生物信息学 蛋白库查询
生物信息研究中常用蛋白质数据库的总结

生物信息研究中常用蛋白质数据库简述内蒙古工业大学理学院呼和浩特孙利霞2010.1.5摘要:在后基因组时代生物信息学的研究当中,离不开各种生物信息学数据库。
尤其在蛋白质从序列到功能的研究当中,目前各种行之有效的方法都是基于各种层次和结构的蛋白质数据库。
随着计算机技术及网络技术的发展,目前的蛋白质数据库不论是所包含数据量还是功能都日新月异,新的数据库层出不穷。
一个新手面对如此浩瀚的数据量往往无从下手。
本文粗浅地为目前蛋白质数据库的使用勾画出一个轮廓,作为自己蛋白质研究入门的一个引导。
关键词:蛋白质;数据库0 引言随着科技的发展,个人的知识往往赶不上快速膨胀的信息量,人们为了解决这个问题,便创建了形形色色的数据库。
蛋白质数据库是指:在蛋白质研究领域根据实际需要,对蛋白质序列、蛋白质结构以及文献等数据进行分析、整理、归纳、注释,构建出具有特殊生物学意义和专门用途的数据库。
蛋白质数据库总体上可分为两大类:蛋白质序列数据库和蛋白质结构数据库,蛋白质序列数据库来自序列测定,结构数据库来自X-衍射和核磁共振结构测定(详见图1)。
这些数据库是分子生物信息学的基本数据资源。
上世纪90年代,我国从事蛋白质研究的学者使用的蛋白质数据库储存介质还是国外实验室发布的激光光盘[1]。
信息的传播储存甚为不便。
随着蛋白质研究的发展飞快,同时伴随着计算机和因特网发展,蛋白质数据库的储存传播方式也发生的巨大的变化。
进入21世纪后,我们所用的各种蛋白质数据库都发展成为存储在网络服务器上,基于“服务器—客户机”的访问查询方式。
伴随着计算机及物理测试技术的发展数据库的容量和功能成数量级膨胀。
但是面对如此浩瀚的数据,新手往往感到无从下手,在需要时找不到自己需要的合适数据库。
本文从目前蛋白质数据库建立的的逻辑层次出发,系统地简绍了常用蛋白质数据的概况,它们的查询方法以及它们相互之间的联系。
同时尽量不涉及数据库建设和维护方面的计算机和网络这些数据库底层的技术,为蛋白质研究的入门者及对蛋白质感兴趣的人员的一个引导。
生物信息学网站网址(全)

