清华大学编译原理第七章 LR分析法
7 编译原理-LR分析法

B 是产生式,则项目 B . 对活前缀 = 1 也是有 效的。
:伽马 :艾塔
据假设,存在一个规范推导S *Aw 1 B 2w
设2w
*
rm
xw,
则对任何B
有规范推导
S *Aw 1 B 2w 1 B xw 1 xw
所以 B . 对活前缀 1 也是有效的。
r1 r1 r1 r1
r2 r2 r2 r2
r3 r3 r3 r3
r5 r5 r5 r5
r4 r4 r4 r4
r6 r6 r6 r6
goto AB
6 7
8 9
第十四页,编辑于星期五:十点 三十四分。
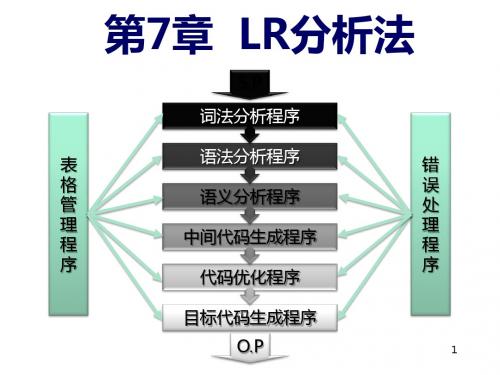
三、LR分析器的结构和工作过程
LR分析器的结构如图,它的工作过程由算法1描述。
输入 a1 ... ai ... an #
+
I6 E E+ T
T E E+ T T T*F
I9
T T*F
(
T F F (E)
F I3
*
I4 F ( E)
E E+T E T
( T T*F
T F F (E)
F id
id
T
I8
I5
I7
F
I2
E F (E ) E + E+T
I6
I3
F id
(
id
I5
)
F (E) I11
F I3 T F
4. 其余情况报错.
第十八页,编辑于星期五:十点 三十四分。
SLR分析算法
算法2 (构造SLR分析表)
输入:一个拓广文法G
输出:对于G的分析表的action 子表和goto子表
编译原理_06_07LR语法分析方法与中间代码

属性可以分为综合属性和继承属性两类。综合属性一 般用于自下而上传递信息,而继承属性常常用于自上而 下传递信息。下述为简单算术表达式求值的属性文法: 规则 语义规则 1. S→E print(E.val) 2. E→E1+T E.val := E1.val+T.val 3. E→T E.va1 := T.valv 4. T→T1 F T.val := T1.val F.val 5. T→T1 T.val := T1.val 6. F→(E) F.val := E.val 7. F→digit F.val := digit.lexval 每一个非终结符都有一个表示整数值的属性val。规 则左部符号E、T、F的属性值取决于各自规则的右部, 称为综合属性;对于文法符号S,其属性是虚的或空的。
6
2. 分析器的动作决定于栈顶状态和当前输入符号,有 四种可能:
(1) 移进:栈顶未出现句柄,当前输入符号进符号栈, 状态转换,新的状态进状态栈; (2) 归约:栈顶出现句柄,按某个产生式进行归约。 归约后的文法符号进符号栈,同时根据状态转换 表,新状态进状态栈。 (3) 接受(acc) :符号栈只剩开始符且当前输入符号为 ‘#’,则分析成功。 (4) 出错(error) :栈顶状态与当前输入符不匹配。
17
例如:若有项目集{ A· , B· }此时 栈顶为,根据项目集无法确定是移进还是归约。 项目集是不相容的。
2. LR(0)分析表的构造 构造原则: 设有文法 G[S],则LR(0)分析表的构造规则为: 对于A · XIk,且GO (Ik,X)= Ij 若X Vt,则置action[Ik,X]= Ij 若X Vn,则置goto[Ik,X]=j
15
(5) 项目类型: 项目类型有归约项目、移进项目、待约项目 和接受项目。 归约项目:圆点后符号为 的项目称为归约 项目。 如:A · 此时已对分析结束,栈顶句柄形 成,从而可按相应的产生式进行归约。 移进项目:符号为终结符的项目称为移进项 目。如A · X , X VT 此时X进符号栈,相应状态进状态栈。 待约项目:圆点后符号为非终结符的项目, 称为待约项目。此时期待着向X进行归约。
第七章LR分析法

