Python网络爬虫之正则表达式精讲
python 正则表达式判断

python 正则表达式判断摘要:1.Python 正则表达式的概念2.Python 正则表达式的语法3.Python 正则表达式的应用4.Python 正则表达式的判断方法正文:一、Python 正则表达式的概念正则表达式(Regular Expression,简称regex)是一种用于匹配字符串模式的字符集,通常用于文本搜索和数据提取等场景。
Python 作为一种广泛应用的编程语言,也提供了正则表达式的支持。
二、Python 正则表达式的语法Python 中的正则表达式主要通过`re`模块进行操作。
以下是一些常用的正则表达式语法:1.`.`:匹配任意字符(除了换行符)。
2.`*`:匹配前面的字符0 次或多次。
3.`+`:匹配前面的字符1 次或多次。
4.`?`:匹配前面的字符0 次或1 次。
5.`{n}`:匹配前面的字符n 次。
6.`{n,}`:匹配前面的字符n 次或多次。
7.`{n,m}`:匹配前面的字符n 到m 次。
8.`[abc]`:匹配方括号内的任意一个字符(a、b 或c)。
9.`[^abc]`:匹配除方括号内字符以外的任意字符。
10.`(pattern)`:捕获括号内的模式,并将其存储以供以后引用。
11.`|`:表示或(or),匹配两个模式之一。
三、Python 正则表达式的应用Python 正则表达式广泛应用于文本处理、数据分析等场景,例如:验证邮箱地址、提取网页链接、筛选特定字符等。
四、Python 正则表达式的判断方法在Python 中,我们可以使用`re`模块的函数来判断字符串是否符合正则表达式的规则。
以下是一些常用的判断方法:1.`re.match(pattern, string)`:从字符串的开头开始匹配,如果匹配成功则返回一个匹配对象,否则返回None。
2.`re.search(pattern, string)`:在整个字符串中搜索匹配,如果匹配成功则返回一个匹配对象,否则返回None。
Python正则表达式精确匹配手机号,邮箱,IP,身份证…..(爬虫利器)

Python正则表达式精确匹配手机号,邮箱,IP,身份证…..(爬虫利器)Python正则表达式大全1.检验手机号要求:手机号码必须为11位数字,以1开头,第二位为1或5或8。
import redef verify_mobile():mob = input('请输入手机号码:')ret = re.match(r'1[358]d{9}', mob)if ret:print('手机号码匹配正确')else:print('匹配错误')verify_mobile()2.检验邮箱import redef verify_email():email = input('请输入邮箱:')ret = re.match(r'^[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+){0,4}@[a-zA-Z0-9_-]+(.[a-zA-Z0-9_-]+){0,4}$', email)if ret:print('邮箱匹配正确')else:print('匹配错误')verify_email()3.验证身份证import redef verify_card():card = input('请输入身份证:')ret = re.match(r'^([1-9]d{5}[12]d{3}(0[1-9]|1[0-2])(0[1-9]|1[0-9]|2[0-9]|3[0-1])d{3}(d|X|x))$', card)if ret:print('身份证匹配正确')else:print('匹配错误')verify_card()4.检验年月日import redef verify_date():date = input('请输入年月日:')ret = re.match(r'^(d{4}-d{1,2}-d{1,2})$', date)if ret:print('日期匹配正确')else:print('匹配错误')verify_date()5.验证数字表达式匹配数字:^[0-9]*$匹配n位的数字:^d{n}$匹配零和非零开头的数字:^(0|[1-9][0-9]*)$匹配正数、负数、和小数:^(-|+)?d+(.d+)?$匹配非零的正整数:^[1-9]d*$ 或^([1-9][0-9]*){1,3}$ 或^+?[1-9][0-9]*$匹配非零的负整数:^-[1-9][]0-9″*$ 或 ^-[1-9]d*$匹配非负整数:^d+$ 或 ^[1-9]d*|0$匹配非正整数:^-[1-9]d*|0$ 或 ^((-d+)|(0+))$匹配浮点数:^(-?d+)(.d+)?$ 或^-?([1-9]d*.d*|0.d*[1-9]d*|0?.0+|0)$匹配正浮点数:^[1-9]d*.d*|0.d*[1-9]d*$匹配负浮点数:^-([1-9]d*.d*|0.d*[1-9]d*)$匹配非正浮点数:^((-d+(.d+)?)|(0+(.0+)?))$匹配非负浮点数:^d+(.d+)?$ 或^[1-9]d*.d*|0.d*[1-9]d*|0?.0+|0$6.验证字符表达式匹配汉字:^[一-龥]{0,}$匹配英文和数字:^[A-Za-z0-9]+$ 或 ^[A-Za-z0-9]{4,40}$匹配大写英文字母组成的字符串:^[A-Z]+$匹配小写英文字母组成的字符串:^[a-z]+$匹配大小写英文组成的字符串:^[A-Za-z]+$匹配中文、英文、数字包括下划线:^[一-龥A-Za-z0-9_]+$禁止输入含有~的字符:[^~x22]+x。
Python系列之正则表达式详解