生物信息学网站分子生物学数据库综合目录1. SRS序列查询系统(分子生物学数据库网络浏览器) http://www.embl-heidelberg.ed/srs5/2. 分子生物学数据库及服务器概览/people/pkarp/mimbd/rsmith.html3. BioMedNet图书馆4. DBGET数据库链接http://www.genome.ad.jp/dbget/dbget.links.html5. 哈佛基因组研究数据库与精选服务器6. 约翰. 霍普金斯大学(Johns Hopkins University) OWL网络服器/Dan/proteins/owl.html7. 生物网络服务器索引,USCS /network/science/biology/index.html8. 分子生物学数据库列表(LiMB) gopher:///11/molbio/other9. 病毒学的WWW服务器,UW-Madison /Welcome.html10. UK MRC 人类基组图谱计划研究中心/11. 生物学家和生物化学家的WWW资源http://www.yk.rim.pr.jp/~aisoai/index.html12. 其他生物网络服务器的链接/biolinks.html13. 分子模型服务器与数据库/lap/rsccom/dab/ind006links.html14. EMBO实际结构数据库http://xray.bmc.uu.se/embo/structdb/links.html15. 蛋白质科学家的网络资源/protein/ProSciDocs/WWWResources.html16. ExPASy分子生物学服务器http://expasy.hcuge.ch/cgi-bin/listdoc17. 抗体研究网页18. 生物信息网址http://biochem.kaist.ac.kr/bioinformatics.html19. 乔治.梅森大学(George Mason University)的生物信息学与计算分子生物学专业/~michaels/Bioinformatics/20. INFOBIOGEN数据库目录biogen.fr/services/dbcat/21. 国家生物技术信息研究室/data/data.html22. 人类基因组计划情报/TechResources/Human_Genome23. 生物学软件及数据库档案/Dan/software/biol-links.html24. 蛋白质组研究:功能基因组学的新前沿(著作目录) http://expasy.hcuge.ch/ch2d/LivreTOC.html序列与结构数据库一.主要的公共序列数据库1. EMBL WWW服务器http://www.EMBL-heidelberg.ed/Services/index.html2. Genbank 数据库查询形式(得到Genbank的一个记录) /genbank/query_form.html3. 蛋白质结构数据库WWW服务器(得到一PDB结构) 4. 欧洲生物信息学研究中心(EBI) /5. EBI产业支持/6. SWISS-PROT(蛋白质序列库) http://www.expasy.ch/sprot/sprot-top.html7. 大分子结构数据库/cgi-bin/membersl/shwtoc.pl?J:mms8. Molecules R Us(搜索及观察一蛋白质分子) /modeling/net_services.html9. PIR国际蛋白质序列数据库/Dan/proteins/pir.html10. SCOP(蛋白质的结构分类),MRC /scop/data/scop.l.html11. 洛斯阿拉莫斯的HIV分子免疫数据库/immuno/index.html12. TIGR数据库/tdb/tdb.html13. NCBI WWW Entrez浏览器/Entrez/index.html14. 剑桥结构数据库(小分子有机的及有机金属的结晶结构) 15. 基因本体论坛/GO/二. 专业数据库1. ANU生物信息学超媒体服务(病毒数据库、分类及病毒的命名法) .au/2. O-GL YCBASE(O联糖基化蛋白质的修订数据库) http://www.cbs.dtu.dk/OGLYCBASE/cbsoglycbase.html3. 基因组序列数据序(GSDB)(已注释的DNA序列的关系数据序) 4. EBI蛋白质拓扑图/tops/Serverintermed.html5. 酶及新陈代谢途径数据库(EMP) /6. 大肠杆菌数据库收集(ECDC)(大肠杆菌K12的DNA序列汇编) http://susi.bio.uni-giessen.de/ecdc.html7. EcoCyc(大肠杆菌基因及其新陈代谢的百科全书) /ecocyc/ecocyc.html8. Eddy实验室的snoRNA数据库/snoRNAdb/9. GenproEc(大肠杆菌基因及蛋白质) /html/ecoli.html10. NRSub(枯草芽胞杆菌的非冗余数据库) http://pbil.univ-lyonl.fr/nrsub/nrsub.html11. YPD(酿酒酵母蛋白质) /YPDhome.html12. 酵母基因组数据库/Saccharomyces/13. LISTA、LISTA-HOP及LISTA-HON(酵母同源数据库汇编) /14. MPDB(分子探针数据库) http://www.biotech.est.unige.it/interlab/mpdb.html15. tRNA序列及tRNA基因序列汇编http://www.uni-bayreuth.de/departments/biochemie/trna/index/html16. 贝勒医学院(Baylor College of Medicine)的小RNA数据库/dbs/SRPDB/SRPDB.html17. SRPDB(信号识别粒子数据库) /dbs/SRPDB/SRPDB.html18. RDP(核糖体数据库计划) /19. 小核糖体亚蛋白RNA结构http://rrna.uia.ac.be/ssu/index.html20. 大核糖体亚蛋白RNA结构http://rrna.uia.ac.be/lsu/index.html21. RNA修饰数据库/RNAmods/22. 16SMDB及23SMDB(16S和23S核糖体RNA突变数据库)/Departments/Biology/Databases/RNA.html23. SWISS-2DPAGE(二维凝胶电泳数据库) http://expasy.hcuge.ch/ch2d/ch2d-top.html24. PRINTS /bsm/dbbrowser/PRINTS/PRINTS.html25. KabatMan(抗体结构及序列信息数据库) /abs26. ALIGN(蛋白质序列比对一览) /bsm/dbbrowser/ALIGN/ALIGN.html27. CATH(蛋白质结构分类系统) /bsm/cath28. ProDom(蛋白质域数据库) http://protein.toulouse.inra.fr/29. Blocks数据库(蛋白质分类系统) /30. HSSP(按同源性导出的蛋白质二级结构数据库) http://www.sander.embl-heidelberg.de/hssp/31. FSSP(基于结构比对的蛋白质折叠分类) /dali/fssp/fssp.html32. SBASE蛋白质域(已注释的蛋白质序列片断) http://www.icgeb.trieste.it/~sbasessrv/33. TransTerm(翻译控制信号数据库) /Transterm.html34. GRBase(参与基因调控的蛋白质的相关信息数据库) /~regulate/trevgrb.html35. REBASE(限制性内切酶和甲基化酶数据库) /rebase/36. RNaseP数据库/RNaseP/home.html37. REGULONDB(大肠杆菌转录调控数据库) http://www.cifn.unam.mx/Computational_Biology/regulondb/38. TRANSFAC(转录因子及其DNA结合位点数据库) http://transfac.gbf.de/39. MHCPEP(MHC结合肽数据库) .au/mhcpep/40. ATCC(美国菌种保藏中心) /41. 高度保守的核蛋白序列的组蛋白序列数据库/Baxevani/HISTONES42. 3Dee(蛋白质结构域定义数据库) /servers/3Dee.html43. InterPro(蛋白质域以及功能位点的完整资源) /interpro/序列相似性搜索1. EBI序列相似性研究网页/searches/searches.html2. NCBI: BLAST注释/BLAST3. EMBL的BLITZ ULTRA快速搜索/searches/blitz_input.html4. EMBL WWW服务器http://www.embl-heidelberg.de/Services/index.html#55. 蛋白质或核苷酸的模式浏览/compbio/PatScan/HTML/patscan.html6. MEME(蛋白质超二级结构模体发现与研究) /meme/website7. CoreSearch(DNA序列保守元件的识别) http://www.gsf.de/biodv/coresearch.html8. PRINTS/PROSIT浏览(搜索motif数据库) /cgi-bin/attwood/SearchprintsForm.pl9. 苏黎世ETH服务器的DARWIN系统http://cbrg.inf.ethz.ch/10. 利用动态规划找出序列相似性的Pima IIhttp://bmerc-www.bu.ede/protein-seq/pimaII-new.html11. 利用与模式库进行哈希码(hashcode)比较找到序列相似性的DashPat /protein-seq/dashPat-new.html12. PROPSEARCH(基于氨基酸组成的搜索) http://www.embl-heidelberg.de/aaa.html13. 序列搜索协议(集成模式搜索) /bsm/dbbrowser/protocol.html14. ProtoMap(SEISS-PROT中所有蛋白质的自动层次分类) http://www.protomap.cs.huji.ac.il/15. GenQuest(利用Fasta、Blast、Smith-Waterman方法在任意数据库中搜索) http://www.gdb.rog/Dan/gq/gq.form.html16. SSearch(对特定数据库的搜索) http://watson.genes.nig.ac.jp/homology/ssearch-e_help.html17. Peer Bork搜索列表(motif/模式序列谱搜索) http://www.embl-heidelberg.de/~bork/pattern.html18. PROSITE数据库搜索(搜索序列的功能位点) /searches/prosite.html19. PROWL(Skirball研究中心的蛋白质信息检索) /index.html序列和结构的两两比对1. 蛋白质两两比对(SIM) http://expasy.hcuge.ch/sprot/sim-prot.html2. LALNVIEW比对可视化观察程序ftp://expasy.hcuge.ch/pub/lalnview3. BCM搜索装置(两两序列比对) /seq-search/alignment.html4. DALI蛋白质三维结构比较/dali/5. DIALIGN(无间隙罚分的比对程序) http://www.gsf.de/biodv/dialign/html多重序列比对及系统进行树1. ClustalW(BCM的多重序列比对) /multi-align/multi-align.html2. PHYLIP(推测系统进行树的程序) /phylip.html3. 其它系统进行树程序,PHYLIP文档的汇编http://expasy.hcuge.ch/info/phylogeny.html4. 系统进行树分析程序(生命树列表) /tree/programs/programs.html5. 遗传分类学软件(Willi hennig协会提供的列表) /education.html6. 用于多重序列比对的BCM搜索装置/multi-align/multi-align.html7. AMAS(分析多重序列比对中的序列) /servers/amas_server.html8. 维也纳RNA二级结构软件包http://www.tbi.univie.ac.at/~ivo/RNA/四. 有代表性的预测服务器1. PHD蛋白质预测服务器,用于二级结构、水溶性以及跨膜片断的预测http://www.embl-heidelberg.de/predictprotein/predictprotein.html2. PhdThreader(利用逆折叠方法预测、识别折叠类) http://www.embl-heidelberg.de/predictprotein/phd_help.html3. PSIpred(蛋白质结构预测服务器) /psipred4. THREADER(戴维. 琼斯) /~jones/threader.html5. TMHMM(跨膜螺旋蛋白的预测) http://www.cbs.dtu.dk/services/TMHMM/6. 蛋白质结构分析,BMERC /protein-seq/protein-struct.html7. 蛋白质域和折叠预测的提交表http://genome.dkfz-heidelberg.de/nnga/def-query.html8. NNSSP(利用最近相邻法预测蛋白质的二级结构) /pss/pss.html9. Swiss-Model(基于知识的蛋白质自动同源建模服务器) http://www.expasy.ch/swissmod/SWISS-MODEL.html10. SSPRED(用多重序列比对进行二级结构预测) /jong/predict/sspred.html11. 法国IBCP的SOPM(自寻优化预测方法、二级结构) http://pbil.ibcp.fr/cgi-bin/npsa_automat.pl?page=/NPSA/npsa_sopm.html12. TMAP(蛋白质跨膜片断的预测服务) http://www.embl-heidelberg.de/tmap/tmap_info.html13. TMpred(跨膜区域和方向的预测) /software/TMPRED_form.html14. MultPredict(多重序列比对的序列的二级结构) /zpred.html15. BCM搜索装置(蛋白质二级结构预测) /seq-search/struc-predict.html16. COILS(蛋白质的卷曲螺旋区域预测) /software/coils/COILS_doc.html17. Coiled Coils(卷曲螺旋) /depts/biol/units/coils/coilcoil.html18. Paircoil(氨基酸序列中的卷曲螺旋定位) /bab/webcoil.html19. PREDATOR(由单序列预测蛋白质二级结构) http://www.embl-heidelberg.de/argos/predator/predator_info.html20. EV A(蛋白质结构预测服务器的自动评估) /eva/五. 其他预测服务器1. SignalP (革兰氏阳性菌、革兰氏阴性菌和真核生物蛋白质的信号肽及剪切位点) http://www.cbs.dtu.dk/services/SignalP/2. PEDANT(蛋白质提取、描述及分析工具) http://pedant.mips.biochem.mpg.de/六. 分子生物学软件链接1. 生物信息学可视化工具/alan/VisSupp/2. EBI分子生物学软件档案/software/software.html3. BioCatalog /biocat/e-mail_Server_ANAL YSIS.html4. 生物学软件和数据库档案/Dan/softsearch/biol-links.html5. UC Santa Cruz的序列保守性HMM的SAM软件/research/compbio/sam.html七. 网上博士课程1. 生物计算课程资源列表:课程大纲http://www.techfak.uni-bielefeld.de/bcd/Curric/syllabi.html2. 生物序列分析和蛋白质建模的Ph.D课程http://www.cbs.dtu.dk/phdcourse/programme.html3. 分子科学虚拟学校/vsms/sbdd/4. EMBnet 生物计算指南http://biobase.dk/Embnetut/Universl/embnettu.html5. 蛋白质结构的合作课程/PPS/index.html6. 自然科学GNA虚拟学校http://www.techfak.uni-bielefeld.de/bcd/Vsns/index.html7. 分子生物学算法/education/courses/590bi。
生物信息学-蛋白质分析

