数据库表关联
数据库中表的关联设计

数据库中表的关联设计数据库中表的关联设计是数据库设计的核心环节之一,它关系到数据的完整性、查询效率以及系统的可扩展性。
在进行数据库表关联设计时,需要遵循一定的原则和方法,以确保数据库结构的合理性和高效性。
本文将深入探讨数据库中表的关联设计,包括关联类型、设计原则、实施步骤以及优化策略等方面。
一、关联类型数据库中的表关联主要分为三种类型:一对一关联(1:1)、一对多关联(1:N)和多对多关联(M:N)。
1. 一对一关联(1:1):指两个表中的记录之间存在一一对应的关系。
例如,一个用户表和一个用户详情表,每个用户都有唯一的详情信息。
在这种关联中,通常将两个表合并为一个表,或者在主表中添加一个唯一的外键列来引用另一个表。
2. 一对多关联(1:N):指一个表中的记录可以与另一个表中的多个记录相关联。
例如,一个部门表可以有多个员工表记录与之关联。
在这种关联中,通常在多的一方添加一个外键列,用于引用一的一方的主键。
3. 多对多关联(M:N):指两个表中的记录都可以与对方表中的多个记录相关联。
例如,学生和课程之间的关系,一个学生可以选修多门课程,一门课程也可以被多个学生选修。
在这种关联中,通常需要引入一个中间表来表示两个表之间的关联关系,中间表包含两个外键列,分别引用两个表的主键。
二、设计原则在进行数据库表关联设计时,需要遵循以下原则:1. 规范化原则:通过数据规范化来消除数据冗余和依赖,确保数据的完整性和一致性。
规范化过程中,将数据分解到多个表中,并定义表之间的关系,以减少数据的重复存储。
2. 完整性原则:确保数据的完整性和准确性。
通过设置主键、外键、唯一约束等数据库对象,来维护数据的完整性。
同时,还需要考虑业务规则和数据校验等方面的需求。
3. 可扩展性原则:数据库设计应具有良好的可扩展性,能够适应未来业务的发展和变化。
在设计过程中,需要预留一定的扩展空间,避免过多的硬编码和固定配置。
4. 性能原则:数据库设计应充分考虑查询性能和数据处理能力。
sql操作数据库(3)--外键约束、数据库表之间的关系、三大范式、多表查询、事务

sql操作数据库(3)--外键约束、数据库表之间的关系、三⼤范式、多表查询、事务外键约束在新表中添加外键约束语法: constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)在已有表中添加外键约束:alter table 从表表名 add constraints 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)删除外键语法: alter table 从表表名 drop foreign key 外键名称;级联操作:注意:在从表中,修改关联主表中不存在的数据,是不合法的在主表中,删除从表中已经存在的主表信息,是不合法的。
直接删除主表(从表中有记录数据关联) 会包删除失败。
概念:在修改或者删除主表的主键时,同时它会更新或者删除从表中的外键值,这种动作我们称之为级联操作。
语法:更新级联 on update cascade 级联更新只能是创建表的时候创建级联关系。
当更新主表中的主键,从表中的外键字段会同步更新。
删除级联 on delete cascade 级联删除当删除主表中的主键时,从表中的含有该字段的记录值会同步删除。
操作:-- 给从表student添加级联操作create table student(s_id int PRIMARY key ,s_name VARCHAR(10) not null,s_c_id int,-- constraint 外键约束名称 foreign key(外键的字段名称) references 主表表名(主键字段名)CONSTRAINT stu_cour_id FOREIGN key(s_c_id) REFERENCES course(c_id) -- 给s_c_id 添加外键约束ON UPDATE CASCADE ON DELETE CASCADE)insert into student VALUE(1,'⼩孙',1),(2,'⼩王',2),(3,'⼩刘',4);insert into student VALUE(4,'⼩司马',1),(5,'⼩赵',1),(6,'⼩钱',1);-- 查询学⽣表中的记录select * from student;-- 级联操作。
数据库表的结构

数据库表的结构1. 概述数据库表是关系型数据库中数据存储的基本单位,它是由若干行和列组成的二维数据结构。
在设计数据库时,合理的表结构设计是至关重要的,它直接影响到数据库的性能、可维护性和扩展性。
本文将详细探讨数据库表的结构,包括表的组成、命名规范、字段设计以及常见的表关系类型。
2. 表的组成数据库表由若干列(字段)和若干行(记录)组成,每一列都具有唯一的列名和数据类型。
每一行代表一个实体或记录,它由各个字段的值组成。
表中的每一列可以存储不同类型的数据,比如整数、字符、日期等。
3. 命名规范为了提高数据库的可读性和可维护性,表的命名应该遵循一定的规范。
以下是一些常见的命名规范:•表名应该具有描述性,能够清楚地反映出表的含义。
•表名应该使用小写字母,并使用下划线分隔单词(例如:employee_info)。
•表名应该是名词或名词短语的复数形式(例如:employees)。
•列名也应该使用小写字母,并使用下划线分隔单词(例如:first_name)。
•列名应该具有描述性,能够清楚地反映出列的含义。
4. 字段设计表的每一列都是一个字段,字段的设计直接影响到数据库的性能和数据的完整性。
以下是一些字段设计的注意事项:•每个字段应该具有明确的数据类型,这样可以有效地节省存储空间,并提高查询效率。
•字段的长度应该与实际数据的长度相匹配,避免过长或过短的字段长度。
•字段应该具有适当的约束,比如唯一约束、非空约束等,以确保数据的完整性。
•字段应该具有描述性的名称,能够清楚地反映出字段的含义。
5. 表关系类型在数据库设计中,表与表之间可以存在不同的关系类型,包括一对一关系、一对多关系和多对多关系。
以下是对每种关系类型的介绍:5.1 一对一关系一对一关系指的是两个表之间存在唯一的关联,这种关系通常可以通过在一方表中添加外键来实现。
一对一关系常用于将某些属性独立出来,形成单独的表。
5.2 一对多关系一对多关系指的是一个表的一条记录对应另一个表中的多条记录。
数据库的创建与表间关系的各种操作

