数据挖掘计算题参考答案
数据挖掘考试题及答案

数据挖掘考试题及答案### 数据挖掘考试题及答案#### 一、选择题(每题2分,共20分)1. 数据挖掘的目的是发现数据中的:- A. 错误- B. 模式- C. 异常- D. 趋势答案:B2. 以下哪项不是数据挖掘的常用算法:- A. 决策树- B. 聚类分析- C. 线性回归- D. 神经网络答案:C3. 关联规则挖掘中,Apriori算法用于发现:- A. 频繁项集- B. 异常值- C. 趋势- D. 聚类答案:A4. K-means算法是一种:- A. 分类算法- B. 聚类算法- C. 预测算法- D. 关联规则挖掘算法答案:B5. 以下哪个指标用于评估分类模型的性能:- A. 准确率- B. 召回率- C. F1分数- D. 所有以上答案:D#### 二、简答题(每题10分,共30分)1. 描述数据挖掘中的“过拟合”现象,并给出避免过拟合的策略。
答案:过拟合是指模型对训练数据拟合得过于完美,以至于失去了泛化能力。
避免过拟合的策略包括:使用交叉验证、正则化技术、减少模型复杂度、获取更多的训练数据等。
2. 解释什么是“数据清洗”以及它在数据挖掘中的重要性。
答案:数据清洗是指从原始数据中识别并纠正(或删除)错误、重复或不完整的数据的过程。
它在数据挖掘中至关重要,因为脏数据会导致分析结果不准确,影响最终的决策。
3. 描述“特征选择”在数据挖掘中的作用。
答案:特征选择是数据挖掘中用来降低数据维度、提高模型性能和减少计算成本的过程。
通过选择最有信息量的特征,可以去除冗余或无关的特征,从而提高模型的准确性和效率。
#### 三、应用题(每题25分,共50分)1. 假设你正在分析一个电子商务网站的用户购买行为,描述你将如何使用数据挖掘技术来识别潜在的营销机会。
答案:首先,我会使用聚类分析来识别不同的用户群体。
然后,通过关联规则挖掘来发现不同用户群体的购买模式。
接着,利用分类算法来预测用户可能感兴趣的产品。
数据挖掘计算题考试题库