有关注释内容的文献、蛋白质名称词典和其他有助于文献
挖掘的人文语言处理技术开发的信息、数据库校正、蛋白 质名称标记和功能注释标准体系(ontology)。使用
iProLINK可以获得描述蛋白质记录的文本文献资源,在
UniProtKB记录(生物词典)中加入蛋白质或基因命名的 图谱,获得用于开发文本挖掘算法的注释数据集、挖掘蛋
分类分布、分级和功能域结构,以及家族
成员,包括功能、结构、传导通路、功能
注释标准体系(ontology)和家族分类。
利用这些信息可以获得蛋白质的准确功能 或预测的功能和该蛋白质所属家族成员共 有的其他特征。
• 4. iProLINK-蛋白质文献、信息和知识整合数据库 iProLINK(/iprolink/)提供
Pfam
• 蛋白质一般是由一个或多个功能区域组成,这些 功能区域通常称作域(domain)。在不同的蛋白 质中不同的域以不同的组合出现,导致在自然界 发现多种多样组成成分的蛋白质。识别出现在蛋
白质中的域可以了解蛋白质的功能。
• Pfam数据库(/)是一个
PIR信息库资源
PIR主要数据库:
• • • • 1. UniProt-通用蛋白质资源库 2. iProClass-蛋白质知识整合数据库 3. PIRSF-蛋白质家族分类系统 4. iProLINK-蛋白质文献、信息和知识整合 数据库
• 1.UniProt-通用蛋白质资源库 UniProt (/)是存储和链接其他 蛋白质数据库的资源库,并且是蛋白质序列和具 有综合功能注释目录的中心资源库。使用 UniprotKB可以检索准确、可靠的蛋白综合信息。 使用UniRef可以减少冗余,加速序列相似性搜索。 使用UniParc可以检索存档序列和它们来源的数 据库。
蛋白质数据库使用说明

