Eviews7.0数据操作
《Eviews数据操作》课件

演示如何汇总和计算变量的统计特 征,如均值、标准差和百分位数。
2
保存数据集
探索将数据保存到本地磁盘以及如何以不同的格式(如CSV、Excel等)导出数据。
3
数据备份
分享数据备份的重要性和最佳实践,以确保数据的安全性和可靠性。
四、加入数据
1 外部数据源
2 内部数据源
3 数据链接
了解如何从外部数据源引入 数据,如数据库、API等。
探索如何将其他Eviews数据 文件和工作簿中的数据合并 到当前项目中。
学会如何建立数据链接,以 便在原始数据发生变化时自 动更新。
五、导入数据
1
文本文件导入
演示如何从文本文件(如CSV、TXT等)中导入数据,讨论不同的导入选项和参数 设置。
2
Excel文件导入
介绍如何从Excel文件中导入数据,包括多个工作表和自定义格式的读取。
3
其他文件格式
探索支持的其他数据格式,如JSON、XML等,并了解如何正确解析和导入这些文 件。
六、数据编辑与选择
数据编辑
学习如何编辑和修改数据的内容,包括添加、删除和 替换值。
数据选择
探索如何根据条件和筛选准则选择和过滤数据,以便 进行精确和重点分析。
七、变量编辑
变量创建
讨论如何创建新的变量,包括基本 算术运算、逻辑运算和函数计算。
变量转换
变量汇总
介绍不同的变量转换技术,如对数、 差分和滞后,以及它们在数据分析 中的应用。
数据转换
探索不同的数据转换技术,如标 准化、归一化和对数变换,并了 解它们在数据分析中的应用。
数据汇总
掌握如何对数据进行汇总和聚合, 从简单的统计量到复杂的分组和 子集分析。
Eviews软件操作概要

Eviews软件操作概要:1, File/new/workfile2, 输入数据:quick/empty group(edit series)3, 将数据绘制成曲线(时间和各数据之间的关系):选中所需要的变量(可以多选),右击open group,在这个页面上,选择view/graph/line4,选中所需要的变量(可以多选),右击open group,点击name(or save)之后,就可以保存这份数据表;若要保存为视图(即两个变量之间的关系,只需:view/graph/scatter/simple scatter,其中首先选中的变量的数据将表示为x轴。
5,回归的估计方法:在空格处填写:ls y c x1 x2 x3 x4 x5,然后按enter键便可,点击name 之后便可以保存。
6,残差图的画法:打开5这个工作簿,点击view/actual, fitted, residual,再选择actual, fitted, residual table, 便可以得到。
7,估计方程的获取:打开5这个工作簿,然后点击view/representations, 通过edit/copy将最后一项数据即Substituted Coefficients进行复制,进而可以复制到word中进行应用。
8,预测:通过7中所获得的回归方程,将其复制粘贴到命令窗口中,并将左边的因变量改为scalar新变量,然后按enter键便可以获得结果。
9,方差的估计:在5中可以得到总体方差的估计值,即S.E. of regression。
但对于经济学家而言,除了这个之外,我们也可能需要残值平方和的方差,获得的方法为:在命令窗口,输【若要完整版,则应操作如下:coef(5)sigma2入coef(1) sigma2回车,sigma2(1)=@ssr回车便可。
回车sigma2(1)=@ssr回车sigma2(2)=@regobs回车sigma2(3)=@ncoef回车sigma2(4)=@ssr/(sigma2(2)-sigma2(3))回车sigma2(5)=(sigma2(4))^0.5回车:解释:coef(5)sigma2表示制造一个储存向量,其中5表示有5个变量,而sigma2表示储存向量的名称。
使用Eviews进行面板数据操作(有图有真相)

(1)建立混合数据型工作文件
1. 建立一个年度工作文件(1996-2002).(file:)
① file ——new—— workfile——object——new object——pool——OK
1 2
② 在弹出的对话框中输入截面个体的名称缩写——点击sheet,输入变量名
注意:由于无法输入个体名称, 容易产生混乱,因此不建议使用 该方法建立面板数据。
方法一:
① 在变量截面中按住ctrl键,依次选择每个个体的因变量和自变量,点击右键, 选择open——as group,在打开的数据窗口中选择view——graph
② 在弹出的对话框中选择scatter——在multiple中选择single graph-XY pairs OK便可得如下的散点图
在估计结果中点击proc——Make Model可以出现估计结果的联立方 程形式,进一步点击Solve键可以 在弹出的对话框中进行动态和静态 预测。
在估计结果或原始的面包数据窗口中点击view——unit root test
这里默认为 Schwarz检 验,因为在 小样本情况 下Schwarz 检验效果最 好。
GLS权重,通过加 权可以克服异方差
每个个体有共
同的参数 bi
bi 随个体不
同而发生
变
变化
参
数
bi 随个体不 同而发生
模 型
变化
下面为个体固定效应的结果。 点击view——representation可以显示具体的回归方程式。
2. 面板数据的检验
① Hausman检验(要在随机效应结果窗口中进行) 对数据进行随机效应模型估计,在估计结果窗口点击view——Fixed/Random Effects testing——Correlated Random Effect-Hausman Test(6.0以上的 版本才可以)
EViews基本操作与数据分析

