python复制和编辑excel
excel 中python用法

一、介绍Excel是一款广泛使用的电子表格软件,Python是一种流行的编程语言。
结合Excel和Python的使用可以提高数据处理的效率和灵活性。
本文将介绍在Excel中使用Python的方法和技巧。
二、Python插件安装1. 打开Excel并进入“文件”菜单。
2. 选择“选项”。
3. 在选项对话框中,选择“加载项”。
4. 点击“Excel加载项”下的“转到”按钮。
5. 在“添加-Ins”对话框中,点击“浏览”。
6. 找到并选择Python插件的安装文件,点击“打开”。
7. 完成安装并重启Excel。
三、使用Python进行数据处理1. 在Excel中新建一个工作表。
2. 在需要进行数据处理的单元格输入Python函数,例如“=Py.COUNTIF(A1:A10,">5")”。
3. 按下Enter键,Excel会调用Python插件执行该函数,并在单元格中显示结果。
四、Python函数示例1. 使用Python的COUNTIF函数统计大于5的数据个数。
2. 使用Python的SUM函数计算数据的总和。
3. 使用Python的AVERAGE函数计算数据的平均值。
4. 使用Python的IF函数进行条件判断。
5. 使用Python的VLOOKUP函数进行数据查找。
五、Python脚本执行1. 在Excel中打开一个工作表。
2. 点击“开发人员”选项卡。
3. 选择“插入”下的“ActiveX 控件”。
4. 在工作表中插入一个按钮控件,右键点击该按钮并选择“属性”。
5. 在“单击”事件中绑定Python脚本文件。
6. 点击按钮执行Python脚本,实现自定义的数据处理逻辑。
六、Python图表生成1. 在Excel中选择需要生成图表的数据范围。
2. 点击“插入”选项卡中的“插入统计图表”按钮。
3. 在弹出的对话框中选择“Python图表”。
4. 根据需要选择图表类型和样式,点击确定生成图表。
使用python操作excel

使⽤python操作excel使⽤python操作excelpython操作excel主要⽤到xlrd和xlwt这两个库,即xlrd是读excel,xlwt是写excel的库。
安装xlrd模块#pip install xlrd使⽤介绍常⽤单元格中的数据类型 empty(空的) string(text) number date boolean error blank(空⽩表格) empty为0,string为1,number为2,date为3,boolean为4, error为5(左边为类型,右边为类型对应的值)导⼊模块import xlrd打开Excel⽂件读取数据data = xlrd.open_workbook(filename[, logfile, file_contents, ...])#⽂件名以及路径,如果路径或者⽂件名有中⽂给前⾯加⼀个r标识原⽣字符。
#filename:需操作的⽂件名(包括⽂件路径和⽂件名称);若filename不存在,则报错FileNotFoundError;若filename存在,则返回值为xlrd.book.Book对象。
常⽤的函数 excel中最重要的⽅法就是book和sheet的操作# (1)获取book中⼀个⼯作表names = data.sheet_names()#返回book中所有⼯作表的名字table = data.sheets()[0]#获取所有sheet的对象,以列表形式显⽰。
可以通过索引顺序获取,table = data.sheet_by_index(sheet_indx))#通过索引顺序获取,若sheetx超出索引范围,则报错IndexError;若sheetx在索引范围内,则返回值为xlrd.sheet.Sheet对象table = data.sheet_by_name(sheet_name)#通过名称获取,若sheet_name不存在,则报错xlrd.biffh.XLRDError;若sheet_name存在,则返回值为xlrd.sheet.Sheet对象以上三个函数都会返回⼀个xlrd.sheet.Sheet()对象data.sheet_loaded(sheet_name or indx)# 检查某个sheet是否导⼊完毕,返回值为bool类型,若返回值为True表⽰已导⼊;若返回值为False表⽰未导⼊# (2)⾏的操作nrows = table.nrows#获取该sheet中的有效⾏数table.row(rowx)#获取sheet中第rowx+1⾏单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_slice(rowx[, start_colx=0, end_colx=None])#以切⽚⽅式获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元,返回值为列表;列表每个值内容为:单元类型:单元数据table.row_types(rowx, start_colx=0, end_colx=None)#获取sheet中第rowx+1⾏从start_colx列到end_colx列的单元类型,返回值为array.array类型。
Python处理Excel效率高十倍(下篇)通篇硬干货,再也不用加班啦

Python处理Excel效率高十倍(下篇)通篇硬干货,再也不用加班啦《用Python处理Excel表格》下篇来啦!身为工作党或学生党的你,平日里肯定少不了与Excel表格打交道的机会。
当你用Excel处理较多数据时,还在使用最原始的人工操作吗?现在教你如何用Python处理Excel,从此处理表格再也不加班,时间缩短数十倍!上篇我们进行了一些事前准备,目的是用Python提取Excel表中的数据。
而这一篇便是在获取数据的基础上,对Excel表格的实操处理。
操作创建新的excel第9行代码用来指定创建的excel的活动表的名字:·不写第9行,默认创建sheet·写了第9行,创建指定名字的sheet表import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.Workbook()sheet = workbook.activesheet.title = '1号sheet'workbook.save('1.xlsx') 修改单元格、excel另存为第9行代码,通过给单元格重新赋值,来修改单元格的值第9行代码的另一种写法sheet['B1'].value = 'age'第10行代码,保存时如果使用原来的(第7行)名字,就直接保存;如果使用了别的名字,就会另存为一个新文件import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表sheet['A1'] = 'name'workbook.save('test.xlsx')添加数据插入有效数据使用append()方法,在原来数据的后面,按行插入数据import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))data = [ ['素子',23], ['巴特',24], ['塔奇克马',2]]for row in data: sheet.append(row) # 使用append 插入数据workbook.save('test.xlsx')插入空行空列·insert_rows(idx=数字编号, amount=要插入的行数),插入的行数是在idx行数的下方插入·insert_cols(idx=数字编号, amount=要插入的列数),插入的位置是在idx列数的左侧插入import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.insert_rows(idx=3, amount=2)sheet.insert_cols(idx=2,amount=1)workbook.save('test.xlsx')删除行、列·delete_rows(idx=数字编号, amount=要删除的行数)·delete_cols(idx=数字编号, amount=要删除的列数)import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.delete_rows(idx=10) # 删除第10行sheet.delete_cols(idx=1, amount=2) # 删除第1列,及往右共2列workbook.save('test.xlsx')移动指定区间的单元格(move_range)move_range(“数据区域”,rows=,cols=):正整数为向下或向右、负整数为向左或向上import osimport openpyxlpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))sheet.move_range('D11:F12',rows=0,cols=-3) # 移动D11到F12构成的矩形格子workbook.save('test.xlsx')字母列号与数字列号之间的转换核心代码from openpyxl.utils import get_column_letter, column_index_from_string# 根据列的数字返回字母print(get_column_letter(2)) # B# 根据字母返回列的数字print(column_index_from_string('D')) # 4举个例子:import osimport openpyxlfrom openpyxl.utils import get_column_letter, column_index_from_stringpath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('2.