几个常见的Python库
python常用模块及第三方库功能简介

python常⽤模块及第三⽅库功能简介前⾔: Python吸引⼈的⼀个出众的优点就是它有众多的第三⽅库函数,可以更⾼效率的实现开发,经过整理与⽐对,整理了运维相关的常⽤模块,并将其功能简介,对其中重要的常⽤模块,接下来的博客会进⾏相应的详细介绍与功能使⽤介绍。
Python运维常⽤的20个库:1、psutil是⼀个跨平台库(https:///giampaolo/psutil)能够实现获取系统运⾏的进程和系统利⽤率(内存,CPU,磁盘,⽹络等),主要⽤于系统监控,分析和系统资源及进程的管理。
2、IPy(/haypo/python-ipy),辅助IP规划。
3、dnspython()Python实现的⼀个DNS⼯具包。
4、difflib:difflib作为Python的标准模块,⽆需安装,作⽤是对⽐⽂本之间的差异。
5、filecmp:系统⾃带,可以实现⽂件,⽬录,遍历⼦⽬录的差异,对⽐功能。
6、smtplib:发送电⼦邮件模块7、pycurl()是⼀个⽤C语⾔写的libcurl Python实现,功能强⼤,⽀持的协议有:FTP,HTTP,HTTPS,TELNET等,可以理解为Linux下curl命令功能的Python封装。
8、XlsxWriter:操作Excel⼯作表的⽂字,数字,公式,图表等。
9、rrdtool:⽤于跟踪对象的变化,⽣成这些变化的⾛⾛势图10、scapy(/projects/scapy/)是⼀个强⼤的交互式数据包处理程序,它能够对数据包进⾏伪造或解包,包括发送数据包,包嗅探,应答和反馈等功能。
11、Clam Antivirus免费开放源代码防毒软件,pyClamad,可以让Python模块直接使⽤ClamAV病毒扫描守护进程calmd。
12、pexpect:可以理解成Linux下expect的Python封装,通过pexpect我们可以实现对ssh,ftp,passwd,telnet等命令⾏进⾏⾃动交互,⽽⽆需⼈⼯⼲涉来达到⾃动化的⽬的。
Python入门教程网络安全网络安全工具

Python入门教程网络安全网络安全工具Python入门教程-网络安全工具Python是一种简单易学的编程语言,它具有广泛的应用领域,包括网络安全。
网络安全是当今互联网时代一个重要的议题,人们越来越重视保护自己的隐私和个人信息。
Python提供了丰富的库和工具,可以帮助我们开发和实现各种网络安全功能。
本文将介绍几个常用的Python网络安全工具,帮助读者入门这个领域。
一、ScapyScapy是一个强大的Python库,用于创建和发送网络数据包。
它可以用于网络嗅探、网络扫描、数据包分析等网络安全任务。
Scapy具有灵活的API,可以自定义和控制数据包的各个字段,从而轻松定制自己的网络工具。
例如,我们可以使用Scapy来实现简单的端口扫描程序,帮助我们发现网络中开放的端口,以便进行进一步的安全检查。
二、hashlibhashlib是Python的内置库,提供了常见的散列算法,如MD5、SHA-1、SHA-256等。
散列算法是密码学中常用的工具,用于验证文件的完整性和一致性。
我们可以使用hashlib来计算文件的哈希值,并与预期的哈希值进行比较,以确保文件的完整性。
这对于下载文件、检查文件的安全性非常有用。
三、requestsrequests是Python中最流行的HTTP库之一,它简化了与网络服务交互的过程。
requests提供了各种方法,例如发送HTTP请求、处理响应、处理Cookies等。
它可以用于编写网络爬虫、构建Web应用程序以及进行各种网络安全测试。
requests库简洁而强大,适合初学者入门。
四、paramikoparamiko是一个Python库,用于SSH(Secure Shell)协议的实现。
SSH是一种安全的网络协议,用于在不安全的网络上进行安全的远程登录和数据交换。
paramiko可以用于编写SSH客户端和服务器,实现安全的远程命令执行、文件传输等功能。
它是开源的,具有良好的可扩展性和灵活性。
数据分析工具:Python中常用的数据分析库

数据分析工具:Python中常用的数据分析库介绍在当今信息时代,随着大数据的兴起,数据分析变得越来越重要。
Python作为一种灵活高效的编程语言,因其丰富的数据分析库而备受青睐。
本文将介绍Python中常用的数据分析库,帮助读者选择合适的工具。
1. NumPyNumPy是Python科学计算领域最基础和最强大的库之一。
它提供了高效的多维数组对象和函数库,用于数值计算、线性代数、傅里叶变换等操作。
NumPy强大的功能使其成为其他数据分析库的基础。
•主要特点:•多维数组(ndarray):NumPy核心功能是ndarray对象,它支持高效的数组运算和广播。
•数学函数库:NumPy提供了丰富的数学函数,如统计函数、线性代数函数等。
2. pandaspandas是一个用于数据操作和分析的强大工具。
它提供了快速、灵活且可扩展的数据结构,如Series和DataFrame,并包含了广泛的数据处理和清洗功能。
•主要特点:•数据结构:pandas通过Series和DataFrame两种主要结构来处理表格型数据。
•数据清洗与处理:pandas提供了诸多函数和方法来处理缺失值、重复值以及其他常见问题。
•数据组合和合并:pandas可以用于合并、连接、聚合和重塑数据集。
3. matplotlibmatplotlib是Python中最流行的数据可视化库之一。
它提供了丰富的绘图工具和展示方式,可以创建各种类型的统计图表、线性图、散点图等,并支持自定义样式。
•主要特点:•创建可视化图表:matplotlib支持创建各种类型的图表,如折线图、条形图、饼状图等。
•定制化:用户可以通过设置各种参数和样式选项来自定义生成的图表。
4. seabornseaborn是基于matplotlib的高级可视化库,旨在简化复杂数据集的可视化工作。
它提供了更漂亮的默认风格和颜色主题,并且支持更高级别的统计可视化。
•主要特点:•默认美观风格:seaborn拥有一套漂亮而灵活的默认风格,使得绘制出的图像更加专业美观。
python的使用方法