数据挖掘计算题考试题库1. 数据挖掘中的“分类”任务是用来做什么的?A. 识别数据集中的异常值B. 将数据集分成不同的类别C. 预测数值型数据D. 找出数据集中的相关性答案: B2. 下面哪种算法不是分类算法?A. 决策树B. K-均值聚类C. 随机森林D. 支持向量机(SVM)答案: B3. 在数据挖掘过程中,“数据清洗”指的是什么?A. 删除重复的记录B. 提取关键特征C. 创建可视化D. 选择重要的数据子集答案: A4. 下面哪个是关联规则学习中的一个常见算法?A. AprioriB. AdaBoostC. 梯度提升机D. 主成分分析甮案: A5. 在数据挖掘中,“过拟合”指的是什么?A. 模型在新数据上的表现很差B. 模型没有捕捉到数据的关键特征C. 模型在训练集上的表现过于完美D. 模型参数过于简单答案: C6. “集成学习”在数据挖掘中指的是什么?A. 使用一个单一的模型进行预测B. 结合多个模型的预测以提高性能C. 对数据进行分层抽样D. 应用一个算法在不同的数据集上答案: B7. 哪个度量标准经常用来评估分类器的性能?A. 均方误差(MSE)B. 精确率和召回率C. 相关系数D. K-均值答案: B8. 下面哪个不是数据预处理的一部分?A. 归一化B. 主成分分析(PCA)C. 数据编码D. 计算数据均值答案: D9. 下面哪个算法适合于处理大量未标记数据?A. 监督学习B. 半监督学习C. 无监督学习D. 强化学习答案: C10. 下面哪个不是异常检测的算法?A. Local Outlier Factor (LOF)B. One-Class SVMC. Isolation ForestD. Linear Regression答案: D11. 在数据挖掘中,“特征选择”是为了什么?A. 减少数据的维度B. 增加更多的数据特征C. 创建数据的可视化D. 计算数据的主成分答案: A12. 下面哪个是决策树算法的一种?A. C4.5B. K-最近邻(K-NN)C. 随机森林D. 线性判别分析(LDA)答案: A13. 在聚类问题中,"轮廓系数"是用来做什么的?A. 评估聚类的紧密度和分离度B. 计算每个点到其最近的聚类中心的距离C. 确定最佳的聚类数D. 预测新数据点的类别答案: A14. 下面哪个技术用于减少过拟合?A. 正则化B. 增加更多的特征C. 使用更复杂的模型D. 删除数据集中的一些样本答案: A15. 支持向量机(SVM)的主要目的是什么?A. 最大化分类器的边界B. 最小化预测误差C. 找到数据的最佳表示D. 减少计算成本答案: A16. 数据挖掘中的“回归分析”用于什么?A. 预测数值型的目标变量B. 分类数据C. 数据的可视化D. 数据的归一化处理答案: A17. 下面哪个算法是基于概率的分类算法?A. 决策树B. 朴素贝叶斯C. 支持向量机(SVM)D. K-最近邻(K-NN)答案: B18. “梯度提升机”(Gradient Boosting Machine)主要用于什么?A. 数据预处理B. 特征选择C. 优化模型性能D. 聚类分析答案: C19. 在K-最近邻(K-NN)算法中,K代表什么?A. 选择的特征数B. 数据点将考虑的最近邻居的数量C. 聚类的数量D. 数据维度的数量答案: B20. 下面哪个不是数据挖掘任务?A. 预测B. 聚类C. 分类D. 数据录入答案: D21. 数据挖掘中的“提升”技术是用来做什么的?A. 减少模型的计算复杂度B. 减小数据集的规模C. 增强模型的预测能力D. 清洗数据集答案: C22. 下面哪个算法通常用于文本数据的分类?A. 朴素贝叶斯B. 线性回归C. K-均值聚类D. 随机森林答案: A23. 时间序列分析在数据挖掘中用于什么?A. 识别数据中的异常点B. 预测未来的数据点C. 分类数据点D. 查找数据集的子集答案: B24. 下面哪个方法不适用于缺失数据的处理?A. 使用均值填充缺失值B. 删除包含缺失值的记录C. 使用模型预测缺失值D. 增加更多的数据特征答案: D25. “维度的诅咒”指的是什么?A. 数据越多越好B. 数据维度增加导致分析变得更加困难C. 低维度数据不足以解释现象D. 高维度数据易于可视化答案: B26. 在数据挖掘中,下面哪个是一个常见的数据变换方法?A. 数据归一化B. 数据扩充C. 数据删除D. 数据复制答案: A27. 什么是数据挖掘中的“支持”?A. 一个数据集的所有数据点B. 关联规则中项集出现的频率C. 分类算法的准确率D. 聚类质量的度量答案: B28. 决策树中的“节点”代表什么?A. 数据特征的一个可能值B. 一个分类规则C. 数据集的一个子集D. 一个概率分布答案: B29. “随机森林”算法中的“森林”是由什么组成的?A. 决策树B. 数据集C. 神经网络D. 聚类答案: A30. 在数据挖掘中,“基于实例的学习”通常指什么?A. 构建一般化模型B. 用大量的数据实例来做决策C. 用少量的代表性实例来做决策D. 仅使用单个实例进行训练答案: C31. 在数据挖掘中,什么是“过度拟合”?A. 模型不能适应新数据B. 模型在训练数据上表现不佳C. 模型对训练数据的噪声也进行了学习D. 模型过于简化,丢失了重要信息答案: C32. 下面哪个是数据挖掘中的一种特征提取方法?A. 主成分分析(PCA)B. 决策树分析C. 线性回归D. 逻辑回归答案: A33. “聚类”在数据挖掘中的目的是什么?A. 找出数据集中的异常值B. 预测数据点的值C. 将数据集分组成相似的子集D. 减少数据维度答案: C34. 数据挖掘中,“神经网络”主要用于什么?A. 数据预处理B. 特征选择C. 复杂模式识别和预测建模D. 数据压缩答案: C35. “深度学习”在数据挖掘中通常用来处理哪些问题?A. 只有小规模数据集的问题B. 高维度和复杂结构的数据问题C. 简单线性问题D. 无需特征工程的问题答案: B36. 关联规则分析中的“置信度”是指什么?A. 规则中的项集出现的频繁程度B. 一条规则被证实为真的次数C. 给定前件时后件出现的条件概率D. 数据集中项集的独立概率答案: C37. 数据挖掘中的“决策树”算法主要用于解决哪类问题?A. 聚类B. 分类和回归C. 关联规则学习D. 数据预处理答案: B38. “模型评估”在数据挖掘中的目的是什么?A. 选择最好的数据预处理方法B. 确定最合适的特征集C. 选择合适的算法D. 评价模型的预测性能答案: D39. 下面哪个是数据挖掘中的一种无监督学习方法?A. 逻辑回归B. 线性判别分析C. 聚类D. 决策树答案: C40. “文本挖掘”通常用于处理什么类型的数据?A. 数值型数据B. 类别数据C. 文本数据D. 时间序列数据答案: C41. 数据挖掘中的“关联分析”用于发现什么之间的关系?A. 数据特征和预测变量之间B. 不同数据库之间C. 数据项之间的频繁模式、关联或相关性D. 模型和算法之间答案: C42. 在数据挖掘中,哪种方法通常用于异常值检测?A. 分类B. 聚类C. 关联规则学习D. 神经网络答案: B43. 数据挖掘中的“Apriori”算法用于解决哪一类问题?A. 分类B. 聚类C. 关联规则挖掘D. 回归分析答案: C44. “数据归约”在数据挖掘中指的是什么?A. 减少数据集的大小,同时尽量保持数据的完整性B. 通过算法提高数据的质量C. 删除数据集中的重复项D. 对数据进行加密保护答案: A45. 在数据挖掘中,什么是“多层感知器”?A. 一种基于规则的分类方法B. 一种数据预处理技术C. 一种基于神经网络的学习算法D. 一种数据可视化工具答案: C46. 下面哪种技术不是用来处理不平衡数据集的?A. 过采样少数类B. 欠采样多数类C. 生成合成样本D. 使用回归分析答案: D47. 在数据挖掘中,“bagging”是用来做什么的?A. 减少模型的偏差B. 增加模型的方差C. 减少模型的方差D. 增加模型的偏差答案: C48. 下面哪个算法适合于大规模数据集?A. 支持向量机B. 朴素贝叶斯C. 线性回归D. K-最近邻答案: B49. “分层聚类”和“K-均值聚类”有什么不同?A. 分层聚类需要预先指定聚类数目B. K-均值聚类是一种分层聚类方法C. 分层聚类不需要预先指定聚类数目D. K-均值聚类可以处理任何形状的数据集答案: C50. 在数据挖掘中,下面哪个是评估聚类质量的指标?A. 准确率B. 召回率C. 轮廓系数D. 均方误差答案: C51. “逻辑回归”通常用于解决哪类数据挖掘问题?A. 聚类B. 分类C. 回归D. 关联规则学习答案: B52. 数据挖掘中的“时间序列分析”通常用于分析什么类型的数据?A. 空间数据B. 文本数据C. 时间相关的数据D. 图像数据答案: C53. 数据挖掘中的“特征工程”包括哪些任务?A. 特征选择、特征提取、特征构造B. 模型选择、模型评估、模型部署C. 数据清洗、数据集成、数据转换D. 模型训练、模型测试、模型优化答案: A54. “随机森林”是什么类型的数据挖掘算法?A. 聚类算法B. 分类和回归算法C. 关联规则挖掘算法D. 异常检测算法答案: B55. 数据挖掘中的“神经网络”可以用于处理哪些问题?A. 仅分类B. 仅回归C. 分类和回归D. 仅聚类答案: C56. 下面哪个不是数据挖掘中的关键挑战?A. 数据质量B. 数据量的大小C. 数据的可视化D. 选择打印机答案: D57. 数据挖掘中的“假设检验”用于什么?A. 验证模型的预测准确性B. 确定数据样本中观察到的模式是否具有统计意义C. 预测未来的数据趋势D. 检测数据集中的异常值答案: B58. 在数据挖掘中,“K-均值聚类”算法的主要缺点是什么?A. 无法处理非线性数据B. 需要预先确定聚类的数量C. 无法处理大规模数据集D. 只能用于二维数据答案: B59. 下面哪个术语描述了一个数据挖掘算法在未见过的数据上的泛化能力?A. 过拟合B. 训练误差C. 模型容量D. 泛化误差答案: D60. 数据挖掘中的“集成方法”通常包括哪些类型?A. Bagging、Boosting和StackingB. 分类、回归和聚类C. 关联、序列模式和预测D. 决策树、神经网络和支持向量机答案: A61. 下面哪个不是在数据挖掘中常用的数据变换技术?A. 平滑B. 聚合C. 泛化D. 分类答案: D62. 在数据挖掘中,如果一个数据集很“稀疏”,这意味着什么?A. 数据集中有很多缺失值B. 数据集非常小C. 数据集分布非常广泛D. 数据点非常接近答案: A63. 数据挖掘中的“朴素贝叶斯”分类器是基于什么原理?A. 支持向量机B. 贝叶斯定理C. 决策树D. 神经网络答案: B64. 下面哪个参数在决策树算法中非常关键?A. 学习率B. 聚类数量C. 树的深度D. 特征数量答案: C65. 数据挖掘中的“支持向量机”算法主要解决什么类型的问题?A. 聚类B. 分类和回归C. 时间序列分析D. 数据预处理答案: B66. 数据挖掘中的“模型选择”是基于什么原则?A. 模型的复杂度B. 训练时间的长短C. 预测的准确性D. 所有上述因素答案: D67. 在数据挖掘中,什么是“抽样”?A. 从一个大的数据集中选出一个代表性的子集B. 收集新的数据点C. 数据的分类D. 数据的排序答案: A68. 数据挖掘中的“关联规则”用于发现数据中的哪种模式?A. 预测模式B. 时间序列模式C. 频繁项集和它们之间的关联D. 回归线答案: C69. 下面哪个是度量分类模型性能的方法?A. 均方误差B. 准确率C. 轮廓系数D. 平均绝对误差答案: B70. 数据挖掘中的“深度学习”通常需要什么?A. 小量的标记数据B. 强大的计算资源C. 一维数据D. 无监督的学习方法答案: B71. 数据挖掘中的“过拟合”通常如何解决?A. 增加更多的数据B. 简化模型C. 增加模型的复杂度D. A和B都是答案: D72. 数据挖掘中的“主成分分析”(PCA)主要用于什么?A. 数据分类B. 降维C. 数据预测D. 数据清洗答案: B73. 在数据挖掘中,哪种算法适合处理文本挖掘?A. K-均值聚类B. 随机森林C. 支持向量机D. 朴素贝叶斯答案: D74. 数据挖掘中的“决策树”通常在哪个阶段剪枝?A. 在构建树的过程中B. 构建树之后C. 选择模型之前D. 在数据预处理阶段答案: B75. 下面哪个不是评价回归模型的指标?A. 均方误差(MSE)B. 决定系数(R²)C. 准确率D. 平均绝对误差(MAE)答案: C76. 在数据挖掘中,什么是“集成学习”?A. 单个模型的学习过程B. 一个学习算法的集合C. 多个模型的组合,用于提高预测性能D. 数据集的集合答案: C77. 数据挖掘中的“神经网络”中的“隐藏层”有什么作用?A. 直接处理输入数据B. 对输入数据进行分类C. 提取输入数据的特征D. 输出预测结果答案: C78. 下面哪个算法是基于树的模型?A. 逻辑回归B. 支持向量机C. 随机森林D. 主成分分析答案: C79. 数据挖掘中的“无监督学习”与“监督学习”有什么不同?A. 无监督学习不需要任何数据B. 监督学习不使用数据标签C. 无监督学习不使用数据标签D. 监督学习用于聚类分析答案: C80. 数据挖掘中,下面哪个方法适合于特征选择?A. 递归特征消除B. K-均值聚类C. 主成分分析D. 线性回归答案: A81. 数据挖掘中的“特征缩放”主要用于什么目的?A. 转换特征到相同的尺度B. 增加数据集的特征数量C. 减少每个特征的值域D. 创建新的特征组合答案: A82. 下面哪个方法通常用于减少一个模型的方差?A. 增加更多特征B. 增加数据点C. 减少模型复杂度D. 进行特征选择答案: B83. 在数据挖掘中,哪种算法可以处理非线性问题?A. 线性回归B. 朴素贝叶斯C. 决策树D. 主成分分析答案: C84. 数据挖掘中的“异常检测”主要用于发现什么?A. 频繁项集B. 数据集中的主要趋势C. 数据中的奇异点D. 数据集中的相关性答案: C85. 在数据挖掘中,“相似性度量”用于什么?A. 比较不同模型的性能B. 确定数据点之间的相似度C. 测量数据集的大小D. 评价算法的运行时间答案: B86. 数据挖掘中的“集群分析”是用来做什么的?A. 预测数据点的类别B. 将数据点分为不同的组C. 分析数据中的基本模式D. 评估分类模型的性能答案: B87. 下面哪个是数据挖掘中的一种预测建模技术?A. K-均值聚类B. Apriori算法C. 线性回归D. 主成分分析答案: C88. 数据挖掘中的“分类器的集成”指的是什么?A. 一个分类器的集合B. 多个分类器的组合用于提高整体性能C. 使用单个分类器进行多次训练D. 集成不同类型的数据挖掘算法答案: B89. 数据挖掘中的“数据压缩”有什么作用?A. 减少数据的存储空间B. 加快算法的运行速度C. 提高数据的质量D. A和B都是答案: D90. 在数据挖掘中,什么是“数据立方体”?A. 数据仓库中的一个三维数据模型B. 一个可视化工具C. 数据挖掘算法的一种D. 用于数据预处理的技术答案: A91. “梯度下降”在数据挖掘中用于什么?A. 数据分类B. 寻找最优的模型参数C. 数据的聚类D. 关联规则的挖掘答案: B92. 在数据挖掘中,“半监督学习”是什么?A. 使用未标记数据进行学习B. 使用一小部分标记数据和大量未标记数据进行学习C. 不使用任何标记数据进行学习D. 仅使用标记数据进行学习答案: B93. 下面哪个是数据挖掘中的一种分类算法?A. 主成分分析B. 决策树C. K-均值聚类D. 均方误差答案: B94. 数据挖掘中的“数据集成”有什么目的?A. 将来自不同源的数据合并在一起B. 分离数据集C. 创建数据的备份D. 增加数据的维度答案: A95. 数据挖掘中的“数据规约”技术包括哪些?A. 数据归一化和标准化B. 数据清洗和数据集成C. 数据压缩和特征提取D. 数据转换和数据平滑答案: C96. 下面哪个概念与“数据挖掘”最不相关?A. 数据可视化B. 大数据C. 数据加密D. 机器学习答案: C97. 数据挖掘中的“数据变换”可能包括哪些操作?A. 平滑、聚合、泛化B. 分类、回归、聚类C. 训练、测试、验证D. 编码、解码、压缩答案: A98. 数据挖掘中的“预处理”是为了什么?A. 提高算法的准确性B. 减少计算时间C. 提高数据的质量D. 所有上述答案: D99. 下面哪个不是数据挖掘中的挑战?A. 数据的多样性B. 数据的质量C. 数据的存储D. 数据的颜色答案: D100. 数据挖掘中的“模型部署”指的是什么?A. 选择合适的模型B. 构建数据挖掘模型C. 在实际环境中实施数据挖掘模型D. 评估数据挖掘模型答案: C101. 在数据挖掘中,“标准化”和“归一化”有什么区别?A. 标准化是缩放到0和1之间,归一化是缩放到特定的平均和标准差B. 标准化是缩放到特定的平均和标准差,归一化是缩放到0和1之间C. 标准化和归一化是同一个概念D. 标准化是数据清洗过程,归一化是数据转换过程答案: B102. 数据挖掘中的“偏差-方差权衡”是什么意思?A. 增加模型的偏差会减少方差B. 减少模型的偏差会增加方差C. 增加模型的方差会减少偏差D. 增加偏差和方差可以提高模型的准确率答案: A103. 下面哪个是时间序列数据挖掘中的一个关键任务?A. 分类B. 聚类C. 预测D. 关联规则挖掘答案: C104. 数据挖掘中的“聚类分析”和“分类”有什么不同?A. 聚类是监督学习,分类是无监督学习B. 聚类和分类都是监督学习C. 聚类是无监督学习,分类是监督学习D. 聚类和分类都是无监督学习答案: C105. 在数据挖掘中,“多维缩放”主要用于什么?A. 降维B. 特征提取C. 数据可视化D. 数据清洗答案: C106. 数据挖掘中的“熵”通常与哪个概念相关?A. 关联规则的强度B. 聚类的紧密度C. 决策树的信息增益D. 回归分析的系数答案: C107. 下面哪个不是构建数据挖掘模型时考虑的因素?A. 数据的质量B. 数据的数量C. 模型的颜色D. 算法的选择答案: C108. 数据挖掘中的“序列模式挖掘”主要用于发现什么?A. 数据中的异常值B. 时间序列数据中的重复模式C. 数据集中的分类标签D. 数据属性之间的相关性答案: B109. 下面哪个技术是处理缺失数据的有效方法?A. 数据删除B. 数据插补C. 数据变换D. A和B都是答案: D110. 数据挖掘中的“关联规则挖掘”用于解决哪类问题?A. 预测问题B. 分类问题C. 聚类问题D. 市场篮子分析答案: D111. 在数据挖掘中,“深度学习”主要用于处理哪种类型的数据?A. 小规模数据集B. 结构化数据集C. 非结构化或半结构化数据集D. 一维数据答案: C112. 下面哪个是度量聚类质量的指标?A. 支持度B. 置信度C. Davies-Bouldin指数D. 平均绝对误差答案: C113. 数据挖掘中的“决策树”用于哪些类型的数据?A. 仅数值型数据B. 仅分类数据C. 数值型和分类数据D. 时间序列数据答案: C114. 数据挖掘中的“神经网络”与“深度学习”有什么关系?A. 完全不相关B. 深度学习是神经网络的一个子集C. 神经网络是深度学习的一个子集D. 完全相同答案: C115. 在数据挖掘中,“梯度提升”算法主要用于什么?A. 数据预处理B. 特征选择C. 预测建模D. 数据可视化答案: C116. 下面哪个算法适用于大规模数据集的分类问题?A. 随机森林B. 支持向量机C. 神经网络D. 逻辑回归答案: A117. 数据挖掘中的“协同过滤”是用于推荐系统的哪个部分?A. 用户界面设计B. 数据存储C. 预测用户偏好D. 数据清洗答案: C118. 在数据挖掘中,什么是“文本挖掘”?A. 从文本数据中提取有用信息的过程B. 创建新文本数据C. 对文本数据进行归类D. 提高文本数据的质量答案: A119. 下面哪个是衡量数据挖掘模型泛化能力的方法?A. 交叉验证B. 决策树C. 特征选择D. 神经网络答案: A120. 数据挖掘中的“支持向量机”主要用于解决什么类型的问题?A. 数据可视化B. 数据预处理C. 分类和回归问题D. 聚类问题答案: C121. 在数据挖掘中,“项集”的概念最常用于哪种分析?A. 聚类分析B. 分类分析C. 关联规则分析D. 回归分析答案: C122. 数据挖掘中的“过采样”和“欠采样”技术用于处理什么问题?A. 缺失数据B. 高维数据C. 不平衡数据集D. 大规模数据集答案: C123. 在数据挖掘中,一条“规则”的“提升度”(lift)指的是什么?A. 规则的支持度与预期支持度的比值B. 规则的支持度与置信度的比值C. 规则的置信度与预期置信度的比值D. 规则的准确率答案: C124. 数据挖掘中的“属性选择”是什么意思?A. 从数据集中选取有用的属性进行分析B. 修改属性的类型C. 删除数据集中的某些属性D. 重命名属性答案: A125. 下面哪个算法是一种基于树的回归方法?A. 线性回归B. 逻辑回归C. 随机森林D. 支持向量机答案: C126. 在数据挖掘中,“模型过度复杂”可能导致什么问题?A. 欠拟合B. 过拟合C. 更快的训练时间D. 更好的用户体验答案: B127. 数据挖掘中的“自编码器”通常用于哪种任务?A. 分类B. 回归C. 数据降维D. 数据增强答案: C128. 在数据挖掘中,“分箱”技术用于什么?A. 数据分类B. 数据聚类C. 将连续变量转换为离散变量D. 预测模型的输出答案: C129. 数据挖掘中的“交叉售卖”是基于哪种分析?A. 聚类分析B. 分类分析C. 关联规则分析D. 时间序列分析答案: C130. 下面哪个是度量模型性能的时间复杂度的方法?A. AUC-ROC曲线B. 计算模型训练时间C. 均方误差D. 准确率答案: B131. 数据挖掘中的“Gini指数”用于评估什么?A. 回归模型的性能B. 关联规则的强度C. 决策树分裂的纯度D. 聚类的质量答案: C132. 在数据挖掘中,什么是“集合外估计”?A. 使用测试集以外的数据评估模型的方法B. 估计模型的准确率C. 使用模型预测集合中没有的数据D. 在数据集之外收集新数据答案: A133. 数据挖掘中的“学习曲线”展示了什么?A. 不同算法的性能比较B. 训练集大小对模型性能的影响C. 特征数量对模型性能的影响D. 不同参数设置对模型性能的影响答案: B134. 下面哪个是数据挖掘中的非线性模型?A. 线性回归B. 朴素贝叶斯C. 决策树D. 线性判别分析答案: C135. 在数据挖掘中,什么是“验证数据集”?A. 用来训练模型的数据集B. 用来测试模型的数据集C. 在模型训练过程中用来调整模型参数的数据集D. 用于最终评估模型性能的数据集答案: C136. 数据挖掘中的“层次聚类”有哪些类型?A. 顺序聚类和并行聚类B. 聚合聚类和分裂聚类C. K-均值聚类和谱聚类D. 监督聚类和无监督聚类答案: B137. 数据挖掘中的“ROC曲线”用于评估哪种类型的模型?A. 聚类模型B. 分类模型C. 回归模型D. 关联规则模型答案: B138. 下面哪个是评估数据挖掘模型“泛化能力”的好方法?A. 增加模型的复杂度B. 减少训练集的大小C. 使用多个测试集D. 使用交叉验证答案: D139. 在数据挖掘中,“强化学习”通常用于解决什么类型的问题?A. 数据分类B. 数据预处理C. 决策过程中的序列化问题D. 数据集成答案: C140. 数据挖掘中的“特征哈希”是用于什么?A. 减少数据的维度B. 加密数据C. 增强数据的特征D. 创建数据的哈希表答案: A141. 数据挖掘中的“时间序列分析”主要用于分析哪种类型的数据?A. 文本数据B. 图像数据C. 音频数据D. 有时间戳的数据答案: D142. 在数据挖掘中,“正则化”用于解决什么问题?A. 缺失数据B. 不平衡数据集C. 过拟合D. 高维数据答案: C143. 下面哪个是数据挖掘中的一种用于减少特征数量的技术?A. 特征增强B. 特征提取C. 特征识别D. 特征映射答案: B144. 数据挖掘中的“聚类”方法通常用于什么?A. 为每个数据点分配一个类别标签B. 预测数值型的目标变量C. 发现数据中的自然分组D. 找出数据中的异常点答案: C145. 数据挖掘中“多元线性回归”主要用于解决什么类型的问题?A. 分类B. 聚类C. 回归D. 关联规则发现答案: C146. 下面哪个是数据挖掘中用于分类任务的算法?A. 主成分分析(PCA)B. K-均值聚类C. 决策树D. 相关系数分析答案: C147. 数据挖掘中的“模型融合”是什么意思?A. 使用不同类型的模型处理不同的数据集B. 将多个模型的预测结果结合起来以改善性能C. 在同一个数据集上训练多个模型D. 合并两个不同的数据集答案: B148. 下面哪个是用于在数据挖掘中评估聚类算法性能的指标?A. 准确率B. 召回率C. Jaccard指数D. F1分数答案: C149. 数据挖掘中的“AdaBoost”算法主要用于什么?A. 数据降维B. 异常检测C. 分类和回归任务D. 关联规则挖掘答案: C150. 在数据挖掘中,“文本预处理”可能包括哪些步骤?A. 词干提取B. 停用词去除C. 词袋模型创建D. 所有上述答案: D151. 数据挖掘中的“特征选择”和“特征提取”有什么区别?A. 特征选择是选择重要的特征,特征提取是创建新的特征B. 特征选择是创建新的特征,特征提取是选择重要的特征C. 它们是同一个概念的不同名称D. 它们都用于降低模型的复杂度答案: A152. 数据挖掘中的“决策边界”是用于哪种类型的任务?A. 聚类。
数据挖掘原理与应用---试题及答案试卷十二答案精选全文完整版

