SQL存储过程基础
PostgreSQL-存储过程(一)基础篇

PostgreSQL-存储过程(⼀)基础篇存储过程其实就是函数,由⼀组 sql 语句组成,实现⽐较复杂的数据库操作;存储过程是存储在数据库服务器上的,⽤户可以像调⽤ sql ⾃带函数⼀样调⽤存储过程语法解析CREATE [OR REPLACE] FUNCTION function_name (arguments)RETURNS return_datatype AS $variable_name$DECLAREdeclaration;[...]BEGIN< function_body >[...]RETURN { variable_name | value }END; LANGUAGE plpgsql;很容易理解,不多解释下⾯我对⼀张表进⾏简单操作,逐步递进的介绍存储过程的语法步骤1-基础版into 表⽰把结果赋值给后⾯的变量,该变量必须在 declare 提前声明调⽤存储过程select mycount3()步骤2-把 sql 语句赋给变量create or replace function mycount3()returns integer as $$declaremysql text;counts integer;beginmysql:='select count("CD_ID") from "CDS"';execute mysql into counts;return counts;end;$$ language plpgsql;步骤3-带变量,且 sql 语句⽤字符串拼接create or replace function mycount4(tableName text, columnName text)returns text as $$declaremysql text;beginmysql:='select count('|| quote_ident(columnName)|| ') from '|| quote_ident(tableName);return mysql;end;$$ language plpgsql;1. 函数的参数必须声明类型2. || 表⽰字符串拼接符号3. 存储过程中的对象不能直接引⽤变量,要⽤ quote_ident,它的作⽤是为字符串加上双引号4. 在 sql 语句中,⼤写,全部会变成⼩写,如果想保留⼤写,需要加双引号调⽤存储过程select mycount4('CDS', 'CD_ID');返回select count("CD_ID") from "CDS"可以看到,输⼊参数是单引号,经过 quote_ident 后,⾃动变成双引号,保留了⼤写步骤4-换⼀种拼接⽅式,并且函数体加了 if 判断create or replace function mycount4(tableName text, columnName text)returns integer as $$declaremysql text;counts integer;beginmysql:='select count("' || $2 || '") from "' || $1 || '" ';execute mysql into counts using tableName, columnName;if counts > 100 thenreturn counts;else return 1;end if;end;$$ language plpgsql;1. ⽤ using 调取变量,此时需要⾃⼰加双引号以保留⼤写2. 112 对应的是函数的参数位置,跟 using 后的顺序⽆关3. if 后⾯有个 then4. text 可变长度字符串5. 每句末尾必须带分号。
SQL存储过程的语句(SQL存储过程)