EViews基本操作与数据分析EViews基本操作与数据分析一、EViews的基本操作与数据处理1、建立工作文件(File/New/Workfile)、数据库(Database)、程序(Program)或文本文件(Text File)。
(1)EViews的界面:菜单栏下面的白色空白区域为命令窗口。
(2)打开空表:Quick/Empty Group。
(3)Workfile的界面:c表示截距序列,resid表示残差序列。
2、输入数据(1)数据分为时间序列数据(Dated-regular Frequency,默认选项)、横界面数据(Unstructured/Undated)和面板数据(Balanced Panel),时间序列的日期间隔符号可以是“:”、“.”或“,”。
Q表示季度,M表示月份,W表示周。
(2)EViews也可以直接打开已有文件(Open/EViews Workfile)、外部数据(Foreign Data)、数据库(Database)、程序(Program)或文本文件(T ext File)。
EViews 5.0可以导入其他的外部数据:File/Open/Foreign Data as Workfile。
(3)调用外部数据:File/Import/……。
先建立工作文件,然后才能调用数据,EViews允许调用3种格式的数据:ASCII、Lotus和Excel工作表。
如果原文件已有序列名称,则只需输入序列个数即可。
3、对象(Object)的操作与处理(1)生成新对象(New Object):Equation、Graph、Group、Matrix、Series、Table、Text、V AR等。
(2)对象的编辑:剪切(Cut)、复制(Copy)、粘贴(Paste)、删除(Delete)、合并(Merge)和替代(Replace)等。
(3)对象的命名:对象必须以半角字符命名,不能用中文命名,命名不宜太长。
eviews操作说明

(二)数据的输入与处理
数据输入的主要方法: 1、一种是通过键盘输入;(手工输入) 2、一种是通过Copy,Paste命令把Excel数据 复制为EViews数据;
1、通过键盘输入数据
具体操作如下: 从EViews主菜单中点击Quick键, 选择Empty Group功 能。这时会打开一个空白表格数据窗口(Group): 每一个空格代表一个观测值位置。 按列依次输入每一个变量(或序列)的观测值。
作以前的状态。
• 剪切(Cut):删除用拖动覆盖法选定的内容并放入剪切
板。
•复制(Copy):把所选定的内容存入剪切板。 •粘贴(Paste):把复制所选定的内容。 •进行(Next):执行下一个预指定操作。 •合并(Merge):把一个文件合并到一个待修改
Eviews 使用操作说明
EViews软件包
EViews是美国GMS公司1981年发行第1版的 Micro TSP的Windows版本,通常称为计量经济 学软件包。 EViews是Econometrics Views的缩写,它的本 意是对社会经济关系与经济活动的数量规律,采 用计量经济学方法与技术进行“观察”。
图(Graph):可画出各种图来,包括折线图、条形图 、 直方图、相关图 、散点图、饼图等。 空数据栏 (Empty Group):按列输入每一个序列的观测 值,并在每一个序列上方的灰色空格内输入序列名。
单序列统计分析(Series Statistics):可以对一个序列 进行各种统计计算。 如:直方图与统计特征值(Histogram and Stars)
二、主菜单说明
(1) File键: 主菜单中File键的主要功能 :
Eviews操作教程_完整版