数据挖掘原理与应用 试题及答案试卷一、(30分,总共30题,每题答对得1分,答错得0分)单选题1、在ID3算法中信息增益是指( D )A、信息的溢出程度B、信息的增加效益C、熵增加的程度最大D、熵减少的程度最大2、下面哪种情况不会影响K-means聚类的效果?( B )A、数据点密度分布不均B、数据点呈圆形状分布C、数据中有异常点存在D、数据点呈非凸形状分布3、下列哪个不是数据对象的别名 ( C )A、样品B、实例C、维度D、元组4、人从出生到长大的过程中,是如何认识事物的? ( D )A、聚类过程B、分类过程C、先分类,后聚类D、先聚类,后分类5、决策树模型中应如何妥善处理连续型属性:( C )A、直接忽略B、利用固定阈值进行离散化C、根据信息增益选择阈值进行离散化D、随机选择数据标签发生变化的位置进行离散化6、假定用于分析的数据包含属性age。
数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70。
问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。
第二个箱子值为:( A )A、18.3B、22.6C、26.8D、27.97、建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?( C )A、根据内容检索B、建模描述C、预测建模D、寻找模式和规则8、如果现在需要对一组数据进行样本个体或指标变量按其具有的特性进行分类,寻找合理的度量事物相似性的统计量,应该采取( A )A、聚类分析B、回归分析C、相关分析D、判别分析9、时间序列数据更适合用( A )做数据规约。
A、小波变换B、主成分分析C、决策树D、直方图10、下面哪些场景合适使用PCA?( A )A、降低数据的维度,节约内存和存储空间B、降低数据维度,并作为其它有监督学习的输入C、获得更多的特征D、替代线性回归11、数字图像处理中常使用主成分分析(PCA)来对数据进行降维,下列关于PCA算法错误的是:( C )A、PCA算法是用较少数量的特征对样本进行描述以达到降低特征空间维数的方法;B、PCA本质是KL-变换;C、PCA是最小绝对值误差意义下的最优正交变换;D、PCA算法通过对协方差矩阵做特征分解获得最优投影子空间,来消除模式特征之间的相关性、突出差异性;12、将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?( C )A、频繁模式挖掘B、分类和预测C、数据预处理D、数据流挖掘13、假设使用维数降低作为预处理技术,使用PCA将数据减少到k维度。
数据挖掘练习题附答案