SQL存储过程的语句(SQL存储过程)SQL语句集锦--语句功能--数据操作SELECT--从数据库表中检索数据⾏和列INSERT--向数据库表添加新数据⾏DELETE--从数据库表中删除数据⾏UPDATE--更新数据库表中的数据--数据定义CREATE TABLE--创建⼀个数据库表DROP TABLE--从数据库中删除表ALTER TABLE--修改数据库表结构CREATE VIEW--创建⼀个视图DROP VIEW--从数据库中删除视图CREATE INDEX--为数据库表创建⼀个索引DROP INDEX--从数据库中删除索引CREATE PROCEDURE--创建⼀个存储过程DROP PROCEDURE--从数据库中删除存储过程CREATE TRIGGER--创建⼀个触发器DROP TRIGGER--从数据库中删除触发器CREATE SCHEMA--向数据库添加⼀个新模式DROP SCHEMA--从数据库中删除⼀个模式CREATE DOMAIN --创建⼀个数据值域ALTER DOMAIN --改变域定义DROP DOMAIN --从数据库中删除⼀个域--数据控制GRANT--授予⽤户访问权限DENY--拒绝⽤户访问REVOKE--解除⽤户访问权限--事务控制COMMIT--结束当前事务ROLLBACK--中⽌当前事务SET TRANSACTION--定义当前事务数据访问特征--程序化SQLDECLARE--为查询设定游标EXPLAN --为查询描述数据访问计划OPEN--检索查询结果打开⼀个游标FETCH--检索⼀⾏查询结果CLOSE--关闭游标PREPARE--为动态执⾏准备SQL 语句EXECUTE--动态地执⾏SQL 语句DESCRIBE --描述准备好的查询---局部变量declare@id char(10)--set @id = '10010001'select@id='10010001'---全局变量---必须以@@开头--IF ELSEdeclare@x int@y int@z intselect@x=1@y=2@z=3if@x>@yprint'x > y'--打印字符串'x > y'else if@y>@zprint'y > z'else print'z > y'--CASEuse panguupdate employeeset e_wage =casewhen job_level = ’1’ then e_wage*1.08when job_level = ’2’ then e_wage*1.07when job_level = ’3’ then e_wage*1.06else e_wage*1.05end--WHILE CONTINUE BREAKdeclare@x int@y int@c intselect@x=1@y=1while@x<3beginprint@x--打印变量x 的值while@y<3beginselect@c=100*@x+@yprint@c--打印变量c 的值select@y=@y+1endselect@x=@x+1select@y=1end--WAITFOR--例等待1 ⼩时2 分零3 秒后才执⾏SELECT 语句waitfor delay ’01:02:03’select*from employee--例等到晚上11 点零8 分后才执⾏SELECT 语句waitfor time ’23:08:00’select*from employee***SELECT***select*(列名) from table_name(表名) where column_name operator valueex:(宿主)select*from stock_information where stockid =str(nid)stockname ='str_name'stockname like'% find this %'stockname like'[a-zA-Z]%'--------- ([]指定值的范围)stockname like'[^F-M]%'--------- (^排除指定范围)--------- 只能在使⽤like关键字的where⼦句中使⽤通配符)or stockpath ='stock_path'or stocknumber <1000and stockindex =24not stock***='man'stocknumber between20and100stocknumber in(10,20,30)order by stockid desc(asc) --------- 排序,desc-降序,asc-升序order by1,2--------- by列号stockname = (select stockname from stock_information where stockid =4) --------- ⼦查询--------- 除⾮能确保内层select只返回⼀个⾏的值,--------- 否则应在外层where⼦句中⽤⼀个in限定符select distinct column_name form table_name --------- distinct指定检索独有的列值,不重复select stocknumber ,"stocknumber +10" = stocknumber +10from table_nameselect stockname , "stocknumber" =count(*) from table_name group by stockname--------- group by 将表按⾏分组,指定列中有相同的值having count(*) =2--------- having选定指定的组select*from table1, table2where table1.id *= table2.id -------- 左外部连接,table1中有的⽽table2中没有得以null表⽰ table1.id =* table2.id -------- 右外部连接select stockname from table1union[all]----- union合并查询结果集,all-保留重复⾏select stockname from table2***insert***insert into table_name (Stock_name,Stock_number) value ("xxx","xxxx")value (select Stockname , Stocknumber from Stock_table2)---value为select语句***update***update table_name set Stockname = "xxx" [where Stockid = 3]Stockname =defaultStockname =nullStocknumber = Stockname +4***delete***delete from table_name where Stockid =3truncate table_name ----------- 删除表中所有⾏,仍保持表的完整性drop table table_name --------------- 完全删除表***alter table***--- 修改数据库表结构alter table database.owner.table_name add column_name char(2) null .....sp_help table_name ---- 显⽰表已有特征create table table_name (name char(20), age smallint, lname varchar(30))insert into table_name select ......... ----- 实现删除列的⽅法(创建新表)alter table table_name drop constraint Stockname_default ---- 删除Stockname的default约束***function(/*常⽤函数*/)***----统计函数----AVG--求平均值COUNT--统计数⽬MAX--求最⼤值MIN--求最⼩值SUM--求和--AVGuse panguselect avg(e_wage) as dept_avgWagefrom employeegroup by dept_id--MAX--求⼯资最⾼的员⼯姓名use panguselect e_namefrom employeewhere e_wage =(select max(e_wage)from employee)--STDEV()--STDEV()函数返回表达式中所有数据的标准差--STDEVP()--STDEVP()函数返回总体标准差--VAR()--VAR()函数返回表达式中所有值的统计变异数--VARP()--VARP()函数返回总体变异数----算术函数----/***三⾓函数***/SIN(float_expression) --返回以弧度表⽰的⾓的正弦COS(float_expression) --返回以弧度表⽰的⾓的余弦TAN(float_expression) --返回以弧度表⽰的⾓的正切COT(float_expression) --返回以弧度表⽰的⾓的余切/***反三⾓函数***/ASIN(float_expression) --返回正弦是FLOAT 值的以弧度表⽰的⾓ACOS(float_expression) --返回余弦是FLOAT 值的以弧度表⽰的⾓ATAN(float_expression) --返回正切是FLOAT 值的以弧度表⽰的⾓ATAN2(float_expression1,float_expression2)--返回正切是float_expression1 /float_expres-sion2的以弧度表⽰的⾓DEGREES(numeric_expression)--把弧度转换为⾓度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型RADIANS(numeric_expression) --把⾓度转换为弧度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型EXP(float_expression) --返回表达式的指数值LOG(float_expression) --返回表达式的⾃然对数值LOG10(float_expression)--返回表达式的以10 为底的对数值SQRT(float_expression) --返回表达式的平⽅根/***取近似值函数***/CEILING(numeric_expression) --返回>=表达式的最⼩整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型FLOOR(numeric_expression) --返回<=表达式的最⼩整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型ROUND(numeric_expression) --返回以integer_expression 为精度的四舍五⼊值返回的数据--类型与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型ABS(numeric_expression) --返回表达式的绝对值返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型SIGN(numeric_expression) --测试参数的正负号返回0 零值1 正数或-1 负数返回的数据类型--与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型PI() --返回值为π即3.1415926535897936RAND([integer_expression]) --⽤任选的[integer_expression]做种⼦值得出0-1 间的随机浮点数----字符串函数----ASCII() --函数返回字符表达式最左端字符的ASCII 码值CHAR() --函数⽤于将ASCII 码转换为字符--如果没有输⼊0 ~ 255 之间的ASCII 码值CHAR 函数会返回⼀个NULL 值LOWER() --函数把字符串全部转换为⼩写UPPER() --函数把字符串全部转换为⼤写STR() --函数把数值型数据转换为字符型数据LTRIM() --函数把字符串头部的空格去掉RTRIM() --函数把字符串尾部的空格去掉LEFT(),RIGHT(),SUBSTRING() --函数返回部分字符串CHARINDEX(),PATINDEX() --函数返回字符串中某个指定的⼦串出现的开始位置SOUNDEX() --函数返回⼀个四位字符码--SOUNDEX函数可⽤来查找声⾳相似的字符串但SOUNDEX函数对数字和汉字均只返回0 值DIFFERENCE() --函数返回由SOUNDEX 函数返回的两个字符表达式的值的差异--0 两个SOUNDEX 函数返回值的第⼀个字符不同--1 两个SOUNDEX 函数返回值的第⼀个字符相同--2 两个SOUNDEX 函数返回值的第⼀⼆个字符相同--3 两个SOUNDEX 函数返回值的第⼀⼆三个字符相同--4 两个SOUNDEX 函数返回值完全相同QUOTENAME() --函数返回被特定字符括起来的字符串/*select quotename('abc', '{') quotename('abc')运⾏结果如下----------------------------------{{abc} [abc]*/REPLICATE() --函数返回⼀个重复character_expression 指定次数的字符串/*select replicate('abc', 3) replicate( 'abc', -2)运⾏结果如下----------- -----------abcabcabc NULL*/REVERSE() --函数将指定的字符串的字符排列顺序颠倒REPLACE() --函数返回被替换了指定⼦串的字符串/*select replace('abc123g', '123', 'def')运⾏结果如下----------- -----------abcdefg*/SPACE() --函数返回⼀个有指定长度的空⽩字符串STUFF() --函数⽤另⼀⼦串替换字符串指定位置长度的⼦串----数据类型转换函数----CAST() 函数语法如下CAST() (<expression>AS<data_ type>[ length ])CONVERT() 函数语法如下CONVERT() (<data_ type>[ length ], <expression>[, style])select cast(100+99as char) convert(varchar(12), getdate())运⾏结果如下------------------------------ ------------199 Jan 152000----⽇期函数----DAY() --函数返回date_expression 中的⽇期值MONTH() --函数返回date_expression 中的⽉份值YEAR() --函数返回date_expression 中的年份值DATEADD(<datepart> ,<number> ,<date>)--函数返回指定⽇期date 加上指定的额外⽇期间隔number 产⽣的新⽇期DATEDIFF(<datepart> ,<number> ,<date>)--函数返回两个指定⽇期在datepart ⽅⾯的不同之处DATENAME(<datepart> , <date>) --函数以字符串的形式返回⽇期的指定部分DATEPART(<datepart> , <date>) --函数以整数值的形式返回⽇期的指定部分GETDATE() --函数以DATETIME 的缺省格式返回系统当前的⽇期和时间----系统函数----APP_NAME() --函数返回当前执⾏的应⽤程序的名称COALESCE() --函数返回众多表达式中第⼀个⾮NULL 表达式的值COL_LENGTH(<'table_name'>, <'column_name'>) --函数返回表中指定字段的长度值COL_NAME(<table_id>, <column_id>) --函数返回表中指定字段的名称即列名DATALENGTH() --函数返回数据表达式的数据的实际长度DB_ID(['database_name']) --函数返回数据库的编号DB_NAME(database_id) --函数返回数据库的名称HOST_ID() --函数返回服务器端计算机的名称HOST_NAME() --函数返回服务器端计算机的名称IDENTITY(<data_type>[, seed increment]) [AS column_name])--IDENTITY() 函数只在SELECT INTO 语句中使⽤⽤于插⼊⼀个identity column列到新表中/*select identity(int, 1, 1) as column_nameinto newtablefrom oldtable*/ISDATE() --函数判断所给定的表达式是否为合理⽇期ISNULL(<check_expression>, <replacement_value>) --函数将表达式中的NULL 值⽤指定值替换ISNUMERIC() --函数判断所给定的表达式是否为合理的数值NEWID() --函数返回⼀个UNIQUEIDENTIFIER 类型的数值NULLIF(<expression1>, <expression2>)--NULLIF 函数在expression1 与expression2 相等时返回NULL 值若不相等时则返回expression1 的值。
(完整版)SQL存储过程全面实例讲解

SQL实例讲解一、创建存储过程结构CREATE PROCEDURE创建存储过程,存储过程是保存起来的可以接受和返回用户提供的参数的Transact-SQL 语句的集合。
可以创建一个过程供永久使用,或在一个会话中临时使用(局部临时过程),或在所有会话中临时使用(全局临时过程)。
也可以创建在 Microsoft SQL Server启动时自动运行的存储过程。
语法CREATE PROC [ EDURE ] procedure_name [ ; number ][ { @parameter data_type }[ VARYING ] [ = default ] [ OUTPUT ]] [ ,...n ][ WITH{ RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ][ FOR REPLICATION ]AS sql_statement [ ...n ]二、存储过程实例讲解1. 使用带有复杂 SELECT 语句的简单过程下面的存储过程从四个表的联接中返回所有作者(提供了姓名)、出版的书籍以及出版社。
该存储过程不使用任何参数。
USE pubsIF EXISTS (SELECT name FROM sysobjectsWHERE name = 'au_info_all' AND type = 'P')DROP PROCEDURE au_info_allGOCREATE PROCEDURE au_info_allASSELECT au_lname, au_fname, title, pub_nameFROM authors a INNER JOIN titleauthor taON a.au_id = ta.au_id INNER JOIN titles tON t.title_id = ta.title_id INNER JOIN publishers pON t.pub_id = p.pub_idGOau_info_all 存储过程可以通过以下方法执行:EXECUTE au_info_all-- OrEXEC au_info_all如果该过程是批处理中的第一条语句,则可使用:au_info_all2. 使用带有参数的简单过程下面的存储过程从四个表的联接中只返回指定的作者(提供了姓名)、出版的书籍以及出版社。
SQL 存储过程