学科实验报告班级2010级金融姓名陈光伟学科管理系统中计算机应用实验名称数据库的创建与表间关系的各种操作实验工具Visual foxpro 6.0实验目的1、掌握数据库结构的创建方式2、表间的关联关系实验步骤一、建立数据库。
1、在项目管理器中建立数据库。
首先选择数据库,然后单击“新建”建立数据库,出现的界面提示用户输入数据库的名称,按要求输入后单击“保存”则完成数据库的建立,并打开i“数据库设计器”。
2、从“新建”对话框建立数据库。
单击工具栏上的“新建”按钮或者选择菜单“文件——新建”打开“新建”对话框,首先在“文件类型”组框中选择“数据库”,然后单击“新建文件”建立数据库,后面的操作和步骤与1相同。
3、用命令交互建立数据库。
命令是create database【databasename ▏?】二、表间关系的各种操作。
1、创建索引文件。
可以再创建数据表时建立其结构复合索引文件,但是也可以先建立好数据表,以后再创建或修改索引文件。
2、索引的操作。
A、打开与关闭。
要使用索引,必须先要打开索引。
一旦数据表文件关闭所有相应的索引文件也就自动关闭了。
B、确定主控索引。
可以使用命令确定当前主控索引。
命令格式1:set order to 【tag】<索引标识>【ascending| desceding】命令格式2:use<表文件名>order【tag】<索引标识>【ascending | esceding】C、删除索引标识。
要删除结构复合索引文件中的索引标识,应当打开数据表文件,并打开其表设计器对话框。
在“索引”页面中选定要删除的索引标识后,单击“删除”按钮删除。
3、创建关联。
在创建数据表之间的关联时,把当前数据表叫做父表,而把要关联的表叫做子表。
必须保证两个要建立关系的数据表中存在能够建立联系的同类字段;同时要求每个数据表事先分别以该字段建立了索引。
A、建立表间的一对一的关系。
如何进行数据库表的关联与联接操作

数据库表的关联与联接操作是数据库管理中非常重要的概念和技术。
通过合理地进行表的关联与联接,我们可以在存储数据的同时,保持数据之间的准确性和完整性,提高数据库的查询效率和灵活性。
接下来,我们将深入探讨如何进行数据库表的关联与联接操作。
一、理解表的关联与联接在数据库中,不同表之间可以通过共享的数据字段进行关联与联接。
表的关联指的是基于共享的数据字段,将不同的表连接起来,以形成逻辑上的关系。
联接则是实际进行的操作,通过对表进行联接,我们可以在查询数据时将相应的数据字段进行匹配与合并。
二、常用的关联与联接类型在数据库中,有几种常用的关联与联接类型,包括内连接、左连接、右连接和全连接。
1. 内连接(Inner Join)内连接是通过返回两个表之间共同字段的匹配记录来进行联接操作。
对于两个表来说,只有在其中一个表中存在相应的匹配记录时,才能返回结果。
2. 左连接(Left Join)左连接是以左表为主,返回左表中的所有记录以及右表中与之相匹配的记录。
如果右表中没有与左表匹配的记录,则返回空值。
3. 右连接(Right Join)右连接是以右表为主,返回右表中的所有记录以及左表中与之相匹配的记录。
如果左表中没有与右表匹配的记录,则返回空值。
4. 全连接(Full Join)全连接返回两个表中所有记录,无论是否有匹配的记录。
如果其中一个表中没有与另一个表匹配的记录,则返回空值。
三、进行关联与联接的步骤要进行数据库表的关联与联接操作,需要进行以下步骤:1. 确定需要联接的表:首先,需要确定需要进行关联与联接的表,保证它们之间有共同的字段。
2. 选择合适的联接类型:根据具体需求,选择合适的联接类型,如内连接、左连接、右连接或全连接。
3. 确定联接条件:在进行联接操作时,需要确定联接的条件,即需要匹配的字段。
通常情况下,联接条件是两个表中的某个字段。
4. 进行联接操作:根据选择的联接类型和联接条件,进行相应的联接操作。
数据库表的名词解释

