汉字点阵字库原理详解+例程
点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法

点阵LED显示原理与点阵汉字库的编码和从标准字库中提取汉字编码的方法。
2009年06月03日下午04:27一.实验要求编程实现中英文字符的显示。
二.实验目的1.了解LED点阵显示的基本原理和实现方法。
2.掌握三.实验电路及连线点阵显示模块WTD3088的(红色)列输入线接至内部LED的阴极端,行输入线接至内部LED的阳极端(若阳极端输入为高电平,阴极端输入低电平,则该LED 点亮)。
发光点的分布如图22-0所示。
Fig 22-0 WTD3088 LED分布如图22-1示,本实验模块使用74LS374来控制列输入线的电平值。
将74LS374的某输出置0,则对应的LED阴极端被置低。
如图22-2示,本实验模块使用74LS273来控制行输入线,并通过9013提供电流驱动。
将74LS273的某输出置1,则对应的LED阳极端被置高。
每次系统重新开启或总清后,74LS273输出为全0,LED显示被关闭。
通过编程控制各显示点对应LED阳极和阴极端的电平,就可以有效的控制各显示点的亮灭。
Fig 22-1 LED模块及列扫描电路Fig 22-2 行扫描电路Fig 22-3地址译码电路本实验模块使用4块WTD3088组成16×16点阵,以满足汉字显示的要求。
为了方便的控制四个单元,使用了一片74LS139译码,产生四个地址片选信号:CLKR1= CSLED,CLKR2= CSLED+1,用于行控制的两片74LS273;CLKC1= CSLED+2,CLKC2= CSLED+3,用于列控制的两片74LS374。
实验接线:按示例程序,模块的CSLED接51/96地址的8000H。
四.实验说明使用高亮度LED发光管构成点阵,通过编程控制可以显示中英文字符、图形及视频动态图形。
LED显示以其组构方式灵活、亮度高、技术成熟、成本低廉等特点在证券、运动场馆及各种室内/外显示场合得到广泛的应用。
所显示字符的点阵数据可以自行编写(即直接点阵画图),也可从标准字库(如ASC16、HZ16)中提取。
点阵汉字的原理及应用

点阵汉字的原理及应用1. 点阵汉字的概述点阵汉字是通过一系列的点阵来表示汉字的一种方法。
每个点阵都代表了一个汉字的一个笔画或者一个组件。
通过将这些点阵组合在一起,我们可以呈现出完整的汉字。
2. 点阵汉字的原理点阵汉字的原理可以分为两个步骤:字形生成和显示。
2.1 字形生成字形生成是指根据汉字的笔画顺序和结构,在点阵上绘制出每个笔画的轮廓。
这可以通过以下步骤完成: 1. 根据汉字的笔画顺序确定每个笔画的起始点和结束点。
2. 根据笔画的形状,确定每个笔画的拐角和曲线。
3. 将每个笔画的拐角和曲线连接起来,形成字形的轮廓。
4. 将字形的轮廓转化为点阵,每个点表示一个像素。
2.2 显示显示是指将生成的点阵汉字在显示设备上呈现出来。
这可以通过以下步骤完成:1. 将点阵汉字发送给显示设备。
2. 在显示设备上按照点阵的位置和颜色信息,点亮对应的像素。
3. 重复上述步骤,直到所有点阵汉字都被显示出来。
3. 点阵汉字的应用点阵汉字广泛应用于各种显示设备和软件中,以下是几个常见的应用领域:3.1 数码产品在数码产品中,点阵汉字常用于显示屏、小型计算器、电子手表等设备的界面上。
通过点阵汉字,用户可以方便地查看和输入文字信息。
3.2 广告牌和标志在广告牌和标志中,点阵汉字可以用于显示商店名称、产品标语等信息。
通过使用点阵汉字,可以将文字信息以更加醒目和吸引人的方式展示出来。
3.3 字符识别在字符识别领域,点阵汉字可以用于机器视觉系统中的文字识别。
通过将图像中的文字转化为点阵汉字,可以方便地对文字进行处理和识别。
3.4 手写输入在智能手机和平板电脑等设备中,点阵汉字可用于手写输入法。
用户可以通过手指在设备屏幕上划出汉字的笔画,系统会自动将笔画转化为点阵汉字,从而实现输入汉字的功能。
3.5 打印和排版在打印和排版领域,点阵汉字可用于生成高质量的印刷品。
通过将文字转化为点阵汉字,可以保证文字在不同尺寸和分辨率的输出设备上都能显示清晰和精确。
点阵字库的原理

汉字点阵数据在字库文件中的偏移= ((区码-1) * 94 +位码) *一个点阵字模占用的字节数
在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:
/*输出一个汉字的函数*/
void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color)
在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的(x,y)坐标出,文字的颜色为color,文字的点阵数据为pdata所指:
/*输出字模的函数*/
void _draw_model(char *pdata, int w, int h, int x, int y, int color)
| | | | | | | | | | | | | | | | |
可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…,当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.
在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.
矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述.对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.