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))# 根据列的数字返回字母print(get_column_letter(2)) # B# 根据字母返回列的数字print(column_index_from_string('D')) # 4字体样式查看字体样式import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:'+str(sheet))cell = sheet['A1']font = cell.fontprint('当前单元格的字体样式是')print(, font.size, font.bold, font.italic, font.color)'''当前活动表是:<Worksheet '1号sheet'>当前单元格的字体样式是等线11.0 False False <openpyxl.styles.colors.Color object>Parameters:rgb=None, indexed=None, auto=None, theme=1, tint=0.0, type='theme'''' 修改字体样式openpyxl.styles.Font(name=字体名称,size=字体大小,bold=是否加粗,italic=是否斜体,color=字体颜色)其中,字体颜色中的color是RGB的16进制表示import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print(sheet)cell = sheet['A1']cell.font = openpyxl.styles.Font(name='微软雅黑', size=20, bold=True, italic=True, color='FF0000')workbook.save('test.xlsx')再者,可以使用for循环,修改多行多列的数据,在这里介绍了获取的方法import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print(sheet)cell = sheet['A']for i in cell: i.font = openpyxl.styles.Font(name='微软雅黑', size=20, bold=True, italic=True, color='FF0000')workbook.save('test.xlsx')设置对齐格式Alignment(horizontal=水平对齐模式,vertical=垂直对齐模式,text_rotation=旋转角度,wrap_text=是否自动换行)水平对齐:'distributed’,'justif y’,'center’,'left’,'centerContinuous’,'right,'general’垂直对齐:'bottom’,'distributed’,'justify’,'center’,'top’import osimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))cell = sheet['A1']alignment = openpyxl.styles.Alignment(horizontal='center', vertical='center', text_rotation=0, wrap_text=True)cell.alignment = alignmentworkbook.save('test.xlsx')当然,你仍旧可以调用for循环来实现对多行多列的操作import osimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))cell = sheet['A']alignment = openpyxl.styles.Alignment(horizontal='center', vertical='center',text_rotation=0, wrap_text=True)for i in cell: i.alignment = alignment workbook.save('test.xlsx')设置行高列宽设置行列的宽高:·row_dimensions[行编号].height = 行高·column_dimensions[列编号].width = 列宽import osimport openpyxlimport openpyxl.stylespath = r'C:\Users\asuka\Desktop'os.chdir(path) # 修改工作路径workbook = openpyxl.load_workbook('test.xlsx') # 返回一个workbook数据类型的值sheet = workbook.active # 获取活动表print('当前活动表是:' + str(sheet))# 设置第1行的高度sheet.row_dimensions[1].height = 50# 设置B列的卷度sheet.column_dimensions['B'].width = 20workbook.save('test.xlsx')设置所有单元格(显示的结果是设置所有,有数据的单元格的)from openpyxl import load_workbookfrom openpyxl.utils import get_column_letterimport osos.chdir(r'C:\Users\asuka\Desktop')workbook = load_workbook('1.xlsx')print(workbook.sheetnames) # 打印所有的sheet表ws = workbook[workbook.sheetnames[0]] # 选中最左侧的sheet表width = 2.0 # 设置宽度height = width * (2.2862 / 0.3612) # 设置高度print('row:', ws.max_row, 'column:', ws.max_column) # 打印行数,列数for i in range(1, ws.max_row + 1): ws.row_dimensions[i].height = heightfor i in range(1, ws.max_column + 1): ws.column_dimensions[get_column_letter(i)].width = widthworkbook.save('test.xlsx')合并、拆分单元格合并单元格有下面两种方法,需要注意的是,如果要合并的格子中有数据,即便python没有报错,Excel打开的时候也会报错。
用python库openpyxl操作excel,从源excel表中提取信息复制到目标excel表中

⽤python库openpyxl操作excel,从源excel表中提取信息复制到⽬标excel表中现代⽣活中,我们很难不与excel表打交道,excel表有着易学易⽤的优点,只是当表中数据量很⼤,我们⼜需要从其他表册中复制粘贴⼀些数据(⽐如⾝份证号)的时候,我们会越来越倦怠,毕竟我们不是机器,没法长时间做某种重复性的枯燥操作。
想象这样⼀个场景,我们有个⼏千⾏的表要填,需要根据姓名输⼊其对应的⾝份证号,但之前我们已经做过⼀个类似的表,同样的⼀些⼈的姓名跟⾝份证号是完整的,那么我们就需要通过⼀个个查找姓名,然后把⾝份证号码复制到我们当前要做的表⾥去。
当我⽇复⼀⽇重复着这些操作的时候,我都很想有⼀个⾃动化⼯具来完成这种操作,把做为⼈的我从这种⾮⼈的折磨⾥解脱出来,最后还是想到了python,因为这样我能很少的关注语⾔内部的⼀些细节,从⽽专注于解决这个问题。
其安装命令为 pip install openpyxl(在线安装)或者 easy_install openpyxl。
openpyxl的操作可以分四步,第⼀步载⼊现有workbook或者创建workbook到内存,分别使⽤from openpyxl import load_workbookfrom openpyxl import Workbook#载⼊现有workbook中wb1=load_workbook('lalala.xlsx')"""在源表数据量很⼤的时候,这⾥我们可以使⽤openpyxl的read_only模式载⼊源表,这样做的好处是不⽤把整个表都载⼊内存"""wb1=load_workbook(filename='lalala.xlsx',read_only=True)#创建workbookwb2 = Workbook()第⼆步就是操作excel表中的sheet了,通过Workbook()创建的workbook默认活动的sheet名称为Sheet,可以通过python交互命令⾏进⾏验证。
python使用xlrd模块读写Excel文件的方法

python使⽤xlrd模块读写Excel⽂件的⽅法本⽂实例讲述了python使⽤xlrd模块读写Excel⽂件的⽅法。
分享给⼤家供⼤家参考。
具体如下:⼀、安装xlrd模块⼆、使⽤介绍1、导⼊模块复制代码代码如下:import xlrd2、打开Excel⽂件读取数据复制代码代码如下:data = xlrd.open_workbook('excelFile.xls')3、使⽤技巧获取⼀个⼯作表复制代码代码如下:table = data.sheets()[0] #通过索引顺序获取table = data.sheet_by_index(0) #通过索引顺序获取table = data.sheet_by_name(u'Sheet1')#通过名称获取获取整⾏和整列的值(数组)复制代码代码如下:table.row_values(i)table.col_values(i)获取⾏数和列数复制代码代码如下:nrows = table.nrowsncols = table.ncols循环⾏列表数据复制代码代码如下:for i in range(nrows ):print table.row_values(i)单元格复制代码代码如下:cell_A1 = table.cell(0,0).valuecell_C4 = table.cell(2,3).value使⽤⾏列索引复制代码代码如下:cell_A1 = table.row(0)[0].valuecell_A2 = table.col(1)[0].value简单的写⼊复制代码代码如下:row = 0col = 0# 类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 errorctype = 1 value = '单元格的值'xf = 0 # 扩展的格式化table.put_cell(row, col, ctype, value, xf)table.cell(0,0) #单元格的值'table.cell(0,0).value #单元格的值'三、Demo代码Demo代码其实很简单,就是读取Excel数据。
python处理excel实例

python处理excel实例Python是一种强大的编程语言,可以用于各种各样的任务,包括数据处理。
Excel是一个广泛使用的电子表格应用程序,用于处理和管理数据。