python的使用方法Python是一种流行的高级编程语言,它简单易学,可读性强,广泛应用于数据分析、人工智能、网络开发等领域。
本文将介绍Python的使用方法,帮助读者快速上手。
一、Python的安装与环境配置在开始Python的使用之前,我们首先需要安装Python解释器。
Python提供了Windows、macOS和Linux等多个操作系统下的安装包,读者可以根据自己的系统选择对应的安装包进行下载。
安装过程中需要注意选择正确的版本,并按照提示进行安装。
安装完成后,我们需要进行环境配置。
在Windows系统下,可以通过配置环境变量将Python解释器的路径添加至系统路径中,以便在命令行中直接使用Python命令。
在macOS和Linux系统下,可以通过修改.bashrc或.bash_profile文件来实现环境变量的配置。
二、Python的基本语法Python的基本语法简洁易懂,深受程序员的喜爱。
下面介绍几个Python的基本语法要点:1. 变量与数据类型:Python是动态类型语言,变量的类型可以根据赋值自动确定。
常见的数据类型包括整数(int)、浮点数(float)、字符串(str)、列表(list)、字典(dict)等。
2. 条件判断与循环:Python提供了if-else语句用于条件判断,可以根据条件的真假来执行不同的代码块。
同时,Python还支持for和while循环,用于重复执行一段代码。
3. 函数与模块:Python支持函数和模块的定义与调用。
函数可以将一段可复用的代码封装起来,可以通过import语句引入其他模块,以便复用其中的函数和变量。
三、Python的常用库和功能Python拥有丰富的第三方库和功能,可以加速开发过程并提升效率。
下面介绍几个常用的库和功能:1. NumPy:高性能科学计算库,提供了多维数组对象和各种计算函数,适用于进行大规模数据运算。
2. Pandas:数据分析工具,提供了数据结构和数据处理函数,方便读取、处理和分析结构化数据。
38个常用Python库:数值计算、可视化、机器学习等8大领域都有了

38个常⽤Python库:数值计算、可视化、机器学习等8⼤领域都有了⼀、数值计算数值计算是数据挖掘、机器学习的基础。
Python提供多种强⼤的扩展库⽤于数值计算,常⽤的数值计算库如下所⽰。
1. NumPy⽀持多维数组与矩阵运算,也针对数组运算提供⼤量的数学函数库。
通常与SciPy和Matplotlib⼀起使⽤,⽀持⽐Python更多种类的数值类型,其中定义的最重要的对象是称为ndarray的n维数组类型,⽤于描述相同类型的元素集合,可以使⽤基于0的索引访问集合中元素。
2. SciPy在NumPy库的基础上增加了众多的数学、科学及⼯程计算中常⽤的库函数,如线性代数、常微分⽅程数值求解、信号处理、图像处理、稀疏矩阵等,可进⾏插值处理、信号滤波,以及使⽤C语⾔加速计算。
3. Pandas基于NumPy的⼀种⼯具,为解决数据分析任务⽽⽣。
纳⼊⼤量库和⼀些标准的数据模型,提供⾼效地操作⼤型数据集所需的⼯具及⼤量的能快速便捷处理数据的函数和⽅法,为时间序列分析提供很好的⽀持,提供多种数据结构,如Series、Time-Series、DataFrame和Panel。
⼆、数据可视化数据可视化是展⽰数据、理解数据的有效⼿段,常⽤的Python数据可视化库如下所⽰。
4. Matplotlib第⼀个Python可视化库,有许多别的程序库都是建⽴在其基础上或者直接调⽤该库,可以很⽅便地得到数据的⼤致信息,功能⾮常强⼤,但也⾮常复杂。
5. Seaborn利⽤了Matplotlib,⽤简洁的代码来制作好看的图表。
与Matplotlib最⼤的区别为默认绘图风格和⾊彩搭配都具有现代美感。
6. ggplot基于R的⼀个作图库ggplot2,同时利⽤了源于《图像语法》(The Grammar of Graphics)中的概念,允许叠加不同的图层来完成⼀幅图,并不适⽤于制作⾮常个性化的图像,为操作的简洁度⽽牺牲了图像的复杂度。
7. Bokeh跟ggplot⼀样,Bokeh也基于《图形语法》的概念。
Python数据压缩