数据挖掘练习题A一、简答题1. 数据对象之间的相似性可用距离来衡量,常见的距离形式有哪些?答:曼哈顿距离,欧几里得距离,切比雪夫距离,闵可夫斯基距离,杰卡德距离2. 简述朴素贝叶斯分类的基本思想。
答:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个概率最大,就认为此待分类项属于哪个类别。
1)设x={a!,a",…,a#}为一个待分类项,a为x的特征属性;2)有类别集合C={y!,y",…,y$}3) 计算p(y!|x),p(y"|x),… p(y$|x)4) 如果p(y%|x)=max {p(y!|x),p(y"|x),…,p(y%|x)},则x∈y%3. 在做数据清洗时,如何处理缺失值?答:处理缺失值的方法有3种:1)忽略元组;2)数据补齐,包括人工填写、特殊值填充、平均值填充、使用最可能的值填充;3)不处理。
4. 简述K-means算法的基本步骤。
答:1)任意选择k个对象作为初始的簇中心;2)计算其它对象与这k个中心的距离,然后把每个对象归入离它“最近”的簇;3)计算各簇中对象的平均值,然后选择簇中心(离平均值“最近”的簇);4)重复第2步到第3步直到簇中心不再变化为止。
5. 在关联规则中,支持度(support)和置信度(confidence)的含义分别是什么?答:支持度support(x->y)=p(x,y),表示项集中同时含有x和y的概率。
置信度confidence(x->y)=p(y/x),表示在关联规则的先决条件x发生的条件下,关联结果y发生的概率,即含有x的项集中,同时含有y的可能性。
二、计算题1.假定属性A的取值x在[x_min,x_max]之间,其中x_min和x_max分别为属性A的最小值和最大值,请利用最小-最大规范化方法(也称离差标准化,是对原始数据的线性变化),将x转化到新的区间[y_min,y_max]中,结果用x’表示。
数据挖掘考试题库及答案

数据挖掘考试题库及答案一、选择题1. 数据挖掘是从大量数据中提取有价值信息的过程,以下哪项不是数据挖掘的主要任务?A. 预测B. 分类C. 聚类D. 数据可视化答案:D2. 以下哪种技术不属于数据挖掘的常用方法?A. 决策树B. 支持向量机C. 关联规则D. 数据仓库答案:D3. 数据挖掘中,以下哪项技术常用于分类和预测?A. 神经网络B. K-均值聚类C. 主成分分析D. 决策树答案:D4. 在数据挖掘中,以下哪个概念表示数据集中的属性?A. 数据项B. 数据记录C. 数据属性D. 数据集答案:C5. 数据挖掘中,以下哪个算法用于求解关联规则?A. Apriori算法B. ID3算法C. K-Means算法D. C4.5算法答案:A二、填空题6. 数据挖掘的目的是从大量数据中提取______信息。
答案:有价值7. 在数据挖掘中,分类任务分为有监督学习和______学习。
答案:无监督8. 决策树是一种用于分类和预测的树形结构,其核心思想是______。
答案:递归划分9. 关联规则挖掘中,支持度表示某个项集在数据集中的出现频率,置信度表示______。
答案:包含项集的记录中同时包含结论的记录的比例10. 数据挖掘中,聚类分析是将数据集划分为若干个______的子集。
答案:相似三、判断题11. 数据挖掘只关注大量数据中的异常值。
()答案:错误12. 数据挖掘是数据仓库的一部分。
()答案:正确13. 决策树算法适用于处理连续属性的分类问题。
()答案:错误14. 数据挖掘中的聚类分析是无监督学习任务。
()答案:正确15. 关联规则挖掘中,支持度越高,关联规则越可靠。
()答案:错误四、简答题16. 简述数据挖掘的主要任务。
答案:数据挖掘的主要任务包括预测、分类、聚类、关联规则挖掘、异常检测等。
17. 简述决策树算法的基本原理。
答案:决策树算法是一种自顶向下的递归划分方法。
它通过选择具有最高信息增益的属性进行划分,将数据集划分为若干个子集,直到满足停止条件。
数据挖掘习题及解答-完美版

