R语句常用函数汇总
r语言查询函数

r语言查询函数
R语言是一种流行的编程语言,用于数据分析和统计。
查询函数是R语言中的一种重要函数,用于从数据框中选择、过滤和排序数据。
以下是一些常用的R语言查询函数。
1. subset()函数:该函数用于从数据框中选择满足一定条件的
行和列。
2. filter()函数:该函数用于从数据框中选择满足一定条件的行。
3. select()函数:该函数用于从数据框中选择指定的列。
4. arrange()函数:该函数用于对数据框中的行按照指定的列进行排序。
5. distinct()函数:该函数用于去除数据框中的重复行。
6. group_by()函数:该函数用于按照指定的列对数据框中的行
进行分组。
7. mutate()函数:该函数用于向数据框中添加新的列。
8. summarize()函数:该函数用于对数据框中的行进行汇总计算。
以上是一些常用的R语言查询函数,它们可以帮助您轻松地操作和处理数据框。
- 1 -。
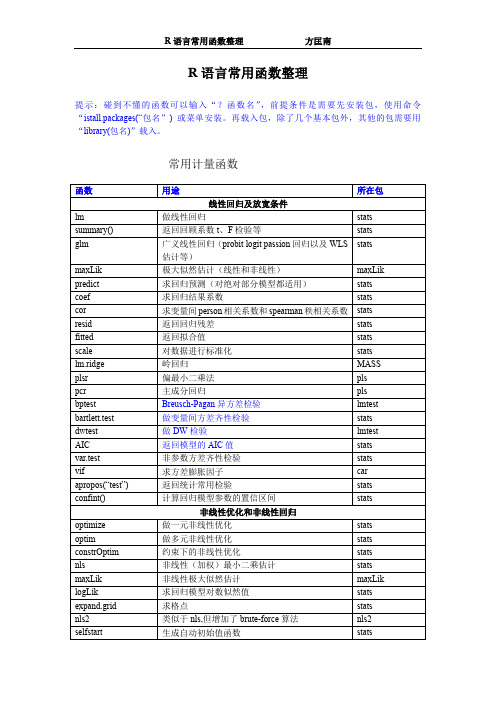
R语言常用函数整理
求时间序列描述统计量(包括均值、标准差、偏度、峰度等) FinTS 检验时间序列均值是否为零(实际上可作单、双样本检验) stats ARMA 相关函数 转换为时间序列格式 将多个时间序列联合起来 将时间相同的列合并,区别不同时间的行 stats stats stats
R 语言常用函数整理 window ts.plot diff.ts as.Date acf pacf Box.test ar arima ARIMA arma predict tsdiag adf.test urdfTest kpss.test pp.test Arima.sim FitAR Auto.arima 提取符合某个时间段的数据 作时序图 时序差分 把非时间向量转为时间向量 求自相关函数和作偏自相关函数图 求偏自相关函数和作偏自相关函数图 作序列自相关 B-P 和 L-B 检验
R 语言常用函数整理
方匡南
R 语言常用函数整理
提示:碰到不懂的函数可以输入“?函数名” ,前提条件是需要先安装包,使用命令 “ istall.packages(“ 包名” ) 或菜单安装。再载入包,除了几个基本包外,其他的包需要用 “library(包名)”载入。
常用计量函数
函数 lm summary() glm maxLik predict coef cor resid fitted scale lm.ridge plsr pcr bptest bartlett.test dwtest AIC var.test vif apropos(“test”) confint() optimize optim constrOptim nls maxLik logLik expand.grid nls2 selfstart 用途 线性回归及放宽条件 做线性回归 返回回顾系数 t、F 检验等 广义线性回归(probit logit passion 回归以及 WLS 估计等) 极大似然估计(线性和非线性) 求回归预测(对绝对部分模型都适用) 求回归结果系数 求变量间 person 相关系数和 spearman 秩相关系数 返回回归残差 返回拟合值 对数据进行标准化 岭回归 偏最小二乘法 主成分回归 Breusch-Pagan 异方差检验 做变量间方差齐性检验 做 DW 检验 返回模型的 AIC 值 非参数方差齐性检验 求方差膨胀因子 返回统计常用检验 计算回归模型参数的置信区间 非线性优化和非线性回归 做一元非线性优化 做多元非线性优化 约束下的非线性优化 非线性(加权)最小二乘估计 非线性极大似然估计 求回归模型对数似然值 求格点 类似于 nls,但增加了 brute-force 算法 生成自动初始值函数 stats stats stats stats maxLik stats stats nls2 stats stats stats stats maxLik stats stats stats stats stats stats MASS pls pls lmtest stats lmtest stats stats car stats stats 所在包
R语言常用函数汇总

R语言常用函数汇总R语言是一种强大的统计计算语言,拥有丰富的函数和包。
下面是常用的R语言函数的汇总(按照字母顺序排列)。
1. abs(x): 返回x的绝对值。
2. append(x, values): 向向量x中追加值values。
3. apply(X, MARGIN, FUN): 在矩阵X的指定维度上应用函数FUN。
4. args(function): 返回指定函数的参数列表。
5. as.character(x): 将对象x转化为字符型。
6. as.data.frame(x): 将对象x转化为数据框。
7. as.factor(x): 将对象x转化为因子型。
8. as.matrix(x): 将对象x转化为矩阵。
9. as.numeric(x): 将对象x转化为数值型。
10. barplot(height): 绘制条形图。
11.c(x,...):将x与其他对象合并为一个向量。
12. colnames(x): 返回矩阵或数据框x的列名。
13. cor(x, y): 计算x和y的相关系数。
14. cut(x, breaks): 将向量x划分为几个离散区间。
15. plot(x, y): 绘制散点图。
16. density(x): 生成x的密度图。
17. diff(x): 计算向量x的差值。
18. dim(x): 返回矩阵或数据框x的维度。
19. mean(x): 计算向量x的平均值。
20. median(x): 计算向量x的中位数。
21. min(x): 返回向量x的最小值。
22. max(x): 返回向量x的最大值。
23. names(x): 返回对象x的变量名。
24. paste(x, ...): 将x和其他对象合并为一个字符型。
25. print(x): 打印对象x。
26. range(x): 返回向量x的范围。
27. read.csv(file): 从CSV文件中读取数据。
28. rownames(x): 返回矩阵或数据框x的行名。
R语言常用函数

