SQL中exists和in的区别
SQL----EXISTS关键字

SQL----EXISTS关键字转⾃:1.EXISTS基本意思英语解释就是存在,不过他的意思也差不多,相当于存在量词'З'。
他不返回数据的,当后带带的查询为空值是,返回“FALSE”,⾮空则返回“TRUE”。
就因为 EXISTS 返回的是真值或假值,所以他所带的⼦查询⼀般直接⽤'select *' 因为给出列名也没多少意义。
其实,EXISTS属于相关⼦查询,也就是说⼦查询的条件依赖于外层⽗查询的查个属性值。
⽐如:select Snamefrom Studentwhere exists (select *from SCwhere Sno=Student.Sno and Cno ='1');所说的依赖也就是这⼀句“ Sno=Student.Sno”。
这⾥要说明⼀下,这个查询过程不是⼀般的⾃下⽽上执⾏,他与外查询依赖,执⾏的时候是先从⽗查询中取⼀个元组,然后根据条件 Sno=Student.Sno 处理内查询,得到结果再进⾏⽗查询中取第⼆个元组,如果反复。
可与NOT 连⽤,反意思反过来理解,如:select Snamefrom Studentwhere not esists (select *from SCwhere Sno=Student.Sno and Cno ='1');EXISTS 的⼦查询,有⼀些是不能被其它形式的⼦查询等价替换的,但是所有 IN、⽐较运算符、ANY 和ALL的⼦查询都能⽤带有EXISTS 的⼦查询等价替换。
但是在做的时候,请考虑效率问题,哪种⾼效⽤啊种,这是优化问题。
例如在上⼀篇 IN 的讲述中第⼀个例⼦,我们就可以改⼀下,变成:select Sno,Sname,Sdeptfrom Student S1where exists (select *from Student S2where S2.Sdept=S1.Sdept and S2.Sname='A');在这⾥,EXISTS只要知道内查询是否为空值就可以了,所以效率要⽐⽤IN的查询要⾼效⼀些。
SQL中IN与EXISTS关键字

SQL中IN与EXISTS关键字 偶遇这样⼀个场景,使⽤IN关键字进⾏检索数据所消耗的时间是使⽤EXISTS关键字进⾏检索数据所消耗的时间的接近30倍。
⼀看差距这么⼤,查阅了⼀本SQL数据,其中也没有介绍多少,不过我们可以从其定义中可以领悟到⼀些差异。
(1)IN关键字:该操作符IN⽤于把⼀个值与⼀个指定列表进⾏⽐较,当被⽐较的值⾄少与列表中的⼀个值相匹配时,它会返回TRUE。
(2)EXISTS关键字:该操作符EXISTS⽤于搜索指定表⾥是否存在满⾜特定条件的记录。
根据这两个关键字作⽤的描述,可知:若是IN⼦句或者EXISTS⼦句都是采⽤SELECT语法检索出来的结果列表进⾏匹配的话,那么在IN⼦句中还要将被⽐较值与结果列表做进⼀步的循环⽐较,当IN中的被⽐较值能够匹配到结果列表中某个值,那么IN⼦句就会返回TRUE,否则的话就会返回FALSE;⽽在EXISTS⼦句中,若SELECT语句检索的结果值不为空,那么EXISTS⼦句直接将该结果集返回,若是检索的结果值为空的,那么EXISTS⼦句就返回空,也就是说EXISTS⼦句返回的就是SELECT语句返回的结果集,不需要再次做⽐较判断了。
-- INSELECT column1FROM table_nameWHERE some_col IN (SELECT column1 FROM table_name WHERE other_col >'xx');-- EXISTSSELECT column1FROM table_nameWHERE EXISTS (SELECT column1 FROM table_name WHERE other_col >'xx'); 上述代码⽰例只是⼀个象征性的对⽐说明,在同⼀个表中进⾏不同条件的多次检索,使⽤IN的⽅式:先根据条件检索出数据,然后some_col与结果列表进⾏循环⽐较;使⽤EXISTS的⽅式:先根据条件检索出数据,然后将该结果集直接返回,作为最终的数据结果了。
SQL中exist与in的区别