Data Mining Take Home Exam学号: xxxx 姓名: xxx 1. (20分)考虑下表的数据集。
(1)计算整个数据集的Gini 指标值。
(2)计算属性性别的Gini 指标值(3)计算使用多路划分属性车型的Gini 指标值 (4)计算使用多路划分属性衬衣尺码的Gini 指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么? 解:(1) Gini=1-(10/20)^2-(10/20)^2=0.5 (2)Gini=[{1-(6/10)^2-(4/10)^2}*1/2]*2=0.48 (3)Gini={1-(1/4)^2-(3/4)^2}*4/20+{1-(8/8)^2-(0/8)^2}*8/20+{1-(1/8)^2-(7/8)^2}*8/2 0=26/160=0.1625(4)Gini={1-(3/5)^2-(2/5)^2}*5/20+{1-(3/7)^2-(4/7)^2}*7/20+[{1-(2/4)^2-(2/4)^2}*4/ 20]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. (20分)考虑下表中的购物篮事务数据集。
(1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(完整word版)数据挖掘题目及答案

(完整word版)数据挖掘题⽬及答案⼀、何为数据仓库?其主要特点是什么?数据仓库与KDD的联系是什么?数据仓库是⼀个⾯向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,⽤于⽀持管理决策。
特点:1、⾯向主题操作型数据库的数据组织⾯向事务处理任务,各个业务系统之间各⾃分离,⽽数据仓库中的数据是按照⼀定的主题域进⾏组织的。
2、集成的数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加⼯、汇总和整理得到的,必须消除源数据中的不⼀致性,以保证数据仓库内的信息是关于整个企业的⼀致的全局信息。
3、相对稳定的数据仓库的数据主要供企业决策分析之⽤,⼀旦某个数据进⼊数据仓库以后,⼀般情况下将被长期保留,也就是数据仓库中⼀般有⼤量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4、反映历史变化数据仓库中的数据通常包含历史信息,系统记录了企业从过去某⼀时点(如开始应⽤数据仓库的时点)到⽬前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
所谓基于数据库的知识发现(KDD)是指从⼤量数据中提取有效的、新颖的、潜在有⽤的、最终可被理解的模式的⾮平凡过程。
数据仓库为KDD提供了数据环境,KDD从数据仓库中提取有效的,可⽤的信息⼆、数据库有4笔交易。
设minsup=60%,minconf=80%。
TID DATE ITEMS_BOUGHTT100 3/5/2009 {A, C, S, L}T200 3/5/2009 {D, A, C, E, B}T300 4/5/2010 {A, B, C}T400 4/5/2010 {C, A, B, E}使⽤Apriori算法找出频繁项集,列出所有关联规则。
解:已知最⼩⽀持度为60%,最⼩置信度为80%1)第⼀步,对事务数据库进⾏⼀次扫描,计算出D中所包含的每个项⽬出现的次数,⽣成候选1-项集的集合C1。
数据挖掘习题及解答-完美版

Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
数据挖掘测试题及答案

数据挖掘测试题及答案一、选择题1. 数据挖掘的目的是:A. 数据清洗B. 数据转换C. 模式发现D. 数据存储答案:C2. 以下哪项不是数据挖掘的常用算法?A. 决策树B. 聚类分析C. 线性回归D. 关联规则答案:C二、填空题1. 数据挖掘中的_________是指在大量数据中发现的有意义的模式。
答案:知识2. 一种常用的数据挖掘技术是_________,它用于发现数据中隐藏的分组。
答案:聚类三、简答题1. 简述数据挖掘与数据分析的区别。
答案:数据挖掘是一种自动或半自动的过程,旨在从大量数据中发现模式和知识。
数据分析通常涉及更具体的查询和问题,使用统计方法来理解数据。
2. 描述什么是关联规则挖掘,并给出一个例子。
答案:关联规则挖掘是一种用于发现变量之间有趣关系的技术,特别是变量之间的频繁模式、关联或相关性。
例如,在市场篮子分析中,关联规则挖掘可以用来发现顾客购买行为中的模式,如“购买面包的顾客中有80%也购买了牛奶”。
四、计算题1. 给定以下数据集,计算支持度和置信度:| 事务ID | 购买的商品 |||-|| 1 | A, B || 2 | A, C || 3 | B, C || 4 | A, B, C || 5 | B, D |(1) 计算项集{A}的支持度。
(2) 计算规则A => B的置信度。
答案:(1) 项集{A}的支持度为4/5,因为A出现在4个事务中。
(2) 规则A => B的置信度为3/4,因为A和B同时出现在3个事务中,而A出现在4个事务中。
五、论述题1. 论述数据挖掘在电子商务中的应用,并给出至少两个具体的例子。
答案:数据挖掘在电子商务中的应用非常广泛,包括:- 客户细分:通过数据挖掘技术,商家可以识别不同的客户群体,为每个群体提供定制化的服务或产品。
- 推荐系统:利用关联规则挖掘,电商平台可以推荐用户可能感兴趣的商品,提高用户满意度和购买率。
- 欺诈检测:通过分析交易模式,数据挖掘可以帮助识别异常行为,预防信用卡欺诈等风险。
数据挖掘测试题及答案

数据挖掘测试题及答案一、单项选择题(每题2分,共10题,共20分)1. 数据挖掘中,用于发现数据集中的关联规则的算法是:A. K-meansB. AprioriC. Naive BayesD. Decision Tree答案:B2. 以下哪个选项不是数据挖掘的步骤之一:A. 数据预处理B. 数据探索C. 数据收集D. 数据分析答案:C3. 在分类问题中,以下哪个算法属于监督学习:A. 聚类B. 决策树C. 关联规则D. 异常检测答案:B4. 数据挖掘中,用于发现数据集中的频繁项集的算法是:A. K-meansB. AprioriC. Naive BayesD. Decision Tree5. 在数据挖掘中,以下哪个选项不是数据预处理的步骤:A. 数据清洗B. 数据集成C. 数据变换D. 数据分类答案:D6. 以下哪个算法主要用于聚类问题:A. K-meansB. AprioriC. Naive BayesD. Decision Tree答案:A7. 在数据挖掘中,以下哪个选项不是数据挖掘的应用领域:A. 市场分析B. 医疗诊断C. 社交网络分析D. 视频游戏开发答案:D8. 以下哪个算法主要用于异常检测:A. K-meansB. AprioriC. Naive BayesD. One-Class SVM答案:D9. 在数据挖掘中,以下哪个选项不是数据挖掘的输出结果:B. 规则C. 趋势D. 软件答案:D10. 以下哪个算法主要用于分类问题:A. K-meansB. AprioriC. Naive BayesD. Decision Tree答案:D二、多项选择题(每题3分,共5题,共15分)1. 数据挖掘中,以下哪些算法可以用于分类问题:A. K-meansB. Decision TreeC. Naive BayesD. Logistic Regression答案:BCD2. 在数据挖掘中,以下哪些步骤属于数据预处理:A. 数据清洗B. 数据集成C. 数据变换D. 数据分类答案:ABC3. 以下哪些算法可以用于聚类问题:A. K-meansB. AprioriC. Hierarchical ClusteringD. DBSCAN答案:ACD4. 在数据挖掘中,以下哪些步骤属于数据探索:A. 数据可视化B. 数据摘要C. 数据分类D. 数据变换答案:AB5. 以下哪些算法可以用于异常检测:A. K-meansB. One-Class SVMC. Isolation ForestD. Apriori答案:BC三、简答题(每题5分,共3题,共15分)1. 简述数据挖掘中关联规则挖掘的主要步骤。
数据挖掘口算练习题及答案2023