识别活前缀的DFA
拓广文法G[S]: 句子abbcde的可归前缀:
S’ → S[0]
S[0]
S → aAcBe[1] ab[1]
A → b[2]
aAb[3]
A → Ab[3]
aAcd[4]
B → d[4]
aAcBe[1]
识别活前缀及可归前缀的有限自动机
0S 2a
a 5
a 9
14 a
1*
b
3
4
6 A7b
第7章 LR分析法
LR分析法
自底向上分析法的关键是如何在分析过程中 确定句柄
LR分析法给出一种能根据当前栈中的符号 串进行分析的方法,即:向右查看输入串的 K个符号就可以唯一确定分析器的动作是移 进还是归约;用哪个产生式归约。
因而也就能唯一地确定句柄 R 最右推导
规范推导 规范句型 规范归约
LR分析算法
then begin pop || 令当前栈顶状态为S’ push GOTO[S’,A]和A(进栈)
end else if ACTION[s,a]=acc
then return (成功) else error end.重复
7.2 LR(0)分析
例 G[S]: S aAcBe A b A Ab B d
⇔aAcBe[1]
用(1)规约,前部aAcBe[1]
⇔S
这些前部符号串为归约时在栈里的符号串, 规范句型的这种前部称为可归前缀。
可归前缀和子前缀
分析上述每个前部的前缀,对应分别为:
ab[2]
,a,ab
aAb[3] ,a,aA,aAb
aAcd[4] ,a,aA,aAc,aAcd
aAcBe[1] ,a,aA,aAc,aAcB,aAcBe
第07章、LR分析法
10
三、 LR分析器
1. LR分析器的组成 由3部分组成:总控程序、分析表、分析栈。 2. LR分析器的构造 (1) 构造识别文法活前缀的确定有限自动机 (2) 根据该自动机构造相应的分析表(ACTION表、GOTO表)
圆点不在产生式右部最左边的项目称为核,唯一的 例外是S’ → • S。因此用GO(I,X)转换函数得到的J为 转向后状态所含项目集的核。 使用闭包函数(CLOSURE)和转换函数(GO (I,X)) 构造文法G’的LR(0)的项目集规范族,步骤如下: (1) 置项目S’→ • S为初态集的核,然后对核求闭包 CLOSURE({S’→ • S})得到初态的项目集; (2) 对初态集或其它所构造的项目集应用转换函数GO (I,X)= CLOSURE(J)求出新状态J的项目集; (3) 重复(2)直到不出现新的项目集为止。
28
例:文法G[S]: (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d
a S2 ACTION c e b d # acc S5 r2 r3 r4 r1 S4 S6 r2 r3 r4 r1 3 r2 S8 r3 r4 r1 r2 r3 r4 r1 GOTO S A B 1
是否推导出abbcde?
每次归约句型的 前部分依次为: ab[2] aAb[3] aAcd[4] aAcBe[1]
9
二、LR分析要解决的问题
• LR分析需要构造识别活前缀的有穷自动机
可以把文法的终结符和非终结符都看成有 穷自动机的输入符号,每次把一个符号进 栈看成已识别过了该符号,同时状态进行 转换,当识别到可归前缀时,相当于在栈 中形成句柄,认为达到了识别句柄的终态。
编译第七章LR分析方法

LR 文法 对于一个上下文无关文法 , 如果能够构造一 张 LR 分析表, 使得它的每一个入口均是唯 一的(Si,rj,acc,空白),则称该上下文无关 是LR 文法.
15
7.1 LR分析概述
对于一个文法,状态集是如何确定的? LR分析表是如何构造的? 引入可归前缀与活前缀概念
16
7.1 LR分析概述
9
文法G[S]: (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d
步骤 符号栈
1) 2) 3) 4) 5) 6) 7) # #a #ab #aA #aAb #aA #aAc
输入符号串
abbcde# bbcde# bcde# bcde# cde# cde# de#
1) 2) # #a abbcde# bbcde#
动作
移进 移进
状态栈
0 02
ACTION
S2 S4
GOTO
对输入串abbcde#的LR分析过程
S
1 * 2 5
d
b
4 3 7
b
e
0
a
A
c B
6 9
29
8
步骤 符号栈 输入符号串
1) 2) 3) # #a #ab abbcde# bbcde# bcde#
then begin pop || 项 若当前栈顶状态为Sk push GOTO[Sk,A] 和A(进栈) end else if ACTION[Si,a]=acc (接受) then return (成功) else error (出错) end . (重复结束)
8
例6.1文法
例6.1:G[S]为: (1)S aAcBe (2)A b (3)A Ab (4)B d
wsx(编译原理第07章) LR分析法

LR分析法是给出一种能根据当前分析栈中的 符号串(通常以状态表示)和向右顺序查看输入 串的K个(K>=0)符号就可唯一地确定分析器的 动作是移进还是归约和用哪个产生式归约,因而 也就能唯一地确定句柄。 LR分析法的归约过程是规范推导的逆过程, 所以LR分析过程是一种规范归约过程。
LR(k)分析法可分析LR(k)文法产生的语言 –L :从左到右扫描输入符号, –R :最右推导对应的最左归约(反序完成最右推导)
第七章
• • • • • •
LR分析法
LR分析概述 LR(0)分析 SLR(1)分析 LR(1)分析 LALR(1)分析 二义性文法在LR分析中的应用
第1页,102页
• 前一部分我们已讨论过,自底向上分析方法是一种移 进-归约过程。 • 先复习一下:移进-归约分析
• 上一章的优先分析方法是当分析的栈顶符号串形成句 柄时就采取归约动作,因而自底向上分析法的关键问 题是在分析过程中如何确定句柄。 • 算符优先分析法存在的问题 –强调算符之间的优先关系的唯一性,这使得它的 适应面比较窄 –算法在发现最左素短语的尾时,需要回头寻找对 应的头
S
1 * 2 5
d
b
4 3 7
b
e
0
a
A
c B
6 9
第21页,102页
8
步骤 符号栈 输入符号串
动作
移进 移进 归约(A→b) 移进 归约(A→Ab) 移进 移进
S A B
8)
9) 10) 11)
# aAcd
#aAcB #aAcBe #S
e#
e# # #
归约(B→d)
移进 归约(S→aAcBe) 接受
A
对输入串abbcde#的移进-规约分析过程
编译原理第七章

