多元回归分析作业(北航)
多元线性回归模型练习题及答案.doc

ESS&i-k)ARSS[(k -1) ESS /(SI)I). TSS/(n-k)多元线性回归模型练习一、单项选择题1. 在由〃 =30的一组样本估计的、包含3个解释变量的线性回归模型中,计算 得可决系数为0.8500,则调整后的可决系数为(D )A. 0. 8603B. 0. 8389C. 0. 8655D. 0. 83272. 用一组有30个观测值的样本估计模型乂 =如玷气+E +0后,在0. 05的 显著性水平上对九的显著性作「检验,则气显著地不等于零的条件是其统计量, 大于等于(C )A. ,O .O 5(3°) B . ‘。
025(28) c.,。
25(27) p ^*0.025 (^28) 3•线性回归模型乂 =4+"1也+勾% +……+ b k x h +ui 中,检验 =0(,= 0,1,2,..人)时,所用的统计量服从(C ) A. t (n _k+l )B. t (n -k -2)C. t (n -k _l )D. t (n -k+2)4.调整的可决系数与多元样本判定系数R ,之间有如下关系( D ) 局=公—/?2职=]_qj R2 A.n-k -1 B ・ n-k-\ R 2=[—- (1 + R2)斤 2 =]— (I-/?2) C. n-k-\D. n-k-\ 5. 对模型Y L B 。
+ B 伏"B 2X 2i + u 「进行总体显著性F 检验,检验的零假设是(A ) A. P 1= 3 2=0 B. 3 i=0 C. B 2-O D. B 0二0 或 B i=06. 设k 为[q 归模型中的参数个数,n 为样本容量。
则对多元线性同归方程进行 显著性检验时,所用的F 统计量可表示为(B )R2/ k B (1-R2)/(D b/d)c. (1-R2)/(S1) 7. 多元线性问归分析中(回归模型中的参数个数为k ),调整后的可决系数与 可决系数R2之间的关系(A )点=1_(1_&2)土AD. 〃-18. 巳知五元线性回归模型估计的残差平方和为1>;=800,样本容量为46,则 随机误差项S 的方差估计量罗为(DA. 33. 33B. 40 9. 多元线性P1归分析中的ESS 反映了 A.因变量观测值总变差的大小小C,因变量观测值与估计值之间的总变差C.点 >0 C.( 38. 09 C )B.因变量回归仙•计值总变差的大D. 20 D.Y 关于X 的边际变化A.B. R 2^R 223.在古典假设成立的条件下用0LS 方法估计线性回归模型参数,则参数估计 量具有(C )的统计性质。
北航数理统计回归分析大作业

应用数理统计第一次大作业学号:姓名:班级:2013年12月国家财政收入的多元线性回归模型摘 要本文以多元线性回归为出发点,选取我国自1990至2008年连续19年的财政收入为因变量,初步选取了7个影响因素,并利用统计软件PASW Statistics 17.0对各影响因素进行了筛选,最终确定了能反映财政收入与各因素之间关系的“最优”回归方程:46ˆ578.4790.1990.733yx x =++ 从而得出了结论,最后我们用2009年的数据进行了验证,得出的结果在误差范围内,表明这个模型可以正确反映影响财政收入的各因素的情况。
关键词:多元线性回归,逐步回归法,财政收入,SPSS0符号说明变 量 符号 财政收入 Y 工 业 X 1 农 业 X 2 受灾面积 X 3 建 筑 业 X 4 人 口 X 5 商品销售额X 6进出口总额X71 引言中国作为世界第一大发展中国家,要实现中华民族的伟大复兴,必须把发展放在第一位。
近年来,随着国家经济水平的飞速进步,人民生活水平日益提高,综合国力日渐强大。
经济上的飞速发展并带动了国家财政收入的飞速增加,国家财政的状况对整个社会的发展影响巨大。
政府有了强有力的财政保证才能够对全局进行把握和调控,对于整个国家和社会的健康快速发展有着重要的意义。
所以对国家财政的收入状况进行研究是十分必要的。
国家财政收入的增长,宏观上必然与整个国家的经济有着必然的关系,但是具体到各个方面的影响因素又有着十分复杂的相关原因。
为了研究影响国家财政收入的因素,我们就很有必要对其财政收入和影响财政收入的因素作必要的认识,如果能对他们之间的关系作一下回归,并利用我们所知道的数据建立起回归模型这对我们很有作用。
而影响财政收入的因素有很多,如人口状况、引进的外资总额,第一产业的发展情况,第二产业的发展情况,第三产业的发展情况等等。
本文从国家统计信息网上选取了1990-2009年这20年间的年度财政收入及主要影响因素的数据,包括工业,农业,建筑业,批发和零售贸易餐饮业,人口总数等。
北航应用数理统计大作业多元线性回归

多元线性回归分析摘要:本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造线性回归模型。
并对模型的回归显著性、拟合度、正态分布等分别进行检验,最终得到最优线性回归模型,寻找影响居民消费的各个因素。
关键字:回归分析;线性;相关系数;正态分布1. 引言变量与变量之间的关系分为确定性关系和非确定性关系,函数表达确定性关系。
研究变量间的非确定性关系,构造变量间经验公式的数理统计方法称为回归分析。
回归分析是指通过提供变量之间的数学表达式来定量描述变量间相关关系的数学过程,这一数学表达式通常称为经验公式。
一方面,研究者可以利用概率统计知识,对这个经验公式的有效性进行判定;另一方面,研究者可以利用经验公式,根据自变量的取值预测因变量的取值。
如果是多个因素作为自变量的时候,还可以通过因素分析,找出哪些自变量对因变量的影响是显著的,哪些是不显著的。
回归分析目前在生物统计、医学统计、经济分析、数据挖掘中得到了广泛的应用。
通过对训练数据进行回归分析得出经验公式,利用经验公式就可以在已知自变量的情况下预测因变量的取值。
实际问题的控制中往往是根据预测结果来进行的,如在商品流通领域,通常用回归分析商品价和与商品需求之间的关系,以便对商品的价格和需求量进行控制。
本文查找2011年《中国统计年鉴》,取我国31个省市自治区直辖市2010年的数据,利用SPSS软件对影响居民消费的因素进行讨论构造多元线性线性回归模型。
以探求影响居民消费水平的各个因素,得到最优线性回归模型。
随后,我们对模型的回归显著性、拟合度、正态分布等分别进行检验,以考察线性回归模型的可信度。
本文将分为5章进行论述。
在第2章,我们介绍多元线性回归模型的概念。
第3章,我们进行模型的建立与数据的收集和整理。
我们在第4章对数据进行处理,得出多元线性回归模型,并对其进行检验。
在第5章,我们进行总结。
2016年秋北航《计量经济学》在线作业2100分答案

