新榜词云词频分析工具使用教程
词频分析的步骤和解读

词频分析的步骤和解读词频分析是文本分析的一种常用方法,通过统计文本中各个词汇的出现频率,可以揭示文本的主题、情感倾向以及作者的写作风格等信息。
本文将介绍词频分析的步骤和解读方法。
一、数据收集进行词频分析首先需要收集文本数据。
可以选择一篇文章、一本书籍、一段对话或者一组推文等作为分析对象。
确保收集到的数据具有代表性,能够准确反映出你想要研究的问题。
二、数据清洗在进行词频分析之前,需要对数据进行清洗,去除一些无关的信息,例如标点符号、停用词(如“的”、“是”、“和”等)以及数字等。
这样可以使分析结果更加准确和有意义。
三、词频统计在数据清洗之后,可以开始进行词频统计。
将文本分割成单词或词组,并统计每个词汇在文本中出现的次数。
可以使用计算机编程语言(如Python)中的相关函数或者专门的文本分析工具来完成这一步骤。
四、词频排序词频排序是将词汇按照出现频率的高低进行排序,以便于后续的分析和解读。
可以选择按照频率从高到低或者从低到高进行排序,根据具体需求来决定。
五、词频解读在词频分析的结果中,可以通过对高频词和低频词的解读来获取更多的信息。
高频词往往是文本的关键词,可以反映出文本的主题和核心内容。
低频词可能是一些特定的词汇或者作者的个性化表达,可以揭示出作者的写作风格和思维方式。
此外,还可以通过比较不同文本的词频分析结果,来进行文本间的比较和对比。
例如,对比两篇文章的高频词和低频词,可以发现它们在主题、情感倾向以及表达方式上的差异。
六、进一步分析除了词频分析,还可以结合其他文本分析方法来进行深入研究。
例如,可以进行情感分析,通过统计文本中正面情感和负面情感词汇的出现频率,来判断文本的情感倾向。
还可以进行主题模型分析,通过识别文本中的主题词,来揭示文本的隐含主题。
总结:词频分析是一种简单而有效的文本分析方法,可以通过统计词汇的出现频率来揭示文本的特点和信息。
在进行词频分析时,需要经过数据收集、数据清洗、词频统计、词频排序以及词频解读等步骤。
python汉语词频统计步骤说明

一、概述Python作为一种流行的编程语言,广泛应用于数据处理和文本分析领域。
词频统计是文本分析中常见的任务,通过Python可以方便地实现对汉语文本的词频统计。
本文将介绍如何使用Python进行汉语词频统计,包括准备工作、代码实现和结果展示等内容。
二、准备工作1. 安装Python在进行汉语词频统计之前,需要安装Python编程环境。
可以前往Python全球信息站下载对应操作系统的安装包,并按照冠方指引进行安装。
2. 安装第三方库为了实现汉语文本处理和词频统计,需要安装一些Python第三方库,包括jieba和matplotlib。
可以通过pip命令进行安装:```pythonpip install jiebapip install matplotlib```三、代码实现1. 导入所需模块```pythonimport jiebaimport matplotlib.pyplot as pltfrom collections import Counter```2. 读取文本文件使用Python的内置函数open()读取要进行词频统计的汉语文本文件,并将其内容存储到一个变量中。
```pythonwith open('chinese_text.txt', 'r', encoding='utf-8') as file:text = file.read()```3. 文本分词利用jieba库对文本进行分词处理,得到词语列表。
```pythonwords = jieba.lcut(text)```4. 统计词频使用Counter类统计词语出现的频率,并取出出现频率最高的前N个词。
```pythonword_count = Counter(words)top_n = word_count.mostmon(10)```5. 绘制词频统计图利用matplotlib库绘制词语的词频统计图,直观展示词语的使用频率。
词频分析

共词聚类分析法
借助数据挖掘中的聚类分析法,对共词关 系网络中的词与词之间的距离进行数学运算 分析,将距离较近的主题词聚集起来,形成一个 个概念相对独立的类团,使得类团内属性相似 性最大,类团间属性相似性最小。
共词关联分析法
关联规则是描述一个事物中物品之间同时 出现的规律的知识模式,更确切地说,就是通过量 化的数据描述物品A的出现对物品B的出现有多 大的影响。共词关联分析以此为原理,通过关联 统计方法,揭示主题词间的依存关系,在这基础上 可现实对文献知识的提取以及组织文献数据库 的作用。在共词关联分析的过程,涉及到4个重要 的概念:a.支持度(Support) b.可信度(Confidence) c.期望可信度(Expected Confidence)d.作用度 (Lift)。
突发词监测法
它关注焦点词-相对增长率突然增长的词。突发 词监测与高频词词频不同,前者主要是从关注词自身 的发展变化出发,关注单个词发展的阶段性,而后者主 要是对领域中各个词的增长势头进行比较。由于科 技领域中的局部热点变化不一定会引起全领域的注 意或者研究,但又是领域发展中不可缺少的部分,比如 关于某学科的教育研究,不一定会引起全领域范围的 讨论,但是它的研究本身也会不断发展。因此基于单 个词的词频增长率变化更有可能涉及到领域局部热 点的变化。突发词监测法更注重的是研究领域内,那 些研究活跃、有潜在影响研究热点的因素,因此,突发 词监测有助于发现推动学科(或主题)研究发展中的微 观因素。
三、高频词的选定
为简化统计的过程及减少低频词对统计过 程带来的干扰,通常共词分析选择高频主题词 为分析的对象。共词分法对高频词数量的选 择没有统一的见解,如果主题的范围过小,则不 能如实反映学科知识点的构成;如果主题的范 围选择过大,则给共词分析过程带来不必要的 干拢。用域值表示高频词划分的频次值,高频 词域值越高,高频词的数量越多。高频词阈值 是被认定高频词的词频总和,占所有词频总和 的比率。
Python数据挖掘:WordCloud词云配置过程及词频分析

CompilerforPython2.7)。但是在微软下载总是没响应。这是最大的问
题,下面我自己提供一个CSDN的地址供大家下载。下载完成,可以进行安
装响应的库函数。资源地址:download.csdn/detail/eastmount/9788218
体文件供程序调用,如下图所示,这是原来的字体DroidSansMono.ttf。
此时的运行结果如下所示,这是分析CSDN多篇博客的主题,”阅读”和”
评论”比较多。
也可以采用下面的代码:
wordcloud=WordCloud(font_path=
'MSYH.TTF').fit_words(word)
在使用WordCloud词云之前,需要使用pip安装相应的包。
pip install WordCloud
pip install jieba
其中WordCloud是词云,jieba是结巴分词工具。问题:在安装
