《编译原理实践及应用》第3章词法分析 (2)
《编译原理》第3章

NFA到相应的DFA的构造的基本思路是: DFA的每 一个状态对应NFA的一组状态. DFA使用它的状 态去记录在NFA读入一个输入符号后可能达到的 所有状态.
NFA M所能接受的符号串的全体记为L(M)
结论:
上一个符号串集V是正规的,当且仅当存 在一个上的不确定的有穷自动机M,使得 V=L(M)。
DFA是NFA的特例.对每个NFA N一定存在一个DFA M,使得 L(M)=L(N)。对每个NFA N存在着与之 等价的DFA M。 有一种算法,将NFA转换成接受同样语言的DFA.这 种算法称为子集法. 与某一NFA等价的DFA不唯一.
0
1
S P
Z
{P} {}
{P}
{S,Z} {Z}
{P}
• δ为S * 到S的子集(2 S)的一种映射
• 从NFA的矩阵表示中可以看出,表项通常是一状态的集合, 而在DFA的矩阵表示中,表项是一个状态
∑*上的符号串t被NFA M接受:
• 对于Σ*中的任何一个串t,若存在一条从某一初态 结点到某一终态结点的道路,且这条道路上所有 弧的标记字依序连接成的串(不理采那些标记为ε 的弧)等于t,则称t可为NFA M所识别(读出或接 受)。 • 若M的某些结点既是初态结点又是终态结点;或 者存在一条从某个初态结点到某个终态结点的道 路,其上所有弧的标记均为ε,那么空字ε可为M所 接受。
其中: δ(S,0)={P}
δ(S,1)={S,Z} δ(Z,0)={P} δ(Z,1)={P} δ(P,1)={Z} • 状态图表示
1 1 S 0 0,1 Z
P
1
• 矩阵表示
状态 输入
δ(S,0)={P} δ(S,1)={S,Z} δ(Z,0)={P} δ(Z,1)={P} δ(P,1)={Z}
编译原理与技术 词法分析 (2)(2)
2024/7/1
《编译原理与技术》讲义
20
正规式与有限自动机
✓ R= R1 | R2
Si
S0 Sj
(3)
fi
f0
fj
引入新的终态f0和 (fi,)=f0和(fj,)=f0
2024/7/1
《编译原理与技术》讲义
21
正规式与有限自动机
✓ R= R1 ·R2
(1)
Si
fi
Sj
fj
R1对应的 NFA,Si为初 态,fi为终态
…
2024/7/1
《编译原理与技术》讲义
5
有限自动机的表示
e.g.7 NFA Mn =(, S, S0,F,),其中:
= { 0,1 } , S = {S0, S1 , S2 , S3 , S4 },F={S2 , S4}
(S0,0)= {S0, S3 } (S0,1)= {S0, S1 }
(S1,0)= ∅
有限自动机
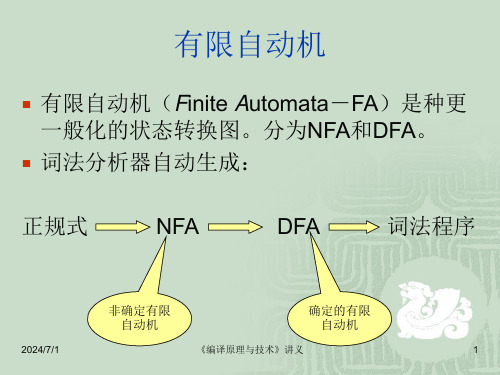
有限自动机(Finite Automata-FA)是种更 一般化的状态转换图。分为NFA和DFA。
词法分析器自动生成:
正规式
NFA
DFA
词法程序
非确定有限 自动机
确定的有限 自动机
2024/7/1
《编译原理与技术》讲义
1
非确定有限自动机-NFA
NFA Mn 是一个五元组 Mn =(, S, S0,F,), 其中:
2024/7/1
《编译原理与技术》讲义
15
比较 DFA 和 NFA(2)
DFA
NFA
容易实现-当输入串结束 由于面临同样输入符号存 时(或不存在相应状态转 在多重状态转换或存在转 换)时,若当前状态为终 换的选择,实现较为复杂。 态即为接受“已读入”的串, 一般地,NFA接受串如果
编译原理与实现03第3章 词法分析

利用状态图识别句子的方法是一种自底向上的分析方法。开始时,处于开 始状态,此时句柄是随后扫描的字符,即输入串的的第一个符号,所要归 约的符号就是从开始状态经过标记有句柄符号的弧到达的下一个状态的名 字。以后每一步(除第一步外)的句柄是当前状态的名字和随后扫描的字 符,而句柄所要归约的符号就是下一个状态的名字。
3.3.2 状态图的用法
例3.2,对句子0110进行的分析。 解:根据上面介绍的状态图使用方法,我们在图3.5(a)列出分析的每一步。 由于这些规则很简单,所以分析也非常简单。首先,在开始状态S下扫描的第 一个符号是0,转到状态V,表示0是句柄,归约到V。接下来,在状态V扫描1, 转到状态Z,此时句柄为V1,归约成Z。再往下扫描1,由状态Z转到状态U,表 示句柄为Z1归约为U。最后,扫描0,转到状态Z,此时句柄为U0,归约为Z, 从而形成图3.5(b)所示的语法树。 步骤 1 2 状态 S V 扫描的字符 0 1 余留部分 110 10
3.3.2 状态图的用法
状态图画好后,就可以利用状态图来分析和识别字符串,其方法如下: 1.首先设置初始状态S为当前状态。从输入串的最左字符开始重复步骤2,直 到到达输入串的右端为止。 2.扫描输入串的下一个字符,在当前状态所射出的弧中,找出标记有该字符 的弧,并沿此弧前进,过渡到下一个状态。如果找不到标记有该字符的弧, 则说明输入串不是合法的句子,分析过程失败结束;如果我们扫描输入串 的最后一个字符,并从当前状态出发沿着标记有该字符的弧到达终结状态, 则表示输入串是该文法的合法句子,识别过程成功结束;如果扫描输入串 的最后一个符号后到达的状态不是状态图的终结状态,则表示输入串不是 该文法的合法句子,识别过程失败结束。
3.3 正则文法及状态图
程序设计语言的单词符号可用3型文法来描述,3型文法也称为正 则文法。对于正则文法所描述的语言可以用一种有穷自动机来识 别。我们的目的是实现词法分析程序,所以为了简化问题,我们 直接介绍这种自动机的非形式表示,即状态图。
《编译原理实践及应用》第3章词法分析

