学年论文(数据结构模板)
数据结构论文

数据管理技术探讨1404091051软工一班范克强摘要:随着计算机技术的发展,特别是在计算机软件.硬件与网络技术发展的前提下,人们的数据处理要求不断提高,在此情况下,数据管理技术也不断改进。
数据库技术是计算机科学技术中发展最快的领域之一,也是应用最广的技术之一,它成为计算机信息系统与应用系统的核心技术和重要基础。
关键字:人工管理、文件系统、数据库系统。
数据管理的水平是和计算机硬件、软件的发展相适应的,是随着计算机技术的发展人们的数据管理技术经历了三个阶段的发展:人工管理阶段;文件系统阶段;数据库系统阶段。
1.人工管理阶段:20世纪50年代中期以前,计算机主要用于科学计算。
硬件方面,计算机的外存只有磁带、卡片、纸带,没有磁盘等直接存取的存储设备,存储量非常小;软件方面,没有操作系统,没有高级语言,数据处理的方式是批处理,也即机器一次处理一批数据,直到运算完成为止,然后才能进行另外一批数据的处理,中间不能被打断,原因是此时的外存如磁带、卡片等只能顺序输入。
人工管理阶段的数据具有以下的几个特点。
(1)数据不保存。
由于当时计算机主要用于科学计算,数据保存上并不做特别要求,只是在计算某一个课题时将数据输入,用完就退出,对数据不作保存,有时对系统软件也是这样。
(2)数据不具有独立。
数据是作为输入程序的组成部分,即程序和数据是一个不可分隔的整体,数据和程序同时提供给计算机运算使用。
对数据进行管理,就像现在的操作系统可以以目录、文件的形式管理数据。
程序员不仅要知道数据的逻辑结构,也要规定数据的物理结构,程序员对存储结构,存取方法及输入输出的格式有绝对的控制权,要修改数据必须修改程序。
要对100组数据进行同样的运算,就要给计算机输入100个独立的程序,因为数据无法独立存在。
(3)数据不共享。
数据是面向应用的,一组数据对应一个程序。
不同应用的数据之间是相互独立、彼此无关的,即使两个不同应用涉及到相同的数据,也必须各自定义,无法相互利用,互相参照。
数据结构论文

数据结构论文【引言】数据结构是计算机科学的基础,它研究如何将数据以及数据之间的关系在计算机中进行组织和存储,以便高效地操作和管理数据。
数据结构的选择对计算机程序的性能和效率有着重要的影响。
本论文将探讨几种常见的数据结构及其应用。
【第一部分:线性数据结构】线性数据结构是最简单且基础的数据结构之一,它的元素之间存在线性的顺序关系。
其中最常见的线性数据结构包括数组、链表和栈。
1. 数组数组是一种能够存储相同类型元素的线性数据结构。
它通过将元素存储在连续的内存位置上来实现快速的随机访问。
数组的插入和删除操作相对较慢,因为需要移动其他元素。
然而,由于其占用连续内存空间的特性,数组在某些应用中具有较高的效率和性能优势。
2. 链表链表是一种使用指针来连接元素的线性数据结构。
与数组不同,链表的元素在内存中可以是离散的。
链表的插入和删除操作相对较快,但随机访问操作相对较慢。
链表的优点在于其动态性,可以根据需求动态添加或删除元素。
3. 栈栈是一种后进先出(LIFO)的线性数据结构。
它只允许在栈顶进行插入和删除操作。
栈的应用广泛,例如计算表达式的后缀表示、递归函数的调用和浏览器的历史记录等。
【第二部分:非线性数据结构】非线性数据结构是数据元素间存在非线性关系的数据结构。
最常见的非线性数据结构包括树和图。
1. 树树是一种由节点和边组成的层次结构,它具有一个根节点和若干个子节点。
每个子节点可以再分为更多子节点,形成多层次的分支结构。
树的应用广泛,例如二叉搜索树用于快速查找和排序,哈夫曼树用于数据压缩。
2. 图图是一种由节点和边组成的网络结构,节点可以表示实体,边表示节点间的连接关系。
图的类型包括有向图和无向图,它们广泛应用于社交网络分析、路由算法和图像处理等领域。
【第三部分:高级数据结构】除了基础的线性和非线性数据结构,还存在一些高级数据结构,用于解决特定的问题。
其中包括散列表、堆和图的扩展结构。
1. 散列表散列表(哈希表)是一种以键值对形式存储数据的数据结构。
数据结构课程论文(总结前两章)