点阵式汉字LED显示屏电路原理与制作(精)

点阵式汉字LED显示屏电路原理与制作汉字显示屏广泛应用与汽车报站器,广告屏等。
本文介绍一种实用的汉字显示屏的制作,考虑到电路元件的易购性,没有使用8*8的点阵发光管模块,而是直接使用了256个高量度发光管,组成了16行16列的发光点阵。
同时为了降低制作难度,仅作了一个字的轮流显示,实际使用时可根据这个原理自行扩充显示的字数。
1汉字显示的原理:我们以UCDOS中文宋体字库为例,每一个字由16行16列的点阵组成显示。
即国标汉字库中的每一个字均由256点阵来表示。
我们可以把每一个点理解为一个像素,而把每一个字的字形理解为一幅图像。
事实上这个汉字屏不仅可以显示汉字,也可以显示在256像素范围内的任何图形。
用8位的AT89C51单片机控制,由于单片机的总线为8位,一个字需要拆分为2个部分。
一般我们把它拆分为上部和下部,上部由8*16点阵组成,下部也由8*16点阵组成。
在本例中单片机首先显示的是左上角的第一列的上半部分,即第0列的p00---p07口。
方向为p 00到p07 ,显示汉字“大”时,p05点亮,由上往下排列,为p0.0 灭,p0.1 灭, p0.2 灭p0.3 灭, p0.4 灭, p0.5 亮,p0.6 灭,p0.7 灭。
即二进制00000100,转换为16进制为 04h.。
上半部第一列完成后,继续扫描下半部的第一列,为了接线的方便,我们仍设计成由上往下扫描,即从p27向p20方向扫描,从上图可以看到,这一列全部为不亮,即为00000000,16进制则为00h。
然后单片机转向上半部第二列,仍为p05点亮,为00000100,即16进制04h.这一列完成后继续进行下半部分的扫描,p21点亮,为二进制00000010,即16进制02h.依照这个方法,继续进行下面的扫描,一共扫描32个8位,可以得出汉字“大”的扫描代码为:04H,00H,04H,02H,04H,02H,04H,04H04H,08H,04H,30H,05H,0C0H,0FEH,00H05H,80H,04H,60H,04H,10H,04H,08H04H,04H,0CH,06H,04H,04H,00H,00H由这个原理可以看出,无论显示何种字体或图像,都可以用这个方法来分析出它的扫描代码从而显示在屏幕上。
点阵式汉字

点阵式汉字LED显示屏电路原理与制作汉字显示屏广泛应用与汽车报站器,广告屏等。
本文介绍一种实用的汉字显示屏的制作,考虑到电路元件的易购性,没有使用8*8的点阵发光管模块,而是直接使用了256个高量度发光管,组成了16行16列的发光点阵。
同时为了降低制作难度,仅作了一个字的轮流显示,实际使用时可根据这个原理自行扩充显示的字数。
1汉字显示的原理:我们以UCDOS中文宋体字库为例,每一个字由16行16列的点阵组成显示。
即国标汉字库中的每一个字均由256点阵来表示。
我们可以把每一个点理解为一个像素,而把每一个字的字形理解为一幅图像。
事实上这个汉字屏不仅可以显示汉字,也可以显示在256像素范围内的任何图形。
用8位的AT89C51单片机控制,由于单片机的总线为8位,一个字需要拆分为2个部分。
一般我们把它拆分为上部和下部,上部由8*16点阵组成,下部也由8*16点阵组成。
在本例中单片机首先显示的是左上角的第一列的上半部分,即第0列的p00---p07口。
方向为p 00到p07 ,显示汉字“大”时,p05点亮,由上往下排列,为p0.0 灭,p0.1 灭, p0.2 灭p0.3 灭, p0.4 灭, p0.5 亮,p0.6 灭,p0.7 灭。
即二进制00000100,转换为16进制为 04h.。
上半部第一列完成后,继续扫描下半部的第一列,为了接线的方便,我们仍设计成由上往下扫描,即从p27向p20方向扫描,从上图可以看到,这一列全部为不亮,即为00000000,16进制则为00h。
然后单片机转向上半部第二列,仍为p05点亮,为00000100,即16进制04h.这一列完成后继续进行下半部分的扫描,p21点亮,为二进制00000010,即16进制02h.依照这个方法,继续进行下面的扫描,一共扫描32个8位,可以得出汉字“大”的扫描代码为:04H,00H,04H,02H,04H,02H,04H,04H04H,08H,04H,30H,05H,0C0H,0FEH,00H05H,80H,04H,60H,04H,10H,04H,08H04H,04H,0CH,06H,04H,04H,00H,00H由这个原理可以看出,无论显示何种字体或图像,都可以用这个方法来分析出它的扫描代码从而显示在屏幕上。
点阵字库生成的原理

所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