Eviews操作教程_完整版1.EVIEWS基础 (3)1.1. E VIEWS简介 (3)1.2. E VIEWS的启动、主界⾯和退出 (3)1.3. E VIEWS的操作⽅式 (6)1.4. E VIEWS应⽤⼊门 (6)1.5. E VIEWS常⽤的数据操作 (15)2.⼀元线性回归模型 (24)2.1. ⽤普通最⼩⼆乘估计法建⽴⼀元线性回归模型 (24) 2.2. 模型的预测 (30)2.3. 结构稳定性的C HOW检验 (34)3. 多元线性回归 (39)3.1. ⽤OLS建⽴多元线性回归模型 (39)3.2. 函数形式误设的RESET检验 (45)4. ⾮线性回归 (48)4.1. ⽤直接代换法对含有幂函数的⾮线性模型的估计 (48) 4.2. ⽤间接代换法对含有对数函数的⾮线性模型的估计 (50) 4.3. ⽤间接代换法对CD函数的⾮线性模型的估计 (53)4.4. NLS对可线性化的⾮线性模型的估计 (55)4.5. NLS对不可线性化的⾮线性模型的估计 (58)4.6. ⼆元选择模型 (62)5. 异⽅差 (68)5.1. 异⽅差的⼽得菲尔德——匡特检验 (68)5.2. 异⽅差的WHITE检验 (72)5.3. 异⽅差的处理 (75)6. ⾃相关 (79)6.1. ⾃相关的判别 (79)6.2. ⾃相关的修正 (83)7. 多重共线性 (87)7.1. 多重共线性的检验 (87)7.2. 多重共线性的处理 (92)8. 虚拟变量 (94)8.1. 虚拟⾃变量的应⽤ (94)8.2. 虚拟变量的交互作⽤ (99)8.3. ⼆值因变量:线性概率模型 (101)9. 滞后变量模型 (106)9.1. ⾃回归分布滞后模型的估计 (106)9.2. 多项式分布滞后模型的参数估计 (111)10. 联⽴⽅程模型 (116)10.1. 联⽴⽅程模型的单⽅程估计⽅法 (116)10.2. 联⽴⽅程模型的系统估计⽅法 (120)2..1.Eviews基础1.1.Eviews简介Eviews:Econometric Views(经济计量视图),是美国QMS公司(Quantitative Micro Software Co.,⽹址为/doc/8e38170bbed126fff705cc1755270722192e59b1.html )开发的运⾏于Windows环境下的经济计量分析软件。
Eviews操作手册.
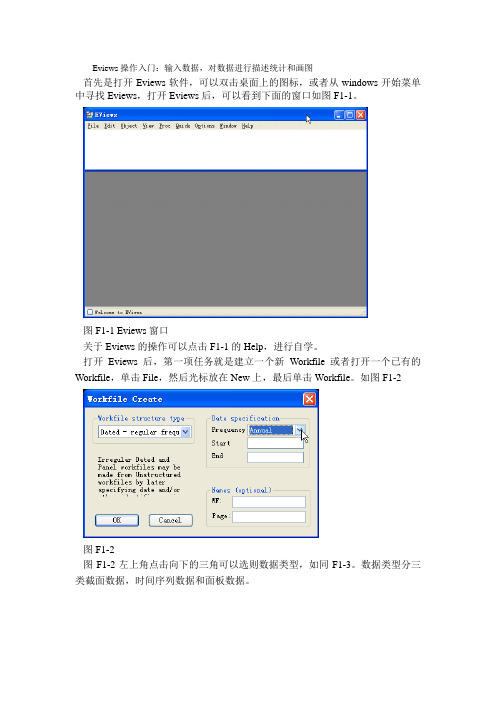
Eviews操作入门:输入数据,对数据进行描述统计和画图首先是打开Eviews软件,可以双击桌面上的图标,或者从windows开始菜单中寻找Eviews,打开Eviews后,可以看到下面的窗口如图F1-1。
图F1-1 Eviews窗口关于Eviews的操作可以点击F1-1的Help,进行自学。
打开Eviews后,第一项任务就是建立一个新Workfile或者打开一个已有的Workfile,单击File,然后光标放在New上,最后单击Workfile。
如图F1-2图F1-2图F1-2左上角点击向下的三角可以选则数据类型,如同F1-3。
数据类型分三类截面数据,时间序列数据和面板数据。
图F1-3图F1-2右上角可以选中时间序列数据的频率,见图F1-4。
图F1-4对话框中选择数据的频率:年、半年、季度、月度、周、天(5天一周或7天1周)或日内数据(用integer data)来表示。
对时间序列数据选择一个频率,填写开始日期和结束日期,日期格式:年:1997季度:1997:1月度:1997:01周和日:8:10:1997表示1997年8月10号,美式表达日期法。
8:10:1997表示1997年10月8号,欧式表达日期法。
如何选择欧式和美式日期格式呢?从Eviews窗口点击Options再点击dates and Frequency conversion,得到窗口F1-5。
F1-5的右上角可以选择日期格式。
图F1-5假设建立一个月度数据的workfile,填写完后点OK,一个新Workfile就建好了。
见图F1-6。
保存该workfile,单击Eviews窗口的save命令,选择保存位置即可。
图F1-6新建立的workfile之后,第二件事就是输入数据。
数据输入有多种方法。
1)直接输入数据,见F1-7在Eviews窗口下,单击Quick,再单击Empty group(edit series),直接输数值即可。
注意在该窗口中命令行有一个Edit+/-,可以点一下Edit+/-就可以变成如图所示的空白格,输完数据后,为了避免不小心改变数据,可以再点一下Edit+/-,这时数据就不能被修改了。
详细的EVIEWS面板数据分析操作

详细的EVIEWS面板数据分析操作引言EVIEWS是一款专业的经济统计软件,广泛应用于经济学和金融领域的数据分析和建模。
EVIEWS提供了丰富的面板数据分析功能,可以帮助用户进行面板数据的处理、描述统计、回归分析等操作。
本文将详细介绍EVIEWS中面板数据分析的操作流程和常用功能。
EVIEWS面板数据的导入首先,我们需要将面板数据导入到EVIEWS中进行分析。
EVIEWS支持多种数据格式的导入,包括Excel、CSV、数据库等。
在导入面板数据时,需要保证数据具有正确的格式,例如面板数据应包含个体(cross-sectional)和时间(time-series)的维度,且面板数据的变量应按照一定的顺序排列。
在导入面板数据后,我们可以利用EVIEWS提供的数据操作命令对数据进行处理和调整。
例如,可以通过group命令将数据按照个体或时间进行分组,通过sort命令对数据进行排序,以便后续的面板数据分析。
面板数据的描述统计分析在面板数据导入并处理完毕后,我们可以进行面板数据的描述统计分析。
EVIEWS提供了丰富的统计功能,可以计算面板数据的平均值、标准差、相关系数等指标。
下面介绍几个常用的描述统计功能:1.summary命令:该命令可以计算面板数据每个变量的平均值、标准差、最大值、最小值等统计指标,并输出到EVIEWS的结果窗口中。
2.correlation命令:该命令可以计算面板数据各变量之间的相关系数矩阵,并输出到结果窗口中。
3.tabulate命令:该命令可以对面板数据进行交叉分组统计,例如计算变量A在变量B的每个取值下的频数和比例。
通过对面板数据进行描述统计分析,可以初步了解数据的分布特征和变量间的关系,为后续的面板数据分析提供基础。
面板数据的回归分析除了描述统计分析,EVIEWS还提供了面板数据的回归分析功能。
通过面板数据回归分析,可以探究变量间的因果关系和影响程度。
下面介绍两个常用的回归分析命令:1.panel least squares(PLS)命令:该命令可以进行面板数据的最小二乘回归分析。
eviews操作说明