R语言常用函数基本一、数据管理vector:向量numeric:数值型向量logical:逻辑型向量character;字符型向量list:列表data.frame:数据框c:连接为向量或列表length:求长度subset:求子集seq,from:to,sequence:等差序列rep:重复NA:缺失值NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量nchar:字符数substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子codes:因子的编码levels:因子的各水平的名字nlevels:因子的水平个数cut:把数值型对象分区间转换为因子table:交叉频数表split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx 和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组matrix:生成矩阵data.matrix:把数据框转换为数值型矩阵lower.tri:矩阵的下三角部分mat.or.vec:生成矩阵或向量t:矩阵转置cbind:把列合并为矩阵rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置nrow, ncol:计算数组的行数和列数dim:对象的维向量dimnames:对象的维名row/colnames:行名或列名%*%:矩阵乘法crossprod:矩阵交叉乘积(内积)outer:数组外积kronecker:数组的Kronecker积apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量scale:矩阵标准化matplot:对矩阵各列绘图cor:相关阵或协差阵Contrast:对照矩阵row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解qr:矩阵的QR分解chol2inv:由Choleski 分解求逆五、逻辑运算,=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量all,any:逻辑向量都为真或存在真ifelse():二者择一match,%in%:查找unique:找出互不相同的元素which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
r语言数学函数

r语言数学函数标题:深入了解r语言中的数学函数作为一位r语言的使用者,熟悉并灵活应用各种数学函数是必要的。
在本文中,我们将深入了解r语言中的数学函数,并提供一些常见的实例供大家参考。
一、 r语言中的基本数学函数1. 加、减、乘、除在r语言中,加法使用“+”符号,减法使用“-”符号,乘法使用“*”符号,除法使用“/”符号。
例如:a <- 5 + 2 # 加b <- 5 - 2 # 减c <- 5 * 2 # 乘d <- 5 / 2 # 除print(a) # 输出结果为7print(b) # 输出结果为3print(c) # 输出结果为10print(d) # 输出结果为2.52. 幂运算在r语言中,幂运算使用“^”符号。
例如:e <- 2^3 # 2的3次幂print(e) # 输出结果为83. 取模运算在r语言中,取模运算使用“%%”符号。
例如:f <- 5 %% 2 # 取5除以2的余数,结果为1print(f) # 输出结果为14. 取整和四舍五入在r语言中,取整使用函数floor()或ceiling(),四舍五入使用函数round()。
例如:g <- floor(2.7) # 取整,结果为2h <- ceiling(2.3) # 取整,结果为3i <- round(2.5) # 四舍五入,结果为3print(g) # 输出结果为2print(h) # 输出结果为3print(i) # 输出结果为35. 绝对值和取余数在r语言中,绝对值使用函数abs(),取余数使用函数abs()。
例如:j <- abs(-3) # 取绝对值,结果为3k <- sign(-5) # 取符号,结果为-1print(j) # 输出结果为3print(k) # 输出结果为-1二、 r语言中的高级数学函数1. 寻找最小值和最大值在r语言中,可以使用函数min()和max()来寻找向量或数据框中的最小值和最大值。
R常用函数表格汇总

表1帮助函数 (2)表2用于管理R工作空间的函数 (2)表3处理数据对象和变量的实用函数 (4)表4日期格式 (7)表 5 数据类型转换函数 (8)表6用于保存图形输出的函数 (8)表7图形输出函数 (9)表8算术运算符 (12)表9逻辑运算符 (12)表10字符处理函数 (13)表11其它使用函数(字符与数字) (15)表12数学函数 (15)表13统计函数 (16)表14概率分布 (16)表15常用控制流语句 (18)表16基本图形 (18)表17基本统计分析函数 (19)表18中级统计分析函数 (22)表19对拟合线性模型非常有用的其它函数 (23)表1帮助函数注:函数RSiteSearch()可在在线帮助手册和R-Help邮件列表的讨论存档中搜索指定主题,并在浏览器中返回结果。
由函数vignette()函数返回的vignette文档一般是PDF格式的实用介绍性文章。
不过,并非所有的包都提供了vignette文档。
表2用于管理R工作空间的函数注:①注意setwd()命令的路径中使用了正斜杠。
R将反斜杠(\)作为一个转义符。
②我通常会在启动一个R会话时使用setwd()命令指定到某一个项目的路径,后接不加选项的load()命令,这样就能继续上一次的会话。
③如果filename中不包含路径,R将假设此文件在当前工作目录中。
④表3处理数据对象和变量的实用函数注:①在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。
②R中的五种数据结构:向量、矩阵、数组、数据框、列表;对应c(),matrix(),arry(),data.frame(),list();另外有factor()。
③read.table()中name必须是file中存在的变量,且无重复值。
④R中没有标量。
标量以单元素向量的形式出现。
⑤R中的下标不从0开始,而从1开始。
在上述向量中,x[1]的值为8。
R语言基本函数、统计量、常用操作函数

R语⾔基本函数、统计量、常⽤操作函数先⾔:R语⾔常⽤界⾯操作帮助:help(nnet) = ?nnet =??nnet清除命令框中所有显⽰内容:Ctrl+L清除R空间中内存变量:rm(list=ls())、gc()获取或者设置当前⼯作⽬录:getwd、setwd保存指定⽂件或者从磁盘中读取出来:save、load读⼊、读出⽂件:read.table、wirte.table、read.csv、write.csv1、⼀些简单的基本统计量[plain] copy1. #基本统计量2. sum/mean/sd/min #⼀些基本统计量3.4. which.min() #找出最⼩值的序号以上是单数列,如果是多变量下的呢?[plain] copy1. #多元数据2. colMeans() #每列,row是⾏(横向)3. colnames() #列名4. colSums() #列求和5. cov() #协⽅差阵6. cor() #相关矩阵7. cor.test() #相关系数abs绝对值sqrt平⽅根exp e^x次⽅log⾃然对数log2,log10其他对数sin,cos,tan三⾓函数sinh,cosh,tanh双曲函数poly正交多项式polyroot多项式求根对象操作:assign赋值操作,等同于“<-”rm删除对象ls显⽰内存中的对象str显⽰对象的内在属性或简要说明对象ls.str展⽰内存中所有对象的详细信息length返回对象中元素的个数names显⽰数据的名称,对于数据框则是列名字levels因⼦向量的⽔平dim数据的维度dim数据的维度nrow矩阵或数据框的⾏数ncol列数rownames数据的⾏名字colnames列名字class数据类型mode数据模式head数据的前n ⾏tail数据的后n ⾏summary显⽰对象的概要attrx 的属性类型is.na检测变量的类型is.nullis.arrayis.data.frameis.numericplexis.character 简单统计:max最⼤元素min最⼩元素range最⼩值和最⼤值组成的向量sum和prod元素连乘pmax向量间相同下标进⾏⽐较最⼤者,并组成新的向量pmin向量间相同下标进⾏⽐较最⼩者,并组成新的向量cumsum累积求和cumprod连乘cummax最⼤cummin最⼩mean均值weighted,mean加权平均数median中位数sd标准差norm正态分布fF 分布unif均匀分布cauchy柯西分布binom⼆项分布geom⼏何分布chisq.test卡⽅检验,进⾏独⽴性检验prop.test 对总体均值进⾏假设检验prop.test对总体均值进⾏假设检验shapiro.test正态分布检验t.test T检验,对总体均值进⾏区间估计aov⽅差分析anova⼀个或多个模型对象的⽅差分析2、向量向量在循环语句中较为⼴泛[plain] copy1. #向量2. #向量在循环语句中较为⼴泛3. M=vector(length = 8);M #⽣成⼀个长为8的布尔向量4. M[1]="1";M #赋值之后就会定义为字符5. M[1]=1;M #赋值之后,定义为数值逻辑向量使⽤[plain] copy1. y[y < 0] <- -y[y < 0] #表⽰将向量(-y)中与向量y的负元素对应位置的元素赋值给向量y中与向量y负元素对应的元素。
R语言时间序列有关各种函数总结