51单片机的13×14点阵缩码汉卡我们历时数载,开发成"51单片机13×14点阵缩码汉卡",适用于目前国内外应用最为广泛的MCSX-51及其兼容系列单片机.与此同时,还开发了13×14点阵汉字字模.13×14点阵字模,可完全与目前通用的16×16点阵汉字字模媲美,其在单片机和嵌入式系统的汉字显示应用中也具有明显的经济价值和实用意义.1.单片机目前的汉字显示信息交流的最主要方式之一即文字交流,但由于我国方块汉字数量繁多,构形迥异,使汉字显示一直是我国计算机普及的障碍.随着计算机技术的迅速发展,PC机的汉字显示已不成问题.但对于成本低、体积小、应用灵活且用量极为巨大的单片机而言,因其结构简单,硬件资源十分有限,其汉字显示仍面对着捉襟见肘,力不从心的窘境.目前单片机的汉字显示有三种基本方法.①采用标准字库法.即将国标汉字库固人ROM中,将单片机的硬件和软件进行特别扩展后以显示汉字.众所周知,即使是16×16点阵标准字库,也须占用200KB以上的单元内存,而就目前主流5l系列单片机而言,最大寻址范围仅64KB,即使程序区与数据区合起来也仅128KB内存.因此,若不加特别的扩展设计,不要说检字程序和用户空间,仅字库都装不下.这种方法虽然可以方便地使用现成标准字库,但却需占用大量的硬件和软件资源,增加很大一部分成本和设计难度,所以不经常使用.②字模直接固化法.即将所显示的汉字,依先后顺序将其字模一一从标准字库中提取后,重新固化,予以显示.此法虽为简捷,但只适于显示少量汉字,且字模的制取繁琐,软件的修改维护都很困难.③带索引小字库法.即将欲显示文件中的汉字字模,从标准字库中逐一提取固化,制成小型字库,并按其在小字库中的位置制成索引表,显示时从索引表查出其新的字模取码地址,取码显示.此方法虽比较灵活,可显示较多的汉字,但仍然局限于只能显示固定文件内容,且字模制取同样麻烦.一种较新的单片机"汉字动态编码与显示方案"(见《单片机与嵌入式系统应用》杂志2003年第1期和第9期),实际上也是一种动态的"小字库"法,只是字库的制取,索引的编写及文件的改码皆由PC机自动完成,免去了繁琐的人工处理.由上可见,目前单片机各种汉字显示方案均不理想.标准字库法,单片机不堪重负;而其它方法最大且又无法克服的缺点是,所显示文字皆有局限.显示内容也皆须专业人员设计而定,用户难于更改.这便极大地限制了单片机在各个领域的开拓和应用.究其原因,皆为单片机本身无汉卡,而这也正是我们致力于"51汉卡"开发的初衷.2.13×14点阵汉字字模为垫定"5l汉卡"的字型基础,首先开发成了l3×14点阵汉字字模.在目前通用的汉字字模中,最简单的是16×16点阵字模.在微型打字机中,也偶见有12×12点阵字模,但实用中不多见.字模点阵数直接决定着每一汉字所占单元内存值,能否在保证字模准确、美观的基础上,寻找一种较少的点阵字模呢?这便是我们最初的想法.于是我们经过反复选择比较,终于在国内首个推出了13×14点阵字模.此设计,一是基于我国汉字为方块字,故其行、列值需相近;二是汉字多有对称1生,故其列值宜奇不宜偶.设计实际表明,若行、列值很少,则难保证字模的准确性和美观性.?13×14点阵字模,是以我国现行简化字为准,并在此基础上设计而成.与目前通用的汉字16×l6点阵字模相比,其准确性和美观性并不逊色.然而其单字所占内存却由32个单元降至26个单元;另外使得每个单字显示由原来的256个像素降至l82个像素,使显示成本和空间均减少近三分之一.100×200点阵LED字屏,可显示16×l6点阵汉字72个,而l3×14点阵汉字便可显示l05个,且显示效果并无太大差异.这无疑对单片机和嵌入式系统汉字显示产品的开发和应用,具有明显的经济价值和实用意义.3.51单片机13×14点阵缩码汉卡"51汉卡"依据我国的汉字特点和单片机的快速构字功能,在13×14点阵字模基础上,以缩码形式开发而成单片机汉卡的开发,应以目前通用的主流单片机为研发对象,还应在囊括国标一、二级汉字及常用字符的前提下,使内存占用必须降至主流单片机可寻址范围内,且需留有足够的检字程序和用户应用空间.另外,字模设计必须准确、美观.字模提取速度也必须满足实用要求."51汉卡"的开发正是依据原则,并达到了以上各项要求.顾名思义,"51汉卡,即以MCS-51系列及其兼容单片机为研发对象.以51系列为代表的8位单片机,在过去、现在以及可以予见的将来,都将是嵌入式系统低端应用的主流机型.此乃业界专家的共识."51汉卡"囊括了"GB2312-80"国标字库的全部一、二级汉字,并增补汉字86个;同时包括了大、小英文字母、阿拉伯数字等160个常用字符和不到4KB的构字程序,却仅总共占用了不足66KB的内存.每字平均约占9.8个单元,相对于16×16点阵每字占32单兀内存而言,尚不到其三分之一.这对于具有相互独立的64KB程序区和64KB数据区的51系列单片机而言,若适当配置内存,可为检字程序和用户留出90%以上的程序空间及相当数量的数据空间,对于一般用户的应用,都将绰绰有余.另外,为使"51汉卡''更便于使用和进一步节省内存,在上述基础上又开发成一套简化版本,删去了部分较偏僻的二级汉字.简化版本包括约5580个汉字,共占用内存58KB.实际上,按有关权威部门的统计,一般文本99%的文字是由2400个字写成的,因此使用简化版本,并配以简单的造字程序,一般亦可满足我们的使用要求."51汉卡"所用字模,即我们开发的完全可与16×16点阵字模媲美的I3×14点阵汉字字模.字模提取速度是我们最为关心的问题之一.经测试及实际使用表明,"51汉卡''的提模速度完全可满足单片机汉字显示的实用要求.我们使用INTEL公司MCS-51经典系列87C51单片机在24MHz频率下测试,平均字模提取速度为2.1ms/字.因人的视觉暂留时间为0.1s,无论理论还是实际使用都表明,50字字模提取并显示,并无迟滞和待机之感.即使在1?2MHz频率下,20字取模,即点即出,在一般拼音检字和少量汉字显示中,完全可满足使用要求.随着单片机技术的迅速发展,目前,INTEL公司、Atmel 公司、philips公司、我国台湾华邦等公司生产的MCS-51兼容单片机时钟频率可达33MHz,增强型可达40MHz,以至达60MHz;现市售的"ST C89LE"系列单片机,最高频率可达90MHz.这些芯片都完全能与MCS-51芯片兼容,对于更高需求的场合,更新升级也十分简便.另外,在单片机和嵌入式系统中,文字显示速度要求并不高,只要满足换屏时的视觉要求即可.其汉字显示字数,一般也不太多.如用LCD显示屏,128×64点阵,才显示32个字;192×64点阵才显48个字;即使使用l3×14点阵字模,满屏也才56个汉字.4."51汉卡"设计依据及说明"51汉卡"设计依据是,我国汉字虽然数量繁多,字型各异,但其中复合结构者占大部分,并素有"偏旁取义,正字取音"之说.如"寸"字与不同偏旁可组成"村"、"付"、"讨"、"守"、"过"等字.因此"51汉卡"除单结构字基本以全码设计外,复台结构字多用相应的单体字及其偏旁,以结构代码写成.利用单片机快速的单元积木式构字程序,便可迅速生成字模代码.这既保证了提码速度,又节省了大量的汉卡内存.有关"51汉卡"的几点说明如下:①凡汉字库中简、繁体字都有的用简体.如"後"以"后"代,"馀"以"余"代等;②《新华字典》未收入字,多未收入,如"酏"、"鼽"等字,但"婧"、"弪"等字仍收入;③对于多体字,一般以常用字代,如"摺"以"折"代,"镟"以"旋,代等,但"吒"不以"咤"代,"雠"不以"仇"代等;④对通常已由其它字取代的字,都以这些字代替,如"岽"以"东"代,"肛''以"船"代等;⑤二级汉字中,不单独构成汉字的偏旁未收入;⑥依据名篇名著,生活用语等,增补汉字86个;⑦收编大、小写英文字母、阿拉伯数字、标点符号等各种常用字符160个.5."51单片机汉卡"应用举例利用"51单片机汉卡",将使51系列单片机的汉字显示轻而易举,并可大为降低成本、体积和设计开发的难度,为单片机在生产控制、信息通信、文化教育和日常生活等领域,特别是计算机终端和手持产品的开发提供极大的便利和支持.?我们现已初步开发成"51汉卡"的"区位码输入法"和"拼音输入法,检字程序,并利用"51汉卡"成功地开发了带有廉价单片机控制器的LED汉字显示屏.这不仅大幅度降低了成本费用.而且用户可以通过单片机控制器,随心所欲地改变显示内容.51硬件设计CPU--87C51、12MHz晶振.程序存储器一1片EPROM?27C512.数据存储器一1片EPROM?27C512;1片EEPROM28C64A;1片6116.控制器显示屏一LCD?HY一19264B(深圳秋田视佳实业有限公司).LED屏选240×16点阵.本系统用标准小键盘检字,一次可予选4000字;控制器LCD满屏显示l3×14点阵汉字56个;LED屏满屏显示汉字19个.地址分配及用途如表l所列.5.2程序设计框图程序设计流程如图1所示.本系统采用12MHz晶振,若LCD取满屏56字,换屏时有约0.1s 的延时,这对人的实际视觉并无大影响.标准点阵汉字字库芯片1 概述GT23L24M1W是一款内含24X24点阵的汉字库芯片,支持GB18030国标汉字(含有国家信标委合法授权)及ASCII字符.排列格式为横置横排.用户通过字符内码,利用本手册提供的方法计算出该字符点阵在芯片中的地址,可从该地址连续读出字符点阵信息.1.1 芯片特点●数据总线: SPI 串行总线接口PLII 精简地址并行总线接口●点阵排列方式:字节横置横排访问速度:SPI 时钟频率:20MHz(max.)PLII 访问速度:130ns(max.) @3.3V●工作电压:2.7V~3.6V●电流:工作电流:12mA待机电流:10uA●封装:SO20W●尺寸(SO20W):12.80mmX10.30mm●工作温度:-20℃~85℃(SPI 模式下);-10℃~85℃(PLII 模式下)2.2 SPI 接口引脚描述串行数据输出(SO):该信号用来把数据从芯片串行输出,数据在时钟的下降沿移出.串行数据输入(SI):该信号用来把数据从串行输入芯片,数据在时钟的上升沿移入.串行时钟输入(SCLK):数据在时钟上升沿移入,在下降沿移出.片选输入(CS#):所有串行数据传输开始于CE#下降沿,CE#在传输期间必须保持为低电平,在两条指令之间保持为高电平.总线挂起输入(HOLD#):2.3 SPI 接口与主机接口电路示意图SPI 与主机接口电路连接可以参考下图(#HOLD管脚建议接2K 电阻3.3V 拉高).若是采用系统电压为5V的,则需要进行电平转换匹配连接GT23 芯片,可以参考下图(#HOLD 管脚建议接2K 电阻3.3V 拉高).2.4 PLII 接口引脚描述2.5 PLII 接口与主机接口电路示意图SPI/PLII_SEL(管脚内部有100K 上拉电阻)接地,字库芯片选择PLII 接口模式,与主机接口电路连接可以参考下图.2.6 PLII 总线接口寻址说明在PLII 总线模式下,芯片内部有3个地址寄存器,主机需要把要读取数据的地址写入这3个地址寄存器,然后再从数据寄存器中读出数据.主机每读一次数据寄存器,芯片内部的地址寄存器会自动增一,从而使主机只写一次首地址,就可以连续读取数据.3 字库调用方法3.1 汉字点阵排列格式每个汉字在芯片中是以汉字点阵字模的形式存储的,每个点用一个二进制位表示,存1的点,当显示时可以在屏幕上显示亮点,存0的点,则在屏幕上不显示.点阵排列格式为横置横排:即一个字节的高位表示左面的点,低位表示右面的点(如果用户按word mode读取点阵数据,请注意高低字节的顺序),排满一行的点后再排下一行.这样把点阵信息用来直接在显示器上按上述规则显示,则将出现对应的汉字.3.1.1 24X24点汉字排列格式24X24 点汉字的信息需要72个字节(BYTE 0 – BYTE 71)来表示.该24X24 点汉字的点阵数据是横置横排的,其具体排列结构如下图:命名规则:最大字符集及字数S:GB2312 6,763汉字M:GB18030 27,484汉字T:GB12345 6,866汉字BIG5 5,401 / 13,060汉字U:Unicode V3.0 27,484汉字。