数据库表的名词解释1. 引言数据库是计算机系统中用于存储和管理数据的重要组成部分。
它通过使用表来组织和存储数据,而数据库表则是数据库中最基本的数据结构。
本文将对数据库表进行详细解释,包括定义、结构、属性、关系以及常见的操作。
2. 定义数据库表是一种二维数据结构,由行和列组成,用于存储和组织相关数据。
每个表都有一个唯一的名称,并且可以包含多个列(也称为字段)和多条记录(也称为行)。
每个列定义了特定类型的数据,并且每个记录则表示一个实体或对象。
3. 结构数据库表由以下几个主要部分组成:3.1 表名表名是对表的唯一标识,用于在数据库中引用该表。
通常使用有意义且描述性强的名称来命名表,以便更好地理解其内容和用途。
3.2 列(字段)列是指表中的垂直方向上的数据存储单元。
每个列都有一个名称和一个特定的数据类型,用于定义该列可以存储什么类型的数据。
例如,在一个员工信息表中,可能包含姓名、年龄、性别等列。
3.3 行(记录)行是指表中的水平方向上的数据存储单元。
每一行都包含了一组相关的数据,表示一个实体或对象。
例如,在一个员工信息表中,每一行可能表示一个具体的员工,包含了该员工的姓名、年龄、性别等信息。
3.4 主键主键是表中用于唯一标识每个记录的列或列组合。
主键可以确保表中每个记录都有唯一的标识,并且可以用于在表中进行快速查找和访问。
常见的主键类型包括自增长整数、全局唯一标识符(GUID)等。
3.5 外键外键是指表中用于与其他表建立关联关系的列。
外键可以将两个或多个表之间的关系进行定义和维护。
通过使用外键,可以实现数据在不同表之间的引用和关联,从而提高数据存储和查询效率。
4. 属性数据库表具有以下几个重要属性:4.1 唯一性每个数据库表都应该具有唯一性,即每张表应该有一个独特的名称,并且在同一个数据库中不能存在两张名称相同的表。
4.2 结构化数据库表是结构化数据存储方式的典型代表。
它以行和列的形式组织数据,使得数据的组织和访问更加方便和高效。
数据库表中的三种关系

数据库表中的三种关系
在数据库表中,存在三种基本的关系:一对一(One-to-One)、一对多(One-to-Many)和多对多(Many-to-Many)。
这些关系描述了表与表之间的连接方式。
1. 一对一关系(One-to-One):这种关系意味着,表中的每一行都与另一个表中的一行相关联。
例如,一个员工有一个唯一的员工ID,这个ID也可以唯一地确定一个员工。
这种关系通常通过在两个表中都使用主键和外键来实现。
2. 一对多关系(One-to-Many):这种关系意味着,表中的每一行都可以与另一个表中的多行相关联,但另一表中的每一行只能与这一表中的一行相关联。
例如,一个班级有多个学生,但每个学生只属于一个班级。
这种关系通常通过在“多”的一方设置一个外键来实现。
3. 多对多关系(Many-to-Many):这种关系意味着,表中的每一行都可以与另一个表中的多行相关联,并且另一表中的每一行也可以与这一表中的多行相关联。
这种关系需要一个单独的关联表来处理。
例如,一个学生可以选多门课程,一门课程也可以有多个学生选。
这种关系通常通过在两个表中都设置外键,并使用关联表来连接两个表来实现。
在设计数据库时,理解并正确使用这些关系是非常重要的,因为它们决定了数据如何在不同的表中存储和检索。
数据库表关联关系、继承关系、聚合关系

数据库表关联关系、继承关系、聚合关系一、数据库表关联关系1.数据库表关联关系是指在关系数据库中,不同表之间存在的一种关系。
这种关系可以通过在表中添加外键来实现。
2.数据库表的关联关系分为一对一关系、一对多关系和多对多关系。
其中,一对一关系是指一个表的每一条记录只能对应另一个表中的一条记录,而另一个表中的每一条记录也只能对应一个记录;一对多关系是指一个表的每一条记录可以对应另一个表中的多条记录,而另一个表中的每一条记录只能对应一个记录;多对多关系是指一个表中的多条记录可以对应另一个表中的多条记录。
3.在实际应用中,数据库表的关联关系被广泛应用于数据的查询和管理。
通过关联表,可以实现数据的多表查询和联合查询,从而满足不同业务需求。
二、数据库表继承关系1.数据库表继承关系是指在关系数据库中,一个表可以从另一个表中继承属性。
这种关系可以通过实现表的继承来实现。
2.数据库表继承关系可以分为单表继承和多表继承。
单表继承是指一个表从另一个表中继承属性,而多表继承是指一个表可以从多个表中继承属性。
3.利用数据库表继承关系,可以实现数据的抽象和组织,提高了数据的可维护性和扩展性。
也可以简化数据的操作和管理。
三、数据库表聚合关系1.数据库表聚合关系是指在关系数据库中,一个表可以包含另一个表。
这种关系可以通过在表中添加外部表的引用来实现。
2.数据库表聚合关系可以分为简单聚合和复杂聚合。
简单聚合是指一个表包含另一个表,而复杂聚合是指一个表可以包含多个表。
3.适当的使用数据库表聚合关系,可以提高数据的组织和管理效率,同时也可以减少数据冗余和提高数据的一致性。
四、总结通过以上分析可以看出,数据库表的关联关系、继承关系和聚合关系在关系数据库中都发挥着重要的作用。
这些关系可以帮助实现数据之间的信息和组织,提高数据的查询和管理效率,从而满足不同的业务需求。
在设计数据库表结构时,应充分考虑不同关系之间的应用场景,合理运用这些关系,从而更好地组织和管理数据。
数据库 关联表