R语言时间序列有关各种函数总结R语言是一种强大的统计分析和数据可视化工具,提供了许多时间序列分析的函数和方法。
下面是一些重要的时间序列分析函数的总结:1. ts(函数:用于创建时间序列对象。
可以指定时间序列的起始时间、结束时间、时间间隔等。
例如,创建从1990年1月到1999年12月的月度时间序列对象可以使用以下代码:```Rts_data <- ts(data, start=c(1990, 1), end=c(1999, 12), frequency=12)``````R```3. stl(函数:基于季节性-趋势-随机性分解的局部回归方法,用于进行季节调整。
该函数可以根据时间序列的特性自动选择适当的分解模型。
以下是使用stl(函数进行季节调整的示例:```Rseasonally_adjusted <- stl(ts_data, s.window="periodic")```4. forecast(函数:用于时间序列的预测。
可以根据历史数据拟合不同的模型,例如ARIMA模型、指数平滑模型等,并生成未来一段时间的预测结果。
以下是使用forecast(函数生成未来12个月的预测结果的示例:```Rforecast_result <- forecast(ts_data, h=12)```5. autocorrelation(函数:用于计算时间序列的自相关系数。
自相关系数可以帮助我们了解时间序列的固定模式和周期性。
以下是计算时间序列的自相关系数的示例:```Racf_result <- autocorrelation(ts_data)```6. arima(函数:用于建立自回归移动平均模型(ARIMA)来拟合时间序列。
ARIMA模型是一种常用的时间序列预测模型,可以预测时间序列的未来值。
以下是使用arima(函数拟合ARIMA模型的示例:```Rarima_model <- arima(ts_data, order=c(p, d, q))```7. ets(函数:用于指数平滑时间序列模型的拟合和预测。
R语言常用函数

R语言常用函数This model paper was revised by the Standardization Office on December 10, 2020R语言常用函数基本一、数据管理vector:向量 numeric:数值型向量 logical:逻辑型向量character;字符型向量list:列表:数据框c:连接为向量或列表 length:求长度 subset:求子集seq,from:to,sequence:等差序列rep:重复 NA:缺失值 NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性 mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量 nchar:字符数 substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子 codes:因子的编码 levels:因子的各水平的名字nlevels:因子的水平个数 cut:把数值型对象分区间转换为因子table:交叉频数表 split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值 range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值 besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组 matrix:生成矩阵:把数据框转换为数值型矩阵:矩阵的下三角部分:生成矩阵或向量t:矩阵转置 cbind:把列合并为矩阵 rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置 nrow, ncol:计算数组的行数和列数dim:对象的维向量 dimnames:对象的维名row/colnames:行名或列名 %*%:矩阵乘法crossprod:矩阵交叉乘积(内积) outer:数组外积kronecker:数组的Kronecker积 apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量 scale:矩阵标准化matplot:对矩阵各列绘图 cor:相关阵或协差阵Contrast:对照矩阵 row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆 eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解 qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算,=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量 all,any:逻辑向量都为真或存在真ifelse():二者择一 match,%in%:查找unique:找出互不相同的元素 which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
r语言常用函数

r语言常用函数r语言是一种用于处理统计和计算的非常受欢迎的编程语言。
它具有许多强大的函数,可以帮助统计学家们非常快速地解决问题。
以下是r语言常用函数的列表:1. c():它用于将多个值合并成一个向量。
2. dim():它可以用于查看对象的维数。
3. seq():这个函数可以用于生成一个指定范围的有序数字序列。
4. apply():它用于在数据框或数组上应用函数,而不必遍历它们。
5. aggregate():统计数据分组之后,这是一种快速汇总函数。
6. lm():它用于建立线性回归模型,可以为数据样本中特定自变量拟合参数模型。
7. plot():这是一个绘制图形所需的核心函数,并可用于绘制散点图,折线图,箱线图和条形图等。
8. mean():这是r语言中函数计算均值的函数,它可用于计算输入向量的平均值。
9. summary():这是一个快速的汇总函数,它可以提供有关数据分布的大量信息,包括均值,中位数,最大值,最小值,标准差等。
10. log():该函数可以用来计算指定数字的对数值。
11. sd():这个函数可以查看样本标准差值。
12. cor():它可以用于检查两个变量间的线性相关性。
13. table():这是一个用于创建交叉表的函数,可用于检查表中分类变量之间的关系。
14. which():它用来查找符合条件的索引值。
15. order():这是一个常用的函数,用于排序,它可以按顺序或倒序对给定向量进行排序。
16. not():它用来查看给定向量的某元素是否满足给定的条件。
17. ifelse():这个函数可以返回由条件判断结果产生的新向量。
18. diff():它用于计算向量中连续元素间的差值。
19. is.na():它可以检测向量中是否存在缺失值。
20. split():它可以用来将数据框拆分为多个新的数据框。
R语言基本操作函数

R语言基本操作函数1.变量变换as.array(x),as.data.frame(x),as.numeric(x),as.logical(x), plex(x),as.character(x),...转换变量类型;使用如下命令可得到全部列表,methods(as)factor():将一个向量转化为一个因子2.变量信息is.na(x),is.null(x),is.array(x),is.data.frame(x),is.numeric(x),is.co mplex(x),is.character (x),...检验变量的类型;使用如下命令得到全部列表,methods(is)length(x):x中元素的个数dim(x):查看变量的维数;重新设置的维数,例如dim(x)=c(3,2) dimnames(x):重新设置对象的名称nrow(x):行的个数ncol(x):列的个数class(x):得到或设置x的类;class(x)<-c(3,2)unclass(x):删除x的类attr(x,which):得到或设置x的属性whichattributes(obj):得到或设置obj的属性列表fix,edit:对数据框数据进行表格形式的编辑3.数据选取和操作which.max(x):返回x中最大元素的指标which.min(x):返回x中最小元素的指标rev(x):翻转x中所有的元素sort(x):升序排列x中的元素;降序排列使用:rev(sort(x))cut(x,breaks):将x分割成为几段(或因子);breaks为段数或分割点向量match(x,y):返回一个和x长度相同且和y中元素相等的向量不等则返回NAwhich(x==a):如果比较操作为真(TRUE),返回向量x的指针choose(n,k):组合数的计算na.omit(x):去除缺失值(NA)(去除相关行如果x为矩阵或数据框)na.fail(x):返回错误信息,如果x包含至少一个NAunique(x):如果x为向量或数据框,返回唯一值table(x):返回一个由x不同值个数组成的表格(通常用于整数或因子),即频数表subset(x,...):根据条件(...选取x中元素,如x$V1<10);如果x为数据框,选项select使用负号给出保留或去除的变量 subset(x, subset, select, drop = FALSE, ...)sample(x,size):不放回的随即在向量x中抽取size个元素,选项replace=TRUE允许放回抽取prop.table(x,margin=):根据margin使用分数表示表格,wumargin时,所有元素和为1* R数据的创建与索引** 向量的操作*** 向量的创建**** c(...)为concatenate的缩写;常见的将一系列参数转化为向量的函数,通过recursive=TRUE 降序排列列表并组合所有的元素为向量*** from:to产生一个序列":"有较高的优先级;1:4+1得到"2,3,4,5"*** seq() 产生一个向量序列seq(from = 1, to = 1, by = ((to - from)/(length.out - 1)),length.out = NULL, along.with = NULL, ...)其中length.out可简写为len。
R语言笔记——常用函数、统计分析、数据类型、数据操作、帮助、安装程序包、R绘图