Python系列之正则表达式详解Python 正则表达式模块 (re) 简介Python 的 re 模块(Regular Expression 正则表达式)提供各种正则表达式的匹配操作,和 Perl 脚本的正则表达式功能类似,使⽤这⼀内嵌于 Python 的语⾔⼯具,尽管不能满⾜所有复杂的匹配情况,但⾜够在绝⼤多数情况下能够有效地实现对复杂字符串的分析并提取出相关信息。
Python 会将正则表达式转化为字节码,利⽤ C 语⾔的匹配引擎进⾏深度优先的匹配。
表 1. 正则表达式元字符和语法符号说明实例.表⽰任意字符,如果说指定了 DOTALL 的标识,就表⽰包括新⾏在内的所有字符。
'abc' >>>'a.c' >>>结果为:'abc'^表⽰字符串开头。
'abc' >>>'^abc' >>>结果为:'abc'$表⽰字符串结尾。
'abc' >>>'abc$' >>>结果为:'abc'*, +, ?'*'表⽰匹配前⼀个字符重复 0 次到⽆限次,'+'表⽰匹配前⼀个字符重复 1次到⽆限次,'?'表⽰匹配前⼀个字符重复 0 次到1次'abcccd' >>>'abc*' >>>结果为:'abccc''abcccd' >>>'abc+' >>>结果为:'abccc''abcccd' >>>'abc?' >>>结果为:'abc'*?, +?, ??前⾯的*,+,?等都是贪婪匹配,也就是尽可能多匹配,后⾯加?号使其变成惰性匹配即⾮贪婪匹配'abc' >>>'abc*?' >>>结果为:'ab''abc' >>>'abc??' >>>结果为:'ab''abc' >>>'abc+?' >>>结果为:'abc'{m}匹配前⼀个字符 m 次'abcccd' >>>'abc{3}d' >>>结果为:'abcccd' {m,n}匹配前⼀个字符 m 到 n 次'abcccd' >>> 'abc{2,3}d' >>>结果为:'abcccd' {m,n}?匹配前⼀个字符 m 到 n 次,并且取尽可能少的情况'abccc' >>> 'abc{2,3}?' >>>结果为:'abcc'\对特殊字符进⾏转义,或者是指定特殊序列 'a.c' >>>'a\.c' >>> 结果为: 'a.c'[]表⽰⼀个字符集,所有特殊字符在其都失去特殊意义,只有: ^ - ] \ 含有特殊含义'abcd' >>>'a[bc]' >>>结果为:'ab'|或者,只匹配其中⼀个表达式,如果|没有被包括在()中,则它的范围是整个正则表达式'abcd' >>>'abc|acd' >>>结果为:'abc' ( … )被括起来的表达式作为⼀个分组. findall 在有组的情况下只显⽰组的内容 'a123d' >>>'a(123)d' >>>结果为:'123'(?#...)注释,忽略括号内的内容特殊构建不作为分组 'abc123' >>>'abc(?#fasd)123' >>>结果为:'abc123'(?= …)表达式’…’之前的字符串,特殊构建不作为分组在字符串’ pythonretest ’中 (?=test) 会匹配’pythonre ’(?!...)后⾯不跟表达式’…’的字符串,特殊构建不作为分组如果’ pythonre ’后⾯不是字符串’ test ’,那么(?!test) 会匹配’ pythonre ’(?<=… )跟在表达式’…’后⾯的字符串符合括号之后的正则表达式,特殊构建不作为分组正则表达式’ (?<=abc)def ’会在’ abcdef ’中匹配’def ’(?:)取消优先打印分组的内容'abc' >>>'(?:a)(b)' >>>结果为'[b]'?P<>指定Key'abc' >>>'(?P<n1>a)>>>结果为:groupdict{n1:a}表 2. 正则表达式特殊序列特殊表达式序列说明\A只在字符串开头进⾏匹配。
python正则表达式

python正则表达式正则表达式应⽤场景特定规律字符串的查找替换切割等邮箱格式、url等格式的验证爬⾍项⽬,提取特定的有效内容很多应⽤的配置⽂件使⽤原则只要能够通过字符串等相关函数能够解决的,就不要使⽤正则正则的执⾏效率⽐较低,会降低代码的可读性世界上最难读懂的三样东西:医⽣的处⽅、道⼠的神符、码农的正则提醒:正则是⽤来写的,不是⽤来读的,不要试着阅读别⼈的正则;不懂功能时必要读正则。
基本使⽤说明:正则是通过re模块提供⽀持的相关函数:match:从开头进⾏匹配,找到就⽴即返回正则结果对象,没有就返回Nonesearch:匹配全部内容,任意位置,只要找到,⽴即返回正则结果对象,没有返回None# python依赖次模块完成正则功能import re# 从开头进⾏匹配,找到⼀个⽴即返回正则结果对象,没有返回Nonem = re.match('abc', 'abchelloabc')# 匹配全部内容,任意位置,只要找到,⽴即返回正则结果对象,没有返回Nonem = re.search('abc', 'helloabcshsjsldj')if m:print('ok')# 获取匹配内容print(m.group())# 获取匹配位置print(m.span())findall:匹配所有内容,返回匹配结果组成的列表,没有的返回⼀个空列表# 匹配所有内容,返回匹配结果组成的列表,没有返回Nonef = re.findall('abc', 'abcsdisuoiabcsjdklsjabc')if f:print(f)compile:根据字符串⽣成正则表达式的对象,⽤于特定正则匹配,通过match、search、findall匹配# 根据字符串⽣成正则表达式的对象,⽤于正则匹配c = pile('abc')# 然后进⾏特定正则匹配# m = c.match('abcdefghijklmn')m = c.search('abcdefghijklmn')if m:print(m)print(c.findall('abcueywiabcsjdkaabc'))将re模块中的match、search、findall⽅法的处理过程分为了两步完成。
Python网络爬虫的房地产行业数据获取与处理方法

Python网络爬虫的房地产行业数据获取与处理方法近年来,随着互联网的发展,房地产行业数据的获取与处理成为了许多人关注的焦点。
而Python网络爬虫作为一种高效、灵活的技术,被广泛运用于房地产数据的抓取和分析。
本文将介绍Python网络爬虫在房地产行业数据获取与处理中的应用方法,并分享一些实用的技巧和工具。
一、数据获取的基本流程1. 确定数据源在使用Python进行数据爬取之前,我们首先需要确定要获取数据的来源。
例如,我们可以选择房地产信息网站、房屋交易平台等作为数据源,以获取想要的房地产数据。
2. 分析网页结构在确定数据源之后,我们需要进一步分析网页的结构,以便正确地抓取所需的数据。
通常,我们可以使用浏览器开发者工具来查看网页源代码,并通过查找元素、观察网页结构等方式来获取有关数据的信息。
3. 编写爬虫程序在分析完网页结构后,我们可以使用Python的相关库,如BeautifulSoup、Scrapy等,根据网页结构编写爬虫程序。
通过模拟浏览器行为,我们可以实现数据的自动抓取、解析和存储等功能。
4. 数据存储与处理爬取到的数据通常以结构化的形式存在,例如CSV、JSON等。
我们可以使用Python的数据处理库(如Pandas)对数据进行清洗、筛选、分析等操作,以便得到我们想要的结果。
二、Python网络爬虫的工具与技巧1. 使用Requests库发送HTTP请求在进行数据爬取时,我们通常需要模拟浏览器发送HTTP请求,以获取网页内容。
Python的Requests库提供了简洁而强大的接口,可以方便地发送各种类型的请求,并得到相应的响应数据。
2. 使用BeautifulSoup库解析网页获取到网页内容后,我们需要对其进行解析,以便从中提取我们需要的数据。
BeautifulSoup库是Python中一个常用的HTML/XML解析库,可以帮助我们方便地提取网页中的各种信息。
3. 使用正则表达式进行数据提取有些情况下,网页的结构比较复杂,使用常规的解析库无法直接提取到目标数据。
python正则表达式详解

python正则表达式详解python 正则表达式详解1. 正则表达式模式模式描述^匹配字符串的开头$匹配字符串的末尾。
.匹配任意字符,除了换⾏符,当re.DOTALL标记被指定时,则可以匹配包括换⾏符的任意字符。
[...]⽤来表⽰⼀组字符,单独列出:[amk] 匹配 'a','m'或'k'[^...]不在[]中的字符:[^abc] 匹配除了a,b,c之外的字符。
re*匹配0个或多个的表达式。
re+匹配1个或多个的表达式。
re?匹配0个或1个由前⾯的正则表达式定义的⽚段,⾮贪婪⽅式re{ n}匹配n个前⾯表达式。
例如,"o{2}"不能匹配"Bob"中的"o",但是能匹配"food"中的两个o。
re{ n,}精确匹配n个前⾯表达式。
例如,"o{2,}"不能匹配"Bob"中的"o",但能匹配"foooood"中的所有o。
"o{1,}"等价于"o+"。
"o{0,}"则等价于"o*"。
re{ n,m}匹配 n 到 m 次由前⾯的正则表达式定义的⽚段,贪婪⽅式a| b匹配a或b(re)匹配括号内的表达式,也表⽰⼀个组(?imx)正则表达式包含三种可选标志:i, m, 或 x 。
只影响括号中的区域。
(?-imx)正则表达式关闭 i, m, 或 x 可选标志。
只影响括号中的区域。
(?: re)类似 (...), 但是不表⽰⼀个组(?imx:re)在括号中使⽤i, m, 或 x 可选标志(?-imx:re)在括号中不使⽤i, m, 或 x 可选标志(?#...)注释.(?= re)前向肯定界定符。
如果所含正则表达式,以 ... 表⽰,在当前位置成功匹配时成功,否则失败。
Python如何利用正则表达式爬取网页信息及图片

Python如何利⽤正则表达式爬取⽹页信息及图⽚⼀、正则表达式是什么?概念:正则表达式是对字符串操作的⼀种逻辑公式,就是⽤事先定义好的⼀些特定字符、及这些特定字符的组合,组成⼀个“规则字符串”,这个“规则字符串”⽤来表达对字符串的⼀种过滤逻辑。
正则表达式是⼀个特殊的字符序列,它能帮助你⽅便的检查⼀个字符串是否与某种模式匹配。
个⼈理解:简单来说就是使⽤正则表达式来写⼀个过滤器来过滤了掉杂乱的⽆⽤的信息(eg:⽹页源代码…)从中来获取⾃⼰想要的内容⼆、实战项⽬1.爬取内容获取上海所有三甲医院的名称并保存到.txt⽂件中2.访问链接3.正则表达式书写的灵感进⼊⽹站查看本页⾯的源代码发现:医院的名称都是放在⼀个<div class="province-box"> ...... </div>盒⼦⾥我们只需要直接把这个盒⼦⾥⾯的数据过滤⼀下就⾏正则表达式:法⼀:1.⼀级过滤 :<div class="province-box">(.*)<div class="wrap-right">开头是:<div class="province-box"> (.*) 结尾是:<div class="wrap-right">2.⼆级过滤:title="(.*[院⼼部])*)" 获取title=" " ⾥⾯的信息法⼆:优化后⼀次性过滤:<li><a href="/[^/].*/" rel="external nofollow" rel="external nofollow" target="_blank" title="(.*)">贴图⽚开头是:结尾是:4.项⽬源代码import requestsimport reurl = "https:///sanjia/shanghai/"# 模拟浏览器的访问headers ={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) ''Gecko/20100101 Firefox/87.0'}res = requests.get(url,headers=headers)if res.status_code == 200:#1.获取⽹页源代码raw_text = res.text#2.正则表达式书写:#2.2注意:正则表达式默认匹配的是⼀⾏我们的源代码是多⾏匹配的要加另⼀个参数 re.DOTALL#2.3正则法⼀:#re.findall() 返回的是lsit集合⼀次过滤re_res = re.findall(r'<div class="province-box">(.*)<div class="wrap-right">', raw_text,re.DOTALL)#re_res[0] 获取下标是的数据⼆次过滤res=re.findall(r'title="(.*[院⼼部])*)"',re_res[0])#检查打印获取到的信息print(res)#2.4正则法⼆:#(优化)不⽤⼆次过滤⼀次过滤就解决了# re_list = re.findall(r'<li><a href="/[^/].*/" rel="external nofollow" rel="external nofollow" target="_blank" title="(.*)">', res.text)#print(re_list)# 写⼊⽂件中read = open("上海医院名单", "w", encoding='utf-8')for i in res:read.write(i)read.write("\n")read.close()else:print("error")项⽬⽬录:部分结果:python 正则表达式-提取图⽚地址import os,sys,time,json,timeimport socket,random,hashlibimport requests,configparserimport json,refrom datetime import datetimefrom multiprocessing.dummy import Pool as ThreadPooldef getpicurl(url):url = "/zipai/comment-page-352"html = requests.get(url).textpic_url = re.findall('img src="(.*?)"',html,re.S)for key in pic_url:print(key + "\r\n")#print(pic_url)getpicurl("/zipai/comment-pag.e-352")输出结果:总结到此这篇关于Python如何利⽤正则表达式爬取⽹页信息及图⽚的⽂章就介绍到这了,更多相关Python正则表达式爬取内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
python正则表达式与JSON-正则表达式匹配数字、非数字、字符、非字符、贪婪模式、非贪。。。