Python数据压缩数据压缩在计算机科学中是一个常见的概念,它指的是通过消除冗余信息,减小数据的体积以节省存储空间或者传输时间的过程。
Python 作为一种功能强大的编程语言,也提供了多种数据压缩的方法和工具。
本文将介绍Python中常用的数据压缩技术和相关的库。
1. 压缩算法数据压缩的核心就是一系列压缩算法,Python提供了多种压缩算法的实现。
下面介绍其中两种常用的压缩算法。
1.1. Huffman压缩算法Huffman压缩算法是一种基于字符频率的压缩算法。
它通过构建Huffman树来实现对字符的编码和解码。
Python的`huffman`库提供了对文本数据进行Huffman编码和解码的功能,使用简单且效率较高。
1.2. Lempel-Ziv-Welch (LZW) 压缩算法LZW压缩算法是一种基于字典的压缩算法。
它通过不断地向字典中添加新的编码来实现对数据的压缩。
Python的`lz4`库是一个快速且高效的LZW压缩库,可以对各种类型的数据进行压缩和解压缩。
2. 压缩库除了以上介绍的压缩算法,Python还提供了一些方便实用的压缩库,可以方便地进行数据压缩和解压缩操作。
2.1. zlibzlib是Python内置的一个压缩库,提供了对数据进行压缩和解压缩的功能。
它支持多种压缩算法,包括DEFLATE(通常用于gzip和zip 文件格式)、LZ77和Huffman编码。
使用zlib库,你可以简单地将数据压缩为字节流或者解压缩已经压缩的字节流。
2.2. zipfilezipfile是Python标准库中提供的一个用于处理zip文件的模块。
它可以用于创建、读取、写入和解压缩zip文件。
通过zipfile库,你可以方便地将多个文件打包成一个zip文件,并且可以选择是否进行数据压缩。
3. 应用实例数据压缩在实际应用中有很多用途,在以下几个方面可以得到广泛的应用。
3.1. 文件压缩数据压缩最常见的应用就是对文件进行压缩。
多目标优化python代码

多目标优化python代码多目标优化(multi-objective optimization)是一个在优化问题中存在多个目标函数的情况下,同时优化多个目标的方法。
在Python中,我们可以利用各种优化算法和工具来实现多目标优化。
多目标优化在实际问题中非常常见,例如在供应链管理中,我们可能需要同时考虑成本最小化和服务水平最大化;在工程设计中,我们可能需要同时优化性能和可靠性等。
传统的单目标优化方法往往只能找到单个最优解,无法同时考虑多个目标。
而多目标优化则能够为决策者提供一系列不同的解决方案,形成一个解集(Pareto set),其中每个解都是在某种意义上是最优的。
在Python中,有几个常用的库和工具可以用于多目标优化。
下面将介绍其中的几个。
1. PyGMO:PyGMO是一个基于Python的开源优化库,它提供了多种多目标优化算法,如NSGA-II、MOEA/D等。
PyGMO的优势在于其丰富的算法库和灵活的接口,可以方便地在多种问题上进行实验。
2. DEAP:DEAP也是一个Python的开源优化库,它提供了多种遗传算法和进化策略的实现。
DEAP的特点是简单易用,适合初学者使用。
3. Platypus:Platypus是一个Python的多目标优化库,它提供了多种多目标优化算法的实现,如NSGA-II、SPEA2等。
Platypus的特点是速度快、易用性好,适合处理中小规模问题。
4. Scipy.optimize:Scipy是一个Python的科学计算库,其中的optimize模块提供了一些基本的优化算法,如COBYLA、SLSQP等。
虽然Scipy.optimize主要用于单目标优化,但也可以通过一些技巧来实现多目标优化。
在使用这些工具进行多目标优化时,我们需要定义适应度函数(fitness function),也就是衡量解决方案好坏的指标。
对于多目标优化问题,适应度函数通常是一个向量,其中每个维度对应一个目标函数。
2023秋招面试python很全的八股文总结

2023秋招面试python很全的八股文总结随着2023年秋季招聘的来临,作为一名求职者,掌握Python面试中的关键知识点显得尤为重要。
本文将为你详细总结Python面试中常见的八股文问题,助你在面试中脱颖而出。
一、Python基础1.解释Python中的self、cls、@staticmethod、@classmethodself:在Python类的方法中,self代表实例本身,用于访问类属性和调用其他方法。
cls:在类方法中,cls代表类本身,用于访问类属性和调用类方法。
@staticmethod:静态方法,不需要传递任何参数,一般用于工具函数。
@classmethod:类方法,需要传递一个参数cls,代表类本身。
2.解释Python中的new()、init()和call()ew():是一个静态方法,用于创建类的新实例。
在创建实例时,Python 会自动调用new()方法。
init():是一个实例方法,用于初始化新创建的实例。
在创建实例后,Python会自动调用init()方法。
call():是一个实例方法,允许实例对象像函数一样被调用。
二、Python高级特性1.Python中的列表推导式和生成器表达式列表推导式:用于生成列表,具有简洁、高效的特点。
生成器表达式:用于生成迭代器,可以节省内存,适用于大数据处理。
2.Python中的装饰器装饰器是一种特殊类型的函数,用于修改其他函数的功能。
它可以用来给函数添加功能,而无需修改函数本身。
三、Python内存管理和垃圾回收机制1.Python中的引用计数Python中的每个对象都有一个引用计数,用于记录该对象被引用的次数。
当引用计数为0时,对象将被销毁。
2.Python垃圾回收机制Python采用标记清除和分代回收两种机制进行垃圾回收。
标记清除:通过遍历所有对象,标记活动对象,然后回收未被标记的对象。
分代回收:将对象分为几个代,分别进行不同的回收策略,以提高垃圾回收效率。
stegano python 隐写方法