帮助●查看帮助文档install.package()help(“install.package”)●函数帮助functionhelp(‘function’)●html帮助Help.start()帮助>Html帮助●关键词搜索RSiteSearch(‘word’)数据类型向量●创建向量c( ),创建向量length( ), 向量长度删除向量vector[-n],即删除第n个向量mode( ), 向量类型rbind( ), 向量元素都作为一行rowcbind( ) ,向量元素都作为一列col*创建向量序列seq(from, to, by = ((to - from)/(length.out - 1)),length...), length是总长度(个数),因此by就是间隔rep(mode,time) 产生mode 重复time次的向量letters[n:m] 产生字符向量r norm(n,mean=…,sd=…) 随机序列●取子集值范围限制如:V(x>m|x<n)索引坐标限制如:V[c()],V[1:3]●创建向量空间V=vector()创建向量空间后就可以对向量元素进行赋值●常用计算函数mean(x ),sum( x),min( x), max( x),var( x), 方差sd( x), 标准差cov(x), 协方差cor(x), 相关度prod(x ),所有值相乘的积which(x的表达式),which.min(x),which.max(x)rev(x),反转sort(x),排序因子因子是用水平来表示所有可能取的值创建(转换)因子factor(v,level=vl) level不指定则默认v中所有值gl(k,n) k是因子的水平个数,n是每个水平重复的个数因子统计nlevels(factor) 查看因子水平table(factor) 频数prop.table(factor) 概率交叉统计对于两个向量进行统计会构成一张交叉的表table(factor1,,factor2)向量命名names(v)=c(“area1”,”area2”,…),命名后就可以按名称取值了,v[“area1”]矩阵创建矩阵1.matrix(v, nrow = 1, ncol = 1, byrow = FALSE),一列(不是行)一列的分配,当数据不够时候就会重复.函数matrix()用来定义最常用的一种数组:二维数组,即矩阵。
R语言常用函数

基本一、数据管理vector:向量numeric:数值型向量logical:逻辑型向量character;字符型向量list:列表data.frame:数据框c:连接为向量或列表length:求长度subset:求子集seq,from:to,sequence:等差序列rep:重复NA:缺失值NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量nchar:字符数substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子codes:因子的编码levels:因子的各水平的名字nlevels:因子的水平个数cut:把数值型对象分区间转换为因子table:交叉频数表split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组matrix:生成矩阵data.matrix:把数据框转换为数值型矩阵lower.tri:矩阵的下三角部分mat.or.vec:生成矩阵或向量t:矩阵转置cbind:把列合并为矩阵rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置nrow, ncol:计算数组的行数和列数dim:对象的维向量dimnames:对象的维名row/colnames:行名或列名%*%:矩阵乘法crossprod:矩阵交叉乘积(内积)outer:数组外积kronecker:数组的Kronecker积apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量scale:矩阵标准化matplot:对矩阵各列绘图cor:相关阵或协差阵Contrast:对照矩阵row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算<,>,<=,>=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量all,any:逻辑向量都为真或存在真ifelse():二者择一match,%in%:查找unique:找出互不相同的元素which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
r中的函数

r中的函数R中的函数是一种非常重要的工具,它们可以帮助我们进行各种数据处理和分析。
在这篇文章中,我将介绍一些常用的R函数,并说明它们的用途和功能。
我们来介绍一下"mean"函数。
这个函数可以计算一组数据的平均值。
例如,我们有一组数据x,可以使用mean(x)来计算它们的平均值。
这个函数在统计分析中非常常用,可以帮助我们了解数据的整体趋势。
接下来,我们来介绍一下"sum"函数。
这个函数可以计算一组数据的总和。
例如,我们有一组数据y,可以使用sum(y)来计算它们的总和。
这个函数在金融分析和商业决策中非常常用,可以帮助我们了解数据的总体规模。
除了计算平均值和总和,R中还有一些其他的函数可以进行数据处理。
例如,"max"函数可以计算一组数据的最大值,"min"函数可以计算一组数据的最小值。
这些函数在数据挖掘和预测分析中非常常用,可以帮助我们找到数据中的极值点和异常值。
R中还有一些用于数据转换和整理的函数。
例如,"sort"函数可以对一组数据进行排序,"unique"函数可以去除重复的数据。
这些函数在数据清洗和数据预处理中非常常用,可以帮助我们整理数据,使其更加规范和易于分析。
除了上述函数外,R中还有一些用于数据可视化的函数。
例如,"plot"函数可以绘制一组数据的散点图,"hist"函数可以绘制一组数据的直方图。
这些函数在数据探索和数据呈现中非常常用,可以帮助我们更直观地理解数据的分布和关系。
除了以上介绍的函数外,R还有很多其他的函数可以帮助我们进行数据处理和分析。
例如,"lm"函数可以进行线性回归分析,"t.test"函数可以进行假设检验,"cor"函数可以计算数据的相关系数。
这些函数在统计分析和数据建模中非常常用,可以帮助我们进行更深入的数据分析和模型建立。
R语句常用函数汇总

R语句常用函数汇总以下是一些在R语言中常用的函数:1.基础函数:- `print(`:打印输出结果。
- `c(`:创建向量(vector)。
- `length(`:计算向量的长度。
- `class(`:显示对象的类型。
- `typeof(`:显示对象的存储模式。
- `is.na(`:判断元素是否为缺失值。
- `is.null(`:判断对象是否为NULL。
- `is.factor(`:判断对象是否为因子(factor)。
- `is.character(`:判断对象是否为字符型(character)。
- `is.numeric(`:判断对象是否为数值型(numeric)。
- `is.vector(`:判断对象是否为向量(vector)。
2.数据管理函数:- `mean(`:计算向量或矩阵的均值。
- `sum(`:计算向量或矩阵的和。
- `min(`:计算向量或矩阵的最小值。
- `max(`:计算向量或矩阵的最大值。
- `median(`:计算向量或矩阵的中位数。
- `var(`:计算向量或矩阵的方差。
- `sd(`:计算向量或矩阵的标准差。
- `quantile(`:计算向量或矩阵的分位数。
- `sort(`:对向量或矩阵进行排序。
- `table(`:创建频数表。
- `subset(`:根据条件筛选数据。
- `merge(`:根据指定的列合并数据框。
- `aggregate(`:根据指定的变量对数据进行聚合。
3.数据操作函数:- `unique(`:返回向量的唯一值。
- `duplicated(`:判断向量是否有重复值。
- `na.omit(`:删除包含缺失值的观察值。
- `na.exclude(`:排除缺失值。
- `names(`:获取或设置对象的名称。
- `as.factor(`:将向量转换为因子(factor)。
- `as.character(`:将向量转换为字符型(character)。
- `as.numeric(`:将向量转换为数值型(numeric)。
R常用