引言:蛋白质数据是生物信息学领域中非常重要的资源之一,它提供了大量关于蛋白质序列、结构、功能以及相互作用等方面的信息。
本文旨在介绍如何使用蛋白质数据库,帮助用户更好地利用这一资源进行研究。
概述:蛋白质数据库是一个集成了许多蛋白质信息的在线资源,用户可以通过搜索、浏览、等方式获取所需的信息。
其中,常用的蛋白质数据库包括NCBI、UniProt、PDB等。
这些数据库提供了丰富的蛋白质数据,并且不断更新以满足用户需求。
正文内容:1.数据库搜索功能1.1.关键词搜索1.1.1.输入蛋白质名称1.1.2.输入序列片段1.1.3.输入关键词1.2.高级搜索选项1.2.1.提供更精确的搜索结果1.2.2.支持过滤和排序功能1.2.3.可以根据相关字段进行搜索2.数据库浏览功能2.1.蛋白质分类2.1.1.按物种分类2.1.2.按功能分类2.1.3.按家族分类2.2.数据表格浏览2.2.1.查看蛋白质基本信息2.2.2.查看蛋白质序列2.2.3.查看蛋白质结构2.3.数据图谱浏览2.3.1.查看蛋白质相互作用网络2.3.2.查看蛋白质结构域分布2.3.3.查看蛋白质功能注释3.数据库功能3.1.蛋白质序列数据3.1.1.全部序列3.1.2.特定物种的序列3.2.蛋白质结构数据3.2.1.已解析的蛋白质结构3.2.2.蛋白质结构预测结果3.3.蛋白质相互作用数据3.3.1.已验证的相互作用数据3.3.2.预测的相互作用数据4.数据库工具与资源4.1.序列比对工具4.1.1.BLAST4.1.2.PSIBLAST4.2.结构预测工具4.2.1.SWISSMODEL4.2.2.Phyre24.3.功能注释资源4.3.1.GeneOntology4.3.2.InterPro4.4.数据库交互接口4.4.1.提供API接口4.4.2.支持数据提交与5.数据库更新与维护5.1.数据更新频率5.2.数据质量保证5.3.用户反馈与支持5.4.数据库版本与历史记录总结:蛋白质数据库为研究人员提供了丰富的蛋白质信息资源,通过搜索、浏览、等功能,用户可以轻松地获取需要的数据。
NCBI_BLAST使用

NCBI的BLast最好生物核酸的数据库NCBI是在NIH的国立医学图书馆(NLM)的一个分支。
NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。
NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
BLAST是一个NCBI开发的序列相似搜索程序,还可作为鉴别基因和遗传特点的手段。
BLAST能够在小于15秒的时间内对整个DNA数据库执行序列搜索。
NCBI提供的附加的软件工具有:开放阅读框寻觅器(ORF Finder),电子PCR,和序列提交工具,Sequin和BankIt。
所有的NCBI数据库和软件工具可以从WWW或FTP来获得。
NCBI还有E-mail服务器,提供用文本搜索或序列相似搜索访问数据库一种可选方法。
NCBI的BLast种类介绍? Gapped BLAST (2.0)—一种BLAST版本,允许在它产生的对齐(alignments)中存在缺口。
统计有效性的评估是基於使用随机序列的优先模拟。
在不久的将来,所有对Gapped BLAST的访问都要通过QBLAST。
? QBLAST —一种新的系统,允许用户以他们方便的方式检索Gapped BLAST结果,并且可以用各种格式选项多次格式化他们的结果。
这个系统也使NCBI更有效的使用计算资源,更好的为大家服务。
到1999年秋季,QBLAST系统用於所有的BLAST搜索。
? PSI-BLAST —位点特异迭代BLAST —用蛋白查询来搜索蛋白资料库的一个程式。
所有被BLAST发现的统计有效的对齐被总和起来形成一个多次对齐,从这个对齐,一个位置特异的分值矩阵建立起来。
这个矩阵被用来搜索资料库,以找到额外的显著对齐,这个过程可能被反复迭代一直到没有新的对齐可以被发现。
? PHI-BLAST —模式发现迭代BLAST —用蛋白查询来搜索蛋白资料库的一个程式。
蛋白质分析相关数据库及网站
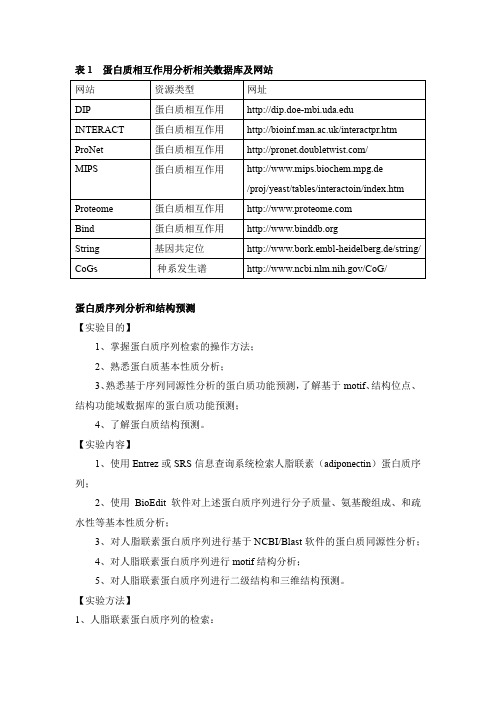
表1蛋白质相互作用分析相关数据库及网站蛋白质序列分析和结构预测【实验目的】1、掌握蛋白质序列检索的操作方法;2、熟悉蛋白质基本性质分析;3、熟悉基于序列同源性分析的蛋白质功能预测,了解基于motif、结构位点、结构功能域数据库的蛋白质功能预测;4、了解蛋白质结构预测。
【实验内容】1、使用Entrez或SRS信息查询系统检索人脂联素(adiponectin)蛋白质序列;2、使用BioEdit软件对上述蛋白质序列进行分子质量、氨基酸组成、和疏水性等基本性质分析;3、对人脂联素蛋白质序列进行基于NCBI/Blast软件的蛋白质同源性分析;4、对人脂联素蛋白质序列进行motif结构分析;5、对人脂联素蛋白质序列进行二级结构和三维结构预测。
【实验方法】1、人脂联素蛋白质序列的检索:(1)调用Internet浏览器并在其地址栏输入Entrez网址(/Entrez);(2)在Search后的选择栏中选择protein;(3)在输入栏输入homo sapiens adiponectin;(4)点击go后显示序列接受号及序列名称;(5)点击序列接受号NP_004788 (adiponectin precursor;adipose most abundant gene transcript 1 [Homo sapiens])后显示序列详细信息;(6)将序列转为FASTA格式保存(参考上述步骤使用SRS信息查询系统检索人脂联素蛋白质序列);2、使用BioEdit软件对人脂联素蛋白质序列进行分子质量、氨基酸组成和疏水性等基本性质分析:打开BioEdit软件→将人脂联素蛋白质序列的FASTA格式序列输入分析框→点击左侧序列说明框中的序列说明→点击sequence栏→选择protein→点击Amino Acid Composition→查看该蛋白质分子质量和氨基酸组成;或者选择protein后,点击Kyte & Doolittle Mean Hydrophobicity Profile→查看该蛋白质分子疏水性水平;3、人脂联素蛋白质序列的蛋白质同源性分析:(1)进入NCBI/Blast网页;(2)选择Protein-protein BLAST (blastp);(3)将FASTA格式序列贴入输入栏;(4)点击BLAST;(5)查看与之同源的蛋白质;4、人脂联素蛋白质序列的motif结构分析:(1)进入http://hits.isb-sib.ch/cgi-bin/PFSCAN网页;(2)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏;(3)点击Scan;(4)查看分析结果(注意Prosite Profile中的motif information);5、人脂联素蛋白质序列的二级结构预测:(1)进入下列蛋白结构预测服务器网址http://www.embl-heidelberg.de/predictprotein//predictprotein.html(The PredictProtein Server);(2)在You can栏点击default;(3)填写email地址和序列名称;(4)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏点击Submit;(5)从email信箱查看分析结果;6、人脂联素蛋白质序列的三维结构预测:(1)进入/swissmod/SWISS-MODEL.html (SwissModel First Approach Mode)网页;(2)填写email地址、姓名和序列名称;(3)将人脂联素蛋白质序列的FASTA格式序列贴入输入栏;(4)点击Send Request;(5)从email信箱查看分析结果(注:需下载软件入rasmol查看三维图象)。
蛋白质组学研究中常用的网站和数据库