SQL中exist与in的区别in 是一个集合运算符.a in {a,c,d,s,d....} P105例子这个运算中,前面是一个元素,后面是一个集合,集合中的元素类型是和前面的元素一样的.而exists是一个存在判断,如果后面的查询中有结果,则exists为真,否则为假.in 运算用在语句中,它后面带的select 一定是选一个字段,而不是select *.比如说你要判断某班是否存在一个名为"小明"的学生,你可以用in 运算:"小明" in (select sname from student)这样(select sname from student) 返回的是一个全班姓名的集合,in用于判断"小明"是否为此集合中的一个数据;同时,你也可以用exists语句:exists (select * from student where sname="小明")select * from 表A where exists(select * from 表B where 表B.id=表A.id)这句相当于select * from 表A where id in (select id from 表B)对于表A的每一条数据,都执行select * from 表B where 表B.id=表A.id的存在性判断,如果表B中存在表A当前行相同的id,则exists为真,该行显示,否则不显示区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执行子查询IN适合于外表大而内表小的情况;EXISTS适合于外表小而内表大的情况。
表AID NAME1 A12 A23 A3表BID AID NAME1 1 B12 2 B23 2 B3表A和表B是1对多的关系 A.ID => B.AIDSELECT ID,NAME FROM A WHERE EXIST (SELECT * FROM B WHERE A.ID=B.AID)执行结果为1 A12 A2原因可以按照如下分析SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=1)--->SELECT * FROM B WHERE B.AID=1有值返回真所以有数据SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=2)--->SELECT * FROM B WHERE B.AID=2有值返回真所以有数据SELECT ID,NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID=3)--->SELECT * FROM B WHERE B.AID=3无值返回真所以没有数据NOT EXISTS 就是反过来SELECT ID,NAME FROM A WHERE NOT EXIST (SELECT * FROM B WHERE A.ID=B.AID)执行结果为3 A3例子查询选修了全部课程的学生姓名。
SQL语句中exists和in的区别

SQL语句中exists和in的区别转⾃https:///liyasong/p/sql_in_exists.html 和 /lick4050312/article/details/4476333表展⽰ 查询中涉及到的两个表,⼀个user和⼀个order表,具体表的内容如下: user表: order表:in ⼀、确定给定的值是否与⼦查询或列表中的值相匹配。
in在查询的时候,⾸先查询⼦查询的表,然后将内表和外表做⼀个笛卡尔积,然后按照条件进⾏筛选。
所以相对内表⽐较⼩的时候,in的速度较快。
具体sql语句如下:1 SELECT2 *3 FROM4 `user`5 WHERE6 `user`.id IN (7 SELECT8 `order`.user_id9 FROM10 `order`11 ) 这条语句很简单,通过⼦查询查到的user_id 的数据,去匹配user表中的id然后得到结果。
该语句执⾏结果如下: 它的执⾏流程是什么样⼦的呢?让我们⼀起来看⼀下。
⾸先,在数据库内部,查询⼦查询,执⾏如下代码:SELECT`order`.user_idFROM`order` 执⾏完毕后,得到结果如下: 此时,将查询到的结果和原有的user表做⼀个笛卡尔积,结果如下: 此时,再根据我们的user.id IN er_id的条件,将结果进⾏筛选(既⽐较id列和user_id 列的值是否相等,将不相等的删除)。
最后,得到两条符合条件的数据。
⼆、select * from A where id in(select id from B)以上查询使⽤了in语句,in()只执⾏⼀次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加⼊结果集中,直到遍历完A表的所有记录. 它的查询过程类似于以下过程List resultSet=[]; Array A=(select * from A); Array B=(select id from B);for(int i=0;i<A.length;i++) { for(int j=0;j<B.length;j++) { if(A[i].id==B[j].id) { resultSet.add(A[i]); break; } } } return resultSet;可以看出,当B表数据较⼤时不适合使⽤in(),因为它会B表数据全部遍历⼀次. 如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差. 再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000*100次,遍历次数⼤⼤减少,效率⼤⼤提升.结论:in()适合B表⽐A表数据⼩的情况exists ⼀、指定⼀个⼦查询,检测⾏的存在。
in和exists的区别与SQL执行效率分析