数据库关联表在数据库设计中,关联表是一种用于建立两个或多个表之间关系的方法。
通过使用关联表,可以实现数据的关联和连接,从而提供更丰富的查询和分析功能。
本文将介绍关联表的概念、作用和使用方法,以及关联表在实际应用中的一些常见场景。
一、关联表的概念关联表是指在数据库中用于建立两个或多个表之间关系的一种表结构。
通过在关联表中存储相关表的主键,可以实现不同表之间的数据关联和连接。
关联表通常包含两个字段,一个字段用于存储第一个表的主键,另一个字段则用于存储第二个表的主键。
通过这种方式,可以建立起两个表之间的关联关系,从而实现数据的关联查询和分析。
二、关联表的作用关联表在数据库设计中起着非常重要的作用。
首先,它可以用于解决多对多关系的数据存储问题。
在数据库中,多对多关系是指一个实体可以与多个其他实体相关联,而每个实体又可以与多个其他实体相关联。
通过使用关联表,可以实现多对多关系的数据存储和查询。
关联表还可以用于解决一对多关系的数据存储问题。
在数据库中,一对多关系是指一个实体可以与多个其他实体相关联,而每个其他实体只能与一个实体相关联。
通过使用关联表,可以实现一对多关系的数据存储和查询。
关联表还可以用于解决多对一关系的数据存储问题。
在数据库中,多对一关系是指多个实体可以与一个实体相关联,而一个实体只能与一个其他实体相关联。
通过使用关联表,可以实现多对一关系的数据存储和查询。
三、关联表的使用方法使用关联表的方法非常简单。
首先,需要在数据库中创建两个或多个相关的表。
然后,在关联表中创建两个字段,一个字段用于存储第一个表的主键,另一个字段用于存储第二个表的主键。
最后,将相关表的主键存储到关联表中,从而建立起两个表之间的关联关系。
在实际应用中,关联表可以根据需要进行扩展。
例如,可以在关联表中添加其他字段,用于存储两个表之间的关联信息。
此外,还可以使用不同类型的关联表,如一对多关联表、多对多关联表等,以满足不同的业务需求。
oracle表关联方式

oracle表关联方式摘要:1.导言2.Oracle 数据库表关联的概念3.Oracle 数据库的三种表关联方式3.1 内连接3.2 外连接3.3 交叉连接4.总结正文:在Oracle 数据库中,表关联是一种查询多个表的方法,通过将两个或多个表中的数据组合在一起,从而实现数据查询的复杂需求。
本文将详细介绍Oracle 数据库的三种表关联方式:内连接、外连接和交叉连接。
1.Oracle 数据库表关联的概念在Oracle 数据库中,表关联是指通过使用关系运算符(如INNER JOIN、OUTER JOIN、CROSS JOIN 等) 将两个或多个表中的记录组合在一起。
表关联可以让查询变得更简单、更高效,同时也可以避免重复数据。
2.Oracle 数据库的三种表关联方式2.1 内连接内连接(Inner Join) 是指查询结果仅包含两个表中共同拥有的记录。
它使用关系运算符INNER JOIN 实现,其语法如下:```SELECT column_name(s)FROM table1INNER JOIN table2ON table1.column_name = table2.column_name;```例如,假设我们有两个表:用户表(user) 和订单表(order),我们想要查询所有用户及其对应的订单信息,可以使用内连接:```SELECT user.id, , order.id, order.productFROM userINNER JOIN orderON user.id = er_id;```2.2 外连接外连接(Outer Join) 包括左外连接(Left Outer Join) 和右外连接(Right Outer Join),它返回两个表中所有的记录,如果某个表中没有匹配的记录,则返回NULL 值。
它使用关系运算符LEFT OUTER JOIN 和RIGHT OUTER JOIN 实现,其语法如下:```SELECT column_name(s)FROM table1LEFT OUTER JOIN table2ON table1.column_name = table2.column_name;``````SELECT column_name(s)FROM table1RIGHT OUTER JOIN table2ON table1.column_name = table2.column_name;```例如,假设我们想要查询所有用户及其对应的订单信息,但是如果用户没有订单,也要显示该用户,可以使用左外连接:```SELECT user.id, , order.id, order.productFROM userLEFT OUTER JOIN orderON user.id = er_id;```2.3 交叉连接交叉连接(Cross Join) 返回两个表中的所有可能的组合,它使用关系运算符CROSS JOIN 实现,其语法如下:```SELECT column_name(s)FROM table1CROSS JOIN table2;```例如,假设我们有两个表:用户表(user) 和订单表(order),我们想要查询所有用户及其对应的订单信息,可以使用交叉连接:```SELECT user.id, , order.id, order.productFROM userCROSS JOIN order;```3.总结本文详细介绍了Oracle 数据库的三种表关联方式:内连接、外连接和交叉连接,以及它们的语法和应用场景。
数据库定义表之间关系(带图)