stegano python 隐写方法一、背景介绍隐写(steganography)是一种信息安全技术,通过将秘密信息嵌入到载体文件中,使得外界难以察觉到信息的存在。
隐写术已经存在了几千年,最早出现在古希腊时期。
如今,随着计算机技术的快速发展,隐写术也得到了广泛应用,尤其是在信息安全领域。
在本文中,我们将探讨使用Python编写的隐写方法。
Python是一种功能强大且易于学习的编程语言,通过结合Python和隐写术,我们可以实现各种各样的隐写技术。
二、Python隐写库Python提供了多个隐写库,可以帮助我们实现隐写操作。
下面是几个常用的Python隐写库:1. SteganoStegano是一个简单易用的Python库,用于在图像、音频和视频文件中嵌入秘密信息。
使用Stegano,我们可以轻松地进行隐写操作,并且支持多种不同算法和文件格式。
2. PycryptoPycrypto是Python的一个加密工具包,它提供了多种加密和隐写算法的实现。
Pycrypto可以帮助我们进行隐写操作,保护我们的秘密信息。
3. PillowPillow是Python Imaging Library(PIL)的一个分支,它可以帮助我们处理图像。
Pillow提供了丰富的图像处理功能,也包括一些隐写技术的实现。
三、图像隐写方法图像隐写是最常见的隐写方法之一。
下面是几种常用的图像隐写方法:1. LSB隐写LSB(Least Significant Bit)隐写是一种简单的图像隐写方法。
它通过改变像素最不显眼的位来嵌入秘密信息。
LSB隐写可以应用于任何图像格式,但是嵌入的信息量相对较小。
2. 色彩分量隐写色彩分量隐写是一种利用图像的色彩分量来嵌入秘密信息的方法。
它基于RGB颜色模型,通过微调每个像素的色彩分量值来隐藏信息。
这种方法可以提供较大的信息容量,并且对人眼不可见。
3. JPEG隐写JPEG隐写是一种将秘密信息嵌入到JPEG图像中的方法。
python 数据压缩方式

在Python中,有多种数据压缩方式可供选择。以下是几种常见的数据压缩方式及其对应 的Python库:
1. ZIP 压缩:使用 zipfile 库可以对文件或文件夹进行 ZIP 压缩。可以使用 zipfile 模块中 的 ZipFile 类来创建、打开和操作 ZIP 文件。
这些库提供了在Python中进行数据压缩和解压缩的功能。你可以根据需要选择适合的压 缩方式,并使用相应的库来实现数据压缩和解压缩操作。
2. GZIP 压缩:使用 gzip 库可以对单个文件进行 GZIP 压缩。可以使用 gzip 模块中的 GzipFile 类来创建、打开和操作 G用 tarfile 库可以对文件或文件夹进行 TAR 压缩。可以使用 tarfile 模块 中的 TarFile 类来创建、打开和操作 TAR 文件。
4. BZIP2 压缩:使用 bz2 库可以对单个文件进行 BZIP2 压缩。可以使用 bz2 模块中的 BZ2File 类来创建、打开和操作 BZIP2 文件。
5. LZMA 压缩:使用 lzma 库可以对单个文件进行 LZMA 压缩。可以使用 lzma 模块中 的 LZMAFile 类来创建、打开和操作 LZMA 文件。
Python标准库介绍

Python标准库介绍Python有⼀套很有⽤的标准库(standard library)。
标准库会随着Python解释器,⼀起安装在你的电脑中的。
它是Python的⼀个组成部分。
这些标准库是Python为你准备好的利器,可以让编程事半功倍。
我将根据我个⼈的使⽤经验中,挑选出标准库三个⽅⾯的包(package)介绍:Python增强系统互动⽹络第⼀类:Python增强Python⾃⾝的已有的⼀些功能可以随着标准库的使⽤⽽得到增强。
1) ⽂字处理Python的string类提供了对字符串进⾏处理的⽅法。
更进⼀步,通过标准库中的re包,Python可以⽤正则表达式(regular expression)来处理字符串。
正则表达式是⼀个字符串模板。
Python可以从字符中搜查符合该模板的部分,或者对这⼀部分替换成其它内容。
⽐如你可以搜索⼀个⽂本中所有的数字。
正则表达式的关键在于根据⾃⼰的需要构成模板。
此外,Python标准库还为字符串的输出提供更加丰富的格式,⽐如: string包,textwrap包。
2) 数据对象不同的数据对象,适⽤于不同场合的对数据的组织和管理。
Python的标准库定义了表和词典之外的数据对象,⽐如说数组(array),队列(Queue)。
⼀个熟悉数据结构(data structure)的Python⽤户可以在这些包中找到⾃⼰需要的数据结构。
此外,我们也会经常使⽤copy包,以复制对象。
3) ⽇期和时间⽇期和时间的管理并不复杂,但容易犯错。
Python的标准库中对⽇期和时间的管理颇为完善(利⽤time包管理时间,利⽤datetime包管理⽇期和时间),你不仅可以进⾏⽇期时间的查询和变换(⽐如:2012年7⽉18⽇对应的是星期⼏),还可以对⽇期时间进⾏运算(⽐如2000.1.1 13:00的378⼩时之后是什么⽇期,什么时间)。
通过这些标准库,还可以根据需要控制⽇期时间输出的⽂本格式(⽐如:输出’2012-7-18‘还是'18 Jul 2012')4) 数学运算标准库中,Python定义了⼀些新的数字类型(decimal包, fractions包), 以弥补之前的数字类型(integer, float)可能的不⾜。
python处理批量数据教案

python处理批量数据教案Python 是一种非常强大的编程语言,特别适合用于批量处理数据。
在本篇文章中,我们将一步一步地探讨如何使用 Python 处理批量数据。
一、Python 数据处理库概述在开始处理批量数据前,我们需要了解 Python 中一些常用的数据处理库。
下面是几个常用的数据处理库:1. NumPy:NumPy 是 Python 中最重要的科学计算库之一。
它提供了高性能的多维数组对象,以及用于处理这些数组的各种函数。
使用 NumPy,我们可以轻松地进行矩阵计算和数值操作。
2. Pandas:Pandas 是 Python 中非常流行的数据处理库,它提供了高效的数据结构和数据分析工具。
Pandas 可以轻松地读取、处理和分析大型数据集,并提供了强大的数据操作和处理功能。
3. Matplotlib:Matplotlib 是一个绘图库,用于在 Python 中创建各种静态、交互式和动画图表。
通过 Matplotlib,我们可以可视化数据,进行数据探索和分析。
4. Seaborn:Seaborn 是基于 Matplotlib 的一个统计数据可视化库。
它提供了更高级别的接口,用于绘制各种统计图形,使数据可视化更加简单和美观。
二、数据导入与预处理在处理批量数据之前,我们首先需要将数据导入到 Python 环境中,并进行一些预处理操作。
常见的数据导入格式包括 CSV、Excel、JSON、SQL 数据库等。
下面是一些常用的数据导入库和方法:1. Pandas 导入:Pandas 提供了多个函数用于从不同格式导入数据集。
例如,使用 `read_csv()` 函数可以从 CSV 文件中导入数据;使用 `read_excel()` 可以从 Excel 文件中导入数据;使用 `read_json()` 可以从 JSON 文件中导入数据。
2. 数据预处理:在导入数据后,我们通常需要进行一些数据预处理操作,以准备好数据进行后续的分析和建模。
hyperf 面试题

hyperf 面试题1.列出5 个常用Python 标准库?os, math, random, time, pymysql,re2.Python 内建数据类型有哪些?数字,字符串,列表,元组,字典,集合,Bytes,布尔等3.简述with 方法打开处理文件帮我我们做了什么?file = open('a.txt','w')try:file.write('test')except:passfinally:file.close()# with方法相当于以上代码finally中的file.close()操作4.列出Python 中可变数据类型和不可变数据类型,为什么?不可变数据类型:数字、字符串、元组,变量不允许修改,值改变后,id 也会变;可变数据类型:集合、列表、字典,值改变后,id不会变5.Python 获取当前日期?import timenow = time.strftime("%Y-%m-%d %H:%M:%S %A")print(now)6.统计字符串每个单词出现的次数import stringstr_input = "Hello world, hello python"str_test = str_input.lower()intab = string.punctuationouttab = " "*32trantab = str.maketrans(intab,outtab)str_test.translate(trantab)li_test = str_test.split(" ")rst = {}for item in li_test:if item in rst.keys():rst[item] = rst[item] + 1else:rst[item] = 1print(rst)返回{'hello': 2, 'world,': 1, 'python': 1}7.用python 删除文件和用linux 命令删除文件方法import os# python删除文件os.remove(path)# python删除目录os.removedirs(path)linux删除文件rm [选项] 文件选项说明:-f -force 忽略不存在的文件,强制删除,无任何提示-i --interactive 进行交互式地删除-r | -R --recursive 递归式地删除列出的目录下的所有目录和文件-v --verbose 详细显示进行的步骤8.写一段自定义异常代码class ShortInputException(Exception):'''自定义异常类'''def __init__(self, length, atleast):self.length = lengthself.atleast = atleasttry:s = input('please input:')if len(s) < 3:raise ShortInputException(len(s), 3)except ShortInputException as e:print('输入长度是%s,长度至少是%s' %(e.length, e.atleast)) else:print('nothing...')如果输入字符长度小于3,那么将会抛出ShortInputException 异常:please input:qw输入长度是2,长度至少是39.举例说明异常模块中try except else finally 的相关意义try:------code-----except Exception as e: # 抛出异常之后将会执行print(e)else: # 没有异常将会执行print('no Exception')finally: # 有没有异常都会执行print('execute is finish')10.遇到bug 如何处理查看报错行和错误类型,debug找出问题所在进行处理。
python爬虫讲解

python爬虫讲解
Python爬虫是一种自动化获取网络数据的技术,它可以快速地从各种网站上抓取大量数据,使得数据处理更加高效。
本文将深入讲解Python爬虫的原理、常用工具和常见问题,帮助读者掌握Python 爬虫的基础知识和实际应用技巧。
我们将从以下几个方面进行讲解: 1. Python爬虫的基本原理和工作流程:介绍Python爬虫的基本概念和原理,以及Python爬虫的工作流程和技术实现。
2. Python爬虫的常用工具和库:介绍Python爬虫中常用的工具和库,如Requests、BeautifulSoup、Scrapy等,帮助读者快速入门。
3. Python爬虫的实际应用:通过实际案例,介绍Python爬虫的实际应用场景,如爬取电商网站商品信息、爬取新闻、爬取社交媒体等。
4. Python爬虫的进阶技巧:介绍Python爬虫的一些进阶技巧,如多线程爬虫、分布式爬虫、反爬虫技术等,帮助读者深入了解Python 爬虫的高级应用和技术。
本文旨在为读者提供一份全面的Python爬虫入门指南,帮助读者快速学习和掌握Python爬虫技术,提升数据处理效率和数据分析能力。
- 1 -。
Python中的推荐系统开发

Python中的推荐系统开发在Python中,推荐系统的开发是一个热门的话题。
随着互联网的发展,推荐系统在电商、社交媒体、在线视频等领域发挥着重要的作用。
本文将介绍Python中的推荐系统开发,并探讨其实现原理和相关技术。
一、推荐系统的概述推荐系统是一种根据用户的兴趣和行为,向其推荐相关商品、内容或服务的系统。
通过分析用户的历史行为数据和个人信息,推荐系统能够预测用户的兴趣,从而提供个性化的推荐。
推荐系统的目标是提高用户的满意度和体验,并促进销售和用户参与度的增长。
二、推荐系统的算法推荐系统的核心是算法,而Python作为一种功能强大的编程语言,为推荐算法的开发提供了便利。
以下是一些常见的推荐算法:1. 基于内容的推荐算法:根据用户过去的行为和喜好,推荐与其相似的内容。
这种算法通常通过文本挖掘和自然语言处理来实现。
2. 协同过滤算法:通过分析用户与其他用户之间的相似度,来为用户推荐那些他们的相似用户喜欢的物品。
协同过滤算法分为基于用户的协同过滤和基于物品的协同过滤。
3. 混合推荐算法:将多种推荐算法结合起来,综合利用它们的优点进行推荐。
三、Python中的推荐系统库Python中有许多强大的推荐系统库,可以加速推荐系统的开发。
以下是一些常用的库:1. Surprise:Surprise是一个用于构建和评估推荐系统的Python库。
它实现了几个流行的推荐算法,并提供了易于使用的API。
2. scikit-learn:scikit-learn是一个通用的机器学习库,它提供了多种用于协同过滤和推荐系统的算法。
3. TensorFlow:TensorFlow是一个强大的深度学习库,可以用于推荐系统的开发。
它提供了高效的推荐算法实现,并支持大规模数据集的处理。
四、推荐系统开发的步骤推荐系统的开发通常包括以下几个步骤:1. 数据收集:收集用户的历史行为数据和个人信息。
这些数据可以来自于网站的日志记录、用户的购买记录等。
Python编程在科学计算中的应用

Python编程在科学计算中的应用在现代科学技术中,计算机已经成为了各行各业必备的工具之一。
对于科学计算领域,Python编程语言的应用已经逐渐成为一种趋势。
Python语言的简单易学性以及其强大的库支持,使得Python成为了科学计算领域中应用最广泛的编程语言之一。
下面将从Python的基本特征、科学计算领域中的应用、Python的优势与不足等角度进行深入的探讨。
一、Python的基本特征Python是一种高级编程语言,最初于1989年由Guido van Rossum设计实现。
Python语言以其简洁明了的语法以及易于阅读的代码风格而广受欢迎。
其主要特点如下:1. 可读性好:Python语言的代码非常直白,易于阅读和维护。
Python程序员的代码质量通常很高,不仅仅是因为Python语言本身的原因,更多的是因为他们用Python编程时的思考方式。
2. 交互式解释器:Python在交互式下开发的能力非常强,可以像执行一行一行的命令一样,实时查看结果。
3. 开源:Python语言是开源的,且可以在多个平台上运行,这使得Python在科学计算领域中得以广泛应用。
4. 模块化:Python拥有丰富的库和模块,比如NumPy,SciPy 等,这些模块都是高度优化过的、与Python紧密集成的。
二、科学计算领域中Python的应用Python在科学计算领域中应用是非常广泛的。
下面介绍一些普遍应用于科学计算的Python库:1. NumPy:NumPy是Python中用于科学计算的一个常用库,它提供了一种简单而又快速的数组处理方式。
NumPy通过一个包含Python对象的多维数组来表示数学上的矩阵或数组。
2. SciPy:SciPy是一个用于科学计算和数学上常见问题的集合,其中包括了线性代数、傅里叶变换、优化、数学函数等。
3. Pandas:Pandas是Python的一个数据分析库。
它所提供的数据结构能够轻松处理表格数据,比如,可以很方便地进行数据清洗、分析、透视表等操作。
Python常用函数库大全(实用)

Python常用函数库大全(实用)本文档旨在介绍一些常用的Python函数库,以帮助开发者更有效地编写Python代码。
以下是一些常见的函数库:1. NumPyNumPy是Python中用于科学计算的基础库。
它提供了一个强大的多维数组对象和一系列用于操作数组的函数。
2. PandasPandas是一个用于数据分析和处理的Python库。
它提供了高效的数据结构和数据分析工具,使得处理和分析数据变得更加简单。
3. MatplotlibMatplotlib是一个用于绘制各种类型图表和可视化数据的Python库。
它提供了丰富的绘图功能,使得用户可以创建高质量的数据可视化结果。
4. BeautifulSoup5. Requests6. SciPySciPy是一个用于科学计算和技术计算的Python库。
它建立在NumPy之上,并提供了一系列高级的数学、科学和工程计算功能。
7. DjangoDjango是一个用于快速开发Web应用程序的高级Python框架。
它提供了一系列强大的工具和功能,使得开发Web应用变得更加简单和高效。
8. FlaskFlask是一个轻量级的Python框架,用于开发简单而灵活的Web应用程序。
它具有简单的API和清晰的文档,使得开发者能够快速构建Web应用。
9. Scikit-learnScikit-learn是一个用于机器研究的Python库。
它提供了一系列机器研究算法和工具,使得开发者能够快速构建和应用各种机器研究模型。
10. TensorFlowTensorFlow是一个用于机器研究和深度研究的开源库。
它提供了一个灵活的计算框架,使得开发者可以轻松构建和训练各种类型的机器研究模型。
以上是一些常用的Python函数库,涉及到科学计算、数据处理、数据可视化、Web开发和机器学习等各个领域。
开发者可以根据自己的需求选择合适的函数库来提高开发效率和代码质量。
python library的用法

python library的用法摘要:1.Python 库的概述2.Python 库的安装与使用3.Python 库的常见类型与功能4.Python 库的优缺点分析5.Python 库的未来发展趋势正文:1.Python 库的概述Python 库是一种扩展Python 编程语言功能的工具集合,它们通常由独立的开发者或团队开发,并通过Python 包管理器(如pip)进行分发。
Python 库的数量众多,涵盖了数据分析、机器学习、网络编程等众多领域,极大地丰富了Python 编程的功能和应用范围。
2.Python 库的安装与使用在使用Python 库之前,首先需要对其进行安装。
一般来说,安装Python 库可以通过pip 工具完成。
例如,要安装名为“requests”的库,只需在终端或命令行中输入“pip install requests”即可。
安装完成后,在Python 代码中通过import 语句导入库,然后就可以使用库中的函数和类进行编程了。
3.Python 库的常见类型与功能Python 库种类繁多,下面介绍一些常见的Python 库及其功能:(1)NumPy:用于科学计算和数据分析,提供了多维数组对象和各种计算功能。
(2)Pandas:用于数据处理和分析,提供了DataFrame 数据结构和强大的数据操作功能。
(3)Matplotlib:用于绘制各种统计图形,如折线图、散点图等。
(4)Scikit-learn:用于机器学习和数据挖掘,提供了许多经典的算法实现,如决策树、支持向量机等。
(5)TensorFlow:用于深度学习和人工智能,提供了构建和训练神经网络的强大功能。
4.Python 库的优缺点分析Python 库的优点包括:(1)易学易用:Python 库的语法简洁明了,易于学习和使用。
(2)功能丰富:Python 库种类繁多,涵盖了众多领域,可以满足各种编程需求。
(3)社区活跃:Python 库的社区庞大,开发者众多,问题解决速度快。
python中常用的库有哪些-Python类库-数据处理

python中常用的库有哪些-Python类库-数据处理Python社区已经非常成熟,为我们提供了很多高质量的类库。
下面介绍一下与机器学习相关的常见Python类库,如:1.数值计算 NumPy;2.科学计算 SciPy;3.数据分析Pandas。
1.数值计算 NumPyNumPy是 "Numeric "和 "Python "的混合物。
顾名思义,它是一个处理数值计算的Python库。
为了提升性能,NumPy参照了CPython(用C语言实现的Python及其解释器)的〔制定〕,而CPython本身是用C语言开发的,也就是说,Numpy的数据处理速度与C语言处于同一水平。
除了提供一些数学运算外,NumPy还提供了与MATLAB(MathWorks公司生产的商业数学软件)类似的函数和操作,同意用户直接有效地操作向量或矩阵。
然而,NumPy被定位为一个基本的数学库,是一个相对低级的Python库。
如果你想快速开发可用的程序,你可以使用更高级的库,如:SciPy和Pandas。
2.科学计算 SciPySciPy的发音为 "Sigh Pie",与NumPy相似,是 "Science "和 "Python "的组合。
"SciPy "建立在 "NumPy "之上,功能更强化大,为求解常微分方程、线性代数、信号处理、图像处理和稀疏矩阵运算提供强大的支持。
与NumPy相比,NumPy是一个纯粹的数学层面的计算模块,SciPy 是一个更高级的科学计算库。
例如,如果你想对矩阵进行操作,如果你只使用纯数学的基本模块,你可以在NumPy库中找到相应的模块。
SciPy库必须要NumPy库的支持。
由于这种依赖性,NumPy 库应该在SciPy库之前安装。
3.数据分析PandasPandas在这里不是指 "熊猫",它的全称是 "Python Data AnalysisLibrary"。
介绍几个python的音频处理库
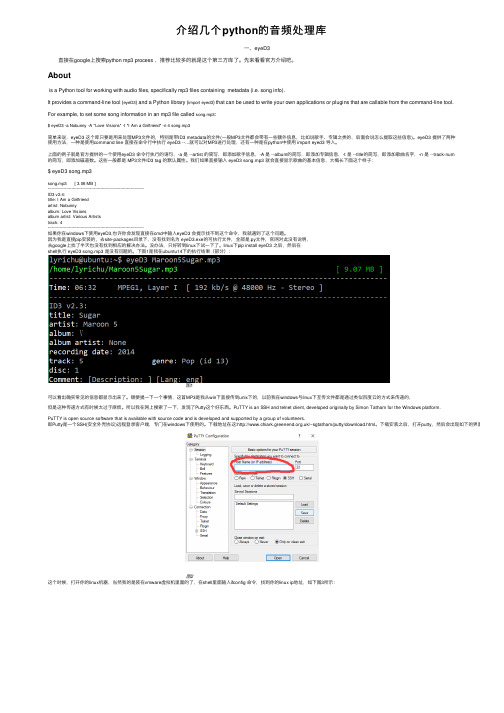
介绍⼏个python的⾳频处理库 ⼀、eyeD3 直接在google上搜索python mp3 process ,推荐⽐较多的就是这个第三⽅库了。
先来看看官⽅介绍吧。
Aboutis a Python tool for working with audio files, specifically mp3 files containing metadata (i.e. song info).It provides a command-line tool (eyeD3) and a Python library (import eyed3) that can be used to write your own applications or plugins that are callable from the command-line tool.For example, to set some song information in an mp3 file called song.mp3:$ eyeD3 -a Nobunny -A "Love Visions" -t "I Am a Girlfriend" -n 4 song.mp3简单来说,eyeD3 这个库只要是⽤来处理MP3⽂件的,特别是带ID3 metadata的⽂件(⼀般MP3⽂件都会带有⼀些额外信息,⽐如说歌⼿、专辑之类的,后⾯会说怎么提取这些信息)。
eyeD3 提供了两种使⽤⽅法,⼀种是使⽤command line 直接在命令⾏中执⾏ eyeD3 --...就可以对MP3进⾏处理,还有⼀种是在python中使⽤ import eyed3 导⼊。
上⾯的例⼦就是官⽅提供的⼀个使⽤eyeD3 命令⾏执⾏的语句,-a 是 --artist 的简写,即添加歌⼿信息,-A 是 --album的简写,即添加专辑信息,-t 是 --title的简写,即添加歌曲名字,-n 是 --track-num的简写,即添加磁道数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NumPy
NumPy是Python科学计算的基础包,它提供了以下功能:
1)快速高效的多维数组对象ndarray;
2)用于对数组执行元素级计算以及直接对数组执行数学运算的函数;3)用于读写硬盘上基于数组的数据集的工具;
4)线性代数运算、傅里叶变换,以及随机数生成;
5)用于将C、C++、Fortran代码集成到Python的工具。
对于数值型数据,NumPy数组在存储和处理数据时要比内置的Python 数据结构高效得多。
此外,由低级语言(比如C和Fortran)编写的库可以直接操作NumPy数组中的数据,无需进行任何数据复制工作。
pandas
pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数。
用得最多的pandas对象是DataFrame,它是一个面向列的二维表结构,且含有行标和列标。
pandas兼具NumPy高性能的数组计算功能以及电子表格和关系型数据库灵活的数据处理功能。
它提供了复杂精细的索引功能,以便更为便捷地完成重塑、切片和切块、聚合以及选取数据子集等操作。
pandas提供了大量适用于金融数据的高性能时间序列功能和工具。
matplotlib
matplotlib是最流行的用于绘制数据图表的Python库。
它非常适合创建出版物上用的图表。
它跟IPython结合得很好。
SciPy
SciPy是一组专门解决科学计算中各种标准问题域的包的集合,主要包括:
1)scipy.integrate: 数值积分列程和微分方程求解器;
2)scipy.linalg: 扩展了由numpy.linalg提供的线性代数例程和矩阵分解功能;
3)scipy.optimize:函数优化器(最小化器)以及根查找算法;
4)scipy.signal:信号处理工具;
5)scipy.sparse:稀疏矩阵和稀疏线性系统求解器;
IPython
IPython是Python科学计算标准工具集的组成部分,它将其它所有的东西联系到了一起。
它为交互式和探索式计算提供了一个强健而高效的环境。
它是一个增强的Python shell,目的是提高编写、测试、调试Pyt hon代码的速度。
它主要用于交互式数据处理和利用matplotlib对数据进行可视化处理。
除标准的基于终端的IPython shell外,该项目还提供了:
1)一个类似于Mathematica的HTML笔记本;
2)一个基于Qt框架的GUI控制台,其中含有绘图、多行编辑以及语法亮亮显示等功能;
3)用于交互式并行和分布式计算的基础架构。
看完本文有收获?请转发分享给更多人
关注「传智播客」,提升IT技能。