SAS主成分分析
主成分分析、判别分析、聚类分析sas程序

一、主成分分析1、数据引入PROC IMPORT OUT= WORK.shuruDA TAFILE= "E:\****\****\数据分析\试验\shouru.xls"DBMS=EXCEL2000 REPLACE;GETNAMES=YES;RUN;2、程序proc princomp data=shouru out=defen;var x1-x9;run;proc sort data=defen;by prin1 prin2;run;proc print data=defen;run;二、判别分析程序2.2方法1:先改变shuru 数据的结构,把待判的数据去掉,再引入数据data shouru1;input diqu $ x1-x9;cards;广东211.3 114 41.44 33.2 11.2 48.72 30.77 14.9 11.1西藏175.93 163.8 57.89 4.22 3.37 17.81 82.32 15.7 0;run;proc discrim data=shourutestdata=shouru1 method=normallist all crosslist testlist;class leixing;var x1-x9;run;方法2:原shuru数据不变,直接判别,但此法虽可判断待判的两省属于那类,但无法给出误判率;proc discrim data=shouruout=a1outstat=a2 outcross=a3method=normallist all crosslist testlist;class leixing;var x1-x9;run;程序2.3proc discrim data=shourutestdata=shouru1 method=normallist all crosslist crossvalidate testlist;class leixing;var x1-x9;priors prop;run;三、聚类分析程序proc cluster data=yjshr method=sin outtree=y1 ;/*最短距离法*/ var x1-x9;run;proc tree data=y1 nclusters=3 out=z1;run;proc print data=z1;run;proc cluster data=yjshr method=com outtree=y2 ;/*最长距离法*/ var x1-x9;run;proc tree data=y2 nclusters=3 out=z2;run;proc print data=z2;run;proc cluster data=yjshr method=ave outtree=y3 ;/*类平均距离法*/ var x1-x9;run;proc tree data=y3 nclusters=3 out=z3;run;proc print data=z3;run;proc fastclus data=yjshr out=a1maxc=3 cluster=c distance list; /*快速聚类分三类情况*/ proc plot;plot x2*x1=c;run;。
SAS学习系列33.-主成分分析

SAS学习系列33.-主成分分析33. 主成分分析(一)原理一、基本思想主成份分析,是数学上对数据降维的一种方法,是将多个变量转化为少数综合变量(集中了原始变量的大部分信息)的一种多元统计方法。
其主要目的是将变量减少,并使其改变为少数几个相互独立的线性组合形成的新变量(主成份,其方差最大),使得原始资料在这些成份上显示最大的个别差异来。
在所有的线性组合中所选取的F1应该是方差最大的,称为第一主成分。
如果第一主成分不足以代表原来所有指标的信息,再考虑选取第二个线性组合F2, 称为第二主成分。
为了有效地反映原有信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求Cov(F1,F2)=0. 依此类推可以构造出第三、第四、…、第p个主成分。
主成份分析,可以用来综合变量之间的关系,也可用来减少回归分析或聚类分析中的变量数目。
二、基本原理设有n个样品(多元观测值),每个样品观测p项指标(变量):X1,…,X p,得到原始数据资料阵:其中,X i = (x1i,x2i,…,x ni)T,i = 1, …, p.用数据矩阵X的p个列向量(即p个指标向量)X1,…,X p作线性组合,得到综合指标向量:简写成:F i = a1i X1 + a2i X2+…+a pi X p i = 1, …, p限制系数a i = (a1i,a2i,…,a pi)T为单位向量,即且由下列原则决定:(1)F i与F j互不相关,即COV(F i, F j)=a i T∑a i=0,其中∑为X 的协方差矩阵;(2)F1是X1,X2,…,X p的所有满足上述要求的线性组合中方差最大的,即F2是与F1不相关的X1,…,X p所有线性组合中方差最大的,…,F p是与F1,…,F p-1都不相关的X1,…,X p所有线性组合中方差最方向对应。
F1,F2,…,F p可以理解为p维空间中互相垂直的p 个坐标轴。
三、基本步骤1. 计算样品数据协方差矩阵Σ = (s ij)p p,其中2. 求出Σ的特征值及相应的特征向量λ1>λ2>…>λp>0, 及相应的正交化单位特征向量:则X的第i个主成分为F i= a i T X,i=1, …, p.3. 选择主成分在已确定的全部p个主成分中合理选择m个来实现最终的评价分析。
sas主成分分析

sas主成分分析sas主成分分析第七章主成分分析实验目的:熟悉并掌握主成分分析和因子分析的原理和在变量分类、综合评价、主成分回归等几个方面的应用,以及相应的SAS程序实现。
实验内容:对我国钢铁行业上市公司的财务绩效状况进行主成分分析,选择的财务指标共有以下几个:流动比率,速动比率,存货周转率,总资产周转率,净资产收益率,经营净利率,每股收益,净资产收益率增长率,股东权益增长率。
数据如下:完成以下工作:(1)选取累积贡献率>85%的前几个主成分,分别计算得分;并对选取的主成分进行解释;(2)对各上市公司的财务绩效进行综合评价;(3)利用选取的主成分得分,借助聚类分析过程对钢铁行业上市公司进行分类。