如何定义数据库表之间的关系特别说明数据库的正规化是关系型数据库理论的基础。
随着数据库的正规化工作的完成,数据库中的各个数据表中的数据关系也就建立起来了。
在设计关系型数据库时,最主要的一部分工作是将数据元素如何分配到各个关系数据表中。
一旦完成了对这些数据元素的分类,对于数据的操作将依赖于这些数据表之间的关系,通过这些数据表之间的关系,就可以将这些数据通过某种有意义的方式联系在一起。
例如,如果你不知道哪个用户下了订单,那么单独的订单信息是没有任何用处的。
但是,你没有必要在同一个数据表中同时存储顾客和订单信息。
你可以在两个关系数据表中分别存储顾客信息和订单信息,然后使用两个数据表之间的关系,可以同时查看数据表中每个订单以及其相关的客户信息。
如果正规化的数据表是关系型数据库的基础的话,那么这些数据表之间的关系则是建立这些基础的基石。
出发点下面的数据将要用在本文的例子中,用他们来说明如何定义数据库表之间的关系。
通过Boyce-Codd Normal Form(BCNF)对数据进行正规化后,产生了七个关系表:Books: {Title*, ISBN, Price}Authors: {FirstName*, LastName*}ZIPCodes: {ZIPCode*}Categories: {Category*, Description}Publishers: {Publisher*}States: {State*}Cities: {City*}现在所需要做的工作就是说明如何在这些表之间建立关系。
关系类型在家中,你与其他的成员一起存在着许多关系。
例如,你和你的母亲是有关系的,你只有一位母亲,但是你母亲可能会有好几个孩子。
你和你的兄弟姐妹是有关系的——你可能有很多兄弟和姐妹,同样,他们也有很多兄弟和姐妹。
如果你已经结婚了,你和你的配偶都有一个配偶——这是相互的——但是一次只能有一个。
在数据表这一级,数据库关系和上面所描述现象中的联系非常相似。
数据库表关联查询语句