WordCloud过程中,你可能遇到的第一个错误如下。
error: Microsoft Visual C++ 9.0 is required. Get it from asa.ms/vcpython27
Python数据挖掘:WordCloud词云配置过程及词频
分析
这篇文章是学习了老曹的微信直播,感觉WordCloud对我的《Python数
据挖掘课程》非常有帮助,希望这篇基础文章对你有所帮助,同时自己也是
词云的初学者,强烈推荐老曹的博客供大家学习。如果文章中存在不足或错
误的地方,还请海涵~
新榜词云词频分析工具使用教程
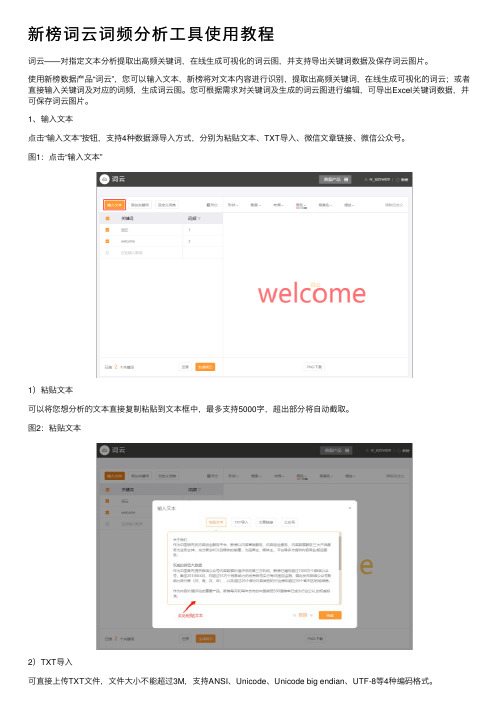
新榜词云词频分析⼯具使⽤教程词云——对指定⽂本分析提取出⾼频关键词,在线⽣成可视化的词云图,并⽀持导出关键词数据及保存词云图⽚。
使⽤新榜数据产品“词云”,您可以输⼊⽂本,新榜将对⽂本内容进⾏识别,提取出⾼频关键词,在线⽣成可视化的词云;或者直接输⼊关键词及对应的词频,⽣成词云图。
您可根据需求对关键词及⽣成的词云图进⾏编辑,可导出Excel关键词数据,并可保存词云图⽚。
1、输⼊⽂本点击“输⼊⽂本”按钮,⽀持4种数据源导⼊⽅式,分别为粘贴⽂本、TXT导⼊、微信⽂章链接、微信公众号。
图1:点击“输⼊⽂本”1)粘贴⽂本可以将您想分析的⽂本直接复制粘贴到⽂本框中,最多⽀持5000字,超出部分将⾃动截取。
图2:粘贴⽂本2)TXT导⼊可直接上传TXT⽂件,⽂件⼤⼩不能超过3M,⽀持ANSI、Unicode、Unicode big endian、UTF-8等4种编码格式。
图3:TXT导⼊⽂本3)微信⽂章链接可输⼊微信⽂章链接,最多⽀持10条链接,将对⽂章内容进⾏⽂本分词。
图4:输⼊微信⽂章链接4)微信公众号可输⼊微信号或名称进⾏搜索,选择您想要分析的公众号,将对该公众号30天内发布的⽂章进⾏⽂本分词。
图5:输⼊微信号或名称2. 关键词列表关键词列表是对指定⽂本分词后的⾼频关键词(最多显⽰TOP100),⽀持添加关键词、编辑关键词、删除关键词、Excel导出及还原。
添加关键词:点击“添加关键词”按钮,可在列表中添加新的关键词及对应的词频;编辑和删除关键词:选中⼀个关键词或词频,可直接进⾏编辑操作,点击右边出现的“删除”按钮,可删除该关键词;Excel导出:点击“导出”按钮,可导出Excel关键词列表,导出结果为选中的关键词及对应的词频;还原:点击“还原”按钮,将清除对关键词及词频的编辑操作,还原⾄初始状态。
图6:关键词列表点击“词频(筛选)”按钮,可在下拉列表中选择词频TOP20、TOP30、TOP50、TOP100的关键词。
词频统计法

词频统计法1. 介绍在自然语言处理(NLP)领域中,词频统计法是一种常用的方法,用于分析文本中各个词语的出现频率。
通过统计文本中词语出现的次数,可以获得词语的使用频率信息,从而对文本进行进一步的分析和理解。
2. 数据预处理在进行词频统计之前,需要对文本数据进行预处理。
数据预处理的步骤可以包括以下几个方面:2.1 去除特殊字符和标点符号在进行词频统计时,通常会去除文本中的特殊字符和标点符号。
这些字符和标点符号不具备明确的语义信息,在词频统计时可以被忽略。
2.2 去除停用词停用词是指在文本中频繁出现但含义相对较弱的词语。
常见的停用词包括“的”、“是”、“在”等。
在进行词频统计时,可以去除这些停用词,从而获得更有价值的统计结果。
2.3 分词分词是将文本按照一定规则切分成词语的过程。
在中文文本处理中,可以使用中文分词工具,如jieba分词,对文本进行分词操作。
分词后的文本可以更方便地进行词频统计。
3. 词频统计方法3.1 单词级别的词频统计在进行词频统计时,可以统计文本中每个单词出现的次数。
可以使用字典(Dictionary)或哈希表(Hashtable)等数据结构来存储单词及其对应的频率。
通过遍历文本中的每个单词,将其添加到字典或哈希表中,并更新对应的频率,最终可以得到每个单词的出现次数。
3.2 词组级别的词频统计除了对单词进行词频统计外,还可以对词组进行词频统计。
词组是由多个单词组成的固定短语或连续文本片段。
常见的词组可以是“人工智能”、“机器学习”等。
在进行词组级别的词频统计时,需要将文本按照一定规则进行分组,然后统计每个词组的出现次数。
4. 词频统计应用4.1 文本挖掘词频统计可以作为文本挖掘的基础工具。
通过统计文本中各个词语的频率,可以发现词汇的重要性和相关性。
词频统计也可以用于构建词云,通过词云可以直观地展示文本中重要的词语。
4.2 文本分类在文本分类任务中,词频统计可以用来提取文本的特征。
词云图Python利用jieba库做词频统计

词云图Python利⽤jieba库做词频统计⼀.环境以及注意事项1.windows10家庭版 python 3.7.12.需要使⽤到的库 wordcloud(词云),jieba(中⽂分词库),安装过程不展⽰3.注意事项:由于wordcloud默认是英⽂不⽀持中⽂,所以需要⼀个特殊字体 simsum.tff.下载地址:请安装到C:\Windows\Fonts ⾥⾯4.测试所⽤的三国演义txt⽂本下载地址(不保证永久有效):5.调试过程可能会出现许多⼩问题,请检查单词是否拼写正确,如words->word等等6.特别提醒:背景图⽚和⽂本需放在和py⽂件同⼀个地⽅⼆.词频统计以及输出 (1) 代码如下(封装为txt函数) 函数作⽤:jieba库三种模式中的精确模式(输出的分词完整且不多余) jieba.lcut(str):返回列表类型def txt(): #输出词频前N的词语txt = open("三国演义.txt","r").read() #打开txt⽂件,要和python在同⼀⽂件夹words = jieba.lcut(txt) #精确模式,返回⼀个列表counts = {} #创建字典excludes = ("将军","⼆⼈","却说","荆州","不可","不能","如此","如何",\"军⼠","左右","军马","商议","⼤喜") #规定要去除的没意义的词语for word in words:if len(word) == 1: #把意义相同的词语归⼀continueelif word == "诸葛亮" or word == "孔明⽈":rword = "孔明"elif word == '关公' or word == '云长':rword = '关⽻'elif word == '⽞德' or word == '⽞德⽈':rword = '刘备'elif word == '孟德' or word == "丞相" or word == '曹躁':rword = '曹操'else:rword = wordcounts[rword] = counts.get(rword,0) + 1 #字典的运⽤,统计词频P167for word in excludes: #删除之前所规定的词语del(counts[word])items = list(counts.items()) #返回所有键值对P168items.sort(key=lambda x:x[1], reverse =True) #降序排序N =eval(input("请输⼊N:代表输出的数字个数"))wordlist=list()for i in range(N):word,count = items[i]print("{0:<10}{1:<5}".format(word,count)) #输出前N个词频的词语 (2)效果图三.