in和exists的区别与SQL执行效率分析本文对in和exists的区别与SQL执行效率进行了全面整理分析……最近很多论坛又开始讨论in和exists的区别与SQL执行效率的问题,本文特整理一些in和exists的区别与SQL执行效率分析SQL中in可以分为三类:1、形如select * from t1 where f1 in ('a','b'),应该和以下两种比较效率select * from t1 where f1='a' or f1='b'或者select * from t1 where f1 ='a' union all select * from t1 f1='b'你可能指的不是这一类,这里不做讨论。
2、形如select * from t1 where f1 in (select f1 from t2 where t2.fx='x'),其中子查询的where里的条件不受外层查询的影响,这类查询一般情况下,自动优化会转成exist语句,也就是效率和exist一样。
3、形如select * from t1 where f1 in (select f1 from t2 where t2.fx=t1.fx),其中子查询的where里的条件受外层查询的影响,这类查询的效率要看相关条件涉及的字段的索引情况和数据量多少,一般认为效率不如exists。
除了第一类in语句都是可以转化成exists 语句的SQL,一般编程习惯应该是用exists而不用in,而很少去考虑in和exists的执行效率.in和exists的SQL执行效率分析A,B两个表,(1)当只显示一个表的数据如A,关系条件只一个如ID时,使用IN更快:select * from A where id in (select id from B)(2)当只显示一个表的数据如A,关系条件不只一个如ID,col1时,使用IN就不方便了,可以使用EXISTS:select * from Awhere exists (select 1 from B where id = A.id and col1 = A.col1)(3)当只显示两个表的数据时,使用IN,EXISTS都不合适,要使用连接:select * from A left join B on id = A.id所以使用何种方式,要根据要求来定。
SQL 里的 EXISTS与in、not exists与not in

SQL 里的EXISTS与in、not exists与not in2011-01-07 10:01:25| 分类:sql | 标签:|字号大中小订阅系统要求进行SQL优化,对效率比较低的SQL进行优化,使其运行效率更高,其中要求对SQL中的部分in/not in修改为exists/not exists修改方法如下:in的SQL语句SELECT id, category_id, htmlfile, title, convert(varchar(20),begintime,112) as pubtimeFROM tab_oa_pub WHERE is_check=1 andcategory_id in (select id from tab_oa_pub_cate where no='1')order by begintime desc修改为exists的SQL语句SELECT id, category_id, htmlfile, title, convert(varchar(20),begintime,112) as pubtimeFROM tab_oa_pub WHERE is_check=1 andexists (select id from tab_oa_pub_cate where tab_oa_pub.category_id=convert(int,no) and no='1') order by begintime desc分析一下exists真的就比in的效率高吗?我们先讨论IN和EXISTS。
select * from t1 where x in ( select y from t2 )事实上可以理解为:select *from t1, ( select distinct y from t2 ) t2where t1.x = t2.y;——如果你有一定的SQL优化经验,从这句很自然的可以想到t2绝对不能是个大表,因为需要对t2进行全表的“唯一排序”,如果t2很大这个排序的性能是不可忍受的。
mysql中=与in区别_浅析mysql中exists与in的区别,空判断

mysql中=与in区别_浅析mysql中exists与in的区别,空判断1、exists的使⽤exists对外表⽤loop逐条查询,每次查询都会查看exists的条件语句,当exists⾥的条件语句能够返回记录⾏时(⽆论记录⾏是的多少,只要能返回),条件就为真,返回当前loop到的这条记录;反之如果exists⾥的条件语句不能返回记录⾏,则当前loop到的这条记录被丢弃,exists的条件就像⼀个bool条件,当能返回结果集则为true,不能返回结果集则为 false。
如下:select * from user where exists (select 1);对user表的记录逐条取出,由于⼦条件中的select 1永远能返回记录⾏,那么user表的所有记录都将被加⼊结果集,所以与 select * from user;是⼀样的。
如下:select * from user where exists (select * from user where userId = 0);可以知道对user表进⾏loop时,检查条件语句(select * from user where userId = 0),由于userId永远不为0,所以条件语句永远返回空集,条件永远为false,那么user表的所有记录都将被丢弃。
not exists与exists相反,也就是当exists条件有结果集返回时,loop到的记录将被丢弃,否则将loop到的记录加⼊结果集。
总的来说,如果A表有n条记录,那么exists查询就是将这n条记录逐条取出,然后判断n遍exists条件。
2、in 的使⽤in查询相当于多个or条件的叠加,这个⽐较好理解,⽐如下⾯的查询:select * from user where userId in (1, 2, 3);等效于select * from user where userId = 1 or userId = 2 or userId = 3;not in 与 in相反,如下select * from user where userId not in (1, 2, 3);等效于select * from user where userId != 1 and userId != 2 and userId != 3;总的来说,in查询就是先将⼦查询条件的记录全都查出来,假设结果集为B,共有m条记录,然后再将⼦查询条件的结果集分解成m个,再进⾏m次查询。
详解sql中exists和in的语法与区别