安徽理工大学
《编译原理》 信息安全系 赵宝
2
空串ε。
定义:对于文法G[S],若有
S
* r
αβ,β∈Vt*
则称α为规范前缀,也称为活前缀。
若α是含句柄的活前缀,并且每个句柄是α 的后缀或本身,则称α是可归规范前缀或可归 前缀(含有句柄的活前缀)。
活前缀不含句柄之右的任何符号。 是规范
由此可见,构造LR分析器的主要工作是构造 分析表
•LR分析表的组成: LR分析表由分析动作(ACTION)表和状态转换 (GOTO)表组成。
1). 分析动作表
安徽理工大学
《编译原理》 信息安全系 赵宝
ቤተ መጻሕፍቲ ባይዱ
10
在分析动作表中,其元素由action(si,aj)来表 示。action(si,aj)表示当前分析栈的状态栈栈顶 元素为si,文法符号栈栈顶元素为aj(当前输入 符号)时,所执行的动作。
特殊符号也可以用“.”,并且要加在产生 式右部的任何地方,表示一个位置。
➢项目集:若干个项目组成的集合称为项目集, 又称为配置集合。
➢后继符号:项目中紧跟在特殊符号“△”后 面的符号称为该项目的后继符号。
安徽理工大学
《编译原理》 信息安全系 赵宝
18
后继符号表示下一时刻读到的符号。有如下两 种情况:
下面我们以输入串 #a,b,a# 为例,具体讲述LR分析过程。
安徽理工大学
《编译原理》 信息安全系 赵宝
15
状态栈 S0 S0S3
S0S2
S0S2S5 S0S2S5S4
S0S2S5S2
S0S2S5S2S5 S0S2S5S2S5S3
S0S2S5S2S5S2
《编译原理》第7章LR分析法

7.2 LR(0)分析表的构造4.构造LR(0)分析表——举例G[S′]:[0] S′→S [1] S→S(S)[2] S→εG[S]:[1] S→S(S)[2] S→εG[S]:[0] S′→SS′→.SS→.S(S)S→S.(S)S→.S(S) S→.7.3 SLR(1)分析表的构造1.LR(0)方法的不足LR(0)分析表的构造方法实际上隐含了这样一个要求:构造出的识别规范句型活前缀的有穷自动机中,每个状态均不能有冲突项目,这显然对文法的要求太高,也限制了该方法的应用。
7.3 SLR(1)分析表的构造1.LR(0)方法的不足例如,对文法G[S]:0S→E1 E→E+T2 E→T3 T→T*F4 T→F5 F→(E)6 F→i1I S→E.E→E.+TT→.T*F T→.FFT E #)(*+i G[S]:7.3 SLR(1)分析表的构造2.LR(0)方法的问题分析状态{ E→T.,T→T.*F}该状态含有移进-归约冲突,在分析表中表现为重定义。
7.3 SLR(1)分析表的构造2.LR(0)方法的问题①若U→x.ay ∈Ii ,且GO(Ii,a)=Ij,a∈VT,则ACTION[i,a]=“Sj”。
②若S′→S. ∈Ii,则置ACTION[i,$]=“acc”。
③若U→x. ∈Ii ,则对任意终结符a和$,均置ACTION[i,a]=“rj”或ACTION[i,$]=“rj”。
④若GOTO(Ii ,U)=Ij,其中U∈VN,则置GOTO[i,U]=“j”。
⑤除上述方法得到的分析表元素外,其余元素均置“报错标志”。
7.3 SLR(1)分析表的构造3.解决问题的方法所以在状态{ E→T.,T→T.*F}中,只需要向前看下一输入符号是*,还是FOLLOW(E)中的符号,便可解决冲突了。
7.3 SLR(1)分析表的构造3.解决问题的方法假设一个状态Ii中含有冲突项目I i ={ U1→x.b1y1,U2→x.b2y2,…,Um→x.bmym,V1→x.,V 2→x.,…,Vn→x.}若{b1,b2,…,bm}和FOLLOW(V1)、FOLLOW(V2)、…、FOLLOW(Vn)两两互不相交,就可以采用向前看一个输入符号的方法来解决状态中的冲突。
编译原理LR分析法

