汉字编码标准
我国汉字编码标准

我国汉字编码标准首先,我国的汉字编码标准在不同阶段都遵循了统一性、规范性和适用性的原则。
在GB2312-80发布之后,我国的计算机领域得到了长足的发展,但是随着信息化建设的深入,GB2312-80已经不能满足当今社会对汉字编码的需求。
因此,1995年发布了GBK编码,它在GB2312-80的基础上增加了对繁体字和少数民族文字的支持。
而随着国际化的发展,GB18030-2005标准的发布则进一步完善了我国汉字编码标准,使其更加符合国际标准。
其次,我国汉字编码标准的发展也受益于技术的进步和应用的需求。
随着计算机技术的不断发展,对于汉字编码的要求也越来越高。
GB18030-2005标准的发布,不仅支持了Unicode标准,还对繁体字和少数民族文字进行了更好的支持,使得我国的汉字编码标准更加符合当今信息化建设的需要。
再者,我国汉字编码标准的发展也受益于国际化的趋势。
随着我国在国际上的地位不断提升,对于国际标准的遵循和应用也越来越重要。
GB18030-2005标准的发布,使得我国的汉字编码标准更加符合国际标准,为我国在国际上的信息交流和合作提供了更好的支持。
最后,我国汉字编码标准的发展也为我国的信息化建设和文化传承提供了更好的支持。
汉字是我国的传统文化符号,对于汉字的数字化编码,不仅可以更好地保护和传承我国的传统文化,还可以更好地适应当今信息化建设的需要。
因此,我国汉字编码标准的不断完善和发展,为我国的信息化建设和文化传承提供了更好的基础和保障。
总之,我国汉字编码标准的发展经历了多个阶段,每一次的更新都是为了更好地适应当代社会的需求。
随着技术的进步、国际化的趋势以及信息化建设的需求,我国汉字编码标准将会不断完善和发展,为我国的信息化建设和文化传承提供更好的支持和保障。
中国汉字编码标准

中国汉字编码标准
中国汉字编码标准是一个用于计算机处理汉字信息的规范。
其主要分为两大类:一是GB码(国标码),二是Unicode。
GB码是针对中文字符而制定的,它根据字符的发音和笔画顺序来分配独一无二的编码。
Unicode则是全球统一的字符编码系统,不仅包含了中文字符,还包括了全世界各种语言所需的字符。
在GB码标准中,每个字符的编码长度为两个字节;而在Unicode中,基本字符编码长度为两个字节,扩展字符编码长度为四个字节。
这些编码标准在计算机处理中文信息时具有广泛的应用。
我国汉字编码标准

我国汉字编码标准
首先,我国汉字编码标准的历史可以追溯到上世纪六十年代。
当时,为了适应计算机技术的发展和推动信息化建设,中国科学院计算技术研究所在1964年开始制定了汉字内码。
此后,经过多年的发展和完善,我国逐渐建立了GB2312、GBK、GB18030等一系列汉字编码标准,为汉字的数字化处理提供了坚实的基础。
其次,我国汉字编码标准的制定过程中,充分考虑了汉字的数量和结构特点,确保了编码的准确性和完整性。
同时,为了适应不同地区和不同行业的需求,我国还制定了繁体字编码标准和行业专用字编码标准,为各行各业的信息化建设提供了有力支持。
此外,我国汉字编码标准的实施对促进信息交流和文化传播发挥了重要作用。
通过统一的编码标准,不同地区、不同系统的计算机可以准确地识别和显示汉字,为信息交流和文化传播提供了便利条件。
同时,汉字编码标准的实施也为汉字的数字化处理提供了技术保障,推动了汉字信息处理技术的发展和应用。
总的来说,我国汉字编码标准的制定和实施,为促进信息化建设、推动数字化进程发挥了重要作用。
在未来,随着信息技术的不
断发展和汉字应用领域的不断拓展,我国汉字编码标准也将不断完
善和发展,更好地适应社会发展的需求。
综上所述,我国汉字编码标准是我国信息化建设的重要组成部分,对于推动数字化进程、促进信息交流和文化传播具有重要意义。
我们应该充分认识到汉字编码标准的重要性,加强对汉字编码标准
的研究和应用,为我国信息化建设和数字化进程做出更大的贡献。
汉字编码字符集

汉字编码字符集汉字编码字符集是指用于表示和存储汉字的一套编码系统。
在计算机领域,为了能够准确地表示和处理汉字,人们设计了多种不同的汉字编码字符集。
本文将介绍几种常见的汉字编码字符集,包括GB2312、GBK、Unicode以及UTF-8。
一、GB2312GB2312是中国国家标准局于1980年发布的一种汉字编码字符集,是最早被广泛使用的汉字字符集之一。
GB2312字符集包含了7445个汉字和682个非汉字字符,采用双字节表示每个字符。
其中,第一个字节的范围是0xB0至0xF7,第二个字节的范围是0xA1至0xFE。
GB2312字符集主要适用于简体中文。
二、GBK随着计算机技术的发展和汉字数量的增加,GB2312字符集的容量已经无法满足需求。
为了解决这个问题,国家标准局于1995年发布了GBK字符集,它是对GB2312字符集的扩充和改进。
GBK字符集兼容GB2312字符集,同时加入了21003个汉字,总计包含了21886个汉字。
GBK字符集同样采用双字节表示每个字符,第一个字节的范围是0x81至0xFE,第二个字节的范围是0x40至0xFE。
GBK字符集支持简体中文和繁体中文。
三、UnicodeUnicode是一种国际标准字符集,旨在为全球所有字符提供唯一的编码。
Unicode采用16位的编码方案,可以支持最多65536个不同的字符。
不仅包括了各个国家语言的文字,还包括了数学符号、技术符号、图形符号等。
Unicode字符集为各种语言的文字提供了一个统一的编码标准。
四、UTF-8UTF-8是一种可变长度的Unicode编码方案,更好地解决了存储效率和兼容性的问题。
UTF-8使用1至4个字节来表示一个字符,根据不同的字符而变化。
对于单字节的字符,编码和ASCII码相同,兼容ASCII码。
对于多字节的字符,第一个字节的高位标识了字节数。
UTF-8字符集可以表示Unicode字符集中的所有字符。
在计算机系统中,为了使不同的系统能够正确地处理汉字编码,一般需要统一选择一种字符集来使用。
汉字机内码取值范围

汉字机内码取值范围
汉字机内码取值范围指的是汉字在计算机中的编码范围。
汉字编码是将汉字字符映射为计算机内部的二进制数字的过程,以便计算机能够识别和处理汉字字符。
在计算机中,常用的汉字编码标准有GBK、GB2312、UTF-8等。
其中,GBK和GB2312是中国国家标准,UTF-8是国际标准。
GBK和GB2312采用了双字节编码方式,每个汉字占用两个字节,编码范围为0xA1A1~0xFEFE。
这种编码方式虽然能够表示所有的中文字符,但是不能表示其他语言的字符。
UTF-8是一种可变长度的编码方式,它能够表示所有Unicode字符,包括汉字、英文字母、数字、符号等。
UTF-8采用1~4个字节表示一个字符,其中汉字占用3个字节。
UTF-8编码范围为
0x0000~0x10FFFF。
综上所述,汉字机内码取值范围主要依据采用的编码方式而定,不同的编码方式有不同的取值范围。
了解汉字编码方式和取值范围可以帮助我们更好地理解和使用计算机中的汉字字符。
- 1 -。
汉字编码标准
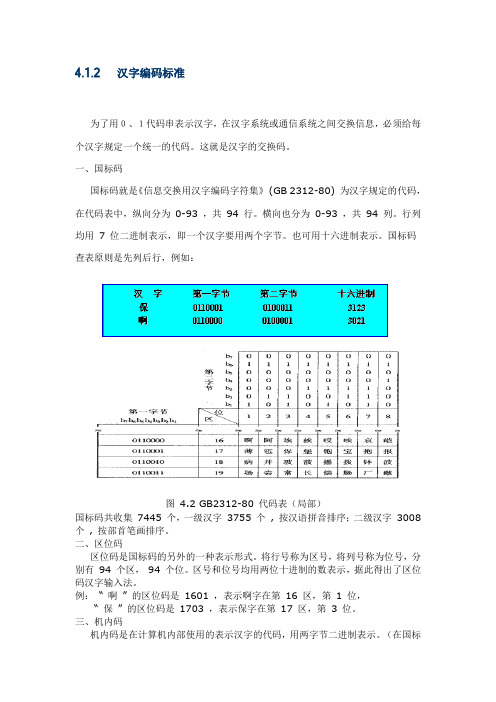
4.1.2 汉字编码标准为了用0、1代码串表示汉字,在汉字系统或通信系统之间交换信息,必须给每个汉字规定一个统一的代码。
这就是汉字的交换码。
一、国标码国标码就是《信息交换用汉字编码字符集》(GB 2312-80) 为汉字规定的代码,在代码表中,纵向分为0-93 ,共94 行。
横向也分为0-93 ,共94 列。
行列均用7 位二进制表示,即一个汉字要用两个字节。
也可用十六进制表示。
国标码查表原则是先列后行,例如:图 4.2 GB2312-80 代码表(局部)国标码共收集7445 个,一级汉字3755 个, 按汉语拼音排序;二级汉字3008 个, 按部首笔画排序。
二、区位码区位码是国标码的另外的一种表示形式。
将行号称为区号,将列号称为位号,分别有94 个区,94 个位。
区号和位号均用两位十进制的数表示,据此得出了区位码汉字输入法。
例:“ 啊” 的区位码是1601 ,表示啊字在第16 区,第 1 位,“ 保” 的区位码是1703 ,表示保字在第17 区,第 3 位。
三、机内码机内码是在计算机内部使用的表示汉字的代码,用两字节二进制表示。
(在国标码每个字节前添1 就是机内码,添1 是为了确保与英文字符区分开)。
输入汉字→国标码( 区位码) →机内码→存储转换关系:十六进制的区位码+ 2020H →国标码十六进制的国标码+ 8080H →机内码8080H 等于二进制的l000000010000000 ,国标码加上8080H ,可以保证机内码每个字节首位均为 1 。
例:“ 啊” 的区位码是:1601 转换成十六进制10011001 +2020=3021 (国标码)再转换成机内码:3021+8080=B0A1二进制表示为1011000010100001 (B0A1 )中山市港口理工学校计算机科温金辉。
中文字符编码表