词频+词云 (1) 词云代码如下(由于是词频与词云结合,此函数不能直接当普通词云函数使⽤,⾃⾏做恰当修改即可)def create_word_cloud(filename):wl = txt() #调⽤函数获取strcloud_mask = np.array(Image.open("love.jpg"))#词云的背景图,需要颜⾊区分度⾼需要把背景图⽚名字改成love.jpgwc = WordCloud(background_color = "black", #背景颜⾊mask = cloud_mask, #背景图cloud_maskmax_words=100, #最⼤词语数⽬font_path = 'simsun.ttf', #调⽤font⾥的simsun.tff字体,需要提前安装height=1200, #设置⾼度width=1600, #设置宽度max_font_size=1000, #最⼤字体号random_state=1000, #设置随机⽣成状态,即有多少种配⾊⽅案)myword = wc.generate(wl) # ⽤ wl的词语⽣成词云# 展⽰词云图plt.imshow(myword)plt.axis("off")plt.show()wc.to_file('1.jpg') # 把词云保存下当前⽬录(与此py⽂件⽬录相同) (2) 词频加词云结合的完整代码如下from wordcloud import WordCloudimport matplotlib.pyplot as pltimport jiebaimport numpy as npfrom PIL import Imagedef txt(): #输出词频前N的词语并且以str的形式返回txt = open("三国演义.txt","r").read() #打开txt⽂件,要和python在同⼀⽂件夹words = jieba.lcut(txt) #精确模式,返回⼀个列表counts = {} #创建字典excludes = ("将军","⼆⼈","却说","荆州","不可","不能","如此","如何",\"军⼠","左右","军马","商议","⼤喜") #规定要去除的没意义的词语for word in words:if len(word) == 1: #把意义相同的词语归⼀continueelif word == "诸葛亮" or word == "孔明⽈":rword = "孔明"elif word == '关公' or word == '云长':rword = '关⽻'elif word == '⽞德' or word == '⽞德⽈':rword = '刘备'elif word == '孟德' or word == "丞相" or word == '曹躁':rword = '曹操'else:rword = wordcounts[rword] = counts.get(rword,0) + 1 #字典的运⽤,统计词频P167for word in excludes: #删除之前所规定的词语del(counts[word])items = list(counts.items()) #返回所有键值对P168items.sort(key=lambda x:x[1], reverse =True) #降序排序N =eval(input("请输⼊N:代表输出的数字个数"))wordlist=list()for i in range(N):word,count = items[i]print("{0:<10}{1:<5}".format(word,count)) #输出前N个词频的词语wordlist.append(word) #把词语word放进⼀个列表a=' '.join(wordlist) #把列表转换成str wl为str类型,所以需要转换return adef create_word_cloud(filename):wl = txt() #调⽤函数获取str!!#图⽚名字需⼀致cloud_mask = np.array(Image.open("love.jpg"))#词云的背景图,需要颜⾊区分度⾼wc = WordCloud(background_color = "black", #背景颜⾊mask = cloud_mask, #背景图cloud_maskmax_words=100, #最⼤词语数⽬font_path = 'simsun.ttf', #调⽤font⾥的simsun.tff字体,需要提前安装height=1200, #设置⾼度width=1600, #设置宽度max_font_size=1000, #最⼤字体号random_state=1000, #设置随机⽣成状态,即有多少种配⾊⽅案)myword = wc.generate(wl) # ⽤ wl的词语⽣成词云# 展⽰词云图plt.imshow(myword)plt.axis("off")plt.show()wc.to_file('1.jpg') # 把词云保存下当前⽬录(与此py⽂件⽬录相同)if __name__ == '__main__':create_word_cloud('三国演义') (3) 效果图如下(输出词频以及词云)(4) 改进代码——⾃定义类,可⾃定义排除词语和同义词注意:如果有OS报错,则尝试把字体⽂件放到.py当前⽬录的other⽬录下# ⾃定义类版class MyWordCloud:filePath = ""number = 1counts = {}excludes = [] # 需要排除的词语,例如不是,天⽓等常见词synonym = () # 同义词,元组,以该元组最后⼀个词语作为前⾯词语的意思def __init__(self, path, number, counts={}, excludes=[], synonym=()):self.filePath = pathself.number = numberself.counts = countsself.excludes = excludesself.synonym = synonym# 使⽤jieba库进⾏词频统计def count(self):txtFile = open(self.filePath, "r").read()words = jieba.lcut(txtFile)for word in words:if len(word) == 1 or len(word) > 4: # 