*
0
字母
1
其它
2
识别过程是:从初始状态0开始,若读入一个字母, 转入1状态,若再读入字母或数字,仍处于1状态, 否则转向2状态,结束一个标识符的识别过程。状 态上的*表示多读入一个符号。
写成C语言的函数形式: recog_id() 0 1 { … 其它 字母 char state = 0; ch = getch(); do { switch(state){ Case 0: if ch 是字母 state = 1; ch = getch();break; Case 1: if ch 是字母或数字 { state = 1; ch = getch(); } else state = 2; break; } } while (state != 2); 回退一个符号。 }
举例
• 3. 其它输出:错误信息和源程序清单
– 错误信息应该详细,准确,指出出错的具体行、 列位置,发生了哪类错误等,方便用户修改
错误处理
• 应尽可能发现更多的错误 • 处理方式
– 每个程序段单独处理错误 – 统一处理错误(商用软件系统)
• 记录式的文件 • 数据库
• 统计表明,现代软件系统中, 75%的程序代码都 是用于处理错误与错误信息 • 商业系统中错误处理的特点是:统一错误编号,编 制文档指出错误信息的含义、应对措施、解决方案
种别码 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
单词 * */ + , — 、 ·· / /* : := ; < <= <> = > >= [ ]
种别码 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
《编译原理》教学课件 第3章-词法分析

单词的定义 • 正则表达式的局限性。
正则表达式
• 基本概念: • 字母表:非空有限集,,其元素称为符号或字母. • 符号串:符号的有限序列,也称为‘字’。或表示
空串 空串集{}不同于空集 。
• 符号串长度:符号串中字符的个数.|| • 符号串连接:和都是符号串,则为符号串的连接
非确定有限自动机NFA
• 定义1:一个非确定有限自动机(NFA)A是 一个五元组A=(,SS,S0,f,TS).其中
• 是字母表
• SS是状态集
• S0是初始状态集 • f是转换函数,但不要求是单值的
•
f: SS (∪{}) 2SS
• TS是终止状态集
非确定有限自动机NFA
• 定义2:设A是一个NFA,A= (,SS,S0,f,TS) • 则定义L(A)为从任意初始状态到任意终止状
❖ 空格符和制表符以及换行符的处理 1.无用的空格符和制表符要删掉; 2.字符串内的空格不能删; 3.换行符不能删。用于错误定位
❖ 复合型特殊符,如“:=”的处理 读到“:”时不能判断是否为冒号,必须读下 一字符。
❖ 括号类配对预检
• 括号类: begin …end ,if … then,[ ],{ },( )
描述程序设计语言中的单词字,进一步为词法 分析程序的自动构造寻找特殊的方法和工具。 主要内容: • 确定有限自动机DFA • 确定有限自动机DFA的实现 • 非确定有限自动机NFA • NFA到DFA的转换 • DFA的化简
确定有限自动机DFA
• 确定有限自动机(DFA:Deterministric Finite Automata ) 为一个五元组
词法分析-编译原理-03-(二)

5. 5.1 5.2 5.3 5.4 5.5 5.6 5.7 6 6.1 6.2
isalpha(ch) : ch→buf; 下一字符→ch WHILE isalpha(ch) OR isdigit(ch) DO ch→buf; 下一字符→ch 回送 ch; key = isKeyword(buf) IF key >= 0 THEN 返回 key Lookup( buf ) → attr 返回 IDN ':' : 下一字符→ch; IF ch等于'=' THEN 返回 ASG 出错处理
第三章 词法分析 3.1 词法分析的任务
输入源程序,输出单词符号
把构成源程序的字符串转换成语义
上关联的单词符号的序列
单词符号
token
按照最小的语义单位设计, 通常表示为二元组
(单词种别,属性值)
1) 单词符号的表示
单词种别
通常按照语法分析的需要设置. 常用: 各关键字,标识符,常数,各
例3-3 状态图的实现算法
1. 2. 3.1 3. 4. 4.1 4.2 4.3 4.4 4.5 读入当前字符 ch //跳过空格 WHILE ch 是空格 DO 下一字符 → ch CASE ch OF isdigit(ch) : ch→buf; 下一字符→ch WHILE isdigit(ch) DO ch→buf; 下一字符→ch 回送 ch 将缓冲区的数字字符串变成数字→attr 返回 NUM
7 8 9 10 11 12 13 14 15 16 17 18
'+' : 返回 ADD '-' : 返回 SUB '*' : 返回 MUL '/' : 返回 DIV '=' : 返回 EQ '>' : 返回 GT '<' : 返回 LT '(' : 返回 LP ')' : 返回 RP ';' : 返回 SEMI 其它 : 出错处理 END OF CASE
第3章 词法分析 (编译原理 陈火旺)

