗。
数据清洗后,一般有两类用途,一是直接用于在线过程控制,二是用于事后分析。
那些数据需要清洗任何直接采集的数据都需要进行清洗,利用清洗程序对数据处理后,会对数据的各种缺陷进行标记,对发现的有缺陷的数据进行抛弃、估计、修改。
很多工厂由于缺乏数据清洗这个环节,会大大影响过程控制的可靠性。
低质量的数据,在事后分析时会带来很大的困难。
不少环境监测类的投资,由于缺乏数据质量控制和数据清洗技术,会使投资回报大大降低。
2、通用性设计常见的原始数据问题1)数据缺失2)跳点3)干扰(白噪声或其它)4)漂移(线性与非线性)5)超限6)滞后造成的时间不同步7)逻辑缺失(因果关系、相关关系)8)数据检验的方法1)上下限制检验法2)斜率检验法3)差值检验法4)频率检验法5)时间区间检验法6)人工数据修正7)关系检验(因果、相关性)8)数据处理的方法1)删除法2)补差法a)取前点b)均值插补c)回归插补d)极大似然估计3)回归法4)均值平滑法5)离群点分析6)小波去噪7)人工修改8)对时间序列数据的定义1)源数据序列(Origin TSD):一般保存人工采集导入和自动测报采集的原始数据,为确保该类型数据安全,数据设置只读。
2)生产时序数据(Production TSD):拷贝自源数据,加以校核和清洗。
对数据的常规维护通常在这类序列上进行。
3)衍生时序数据(Derived TSD):一般是通过一些标准方法计算的统计序列,例如日月年特征值等。
3、数据处理数据处理的过程是通过数据计算任务来执行,数据清洗属于计算任务的一部分。
1)用于在线过程控制的计算任务,此类计算任务的执行实时性高,例如AVS,少人无人值守控制平台,计算任务在常规自控的轮询周期中。
一般的刷新率是秒级或毫秒级。
此类计算任务最好在PLC中处理,如无法再PLC中处理,就在上位机进行计算。
进行数据清洗的计算任务,一般属于此类,计算是实时进行。
2)用于事后分析的计算任务,此类计算任务的实时性不高,用途主要是数据分析,例如各类KPI、周期性的数据整理、各类自定义的计算等等,大数据分析通常也是利用这些数据。
此类数据的计算任务实时性不高,可以在事后按照固定的周期或者条件进行。
4、数据质量(DQ)的定义:1)完整性Completeness完整性指的是数据信息是否存在缺失的状况,数据缺失的情况可能是整个数据记录缺失,也可能是数据中某个字段信息的记录缺失。
不完整的数据所能借鉴的价值就会大大降低,也是数据质量最为基础的一项评估标准。
2)一致性Consistency一致性是指数据是否遵循了统一的规范(这些规范可以是格式,数位,或者是数据的统计性特征),研判数据集合是否保持了统一的规范。
数据质量的一致性主要体现在数据记录的规范和数据是否符合逻辑。
规范可以特指:一项数据存在它特定的格式,例如手机号码一定是13位的数字,IP地址一定是由4个0到255间的数字加上”.”组成的。
规范也可以特指,多项数据间存在着固定的逻辑关系,例如PV一定是大于等于UV的,跳出率一定是在0到1之间的,还有数据统计性特征,比如仪表测量的数据和人为伪造的数据的统计特征是显著不同的。
3)准确性Accuracy准确性是指数据记录的信息是否存在异常或错误。
和一致性不一样,存在准确性问题的数据不仅仅只是规则上的不一致。
最为常见的数据准确性错误就如乱码。
其次,异常的大或者小的数据也是不符合条件的数据。
一般而言,仅仅靠一些简单规则无法判断数据的准确性,通常会借助人工或自动系统的检验,或者在检测过程中增加一些标准样的测量。
比较特定样品的检测值就可以判断该批次检测的数据质量。
数据质量的准确性可能存在于个别记录,也可能存在于整个数据集,例如数量级记录错误。
这类错误则可以使用多种方法去审核。
一般数据都符合正态分布的规律,如果一些占比少的数据存在问题,则可以通过比较其他数量少的数据比例,来做出判断。
4)及时性Timeliness不同的应用场景对数据的及时性要求不同,在线控制条件下,假如某个关键性的输入数据无法及时获得,会影响后后续的过程控制。
在事后分析中,对及时性的要求就大大降低。
5)合理性Validation6)关联性Integration7)绝对质量8)过程质量数据标注的方法源数据序列ODSN = Normal 正常U = Unchecked 未检验E = Estimated 估计数据M = Missing 丢失数据生产数据序列PDSG = Good 优质E = Estimated 估计,包括自动修改及人工修改,标注方法S = Suspect 可疑数据U = Unchecked 未检查L = Loss 丢失数据M = Manual input 人工输入数据C = CheckPoint 质控检查点(用于和鸿海配合)衍生时序数据DDSD = Derived 衍生的,这个部分设计请参考测点数据管理(计算任务)数据标记除了上述表述数据分析结果的项次外,建议还记录标记数据的算法名称、版本、计算时间等。