去除长度为1和⼤于4的字符continuefor i in range(len(self.synonym)):for j in range(len(synonym[i])):if word == synonym[i][j]:word = synonym[i][len(synonym[i]) - 1]rword = wordself.counts[rword] = self.counts.get(rword, 0) + 1 # <class 'int'> 统计词频,0为初值# 删除排除词语for x in self.excludes:del (self.counts[x])return self.counts# 输出前number词频最⾼的词语def printPreNumberWord(self):self.counts = self.count()for i in range(15):items = list(self.counts.items())items.sort(key=lambda x: x[1], reverse=True) # 降序排序word, count = items[i]print("{0:<10}{1:<5}".format(word, count))# 获取词频最⾼的前number个词语def getPreNumberWord(self, counts=None):if (self.counts == None and counts == None):counts = self.count()else:counts = self.countsitems = list(counts.items())items.sort(key=lambda x: x[1], reverse=True) # 降序排序wordlist = []for i in range(self.number):word, count = items[i]# print("{0:<10}{1:<5}".format(word, count)) # 输出前N个词频的词语wordlist.append(word) # 把词语word放进⼀个列表return wordlist# ⽣成词云图def create_word_cloud(self):cloud_mask = np.array(Image.open("./picture/worlCloud.jpg"))wc = WordCloud(background_color="black", # 背景颜⾊mask=cloud_mask, # 背景图cloud_maskmax_words=100, # 最⼤词语数⽬font_path='./other/simsun.ttf', # 调⽤font⾥的simsun.tff字体,需要提前安装/下载height=1200, # 设置⾼度width=1600, # 设置宽度max_font_size=1000, # 最⼤字体号random_state=1000, # 设置随机⽣成状态,即有多少种配⾊⽅案)wl = ' '.join(self.getPreNumberWord()) # 把列表转换成str wl为str类型,所以需要转换img = wc.generate(wl) # ⽤ wl的词语⽣成词云# 展⽰词云图plt.imshow(img)plt.axis("off")plt.show()wc.to_file('./picture/1.jpg') # 把词云保存if __name__ == '__main__':filePath = "./txt/三国演义.txt"number = 20excludes = ["将军", "⼆⼈", "却说", "荆州", "不可", "不能", "引兵","次⽇", "如此", "如何", "军⼠", "左右", "军马", "商议", "⼤喜"]synonym = (("诸葛亮", "孔明⽈", "孔明"), ("关公", "云长", "关⽻"), ("⽞德", "⽞德⽈", "刘备"), ("孟德", "丞相", "曹躁", "曹操"))wl = MyWordCloud(filePath, number=number, excludes=excludes, synonym=synonym)wl.printPreNumberWord()wl.create_word_cloud()。
词频统计的主要流程

词频统计的主要流程引言词频统计是一种非常常见且实用的文本分析方法,它可以揭示文本中词语的使用情况和重要性。
在文本挖掘、自然语言处理、信息检索等领域中,词频统计被广泛应用于文本预处理、特征提取和文本分类等任务中。
本文将介绍词频统计的主要流程,包括数据预处理、构建词汇表、计算词频和排序等关键步骤。
我们将逐步深入探讨这些步骤,并给出详细的示例代码,以帮助读者更好地理解词频统计的过程和方法。
数据预处理在进行词频统计之前,需要对原始文本进行预处理,以便去除无用的标点符号、停用词等干扰因素,并将文本转换为合适的形式进行处理。
数据预处理的具体步骤如下: 1. 将文本转换为小写字母,以避免大小写的差异对统计结果造成影响。
2. 去除标点符号,包括句号、逗号、双引号等。
3. 去除停用词,停用词是指在文本分析中无实际含义的高频词汇,如“的”、“了”、“是”等。
常用的停用词列表可以从开源项目或自然语言处理工具包中获取。
4. 进行词干提取,将词语的不同形式转换为其原始形式。
例如,将单词的复数形式、时态变化等转换为词干形式。
5. 分词,将文本按照词语为单位进行切分。
常用的中文分词工具包有jieba、snownlp等。
下面给出一个示例代码,展示如何对原始文本进行数据预处理:import reimport stringfrom nltk.corpus import stopwordsfrom nltk.stem import SnowballStemmerimport jiebadef preprocess_text(text):# 将文本转换为小写text = text.lower()# 去除标点符号text = text.translate(str.maketrans('', '', string.punctuation)) # 去除停用词stop_words = set(stopwords.words('english')) # 英文停用词text = ' '.join([word for word in text.split() if word not in stop_words]) # 进行词干提取stemmer = SnowballStemmer('english')text = ' '.join([stemmer.stem(word) for word in text.split()]) # 中文分词text = ' '.join(jieba.cut(text))return text# 示例文本text = "Hello, world! This is a sample text."preprocessed_text = preprocess_text(text)print(preprocessed_text)以上代码演示了如何对英文文本进行预处理。