datazcf;inputname$x1-x9;cards;邯郸钢铁1.5510.9717.1650.88910.7689.2680.451-16.0246.122武钢股份2.1921.828.0880.97515.05411.1140.336-3.0392.588钢联股份1.2860.9418.0441.1247.3894.5990.205-59.988122.041宝钢股份0.9790.5718.130.6019.7428.780.205-17.6853.989莱钢股份1.3640.4975.0780.9314.1039.1370.523-24.26114.16西宁特钢1.4330.6721.4620.4716.4297.2680.1559.3493.027杭钢股份2.1081.4988.3731.41816.7567.9370.531-18.72513.662邢台轧辊2.11.5951.8830.3966.4848.9810.1325.275-1.061宁夏恒力1.3641.0641.8680.2787.46919.8420.201-35.19455.428凌钢股份1.7721.0617.8411.11912.8838.8040.5285.34310.107南钢股份1.8181.3928.8661.54612.8855.1530.409-7.0286.131酒钢宏兴1.4410.88410.1681.07112.8317.8250.36744.0376.686抚顺特钢0.9550.6523.4160.5097.1476.8510.193-8.0741.93安阳钢铁1.8931.3335.1070.9810.9497.9150.3500上海科技1.3131.1824.6430.5689.5499.4230.19935.6353.582沪昌特钢10.8139.536.5850.5671.1031.6560.01915.031-7.171山川股份1.2520.5851.4850.45110.34414.6930.209-1.6159.799浦东不锈6.1865.1212.3630.2650.7542.5130.013-45.439-1.176新华股份1.8171.3143.2910.7469.9249.0280.137-3.5771.985工益股份1.8091.2674.0460.8280.6950.450.011104.419-4.714马钢股份1.5841.0694.3180.5692.0032.1830.03235.279-12.487宝信软件3.5943.2015.0140.82114.669.7210.147126.91123.243北特钢1.3851.0922.6910.467-11.21-7.917-0.14853.839-11.058广钢股份0.8590.513.8840.7224.2472.6850.096-32.409-4.004;procprincompn=9out=prin;varX1-x9;run;procprintdata=prin;varprin1-prin9;run;主要输出结果:相关阵的特征值和特征向量EigenvalueDifferenceProportionCumulative13.626730451.710877240.40300.403021.915853210.519337180.21290.615831.396516020.349008540.15520.771041.047507480.371047740.11640.887450.676459740.478913290.07520.962660.197546440.106501190.02190.984570.091045260.044878480.01010.994680.046166770.043992140.00510.999890.002174630.00021.0000EigenvectorsPrin1Prin2Prin3Prin4Prin5Prin6Prin7Prin8Prin9x1-.2632570.5528190.3251720.0999320.0123340.1292890.077190-.0215500.697189x2-.2696730.5512290.3176490.0909930.0600930.065411-.0196680.049407-.709595x30.3207430.454750-.227474-.1958410.013020-.7729000.0382700.0086860.033825x40.3790330.331485-.342911-.1840840.0144020.490904-.3231210.4986720.026498x50.4608530.1052280.1235360.3670920.0903870.094185-.486791-.610331-.003691x60.308953-.1918380.4762280.4505290.202663-.228562-.0285870.5848690.042126x70.4802260.1255120.0219100.155827-.2454280.2558630.762567-.122168-.082054x8-.1693840.077314-.5106640.4440140.6759650.0353110.220767-.0214310.005659x90.210440-.0652010.347445-.5918860.6553280.1132300.140544-.1355950.001607由输出特征值可知,第一主成分的贡献率为40.30%,第二个主成分的.贡献率为61.58%,第三个主成分的贡献率为77.10%,前四个主成分累计贡献率为88.74%。
SAS软件应用之主成分分析

本章小节
在大部分实际问题中,变量之间是有一定的相关性的,人们 自然希望找到较少的几个彼此不相关的综合指标尽可能多地 反映原来众多变量的信息。本章介绍了主成分分析的数学模 型、方法步骤以及主成分分析的应用。我们需要一种综合性 的分析方法,既可减少指标变量的个数,又尽量不损失原指 标变量所包含的信息,对资料进行全面的综合分析。主成分 分析正是适应这一要求产生的,是解决这类题的理想工具。 主成份分析的基本思想就是将彼此相关的一组指标变量转化 为彼此独立的一组新的指标变量,并用其中较少的几个新指 标变量就能综合反应原多个指标变量中所包含的主要信息, 符合专业含义。