编译原理是研究如何将高级语言程序转换成等价的低级机器语言程序的学科, LR分析法是其中一种重要的语法分析方法。
何为编译原理
编译原理是计算机科学的一个分支,研究将高级语言程序转换为等价的底层机器代码的过程。它涉及词法分析、 语法分析、语义分析、优化和代码生成等多个阶段。
LR分析法的概述
LR分析法的步骤
1
1. 构建LR项集族
基于文法的产生式,生成LR(0)项集族,
2. 构建LR分析表
2
包括起始项集和其它项集。
根据LR项集族和文法的终结符和非终结
符,构建LR分析表,包括移进、规约和
接受操作。Leabharlann 33. 进行语法分析
使用构建的LR分析表,对输入的符号串 进行逐步解析,直到接受或出错。
构建LR分析表
项集的闭包
通过对项集进行闭包运算,计算 出项集中的所有项。
项集的转移
根据项目集的状态和接收符号, 进行项集的状态转移。
规约项的处理
确定规约的产生式和规约动作, 构建规约表。
LR分析表的使用
使用构建的LR分析表,可进行能够解析输入符号串的自底向上语法分析。它 根据输入符号和栈顶符号,执行移进、规约或接受操作来推导和验证语法结 构。
优缺点和应用
优点
具有广泛适用性,支持大多 数上下文无关文法。解析效 率高,能够快速生成语法树。
缺点
对于某些复杂的语法,可能 需要构建大型的分析表。编 写LR分析器的难度较高。
应用
LR分析法被广泛用于编译器 设计、解析器生成器和语法 分析工具的开发中。
LR分析法是一种自底向上的语法分析方法,用于构建一个确定性的有限状态 自动机(LR自动机)以解析各种语法结构。它具有广泛的应用,包括编译器 设计和语法分析工具的开发。
编译原理7

§3.7 LR分析器(LR Parser)*本节提出一种有效的﹑自下而上的语法分析技术, LR(k) 分析技术, 它能适用于一大类上下文无关文法的分析.*其中:L表示从左到右扫描输入符号串,R表示构造最右推导的逆过程, k表示在作分析决定时要向前看k个输入符号. 在实际的编译器中,我们只考虑k=0或k=1的情形. 当(k)省略时,表示k=1.一.LR分析方法的优缺点优点:能够构造LR分析器来识别所有能用上下文无关文法写的程序设计语言的结构.LR分析方法是已知的最一般的无回溯移进―归约方法.它能够和其它移进―归约方法一样有效地实现.LR分析方法能分析的文法类是预测分析法能分析的文法类的真超集(proper superset).*LR分析方法向前看k个符号只需看右句型中某个产生式右边的k个符号,而预测分析方法向前看k个符号要看某个产生式右边的文法符号能推出的前k个符号. 因此,LR分析法比LL分析法简单,适用的文法类更广.LR分析器能及时察觉语法错误,在自左向右扫描输入时,尽可能快地发现错误.缺点:对典型的程序设计语言文法,手工构造LR 分析器工作量太大.*目前已有许多自动生成LR 分析器的生成器, 例如: Yacc.二. LR 分析算法1.结构: (见书 P248)栈中: s 0X 1s 1X 2s 2…X m s m其中: s i : 状态(state) , X i : 文法符号(grammar symbol)分析表: 动作函数action 和转移函数goto2. 动作: 根据当前栈顶状态s m 和当前输入符号a i , action[s m ,a i ]有四种可能动作:(1) 移进(shift)s, s 是一个状态(2) 按文法产生式A →β归约(reduce)(3) 接受(accept)(4) 出错3. 活前缀(viable prefix)文法G 的活前缀是它的右句型(right sentential form)的前缀, 它不超过该句型中最左句柄(handle)的右端.例: 文法 E →E+T | T , T →T *F | F , F →(E) | id , 存在最右推导: E rm ⇒T rm ⇒T *F rm ⇒T *id rm ⇒F *id rm⇒(E)*id (, (E, (E) 都是右句型(E)*id 的活前缀.4. 格局(configuration):栈中内容: s0X1s1X2s2…X m s m, 剩余输入串: a i a i+1…a n$组成当前格局: (s0X1s1X2s2…X m s m, a i a i+1…a n$)这个格局代表右句型: X1X2…X m a i a i+1…a n5. 分析器动作: 设当前格局是(s0X1s1X2s2…X m s m, a i a i+1…a n$)(1)如果action[s m,a i] =移进s, 分析器进入格局:(s0X1s1X2s2…X m s m a i s, a i+1a i+2…a n$)(2)如果action[s m,a i] =归约A→β, 分析器进入格局:(s0X1s1X2s2…X m-r s m-r As, a i a i+1…a n$)其中: s = goto[s m-r , A], r是β的长度.这里分析器首先从栈中弹出2r个符号,包括r个状态和r个文法符号,这些文法符号刚好匹配产生式的右部β,即β=X m-r+1X m-r+2…X m.(3)如果action[s m, a i] =接受, 分析完成.(4)如果action[s m,a i] =出错, 分析器发现错误,调用错误恢复例程.6. 例子: 文法(1)E→E+T(2)E→T(3)T→T*F(4)T→F(5)F→(E)(6)F→id分析表(parsing table) (见书P252)给出串id*id+id的移进―归约过程.(见书P253)*注意: 在实际的LR分析器中, 栈中不保存文法符号, 栈顶的状态代表栈中的内容.三.构造SLR分析表1.项目(item): 是右部的某个地方加点的G的产生式.例如: 产生式A→XYZ有项目: A→.XYZA→X.YZA→XY.ZA→XYZ.产生式A→ε只有一个项目 A→.*解释项目中加点的意义.2. 拓广文法(augmented grammar):在文法G中引入产生式: S’→ S, 得拓广文法G’, S’是G’的开始符号,S是G原来的开始符号.*引入这个新的产生式的目的是指出什么时候分析结束,宣布接受输入串.3. 闭包函数设I是项目集, 那么closure(I)是由下面两条规则从I构造的项目集(set of items):(1)初始, I的每个项目都加入closure(I);(2)如果A→α.Bβ在closure(I)中, 且B→γ是产生式, 那么, 如果B→.γ不在closure(I)中, 则把它加入.反复运用这条规则, 直到没有更多的项目可加入closure(I)为止.*A→α.Bβ的直观意义和B→.γ加入closure(I)的意义. 例: 文法: E’→EE→E+T | TT→T*F | FF→(E) | id设I = { E’→.E }, 那么closure(I)为{ E’→.E ,E→.E+T ,E→.T ,T→.T*F ,T→.F ,F→.(E) ,F→.id }4. 核心项目与非核心项目(kernel items and nonkernel items) (1)核心项目: 它包括初始项目S’→.S和所有点不在左端的项.(2)非核心项目: 它们的点在左端.*一个项目集可以只保留核心项目, 并通过求闭包求得该项目集.5. goto函数:设I是项目集, X是文法符号, 并设I中包含项目A→α.Xβ . 那么goto(I,X) = closure(I’), 其中I’是包含A→αX.β的项目集.例: I = { E’→E. , E→E.+T }goto(I, +)包含: E→E+.T T→.T*F T→. FF→.(E) F→. id6. 求拓广文法G’的LR(0)项目集规范族(canonical collection of sets of LR(0) items) 的算法Procedure item(G’);BEGINC := { closure({[S’→.S]})};REPEATFOR C的每个项目集I和每个文法符号X DOIF goto(I, X)非空且不在C中THEN把goto(I, X)加入C;UNTIL 本次循环没有项目集可以加入CEND例子: 文法: E’→E , E→E+T | T , T→T*F | F , F→(E) | idLR(0)项目集规范族(见书P244)该项目集规范族可构成一个DFA (见书P244)7. 构造SLR分析表算法输入: 拓广文法G’输出: G’的SLR分析表函数action和goto方法:(1)构造C = {I0, I1, …, I n }, 即G’的LR(0)项目集规范族.(2)状态i从I i构造, 它的分析动作如下确定:a)如果[A→α.aβ]在I i中, 并且goto(I i , a) = I j , 那么置action[i, a]为sj .b)如果[A→α.]在I i中, 那么对所有FOLLOW(A)中的a,置action[i, a]为rj, j是产生式A→α的编号.c)如果[S’→S.]在I i中, 那么置action[i, $]为接受acc.(3)对所有的非终结符A, 使用下面规则构造状态i的转移:如果goto(I i , A) = I j , 那么goto[i, A] = j .(4)不能由规则(2)和(3)定义的条目都置为出错.(5)分析器的初始状态是从包含[S’→.S]的项目集构造的状态.8. 例子: 从第6条的文法和LR(0)项目集规范族构造分析表(见书P252)9. 非SLR文法*若对某个文法G, 按上述方法构造的SLR分析表的每一个条目都没有多重定义, 那么该文法G称为SLR文法.*存在非SLR的上下文无关文法.例: 文法: S→L=R | RL→*R | idR→LLR(0)项目集规范族(见书P255).*项目集I2面临输入“=”时, 产生移进/归约冲突.*该文法虽然不是二义文法, 但也不是SLR文法.阅读: 教材 4.6 节作业:1.考虑下面文法E→E+T | TT→TF | FF→F* | a | b为此文法构造SLR分析表.。
编译原理LR分析法