python正则表达式与JSON-正则表达式匹配数字、⾮数字、字符、⾮字符、贪婪模式、⾮贪。
1、正则表达式:⽬的是为了爬⾍,是爬⾍利器。
正则表达式是⽤来做字符串匹配的,⽐如检测是不是电话、是不是email、是不是ip地址之类的2、JSON:外部数据交流的主流格式。
3、正则表达式的使⽤re python 内置的模块,可以进⾏正则匹配re.findall(pattern,source)pattern:正则匹配规则-也叫郑泽表达式source:需要查找的⽬标源import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("Java",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['Java', 'Java']4、正则表达式的应⽤查数字⽤概括字符集:\dimport rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("\d",a)print res# Project/python_ToolCodes/test10.py"# ['0', '7', '8', '6']⽤另外⼀种匹配模式-字符集:[0-9]import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("[0-9]",a)print res# Project/python_ToolCodes/test10.py"# ['0', '7', '8', '6']其中"Java"叫普通字符,"/d" 源字符查⾮数字⽤概括字符集:\Dimport rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("\D",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['C', 'C', '+', '+', 'J', 'a', 'v', 'a', 'C', '#', 'P', 'y', 't', 'h', 'o', 'n', 'J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']⽤另外⼀种匹配模式-字符集:[^0-9]import rea = "C0C++7Java8C#Python6JavaScript"res = re.findall("[^0-9]",a)print res# Project/python_ToolCodes/test10.py"# ['C', 'C', '+', '+', 'J', 'a', 'v', 'a', 'C', '#', 'P', 'y', 't', 'h', 'o', 'n', 'J', 'a', 'v', 'a', 'S', 'c', 'r', 'i', 'p', 't']正则表达式的罗列:https:///item/正则表达式/1700215?fr=aladdin,挨个练习是没有必要的,⽤到去查即可4、匹配模式源字符+普通字符混合模式[]中的或操作#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#匹配acc和afcres = re.findall("a[cf]c",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['acc', 'afc']取反操作:^#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#取出⾮(acc和afc)的字符res = re.findall("a[^cf]c",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py"# ['abc', 'adc', 'aec', 'ahc']取范围操作:-#coding=utf-8import rea = "abc,acc,adc,aec,afc,ahc"#取出acc,adc,aec,afc(中间字符是c到f范围的)res = re.findall("a[c-f]c",a)print res#[Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" #['acc', 'adc', 'aec', 'afc']匹配数字和字母:概括字符集匹配:\wimport rea = "abc&cba"res = re.findall("\w",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['a', 'b', 'c', 'c', 'b', 'a']使⽤字符集匹配:[A-Za-Z0-9]import rea = "abc123&cba321"res = re.findall("[A-Za-z0-9]",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['a', 'b', 'c', '1', '2', '3', 'c', 'b', 'a', '3', '2', '1']显然,是\w是不匹配⾮字母和数字的,⽐如“&”符号匹配⾮单词⾮数字字符概括字符集:\Wimport rea = "abc123&cba321"res = re.findall("\W",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['&']使⽤字符集匹配:^A-Za-z0-9import rea = "abc123&cba321"res = re.findall("[^A-Za-z0-9]",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['&']空格、制表符、换⾏符号之类的匹配:\simport rea = "python 111\tjava&67p\nh\rp"res = re.findall("\s",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # [' ', '\t', '\n', '\r']匹配量词:匹配出python Java php必须三个⼀组:[a-z]{3}import rea = "python 1111java678php"res = re.findall("[a-z]{3}",a)print res[Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" ['pyt', 'hon', 'jav', 'php']可以3-6个⼀组:因为最长python 为6 最短PHP为3:[a-z]{3,6}import rea = "python 1111java678php"res = re.findall("[a-z]{3,6}",a)print res# [Running] python -u "/Users/anson/Documents/Project/python_ToolCodes/test10.py" # ['python', 'java', 'php']疑问:为什么3个能匹配匹配到pyt的时候为什么不终⽌?因为正则表达式的数量词分为贪婪和⾮贪婪模式,默认情况下,python 认为是贪婪模式的。
python常用的正则表达式大全
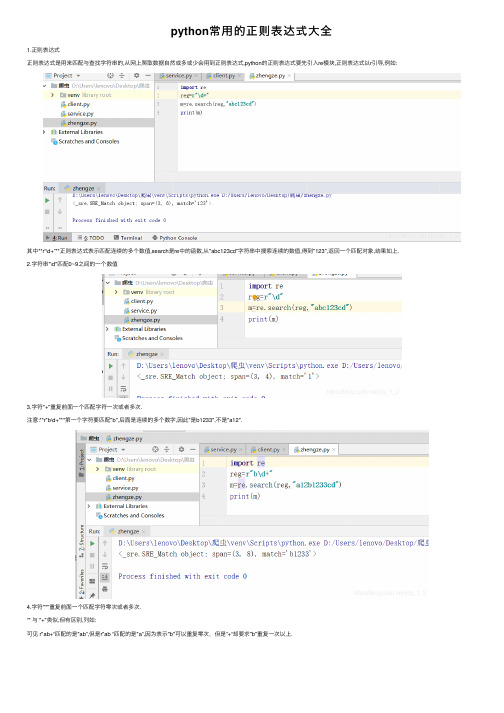
python常⽤的正则表达式⼤全1.正则表达式正则表达式是⽤来匹配与查找字符串的,从⽹上爬取数据⾃然或多或少会⽤到正则表达式,python的正则表达式要先引⼊re模块,正则表达式以r引导,例如:其中**r“\d+”**正则表达式表⽰匹配连续的多个数值,search是re中的函数,从"abc123cd"字符串中搜索连续的数值,得到"123",返回⼀个匹配对象,结果如上.2.字符串"\d"匹配0~9之间的⼀个数值3.字符"+"重复前⾯⼀个匹配字符⼀次或者多次.注意:**r"b\d+"**第⼀个字符要匹配"b",后⾯是连续的多个数字,因此"是b1233",不是"a12".4.字符"*"重复前⾯⼀个匹配字符零次或者多次.“" 与 "+"类似,但有区别,列如:可见 r"ab+“匹配的是"ab”,但是r"ab “匹配的是"a”,因为表⽰"b"可以重复零次,但是”+“却要求"b"重复⼀次以上.5.字符"?"重复前⾯⼀个匹配字符零次或者⼀次.匹配结果"ab”,重复b⼀次.6.字符".“代表任何⼀个字符,但是没有特别声明时不代表字符”\n".结果“.”代表了字符"x".7."|"代表把左右分成两个部分 .结果匹配"ab"或者"ba"都可以.8.特殊字符使⽤反斜杠"“引导,例如”\r"、"\n"、"\t"、"\"分别表⽰回车、换⾏、制表符号与反斜线⾃⼰本⾝.9.字符"\b"表⽰单词结尾,单词结尾包括各种空⽩字符或者字符串结尾.结果匹配"car",因为"car"后⾯是⼀个空格.10."[]中的字符是任选择⼀个,如果字符ASCll码中连续的⼀组,那么可以使⽤"-"字符连接,例如[0-9]表⽰0-9的其中⼀个数字,[A-Z]表⽰A-Z的其中⼀个⼤写字符,[0-9A-z]表⽰0-9的其中⼀个数字或者A-z的其中⼀个⼤写字符.11."^"出现在[]的第⼀个字符位置,就代表取反,例如[ ^ab0-9]表⽰不是a、b,也不是0-9的数字.12."\s"匹配任何空⽩字符,等价"[\r\n 20\t\f\v]"13."\w"匹配包括下划线⼦内的单词字符,等价于"[a-zA-Z0-9]"14."$"字符⽐配字符串的结尾位置匹配结果是最后⼀个"ab",⽽不是第⼀个"ab"15.使⽤括号(…)可以把(…)看出⼀个整体,经常与"+"、"*"、"?"的连续使⽤,对(…)部分进⾏重复.结果匹配"abab","+“对"ab"进⾏了重复16.查找匹配字符串正则表达式re库的search函数使⽤正则表达式对要匹配的字符串进⾏匹配,如果匹配不成功返回None,如果匹配成功返回⼀个匹配对象,匹配对象调⽤start()函数得到匹配字符的开始位置,匹配对象调⽤end()函数得到匹配字符串的结束位置,search虽然只返回匹配第⼀次匹配的结果,但是我们只要连续使⽤search函数就可以找到字符串全部匹配的字符串.匹配找出英⽂句⼦中所有单词我们可以使⽤正则表达式r”[A-Za-z]+\b"匹配单词,它表⽰匹配由⼤⼩写字母组成的连续多个字符,⼀般是⼀个单词,之后"\b"表⽰单词结尾.程序开始匹配到⼀个单词后m.start(),m.end()就是单词的起始位置,s[start:end]为截取的单词,之后程序再次匹配字符串s=s[end:],即字符串的后半段,⼀直到匹配完毕为⽌就找出每个单词.总结到此这篇关于python常⽤正则表达式的⽂章就介绍到这了,更多相关python正则表达式内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
python正则表达式详解

python正则表达式详解Python正则表达式详解正则表达式是一种强大的文本处理工具,它可以用来匹配、查找、替换文本中的特定模式。
在Python中,正则表达式是通过re模块来实现的。
本文将详细介绍Python中正则表达式的使用方法。
一、基本语法正则表达式是由一些特殊字符和普通字符组成的字符串。
其中,特殊字符用来表示一些特定的模式,普通字符则表示普通的文本。
下面是一些常用的正则表达式特殊字符:1. ^:匹配字符串的开头。
2. $:匹配字符串的结尾。
3. .:匹配任意一个字符。
4. *:匹配前面的字符出现0次或多次。
5. +:匹配前面的字符出现1次或多次。
6. ?:匹配前面的字符出现0次或1次。
7. []:匹配方括号中的任意一个字符。
8. [^]:匹配不在方括号中的任意一个字符。
9. ():将括号中的内容作为一个整体进行匹配。
10. |:匹配左右两边任意一个表达式。
二、常用函数Python中re模块提供了一些常用的函数来操作正则表达式,下面是一些常用的函数:1. re.match(pattern, string, flags=0):从字符串的开头开始匹配,如果匹配成功则返回一个匹配对象,否则返回None。
2. re.search(pattern, string, flags=0):在字符串中查找第一个匹配成功的子串,如果匹配成功则返回一个匹配对象,否则返回None。
3. re.findall(pattern, string, flags=0):在字符串中查找所有匹配成功的子串,返回一个列表。
4. re.sub(pattern, repl, string, count=0, flags=0):将字符串中所有匹配成功的子串替换为repl,返回替换后的字符串。
三、实例演示下面是一些实例演示,展示了正则表达式的使用方法:1. 匹配邮箱地址import reemail='*************'pattern = r'\w+@\w+\.\w+' result = re.match(pattern, email) if result:print(result.group())else:print('匹配失败')2. 匹配手机号码import rephone='138****5678' pattern = r'^1[3-9]\d{9}$' result = re.match(pattern, phone) if result:print(result.group())else:print('匹配失败')3. 查找所有数字import retext = 'abc123def456ghi789' pattern = r'\d+'result = re.findall(pattern, text)print(result)4. 替换字符串中的空格import retext = 'hello world'pattern = r'\s+'result = re.sub(pattern, '-', text)print(result)四、总结本文介绍了Python中正则表达式的基本语法和常用函数,并通过实例演示展示了正则表达式的使用方法。
基于 Python的网络爬虫程序设计

基于 Python的网络爬虫程序设计内蒙古自治区呼和浩特市 010057摘要:网络信息量的迅猛增长,从海量的信息中准确的搜索到用户需要的信息提出了极大的挑战。
网络爬虫具有能够自动提取网页信息的能力。
对现在流行的网络爬虫框架进行分析和选择,在现有框架的基础上设计了一种适合资源库建设的爬虫系统,利用爬虫的自动化特性完成教学资源库的内容获取及入库工作。
同时,选用Scrapyredis对爬虫进行拓展,利用Redis实现对目标网站资源的分布式爬取,提高获取资源的速度。
关键词:Python的网络爬虫程序;设计;应用一、概述1、Python 语言。
Python 语言语法简单清晰、功能强大,容易理解。
可以在 Windows、Linux 等操作系统上运行;Python 是一种面向对象的语言,具有效率高、可简单地实现面向对象的编程等优点。
Python 是一种脚本语言,语法简洁且支持动态输入,使得 Python在很多操作系统平台上都是一个比较理想的脚本语言,尤其适用于快速的应用程序开发。
2、网络爬虫。
网络爬虫是一种按照一定的规则,自动提取 Web 网页的应用程序或者脚本,它是在搜索引擎上完成数据抓取的关键一步,可以在Internet上下载网站页面。
爬虫是为了将 Internet 上的网页保存到本地,爬虫是从一个或多个初始页面的 URL[5],通过分析页面源文件的 URL,抓取新的网页链接,通过这些网页链接,再继续寻找新的网页链接,反复循环,直到抓取和分析所有页面。
这是理想情况下的执行情况,根据现在公布的数据,最好的搜索引擎也只爬取整个互联网不到一半的网页。
二、网络爬虫的分类网络爬虫作为一种网页抓取技术,其主要分为通用网络爬虫、聚焦网络爬虫两种类型。
其中通用网络爬虫是利用捜索引擎,对网页中的数据信息进行搜索、采集与抓取的技术,通过将互联网网页下载到本地,来保证网络内容的抓取、存储与镜像备份。
首先第一步是对网站 URL 低质进行抓取,解析 DNS 得到主机IP 地址,并对相应的 URL 网页进行下载。
python正则表达式基础,以及pattern.match(),re.match(),pa。。。

python正则表达式基础,以及pattern.match(),re.match(),pa。
正则表达式(regular expression)是⼀个特殊的字符序列,描述了⼀种字符串匹配的模式,可以⽤来检查⼀个字符串是否含有某种⼦字符串。
将匹配的⼦字符串替换或者从某个字符串中取出符合某个条件的⼦字符串,或者是在指定的⽂章中抓取特定的字符串等。
Python处理正则表达式的模块是re模块,它是Python语⾔中拥有全部的正则表达式功能的模块。
正则表达式由⼀些普通字符和⼀些元字符组成。
普通字符包括⼤⼩写的字母、数字和打印符号,⽽元字符是具有特殊含义的字符。
正则表达式⼤致的匹配过程是:拿正则表达式依次和字符串或者⽂本中的字符串做⽐较,如果每⼀个字符都匹配,则匹配成功,只要有⼀个匹配不成功的字符,则匹配不成功。
正则表达式模式正则表达式是⼀种⽤来匹配字符串得强有⼒的武器。
它的设计思想是⽤⼀种描述性的语⾔来给字符串定义⼀个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,就是匹配不成功。
模式字符串使⽤特殊的语法来表⽰⼀个正则表达式:字母和数字匹配它们⾃⾝;多数字母和数字前加⼀个反斜杠(\)时会有特殊的含义;特殊的标点符号,只有被转义以后才能匹配⾃⾝;反斜杠本⾝需要反斜杠来转义;注意:由于正则表达式通常包含反斜杠等特殊字符,所以我们最好使⽤原始字符串来表⽰他们。
如:r’\d’,等价于’\\d’,表⽰匹配⼀个数字。
Python正则表达式中,数量词默认都是贪婪的,它们会尽⼒尽可能多的去匹配满⾜的字符,但是如果我们在后⾯加上问号“?”,就可以屏蔽贪婪模式,表⽰匹配尽可能少的字符。
如字符串:“xyyyyzs”,使⽤正则“xy*”,就会得到“xyyyy”;如果使⽤正则“xy*?”,将只会匹配“x”下表列出了正则表达式模式语法中的特殊元素。
如果你是使⽤模式的同时提供了可选的标志参数,某些模式元素含义就会改变。
编译正则表达式基础Python通过re模块提供对正则表达式的⽀持。
python7个爬虫小案例详解(附源码)

python7个爬虫小案例详解(附源码)Python 7个爬虫小案例详解(附源码)1. 爬取百度贴吧帖子使用Python的requests库和正则表达式爬取百度贴吧帖子内容,对网页进行解析,提取帖子内容和发帖时间等信息。
2. 爬取糗事百科段子使用Python的requests库和正则表达式爬取糗事百科段子内容,实现自动翻页功能,抓取全部内容并保存在本地。
3. 抓取当当网图书信息使用Python的requests库和XPath技术爬取当当网图书信息,包括书名、作者、出版社、价格等,存储在MySQL数据库中。
4. 爬取豆瓣电影排行榜使用Python的requests库和BeautifulSoup库爬取豆瓣电影排行榜,并对数据进行清洗和分析。
将电影的名称、评分、海报等信息保存到本地。
5. 爬取优酷视频链接使用Python的requests库和正则表达式爬取优酷视频链接,提取视频的URL地址和标题等信息。
6. 抓取小说网站章节内容使用Python的requests库爬取小说网站章节内容,实现自动翻页功能,不断抓取新的章节并保存在本地,并使用正则表达式提取章节内容。
7. 爬取新浪微博信息使用Python的requests库和正则表达式爬取新浪微博内容,获取微博的文本、图片、转发数、评论数等信息,并使用BeautifulSoup 库进行解析和分析。
这些爬虫小案例涵盖了网络爬虫的常见应用场景,对初学者来说是很好的入门教程。
通过学习这些案例,可以了解网络爬虫的基本原理和常见的爬取技术,并掌握Python的相关库的使用方法。
其次,这些案例也为后续的爬虫开发提供了很好的参考,可以在实际应用中进行模仿或者修改使用。
最后,这些案例的源码也为开发者提供了很好的学习资源,可以通过实战来提高Python编程水平。
python中正则表达式的使用详解

python中正则表达式的使⽤详解从学习Python⾄今,发现很多时候是将Python作为⼀种⼯具。
特别在⽂本处理⽅⾯,使⽤起来更是游刃有余。
说到⽂本处理,那么正则表达式必然是⼀个绝好的⼯具,它能将⼀些繁杂的字符搜索或者替换以⾮常简洁的⽅式完成。
我们在处理⽂本的时候,或是查询抓取,或是替换.⼀.查找如果你想⾃⼰实现这样的功能模块,输⼊某⼀个ip地址,得到这个ip地址所在地区的详细信息.但是⼈家没有提供api供外部调⽤,但是我们可以通过代码模拟查询然后对结果进⾏抓取.通过查看这个相应页⾯的源码,我们可以发现,结果是放在三个<li></li>中的复制代码代码如下:<table width="80%" border="0" align="center" cellpadding="0" cellspacing="0"><tr><td align="center"><h3> IP查询(搜索IP地址的地理位置)</h3></td></tr><tr><td align="center"><h1>您查询的IP:121.0.29.231</h1></td></tr><tr><td align="center"><ul class="ul1"><li>本站主数据:浙江省杭州市阿⾥巴巴</li><li>参考数据⼀:浙江省杭州市阿⾥巴巴</li><li>参考数据⼆:浙江省杭州市阿⾥巴巴</li></ul></td></tr><tr><td align="center">如果您发现查询结果不详细或不正确,请使⽤<a href="ip_add.asp?ip=121.0.29.231"><fontcolor="#006600"><b>IP数据库⾃助添加</b></font></a>功能进⾏修正<br/><br/><iframe src="/jss/bd_460x60.htm" frameborder="no" width="460" height="60" border="0" marginwidth="0" marginheight="0" scrolling="no"></iframe><br/><br/></td></tr><form method="get" action="ips8.asp" name="ipform" onsubmit="return checkIP();"><tr><td align="center">IP地址或者域名:<input type="text" name="ip" size="16"> <input type="submit" value="查询"><input type="hidden" name="action" value="2"></td></tr><br><br></form></table>如果你了解正则表达式你可能会写出正则表达式复制代码代码如下:(?<=<li>).*?(?=</li>)这⾥使⽤了前瞻:lookahead 后顾: lookbehind,这样的好处就是匹配的结果中就不会包含html的li标签了.如果你对⾃⼰写的正则表达式不是很⾃信的话,可以在⼀些在线或者本地的正则测试⼯具进⾏⼀些测试,以确保正确.接下来的⼯作就是如果⽤Python实现这样的功能,⾸先我们得将正则表达式表⽰出来:复制代码代码如下:r"(?<=<li>).*?(?=</li>)"Python中字符串前⾯加上前导r这个字符,代表这个字符串是R aw String(原始字符串),也就是说Python字符串本⾝不会对字符串中的字符进⾏转义.这是因为正则表达式也有转义字符之说,如果双重转义的话,易读性很差.这样的串在Python中我们把它叫做"regular expression pattern"如果我们对pattern进⾏编译的话复制代码代码如下:prog = pile(r"(?<=<li>).*?(?=</li>)")我们便可以得到⼀个正则表达式对象regular expression object,通过这个对象我们可以进⾏相关操作.⽐如复制代码代码如下:result=prog.match(string)##这个等同于result=re.match(r"(?<=<li>).*?(?=</li>)",string)##但是如果这个正则需要在程序匹配多次,那么通过正则表达式对象的⽅式效率会更⾼接下来就是查找了,假设我们的html结果已经以html的格式存放在text中,那么通过复制代码代码如下:result_list = re.findall(r"(?<=<li>).*?(?=</li>)",text)便可以取得所需的结果列表.⼆.替换使⽤正则表达式进⾏替换⾮常的灵活.⽐如之前我在阅读Trac这个系统中wiki模块的源代码的时候,就发现其wiki语法的实现就是通过正则替换进⾏的.在使⽤替换的时候会涉及到正则表达式中的Group分组的概念.假设wiki语法中使⽤!表⽰转义字符即感叹号后⾯的功能性字符会原样输出,粗体的语法为写道'''这⾥显⽰为粗体'''那么有正则表达式为复制代码代码如下:r"(?P<bold>!?''')"这⾥的?P<bold>是Python正则语法中的⼀部分,表⽰其后的group的名字为"bold"下⾯是替换时的情景,其中sub函数的第⼀个参数是pattern,第⼆个参数可以是字符串也可以是函数,如果是字符串的话,那么就是将⽬标匹配的结果替换成指定的结果,⽽如果是函数,那么函数会接受⼀个match object的参数,并返回替换后的字符串,第三个参数便是源字符串.复制代码代码如下:result = re.sub(r"(?P<bold>!?''')", replace, line)每当匹配到⼀个三单引号,replace函数便运⾏⼀次,可能这时候需要⼀个全局变量记录当前的三单引号是开还是闭,以便添加相应的标记.在实际的trac wiki的实现的时候,便是这样通过⼀些标记变量,来记录某些语法标记的开闭,以决定replace函数的运⾏结果.--------------------⽰例⼀. 判断字符串是否是全部⼩写代码复制代码代码如下:# -*- coding: cp936 -*-import res1 = 'adkkdk's2 = 'abc123efg'an = re.search('^[a-z]+$', s1)if an:print 's1:', an.group(), '全为⼩写'else:print s1, "不全是⼩写!"an = re.match('[a-z]+$', s2)if an:print 's2:', an.group(), '全为⼩写'else:print s2, "不全是⼩写!"结果究其因1. 正则表达式不是python的⼀部分,利⽤时需要引⽤re模块2. 匹配的形式为: re.search(正则表达式,带匹配字串)或re.match(正则表达式,带匹配字串)。
Python网络爬虫中的数据验证与验证技术

Python网络爬虫中的数据验证与验证技术在Python网络爬虫的开发中,数据验证是一项至关重要的任务。
由于网络上存在着大量的信息和数据,我们需要通过验证技术确保我们获取的数据是准确可靠的。
本文将讨论Python网络爬虫中的数据验证以及一些常用的验证技术。
一、数据验证的重要性在进行数据的提取和解析过程中,我们往往依赖于特定网站或API 的数据接口。
然而,这些数据接口的响应并不总是可靠的,可能会存在数据缺失、错误或者异常情况。
为了确保我们获取的数据是准确可靠的,数据验证就变得至关重要。
二、数据验证方法1. 基本数据验证基本数据验证是最基础也是最常用的数据验证方法之一。
通过对数据进行类型与格式的检查,我们可以初步验证数据的正确性。
例如,我们可以使用正则表达式对提取的字符串进行格式验证,或者使用Python的内置函数对数据进行类型判断。
2. 数据一致性验证数据一致性验证是指对不同数据源提取的数据进行验证,并确保它们在同一语义范围内是一致的。
常用的数据一致性验证方法包括比对数据的关键信息、比对数据的属性、比对数据的结构等。
3. 异常数据验证异常数据验证是指对数据进行异常值判断和处理。
在实际的数据提取中,我们经常会遇到一些异常情况,例如数据为空、数字超过范围等。
通过对这些异常数据进行验证和处理,我们可以提高数据的可靠性和准确性。
4. 数据库验证在爬虫开发中,我们往往需要将提取的数据存储到数据库中。
数据验证在此时尤为重要。
通过合理的数据库设计和数据结构,我们可以对数据进行完整性和一致性验证。
例如,可以通过约束条件、索引等机制来保证数据的正确性和准确性。
5. 机器学习验证机器学习验证是一种高级的数据验证方法。
通过训练机器学习模型,我们可以对提取的数据进行模式识别和异常检测,从而提高数据的验证精度和效果。
然而,机器学习验证通常需要大量的数据和计算资源,在实际应用中需要权衡利弊。
三、验证技术1. 数据库验证技术数据库验证技术是一种常用的数据验证方法。
python 常用正则表达式

python 常用正则表达式
正则表达式是一种强大的文本处理工具,在Python中也得到了
广泛的应用。
下面是Python中常用的正则表达式:
1. 匹配任意字符
. 表示匹配任意一个字符,但不包括换行符。
2. 匹配特定字符
表示转义字符,可以用来匹配一些特殊字符,如匹配反斜杠本身需要使用。
[] 表示匹配括号内的任意一个字符。
例如 [abc] 表示匹配 a、b、c中的任意一个字符。
^ 表示在括号内使用时表示取反,例如 [^abc] 表示匹配除了 a、
b、c之外的任意一个字符。
3. 匹配多个字符
* 表示匹配前面的字符0次或多次。
+ 表示匹配前面的字符1次或多次。
?表示匹配前面的字符0次或1次。
{n} 表示匹配前面的字符恰好n次。
{n,} 表示匹配前面的字符至少n次。
{n,m} 表示匹配前面的字符至少n次,但不超过m次。
4. 匹配字符串的开头和结尾
^ 表示字符串的开头,例如 ^hello 表示字符串以 hello开头。
$ 表示字符串的结尾,例如 world$ 表示字符串以 world结尾。
5. 匹配单词边界
b 表示单词的边界,例如bhellob表示匹配单词 hello。
6. 分组
() 表示分组,可以对文本进行分组,例如 ([a-z]+) 表示匹配一个或多个小写字母。
7. 贪婪匹配与非贪婪匹配
默认情况下,正则表达式是贪婪匹配的,即会尽可能多地匹配文本。
使用?可以实现非贪婪匹配。
以上是Python中常用的正则表达式,掌握这些正则表达式可以帮助你更高效地处理文本。
《Python网络爬虫课件》

1
灵活性与易用性
2
BeautifulSoup提供了简单的API,使
得HTML解析和数据提取变得非常容
易。
3
什么是BeautifulSoup?
BeautifulSoup是一个功能强大的 Python库,用于解析和提取 HTML/XML文档中的信息。
实战案例
我们将一起编写实例代码,演示如何 使用BeautifulSoup库解析网页并提取 所需信息。
Python网络爬虫课件
在这个《Python网络爬虫课件》中,我们将深入研究网络爬虫的概念、工作 原理以及实际应用。准备好发现新知识的奇妙世界吧!
网络爬虫介绍
什么是网络爬虫?
网络爬虫是一种自动检索 万维网信息的程序,它能 够浏览并收集各种网页上 的数据,为我们提供宝贵 的资源。
应用领域
网络爬虫在数据挖掘、市 场调研、舆情监控等领域 发挥着重要作用,掌握网 络爬虫技术将给你带来巨 大的优势。
伦理与法律
在使用网络爬虫时,我们 要遵守伦理规范和法律法 规,尊重数据的所有权和 隐私。
网络爬虫工作原理
工作流程
网络爬虫通过发送HTTP请求 并解析网页响应,从中提取有 用的信息,并将其存储或进一 步处理。
数据解析
网页遍历
为了获取所需的信息,我们使 用各种解析技术,如正则表达 式、XPath和BeautifulSoup库。
正则表达式
什么是正则表达式?
正则表达式是一种强大的文本模式匹配工具,用于识别和提取满足特定规则 的文本。
常用字符类
学习正则表达式中的常用字符类,如数字、字母、空白字符等。
实用技巧
掌握一些正则表达式的实用技巧,如捕获组、量词和转义字符。
python中正则表达式 re.search 用法

在Python编程语言中,正则表达式(re.search)是一种强大的字符串匹配工具。
它能够帮助开发者在文本中快速定位特定的模式,实现字符串的搜索和替换。
在本文中,我们将介绍re.search的基本用法和示例,帮助读者更好地理解和运用这一功能。
一、re.search的基本语法re.search函数用于在一个字符串中搜索匹配正则表达式的第一个位置,并返回相应的匹配对象。
其基本语法如下:result = re.search(pattern, string, flags=0)其中,pattern为要匹配的正则表达式,string为要搜索的字符串,flags为匹配模式,可选参数。
函数返回一个匹配对象,如果匹配成功,否则返回None。
二、示例说明现假设有一个字符串s,内容为"Python is powerful",我们想要查找其中是否包含"powerful"这个单词。
我们可以使用re.search函数来实现:```pythonimport res = "Python is powerful"result = re.search(r'powerful', s)if result:print("匹配成功!")else:print("匹配失败!")```这段代码的执行结果将会是"匹配成功!",因为字符串s中包含了"powerful"这个单词。
除了简单的字符串匹配之外,re.search还支持使用正则表达式进行更复杂的匹配操作。
我们可以使用"."匹配任意字符,"^"匹配字符串的开头,"$"匹配字符串的结尾,"[]"匹配指定范围的字符等等。
下面是一个稍复杂一点的示例:```pythonimport res = "The price is $50"result = re.search(r'\$\d+', s)if result:print("价格为:" + result.group())else:print("未找到价格信息!")```这段代码将会输出"价格为:$50",因为字符串s中包含了"$50"这个匹配项。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
主讲老师:XXX
1
什么是正则表达式
2
原子
3
元字符
4
模式修正符
5
贪婪模式与懒惰模式
6
正则表达式函数
目录
正则表达式介绍
世界上信息非常多,而我们关注的信息有限。假如我们希望只提取出关注的数据,此时可以通过一些表达式 进行提取,正则表达式就是其中一种进行数据筛选的表达式。
正则表达式(Regular Expression),此处的“Regular”即是“规则”、“规律”的意思,Regular Exp ression即“描述某种规则的表达式”,因此它又可称为正规表示式、正规表示法、正规表达式、规则表达式、 常规表示法等,在代码中常常被简写为regex、regexp或RE。正则表达式使用某些单个字符串,来描述或匹配 某个句法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索或替换那些符合某个模式的文本。
原子
\w 匹配字符、数字、下划线 \W 匹配除字母、数字、下划线以外的字符 \d 匹配十进制数字 \D 匹配除十进制数字以外的字符 \s 匹配空白字符 \S 匹配除空白字符以外的字符 import re s="Thisbookis1205yuan" pat=“\d\d” #通用字符作为原子 rst=re.search(pat,s) print(rst) 运行结果: <re.Match object; span=(10, 12), match='12'>
运行结果: <re.Match object; span=(10, 18), match='1205yuan'> 拓展: pat=“\d\d\d\d[^xyz]uan” #原子表 ,^表示非
元字符
元字符
所谓的元字符,就是正则表达式中具有一些特殊含义的字符,比如重复N次前面的字符等。常见的元字符包括: . 除换行符外任意一个字符串 ^ 不在原子表里,表示开始位置,在原子表里表示非 $ 结束位置 * 前面的字符出现0\1\多次 ? 前面的字符出现0\1次 + 前面的字符出现1\多次 {n} 前面的字符恰好出现n次 {n,} 前面的字符至少出现n次 {n,m} 前面的字符至少出现n次,至多m次 | 模式选择符 () 模式单元
3.使用正则表达式的re.search(正则,字符串)函数进行匹配,示例如下:
import re
s=“Ilovefootball”
pat=“love” #普通字符作为原子
rst=re.search(pat,s)
print(rst)
运行结果: <re.Match object; span=(1, 5), match='love'>
贪婪模式与懒惰模式
贪婪模式与懒惰模式
ቤተ መጻሕፍቲ ባይዱ
贪婪模式的核心点就是尽可能多的匹配,而懒惰模式的核心点就是尽可能少的匹配。
示范一: import re s="pythony" pat="p.*y" #默认为贪婪模式 rst=re.findall(pat,s) print(rst)
结果:['pythony']
示范二: import re s="pythony" pat=“p.*?y” #加上?懒惰模式 rst=re.findall(pat,s) print(rst)
原子
常见的非打印字符有: \n换行符 \t制表符 import re s="""I love football do you love football""" pat=“\n“ #非打印字符作为原子 rst=re.search(pat,s) print(rst)
非打印字符作为原子
输出结果: <re.Match object; span=(15, 16), match='\n'>
元字符
示范: import re s="Thisbookis1205yuanqian" pat="(\w*book)" rst=re.search(pat,s) print(rst)
元字符
运行结果: <re.Match object; span=(0, 8), match='Thisbook'>
模式修正符
结果:['py']
贪婪模式比较模糊,懒惰模式比较精准。
正则表达式函数
正则表达式函数
在Python中需要通过正则表达式对字符串进行匹配的时候,可以导入一 个库(模块),名字为re,它提供了
对正则表达式操作所需的方法。 方法
说明
re.match(pattern,string flags)
从字符串的开始匹配一个匹配对象, 例如匹配第一个 单词
模式修正符
所谓的模式修正符,即可以在不改变正则表达式的情况下,通过模式修正符改变正则表达式的含义,从而实 现一些匹配结果的调整等功能。
I 匹配时忽略大小写 M 多行匹配 L 本地化识别匹配 U 根据Unicode匹配 S 让.匹配包括换行符 import re s="""ILovefootball Doyou love football""" pat="love" rst=re.findall(pat,s,re.I) print(rst)
re.search(pattern,string flags)
在字符串中查找匹配的对象,找到第一个后就返回,如 果没有找到就返回None
re.sub(pattern,repl,string count) re.split(r',',text)
re.findall(pattern,string flags)
通用字符作为原子
原子
原子表
将几个原子组成一个表,通常用[]来表示,如:[xyz],表示从x,y,z三个字符中任意选择一个。 import re s="Thisbookis1205yuanqian" pat=“\d\d\d\d[xyz]uan” #原子表 rst=re.search(pat,s) print(rst)
原子
原子是正则表达式中最基本的组成单位,每个正则表达式中至少要包含一个原子。常见的原子类 型有。 普通字符作为原子 非打印字符作为原子 通用字符作为原子 原子表
1.有如下字符串:
原子
普通字符作为原子
s=“Ilovefootball”
2.要从中提取“love”子字符串,则可以定义一个正则表达式:pat=“love”