蛋白质组学研究中常用的网站和数据库蛋白质, 数据库, 研究本帖引用网址:/thread-35586-1-1.html一、蛋白质数据库1.UniProt (The Universal Protein Resource) 网址://uniprot/简介:由EBI(欧洲生物信息研究所)、PIR(蛋白信息资源)和SIB(瑞士生物信息研究所)合作建立而成,提供详细的蛋白质序列、功能信息,如蛋白质功能描述、结构域结构、转录后修饰、修饰位点、变异度、二级结构、三级结构等,同时提供其他数据库,包括序列数据库、三维结构数据库、2-D凝聚电泳数据库、蛋白质家族数据库的相应链接。
2.PIR(Protein Information Resource) 网址:/简介:致力于提供及时的、高质量、最广泛的注释,其下的数据库有iProClass、PIRSF、PIR-PSD、PIR-NREF、UniPort,与90多个生物数据库(蛋白家族、蛋白质功能、蛋白质网络、蛋白质互作、基因组等数据库)存在着交叉应用。
3.BRENDA(enzyme database) 网址:简介:酶数据库,提供酶的分类、命名法、生化反应、专一性、结构、细胞定位、提取方法、文献、应用与改造及相关疾病的数据。
4.CORUM(collection of experimentally verifiedmammalian protein complexes) 网址:http://mips.gsf.de/genre/proj/corum/index.html简介:哺乳动物蛋白复合物数据库,提供的数据包括蛋白复合物名称、亚基、功能、相关文献等5.CyBase(cyclic protein database) 网址:.au/cybase简介:环状蛋白数据库,提供环状蛋白的序列、结构等数据,提供环化蛋白预测服务。
6.DB-PABP 网址:/DB_PABP/简介:聚阴离子结合蛋白数据库。
第二章-生物信息检索-2.4 蛋白质数据库

Databases of proteinProtein sequence DatabasesProtein sequence databases :SwissProt, PIR, TrEMBL,PRF, TCDB,NRichD,NCBI Protein database,……UniProtUniRef(UniProt Reference Clusters)UniParc(UniProt Archive)ProteomesUniProtKB(UniProt Knowledgebase)a single worldwide database of protein= PIR + SWISS-PROT + TrEMBLUniProtKB(UniProt Knowledgebase)*linked with other databases (NCBI, EBI)*Reviewed (Swiss-Prot) -Manually annotated Unreviewed (TrEMBL) -Computationally analyzedThe UniProt Knowledgebase (UniProtKB)is the central hub for the collection of functional information on proteins,with accurate,consistent and rich annotation.UniRef(reference clusters of sequences )Best non-redundant protein sequence databases for nowUniRef100UniRef90UniRef provides clustered sets of sequences from the UniProt Knowledgebase and selected UniParc records.This hides redundant sequences and obtains complete coverage of the sequence space at three resolutions.UniRef50combines identical sequences and sub-fragments with 11 or more residues from any organism into a single UniRef entry.Based on UniRef100, sequences that have at least 90% sequence identity to, and 80% overlap with, the longest sequence.Based on UniRef90 seed sequences that have at least 50% sequence identity注释信息一览工具栏序列基本信息注释详情•Reviewed (reliable)•Unreviewed(TrEMBL)• 1. Experimental evidence at protein level2. Experimental evidence at transcript level3. Protein inferred from homology4. Protein predicted5. Protein uncertainProtein Structure Databases/RCSB PDBPDB/pdb The Protein Data Bank (PDB) archivethe single worldwide repository of information about the 3D structures of large biological molecules, includingproteins and nucleic acids.All Data from experimentally measurements mainly by X-ray diffraction orNuclear Magnetic ResonanceRCSB: Research Collaboratory for Structural Bioinformatics“每月之星”有缘学习更多+谓ygd3076或关注桃报:奉献教育(店铺)。
生物信息学蛋白质数据库

蛋白质
The Central Dogma
生物信息学 (Bioinformatics)
是由生物学和信息科学交 叉融合形成的。包含生物 信息的获取、处理、存储、 发布、分析和解释等各个 方面,它综合运用数学、 生物学、计算机、信息科 学等诸多学科的理论方法 及国际互联网,阐明和解 释大量数据所包含的生物 学意义。
生物信息学的重要组成:
1. 数据库 (DataBase)
《Nucleic Acids Research》杂 志每年的第一期中详细介绍最新 版本的各种数据库。到2013年共 有1512个数据库。
1. 检索工具 (Retrieve Tool)
1. 分析软件 (Analysis Software)
利用在线工具和离线工具分析功 能和结构
5.美国国家生物医学基金会
(National Biomedical Research Foundation, NBRF) 数据库:PIR
6.布鲁克黑文国家实验室
(Brookhaven national laboratory) 数据库:PDB
7. 桑格研究所
(Wellcome Trust Sanger Institute) 数据库:PFAM
SRS FASTA
3.日本国立遗传学研究所
National Institute of Genetics,NIG
DNA Data Bank of Japan(DDBJ),日本DNA数据库 是日本遗传学各方面研究的中心研究机构及生命科学所有
领域的研究基地。(亚洲) 工具:
DBGET SEARCH KEGG
• TREMBL – Translation of mRNAs (RefSeq), UniGene, open reading frames (ORFs) and predicted genes from genomes – Automatic annotations
生物信息学工具介绍