点阵字库的原理与应用

点阵字库的原理与应用1. 点阵字库的定义点阵字库是一种用来表示字符、数字和符号的编码系统。
它将每个字符、数字和符号映射成一个矩阵,其中的每个元素都表示一个像素点。
通过控制这些像素点的亮暗,我们可以在屏幕上显示出各种字符、数字和符号。
2. 点阵字库的原理点阵字库的原理是将每个字符表示成一个矩阵,其中的每个元素都表示一个像素点。
这些像素点可以通过不同的显示方式来呈现出不同的字符效果。
例如,一个常见的5x7点阵字库可以表示出128个字符。
每个字符由5行7列的像素矩阵组成,其中的每个元素可以是亮或暗。
通过控制这些像素的状态,我们可以显示出各种字符。
3. 点阵字库的应用点阵字库广泛应用于各种显示设备和系统中,例如计算机、手机、LED显示屏等。
它可以用来显示各种文字和图形,提供丰富的显示效果。
以下是点阵字库的一些常见应用:•计算机显示:在计算机上,点阵字库被用来显示各种字符、数字和符号。
它可以显示出不同的字体和大小,提供更好的可读性和用户体验。
•手机显示:点阵字库也被广泛用于手机屏幕上,用来显示各种文字和图标。
手机屏幕的分辨率越高,点阵字库所能呈现的效果就越清晰和细腻。
•LED显示屏:在LED显示屏上,点阵字库可以用来显示各种文字和图形,并且可以通过控制像素的亮暗和颜色来呈现出更丰富的效果。
•打印机:打印机也使用点阵字库来打印出文字和图形,通过控制打印头上的针或墨滴,将点阵字库中的信息转化为实际的印刷图案。
4. 点阵字库的优缺点使用点阵字库有以下优点:•灵活性:点阵字库可以根据需要显示不同的字体、大小和样式,从而满足用户的不同需求。
•可读性:因为点阵字库是基于像素的,所以能够提供较高的显示清晰度和可读性。
•节省存储空间:由于点阵字库是基于矩阵的存储方式,它可以有效地节省存储空间,使得系统更加高效。
然而,点阵字库也有一些缺点:•分辨率限制:点阵字库的显示效果受到分辨率的限制,低分辨率的显示设备可能无法呈现出更精细的字体和图形。
汉字显示16X16点阵2
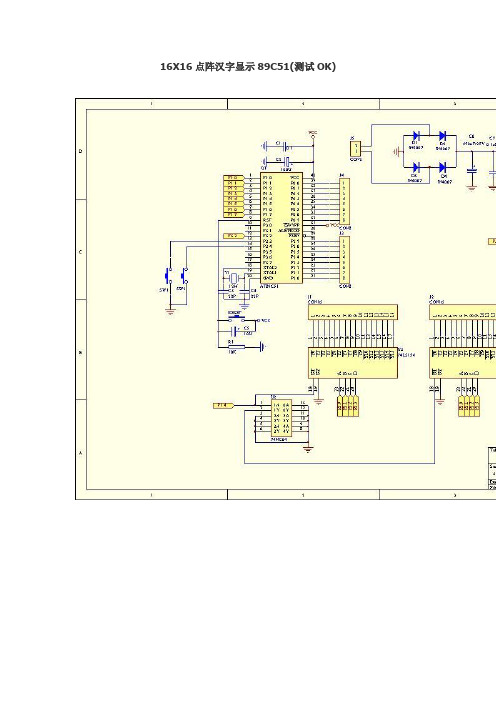
16X16点阵汉字显示89C51(测试OK)1汉字显示的原理:我们以UCDOS中文宋体字库为例,每一个字由16行16列的点阵组成显示。
即国标汉字库中的每一个字均由256点阵来表示。
我们可以把每一个点理解为一个像素,而把每一个字的字形理解为一幅图像。
事实上这个汉字屏不仅可以显示汉字,也可以显示在256像素我们以显示汉字“大”为例,来说明其扫描原理:在UCDOS中文宋体字库中,每一个字由16行16列的点阵组成显示。
如果用8位的AT89C51单片机控制,由于单片机的总线为8位,一个字需要拆分为2个部分。
一般我们把它拆分为上部和下部,上部由8*16点阵组成,下部也由8*16点阵组成。
在本例中单片机首先显示的是左上角的第一列的上半部分,即第0列的p00---p 07口。
方向为p00到p07 ,显示汉字“大”时,p05点亮,由上往下排列,为p0.0 灭,p0.1 灭, p0.2 灭p0.3 灭, p0.4 灭, p0.5 亮,p0.6 灭,p0.7 灭。
即二进制00000100,转换为16进制为 04h.。
上半部第一列完成后,继续扫描下半部的第一列,为了接线的方便,我们仍设计成由上往下扫描,即从p27向p20方向扫描,从上图可以看到,这一列全部为不亮,即为00000000,16进制则为00h。
然后单片机转向上半部第二列,仍为p05点亮,为00000100,即16进制04 h.这一列完成后继续进行下半部分的扫描,p21点亮,为二进制00000010,即16进制02h.依照这个方法,继续进行下面的扫描,一共扫描32个8位,可以得出汉字“大”的扫描代码为:04H,00H,04H,02H,04H,02H,04H,04H04H,08H,04H,30H,05H,0C0H,0FEH,00H05H,80H,04H,60H,04H,10H,04H,08H04H,04H,0CH,06H,04H,04H,00H,00H由这个原理可以看出,无论显示何种字体或图像,都可以用这个方法来分析出它的扫描代码从而显示在屏幕上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
汉字点阵字库原理一、汉字编码1. 区位码在国标GD2312—80 中规定,所有的国标汉字及符号分配在一个94 行、94 列的方阵中,方阵的每一行称为一个“区”,编号为01 区到94 区,每一列称为一个“位”,编号为01 位到94位,方阵中的每一个汉字和符号所在的区号和位号组合在一起形成的四个阿拉伯数字就是它们的“区位码”。
区位码的前两位是它的区号,后两位是它的位号。
用区位码就可以唯一地确定一个汉字或符号,反过来说,任何一个汉字或符号也都对应着一个唯一的区位码。
汉字“母”字的区位码是3624,表明它在方阵的36 区24 位,问号“?”的区位码为0331,则它在03区3l位。
一级汉字16-55区二级汉字56-87区三级汉字1-9区空闲未用10-15区2. 机内码汉字机内码,又称“汉字ASCII码”,简称“内码”,汉字的机内码是指在计算机中表示一个汉字的编码。
机内码与区位码稍有区别。