编译原理LR分析法编译原理中的LR分析法是一种自底向上的语法分析方法,用于构建LR语法分析器。
LR分析法将构建一个识别句子的分析树,并且在分析过程中动态构建并操作一种非常重要的数据结构,称为句柄(stack)。
本文将详细介绍LR分析法的原理、算法以及在实际应用中的一些技巧。
1.LR分析法的原理LR分析法是从右向左(Right to Left)扫描输入串,同时把已处理的输入串的右侧部分作为输入串的前缀进行分析的。
它的核心思想是利用句柄来识别输入串中的语法结构,从而构建分析树。
为了实现LR分析法,需要识别和操作两种基本的语法结构:可规约项和可移近项。
可规约项指的是已经识别出的产生式右部,可以用产生式左部进行规约。
可移近项指的是当前正在处理的输入符号以及已处理的输入串的右侧部分。
2.LR分析法的算法LR分析法的算法包括以下几个步骤:步骤1: 构建LR分析表,LR分析表用于指导分析器在每个步骤中的动作。
LR分析表包括两个部分:动作(Action)表和状态(Goto)表。
步骤2: 初始化分析栈(stack),将初始状态压入栈中。
步骤3:从输入串中读取一个输入符号,并根据该符号和当前状态查找LR分析表中的对应条目。
步骤4:分析表中的条目可能有以下几种情况:- 移进(shift):将输入符号移入栈中,并将新的状态压入栈中。
- 规约(reduce):将栈中符合产生式右部的项规约为产生式左部,并将新的状态压入栈中。
- 接受(accept):分析成功,结束分析过程。
- 错误(error):分析失败,报告错误。
步骤5:重复步骤3和步骤4,直到接受或报错。
3.LR分析法的应用技巧在实际应用中,为了提高LR分析法的效率和准确性,一般会采用以下几种技巧:-使用LR分析表的压缩表示:分析表中的大部分条目具有相同的默认动作(通常是移进操作),因此可以通过压缩表示来减小分析表的大小。
-使用语法冲突消解策略:当分析表中存在冲突时,可以使用优先级和结合性规则来消解冲突,以确定应该选择的操作。
编译原理(清华)第七章LR分析法