生物信息学工具介绍1、FASTA[10](/fasta33/)和BLAST[11](http://www.nc /BLAST/)是目前运用较为广泛的相似性搜索工具。
比较和确定某一数据库中的序列与某一给定序列的相似性是生物信息学中最频繁使用和最有价值的操作。
本质上这与两条序列的比较没有什么两样,只是要重复成千上万次。
但是要严格地进行一次比较必定需要一定的耗时,所以必需考虑在一个合理的时间内完成搜索比较操作。
FASTA使用的是Wilbur-Lipman 算法的改进算法,进行整体联配,重点查找那些可能达到匹配显著的联配。
虽然FASTA不会错过那些匹配极好的序列,但有时会漏过一些匹配程度不高但达显著水平的序列。
使用FASTA和BLAST,进行数据库搜索,找到与查询序列有一定相似性的序列。
一般认为,如果蛋白的序列一致性为25-30%,则可认为序列同源。
BLAST(Basic Loc al Alignment Search Tool,基本局部联配搜索工具)是基于匹配短序列片段,用一种强有力的统计模型来确定未知序列与数据库序列的最佳局部联配。
BLAST 是现在应用最广泛的序列相似性搜索工具,相比FASTA 有更多改进,速度更快,并建立在严格的统计学基础之上。
这两个工具都采用局部比对的方法,选择计分矩阵对序列计分,通过分值的大小和统计学显著性分析确定有意义的局部比对。
BLAST根据搜索序列和数据库的不同类型分为5种:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
蛋白质数据库使用说明

蛋白质数据库使用说明1.高级查询 (1)2.限定词说明 (1)3.显示格式说明 (2)3.1.Summary显示格式 (2)3.2.FASTA显示格式 (3)3.3.SwissProt显示格式 (4)4.数据下载流程 (5)5.数据提交 (6)6.附录 (6)6.1.蛋白质研究的历史 (6)6.2.蛋白质组学与生物信息学 (7)2009年10月16日1.高级查询在首页上点击“数据库”按钮,选择“蛋白数据库”进入蛋白质数据库主页。
在蛋白质主页的左侧栏点击“高级检索”,进入如下图的高级检索页面:蛋白质数据库的高级检索可以最多使用三个限定词来进行更精确的检索,三个限定词之间可以用“AND”和“OR”相连接,其中“AND”表示查询的结果中必须包含它所连接的两个关键词,“OR”表示查询的结果中至少包含它所连接的关键词中的一个。
在左侧的限定词框中可以选择的限定词包括:CAC、AC、Entry Name、Description、Tax ID、Organism、Keywords、Gene Name、Organelle、Length以及Molecular Weight等十一个限定词。
其中Length和Molecular Weight可以进行范围查询。
2.限定词说明蛋白质数据库中相关的限定词说明如下:限定词描述CAC国内用户提交的数据编号AC SwissProt的序列或记录唯一的接收编号Entry Name录入名Description描述Tax ID物种分类号Organism与蛋白质有关的物种的学名和通用名Keywords与其它数据库专用词汇有关的索引名词Gene Name基因的标准名和通用名Organelle细胞器官Length序列的总长度Molecular Weight蛋白质的分子量,单位为道尔顿(Da)3.显示格式说明蛋白质数据库的查询结果有三种显示结果:Summary、FASTA和SwissProt。
3.1.Summary显示格式Summary格式显示了蛋白质条目的摘要信息,主要有两部分组成:1)蛋白质的名称,AC号以及来源物种2)对蛋白质的简要描述信息,如该组成该蛋白质的亚基和生物功能等3.2.FASTA显示格式FASTA格式第一行显示信息包括蛋白质录入名、AC号以及来源物种。
生物大数据技术的生物信息学数据库查询方法

生物大数据技术的生物信息学数据库查询方法生物大数据技术的快速发展为生物信息学领域带来了巨大的变革。
生物信息学数据库作为存储和管理生物学数据的重要工具,被广泛应用于生物大数据的分析和挖掘。
在这篇文章中,我将介绍几种常用的生物信息学数据库查询方法,帮助读者利用生物大数据技术更好地进行生物学研究。
首先,我们来讨论最常用的生物信息学数据库之一,基因组数据库。
基因组数据库包含了各种生物的基因组序列信息,如人类、小鼠、果蝇等。
要查询一个特定基因组的序列信息,最简单的方法是利用基因名或基因符号进行搜索。
将目标基因的名称或符号输入数据库的搜索栏,即可获得与该基因相关的详细信息,例如基因的序列、结构、功能等。
另一个常用的生物信息学数据库是序列数据库。
序列数据库存储了各种生物分子序列的信息,如DNA、RNA和蛋白质序列。
在进行DNA或蛋白质序列的查询时,一种常见的方法是使用序列相似性搜索工具,如BLAST(Basic Local Alignment Search Tool)。
BLAST可以比对查询序列与数据库中的序列,找出最相似的序列并计算相似度。
通过BLAST的结果,我们可以了解到查询序列在数据库中的分布情况、物种来源以及与其他序列的相似性。
另外,功能注释数据库也是生物信息学研究中重要的查询工具。
功能注释数据库存储了各种生物分子的功能和特征信息,如基因的功能、通路信息、蛋白质的结构、功能域等。
要查询一个基因或蛋白质的功能信息,可以使用功能注释数据库提供的工具和接口。
输入目标基因或蛋白质的名称或序列,即可获得与该生物分子相关的功能注释信息,例如其参与的通路、功能域和蛋白质结构等。
此外,还有一些特定领域的生物信息学数据库,如药物数据库、代谢通路数据库等。
这些数据库针对特定的生物学问题提供了更加专门化的查询方法和功能。
例如,药物数据库可以用于查询了解药物的化学结构、药理学特性以及在人体中的作用。
代谢通路数据库则可以帮助研究人员深入了解生物体内代谢通路的结构和功能。
蛋白质常用数据库一文看懂!