第一章——绪论前言(为什么会有数据结构这门课)计算机主要应用在两个方面:一个是数值计算,另一个是非数值计算。
早期的计算机只能处理数值计算(也就是数学上的运算,特点是计算过程复杂,数据类型相对简单,数据量较少),这时候人们主要通过程序设计的思想来处理处理问题。
随着计算机渗入生活,人们开始要求计算机参与处理非数值计算(特点是计算过程相对简单,数据结构相对复杂,数据的组织排列结构从某种意义上决定着非数据计算应用的有效性,数据的组织排列结构成为处理和解决数据处理问题的核心),这时候原来的程序设计以程序为中心的设计过程已经无法满足大量的非数值计算。
急需一门以复杂数据为中心,研究数据的合理组织形式,并设计出基于合理数据组织结构下的高效程序的科学来指导计算机的发展。
数据结构就是在这种环境下诞生的。
每种数据结构类型都分四个描述层次——概念层、逻辑层、存储层、运算实现层。
而数据结构往往在逻辑层上为程序抽象出算法,并对算法进行优化。
最终推出较优的指导性算法,方便后续的具体程序设计。
什么是数据结构数据结构是随着计算机科学的发展而建立起来的围绕非数值计算问题的一门科学。
准确来说,数据结构就是研究大量数据在计算机中存储的组织形式,并定义且实现对数据相应的高效运算,以提高计算机的数据处理能力的一门科学。
这里的运算主要指的是非公式化的运算,如数据存取、插入、删除、查找、排序和遍历等运算。
也就是说,数据结构是管信息管理和存储的,研究怎么存比较好,怎么管理相对比较优化。
而这里就涉及到一个问题:信息应该怎么表示,根据程序设计中介绍的思路,要在电脑中写入一个数据,应该包括它的属性和它的位置。
只要有他的位置和属性都确定了,那这个数据就完整地被存储到计算机中了。
所以,信息是由信息元素的值及信息元素之间的相互关系(逻辑顺序)和信息元素在计算机中的存储方式(物理顺序)共同组成。
逻辑结构就是代表了信息本身的属性,他是与计算机本身无关的“逻辑组织结构”它的构成是由数据的值、数据与数据之间的关联方式两个部分组成。
数据结构论文——数据结构在生后中的应用

数据结构——数据结构在生活中的应用专业:学号:姓名:数据结构在生活中的应用数据结构是计算机存储、组织数据的方式。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
数据结构往往同高效的检索算法和索引技术有关。
数据结构是指同一数据元素类中各数据元素之间存在的关系。
数据结构分别为逻辑结构、存储结构(物理结构)和数据的运算。
数据结构包括的主要内容有数组(Array) 栈(Stack) 队列(Queue) 链表(Linked List)树(Tree) 图(Graph) 堆(Heap) 散列表(Hash)等。
数据结构在生活中的很多地方又有应用,在我们的日常生活中,应用到数据结构的地方有很多地方,实例到处都是,比如说,做搜索引擎,对字符串的各种查找、索引的算法就有很高要求;做人工智能,对模式识别、搜索的要求就很高;做数据库设计,对字典、内外排序、搜索与索引以及数据的连接方式都有很高要求;做通讯密码,对数论、Fourier分析有要求;等等。
具体内容的应用也有很多,例如:抽象数据类型可以使我们更容易描述现实世界。
例:用线性表描述学生成绩表,用树或图描述遗传关系等;。
栈是数据结构中重要的线性结构,是一种特殊的线性表,只允许在表的一端进行插入或删除操作的线性表。
表中允许进行插入、删除操作的一端称为栈顶,另一端称为栈底。
栈项的当前位置是动态的,对栈顶当前位置的标记称为栈项指针。
当栈中没有数据元素时,称为空栈。
栈的插入操作称为进栈或入栈,栈的删除操作称为退栈或出栈。
栈的应用非常广泛,在日常生活中,有许多类似栈的例子,如刷洗盘子时,依次把每个洗净的盘子放到洗好的盘子上。
相当于进栈;取用盘子时,从一摞盘子上一个接一个地向下拿,相当于出栈。
在计算机中进行算术表达式的计算是通过栈来实现的。
除此之外,栈还在游戏中应用到,例如迷宫问题。
队列(Queue)是运算受到限制的一种线性表。
数据结构应用论文

数据结构应用论文在当今数字化的时代,数据结构作为计算机科学中的重要基石,其应用广泛且深远。
数据结构不仅是软件开发的基础,更是解决各种实际问题的有力工具。
从简单的日常应用到复杂的科学计算,数据结构都发挥着关键作用。
数据结构的定义可以理解为是相互之间存在一种或多种特定关系的数据元素的集合。
常见的数据结构包括数组、链表、栈、队列、树和图等。
每种数据结构都有其独特的特点和适用场景。
数组是最简单的数据结构之一,它在内存中连续存储元素,具有随机访问的优势,适用于需要频繁查找和修改特定位置元素的情况。
例如,在一个学生成绩管理系统中,可以使用数组来存储学生的各科成绩,通过索引快速获取和修改某个学生的某科成绩。
链表则与数组不同,它的元素在内存中不一定连续存储,通过指针将各个元素链接起来。
链表适用于频繁插入和删除元素的操作。
比如,在一个任务管理系统中,任务的添加和删除较为频繁,使用链表可以更高效地进行这些操作。
栈是一种具有“后进先出”特点的数据结构,常用于函数调用、表达式求值等场景。
想象一下一个自助餐厅的餐盘回收处,新放入的餐盘总是在最上面,先取出的也是最上面的餐盘,这就类似于栈的操作。
队列则是“先进先出”的代表,常用于排队系统、消息队列等。
比如银行的叫号系统,先排队的客户先得到服务。
树是一种分层的数据结构,常见的有二叉树、二叉搜索树等。
二叉搜索树在查找、插入和删除操作上具有较高的效率,常用于实现数据库的索引结构。
图则用于表示多对多的关系,在网络路由、社交网络分析等领域有着广泛的应用。
在实际应用中,数据结构的选择往往取决于具体的问题需求和性能要求。
以电商网站的商品推荐系统为例,为了快速找到与用户兴趣相关的商品,可能会使用图结构来表示用户和商品之间的复杂关系。
通过分析用户的浏览历史和购买行为,构建用户与商品的关系图,从而实现精准的推荐。
在操作系统中,进程调度也离不开数据结构。
例如,使用队列来存储等待执行的进程,根据一定的调度算法进行进程的切换和执行。
数据结构论文