北航《计量经济学》在线作业2一、单选题(共 10 道试题,共 30 分。
)1. 在多元线性回归模型中对样本容量的基本要求是(k 为解释变量个数):()A. n≥k+1B. n<k+1C. n≥30或n≥3(k+1)D. n≥30正确答案:C2. 横截面数据是指()。
A. 同一时点上不同统计单位相同统计指标组成的数据B. 同一时点上相同统计单位相同统计指标组成的数据C. 同一时点上相同统计单位不同统计指标组成的数据D. 同一时点上不同统计单位不同统计指标组成的数据正确答案:A3.在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( )A. 异方差性B. 序列相关C. 多重共线性D. 高拟合优度正确答案:C4. 根据决定系数R2与F统计量的关系可知,当R2=1时,有()。
A. F=1B. F=-1C. F=0D. F=∞正确答案:D5. 计量经济模型的基本应用领域有()。
A. 结构分析、经济预测、政策评价B. 弹性分析、乘数分析、政策模拟C. 消费需求分析、生产技术分析、D. 季度分析、年度分析、中长期分析正确答案:A6. 变量之间的关系可以分为两大类,它们是()。
A. 函数关系与相关关系B. 线性相关关系和非线性相关关系C. 正相关关系和负相关关系D. 简单相关关系和复杂相关关系正确答案:A7. 经济计量分析的工作程序()A. 设定模型,检验模型,估计模型,改进模型B. 设定模型,估计参数,检验模型,应用模型C. 估计模型,应用模型,检验模型,改进模型D. 搜集资料,设定模型,估计参数,应用模型正确答案:B8. 样本数据的质量问题,可以概括为完整性、准确性、可比性和()。
A. 时效性B. 一致性C. 广泛性D. 系统性正确答案:B9. 外生变量和滞后变量统称为()。
A. 控制变量B. 解释变量C. 被解释变量D. 前定变量正确答案:D10.加权最小二乘法克服异方差的主要原理是通过赋予不同观测点以不同的权数,从而提高估计精度,即()A. 重视大误差的作用,轻视小误差的作用B. 重视小误差的作用,轻视大误差的作用C. 重视小误差和大误差的作用D. 轻视小误差和大误差的作用正确答案:B北航《计量经济学》在线作业2二、多选题(共 10 道试题,共 40 分。
多元回归分析练习(1016)1、考虑以下方程(括号内为标准差):(0080

多元回归分析练习(10.16)1、考虑以下方程(括号内为标准差):1ˆ8.5620.3640.004 2.560t t t tW P P U -=++- (0.080) (0.072) (0.658) 19=n 873.02=R其中:t W ——t 年的每位雇员的工资t P ——t 年的物价水平 t U ——t 年的失业率要求:(1)进行变量显著性检验;(2)对本模型的正确性进行讨论,1-t P 是否应从方程中删除?为什么?2、以企业研发支出(R&D )占销售额的比重为被解释变量(Y ),以企业销售额(X 1)与利润占销售额的比重(X 2)为解释变量,一个容量为32的样本企业的估计结果如下:1220.4720.32ln 0.05(1.37)(0.22)(0.046)0.099i i iY X X R =++=其中,括号中的数据为参数估计值的标准差。
(1)解释ln(X 1)的参数。
如果X 1增长10%,估计Y 会变化多少个百分点?这在经济上是一个很大的影响吗?(2)检验R&D 强度不随销售额的变化而变化的假设。
分别在5%和10%的显著性水平上进行这个检验。
(3)利润占销售额的比重X 2对R&D 强度Y 是否在统计上有显著的影响?3求:(1)样本容量是多少?RSS是多少?ESS和RSS的自由度各是多少?R和2R?(2)2(3)检验假设:解释变量总体上对Y无影响。
你用什么假设检验?为什么?(4)根据以上信息,你能确定解释变量各自对Y的贡献吗?4、在经典线性回归模型的基本假定下,对含有三个自变量的多元线性回归模型:0112233i i i i i Y X X X ββββμ=++++你想检验的虚拟假设是0H :1221=-ββ。
(1)用21ˆ,ˆββ的方差及其协方差求出)ˆ2ˆ(21ββ-Var 。
(2)写出检验H 0:1221=-ββ的t 统计量。
(3)如果定义θββ=-212,写出一个涉及β0、θ、β2和β3的回归方程,以便能直接得到θ估计值θˆ及其样本标准差。
计量经济学多元线性回归模型(老师作业要求范本)范文

计量经济学·多元线性回归模型应用作业一、概述在当今市场上,一国的原油产量与多个因素存在着紧密的联系,例如民用汽车拥有量、宏观经济等都是影响一国原油产量的重要因素。
本次将以中国1990-2006年原油产量与国内民用汽车拥有量、GDP等因素的数据,通过建立计量经济模型来分析上述变量之间的关系,强调的重要性,从而促进国内原油产业的发展。
二、模型构建过程⒈变量的定义解释变量:X1民用汽车拥有量,X2电力产量,X3国内生产总值,X4能源消费总量。
被解释变量:Y 原油产量建立计量经济模型:解释原油产量与民用汽车拥有量、电力产量、国内生产总值、以及能源消费总量之间的关系。
⒉模型的数学形式设定原油产量与五个解释变量相关关系模型,样本回归模型为:∧Y i=∧β+∧β1X i1+∧β2X i2+∧β3X i3+∧β4X i4+e i⒊数据的收集该模型的构建过程中共有四个变量,分别是中国从1990-2006年民用汽车拥有量、电力产量、国内生产总值以及能源消费总量,因此为时间序列数据,最后一个即2006年的数据作为预测对比数据,收集的数据如下所示:⒋用OLS法估计模型回归结果,散点图分别如下:Y=20425.46-2.1872X1-0.1981X2+0.0823X3+0.0011X4 id.f.=12 ,R 2=0.9933 ,Se=(531.1592) (0.4879) (0.1123) (0.0082) (0.0057) t=(38.4545) (-4.4825) (-1.7635) (10.0106) (0.1998)三、 模型的检验及结果的解释、评价⒉拟合优度检验及统计检验R 2=0.9933,可以看到模型的拟合优度非常高,说明原油产量与上述四个解释变量之间总体线性关系显著。
● 模型总体性检验(F 检验):给定显著水平α=0.05,查自由度为(4,12)的F 分布表,得F(4,12)=3.26,可见该模型的F 值远大于临界值,因此该回归方程很明显是显著的。
第三章 多元线性回归模型案例及作业

1. 表1列出了中国2000年按行业分的全部制造业国有企业及规模以上制造业非国有企业的工业总产值Y ,资产合计K 及职工人数L 。
序号 工业总产值Y/亿元资产合计K/亿元职工人数L/万人序号 工业总产值Y/亿元资产合计K/亿元职工人数L/万人1 3722.700 3078.220 113.0000 17 812.7000 1118.810 43.000002 1442.520 1684.430 67.00000 18 1899.700 2052.160 61.000003 1752.370 2742.770 84.00000 19 3692.850 6113.110 240.00004 1451.290 1973.820 27.00000 20 4732.900 9228.250 222.00005 5149.300 5917.010 327.0000 21 2180.230 2866.650 80.000006 2291.160 1758.770 120.0000 22 2539.760 2545.630 96.000007 1345.170 939.1000 58.00000 23 3046.950 4787.900 222.00008 656.7700 694.9400 31.00000 24 2192.630 3255.290 163.00009 370.1800 363.4800 16.00000 25 5364.830 8129.680 244.0000 10 1590.360 2511.990 66.00000 26 4834.680 5260.200 145.0000 11 616.7100 973.7300 58.00000 27 7549.580 7518.790 138.0000 12 617.9400 516.0100 28.00000 28 867.9100 984.5200 46.00000 13 4429.190 3785.910 61.00000 29 4611.390 18626.94 218.0000 14 5749.020 8688.030 254.0000 30 170.3000 610.9100 19.00000 15 1781.370 2798.900 83.00000 31325.5300 1523.190 45.00000161243.070 1808.440 33.00000设定模型为:Y AK L e αβμ=(1) 利用上述资料,进行回归分析;(2) 回答:中国2000年的制造业总体呈现规模报酬不变状态吗? 将模型进行双对数变换如下:ln ln ln ln Y A K L αβμ=+++1)进行回归分析:得到如下回归结果:于是,样本回归方程为:ˆ=++Y K Lln 1.1540.609ln0.361ln(1.59) (3.45) (1.79)20.8099,0.7963,59.66===R R F从回归结果可以看出,模型的拟合度较好,在显著性水平0.1的条件下,各项系数均通过了t检验。
多元回归作业答案