文法的识别活前缀的有穷自动机以“项目”作为它的状态在文法G中每个产生式的右部适当位置添加一个圆点构成项目例:产生式 U→XYZ 对应有4个项目 [0] U→ • XYZ [1] U→X • YZ [2] U→XY • Z [3] U→XYZ • 产生式A→ε只有一个项目A→•
GOTO
ACTION
输入串
符号栈
状态栈
步骤
A
3
3
3
A
3
7
B
7
1
S
1
7.2 LR(0) 分析
使用LR(0)分析表的LR分析器称为LR(0)分析器。LR(0)分析器在分析的过程中只根据符号栈的内容就能确定句柄,不需要向右查看输入符号对文法的限制较大,对绝大多数高级语言的语法分析器不适用构造LR(0)分析表的思想和方法是构造其他LR分析表的基础。
将NFA确定化得到:
S[0],ab[2],aAb[3],aAcd[4],aAcBe[1]
ACTION
GOTO
a
cHale Waihona Puke ebd#
S
A
B
X
S2
1
1
acc
2
S3
4
3
r2
r2
r2
r2
r2
r2
4
S6
S5
5
r3
r3
r3
r3
r3
r3
6
S7
8
7
r4
r4
r4
r4
r4
r4
8
S9
9
r1
r1
r1
r1
r1
r1
对任何一个上下文无关文法只要构造出它的识别活前缀和可归前缀的有穷自动机,就可以构造其相应的分析表(ACTION表和GOTO表),进行LR分析
编译原理第七章_自下而上的LR(K)分析方法

二、求出文法的所有项目,按一定规则构造识别 活前缀的NFA再确定化为DFA(了解)
三、使用闭包函数(CLOSURE)和转向函数 (GOTO(I,X))构造文法G’的LR(0)的项目集规范 族,再由转换函数建立状态之间的连接关系得 到识别活前缀的DFA(掌握)
编译原理 Compilers Principles 第7章9
移进-归约中的问题分析
3) #ab 4) #aA 5) #aAb 6) #aA
bcde# bcde# cde# cde#
归约(A→b) 移进
归约(A→Ab) 移进
分析:已分析过的部分在栈中的前缀不同,而且移 进和归约后栈中的状态会发生变化
S aA cBe
Ab d b
0 S 1*
1 * 句子识别态
2a 3b 4
i
5a 6 A 7 b 8
9 a 10 A 11 c 12 d 13
14 a 15 A 16 c 17 B 18 e 10
构造识别活前缀的有限自动机 例子
句柄识别态
X
0S 2a 5a 9a
14 a
*
1
3b 4 6 A7b 10 A 11 c 15 A 16 c
1) # 2) #a 3) #ab
abbcde# bbcde# bcde#
动作
移进 移进 归约(A→b)
状态栈
0 02 024
ACTION
S2 S4 r2
GOTO
3
对输入串abbcde#的LR分析过程
S
1*
b
4
0 a 2 A 3 b 6
编译原理第七章答案

第7 章 LR 分析第1 题已知文法A→aAd|aAb|ε判断该文法是否是SLR(1)文法,若是构造相应分析表,并对输入串ab#给出分析过程。
答案:文法:A→aAd|aAb|ε拓广文法为G′,增加产生式S′→A若产生式排序为:0 S' →A1 A →aAd2 A →aAb3 A →ε由产生式知:First (S' ) = {ε,a}First (A ) = {ε,a}Follow(S' ) = {#}Follow(A ) = {d,b,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示:所以在I0、I2 中的移进-归约冲突可以由Follow 集解决,所以G 是SLR(1)文法。
构造的SLR(1)分析表如下:题目1 的SLR(1)分析表分析成功,说明输入串ab 是文法的句子。
第2 题若有定义二进制数的文法如下:S→L·L|LL→LB|BB→0|1(1) 试为该文法构造LR 分析表,并说明属哪类LR 分析表。
(2) 给出输入串101.110 的分析过程。
答案:文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→S若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA 如下图所示:在I2 中:B →.0 和 B →.1 为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
在I2、I8 中:Follow(s) ∩{0,1}= { #} ∩{0,1}=所以在I2 、I8 中的移进-归约冲突可以由Follow 集解决,所以G 是SLR(1)文法。
编译原理chapter7LR