Python可以与Excel相结合,提供更高效和灵活的数据处理方式。
下面是一些Python处理Excel的实例:1.读取Excel文件: Python可以使用pandas包中的read_excel 函数读取Excel文件。
下面是一个简单的读取Excel文件的代码示例: import pandas as pd#读取Excel文件data = pd.read_excel('file.xlsx')print(data)2.写入Excel文件: Python也可以使用pandas包中的to_excel 函数将数据写入Excel文件。
下面是一个简单的写入Excel文件的代码示例:import pandas as pd#创建数据data = {'姓名': ['张三', '李四', '王五'], '年龄': [20, 25, 30]}#将数据转换为DataFrame格式df = pd.DataFrame(data)#将DataFrame写入Excel文件df.to_excel('file.xlsx', index=False)3.修改Excel文件: Python可以使用openpyxl包中的load_workbook函数打开Excel文件,并使用它的方法修改文件。
下面是一个简单的修改Excel文件的代码示例:from openpyxl import load_workbook#加载Excel文件wb = load_workbook('file.xlsx')#获取工作表ws = wb.active#修改单元格ws['A1'] = '姓名'ws['B1'] = '年龄'#保存文件wb.save('file.xlsx')这些实例只是Python处理Excel的基础知识,还有很多其他的功能和技巧可以使用。
python处理excel实例

python处理excel实例Python是一种功能强大的编程语言,可以用来处理各种数据类型,包括Excel文件。
Python处理Excel文件的能力极强,可以进行数据提取、数据处理、数据分析等多方面操作。
下面是一个Python处理Excel文件的实例:1. 导入所需的库```pythonimport openpyxl```2. 读取Excel文件```pythonwb = openpyxl.load_workbook('example.xlsx')```这个代码块会打开名为example.xlsx的Excel文件,并将其存储在变量wb中。
3. 选择工作表```pythonsheet = wb['Sheet1']```这个代码块会选择名为Sheet1的工作表,并将其存储在变量sheet中。
4. 读取单元格数据cell_value = sheet['A1'].value```这个代码块会读取A1单元格的数据,并将其存储在变量cell_value中。
5. 读取行数据```pythonrow_values = []for row in sheet.iter_rows(min_row=2, max_col=3):row_values.append([cell.value for cell in row])```这个代码块会读取工作表中第2行到最后一行、第1列到第3列的数据,并将其存储在列表row_values中。
6. 读取列数据```pythoncolumn_values = []for column in sheet.iter_cols(min_row=2, max_row=4):column_values.append([cell.value for cell in column]) ```这个代码块会读取工作表中第2列到第4列、第1行到最后一行的数据,并将其存储在列表column_values中。
python读取excel指定列数据并写入到新的excel方法

以上这篇python读取excel指定列数据并写入到新的excel方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也 希望大家多多支持。
sh=bk.sheet_by_name("Sheet1") except:
print "代码出错" nrows=sh.nrows #获取行数 book = Workbook(encoding='utf-8') sheet = book.add_sheet('Sheet1') #创建一个sheet for i in range(1,nrows):
这篇文章主要介绍了如何基于python代码实现高精度免费ocr工具文中通过示例代码介绍的非常详细对大家的学习或者工作具有一定的参考学习价值需要的朋友可以参考下
pythoቤተ መጻሕፍቲ ባይዱ读取 excel指定列数据并写入到新的 excel方法
如下所示:
#encoding=utf-8 import xlrd from xlwt import * #------------------读数据--------------------------------fileName="C:\\Users\\st\\Desktop\\test\\20170221131701.xlsx" bk=xlrd.open_workbook(fileName) shxrange=range(bk.nsheets) try:
python:openpyxl带格式复制excel

python: openpyxl带格式复制 excel
以下代码可实现excel带格式复制
import copy import openpyxl from openpyxl.utils import get_column_letter
path = "数据.xlsx" save_path = "数据-复制.xlsx"
wb = openpyxl.load_workbook(path) wb2 = openpyxl.Workbook()
sheetnames = wb.sheetnames for sheetname in sheetnames:
target_cell._style = copy.copy(source_cell._style) target_cell.font = copy.copy(source_cell.font) target_cell.border = copy.copy(source_cell.border) target_cell.fill = copy.copy(source_cell.fill) target_cell.number_format = copy.copy(source_cell.number_format) target_cell.protection = copy.copy(source_cell.protection) target_cell.alignment = copy.copy(source_cell.alignment)
if 'Sheet' in wb2.sheetnames: del wb2['Sheet']
npoi带合并的单元格复制

npoi带合并的单元格复制如何使用NPOI复制带有合并单元格的Excel表格?[npoi带合并的单元格复制]在日常工作中,我们经常需要处理包含大量数据的E x c e l表格。
其中,合并单元格是一种常见的方式,可以提供更好的可读性和美观性。
然而,当我们需要复制或处理这些包含合并单元格的E x c e l表格时,可能会遇到一些困难。
本文将为您介绍如何使用N P O I(一款.N E T的E x c e l处理工具)来复制带有合并单元格的E x c e l表格。
第一步:准备工作在开始编写代码之前,您需要先准备好所需的工具和环境。
以下是一些必要的步骤:1.下载并安装N P O I库N P O I是一款用于.N E T平台的E x c e l处理工具,支持读写、操作和创建E x c e l文件。
您可以在N P O I官方网站(2.创建新的.N E T项目打开V i s u a l S t u d i o(或其他C#开发环境),创建一个新的.N E T项目。
选择您偏好的项目类型,如控制台应用程序或A S P.N E T网站。
第二步:引用N P O I库在您的项目中添加对N P O I库的引用,以便能够使用其提供的功能。
可以通过以下步骤完成:1.在V i s u a l S t u d i o的“解决方案资源管理器”中找到您的项目,并右键单击,选择“管理N u G e t程序包”。
2.在打开的“N u G e t包管理器”窗口中,搜索“N P O I”。
3.找到N P O I包,并点击右侧的“安装”按钮进行安装。
第三步:读取源E x c e l文件在本例中,我们将复制一个带有合并单元格的E x c e l表格。
首先,我们需要读取源Ex c e l文件的内容。
以下是一段示例代码,用于打开并读取源文件:```c s h a r pu s i n g S y s t e m;u s i n g N P O I.S S.U s e r M o d e l;u s i n g N P O I.X S S F.U s e r M o d e l;u s i n g S y s t e m.I O;//将源文件加载到工作簿中u s i n g(F i l e S t r e a m f i l e=n e wF i l e S t r e a m("s o u r c e.x l s x",F i l e M o d e.O p e n, F i l e A c c e s s.R e a d)){I W o r k b o o k w o r k b o o k=n e wX S S F W o r k b o o k(f i l e);I S h e e t s h e e t=w o r k b o o k.G e t S h e e t A t(0);//遍历工作表中的所有行f o r(i n t i=s h e e t.F i r s t R o w N u m;i<= s h e e t.L a s t R o w N u m;i++){I R o w r o w=s h e e t.G e t R o w(i);i f(r o w!=n u l l){//遍历行中的所有单元格f o r(i n t j=r o w.F i r s t C e l l N u m; j < r o w.L a s t C e l l N u m; j++){I C e l l c e l l=r o w.G e t C e l l(j);i f(c e l l!=n u l l){//输出单元格的值C o n s o l e.W r i t e L i n e(c e l l.T o S t r i n g());}}}}}```以上代码将源E x c e l文件的内容读取到控制台中,您可以根据实际需求进行修改。