分析: 分析:
在述存储过程添加1个输入参数: 在述存储过程添加 个输入参数: 个输入参数 @gradeExc 成绩优秀的标准
带输入参数的存储过程
CREATE PROCEDURE proc_stu @standard int AS print '--------------------------------------------------' print ' 考试成绩优秀的学生:' 考试成绩优秀的学生: 输入参数: 输入参数:成绩优秀的标准
带输出参数的存储过程
调用带输出参数的存储过程
调用时必须带OUTPUT关键字 ,返 调用时必须带 关键字 /*---调用存储过程 调用存储过程----*/ 调用存储过程 回结果将存放在变量@x中 回结果将存放在变量 中 DECLARE @x int EXEC proc_stu @x OUTPUT ,80 print '--------------------------------------------------' 后续语句引用返回结果 IF @x>=4 print '优秀人数:'+convert(varchar(5),@sum)+ '人, 优秀人数: 优秀人数 人 超过30%,成绩优秀分数线还应上调 成绩优秀分数线还应上调' 超过 成绩优秀分数线还应上调 ELSE print '优秀人数:'+convert(varchar(5),@sum)+ '人, 优秀人数: 优秀人数 人 已控制在30%以下,成绩优秀分数线适中 以下, 已控制在 以下 成绩优秀分数线适中' GO
问题: 问题:
如果试卷的难易程度合适, 如果试卷的难易程度合适,则调用者还是必须 如此调用: EXEC proc_stu 85,比较麻烦 如此调用: , 这样调用就比较合理: 这样调用就比较合理: EXEC proc_stu 成绩优秀的标准默认为85分 成绩优秀的标准默认为 分
sqlserver存储过程的编写

SQL Server存储过程是一种预先编译的SQL语句集,存储在数据库中,可以通过存储过程的名称和参数来调用。
存储过程的编写可以大大提高数据库的性能和安全性,同时也可以简化复杂的数据库操作。
下面将从存储过程的基本语法、参数传递、错误处理、性能优化等方面来介绍SQL Server存储过程的编写。
一、存储过程的基本语法1.1 创建存储过程在SQL Server中,可以使用CREATE PROCEDURE语句来创建存储过程,例如:```sqlCREATE PROCEDURE proc_nameASBEGIN-- 存储过程的逻辑代码END```1.2 存储过程的参数存储过程可以接受输入参数和输出参数,例如:```sqlCREATE PROCEDURE proc_nameparam1 INT,param2 VARCHAR(50) OUTPUTASBEGIN-- 存储过程的逻辑代码END```1.3 调用存储过程使用EXECUTE语句可以调用存储过程,例如:```sqlEXECUTE proc_name param1, param2 OUTPUT```二、参数传递2.1 输入参数输入参数用于向存储过程传递数值、字符等数据,可以在存储过程内部进行计算和逻辑操作。
2.2 输出参数输出参数用于从存储过程内部传递数据到外部,通常用于返回存储过程的计算结果或状态信息。
2.3 默认参数在创建存储过程时可以指定默认参数值,当调用存储过程时如果未传入参数,则使用默认值。
三、错误处理3.1 TRY...CATCH语句使用TRY...CATCH语句可以捕获存储过程中的异常并进行处理,例如:```sqlBEGIN TRY-- 存储过程的逻辑代码END TRYBEGIN CATCH-- 异常处理代码END CATCH```3.2 R本人SEERROR函数可以使用R本人SEERROR函数来抛出自定义的异常信息,例如: ```sqlR本人SEERROR('Custom error message', 16, 1)```四、性能优化4.1 索引优化在存储过程中执行的SQL语句涉及到大量数据查询时,可以使用索引来提升查询性能。
sql select 调用存储过程

sql select 调用存储过程[SQL Select 调用存储过程] 是关于如何使用存储过程来执行SQL Select 查询的主题。
在本篇文章中,我将一步一步回答这个问题,并提供详细的解释和示例。
第一部分:存储过程的概述第一步:什么是存储过程?第二步:为什么使用存储过程?第二部分:创建存储过程第一步:语法和结构第二步:创建一个简单的存储过程第三步:存储过程的参数和返回值第三部分:调用存储过程第一步:语法和示例第二步:执行一个存储过程第三步:传递参数第四部分:优势和示例第一步:优势和好处第二步:示例第一部分:存储过程的概述第一步:什么是存储过程?存储过程是预编译一组SQL 语句并将其保存在数据库中以供重复使用的查询。
它可以包含任意数量的SQL 语句,并且可以接受输入参数并返回输出结果。
存储过程可以在不同的应用程序中重复使用,提供了更高的性能和安全性。
第二步:为什么使用存储过程?使用存储过程的主要好处如下:1. 重用代码:可以在多个应用程序或模块中重复使用存储过程,减少了代码的重复编写。
2. 提高性能:存储过程是预编译的,可以减少每次执行查询时的解析和编译时间,提高查询的执行效率。
3. 提供安全性:存储过程可以通过授权机制限制用户对数据库的访问权限,保护数据的安全性。
4. 简化维护:将查询逻辑集中在存储过程中,使得维护和修改更加方便。
第二部分:创建存储过程第一步:语法和结构创建存储过程的语法如下:sqlCREATE PROCEDURE [procedure_name][parameter1 data_type,][parameter2 data_type,]...ASBEGINSQL statementsEND可以使用CREATE PROCEDURE 语句创建一个存储过程,指定存储过程的名称和参数列表。
存储过程的主体是BEGIN 和END 之间的SQL 语句块。
第二步:创建一个简单的存储过程下面是一个创建一个简单存储过程的示例,该存储过程返回一个指定员工ID的信息:sqlCREATE PROCEDURE GetEmployeeEmployeeID INTASBEGINSELECT * FROM Employees WHERE EmployeeID = EmployeeID END上述示例中,我们创建了一个名为GetEmployee 的存储过程,该存储过程接受一个EmployeeID 参数,并根据传入的参数值查询Employees 表中的数据。
sql存储过程详解