EViews软件包
EViews是美国GMS公司1981年发行第1版的 Micro TSP的Windows版本,通常称为计量经济 学软件包。 EViews是Econometrics Views的缩写,它的本 意是对社会经济关系与经济活动的数量规律,采 用计量经济学方法与技术进行“观察”。
的程序、模型或系统中
(3) Objects键
Objects 键 包 含 有 很 多 命 令 和 程 序 是 对 对 象 (Object)进行操作。 如果内存中没有工作文件,Objects键的多数功 能转为灰色,表明目前它们不能使用。 主菜单中Objects键的主要功能如下 :
新对象(New Object):创建一个新的EViews 对象,选 New Object 后,立刻得到一个关于对 象类型或名称的提示。从而可做进一步选择。 对象名称包括:Series, Group, Matrix-VectorCoef., Equation, VAR, System, Pool, Model, Sample, Table, Graph, Text。 提取(Fetch):把一个对象从EViews数据库调 入内存。并得到一个关于为对象起名字的提示。
删除( Delete ):在当前(激活)窗口中删除对象。若 当前(激活)窗口是工作文件窗口,则删除已选定的对 象。 复制对象(Copy Object):复制一个
• 打印(Print):打印当前(激活)窗口中的内容。
功能选择(View Options):改变当前对象的操作功能。 随着当前对象性质的不同,功能选择(View Options) 中的内容也不同。
eviews处理面板数据操作步骤(特别好)

File/New/ Workfile Workfile structure type : Balanced Panel
Start date 1935 End date 1954 Number of cross 1 OK Cross Section Identifiers:_GM _CH _GE _WE _US
.
10
思路一:变量之间是非同阶单整 :序列变换
◎变量之间是非同阶单整的指即面板数据中有些序列平稳而有些序列不平稳,
此时不能进行协整检验与直接对原序列进行回归。
◎对序列进行差分或取对数使之变成同阶序列
若变换序列后均为平稳序列可用变换后的序列直接进行回归
思路二 若变换序列后均为同阶非平稳序列,则请点
.
若拒绝H1 ,则模型为变参数模型(模型一)。 构建统计量:请点F统计量
.
26
假设检验的 F 统计量的计算方法
构建变参数模型得残差平方和S1 并考虑其自由度 请点
构建变截距模型得残差平方和S2并考虑其自由度 请点
构建不变参数模型得残差平方和S3并考虑其自由度 请点
计算 F2 统计量
F 2 ( S 3 S 1 S ( 1 N ) / N [ N T ( 1 k ( ) k 1 ) ( 1 ) ) ~ ] F [N ( 1 )k ( 1 )N , ( T k 1 )]
第十章 Panel Data模型
第一步 录入数据
第二步 分析数据的平稳性(单位根检验)
第三步 平稳性检验后分析路径选择
第四步 协整检验`
第五步 回归模型
.
1
第一步 录入数据
一 请点 实例数据 二 请点 录入数据软件操作
Eviews 操作步骤

Eviews 操作步骤:一、数据下载(百度国泰安)1、关于指数下载步骤:数据中心→单表查询→股票市场→指数信息2、字段选择指数代码如下:000001 上证指数000002 上证A股指数000003 上证B股指数399001 深成指数399106 深圳综合指数3991007 深圳综合A指数3、时间选择:2010.1.1~2017.9.204、条件筛选:指数代码→选条件→条件值→添加5、预览数据6、下载数据下载格式:.xsl下载详情→下载二、货币量下载1、数据中心→单表查询→经济研究系列→宏观经济→金融业2、字段:M0、M1、M23、时间:2010.1.1-2017.9.204、下载详情→下载5、居民消费指数和国内贷款总量的下载步骤:经济研究系列→宏观经济→固定资产投资三、EVIEWS数据导入File→Open→Foreign data as workfile→rename→File→Save as四、单位根检验Quick→Series Statistics→Unit root test→Seires name(输入如m等)→ok→选择level(1st different、2st different)分别检验,看显著性水平和p值五、VAR 模型Quick→Estimate VAR→Endogenous→输入shz、M0、M1、M2、LOAN→lag Internval →填两个数12或14等(确认找AIC最小的数)→确立六、脉冲影应函数在上面输出结果工具栏:Impulse(或view→impulse response)→display format(选如:mutiple sraphs)→选择冲击变量如:M0→在response中选入shz→ok七、方差分解:在六的结果中→View→variance→decomposition of:shz、m0、m1、m2、loan→ok八、协整检验:1、五、六、七中任选一结果→VIEW→cointegratiom→display format(选table)→decomposition of:shz、m0、m1、m2、loan→ok2、两个变量(两步法):Quick→Estimation Equation→Equationg specification shz、m0等→ok3、Pro→make residual series(保存残差)→name for residual series(命名)→ok→view→unit root test→ok九、格兰杰因果检验:Quick→group statistics→granger causality test→series list(输变量,可以多个变量)十、保存输出结果→freez(然后编辑)→保存。
EVIEW软件指导一录入数据操作实例解说解析