Java实现新闻报道的文本词云分析

Java实现新闻报道的文本词云分析简介本文档介绍了如何使用Java实现对新闻报道的文本进行词云分析。
词云分析是一种数据可视化技术,通过对文本中出现频率较高的词语进行可视化展示,可以帮助我们更直观地了解文本的主题和关键词。
步骤以下是使用Java实现新闻报道文本词云分析的步骤:1. 收集新闻报道文本数据:首先,需要收集大量的新闻报道文本数据。
可以通过爬取新闻网站、获取已有的新闻数据集等方式获得。
收集新闻报道文本数据:首先,需要收集大量的新闻报道文本数据。
可以通过爬取新闻网站、获取已有的新闻数据集等方式获得。
3. 计算词频:对预处理后的文本进行词频统计,统计每个词语在文本中出现的次数。
可以使用HashMap等数据结构来记录每个词语的出现次数。
计算词频:对预处理后的文本进行词频统计,统计每个词语在文本中出现的次数。
可以使用HashMap等数据结构来记录每个词语的出现次数。
4. 生成词云:根据统计出的词频数据,使用Java中的词云生成库(如WordCloud或JWordCloud)生成词云图像。
可以根据需要自定义词云的样式和配置参数。
生成词云:根据统计出的词频数据,使用Java中的词云生成库(如WordCloud或JWordCloud)生成词云图像。
可以根据需要自定义词云的样式和配置参数。
5. 展示和保存词云:将生成的词云图像展示在图形界面中或保存为图片文件进行进一步分析或展示。
展示和保存词云:将生成的词云图像展示在图形界面中或保存为图片文件进行进一步分析或展示。
注意事项在进行新闻报道文本词云分析时,需要注意以下几点:- 数据安全:确保获取和处理的新闻报道文本数据符合相关法律法规和数据使用规范。
数据安全:确保获取和处理的新闻报道文本数据符合相关法律法规和数据使用规范。
- 数据预处理:对文本数据进行预处理时,通过去除非文本内容、分词和去除停用词等步骤,能够提高词云分析的质量和准确性。
数据预处理:对文本数据进行预处理时,通过去除非文本内容、分词和去除停用词等步骤,能够提高词云分析的质量和准确性。
怎么分析词云图内容的方法

怎么分析词云图内容的方法词云图是一种用于可视化文本数据的工具,可以通过展示关键词的频率和重要性来揭示文本的主题和趋势。
分析词云图内容的方法主要包括以下几个方面:1. 收集并清洗数据:首先需要收集相关的文本数据,可以是文章、评论、社交媒体数据等。
然后需要对数据进行清洗,去除停用词、标点符号、数字和特殊符号等,只保留文本信息。
2. 词频统计:对于清洗后的文本数据,可以通过统计每个词语的出现频率来了解词语的重要性。
可以使用Python中的nltk、jieba等自然语言处理库进行词频统计。
3. 词云图生成:根据词语的频率和重要性,可以使用Python中的WordCloud 或其他可视化库生成词云图。
词云图中,词语的大小和颜色可以反映其出现的频率和重要性。
4. 主题分析:观察词云图中较大且颜色较深的词语,可以得出主题和关键词。
可以通过词语的相关性或者上下文来理解词云图所展示的文本主题。
5. 上下文分析:除了词语本身的重要性,还可以通过词语在文本中的上下文关系来进一步分析内容。
例如,可以观察某个关键词与其他词语之间的关系,了解其在文本中的语义含义。
6. 数据可视化:除了词云图,还可以通过其他图表来进一步分析文本内容。
例如,柱状图可以展示词语的频率分布,折线图可以展示词语的变化趋势等。
7. 情感分析:根据词云图中词语的情感倾向(积极、消极或中性),可以得出文本的整体情感。
可以使用情感分析工具如TextBlob、NLTK等来判断词语的情感倾向。
总结起来,分析词云图内容的方法主要包括数据收集和清洗、词频统计、词云图生成、主题分析、上下文分析、数据可视化和情感分析。
这些方法的结合可以帮助我们深入了解文本数据的主题、情感和趋势,从而进行更深入的分析和决策。
词频统计的主要流程

词频统计的主要流程
词频统计是一种文本分析技术,用于计算文本中每个单词出现的频率。
它可以帮助我们了解文本的主题、情感和重点,以及识别常见的词汇
模式。
下面是词频统计的主要流程和内容。
1. 收集文本数据
首先,需要收集要分析的文本数据。
这可以是一篇文章、一本书、一
段对话、一组评论或任何其他文本形式。
文本可以从互联网、数据库、文件或其他来源中获取。
2. 清理文本数据
在进行词频统计之前,需要对文本数据进行清理。
这包括去除标点符号、数字、停用词和其他无关的字符。
停用词是指在文本中频繁出现
但没有实际含义的单词,如“the”、“and”、“a”等。
3. 分词
分词是将文本分成单独的单词或短语的过程。
这可以通过使用自然语
言处理工具或手动分词来完成。
分词后,每个单词都可以被计算其出
现的频率。
4. 统计词频
统计词频是计算每个单词在文本中出现的次数。
这可以通过编写计算机程序或使用现有的文本分析工具来完成。
一旦词频被计算出来,就可以对文本进行更深入的分析。
5. 可视化结果
最后,可以将词频统计结果可视化,以便更好地理解文本数据。
这可以通过制作词云、柱状图、折线图或其他图表来完成。
可视化结果可以帮助我们快速了解文本的主题、情感和重点。
总之,词频统计是一种简单而有效的文本分析技术,可以帮助我们了解文本的特征和模式。
它可以应用于各种领域,如社交媒体分析、市场调研、情感分析和自然语言处理。
如何进行有效的文本词频分析与主题模型

如何进行有效的文本词频分析与主题模型在大数据时代,文本数据的处理和分析变得越来越重要。
而文本词频分析和主题模型是文本数据分析的两个重要方法。
本文将介绍如何进行有效的文本词频分析与主题模型。
一、文本词频分析文本词频分析是指对文本数据中单词出现的频率进行统计分析的方法。
它通常用于了解文本数据中哪些单词出现频率较高,从而帮助我们理解文本的主题和特点。
以下是进行文本词频分析的步骤:1. 数据预处理:首先,我们需要对文本数据进行预处理,包括去除标点符号、停用词和数字,将文本转换为小写等。
这样可以清理文本数据,使得后续分析更加准确。
2. 单词计数:接下来,我们需要统计文本数据中每个单词出现的频次。
这可以通过遍历文本数据并使用字典或哈希表来实现。
在计数时,可以使用正则表达式或分词工具将文本数据切分为单词,并统计每个单词的频次。
3. 排序与展示:最后,我们将根据单词的频次进行排序,并展示出现频率较高的前几个单词。
这可以帮助我们了解文本数据的关键词,从而揭示文本的主题和特点。
二、主题模型主题模型是一种从文本数据中挖掘主题信息的方法。
它可以帮助我们了解文本数据中隐藏的主题,发现不同文档之间的共同主题,并进行文本分类和推荐等任务。
以下是进行主题模型分析的步骤:1. 数据预处理:同样,我们需要对文本数据进行预处理,包括去除标点符号、停用词和数字,将文本转换为小写等。