主成分分析的方法步骤
计算主成分得分 如果标准化指标变量 X 1 , X 2 ,, X k 的第i个主成分是:
Z i liX li1 X 1 li 2 X 2 lik X k xij x j 其中, X ij , j, 1,2,, k sj 是xj的标准化指标变量。那么,第i个主成分可以 转换为原始指标变量的线性组合:
主成分分析的方法步骤
对原始指标数据进行标准化变换:
X ij xij x j sj , j 1,2,, k
将原始数据标准化,然后利用标准化的数据 计算主成分。X为标准化后的数据矩阵,则:
X 11 X X 21 X n1 X 12 X 22 X n2 X 1k X 2k X nk
li1 li 2 lik li1 x1 li 2 x2 lik xk zi x1 x2 xk ( ),i 1,2,, k s1 s2 sk s1 s2 sk
主成分分析的应用
主成份分析报告(包含sas程序)
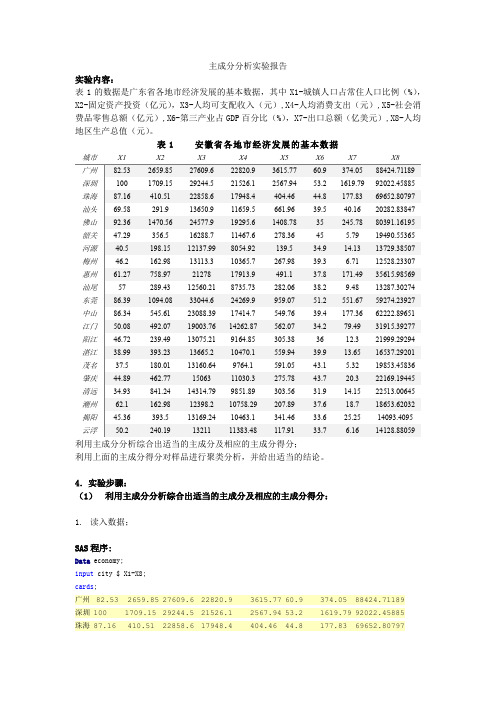
主成分分析实验报告实验内容:表1的数据是广东省各地市经济发展的基本数据,其中X1-城镇人口占常住人口比例(%),X2-固定资产投资(亿元),X3-人均可支配收入(元),X4-人均消费支出(元),X5-社会消费品零售总额(亿元),X6-第三产业占GDP百分比(%),X7-出口总额(亿美元),X8-人均地区生产总值(元)。
表1 安徽省各地市经济发展的基本数据城市X1X2X3X4X5X6X7X8广州82.532659.8527609.622820.93615.7760.9374.0588424.71189深圳1001709.1529244.521526.12567.9453.21619.7992022.45885珠海87.16410.5122858.617948.4404.4644.8177.8369652.80797汕头69.58291.913650.911659.5661.9639.540.1620282.83847佛山92.361470.5624577.919295.61408.7835245.7880391.16195韶关47.29356.516288.711467.6278.3645 5.7919490.55365河源40.5198.1512137.998054.92139.534.914.1313729.38507梅州46.2162.9813113.310365.7267.9839.3 6.7112528.23307惠州61.27758.972127817913.9491.137.8171.4935615.98569汕尾57289.4312560.218735.73282.0638.29.4813287.30274东莞86.391094.0833044.624269.9959.0751.2551.6759274.23927中山86.34545.6123088.3917414.7549.7639.4177.3662222.89651江门50.08492.0719003.7614262.87562.0734.279.4931915.39277阳江46.72239.4913075.219164.85305.383612.321999.29294湛江38.99393.2313665.210470.1559.9439.913.6516537.29201茂名37.5180.0113160.649764.1591.0543.1 5.3219853.45836肇庆44.89462.771506311030.3275.7843.720.322169.19445清远34.93841.2414314.799851.89303.5631.914.1522513.00645潮州62.1162.9812398.210758.29207.8937.618.718653.62032揭阳45.36393.513169.2410463.1341.4633.625.2514093.4095云浮50.2240.191321111383.48117.9133.7 6.1614128.88059利用主成分分析综合出适当的主成分及相应的主成分得分;利用上面的主成分得分对样品进行聚类分析,并给出适当的结论。
SAS编程:主成分分析和因子分析

SAS 统计分析与应用 从入门到精通 二、因子分析
语句说明:
4、FACTOR过程
(1)PROC语句用于规定运行FACTOR过程,并指定要分析的数据 集名。选项有: OUT=数据集名——规定一个输出数据集,其中包含原始数据以及 公共因子得分。在使用选项时,要指定公共因子的个数。 METHOD=选项——规定提取公共因子的方法。 N=n——规定被提取因子的最大数目,缺省值为变量的个数。 SCORE——规定打印因子得分系数。
SAS 统计分析与应用 从入门到精通 一、主成分分析
4、PRINCOMP过程
语句说明: (1)PROC语句用于规定运行PRINCOMP过程,并指定要分析的 数据集名。选项有: OUT=数据集名——规定一个输出数据集,其中包含原始数据以及 主成分得分。 N=n——规定要计算的主成分个数。 STANDARD——规定将OUT=的数据集中的主成分得分标准化为 单位方差。如果没有规定此选项,主成分得分的方差等于相应的特征值。 (2)VAR语句用来列出要分析的数值型变量的名字。如果不使用该 语句,则没有在其它语句规定的所有数值型变量都是要分析的变量。 (3)PARTIAl语句规定了偏出变量,使得PRINCOMP过程基于偏 相关阵或偏协方差阵进行主成分分析。
SAS 统计分析与应用 从入门到精通 二、因子分析
2、基本模型
SAS 统计分析与应用 从入门到精通 二、因子分析
2、基本模型
SAS 统计分析与应用 从入门到精通 二、因子分析
3、基本步骤
(1) 参数估计:为建立因子模型,首先要估计因子载荷和特殊因 子的方差,常用的方法有主成分法,主因子法和极大似然估计法等。
SAS 统计分析与应用 从入门到精通 二、因子分析
语句说明:
SAS主成分分析 示例
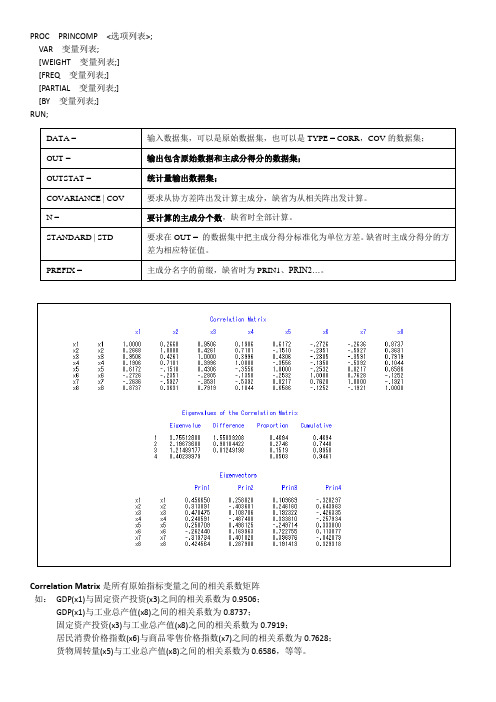