数据库表关联查询语句数据库表关联查询语句用于从多个表中检索数据,并根据它们之间的关系将结果组合在一起。
以下是一些常见的数据库表关联查询语句的示例:1. 内连接(INNER JOIN):返回两个表中匹配的记录。
```sqlSELECT *FROM table1INNER JOIN table2ON table1.id = table2.table1_id;```2. 左连接(LEFT JOIN):返回左表中的所有记录,以及右表中匹配的记录。
如果右表中没有匹配的记录,则返回NULL 值。
```sqlSELECT *FROM table1LEFT JOIN table2ON table1.id = table2.table1_id;```3. 右连接(RIGHT JOIN):返回右表中的所有记录,以及左表中匹配的记录。
如果左表中没有匹配的记录,则返回NULL 值。
```sqlSELECT *FROM table1RIGHT JOIN table2ON table1.id = table2.table1_id;```4. 全连接(FULL JOIN):返回左表和右表中的所有记录。
如果某个表中没有匹配的记录,则返回NULL 值。
```sqlSELECT *FROM table1FULL JOIN table2ON table1.id = table2.table1_id;```以上示例中的`table1` 和`table2` 是要关联的表名,`id` 和`table1_id` 是用于关联的列名。
你可以根据自己的数据库结构和需求进行调整。
除了上述基本的关联查询语句外,你还可以使用其他条件来过滤结果,例如使用`WHERE` 子句来添加额外的条件,或者使用`ORDER BY` 子句对结果进行排序。
请注意,关联查询语句的具体语法可能因使用的数据库管理系统而有所不同。
上述示例是基于SQL 的通用语法,但具体的语法细节可能会有所不同。
预算任务取数及数据库表关系说明
Part1 相关部分数据字典:1.预算任务对应的是MdTask对象,其实例所存在的数据库表名称为:tb_md_task,清单如下:表格tb_md_task(任务实例)的列清单:2.任务与套表(MdWorkBook)关联,套表在数据库中对应的表tb_md_workbook(套表工作簿),清单如下:表格tb_md_workbook(套表工作簿)的列清单3.每个任务中存在多张表格MdSheet对象,其数据库表tb_md_sheet(表单页)的列清单:4.每个MdSheet中存在多个区域MdArea,其数据表格tb_md_area (表单区域函数)表格tb_md_area(表单区域函数)的列清单5.多维数据与任务的关联表:tb_dcrelaPK_OBJ 主键UNIQKEY 对应多维数据tb_cube_XXX中的uniqkeyCUBECODE 模型编码(XXX)PK_TASK 任务Pk另,在63ehp2以上版本会添加多维数据的X,Y坐标字段该表的存在旨在区分出在两条或多条数据所有维度一样的时候,数据到底属于哪个任务.Part 2: 关联关系:1.预算在数据库里的表名命名规则:以tb_开头;2.预算数据存储的表是动态生成,是以一个模型一张表来存储的,其命名规则是tb_cube_+”cubecode”,其中”cubecode”字符串来源于表tb_md_area中的cubecode字段,也就是说想要知道数据存在哪张表,需要先根据条件查询到cubecode字段,拼写出tb_cube_XXX表名,才可以查到数据.3.tb_md_area.pk_task = tb_md_task.pk_obj , tb_md_area.pk_workbook =tb_md_workbook.pk_obj4.cubecode字段存在于表tb_md_area中,在v63版本及以上在tb_md_workbook中也可取到,但是这里取到的是主模型(main cube-----main cube的数据才可以在任务(MdTask)中展现并允许被编写修改,其他cube的作用可能仅为了展示一些数据),为统一起见,都从tb_md_area上取.原因是每张表Mdsheet(表单)可能有多个mdArea(多维数据区),每个mdArea都关联一个模型(cube),当且仅当知道当前任务使用唯一模型时可以去tb_md_workbook上cubecode.5.在查询到具体的一张tb_cube_XXX时,可以查询到多维数据的value以及各维度的pk及code,以指标和组织为例,在tb_cube_XXX有pk_measure(指标Pk) ,pk_entity(组织)字段6.如果需要定位到具体组织名称,则需要根据pk_entity去表org_orgs里查询,关联关系是org_orgs.pk_org = tb_cube_XXX.pk_entity例:select distinct ,t.pk_entity from org_orgs o,tb_cube_001 t where t.pk_entity=o.pk_org and t.pk_entity ='000127100000000006AT'中国建筑工程总公司000127100000000006AT7.如果需要查询到具体指标明细,则首先要明确当前使用的指标所在的档案表,其查询方法如下:select t.objname,t.tables from tb_mbrreadstruct t wherepk_dimhier='TB_DIMHIER_MEASURE_0';常见档案表如下:会计科目bd_account,bd_accasoa,业务量指标resa_bizindex收支项目bd_inoutbusiclass预算科目tb_budgetsub资金计划项目bd_fundplan报表项目bd_reportitem现金流量项目bd_cashflow责任会计_核算要素resa_factor另外,如果是其他的档案,则取select t.objname,t.tables from tb_mbrreadstruct t where pk_dimhier='TB_DIMHIER_MEASURE_0'查询结果中tables字段value 对应的字符串是逗号隔开的表名,我们只需取第一个逗号前的那个表.以预算科目为例:tb_cube_XXX.pk_measure 对应的则是tb_budgetsub表中的pk_obj字段8.如果应用模型上应用了自定义档案,那么,查询某一条自定义档案相关的信息方式如下:所有的自定义档案都存在表: bd_defdoc中,具体字段详见表结构,与之相关的表是:bd_defdoclist,该表用于保存档案名称等.在编码为XXX的模型中可能是用了自定义档案,则表tb_cube_XXX将会多出pk_xxx的字段,比如该表中存在pk_003字段,则003是自定义档案的code.即表bd_defdoc的code字段.9.预算维度档案存储的表名在表tb_dimtable中,以业务方案为例,则具体业务方案档案数据存在表tb_dataattr中.其他维度档案表表明对应tb_dimtable.dbtablename 字段.。
SDE数据库表关系总结(待扩充)
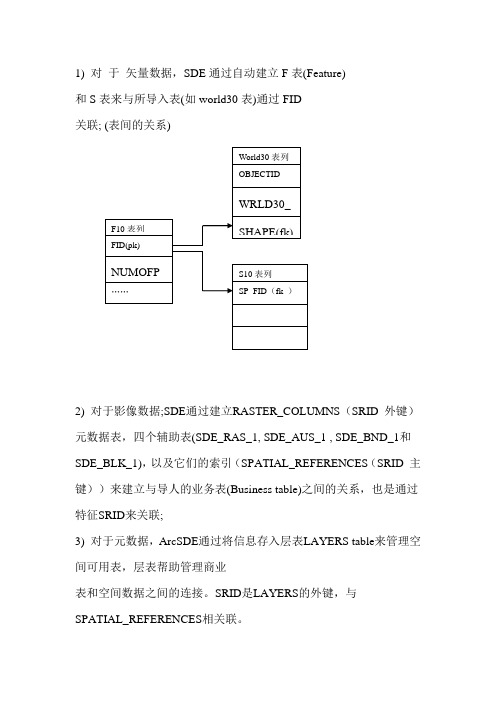
1) 对于矢量数据,SDE通过自动建立F表(Feature)和S表来与所导入表(如world30表)通过FID关联; (表间的关系)2) 对于影像数据;SDE通过建立RASTER_COLUMNS(SRID 外键)元数据表,四个辅助表(SDE_RAS_1, SDE_AUS_1 , SDE_BND_1和SDE_BLK_1),以及它们的索引(SPATIAL_REFERENCES(SRID 主键))来建立与导人的业务表(Business table)之间的关系,也是通过特征SRID来关联;3) 对于元数据,ArcSDE通过将信息存入层表LAYERS table来管理空间可用表,层表帮助管理商业表和空间数据之间的连接。
SRID是LAYERS的外键,与SPATIAL_REFERENCES相关联。
在LARYERS表中的TABLENAME字段存储的是那些包含空间数据列的表(在SDE中称为商业表BusinessTable)的名称。
SPATIALCOLUMN字段中的数据(是个字符串)指明了商业表中存放空间数据列的字段名称。
例如:CREAT这个商业表中存放空间数据的字段名称为FOOTPRINT,打开CREAT这个表,可以看到有FOOTPRINT这个字段,存放数值为1。
现以WORLD30这张商业表为例,详细说明这几个表之间的关系。
因为在LARYERS表中与WORLD30相对的LARYERID是10,所以WORLD30表所对应的空间数据及其索引一定存放在F10和S10这两个表之中。
其中,F10是空间数据表,S10是索引表。
在WORLD30这张商业表中,SHAPE是一个标准的NUMBER类型的字段,它只是起到一个索引的功能,即通过SHAPE中的数值就能由F表和S表(其后的数字由这个空间对象的ObjectID决定)的FID字段找到与其对应的行。
另外,F表中的POINTS字段是一个LONGROW类型的字段,其中存放着空间对象所有坐标值序列的二进制编码。
如何进行数据库表的关联与联接操作(一)