11.2、SUMMARY OUTPUT回归统计 Multiple R 0.995651 R Square 0.991321 Adjusted R Square 0.986982 标准误差 261.431观测值 7方差分析 dfSS MS F SignificanceF 回归分析 2 31226615 15613308 228.4445 7.53E-05残差 4 273384.7 68346.19 总计 6 31500000Coefficients标准误差 t Stat P-value Lower 95% Upper 95% Intercept -0.591 505.0042 -0.00117 0.999122 -1402.71 1401.526 X Variable 1 22.38646 9.600544 2.331791 0.080095 -4.26892 49.04184 X Variable 2327.6717 98.79792 3.316585 0.029472 53.3647 601.9787(1)回归方程为:120.59122.386327.672y x x =-++(在α=0.05时,常数项和x 1的t-检验值没过)(2)b 1表示降雨量每增加1mm ,早稻的平均收获量将增加22.386kg/hm 2;b 2表示温度没升高1。
C ,早稻的平均收获量将增加327.672kg/hm 2。
(3)模型中存在多重共线性。
(R 2值很高,F 检验通过,常数项和x 1的t-检验值没过,也可以通过计算其自变量之间相关系数)11.3、SUMMARY OUTPUT回归统计 Multiple R 0.947362R Square 0.897496Adjusted R Square 0.878276标准误差 791.6823观测值 20方差分析dfSS MS F SignificanceF回归分析 3 87803505 29267835 46.69697 3.88E-08残差 16 10028175 626760.9总计 19 97831680Coefficients标准误差 t Stat P-value Lower 95% Upper 95% Intercept 148.7005 574.4213 0.25887 0.799036 -1069.02 1366.419 X Variable 1 0.814738 0.511989 1.591321 0.131099 -0.27063 1.900105 X Variable 2 0.82098 0.211177 3.887646 0.001307 0.373305 1.268654 X Variable 30.1350410.0658632.0503220.057088 -0.00458 0.274665(1) 回归方程为:123148.7010.8150.8210.135y x x x =+++(2) 在总变差中,被估计的回归方程所解释的比例:20.897SSRR SSE== (3) F 检验值为46.697>>5,线性关系显著;(4) 当α=0.05时,X 1、X 3解释作用均不显著, X 2解释作用显著。
北航数理统计大作业

北航数理统计大作业(逐步回归)(总14页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--应用数理统计第一次大作业学号:姓名:班级: B11班2015年12月民航客运量的多元线性回归分析摘要:本文为建立以民航客运量为因变量的多元线性回归模型,选取了1996年至2013年的统计数据,包含国民生产总值,民航航线里程,过夜入境旅游人数,城镇居民可支配收入等因素,利用统计软件SPSS对各因素进行了筛选分析,采用逐步回归法得到最优多元线性回归模型,并对模型的回归显著性、拟合度以及随机误差的正态性进行了检验,并采用2014年的数据进行检验,得到的结果达到预期,证明该模型建立是较为成功的。
关键词:多元线性回归,逐步回归法,民航客运量0.符号说明1铁路客运量X2民航航线里程X3入境过夜旅游人数X4城镇居民人均可支配收入X51.引言随着社会的进步,人民生活水平的提高,如何获得更快捷方便的交通成为人们日益关注的问题。
因为航空的安全性,快速且价格水平越来越倾向大众,越来越多的人们选择航空这种交通方式。
近年来,我国的航空客运量已经进入世界前列,为掌握航空客运的动态,合理安排班机数量。
科学地对我国民航客运量的影响因素的分析,并得出其回归方程,进而能够估计航空客运量是非常有必要的。
本文收集整理了与我国航空客运量相关的历年数据,运用SPSS软件对数据进行分析,研究1996年起至2013年我国民航客运量y(万人)与国民生产总值X1(亿元)、铁路客运量X2(万人)、民航航线里程X3(万公里)、入境过夜旅游人数X4(万人)、城镇居民人均可支配收入X5(元)的关系。
采用逐步回归法建立线性模型,选出较优的线性回归模型。
2.数据的统计与分析本文在进行统计时,查阅《中国统计摘要》,《中国统计年鉴2014》以及中国知网数据查询中的数据,收集了1996年至2013年各个自变量因素的数据,分析它们之间的联系。
回归大作业-基于多元线性回归的期权价格预测模型

基于多元线性回归的期权价格预测模型王某某(北京航空航天大学计算机学院北京100191)1摘要:期权是国际市场成熟、普遍的金融衍生品,是金融市场极为重要的金融工具。
2015年2月9日,上海证券交易所正式推出了我国首支场内交易期权——上证50ETF期权,翻开了境内场内期权市场的新篇章。
50ETF期权上市以来,市场规模逐步扩大,其发展情况境外期权产品相同时期。
本文以此为研究背景,以“50ETF购12月1.95”这支期权为研究对象,以今日开盘价、收盘价、最高价、最低价、结算价、成交量、成交额、持仓量、涨停价和跌停价为解释变量,通过多元线性回归模型,预测该期权的明日收盘价。
本次研究以多元线性回归的全模型(模型1)为出发点,通过异方差检验、残差的独立性检验、误差的正太分布检验以及多重共线性检验,说明该模型不违反回归的基本假设条件。
进而通过主成分回归(模型4)和逐步回归(模型5)进行降维,结果表明因变量与解释变量之间存在强烈的线性相关关系,且主成分回归和逐步回归相比全模型有更好的预测能力。
关键词:期权价格多元线性回归50ETF 多重共线性因子分析一、引言期权(option)是依据合约形态划分的一种衍生品,指赋予其购买方在规定期限内按买卖双方约定的价格(即协议价格或行权价格)购买或者出售一定数量某种金融资产(即标的资产)的权利的合约。
期权购买方为了获得这个权利,必须支付给期权出售方一定的费用,称为权利金或期权价格[1]。
2015年2月9日,上海证券交易所正式推出了我国首支场内交易期权——上证50ETF,翻开了境内场内期权市场的新篇章。
期权是与期货并列的基础衍生产品,是金融市场极为重要的金融工具之一。
自50ETF上市以来,市场规模逐步扩大。
2015年2月日均合约成交面值为5.45亿元,12月就达到了47.69亿元,增长了7.75倍;2月日均合约成交量为2.33万张,12月就达到了19.81万张,增长了7.5倍;2月权利金总成交额为2.48亿元,12月就达到了35.98亿元,增长了13.51倍[1]。
多元线性回归(习题答案)