此外,还可以使用词性标注和词干提取等技术进行进一步的文本处理。
2. 文本向量化:将文本数据转化为数值向量是进行主题模型分析的关键步骤。
常用的方法包括词袋模型(Bag-of-Words)和TF-IDF(词频-逆文档频率)等。
这些方法可以将文本数据表示为高维向量,以便进行后续的主题模型建模。
3. 主题建模:接下来,我们可以使用概率模型(如隐含狄利克雷分布LDA)对文本数据进行主题建模。
主题模型可以自动挖掘文本数据中的主题信息,并将不同文档关联到不同主题上。
通过调整模型参数和主题个数,我们可以得到不同的主题模型结果。
简述词云的使用方法

简述词云的使用方法一、什么是词云词云是一种可视化展示文本数据的工具,它通过将文本中出现频率较高的关键词以不同大小、颜色、字体等形式呈现在一个图形中,直观地反映出文本的主题和重点。
二、词云的使用方法1. 准备数据首先需要准备一份要制作词云的文本数据,可以是文章、新闻、书籍等等。
如果数据比较庞大,可以使用Python等编程语言进行处理。
2. 安装并打开词云工具目前市面上有很多种词云工具可供选择,例如Wordle、Tagxedo、Wordclouds等。
在此以Wordclouds为例进行讲解。
首先需要在电脑上安装并打开Wordclouds工具。
3. 导入数据点击“File”菜单下的“Open”,选择要制作词云的文本文件并导入。
4. 配置参数接下来需要配置一些参数,例如字体样式、背景颜色、最大字体大小等。
这些参数可以根据个人喜好和实际需求进行调整。
5. 生成词云点击“Create Word Cloud”按钮即可生成一个基础版的词云图。
如果想要进一步美化和调整词云图,可以使用Wordclouds提供的一些高级功能,例如调整词语间距、添加形状、调整颜色等。
6. 导出词云生成完毕后,可以将词云图导出为图片或PDF格式,方便在报告、PPT等场合使用。
三、词云的应用场景1. 文本分析词云可以帮助我们快速了解一份文本数据的主题和重点,为后续的文本分析提供参考。
2. 舆情监测通过对新闻报道、社交媒体等大量文本数据进行词云分析,可以了解公众对某个话题或事件的关注点和情感倾向。
3. 品牌营销在品牌营销中,可以使用词云工具对消费者的评论、反馈等进行分析,从而了解消费者需求和品牌形象,并针对性地改进产品和服务。
4. 教育教学在教育教学中,可以使用词云工具对学生作文、论文等进行分析,从而了解学生思维方式和表达能力,并针对性地进行指导。
生成词云的方法

生成词云是一种可视化文本数据的方式,它能够展示文本中出现频率较高的词汇。
以下是生成词云的基本步骤:1. 文本数据准备:-首先,您需要准备您的文本数据。
这可以是从新闻文章、社交媒体帖子、书籍或任何其他文本来源收集的数据。
2. 文本清洗:-去除文本中的无关信息,比如HTML标签(如果数据来自网页),非字母字符,以及标点符号等。
-转换文本为小写,以便词汇比较时不区分大小写。
-删除停用词,如“的”、“和”、“是”等,这些词在文本中频繁出现但通常不包含太多信息。
3. 词频统计:-使用Python中的库,如`collections`中的`Counter`,统计每个词汇出现的次数。
-对词汇进行排序,以便后续使用。
4. 词云生成:-利用Python中的`wordcloud`库来生成词云。
这个库提供了简单的API来创建词云。
-设置词云的参数,如背景颜色、字体、词汇最大数量、词频的颜色等。
5. 可视化展示:-生成词云后,您可以将其保存为图片文件,或者在JupyterNotebook中直接显示。
-您还可以将词云图片导出为格式如PNG或JPEG,以便于分享或打印。
以下是一个使用Python生成词云的简单示例代码:```python导入必要的库from wordcloud import WordCloudimport matplotlib.pyplot as plt准备文本数据text = "这里是您要生成词云的文本数据"创建词云对象,并设置参数wordcloud = WordCloud(font_path='path/to/font/SimHei.ttf', 设置字体路径,以支持中文字符background_color='white', 设置背景颜色width=800, height=600, 设置词云图片的大小max_words=200, 设置最大显示的词汇数量min_font_size=10, 设置字体最小大小max_font_size=100, 设置字体最大大小).generate(text)显示生成的词云图片plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off') 隐藏坐标轴保存词云图片wordcloud.to_file('word_cloud.png')也可以在Jupyter Notebook中直接显示wordcloud```在使用这些工具和方法时,请确保您遵守相关的数据保护法规和版权法律,尤其是在处理他人数据时。
主题讨论生成词云

生成词云是一种可视化技术,用于展示文本数据中出现频率较高的关键词。
通过分析生成词云,可以了解文本的主题、关键词分布和热点话题等。
下面将详细分析生成词云的几个主要步骤和应用。
1. 文本预处理:首先需要对原始文本数据进行预处理,包括去除停用词 如,a、an、the等),删除标点符号和特殊字符,转换为小写字母等。
这样可以保留文本中的有效信息,避免干扰词云结果。
2. 分词处理:将文本按照一定的规则或模型进行分词处理,将文本拆分成一个一个的词语。
常用的分词工具包括jieba、NLTK等。
分词后的结果是一个个的词语列表。
3. 统计词频:统计每个词语在文本中出现的频次,可以使用字典或者计数器来记录词语出现的次数。
通过这一步分析,可以得到每个词语的出现频率信息。
4. 生成词云图:根据词频信息,在图像中生成对应的词云图。
高频词会显示得更大、更显眼,低频词则较小。
可以使用Python的词云库,如wordcloud、pyecharts中的词云模块,调整词云的字体、颜色和形状等参数。
应用场景:1. 社交媒体分析:生成词云可以用于分析社交媒体平台上用户的评论、回复和新闻资讯等,了解用户关注的热点话题和关键词。
2. 情感分析:通过生成词云,可以分析情感文本中出现频率较高的积极或消极词语,帮助判断文本的情感倾向。
3. 可视化文本摘要:生成词云可以将文本关键词以图像的形式展示,更直观地呈现文本的主旨和核心内容。
4. 市场营销策略:在推广活动中,生成词云可以分析消费者对某一品牌或产品的评价,了解用户的需求和关注点,从而优化产品和服务。
总之,生成词云是一种简单而有趣的文本可视化方法,通过统计词频并将其可视化,可以更好地理解文本内容和重点。
这一技术在多个领域都有广泛的应用和探索价值。
中文词频统计与词云生成

中⽂词频统计与词云⽣成中⽂词频统计:作业连接:1. 下载⼀长篇中⽂⼩说。
2. 从⽂件读取待分析⽂本。
3. 安装并使⽤jieba进⾏中⽂分词。