利用python对excel中的特定数据提取并写入新表的方法

利用python对excel中的特定数据提取并写入新表的方法如果你正在寻找一种简单而有效的方法来提取Excel中的特定数据,并将其写入新的表格,那么下面这个方法可能会对你有所帮助。
我们将使用Python的pandas和openpyxl库来完成这个任务。
**步骤一:安装必要的库**首先,你需要确保已经安装了pandas和openpyxl库。
你可以通过以下命令在命令行中安装它们:```pip install pandas openpyxl```**步骤二:导入必要的库**在Python脚本中,你需要导入这些库以使用它们的功能。
这可以通过以下代码完成:```pythonimport pandas as pd```**步骤三:读取Excel文件**接下来,我们需要使用pandas的read_excel函数来读取Excel文件。
我们可以将Excel文件的内容读入一个DataFrame对象,这个对象就像一个表格。
例如:```pythondata = pd.read_excel('原始文件.xlsx')```这里假设你的Excel文件名为"原始文件.xlsx",你需要将其替换为你的实际文件名。
**步骤四:提取特定数据**现在,我们可以使用pandas的数据选择功能来提取我们感兴趣的数据。
例如,如果我们想要提取名为'张三'的所有行的数据,我们可以这样做:```python我们想要的数据 = data[data['姓名'] == '张三']```你也可以使用其他条件来选择数据,例如按特定列进行排序。
**步骤五:写入新Excel文件**最后,我们可以使用pandas的to_excel函数将提取的数据写入新的Excel文件。
例如:```python我们想要的数据.to_excel('新文件.xlsx', index=False)```这段代码会将我们提取的数据写入名为"新文件.xlsx"的新Excel 文件中,并且不会包含行索引。
Python文件操作(读写Excel)

Python⽂件操作(读写Excel)⽂件读写Excel1.使⽤xlrd读取excel#使⽤xlrd读取excel#1.导⼊模块import xlrd# 2. 使⽤xlrd的函数打开本地⽂件workbook=xlrd.open_workbook('案例.xlsx')#3. 获取⼯作表# sheets=workbook.sheets()#获取所有⼯作表组成list,具体某个表⽤下标# sheetOne=sheets[0]# sheetOne=workbook.sheet_by_index(0)#使⽤函数通过int 获取第⼏张# 返回⼯作表名称组成的列表sheetNames=workbook.sheet_names()sheetOne=workbook.sheet_by_name(sheetNames[0])# ⾏数row=sheetOne.nrows# 列数col=sheetOne.ncols# ⽤for遍历⾏数,输出每⾏for i in range(row):each_row=sheetOne.row_values(i)print(each_row)# ⽤for 遍历列数,输出每列for i in range(col):each_col=sheetOne.col_values(i)print(each_col)# 精确到单元格# 尝试输出第⼆⾏,第⼆列的值,读取列表的⽅式print(sheetOne.row_values(1)[1])# sheetOne.cell(row,col) 获取单元格# 单元格.value 是值# sheetOne.cell_value(row,col)直接返回值print(sheetOne.cell(8,1).value)print(sheetOne.cell_value(8,1))# ⽤循环输出所有单元格的内容# ⽅法⼀# for i in range(row):# eachrow=sheetOne.row_values(i)# for each in eachrow:# print(each)# ⽅法⼆for i in range(row):for j in range(col):print(sheetOne.cell_value(i,j))2.使⽤xlwt模块写⼊excel # 导⼊xlwt模块import xlwt# 创建⼯作簿wb=xlwt.Workbook()#创建⼯作表sheet=wb.add_sheet('newSheet')for i in range(1,10):for j in range(1,i+1):sheet.write(i,j-1,str(j)+'x'+str(i)+'='+str(i*j)) # 保存⽂件wb.save('newExcel.xls')3.使⽤xlutils模块修改excel# 使⽤xlutils模块修改 excelimport xlrdfrom xlutils.copy import copy# xlrd 读取⼯作簿wb=xlrd.open_workbook('案例.xlsx')# 复制⼀份⼯作簿,⽤来写⼊copyed=copy(wb)# 获取复制来的⼯作簿的⼯作表sheetOne=copyed.get_sheet(0)# 使⽤writr()写⼊sheetOne.write(3,0,'我是更改的内容')# 保存,如果保存的⽂件名存在则覆盖,不存在则保存个新的copyed.save('new新存的.xls')4.使⽤openpyxl操作excel#使⽤openpyxl操作excelfrom openpyxl import Workbook# 1. 实例化对象,创建⼯作簿wb=Workbook()# 2. 使⽤第⼀张⼯作表sheet=wb.active# 3. 给表取个名字sheet.title='表的名称1'# 4. 给表增加内容:sheet.append(list类型)sheet.append([1,2,3])# 5.保存⼯作簿wb.save('new1.xlsx')5.⼯作簿属性与⽅法from openpyxl import Workbook # 创建新的⼯作簿from openpyxl import load_workbook # 打开已有⼯作簿# wb = load_workbook('new1.xls') 打开不了 xls 的⽂件wb = load_workbook('F:\Python资料\data.xlsx')'''workbook 的属性:workbook.sheetnames : 所有⼯作表的名字组成的列表workbook.worksheets : 所有⼯作表组成的列表workbook.active : 默认的⼯作表(第⼀张)workbook 的⽅法:workbook.get_sheet_names() : 同 workbook.sheetnamesworkbook.get_active_sheet() : 同 workbook.activeworkbook.get_sheet_by_name(name): 根据name获取 sheetworkbook.create_sheet(sheetname,index) : 创建sheet,以及名称与index位置workbook.save(filename) : 保存'''sheet = wb.create_sheet('新的',2)sheet.append([1,2,3])wb.save('data.xlsx')6.⼯作表属性与⽅法(上)from openpyxl import load_workbookwb = load_workbook('data.xlsx')# 获取表格 wb[ 'sheetname' ]sheet = wb['新的']'''⼯作表的属性:sheet.rows :⾏数对象sheet.columns :列数对象sheet.max_row :有效的最⼤⾏数sheet.min_row :有效的最⼩⾏数sheet.max_column:有效的最⼤列数sheet.min_column:有效的最⼩列数sheet.values :所有单元格的值组成的2维列表。
Python的excel操作——PasteSpecial实现选择性粘贴自动化

Python的excel操作——PasteSpecial实现选择性粘贴⾃动化前提要景: 最近收到这么⼀个需求,excel表格⾥⾯我们只想要结果,不要把底表发出来,也就是把excel⾥⾯做好的数据粘贴在新的excel,并选择性粘贴为数值,并且保留格式。
完成后发邮件给相应的经理⽼板们。
在经过⼀系列跌跌撞撞,磕磕碰碰的错误下,写了个excel⾃动把特定的区域复制粘贴到新的excel的sheet中,并保留了数值和格式。
Python操作excel的模块有千千万,本⽂只挑选了win32com.client来进⾏操作,如有其它模块的操作,记得艾特我学习⼀下!启动excelPython启动excel的常规操作有两种:第⼀种:os.system('taskkill /IM EXCEL.exe /F')xlapp = Dispatch('Excel.Application')第⼆种:os.system('taskkill /IM EXCEL.exe /F')xlapp = win32com.client.gencache.EnsureDispatch('Excel.Application')有什么区别呢?我也清楚得不仔细,EnsureDispatch的启动⽅式要求格式⽐较严格,⽅法必须⾸字母⼤写,最主要的是这种启动⽅式可以使⽤win32com.client⾥⾯的excelVBA常量constants,⽽普通Dispatch不可以完成,选择性粘贴PasteSpecial必须要⽤到constants的常量,故本⽂使⽤EnsureDispatch的⽅式启动excel。
然后使⽤Visible为true,表⽰⼯作簿可见,xlapp.Visible = TrueDisplayAlerts为False表⽰为关闭警告,⽐如在保存时候,提⽰我们已经有相同⽂件了,是否保存并覆盖,为false表⽰为不提⽰警告并覆盖此⽂件。
利用python对excel中的特定数据提取并写入新表的方法

利用python对excel中的特定数据提取并写入新表的方法一、引言在实际工作中,我们常常需要利用Python对Excel文件中的特定数据进行提取,并将其写入新的表格。
本文将详细介绍如何利用Python实现这一目的,从而提高数据处理的效率。