第3章练习题参考解答3.1为研究中国各地区入境旅游状况,建立了各省市旅游外汇收入(Y ,百万美元)、旅行社职工人数(X1,人)、国际旅游人数(X2,万人次)的模型,用某年31个省市的截面数据估计结果如下:ii i X X Y 215452.11179.00263.151ˆ++-= t=(-3.066806) (6.652983) (3.378064)(1) 从经济意义上考察估计模型的合理性。
(2) 在5%显著性水平上,分别检验参数21,ββ的显著性。
(3) 在5%显著性水平上,检验模型的整体显著性。
3.1参考解答:由模型估计结果可看出:旅行社职工人数和国际旅游人数均与旅游外汇收入正相关。
平 均说来,旅行社职工人数增加1人,旅游外汇收入将增加0.1179百万美元;国际旅游人数增加1万人次,旅游外汇收入增加1.5452百万美元。
取0.05α=,查表得0.025t (313) 2.048-=因为3个参数t 统计量的绝对值均大于048.2)331(025.0=-t ,说明经t 检验3个参数均显著不为0,即旅行社职工人数和国际旅游人数分别对旅游外汇收入都有显著影响。
取0.05α=,查表得0.05(1,)(2,28) 3.34F k n k F α--==由于34.3)28,2(1894.19905.0=>=F F ,说明旅行社职工人数和国际旅游人数联合起来对旅游外汇收入有显著影响,线性回归方程显著成立。
3.2根据下列数据试估计偏回归系数、标准误差,以及可决系数与修正的可决系数:3.2参考解答:由已知,偏回归系数21221222221212ˆ()i iii ii i iii iy x x y x x xx x x x β-=-∑∑∑∑∑∑∑274778.346280.0004250.9004796.00084855.096280.0004796.000⨯-⨯=⨯- 0.726594= 22111232221212ˆ()i iii ii i iii iy x x y x x xx x x x β-=-∑∑∑∑∑∑∑24250.90084855.09674778.3464796.00084855.096280.0004796.000⨯-⨯=⨯- 2.73628=12132ˆˆˆY X X βββ=-+ 367.6930.726594402.760 2.736288.0=-⨯-⨯ 53.1598=可决系数 213222ˆˆi i i iiy x y x R yββ+=∑∑∑0.72659474778.346 2.736284250.966042.269⨯+⨯=0.998832=修正的可决系数2211(1)n R R n k-=--- 1511(10.998832)153-=--- 0.998637=标准误差 由于 2∑i e =21RSSR TSS=- 即22(1)ieR TSS =-∑(10.998832)66042.269=-⨯ 77.1374= F 统计量2211n k R F k R -=--=1530.9988323110.998832---=5130.986标准误差22ˆie n kσ=-∑77.1374153=-6.4281=所以标准误差ˆ 2.5354σ=3.3参考解答:(1)建立家庭书刊消费的计量经济模型: i i i i u T X Y +++=321βββ其中:Y 为家庭书刊年消费支出、X 为家庭月平均收入、T 为户主受教育年数 (2)估计模型参数,结果为Dependent Variable: Y Method: Least Squares Date: 10/20/13 Time: 18:32 Sample: 1 18Included observations: 18Variable Coefficient Std. Error t-Statistic Prob. C -50.01638 49.46026 -1.011244 0.3279 X 0.086450 0.029363 2.944186 0.0101 T52.370315.202167 10.067020.0000 R-squared0.951235 Mean dependent var 755.1222 Adjusted R-squared 0.944732 S.D. dependent var 258.7206 S.E. of regression60.82273 Akaike info criterion11.20482Sum squared resid 55491.07 Schwarz criterion 11.35321 Log likelihood -97.84334 Hannan-Quinn criter. 11.22528 F-statistic 146.2974 Durbin-Watson stat 2.605783 Prob(F-statistic)0.000000即 ˆ50.01640.086552.3703i i iY X T =-++ (49.46026)(0.02936) (5.20217)t= (-1.011244) (2.944186) (10.06702) R 2=0.951235 944732.02=R F=146.2974(3)检验户主受教育年数对家庭书刊消费是否有显著影响:由估计检验结果, 户主受教育年数参数对应的t 统计量为10.06702, 明显大于t 的临界值131.2)318(025.0=-t ,(户主受教育年数参数所对应的P 值为0.0000,明显小于05.0=α)可判断户主受教育年数对家庭书刊消费支出确实有显著影响;同理可以判断,家庭月平均收入对家庭书刊消费支出的影响也是显著的。
多元统计分析作业一(第三题).doc

课程名称:多元统计回归分析
实验项目:边远及少数民族聚居区和会经济发展水平实验类型:验证性
学生学号:
学生姓名:
学生班级:
课程教师:
实验日期: 2016-03-28
)做出统计判断,最后对统计判断作出具体的解释
模块可以完成多元正态分布有关均值与方差的检验。
依次点选
、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲
,由此我们可以知道边远及少数民族聚居区社会经济发展水平与全国平均发展水平中的人均消费存在显著差别,即全国的平均人均消费大于边远及少数民族聚居区人均消费,相差值为
均大于显著性水平
发展水平与全国平均发展水平中的人均
盲半文盲等指标无明显差别。
注:验证性实验仅上交电子文档,设计性试验需要同时上交电子与纸质文档进行备份存档。
(完整word版)北航数理统计大作业1-线性回归分析