sql存储过程详解SQL存储过程是指一段预先编写好的SQL代码,可以被多次调用,用于执行特定的任务或操作。
存储过程通常由一系列SQL语句、变量、分支结构和循环结构组成。
在数据库中,存储过程可以提高数据处理效率、简化复杂的业务逻辑和保证数据安全性。
本文将详细介绍SQL 存储过程的定义、创建、调用和优化等方面。
一、定义SQL存储过程是指一段预先编写好的SQL代码,可以被多次调用,用于执行特定的任务或操作。
存储过程通常由一系列SQL语句、变量、分支结构和循环结构组成。
在数据库中,存储过程可以提高数据处理效率、简化复杂的业务逻辑和保证数据安全性。
二、创建在创建一个存储过程之前,需要确保已经连接到了正确的数据库,并且有足够的权限来创建一个新的存储过程。
下面是一个简单的创建存储过程的示例:CREATE PROCEDURE sp_exampleASBEGIN-- SQL code goes hereEND其中,“sp_example”是存储过程名称,“AS”关键字表示开始定义该存储过程,“BEGIN”和“END”之间是该存储过程所包含的所有代码。
三、调用当需要使用某个存储过程时,可以使用以下语法来调用该存储过程:EXEC sp_example其中,“sp_example”是需要调用的存储过程名称,“EXEC”关键字表示执行该存储过程。
四、优化为了提高SQL存储过程的性能和效率,可以采取以下一些优化措施:1. 尽量避免使用“SELECT *”语句,因为这会导致查询所有列,而不仅仅是需要的列。
2. 尽量避免使用“CURSOR”游标,因为这会导致性能下降。
3. 尽量避免在存储过程中使用大量的循环结构和条件判断语句,因为这会导致代码复杂度增加,从而影响性能。
4. 尽量避免在存储过程中使用大量的临时表或变量,因为这会导致内存占用增加,从而影响性能。
5. 使用参数化查询可以提高查询效率和安全性。
参数化查询是指将SQL查询语句中的变量替换成占位符,在执行时再将具体值传入占位符中。
PGSQL存储过程学习
PGSQL存储过程学习⼀、存储过程定义:存储过程(Stored Procedure)是在⼤型中,⼀组为了完成特定功能的SQL 语句集,它存储在数据库中,⼀次后永久有效,⽤户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执⾏它。
存储过程是数据库中的⼀个重要对象。
在数据量特别庞⼤的情况下利⽤存储过程能达到倍速的效率提升。
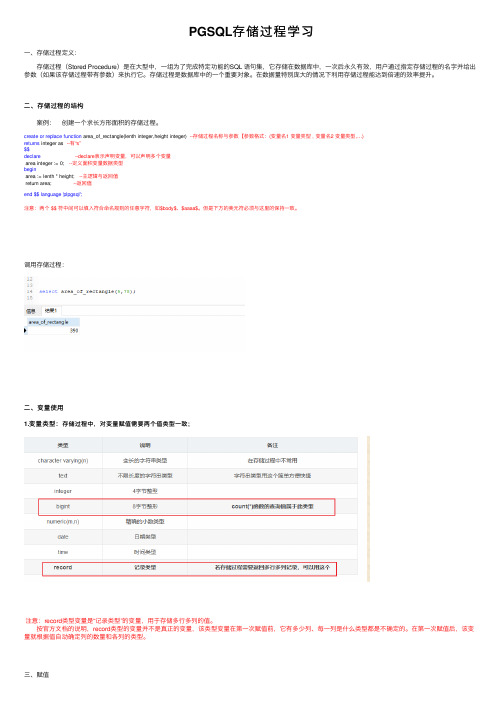
⼆、存储过程的结构 案例: 创建⼀个求长⽅形⾯积的存储过程。
create or replace function area_of_rectangle(lenth integer,height integer) --存储过程名称与参数【参数格式:(变量名1 变量类型 , 变量名2 变量类型,…)returns integer as --有“s”$$declare --declare表⽰声明变量,可以声明多个变量area integer := 0; --定义⾯积变量数据类型beginarea := lenth * height; --主逻辑与返回值return area; --返回值end $$ language 'plpgsql';注意:两个 $$ 符中间可以填⼊符合命名规则的任意字符,如$body$、$aaaa$。
但是下⽅的美元符必须与这⾥的保持⼀致。
调⽤存储过程:⼆、变量使⽤1.变量类型:存储过程中,对变量赋值需要两个值类型⼀致;注意:record类型变量是“记录类型”的变量,⽤于存储多⾏多列的值。
按官⽅⽂档的说明,record类型的变量并不是真正的变量,该类型变量在第⼀次赋值前,它有多少列、每⼀列是什么类型都是不确定的。
在第⼀次赋值后,该变量就根据值⾃动确定列的数量和各列的类型。
三、赋值 3.1、静态赋值: student_name := '张静'; 3.2、动态赋值: select name into student_name from class where stu_No = 1; --或者 execute 'select name from class where stu_No = 1' into student_name;四、基本流程语句:存储过程中,使⽤RAISE NOTICE可以在运⾏时将变量输出显⽰4.1、if语句IF ... THEN ... END IF;IF ... THEN ... ELSE ... END IF;IF ... THEN ... ELSE ... THEN ... ELSE ... END IF;--例:if student_name = '张静' thenRAISE NOTICE '我是张静';else if student_name like '%李%' thenRAISE NOTICE '我姓李';elseRAISE NOTICE '我不是张静,也不姓李';4.2、case语句CASE ... WHEN ... THEN ... ELSE ... END CASE;CASE WHEN ... THEN ... ELSE ... END CASE;--例:case student_name when '张静','晓静' thenRAISE NOTICE '张静和晓静都是我的名称';elseRAISE NOTICE '你叫错名字了';end case;--例:case when student_name = '张静'or student_name = '晓静' thenRAISE NOTICE '张静和晓静都是我的名称';elseRAISE NOTICE '你叫错名字了';end case;4.3、循环[ <<label>> ]LOOP循环体语句;EXIT [ label ] [ WHEN 判断条件表达式 ];END LOOP [ label ];--例-计算1到100的和:sum := 0;i := 0;loopi := i + 1;sum := sum + i;exit when i = 100 ;end loop;RAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]WHILE 判断条件表达式 LOOP循环体语句;END LOOP [ label ];--例 - 计算1到100的和:sum := 0;i := 1;while i<=100 loopsum := sum + i;i := i + 1;end loopRAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]FOR 循环控制变量 IN [ REVERSE ] 循环范围 [ BY expression ] LOOP循环体语句;END LOOP [ label ];--计算1到100的和:--例1 - 循环执⾏过程类似于:for(i=1;i<=100;i++){}sum := 0;for i in 1..100 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;--例2 - 循环执⾏过程类似于:for(i=100;i>=1;i--){}sum := 0;for i in REVERSE 100..1 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;--计算1到100之间所有奇数的和--例3 - 循环执⾏过程类似于:for(i=1;i<=100;i=i+2){}sum := 0;for i in 1..100 by 2 loopsum := sum + i;end loop;RAISE NOTOCE '1到100的和为:%',sum;[ <<label>> ]FOR 变量 IN 查询语句 LOOP循环体语句;END LOOP [ label ];--例 - 遍历班级中每个⼈的名字:for student_name in select name from class loopRAISE NOTICE '姓名:%',student_name;end loop;四、查询并返回多条记录案例1:create or replace function f_get_member_info(id integer)returns setof record as --setof是关键字,暂时不清楚其作⽤;record是返回的数据类型,即记录类型数据;$$ --两个美元符必须存在,中间可以填⼊符合命名规则的字符(如$body$,$abc$),但必须与下⽅的两个美元符相统⼀declarerec record; --定义记录类型的变量,⽤于存储查询的结果begin--开始for循环,执⾏SELECT语句。
SQL带参数的存储过程

SQL带参数的存储过程SQL存储过程是一种预编译的SQL语句集合,可以重复调用,提供了一种封装和模块化的数据库开发方式。
带参数的存储过程在实际开发中非常常见,它可以帮助我们更加灵活地处理不同的数据操作需求。
本文将详细介绍SQL带参数的存储过程的概念、使用场景、开发步骤以及一些实际应用案例。
一、SQL带参数的存储过程概述带参数的存储过程是指在创建存储过程时,我们可以定义一些参数,使得存储过程能根据这些参数的不同值来执行不同的数据库操作。
存储过程的参数可以分为输入参数和输出参数两种类型。
输出参数是存储过程在执行完毕后返回给用户的值。
输出参数可以用来返回查询结果、执行状态等信息。
二、SQL带参数的存储过程使用场景带参数的存储过程在实际开发中具有广泛的应用场景,以下是一些常见的使用场景:1.数据库查询:通过传入参数的不同值,可以实现不同的查询操作。
例如,我们可以根据传入的员工ID查询该员工的详细信息。
2.数据库更新:通过传入参数的不同值,可以实现不同的数据更新操作。
例如,我们可以根据传入的订单ID和状态值,更新订单的状态信息。
3.数据库插入:通过传入参数的不同值,可以实现不同的数据插入操作。
例如,我们可以根据传入的用户ID和用户名插入一个新的用户记录。
4.数据库删除:通过传入参数的不同值,可以实现不同的数据删除操作。
例如,我们可以根据传入的商品ID删除对应的商品记录。
三、SQL带参数的存储过程的开发步骤开发SQL带参数的存储过程需要以下几个步骤:1.定义存储过程:使用CREATEPROCEDURE语句来创建存储过程,其中可以定义存储过程的名称、参数以及执行的具体SQL语句。
2.编写存储过程代码:在存储过程中,可以使用DECLARE语句定义输入参数和输出参数,使用SET语句来给参数赋值,使用SELECT、INSERT、UPDATE、DELETE等SQL语句来执行具体的数据库操作。
3.调用存储过程:使用EXECUTE或者CALL语句来调用存储过程,并传入相应的参数值。
sql存储过程语句

sql存储过程语句SQL存储过程是一种在数据库中存储的程序,它可以接收参数并执行一系列的SQL语句。
存储过程可以提高数据库的性能和安全性,减少网络流量,同时也可以简化应用程序的开发。
本文将介绍SQL存储过程的基本概念、语法和应用,以及如何使用SQL存储过程来提高数据库的性能和安全性。
一、SQL存储过程的基本概念SQL存储过程是一种预编译的程序,它可以存储在数据库中,并在需要的时候被调用。
存储过程可以接收参数,并执行一系列的SQL 语句,最终返回结果集或输出参数。
SQL存储过程与函数类似,但它可以执行更复杂的操作,比如控制流程、事务处理、异常处理等。
存储过程还可以提高数据库的性能和安全性,因为它可以预编译和缓存SQL语句,减少网络流量,并且只有授权用户才能调用。
二、SQL存储过程的语法SQL存储过程的语法与SQL语句类似,但它需要使用特定的语法结构和关键字。
下面是一个简单的SQL存储过程的示例:CREATE PROCEDURE sp_get_customer_info@customer_id INTASBEGINSELECT * FROM customers WHERE customer_id = @customer_idEND这个存储过程接收一个整型参数customer_id,然后根据这个参数查询customers表中的数据,并返回结果集。
下面是SQL存储过程的语法结构:CREATE PROCEDURE procedure_name@parameter_name data_type [= default_value] [OUT]ASBEGIN-- SQL statementsEND其中,CREATE PROCEDURE是创建存储过程的关键字,procedure_name是存储过程的名称,@parameter_name是存储过程的参数名称,data_type是参数的数据类型,default_value是参数的默认值(可选),[OUT]表示该参数是输出参数(可选),AS是存储过程的开始标记,BEGIN和END之间是存储过程的SQL语句。
sql存储过程