详解sql中exists和in的语法与区别exists和in的区别很⼩,⼏乎可以等价,但是sql优化中往往会注重效率问题,今天咱们就来说说exists和in的区别。
exists语法:select … from table where exists (⼦查询)将主查询的结果,放到⼦查询结果中进⾏校验,如⼦查询有数据,则校验成功,那么符合校验,保留数据。
create table teacher(tid int(3),tname varchar(20),tcid int(3));insert into teacher values(1,'tz',1);insert into teacher values(2,'tw',2);insert into teacher values(3,'tl',3);例如:select tname from teacher exists(select * from teacher);此sql语句等价于select tname from teacher(主查询数据存在于⼦查询,则查询成功(校验成功))此sql返回为空,因为⼦查询并不存在这样的数据。
in语法:select … from table where 字段 in (⼦查询)select ..from table where tid in (1,3,5) ;select * from A where id in (select id from B);区别:如果主查询的数据集⼤,则使⽤in;如果⼦查询的数据集⼤,则使⽤exists;例如:select tname from teacher where exists (select * from teacher);这⾥很明显,⼦查询查询所有,数据集⼤,使⽤exists,效率⾼。
select * from teacher where tname in (select tname from teacher where tid = 3);这⾥很明显,主查询数据集⼤,使⽤in,效率⾼。
“exists”和“in”的区分

T1数据量非常大而T2数据量小时,T1>>T2 时,2) 的查询效率高。
exists 用法:
请注意 1)句中的有颜色字体的部分 ,理解其含义;
其中 “select 1 from T2 where T1.a=T2.a” 相当于一个关联表查询,相当于
“select 1 from T1,T2 where T1.a=T2.a”
Select name from employee where name not in (select name from student);
Select name from employee where not exists (select name from student);
第一句SQL语句的执行效率不如第二句。
但是,如果你当当执行 1) 句括号里的语句,是会报语法错误的,这也是使用exists需要注意的地方。
“exists(xxx)”就表示括号里的语句能不能查出记录,它要查的记录是否存在。
因此“select 1”这里的 “1”其实是无关紧要的,换成“*”也没问题,它只在乎括号里的数据能不能查找出来,是否存在这样的记录,如果存在,这 1) 句的where 条件成立。
有两个简单例子,以说明 “exists”和“in”的效率问题
1) select * from T1 where exists(select 1 from T2 where T1.a=T2.a) ;
sql中的exists

sql中的exists刚开始⼯作的开发,很容易过度的使⽤in、not in。
其实,在有些时候可以⽤exists、not exists来代替in和not in,实现查询性能的提升。
exists操作符时候会和in操作符产⽣混淆。
因为他们都是⽤于检查某个属性是否包含在某个集合中。
但是相同点也仅限于此。
exists的真正⽬的是检查⼦查询是否⾄少包含⼀条记录。
例如,下⾯的查询会返回⾏1和2:WITH numbers (nr) AS (SELECT 1 AS nr UNION ALLSELECT 2 AS nr UNION ALLSELECT 3 AS nr), letters (letter, nr) AS (SELECT 'A' AS letter, 1 AS nr UNION ALLSELECT 'B' AS letter, 2 AS nr)SELECT * FROM numbers n WHERE EXISTS (SELECT nr FROM letters WHERE nr= n.nr);当然,你也可以改写成in:WITH numbers (nr) AS (SELECT 1 AS nr UNION ALLSELECT 2 AS nr UNION ALLSELECT 3 AS nr), letters (letter, nr) AS (SELECT 'A' AS letter, 1 AS nr UNION ALLSELECT 'B' AS letter, 2 AS nr)SELECT * FROM numbers n WHERE n.nr IN (SELECT nr FROM letters);这两种写法,都可以返回相同的记录。
区别是exists会更快,因为在得到第⼀条满⾜条件的记录之后就会停⽌,⽽in会查询所有的记录(如果in返回很多⾏的话)。
sql中exists用法

sql中exists用法exists是SQL中的一种检查函数,用于判断一条SQL子句是否存在结果集,在SQL中exists的使用可以极大地提高查询效率。
exists函数相比"in"函数有很大的优势,即exists在找到结果情况下,会立刻返回True,而"in"函数会把所有结果查出来才进行判断。
如需要确定是否有顾客名叫“张三”的,一般会使用in函数:select * from customers where name in("张三");此SQL会把customers表中所有的name值为“张三”的记录拿出来,然后再处理,比较耗时的情况下,可以使用exists:select * from customers where exists(select 1 from customers where name = "张三");exists把结果集直接返回,无需在customers表上多余的查询,大大提高查询效率。
这也是当今大数据场景下exists函数受到青睐。
除了简单用法之外,exists函数还可以与其它结合起来使用,比如查找满足条件X和Y其中一个的记录:select * from customers where exists(select 1 from customers where name = "张三") or exists(select 1 from customers where name = ”Ping";由于存在exists函数,当今的查询任务变得超级快捷。
exists函数不仅用于极大地提升SQL查询效率,也可以启发我们在生活中不断改善效率,把更多时间留出来完成更有意义的事情。
oracle中exist与in的区别