pip install jiebaimport jiebajieba.lcut(text)4. 更新词库,加⼊所分析对象的专业词汇。
jieba.add_word('天罡北⽃阵') #逐个添加jieba.load_userdict(word_dict) #词库⽂本⽂件参考词库下载地址:https:///dict/转换代码:scel_to_text5. ⽣成词频统计6. 排序7. 排除语法型词汇,代词、冠词、连词等停⽤词。
stops8. 输出词频最⼤TOP20,把结果存放到⽂件⾥9. ⽣成词云。
本案例统计红楼梦词频:1.在⽹上下载红楼梦txt⽂件2.使⽤PyCharm 编译器⾃动下载 jieba 包3.搜狗⽂库中下载红楼梦词库,并将词库.scel⽂件转化为txt⽂件4.先将转化为txt形式的词库⽂件加⼊,再对红楼梦⽂本进⾏词频统计,统计出频率最⾼的20个词:```import jiebatxt = open(r"C:\Users\Administrator\Desktop\all.txt",'r',encoding='utf-8').read() word_dict =r"C:\Users\Administrator\Desktop\11.txt"jieba.load_userdict(word_dict)words = jieba.cut(txt)# 键值对形式 {}counts={}for word in words:if len(word)==1:continueelse:counts[word] = counts.get(word,0) +1 #遍历所有,并加1items = list(counts.items())#键值对变成列表items.sort(key=lambda x: x[1], reverse=True)for i in range(20):word, count = items[i]print("{0:<5}{1:>5}".format(word, count))```5.编译结果:曹操 934孔明 831将军 760却说 647⽞德 571关公 509丞相 488⼆⼈ 463不可 435荆州 420孔明⽈ 384⽞德⽈ 383不能 383如此 376张飞 348商议 344如何 336主公 327军⼠ 309吕布 2996:词云形式:·。
在线词频、语义、情感分析工具

在线词频、语义、情感分析工具根据之前在@数据化管理微博那里看到的一些在线效率工具,来试用一下。
首先就从在线词频、语义、情感分析工具开始吧。
@数据化管理推荐了三个网站,分别是图悦、大数据搜索与挖掘平台和腾讯文智。
以新浪微博“英国公投决定脱欧新浪正实时解读”的直播页面为试用对象,地址为/zt/l/v/news/ygtogt2016/①图悦:/初始页面背景是黑色的,看着不舒服,页面换肤后变成白底还可以接受。
左边文本栏可输入待分析的文本,也可以直接复制链接,很人性化。
贴入要分析的网页地址,点击分析出图,右边就获得了分析结果。
、结果显示有多种模式,下面截图显示的是默认的热词权重图-标准模式。
热词词频图是每个热词后面带括号显示词频,比较乱,不好看。
微信模式是圆形的显示框变成扁椭圆式,地图模式是显示框为中国地图的轮廓。
可以导出EXCEL,列明分析出来的关键词、词频和权重。
②大数据搜索与挖掘平台:/nlpir/看上去功能比较强大,同样可以输入网页URL进行文本抓取。
分析结果分为多个板块:分词标注:可以对词语的词性进行分类分析,发现新词实体抽取:对文本的实体类型和实体内容进行分析,下图是图表效果,●代表实体类型,●代表实体内容。
另外还有文本效果,内容是一样的,效果不如这个好看,就不截图了。
词频统计:按照名词、动词、形容词分类显示词频,有柱状图和折线图两类图表,鼠标停留在某个词上会显示词频数量。
文本分类:似乎是对文本所讨论的问题进行归类,猜哒。
情感分析:不太明确是啥意思 -。
-,什么叫正面,什么又叫负面呢,特定人物又是谁?关键词提取:有两种模式,一是图表,二是文本。
图表是个动态图,鼠标放上去的时候会不停的转动,所以看到的文字大小不代表权重。
Word2vec:似乎是分析词的相关性的,有两种模式,一是力导向布局图,二是和弦图依存文法:看不懂简繁转换:不解释自动注音:不解释摘要提取:所分析的网页本身就有事件简介,所以看不出太多,下文中到“脱欧派取得胜利”是原来的简介,后面两句是根据后续的消息自己补上的??英国公投决定脱欧新浪正实时解读_直播_新闻中心_新浪网时间:2016年06月22日11:26直播已进行3小时12分简介自1973年加入欧盟前身欧共体后,英国姓“欧”已43年,6月24日,英国全民公投,根据投票结果,脱欧派取得胜利。
python使用matplotlib画词频分析的图_如何使用matplotlib或任何其他

python使用matplotlib画词频分析的图_如何使用matplotlib或任何其他要使用matplotlib来绘制词频分析的图表,可以按照以下步骤进行操作:1.导入需要的库:```pythonimport matplotlib.pyplot as plt```2.准备数据,可以是一段文本或者是一个字典,表示每个词及其对应的频率。
3.根据数据绘制图表,可以使用不同的图表类型,如柱状图或词云图等。
下面分别介绍如何使用matplotlib绘制柱状图和词云图。
使用matplotlib绘制词频柱状图的示例代码如下:```pythonimport matplotlib.pyplot as plt#准备数据words = ['apple', 'banana', 'orange', 'grape', 'peach']frequency = [10, 15, 8, 12, 6]#绘制柱状图plt.bar(words, frequency)plt.title('Word Frequency')plt.xlabel('Words')plt.ylabel('Frequency')#展示图表plt.show```以上代码会生成一个柱状图,横轴表示单词,纵轴表示频率。
使用matplotlib绘制词云图的示例代码如下:```pythonimport matplotlib.pyplot as pltfrom wordcloud import WordCloud#准备数据text = "apple apple apple banana banana orange grape peach" #创建词云对象wordcloud = WordCloud(.generate(text)#绘制词云图plt.imshow(wordcloud, interpolation='bilinear')plt.axis('off')#展示图表plt.show```以上代码会生成一个词云图,其中的单词的大小表示其频率。
python 词云 理解

python 词云理解Python词云是一种用于可视化文本数据的工具,通过统计文本中各个词语的出现频率,并根据频率生成一个词云图。