数据库表的关联与联接操作是在数据库中常见的一种数据处理方式。
通过将多个表之间的数据进行关联,可以实现数据的查找、筛选和分析。
在进行表的关联和联接操作时,需要注意一些细节和技巧。
一、理解表的关联操作表的关联操作是指通过共享一个或多个列,将一个表与另一个表进行连接。
常见的关联操作有内连接、外连接和交叉连接等。
其中,内连接是根据两个表之间共有的列的值进行匹配,仅返回满足条件的行。
外连接则是返回满足条件的行以及未满足条件的行。
交叉连接是将两个表的所有行进行组合,生成的结果集是两个表行数的乘积。
在选择表的关联操作时,需考虑两个表之间的逻辑关系和数据需求。
如果需要获取两个表中共同的数据,可选择内连接;如果需要获取一个表中的所有数据,无论是否与另一个表满足条件,可选择外连接;如果需要获取两个表的所有组合,可选择交叉连接。
二、使用JOIN语句进行表的联接操作JOIN是SQL中用于实现表关联操作的关键字。
使用JOIN语句可以根据指定的条件连接两个或多个表,并根据条件返回满足条件的数据。
常见的JOIN语句有内连接、左连接、右连接和全连接。
内连接可以通过INNER JOIN关键字实现,它通过共享一个或多个列进行匹配,并返回满足条件的结果。
例如,SELECT * FROM 表A INNER JOIN 表B ON 表A.列 = 表B.列。
左连接可以通过LEFT JOIN关键字实现,它返回左表中所有的行以及满足条件的右表中的行。
例如,SELECT * FROM 表A LEFT JOIN 表B ON 表A.列 = 表B.列。
右连接可以通过RIGHT JOIN关键字实现,它返回右表中所有的行以及满足条件的左表中的行。
例如,SELECT * FROM 表A RIGHT JOIN 表B ON 表A.列 = 表B.列。
全连接可以通过FULL JOIN关键字实现,它返回左表和右表中所有的行,并根据条件返回满足条件的数据。
例如,SELECT * FROM 表A FULL JOIN 表B ON 表A.列 = 表B.列。
如何使多个数据库的表格合并成一张表并显示在一个gridview中

如何使多个数据库的表格合并成一张表并显示在一个gridview中篇一:DataSet多表关联实现本地数据复杂的查询如果要显示两张数据库表的记录,最简单的方法是检索时将两张表中你要的数据一次检索出来,放入同一个DataTable来显示。
如果要显示两个以上DataTable中的数据,则需要将DataTable放入DataSet并建立relation就可以显示了。
下面是刚做的一个例子。
另外,父表一定要有主键。
建立关联时要用主键。
private void button1_Click(object sender, System.EventArgs e){DataTable dtName = new DataTable(NameDt);dtName.Columns.Add(ID, typeof(string));dtName.Columns.Add(Name, typeof(string));dtName.PrimaryKey = new DataColumn[]{dtName.Columns[ID] }; dtName.Rows.Add(1, Name1); DataTable dtAddress = new DataTable(AddressDt); dtAddress.Columns.Add(ID, typeof(string)); dtAddress.Columns.Add(Address, typeof(string)); dtAddress.Rows.Add(1, Address1);dtAddress.Rows.Add(1, Address2);DataSet ds = new DataSet();ds.Tables.Add(dtName);ds.Tables.Add(dtAddress);// 关键!建立表之间的关联ds.Relations.Add(ForName, dtName.Columns[ID], dtAddress.Columns[ID]);// 在子表中添加计算列,引用父表的数据。
数据库表的几种表示方式