中文字符编码表
以下是一部分中文字符编码:
GB2312:这是中国国家强制标准,也被称为国标码。
该编码包含了多达6000多个汉字,以及包括英文字母、数字、符号在内的600多个字符。
它主要由两个字节组成,其中0xB0-0xF7是第一个字节,0xA0-0xFE是第二个字节。
Big5:这是一种主要用于繁体中文的字符编码,也被称为大五码。
它主要在台湾和香港地区使用,包含了超过13000个汉字。
每个汉字由两个字节表示,第一个字节的范围是0X81-0XFE,共126种。
以上内容仅供参考,如需更多中文字符编码表,建议查阅计算机相关书籍或咨询计算机专业人士。
汉字字符的编码范围 -回复

汉字字符的编码范围-回复汉字字符的编码范围,是指用于表示汉字的字符编码的范围。
在计算机中,常用的汉字字符编码方式有GBK、GB2312、Big5、Unicode等。
这些编码方式用于将汉字字符转换为计算机可以识别和储存的数字代码,以便于计算机进行处理和显示。
首先,让我们来了解一下GBK编码和GB2312编码。
GBK编码是中国国家标准GB 2312-1980的扩展,包含了全部的中文汉字字符以及繁体汉字;GB2312编码是最早的汉字字符集,只包含了简体中文的6763个常用字。
它们的编码范围分别是0x8140至0xFEFE和0xA1A1至0xFEFE。
在计算机发展的过程中,为了统一不同国家和地区的字符编码,出现了Unicode编码,它使用16位或32位来映射世界上几乎所有的字符,包括汉字。
Unicode的编码范围是0x4E00到0x9FA5,这个范围包含了绝大部分的中文汉字。
然而,由于Unicode编码通常使用16位字符表示,这导致了一些问题,比如存储空间的浪费。
为了解决这个问题,出现了UTF-8编码。
UTF-8是一种针对Unicode的可变长度字符编码,可以用一个字节或多个字节来表示一个字符,根据字符的不同而变化。
对于汉字,UTF-8编码通常使用3个字节表示。
UTF-8编码的汉字字符范围是0xE4B880至0xEEA5BF。
除了以上介绍的常用编码方式外,还有一种比较特殊的编码方式是Big5编码。
Big5编码主要用于繁体中文,它的字符范围覆盖了繁体中文的所有字符。
Big5编码的汉字字符范围是0xA440至0xC67E和0xC940至0xF9D5。
对于这些不同的汉字字符编码范围,计算机内部会将汉字字符转换为对应的编码值进行存储和处理。
当需要显示汉字时,计算机则会根据字符编码值,选择对应的字形进行显示。
这也是为什么在不同的字符编码下,同一个字符可能会有不同的显示效果。
总结起来,汉字字符的编码范围包括GBK编码的0x8140至0xFEFE,GB2312编码的0xA1A1至0xFEFE,Unicode编码的0x4E00至0x9FA5,UTF-8编码的0xE4B880至0xEEA5BF,以及Big5编码的0xA440至0xC67E和0xC940至0xF9D5。
汉字编码常用的字符集

汉字编码常用的字符集
1. GB2312,GB2312是中国国家标准简化汉字字符集,于1980年发布。
它包含了6763个常用汉字和682个非汉字字符,使用双字节编码,其中包括了简体中文的基本字符。
2. GBK,GBK是GB2312的扩展字符集,于1995年发布。
它兼容GB2312,并增加了近两万个汉字和符号。
GBK使用双字节编码,其中包括了简体中文的扩展字符。
3. GB18030,GB18030是中国国家标准的多字节字符集,于2000年发布。
它兼容GB2312和GBK,并增加了更多的汉字和字符,包括繁体中文和一些少数民族文字。
GB18030使用单字节、双字节和四字节编码。
4. Unicode,Unicode是国际标准字符集,旨在涵盖地球上所有的字符。
Unicode采用统一的编码方式,为每个字符分配唯一的编码值。
其中,汉字统一采用了CJK统一汉字扩展A(CJK Unified Ideographs Extension A)和CJK统一汉字扩展B(CJK Unified Ideographs Extension B)等多个扩展区。
5. UTF-8,UTF-8是一种可变长度的Unicode编码方式,它可以表示任意Unicode字符。
UTF-8使用1到4个字节来表示不同的字符,其中包括了汉字。
这些字符集在不同的环境下使用,常见的应用包括操作系统、编程语言、文本编辑器、网页浏览器等。
使用不同的字符集可以满足不同的需求,如支持不同语言的文字显示和输入。
汉字编码对照表(gb2312unicodeutf8)

汉字编码对照表(gb2312unicodeutf8)⼀、汉字编码的种类汉字编码中现在主要⽤到的有三类,包括GBK,GB2312和Big5。
1、GB2312⼜称国标码,由国家标准总局发布,1981年5⽉1⽇实施,通⾏于⼤陆。
新加坡等地也使⽤此编码。
它是⼀个简化字的编码规范,当然也包括其他的符号、字母、⽇⽂假名等,共7445个图形字符,其中汉字占6763个。
我们平时说6768个汉字,实际上⾥边有5个编码为空⽩,所以总共有6763个汉字。
GB2312规定“对任意⼀个图形字符都采⽤两个字节表⽰,每个字节均采⽤七位编码表⽰”,习惯上称第⼀个字节为“⾼字节”,第⼆个字节为“低字节”。
GB2312中汉字的编码范围为,第⼀字节0xB0-0xF7(对应⼗进制为176-247),第⼆个字节0xA0-0xFE(对应⼗进制为160-254)。
GB2312将代码表分为94个区,对应第⼀字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第⼆字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。
01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进⼀步标准化的空⽩区。
2、Big5⼜称⼤五码,主要为⾹港与台湾使⽤,即是⼀个繁体字编码。
每个汉字由两个字节构成,第⼀个字节的范围从0X81-0XFE(即129-255),共126种。
第⼆个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
3、GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。
另外,GBK中还包含繁体字的编码,它与Big5编码之间的关系我还没有弄明⽩,好像是不⼀致的。
GBK中每个汉字仍然包含两个字节,第⼀个字节的范围是0x81-0xFE(即129-254),第⼆个字节的范围是0x40-0xFE(即64-254)。
汉字编码对照表(gb2312unicodeutf8)