• 年度:用4位数字表示;如 1978
• 半年:年后加1或2; 如 1978 2
• 季度:年后加1~4; 如 1978 3
• 月度:年后加1~12; 如 1978 11
• 周:月/日/年;
如 3 1 1978
• 日:月/日/年;
如 3 1 1978
15
第一步:创建并保存工作文件
1-3:保存工作文件 操作:工作文件页Save as /ok
第二步:复制季度数据
回到原有的数据工作文件,右键单击G78选中COPY 第三步:打开第一步建立的工作文件,在窗口空白处右键单击 并选择paste specify,在出现的窗口中选择:低频向高频转换, 方法:二次函数——与和相匹配,OK,大成告成!
30
先行指标、滞后指标和差分
处理序列中的先行、滞后指标是很容易的,只要在序列名
27
高频率数据向低频率【如月》》季》》年等等】数 据转换,有7种选择:
1.EViews缺省; 2.观测值的平均值; 3.观测值的和; 4.第一个观测值; 5.最后一个观测值; 6.观测值的最大值; 7.观测值的最小值。 Conversion propagates Nas选择项如果选上,则 遇 到 缺 少 的 数 据 就 添 上 NA , 如 果 不 选 , 则 在 部 分区间选值。
19
第三步:录入数据
(1) 键盘输入 (2) 粘贴输入 (3) 文件输入
① 文本文件
② Excel(.XLS)文件
20
(1) 键盘输入 在主菜单下,选择Quick/Empty Group(Edit Serirs)打 开一个新序列后,在编辑状态下,通过键盘输入数据,并给定 一个序列名。
(2) 粘贴输入 通过主菜单中的Edit/Copy和Edit/Paste功能复制、粘贴 数据,注意粘贴数据的时间区间要和表单中的时间区间一致。
Eviews软件操作指令

EViews软件操作及练习题指令一、建立工作文件打开EViews主窗口;从EViews主菜单中点击File键,选择New→Workfile,则打开一个Workfile Range选择框,其中需做三项选择:①Workfile frequency;②Start date;③End date 。
根据数据的性质做①Workfile frequency;②Start date;③End date各项选择。
点击OK键。
这时会建立一个尚未命名的工作文件(Workfile:UNTITLED)。
点击name 键(起名,保存)。
二、关闭工作文件从EViews三、打开工作文件双击EViews标识,从主窗口,点击File→open→Workfile→工作文件名(工作文件名字符不得超过16个)。
四、输入数据从主窗口,点击Quick→Empty Group→用手工输入数据。
输入好数据后,对时间序列数据name(起名)→save(保存)。
也可从Ecxel中把数据粘贴到Empty Group,name→save。
注意:如果输入数据错误,如何该?从Eviews主菜单中点击Edit键。
五、用公式生成新序列从主窗口,点击Quick→Generate Series→输入计算公式。
最常用运算符号:加(+),减(-),乘(*),除(/),乘方(^),X的一阶差分(D(X),即X-X(-1)),对X取自然对数(log(X)),对X取自然对数后做一阶差分(Dlog(X)),下面是@函数及其含义:@SUM(X)——序列X的和@MEAN(X)——序列X的均值@ V AR(X)——序列X的方差@ SUMSQ(X)——序列X的平方和@ COV(X,Y)——序列X和序列Y协方差@ COR(X,Y)——序列X和序列Y@ R2——R2统计量@RBA R2——调整的R2统计量@ SE——回归函数的标准误差@ F——F统计量@ MOV A V(X,n)——序列X的n期移动平均,其中n为整数六、改变工作文件区间从主窗口,点击proc→structure/Resize Current Page→改变区间。
Eviews操作教程全套完整版

1.EVIEWS基础 (3)1.1. E VIEWS简介 (3)1.2. E VIEWS的启动、主界面和退出 (3)1.3. E VIEWS的操作方式 (6)1.4. E VIEWS应用入门 (6)1.5. E VIEWS常用的数据操作 (15)2.一元线性回归模型 (24)2.1. 用普通最小二乘估计法建立一元线性回归模型 (24)2.2. 模型的预测 (30)2.3. 结构稳定性的C HOW检验 (34)3. 多元线性回归 (39)3.1. 用OLS建立多元线性回归模型 (39)3.2. 函数形式误设的RESET检验 (45)4. 非线性回归 (48)4.1. 用直接代换法对含有幂函数的非线性模型的估计 (48)4.2. 用间接代换法对含有对数函数的非线性模型的估计 (50)4.3. 用间接代换法对CD函数的非线性模型的估计 (53)4.4. NLS对可线性化的非线性模型的估计 (55)4.5. NLS对不可线性化的非线性模型的估计 (58)4.6. 二元选择模型 (62)5. 异方差 (68)5.1. 异方差的戈得菲尔德——匡特检验 (68)5.2. 异方差的WHITE检验 (72)5.3. 异方差的处理 (75)6. 自相关 (79)6.1. 自相关的判别 (79)6.2. 自相关的修正 (83)7. 多重共线性 (87)7.1. 多重共线性的检验 (87)7.2. 多重共线性的处理 (92)8. 虚拟变量 (94)8.1. 虚拟自变量的应用 (94)8.2. 虚拟变量的交互作用 (99)8.3. 二值因变量:线性概率模型 (101)9. 滞后变量模型 (105)9.1. 自回归分布滞后模型的估计 (105)9.2. 多项式分布滞后模型的参数估计 (110)10. 联立方程模型 (115)10.1. 联立方程模型的单方程估计方法 (115)10.2. 联立方程模型的系统估计方法 (119)21.Eviews基础1.1. Eviews简介Eviews:Econometric Views(经济计量视图),是美国QMS公司(Quantitative Micro Software Co.,网址为)开发的运行于Windows环境下的经济计量分析软件。
Eviews的基本操作
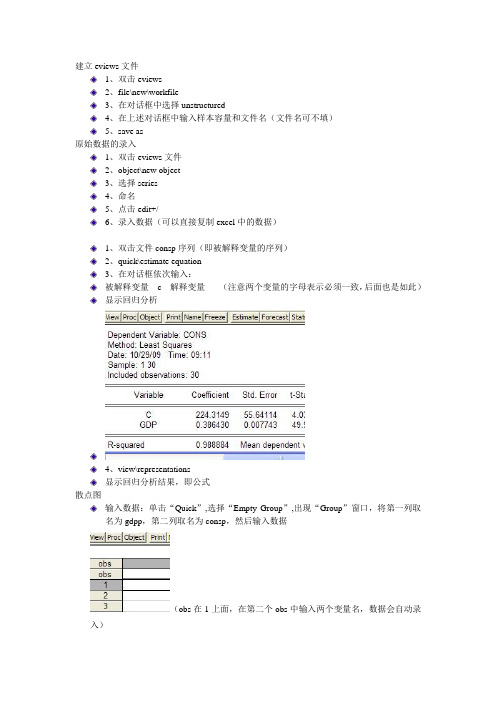
建立eviews文件
1、双击eviews
2、file\new\workfile
3、在对话框中选择unstructured
4、在上述对话框中输入样本容量和文件名(文件名可不填)
5、save as
原始数据的录入
1、双击eviews文件
2、object\new object
3、选择series
4、命名
5、点击edit+/-
6、录入数据(可以直接复制excel中的数据)
1、双击文件consp序列(即被解释变量的序列)
2、quick\estimate equation
3、在对话框依次输入:
被解释变量 c 解释变量(注意两个变量的字母表示必须一致,后面也是如此)
显示回归分析
4、view\representations
显示回归分析结果,即公式
散点图
输入数据:单击“Quick”,选择“Empty Group”,出现“Group”窗口,将第一列取
名为gdpp,第二列取名为consp,然后输入数据
(obs在1上面,在第二个obs中输入两个变量名,数据会自动录入)
(二)绘制散点图:
单击“Quick”,选择“Graph”, 在“Graph”里选择“Scatter ”,点击“OK”,出现“Series List”对话框,输入gdpp consp(有空格),点击“OK”。
出现散点图。
如下图:
如果要模型做出来,则在下图状态下
选择view——>graph——>scatter——>scattered with regression,点击ok,即出现。
Eviews操作入门输入数据-对数据进行描述统计和画图【可编辑全文】

可编辑修改精选全文完整版Eviews操作入门:输入数据,对数据进行描述统计和画图首先是打开Eviews软件,可以双击桌面上的图标,或者从windows开始菜单中寻找Eviews,打开Eviews后,可以看到下面的窗口如图F1-1。
图F1-1 Eviews窗口关于Eviews的操作可以点击F1-1的Help,进行自学。
打开Eviews后,第一项任务就是建立一个新Workfile或者打开一个已有的Workfile,单击File,然后光标放在New上,最后单击Workfile。
如图F1-2图F1-2图F1-2左上角点击向下的三角可以选则数据类型,如同F1-3。
数据类型分三类截面数据,时间序列数据和面板数据。
图F1-3图F1-2右上角可以选中时间序列数据的频率,见图F1-4。
图F1-4对话框中选择数据的频率:年、半年、季度、月度、周、天(5天一周或7天1周)或日内数据(用integer data)来表示。
对时间序列数据选择一个频率,填写开始日期和结束日期,日期格式:年:1997季度:1997:1月度:1997:01周和日:8:10:1997表示1997年8月10号,美式表达日期法。
8:10:1997表示1997年10月8号,欧式表达日期法。
如何选择欧式和美式日期格式呢?从Eviews窗口点击Options再点击dates and Frequency conversion,得到窗口F1-5。
F1-5的右上角可以选择日期格式。
图F1-5假设建立一个月度数据的workfile,填写完后点OK,一个新Workfile就建好了。
见图F1-6。
保存该workfile,单击Eviews窗口的save命令,选择保存位置即可。
图F1-6新建立的workfile之后,第二件事就是输入数据。
数据输入有多种方法。
1)直接输入数据,见F1-7在Eviews窗口下,单击Quick,再单击Empty group(edit series),直接输数值即可。
eviews教程