在Oracle SQL中取数据时有时要用到in 和exists 那么他们有什么区别呢?1 性能上的比较比如Select * from T1 where x in ( select y from T2 )执行的过程相当于:select *from t1, ( select distinct y from t2 ) t2where t1.x = t2.y;相对的select * from t1 where exists ( select null from t2 where y = x )执行的过程相当于:for x in ( select * from t1 )loopif ( exists ( select null from t2 where y = x.x )thenOUTPUT THE RECORDend ifend loop表 T1 不可避免的要被完全扫描一遍分别适用在什么情况?以子查询 ( select y from T2 )为考虑方向如果子查询的结果集很大需要消耗很多时间,但是T1比较小执行( select null from t2 where y = x.x )非常快,那么exists就比较适合用在这里相对应得子查询的结果集比较小的时候就应该使用in.2 含义上的比较在标准的scott/tiger用户下执行SQL> select count(*) from emp where empno not in ( select mgr from emp );COUNT(*)----------SQL> select count(*) from emp T12 where not exists ( select null from emp T2 where t2.mgr =t1.empno ); -- 这里子查询中取出null并没有什么特殊作用,只是表示取什么都一样。
COUNT(*)----------8结果明显不同,问题就出在MGR=null的那条数据上。
MySQL中in和exists区别详解
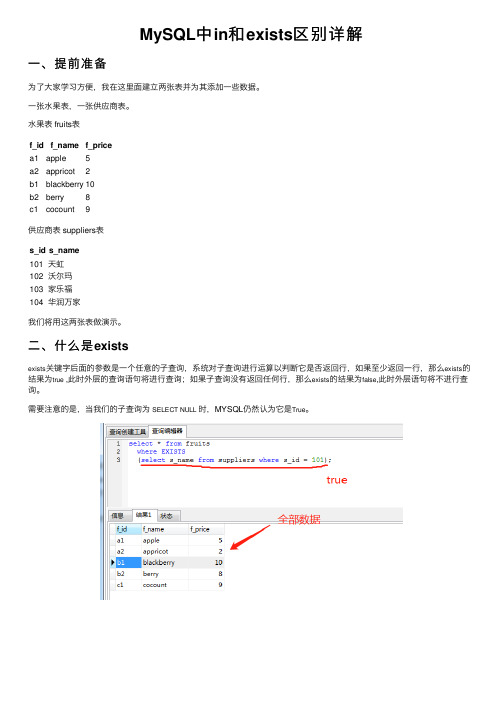
MySQL中in和exists区别详解⼀、提前准备为了⼤家学习⽅便,我在这⾥⾯建⽴两张表并为其添加⼀些数据。
⼀张⽔果表,⼀张供应商表。
⽔果表 fruits表f_id f_name f_pricea1apple5a2appricot2b1blackberry10b2berry8c1cocount9供应商表 suppliers表s_id s_name101天虹102沃尔玛103家乐福104华润万家我们将⽤这两张表做演⽰。
⼆、什么是existsexists关键字后⾯的参数是⼀个任意的⼦查询,系统对⼦查询进⾏运算以判断它是否返回⾏,如果⾄少返回⼀⾏,那么exists的结果为true ,此时外层的查询语句将进⾏查询;如果⼦查询没有返回任何⾏,那么exists的结果为false,此时外层语句将不进⾏查询。
需要注意的是,当我们的⼦查询为SELECT NULL时,MYSQL仍然认为它是True。
三、什么是inin 关键字进⾏⼦查询时,内层查询语句仅仅返回⼀个数据列,这个数据列的值将提供给外层查询语句进⾏⽐较操作。
为了测试in 关键字,我在⽔果表中加了s_id⼀列⽔果表 fruits表f_id f_name f_price s_ida1apple5101a2appricot2103b1blackberry10102b2berry8104c1cocount9103四、exists和inin和exists到底有啥区别那,要什么时候⽤in,什么时候⽤exists?我们先记住⼝诀再说细节!“外层查询表⼩于⼦查询表,则⽤exists,外层查询表⼤于⼦查询表,则⽤in,如果外层和⼦查询表差不多,则爱⽤哪个⽤哪个。
”我想你已经看出来了,当fruits表数据很⼤的时候不适合⽤in,因为它最多会将fruits表数据全部遍历⼀次。
如:suppliers表有10000条记录,fruits表有1000000条记录,那么最多有可能遍历10000*1000000次,效率很差。
数据库in和exists的用法

数据库in和exists的用法数据库in和exists的用法的用法如下:SELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001 FROM BOMMC)NOT EXISTS,exists的用法跟in不一样,一般都需要和子表进行关联,而且关联时,需要用索引,这样就可以加快速度select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM BOMMC where BOMMC.MC001 = BOMMD.MD001)exists是用来判断是否存在的,当exists(查询)中的查询存在结果时则返回真,否则返回假。
not exists则相反。
exists做为where 条件时,是先对where 前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
in和existsin 是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:例如:表A(小表),表B(大表)1:select * from A where cc in (select cc from B)效率低,用到了A表上cc列的索引;select * from A where exists(select cc from B where cc=)效率高,用到了B 表上cc列的索引。
相反的2:select * from B where cc in (select cc from A)效率高,用到了B表上cc列的索引;select * from B where exists(select cc from A where cc=)效率低,用到了A表上cc列的索引。
数据库in和exists的用法

数据库in和exists的用法数据库in和exists的用法的用法如下:SELECTDISTINCTMD001FROMBOMMDWHEREMD001NOTIN(SELECTMC001F ROMBOMMC)NOTEXISTS,exists的用法跟in不一样,一般都需要和子表进行关联,而且关联时,需要用索引,这样就可以加快速度selectDISTINCTMD001fromBOMMDWHERENOTEXISTS(SELECTMC001FR OMBOMMCwhereBOMMC.MC001=BOMMD.MD001)exists是用来判断是否存在的,当exists(查询)中的查询存在结果时则返回真,否则返回假。
notexists则相反。
exists做为where条件时,是先对where前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
in和existsin是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in 效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:例如:表A(小表),表B(大表)1:select*fromAwhereccin(selectccfromB)效率低,用到了A表上cc列的索引;select*fromAwhereexists(selectccfromBwherecc=)效率高,用到了B表上cc列的索引。
相反的2:select*fromBwhereccin(selectccfromA)效率高,用到了B表上cc列的索引;select*fromBwhereexists(selectccfromAwherecc=)效率低,用到了A表上cc列的索引。
SQL中IN和EXISTS用法的区别

SET NOCOUNT ON,SET NOCOUNT OFF当SET NOCOUNT 为ON 时,不返回计数(表示受Transact-SQL 语句影响的行数)。
当SET NOCOUNT 为OFF 时,返回计数。
如果存储过程中包含的一些语句并不返回许多实际的数据,则该设置由于大量减少了网络流量,因此可显著提高性能。
SQL中IN和EXISTS用法的区别NOT INSELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001 FROM BOMMC)NOT EXISTS,exists的用法跟in不一样,一般都需要和子表进行关联,而且关联时,需要用索引,这样就可以加快速度select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM BOMMC where BOMMC.MC001 = BOMMD.MD001)exists是用来判断是否存在的,当exists(查询)中的查询存在结果时则返回真,否则返回假。
not exists则相反。
exists做为where 条件时,是先对where 前的主查询询进行查询,然后用主查询的结果一个一个的代入exists的查询进行判断,如果为真则输出当前这一条主查询的结果,否则不输出。
in和existsin是把外表和内表作hash 连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
如果查询的两个表大小相当,那么用in和exists差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用exists,子查询表小的用in:例如:表A(小表),表B(大表)1:select*from A where cc in (select cc from B)效率低,用到了A表上cc列的索引;select*from A where exists(select cc from B where cc=)效率高,用到了B表上cc列的索引。
SQL中的EXISTS、IN与JOIN性能分析

EXISTS、IN与JOIN性能分析EXISTS、IN与JOIN,都可以用来实现形如“查询A表中在(或不在)B表中的记录”的查询逻辑。
在论坛上看到很多人对此有所误解(如关于in的疑惑、用外连接和Is Null 代替not in两帖),特做一简单测试。
测试结果:测试代码较长,附于本帖最后。
图表中百分数表示同一组3个查询的执行时间比例。
红色表示3个语句中最慢,绿色表示3个语句中最快的,并列则没加颜色。
其中索引只测试了聚集索引,当表中字段较多且查询字段是非聚集索引时,选择执行计划的条件比较复杂,没有测试。
并且当表中数量变化后,执行计划可能也有差异。
图表反映了3种查询方式的解析机制的不同,基本结论是类似的,但具体情况还要视执行计划而定。
分析结论:通常情况下,3种查询方式的执行时间:EXISTS <= IN <= JOINNOT EXISTS <= NOT IN <= LEFT JOIN只有当表中字段允许NULL时,NOT IN的方式最慢:NOT EXISTS <= LEFT JOIN <= NOT IN综上:IN的好处是逻辑直观简单(通常是独立子查询);缺点是只能判断单字段,并且当NOT IN 时效率较低,而且NULL会导致不想要的结果。
EXISTS的好处是效率高,可以判断单字段和组合字段,并不受NULL的影响;缺点是逻辑稍微复杂(通常是相关子查询)。
JOIN用在这种场合,往往是吃力不讨好。
JOIN的用途是联接两个表,而不是判断一个表的记录是否在另一个表。
编程建议:(以下三条建议中EXISTS和IN同时代指肯定式逻辑和加NOT后的否定式逻辑)如果查询条件是单字段主键(有索引且不允许NULL),则EXISTS和IN的性能基本一样,IN的查询通常写法简单、逻辑直观。
如果查询条件涉及多个字段,则最好选择EXISTS,千万不要用字段拼接再IN的方式(索引会失效)。
如果条件不确定,选用EXISTS是最保险的办法,性能最好,不受三值逻辑影响(EXISTS 只会返回True/False不会返回Unknown),但代码逻辑稍稍复杂,思路要理清楚,而且相关字段最好采用“表(别)名.字段名”的形式。
sql逻辑运算符

sql逻辑运算符SQL逻辑运算符,是指在SQL语句中使用的条件运算符,它们用于构建复杂的逻辑表达式,比如检索或更新数据库中的数据。
这些运算符也可以帮助用户构建更高级的查询条件,从而获取比基本查询更精确的结果。
SQL逻辑运算符包括AND, OR, NOT, IS NULL, IN, BETWEEN, EXISTS, ALL, ANY, SOME等。
AND算符是SQL中最常用的逻辑运算符之一,可以用来检查多个条件是否都满足。
它的语法结构为:WHERE段名 = AND段名 =。
当两个条件都满足时,返回结果才是真的,否则,结果为假。
例如,要查找年龄为18岁且性别为女性的人,可以使用以下语句: SELECT * FROM名 WHERE龄 = 18 AND别 = 女OR算符与AND运算符正好相反,它的意思是检查多个条件,任意一个条件满足即可。
它的语法为:WHERE段名 = OR段名 =。
例如,要查询年龄为19岁或20岁的人,可以使用以下语句:SELECT * FROM名 WHERE龄 = 19 OR龄 = 20NOT算符可以取反某条件。
它的语法为:WHERE NOT段名 =。
例如,要查询年龄不是18岁的人,可以使用以下语句:SELECT * FROM名 WHERE NOT龄 = 18IS NULL算符可以检查某个字段是否为空,它的语法为:WHERE 段名 IS NULL。
例如,要查询字段值为空的记录,可以使用以下语句:SELECT * FROM名 WHERE段名 IS NULLIN算符可用于检查字段的值是否存在于一个给定的列表之中。
它的语法为:WHERE段名 IN(值1,值2,值3)。
例如,要查询年龄为18,19,20的人,可以使用以下语句:SELECT * FROM名WHERE龄 IN(18,19,20)BETWEEN算符可以用于查询字段值介于两个给定值之间的记录。
它的语法结构为:WHERE段名 BETWEEN1 AND2。
举例说明in子查询、比较子查询和exist子查询的用法。

举例说明in子查询、比较子查询和exist子查询的用法。
x
IN 子查询:
IN 子查询是一种将一个查询结果作为输入参数传递给另一个查询的子查询。
它能够以一个值集合(由满足 WHERE 子句的行构成)作为参数。
举例:
SELECT * FROM Customers
WHERE Country IN (SELECT Country FROM Suppliers);
比较子查询:
比较子查询是比较一列值中的每一行与另一个查询返回的值的
子查询。
举例:
SELECT * FROM Customers
WHERE Country=(SELECT Country FROM Suppliers WHERE SupplierName='Microsoft');
EXISTS 子查询:
EXISTS 子查询返回一个 Boolean 值来标识子查询是否返回行。
如果子查询返回任何一行,则为 true;如果子查询没有返回任何行,则为 false。
- 1 -。
数据库sql语句的exists和in的区别