应用数理统计作业一学号:姓名:电话:二〇一四年十二月国内生产总值的多元线性回归模型摘要:本文首先选取了选取我国自1978至2012年间的国内生产总值为因变量,并选取了7个主要影响因素,进一步利用统计软件SPSS对以上数据进行了多元逐步线性回归。
从而找到了能反映国内生产总值与各因素之间关系的“最优”回归方程.然后利用多重线性的诊断找出存在共线性的自变量,剔除缺失值较多的因子.再次进行主成份线性回归分析,找出最优回归方程。
所得结论与我国当前形势相印证。
关键词:多元线性回归,逐步回归法,多重共线性诊断,主成份分析目录0符号说明 (1)1 介绍 (2)2 统计分析步骤 (3)2。
1 数据的采集和整理 (3)2。
2采用多重逐步回归分析 (7)2.3进行共线性诊断 (17)2。
4进行主成分分析确定所需主成份 (24)2。
5进行主成分逐步回归分析 (27)3 结论 (30)参考文献 (31)致谢 (32)0符号说明1 介绍文中主要应用逐步回归的主成份分析方法,对数据进行分析处理,最终得出能够反映各个因素对国内生产总值影响的最“优”模型及线性回归方程.国内生产总值是指在一定时期内(一个季度或一年),一个国家或地区的经济中所生产出的全部最终产品和劳务的价值,常被公认为衡量国家经济状况的最佳指标.它不但可反映一个国家的经济表现,还可以反映一国的国力与财富。
2012年1月,国家统计局公布2011年重要经济数据,其中GDP增长9.2%,基本符合预期。
2012年10月18日,统计显示,2012年前三季度国内生产总值353480亿元,同比增长7.7%;其中,一季度增长8.1%,二季度增长7。
6%,三季度增长7.4%,三季度增幅创下2009年二季度以来14个季度新低。
中国的GDP核算历史不长,上世纪90年代之前通常用“社会总产值”来衡量经济发展情况。
上世纪80年代初中国开始研究联合国国民经济核算体系的国内生产总值(GDP)指标。
多元回归分析习题.doc
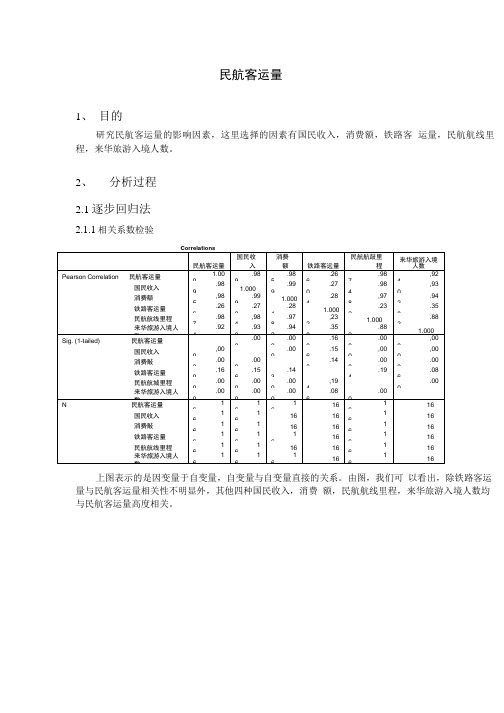
民航客运量1、目的研究民航客运量的影响因素,这里选择的因素有国民收入,消费额,铁路客运量,民航航线里程,来华旅游入境人数。
2、分析过程2.1逐步回归法2.1.1相关系数检验上图表示的是因变量于自变量,自变量与自变量直接的关系。
由图,我们可以看出,除铁路客运量与民航客运量相关性不明显外,其他四种国民收入,消费额,民航航线里程,来华旅游入境人数均与民航客运量高度相关。
2.1.2拟合优度检验a.b. Predictors: (Constant),国民收入,民航航线里程c. Dependent Variable:民航客运量由图知,逐步回归方法最终选择的是,国民收入和民航航线里程两个变量。
其相关系数R,判断系数R Square,调整后的R Square,均接近于1,拟合程度高。
通过检验。
2.1.3方程显著性检验Cb. Predictors: (Constant),国民收入,民航航线里程c. Dependent Variable:民航客运量Sig.值小于0.05,拒绝原假设,所以,方程线性相关性显著。
2.1.4回归方程3其中,Model 2是我们所需要的结果。
它们变量的显著性检验中,sig.值均小于0.05,所以,变量的相关性显著。
所以,我们可以得出以下方程, 民航客运量=-299.004+0.083*国民收入+17.316*民航航线里程。
而此种方法选择的并不是最优的方程。
因此,我们采用后退法。
2.2后退法2.2.1相关系数由图,我们可以看出,除铁路客运量与民航客运量相关性不明显外,其他四种国民收入,消费额,民航航线里程,来华旅游入境人数均与民航客运量高度相关。
2.2.2拟合优度检验a. Predictors: (Constant),来华旅游入境人数,铁路客运量,民航航线里程,消费额,国民收入b. Predictors: (Constant),来华旅游入境人数,民航航线里程,消费额,国民收入c. Dependent Variable:民航客运量由图知,逐步回归方法最终选择的是,国民收入和民航航线里程两个变量。
(完整版)多元线性回归模型习题及答案

多元线性回归模型一、单项选择题1.在由30n =的一组样本估计的、包含3个解释变量的线性回归模型中,计算得多重决定系数为0.8500,则调整后的多重决定系数为( D )A. 0.8603B. 0.8389C. 0.8655D.0.8327 2.下列样本模型中,哪一个模型通常是无效的(B ) A.iC (消费)=500+0.8iI (收入)B. di Q (商品需求)=10+0.8i I (收入)+0.9i P (价格) C. si Q (商品供给)=20+0.75i P (价格)D. iY (产出量)=0.650.6i L (劳动)0.4i K (资本)3.用一组有30个观测值的样本估计模型01122t t t ty b b x b x u =+++后,在0.05的显著性水平上对1b 的显著性作t 检验,则1b 显著地不等于零的条件是其统计量t 大于等于( C )A.)30(05.0t B.)28(025.0t C.)27(025.0t D.)28,1(025.0F4.模型tt t u x b b y ++=ln ln ln 10中,1b 的实际含义是( B )A.x 关于y 的弹性B. y 关于x 的弹性C. x 关于y 的边际倾向D. y 关于x 的边际倾向5、在多元线性回归模型中,若某个解释变量对其余解释变量的判定系数接近于1,则表明模型中存在( C )A.异方差性B.序列相关C.多重共线性D.高拟合优度6.线性回归模型01122......t t t k kt t y b b x b x b x u =+++++ 中,检验0:0(0,1,2,...)t H b i k ==时,所用的统计量服从( C )A.t(n-k+1)B.t(n-k-2)C.t(n-k-1)D.t(n-k+2)7. 调整的判定系数 与多重判定系数之间有如下关系( D )A.2211n R R n k -=-- B. 22111n R R n k -=---C. 2211(1)1n R R n k -=-+-- D. 2211(1)1n R R n k -=----8.关于经济计量模型进行预测出现误差的原因,正确的说法是( C )。
北航数理统计回归分析大作业

北航数理统计回归分析大作业(总17页)-CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除数理统计(课程大作业1) 逐步回归分析学院:机械工程学院专业:材料加工工程日期:2014年12月7日摘要:本文介绍多元线性回归分析方法以及逐步回归法,然后结合实际,以我国1995-2012年的财政收入为因变量,选取了8个可能的影响因素,选用逐步回归法对各影响因素进行了筛选分析,最终确定了其“最优”回归方程。
关键字:多元线性回归 逐步回归法 财政收入 SPSS1 引言自然界中任何事物都是普遍联系的,客观事物之间往往都存在着某种程度的关联关系。
为了研究变量之间的相关关系,人们常用回归分析的方法,而回归分析是数理统计中一种常用方法。
数理统计作为一种实用有效的工具,广泛应用于国民经济的各个方面,在解决实际问题中发挥了巨大的作用,是一种理论联系实践、指导实践的科学方法。
财政收入,是指政府为履行其职能、实施公共政策和提供公共物品与服务需要而筹集的一切资金的总和。
财政收入表现为政府部门在一定时期内(一般为一个财政年度)所取得的货币收入。
财政收入是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量,在很大程度上决定于财政收入的充裕状况。
本文将以回归分析为方法,运用数理统计工具探求财政收入与各种统计指标之间的关系,总结主要影响因素,并对其作用、前景进行分析和展望。
2 多元线性回归2.1 多元线性回归简介在实际问题中,某一因素的变化往往受到许多因素的影响,多元回归分析的任务就是要找出这些因素之间的某种联系。
由于许多非线性的情形都可以通过变换转化为线性回归来处理,因此,一般的实际问题都是基于多元线性回归问题进行处理的。
对多元线性回归模型简要介绍如下:如果随机变量y 与m )2(≥m 个普通变量m x x x 21,有关,且满足关系式:εββββ++++=m m x x x y 22110 2,0σεε==D E(2.1)其中,2210,,,σββββm 是与m x x x 21,无关的未知参数,ε是不可观测的随机变量,),0(~2N I N σε。
多元线性回归模型(习题与解答)