对时间序列数据整体质量的定义时间序列数据表现为按照一定频率不断记录的数据,如每秒记录1次的时间序列数据在1小时内会有3600个记录,每分钟记录1次的数据每天会有1440个记录。
需要有一种方法整体性的评估某个时间区间内的时间序列数据的整体质量。
例如:某个采集频率为1/min的源数据在10天时间内的整体数据质量,根据自动检验的方法检验后,结果为:正常88.2%,丢失11.3%,估计数据0.5%,检测率100%;没有经过自动检测的数据,统计标记为未检测。
某个采集频率为1/min的生产序列数据在10天时间内的整体数据质量,根据自动检验的方法检验后,结果为:优质83.5%,估计15.7%,可疑0.8% ,检测率100%;没有经过自动检测的数据,统计标记为未检测。
根据数据的自动检测情况,可以将源数据或者生产序列数据分类为优质、正常、较差、不可用等类别【这个部分尚需讨论】。
在后续的大数据分析中,如果采用了较差、不可用等标记的数据,会极大的影响分析结果,导致错误的结论。
用于在线控制的数据清洗功能在线数据清洗的基本功能如下:1)数据清洗任务应该在轮巡任务中,循环一周,该任务就会执行一次。
2)该场景下的数据清洗任务主要是目标是加工生成:生产序列数据。
3)4)每个控制器既可以有自控程序判断启动,也可以由人工启动(S2);5)当前控制器的某一路信号被判断为不可信时,系统可以用虚拟信号替代(S2)6)需要有一张图,可以呈现所有的控制器的在用状态,最好采用自控中的标准图形和标注方法(S2)注:这里后面标记为S2的需求,以后并入少人无人值守系统设计的需求中。
用于事后数据分析的数据清洗用于事后分析数据清洗的基本功能如下:1)数据清洗任务根据任务特点,选择定时清洗、逢变清洗、条件清洗等,常见的事后处理规则是间隔一定时间后批处理。
处理时需要考虑依赖关系,即首先是对ODS数据处理,然后是PDS、DDS,其它的再加工应该在上述任务之后。
2)数据清洗任务应该在专用的数据处理程序中进行,在大任务量情况下支持多机部署。
3)数据清洗应该可以并入DAX平台中,作为一个必要的功能模块。
4)支持对第三方数据进行数据清洗,第三方数据必须符合DAX的数据规范,导入DAX数据库中,进行清洗选项的配置,启动清洗,生成结果,结果导出。
5)支持第三方软件通过接口,条件是这些数据应该在被合理的配置过了,获取我们的清洗后数据结果,作为一个数据服务。
6)其它数据应用程序在使用清洗过的数据时,可以根据读到的数据标记,制定自己的处理规则。
7)DAX中的报表功能,推荐使用PDS和DDS作为源数据。
8)DAX中的曲线绘制功能,在读取数据标记后,绘制PDS和DDS趋势曲线时,可以解析不同的标记,并在曲线上显示出来《参见数据清洗的管理.1》。
9)DAX中曲线绘制功能中的数据列表选项,应该能够对异常数据做出醒目标记。
10)可以接收特定质控数据(如鸿海),将数据和某一个TSD进行合并分析。
接收的方法推荐由鸿海直接采集进我们的DAX数据库,其次允许数据导入后分析。
11)数据脱敏..12)5、数据清洗的管理数据清洗是DAX功能的一部分,但在一些特定情况下,可以单独使用。
数据清洗后需要呈现以下几个场景1)针对单测点的时间序列数据(选定的时间段内)a)可以用趋势图,或者用数据表的形式,展示该数据中存在问题的数据点,并可以把这些数据点用特殊的图形、符号或颜色标记出来。
b)可以用饼图或者百分比的数字,表现出某段时间区间内的存在问题的数据比例,并分类展示。
c)分布特征等,特殊情况下这些统计性指标可以用于判定不同期限的数据是否一致。
因测量方法、传感器器更换、传感器位置更换可能会带来一致性的不同。
一般而言,人工伪造的数据,不符合正态分布,比较容易识别。
d)在趋势图下面X轴下部,有个色带可以用不同的颜色标记不同质量数据的颜色,进而呈现出分布情况。
i.例如绿色是优质数据,黄色是未检验数据,红色是可疑数据等等2)针对多测点的时间序列数据(选定的时间段内)a)在一个数据表中,可以用不同的标记(颜色、)表现出不同的测点数据的质量情况,参见《对时间序列数据整体质量的定义》。
数据质量低于某个指标,需要显著的标记为不可用。
排序中的不同的列,可以是单测点数量质量的某个维度。
b)可以用排序的方法罗列出数据表中数据质量从高到低,或者从低到高的排序。
c)检验多测点时间的相关性,并采用适合表达相关性的图表方式(参考某些BI软件,如SPSS)进行表达。
根据不同的相关性群组,进一步可以进行聚类分析,因果检验等。
d)3)为后续数据挖掘和分析做好数据基础a)了解行业排名前三的数据分析和挖掘软件,了解他们的数据结构,DCM应该能够输出和他们匹配的数据结构,有这些软件的用户可以直接使用DAX。
b)4)数据清洗的配置a)提供为任意一个单测点进行数据清洗所需的配置项,内容包括需要进行的自动检测,需要检测的项目进行勾选,某些检测项勾选后还需要填充必要的参数。
该配置项可以并入DAX的数据基础配置中。
b)任何已经配置好的清洗选项,在使用过程中可以修改,修改后可以选择立即启用,或某具体时间后启用。