二、Python提取Excel数据库方法1.安装库要处理Excel文件,我们需要安装python-openpyxl库。
在命令行中输入以下命令进行安装:```pip install openpyxl```2.读取Excel文件首先,我们需要导入openpyxl库,并使用openpyxl.load_workbook()函数读取Excel文件。
```pythonimport openpyxl# 读取Excel文件workbook = openpyxl.load_workbook("example.xlsx")```3.提取特定数据接下来,我们需要根据需求提取Excel文件中的特定数据。
以下是一个简单的示例,提取A1单元格的值:```python# 提取A1单元格数据cell_value = workbook["Sheet1"].cell(1, 1).value```三、将提取的数据写入新表1.创建新表结构首先,我们需要创建一个新的Excel文件,并设置新表的结构。
以下代码示例创建了一个包含3列的新表:```python# 创建新表ew_workbook = workbook.copy(title="New Sheet")# 获取新表ew_sheet = new_workbook["New Sheet"]# 设置新表列宽for col in range(1, 4):new_sheet["A" + str(col)].column_width = 10```2.写入数据接下来,我们将提取的特定数据写入新表。
python操作Excel的5种方式

python操作Excel的5种⽅式Python对Excel的读写主要有xlrd、xlwt、xlutils、openpyxl、xlsxwriter⼏种。
1.xlrd主要是⽤来读取excel⽂件import xlrddata = xlrd.open_workbook('abcd.xls') # 打开xls⽂件table = data.sheets()[0] # 打开第⼀张表nrows = table.nrows # 获取表的⾏数for i in range(nrows): # 循环逐⾏打印if i == 0:# 跳过第⼀⾏continueprint (table.row_values(i)[:13]) # 取前⼗三列⽰例:#coding=utf-8########################################################filename:test_xlrd.py#author:defias#date:xxxx-xx-xx#function:读excel⽂件中的数据#######################################################import xlrd#打开⼀个workbookworkbook = xlrd.open_workbook('E:\\Code\\Python\\testdata.xls')#抓取所有sheet页的名称worksheets = workbook.sheet_names()print('worksheets is %s' %worksheets)#定位到sheet1worksheet1 = workbook.sheet_by_name(u'Sheet1')"""#通过索引顺序获取worksheet1 = workbook.sheets()[0]#或worksheet1 = workbook.sheet_by_index(0)""""""#遍历所有sheet对象for worksheet_name in worksheets:worksheet = workbook.sheet_by_name(worksheet_name)"""#遍历sheet1中所有⾏rownum_rows = worksheet1.nrowsfor curr_row in range(num_rows):row = worksheet1.row_values(curr_row)print('row%s is %s' %(curr_row,row))#遍历sheet1中所有列colnum_cols = worksheet1.ncolsfor curr_col in range(num_cols):col = worksheet1.col_values(curr_col)print('col%s is %s' %(curr_col,col))#遍历sheet1中所有单元格cellfor rown in range(num_rows):for coln in range(num_cols):cell = worksheet1.cell_value(rown,coln)print cell"""#其他写法:cell = worksheet1.cell(rown,coln).valueprint cell#或cell = worksheet1.row(rown)[coln].valueprint cell#或cell = worksheet1.col(coln)[rown].valueprint cell#获取单元格中值的类型,类型 0 empty,1 string, 2 number, 3 date, 4 boolean, 5 errorcell_type = worksheet1.cell_type(rown,coln)print cell_type"""2.xlwt主要是⽤来写excel⽂件#Python学习交流群:778463939import xlwtwbk = xlwt.Workbook()sheet = wbk.add_sheet('sheet 1')sheet.write(0,1,'test text')#第0⾏第⼀列写⼊内容wbk.save('test.xls')3.xlutils结合xlrd可以达到修改excel⽂件⽬的import xlrdfrom xlutils.copy import copyworkbook = xlrd.open_workbook(u'有趣装逼每⽇数据及趋势.xls')workbooknew = copy(workbook)ws = workbooknew.get_sheet(0)ws.write(3, 0, 'changed!')workbooknew.save(u'有趣装逼每⽇数据及趋势copy.xls')4.openpyxl可以对excel⽂件进⾏读写操作from openpyxl import Workbookfrom openpyxl import load_workbookfrom openpyxl.writer.excel import ExcelWriterworkbook_ = load_workbook(u"新歌检索失败1477881109469.xlsx") sheetnames =workbook_.get_sheet_names() #获得表单名字print sheetnamessheet = workbook_.get_sheet_by_name(sheetnames[0])print sheet.cell(row=3,column=3).valuesheet['A1'] = '47'workbook_.save(u"新歌检索失败1477881109469_new.xlsx")wb = Workbook()ws = wb.activews['A1'] = 4wb.save("新歌检索失败.xlsx")⽰例:import openpyxl# 新建⽂件workbook = openpyxl.Workbook()# 写⼊⽂件sheet = workbook.activesheet['A1']='A1'# 保存⽂件workbook.save('test.xlsx')5.xlsxwriter可以写excel⽂件并加上图表import xlsxwriterdef get_chart(series):chart = workbook.add_chart({'type': 'line'})for ses in series:name = ses["name"]values = ses["values"]chart.add_series({'name': name,'categories': 'A2:A10','values':values})chart.set_size({'width': 700, 'height': 350})return chartif __name__ == '__main__':workbook = xlsxwriter.Workbook(u'H5应⽤中⼼关键数据及趋势.xlsx') worksheet = workbook.add_worksheet(u"每⽇PV,UV")headings = ['⽇期', '平均值']worksheet.write_row('A1', headings)index=0for row in range(1,10):for com in [0,1]:worksheet.write(row,com,index)index+=1series = [{"name":"平均值","values":"B2:B10"}]chart = get_chart(series)chart.set_title ({'name': '每⽇页⾯分享数据'})worksheet.insert_chart('H7', chart)workbook.close()openpyxl⽰例:import xlsxwriter as xw#新建excelworkbook = xw.Workbook('myexcel.xlsx')#新建⼯作薄worksheet = workbook.add_worksheet()#写⼊数据worksheet.wirte('A1',1)#关闭保存workbook.close()合并表格实例:#coding:utf-8import xlsxwriterimport xlrd#新建excelworkbook = xlsxwriter.Workbook('⼴东.xlsx')#新建⼯作薄worksheet = workbook.add_worksheet()count = 1worksheet.write("A%s"%count,"公司名称")worksheet.write("B%s"%count,"法⼈")worksheet.write("C%s"%count,"电话")worksheet.write("D%s"%count,"注册资⾦")worksheet.write("E%s"%count,"注册时间")count+=1for i in range(1,153):data = xlrd.open_workbook('ah (%s).xls'%i) # 打开xls⽂件 table = data.sheets()[0] # 打开第⼀张表nrows = table.nrows # 获取表的⾏数for i in range(nrows): # 循环逐⾏打印if i == 0:# 跳过第⼀⾏continue# print (table.row_values(i)[:5]) # 取前⼗三列print(count,table.row_values(i)[:5][0])#写⼊数据#设定第⼀列(A)宽度为20像素 A:E表⽰从A到Eworksheet.set_column('A:A',30)worksheet.set_column('B:E',20)worksheet.write("A%s"%count,table.row_values(i)[:5][0]) worksheet.write("B%s"%count,table.row_values(i)[:5][1]) worksheet.write("C%s"%count,table.row_values(i)[:5][2]) worksheet.write("D%s"%count,table.row_values(i)[:5][3]) worksheet.write("E%s"%count,table.row_values(i)[:5][4]) count+=1#关闭保存workbook.close()。