蛋白质常用数据库|一文看懂!蛋白质数据库是指专门存储蛋白质相关信息的数据库。
它们收集、整理和存储大量的蛋白质数据,包括蛋白质序列、结构、功能、互作关系、表达模式、疾病关联等信息。
蛋白质数据库提供了对这些数据的检索、查询和分析功能,为科学研究人员、生物信息学家和药物研发人员等提供了重要的资源。
蛋白质数据库的内容通常来自于实验室实际测定的蛋白质数据,如蛋白质序列测定、结晶学、核磁共振、质谱等技术获得的数据。
这些数据经过验证和标准化后,被整合到数据库中,使研究者能够方便地访问和利用这些数据进行各种研究工作。
下面是笔者总结的常用蛋白质数据库及网址,供大家参考。
⓪BioXFinder:BioXFinder是国内第一个也是唯一一个生物数据库:收录50多万条高质量的、整合多个来源数据,手工注释的非冗余的蛋白质信息,包含蛋白质的基本信息、序列、序列特征、功能、名称和谱系、亚细胞定位、疾病与变异、翻译后修饰、表达、相互作用等信息。
蛋白结构库:收录19多万条经过X射线单晶衍射、核磁共振、电子衍射等实验手段确定的蛋白质结构数据。
包括蛋白3D结构、基本信息、实验数据、参考文献等。
①UniProt:UniProt是一个综合性的蛋白质数据库,提供了大量蛋白质的序列、结构、功能、互作关系和注释信息。
它整合了多个来源的数据,包括Swiss-Prot、TrEMBL和PIR数据库。
②Protein Data Bank (PDB):PDB是存储蛋白质和其他生物大分子结构的数据库。
它提供了实验确定的蛋白质结构的三维坐标数据,可用于结构生物学研究、药物设计和分子模拟等领域。
③NCBI Protein:NCBI Protein是美国国家生物技术信息中心(NCBI)提供的蛋白质数据库,包含了大量的蛋白质序列数据,可以进行蛋白质的基本信息查询和比对分析。
④Ensembl:Ensembl是一个综合性的基因组注释数据库,包含了多个物种的基因组序列、基因结构、转录本和蛋白质信息。
蛋白质生物信息学-数据库

Pfam数据库由英国生物化学物理研究所(European Bioinformatics Institute,EBI) 维护,利用隐马尔可夫模型(Hidden Markov Model,HMM)进行蛋白质序列分析 ,将序列划分为不同的家族。Pfam数据库提供了丰富的注释信息和可视化的家族结构
图。
外,Pfam数据库还提供了丰富的注释信息 ,有助于深入了解蛋白质家族的特性和进化
关系。
InterPro数据库在蛋白质功能预测中的应用
总结词
InterPro数据库整合了多种蛋白质序列和结构信息,为 预测蛋白质功能提供了全面的资源。
详细描述
InterPro数据库将多个蛋白质数据库(如SWISS-PROT 、Pfam等)进行整合,提供了一个统一的查询平台。通 过比对InterPro数据库,可以同时获取多个数据库中的 注释信息,从而更全面地了解蛋白质的结构和功能。此 外,InterPro数据库还提供了功能域、跨膜结构等更深 入的信息,有助于更准确地预测蛋白质的功能。
云计算平台将提供更灵活、可扩展的计算资源, 支持蛋白质生物信息学数据库的高效运行和数据 共享。
人工智能和机器学习
人工智能和机器学习技术将被应用于蛋白质生物 信息学数据库,以自动提取有价值的信息,提高 数据分析的准确性和效率。
数据库在蛋白质生物信息学中的重要性和应用前景
蛋白质结构预测
数据库中存储的蛋白质序列和结构信息,可用于预测蛋白质的三维 结构,有助于理解蛋白质的功能和相互作用。
选择合适的查询方式
根据需要选择合适的查询方式,如 简单查询或复合查询。
使用适当的关键词
选择与主题相关的关键词进行查询 ,避免使用过于宽泛或模糊的关键 词。
筛选结果
如何用NCBI和uniprot数据库查找目的蛋白的氨基酸序列或目的基因的碱基序列

运用NCBI数据库查找目的蛋白序列或目的碱基序列
第1种方法
1.打开NCBI官网,并选择Gene菜单,如下图。
2.在搜索栏内输入想要查找的蛋白名称或基因名称,此处以基因RSK2为例,如图。
3.在搜索结果中查找目的蛋白,注意Description栏会标明物种信息,以human为例,Aliases 栏会列出目的蛋白的各种别名。
4.在Searchresult页面中点击你要找的蛋白名称(Name/Gene ID),进入页面并在页面找到“”“NCBI Reference Sequences (RefSeq)”条目,并在其子条目中找到“mRNA and Protein(s) ”,查找mRNA碱基序列点击NM,查找蛋白氨基酸序列点击NP,以下以查找mRNA碱基序列为例如下:
点击NM-004586.2进入页面后如下:
在页面下方会列出mRNA的序列:
第2中方法
1.进入Uniplot数据库,在搜索栏中直接输入要查找的基因或蛋白名称,如下图:
2.进入以下页面:
3.在搜索结果Entry name栏中会列出不同物种选项,且会有Protein names及Gene names,点击所要选择物种蛋白,进入以下页面。
4.点击页面页面左侧的Sequence栏,并找到Sequence databases,其下面表格中有RefSeq i,其中包含NP及NM。
5.此处以查找mRNA为例,点击NM,页面会跳转至NCBI的查找页面,如下:。
ncbi使用指导