10
#
i+(i)#
2 04
#i
+(i)#
3 02
#T
+(i)#
4 01
#E
+(i)#
5 015
#E+
(i)#
6 0153 #E+(
i)#
7 01534 #E+(i
)#
8 01532 #E+(T
)#
9 01536 #E+(E
)#
10 015367 #E+(E)
#
11 0158 #E+T
S9
r4 r4 r4 r4 r4 r4
r1 r1 r1 r1 r1 r1
3 7
步骤 6 7 8 9 10 11
状态栈 023 0235 02358 02357 023579 01
符号栈 #aA #aAc #aAcd #aAcB #aAcBe #S
输入串 cde# de# e# e# # #
ACTION
S5 S8 r4 S9 r1 acc
GOTO
7 1
1) E –> E + T 2) E –> T 3) T –> (E) 4) T –> i
对输入串i+(i)#Байду номын сангаас行分析
1) E –> E + T 2) E –> T 3) T –> (E) 4) T –> i
对输入串i+(i)#进行分析
步骤 状态栈 符号栈 剩余输入串
0 S2 1
1 acc
2
S4
3
S5
S6
4 r2 r2 r2 r2 r2 r2
编译原理7-LR(0)

ACTION表和GOTO表
ACTION a
0 1 2 3 4 5 6 7 8 r4 r4 r2 S5 r2 r2 S4 S6 r2 r2 S8 r2 7 S2 acc 3
GOTO d # S
1
c
e
b
A
B
r3
r3
r3 S9
r4
r3
r4
r3
r4
r3
r4
9
r1
r1
r1
r1
r1
文法的拓广
文法的开始符号可以出现在右部,也就可 能作为前缀的一个部分出现。为了保证文 法的开始符号只出现在产生式的左部,对 原有文法进行简单的拓广 具体地,如果原有文法开始符号是S,则增 加一个产生式S→S得到相应的拓广文法。 显然,S只会出现在所有产生式的左部;拓 广文法和原有文法是等价的
编译原理 计算机学院 李金厚
识别活前缀的有穷自动机
加一个统一的开始状态X,从而从上面若干 有限自动机合并得到一个完整的有限自动 机用于识别活前缀如下:
0 X 2 5 9 14 S a a a a 1 * 3 b A A A 4
6
10
7
11
b c c
8 12 d B 13
15
16
17
18
e
19
编译原理 计算机学院 李金厚
识别活前缀的有限自动机
进一步地,将上述NFA转换可得到下面如 图所示的DFA:
S X a 2 6 d 1 b A c B 4 8 b e 5 9 3
7
编译原理 计算机学院 李金厚
识别活前缀的有限自动机
用有限自动机识别时,每当识别完句柄,则状态 回退句柄串长度的状态数。例如,在前图,若已 识别到状态 5 ,这时句柄已形成,而且句柄是Ab, 2 则应用A→Ab归约,状态应退回到 ,又因左部 2 为A,所以相当于在状态 时又遇到A,这时应转 向状态 4 在状态 4 再遇到输入串的一个b,又转到状态 5 , 重复上述过程
编译原理第七章_LR(0)