标识符的符号表入口地址作为其单词符号的属性值,常
每个基本字占一个单词种别,单词符号的属性值缺省。
对于界符,运算符通常一个符号一个种别,单词符号的
属性值缺省
例: 参见P42.表3.1 单词符号及种别编码
10
3.1.3 词法分析器作为独立子程序
词法分析可采用如下两种处理结构:
把词法分析程序作为主程序。将词法分析作为
19
3.2.1 正规文法、正规式与正规集
正规集:由正规文法产生的语言所构成的集合。
注:正规集是集合,可有穷也可无穷。 可通过正规式来形式化表示。
对于一个正规文法的语言提炼出一个简洁的公式,用这个
式子来对它进行形式化的表示,这个式子叫正规式。
正规式:也称正则表达式,是说明单词的模式的一种重要的 表示法(记号);是定义正规集的数学工具;用来描述单词 符号。
在设计一个编译程序时,通常是把对源程序的结构分析分为词 法分析和语法分析两个相对独立的阶段来完成。
第一,描述单词的结构比描述源程序的其它语法结构要简单
得多,仅使用3型文法也就基本够用了。
第二,由于把词法分析和语法分析分开,可使编译程序各部
分的功能更为单一,整个编译程序的结构也更加清晰,从而 有利于编译程序的编写和调整。 上述词法分析和语法分析两个阶段的划分,仅仅是对整个编译 程序的逻辑功能而言,而不一定指的是编译程序的执行流程。
25
例3.2 判断下述正规式之间是否等价: (1)b(ab)*与(ba)*b (2)(ab)*与a*b* 解: (1) b(ab)*对应的正规集是b后面出现任意多个ab对
L(b(ab)*)={b,bab,babab, ……}
编译原理第三章词法分析解析

(30,_)
采用一符一种的编码方式。
(19,‘100’的二进制表示)1内0部0为的标值号用,10种0别的编二码进制19表,示单。词
例:下述C++代码段:while ( i >= j ) i - -; 经词法分析器处理以后,它将被转换为如下的单词符号串
( while ,_ ) ( ( ,_ ) ( id ,指向i的符号表指针 ) ( >= ,_ ) ( id ,指向j的符号表指针 ) ( ) ,_ ) ( id ,指向i的符号表指针 ) ( - - ,_ ) ( ; ,_ )
3、常数:常数的类型一般有整型、实型、布尔型、文字型 等。它是不限的。
4、运算符:如+、-、*、/ 等。它是确定的。
5、界符:如逗号、分号、括号、/*,*/ 等。它是确定的。
单词符号的表示形式:词法分析器所输出的单词符号常常表示成 二元式(单词种别,单词自身的值)。
单词种别可以用以下形式表示:
1、一类单词统一用一个整数值代表其属性。例如:1代表关键字, 2代表标识符等。
例如:在标准FORTRAN中 1、DO99K = 1,10 2、IF(5.EQ.M)I = 10 3、DO99K = 1.10 4、IF(5) = 55
其中的DO、 IF为关键字
其中的DO、 IF为标识符 的一部分
标识符的识别
多数语言的标识符是字母开头的“字母/数字”串, 而且在程序中标识符的出现后都跟着算符或界符。因此, 不难识别。
(2,_)
用一符一种的编码方式。
(20,‘5’的二进制表示)
常数类型,种别编码20,单词自 身等的号值为为运‘算5符’,的种二别进编制码表6示,。
(6,_)
M采为用标一识符符一,种种的别编编码码方26式,。单
《编译原理实践及应用》第3章词法分析—DFA与NFA

其中 Κ ={ S 0 ,S1 ,S 2 } Σ ={a,b}
Ѕ={ S 0 , S1 } ( S0 ,a)={ S1 }
F={ S 2 }
( S 0 ,b)={ S 0 ,S 2 }
( S1 ,a)= Φ
(S1 ,b)={S 2 }
( S 2 ,a)= Φ
(S 2 ,b)={S1 }
②以每个非终结符号做其它状态
③对于形如Q→q的规则,
q
S
Q
对于形如Q→Rq的规则,
Rq Q
④以文法开始符号为终止状态。
例3-1: 文法G[Z]: Z→Za|Aa|Bb
aA
a
A→Ba|a B→Ab|b
Sb a
Za
b
Bb
2.应用状态转换图识别句子
识别句子:从开始状态到终止状态经过的边上的符号序列。 识别句子的步骤: ①从开始状态出发,以欲识别符号串的最左字符开始,寻找标
Z→Cb C→b|Bb B→Ab A→a|Ba
有限自动机(FA)
FA可看作一个机器模型,由一个带读头的有限控制器和 一条字符输入带组成。
#
a b a ba
…
输入带
控制器
工作原理:读头从左到右扫描输入带,读到一个字符,状态改
变,同时读头右移一个字符,…,直到读头读到
“#”,状态进入终止状态。
控制器中包括有限个状态,读入一个字符形成状态转换。
( S1 ,a)= S0 ( S1 ,c)= S3 ( S 2 ,b)= S1
( S3 ,b)= S3
a
b
S2 a
S0 a S1
ba
C
S3 b
定义: 所接收的语言(正则集)
L( AD)={β | S β S, S∈ F },
编译原理之词法分析PPT课件

12
Wensheng Li BUPT @ 2008
二、设置缓冲区的必要性
超前搜索:为了得到某一个单词符号的确切性质, 需要超前扫描若干个字符。
例:有合法的FORTRAN语句: DO99K=1,10 和 DO99K=1.10
为了区别这两个语句,必须超前扫描到等号后的第一个 分界符处。
开始指针 向前指针
16
Wensheng Li BUPT @ 2008
测试指针的过程(2)
向前指针前移一个位置; IF (向前指针指向 eof ) {
IF (向前指针在左半区的终点) { 读入字符串,填充右半区; 向前指针前移一个位置;
}; ELSE IF (向前指针在右半区的终点) {
读入字符串,填充左半区; 向前指针指向缓冲区的开始位置; }; ELSE 终止词法分析; }
P1
P2
唤醒P2 唤醒P2
唤醒P1 唤醒P1
Wensheng Li BUPT @ 2008
8
分离词法分析程序的好处
可以简化设计
–词法程序很容易识别并去除空格、注释,使语法分析程序 致力于语法分析,结构清晰,易于实现。
可以改进编译程序的效率
–利用专门的读字符和处理记号的技术构造更有效的词法分 析程序。
11
Wensheng Li BUPT @ 2008
一、词法分析程序的实现方法
利用词法分析程序自动生成器
–从基于正规表达式的规范说明自动生成词法分析程序。 –生成器提供用于源程序字符流读入和缓冲的若干子程序
利用传统的系统程序设计语言来编写
–利用该语言所具有的输入/输出能力来处理读入操作
利用汇编语言来编写
基本方法
《编译原理》第三章 词法分析器