五、时间序列
ts:时间序列对象
diff:计算差分
time:时间序列的采样时间
window:时间窗
六、统计模型
lm,glm,aov:线性模型、广义线性模型、方差分析
文件操作
一、文件执行:
在用R生成一个PDF文档后,如果想去打开它,你可能会在文件夹里找到再点开。再或者我们想调用系统中的其它程序来做点事情,可能要打开cmd敲点命令。实际上这都可以在R内部完成。举例来说用pandoc转换na.md成docx再打开它。
ifelse():二者择一
match,%in%:查找
unique:找出互不相同的元素
which:找到真值下标集合
duplicated:找到重复元素
六、优化及求根
optimize,uniroot,polyroot:一维优化与求根
程序设计
一、控制结构
if,else,ifelse,switch:分支
向量可以进行那些常规的算术运算,不同长度的向量可以相加,这种情况下最短的向量将被循环使用。
> x <- 1:4
> a <- 10
> x * a
[1] 10 20 30 40
> x + a
[1] 11 12 13 14
> sum(x) #对x中的元素求和
[1] 10
> prod(x) #对x中的元素求连乘积
[1] 24
> prod(2:8) #8的阶乘
[1] 40320
> prod(2:4) #4的阶乘
[1] 24
r语言数据整理常用函数

r语言数据整理常用函数R语言是一种流行的数据分析和统计建模工具,它提供了许多强大的函数和包,用于数据整理和处理。
在本文中,我们将介绍一些常用的R语言数据整理函数,以帮助您更有效地处理和分析数据。
1. dplyr包。
dplyr包是R语言中最流行的数据整理包之一,它提供了一组简单而一致的函数,用于对数据进行筛选、排序、汇总和变换。
其中一些常用的函数包括:filter(),用于筛选数据集中满足特定条件的观测值。
select(),用于选择数据集中的特定变量。
mutate(),用于创建新的变量,或者修改现有的变量。
summarise(),用于对数据进行汇总统计。
这些函数使得数据整理变得更加直观和简单,同时也提高了代码的可读性和可维护性。
2. tidyr包。
tidyr包是另一个常用的数据整理包,它提供了一些函数,用于对数据进行重塑和整理。
其中一些常用的函数包括:gather(),用于将宽格式数据转换为长格式数据。
spread(),用于将长格式数据转换为宽格式数据。
separate()和unite(),用于对一个变量进行拆分或者合并。
这些函数可以帮助您轻松地处理不同格式的数据,使得数据整理更加灵活和高效。
3. reshape2包。
reshape2包也提供了一些函数,用于数据的重塑和整理。
其中最常用的函数是melt()和dcast(),它们分别用于将数据从宽格式转换为长格式,以及从长格式转换为宽格式。
总结。
在本文中,我们介绍了一些常用的R语言数据整理函数和包,包括dplyr、tidyr和reshape2。
这些函数和包提供了丰富的功能,可以帮助您更加高效地处理和整理数据,使得数据分析工作变得更加简单和愉快。
希望本文对您有所帮助,谢谢阅读!。
R语言常用函数汇总

R语言常用函数汇总今天把R常用函数大体汇总了一下,其中包括一般数学函数,统计函数,概率函数,字符处理函数,以及一些其他函数;1. 数学函数函数作用abs() 绝对值sqrt() 平方根ceiling(x) 不小于x的最小整数floor(x) 不大于x的最大整数round(x, digits=n) 将x舍入为指定位的小数signif(x, digits=n) 将X舍入为指定的有效数字位数2. 统计函数函数作用mean(x) 平均值median(x) 中位数sd(x) 标准差var(x) 方差quantile(x, probs) 求分位数,x为待求分位数的数值型向量,probs是一个由[0,1]的概率值组成的数值型向量range(x) 求值域sum(x) 求和min(x) 求最小值max(x) 求最大值scale(x, center=TRUE,scale=TRUE) 以数据对象x按列进行中心化或标准化,center=TRUE表示数据中心化,scale=TRUE表示数据标准化diff(x, lag=n) 滞后差分,lag用以指定滞后几项,默认为1difftime(time1,time2,units=c(“auto”,”secs”,”mins”,”hou rs”,”days”,”weeks”))计算时间间隔,并以星期,天,时,分,秒来表示3. 概率函数分布名称缩写beta分布beta 二项分布binom 柯西分布Cauchy 卡方分布chisp 指数分布expF分布 fgamma分布gamma几何分布geom超几何分布hyper对数正态分布lnormlogistics分布logis多项分布multinom负二项分布nbinom正态分布norm泊松分布poisWilcoxon分布signrankt分布t均匀分布unifweibull分布weibullWilcoxon秩和分布W ilcox在R中,函数函数行如:[x][function]。
R语句常用函数汇总

R语句常用函数汇总以下是一些常用的R语句函数:1.数据导入和处理函数:- read.csv(:读取csv文件- read.table(:读取文本文件- str(:显示对象的结构和属性- summary(:显示对象的统计摘要- head(:显示对象的前几行数据- tail(:显示对象的后几行数据- subset(:从数据框中选择满足条件的观测- merge(:根据键合并数据框2.数据转换函数:- transform(:根据变量的计算规则创建新变量- aggregate(:根据变量的组合创建汇总统计量- apply(:对矩阵或数据框的行或列进行逐行/逐列操作- lapply(:对列表中的每个元素应用函数- sapply(:对列表中的每个元素应用函数,并返回简化的结果- tapply(:根据向量的分组变量应用函数3.统计函数:- mean(:计算均值- median(:计算中位数- sd(:计算标准差- var(:计算方差- min(:计算最小值- max(:计算最大值- sum(:计算总和- quantile(:计算分位数- cor(:计算变量之间的相关系数4.绘图函数:- plot(:绘制散点图或折线图- hist(:绘制直方图- boxplot(:绘制箱线图- barplot(:绘制柱状图- pie(:绘制饼图- lines(:在已有图形上添加线条- points(:在已有图形上添加点- legend(:添加图例5.模型拟合和预测函数:- lm(:拟合线性回归模型- glm(:拟合广义线性模型- predict(:使用模型预测新数据- anova(:分析方差表- t.test(:执行单样本或双样本t检验- chisq.test(:执行卡方检验- cor.test(:执行相关性检验这只是一小部分常用的R函数,R语言还有很多其他函数可以用于各种数据处理和分析任务。
摘抄-R语言常用数学函数