数据结构论文数据结构学科是计算机科学中一门重要的基础课程。
它研究数据的组织、存储、管理和操作的方法,对于解决实际问题具有重要意义。
在本文中,我将介绍数据结构的基本概念和常见的数据结构类型,并探讨它们在算法设计和软件开发中的应用。
一、概述数据结构是计算机科学的基础块之一,它是指一组数据对象及在这些对象上的一组操作。
数据结构的设计和选择对于算法的执行效率和软件的性能至关重要。
一个好的数据结构可以提高算法的效率,同时也能简化程序代码的编写和维护。
二、数据结构的基本概念1. 线性结构线性结构是最基本的数据结构之一,它的特点是数据元素之间存在一对一的关系。
常见的线性结构有数组、链表、堆栈和队列。
数组是一种连续存储的线性结构,它的元素在内存中占据连续的地址空间。
链表则是一种离散存储的线性结构,它的元素在内存中可以分散存储。
堆栈和队列是基于线性结构的特殊形式,它们分别采用"后进先出"和"先进先出"的操作方式。
2. 树形结构树形结构是一种非线性的数据结构,它的特点是数据元素之间存在一对多的关系。
树形结构通常分为二叉树、平衡二叉树、红黑树等类型。
二叉树是最简单的树形结构,每个节点最多有两个子节点。
平衡二叉树是一种自平衡的二叉树,可以提高查找和插入操作的效率。
红黑树是一种平衡二叉树的特殊类型,它通过颜色标记节点,具有较好的平衡性和插入、删除操作的高效性。
3. 图形结构图形结构是一种非线性的数据结构,它的特点是数据元素之间存在多对多的关系。
图形结构通常用于描述网络、社交关系等复杂的实际问题。
图形结构包括有向图和无向图,以及它们的衍生类型如带权图、有向无环图等。
三、数据结构的应用数据结构在算法设计和软件开发中具有广泛的应用。
以下是其中一些常见的应用领域:1. 算法设计数据结构为算法的设计和实现提供了基础。
选择合适的数据结构可以增加算法的效率,降低时间和空间复杂度。
比如,对于大规模的数据排序问题,快速排序和归并排序是常用的算法,它们通过合理选择数据结构来提高排序效率。
数据结构论文

一、需求分析概要说明本组设计的各种排序算法,用菜单实现选择某种排序算法。
用程序实现直接插入排序算法、折半插入排序算法、谢尔排序算法、选择排序算法、堆排序算法、2-路归并排序算法、冒泡排序算法。
输入的数据形式为任何一个正整数(大小不限),输出数字大小逐个递增的数列。
程序的控制设计,不论是多简单的程序,都应该有良好的用户界面,只要程序一运行,就能从显示内容上看出这个是干什么的程序,能根据提示进行输入输出。
可以设置多级菜单,用于各级功能模块的入口,并控制好如何返回,虽然实现的功能跟顺序执行的一样,但增加了不少灵活性,一个程序就应该尽最大努力来适应用户而不是让用户来适应程序。
在具体函数的实现上也要好好斟酌算法,用以节省CPU和内存资源。
在系统软件和应用软件的开发设计过程中,都会不可能避免地遇到这样排序问题。
在数据库和知识库管理系统中,排序应用更为广泛。
在现今的高级计算机体系结构中,花费在排序上的时间占系统cpu时间的比重很大,据统计,在一些商用计算机系统中,花费在排序操作上的时间占cpu的时间可高达15%-75%。
可见,排序是值得深入研究和认真剖析的有趣课题。
二概要设计1·简要说明本组设计的功能利用不同的算法尽量缩短时间复杂度,提高查找时间效率,能够将一个案值无序的数据元素序列转换成一个案值有序的数据元素序列。
本设计由7个被调用函数和一个主函数组成。
先通过主函数mian()登录界面,显示菜单(不同的排序方法),申请一个动态空间(*c)即数组长度(排序的个数),然后输入数字排序的个数;再输入相应排序个数的数字即任何一个正整数(大小不限)。
然后输入排序算法的序号,是通过switch函数选择排序的算法(调用算法函数),由用户自己选择。
最后通过for循环语句将按数字大小逐个递增的数列输出。
程序的主要子函数声明如下:冒泡排序算法:void BubbleSort(int*k,int Count);折半排序算法:void bin_insertsort(int*k,int n);谢尔排序算法:void shellsort(int*k,int n);插入排序算法:void insertsort(int*k,int n);选择排序算法:void selectsort(int*k,int n);堆积排序算法:void adjust(int*k,int i,int n);二路归并排序算法:void MergeSort(RecType R[],int low,int high)【通过void Merge(RecType *R,int low,int m,int high)】实现这种算法;通过这些不同的算法实现数字大小的排序。
学年论文模板范文

标题:xxx(根据论文具体内容自行命名)
摘要:
本论文主要研究xxx(论文研究的问题、目的和方法等)。
通过对相
关文献的综述和实证研究的分析,得出了以下结论:1)xxx;2)xxx;3)xxx。
本研究对于解决xxx问题有一定的理论和实践价值。
关键词:xxx、xxx、xxx(根据论文具体内容自行设置关键词)
引言:
(1)背景介绍:对论文研究的问题或主题进行简要介绍,说明其理
论和实践意义。
(2)研究目的和意义:明确研究目的和意义,解释为何进行该研究。
文献综述:
(1)相关理论:对该领域相关理论进行综述,介绍前人的研究成果
和理论基础。
(2)研究现状:概括目前国内外关于该领域相关研究的主要研究方
法和结果。
方法:
(1)研究设计:阐述研究方法和研究设计,包括研究对象、数据源、研究工具等。
(2)数据分析:介绍研究数据的收集和分析方法。
结果与讨论:
(1)结果呈现:根据数据分析结果,简明扼要地描述实证研究的结果。
(2)讨论分析:对结果进行详细讨论,并与前人研究进行比较、分析。
结论:
总结研究所得出的结果,提出对该领域的启示和建议,以及进一步研究的展望。
列举本文中所引用的相关文献,格式要符合学术规范。
附录:
(例:问卷调查原始数据、图片、图表等)
以上为一个学年论文模板的框架,具体内容可根据论文的实际主题和要求进行调整和补充。
希望对你的学年论文写作有所帮助!。
数据结构论文

数据结构论文目录一、题目:实验题7.6 (2)二、实验原理: (2)2.1赫夫曼树的构造: (2)2.1.1哈夫曼树的算法 (3)2.2哈夫曼编码: (3)2.2.1哈夫曼编码的算法 (4)三、设计思想 (5)3.1概述 (5)3.2思路 (6)3.3程序流程图 (7)四、实现算法如下: (9)4.1定义存储结构和类型 (9)4.2哈夫曼树生成函数 (9)4.3哈夫曼编码函数 (10)4.4哈夫曼译码函数 (10)4.5主函数 (11)4.6仿真过程及结果 (11)五、实验总结 (12)一、题目:实验题7.6设计一个程序exp7-6.cpp,构造一棵哈夫曼树,输出对应的哈夫曼编码和平均长度。
并用下表所示的数据进行验证。
表7.8 单词及出现的频度单词The of a to and in that 出现频度1192 677 541 518 462 450 242 he is at on for His are be 195 190 181 174 157 138 124 123任务:首先要构造一个哈夫曼树,然后进行哈夫曼编码要求:可以建立函数输入二叉树,实现赫夫曼树的编码和译码系统,重复地显示并处理编码/解码功能,直到选择退出为止。
二、实验原理:2.1赫夫曼树的构造:假设有n个权值,则构造出的赫夫曼树有n个叶子结点。
n个权值分别为w1,w2,………wn,则赫夫曼树构造规则为:<1>将w1,w2,…….wn,看成有n棵树的森林。
<2>在森林中选出两个根结点最小的树合并,作为一棵新树的左右子书,且新树根结点权值为左右子树根结点权值之和。
<3>从森林中删除选取的两棵树,并将新树加入森林。
<4>重复2和3步骤,直到森林中只剩一棵树为止。
现举例如下:7 5 2 4 18116 7 117 5 7 5 6 52 4 2 4 2 42.1.1哈夫曼树的算法void CreateHT(HTNode ht[],int n) //调用输入的数组ht[],和节点数n{int i,k,lnode,rnode;int min1,min2;for (i=0;i<2*n-1;i++)ht[i].parent=ht[i].lchild=ht[i].rchild=-1; //所有结点的相关域置初值-1 for (i=n;i<2*n-1;i++) //构造哈夫曼树{min1=min2=32767; //int的范围是-32768—32767lnode=rnode=-1; //lnode和rnode记录最小权值的两个结点位置for (k=0;k<=i-1;k++){if (ht[k].parent==-1) //只在尚未构造二叉树的结点中查找{if (ht[k].weight<min1) //若权值小于最小的左节点的权值{min2=min1;rnode=lnode;min1=ht[k].weight;lnode=k;}else if (ht[k].weight<min2){min2=ht[k].weight;rnode=k;}}}ht[lnode].parent=i;ht[rnode].parent=i; //两个最小节点的父节点是iht[i].weight=ht[lnode].weight+ht[rnode].weight; //两个最小节点的父节点权值为两个最小节点权值之和ht[i].lchild=lnode;ht[i].rchild=rnode; //父节点的左节点和右节点}}2.2哈夫曼编码:构造方法如下:设需要编码的字符集合为{d1,d2,.....,dn}各个字符在电文中出现的次数集合为{w1,w2,.......,wn},以d1,d2,.........,dn作为叶子节点,以w1,w2,........,wn作为各个叶子节点的权值构造一颗哈夫曼树,规定哈夫曼树中的左分支为0,右分支为1,则从根节点到每个叶子节点所经过的分支对应的0和1组成的序列便为该节点对应字符的编码,即哈夫曼编码。
数据结构课程设计论文

数据结构数据结构课程设计(论文)题目魔方阵作者杨政冬院系信息工程学院专业信息管理与信息系统学号 1314210140 指导老师安强强答辩时间摘要我的实验题目是利用数据结构相关算法来设计——魔方阵,主要的功能是实现每一行,每一列以及对角线的相加结果相同,而且每一个数字均不相等。
本次实验能够充分的考核我们对数据结构相关算法以及C语言的学习程度、动手操作能力有极大的帮助,所以本次课程设计是十分有必要的。
我的设计内容就是利用幻方算法(劳伯法、斯特拉兹法、罗伯法、海尔法)循环语句,以及判断条件等函数的合理使用,通过不断的运行,调试,输出,对本程序进行合理的解决,对魔方阵进一步的了解掌握。
关键字:算法、C语言魔方阵程序设计AbstractMy experiment topic is the use of data structure algorithms to design - the magic square, the main function is to implement each row, every column, and diagonal together in the same result, and each number are not equal.This experiment can fully conducted by our algorithms for data structure and the degree of learning C language is of great help, hands-on ability, so the curriculum design is very necessary.My design content is to use magic square algorithm (rob, stern raz, rob, haier) loop, and the judgment function, such as the condition of reasonable use, through continuous running, debugging, output, the reasonable solution to the program, the magic square to further grasp.Key words: magic square algorithm, C language program design1 绪论计算机是随着社会的发展应运而生,它贯穿了人们生活的方方面面。
数据结构小论文

表达式求值运算一、数据结构的概念数据结构是计算机存储、组织数据的方式。
数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。
通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。
数据结构往往同高效的检索算法和索引技术有关。
根据数据元素间关系的不同特性,通常有下列四类基本的结构:⑴集合结构。
该结构的数据元素间的关系是“属于同一个集合”。
⑵线性结构。
该结构的数据元素之间存在着一对一的关系。
⑶树型结构。
该结构的数据元素之间存在着一对多的关系。
⑷图形结构。
该结构的数据元素之间存在着多对多的关系,也称网状结构。
常用结构有链表、栈、队列、数组、树、图、堆、散列表。
二、运用的数据结构——栈栈是只能在某一端插入和删除的特殊线性表。
它按照先进后出的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶,需要读数据的时候从栈顶开始弹出数据,即最后一个数据被第一个读出来。
三、构建的数学模型四、程序代码#include "stdio.h"#include <stack>#include <iostream>#include <string>using namespace std;int in(char c){switch (c){case'+':case'-':case'*':case'/':case'(':case')':case'#':return 1;default: return 0;}}//判断C是否是运算符char precede(char t1,char t2){ char f;switch(t2){case'+':case'-':if(t1=='('||t1=='#')f='<';elsef='>';break;case'*':case'/':if(t1=='*'||t1=='/'||t1==')')f='>';elsef='<';break;case'(':if(t1==')'){printf("input error\n");return (0);}elsef='<';break;case')':switch(t1){case'(':f='=';break;case'#':printf("input error\n");return (0);default:f='>';}break;case'#':switch(t1){case'#':f='=';break;case'(':printf("input error\n");return (0);default:f='>';}}return f;}//判断两个运算符的优先级int operate(int b,char theta,int a){int c;switch(theta){case'+':c=(a+b);break;case'-':c=(a-b);break;case'*':c=(a*b);break;case'/':c=(a/b);}return c;}//对两个操作数进行计算,theta是运算符int evaluateexpress(){stack<int> opnd;//声明了1个存储int型元素的栈,存储操作数opndstack<char> optr;//声明了1个存储char型元素的栈,存储运算符optr char theta,c[100];char d[]={'#','\0'};//将#放入定义的d数组int a,x,b;//初始化操作数a,x,bchar n;optr.push('#');cin>>c;strcat(c,d);//合并c,d数组,输入算术表达式时不用在末尾输入#int i=0;while(c[i]!='\0'){if(!in(c[i])){c[i]-='0';int m;m=c[i];int j=i+1;if(!in(c[j])){c[j]-='0';m=m*10+c[j];i++;}opnd.push(m);i++;}else{n=optr.top();switch(precede(n,c[i])){ //c[i]尚未入栈,n是运算符栈的栈顶元素case'<':optr.push(c[i]);break;case'=':optr.pop();break;case'>':theta=optr.top();optr.pop();a=opnd.top();opnd.pop();b=opnd.top();opnd.pop();opnd.push(operate(a,theta,b));continue;}i++;}}x=opnd.top();opnd.pop();return x;}int main(){int n=evaluateexpress();cout<<'\n'<<n;}五、结果截图输入数据:1、1+(20+4)/(4-1)2、2*9-6-(20+4)/(4-1)六、总结程序设计时,不要怕遇到错误,在实际操作过程中犯的一些错误还会有意外的收获,也不要一味相信教科书上给的代码,碰到断点逐行调试找出问题能收获更多,利用栈表达式求值这个实验中很多人用7*7的二维数组存储运算符优先级表,我觉得这是对空间的一种浪费,故采用了参考书讲解的另一种算法。
数据结构 毕业论文

数据结构毕业论文数据结构毕业论文引言:在计算机科学领域,数据结构是研究数据组织、存储和管理的一门学科。
它是计算机科学的基础知识,对于软件开发和算法设计至关重要。
本篇毕业论文将探讨数据结构的基本概念、常见的数据结构类型以及它们在实际应用中的作用。
一、数据结构的定义和基本概念数据结构是指一组数据元素及其相互之间的关系,它们之间的关系可以通过逻辑和物理方式来表示。
数据结构可以分为线性结构和非线性结构两种类型。
线性结构中的数据元素之间存在一对一的关系,而非线性结构中的数据元素之间存在一对多或多对多的关系。
二、常见的数据结构类型及其特点1. 数组数组是一种线性结构,它将相同类型的数据元素按照一定的顺序存储在连续的内存空间中。
数组的特点是可以通过索引快速访问任意位置的元素,但插入和删除操作的效率较低。
2. 链表链表也是一种线性结构,它将数据元素存储在不连续的内存空间中,并通过指针将它们连接起来。
链表的特点是插入和删除操作的效率较高,但访问任意位置的元素需要遍历整个链表。
3. 栈栈是一种特殊的线性结构,它只能在一端进行插入和删除操作。
栈的特点是后进先出(LIFO),即最后插入的元素最先被删除。
4. 队列队列也是一种特殊的线性结构,它只能在一端进行插入操作,在另一端进行删除操作。
队列的特点是先进先出(FIFO),即最先插入的元素最先被删除。
5. 树树是一种非线性结构,它由节点和边组成。
树的特点是每个节点可以有多个子节点,但每个子节点只能有一个父节点。
树的应用非常广泛,例如表示文件系统、组织结构等。
6. 图图是一种非线性结构,它由顶点和边组成。
图的特点是顶点之间可以有多条边相连,它常用于表示网络、社交关系等复杂的关联关系。
三、数据结构在实际应用中的作用1. 数据库管理系统数据库管理系统(DBMS)是一种用于管理和存储大量数据的软件。
数据结构在数据库中起着重要的作用,它可以帮助我们高效地组织和检索数据,提高数据库的性能和可靠性。
数据结构论文

数据结构论文数据结构关于链表的研究摘要:链表是数据结构中的重要概念,是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。
每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
相比于线性表顺序结构,链表比较方便插入和删除操作。
关键词:链表;指针;插入;删除1.引言链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。
由于不必按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表:顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。
但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
在计算机科学中,链表作为一种基础的数据结构可以用来生成其它类型的数据结构。
链表通常由一连串节点组成,每个节点包含任意的实例数据(data fields)和一或两个用来指向明上一个/或下一个节点的位置的链接("links")。
链表最明显的好处就是,常规数组排列关联项目的方式可能不同于这些数据项目在记忆体或磁盘上顺序,数据的存取往往要在不同的排列顺序中转换。
而链表是一种自我指示数据类型,因为它包含指向另一个相同类型的数据的指针(链接)。
链表允许插入和移除表上任意位置上的节点,但是不允许随机存取[1]。
链表有很多种不同的类型:单向链表,双向链表以及循环链表。
链表可以在多种编程语言中实现。
像Lisp 和Scheme这样的语言的内建数据类型中就包含了链表的存取和操作。
毕业论文提纲模板范文:数据结构课程建设

毕业论文提纲模板范文:数据结构课程建设题目:主标题数据结构课程建设副标题——网络教学平台的设计与现实关键词:网络教学asp 网络课程摘要:本问简要介绍了关于网络教学的意义,以及我过网络教学的模式现状,网络教学平台的设计与现实目录;摘要————————————————————(300字)引言————————————————————(500字)一,网络教学(xx字)1.1 .网络教学现状-----------------------------------1.2.网络教学与传统教学的比较分析--------------1.3.网络教学的优势-------------------------------二,网络课程(xx字)2.1. 教育建设资源规范-----------------------------2.2. 我过网络课程模式现状与问题的思考------------------三, 网络教学平台设计的理论基础(xx字)四, 网络教学平台功能描述(1000字)公告板--课堂学习--答疑教室--概念检索--作业部分--试题部分--算法演示------- 技术文章--课件推荐--课件下载--资源站点--管理部分五,网络教学平台的设计与现实(xx字)5.1.课堂学习-----------------------------5.2. 公告板------------------------------------5.3.概念检索-----------------------------5.4.技术文章---------------------------------六,数据库部分的设计与现实(1000字)----------七,用户管理权限部分的设计与实现(1000字)------八,结论(500字)------------------------------九,参考文献(200字)----------------------。
数据结构论文

数据结构论文题目:数据结构院(部)名称:学生姓名:专业:指导教师姓名:论文提交时间:学位授予时间:论文题目:数据结构前言数据结构与算法这门课程中,基础性实验设计十分重要。
虽然有许许多多的关于数据结构与算法的书籍,但这些书籍基本上都是着重理论讲解,很少对课程中所涉及的实验进行单独的研究与开发。
而本论文通过单独及全面的强化课程的核心实验研究,进一步利用C语言进行编程和调试程序,能够利用C语言编写较复杂的程序,加深对教学内容的理解,验证所学的算法和数据结构,培养了设计数据结构的能力和根据数据结构设计算法的能力,掌握了非数值问题的数据结构和算法的设计方法,通过对具体问题的分析、设计和实现,培养了软件开发所需要的实践能力。
什么是数据结构;《数据结构》作为计算机专业的一门专业基础课,其主要内容包括将现实世界转化为在计算机世界中的抽象的数据描述,数据在计算机中的组织以及不同数据类型的基本操作实现等,是相对比较难于理解和掌握的课程。
它不仅要有计算机方面的高级语言、计算机基础和计算机组成原理等软硬件基础知识,还需要有一定的如离散数学等数学理论。
这门课程也是联系一般基础课和专业课的“桥梁”,它既是程序设计的入门课程,也是诸如操作系统、编译原理、计算机网络以及数据库原理等后续课程的重要的基础课程,它不仅是构筑这些课程体系与知识结构的核心课程之一,同时对奠定学生计算机专业的基础具有重要意义从多年对计算机专业的学生跟踪情况看,数据结构课程掌握的程度与学生对学习后续课程的积极性密切相关,甚至影响到对整个专业知识的掌握。
对毕业学生工作情况的跟踪调查看,工作中的程序设计能力也需要有数据结构的相关知识。
一般来说,具有较好数据结构基础知识的学生,在工作过程中适应工作变动、开辟新的研究阵地的能力较强。
从而能较好地紧跟信息技术的高速发展。
在计算机当中数据结构是计算机的基础但是也是很重要的一门专业课,学好并了解其中的知识对今后的社会和经济发展起到很好的促进作用。
数据结构论文

级课程(设计)论文题目阿克曼函数专业班级学号学生姓名指导教师指导教师职称学院名称完成日期:年月日武汉工程大学本科课程设计(论文)目录目录 (I)摘要 (II)前言 (II)第1章绪论 (1)1.1课题背景 (1)1.2课题意义 (1)1.3文献综述 (1)第2章课题的具体分析及程序的实现 (1)2.1 课题分析 (1)2.2 递归算法 (3)2.2.1 递归 (3)2.2.2 递归算法程序的设计 (3)2.2.3 实验结果 (3)2.3 利用栈的非递归算法 (9)2.3.1 栈 (9)2.3.2 主要成员函数的设计 (9)2.3.3利用栈的非递归算法程序的设计 (88)2.3.4实验结果 (99)2.4算法的复杂性分析 (10)2.5存在的问题及改进 (10)第3章总结 (11)致谢 (11)参考文献 (11)附录 (15)武汉工程大学本科课程设计(论文)摘要“数据结构”是计算机程序设计的重要理论技术基础,它是计算机学科的核心课程。
用数据结构中的知识、算法、思想解决一些实际问题可使得一些问题变得一目了然,易懂。
本课程设计的目的是通过C++语言平台实现阿克曼函数问题的算法设计,采用递归调用和以栈作为存储的非递归调用的方法解决,使抽象的数学问题程序化,并一目了然,更便于理解。
关键词:数据结构,阿克曼函数,递归,非递归武汉工程大学本科课程设计(论文)前言本文解决了递归和非递归方法实现阿克曼函数的问题,同时在非递归调用时利用了栈作为元素的存储空间。
全文共3章,详细的介绍了对本课题的算法设计过程及类容。
第1章介绍了课题背景和课题的意义。
在本章中,还给出了我们查阅并借用的一些参考文献的主要内容。
第2章主要介绍了课题的分析与算法的设计,对存在的问题作了简要分析并予以改进以及算法的复杂性的分析。
第3章是本次课程设计的总结。
全文的最后是致谢、参考文献和对程序优化处理的源代码。
高金金2011-1-6于武汉工程大学理学院武汉工程大学本科课程设计(论文)第1章 课题背景1.1课题背景阿克曼函数是数学中的经典问题,是非原始递归函数的例子。
数据结构图的算法的毕业论文---精品模板

图图形结构是一种比树形结构更复杂的非线性结构.树形结构中的结点之间具有明显的层次关系,且每一层上的结点只能和上一层中的一个结点相关,但可能和下一层的多个结点相关。
在图形结构中,任意两个结点之间都可能相关,即结点与结点之间的邻接关系可以是任意的。
因此,图形结构可用来描述更加复杂的对象。
1 图的基本概念和存储结构1。
1 图的定义图(Graph )是由非空的顶点集合V 与描述顶点之间关系--边(或者弧)的集合E 组成,其形式化定义为:G=(V , E)如果图G 中的每一条边都是没有方向的,则称G 为无向图。
无向图中边是图中顶点的无序偶对。
无序偶对通常用圆括号“( )”表示.例如,顶点偶对(v i ,v j )表示顶点v i 和顶点v j 相连的边,并且(v i ,v j )与(v j ,v i )表示同一条边。
如果图G 中的每一条边都是有方向的,则称G 为有向图。
有向图中的边是图中顶点的有序偶对,有序偶对通常用尖括号“< >"表示.例如,顶点偶对<v i ,v j 〉表示从顶点v i 指向顶点v j 的一条有向边;其中,顶点v i 称为有向边〈v i ,v j >的起点,顶点v j 称为有向边<v i ,v j 〉的终点。
有向边也称为弧;对弧〈v i ,v j 〉来说,v i 为弧的起点,称为弧尾;v j 为弧的终点,称为弧头。
图是一种复杂的数据结构,表现在不仅各顶点的度可以不同,而且顶点之间的逻辑关系也错综复杂。
从图的定义可知:一个图的信息包括两个部分:图中顶点的信息以及描述顶点之间的关系——边或弧的信息。
因此无论采取什么方法来建立图的存储结构,都要完整、准确地反映这两部分的信息。
为适于用C 语言描述,从本节起顶点序号由0开始,即图的顶点集的一般形式为:V={v 0,v 1,…,v n —1}。
下面介绍几种常用的图的存储结构。
1.2 邻接矩阵所谓邻接矩阵存储结构,就是用一维数组存储图中顶点的信息,并用矩阵来表示图中各顶点之间的邻接关系。
数据结构小论文
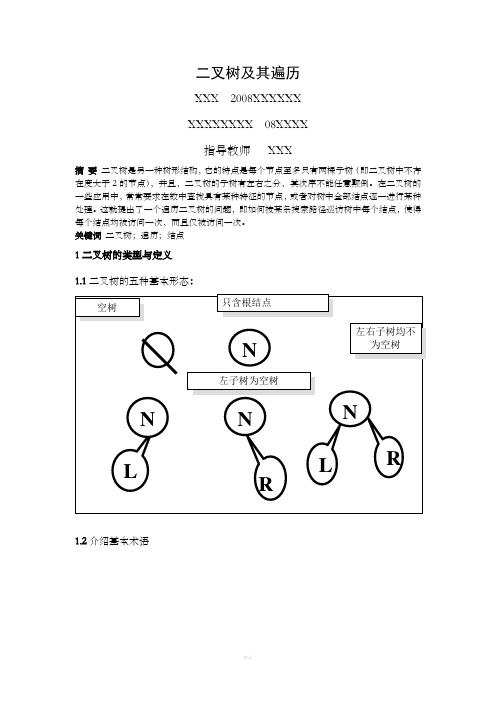
二叉树及其遍历XXX 2008XXXXXXXXXXXXXX 08XXXX指导教师XXX摘要二叉树是另一种树形结构,它的特点是每个节点至多只有两棵子树(即二叉树中不存在度大于2的节点),并且,二叉树的子树有左右之分,其次序不能任意颠倒。
在二叉树的一些应用中,常常要求在数中查找具有某种特征的节点,或者对树中全部结点逐一进行某种处理。
这就提出了一个遍历二叉树的问题,即如何按某条搜索路径巡访树中每个结点,使得每个结点均被访问一次,而且仅被访问一次。
关键词二叉树;遍历;结点1二叉树的类型与定义1.1二叉树的五种基本形态:1.2介绍基本术语1.2二叉树的性质性质1 :在二叉树的第i层上至多有2i-1个结点。
(i≥1)用归纳法证明:归纳基:i = 1层时,只有一个根结点,2i-1 = 20 = 1;归纳假设:假设对所有的j,1≤j < i,命题成立;归纳证明:二叉树上每个结点至多有两棵子树,则第i 层的结点数= 2i-2´ 2 = 2i-1 。
性质2 :深度为k 的二叉树上至多含2k-1 个结点(k≥1)证明:基于上一条性质,深度为k 的二叉树上的结点数至多为20+21+ × × × × × × +2k-1 = 2k-1性质3 :对任何一棵二叉树,若它含有0n个叶子结点、2n个度为2 的结点,则必存在关系式:0n=2n+1证明:设二叉树上结点总数n= 0n+ 1n+ 2n又二叉树上分支总数b= 1n+22n而b= n-1 =0n+1n+ 2n- 1由此,0n= 2n+ 1两类特殊的二叉树:性质4 :具有n 个结点的完全二叉树的深度为ëlog2nû +1证明:设完全二叉树的深度为k则根据第二条性质得2k-1≤n < 2k即k-1 ≤log2 n < k因为k 只能是整数,因此,k =ëlog2nû + 12二叉树的遍历2.1对“二叉树”而言,可以有三条搜索路径:1.先上后下的按层次遍历;2.先左(子树)后右(子树)的遍历;3.先右(子树)后左(子树)的遍历。
数据结构学年论文