有限自动机模型
Finite Automata (FA):
一个有限自动机的模型如下所示:
... ... head finite control input tape
输入带被分成一个个的小单元来装输入符号, 其右边是无限延伸的。 有限状态控制器由有限个状态组成,并根据读 入字符将当前状态转换成下一个状态
有限自动机与正规式的等价性证明
• 证明一: 对于∑上的NFA M,我们来构造∑上的正规式r, 使得L(r)=L(M)。 首先,我们将状态图的概念拓广,令每条弧可 用正规式作标记。并在M的转换图上加进两个 结点,一个为X,一个为Y。从X用ε弧连接到Y, 从而形成一个新的NFA,记为M’,它只有一个初 态X和一个终态Y。显然L(M)=L(M’)。即,这 两个NFA是等价的。 现在来逐步消去M’中的所有结点,直至只剩下 X和Y为止。
有限自动机接受的语言
The language accepted by FA
一个FA 能够接受的语言定义如下:
• 对于一个 DFA M, 可接受的语言表示为: L(M)={ x | x∈Σ* and f(s0 , x)∈Z} • 对于一个 NFA M, 其接受的语言为: L(M)={x | x∈Σ*and f(s0, x)∩Z≠Φ} • 两个 FA M and M’ 是等价的当且仅当 L(M) = L(M’)
M
M
a
M
假设对于任意 正规式 r1 and r2, 如果 |r1| < k 而 且 |r2| < k, 那么就于一个NFA M1 and M2 对应 于r1 和 r2. 所以对于任意 RE r, |r| = k, 我们有:
• 这个自动机所接受的语言是所有被3整除 以后余数为2的二0, q1, q2, q3}, {0, 1}, f1, q0 {q3} ) . 其中f1如下所示 :
编译原理 第 3 讲 词法分析 (2)

其中 • “”读为“或”(也有使用“+”代替 “” 的); • “• ”读为“连接”; • “”读为“闭包”(即,任意有限次的自重复连接)。 • 在不致混淆时,括号可省去。 • 规定算符的优先顺序为“”、“• ”、“” 。 • 连接符“• ”一般可省略不写。 • “”、“• ”和“” 都是左结合的。
“连接”的可结合律
4、r(st) = rsrt
(st)r = srtr
分配律
5、 r = r, r = r
是“连接”的恒等元素
6、 rr = r r = rrr…
“或”的抽取律
20
五、正规文法和正规式的等价变换
对上的正规式 r , 存在一个 G=(VN,VT,P,S) 使得 L(G) = L(r) , 反之亦然。
其中:l 表示字母;d表示数字
10
• 无符号实数:
〈无符号实数〉→ d 〈余留无符号数〉| . 〈十进小数〉 | e〈指数部分〉
〈余留无符号数〉→ d 〈余留无符号数〉| . 〈十进小数〉 | e〈指数部分〉|ε
〈十进小数〉 → d 〈余留十进小数〉 〈余留十进小数〉 → e〈指数部分〉| d 〈余留十进小数〉| ε 〈指数部分〉 → d 〈余留整指数〉| s〈整指数〉 〈整指数〉 → d 〈余留整指数〉 〈余留整指数〉 → d 〈余留整指数〉 |ε
f(Q,)= Q
递归定义
33
4. ∑* 上的符号串 t 被 M 接受
– 对于∑*中的任何字符串t,若存在一条从初态结点 到某一终态结点的道路,且这条路上所有弧的的 标记符连接成的字符串等于t,则称t可为DFA M 所接受,若M的初态结点同时又是终态结点,则 空字()可为M所接受(识别)。
– 若 t ∑*,f(S,t) = P,其中 S 为 DFA M 的开始 状态,P Z,Z为终态集。 则称 t 为 DFA M所接受(识别)。
编译原理-第3章 词法分析--习题答案

第3章词法分析习题答案1.判断下面的陈述是否正确。
(1)有穷自动机接受的语言是正规语言。
(√)(2)若r1和r2是Σ上的正规式,则r1|r2也是Σ上的正规式。
(√)(3)设M是一个NFA,并且L(M)={x,y,z},则M的状态数至少为4个。
(× )(4)设Σ={a,b},则Σ上所有以b为首的符号串构成的正规集的正规式为b*(a|b)*。
(× )(5)对任何一个NFA M,都存在一个DFA M',使得L(M')=L(M)。
(√)(6)对一个右线性文法G,必存在一个左线性文法G',使得L(G)=L(G'),反之亦然。
(√) (7)一个DFA,可以通过多条路识别一个符号串。
(× )(8)一个NFA,可以通过多条路识别一个符号串。
(√)(9)如果一个有穷自动机可以接受空符号串,则它的状态图一定含有 边。
(× )(10)DFA具有翻译单词的能力。
(× )2.指与出正规式匹配的串.(1)(ab|b)*c 与后面的那些串匹配?ababbc abab c babc aaabc(2)ab*c*(a|b)c 与后面的那些串匹配? acac acbbc abbcac abc acc(3)(a|b)a*(ba)* 与后面的那些串匹配? ba bba aa baa ababa答案(1) ababbc c babc(2) acac abbcac abc(3) ba bba aa baa ababa3. 为下边所描述的串写正规式,字母表是{0, 1}.(1)以01 结尾的所有串(2)只包含一个0的所有串(3) 包含偶数个1但不含0的所有串(4)包含偶数个1且含任意数目0的所有串(5)包含01子串的所有串(6)不包含01子串的所有串答案注意 正规式不唯一(1)(0|1)*01(2)1*01*(3)(11)*(4)(0*10*10*)*(5)(0|1)*01(0|1)*(6)1*0*4.请描述下面正规式定义的串. 字母表{x, y}.(1) x(x|y)*x(2)x*(yx)*x*(3) (x|y)*(xx|yy) (x|y)*答案(1)必须以 x 开头和x结尾的串(2)每个 y 至少有一个 x 跟在后边的串 (3)所有含两个相继的x或两个相继的y的串5.处于/* 和 */之间的串构成注解,注解中间没有*/。
编译原理chapter3 词法分析

18
3.2.2 手工构造识Байду номын сангаас单词的DFA m
根椐DFA识别单词的定义,在研究给定程 序语言单词结构的基础上,能直接构造出识 别它的DFA m。例如:对于Pascal,
标识符:字母开始的字母数字串。 整数:非空数字串。 无符号实数(用表示数字): (a) dd.d dE(+- ) dd
3.1.3 词法分析程序作为一个独立子程序 (1)语法分析程序的子程序; (2)组织成一遍扫描。
3
While i<>j do if i>j then i:=i-j else j:=j-
I
词法分析器
‘while’,‘i’,‘<>’,‘j’, ‘do’,
‘if’,‘i’,‘>’,‘j’,‘then’,
读头
11
2. 状态集:它记忆已读入w子串的状态,m 是奇偶校验器,它应该记住,初始序列是奇 数个1还是偶数个1。因此,m有even和odd两 个状态. 3 .even为开始状态。
4 . 转换函数,(qold , ,a)=qnew
m有: (even ,,0)=even (even ,1)=odd
(odd ,0)=odd (odd ,1)=even
5
词法分析器的输出:
(词类编码,单词自身的属性值)
词类编码提供给语法分析程序使用;单词自 身的属性值提供给语义分析程序使用。具体 的分类设计以方便语法分析程序使用为原则。 关键字可分成一类,也可以一个关键字分成 一类。常数可统归一类,也可按类型(整型、 实型、布尔型等),每个类型的常数划分成 一类。单词自身的属性值提供的内容,是由 词法分析和语义分析的任务划分决定的。
编译原理第3章课后习题答案

Dtran[I,b] =ε-closure(move(I,b))= ε-closure({5, 16})=G DFA D 的转换表 Dtran NFA 状态 {0,1,2,4,7} {1,2,3,4,6,7,8} {1,2,4,5,6,7} {1,2,4,5,6,7,9} {1,2,4,5,6,7,10,11,12,13,15} {1,2,3,4,6,7,8,12,13,14,15,17,18} {1,2,4,5,6,7, 12,13,15,16,17,18} {1,2,4,5,6,7, 9,12,13,15,16,17,18} {1,2,4,5,6,7, 10,11,12,13,15,16,17,18} 可得 DFA 的如下状态转换图: DFA 状态 A B C D E F G H I a B B B B F F F F F b C D C E G H G I G
3.3.1 给出 3.2.2 中正则表达式所描述的语言的状态转换图。
(1)a( a|b )*a 的状态转换图如下:
(2)
ε
ε a
b
(3)
a
start 0
a a a
1 2
4
b a b
5
b b
3
6
7
(4)a*ba*ba*ba*
a b
a b
a b
a
3.6.3 使用算法 3.25 和 3.20 将下列正则表达式转换成 DFA: (1)
注:consonant 为除五元音外的小写字母,记号 ctnvowels 对应的定义即为题目要求的正则
定义。
(2) 所有由按字典顺序递增序排列的小写字组成的串。 a*b*……z* (3)注释,即/*和*/之间的串,且串中没有不在双引号( “)中的*/。 head——>/* tail ——>*/ * * incomment->(~(*/)|“. ”) comment->head incomment tail (9)所有由 a 和 b 组成且不含有子串 abb 的串。 * * A->b (a︱ab)
编译原理第三章词法分析

z19
step1 : 对语言的各类单词分别构造状态图;
step1
L
1
2
other
*
3 其中: other表示非L| D | _字符
z8
3.2.1 单词与属性字
注意:
(1) 同一个字符开头+后续字符->跨多个单词类;
(2) 非单词成分和预处理成分;
•例:源程序注释;/* …….*/
预处理指令:
•# define… # include…
z9
3.2.1 单词与属性字
2. 属性字 对所识别的单词的数据结构表示。
控制线
数据线
X : 固定长度的存储空间 ; z16
预处理程序(作用)
(1) 减少内存空间占用;
(2) 减轻扫描器实质性处理的负担;
预处理程序主要任务:
(1) 滤掉源程序中的非单词成分(如无用空格;换行
符等);
•滤掉注释;
(2) 实际的预处理工作
•宏替换; •文件包含的嵌入;
L1= ( T,C)
属性字 Token
Code
刻画单词类别(单词性质)
如:标识符;运算符;…
单词的内码值(可空)
z10
说明
单词类别通常用整数编码 单词类别提供给语法分析程序使用 单词符号属性信息记录单词符号的特征或特性 单词的属性值提供给语义分析程序使用
编码形式:
一类一种:关键字、标识符、常数、运算符、界符 一字一种:关键字、运算符、分界符各一码
北邮大三上-编译原理-词法分析实验报告

北邮大三上-编译原理-词法分析实验报告编译原理第三章词法分析班级:2009211311学号:姓名:schnee目录1.实验题目和要求 (3)2.检测代码分析 (3)3.源代码 (4)1.实验题目和要求题目:词法分析程序的设计与实现。
实验内容:设计并实现C语言的词法分析程序,要求如下。
(1)、可以识别出用C语言编写的源程序中的每个单词符号,并以记号的形式输出每个单词符号。
(2)、可以识别并读取源程序中的注释。
(3)、可以统计源程序汇总的语句行数、单词个数和字符个数,其中标点和空格不计算为单词,并输出统计结果(4)、检查源程序中存在的错误,并可以报告错误所在的行列位置。
(5)、发现源程序中存在的错误后,进行适当的恢复,使词法分析可以继续进行,通过一次词法分析处理,可以检查并报告源程序中存在的所有错误。
实验要求:方法1:采用C/C++作为实现语言,手工编写词法分析程序。
方法2:通过编写LEX源程序,利用LEX软件工具自动生成词法分析程序。
2.检测代码分析1、Hello World简单程序输入:2、较复杂程序输入:3. 异常程序输入检测三,源代码#include <cmath>#include <cctype>#include <string>#include <vector>#include <cstdio>#include <cstdlib>#include <cstring>#include <fstream>#include <iostream>#include <algorithm>using namespace std;const int FILENAME=105;const int MAXBUF=82;const int L_END=40;const int R_END=81;const int START=0; //开始指针vector<string> Key; //C保留的关键字表class funtion //词法分析结构{public://变量声明char filename[FILENAME]; //需要词法分析的代码文件名ifstream f_in;char buffer[MAXBUF]; //输入缓冲区int l_end, r_end, forward; //左半区终点,右半区终点,前进指针,bool l_has, r_has; //辅助标记位,表示是否已经填充过缓冲区vector<string> Id; //标识符表char C; //当前读入的字符int linenum, wordnum, charnum; //行数,单词数,字符数string curword; //存放当前的字符串//函数声明void get_char(); //从输入缓冲区读一个字符,放入C中,forward指向下一个void get_nbc(); //检查当前字符是否为空字符,反复调用直到非空void retract(); //向前指针后退一位void initial(); //初始化要词法分析的文件void fillBuffer(int pos); //填充缓冲区,0表示左,1表示右void analyzer(); //词法分析void token_table(); //以记号的形式输出每个单词符号void note_print(); //识别并读取源程序中的注释void count_number(); //统计源程序汇总的语句行数、单词个数和字符个数void error_report(); //检查并报告源程序中存在的所有错误void solve(char* file); //主调用函数};void welcome(){printf("\n************************************** *******************\n");printf( "** Welcome to use LexicalAnalyzer **\n");printf( "** By schnee @BUPT Date: 2011/20/10 **\n");printf( "*********************************************************\n\n\n");}void initKey(){Key.clear();Key.push_back("auto"); Key.push_back("break"); Key.push_back("case"); Key.push_back("char");Key.push_back("const");Key.push_back("continue");Key.push_back("default"); Key.push_back("do");Key.push_back("double");Key.push_back("else"); Key.push_back("enum"); Key.push_back("extern");Key.push_back("float"); Key.push_back("for"); Key.push_back("goto"); Key.push_back("if");Key.push_back("int");Key.push_back("long");Key.push_back("register");Key.push_back("return");Key.push_back("short");Key.push_back("signed"); Key.push_back("static"); Key.push_back("sizeof");Key.push_back("struct");Key.push_back("switch"); Key.push_back("typedef"); Key.push_back("union");Key.push_back("unsigned");Key.push_back("void"); Key.push_back("volatile");Key.push_back("while");}void funtion::get_char(){C=buffer[forward];if(C==EOF)return ; //结束if(C=='\n')linenum++; //统计行数和字符数else if(isalnum(C)) charnum++;forward++;if(buffer[forward]==EOF){if(forward==l_end){fillBuffer(1);forward++;}else if(forward==r_end){fillBuffer(0);forward=START;}}}void funtion::get_nbc(){while(C==' ' || C=='\n' || C=='\t' || C=='\0') get_char();}void funtion::initial(char* file){Id.clear(); //清空标识符表l_end=L_END;r_end=R_END; //初始化缓冲区forward=0;l_has=r_has=false;buffer[l_end]=buffer[r_end]=EOF;fillBuffer(0);linenum=wordnum=charnum=0; //初始化行数,单词数,字符数}void funtion::fillBuffer(int pos){if(pos==0)//填充缓冲区的左半边{if(l_has==false){fin.read(buffer, l_end);if(fin.gcount()!=l_end)buffer[fin.gcount()]=EOF;}else l_has=false;}else //填充缓冲区的右半边{if(r_has==false){fin.read(buffer+l_end+1, l_end);if(fin.gcount()!=l_end)buffer[fin.gcount()+l_end+1]=EOF;}else r_has=false;}}void funtion::retract(){if(forward==0){l_has=true; //表示已经读取过文件,避免下次再次读取forward=l_end-1;}else{forward--;if(forward==l_end){r_add=true;forward--;}}}void funtion::analyzer(){FILE *token_file, *note_file, *count_file, *error_file;token_file=fopen("token_file.txt", "w");note_file=fopen("note_file.txt", "w");count_file=fopen("count_file.txt", "w");error_file=fopen("error_file.txt", "w");int i;curword.clear();get_char();get_nbc();if(C==EOF)return false;if(isalpha(C) || C=='_')//关键字和标识符的处理,以字母或下划线开头{curword.clear();while(isalnum(C) || C=='_'){curword.push_back(C);get_char();}retract();wordnum++;Id.push_back(curword);for(i=0; i<Key.size(); i++)if(Key[i]==curword)break;//输出每一个单词的标识符if(i<Key.size()) //关键字fprintf(token_file, "%8d----%20s %s\n", wordnum, "KEY WORD", curword);elsefprintf(token_file, "%8d----%20s %s\n", wordnum, "Identifier", curword);}else if(isdigit(C))//无符号数的处理{curword.clear();while(isdigit(C)){curword.push_back(C);get_char();}if(C=='.' || C=='E' || C=='e')//处理小数和指数形式{curword.push_back(C);get_char();while(isdigit()){curword.push_back(C);get_char();}}retract();wordnum++;Id.push_back(curword);fprintf(token_file, "%8d----%20s %s\n", wordnum, "Unsigned Number", curword);}else if(C=='#')//过滤掉以#开头的预处理{fprintf(note_file, "preproccess Line %d : ", linenum);get_char();fprintf(note_file, "%c", C);while(C!='\n'){get_char();fprintf(note_file, "%c", C);}fprintf(note_file, "%c", C);}else if(C=='"')//""内的句子当成整个串保存起来{curword.clear();get_char();while(C!='"'){curword.push_back(C);get_char();}fprintf(token_file, "*****string in ""----%s\n", curword);}else if(C=='/'){get_char();if(C=='/')//过滤掉//开头的行注释{fprintf(note_file, "single-line note Line %d : ", linenum);get_char();curword.clear();while(C!='\n'){curword.push_back(C);get_char();}fprintf(note_file, "%s\n", curword);}else if(C=='*')//过滤掉/**/之间的段注释{fprintf(note_file, "paragraph note Line %d : ", linenum);get_char();while(true){while(C!='/'){fprintf(note_file, "%c", C);get_char();}get_char();if(C=='*'){fprintf(note_file, "\nto Line %d\n", linenum);break;}fprintf(note_file, "%c", C);}}else if(C=='=')fprintf(token_file, "*****ASSIGN-OP, DIV\n");else{fprintf(token_file, "*****CAL-OP, DIV\n");retract();}} //处理各种比较,赋值,运算符号else if(C=='<'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, LE\n");else{fprintf(token_file, "*****RELOP, LT\n");retract();}}else if(C=='>'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, GE\n");else{fprintf(token_file, "*****RELOP, GT\n");retract();}}else if(C=='='){get_char();if(C=='=')fprintf(token_file, "*****RELOP, EQ\n");else{fprintf(token_file, "*****ASSIGN-OP, EASY\n");retract();}}else if(C=='+'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, ADD\n");else{fprintf(token_file, "*****CAL-OP, ADD\n");retract();}}else if(C=='-'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, SUB\n");else{fprintf(token_file, "*****CAL-OP, SUB\n");retract();}}else if(C=='*'){get_char();if(C=='=')fprintf(token_file, "*****ASSIGN-OP, MUL\n");else{fprintf(token_file, "*****CAL-OP, MUL\n");retract();}}else if(C=='!'){get_char();if(C=='=')fprintf(token_file, "*****RELOP, UE\n");else if(!isalpha(C) && C!='_'){fprintf(error_file, "Line %d: error: '!' was illegal char \n", linenum);}}else if(C==':' || C=='(' || C==')' || C==';' || C=='{' || C=='}' || C==',')fprintf(token_file, "*****Other char----%c\n", C);elsefprintf(error_file, "Line %d: error: '%c' was illegal char \n", linenum, C);fprintf(count_file, "The Line number is %d\n", linenum);fprintf(count_file, "The word number is %d\n", wordnum);fprintf(count_file, "The char number is %d\n",charnum);fclose(token_file);fclose(note_file);fclose(count_file);fclose(error_file);}void funtion::token_table(){fin.open("token_file.txt");printf("The token_table is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::note_print(){fin.open("note_file.txt");printf("The note is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::count_number(){fin.open("count_file.txt");printf("The count result is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::error_report(){fin.open("error_file.txt");printf("The error report is as following:\n");char str[1];while(1){fin.read(str, 1);if(str[0]!=EOF)printf("%c", str[0]);}}void funtion::solve(char* file){filename=file;fin.open(filename);intitial();analyzer();int choice;printf("**** We have analyzed %s \n");printf("**0: To end\n");printf("**1: To get the token table\n");printf("**2: To get the note part of file\n");printf("**4: To report all the error of the file\n");printf("**3: To get the line num, word num and charter num\n\n");while(1){printf("****please input your choice: ");scanf("%d", &choice);if(choice==0)break;if(choice==1)token_table();else if(choice==2)note_print();else if(choice==3)count_number();else error_report();printf("\n");}}void LexicalAnaylzer(char* file){funtion test;test.solve(file);}int main(){welcome();initKey();char file[FILENAME];while(1){printf("\nDo you want to continue? ("YES" or "NO"): ");scanf("%s", file);if(strcmp(file, "NO")==0){printf("Thanks for your use! GoodBye next time!\n\n");break;}printf("Please type your C file name(for example: a.cpp): ");scanf("%s", file);LexicalAnalyzer(file);}return 0;}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