Python学习笔记_使用openpyxl操作Excel,在同一个文件里复制某一个sheet
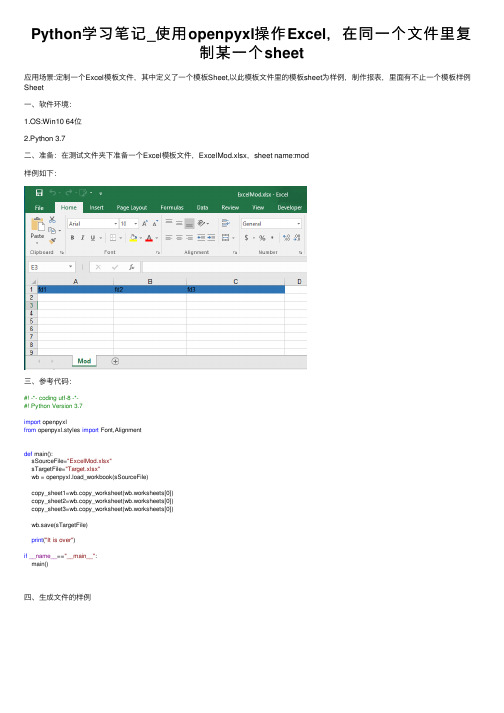
Python学习笔记_使⽤openpyxl操作Excel,在同⼀个⽂件⾥复制某⼀个sheet应⽤场景:定制⼀个Excel模板⽂件,其中定义了⼀个模板Sheet,以此模板⽂件⾥的模板sheet为样例,制作报表,⾥⾯有不⽌⼀个模板样例Sheet⼀、软件环境:1.OS:Win10 64位2.Python3.7⼆、准备:在测试⽂件夹下准备⼀个Excel模板⽂件,ExcelMod.xlsx,sheet name:mod样例如下:三、参考代码:#! -*- coding utf-8 -*-#! Python Version 3.7import openpyxlfrom openpyxl.styles import Font,Alignmentdef main():sSourceFile="ExcelMod.xlsx"sTargetFile="Target.xlsx"wb = openpyxl.load_workbook(sSourceFile)copy_sheet1=wb.copy_worksheet(wb.worksheets[0])copy_sheet2=wb.copy_worksheet(wb.worksheets[0])copy_sheet3=wb.copy_worksheet(wb.worksheets[0])wb.save(sTargetFile)print("It is over")if__name__=="__main__":main()四、⽣成⽂件的样例⽣成的Sheet name分别是Mod Copy、Mod Copy1、Mod Copy2五、Sheet name改名如果想定制复制好的sheet name,可对sheet name进⾏修改,下例,把复制的第⼀个sheet,改为sheet1参考代码:#! -*- coding utf-8 -*-#! Python Version 3.7import openpyxlfrom openpyxl.styles import Font,Alignmentdef main():sSourceFile="ExcelMod.xlsx"sTargetFile="Target.xlsx"wb = openpyxl.load_workbook(sSourceFile)copy_sheet1=wb.copy_worksheet(wb.worksheets[0])copy_sheet2=wb.copy_worksheet(wb.worksheets[0])copy_sheet3=wb.copy_worksheet(wb.worksheets[0])copy_sheet1.title="Sheet1"wb.save(sTargetFile)print("It is over")if__name__=="__main__":main()⽣成结果:其它两个复制的sheet,也可以分别修改copy_sheet2.title="Sheet2"copy_sheet3.title="Sheet3"六、注意事项:Excel模板⽂件,只能是.xlsx格式的,不能是早期版本的.xls格式的,否则会报错。
python excel copy单元格公式

python excel copy单元格公式
在Python中,我们可以使用openpyxl库来操作Excel文件。
以下是一个简单的例子,演示如何复制一个单元格的公式到另一个单元格:
python复制代码
from openpyxl import load_workbook
# 加载工作簿
workbook = load_workbook(filename="你的文件名.xlsx")
# 选择工作表
sheet = workbook["Sheet1"]
# 获取公式单元格的值
formula_cell = sheet["A1"]
# 复制公式单元格的公式到B1单元格
sheet["B1"] = formula_cell.value
请注意,openpyxl库无法直接复制公式。
因此,上述代码将公式单元格的值(即结果)复制到了B1单元格。
如果你想完全复制公式(包括其引用的单元格和相对引用),那就更复杂了,可能需要写一个函数来处理这个问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#coding=utf-8import osimport os.pathimport sysfrom xlrd import open_workbookfrom xlutils.copy import copyfrom g315.config import confimport chardetimport rep=pile(r'(?i){{(.*?)}}')source_file_mold = os.path.join(conf.APP_DIR, "public/excel/source/module.xls") target_file_mold = os.path.join(conf.APP_DIR, "public/excel/target/result.xls")import xlrdimport xlwtfrom xlrd import open_workbook,cellnameabsfrom xlutils.copy import copydef copy_xf(rdbook,rdxf):"""clone a XFstyle from xlrd XF class,the code is copied from xlutils.copy module """wtxf = xlwt.Style.XFStyle()## number format#wtxf.num_format_str = rdbook.format_map[rdxf.format_key].format_str## font#wtf = wtxf.fontrdf = rdbook.font_list[rdxf.font_index]wtf.height = rdf.heightwtf.italic = rdf.italicwtf.struck_out = rdf.struck_outwtf.outline = rdf.outlinewtf.shadow = rdf.outlinewtf.colour_index = rdf.colour_indexwtf.bold = rdf.bold #### This attribute is redundant, should be driven by weight wtf._weight = rdf.weight #### Why "private"?wtf.escapement = rdf.escapementwtf.underline = rdf.underline_type ##### wtf.???? = rdf.underline #### redundant attribute, set on the fly when writing wtf.family = rdf.familywtf.charset = rdf.character_set = ## protection#wtp = wtxf.protectionrdp = rdxf.protectionwtp.cell_locked = rdp.cell_lockedwtp.formula_hidden = rdp.formula_hidden## border(s) (rename ????)#wtb = wtxf.bordersrdb = rdxf.borderwtb.left = rdb.left_line_stylewtb.right = rdb.right_line_stylewtb.top = rdb.top_line_stylewtb.bottom = rdb.bottom_line_stylewtb.diag = rdb.diag_line_stylewtb.left_colour = rdb.left_colour_indexwtb.right_colour = rdb.right_colour_indexwtb.top_colour = rdb.top_colour_indexwtb.bottom_colour = rdb.bottom_colour_indexwtb.diag_colour = rdb.diag_colour_indexwtb.need_diag1 = rdb.diag_downwtb.need_diag2 = rdb.diag_up## background / pattern (rename???)