LR(0)项目集规范族的构造
把文法的所有产生式的项目都引出,每个项目都 为NFA的一个状态。 • 其中文法的第一个产生式的第一个项目为文法的初 态,文法的接受项目为文法的句子识别态; • 文法的每一个产生式的归约项目为文法的句柄识别 态。 •
拓广文法:在原文法中增加产生式S’→S (开始符号)。 使得开始符号只有S’,接受项目唯一。
LR(0)项目集规范族的构造
项目(item):在每个产生式的右部适当位置添加一个圆点 构成项目。 例如:产生式S → aAcBe对应有6个项目: [0] S → .aAcBe [1] S → a . AcBe [2] S → aA . cBe [3] S → aAc . Be [4] S → aAcB . E [5] S → aAcBe . 产生式A → ε的仅有项目A → .
构造识别活前缀和可归前缀的有穷自动机 LR(0)项目集规范族的构造 LR(0)分析表的构造 LR(0)分析器的工作过程
LR(0)项目集规范族的构造
我们知道一个有限自动机主要由三部分组成: (1) 输入带:由输入字母表组成。 (2) 有限状态集:包括初始状态和终结状态集。 (3) 状态之间的映射函数。 所以,构造识别活前缀和可归前缀的有穷自动机也应该从 这三方面来构造。 (1)可以把文法的终结符和非终结符都看成有穷自动机的 输入符号; (2)有限自动机状态集的每一个状态由一个项目构成,确 定初态、句柄识别态、句子识别态; (3)确定状态之间的转换关系
01
#aAcBe
#S
#
#
r1
acc
1
LR(0)分析
可归前缀和活前缀 识别活前缀的有限自动机 活前缀及其可归约前缀的一般计算方法 LR(0)项目集规范族的构造
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Shift Shift Reduce: Reduce: Shift Shift Reduce: Reduce: Shift Reduce: Reduce: Reduce:
T → int E→T
T → int E→E+T T → (E) E→T S→E
8 9 9
(E + T
(E
)# Reduce:E → E + T why?不用 E → T )#
当规约到文法符号栈中只剩文法的开始符号时,并且输 入符号串已结束即当前输入符号是“#”,则分析成功。
(4)报错:
当遇到状态栈顶为某一状态下不该遇到的文法符号时, 说明输入串不是该文法的一个句子,则报错。
LR分析器
一个LR分析器由3个部分组成:
程序都是相同的。
(1)总控程序:也称驱动程序。对所有的LR分析器总控 (2)分析表(或分析函数):不同的文法其分析表不同,
或者分析程序归约时有多个产生式可选
例子 ( dangling el| if E then S else S
如输入if E then if E then S else S 分析某一时刻,栈的内容:if E then if E then S 而 else 是下一 token 归约还是移进?
栈
SP
Input#
Si Xm 总控程序 … … S1 X1 S0 #
状态 文法符号
output
ACTION GOTO LR分析表
SP:栈指针 S[i]:状态栈 X[i]:文法符号栈
产 生 式 表
文法要求
shift-reduce or reduce-reduce 冲突(conflicts)
分析程序不能决定是shift 还是 reduce
由规范推导所得的句型称为规范句型
G[S]: S→E E→E+T|T T→(E)|int SE T (E) (E+T) (E+int) (T+int) (int+int)
规范归约
假定α 是G的一个句子,称序列α 如果该序列满足:
( 1) α
n
n
,α
n-1
…,α 0是 α 的一个规范归约
= α
REMAINING INPUT
PARSER ACTION
1 (int + int)# 2 ( int + int)# 3 (int + int)# 4 (T + int)# 5 (E + int)# 6 (E + int)# 7 (E + int )# 8 (E + T )# 9 (E )# 10 (E) # 11 T # 12 E # 13 S #
LR(0)分析表的结构
LR(0)分析法采用规范规约。
LR(0)分析表的构造思想和方法是构造其它LR
分析表的基础。 LR(0)分析表分为两个部分:
(1)ACTION(动作表)部分: 列标志为文法的终结符号以及输入结束符#。表中的元 素为某个状态或某条规则,或接受标志acc。 (2)GOTO(转换表)部分: 列标志为非终结符号。表中的元素为要装入的状态。
LR(K)的含义:
L表示由左向右处理输入;
R表示生成了最右推导; 数字K表示使用了先行的K个符号。
LR分析法同样要用到先行集合(FIRST集合)和 后跟集合(FOLLOE集合)。
SLR(1)是“简单LR(1)”的简写,是对LR
(1)分析的改进。
LALR(1)即先行LR(1),是比SLR(1)分析
Reduce的一个特殊情况:栈中的全部内容w 归约为开始符号S (即施用 S → w) ,且 没有余留输入了,意味着已成功分析了整个 输入串. 移进归约分析中还会出现一种情况,就是出 错,比如当前的token不能构成一个合法句 子的一部分,例如上面的文法,试分析 int+)时就会发生错误。
STACK
稍微强大但却比一般LR(1)分析简单的方法。
S→E
E→T|E+T
T → int | (E)
Reduce: 如能找到一产生式 A → w 且栈中的内容是 qw (q 可能为空), 则可以将其归约为 qA。即倒过 来用这个产生式。 如上例, 若栈中内容是 (int ,我们使用产生式 T → int 并把栈中内容归约为(T Shift: 如不能执行一个归约且在输入串中还有 token , 就把它从输入串移到栈中。 如上例,假定栈中内容是 ( ,输入中还有 int+int)#.不 能对( 执行一个归约,因为它不和任何产生式的右 端匹配,所以把输入的第一个符号移到栈中,于是栈 中内容是 (int ,而余留的输入是 +int)# 。
同一文法采用的LR分析器不同时,分析表也将不同。分析 表由动作表(ACTION)和状态转换表(GOTO)组成,在 计算机里常用二维数组表示。
(3)分析栈:包括文法符号栈和相应的状态栈。都为先进
后出栈。
分析器的动作由栈顶状态和当前输入符号 决定。 LR分析器的关键部分是LR分析表的构造。
LR分析器模型
(2) α 0为文法的开始符号 (3)对任何j,0<j<=n, α
j-1是从α j
经把句柄替换为相应产生式的左部而得到的
LR分析表中动作表的四种动作
(1)移进:
把Sj=GOTO[Si,a]移入到状态栈,把a移入到文法符号 栈。(i,j表示状态号)
(2)规约:
在确定当前句柄时进行的替换操作。
(3)接受acc:
第7章 LR分析法
7.1 LR类分析法
LR分析法根据当前分析栈和输入串来确定 句柄。 LR分析过程是一种规范规约过程。 LR分析法适用于大多数无二义性的上下文 无关文法。 常用的LR分析法有:
(1)LR(0)分析法 (2)SLR(1)分析法 (3)LALR(1)分析法 (4)LR(1)分析法
若使用了E → T,在栈中形成的(E+E不是规范句 型的活前缀(viable prefixes) (E+E不能和任何产生式的右端匹配 (E+E)不是 规范句型 活前缀:是规范句型(右句型)的前缀,但不超 过句柄
移进归约分析的栈中出现的内容加上余留输入 构成规范句型
规范推导 规范句型 规范归约
最右推导:在推导的任何一步α β ,其中α 、β 是句型,都是对α 中 的最右非终结符进行替换。 最右推导被称为规范推导。