摘抄-R语⾔常⽤数学函数R语⾔常⽤数学函数(2013-01-04 22:09:00)转载▼标签:杂谈分类:R语⾔语⾔的数学运算和⼀些简单的函数整理如下:向量可以进⾏那些常规的算术运算,不同长度的向量可以相加,这种情况下最短的向量将被循环使⽤。
> x <- 1:4> a <- 10> x * a[1] 10 20 30 40> x + a[1] 11 12 13 14> sum(x) #对x中的元素求和[1] 10> prod(x) #对x中的元素求连乘积[1] 24> prod(2:8) #8的阶乘[1] 40320> prod(2:4) #4的阶乘[1] 24> max(x) #x中元素的最⼤值[1] 4> min(x) #x中元素的最⼩值[1] 1> which.max(x) #返回x中最⼤元素的下标[1] 4> which.min(x) #返回x中最⼩元素的下标[1] 1> x <- 4:1 #对向量x重新赋值> x[1] 4 3 2 1> which.min(x)[1] 4> which.max(x)[1] 1> range(x) #与c(min(x), max(x))作⽤相同[1] 1 4> mean(x) #x中元素的均值[1] 2.5> median(x) #x中元素的中位数[1] 2.5> var(x) #x中元素的的⽅差(⽤n-1做分母)[1] 1.666667> x[1] 4 3 2 1> rev(x) #对x中的元素取逆序[1] 1 2 3 4> sort(x) #将x中的元素按升序排列;[1] 1 2 3 4> x[1] 4 3 2 1> cumsum(x) #求累积和,返回⼀个向量,它的第i个元素是从x[1]到x[i]的和[1] 4 7 9 10> cumsum(rev(x))[1] 1 3 6 10> y <- 11:14> pmin(x,y) #返回⼀个向量,它的第i个元素是x[i], y[i], . . .中最⼩值[1] 4 3 2 1> x <- rev(x) #重新赋值> pmin(x,y)[1] 1 2 3 4> pmax(x,y) #返回⼀个向量,它的每个元素是向量x和y在相应位置的元素的最⼤者[1] 11 12 13 14> cumprod(x) #求累积(从左向右)乘积[1] 1 2 6 24> cummin(x) #求累积最⼩值(从左向右)[1] 1 1 1 1> cummax(x) #求累积最⼤值(从左向右)[1] 1 2 3 4> match(x, y) #返回⼀个和x的长度相同的向量,表⽰x中与y中元素相同的元素在y中的位置(没有则返回NA)[1] NA NA NA NA> y[c(2,4)] <- c(2,4)> y[1] 11 2 13 4> match(x, y)[1] NA 2 NA 4na.omit(x)函数忽略有缺失值(NA)的观察数据(如果x是矩阵或数据框则忽略相应的⾏)> na.omit(match(x,y))[1] 2 4attr(,"na.action")[1] 1 3attr(,"class")[1] "omit"> na.fail(match(x,y)) #na.fail(x) 如果x包含⾄少⼀个NA则返回⼀个错误消息错误于na.fail.default(match(x,y)) : 对象⾥有遺漏值which()函数返回⼀个包含x符合条件(当⽐较运算结果为真(TRUE)的下标的向量,在这个结果向量中数值i说明x[i] == a(这个函数的参数必须是逻辑型变量)> which( x == 2)[1] 2> which( x <= 2)[1] 1 2求组合数> choose(4,2)[1] 6> choose(3,1)[1] 3> choose(-3,1)[1] -3> choose(-4,2)[1] 10> y <- c(1:4, rep(4,1))> y[1] 1 2 3 4 4> unique(y) #如果y是⼀个向量或者数据框,则返回⼀个类似的对象但是去掉所有重复的元素(对于重复的元素只取⼀个)[1] 1 2 3 4> table(y) #返回⼀个表格,给出y中重复元素的个数列表(尤其对于整数型或者因⼦型变量)y1 2 3 41 1 1 2> subset(x, x>2) #返回x中的⼀个满⾜特定条件...的⼦集[1] 3 4> sample(x, 2) #从x中⽆放回抽取size个样本,选项replace= TRUE表⽰有放回的抽样[1] 1 2> sample(x, 2, replace = TRUE) #有放回的抽样[1] 2 3R中⽤来处理数据的函数太多了⽽不能全部列在这⾥。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R-note一、基本函数1.函数c()—向量,length()—长度,mode()—众数,rbind()—组合,cbind()—转置,mode()—属性(数值、字符等)2.函数mean( )-中位数, sum( )-求和, min( )-最小值,max( )-最大值, var( )-方差, sd( )-标准差, prod( ) –连乘3.函数help()--帮助4.正态分布函数rnorm( ) 、泊松分布函数rpois( ) 、指数分布函数rexp( ) 、Gamma分布函数rgamma( ) 、均匀分布函数runif( ) 、二项分布函数rbinom( ) 、几何分布函数rgeom( ) (一)基本函数1.>2:60*2+1[1]5 7 9 11……..。
(共60个数)2. a[5]:a数列第5个数,a[-5]:删除a数列第5位数a[-(1:5)]: 删除a数列第1-5位数a[c(2,4,7)]:a数列第2,4,7位数a[a<20]:a数列小于20的数a[a[3]]:先查找a数列第3位数对应数值,然后找第该位数对应数值5.Seq()函数---序列数产生器Seq(5,20):产生5,6。
20的数集Seq(5,100,by=2):产生5开始,步长为2的数集,最大值为100Seq(5,100,length=10):产生从5开始,从第三个数开始等于第二个数加上第二个数减去第一个数的差值,最后一个数为100.5.00000 11.78571 18.57143 25.35714 32.14286 38.92857 45.7142952.50000 59.28571 66.07143 72.85714 79.64286 86.42857 93.21429 100.00000如:18.57143=11.78571+(11.78571-5.00000)6.letters():产生字母序列letters[1:30]:a,b,c,d…..30个字母6.which()选择which.max(a):a数列里面最大数which(a==2):查找a数列中等于2的数,并返回该数所对应位置a[which(a==2)]:先查找查找a数列中等于2的数,并返回该数所对应位置,然后对应的数值举例:a<-c(1,3,5,7)> which(a>5)[1] 4> a[which(a>5)][1] 77.rev()函数---反转举例:> a=1:10> rev(a)[1] 10 9 8 7 6 5 4 3 2 18.sort()函数---升序排列举例:> a=c(1,4,2,5,3,5,4,7,4)> sort(a)[1] 1 2 3 4 4 4 5 5 79.matrix()函数---将数据转变成按行列排布举例:> a=1:20> matrix(a,nrow=5,ncol=4)[,1] [,2] [,3] [,4][1,] 1 6 11 16[2,] 2 7 12 17[3,] 3 8 13 18[4,] 4 9 14 19[5,] 5 10 15 2010.函数t()----矩阵行列反置举例:> matrix(a,nrow=5,ncol=4)[,1] [,2] [,3] [,4][1,] 1 6 11 16[2,] 2 7 12 17[3,] 3 8 13 18[4,] 4 9 14 19[5,] 5 10 15 20> t( matrix(a,nrow=5,ncol=4))[,1] [,2] [,3] [,4] [,5][1,] 1 2 3 4 5[2,] 6 7 8 9 10[3,] 11 12 13 14 15[4,] 16 17 18 19 2011. diag():矩阵对角元素向量或生成对角矩阵举例:> a=matrix(1:16,nrow=4,ncol=4)> a[,1] [,2] [,3] [,4][1,] 1 5 9 13[2,] 2 6 10 14[3,] 3 7 11 15[4,] 4 8 12 16> diag(a)[1] 1 6 11 16> diag(diag(a))[,1] [,2] [,3] [,4][1,] 1 0 0 0[2,] 0 6 0 0[3,] 0 0 11 0[4,] 0 0 0 1612.统计分布每一种分布有四个函数:d――density(密度函数),p――分布函数,q――分位数函数,r――随机数函数。
比如,正态分布的这四个函数为dnorm,pnorm,qnorm,rnorm。
下面我们列出各分布后缀,前面加前缀d、p、q或r就构成函数名:norm:正态,t:t分布,f:F分布,chisq:卡方(包括非中心)unif:均匀,exp:指数,weibull:威布尔,gamma:伽玛,beta:贝塔lnorm:对数正态,logis:逻辑分布,cauchy:柯西,binom:二项分布,geom:几何分布,hyper:超几何,nbinom:负二项,pois:泊松signrank:符号秩,wilcox:秩和,tukey:学生化极差13.solve():矩阵求逆或解线性方程14. eigen():矩阵的特征值分解15.data.frame():生成excel类似的数组举例:> a=c(1,3,5,6,7)> b=c(2,4,6,6,8)> x=data.frame(a,b)> xa b1 1 22 3 43 5 64 6 65 7 8> (x=data.frame('重量'=a,'运费'=b))重量运费1 1 22 3 43 5 64 6 65 7 816.画散点图plot()(二)初级函数1.txt文件读取:举例:>(x=read.table("D://百度云/abc.txt"))V1 V2 V31 12 32 4 5 62.读取excel文件1)先将excel文件保存为prn文件> y<-read.table("D://百度云//a.prn",header=T)> yage high weight1 18 150 502 17 160 602)安装RODBC安装包,导入excle文件举例:> local({pkg<-select.list(sort(.package(all.available=TRUE)),graphics=T$ + if(nchar(pkg))library(pkg,character.onError: unexpected 'if' in:"local({pkg<-select.list(sort(.package(all.available=TRUE)),graphics=T$if"> library(RODBC)> z<-odbcConnectExcel("D://百度云//a.xls")> (w<-sqlFetch(z,"Sheet1"))age high weight1 18 150 502 17 160 603. 循环语句:for举例:> for(i in 1:20){a[i]=i*2+3}> a[1] 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 41 434.循环语句:whil e举例:> a[1]=5> i=1> while(a[i]<121){i=i+1;a[i]=a[i-1]+2}> a[1] 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39 [19] 41 43 45 47 49 51 53 55 57 59 61 63 65 67 69 71 73 75 [37] 77 79 81 83 85 87 89 91 93 95 97 99 101 103 105 107 109 111 [55] 113 115 117 119 1215.source():数据来源,可将txt编辑好的程序直接读取,并运行。
举例:> source("D:\\百度云\\a.txt")[1] 5 7 9 11 13 15 17 19 21 23 25 27 29 31 33 35 37 39[19] 41 43 45 47 49 51 53 55 57 59 61 63 65 67 69 71 73 75[37] 77 79 81 83 85 87 89 91 93 95 97 99 101 103 105 107 109 111[55] 113 115 117 119 1216.综合举例题目:模拟产生统计专业同学的名单(学号区分),记录数学分析,线性代数,概率统计三科成绩,然后进行一些统计分析结果:> num=seq(1008001,1008100)> num[1] 1008001 1008002 1008003 1008004 1008005 1008006 1008007 1008008 1008009 [10] 1008010 1008011 1008012 1008013 1008014 1008015 1008016 1008017 1008018 [19] 1008019 1008020 1008021 1008022 1008023 1008024 1008025 1008026 1008027 [28] 1008028 1008029 1008030 1008031 1008032 1008033 1008034 1008035 1008036 [37] 1008037 1008038 1008039 1008040 1008041 1008042 1008043 1008044 1008045 [46] 1008046 1008047 1008048 1008049 1008050 1008051 1008052 1008053 1008054 [55] 1008055 1008056 1008057 1008058 1008059 1008060 1008061 1008062 1008063 [64] 1008064 1008065 1008066 1008067 1008068 1008069 1008070 1008071 1008072 [73] 1008073 1008074 1008075 1008076 1008077 1008078 1008079 1008080 1008081 [82] 1008082 1008083 1008084 1008085 1008086 1008087 1008088 1008089 1008090 [91] 1008091 1008092 1008093 1008094 1008095 1008096 1008097 1008098 1008099 [100] 1008100> x1=round(runif(100,min=80,max=100))> x1[1] 83 97 100 90 95 91 93 91 97 87 89 86 94 99 94 97 89 83 [19] 82 98 98 84 100 87 89 97 99 94 88 93 89 90 89 83 93 95 [37] 90 81 94 95 82 94 94 96 82 94 90 91 83 96 97 93 98 81 [55] 87 80 94 84 94 80 87 84 83 85 96 81 97 87 93 97 98 82[73] 85 90 89 90 88 89 98 88 81 81 96 85 98 87 96 91 86 98 [91] 100 89 87 85 90 90 82 80 81 95>> x2=round(rnorm(100,mean=80,sd=7))> x2[1] 73 79 88 88 92 79 77 90 87 83 93 85 80 80 84 87 63 72 78 77 85 81 80 78[25] 79 73 73 90 82 83 80 86 79 74 83 88 90 83 79 83 68 69 71 85 83 86 82 67[49] 84 72 66 91 74 83 73 78 86 77 81 81 89 84 83 82 91 81 80 69 92 85 82 79[73] 88 69 80 71 89 79 82 71 81 67 82 72 87 78 87 84 81 94 75 80 71 86 78 75[97] 75 72 95 75> x3=round(rnorm(100,mean=83,sd=18))> x3[1] 71 64 84 97 56 71 72 72 96 85 93 80 80 110 78 118 55 85 [19] 99 83 92 113 65 91 76 120 63 78 72 70 94 101 69 84 100 87 [37] 103 114 77 70 73 54 89 78 66 83 46 113 68 94 89 115 80 105 [55] 67 100 73 89 80 64 115 74 81 99 82 90 92 90 73 101 88 96 [73] 101 80 100 64 74 121 81 94 72 55 78 88 60 103 70 63 96 72 [91] 104 93 92 110 74 82 80 111 64 92> x3[which(x3>100)]=100> x3[1] 71 64 84 97 56 71 72 72 96 85 93 80 80 100 78 100 55 85 [19] 99 83 92 100 65 91 76 100 63 78 72 70 94 100 69 84 100 87 [37] 100 100 77 70 73 54 89 78 66 83 46 100 68 94 89 100 80 100 [55] 67 100 73 89 80 64 100 74 81 99 82 90 92 90 73 100 88 96 [73] 100 80 100 64 74 100 81 94 72 55 78 88 60 100 70 63 96 72 [91] 100 93 92 100 74 82 80 100 64 92> x=data.frame(num,x1,x2,x3) –数据合并> xnum x1 x2 x31 1008001 83 73 712 1008002 97 79 643 1008003 100 88 844 1008004 90 88 975 1008005 95 92 566 1008006 91 79 717 1008007 93 77 728 1008008 91 90 729 1008009 97 87 9610 1008010 87 83 8511 1008011 89 93 9312 1008012 86 85 8013 1008013 94 80 8014 1008014 99 80 10015 1008015 94 84 7817 1008017 89 63 5518 1008018 83 72 8519 1008019 82 78 9920 1008020 98 77 8321 1008021 98 85 9222 1008022 84 81 10023 1008023 100 80 6524 1008024 87 78 9125 1008025 89 79 7626 1008026 97 73 10027 1008027 99 73 6328 1008028 94 90 7829 1008029 88 82 7230 1008030 93 83 7031 1008031 89 80 9432 1008032 90 86 10033 1008033 89 79 6934 1008034 83 74 8435 1008035 93 83 10036 1008036 95 88 8737 1008037 90 90 10038 1008038 81 83 10039 1008039 94 79 7740 1008040 95 83 7041 1008041 82 68 7342 1008042 94 69 5443 1008043 94 71 8944 1008044 96 85 7845 1008045 82 83 6646 1008046 94 86 8347 1008047 90 