#wtpat = wtxf.patternrdbg = rdxf.backgroundwtpat.pattern = rdbg.fill_patternwtpat.pattern_fore_colour = rdbg.pattern_colour_indexwtpat.pattern_back_colour = rdbg.background_colour_index## alignment#wta = wtxf.alignmentrda = rdxf.alignmentwta.horz = rda.hor_alignwta.vert = rda.vert_alignwta.dire = rda.text_direction# wta.orie # orientation doesn't occur in BIFF8! Superceded by rotation ("rota").wta.rota = rda.rotationwta.wrap = rda.text_wrappedwta.shri = rda.shrink_to_fitwta.inde = rda.indent_level# wta.merg = ????#return wtxfdef fill_value(position_sheet={},cell_value=""):"""replace the position({{varible}}) of the cellvalue with the varible's value"""if cell_value:m=p.search(cell_value)#查询是否存在{{?p<name>}}while m:var_name=m.groups()[0]print "var_name:",var_nametry:value = position_sheet.get(var_name) #读取第一个参数的值except Exception, e:error= u"模板文件:%(source_file)s的第%(index)s个sheet中的参数{{%(var_name)s}}在position中找不到对应的key" % \{"source_file":os.path.split(source_file)[1],"index":i+1,"var_name":var_name}print errorreturn dict(error=error,e=e)if value and not isinstance(value, unicode):value= value.decode("utf-8")print 'value', valueif not value:breakcell_value=p.sub(value,cell_value,count=1)#用这个值替换cell_value中的该{{参数}}m=p.search(cell_value)#检查是否还有参数return cell_valuedef excel_create(source_file="",position=[{}],target_file=""):'''根据source_file传入的excel模板文件路径,使用position中map对模板中的{{varible}}中的varible字段进行数据填充,生成新的文件放入file_pathsource_file:模板文件名;非空路径为:/public/excel/source/<name>.xls,空值默认模板:/public/excel/source/module.xls,position:[{key:value,key1:value1,key2:value2,...},#模板excel的sheet[0]内的参数map {key:value,key1:value1,key2:value2,...},#模板excel的sheet[1]内的参数map{key:value,key1:value1,key2:value2,...},#模板excel的sheet[...]内的参数map]file_path:生成的文件路径以及文件名;空值为默认路径:public/excel/target/result.xls '''warning=""if target_file:result_file=os.path.join(conf.APP_DIR, "public/excel/target", target_file) else:result_file=target_file_moldif source_file:source_file=os.path.join(conf.APP_DIR, "public/excel/source", source_file) else:source_file=source_file_moldtry:rb = open_workbook(source_file,on_demand=True,formatting_info=True) except:error= u"the (%s) is not a correct path!" % source_filereturn dict(error=error)wb = copy(rb)shxrange = range(rb.nsheets)while len(shxrange)>len(position):warning= u"the length of position's map is lesser than the number of the module Excel's sheets!"position.append({})for i in shxrange:ws = wb.get_sheet(i)sheet = rb.sheet_by_index(i)for rowx in range(0,sheet.nrows):for colx in range(0,sheet.ncols):#get the cell valuecellvalue=sheet.cell_value(rowx,colx)#get the cell typecelltype=sheet.cell_type(rowx,colx)if celltype == xlrd.XL_CELL_DATE:try:showval = xlrd.xldate_as_tuple(cellvalue, rb.datemode)except xlrd.XLDateError:e1, e2 = sys.exc_info()[:2]showval = "%s:%s" % (e1.__name__, e2)elif celltype == xlrd.XL_CELL_ERROR:showval = xlrd.error_text_from_code.get(cellvalue, 'Unknown error code 0x%02x' % cellvalue)else:showval = cellvalue#get stylexf=rb.xf_list[sheet.cell_xf_index(rowx,colx)]wtxf=copy_xf(rb,xf)#fill value(replace the varible in the cell_value)if showval:m=p.search(showval)#查询是否存在{{?p<name>}}while m:var_name=m.groups()[0]try:if var_name in position[i].keys():value = position[i].get(var_name,"") #读取第一个参数的值print "begin||",var_name,":",value,chardet.detect(value)# assert value is Trueif value:if not isinstance(value, unicode):value= value.decode("utf-8")else:value=""print "decode||",var_name,":",valueprint "-----------------------------------"else:raise Exceptionexcept Exception, e:error= u"the param:{{%(var_name)s}} in sheet(%(index)s) of the template:%(source_file)s can't be found in position's keys list" % \{"source_file":os.path.split(source_file)[1],"index":i+1,"var_name":var_name}print error,ereturn dict(error=error.encode('utf-8'))showval=p.sub(value,showval,count=1)#用这个值替换cell_value 中的该{{参数}}m=p.search(showval)#检查是否还有参数ws.write(rowx,colx,showval,wtxf)wb.save(result_file)return dict(target_file=os.path.join("/public/excel/target",target_file),warning=warning)def _test():#open the excel filerb=open_workbook("test1.xls",on_demand=True,formatting_info=True)for attr in ("biff_version","codepage","countries","encoding","colour_map","font_list","format_list","format_map","user_name","nsheets"):print "%s=%s" %(attr, rb.__getattribute__(attr))#show the loaded status for sheetsfor sheet_name in rb.sheet_names():print "%s loaded = %s" %(sheet_name, rb.sheet_loaded(sheet_name))#get the sheet1sheet=rb.sheet_by_index(0)print "%s has %d rows, %d cols" %(, sheet.nrows, sheet.ncols)print "Shoe the file content"for rowx in range(0,sheet.nrows):for colx in range(0,sheet.ncols):#get the cell valuecellvalue=sheet.cell_value(rowx,colx)#get the cell typecelltype=sheet.cell_type(rowx,colx)#init the showable valueshowvalue=""if celltype == xlrd.XL_CELL_DATE:try:showval = xlrd.xldate_as_tuple(cellvalue, rb.datemode)except xlrd.XLDateError:e1, e2 = sys.exc_info()[:2]showval = "%s:%s" % (e1.