(1) β1 + β 2 = 1
(2) β1 = β 2
分别求出 β1 和 β 2 的最小二乘估计量。
3-12.多元线性计量经济学模型
yi = β0 + β1x1i + β2 x2i + ⋅ ⋅ ⋅ + βk xki + μi
i = 1,2,…,n
(2.11.1)
的矩阵形式是什么?其中每个矩阵的含义是什么?熟练地写出用矩阵表示的该模型的普通
(2)证明:残差的最小二乘估计量相同,即: uˆi = uˆi′
(3)在何种情况下,模型Ⅱ的拟合优度 R22 会小于模型Ⅰ拟合优度 R12 。
3-17.假设要求你建立一个计量经济模型来说明在学校跑道上慢跑一英里或一英里以上的人 数,以便决定是否修建第二条跑道以满足所有的锻炼者。你通过整个学年收集数据,得到两 个可能的解释性方程:
)
+
ε
i
7) Yi = β 0 + β1 X 1i + β 2 X 2i 10 + ε i
3-3.多元线性回归模型与一元线性回归模型有哪些区别? 3-4.为什么说最小二乘估计量是最优的线性无偏估计量?多元线性回归最小二乘估计的正 规方程组,能解出唯一的参数估计的条件是什么? 3-5.多元线性回归模型的基本假设是什么?试说明在证明最小二乘估计量的无偏性和有效 性的过程中,哪些基本假设起了作用? 3-6.请说明区间估计的含义。 (二)基本证明与问答类题型
(1)产出量的资本弹性和劳动弹性是等同的;
(2)存在不变规模收益,即α + β = 1 。
3-14.对模型 yi = β0 + β1x1i + β 2 x2i + L + β k xki + ui 应用 OLS 法,得到回归方程如下: yˆi = βˆ0 + βˆ1x1i + βˆ2 x2i + L + βˆk xki
第二次作业:多元回归分析

第二次作业:多元回归分析本次作业研究的是和三个因素的关系-省人均国民生产总值、15岁人口以上文盲半文盲比例、平均家庭数规模(家庭人口数)一、模型设定:被解释变量是省人口出生率(1999年),这是一个比率。
解释变量是省人均国民生产总值(单位是亿元),15岁人口以上文盲半文盲比例和平均家庭数规模(单位是人)。
数学形式是Y=B1+B2X1+B3X2+B4X3+e首先进行回归分析,考虑到共线与不共线的问题,程序为:data zuoye2;input y x1-x3@@;card;6.50 19846 6.45 3.059.68 15976 8.03 3.2312.99 6932 11.42 3.5915.93 4727 9.14 3.6313.32 5350 16.44 3.3410.38 10086 7.18 3.2410.68 6341 6.81 3.4310.55 7660 9.77 3.385.40 30805 8.68 3.0310.50 10665 16.79 3.4010.64 12037 15.70 3.1715.10 4707 20.28 3.6511.06 10797 18.46 3.5816.51 4661 13.15 3.6611.08 8673 20.15 3.2014.07 4894 16.31 3.8511.57 6514 14.98 3.6911.72 5105 11.13 3.4915.32 11728 9.23 4.1614.96 4148 12.35 4.1317.26 6383 14.58 4.3311.90 4826 14.75 3.3613.80 4452 16.77 3.3821.92 2475 24.46 3.9619.48 4452 24.34 4.0223.20 4262 66.18 6.7912.51 4101 18.29 3.8015.61 3668 25.64 4.0920.68 4662 30.52 4.1117.97 4473 23.32 4.0318.76 6470 9.77 3.77 ;proc reg;model y=x1-x3/collin collinoint;run;结果为: The SAS System 111:33 Wednesday,May 7, 1997Model: MODEL1Dependent Variable: YAnalysis of VarianceSum of MeanSource DF Squares Square F Value Prob>FModel 3 383.86226 127.95409 26.8450.0001Error 26 123.92717 4.76643C Total 29 507.78943Root MSE 2.18322 R-square 0.7559Dep Mean 13.74300 Adj R-sq 0.7278C.V. 15.88602The SAS System 211:33 Wednesday,May 7, 1997Parameter EstimatesParameter Standard T for H0:Variable DF Estimate Error Parameter=0 Prob >|T|INTERCEP 1 5.269100 3.64771675 1.4440.1605X1 1 -0.000330 0.00007574 -4.3620.0002X2 1 0.055221 0.07052014 0.7830.4407X3 1 2.717623 1.17211950 2.3190.0285The SAS System 311:33 Wednesday,May 7, 1997Collinearity DiagnosticsCondition Var Prop Var Prop Var Prop VarPropNumber Eigenvalue Index INTERCEP X1 X2 X31 3.44284 1.00000 0.0010 0.0172 0.00530.00072 0.45631 2.74681 0.0000 0.4035 0.05850.00053 0.09611 5.98515 0.0421 0.5095 0.31120.00924 0.00474 26.95536 0.9569 0.0698 0.62500.9897The SAS System 411:33 Wednesday,May 7, 1997Collinearity Diagnostics(intercept adjusted)Condition Var Prop Var Prop Var PropNumber Eigenvalue Index X1 X2 X31 2.11850 1.00000 0.0751 0.05020.04982 0.73896 1.69318 0.9168 0.04040.02743 0.14254 3.85526 0.0081 0.90940.9227可以看到,这个回归中存在中等程度的共线性问题,需要对程序进行修改,先去掉截距项因此可得程序2:proc reg;model y=x1-x3/noint selection=stepwise sle=0.3 sls=0.1 stb;run;采用了逐步回归的方法,并要求变量进入方程的显著性水平和剔除变量的显著性水平,结果为:The SAS System 21:46 Sunday, May 4, 1997 19Stepwise Procedure for Dependent Variable YStep 1 Variable X3 Entered R-square = 0.96263538 C(p) =18.52555385DF Sum of Squares Mean Square F Prob>FRegression 1 5943.20582193 5943.20582193747.14 0.0001Error 29 230.68507807 7.95465786Total 30 6173.89090000Parameter Standard Type IIVariable Estimate Error Sum of Squares F Prob>FX3 3.71815440 0.13602784 5943.20582193747.14 0.0001Bounds on condition number: 1, 1The SAS System 21:46 Sunday, May 4, 1997 20Step 2 Variable X1 Entered R-square = 0.97827663 C(p) =1.04943153DF Sum of Squares Mean Square F Prob>FRegression 2 6039.77320108 3019.88660054630.47 0.0001Error 28 134.11769892 4.78991782Total 30 6173.89090000Parameter Standard Type IIVariable Estimate Error Sum of Squares F Prob>FX1 -0.00027974 0.00006230 96.5673791520.16 0.0001X3 4.25870227 0.16011005 3388.79595907707.49 0.0001Bounds on condition number: 2.30078, 9.203119------------------------------------------------------------------------------All variables left in the model are significant at the 0.1000 level. No other variable met the 0.3000 significance level for entry into the model.The SAS System 21:46 Sunday, May 4, 1997 21Summary of Stepwise Procedure for Dependent Variable YVariable Number Partial ModelStep Entered Removed In R**2 R**2 C(p) F Prob>F1 X3 1 0.9626 0.9626 18.5256747.1353 0.00012 X1 2 0.0156 0.9783 1.049420.1606 0.0001The SAS System 21:46 Sunday, May 4, 1997 22Model: MODEL1NOTE: No intercept in model. R-square is redefined.Dependent Variable: YAnalysis of VarianceSum of MeanSource DF Squares Square F Value Prob>FModel 2 6039.77320 3019.88660 630.467 0.0001Error 28 134.11770 4.78992U Total 30 6173.89090Root MSE 2.18859 R-square 0.9783Dep Mean 13.74300 Adj R-sq 0.9767C.V. 15.92511The SAS System 21:46 Sunday, May 4, 1997 23Parameter EstimatesParameter Standard T for H0:Variable DF Estimate Error Parameter=0 Prob > |T|X1 1 -0.000280 0.00006230 -4.490 0.0001X3 1 4.258702 0.16011005 26.599 0.0001StandardizedVariable DF EstimateX1 1 -0.18970260X3 1 1.12377863因此可以得到最后结果为:y=-0.00028x1+4.26X3即15岁人口以上文盲半文盲比例这个变量不显著,从方程中剔除。
多元的回归作业的