Eviews教程1. 介绍Eviews是一款被广泛应用于数据分析和经济建模的统计软件。
它提供了丰富的统计分析功能、高级计量经济学模型和强大的数据处理能力。
本教程将向您介绍Eviews的基本功能和操作,以帮助您快速上手使用Eviews进行数据分析和模型建立。
2. 安装和启动在开始之前,您需要先安装Eviews软件。
请根据官方网站提供的安装步骤下载和安装Eviews。
安装完成后,您可以通过以下步骤启动Eviews:1.双击桌面上的Eviews图标,或者在开始菜单中找到Eviews并点击打开。
2.Eviews启动后,您将看到一个欢迎界面。
您可以选择创建新工作文件或打开已有的文件。
3. Eviews界面介绍Eviews的界面由菜单栏、工具栏、项目管理器、文本窗口、对象浏览器和输出窗口等组成。
以下是对每个组件的简要介绍:•菜单栏:提供了各种菜单,包含Eviews的所有功能和选项。
•工具栏:包含一些常用的工具按钮,例如打开、保存、运行等。
•项目管理器:用于管理当前工作文件的对象和数据。
•文本窗口:用于编写Eviews命令和进行输出结果的展示。
•对象浏览器:显示当前工作文件中的对象列表,并提供了一些操作选项。
•输出窗口:显示Eviews的输出结果,例如数据统计、图表等。
4. 导入数据在Eviews中,您可以导入多种格式的数据,包括Excel、CSV、文本文件等。
以下是一些常用的数据导入方法:4.1 导入Excel数据要导入Excel数据,请按照以下步骤操作:1.在菜单栏中选择文件(File) -> 导入(Import) -> 导入数据(Import Data)。
2.浏览并选择要导入的Excel文件。
3.在导入向导中选择导入选项,例如数据范围、工作表等。
4.点击导入(Import)按钮完成导入过程。
4.2 导入CSV数据要导入CSV数据,请按照以下步骤操作:1.在菜单栏中选择文件(File) -> 导入(Import) -> 导入数据(Import Data)。
EVIEWS7.0讲解解读