如上所述,汉字区位码的区码和位码的取值均在1~94 之间,如直接用区位码作为机内码,就会与基本ASCII码混淆。
为了避免机内码与基本ASCII码的冲突,需要避开基本ASCII码中的控制码(00H~1FH),还需与基本ASCII码中的字符相区别。
为了实现这两点,可以先在区码和位码分别加上20H,在此基础上再加80H(此处“H”表示前两位数字为十六进制数)。
经过这些处理,用机内码表示一个汉字需要占两个字节,分别称为高位字节和低位字节,这两位字节的机内码按如下规则表示:高位字节= 区码+ 20H + 80H(或区码+ A0H)低位字节= 位码+ 20H + 80H(或位码+ AOH)由于汉字的区码与位码的取值范围的十六进制数均为01H~5EH(即十进制的01~94),所以汉字的高位字节与低位字节的取值范围则为A1H~FEH(即十进制的161~254)。
例如,汉字“啊”的区位码为1601,区码和位码分别用十六进制表示即为1001H,它的机内码的高位字节为B0H,低位字节为A1H,机内码就是B0A1H。
二、点阵字库结构1. 点阵字库存储在汉字的点阵字库中,每个字节的每个位都代表一个汉字的一个点,每个汉字都是由一个矩形的点阵组成,0代表没有,1代表有点,将0和1分别用不同颜色画出,就形成了一个汉字,常用的点阵矩阵有12*12, 14*14, 16*16三种字库。
字库根据字节所表示点的不同有分为横向矩阵和纵向矩阵,目前多数的字库都是横向矩阵的存储方式(用得最多的应该是早期UCDOS字库),纵向矩阵一般是因为有某些液晶是采用纵向扫描显示法,为了提高显示速度,于是便把字库矩阵做成纵向,省得在显示时还要做矩阵转换。
我们接下去所描述的都是指横向矩阵字库。
2. 16*16点阵字库对于16*16的矩阵来说,它所需要的位数共是16*16=256个位,每个字节为8位,因此,每个汉字都需要用256/8=32个字节来表示。
即每两个字节代表一行的16个点,共需要16行,显示汉字时,只需一次性读取32个字节,并将每两个字节为一行打印出来,即可形成一个汉字。
点阵结构如下图所示:3. 14*14与12*12点阵字库对于14*14和12*12的字库,理论上计算,它们所需要的点阵分别为(14*14/8)=25, (12*12/8)=18个字节,但是,如果按这种方式来存储,那么取点阵和显示时,由于它们每一行都不是8的整位数,因此,就会涉到点阵的计算处理问题,会增加程序的复杂度,降低程序的效率。
为了解决这个问题,有些点阵字库会将14*14和12*12的字库按16*14和16*12来存储,即,每行还是按两个字节来存储,但是14*14的字库,每两个字节的最后两位是没有使用,12*12的字节,每两字节的最后4位是没有使用,这个根据不同的字库会有不同的处理方式,所以在使用字库时要注意这个问题,特别是14*14的字库。
三、汉字点阵获取1. 利用区位码获取汉字汉字点阵字库是根据区位码的顺序进行存储的,因此,我们可以根据区位来获取一个字库的点阵,它的计算公式如下:点阵起始位置= ((区码- 1)*94 + (位码–1)) * 汉字点阵字节数获取点阵起始位置后,我们就可以从这个位置开始,读取出一个汉字的点阵。
2. 利用汉字机内码获取汉字前面我们己经讲过,汉字的区位码和机内码的关系如下:机内码高位字节= 区码+ 20H + 80H(或区码+ A0H)机内码低位字节= 位码+ 20H + 80H(或位码+ AOH)反过来说,我们也可以根据机内码来获得区位码:区码= 机内码高位字节- A0H位码= 机内码低位字节- AOH将这个公式与获取汉字点阵的公式进行合并计就可以得到汉字的点阵位置。
发现这个不错的程序,可以读取显示汉字点阵字库,如果想做个电子书之类的东东,很有参考价值,程序虽然是用TC20写的,但是DOS时代的C和单片机的很相似的,主要的公式部分看明白就行了/******************************************************文件名:All.c描述:12,14,16点阵汉字显示文件语言:TC2.0作者:刘利国修改:日期:2002-11-5说明:需要12,14,16点阵汉字字库的支持******************************************************/#include <stdio.h>#include <graphics.h>#include <fcntl.h>#include <io.h>int hzk_p,asc_p;void open_hzk(char filename[]);void open_asc(char filename[]);void get_hz(char incode[],char bytes[],unsigned long uiSize );void get_asc(char incode[],char bytes[],unsigned long uiSize );void disasc(int x,int y,char code[],int color,unsigned int uiDianZhenSize);void dishz(int x0,int y0,char code[],int color,unsigned int uiDianZhenSize,unsigned int uiDuoYuBit);/*字模的大小16*16点阵ZI_MO_SIZE=3214*14点阵ZI_MO_SIZE=2812*12点阵ZI_MO_SIZE=24//该变量一定为long,否则出错*/unsigned