PROC PRINCOMP <选项列表>;VAR 变量列表;[WEIGHT 变量列表;][FREQ 变量列表;][PARTIAL 变量列表;][BY 变量列表;]RUN;DATA = 输入数据集,可以是原始数据集,也可以是TYPE = CORR,COV的数据集;OUT = 输出包含原始数据和主成分得分的数据集;OUTSTAT = 统计量输出数据集;COVARIANCE | COV要求从协方差阵出发计算主成分,缺省为从相关阵出发计算。
N = 要计算的主成分个数,缺省时全部计算。
STANDARD | STD要求在OUT = 的数据集中把主成分得分标准化为单位方差。
缺省时主成分得分的方差为相应特征值。
PREFIX = 主成分名字的前缀,缺省时为PRIN1、PRIN2…。
Correlation Matrix是所有原始指标变量之间的相关系数矩阵如:GDP(x1)与固定资产投资(x3)之间的相关系数为0.9506;GDP(x1)与工业总产值(x8)之间的相关系数为0.8737;固定资产投资(x3)与工业总产值(x8)之间的相关系数为0.7919;居民消费价格指数(x6)与商品零售价格指数(x7)之间的相关系数为0.7628;货物周转量(x5)与工业总产值(x8)之间的相关系数为0.6586,等等。
Eigenvalues of Correlation Matrix给出了由相关系数矩阵计算出来的全部特征值(Eigenvalue)、相邻两个特征值的差异(difference)、每个主成分的贡献率(proportion)和累积贡献率(cumulative)。
如:第一主成分对方差的贡献率为46.94%,第二主成分对方差的贡献率为27.46%,第三主成分对方差的贡献率为15.19%,之后的主成分的贡献率为0.05。
前三个主成分的累积贡献率为89.58%,因此,对第四主成分以后的主成分完全可以忽略不计,用前三个主成分就可以很好地概括这组数据。
SAS主成分分析实例

王笑(孝)权安徽省五河县临北乡石家村卫生室233316 *****************.cn主成分分析又称主分量、主轴分析,实质就是对较多的变量在尽量保存原信息的情况下加以线性概括。
在此过程前,为消除变量量纲不同造成的影响,首先要对各原始指标进行标准化处理。
迄今为止,所见教材的“主成分分析”实质都是用求得主成分再对原始变量的回归分析。
教材的通病都是未详细说明最后的回归过程,往往令初学者感觉到莫名其妙。
目前,由网上的一些所谓的“主成分分析”可知,或者其资料不适用主成分分析,还有根本就不是主成分分析。
有鉴于此,现利用网上获得的数据,进行主成分分析的探讨。
1 资料与方法1.1 资料来源资料来源于中华人民共和国卫生部网站[1],我国“2006年工业部门职业病发病及死亡情况”,剔除其中的第1、2、14号无意义指标,以及末尾的观测“其它”,剩余11个指标,观测值有缺失则用0补齐。
程序分别赋这些指标为x1-x11,其名称标签见附件1;余详见数据1。
数据1 2006年工业部门职业病发病及死亡情况相关数据name x1 x2 x3 x4 x5 x6 x7 x8 x9 x10 x11煤炭4567 212 41 0 34 0 13 0 1 57 0石油 2 4 1 0 14 0 0 1 0 14 0电力110 1 1 0 28 1 0 1 1 16 1核工业0 0 0 0 0 0 0 0 0 3 0冶金494 65 40 2 159 0 0 3 5 24 11有色金属1193 120 38 4 190 11 0 7 2 38 1333 13 34 1 84 5 0 29 33 50 1电子7 0 14 3 120 0 0 51 13 3 0兵器7 0 4 0 22 0 0 0 113 6 0船舶18 0 1 0 1 1 0 0 0 2 0化工103 2 105 3 62 2 0 89 170 24 4医药 5 0 8 0 15 0 1 19 8 1 0铁道64 6 2 0 2 1 0 1 0 4 1交通61 1 6 0 14 3 0 6 6 8 0建材698 17 6 0 5 1 0 10 3 20 0建设126 1 23 8 1 3 0 5 2 3 1地质矿产253 3 1 0 4 0 0 1 0 0 0水利 2 17 0 0 0 0 0 0 0 0 0农业23 0 2 0 0 22 5 0 1 0 0森林工业 2 0 1 0 0 0 1 1 1 0 0轻工189 16 101 3 294 10 12 32 4 21 3纺织20 2 12 0 12 1 1 4 2 36 1航空航天 1 0 0 0 1 0 0 5 0 4 0商业11 0 2 0 0 3 1 2 0 2 0邮电 2 0 1 1 0 0 0 0 0 0 0石化工业9 1 5 0 6 0 0 1 1 2 0回收加工业0 0 2 2 0 0 0 0 0 0 01.2 方法将数据1倒入SAS9.1逻辑库sasuser后调用,程序默认对原始数据标准化后进行主成分分析。
主成分分析与因子分析(二):使用SAS实现主成分分析--PRINCOMP过程

主成分分析与因子分析(二):使用SAS实现主成分分析--PRINCOMP过程上一系列文章介绍了主成分分析概述。
今天,我们将介绍使用PRINCOMP过程进行主成分分析。
在SAS中,某种统计方法可能可以通过多个过程步实现。
这时候有必要了解过程步之间的区别。
比如,主成分分析就可以通过PROC FACTOR或PROCPRINCOMP实现。
PRINCOMP过程使用PROC PRINCOMP进行主成分分析时,其输入可以是原始数据集、协方差矩阵或相关矩阵等,其输出数据集包含特征根、特征向量以及标准化或未标准化的主成分得分。
此外,使用者还可以通过ODS图像选项输出陡坡图(Scree Plot)、成分特征图(Component Pattern Plot)等图形,这些图形都是进行主成分分析的有用工具。
过程步PROC PRINCOMP的一般形式为:其中:•PROC PRINCOMP语句中常见的选项如表12.1所示。
•BY语句指定分组变量。
PROC PRINCOMP根据BY语句中的变量对原数据进行分组分析。
若BY语句中的变量多于一个,那么仅最后一个变量起作用。
该语句要求原始数据已按照BY语句中的变量排序。
•VAR 语句指定数据集中用来进行主成分分析的变量,这些指定变量类型必须为数值型。
表12.1 PROC PRINCOMP常见的选项及含义例12.1:数据集sashelp.cars包含不同型号的汽车的一些参数,共有15个变量以及428条观测,具体变量的含义如表12.2所示。
现在要根据数据集sashelp.cars中的变量MPG_City、MPG_Highway、Weight、Wheelbase以及 Length,对其进行主成分分析。
表12.2 数据集sashelp.cars中的变量具体信息示例代码如下:程序的输出结果中包含了数据集的一些简单统计量,具体如图12.3所示。
图12.3 数据集sashelp.cars的简单统计量紧接着是相关矩阵以及该矩阵对应的特征值,如图12.4所示。
主成分分析SAS实验

主成分分析和因子分析也可以用下列各种统计 分析的中间结果矩阵进行分析:
CORR 相关系数矩阵 SSCP 平方和、积和矩阵 CSSCP 离均差平方和、积和矩阵 COV 方差、协方差矩阵 UCOV 为平方和、积和矩阵/n UCORR 为 XY / X 2Y 2 矩阵 FACTOR 因子矩阵
eigenvalue )>70% 碎石图(Scree plot) 能有恰当的专业解释
练习1:主成分分析(变量单位不同)
20例肝病患者4项肝功能指标: X1:转氨酶(SGPT); X2:肝大指数(F); X3:硫酸锌浊度(ZnT); X4:甲胎球蛋白(AFP)
试作主成分分析
程序: \unit4\princomp1.sas 数据: \unit4\princomp1.xls
练习2:主成分分析(变量单位相同)
我国27个少数民族体型资料
X1:头长; X2: 头宽;
X3: 额最小宽;
X4: 面宽;
X5: 下额角间宽; X6: 容貌面高;
X7: 形态面高; X8: 鼻高;
X9: 鼻宽;
X10: 口裂宽; X11:身长;
X12: 肩宽;
X13: 胸围; X14:骨盆宽; X15:全头高;
主成分分析
公共卫生学院信息数据处理教学实验室
一、主成分分析
实际工作中原始数据的变量之间常有一定 的相关性。人们希望找到较少的几个互不相关 的综合指标,尽可能多的反映原来的信息。
主成分分析就是由原变量X1~Xp中线性组 合出m个(m≤p)互不相关、且尽量少丢失信息的 新变量(主成分),并能给各主成分所包含的信 息以恰当的专业解释。
需要在数据步中指定: _TYPE_= ‘CORR';
SAS主成分分析

S A S主成分分析(总19页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除SAS主成分分析分类:数据之美 2013-07-28 20:18 2343人阅读评论(0) 收藏举报目录()[-]1.主成分分析流程2.SAS主成分分析示例3.SAS主成分分析输出结果详解4.特征值和特征向量隐藏的秘密5.总结6.参考文献同事讲主成分分析,举了这么个例子:就像你选女人,有身材、相貌两个指标,如果身材、相貌都很突出,那当然很好选择;但如果两个女人,一个身材突出,一个相貌出众,看着都很喜欢,那可如何是好!这个时候通过主成分分析,汇总出一个指标,这个指标可以一定程度上代替原来的身材、相貌,这时就可以排序做出选择了。
这例子当然有很多缺陷,但至少指出了主成分分析的目的之一:减少决策变量数,也就是降维。
主成分分析的另一个目的是防范多重共线性。
实际问题往往涉及很多变量,但某些变量之间会有一定的相关性,我们希望构造较少的几个互不相关的新指标来代替原始变量,去除多重共线性,减少所需分析的变量,同时尽可能减少这一过程的信息损失。
主成分分析正是基于这样的目的而产生的有效方法。
主成分分析流程主成分分析包含以下流程:1、原始数据标准化。
2、计算标准化变量间的相关系数矩阵。
3、计算相关系数矩阵的特征值和特征向量。
4、计算主成分变量值。
5、统计结果分析,提取所需的主成分。
SAS主成分分析示例我们从实战入手,先来个简单的例子,完整体验使用SAS进行主成分分析的过程。
准备好图1所示的数据集,该数据集包含5个变量和22个观测。
其中变量num用于标识每条观测。
图1可以直接复制下面的程序完成输入:data;input num var1 var2 var3 var4;cards;1 2123 904 1256789101112131415 9016171819202122;run;我们的目的是,化简var1-var4四个变量,找出可以替代这四个变量的若干个彼此独立的新变量,也就是找出主成分。
SAS主成分分析报告

SAS主成分分析分类:数据之美2013-07-28 20:18 2343人阅读评论(0) 收藏举报目录(?)[-]1. 主成分分析流程2. SAS主成分分析示例3. SAS主成分分析输出结果详解4. 特征值和特征向量隐藏的秘密5. 总结6. 参考文献同事讲主成分分析,举了这么个例子:就像你选女人,有身材、相貌两个指标,如果身材、相貌都很突出,那当然很好选择;但如果两个女人,一个身材突出,一个相貌出众,看着都很喜欢,那可如何是好!这个时候通过主成分分析,汇总出一个指标,这个指标可以一定程度上代替原来的身材、相貌,这时就可以排序做出选择了。
这例子当然有很多缺陷,但至少指出了主成分分析的目的之一:减少决策变量数,也就是降维。
主成分分析的另一个目的是防范多重共线性。
实际问题往往涉及很多变量,但某些变量之间会有一定的相关性,我们希望构造较少的几个互不相关的新指标来代替原始变量,去除多重共线性,减少所需分析的变量,同时尽可能减少这一过程的信息损失。
主成分分析正是基于这样的目的而产生的有效方法。
主成分分析流程主成分分析包含以下流程:1、原始数据标准化。
2、计算标准化变量间的相关系数矩阵。
3、计算相关系数矩阵的特征值和特征向量。
4、计算主成分变量值。
5、统计结果分析,提取所需的主成分。
SAS主成分分析示例我们从实战入手,先来个简单的例子,完整体验使用SAS进行主成分分析的过程。
准备好图1所示的数据集,该数据集包含5个变量和22个观测。
其中变量num用于标识每条观测。
图1可以直接复制下面的程序完成输入:data Practice.PCA_Demo;input num var1 var2 var3 var4;cards;1 21 10.7 99.7 9.52 9.5 17.9 139.6 18.73 21.2 8.4 90 6.84 12 22.7 42.5 24.15 6.8 21.2 55.2 22.46 8.2 22.4 55.6 22.67 3.6 29.2 68.3 26.78 19.5 15.2 18.8 17.49 24.8 5.4 43.7 2.910 8.4 18.6 146.2 19.711 28.9 4.4 4.9 1.112 19.5 15.1 10.2 18.513 28.3 4.7 13.3 1.814 24.7 12.1 116.8 12.615 12.8 23.6 90 23.716 23.1 6.8 100.1 3.717 15.1 13.7 100.9 14.218 2.9 6.2 80.7 2.719 18.4 11.8 99.3 13.820 22.9 12.3 47.6 13.321 5.8 29.4 83.5 27.622 18.8 8.6 61.1 8.9;run;我们的目的是,化简var1-var4四个变量,找出可以替代这四个变量的若干个彼此独立的新变量,也就是找出主成分。
SAS主成分分析

cov( y1 , y 2 ) = 0
(7.25)
'
于是,我们在约束条件(7.2.2)式和(7.2.5)式下寻求向量 a 2 ,使 V ( y 2 ) = a 2 Sa 2 达到最 大,所求的 y 2 称为第二主成分。类似地,我们可以再定义第三主成分、…、第 p 主成分。 一般来说, x 的第 i 主成分 y i = a i x 是指:在约束条件(7.2.2)和
k 设 X 和 Y 是随机变量,若 E ( X ) , k = 1, 2, L 存在,称它为 X 的 k 阶原点矩,简称 k
阶矩。 若 E [ X - E ( X )] k , k = 1, 2, L 存在,称它为 X 的 k 阶中心矩。 若 E ( X k Y l ) , k , l = 1, 2, L 存在,称它为 X 和 Y 的 k + l 阶混合矩。
y i = t i' x ,它具有方差 li , i = 1,2, L , p 。
二、主成分的性质
5
1. 主成分的均值和协方差矩阵 记
æ y1 ö æ l1 ç ÷ ç ç y2 ÷ ç y = ç ÷ , u = E ( y) , L = ç M ç ÷ ç ç0 ç yp ÷ è è ø
由于
l2
ål
i =1
i =1 i =1 i =1
p
p
p
= l1 (t t ) + l 2 (t t ) + L + l p (t t )
' 2 1 1 ' 2 1 2
' 2 1 p
= l1 + 0 = l1
所以, y1 = t1' x 就是所求的第一主成分,它的方差具有最大值 l1 。 如果第一主成分所含信息不够多,还不足以代表原始的 p 个变量,则需考虑使用 y 2 , 为了使 y 2 所含的信息与 y1 不重叠,应要求
SAS软件与统计应用教程ch6――主成分分析与因子分析PPT课件

求出协方差矩阵Σ的特征值12…p>0及相应的正
交化单位特征向量:
a11
a12
a1p
a1
a21,
a2
a22, ...,ap
a2p
ap1
ap2
app
则X的第i个主成分为Fi = ai'X i = 1,2,…,p。
SAS软件与统计应用教程
STAT
(3) 选择主成分
图中看出,上海在第二主成分PCR2的得分远远高于 其他省市,而在第一主成分PCR1的得分则处于中间。 广东、江苏、山东和浙江则在第1主成分的得分上位于 前列。
SAS软件与统计应用教程
பைடு நூலகம்
STAT
6) 回到INSIGHT的数据窗口,可以看到前两个主成 分的得分情况(如图6-8左)。
单击数据窗口左上角的箭头,在弹出的菜单中选择 “Sort(排序)”选项,在打开的对话框中选定排序变 量PCR1,并单击“Asc/Des”按钮将其设为降序(Des), 如图6-8所示。
(5) 标准化 实际应用时,指标的量纲往往不同,所以在主成分计
算之前应先消除量纲的影响。消除数据的量纲有很多方 法,常用方法是将原始数据标准化,即做如下数据变换:
其中
xi*j,xijs jxj
i1,2,..n;.j,1,2,..p.,
,j = 1,2,…,p。
标准化x j后 的n1 i数n1 x据ij 阵s2j记为n1X1*,in1其(xi中j 每xj)个2 列向量(标准化变
对于第一主成分而言,除了x2(人均GDP)外,各变 量所占比重均在0.3左右以上,因此第一主成分(Prin1)主
要由x1、x3~x9八个变量解释;而第二主成分则主要由 x2这一个变量解释。
SAS主成分分析

SAS 大作业主成分分析法理学院07统计学01班孙禹40708030104SAS 主成分分析利用SAS 程序我们可以进行主成分分析以及因子分析,因此首先要明白主成分分析与因子分析的概念与步骤,以方便进行后续工作1. 主成分分析的基本思想主成分分析是数学上对数据降维德一种方法。
其基本思想是设法将原来众多的具有一定相关性的指标,重新组合成一组新的互不相关的综合指标来代替原来指标。
这种线性组合有很多种,选取时,在所有的线性组合中所选取的F1应该是方差最大的,故称F1为第一主成分。
如果第一主成分不足以代表原来P 个指标的信息,再选取F2即第二个线性组合,依次类推。
一般地说,利用主成分分析得到的主成分与原始变量之间有如下的关系:(1)、每个主成分都是各原始量的线性组合。
(2)、主成分的数目大大少于原始变量的数目。
(3)、主成分保留了原始变量绝大多数信息。
(4)、各主成分之间互不相关2主成分分析的基本理论假设我们所讨论的实际问题中,有p 个指标,我们把这p 个指标看作p 维随机变量,记为X=(X 1,X 2,…,X p )T ,主成分分析就是要把这p 个指标的问题,转变为讨论p 个指标的线性组合的问题,而这些新的指标F 1,F 2,…,F k (k ≤p ),按照保留主要信息量的原则充分反映原指标的信息,并且相互独立。
3主成分分析步骤根据研究问题选取初始分析变量;根据初始变量特性判断由协方差阵求主成分还是由相关阵求主成分; 求协方差阵或相关阵的特征根与特征向量;11112121212122221122p p p p p p p pp pY u X u X u X Y u X u X u X Y u X u X u X =+++=+++=+++判断是否存在明显的多重共线性,若存在,则回到第一步;得到主成分表达式并确定主成分个数,选取主成分;结合主成分对研究问题进行分析并深入研究。
4主成分的上机实验例:北京1961~1986年冬季的气温资料如表,变量个数p=3,对这些资料进行主成分分析。
11-使用SAS进行主成分分析

例如:评价儿童的生长发育情况,某研究者收集了12 个指标,如身高、体重、胸围、肩宽、肺活量等资料。应 如何利用这12个指标进行评价?
这些指标个数很多,且指标间往往是彼此相关的。 如仅选用其中一个指标来评价,则:损失信息 如分别应用每个指标,则:评价是孤立的,非综合性
主成分分析的一般步骤
1、 收集数据并建立数据库
2、 对变量进行标准化处理
yi
xi xi si
,i1,2,p
3、 求主成分:
(1) 求相关矩阵R
r11
R
r1 p
(2) 求R的特征根:
rp1 rpp
λ1≥λ2≥….≥λP
(3) 求R的关于特征根λi的满足正规条件的特征 向量 ai, (ai1,ai2 ,…,aip ) i=1,2,…P
由表达式z2=-0.707lyl十0.707ly 2,可见y1、y2的系数绝对值相 等,符号相反,前者为负后者为正,说明前音(体重)愈大,第二主 成分的取值愈小,后者(身高)愈大,第二主成分的取值也愈大,即 矮胖者第二主成分取值大,瘦高者第二主成分取值小,说朗第二主 成分描述的是幼儿的体型。
(四)、计算主成分得分
主成分分析的好坏关键在于给综合指标所蕴藏的信 息以恰当的解释。
三、 主成分分析的基本原理:
主成分分析是对多个指标的观察数据 降维压缩,对指标间的内部从属性作客观 评价的多元分析方法。
例:对n个儿童测量其身高(x1)、体重(x2)两个指标, 显然这两个指标是高度相关的,若以x1为横,以x2 为纵轴,用n个对象的数据作散点图。
i p
i
SAS主成分分析
C1
• • • • • • • • • • • •• • •
x1
10/41
平移、旋转坐标轴 主 成 分 分 析 的 几 何 解 释
C2
x2
•
C1
• • • •• • • • • • • •• • •• • • • • • • • • •• •• • • •• • • •••• • • • • •• •• • • • • • • • ••• • • • • • • •• • • • • • •• •• • • • • • • • • • • •• • • •• • • • • • • •
20/41
变量的标准化
获得相关矩阵
rij
(x
k 1
n
r11 r12 r21 r22 R rm1 rm 2
xi )(xkj x j )
2ቤተ መጻሕፍቲ ባይዱn
r1m r2 m rmm
ki
(x
k 1
n
ki
xi )
(x
k 1
kj
xj)
2
21/41
x1 x1 1
x2
x3
x4
2 11 2 12
a 1
2 1m
实际上就是要找个最好的方向,使得所有变 量在该方向最分散
14/41
第二主成分
第二主成分C2 也必须是原始变量z1, z2, …, zm的一个线性组合: C2=a21z1+a22z2+…+a2mzm
同样具有限制:
a a
2 21 2 22
a
2 2m
x1
11/41
变量的标准化
正式分析之前,为了消除原指标取值单位对分析 的影响,需要对原指标进行标准化变换。经过标
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SAS主成分分析分类:数据之美2013-07-28 20:18 2343人阅读评论(0) 收藏举报目录(?)[-]1. 主成分分析流程2. SAS主成分分析示例3. SAS主成分分析输出结果详解4. 特征值和特征向量隐藏的秘密5. 总结6. 参考文献同事讲主成分分析,举了这么个例子:就像你选女人,有身材、相貌两个指标,如果身材、相貌都很突出,那当然很好选择;但如果两个女人,一个身材突出,一个相貌出众,看着都很喜欢,那可如何是好!这个时候通过主成分分析,汇总出一个指标,这个指标可以一定程度上代替原来的身材、相貌,这时就可以排序做出选择了。
这例子当然有很多缺陷,但至少指出了主成分分析的目的之一:减少决策变量数,也就是降维。
主成分分析的另一个目的是防范多重共线性。
实际问题往往涉及很多变量,但某些变量之间会有一定的相关性,我们希望构造较少的几个互不相关的新指标来代替原始变量,去除多重共线性,减少所需分析的变量,同时尽可能减少这一过程的信息损失。
主成分分析正是基于这样的目的而产生的有效方法。
主成分分析流程主成分分析包含以下流程:1、原始数据标准化。
2、计算标准化变量间的相关系数矩阵。
3、计算相关系数矩阵的特征值和特征向量。
4、计算主成分变量值。
5、统计结果分析,提取所需的主成分。
SAS主成分分析示例我们从实战入手,先来个简单的例子,完整体验使用SAS进行主成分分析的过程。
准备好图1所示的数据集,该数据集包含5个变量和22个观测。
其中变量num用于标识每条观测。
图1可以直接复制下面的程序完成输入:data Practice.PCA_Demo;input num var1 var2 var3 var4;cards;1 21 10.7 99.7 9.52 9.5 17.9 139.6 18.73 21.2 8.4 90 6.84 12 22.7 42.5 24.15 6.8 21.2 55.2 22.46 8.2 22.4 55.6 22.67 3.6 29.2 68.3 26.78 19.5 15.2 18.8 17.49 24.8 5.4 43.7 2.910 8.4 18.6 146.2 19.711 28.9 4.4 4.9 1.112 19.5 15.1 10.2 18.513 28.3 4.7 13.3 1.814 24.7 12.1 116.8 12.615 12.8 23.6 90 23.716 23.1 6.8 100.1 3.717 15.1 13.7 100.9 14.218 2.9 6.2 80.7 2.719 18.4 11.8 99.3 13.820 22.9 12.3 47.6 13.321 5.8 29.4 83.5 27.622 18.8 8.6 61.1 8.9;run;我们的目的是,化简var1-var4四个变量,找出可以替代这四个变量的若干个彼此独立的新变量,也就是找出主成分。
主成分分析代码如下:proc princompdata= Practice.PCA_Demoout= Work.PCA_Demo_outprefix= compoutstat= Work.PCA_Demo_stat;var var1 var2 var3 var4;run;这段代码翻译过来的意思是:对源数据Practice.PCA_Demo的四个变量var1、var2、var3和var4(以下简称原始变量)做主成分分析,输出结果(包含源数据的所有变量及新增的主成分变量)放在Work.PCA_Demo_out数据集,主成分变量名的前缀使用comp。
相关变量的统计结果(均值、方差、特征值、特征向量等)输出到Work.PCA_Demo_stat。
程序运行后,输出界面显示如图2。