多元回归作业课本P92-93一.Excel回归结果回归统计Multiple R 0.959102R Square 0.919876Adjusted R Square 0.905308标准误差 1.418316观测值14方差分析df SS MS F Significance F 回归分析 2 254.0408 127.0204 63.14335 9.35E-07 残差11 22.12781 2.011619总计13 276.1686Coefficients 标准误差t Stat P-value Lower95%Upper95%下限95.0%Intercept 21.31605 8.626069 2.47112 0.03106 2.330201 40.3019 2.330201 x1 0.109054 0.010531 10.35523 5.21E-07 0.085875 0.132233 0.085875 x2 -0.38787 0.1077 -3.60138 0.00416 -0.62491 -0.15082 -0.62491 Eviews回归结果Dependent Variable: YMethod: Least SquaresDate: 10/31/10 Time: 15:16Sample: 2001 2014Included observations: 14Variable Coefficient Std. Error t-Statistic Prob.C 21.31605 8.626069 2.471120 0.0311 X1 0.109054 0.010531 10.35523 0.0000 X2 -0.387868 0.107700 -3.601379 0.0042R-squared 0.919876 Mean dependentvar 19.72857Adjusted R-squared 0.905308 S.D. dependentvar 4.609093S.E. of regression 1.418316 Akaike infocriterion 3.724226 Sum squared resid 22.12781 Schwarz criterion 3.861167 Log likelihood -23.06958 F-statistic 63.14335Durbin-Watson stat 2.819875 Prob(F-statistic) 0.000001 所以回归方程为y =21.3161+0.19011x-0.38792x1)F 检验假设不全为零和211210:0:b b H b b H ==F=63.1434 由05.0=α 98.3)1214,2(05.0=--F 所以F>)11,2(05.0F 所以否定原假设,说明回归方程显著 2)回归系数的显著性检验 t 检验:)2,1(0:10≠==i i b H i b H 3552.101=t 6014.32-=t 由05.0=α 查表得201.2)314(025.0=-t 得)11(025.0t t i > 所以参数估计值都能通过t 检验,在统计上是显著的,可以认为销售额和经营费对利润有显著影响 3)序列相关检验DW=2.8199 (n=14, p=2)由DW 统计表可以看到,当n=15,自变量个数p=2,54.195.0==U L d d 当n=14时,DW 检验上下临界值会更小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
单位代码学号SY*******分类号密级应用数理统计(第一个论文)山东省旅游发展影响因素多元回归分析院(系)名称材料科学与工程学院专业名称材料科学与工程学生姓名李新杰任课教师冯伟2014年12月摘要本文主要通过对山东省旅游收入的多因素分析,建立以山东省旅游总收入为因变量,以国内旅游人数、接待入境人数、旅行社总数、旅游饭店数量以及旅游社职工人数等为自变量的多元线性回归模型,并利用SPSS统计软件建立逐步回归模型,找到影响山东省旅游业发展的显著性变量,并对所得的模型给予合理的经济解释。
关键词:逐步回归法山东省旅游发展SPSS 相关性显著性主成分目录摘要 (1)1 引言 (1)2 数据收集 (2)3统计数据的初步分析 (3)3.1 变量间的相关性分析 (3)3.2一元线性模型的验证 (3)4 回归分析 (5)4.1 回归模型的建立 (5)4.2 回归模型参数的估计 (6)4.2.1构建模型 (6)4.2.2剔除变量分析 (7)4.2.3回归系数分析 (7)5 回归模型的验证与修正 (8)5.1 方差分析 (8)5.2 回归方程的拟合度检验 (9)5.3 残差检验 (9)5.3多重共线性检验 (11)5.4 回归模型的修正 (12)6 结果 (13)参考文献 (15)山东省旅游发展影响因素多元回归分析学号:SY1401138姓名:李新杰1 引言随着社会经济快速发展,生活节奏加快,人们的压力变得越来越大,为减轻压力,既能放松自己,又能拓展自我视野的旅游就成为了人们的首要选择。
从我国近5 年的统计数据来看,我国每年的旅游收入正在逐年递增,旅游消费已成为中国人们日常支出中的重要部分。
山东省地处黄海之滨和黄河入海口,有着秀丽的自然风光,众多的人文景观,旅游资源十分丰富。
全省拥有旅游景区、景点509处,其中泰山和曲阜“三孔”列入世界遗产名录,青岛烟台、威海代表了中国海滨旅游的一大片。
全省旅游资源品位高,种类全,分布广,综合条件好,旅游业发展和旅游总收入位于全国前列,为了更好地了解山东省旅游业的发展,对山东省旅游业发展的影响因素建立回归模型分析,找出其核心影响因素。
在应用回归分析去处理实际问题时,必须通过合理经济的方法建立最优回归方程。
建立最优回归方程时要注意两个方面:(1)方程中要包含所有的显著作用的自变量,不能遗漏;(2)希望变量个数尽可能少,不含有无意义的变量,而且还应该使这类方程的S达到最小。
目前最常用的是逐步回归分析方法,即利用自变量和因变量的一系列同步观测数据,通过对相关矩阵的变换和数理统计的假设检验,逐步把显著性的自变量选入回归方程中,同时也把非显著性的自变量从回归方程中剔除,最终建立一个最优回归方程。
2 数据收集表2-1 2000-2013年山东省旅游总收入、国内旅游人数、入境旅游人数、旅游社总数、旅游饭店总数、旅行社职工人数注:以上数据根据《山东省统计年鉴2000-2013年》整理所得3统计数据的初步分析3.1 变量间的相关性分析为了知道旅游总收入具体和哪些变量有较大的关系,并将这些变量加入到线性模型中,首先要对旅游总收入和5个变量进行相关性分析,得到各个数据之间的相关系数表:表3-1 各个变量之间的相关系数表从表3-1可以看出旅游总收入Y和其他变量之间的相关系数,其中旅游总收入(亿元)和X1:国内旅游人数(万人次)的线性正相关程度最高,其次是X2:入境旅游人数(万人次),而旅行社职工人数等相关程度相对较小,所以需要对变量进行一元线性模型验证,以确定是否需要排除掉变量。