数据挖掘口算练习题及答案2023一、单选题(每题2分)1. 数据挖掘是一种从大量数据中提取模式、关系和知识的技术。
以下哪个选项不是数据挖掘的应用领域?A. 金融风险管理B. 医疗诊断C. 网络安全D. 地球科学研究答案:D2. 在数据挖掘任务中,分类是指将样本划分到已知类别中的一种方法。
以下哪种算法不属于分类算法?A. 决策树B. 聚类C. 支持向量机D. 朴素贝叶斯答案:B3. 在数据挖掘中,关联规则是指描述数据项之间的关联关系的一种方法。
以下哪个指标用来衡量关联规则的强度?A. 支持度B. 准确度C. 置信度D. 压缩度答案:C4. 数据挖掘中的聚类算法用于将相似的数据项划分到同一个簇中。
以下哪种算法不属于聚类算法?A. K-meansB. 傅立叶变换C. DBSCAND. 层次聚类答案:B5. 在数据挖掘中,预测建模是指通过已有的数据建立一个模型,用于对未知数据进行预测。
以下哪个算法不适用于预测建模?A. 线性回归B. 决策树C. 马尔可夫链D. 神经网络答案:C二、填空题(每题2分)1. ______是数据挖掘的最基本任务,其目的是发现数据中隐藏的模式和关系。
答案:模式发现2. 负责对数据进行采集、清洗和预处理的环节称为______。
答案:数据预处理3. ______用于评估分类模型的性能,包括准确率、召回率和F1值等指标。
答案:分类效果评估4. 在聚类算法中,用于计算数据项之间相似度的度量称为______。
答案:距离度量5. 在数据挖掘中,用于发现异常和离群点的方法称为______。
答案:异常检测三、解答题1. 请简要说明数据挖掘的主要步骤。
答案:数据挖掘的主要步骤包括数据收集和预处理、数据转换与变换、模型选择和建立、模型评估与优化等环节。
首先,需要采集、清洗和预处理数据,确保数据质量。
然后,对数据进行转换和变换,以适应数据挖掘算法的要求。
接下来,选择适合的模型,并利用已有的数据建立模型。
数据挖掘及应用考试试题及答案

数据挖掘及应用考试试题及答案一、选择题(每题2分,共20分)1. 以下哪项不属于数据挖掘的主要任务?A. 分类B. 聚类C. 关联规则挖掘D. 数据清洗答案:D2. 数据挖掘中,以下哪项技术不属于关联规则挖掘的方法?A. Apriori算法B. FP-growth算法C. ID3算法D. 决策树算法答案:C3. 以下哪个算法不属于聚类算法?A. K-means算法B. DBSCAN算法C. Apriori算法D. 层次聚类算法答案:C4. 数据挖掘中,以下哪个属性类型不适合进行关联规则挖掘?A. 连续型属性B. 离散型属性C. 二进制属性D. 有序属性答案:A5. 数据挖掘中,以下哪个评估指标用于衡量分类模型的性能?A. 准确率B. 精确度C. 召回率D. 所有以上选项答案:D二、填空题(每题3分,共30分)6. 数据挖掘的目的是从大量数据中挖掘出有价值的________和________。
答案:知识;模式7. 数据挖掘的主要任务包括分类、聚类、关联规则挖掘和________。
答案:预测分析8. Apriori算法中,最小支持度(min_support)和最小置信度(min_confidence)是两个重要的参数,它们分别用于控制________和________。
答案:频繁项集;强规则9. 在K-means聚类算法中,聚类结果的好坏取决于________和________。
答案:初始聚类中心;迭代次数10. 数据挖掘中,决策树算法的构建过程主要包括________、________和________三个步骤。
答案:选择最佳分割属性;生成子节点;剪枝三、判断题(每题2分,共20分)11. 数据挖掘是数据库技术的一个延伸,它的目的是从大量数据中提取有价值的信息。
()答案:√12. 数据挖掘过程中,数据清洗是必不可少的步骤,用于提高数据质量。
()答案:√13. 数据挖掘中,分类和聚类是两个不同的任务,分类需要训练集,而聚类不需要。
数据挖掘习题及解答-完美版
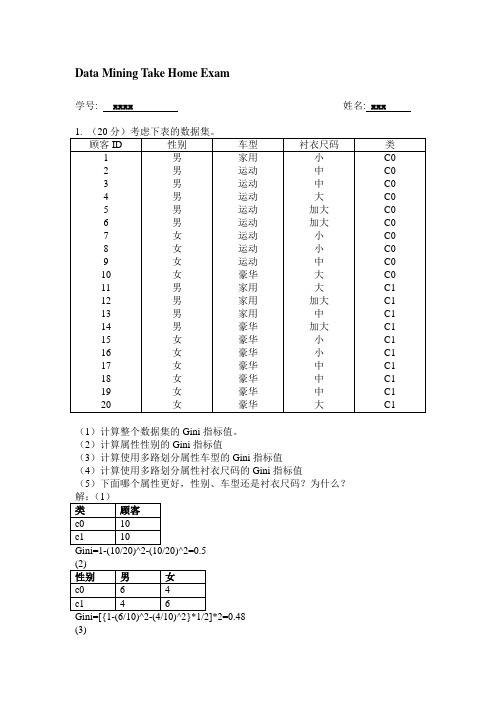
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
数据挖掘期末考试试题及答案详解

数据挖掘期末考试试题及答案详解一、选择题(每题2分,共20分)1. 数据挖掘中,关联规则分析主要用于发现数据中的哪种关系?A. 因果关系B. 相关性C. 聚类关系D. 顺序关系答案:B2. 在决策树算法中,哪个指标用于评估特征的重要性?A. 信息增益B. 支持度C. 置信度D. 覆盖度答案:A3. 以下哪个是数据挖掘的常用方法?A. 线性回归B. 逻辑回归C. 神经网络D. 所有选项答案:D4. K-means聚类算法中,K值的选择是基于什么?A. 数据的维度B. 聚类中心的数量C. 数据的分布情况D. 数据的规模答案:B5. 以下哪个是数据挖掘中常用的数据预处理技术?A. 数据清洗B. 数据转换C. 数据归一化D. 所有选项答案:D...(此处省略其他选择题)二、简答题(每题10分,共30分)1. 简述什么是数据挖掘,并列举其主要的应用领域。
答案:数据挖掘是从大量数据中自动或半自动地发现有趣模式的过程。
它主要应用于市场分析、风险管理、欺诈检测、客户关系管理等领域。
2. 解释什么是朴素贝叶斯分类器,并说明其在数据挖掘中的应用。
答案:朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。
在数据挖掘中,朴素贝叶斯分类器常用于文本分类、垃圾邮件检测等任务。
3. 描述K-means聚类算法的基本原理,并举例说明其在实际问题中的应用。
答案:K-means聚类算法是一种基于距离的聚类方法,其目标是将数据点划分到K个簇中,使得每个数据点与其所属簇的中心点的距离之和最小。
例如,在市场细分中,K-means聚类可以用来将客户根据购买行为划分为不同的群体。
三、计算题(每题25分,共50分)1. 给定一组数据点:{(1,2), (2,3), (3,4), (4,5)},请使用K-means算法将这些点分为两个簇,并计算簇的中心点。
答案:首先随机选择两个点作为初始中心点,然后迭代地将每个点分配到最近的中心点,接着更新中心点。
数据挖掘考试题及答案

数据挖掘考试题及答案一、单项选择题(每题2分,共20分)1. 数据挖掘的主要任务不包括以下哪一项?A. 分类B. 聚类C. 预测D. 数据清洗答案:D2. 以下哪个算法不是用于分类的?A. 决策树B. 支持向量机C. K-meansD. 神经网络答案:C3. 在数据挖掘中,关联规则挖掘主要用于发现以下哪种类型的模式?A. 频繁项集B. 异常检测C. 聚类D. 预测答案:A4. 以下哪个指标用于评估分类模型的性能?A. 准确率B. 召回率C. F1分数D. 以上都是答案:D5. 在数据挖掘中,过拟合是指模型:A. 过于复杂,无法泛化到新数据B. 过于简单,无法捕捉数据的复杂性C. 无法处理缺失值D. 无法处理异常值答案:A6. 以下哪个算法是用于异常检测的?A. AprioriB. K-meansC. DBSCAND. ID3答案:C7. 在数据挖掘中,哪个步骤是用于减少数据集中的噪声和不相关特征?A. 数据预处理B. 数据探索C. 数据转换D. 数据整合答案:A8. 以下哪个是时间序列分析中常用的模型?A. 线性回归B. ARIMAC. 决策树D. 神经网络答案:B9. 在数据挖掘中,哪个算法是用于处理高维数据的?A. 主成分分析(PCA)B. 线性回归C. 逻辑回归D. 随机森林答案:A10. 以下哪个是文本挖掘中常用的技术?A. 词袋模型B. 决策树C. 聚类分析D. 以上都是答案:D二、多项选择题(每题3分,共15分)11. 数据挖掘过程中可能涉及的步骤包括哪些?A. 数据清洗B. 数据转换C. 数据探索D. 模型训练答案:ABCD12. 以下哪些是数据挖掘中常用的数据预处理技术?A. 缺失值处理B. 特征选择C. 特征缩放D. 数据离散化答案:ABCD13. 在数据挖掘中,哪些因素可能导致模型过拟合?A. 训练数据量过少B. 模型过于复杂C. 训练数据噪声过多D. 训练数据不具代表性答案:ABCD14. 以下哪些是评估聚类算法性能的指标?A. 轮廓系数B. 戴维斯-邦丁指数C. 兰德指数D. 互信息答案:ABCD15. 在数据挖掘中,哪些是常用的特征工程方法?A. 特征选择B. 特征提取C. 特征构造D. 特征降维答案:ABCD三、简答题(每题10分,共30分)16. 简述数据挖掘中的“挖掘”过程通常包括哪些步骤。
(完整word版)数据挖掘计算题参考答案