存储过程百科名片存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,是利用SQL Server 所提供的Transact-SQL语言所编写的程序。
经编译后存储在数据库中。
存储过程是数据库中的一个重要对象,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。
存储过程是由流控制和SQL语句书写的过程,这个过程经编译和优化后存储在数据库服务器中,存储过程可由应用程序通过一个调用来执行,而且允许用户声明变量。
同时,存储过程可以接收和输出参数、返回执行存储过程的状态值,也可以嵌套调用。
目录功能优点缺点种类格式1实例数据库存储过程1SQL Server中执行存储过程1Oracle中的存储过程1操作临时表1触发器1常用格式展开编辑本段功能这类语言主要提供以下功能,让用户可以设计出符合引用需求的程序:1)、变量说明2)、ANSI兼容的SQL命令(如Select,Update….) 3)、一般流程控制命令(if…else…、while….) 4)、内部函数编辑本段优点* 存储过程的能力大大增强了SQL语言的功能和灵活性。
存储过程可以用流控制语句编写,有很强的灵活性,可以完成复杂的判断和较复杂的运算。
* 可保证数据的安全性和完整性。
# 通过存储过程可以使没有权限的用户在控制之下间接地存取数据库,从而保证数据的安全。
# 通过存储过程可以使相关的动作在一起发生,从而可以维护数据库的完整性。
* 在运行存储过程前,数据库已对其进行了语法和句法分析,并给出了优化执行方案。
这种已经编译好的过程可极大地改善SQL语句的性能。
由于执行SQL语句的大部分工作已经完成,所以存储过程能以极快的速度执行。
* 可以降低网络的通信量。
* 使体现企业规则的运算程序放入数据库服务器中,以便:# 集中控制。
# 当企业规则发生变化时在服务器中改变存储过程即可,无须修改任何应用程序。
企业规则的特点是要经常变化,如果把体现企业规则的运算程序放入应用程序中,则当企业规则发生变化时,就需要修改应用程序工作量非常之大(修改、发行和安装应用程序)。
sql中存储过程的用法

sql中存储过程的用法一、概述存储过程是一种保存在数据库中的程序,可以执行一系列操作,包括数据查询、数据更新、事务控制和多个SQL语句的执行,等等。
存储过程可以简化许多重复的工作,提高数据库的性能,增加数据的安全性和保密性。
二、创建存储过程在SQL Server中,创建存储过程可以使用CREATE PROCEDURE语句。
例如:```CREATE PROCEDURE [dbo].[proc_SelectUsers]ASBEGINSELECT * FROM UsersEND```上述语句创建了一个名为proc_SelectUsers的存储过程,它会查询Users表中所有的数据。
注意,存储过程创建语句的标准格式如下:```CREATE [OR ALTER] PROCEDURE procedure_name [parameter_list][WITH <procedure_option> [,...n]]ASsql_statement [;] [,...n]```参数列表(parameter_list)是可选的,用于指定存储过程所需的参数。
WITH子句是可选的,用于指定存储过程的一些选项,如ENCRYPTION、EXECUTE AS和RECOMPILE等。
sql_statement则是存储过程要执行的一系列SQL语句。
三、执行存储过程在SQL Server中,可以使用EXECUTE语句或者EXEC语句(两者等效)来执行存储过程。
例如:```EXEC proc_SelectUsers```以上语句将会执行名为proc_SelectUsers的存储过程,返回查询结果。
如果存储过程有参数,则执行语句应该像这样:```EXEC proc_SelectUsersByGender @Gender = 'F'```上述语句将会执行名为proc_SelectUsersByGender的存储过程,传递Gender参数值为“F”,返回查询结果。
SQLSERVER存储过程基本语法

SQLSERVER存储过程基本语法⼀、定义变量--简单赋值declare@a intset@a=5print@a--使⽤select语句赋值declare@user1nvarchar(50)select@user1='张三'print@user1declare@user2nvarchar(50)select@user2= Name from ST_User where ID=1print@user2--使⽤update语句赋值declare@user3nvarchar(50)update ST_User set@user3= Name where ID=1print@user3⼆、表、临时表、表变量--创建临时表1create table #DU_User1([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL);--向临时表1插⼊⼀条记录insert into #DU_User1 (ID,Oid,[Login],Rtx,Name,[Password],State) values (100,2,'LS','0000','临时','321','特殊');--从ST_User查询数据,填充⾄新⽣成的临时表select*into #DU_User2 from ST_User where ID<8--查询并联合两临时表select*from #DU_User2 where ID<3union select*from #DU_User1--删除两临时表drop table #DU_User1drop table #DU_User2--创建临时表CREATE TABLE #t([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL,)--将查询结果集(多条数据)插⼊临时表insert into #t select*from ST_User--不能这样插⼊--select * into #t from dbo.ST_User--添加⼀列,为int型⾃增长⼦段alter table #t add[myid]int NOT NULL IDENTITY(1,1)--添加⼀列,默认填充全球唯⼀标识alter table #t add[myid1]uniqueidentifier NOT NULL default(newid())select*from #tdrop table #t--给查询结果集增加⾃增长列--⽆主键时:select IDENTITY(int,1,1)as ID, Name,[Login],[Password]into #t from ST_Userselect*from #t--有主键时:select (select SUM(1) from ST_User where ID<= a.ID) as myID,*from ST_User a order by myID--定义表变量declare@t table(id int not null,msg nvarchar(50) null)insert into@t values(1,'1')insert into@t values(2,'2')select*from@t三、循环--while循环计算1到100的和declare@a intdeclare@sum intset@a=1set@sum=0while@a<=100beginset@sum+=@aset@a+=1endprint@sum四、条件语句--if,else条件分⽀if(1+1=2)beginprint'对'endelsebeginprint'错'end--when then条件分⽀declare@today intdeclare@week nvarchar(3)set@today=3set@week=casewhen@today=1then'星期⼀'when@today=2then'星期⼆'when@today=3then'星期三'when@today=4then'星期四'when@today=5then'星期五'when@today=6then'星期六'when@today=7then'星期⽇'else'值错误'endprint@week五、游标declare@ID intdeclare@Oid intdeclare@Login varchar(50)--定义⼀个游标declare user_cur cursor for select ID,Oid,[Login]from ST_User --打开游标open user_curwhile@@fetch_status=0begin--读取游标fetch next from user_cur into@ID,@Oid,@Loginprint@ID--print @Loginendclose user_cur--摧毁游标deallocate user_cur六、触发器 触发器中的临时表: Inserted 存放进⾏insert和update 操作后的数据 Deleted 存放进⾏delete 和update操作前的数据--创建触发器Create trigger User_OnUpdateOn ST_Userfor UpdateAsdeclare@msg nvarchar(50)--@msg记录修改情况select@msg= N'姓名从“'+ + N'”修改为“'+ +'”'from Inserted,Deleted --插⼊⽇志表insert into[LOG](MSG)values(@msg)--删除触发器drop trigger User_OnUpdate七、存储过程--创建带output参数的存储过程CREATE PROCEDURE PR_Sum@a int,@b int,@sum int outputASBEGINset@sum=@a+@bEND--创建Return返回值存储过程CREATE PROCEDURE PR_Sum2@a int,@b intASBEGINReturn@a+@bEND--执⾏存储过程获取output型返回值declare@mysum intexecute PR_Sum 1,2,@mysum outputprint@mysum--执⾏存储过程获取Return型返回值declare@mysum2intexecute@mysum2= PR_Sum2 1,2print@mysum2⼋、⾃定义函数 函数的分类: 1)标量值函数 2)表值函数 a:内联表值函数 b:多语句表值函数 3)系统函数--新建标量值函数create function FUNC_Sum1(@a int,@b int)returns intasbeginreturn@a+@bend--新建内联表值函数create function FUNC_UserTab_1(@myId int)returns tableasreturn (select*from ST_User where ID<@myId)--新建多语句表值函数create function FUNC_UserTab_2(@myId int)returns@t table([ID][int]NOT NULL,[Oid][int]NOT NULL,[Login][nvarchar](50) NOT NULL,[Rtx][nvarchar](4) NOT NULL,[Name][nvarchar](5) NOT NULL,[Password][nvarchar](max) NULL,[State][nvarchar](8) NOT NULL)asbegininsert into@t select*from ST_User where ID<@myIdreturnend--调⽤表值函数select*from dbo.FUNC_UserTab_1(15)--调⽤标量值函数declare@s intset@s=dbo.FUNC_Sum1(100,50)print@s--删除标量值函数drop function FUNC_Sum1谈谈⾃定义函数与存储过程的区别:⼀、⾃定义函数: 1. 可以返回表变量 2. 限制颇多,包括 不能使⽤output参数; 不能⽤临时表; 函数内部的操作不能影响到外部环境; 不能通过select返回结果集; 不能update,delete,数据库表; 3. 必须return ⼀个标量值或表变量 ⾃定义函数⼀般⽤在复⽤度⾼,功能简单单⼀,争对性强的地⽅。
SQL学习之存储过程

SQL学习之存储过程存储过程是一种SQL语句的集合,通过定义一组操作来实现特定功能。
它可以被保存在数据库中,并且可以在需要的时候被调用,减少了重复编写相同的SQL语句的工作量,并且可以提高数据库运行的效率。
本文将介绍存储过程的概念、优点、创建和调用方法,以及一些存储过程的应用场景。
概念:存储过程是一组预编译的SQL语句和控制语句的集合,被存储在数据库中。
它们可以被视为数据库中的子程序,可以实现特定的业务逻辑或数据操作功能。
存储过程可以接受输入参数,执行一系列操作,然后返回结果。
优点:1.重用性:存储过程可以被多次调用,避免了重复编写相同的SQL语句的工作量。
2.性能优化:存储过程可以提前编译和优化,提高数据库运行的效率。
3.安全性:存储过程可以限制用户对数据库的访问权限,提高数据库的安全性。
4.维护性:存储过程的修改只需要在数据库中进行一次操作,而不需要在应用程序中修改多次。
创建和调用存储过程:1.创建存储过程:可以使用CREATEPROCEDURE语句来创建存储过程。
存储过程由一些SQL语句和控制语句组成,并且可以接受输入参数。
例如,下面的代码创建了一个简单的存储过程,接受一个参数并返回查询结果:```sqlCREATE PROCEDURE GetEmployeesByDepartment(IN department_id INT)BEGINSELECT * FROM employees WHERE department_id = department_id;END```2.调用存储过程:可以使用CALL语句或者执行存储过程的方式来调用存储过程。
可以传递参数给存储过程,并且获取存储过程的返回结果。
例如,下面的代码调用了上面创建的存储过程,并且传递了一个参数:```sqlCALL GetEmployeesByDepartment(1);```应用场景:存储过程在实际应用中有广泛的应用场景,下面是一些常见的应用场景:1.数据验证和处理:存储过程可以用来对数据进行验证和处理,例如对数据进行格式校验、计算、数据清洗等操作。
ORACLE_PLSQL存储过程教程

(1)SEQNAME.NEXTV AL里面的值如何读出来?可以直接在insert into test values(SEQNAME.NEXTV AL) 是可以用这样:SELECT tmp#_seq.NEXTV ALINTO id_tempFROM DUAL; 然后可以用id_temp(2)PLS-00103: 出现符号">"在需要下列之一时:代码如下:IF (sum>0)THENbeginINSERT INTO emesp.tp_sn_production_logV ALUES (r_serial_number, , id_temp);EXIT;end;一直报sum>0 这是个很郁闷的问题因为变量用了sum 所以不行,后改为i_sum>0(3)oracle 语法1. Oracle应用编辑方法概览答:1) Pro*C/C++/... : C语言和数据库打交道的方法,比OCI更常用;2) ODBC3) OCI: C语言和数据库打交道的方法,和ProC很相似,更底层,很少用;4) SQLJ: 很新的一种用Java访问Oracle数据库的方法,会的人不多;5) JDBC6) PL/SQL: 存储在数据内运行, 其他方法为在数据库外对数据库访问;2. PL/SQL答:1) PL/SQL(Procedual language/SQL)是在标准SQL的基础上增加了过程化处理的语言;2) Oracle客户端工具访问Oracle服务器的操作语言;3) Oracle对SQL的扩充;4. PL/SQL的优缺点答:优点:1) 结构化模块化编程,不是面向对象;2) 良好的可移植性(不管Oracle运行在何种操作系统);3) 良好的可维护性(编译通过后存储在数据库里);4) 提升系统性能;第二章PL/SQL程序结构1. PL/SQL块答:1) 申明部分, DECLARE(不可少);2) 执行部分, BEGIN...END;3) 异常处理,EXCEPTION(可以没有);2. PL/SQL开发环境答:可以运用任何纯文本的编辑器编辑,例如:VI ;toad很好用3. PL/SQL字符集答:PL/SQL对大小写不敏感4. 标识符命名规则答:1) 字母开头;2) 后跟任意的非空格字符、数字、货币符号、下划线、或# ;3) 最大长度为30个字符(八个字符左右最合适);5. 变量声明答:语法V ar_name type [CONSTANT][NOT NULL][:=value];注:1) 申明时可以有默认值也可以没有;2) 如有[CONSTANT][NOT NULL], 变量一定要有一个初始值;3) 赋值语句为“:=”;4) 变量可以认为是数据库里一个字段;5) 规定没有初始化的变量为NULL;第三章1. 数据类型答:1) 标量型:数字型、字符型、布尔型、日期型;2) 组合型:RECORD(常用)、TABLE(常用)、V ARRAY(较少用)3) 参考型:REF CURSOR(游标)、REF object_type4) LOB(Large Object)2. %TYPE答:变量具有与数据库的表中某一字段相同的类型例:v_FirstName studengts.first_name%TYPE;3. RECORD类型答:TYPE record_name IS RECORD( /*其中TYPE,IS,RECORD为关键字,record_name 为变量名称*/field1 type [NOT NULL][:=expr1], /*每个等价的成员间用逗号分隔*/field2 type [NOT NULL][:=expr2], /*如果一个字段限定NOT NULL,那么它必须拥有一个初始值*/... /*所有没有初始化的字段都会初始为NULLfieldn type [NOT NULL][:=exprn]);4. %ROWTYPE答:返回一个基于数据库定义的类型DECLAREv_StuRec Student%ROWTYPE; /*Student为表的名字*/注:与3中定一个record相比,一步就完成,而3中定义分二步:a. 所有的成员变量都要申明; b. 实例化变量;5. TABLE类型答:TYPE tabletype IS TABLE OF type INDEX BY BINARY_INTEGER;例:DECLARETYPE t_StuTable IS TABLE OF Student%ROWTYPE INDEX BY BINARY_INTERGER;v_Student t_StuTable;BEGINSELECT * INTO v_Student(100) FROM Student WHERE id = 1001;END;注:1) 行的数目的限制由BINARY_INTEGER的范围决定;6. 变量的作用域和可见性答:1) 执行块里可以嵌入执行块;2) 里层执行块的变量对外层不可见;3) 里层执行块对外层执行块变量的修改会影响外层块变量的值;第四章1. 条件语句答:IF boolean_expression1 THEN...ELSIF boolean_expression2 THEN /*注意是ELSIF,而不是ELSEIF*/... /*ELSE语句不是必须的,但END IF;是必须的*/ELSE...END IF;2. 循环语句答:1) Loop...IF boolean_expr THEN /* */EXIT; /* EXIT WHEN boolean_expr */END IF; /* */END LOOP;2) WHILE boolean_expr LOOP...END LOOP;3) FOR loop_counter IN [REVERSE] low_blound..high_bound LOOP...END LOOP;注:a. 加上REVERSE 表示递减,从结束边界到起始边界,递减步长为一;b. low_blound 起始边界; high_bound 结束边界;3. GOTO语句答:GOTO label_name;1) 只能由内部块跳往外部块;2) 设置标签:<<label_name>>3) 示例:LOOP...IF D%ROWCOUNT = 50 THENGOTO l_close;END IF;...END LOOP;<<l_close>>;...4. NULL语句答:在语句块中加空语句,用于补充语句的完整性。
sql 存储过程写法

sql 存储过程写法
SQL存储过程是一种在数据库中存储的可重复执行的SQL代码块。
以下是一个示例SQL存储过程的基本写法:
CREATE PROCEDURE procedure_name
@parameter1 datatype,
@parameter2 datatype
AS
BEGIN
-- 存储过程主体,包含一系列SQL语句
-- 可以使用参数(parameter)来传递数据或条件
-- 例如:
SELECT column1, column2
FROM table_name
WHERE column3 = @parameter1;
-- 其他SQL语句和逻辑
END;
在上面的示例中:
CREATE PROCEDURE用于创建存储过程。
procedure_name是你为存储过程指定的名称。
@parameter1和@parameter2是存储过程的参数,用于传递值给存储过程。
AS标志着存储过程主体的开始。
存储过程主体包含了一系列SQL语句和逻辑,可以执行各种数据库操作。
存储过程可以接受参数,以便根据需要定制其行为。
当你创建存储过程后,可以通过调用存储过程的名称以及传递给它的参数来执行它。
例如:
EXEC procedure_name @parameter1 = 'value1', @parameter2 = 'value2';
这将执行存储过程并使用提供的参数值。
存储过程的具体内容和功能将根据你的需求而定,可以包括各种SQL查询、事务处理、条件逻辑等。
sql 中使用存储过程

sql 中使用存储过程在SQL中,存储过程是一组预编译的SQL语句,它们被存储在数据库中,可以在需要时被多次调用。
存储过程可以帮助简化复杂的数据库操作,并提高数据库的性能和安全性。
下面我将从多个角度来介绍SQL中使用存储过程的相关内容。
首先,我们可以讨论存储过程的创建和语法。
在SQL中,创建存储过程的语法通常如下:sql.CREATE PROCEDURE procedure_name.AS.BEGIN.-在这里编写存储过程的SQL语句。
END.在这个语法中,`CREATE PROCEDURE`关键字用于创建存储过程,`procedure_name`是存储过程的名称,`AS`关键字用于指示存储过程的开始,`BEGIN`和`END`之间的部分是存储过程的实际SQL代码。
其次,我们可以讨论存储过程的参数和返回值。
存储过程可以接受输入参数,并且可以返回一个或多个输出参数。
在创建存储过程时,可以指定参数的名称、数据类型和方向(输入、输出或输入/输出)。
下面是一个简单的存储过程,它接受一个输入参数并返回一个输出参数的示例:sql.CREATE PROCEDURE get_employee_name.@employee_id INT,。
@employee_name NVARCHAR(50) OUTPUT.AS.BEGIN.SELECT @employee_name = name.FROM employees.WHERE id = @employee_id.END.在这个示例中,`@employee_id`是输入参数,`@employee_name`是输出参数。
此外,我们还可以讨论存储过程的优点。
存储过程可以提高数据库的性能,因为它们在数据库中预编译并存储,减少了每次执行相同操作时的解析和编译时间。
此外,存储过程还可以提高数据库的安全性,因为用户只能通过存储过程执行特定的操作,而无法直接访问数据库表。
最后,我们还可以讨论存储过程的用途。
sql存储过程简单教程

sql存储过程简单教程①为什么要使⽤存储过程?因为它⽐SQL语句执⾏快.②存储过程是什么?把⼀堆SQL语句罗在⼀起,还可以根据条件执⾏不通SQL语句.(AX写作本⽂时观点)③来⼀个最简单的存储过程CREATE PROCEDURE dbo.testProcedure_AXASselect userID from USERS order by userid desc注:dbo.testProcedure_AX是你创建的存储过程名,可以改为:AXzhz等,别跟关键字冲突就⾏了.AS下⾯就是⼀条SQL语句,不会写SQL语句的请回避.④我怎么在中调⽤这个存储过程?下⾯黄底的这两⾏就够使了.public static string GetCustomerCName(ref ArrayList arrayCName,ref ArrayList arrayID){SqlConnection con=ADConnection.createConnection();SqlCommand cmd=new SqlCommand("testProcedure_AX",con);mandType=CommandType.StoredProcedure;con.Open();try{SqlDataReader dr=cmd.ExecuteReader();while(dr.Read()){if(dr[0].ToString()==""){arrayCName.Add(dr[1].ToString());}}con.Close();return "OK!";}catch(Exception ex){con.Close();return ex.ToString();}}注:其实就是把以前SqlCommand cmd=new SqlCommand("select userID from USERS order by userid desc",con);中的SQL语句替换为存储过程名,再把cmd的类型标注为CommandType.StoredProcedure(存储过程)⑤写个带参数的存储过程吧,上⾯这个简单得有点惨不忍睹,不过还是蛮实⽤的.参数带就带两,⼀个的没⾯⼦,太⼩家⼦⽓了.CREATE PROCEDURE dbo.AXzhz/*这⾥写注释*/@startDate varchar(16),@endDate varchar(16)ASselect id from table_AX where commentDateTime>@startDate and commentDateTime<@endDate order by contentownerid DESC注:@startDate varchar(16)是声明@startDate 这个变量,多个变量名间⽤【,】隔开.后⾯的SQL就可以使⽤这个变量了.⑥我怎么在中调⽤这个带参数的存储过程?public static string GetCustomerCNameCount(string startDate,string endDate,ref DataSet ds){SqlConnection con=ADConnection.createConnection();//-----------------------注意这⼀段--------------------------------------------------------------------------------------------------------SqlDataAdapter da=new SqlDataAdapter("AXzhz",con);para0=new SqlParameter("@startDate",startDate);para1=new SqlParameter("@endDate",endDate);da.SelectCommand.Parameters.Add(para0);da.SelectCommand.Parameters.Add(para1);mandType=CommandType.StoredProcedure;//-------------------------------------------------------------------------------------------------------------------------------try{con.Open();da.Fill(ds);con.Close();return "OK";}catch(Exception ex){return ex.ToString();}}注:把命令的参数添加进去,就OK了⑦我还想看看SQL命令执⾏成功了没有.注意看下⾯三⾏红⾊的语句CREATE PROCEDURE dbo.AXzhz/*@parameter1 ⽤户名@parameter2 新密码*/@passWord nvarchar(20),@userName nvarchar(20)ASdeclare @err0 intupdate WL_user set password=@password where UserName=@userNameset @err0=@@errorselect @err0 as err0注:先声明⼀个整型变量@err0,再给其赋值为@@error(这个是系统⾃动给出的语句是否执⾏成功,0为成功,其它为失败),最后通过select把它选择出来,某位⾼⼈说可以通过Return返回,超出本⼈的认知范围,俺暂时不会,以后再补充吧⑧那怎么从后台获得这个执⾏成功与否的值呢?下⾯这段代码可以告诉你答案:public static string GetCustomerCName(){SqlConnection con=ADConnection.createConnection();SqlCommand cmd=new SqlCommand("AXzhz",con);mandType=CommandType.StoredProcedure;para0=new SqlParameter("@startDate","2006-9-10");para1=new SqlParameter("@endDate","2006-9-20");da.SelectCommand.Parameters.Add(para0);da.SelectCommand.Parameters.Add(para1);con.Open();try{Int32 re=(int32)cmd.ExecuteScalar();con.Close();if (re==0)return "OK!";elsereturn "false";}catch(Exception ex){con.Close();return ex.ToString();}}注:就是通过SqlCommand的ExecuteScalar()⽅法取回这个值,这句话是从MSDN上找的,俺认为改成:int re=(int)cmd.ExecuteScalar(); 99%正确,现在没时间验证,期待您的测试1)执⾏⼀个没有参数的存储过程的代码如下:SqlConnection conn=new SqlConnection(“connectionString”);SqlDataAdapter da = new SqlDataAdapter();da.selectCommand = new SqlCommand();da.selectCommand.Connection = conn;mandText = "NameOfProcedure";mandType = CommandType.StoredProcedure;(2)执⾏⼀个有参数的存储过程的代码如下SqlConnection conn=new SqlConnection(“connectionString”);SqlDataAdapter da = new SqlDataAdapter();da.selectCommand = new SqlCommand();da.selectCommand.Connection = conn;mandText = "NameOfProcedure";mandType = CommandType.StoredProcedure;param = new SqlParameter("@ParameterName", SqlDbType.DateTime);param.Direction = ParameterDirection.Input;param.Value = Convert.ToDateTime(inputdate);da.selectCommand.Parameters.Add(param);若需要添加输出参数:param = new SqlParameter("@ParameterName", SqlDbType.DateTime);param.Direction = ParameterDirection.Output;param.Value = Convert.ToDateTime(inputdate);da.selectCommand.Parameters.Add(param);若要获得参储过程的返回值:param = new SqlParameter("@ParameterName", SqlDbType.DateTime);param.Direction = ParameterDirection.ReturnValue;param.Value = Convert.ToDateTime(inputdate);da.selectCommand.Parameters.Add(param);两种不同的存储过程调⽤⽅法为了突出新⽅法的优点,⾸先介绍⼀下在.NET中调⽤存储过程的“官⽅”⽅法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
存储过程的概念
SQL Server提供了一种方法,它可以将一些固定的操作集中起来由SQL Server数据库服务器来完成,以实现某个任务,这种方法就是存储过程。
存储过程是SQL语句和可选控制流语句的预编译集合,存储在数据库中,可由应用程序通过一个调用执行,而且允许用户声明变量、有条件执行以及其他强大的编程功能。
1、在建立存储过程时设定重新编译
语法格式:CREATE PROCEDURE procedure_name WITH RECOMPILE AS sql_statement
2、在执行存储过程时设定重编译
语法格式: EXECUTE procedure_name WITH RECOMPILE
使用CREATE PROCEDURE创建存储过程的语法形式如下:
QUOTE:
CREATE PROC[EDURE]procedure_name[;number][;number]
[{@parameter data_type}
[VARYING][=default][OUTPUT]
[,...n]
[ WITH RECOMPILE ]
使用 EXECUTE 命令传递单个参数,它执行 showind 存储过程,以 titles 为参数值。showind 存储过程需要参数 (@tabname),它是一个表的名称。其程序清单如下:
EXEC showind titles
使用企业管理器查看用户创建的存储过程
在企业管理器中,打开指定的服务器和数据库项,选择要创建存储过程的数据库,单击存储过程文件夹,此时在右边的页框中显示该数据库的所有存储过程。用右键单击要查看的存储过程,从弹出的快捷菜单中选择属性选项,此时便可以看到存储过程的源代码。
使用系统存储过程来查看用户创建的存储过程
[{@parameterdata_type}
[VARYING][=default][OUTPUT]][,...n] [WITH
{RECOMPILE|ENCRYPTION|RECOMPILE,ENCRYPTION}]
[FOR REPLICATION]
AS
sql_statement [ ...n ]
@ProductName_2 nvarchar(40) output)
AS
select @ProductName_2 = ProductName from products
where SupplierID = @SupplierID_1
执行该存储过程来查询SupplierID为1的产品名:
存储过程在创建时即在服务器上进行编译,所以执行起来比单个SQL语句快,而且减少网络通信的负担。
安全性更高。
创建存储过程
在SQL Server中,可以使用三种方法创建存储过程 :
①使用创建存储过程向导创建存储过程。
②利用SQL Server 企业管理器创建存储过程。
当然,在执行过程中变量可以显式命名:
EXEC showind @tabname = titles
如果这是 isql 脚本或批处理中第一个语句,则 EXEC 语句可以省略:
showind titles或者showind @tabname = titles
下面的例子使用了默认参数
直接执行存储过程可以使用EXECUTE命令来执行,其语法形式如下:
[[EXEC[UTE]]
{ [@return_status=]
{procedure_name[;number]|@procedure_name_var} [[@parameter=]{value|@variable[OUTPUT]|[DEFAULT]}
AS ቤተ መጻሕፍቲ ባይዱNSERT INTO Products
(ProductName,SupplierID,CategoryID)
VALUES
(@ProductName_1,@SupplierID_2,@CategoryID_3)
GO
exec insert_Products_1 1,1
declare @product nvarchar(40)
exec query_products 1,@product output
select '产品名'= @product
go
查看存储过程
存储过程被创建之后,它的名字就存储在系统表sysobjects中,它的源代码存放在系统表syscomments中。可以使用使用企业管理器或系统存储过程来查看用户创建的存储过程。
③使用Transact-SQL语句中的CREATE PROCEDURE命令创建存储过程。
下面介绍使用Transact-SQL语句中的CREATE PROCEDURE命令创建存储过程
创建存储过程前,应该考虑下列几个事项:
①不能将 CREATE PROCEDURE 语句与其它 SQL 语句组合到单个批处理中。
Select * from Products where SupplierID=1 and CategoryID=1
GO
想要就下载吧
下面的例子使用了返回参数
USE Northwind
GO
CREATE PROCEDURE query_products
( @SupplierID_1 int,
drop procedure productinfo
GO
create procedure productinfo
as
select * from products
GO
通过下述sql语句执行该存储过程:execute productinfo
即可检索到产品信息。
执行存储过程
参数name为要查看的存储过程的名称。
sp_depends:用于显示和存储过程相关的数据库对象
sp_depends [@objname=]’object’
参数object为要查看依赖关系的存储过程的名称。
sp_stored_procedures:用于返回当前数据库中的存储过程列表
修改存储过程
存储过程可以根据用户的要求或者基表定义的改变而改变。使用ALTER PROCEDURE语句可以更改先前通过执行 CREATE PROCEDURE 语句创建的过程,但不会更改权限,也不影响相关的存储过程或触发器。其语法形式如下:
ALTERPROC[EDURE]procedure_name[;number]
在SQL Server中存储过程分为两类:即系统提供的存储过程和用户自定义的存储过程。
可以出于任何使用SQL语句的目的来使用存储过程,它具有以下优点:
可以在单个存储过程中执行一系列SQL语句。
可以从自己的存储过程内引用其他存储过程,这可以简化一系列复杂语句。
重命名和删除存储过程
1. 重命名存储过程
修改存储过程的名称可以使用系统存储过程sp_rename,其语法形式如下:
sp_rename 原存储过程名称,新存储过程名称
另外,通过企业管理器也可以修改存储过程的名称。
删除存储过程
删除存储过程可以使用DROP命令,DROP命令可以将一个或者多个存储过程或者存储过程组从当前数据库中删除,其语法形式如下:
USE Northwind
GO
CREATE PROCEDURE insert_Products_1
( @SupplierID_2 int,
@CategoryID_3 int,
@ProductName_1 nvarchar(40)='无')
number:该参数是可选的整数,它用来对同名的存储过程分组,以便用一条 DROP PROCEDURE 语句即可将同组的过程一起除去。
@parameter:过程中的参数。在 CREATE PROCEDURE 语句中可以声明一个或多个参数。
data_type:用于指定参数的数据类型。
VARYING:用于指定作为输出OUTPUT参数支持的结果集。
Default:用于指定参数的默认值。
OUTPUT:表明该参数是一个返回参数。
例如:下面创建一个 简单的存储过程productinfo,用于检索产品信息。
USE Northwind
if exists(select name from sysobjects
where name='productinfo' and type = 'p')
2.扩展存储过程:
扩展存储过程以xp_为前缀,它是关系数据库引擎的开放式数据服务层的一部分,其可以使用户在动态链接库(DLL)文件所包含的函数中实现逻辑,从而扩展了Transact-SQL的功能,并且可以象调用Transact-SQL过程那样从Transact-SQL语句调用这些函数。
][,...n] WITH
{RECOMPILE|ENCRYPTION|RECOMPILE,ENCRYPTION}]
[FOR REPLICATION]
AS sql_statement [ ...n ]
用CREATE PROCEDURE创建存储过程的语法参数的意义如下:
procedure_name:用于指定要创建的存储过程的名称。
例: 利用扩展存储过程xp_cmdshell为一个操作系统外壳执行指定命令串,并作为文本返回任何输出。
执行代码:
use master
exec xp_cmdshell 'dir *.exe'
执行结果返回系统目录下的文件内容文本信息。