ncbi使用指导摘要:一、NCBI 简介1.NCBI 的定义和作用2.NCBI 的主要数据库二、NCBI 数据库使用方法1.基因数据库查询2.蛋白质数据库查询3.核酸序列数据库查询4.文献数据库查询三、NCBI 工具使用方法1.BLAST 工具2.ClustalW 工具3.Primer-BLAST 工具四、NCBI 的高级功能1.基因变异数据库查询2.基因表达数据库查询3.基因组数据库查询正文:一、NCBI 简介CBI(National Center for Biotechnology Information,美国国家生物技术信息中心)是一个提供生物科学和生物医学研究的公共资源网站。
它包含了大量的生物学和医学信息,为科研工作者提供了便捷的生物信息学资源。
NCBI 的主要数据库包括基因数据库、蛋白质数据库、核酸序列数据库和文献数据库等。
二、NCBI 数据库使用方法1.基因数据库查询基因数据库(Gene Database)是NCBI 的核心数据库之一,包含了大量已知的基因信息。
用户可以通过基因名称、序列标签、转录因子结合位点等信息进行查询。
查询结果包括基因的详细信息、基因序列、表达数据等。
2.蛋白质数据库查询蛋白质数据库(Protein Database)包含了大量已知的蛋白质信息,包括蛋白质序列、功能域、结构域等。
用户可以通过蛋白质名称、序列、功能等信息进行查询。
查询结果包括蛋白质的详细信息、序列、结构等。
3.核酸序列数据库查询核酸序列数据库(Nucleotide Database)包含了大量已知的核酸序列信息,包括基因组序列、cDNA 序列等。
用户可以通过序列名称、物种等信息进行查询。
查询结果包括核酸序列的详细信息、序列等。
4.文献数据库查询文献数据库(PubMed Database)是生物医学领域的文献摘要数据库,收录了大量的生物学和医学文献。
用户可以通过关键词、作者、杂志等信息进行查询。
查询结果包括文献的详细信息、摘要等。
蛋白家族信息查询数据库

蛋白家族信息查询数据库数据库输入对于这个数据库而言,数据库提供了多种输入方式,我们可以: 1)输入序列来进行比对查看具体是哪个蛋白家族的;2)可以输入蛋白相关的结果:结构域; 3) 也可以通过检测词来检索符合要求的蛋白家族信息;4)同时可以基于物image这里我们想要使用和凋亡相关的有哪些蛋白,所以我们就在关键词检索里面输入:apopt osis image数据库输出由于我们这里是进行了关键词的检索,所以会出来很多相似的结果。
如果靶定到一个具体的结构域上的话,那就可以直接到结果界面了。
在关键词检索完之后,我们会得到一个和这个关键词相关的表格。
在这个表格当中,可以看到每一个相关家族在数据库当中都包括哪些信息。
image我们以Bcl-2家族来进行结果说明。
基本家族信息汇总在总的结果的界面,我们首先看到的是这个蛋白家族的基本信息,这些基本的介绍主要来自于维基百科。
这里我们能看到这个蛋白家族基本的构造、功能、家族相关结构域以及可能相关的基因。
image主要结构域汇总由于这里能查找的一系列具有相似功能的蛋白家族,但是一个蛋白不可能只有一个结构域的情况。
所以这个部分就汇总了包含bcl-2的所有的蛋白结构域情况。
image不同物种蛋白相关进化情况在进行基因研究的时候,我们经常要比较各个物种之间蛋白序列的保守型情况。
这种比较的方式基本上是通过进化树的方式来进行实现的。
所以数据库也进行了简单的进化树构建。
当然这个只是基本的查看。
想要构建好看的进击下载,然后用别的软件进行美化即可。
image相互作用关系蛋白与蛋白不是单独发挥作用的。
所以我们经常也需要查看这些蛋白家族是和哪些蛋白有相互作用关系的。
在这个部分,数据库就提供了可能相互所有的其他蛋白image每个物种包括的相似蛋白结构域的蛋白名称以上都是基本的汇总,有时候我们想要知道到底哪些蛋白具有这个结构域。
这个时候就可以在在结构当中查看了。
这里提供了蛋白的PDB ID号。
一站式查询蛋白分子量、功能、结构域和经典转录本等信息

一站式查询蛋白分子量、功能、结构域和经典转录本等信息今天科研小助手为大家介绍一个蛋白质的数据库UniProt,做质谱等蛋白质组的童鞋对这个数据库可能比较熟悉,不过对于做基础科研的小伙伴,这个数据库同样非常实用!UniProt(Universal Protein)整合了三个老字号数据库:Swiss-Prot、TrEMBL和PIR-PSD的数据。
是目前信息最丰富、资源最广的免费蛋白质数据库(没有之一!)。
首先看一下这个数据库的首页:/从首页我们可以看到UniProt包括五大块:UniProtKB、UniRef、UniParc、Proteomes和Supporting data。
今天科研小助手着重为大家介绍的是UniProtKB部分。
这部分又包含两部分数据:Swiss-Prot和TrEMBL。
这两个有什么区别呢?Swiss-Prot是经过人工检查和校验的条目,是一个高质量的、人工注释的、非冗余的数据集;主要来自文献中的研究成果和E-value校验过的计算分析结果。
截止到2017年10月17日,已囊括了555594条记录!TrEMBL是计算机自动注释的、未经人工校验的条目,该数据主要是利用计算机对大量基因组数据流进行分析注释。
截止到2017年10月17日,已囊括了90050711条记录!从以上数据我们可以看出来,这个数据库的量还是非常大的!那么接下来就让科研小助手带大家结合实例看一下怎么利用这个数据吧!我们以人的EGFR为例来查询,首先在检索框中输入EGFR Human(当然你不加种属也可以,只不过有的时候找起来麻烦),结果如下:点前面的Entry号P00533进入EGFR的介绍页面:最顶部是EGFR的基本信息:蛋白全称、对应的基因名字、物种和状态。
基本信息下面接着就是对EGFR功能的概括性介绍,这个对于快速了解该蛋白的功能还是非常有用的。
再就是大概或许可以参考着写入文章中的Introduction部分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、对该段序列进行同源性搜索
首先进入www.espasy.ory点击进入Resources A..Z 点击如下图
点击BLAST 输入蛋白质序列
搜索得到同源性分析如下3图示:Score分值越大,相似性越高。
E值越小,匹配度越好。
所以蛋白序列应与p04626相似性高匹配度好
二、对该段序列进行基本性质分析:蛋白质的氨基酸组成、等电点、相对分子质量、亲水性、疏水性、消光系数、信号肽、跨膜区域等。
氨基酸组成
等电点、相对分子质量
消光系数
亲水性、疏水性
打开/protscale
如下图(网速慢,读图等好久都读不出来)
TMPred 跨膜区结构预测,打开/software/TMPRED_form.html输入已知序列
三、分析该段序列的MOTIF
四、对该段序列进行三维结构的分析选择符合条件的一个同源建模
5、分析该序列所代表蛋白的修饰情况、所参与的代谢途径、相互作用的蛋白,以及与疾病的相关性。
蛋白质的修饰后翻译
蛋白质的相互作用
所参与的代谢途径,相关疾病。