汉字编码对照表(gb2312unicodeutf8)⼀、汉字编码的种类汉字编码中现在主要⽤到的有三类,包括GBK,GB2312和Big5。
1、GB2312⼜称国标码,由国家标准总局发布,1981年5⽉1⽇实施,通⾏于⼤陆。
新加坡等地也使⽤此编码。
它是⼀个简化字的编码规范,当然也包括其他的符号、字母、⽇⽂假名等,共7445个图形字符,其中汉字占6763个。
我们平时说6768个汉字,实际上⾥边有5个编码为空⽩,所以总共有6763个汉字。
GB2312规定“对任意⼀个图形字符都采⽤两个字节表⽰,每个字节均采⽤七位编码表⽰”,习惯上称第⼀个字节为“⾼字节”,第⼆个字节为“低字节”。
GB2312中汉字的编码范围为,第⼀字节0xB0-0xF7(对应⼗进制为176-247),第⼆个字节0xA0-0xFE(对应⼗进制为160-254)。
GB2312将代码表分为94个区,对应第⼀字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第⼆字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。
01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进⼀步标准化的空⽩区。
2、Big5⼜称⼤五码,主要为⾹港与台湾使⽤,即是⼀个繁体字编码。
每个汉字由两个字节构成,第⼀个字节的范围从0X81-0XFE(即129-255),共126种。
第⼆个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
3、GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。
另外,GBK中还包含繁体字的编码,它与Big5编码之间的关系我还没有弄明⽩,好像是不⼀致的。
GBK中每个汉字仍然包含两个字节,第⼀个字节的范围是0x81-0xFE(即129-254),第⼆个字节的范围是0x40-0xFE(即64-254)。
中文编码标准

中文编码标准主要有以下几种:
1. GB2312:是中国国家标准,包含了6763个常用汉字和682个非汉字字符。
每个汉字使用两个字节表示,最高位为1。
2. GBK:是GB2312的扩展,包含了21003个汉字和883个非汉字字符。
每个汉字使用两个字节或三个字节表示,最高位为1。
3. GB18030:是GBK的扩展,包含了27484个汉字和其他字符。
每个汉字使用两个字节、三个字节或四个字节表示,最高位为1。
4. Unicode:是一种国际标准,包含了世界上几乎所有的字符。
每个字符使用两个字节或四个字节表示,最高位可以是0也可以是1。
5. UTF-8:是一种变长编码方式,可以表示Unicode中的任何字符。
每个字符使用1到4个字节表示,第一个字节的前几位用于表示字符的长度。
汉字编码的种类和用途

汉字编码的种类和用途
汉字编码是指将汉字字符编码成计算机可识别的二进制数据的方式。
主要的汉字编码种类包括:
1. GB2312编码:是中国国家标准的汉字编码,包含了大约7000个最常用的汉字。
2. GBK编码:是GB2312编码的扩展,包含了约21000个汉字,包括繁体字以及一些生僻字。
3. GB18030编码:是中华人民共和国现时最新的汉字编码标准,包含了27000多个汉字,不仅涵盖了繁体字和繁简混排,还包含了一些少数民族的文字。
4. Unicode编码:是国际标准的汉字编码,用于表示世界上所有的字符。
其中Unicode的基本多文种平面(BMP)包含了汉字以及各种其他字符,而扩展的Unicode平面则用于表示更多的字符。
汉字编码的用途主要包括:
1. 文字显示:汉字编码使得计算机能够正确显示、输入和输出汉字字符,方便使用者进行文字的阅读和书写。
2. 搜索和检索:在计算机系统中,汉字编码可以用于对文本进行搜索、排序和索引,实现快速的文本检索功能。
3. 多语言处理:汉字编码是支持多种语言的基础,可以用于处理多种文字和字符集,促进了跨语言和跨文化的计算机通信和协作。
4. 自然语言处理:汉字编码在自然语言处理任务中也起着重要的作用,例如机器翻译、信息抽取、文本分类等。
总之,汉字编码是将汉字字符转化为可计算机识别的二进制数据的方式,它的种类和用途在计算机中起到了重要的作用,方便了汉字的处理和应用。
汉字编码对照表(gb2312Big5GB2312)

汉字编码对照表(gb2312Big5GB2312)⼀、汉字编码的种类1、GB2312⼜称国标码,由国家标准总局发布,1981年5⽉1⽇实施,通⾏于⼤陆。
新加坡等地也使⽤此编码。
它是⼀个简化字的编码规范,当然也包括其他的符号、字母、⽇⽂假名等,共7445个图形字符,其中汉字占6763个。
我们平时说6768个汉字,实际上⾥边有5个编码为空⽩,所以总共有6763个汉字。
GB2312规定“对任意⼀个图形字符都采⽤两个字节表⽰,每个字节均采⽤七位编码表⽰”,习惯上称第⼀个字节为“⾼字节”,第⼆个字节为“低字节”。
GB2312中汉字的编码范围为,第⼀字节0xB0-0xF7(对应⼗进制为176-247),第⼆个字节0xA0-0xFE(对应⼗进制为160-254)。
GB2312将代码表分为94个区,对应第⼀字节(0xa1-0xfe);每个区94个位(0xa1-0xfe),对应第⼆字节,两个字节的值分别为区号值和位号值加32(2OH),因此也称为区位码。
01-09区为符号、数字区,16-87区为汉字区(0xb0-0xf7),10-15区、88-94区是有待进⼀步标准化的空⽩区。
2、Big5⼜称⼤五码,主要为⾹港与台湾使⽤,即是⼀个繁体字编码。
每个汉字由两个字节构成,第⼀个字节的范围从0X81-0XFE(即129-255),共126种。
第⼆个字节的范围不连续,分别为0X40-0X7E(即64-126),0XA1-0XFE(即161-254),共157种。
3、GBK是GB2312的扩展,是向上兼容的,因此GB2312中的汉字的编码与GBK中汉字的相同。
另外,GBK中还包含繁体字的编码,它与Big5编码之间的关系我还没有弄明⽩,好像是不⼀致的。
GBK中每个汉字仍然包含两个字节,第⼀个字节的范围是0x81-0xFE(即129-254),第⼆个字节的范围是0x40-0xFE(即64-254)。
GBK中有码位23940个,包含汉字21003个。
我国已颁布的汉字编码标准(一)

我国已颁布的汉字编码标准(一)我国已颁布的汉字编码标准汉字编码的重要性•汉字是中文的基本表达单位,是中华文化的瑰宝。
•汉字编码是对汉字进行数字化处理的重要工具。
•汉字编码标准的制定对于信息技术的发展和文化遗产的传承都有着重要意义。
GB2312——第一个汉字编码标准•GB2312是我国于1980年颁布的第一个汉字编码标准。
•GB2312收录了6763个常用汉字,使用两个字节表示一个汉字。
•GB2312以拼音排序,是在早期计算机系统中广泛使用的编码标准。
GBK——对GB2312的扩展和完善•GBK是GB2312的扩展编码标准,于1995年颁布。
•GBK在GB2312的基础上增加了繁体字和一些生僻字,共收录了21003个汉字。
•GBK兼容GB2312,使用一个或两个字节表示一个汉字,扩展了汉字的编码范围。
GB18030——对汉字编码的进一步拓展•GB18030是我国于2000年颁布的汉字编码标准,对汉字编码进行了更大范围的拓展。
•GB18030收录了27533个汉字,包括繁体字、异体字以及部分少数民族文字。
•GB18030兼容GBK和GB2312,是目前广泛使用的汉字编码标准之一。
Unicode——国际化的汉字编码方案•Unicode是一种全球通用的字符编码系统,它为世界上几乎所有的字符都分配了一个唯一的码位。
•Unicode对汉字的编码采用了统一的标准,解决了不同国家和地区使用不同编码的问题。
•Unicode可以使用不同的字符集来表示汉字,其中包括UTF-8、UTF-16等多种编码方式。
总结•我国已颁布的汉字编码标准经过多年的发展和完善,为计算机系统处理中文提供了重要支持。
•从GB2312到GBK再到GB18030,汉字编码标准逐步拓展了编码范围,收录了更多的汉字。
•Unicode作为国际化的汉字编码方案,解决了全球字符编码的一致性问题。
•汉字编码标准的制定和使用对于促进信息技术的发展和文化遗产的保护具有重要意义。
汉字字符的编码范围 -回复

汉字字符的编码范围-回复汉字字符的编码范围,指的是将汉字转化为计算机可以识别和处理的数字编码范围。
在计算机上,汉字字符的编码范围主要有Unicode和GBK两种标准。
本文将一步一步解答汉字字符的编码范围相关的主题。
第一步:认识汉字编码汉字是中文的文字,具有数万个字符。
由于计算机只能处理数字,为了能够在计算机上处理汉字,就需要将汉字转换为对应的数字编码。
汉字编码是指将汉字字符映射到具体的数字编码的过程。
第二步:Unicode编码Unicode是一种全球通用的字符编码标准,它包含了世界上几乎所有的字符,包括汉字。
Unicode将每一个字符分配了一个唯一的编号,这个编号被称为码点。
汉字在Unicode中的编码范围是4E00到9FFF,共有20992个字符。
这个范围包含了现代汉字、部分古代汉字以及一些中日韩等其他国家使用的汉字。
第三步:GBK编码GBK编码是汉字编码的一种扩展方式,它包含了Unicode编码中的汉字字符,并且还包含了更多的汉字字符。
GBK编码是在GB2312编码的基础上扩展而来,GB2312是中国国家标准局于1981年发布的一个双字节字符集编码标准。
GBK编码将汉字字符的编码范围扩展到8140至FEFE之间,共有21886个字符。
第四步:Unicode与GBK的关系Unicode是一个全球通用的字符编码标准,而GBK是在GB2312的基础上扩展的汉字编码标准。
Unicode包含了更多的字符范围,而GBK则专注于处理汉字字符。
因此,在Unicode中的汉字字符编码范围内,也包含了GBK中的字符编码范围。
第五步:其他汉字编码标准除了Unicode和GBK之外,还存在其他一些汉字编码标准。
例如,Big5是台湾地区使用的一种汉字编码标准,它包含了繁体字的编码范围。
还有日文中使用的Shift-JIS编码、韩文中使用的EUC-KR编码等,它们也都包含了汉字字符的编码范围。
第六步:应用中的汉字编码在实际的应用中,不同的系统和软件可能会采用不同的汉字编码标准。
根据汉字国标gb231280的规定

根据汉字国标gb231280的规定中国有着悠久的历史文化,也是一个拥有大量汉字的国家,使得传统文字受到珍视和尊崇。
汉字有着独特的价值,在表达文化和思想方面发挥着重要作用。
为了保护汉字传统文化,中国国家设立了GB231280国家规范标准,以确保汉字在计算机和信息处理方面能够被准确地表示和处理。
GB231280是一个政府颁布的国家规范,用来定义汉字的汉字编码,根据此国家规范,在计算机中汉字的字符代码可以用一组八位二进制数表示,以确保汉字的专业性和真实性。
GB231280是汉字编码的国家标准,它可以将汉字作为计算机的字符处理,也就是把汉字编码成一组8位二进制数字,以便汉字在计算机中表示正确,统一汉字的表面形式,这是计算机技术下汉字国标标准的重要性。
而GB231280国家规范更是为了防止汉字在计算机系统中出现乱码,维护中国传统文化。
在实际应用中,GB231280规范根据汉子的笔画细分,采用了汉字编码的方式,将汉字按照编码根据划分成了894个区,每个区分别是一个两位的16进制代码,由笔形和书写的结构,每个汉字被编码成8位二进制数字,并将这些编码可以通过计算机字符集进行识别,在计算机上可以正确准确表示汉字,从而达到了统一编码的目的。
在计算机应用领域中,根据GB231280国家规范进行汉字的编码,可以有效的处理汉字信息,不仅可以正确的翻译汉字,也可以用此编码表示汉字,在网络技术中也可以有效的处理汉字,进一步增强汉字的信息技术传播力。
此外,GB231280国家规范的另一个优点是可以改善人们输入文字的速度和准确性,系统将可以根据用户输入的信息智能提示,从而减少用户输入汉字过程中出错的机率。
另外,由于编码表示汉字的唯一性,在不同的计算机平台上也可实现汉字的跨平台交互传输,这也是GB231280国家规范应用传统文化和现代信息技术的一个重要体现。
总之,GB231280国家规范标准是一项政府颁布的国家标准,用来定义和统一汉字的编码,旨在保护中国的传统文化,确保汉字在计算机和信息处理方面能够得到准确的表达和处理,提高汉字的跨平台信息传播的准确性和有效性,从而实现对汉字的正确表达和传播,促进计算机技术对汉字的传播和发展。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字编码标准
汉字编码标准是汉字电子化的基础,是计算机技术与汉字文化相结合的产物。
它的出现,标志着汉字在计算机领域得到了广泛的应用和推广,为汉字信息的处理和传播提供了重要的支撑。
本文将从汉字编码标准的历史、现状和未来三个方面来探讨。
一、汉字编码标准的历史
汉字编码标准的历史可以追溯到上世纪60年代末期,当时,中国开始引进计算机技术,但由于汉字的复杂性和多样性,计算机无法直接处理汉字信息。
因此,当时的研究人员开始探索汉字编码的问题,并提出了一系列的编码方案。
最初的汉字编码方案是GB2312,它于1980年发布,采用了双字节编码方式,将汉字编码在0xA1-0xFE的范围内。
GB2312的出现,标志着汉字电子化的开始,并被广泛应用于计算机软件、打印机和操作系统等领域。
随着计算机技术的不断发展和应用的不断扩大,GB2312的局限性也逐渐显现出来。
首先,它只能表示简体中文,无法表示繁体中文和其他汉字方言。
其次,它的编码范围有限,只能表示6763个汉字,无法满足日益增长的汉字需求。
因此,在GB2312的基础上,人们又相继提出了GBK、GB18030等一系列汉字编码标准,不断完善和扩展汉字编码的能力和范围。
二、汉字编码标准的现状
当前,汉字编码标准已经得到了广泛的应用和推广。
在计算机软
件、操作系统、网站建设、电子出版等领域,汉字编码标准已经成为必备的技术和工具。
同时,随着移动互联网的发展和智能手机的普及,汉字编码标准的应用也进一步拓展到了移动应用、智能家居等领域。
目前,汉字编码标准主要分为两大类:一是Unicode编码,它是一种国际标准,可以表示全球各种语言的字符,包括汉字在内;二是GB编码,它是中国特有的汉字编码标准,主要用于国内的计算机应
用和信息处理。
在Unicode编码方面,目前最新的版本是Unicode 13.0,它可
以表示超过143,000个字符,包括汉字在内的各种语言和符号。
Unicode编码采用了统一的编码方式,使得不同的计算机系统和软件可以互相兼容和交换信息,为全球信息交流和共享提供了重要的支持。
在GB编码方面,目前最新的版本是GB18030,它可以表示超过70,000个汉字和符号,包括简体中文、繁体中文和其他汉字方言。
GB18030采用了双字节和四字节的编码方式,具有很好的兼容性和扩展性,可以满足不同领域和需求的汉字处理要求。
三、汉字编码标准的未来
随着人工智能、大数据、云计算等新技术的发展和应用,汉字编码标准也将面临新的挑战和机遇。
一方面,汉字编码标准需要不断完善和更新,以满足新的汉字需求和应用场景;另一方面,汉字编码标准还需要与其他技术和应用进行深度融合和协同,实现更高效、更智能、更便捷的汉字信息处理和传播。
未来,汉字编码标准的发展方向主要包括以下几个方面:
一是向更广泛的领域和应用拓展。
随着智能家居、智能医疗、智能交通等领域的发展,汉字编码标准需要进一步拓展到更多的应用场景和领域,以满足不同行业和用户的需求。
二是向更高效的处理和传播方向发展。
随着人工智能、大数据、云计算等新技术的发展和应用,汉字编码标准需要不断提高处理和传播的效率和精度,实现更高质量、更智能化的汉字信息处理和传播。
三是向更开放和共享的方向发展。
随着全球化和信息化的趋势不断加强,汉字编码标准需要更加开放和共享,与国际标准和技术进行深度融合和交流,共同推进全球汉字电子化的进程。
四是向更智能化的方向发展。
随着人工智能技术的不断发展和应用,汉字编码标准需要与人工智能技术进行深度结合,实现更智能、更自动化的汉字信息处理和应用。
总之,汉字编码标准是汉字电子化的基础和关键技术,它的发展和应用对于推进汉字信息化和文化传播具有重要意义。
未来,汉字编码标准需要不断完善和更新,与其他技术和应用进行深度融合和协同,为汉字信息化和文化传播提供更好的支撑和服务。