数据库表的几种表示方式数据库是应用程序中非常重要的组成部分,主要用于存储和管理数据。
在数据库中,表是最基本和常用的数据存储单元。
表的表示方式在数据库设计和开发中扮演着重要的角色。
下面我们来介绍一下数据库表的几种表示方式。
1. 表表是数据库中最基本的数据存储单位,由列和行组成。
通常使用关系代数(R-algebra)符合列是有关的数据表来表示数据表。
表是数据库中最常见的用于存储数据的结构,它们是一个基本的数据存储容器,可以在其中添加、更新或删除行,或查询其内容以检索所需的信息。
2. 关系图关系图是表之间关系的可视表示,可用于理解复杂数据库中各个表之间的关联关系。
关系图通常由矩形和菱形组成,矩形表示表格,而菱形表示外部键/主键。
通过对关系图的可视化该表之间的关系可以更加直观。
3. UML类图UML类图是一种构建标准的软件建模和设计的方法,它可以帮助开发人员更好地理解数据库表之间的关系。
UML类图可以在多个层次上描述数据库结构,例如,描述表、列、主键、外键等,并允许开发人员绘制关系以更好地组织和管理数据。
4. ER图ER图(Entity Relationship Diagram)是一种流行的关系数据库设计工具,它使用图表方式描述了不同实体之间的关系以及这些实体如何关联。
ER图用于可视化数据库结构,为数据库开发人员提供了一种方便的方法来设计数据库结构,同时也可以为业务用户、架构师和其他团队成员提供更好的基础——能够更好地理解复杂的数据库设计和查询逻辑。
总之,以上提到的数据库表的几种表示方式,各有优缺点,适用于不同的场景。
数据库设计人员和开发人员可以根据实际情况选择合适的表示方法来设计和管理数据库表。
只有合理的设计才能让数据库结构更加清晰、规范,同时又满足开发和业务需求的要求。
数据库表之间的关联关系

数据库表之间的关联关系
咱来说说数据库表之间的关联关系。
有一次我整理我的书架,发现有些书是一个系列的,它们之间就有联系。
这时候我就想到了数据库表之间的关联关系。
数据库表之间的关联关系呢,就像是书和书之间的联系。
比如说,有一个表是关于人的信息,另一个表是关于人的订单信息。
这两个表就可以通过人的编号联系起来。
就像我书架上的书,一个系列的书可能有共同的主题或者作者,数据库表之间也有各种联系。
在生活中,数据库表之间的关联关系很重要呢。
比如你在网上买东西,你的订单信息和你的个人信息就通过数据库表的关联关系联系在一起。
这样商家就能知道是谁买了什么东西。
就像我整理书架那次,让我对数据库表之间的关联关系有了更直观的认识。
嘿嘿。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
多对多:两个数据表里的每条记录都可以和另一个数据表里任意数量的记录(或者
一对一:在这种关系中,关系表的每一边都只能存在一个记录。每个数据表中的关键 字在对应的关系表中只能存在一个记录或者没有对应的记录。这种关系和一对配偶之间的关系非常相似——要么你已经结婚,你和你的配偶只能有一个配偶,要么你 没有结婚没有配偶。大多数的一对一的关系都是某种商业规则约束的结果,而不是按照数据的自然属性来得到的。如果没有这些规则的约束,你通常可以把两个数据 表合并进一个数据表,而且不会打破任何规范化的规则。 一对多:主键数据表中只能含有一个记录,而在其关系表中这条记录可以与一个或者多个记录相关,也可以没有记录与之相关。这种关系类似于你和你的父母之间的关系。你只有一位母亲,但是你母亲可以有几个孩子。
{Publisher*}States: {State*}Cities: {City*}
现在所需要做的工作就是说明如何在这些表之间建立关系。
关系类型在家中,你与其他的成员一起存在着许多关系。例如,你和你的母亲是有关 系的,你只有一位母亲,但是你母亲可能会有好几个孩子。你和你的兄弟姐妹是有关系的——你可能有很多兄弟和姐妹,同样,他们也有很多兄弟和姐妹。如果你已 经结婚了,你和你的配偶都有一个配偶——这是相互的——但是一次只能有一个。在数据表这一级,数据库关系和上面所描述现象中的联系非常相似。有三种不同类 型的关系:
各个关系数据 表中。一旦完成了对这些数据元素的分类,对于数据的操作将依赖于这些数据表之间的关系,通过这些数据表之间的关系,就可以将这些数据通过某种有意义的方式 联系在一起。例如,如果你不知道哪个用户下了订单,那么单独的订单信息是没有任何用处的。但是,你没有必要在同一个数据表中同时存储顾客和订单信息。你可 以在两个关系数据表中分别存储顾客信息和订单信息,然后使用两个数据表之间的关系,可以同时查看数据表中每个订单以及其相关的客户信息。如果正规化的数据 表是关系型数据库的基础的话,那么这些数据表之间的关系则是建立这些基础子中,用他们来说明如何定义数据库表之间的关系。通过Boyce-Codd Normal Form(BCNF)对数据进行正规化后,产生了七个关系表:
Books: {Title*, ISBN, Price}Authors: {FirstName*, LastName*}ZIPCodes: {ZIPCode*}Categories: {Category*, Description}Publishers: