Kafka介绍
kafka topic类型

kafka topic类型摘要:1.主题介绍2.Kafka 简介3.Kafka 主题类型a.保留主题b.轮询主题c.键值主题d.顺序主题4.主题类型的应用场景5.总结正文:【主题介绍】本文将介绍Kafka 中的主题类型,帮助大家了解不同类型的主题及其应用场景。
【Kafka 简介】Kafka 是一个分布式流处理平台,主要用于构建实时数据流管道和流处理应用程序。
它具有高吞吐量、可扩展性和容错能力,广泛应用于大数据、实时计算和日志收集等领域。
【Kafka 主题类型】Kafka 中的主题(Topic)是用于存储消息的逻辑容器。
根据不同的需求,Kafka 提供了以下几种主题类型:a.保留主题(Topic with retention): 保留主题允许你设置消息的最大保留时间。
当消息被发送到保留主题时,如果在指定的时间内没有消费者消费该消息,Kafka 会将消息从主题中删除。
这种主题类型适用于有明确过期时间的数据,如日志记录。
b.轮询主题(Topic with partition count): 轮询主题允许你为每个分区和消费者组设置轮询偏移量。
这种主题类型适用于需要按顺序消费消息的应用程序,如消息队列。
c.键值主题(Topic with key): 键值主题是一种特殊类型的主题,它将消息与键关联起来。
这使得消费者可以按键对消息进行分组和处理。
键值主题适用于需要对消息进行复杂查询和处理的应用程序,如实时数据仓库。
d.顺序主题(Topic with orderliness): 顺序主题确保生产的消息按照发送顺序存储和消费。
这种主题类型适用于需要确保消息顺序的应用程序,如金融交易系统。
【主题类型的应用场景】1.保留主题:适用于有明确过期时间的数据,如日志收集。
2.轮询主题:适用于需要按顺序消费消息的应用程序,如消息队列。
3.键值主题:适用于需要对消息进行复杂查询和处理的应用程序,如实时数据仓库。
4.顺序主题:适用于需要确保消息顺序的应用程序,如金融交易系统。
kafka读写原理

kafka读写原理Kafka是一个高性能、分布式的消息队列系统,它具有高吞吐量、高可靠性、可扩展性等优点。
对于Kafka的读写原理,我们可以从以下几个方面来进行介绍:1. 消息生产者的写入原理:消息生产者通过Kafka提供的API接口将消息写入Kafka的主题(Topic)中,Kafka将消息按照分区(Partition)进行划分,并将消息存储在对应的分区副本中。
在写入过程中,Kafka会根据配置的副本因子(Replication Factor)将消息复制到其他节点的分区副本中,以实现数据的冗余存储和高可靠性。
2. 消息消费者的读取原理:消息消费者通过订阅(Subscription)Kafka主题来获取消息。
在读取过程中,Kafka会根据消费者的消费位置(Offset)来确定下一条要读取的消息所在的分区副本以及偏移量,消费者接收到消息后可以对消息进行处理,同时将消费位置更新到Kafka中,以便下次读取时从更新后的位置开始。
3. 分区和副本的管理:Kafka中的分区(Partition)是消息存储的最小单位,每个分区可以有多个副本(Replica)。
在分区和副本的管理中,Kafka采用了分布式的方式进行管理,每个节点都可以成为分区副本的备选节点,并通过Zookeeper进行状态同步和选主,以保证Kafka集群的高可用性和可靠性。
4. 消息的持久化和压缩:Kafka将消息持久化到磁盘中,以保证数据的可靠性和持久性。
同时,Kafka还提供了消息压缩功能,可以对消息进行压缩,以减少网络传输的数据量,提高数据的传输效率。
总之,Kafka的读写原理涉及到多个方面,包括消息生产者的写入、消息消费者的读取、分区和副本的管理以及消息的持久化和压缩等。
了解Kafka的读写原理对于使用和优化Kafka非常重要,希望本文能够对大家有所启发和帮助。
kafka的偏移量

Kafka的偏移量1. 背景介绍Kafka是一个高性能、可扩展的分布式消息传递系统,被广泛应用于大数据领域。
在Kafka中,每个消息都有一个唯一的偏移量(Offset),用于标识消息在分区中的位置。
偏移量在Kafka集群中的存储、管理和使用是非常重要的。
2. 偏移量的定义和作用2.1 偏移量的定义偏移量是一个64位的长整型数字,用于唯一标识一条消息在一个分区中的位置。
它可以理解为一个消息在分区中的索引,类似于数组的索引。
每个分区都有自己独立的偏移量序列。
2.2 偏移量的作用偏移量在Kafka中有多种作用: 1. 消费者通过偏移量可以准确地指定从哪个位置开始消费消息,实现断点续传的功能。
2. 生产者在发送消息时需要获取下一个可用的偏移量,确保消息的有序性。
3. Kafka通过偏移量来实现数据的持久化和数据的可靠性,可以根据偏移量来恢复或者重放数据。
3. 偏移量的管理和存储3.1 偏移量的管理Kafka使用消费者组(Consumer Group)的概念来管理偏移量。
每个消费者组都有一个唯一的标识符,并且每个分区都可以被一个消费者组中的一个消费者进行消费。
消费者组维护着每个消费者在每个分区上消费的偏移量。
3.2 偏移量的存储Kafka使用一个专门的主题(__consumer_offsets)来存储消费者组的偏移量。
在该主题中,每个分区都有一个对应的消息存储着消费者组在该分区上的偏移量信息,包括消费者组、分区、消费者的偏移量以及相关的元数据。
4. 偏移量的管理和维护4.1 消费者组的偏移量提交消费者在消费消息时,需要定期将消费的偏移量提交给Kafka集群。
如果消费者发生故障或者重启,可以通过提交的偏移量来恢复消费状态。
4.2 偏移量的维护Kafka提供了两种方式来维护偏移量: 1. 手动维护偏移量:消费者可以通过调用API手动提交偏移量,灵活性较高,但需要消费者自己实现偏移量的存储和管理。
2. 自动维护偏移量:Kafka的消费者客户端会自动定期提交偏移量,Kafka集群会将偏移量存储在特定的主题中,简化了偏移量的管理和维护。
kafka的assign机制

kafka的assign机制Kafka是一个高性能、分布式、可扩展的消息队列,广泛应用于各种场景,比如日志收集、流式计算等。
Kafka的核心是分布式存储和消息发布-订阅机制。
在消息发布-订阅机制中,Kafka通过assign机制将消息分配给不同的消费者,下面我们来详细了解Kafka的assign 机制。
一、Kafka的消费者组概念Kafka的消费者被组织成逻辑上的消费者组,每个消费者组中可以有一个或多个消费者,每个消费者组只能消费一个topic下的所有分区中的消息,同一个分区只能被同一个消费者组中的一个消费者消费。
消费者组中的每个消费者订阅的是完整的主题,而不是某一个分区。
二、Kafka的assign机制在消费者组中,每个消费者负责消费一个或多个分区,分配分区的过程就是通过assign机制来实现的。
assign机制可以在程序代码中指定,也可以通过Kafka的命令行工具进行分配。
assign机制的核心是指定每个消费者需要消费的分区列表,然后将这个列表传递给Kafka 服务端。
三、指定每个消费者需要消费的分区对于Kafka的assign机制,用户需要手动指定每个消费者需要消费哪些分区。
这个过程可以在程序代码中进行,也可以通过Kafka 的命令行工具kafka-consumer-groups.sh完成。
具体操作步骤如下:1. 在程序代码中指定在代码中使用assign()方法来指定消费者需要消费的分区列表:```javaConsumer consumer = new KafkaConsumer(props);List<PartitionInfo> partitionInfos =consumer.partitionsFor(topic);List<TopicPartition> partitions = newArrayList<TopicPartition>();for (PartitionInfo partition : partitionInfos) {if (partition.partition() == 0 || partition.partition()== 1) {partitions.add(new TopicPartition(partition.topic(), partition.partition()));}}consumer.assign(partitions);```上面的代码中,我们通过调用consumer.partitionsFor(topic)方法获取到主题topic中所有的分区信息,然后通过一个循环语句将分区列表添加到一个List<TopicPartition>类型的partition列表中,最后调用consumer.assign(partitions)方法进行分配。
kafka精确一次原理

Kafka精确一次原理1. 引言Apache Kafka是一种高吞吐量、低延迟的分布式消息队列系统,被广泛应用于实时数据处理和大数据流处理场景。
在数据传输过程中,确保消息的精确一次处理是至关重要的。
本文将介绍Kafka如何实现消息的精确一次处理。
2. 消息传递语义在理解Kafka的精确一次处理原理之前,首先需要了解Kafka的消息传递语义。
有三种常见的消息传递语义,分别是至多一次、至少一次和精确一次。
•至多一次:消息可能会丢失,但不会重复传递。
•至少一次:消息不会丢失,但可能会重复传递。
•精确一次:消息不会丢失,也不会重复传递。
Kafka在设计时选择了至少一次的传递语义,这意味着消息不会丢失,但有可能发生重复传递。
为了实现精确一次的处理,Kafka结合了消息的偏移量和消费者的位移提交机制。
3. 偏移量和位移提交在Kafka中,每个消息都有一个唯一的偏移量(offset),用于标识消息在分区内的位置。
消费者可以使用偏移量来追踪处理过的消息。
Kafka消费者通过定期提交位移(offset commit)来表示已经处理完一批消息。
位移提交的方式包括同步提交和异步提交。
同步提交是阻塞方式,直到得到提交结果才继续进行消费。
异步提交则不会阻塞,允许并发提交多个位移。
4. 再平衡和消费者组Kafka支持以消费者组(consumer group)的方式来进行消息的分发和负载均衡。
每个消费者属于一个消费者组,并且每个分区只能由一个消费者组内的一个消费者进行消费。
当消费者组发生变化,例如有新的消费者加入或某个消费者离开,Kafka会触发再平衡(rebalance)操作,重新分配分区给各个消费者,以实现负载均衡。
5. 重复消费的情况在Kafka的消费者群组中,由于再平衡的影响,有可能造成某些消息被重复消费的情况。
例如,在消费者A处理消息后提交了位移,但由于再平衡的发生,在同一分区上被消费者B接管。
此时消费者B需要从提交的位移继续消费,导致了消息的重复。
kafka消息广播原理

kafka消息广播原理Kafka是一种高吞吐量的分布式发布-订阅消息系统,它被广泛应用于大数据处理、实时分析、流处理等领域。
Kafka通过其独特的消息广播机制,实现了消息的快速传递和高效处理。
本篇文档将详细介绍Kafka的广播机制原理。
一、Kafka广播机制概述Kafka的广播机制主要通过Kafka集群中的Broker节点实现。
当有新的消息产生时,生产者会将消息发送到Kafka集群中的某一个Broker节点,该节点会将消息广播到所有的订阅该主题的消费者中。
这种广播机制保证了消息的高效传递和实时性。
二、Kafka广播流程1. 生产者将消息发送到Kafka集群中的某一个Broker节点,该节点接收到消息后,将其存储到本地磁盘上。
2. Broker节点会将接收到的消息广播到所有的订阅该主题的消费者中。
具体实现方式是通过Kafka的分布式协调服务(Zookeeper)来实现。
3. 消费者接收到消息后,对其进行处理,并将结果存储到本地磁盘上。
三、Kafka广播原理分析Kafka广播机制的实现原理主要基于以下几个关键点:1. 分布式协调服务(Zookeeper):Kafka的分布式协调服务(Zookeeper)用于维护Kafka集群的元数据,包括Broker节点的状态、Topic的配置等。
当有新的消息产生时,Broker节点会将其注册到Zookeeper中,以便消费者能够快速找到并订阅该消息。
2. Broker节点间的同步:Kafka采用了基于拉取模式的分布式协调策略,Broker节点间会定期同步彼此的状态和消息数据。
这样,当某个Broker节点接收到新的消息时,其他Broker节点也会同步收到该消息。
3. 消息负载均衡:Kafka会根据消费者的ID、分组等信息将消息分发到不同的消费者中,实现了负载均衡。
这样可以确保不同的消费者都能接收到同一份消息,避免消息的不均匀分布。
4. 消息持久化:Kafka将接收到的消息存储到本地磁盘上,并通过日志文件的形式实现了数据的持久化存储。
Kafaka详细介绍机制原理

Kafaka详细介绍机制原理1. kafka介绍1.1. 主要功能根据官⽹的介绍,ApacheKafka®是⼀个分布式流媒体平台,它主要有3种功能: 1:It lets you publish and subscribe to streams of records.发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因 2:It lets you store streams of records in a fault-tolerant way.以容错的⽅式记录消息流,kafka以⽂件的⽅式来存储消息流 3:It lets you process streams of records as they occur.可以再消息发布的时候进⾏处理1.2. 使⽤场景1:Building real-time streaming data pipelines that reliably get data between systems or applications.在系统或应⽤程序之间构建可靠的⽤于传输实时数据的管道,消息队列功能2:Building real-time streaming applications that transform or react to the streams of data。
构建实时的流数据处理程序来变换或处理数据流,数据处理功能1.3. 详细介绍Kafka⽬前主要作为⼀个分布式的发布订阅式的消息系统使⽤,下⾯简单介绍⼀下kafka的基本机制1.3.1 消息传输流程 Producer即⽣产者,向Kafka集群发送消息,在发送消息之前,会对消息进⾏分类,即Topic,上图展⽰了两个producer发送了分类为topic1的消息,另外⼀个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注⾃⼰需要的Topic中的消息 Consumer即消费者,消费者通过与kafka集群建⽴长连接的⽅式,不断地从集群中拉取消息,然后可以对这些消息进⾏处理。
kafka监控工作原理

Kafka监控工作原理1. 介绍Kafka是一个分布式流处理平台,广泛应用于构建实时数据流应用。
为了保证Kafka集群的稳定性和性能,对其进行监控是至关重要的。
Kafka监控工作原理涉及到监控指标的收集、存储、展示和告警等方面。
2. 监控指标监控指标是衡量系统状态的重要指标,对于Kafka来说,常见的监控指标包括:•生产者指标:包括生产速率、消息堆积、消息丢失率等。
•消费者指标:包括消费速率、消费延迟、消费者偏移量等。
•Broker指标:包括网络流量、磁盘使用率、CPU利用率等。
•主题指标:包括分区数量、副本数量、ISR(In-Sync Replica)数量等。
3. 监控数据收集为了收集监控数据,通常有以下几种方式:3.1 JMXKafka内置了JMX(Java Management Extensions)支持,可以通过JMX来获取Kafka的各种监控指标。
JMX是Java平台的一种管理和监控标准,通过Java代码可以访问和操作被监控应用程序的各种资源。
Kafka的JMX支持允许将监控指标暴露为MBean(Managed Bean),通过JMX客户端可以获取这些指标。
MBean是一种Java对象,提供了一组属性和方法,用于描述和操作被管理资源。
3.2 Exporter除了JMX,还可以使用Exporter来收集Kafka的监控数据。
Exporter是一种独立的组件,用于将监控数据从Kafka集群导出到外部系统,如Prometheus、InfluxDB等。
Exporter通常通过Kafka的Metrics API获取监控数据,并将其转换为外部系统可以理解的格式,如Prometheus的数据格式。
然后,外部系统可以通过HTTP接口获取这些数据并进行展示和分析。
3.3 第三方工具除了使用JMX和Exporter,还可以使用第三方工具来收集Kafka的监控数据。
例如,可以使用Kafka Manager、Burrow等工具来监控Kafka的各种指标。
kafka各个版本特点介绍和总结

kafka各个版本特点介绍和总结kafka各个版本特点介绍和总结1.1 kafka的功能特点:分布式消息队列消息队列的数据模型,形成流式数据。
提供Pub/Sub⽅式的海量消息处理。
以⾼容错的⽅式存储海量数据流。
保证数据流的顺序。
消费者:⼀份消息可多个消费者都处理,也可以只由⼀个消费者处理线性扩展,⾼可⽤分布式系统,易于向外扩展。
所有的producer、broker和consumer都会有多个,均为分布式的。
⽆需停机即可扩展机器。
动态的增加⼀个topic的partition⽂件数量,就可以线性扩展⼀个topic的处理能⼒。
以⾼容错的⽅式存储海量数据流。
每个topic包含多个partition,partiton⼜有多个副本,均匀的分布在多个机器上。
⾼吞吐量:⽣成和消费速度⾮常快1. kafka server ⽣成⽇志的速度可以接近磁盘的只写速度(⼏⼗兆 ~ 百兆)。
kafka的实现思想是⽂件直写(直接使⽤linux ⽂件系统的cache)的commit log. 速度⾮常的快.如果消息⼤⼩为百字节级别的话,那么也就是说单机写⼊可以达到⼏⼗W/S。
2. 磁盘顺序读写3. 采⽤linux Zero-Copy提⾼消息发送到consumer的性能。
减少IO操作步骤;可以提⾼60%的数据发送性能。
1.2 kafka的使⽤场景:kafka的使⽤场景,即kafka的⽤途。
数据总线(数据管道)Kafka主要⽤途是数据集成,或者说是流数据集成,以Pub/Sub形式的消息总线形式提供。
Kafka可以让合适的数据以合适的形式出现在合适的地⽅。
1. 降低系统组⽹复杂度。
2. 降低编程复杂度,各个⼦系统不在是相互协商接⼝,各个⼦系统类似插⼝插在插座上,Kafka承担⾼速数据总线的作⽤。
⽇志收集,⽤户⾏为数据,运维监控数据收集,都可以适合该场景。
海量数据发布/订阅的消息队列实时计算的流式数据源(storm,spark-streaming)离线计算的数据源1. kafka的数据⽂件作为离线计算的数据源。
kafka jvm参数

kafka jvm参数摘要:1.Kafka简介2.JVM参数的作用3.Kafka JVM参数优化建议正文:Kafka是一款高性能、可扩展的分布式消息队列系统,广泛应用于大数据处理、实时数据流分析和日志收集等场景。
Kafka在运行时,JVM参数的设置对系统的性能和稳定性有着重要影响。
本文将详细介绍Kafka JVM参数的相关知识。
JVM参数是Java虚拟机参数的简称,它影响Java程序运行时的性能和稳定性。
对于Kafka这样的Java应用程序来说,合理调整JVM参数可以提高资源利用率、提高系统性能,同时避免一些潜在的稳定性问题。
以下是一些建议的Kafka JVM参数优化设置:1.调整堆大小(-Xms和-Xmx)堆大小是JVM分配给应用程序的最大内存。
Kafka作为大数据处理系统,需要大量的堆内存来存储消息数据和元数据。
通常,可以将Kafka的堆大小设置为服务器总内存的50%-70%。
具体数值需要根据服务器实际硬件资源和Kafka的负载情况来调整。
2.启用压缩指针(-XX:+UseCompressedOops)启用压缩指针可以减少堆内存的使用,提高堆内存的利用率和垃圾回收效率。
对于Kafka这种大数据处理系统来说,可以显著减少内存消耗。
3.调整垃圾回收器(G1和CMS)Kafka在生产环境中,可以根据服务器的硬件资源和负载情况,选择合适的垃圾回收器。
G1垃圾回收器适用于大内存、高吞吐量的场景,而CMS垃圾回收器适用于对低延迟要求不高的场景。
4.调整新生代与老年代的比例(-XX:NewRatio和-XX:SurvivorRatio)调整新生代与老年代的比例可以影响垃圾回收的频率和性能。
通常,可以将新生代与老年代的比例设置为1:2,以平衡垃圾回收的性能和内存占用。
5.启用类数据共享(-XX:+UseClassDataSharing)启用类数据共享可以减少垃圾回收时的内存访问开销,提高垃圾回收性能。
对于Kafka这种大数据处理系统来说,可以显著提高性能。
kafkatemplate详解

kafkatemplate详解摘要:1.简介2.Kafka 模板的使用场景3.Kafka 模板的设计原则4.Kafka 模板的实现细节5.Kafka 模板的使用示例6.Kafka 模板的优缺点分析7.总结正文:Kafka 是一个分布式的流处理平台,广泛应用于大数据领域。
在实际应用中,开发者需要根据业务需求编写各种类型的Kafka 生产者和消费者。
为了简化开发过程,提高代码复用性,Kafka 提供了一种叫做Kafka 模板的机制。
本文将详细介绍Kafka 模板的使用方法、设计原则及实现细节。
一、简介Kafka 模板(Kafka Template)是Kafka 提供的一种生产者与消费者配置抽象,可以简化生产者和消费者的开发过程。
开发者只需实现一个简单的接口,即可生成适用于各种场景的生产者和消费者。
二、Kafka 模板的使用场景Kafka 模板主要用于以下场景:1.简化生产者和消费者的开发过程,提高代码复用性。
2.自动配置生产者和消费者的参数,如bootstrap.servers、key.deserializer、value.deserializer 等。
3.自动处理生产者和消费者的事件,如onSend、onReceive 等。
三、Kafka 模板的设计原则Kafka 模板遵循以下设计原则:1.简单易用:开发者只需实现一个简单的接口,即可生成适用于各种场景的生产者和消费者。
2.高度可定制:Kafka 模板提供了丰富的配置选项,开发者可以根据需求灵活定制生产者和消费者的行为。
3.易于扩展:Kafka 模板采用了模板方法模式,开发者可以轻松地扩展和修改模板的行为。
四、Kafka 模板的实现细节Kafka 模板主要包含以下类:1.KafkaTemplate:Kafka 模板的顶层接口,开发者只需实现该接口,即可生成适用于各种场景的生产者和消费者。
2.ProducerTemplate:Kafka 生产者模板,继承自KafkaTemplate。
kafka底层原理

kafka底层原理Kafka是一个开源分布式流处理平台,它提供了可靠的发布-订阅消息系统,以及流处理功能。
Kafka最初是由LinkedIn开发的,但现在已经成为Apache软件基金会的一部分。
Kafka的底层原理是建立在分布式系统基础之上的。
它使用主题(topic)作为消息的逻辑分组,消息可以在主题中发布和订阅。
Kafka的分布式系统使用集群来存储和处理消息,集群由多个服务器组成,每个服务器都可以处理消息,即使一台服务器出现故障,也不会影响集群的功能。
Kafka底层原理的核心是zookeeper。
zookeeper是一个高可用的分布式协调服务,它可以检测服务器的状态,使Kafka集群可以安全运行。
zookeeper可以通过临时节点(ephemeral node)来监控Kafka的节点,如果某个节点出现故障,zookeeper可以将该节点从Kafka集群中删除,以确保Kafka的高可用性。
在Kafka的底层原理中,消息传递通过分区(partition)实现。
Kafka支持多个分区,这样可以提高Kafka的吞吐量。
每个分区都有一个主副本和多个从副本,主副本负责处理消息读取,而从副本负责复制消息,以确保消息的安全性。
Kafka的底层原理还支持消息持久性,也就是说,Kafka可以将消息存储到磁盘上,并在需要时将其读取出来。
Kafka支持多种文件系统,包括本地文件系统和分布式文件系统,例如HDFS。
这样一来,Kafka可以将消息保存到不同的文件系统中,以确保数据的安全性和可用性。
Kafka的底层原理还支持消息路由(message routing)。
Kafka消息可以在不同的主题中发布和订阅,Kafka可以根据消息的内容(如标签、关键字等)来路由消息,比如,如果某个消息包含标签“news”,那么Kafka可以将该消息路由到“news”主题中。
Kafka的底层原理还支持流处理(stream processing)。
Kafka版本介绍

Kafka版本介绍1. Kafka 只是⼀个消息引擎系统吗?Apache Kafka 是消息引擎系统,也是⼀个分布式流处理平台(Distributed Streaming Platform)Kafka 在设计之初就旨在提供三个⽅⾯的特性:提供⼀套 API 实现⽣产者和消费者降低⽹络传输和磁盘存储开销实现⾼伸缩性架构批处理:批量处理冷数据,单个处理数据量⼤流处理:处理在线,实时产⽣的数据,单次处理的数据量⼩,但处理速度更快流处理要最终替代它的“兄弟”批处理需要具备两点核⼼优势:1. 要实现正确性,实现正确性是流处理能够匹敌批处理的基⽯2. 提供能够推导时间的⼯具。
正确性⼀直是批处理的强项,⽽实现正确性的基⽯则是要求框架能提供精确⼀次处理语义,即处理⼀条消息有且只有⼀次机会能够影响系统状态。
⽬前主流的⼤数据流处理框架都宣称实现了精确⼀次处理语义,但这是有限定条件的,即它们只能实现框架内的精确⼀次处理语义,⽆法实现端到端的。
l Kafka Streams 正是它提供了 Kafka 实时处理流数据的能⼒l Kafka Connect 通过⼀个个具体的连接器(Connector),串联起上下游的外部系统2. apache Kafka 流处理平台主要组件介绍Kafka Streams 正是它提供了 Kafka 实时处理流数据的能⼒Kafka Connect 通过⼀个个具体的连接器(Connector),串联起上下游的外部系统3.不同版本间的Kafka应该如何选择?1. Apache KafkaApache Kafka 是最“正宗”的 Kafka,⾃ Kafka 开源伊始,它便在 Apache 基⾦会孵化并最终毕业成为顶级项⽬,它也被称为社区版 Kafka,也就是说,后⾯提到的发⾏版要么是原封不动地继承了 Apache Kafka,要么是在此之上扩展了新功能,总之 Apache Kafka 是我们学习和使⽤ Kafka 的基础优点:是开发⼈数最多、版本迭代速度最快的 Kafka,当使⽤ Apache Kafka 碰到任何问题并提交问题到社区,社区都会⽐较及时地作出响应。
kafka默认的分区机制

kafka默认的分区机制Kafka是一个分布式流数据平台,具有高吞吐量、可扩展性和持久性的特点。
Kafka通过将数据分为多个主题(topic)和多个分区(partition),来实现高效的数据传输和处理。
Kafka默认的分区机制是一种基于哈希算法的分区方式,下面将详细介绍Kafka默认的分区机制。
在Kafka中,每个主题都被划分为多个分区,每个分区都是有序的、不可变的消息序列。
消息被写入分区的尾部,并由分区的偏移量来唯一标识。
而每个消费者组(consumer group)则可以同时消费多个分区内的消息。
Kafka的分区机制是基于哈希的分配方式,将消息根据其键(key)进行哈希计算,并将计算结果与主题的分区数取模,从而确定消息所属的分区。
这样,每个分区都会被均匀地分配到不同的broker节点上,实现负载均衡。
使用哈希算法的好处之一是,相同键的消息总是被分配到同一个分区中。
这保证了具有相同键的消息将被按顺序处理,可以使得相关的消息聚集在一起。
同时,由于使用了哈希计算,分区的分配是确定性的,同一键的消息总是被分配到同一个分区,这保证了Kafka的可重复性和可靠性。
Kafka的默认分区机制还支持自定义分区策略。
在创建主题时,可以指定分区策略,如按照键进行分区,或者使用自定义的分区器。
自定义分区器需要实现Partitioner接口,并重写其partition方法。
通过自定义分区策略,可以根据实际需求对消息进行更精准的分区控制。
Kafka的分区机制还有以下几个特点:1.分区的扩展性:Kafka的分区机制能够很好地支持集群的扩展。
当新增加的broker节点加入集群时,旧有的分区会被重新分配,从而实现负载均衡。
2.消费者组的并行度:由于每个主题可以被划分为多个分区,每个分区可以由不同的消费者组并行消费。
这样,Kafka能够同时支持多个消费者组并行消费,从而提高数据的处理速度和吞吐量。
3.消息的顺序性:在同一个分区内,消息的顺序是有序的,且分区之间是相互独立的。
Kafka架构及基本原理简析
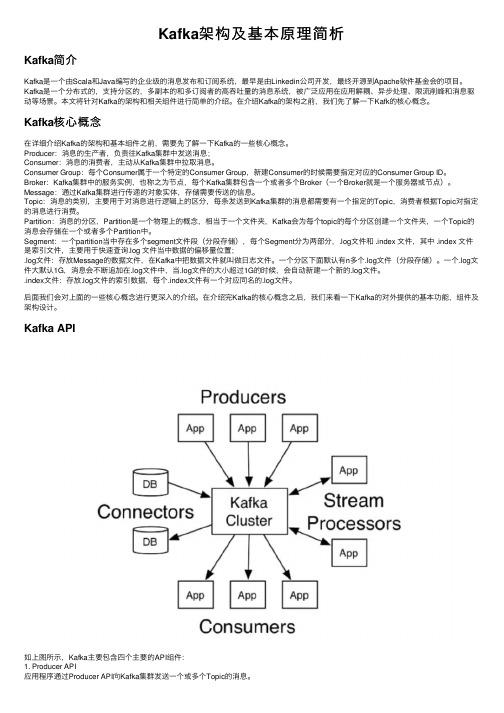
Kafka架构及基本原理简析Kafka简介Kafka是⼀个由Scala和Java编写的企业级的消息发布和订阅系统,最早是由Linkedin公司开发,最终开源到Apache软件基⾦会的项⽬。
Kafka是⼀个分布式的,⽀持分区的,多副本的和多订阅者的⾼吞吐量的消息系统,被⼴泛应⽤在应⽤解耦、异步处理、限流削峰和消息驱动等场景。
本⽂将针对Kafka的架构和相关组件进⾏简单的介绍。
在介绍Kafka的架构之前,我们先了解⼀下Kafk的核⼼概念。
Kafka核⼼概念在详细介绍Kafka的架构和基本组件之前,需要先了解⼀下Kafka的⼀些核⼼概念。
Producer:消息的⽣产者,负责往Kafka集群中发送消息;Consumer:消息的消费者,主动从Kafka集群中拉取消息。
Consumer Group:每个Consumer属于⼀个特定的Consumer Group,新建Consumer的时候需要指定对应的Consumer Group ID。
Broker:Kafka集群中的服务实例,也称之为节点,每个Kafka集群包含⼀个或者多个Broker(⼀个Broker就是⼀个服务器或节点)。
Message:通过Kafka集群进⾏传递的对象实体,存储需要传送的信息。
Topic:消息的类别,主要⽤于对消息进⾏逻辑上的区分,每条发送到Kafka集群的消息都需要有⼀个指定的Topic,消费者根据Topic对指定的消息进⾏消费。
Partition:消息的分区,Partition是⼀个物理上的概念,相当于⼀个⽂件夹,Kafka会为每个topic的每个分区创建⼀个⽂件夹,⼀个Topic的消息会存储在⼀个或者多个Partition中。
Segment:⼀个partition当中存在多个segment⽂件段(分段存储),每个Segment分为两部分,.log⽂件和 .index ⽂件,其中 .index ⽂件是索引⽂件,主要⽤于快速查询.log ⽂件当中数据的偏移量位置;.log⽂件:存放Message的数据⽂件,在Kafka中把数据⽂件就叫做⽇志⽂件。
Kafka简介及各个组件介绍【转】

Kafka简介及各个组件介绍【转】Kafka:分布式发布-订阅消息系统注:本⽂翻译⾃官⽅⽂档。
1. 介绍Kafka is a distributed,partitioned,replicated commit log service. It provides the functionality of a messaging system, but with a unique design.Kafka是⼀种分布式发布-订阅消息系统,它提供了⼀种独特的消息系统功能。
Kafka maintains feeds of messages in categories called topics.We’ll call processes that publish messages to a Kafka topic producers.We’ll call processes that subscribe to topics and process the feed of published messages consumers..Kafka is run as a cluster comprised of one or more servers each of which is called a broker.1) Kafka维护的消息流称为topic。
2) 发布消息者称为 producer。
3) 订阅并消费消息的称为 consumers。
4) Kafka运⾏在多server的集群之上,每个server称为broker。
2. 组件Topics and LogsA topic is a category or feed name to which messages are published. For each topic, the Kafka cluster maintains a partitioned log that looks like this:⼀个Topic可以认为是⼀类消息,Kafka集群将每个topic将被分成多个partition(区),逻辑上如上图所⽰。
kafka在java中的使用

kafka在java中的使用Kafka是一个高性能的分布式消息队列系统,可以用于构建实时数据流处理系统。
Kafka在处理大量实时数据的场景下非常有效,可以实现高吞吐量、低延迟的消息传递。
本篇文章主要介绍kafka在Java中的使用。
一、Kafka的基础知识在开始kafka的Java实现之前,我们需要先了解Kafka的一些基本概念和使用方法。
1. 消息在Kafka中,消息是指一条可以被生产者发送到Kafka服务器上的数据。
消息可以是任意类型的数据,比如文本、二进制数据、JSON数据等等。
每条消息包含一个键和一个值,键和值都是字符串。
2. 生产者生产者是指向Kafka队列发送消息的应用程序。
生产者可以将消息发送到一个或多个主题中,每个主题可以有一个或多个分区,每个分区都保存了消息的有序序列。
3. 主题主题是Kafka的基本概念,它是消息的逻辑容器,用于分类不同类型的消息。
主题是由若干个分区组成的,每个分区都是有序的消息序列。
4. 分区分区是主题的基本单元,每个分区中包含了一系列有序的消息。
一个主题可以有一个或多个分区,每个分区的消息是互相独立的。
分区的目的是将主题中的消息分布在不同的Kafka服务器上,使得消息可以更快地被处理。
5. 消费者消费者是指从Kafka队列中读取消息的应用程序。
消费者可以订阅一个或多个主题中的消息,并从订阅的主题中读取消息。
6. ZooKeeperZooKeeper是一个分布式协调系统,它用于管理Kafka集群中的各个节点。
ZooKeeper 可以用于管理Kafka集群的节点列表、分区的分布以及Leader的选举等。
7. BrokerBroker是指Kafka集群中的一个节点,它可以存储一个或多个分区的消息。
Kafka集群中的所有节点都是对等的,每个节点都可以充当生产者或消费者。
节点之间通过ZooKeeper进行协调和管理。
消费者组是指一组消费者共同消费一个或多个主题中的消息。
kafka基本概念

kafka基本概念Kafka是一个高性能、分布式、可扩展的消息队列系统,最初由LinkedIn开发,现在已经成为Apache基金会的顶级开源项目。
Kafka 的设计目标是为了处理大规模的实时数据流,它可以处理数百万条消息的流,并能够在多个应用程序之间进行高效的数据传输。
本文将介绍Kafka的一些基本概念,包括Kafka的结构、消息的生产和消费、Kafka的分区和副本、以及Kafka的持久化机制等。
1. Kafka的结构Kafka由多个组件组成,包括Producer、Broker、Consumer和Zookeeper。
Producer负责生产消息,将消息发送到Kafka集群中的Broker。
Broker是Kafka集群中的中心节点,负责接收、存储、转发和分发消息。
Consumer从Broker中消费消息。
Zookeeper是Kafka 集群的协调者,负责维护集群的元数据和分布式锁。
2. 消息的生产和消费在Kafka中,Producer将消息发送到指定的Topic中,可以同时向多个Topic发送消息。
Topic是Kafka中的逻辑概念,用于分类和管理消息。
每个Topic可以被分为多个Partition,每个Partition 是一个有序的消息队列。
Producer将消息发送到指定的Partition 中,如果没有指定Partition,则消息将被随机分配到一个Partition 中。
Consumer从指定的Partition中消费消息,可以同时消费多个Partition中的消息。
Consumer可以从指定的Offset开始消费消息,也可以从最新的消息开始消费。
Kafka支持两种消费方式:Push和Pull。
Push方式是将消息推送到Consumer,Pull方式是Consumer主动拉取消息。
3. Kafka的分区和副本Kafka将每个Topic分为多个Partition,每个Partition是一个有序的消息队列。
filebeat和kafka之间版本对应表

一、介绍filebeat和kafkaFilebeat是一个轻量级的日志数据收集器,专门用于将日志文件发送到ELK堆栈中。
它可以帮助用户收集和发送各种类型的日志数据到Elasticsearch或Logstash,从而方便用户进行搜索、分析和可视化。
Kafka是一个分布式的流式评台,可以用于构建实时数据管道和流式应用程序。
它将消息发布到订阅的消息队列中,并允许应用程序根据需要拉取消息。
Kafka可以处理来自各种来源的实时数据流,并将这些数据流传递给其他系统进行处理。
二、 filebeat和kafka之间的版本对应关系1. Filebeat版本6.x对应的Kafka版本- Filebeat 6.0.0对应Kafka 1.0.0- Filebeat 6.1.0对应Kafka 1.1.0- Filebeat 6.2.0对应Kafka 1.1.1- Filebeat 6.3.0对应Kafka 1.1.1- Filebeat 6.4.0对应Kafka 1.1.12. Filebeat版本7.x对应的Kafka版本- Filebeat 7.0.0对应Kafka 2.0.0- Filebeat 7.1.0对应Kafka 2.1.0- Filebeat 7.2.0对应Kafka 2.2.0- Filebeat 7.3.0对应Kafka 2.3.0- Filebeat 7.4.0对应Kafka 2.3.03. Filebeat版本8.x对应的Kafka版本- Filebeat 8.0.0对应Kafka 2.4.0- Filebeat 8.1.0对应Kafka 2.5.0- Filebeat 8.2.0对应Kafka 2.6.0三、版本对应关系的重要性正确地将Filebeat和Kafka进行版本对应是非常重要的。
由于不同版本的软件可能会具有不同的功能和API,如果Filebeat和Kafka的版本不匹配,就可能导致数据传输的失败或数据丢失。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Kafka的offset
• 每条消息在文件中的位置称为offset(偏移量)。offset 为一个long型
数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有 提供其他额外的索引机制来存储offset,因为在kafka中几 乎不允许对
消息进行“随机读写”。
• Partition中的每条Message由offset来表示它在这个partition中的偏
• Logs文件根据broker中的配置要求,保留一定时间后删除来释放磁盘空间。
Partition: Topic 物理上的分组, 一个 topic 可以分为多个 partition, 每个 partition 是一个有序的队列。 partition 中的每条消息 都会被分配一个有序的 id (offset)。
当消息的个数(或尺寸)达到一定阀值时,再flush到磁盘,这样 减少了磁盘IO调用的次数。
Kafka的broker无状态机制
• 1. Broker没有副本机制,一旦broker宕机,该broker的消息将都不可
用。
• 2. Broker不保存订阅者的状态,由订阅者自己保存。 • 3. 无状态导致消息的删除成为难题(可能删除的消息正在被订阅),
Kafka的Consumer group
• 1. 允许consumer group(包含多个consumer,如一个集
群同时消费)对一个topic进行消费,不同的consumer group之间独立订阅。
• 2. 为了对减小一个consumer group中不同consumer之间
的分布式协调开销,指定partition为最小的并行消费单位, 即一个group内的consumer只能消费不同的partition。
2.
3.
4.
5.
支持 online 和 offline 的场景。
Kafka的两大法宝
• 数据文件的分段: • Kafka解决查询效率的手段之一是将数据文件分段; • 为数据文件建索引:
为了进一步提高查找的效率,Kafka为每个分段后的数据文件建立了索引文件,文 件名与数据文件的名字是一样的,只是文件扩展名为.index。 索引文件中包含若干个索引条目,每个条目表示数据文件中一条Message的索引。 索引包含两个部分(均为4个字节的数字),分别为相对offset和position。
Kafka的Consumers
• 注: kafka的设计原理决定,对于一个topic,同一个group中
不能有多于partitions个数的consumer同时消费,否则将意 味着某些consumer将无法得到消息.
一个partition中的消息只会被group中的一个consumer消费; 每个group中consumer消息消费互相独立;
partition是在创建topic时指定的),每个partition存储一部分Message。
• partition中的每条Message包含了以下三个属性:
• offset • MessageSize • data
对应类型:long 对应类型:int32
是message的具体内容
Kafka的Message
2. 对于消费者而言,它们消费消息的顺序和日志中消 息顺序一致. 3. 如果Topic的"replication factor"为N,那么允许N1个kafka实例失效.
•
•
Kafka的消息处理机制
• 4. kafka对消息的重复、丢失、错误以及顺序型没有严格的要求。 • 5. kafka提供at-least-once delivery,即当consumer宕机后,有
些消息可能会被重复delivery。
• 6. 因每个partition只会被consumergroup内的一个consumer
消费,故kafka保证每个partition内的消息会被顺序的订阅。
• 7. Kafka为每条消息为每条消息计算CRC校验,用于错误检测,
crc校验不通过的消息会直接被丢弃掉。 • ack校验,当消费者消费成功,返回ack信息!
每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的 每个group中的一个consumer消费.
• 可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"
订阅者"中的一个consumer消费,不过一个 consumer可以消费多个partitions 中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息 是顺 序的.事实上,从Topic角度来说,消息仍不是有序的.
数据传输的事务定义
• at most once: 最多一次,这个和JMS中"非持久化"消息类似.发送一次,无论成败,将不会重发. • at least once: 消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功. • exactly once: 消息只会发送一次.
• at most once: 消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但
索引优化:稀疏存储,每隔一定字节的数据建立一条索引。
消息队列分类
• 点对点: • 消息生产者生产消息发送到queue中,然后消息消费者从queue中取出并且消费消息。
• 注意:
• 消息被消费以后,queue中不再有存储,所以消息消费者不可能消费到已经被消费的
消息。
• Queue支持存在多个消费者,但是对一个消息而言,只会有一个消费者可以消费。
长的高级/复杂的队列,但是技术也复杂,并且只提供非持久性的队列pache下的一个子项,类似ZeroMQ,能够以代理人和点对
• Redis:是一个key-Value的NOSql数据库,但也支持MQ功能,数据量较
小,性能优于RabbitMQ,数据超过10K就慢的无法忍受
移量,这个offset不是该Message在partition数据文件中的实际存储 位置,而是逻辑上一个值,它唯一确定了partition中的一条Message。 因此,可以认为offset是partition中Message的id。
Kafka的 offset
• 怎样记录每个consumer处理的信息的状态?在Kafka中仅
费的能力.
Kafka的Message
• Message消息:是通信的基本单位,每个 producer 可以向一个 topic
(主题)发布一些消息。
• Kafka中的Message是以topic为基本单位组织的,不同的topic之间是相
互独立的。每个topic又可以分成几个不同的partition(每个topic有几个
kafka采用基于时间的SLA(服务水平保证),消息保存一定时间(通常 为7天)后会被删除。
• 4. 消息订阅者可以rewind back到任意位置重新进行消费,当订阅者
故障时,可以选择最小的offset(id)进行重新读取消费消息。
Kafka的Consumers
• 消息和数据消费者,订阅 topics 并处理其发布的消息的过程叫做 consumers。 • 本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,
• 发布/订阅: • 消息生产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该
消息。和点对点方式不同,发布到topic的消息会被所有订阅者消费。
消息队列MQ对比
• RabbitMQ:支持的协议多,非常重量级消息队列,对路由(Routing),负载均衡 (Load balance)或者数据持久化都有很好的支持。 • ZeroMQ:号称最快的消息队列系统,尤其针对大吞吐量的需求场景,擅
Kafka的Topics/Log
• 一个Topic可以认为是一类消息,每个topic将被分成多partition(区),每
个partition在存储层面是append log文件。任何发布到此partition的 消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为 offset(偏移量),partition是以文件的形式存储在文件系统中。
KAFKA介绍
内容
• kafka是什么 • kafka体系结构
• kafka设计理念简介
• kafka安装部署 • kafka producer和consumer开发
Kafka关键词
• 分布式发布-订阅消息系统 • LinkedIn 公司开发 • Scala语言 • 分布式的,可划分的,多订阅者 • 冗余备份 • 持久性 • 重复消费
是在消息处理过程中出现了异常,导致部分消息未能继续处理.那么此后"未处理"的消息将不 能被fetch到,这就是"at most once". 在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时 可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给 zookeeper,zookeeper恢复正常还是之前offset状态. kafka中是没有必要的.
• 批量发送可以很有效的提高发送效率。Kafka producer的
异步发送模式允许进行批量发送,先将消息缓存在内存中, 然后一次请求批量发送出去。
Kafka的Broker
• Broker:缓存代理,Kafka 集群中的一台或多台服务器统
称为 broker。
• 为了减少磁盘写入的次数,broker会将消息暂时buffer起来,
Kafka的partitions
• 设计目的: • kafka基于文件存储.通过分区,可以将日志内容分散到多个server上, 来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前 server(kafka实例)保存;