数据仓库与数据挖掘复习题1. 假设数据挖掘的任务是将如下的8个点(用(x,y)代表位置)聚类为3个类:X1(2,10)、X2(2,5)、X3(8,4)、X4(5,8)、X5(7,5)、X6(6,4)、X7(1,2)、X8(4,9),距离选择欧几里德距离。
假设初始选择X1(2,10)、X4(5,8)、X7(1,2)为每个聚类的中心,请用K_means算法来计算:(1)在第一次循环执行后的3个聚类中心;答:第一次迭代:中心点1:X1(2,10),2:X4(5,8),X7(1,2)答案:在第一次循环执行后的3个聚类中心:1:X1(2,10)2:X3,X4,X5,X6,X8 (6,6)3:X2,X7 (1.5,3.5)(2)经过两次循环后,最后的3个族分别是什么?第二次迭代:答案:1:X1,X8 (3.5,9.5)2:X3,X4,X5,X6 (6.5,5.25) 3:X2,X7 (1.5,3.5)2. 数据库有4个事务。
设min_sup=60%,min_conf=80%。
TID data Transaction T100 6/6/2007 K,A,D,B T200 6/6/2007 D,A,C,E,B T300 6/7/2007 C,A,B,E T4006/10/2007B,A,Da.使用Apriori 算法找出频繁项集,并写出具体过程。
答:(a)Apriori 算法:{K} 1 {A} 4 {A,B} 4 {A,B,D} 3{A} 4 {B} 4 {A,D} 3 {B} 4 {D} 3 {B,D} 3 {D} 3 {C} 2 {E} 2频繁项集为3项集{A,B,D}:3b.列出所有的强关联规则,使它们与下面的元规则匹配,其中,X 是代表顾客的变量,i item 是表示项的变量(例如,“A ”、“B ”等):123,(,)(,)(,)x transaction buys X item buys X item buys X item ∀∈∧⇒ [s,c] 答:所有频繁子项集有{A},{B},{D},{A,B},{A,D},{B,D} A^B=>D conf=3/4=75% × A^D=>B conf=3/3=100% √ B^D=>A conf=3/3=100% √ 因此,满足条件的强关联规则有:A^D=>B{supp=75%,conf=100%} B^D=>A{supp=75%,conf=100%}1.给定如下的数据库表:IDSky AirTe Humidi Wind Water Foreca Enjoyspo请计算属性Sky的信息增益。
数据挖掘期末考试计算题及答案

题一:一阶项目集支持度a 5b 4c 2d 5e 3f 4g 6一阶频繁集支持度a 5b 4d 5f 4g 6二阶候选集支持度ab 3ad 4af 2ag 5bd 3bf 1bg 3df 3dg 4fg 3二阶频繁集支持度ad 4ag 5dg 4三阶候选集支持度adg 4三阶频繁集支持度adg 4题二Distance(G,A)2=0.1; Distance(G,B)2=0.03; Distance(G,C)2=0.11 Distance(G,D)2=0.12; Distance(G,E)2=0.16; Distance(G,F)2=0.05 G的三个最近的邻居为B,F,A,因此G的分类为湖泊水Distance(H,A)2=0.03; Distance(H,B)2=0.18; Distance(H,C)2=0.22Distance(H,D)2=0.03; Distance(H,E)2=0.21; Distance(H,F)2=0.16 H的三个最近的邻居为A,D,F,因此H的分类为冰川水题三首先计算各属性的信息增益Gain(Ca+浓度)=0Gain(Mg+浓度)=0.185Gain(Na+浓度)=0Gain(Cl-浓度)=0.32选择Cl-浓度作为根节点计算各属性的信息增益Gain(Ca+浓度)=0 Gain(Mg+浓度)=0.45 Gain(Na+浓度)=0.24 选择Mg+浓度作为节点Cl-浓度冰川水?高低Cl-浓度冰川水Mg+浓度高低高低湖泊水计算各属性的信息增益Gain(Ca+浓度)=0.24Gain(Na+浓度)=0.91Cl-浓度高低冰川水Mg+浓度高低Na+浓度湖泊水高低湖泊水冰川水题四P(Ca+浓度=低,Mg+浓度=高,Na+浓度=高,Cl-浓度=低| 类型=冰川水)*P(冰川水)=P(Ca+浓度=低| 类型=冰川水)* P(Mg+浓度=高| 类型=冰川水)* P(Na+浓度=高| 类型=冰川水)* P(Cl-浓度=低| 类型=冰川水) *P(冰川水)=0.5*0.75*0.5*0.5*0.5=0.0468P(Ca+浓度=低,Mg+浓度=高,Na+浓度=高,Cl-浓度=低| 类型=湖泊水)*P(湖泊水)=P(Ca+浓度=低| 类型=湖泊水)* P(Mg+浓度=高| 类型=湖泊水)* P(Na+浓度=高| 类型=湖泊水)* P(Cl-浓度=低| 类型=湖泊水) *P(湖泊水)=0.5*0.25*0.5*1*0.5=0.03123第一个样本为冰川水P(Ca+浓度=高,Mg+浓度=高,Na+浓度=低,Cl-浓度=高| 类型=冰川水)*P(冰川水)=P(Ca+浓度=高| 类型=冰川水)* P(Mg+浓度=高| 类型=冰川水)* P(Na+浓度=低| 类型=冰川水)* P(Cl-浓度=高| 类型=冰川水) *P(冰川水)=0.5*0.75*0.5*0.5*0.5=0.0468P(Ca+浓度=高,Mg+浓度=高,Na+浓度=低,Cl-浓度=高| 类型=湖泊水)*P(湖泊水)=P(Ca+浓度=高| 类型=湖泊水)* P(Mg+浓度=高| 类型=湖泊水)* P(Na+浓度=低| 类型=湖泊水)* P(Cl-浓度=高| 类型=湖泊水) *P(湖泊水)=0.5*0.25*0.5*0*0.5=0第二个样本为冰川水题五A,B,C,D,E,F,G之间的距离矩阵如下表A B C D E F G AB 1C 25D 415045E 5.425.505.485.0F 25.2825.3625.3125.1 1.5G 686590455.362546.根据距离矩阵建立的树如下题六第一次迭代以A ,B 作为平均点,对剩余的点根据到A 、B 的距离进行分配{A,C,D,E,F,G,H}, {B} 计算两个簇的平均点(6.5, 1.7), (4, 5)第二次迭代,对剩余的点根据到平均点的距离进行分配,得到两个簇{D,E,F,H}和{A,B,C,G} 计算两个簇的平均点BC D AEFG(9.1, 0.5), (3.25, 3.75)第三次迭代,对剩余的点根据到平均点的距离进行分配,得到两个簇{D,E,F,H}和{A,B,C,G}由于所分配的簇没有发生变化,算法终止。
数据挖掘试题及答案

数据挖掘试题及答案### 数据挖掘试题及答案#### 一、选择题1. 数据挖掘的最终目标是什么?- A. 数据清洗- B. 数据集成- C. 数据分析- D. 发现知识答案:D2. 以下哪个算法不属于聚类算法?- A. K-means- B. DBSCAN- C. Apriori- D. Hierarchical Clustering答案:C3. 在数据挖掘中,关联规则挖掘主要用于发现什么? - A. 异常值- B. 频繁项集- C. 趋势- D. 聚类答案:B4. 决策树算法中的剪枝操作是为了解决什么问题?- A. 过拟合- B. 欠拟合- C. 数据不平衡- D. 特征选择答案:A5. 以下哪个是时间序列分析的常用方法?- A. 逻辑回归- B. 线性回归- C. ARIMA模型- D. 支持向量机答案:C#### 二、简答题1. 简述数据挖掘中的分类和聚类的区别。
答案:分类是监督学习过程,它使用标记的训练数据来预测数据的类别。
聚类是无监督学习过程,它将数据分组,使得同一组内的数据点相似度较高,不同组之间的数据点相似度较低。
2. 解释什么是异常检测,并给出一个实际应用的例子。
答案:异常检测是一种识别数据集中异常或不寻常模式的方法。
它通常用于识别欺诈行为、网络安全问题或机械故障。
例如,在信用卡交易中,异常检测可以用来识别潜在的欺诈行为。
3. 描述决策树的工作原理。
答案:决策树通过一系列的问题(通常是二元问题)来对数据进行分类。
从根节点开始,数据被分割成不同的子集,然后每个子集继续被分割,直到达到叶节点,叶节点代表最终的分类结果。
#### 三、应用题1. 给定一组客户数据,包括年龄、收入和购买历史。
使用数据挖掘技术来识别哪些客户更有可能购买新产品。
答案:可以使用决策树或逻辑回归等分类算法来分析客户数据,识别影响购买行为的关键特征。
通过训练模型,可以预测哪些客户更有可能购买新产品。
2. 描述如何使用关联规则挖掘来发现超市中商品的购买模式。
数据挖掘期末试题及答案