词法分析
主要内容
• 词法分析的任务 • 手工实现词法分析程序 • 正规式与有穷自动机 • 词法分析程序的自动生成
教学要求
• 重点掌握 词法分析器的功能和接口,用状态转换图设计
和实现词法分析程序,正规文法、正规式和有穷 自动机的概念及相互转换
词法分析程序 所处的位置
词分器法析取下单ktnoe一词符个语分表器号法 析
写成C语言的函数形式: recog_id() {…
char state = 0;
字母或数字
* 0 字母 1 其它 2
ch = getch();
do {
switch(state){ Case 0: if ch 是字母 state = 1; ch = getch();break; Case 1: if ch 是字母或数字 {
数字 6
数字 其他(为整数)
(出错)
7*
*
10
其他 (为指数)
*
8
*
9
练习2
• 画出识别标识符和整常数(可带正负号)的状态转 换图
练习3
• 以下状态转换图接受的字符集合是什么?
0
X
Y1
0
某简单语言的词法 分析程序的实现
状态转换图的实 现:使用一个 switch case 语 句:每条分支对 应一个case语句 段 见书P45 例
char
const
关 begin 键 if 字 then
else
while
do
for
to
end
read
种别码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
类 别
单词
关 write 键 true 字 false
not
and
or +
-
* 运/ 算 符<
>
<=
>=
==
<>
一、正规文法
• 正规文法:文法G=(VN,VT,P,S)中的每个产生式 的形式都是A→aB或A→a,其中A和B都是非终结符, a是终结符串。
下面定义的标识符和无符号整数都是正规文法: <ID> → <LETTER>|<ID><LETTER>|<ID><DIGIT> <UINT> → <DIGIT>| <UINT><DIGIT> <AOP> → +|-| * | / <LETTER> → a|b|c|…|z|A|B|…|Z <DIGIT> → 0|1|2|…|9
词法分析程序的接口
符号表
源程序
词法分析程序
token文件
源程序清单 和错误信息
源程序
识别 单词1
token文件
标识符 常数
查填符 号表2
源程序清单 和错误信息
ห้องสมุดไป่ตู้
符号表
源程序
读入一 行1.1
字 母
缓冲区
源程序清单
buffer
数字
读一非 字符 首字符
/
空字符
分类1.3
1.2
‘
标识符/关键字 其它界符和运算符
compiling process} var
a,b,c:integer; x:char; begin if (a+c*3 > b) and (b>3) then c:=3; End.
举例
符号表
• 其它输出:错误信息和源程序清单
– 错误信息应该详细,准确,指出出错的具体行、列位置, 发生了哪类错误等,方便用户修改
• 如:下面几个数应该是符合规则的数:
3,3.51,34E3,34.5E2,34.5E+2,34.5E-2
E/e
. 数字
=> 0 数字 1
数字
数字
2 数字 3 E/e 4 5 +或- 数字 6 其他
7
其他
数字
其他
数字
∙ => 0 数字 1
2 数字 3
数字
E/e
其他 (为小数)
其他
其他
数字
5 E/e 4 +/-
符号表和token 表写入文件 write_sym()
write_token()
Y 缓冲区空?
N 读取单词的第1个字 符get_nextchar()
关闭所有文件 结束
数字 识别数值常数 recog_dig()
’
识别字符常数 recog_str()
根据第1 个字符进行分类
sort()
字母 识别标识符/关 键字recog_id()
pattern的一种重要的表示法,是单词构成规则的 描述工具。
正规式和正规集的递归定义:(设字母表为) 1. 和都是上的正规式,表示{}和{ }; 2.任何a ,则a是正规式,表示{a}; 3.假定r和s都是上的正规式,分别表示语言L(r)和L(s):
a) (r) | (s)是正规式,表示L (r) U L (s) ; b) (r)(s)是正规式,表示L (r)L (s); c) (r)*是正规式,表示(L (r) )*; d) (r)是正规式,表示L (r); 4.有限次使用上述三步骤而定义的表达式才是上的正 规式,仅由这些正规式所表示的集合才是上的正规集。
– 格式: (单词的种别码,单词符号的属性值) – 单词种别:是对能识别的单词的分类编码 – 单词符号的属性值:单词的某种特性或特征
• 常数的值,标识符的名字等 • 保留字、运算符、分界符的属性值可以省略 – 文件存放最好有格式,如每个单词占一行方便“语法分 析”程序调用
源程序
{this is a sample program writing in simple language}
• 识别单词前作如下假定
– 关键字就是保留字 – 单词中间不能有分界符(如空格、空白、界符和算符等) – 单词中间不能有注释 – 单词必须在一行内写完,换行后认为是另一个单词 – 一个单词不能超过规定长度
识别单词
超前搜索技术:如在读取/* */时,当读到/时,如 何判别是注释还是除法运算?
识别单词:掌握单词的构成规则很重要 • 主要包括如下几种单词的识别:
词法分析器的自动生成
• 正规式 • 正规文法 • 有穷自动机
3.3 正规文法、正规式与有穷自动机
• 本节要求 1 能根据自然语言描述构造正规式、NFA 2 掌握NFA转换为DFA,DFA的化简 3 掌握正规文法、正规式和有穷自动机间的转换
为了讨论词法分析程序的自动生成问题,将状态 转换图加以形式化。
种别码 类别
单词
18
标识
19
符
id
20
21
整常数
22
常 实常数
23
数 字符常数
24
布尔常数
25
=
26
;
27
,
28
'
29
界 /*
30
符 */
31
:
32
(
33
)
.
种别码
34
35 36 37 38 39 40 41 42 43 44 45 46 47 48
词法分析器的输出
• Token串 (二元式) 输出源文件中各个有用的单词
program example1;
{used for illustrating compiling process}
举例
var
a,b,c:integer;
x:char;
begin
if (a+c*3 > b) and (b>3) then c:=3;
end.
注意token文 件的格式
token文件
program example1 ; var a , b , c : integer ; x : char ; begin if
错误处理
• 应尽可能发现更多的错误 • 处理方式
– 每个程序段单独处理错误 – 统一处理错误(商用软件系统)
• 记录式的文件 • 数据库 统计表明,现代软件系统中, 75%的程序代码都是用于处 理错误与错误信息。 商业系统中错误处理的特点是:统一错误编号,编制文档 指出错误信息的含义、应对措施、解决方案。
语法 树
编译 程序
的后
续部
分
• 功能
源程序
3.1 词法分析器的功能
词法分析程序 Token串 语法分析程序
– 逐个读入源程序字符并按照构词规则切分成一系列单词
• 主要任务
– 读入源程序,识别出各个单词符号,并输出。
• 其他任务
– 滤掉程序中的无用成分,如空格、注释、换行符 – 调用符号管理程序,对识别出的符号进行管理 – 追踪换行标志,指出源程序出错的行列位置
识别标 识符/关 键字1.5
识别数 值常数
1.6
处理注 释和除 号1.7
识别文 字常数
1.8
识别界 符和运 算符1.9
数值常数
除号/
输出 标识符 token串 常数
文界字符常和数运算符
1.4 token文件
其它
查填符 号表2
符号表
初始化 打开源文件
源程序结束? Y
N 读入一行到string中
get_line()
• 结论:每一种程序设计语言,都有它自己的字符 集V,语言中的每一个单词或者是V上的单个字 符,或者是V上的字符按一定方式组成的字符串。 组成方式就是对字符或字符串进行(连接)“.”、 或“|”(并)、或“*/+”闭包运算。