__name__, e2)elif celltype == xlrd.XL_CELL_ERROR:showval = xlrd.error_text_from_code.get(cellvalue, 'Unknown error code 0x%02x' % cellvalue)else:showval = cellvalue#get stylexf=rb.xf_list[sheet.cell_xf_index(rowx,colx)]#print rb.colour_map[xf.background.background_colour_index]#display the cell forecolorcolor=rb.colour_map[xf.background.pattern_colour_index]#show the contentprint ("[%s]=%s,[color]=%s" % (cellnameabs(rowx,colx),showval,color))#show the loaded status for sheets after load sheet1for sheet_name in rb.sheet_names():print "%s loaded = %s" %(sheet_name, rb.sheet_loaded(sheet_name))##################change the excel and write it out##################get the xlwt object from rb objectwb = copy(rb)#get the original excel cell stylerbxf=rb.xf_list[sheet.cell_xf_index(0,0)]#copy the xlrd style to xlwt stylewtrf=copyXF(rb,rbxf)#change an attribute of this style, the color index can refer to VBA document wtrf.pattern.pattern_fore_colour=15#set the new value and new style#wb.get_sheet(0).write(0,0,'changed!')wb.get_sheet(0).write(0,0,'changed!',wtrf)#output to filewb.save('test2.xls')def test(source_file="",position=[{}],target_file=""):'''根据source_file传入的excel模板文件路径,使用position中map对模板中的{{varible}}中的varible字段进行数据填充,生成新的文件放入file_pathsource_file:模板文件名;非空路径为:/public/excel/source/<name>.xls,空值默认模板:/public/excel/source/module.xls,position:[{key:value,key1:value1,key2:value2,...},#模板excel的sheet[0]内的参数map {key:value,key1:value1,key2:value2,...},#模板excel的sheet[1]内的参数map{key:value,key1:value1,key2:value2,...},#模板excel的sheet[...]内的参数map]file_path:生成的文件路径以及文件名;空值为默认路径:public/excel/target/result.xls '''print positionif target_file:target_file=os.path.join(conf.APP_DIR, "public/excel/target", target_file) else:target_file=target_file_moldif source_file:source_file=os.path.join(conf.APP_DIR, "public/excel/source", source_file) else:source_file=source_file_moldtry:rb = open_workbook(source_file,formatting_info=True)except:print "(%s)路径名不正确" % source_fileerror= "(%s)路径名不正确" % source_filereturn dict(error=error)wb = copy(rb)shxrange = range(rb.nsheets)while len(shxrange)>len(position):print '警告:position的map数小于sheets个数'position.append({})for index in shxrange:ws = wb.get_sheet(index)sh = rb.sheet_by_index(index)nrows = sh.nrowsncols = sh.ncolsfor i in range(0,nrows):for j in range(0,ncols):cell_value=sh.cell(i,j).valuecell_type=sh.cell(i,j).typem=p.search(cell_value)#查询是否存在{{?p<name>}}while m:var_name=m.groups()[0]print "var_name:",var_nametry:value = position[index].get(var_name) #读取第一个参数的值if value and not isinstance(value, unicode):value= value.decode("utf-8")except Exception, e:error= u"模板文件:%(source_file)s的第%(index)s个sheet中的参数{{%(var_name)s}}在position中找不到对应的key" % \{"source_file":os.path.split(source_file)[1],"index":index+1,"var_name":var_name}print errorreturn dict(error=error)print 'value', valueif not value:breakcell_value=p.sub(value,cell_value,count=1)#用这个值替换cell_value中的该{{参数}}m=p.search(cell_value)#检查是否还有参数#把处理后的cell_value填入结果单元格try:ws.write(i, j, cell_value)except:error= u"excel写入失败"return dict(error=error)wb.save(target_file)return dict(target_file=target_file)def test2():pass# Step 1: Create an input file for the demodef create_input_file():wtbook = xlwt.Workbook()wtsheet = wtbook.add_sheet(u'First')colours = 'white black red green blue pink turquoise yellow'.split()fancy_styles = [xlwt.easyxf('font: name Times New Roman, italic on;''pattern: pattern solid, fore_colour %s;'% colour) for colour in colours]for rowx in xrange(8):wtsheet.write(rowx, 0, rowx)wtsheet.write(rowx, 1, colours[rowx], fancy_styles[rowx]) wtbook.save('demo_copy2_in.xls')# Step 2: Copy the file, changing data content# ('pink' -> 'MAGENTA', 'turquoise' -> 'CYAN')# without changing the formattingfrom xlutils.filter import process,XLRDReader,XLWTWriter# Patch: add this function to the end of xlutils/copy.pydef copy2(wb):w = XLWTWriter()process(XLRDReader(wb,'unknown.xls'),w)return w.output[0][1], w.style_listdef update_content():rdbook = xlrd.open_workbook('demo_copy2_in.xls', formatting_info=True) sheetx = 0rdsheet = rdbook.sheet_by_index(sheetx)wtbook, style_list = copy2(rdbook)wtsheet = wtbook.get_sheet(sheetx)fixups = [(5, 1, 'MAGENTA'), (6, 1, 'CYAN')]for rowx, colx, value in fixups:xf_index = rdsheet.cell_xf_index(rowx, colx)wtsheet.write(rowx, colx, value, style_list[xf_index])wtbook.save('demo_copy2_out.xls')。