3.2一元线性模型的验证以上我们通过相关性分析确定了各相应变量对旅游总收入Y的影响,为了确定是否需要将所有的变量都加入到线性模型中,下面将通过做出旅游总收入Y分别和其他5个变量的散点图来进行验证:(a)(b)(c)(d)(e)图3-1 因变量和自变量间的散点图:(a)为旅游总收入Y和国内旅游人数的散点图,(b)为旅游总收入Y和入境旅游人数的散点图,(c)为旅游总收入Y和旅行社总数的散点图,(d)为旅游总收入Y和旅游饭店总数的散点图,(e)为旅游总收入Y和旅行社职工人数的散点图从图3-1中的因变量旅游总收入和5个自变量的散点图来看,旅游总收入和5个自变量都有很好的线性关系,这说明通过相关性分析得到的这5个和旅游总收入有关系的自变量都是正确的,而旅游社总数、饭店总数、旅行社职工人数与旅游总收入的相关性差不多,故无需对数据进行删除,因此在接下来进行多元逐步回归分析的时候会将这5个变量都加入到多元线性模型中进行模型建立和分析。
4 回归分析4.1 回归模型的建立采用线性回归分析建立的模型为:Y=a+b1X1+b2X2+ … +bnXn;其中Y为因变量的预测值或估计值;X1,X2……Xn为自变量。
a和b1、b2…… bn为回归系数。
若使以上线性回归分析方法达到最优,就要求自变量满足以下两个条件:(1)在线性回归分析模型中,要包含所有对Y影响显著的自变量,消除对Y 影响不显著的自变量。
(2)模型包含的各自变量之间不存在多重共线性,即各自变量之间不存在线性关系或近似线性关系。
为了解决以上两个问题,最有效的方法是采用逐步回归分析方法。
其基本思想是在所考虑的全部因素中,按其对Y作用显著程度的大小,由大到小地逐个引入回归方程。
那些对Y作用不显著的变量可能自始至终都未被引人回归方程。
另一方面,已被引人回归方程的变量在引入新变量后也可能因为变成对Y作用不显著而从回归方程中剔除。
在回归分析中,对自变量的选择很重要。
逐步回归法能使回归式子保留几个最为显著的自变量经过分析,影响山东省旅游收入的主要因素有国内旅游人数、接待入境人数、旅行社总数、旅游饭店数量以及旅游社职工人数,为此设定以下多元线性回归模型:Y=a + b1X1 + b2X2 + b3X3 + b4X4 + b5X5其中Y 为山东省旅游总收入(亿元),X1为国内旅游人数(万人次)、X2为入境游客人数(万人次)、X3为旅行社总数(家)、X4为旅游饭店总数(家)、X5为旅行社职工人数(人次)。
其中:b i =(1,2,3,4,5)分别表示各变量系数,表示各解释变量对被解释变量Y的影响程度。
4.2 回归模型参数的估计4.2.1构建模型通过利用SPSS 软件的线性回归分析,将国内旅游人数(万人次)、入境游客人数(万人次)、旅行社总数(家)、旅游饭店总数(家)、旅行社职工人数(人次)作为自变量,将山东省旅游总收入作为因变量,进行逐步分析法,得到表4-1。
表4-1 输入或者移出到模型中的变量表从表4-1中可以看到最终模型中存在的自变量是国内旅游人数和入境旅游人数。
选择的判据是变量进入回归方程的F的概率不大于0.05,剔除的判据是变量进入回归方程的F的概率不小于0.10。
最先进入构建模型1的变量是国内旅游人数,之后分别进入的是入境旅游人数,构成了模型2。
4.2.2剔除变量分析表4-2中给出了2种模型中分别不处在其中的相关变量的有关统计量,包括标准化回归系数Beta、回归系数显著性检验的t值、P(Sig)值、偏相关系数、共线性统计容差。
表4-2逐步回归过程中不在模型中的变量4.2.3回归系数分析表4-3中给出了各个模型的偏回归系数B、标准差、常数、标准化回归系数、回归系数显著性检验的t值和P值。
按照表格数据,最终得到的线性回归的结果为:Model1:Y= -352.656+0.100X1Model2:Y= -305.679+0.117X1-1.893X2两个模型经t检验的P值分别都是0.000,按照=0.10水平,均有显著性意义。
表4-3逐步回归过程的各方程的系数表5 回归模型的验证与修正5.1 方差分析对回归方程的显著性检验就是要看自变量从整体上对随机变量Y是否有明显的影响,主要检验方法有F检验法和t检验法,在这里通过t检验法来进行,在=0.05的水平下得到表5-1所示的方差分析表:表5-1各个模型的方差分析表表5-1为方差分析表,从图中可以看出统计量F(1)= 9141.508,F(2)= 13209.207,相伴P值均小于0.000。
其明显小于0.05的水平值,拒绝原假设,所以得到的四个模型都是具有显著性水平的,表明Y与X1,X4之间存在线性回归关系。
另外,sum of squares 栏中给出了回归平方和,残差平方和和总平方和,df 为自由度。
模型2的回归平方差和残差平方差等均小于第1个模型,说明第2个模型更好。
5.2 回归方程的拟合度检验拟合度用于检验回归方程对样本观测值的拟合程度。
其值越接近1,表明回归拟合的效果越好。
表5-2展示了逐步回归过程中2个模型的相关系数值。
表5-2 回归过程的拟合度表从表格中可以看出模型1为只用X1:国内旅游人数(万人次)表示旅游总收入Y时的相关系数R=0.999,判定系数R2=0.999,调整判定系数为0.999,回归估计的标准方差为59.60734。
模型2为用X1:国内旅游人数(万人次),X4:旅游饭店总数表示游总收入Y时的相关系数R=1.000,判定系数R2=1.000,调整判定系数为1.000,回归估计的标准方差为35.07921。
表中列出了回归方程常用统计量,可以看出,随着模型中自变量个数的增加,系数的值也在增加,估计的标准误差下降。
一般的,修正的值可以比较正确的反映拟合度。
可以看出模型2的回归效果较好,故选择模型2为线性回归方程。
5.3 残差检验如表5-3为残差统计表,表中显示预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量。
准化残差的绝对值最大值<3,说明样本数据中没有奇异数据。
表5-3残差统计表图5-1给出了观测累计概率的P-P图:图5-1 回归标准化残差的标准P-P图图5-2给出了回归残差和标准预测值的散点图:5.3多重共线性检验多元线性回归模型的基本假设中要求设计矩阵X中列向量之间不存在密切的线性关系。
若自变量的观测值之间存在线性关系,则称它们之间有着多重共线性。
当自变量存在多重共线性时,利用最小二乘法得到的参数估计值很不稳定,回归系数的方差随着共线性强度的增加而加速增长,会造成回归方程高度显著的情况下,所有回归系数都通不过显著性检验,甚至会出现回归系数的正负号无法得到合理解释的的情况。
对于多重共线性的诊断,这里采用的方法是方差扩大因子法(VIF),通过SPSS计算出各变量的VIF值如下表5-4所示:表5-4 VIF值检验结果一般认为VIF>10时即说明自变量之间有严重的多重共线性,由表5-4中可以看出,对于模型2,自变量国内旅游人数(X1)和入境旅游人数(X2)的VIF值均为29.486>10,故自变量X1和X2之间存在严重的多重共线性,需要进行修正。