long ZI_MO_SIZE[3]={32,28,24};/*汉字点阵16*16点阵ZI_MO_SIZE=1614*14点阵ZI_MO_SIZE=1412*12点阵ZI_MO_SIZE=12*/unsigned int DIAN_ZHEN_SIZE[3]={16,14,12};/*多余位数(对于12*12和14*14点阵字库,该位有意义)16*16点阵ZI_MO_SIZE=014*14点阵ZI_MO_SIZE=212*12点阵ZI_MO_SIZE=4 */unsigned int DUO_YU_BIT[3]={0,2,4};#define ZOOMX 1 /*X方向的放大倍数,1为原始尺寸*/#define ZOOMY 1 /*Y方向的放大倍数,1为原始尺寸*/main(){int x=10,i;int y=10;char *s;char *filename[3]={"e:\\hzk\\hzk16","e:\\hzk\\hzk14","e:\\hzk\\hzk12"};char *fileasc[3]={"e:\\hzk\\asc16","e:\\hzk\\asc14","e:\\hzk\\asc12"};char code[32];/*因为不能动态定位,所以取最大值32*/char tmpcode[3]={0};unsigned char mask=0x80;int driver=DETECT,errorcode;int mode;int iOffset;initgraph(&driver,&mode,"");errorcode=graphresult();if(errorcode!=0){printf("error ");getch();exit(1);}for(i=0;i<3;i++){open_hzk(filename[i]);open_asc(fileasc[i]);s="北京惠234悦12通234电s子技术有限234公司";while(*s!=NULL){while(x<600 && (*s!=NULL)){tmpcode[0]=*s;tmpcode[1]=*(s+1);if(tmpcode[0] & mask){get_hz(s,code,ZI_MO_SIZE[i]);dishz(x,y,code,GREEN,DIAN_ZHEN_SIZE[i],DUO_YU_BIT[i]);x+=20*ZOOMX;s+=2; }else{disasc(x,y,s,LIGHTGREEN,DIAN_ZHEN_SIZE[i]);x+=10*ZOOMX;s+=1;}}x=10;y+=20*ZOOMY;}y+=20;/*换行*/close(hzk_p);close(asc_p);}getch();closegraph();}/******************************************************函数名称:open_hzk函数功能:打开字库文件传入参数:无返回值:无建立时间:修改时间:建立人:修改人:其它说明:如果失败,则直接退出程序******************************************************/void open_hzk(char filename[]){hzk_p=open(filename,O_BINARY|O_RDONL Y);if(hzk_p==-1){printf("The file HZK not exits!");getch();closegraph();exit(1);}}/****************************************************** 函数名称:open_asc函数功能:打开字库文件传入参数:无返回值:无建立时间:修改时间:建立人:修改人:其它说明:如果失败,则直接退出程序******************************************************/ void open_asc(char filename[]){asc_p=open(filename,O_BINARY|O_RDONL Y);if(asc_p==-1){printf("The file asc not exits!");getch();closegraph();exit(1);}}/****************************************************** 函数名称:函数功能:传入参数:返回值:建立时间:修改时间:建立人:修改人:其它说明:******************************************************/void get_hz(char incode[],char bytes[],unsigned long uiSize ){unsigned char qh,wh;unsigned long offset;qh=incode[0]-0xa0;wh=incode[1]-0xa0;offset=(94*(qh-1)+(wh-1))*uiSize;lseek(hzk_p,offset,SEEK_SET);read(hzk_p,bytes,uiSize);}/******************************************************函数名称:函数功能:传入参数:返回值:建立时间:修改时间:建立人:修改人:其它说明:******************************************************/void