图2输出结果Work.PCA_Demo_out存放了原始数据集的所有变量以及新变量comp1、comp2、comp3和comp4,分别代表第1至第4主成分,它们对原始变量的解释力度依次减少。
图3一同输出的还有统计结果Work.PCA_Demo_stat:图4现在,我先假设你是个急性子,你可能会对我说:“不必告诉我这些输出结果的含义,我给了你四个变量,你只要返回给我较少的可用的字段就可以了。
”那么我会回答你,新的变量comp1和comp2就可以替代原来的四个变量var1、var2、var3和var4,因为这两个变量合起来解释了原来四个变量91.27%的信息,能够满足要求。
何以见得?请看图2的第4部分输出Eigenvalues of the Correlation Matrix,第四列Cumulative显示,第一个特征值分量占比0.6749(67.49%),第1、2个特征值合起来占比91.27%>85%,因此新变量comp1和comp2已经足以替代原有四个变量,它们是源数据集的主成分。
没错,在SAS上进行主成分分析,就是这么简单,结果的使用也不复杂,大多数情况下到此也就足够了。
不过出于对科学本质的好奇,我们还是要详细研究下每项输出结果的含义,以便更好地理解主成分分析。
SAS主成分分析输出结果详解作为细节强迫症重度患者,图2~图4只要有个点没搞清楚都觉得寝食难安。
我们先来看图2。
第1部分很简单,指出观测数为22,变量数为4,也就是我们在var 语句中指定4个原始变量。
第2部分Simple Statistics是对原始变量的简单描述性统计,Mean 是均值,StD是标准偏差(注意标准偏差与标准差的区别)。
Mean的计算公式我们都很熟悉,就是(1)标准偏差StD的计算公式是:(2)第3部分Correlation Matrix是原始变量的相关系数矩阵,其中的元素代表4个原始变量两两之间的相关系数。
相关系数的计算公式是:(3)从原始变量的相关系数矩阵可以看出,变量var1和var2、var1和var4呈现出较为显著的负相关,变量var2和var4则是强烈的正相关,其相关系数高达0.9752。
第4部分Eigenvalues of the Correlation Matrix输出了相关系数矩阵的特征值。
Eigenvalue一列从大到小依次展示了4个特征值,特征值越大,表示对应的主成分变量包含的信息越多,对原始变量的解释力度越强。
Difference是相邻两个特征值的差,比如1.74819156 = 2.69946764 - 0.95127608。
Proportion表示主成分的贡献率,也就是,比如第1个特征值的贡献率0.6749 = 2.69946764 /(2.69946764+0.95127608+0.32758452+0.02167176)。
Cumulative则是累计贡献率,到第2个特征值累计贡献率0.9127 = 0.6749 + 0.2378。
我们在判断应提取多少个主成分时,根据的就是累计贡献率。
0.9127的累计贡献率说明特征值1和特征值2对应的主成分变量comp1和comp2合起来能够反映原始变量91.27%的信息,能够满足应用需求。
这时我们可以作出决策:提取两个主成分comp1和comp2代替4个原始变量。
而如果我们希望主成分变量对原始变量的解释力度应达到95%以上,那么就需要加入comp3,共提取3个主成分,其累计贡献率达到99.46%。
而提取全部4个主成分变量,则没有达到降维的目的,意义已经不大。
至于这个累计贡献率要达到多少才算满足需求,需要视具体业务需求而定,我们的参考值是85%。
第5部分Eigenvectors是特征值对应的特征向量。
图5一秒钟告诉你特征值和特征向量如何对应。
图中的第1个特征值=2.699467638对应第一个特征向量V=(-0.530270329, 0.582022127, 0.232614551, 0.570923894)。
同理可知第2个特征值和第2个特征向量的对应。
图5特征值和特征向量的计算,依据的公式。
这里A是相关系数矩阵(见图5)。
可以自行验证下面的等式是成立的。
-0.73525564710.182570450.975217499,-0.3579002430.1825704510.173888292,-0.6830847460.9752174990.1738882921};call eigen(eigenvalues, eigenvectors, A);print A eigenvalues eigenvectors;quit;现在,我们要解读图3,根据前面的分析,在图3的数据集Work.PCA_Demo_out中,我们只要保留num、comp1和comp2三个字段,所形成的新数据集就可以替代源数据集,供未来的分析所使用。
接下来,我们要来回答:主成分变量comp1、comp2、comp3和comp4的值是怎么来的?我们知道,主成分变量是原始变量的线性表示,用公式表示如下:(4)其中,X表示原始变量对应数据组成的矩阵(以下称为原始数据矩阵),U是特征向量以列向量形式依次排列组成的矩阵(以下称为特征向量矩阵)。
在我们的示例中,那么公式(4)的计算结果是:什么?跟实际输出结果不符?挺好的,掉一次坑你就印象深刻了。
事实上主成分数据矩阵不是原始数据矩阵和特征向量矩阵直接相乘的结果,而是原始数据标准化后的数据矩阵和特征向量矩阵相乘的结果。
这就回到我们在主成分分析流程就已经提到的至关重要的第一步:原始数据标准化!数据标准化使得变量的平均值为0,标准偏差为1,消除了不同量纲对分析过程的影响。
图3的输出结果是有缺失的,我们看不到原始变量的标准化变量。
我们可以使用proc standard过程步来查看数据标准化的结果,代码如下:proc standarddata= Practice.PCA_Demoout= Work.PCA_Demo_stdmean=0std=1;var var1 var2 var3 var4;run;打开输出数据集Work.PCA_Demo_std,就能看到转化结果:图6现在,我们来修正下公式(4)(5)其中,是的数据标准化后的矩阵现在再计算一遍Y,看看是不是如下结果呢?矩阵的乘法公式告诉我们,本质上,某一个样本(比如样本1:(1, 21, 10.7, 99.7,9.5))的第一主成分变量的值(-0.75812),就是原始变量标准化后组成的行向量(0.598, -0.503, 0.711, -0.55)与第一特征向量(列向量)(-0.530270329; 0.582022127; 0.232614551;0.570923894)的乘积。
第二主成分变量值,是原始变量组成的行向量与第二特征向量(列向量)的乘积。
依次类推。
我们来验证一下主成分变量之间是否线性无关。