数据挖掘期末试题及答案一、选择题(每题2分,共20分)1. 数据挖掘中,以下哪个算法是用于分类的?A. AprioriB. K-meansC. KNND. ID32. 以下哪个不是数据挖掘的步骤?A. 数据预处理B. 数据集成C. 数据可视化D. 数据存储3. 在关联规则挖掘中,支持度(Support)是指什么?A. 规则出现的频率B. 规则的可信度C. 规则的覆盖范围D. 规则的强度4. 以下哪个是聚类算法?A. Logistic RegressionB. Decision TreeC. Naive BayesD. Hierarchical Clustering5. 数据挖掘中,特征选择的目的是什么?A. 增加数据量B. 减少数据量C. 增加模型复杂度D. 减少模型复杂度二、简答题(每题10分,共30分)1. 请简述数据挖掘中过拟合的概念及其预防方法。
2. 解释什么是决策树,并说明其在数据挖掘中的应用。
3. 描述数据预处理的重要性及其主要步骤。
三、应用题(每题25分,共50分)1. 假设你有一个包含客户购买历史的数据集,描述如何使用数据挖掘技术来发现潜在的购买模式。
2. 给出一个实际例子,说明如何使用关联规则挖掘来提高零售业的销售效率。
四、案例分析(共30分)1. 阅读以下案例描述,并分析使用数据挖掘技术解决该问题的优势和可能遇到的挑战。
案例描述:一家电子商务公司想要通过分析用户浏览和购买行为来优化其推荐系统。
公司收集了大量用户数据,包括浏览历史、购买记录、用户评分和反馈。
答案:一、选择题1. D2. D3. A4. D5. D二、简答题1. 过拟合是指模型在训练数据上表现良好,但在新的、未见过的数据上表现差的现象。
预防过拟合的方法包括:使用交叉验证、正则化技术、减少模型复杂度等。
2. 决策树是一种监督学习算法,用于分类和回归任务。
它通过一系列的问题将数据分割成不同的子集,直到达到一个纯度的节点,即决策点。
数据挖掘期末考试题及答案

数据挖掘期末考试题及答案一、选择题(每题2分,共20分)1. 数据挖掘中的关联规则挖掘主要用来发现数据项之间的什么关系?A. 因果关系B. 相关性C. 线性关系D. 依赖关系答案:B2. 决策树算法中,哪个指标用于选择分裂节点?A. 信息增益B. 支持度C. 置信度D. 精确度答案:A3. 聚类分析中,K-means算法的K值表示什么?A. 聚类中心的数量B. 聚类半径C. 聚类成员的最小数量D. 聚类成员的最大数量答案:A4. 在数据挖掘中,哪个算法常用于分类问题?A. Apriori算法B. K-means算法C. KNN算法D. ID3算法答案:C5. 数据挖掘中的异常检测通常用于哪些领域?A. 市场分析B. 客户细分C. 欺诈检测D. 趋势预测答案:C6. 朴素贝叶斯分类器属于哪种类型的学习算法?A. 监督学习B. 非监督学习C. 半监督学习D. 强化学习答案:A7. 在关联规则挖掘中,支持度是指什么?A. 规则出现的频率B. 规则的置信度C. 规则的覆盖度D. 规则的强度答案:A8. 神经网络在数据挖掘中通常用于解决什么问题?A. 聚类B. 分类C. 回归D. 所有上述问题答案:D9. 哪个算法是数据挖掘中用于特征选择的算法?A. 主成分分析(PCA)B. 线性判别分析(LDA)C. 独立成分分析(ICA)D. 随机森林答案:D10. 数据挖掘中的时间序列分析通常用于哪些领域?A. 股票市场预测B. 销售预测C. 天气预报D. 所有上述领域答案:D二、简答题(每题10分,共30分)1. 简述数据挖掘中的主要任务有哪些?答案:数据挖掘的主要任务包括分类、聚类、关联规则挖掘、异常检测、趋势预测等。
2. 描述决策树算法的基本原理。
答案:决策树算法是一种监督学习算法,它通过从数据特征中选择最优特征来构建决策树,从而实现对数据的分类或回归。
算法通过递归地选择最优分裂节点,构建树状结构,直到满足停止条件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据仓库与数据挖掘复习题
1. 假设数据挖掘的任务是将如下的8个点(用(x,y)代表位置)聚类为3个类:X1(2,10)、X2(2,5)、X3(8,4)、X4(5,8)、X5(7,5)、X6(6,4)、X7(1,2)、X8(4,9),距离选择欧几里德距离。
假设初始选择X1(2,10)、X4(5,8)、X7(1,2)为每个聚类的中心,请用 K_means算法来计算:
(1)在第一次循环执行后的3个聚类中心;
答:第一次迭代:中心点1:X1(2,10),2:X4(5,8),X7(1,2)
答案:在第一次循环执行后的3个聚类中心:
1:X1(2,10)
2:X3,X4,X5,X6,X8 (6,6)
3:X2,X7 (,)
(2)经过两次循环后,最后的3个族分别是什么?
答案:1:X1,X8 ,
2:X3,X4,X5,X6 (,)
3:X2,X7 (,)
a.使用Apriori算法找出频繁项集,并写出具体过程。
答:
(a)Apriori算法:
{K} 1 {A} 4 {A,B} 4 {A,B,D} 3
{A} 4 {B} 4 {A,D} 3 {B} 4 {D} 3 {B,D} 3 {D} 3 {C} 2 {E} 2
频繁项集为3项集{A,B,D}:3
b.列出所有的强关联规则,使它们与下面的元规则匹配,其中,X 是代表顾客的变量,i item 是表示项的变量(例如,“A ”、“B ”等):
123,(,)(,)(,)x transaction buys X item buys X item buys X item ∀∈∧⇒ [s,c] 答:所有频繁子项集有{A},{B},{D},{A,B},{A,D},{B,D} A^B=>D conf=3/4=75% × A^D=>B conf=3/3=100% √ B^D=>A conf=3/3=100% √ 因此,满足条件的强关联规则有:
A^D=>B{supp=75%,conf=100%} B^D=>A{supp=75%,conf=100%}
ID
Sky AirTemp Humidity Wind Water Forecast Enjoysport 1 Sunny Warm Normal Strong Warm Same Yes 2 Sunny Warm High Strong Warm Same Yes 3 Rainy
Cold
High
Strong Warm
Change No
4
Sunny Warm High Strong
Cool Change
yes
请计算属性Sky 的信息增益。
答:
C1 :Enjoysport=yes=3 C2 :Enjoysport=no=1
2 2 1/4=
sky C1 C2 rainy 0 1 sunny
3
I(sky)=1/4I(0,1)+3/4I(3,0)=0 Gain(sky)= 习题:
1. 以汽车保险为例:假定训练数据库具有两个属性:年龄和汽车类型。
年龄————序数属性 汽车类型——分类属性
年龄
汽车类型
类
>21Maruti L
>21Hyundai H
<21Maruti H
<21Indica H
>21Maruti L
>21Hyundai H 使用ID3算法得到一个决策树。
2.下面是一个超市某商品连续24个月的销售数据(单位:百万元):
21,16,21, 19, 24, 27, 23, 22, 21, 20, 17, 16, 20, 23, 22, 18, 24, 26, 25, 20, 26, 23, 21, 15, 17。
请使用等深、等宽和自定义区间的方法对数据进行分箱,做出利用各种分箱方法得到的直方图。
3.数据库有4 个事务。
设min_sup = 60%,min_conf = 80%。
使用
Apriori 算法找出所有的频繁项集,并针对每个频繁项集构造强关联规则,列出每个规则的支持度和置信度。
答:
(b)Apriori算法:
{K} 1 {A} 4 {A,B} 4 {A,B,D} 3
{A} 4 {B} 4 {A,D} 3
{B} 4 {D} 3 {B,D} 3
{D} 3
{C} 2
{E} 2
频繁项集为3项集{A,B,D}:3
所有频繁子项集有{A},{B},{D},{A,B},{A,D},{B,D}
A^B=>D conf=3/4=75% ×
A^D=>B conf=3/3=100% √
B^D=>A conf=3/3=100% √
因此,满足条件的强关联规则有:
A^D=>B{supp=75%,conf=100%} B^D=>A{supp=75%,conf=100%}。