get_asc(char incode[],char bytes[],unsigned long uiSize ){unsigned char qh,wh;unsigned long offset;offset=incode[0]*uiSize;lseek(asc_p,offset,SEEK_SET);read(asc_p,bytes,uiSize);}/******************************************************函数名称:函数功能:传入参数:返回值:建立时间:修改时间:建立人:修改人:其它说明:对于24*24的点阵字库,存放格式如下:纵向存放3个字节(24位),横向存放24个字节,每个字模占72个字节字符排列顺序如下:1 4 7 10 ......2 5 8 11 ......3 6 9 12 ......对于16*16的点阵字库,存放格式如下:横向存放2个字节(16位),其中第二个字节没有多余的数据纵向存放16个字节,每个字模占32个字节字符排列顺序如下:1 23 45 6......对于14*14的点阵字库,存放格式如下:横向存放2个字节(16位),其中第二个字节的后2位是多余的数据纵向存放14个字节,每个字模占28个字节字符排列顺序如下:1 23 45 6......对于12*12的点阵字库,存放格式如下:横向存放2个字节(16位),其中第二个字节的后4位是多余的数据纵向存放12个字节,每个字模占24个字节字符排列顺序如下:1 23 45 6......******************************************************/void dishz(int x0,int y0,char mat[],int color,unsigned int uiDianZhenSize,unsigned int uiDuoYuBit){unsigned char mask[]={0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01};register int x,y,row,col;register int byte;int zoomX,zoomY;/*x,y方向*/x=x0;y=y0;byte=0;for(col=0;col<uiDianZhenSize;col++) /*列*/{for(zoomY=0;zoomY<ZOOMY;zoomY++) /*纵向放大*/{for(row=0;row<uiDianZhenSize;row++) /*16行(2个8位)*/{for(zoomX=0;zoomX<ZOOMX;zoomX++) /*横向放大*/{if((mask[byte%8]& mat[byte/8])!=NULL){putpixel(x,y,color);}x++; /*x位置加一*/}byte++;}byte+=uiDuoYuBit; /*去掉多余位,对于16*16点阵来说,该位为0*/x=x0; y++;/*y坐标加1*/byte-=16; /*重新修正byte,重复绘制y像点*/}byte+=16; /*每次写完1行(2个字节,16位),修正byte*/}}void disasc(int x0,int y0,char code[],int color,unsigned int uiDianZhenSize){unsigned char mask[]={0x80,0x40,0x20,0x10,0x08,0x04,0x02,0x01};register int x,y,row,col;register int byte;int zoomX,zoomY;/*x,y方向*/char mat[16]={0};/*因为不能动态定位,所以取最大值16*/get_asc(code,mat,uiDianZhenSize);x=x0;y=y0;byte=0;for(col=0;col<uiDianZhenSize;col++) /*列*/{for(zoomY=0;zoomY<ZOOMY;zoomY++) /*纵向放大*/{for(row=0;row<8;row++){for(zoomX=0;zoomX<ZOOMX;zoomX++) /*横向放大*/{if((mask[byte%8]& mat[byte/8])!=NULL){putpixel(x,y,color);}x++; /*x位置加一*/}byte++;}x=x0;y++;/*y坐标加1*/byte-=8; /*重新修正byte,重复绘制y像点*/}byte+=8; /*每次写完1行(2个字节,16位),修正byte*/}}运用在单片机的例程:INT8U *HZK = (INT8U *)0x801c0000; /* 汉字字库的存储地址*/INT8U *ASCII = (INT8U *)0x801fba00; /* ASCII码字库的存储地址*/INT8U const cmp_w[8]={128,64,32,16,8,4,2,1};/****************************************************************** ***************************************** Function : DisplayHZ()** Description: 该函数用于在FDGK/GUI上显示一个汉字。