目录摘要 (1)关键词 (1)前言 (2)1.拓扑排序的定义 (3)2.图的邻接表表示 (4)2.1邻接表的定义 (4)2.2邻接表的存储方式 (5)2.3用邻接表构造有向图 (6)2.4有向图中顶点的入度 (6)3.拓扑排序 (7)3.1拓扑排序的方法 (7)3.2举例说明 (7)4.在计算机中实现拓扑排序 (8)5.参考文献 (10)拓扑排序摘要:在现代化管理中,人们常用有向图来描述和分析一项工程的计划和实施过程,一个工程常被分为多个小的子工程,这些子工程被称为活动(Activity),在有向图中若以顶点表示活动,有向边表示活动之间的先后关系,这样的图简称为AOV网。
在AOV网中为了更好地完成工程,必须满足活动之间先后关系,需要将各活动排一个先后次序即为拓扑排序。
关键词:拓扑排序、拓扑有序Abstract: in modern management, people commonly used directed graph to describe and analysis of a project plan and implementation process, a project are often divided into a number of small son engineering, the child project called activities (Activity), in the directed graph with vertices if said activities, directed edge between the said activities have relations, so chart referred to as AOV net. In the AOV net in order to better perform engineering, must meet between activities have relations, need to each activity row a sequence that is for topological sort.Keywords: topological sort, topology and orderly1前言:什么是拓扑排序?从离散数学的角度来看,拓扑排序就是由某集合上的一个偏序得到该集合上的一个全序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
学年论文
(数据结构、2015-2016第二学期)
题目:
作者:
所在学院:信息科学与工程学院
专业年级:计算机13-2班
指导教师:吐尔地·托合提
职称:副教授
年月日
1 系统概述
本程序是一个学生成绩管理程序,主要功能包括学生成绩的输入,查询,排序,删除,统计等。
输入功能是按照已指定的格式输入学生信息并存储。
;查询功能是。
;排序功能是。
;删除功能是。
;统计功能是。
2 系统结构及流程
给出系统总体结构图或流程分析…..
3 存储结构定义和说明
顺序还是链式(链表或数组定义和说明)
4 函数设计
函数1原型:Score_Sort(float score);
功能:学生成绩自动排名;
入口参数:要排列的数组名score;
返回值:无;
函数2原型:int max(float score,long num);
功能:求出最高成绩对应的学号;
入口参数:成绩数组名score,学号数组名num;
返回值:最高成绩对应的学号;
函数3原型:int min(float score,long num);
功能:……..
入口参数:……..
返回值:………
5 系统使用说明及运行结果
本系统以一级菜单形式操作,启动系统时出现如下菜单,如下图所示:
当输入学生成绩后,输入代码5,可以对输入的学生的成绩进行排名,如下图所示:
6 总结和体会
通过本学期数据结构小学期……
7 程序代码:
void SortData(SqLinkList &L){ //学生成绩排名;Node *p1,*p2,*q=0; //q是上次最后一次交换的地点;bool s=true; //是否发生了交换;
int t=1;
if(L.length){
//当线性表不为空时进行排序;
while (s){ //优化冒泡排序法;
s=false;。