数据库sql语句的exists和in的区别性能变化的关键:#1 执⾏的先后顺序谁是驱动表,谁先执⾏查询,谁后执⾏查询#2 执⾏过程exists的优点是:只要存在就返回了,这样的话很有可能不需要扫描整个表。
in需要扫描完整个表,并返回结果。
所以,在字表⽐较⼩的情况下,扫描全表和部分表基本没有差别;但在⼤表情况下,exists就会有优势。
看这两个语句:--⼦查询会执⾏完全关联,并返回所有符合条件的city_idselect * from areas where id in (select city_id from deals where deals.city_id = areas.id);--⼦查询的关联其实是⼀样的,但⼦查询只要查到⼀个结果,就返回了,所以效率还是⽐较⾼些的select * from areas where exists (select null from deals where deals.city_id = areas.id);#3 字表查询的结果exists判断⼦查询的结果是不是存在,但查到什么结果,什么字段,并不关⼼;in 需要⼦查询查得的结果给主查询使⽤对于in和exists的性能区别:如果⼦查询得出的结果集记录较少,主查询中的表较⼤且⼜有索引时应该⽤in,反之如果外层的主查询记录较少,⼦查询中的表⼤,⼜有索引时使⽤exists。
其实我们区分in和exists主要是造成了驱动顺序的改变(这是性能变化的关键),如果是exists,那么以外层表为驱动表,先被访问,如果是IN,那么先执⾏⼦查询,所以我们会以驱动表的快速返回为⽬标,那么就会考虑到索引及结果集的关系了另外IN时不对NULL进⾏处理。
注意:NOT EXISTS与 NOT IN不能完全互相替换,看具体的需求。
如果选择的列可以为空,则不能被替换。
对于not in和 not exists的性能区别:not in只有当⼦查询中,select 关键字后的字段有not null约束或者有这种暗⽰时⽤not in,另外如果主查询中表⼤,⼦查询中的表⼩但是记录多,则应当使⽤not in,并使⽤anti hash join.如果主查询表中记录少,⼦查询表中记录多,并有索引,可以使⽤not exists,另外not in最好也可以⽤/*+ HASH_AJ */或者外连接+is null NOT IN在基于成本的应⽤中较好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
in()后面的子查询 是返回结果集的,换句话说执行次序和exists()不一样.子查询先产生结果集,然后主查询再去结果集里去找符合要求的字段列表去.符合要求的输出,反之则不输出.
对于userid=2,需要找所有记录,返回记录集
2
2
,比较判断
对于userid=3需要找所有记录,返回记录集
3
3 3 Βιβλιοθήκη 3 ,比较判断 表中如果没有聚集索引,对exists每个userid查找的条数都不同,但都是<=第三个语句需要扫描的条数,极端的(比如> 5000的都是在最后)与第三个语句效率相似,一般的比第二个语句快,所以说,“一般”exists比in效率高
假设如下应用:
两张表——用户表TDefUser(userid,address,phone)和消费表 TAccConsume(userid,time,amount),需要查消费超过5000的用户记录。
用exists:
select * from TDefUser
where exists (select 1 from TAccConsume where erid=erid and TAccConsume.amount>5000)
对于userid=2,找到2006-1-3的记录,就返回true,比第而个语句的效率高
对于userid=3,第一条记录就返回true,比第二个语句的效率高
语句
select * from TDefUser
where userid in (select userid from TAccConsume where TAccConsume.amount>5000)
where exists (select 1 from TAccConsume where erid=erid and TAccConsume.amount>5000)
对于userid=1,需要找所有记录,才返回false,与第二个语句的效率差不多
用in:
select * from TDefUser
where userid in (select userid from TAccConsume where TAccConsume.amount>5000)
通常情况下采用exists要比in效率高。
exists()后面的子查询被称做相关子查询 他是不返回列表的值的.只是返回一个ture或false的结果(这也是为什么子查询里是"select 1"的原因,换成"select 6"完全一样,当然也可以select字段,但是明显效率低些)
2 2006-1-3 6000
2 2006-1-4 400
2 2006-1-5 8000
3 2006-1-1 7000
3 2006-1-2 30000
3 2006-1-2 50000
3 2006-1-3 20000
语句:
select * from TDefUser
1 2006-1-2 500
1 2006-1-3 2000
1 2006-1-3 2000
1 2006-1-4 400
1 2006-1-5 500
2 2006-1-1 200
2 2006-1-2 300
2 2006-1-2 500
2 2006-1-3 2000
返回空记录集
2
2
3
3
3
3
再判断
语句
select * from TDefUser
where userid in (select userid from TAccConsume where userid=erid and amount>5000)
对于userid=1,需要找所有记录,返回空记录集,比较判断
比如用户表TDefUser(userid,address,phone),消费表 TAccConsume(userid,time,amount)数据如下:
消费表聚集索引是userid,time
数据(注意因为有聚集索引,实际存储也是按以下次序的)
1 2006-1-1 200
1 2006-1-2 300