82 4648 1008048 91 67 10049 1008049 83 84 6850 1008050 96 72 9451 1008051 97 66 8952 1008052 93 91 10053 1008053 98 74 8054 1008054 81 83 10055 1008055 87 73 6756 1008056 80 78 10057 1008057 94 86 7358 1008058 84 77 8959 1008059 94 81 8061 1008061 87 89 10062 1008062 84 84 7463 1008063 83 83 8164 1008064 85 82 9965 1008065 96 91 8266 1008066 81 81 9067 1008067 97 80 9268 1008068 87 69 9069 1008069 93 92 7370 1008070 97 85 10071 1008071 98 82 8872 1008072 82 79 9673 1008073 85 88 10074 1008074 90 69 8075 1008075 89 80 10076 1008076 90 71 6477 1008077 88 89 7478 1008078 89 79 10079 1008079 98 82 8180 1008080 88 71 9481 1008081 81 81 7282 1008082 81 67 5583 1008083 96 82 7884 1008084 85 72 8885 1008085 98 87 6086 1008086 87 78 10087 1008087 96 87 7088 1008088 91 84 6389 1008089 86 81 9690 1008090 98 94 7291 1008091 100 75 10092 1008092 89 80 9393 1008093 87 71 9294 1008094 85 86 10095 1008095 90 78 7496 1008096 90 75 8297 1008097 82 75 8098 1008098 80 72 10099 1008099 81 95 64100 1008100 95 75 92> write.table(x,file="D:\\百度云\\mark.txt",s=F,s=F,sep="") -保存数据7.data.frame():数据合并-合成举例:>x=data.frame(num,x1,x2,x3)8.write.table():将数据写入(保存)txt文档举例:write.table(x,file="D:\\百度云\\mark.txt",s=F,s=F,sep=" ")9. mean():均值举例:10.colMeans():列均值举例:> colMeans(x)num x1 x2 x31008050.50 90.18 80.42 82.91> colMeans(x)[c("x1","x2","x3")]x1 x2 x390.18 80.42 82.9111.apply():举例:>apply(x,2,mean)num x1 x2 x31008050.50 90.18 80.42 82.91> apply(x,2,max)num x1 x2 x31008100 100 95 100> apply(x,2,min)num x1 x2 x31008001 80 63 46> apply(x[c("x1","x2","x3")],1,sum)—求总分[1] 227 240 272 275 243 241 242 253 280 255 275 251 254 279 256 284 207 240 259 258[21] 275 265 245 256 244 270 235 262 242 246 263 276 237 241 276 270 280 264 250 248[41] 223 217 254 259 231 263 218 258 235 262 252 284 252 264 227 258 253 250 255 225[61] 276 242 247 266 269 252 269 246 258 282 268 257 273 239 269 225 251 268 261 253[81] 234 203 256 245 245 265 253 238 263 264 275 262 250 271 242 247 237 252 240 262> which.max(apply(x[c("x1","x2")],1,sum))---求总分最大的人是第几个[1] 46> x$num[which.max(apply(x[c("x1","x2")],1,sum))]---求总分最大的人num[1] 1008046第二讲12.hist():绘制直方图接上例:>hist(x$x1)13.plot():绘制散点图接上例:> plot(x1,x2)> plot(x$x1,x$x2)14.table():列联函数> table(x$x1)-----各数出现频数80 81 82 83 85 86 87 88 896 6 4 6 8 3 5 4 190 91 92 93 94 95 96 97 983 5 5 7 104 25 799 1004 515.barplot():柱状图接上例:> barplot(table(x$x1))16.pie():饼图接上例:> pie(table(x$x1))17.boxplot():箱尾图接上例:> boxplot(x$x1,x$x2,x$x3)1)箱子的上下横线为样本的25%和75%分位数2)箱子中间的横线为样本的中位数3)上下延伸的直线称为尾线,尾线的尽头为最高值和最低值4)异常值18.boxplot():箱线图接上例:> boxplot(x$x1,x$x2,x$x3,col=c("red","green","blue"),notch=T) 或者:> boxplot(x[2:4],col=c("red","green","blue"),notch=T)19.boxplot():水平放置箱尾图接上例:>boxplot(x$x1,x$x2,x$x3,horizontal=T)20.star():星象图1)每个观测单位的数值表示为一个图形2)每个图的每个角表示一个变量,字符串类型会标注在图的下方3)角线的长度表达值的大小A:接上例:> stars(x[c("x1","x2","x3")])B: > stars(x[c("x1","x2","x3")],full=T,draw.segment=T)—饼状分割C: > stars(x[c("x1","x2","x3")],full=F,draw.segment=T)20.aplpack():脸谱图1)用五官的宽度和高度来描绘数值2)人对脸谱高度敏感和强记忆3)适合较少样本的情况接上例:> library(tcltk2)> library(aplpack)> faces(x[c("x1","x2","x3")])effect of variables:modified item Var"height of face " "x1""width of face " "x2""structure of face" "x3""height of mouth " "x1""width of mouth " "x2""smiling " "x3""height of eyes " "x1""width of eyes " "x2" "height of hair " "x3" "width of hair " "x1" "style of hair " "x2" "height of nose " "x3" "width of nose " "x1" "width of ear " "x2" "height of ear " "x3"21.其他脸谱:> library(TeachingDemos)> faces2(x)22.Stem():茎叶图> stem(x$x1)The decimal point is at the |80 | 00000000000082 | 000000000084 | 0000000086 | 0000000088 | 0000090 | 0000000092 | 00000000000094 | 0000000000000096 | 000000098 | 00000000000100 | 0000023.QQ图:qqnorm(),qqline(),1)可用于判断是否正态分布2)直线的斜率是标准差,截距是均值3)点的散布越接近直线,则越接近正态分布接上例:> qqnorm(x1)> qqline(x1)24.散点图加深:plot()> plot(x$x1,x$x2,main="数学分析与线性代数成绩的关系",xlab="数学",ylab="线性",xlim=c(0,100),ylim=c(0,100),xaxs="i",yaxs="i",col="red",pch=19)25.折线图:pl ot()26.density():密度图> plot(density(rnorm(1000)))27.内置数集:mtcars,iris,示例:>iris> sunflowerplot(iris[,3:4],col="red",seg.col="gold")28.散点图集:pairs()遍历样本中全部的变量配对,画出二元图,直观地了解所有变量之间的关系示例:> pairs(iris[,1:4])2)> plot(iris[,1:4],main="因素关系",pch=19,col="red",cex=0.9)2)3)par函数> par(mfrow=c(3,1))> plot(x1,x2);plot(x2,x3);plot(x3,x1)29.绘图颜色:col ors()>colors()30.绘图设备:dev.cur():31:绘图参数:mai():32.三维散点图:scatterpl ot3d()> library(scatterplot3d)> scatterplot3d(x[2:4])33.地图:map()> map("state",interior=FALSE)> map("world",fill=TRUE,col=heat.colors(10))。