词云图可以直观地展示文本数据中的关键词,帮助人们更好地理解和分析文本内容。
Python词云的使用非常简单,只需要几行代码就可以生成一个漂亮的词云图。
首先,我们需要安装一个词云库,比如常用的wordcloud库。
安装完成后,我们可以导入该库,并读取文本数据,将其转化为一个字符串。
接下来,我们可以使用wordcloud库提供的函数,根据文本数据生成词云图。
我们可以设置词云图的样式、颜色和形状等参数,以使其更符合我们的需求。
最后,我们可以将生成的词云图保存到本地或在程序中直接显示出来。
词云图的生成原理是通过统计文本中各个词语的出现频率来确定词语在词云图中的大小。
出现频率较高的词语在词云图中会显示得更大,而出现频率较低的词语则会显示得更小。
通过观察词云图,我们可以直观地了解文本数据中的关键词,从而更好地理解和分析文本内容。
除了生成词云图,Python词云还可以进行一些其他的操作。
比如,我们可以设置词云图的背景颜色、字体颜色和字体样式等参数,以使其更加美观。
我们还可以通过设置停用词来过滤掉一些常用词语,从而更好地突出文本中的关键词。
此外,我们还可以根据词云图中词语的颜色、大小和位置等信息,进一步分析文本数据中的关联性和趋势。
总结来说,Python词云是一种用于可视化文本数据的工具,通过统计文本中各个词语的出现频率,并根据频率生成一个词云图。
词云图可以直观地展示文本数据中的关键词,帮助人们更好地理解和分析文本内容。
Python词云的使用非常简单,只需要几行代码就可以生成一个漂亮的词云图。
通过设置词云图的样式、颜色和形状等参数,我们可以使其更符合我们的需求。
除了生成词云图,Python词云还可以进行一些其他的操作,如设置词云图的背景颜色和字体样式等。
通过使用Python词云,我们可以更好地理解和分析文本数据,并从中获取有价值的信息。
词云的原理

词云的原理什么是词云词云是一种数据可视化技术,通过将文本数据中的关键词按照频率等信息呈现在图形界面上,形成一个以关键词为基础的图形展示效果。
词云既可以直观地展示文本数据的特征,又可以帮助我们从海量的文本数据中提取出有用的信息。
词云的应用领域词云广泛应用于文本分析、舆情监测、情感分析、关键词提取、主题分析等领域。
在新闻报道、社交媒体分析、市场调研等场景中,词云可以帮助人们迅速把握大量文本数据的关键信息,为决策提供支持。
词云的生成步骤要生成一个词云,通常需要经过以下几个步骤:1. 文本预处理首先,需要对原始文本进行预处理,包括去除停用词、标点符号等无意义的字符,将文本内容规范化为纯净的关键词序列。
2. 统计词频接下来,需要统计每个关键词在文本中出现的频率。
通常可以使用词频统计算法,如TF-IDF算法,来计算每个关键词的重要程度。
3. 生成词云图一般而言,词云是由多个关键词按照不同的权重大小排列并呈现在图形界面上的。
生成词云图的过程通常包括以下几个步骤:1.确定画布大小和背景颜色等参数。
2.设置字体库,根据需求选择适合的字体风格。
3.根据关键词的词频计算每个关键词在词云图中的大小。
4.将关键词按照词频大小进行排序和排列。
5.将关键词根据词频大小和字体设置的风格进行适当的渲染,以增加视觉效果。
6.在画布上绘制出词云图。
4. 优化和美化为了增强词云的可读性和美观性,通常需要进行一些优化和美化的操作,比如调整关键词的字体颜色、字号、布局位置等。
词云生成工具为了方便用户生成词云,现在有很多词云生成工具可供选择。
其中,一些常用的词云生成工具包括WordArt、Wordle、TagCrowd、WordCloud等。
这些工具一般提供了用户友好的界面和参数设置选项,使得用户可以根据自己的需求定制生成词云的效果。
词云的局限性和改进尽管词云具有直观、简洁、易于理解的优点,但也存在一些局限性。
首先,词云无法显示关键词之间的关联性和语义信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
词云——对指定文本分析提取出高频关键词,在线生成可视化的词云图,并支持导出关键词数据及保存词云图片。
使用新榜数据产品“词云”,您可以输入文本,新榜将对文本内容进行识别,提取出高频关键词,在线生成可视化的词云;或者直接输入关键词及对应的词频,生成词云图。
您可根据需求对关键词及生成的词云图进行编辑,可导出Excel关键词数据,并可保存词云图片。
1、输入文本
点击“输入文本”按钮,支持4种数据源导入方式,分别为粘贴文本、TXT导入、微信文章链接、微信公众号。
图1:点击“输入文本”
1)粘贴文本
可以将您想分析的文本直接复制粘贴到文本框中,最多支持5000字,超出部分将自动截取。
图2:粘贴文本
2)TXT导入
可直接上传TXT文件,文件大小不能超过3M,支持ANSI、Unicode、Unicode big endian、UTF-8等4种编码格式。
图3:TXT导入文本
3)微信文章链接
可输入微信文章链接,最多支持10条链接,将对文章内容进行文本分词。
图4:输入微信文章链接
4)微信公众号
可输入微信号或名称进行搜索,选择您想要分析的公众号,将对该公众号30天内发布的文章进行文本分词。
图5:输入微信号或名称
2. 关键词列表
关键词列表是对指定文本分词后的高频关键词(最多显示TOP100),支持添加关键词、编辑关键词、删除关键词、Excel导出及还原。
添加关键词:点击“添加关键词”按钮,可在列表中添加新的关键词及对应的词频;
编辑和删除关键词:选中一个关键词或词频,可直接进行编辑操作,点击右边出现的“删除”按钮,可删除该关键词;
Excel导出:点击“导出”按钮,可导出Excel关键词列表,导出结果为选中的关键词及对应的词频;
还原:点击“还原”按钮,将清除对关键词及词频的编辑操作,还原至初始状态。
图6:关键词列表
点击“词频(筛选)”按钮,可在下拉列表中选择词频TOP20、TOP30、TOP50、TOP100的关键词。
图7:词频筛选
3. 生成、编辑并保存词云
点击“生成词云”按钮,即可快速生成可视化的词云图。
可对词云图的形状、字体、布局、颜色、背景色、大小进行自定义编辑。
形状:支持长方形、圆形、五角星、三角形四种形状;
字体:支持雅黑、宋体、楷体、黑体、隶书、arial六种字体;
布局:支持字体正常和倾斜两种状态;
颜色:支持六种配色,并可自定义配色;
背景色:支持自定义词云图的背景颜色;
缩放:支持对词云图的大小进行1%-150%范围内的缩放。
点击“清除自定义”按钮,可对上述自定义操作进行重置,回到词云图初始状态。
点击“PNG下载”按钮,可将生成的词云图保存在本地。
图8:词云图
4. 自定义词典
自定义词典是对希望不要被拆分及希望不出现在关键词列表中的词进行定义。
添加:在对应的文本框中添加需要词和排除词,点击“添加”按钮,即可成功添加。
需要注意的是,添加的需要词和排除词不能超过40个字符,且两者不能重复。
删除:鼠标定位到想删除的关键词上,点击右上方删除按钮,即可删除该词。
图9:自定义需要词
图10:自定义排除词。