图 8.1 案例8.1工作窗口
图 8.2 指数平滑窗口设定
Eviews 统计分析 从入门到精通
图 8.3平滑结果
图 8.4 平滑序列与原序列折线图
Eviews 统计分析 从入门到精通 三、趋势分解的滤波方法
对于非平稳时间序列(带有长期趋势的序列必定是非平稳的) 而言,研究时通常需要将其趋势与循环成分进行分解,以便进 行进一步的研究。目前主要的分解方法有结构性分解和状态性 分解两种。 结构性分解需要通过其他经济变量,通过变量之间的替代和 影响关系,例如Okun分解和Philllips曲线关系等,将时间序列 中的趋势成分和周期成分分离出来;状态性分解是通过时间序 列的时间序列性质,将其分解为趋势要素和周期要素。其中状 态性分解还可以分为状态域分解和时频域分解等。。
设置要点: (1)打开lsze序列,点击Proc/Hodrick-Prescott Filter,打开如图8.5所示的 H-P滤波操作窗口。在Output series选项组中可以设置输出的趋势成分序列 和波动成分序列的名称。系统默认趋势成分序列名为“hptrend01”,波动 成分序列名默认为空。如果此栏不填,则系统不输出该序列,本例中填写 cycle01以输出该序列。在Smoothing Parameter选项组中可以设置滤波参 数,即上文背景知识中提到的 值。
c( L) ( L1 1) (1 L)
8-7
Eviews 统计分析 从入门到精通
T 2 最小化问题用[c(L)Y t ] 来调整趋势的变化,并随着 的增大而增大。 是对趋势光滑程度和对 HP滤波依赖于参数 ,该参数需要先给定。 原数据拟合程度的一个权衡参数,读者根据需要在趋势要素对实际序列 的跟踪程度和趋势光滑程度之间做一个选择。当 =0时,满足最小化 问题的趋势序列为{Yt}序列;随着 值的增加,估计的趋势越光滑;当 趋于无穷大时,估计的趋势将接近线性函数。 一般经验, 的取值如下:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Eviews6.0面板数据操作
一、数据输入
1、创建工作文档。
如下图操作,在” workfile create”文本框的“workfile structure type”选择“balanced panel”,”panel specification”的”start date”和”end date”输入数据的起止期间,”wf”输入工作文档的名称,点击” OK”即跳出新建的工作文档a界面。
2、创建新对象。
操作如下图。
在”new object”文本框的”type of object”选择”pool”,”name for object ”输入新对象的名称。
创建成功后的界面如下面第3张图所示。
3、输入数据。
双击”workfile”界面的,跳出”pool”界面,输入个体。
一般输入方式为
如下:若上海输入_sh,北京输入_bj,…。
个体输入完成后,点击该界面的键,在跳出的”series list”输入变量名称,注意变量后要加问号。
格式如下:y? x?。
点击”OK”后,跳出
数据输入界面,如下面第4张图所示。
在这个界面上点击键,即可以z输入或者从
EXCEL处复制数据。
在输入数据后,记得保存数据。
保存操作如下:
然后在“workfile”界面如下会显示保存路径:d:\my documents\a.wf1。
若要保存到自己选择的路径下面,则在保存时选择“save as”,
在跳出的文本框里选择自己要保存的路径以及命名文件名称。
4、单位根检验。
一般回归前要检验面板数据是否存在单位根,以检验数据的平稳性,避免伪回归,或虚假回归,确保估计的有效性。
单位根检验时要分变量检验。
(补充:网上对面板数据的单位根检验和协整检验存在不同意见,一般认为时间区间较小的面板数据无需进行这两个检验。
)
(1)生成数据组。
如下图操作。
点击”make group”后在跳出的”series list”里输入要单位根检验的变量,完成后就会跳出如下图3所示的组数据。
(2)生成时序图。
如下图操作。
在”gragh options”界面的”specifi”下选择生成的时序图的形状,一般都默认设置,生成的时序图如下图3所示。
观察时序图的趋势,以确定单位根检验的检验模式。
(3)单位根检验。
单位根检验时,在”group unit root test”里的”test for root in”按检验结果一步步检验,如果原值”level”的检验结果符合要求,即不存在单位根,则单位根检验就不需要检验下去了,如果不符合要求,则需继续检验一阶差分”1st difference”、二阶差分”2nd
difference”。
”include in test equation”是检验模式的选择,根据上面时序图的形状来选择。
从上面的时序图可以看出,原值的检验模式应该选择含有截距项和趋势的检验模式,即”include in test equation”选择”individual intercept and trend”。
检验结果如下图3所示。
从检验结果可以看出,检验结果除了levin检验方法外其他方法的结果都不符合要求(Prob.xx小于置信度(如0.05),则认为拒绝单位根的原假设,通过检验)。
所以继续检验一阶差分和二阶差分,直到检验结果达到要求。
如果变量原值序列通过单位根检验,则称变量为0阶单整;如果变量一阶差分后的序列通过单位根检验,则称变量为一阶单整,以此推之。
注意:单位根检验的方法(test type)较多,可以使用LLC、IPS、Breintung、ADF-Fisher 和PP-Fisher这5种方法进行面板单位根检验。
一般,为了方便起见,只采用相同根单位根检验LLC和不同根单位根检验Fisher-ADF这两种检验方法,如果它们都拒绝存在单位根的原假设,则可以认为此序列是平稳的,反之就是非平稳的。
变量和被解释变量在单位根检验时为同阶单整。
操作如下图所示。
6、回归估计
面板数据模型根据常数项和系数向量是否为常数,分为3种类型:混合回归模型(都为常数)、
变截距模型(系数项为常数)和变系数模型(皆非常数)。
混合模型:
i t i t i t
y x αβμ=++ 1,2,,;1,2,,i N t T ==
变截距模型:it i it it y x αβμ=++ 1,2,,;1,2,,i N t T == 变系数模型:it
i it i it y x αβμ=++ 1,2,,;1,2,,i N t T ==
判断一个面板数据究竟属于哪种模型,用F 统计统计量:
()[]
()2111()/11,(1)/(1)S S N K F F N K N T K S NT N K --⎡⎤⎣⎦=
---⎡⎤⎣⎦
-+
()[]
()3121()/1(1)1(1),(1)/(1)S S N K F F N K N T K S NT N K --+⎡⎤⎣⎦=
-+--⎡⎤⎣⎦-+
来检验以下两个假设:
121:N H βββ===,12122:,N N H αααβββ======。
其中,1S 、2S 、3S 分别为变系数模型、变截距模型和混合模型的残差平方和,K 为解释变量的个数,N 为截面个体数量,α为常数项,β为系数向量。
若计算得到的统计量
2F 的值小于给定显著性水平下的相应临界值,则接受假设2H ,用混合模型拟合样本。
反之,则需用1F 检验假设1H ,如果计算得到的1F 值小于给定显著性水平下的相应临界值,则认为接受假设1H ,用变截距模型拟合,否则用变系数模型拟合。
具体操作: 1)、分别对面板数据进行3种类型模型的回归,得到1S 、2S 、3S 。
此外,一般来说,用样本数据推断总体效应,应用随机效应回归模型;直接对样本数据进行分析,采用固定效应回归模型。
首先回到面板数据表,如果是在如下这个界面时,
点击按钮,在跳出的“series list ”文本框里输入模型变量,如下图。
也可以通过重新打开工作文件,如下图操作。
选择自己当初保存的路径和文件名,点击打开。
打开后,跳出工作文件
双击,
然后分别进行变系数、变截距和混合模型的回归估计:点击,进行变系数回归
(变系数)
变截距回归
前面同2)操作,在“pool estimation”输入如下
2)、确定模型形式
把模型估计取得的s1、s2、s3数值代入前述公式(第13页),如下
()[]
()2111()/11,(1)/(1)S S N K F F N K N T K S NT N K --⎡⎤⎣⎦=
---⎡⎤⎣⎦
-+
()[]
()3121()/1(1)1(1),(1)/(1)S S N K F F N K N T K S NT N K --+⎡⎤⎣⎦=
-+--⎡⎤⎣⎦
-+
计算得到F1、F2值,检验假设H1、H2,从而确定采用何种模型形式(变系数、变截距、混合效应)。
3)、回归分析
若检验结果表明应采用变系数模型,回到以下界面进行估计
点击,进行变系数回归
上图列示了回归结果,其中:
①Coefficient为系数,比如AH的系数为0.760053,截距项为477.4820-315.8649
②t-Statistic为t值,检验每一个自变量的合理性。
|t|大于临界值表示可拒绝系数为0的假设,即系数合理。
Prob为系数的概率,若其小于置信度(如0.05)则表明|t|大于临界值,即认为系数合理。
从结果可以看出,本例中系数合理。
③R-squared为样本决定系数,表示总离差平方和中由回归方程可以解释部分的比例,比例越大说明回归方程可以解释的部分越多。
值为0-1,越接近1表示拟合越好,>0.8认为可以接受,但是R2随因变量的增多而增大,所以可以通过增加自变量的个数来提高模型的R-squared。
本例中R-squared0.995382,接近1,拟合度相当好。
Adjust R-seqaured为修正的R-squared,与R-squared有相似意义。
④F-statistic表示模型拟合样本的效果,即选择的所有自变量对因变量的解释力度。
F大于临界值则说明拒绝0假设。
若Prob(F-statistic)小于置信度(如0.05)则说明F大于临界值,方程显著性明显。
本例中Prob(F-statistic)为0.000000,模型方程显著。
⑤Durbin-Watson stat:检验残差序列的自相关性。
其值在0-4之间。