统计数据库和日志每天的大小和增加量
SQL语句统计每天、每月、每年的数据

1.//按天统计2.selectcount(dataid) as 每天操作数量, sum()3.from4.where5.group by trunc(createt ime, 'DD'))6.//按自然周统计7.selectto_char(date,'iw'),sum()8.from9.where10.group by to_char(date,'iw')11.//按自然月统计12.selectto_char(date,'mm'),sum()13.from14.where15.group by to_char(date,'mm')16.//按季统计17.selectto_char(date,'q'),sum()18.from19.where20.group by to_char(date,'q')21.//按年统计22.selectto_char(date,'yyyy'),sum()23.from24.where25.group by to_char(date,'yyyy')SQL语句统计每天、每月、每年的数据1、每年selectyear(orderti me) 年,sum(Total) 销售合计from 订单表group by year(orderti me)2、每月selectyear(orderti me) 年,month(orderti me) 月,sum(Total) 销售合计from 订单表group by year(orderti me),month(orderti me3、每日selectyear(orderti me) 年,month(orderti me) 月,day(orderti me) 日,sum(Total) 销售合计from 订单表group by year(orderti me),month(orderti me),day(orderti me)另外每日也可以这样:selectconvert(char(8),orderti me,112) dt,sum(Total) 销售合计from 订单表group by convert(char(8),orderti me,112)sql题如何统计查询一个月中每天的记录怎么写啊?写出来啊!比如说要查2010年3月份每天的记录提问者:Java_Tr avler- 一级最佳答案selectcount(*),substr(t.date,1,10) from table t where t.date like '2010-03%' group by substr(t.date,1,10)这里date的格式是YYY Y-mm-ddhh:mm:sssql数据分月统计,表中只有每天的数据,现在要求求一年中每个月的统计数据(一条sql)SELECTMONTH ( 那个日期的字段),SUM( 需要统计的字段,比如销售额什么的)FROM表WHEREYEAR ( 那个日期的字段) = 2010 -- 这里假设你要查2010年的每月的统计。
网络数据的背后——网络日志的分析指标

网络数据的背后——网络日志的分析指标常用的定量分析是问卷调查,这可以收集到用户对产品的主观反馈,它的结果受问卷题目的影响,不能完全客观地反映用户如何使用产品,他们在实际环境中遇到了哪些问题。
而针对网站的定量分析,网络服务器的日志文件能真实反映用户的当前体验,解释行为的深层特点,能够更有效地改进产品。
网络日志可以帮我们回答很多问题,比如用户在什么时间段浏览网站;对网站的什么板块比较感兴趣;是怎样了解到网站;多少用户会转成重复用户;在网站上找到兴趣点的路径是什么;应该怎样优化使用过程,提高用户体验,等等。
要系统地分析日志,得到有价值的用户反馈,主要考虑聚合度量、基于会话的统计、基于用户的统计和点击流分析四方面。
1. 聚合度量可以理解为将大量网站数据进行合并分析。
下面结合某旅游论坛的日志数据说明常用的聚合度量指标。
特别说明一下,本论坛纯属虚构,数据也是为了说明概念虚构的。
(1)网站的浏览量。
同时间段的浏览量比较,可以得出用户关注度的变化趋势。
图1显示了某旅游论坛2008年6月至2010年12月浏览量变化情况,其中09年6月左右浏览量骤然上升,09年12月逐渐趋于平缓,曲线的变化可能与论坛的营销手段、设计等有关,因此能见证采取措施带来的效果。
图1 某旅游论坛的浏览量(2)一天内各时间段浏览量的分布。
从图2可以判断用户主要在休息时间浏览该论坛,因此论坛应当突出休闲轻松的内容。
图2 某旅游论坛一天内各时间段的浏览量(3)网站各板块的浏览分布。
可以分析具体板块、单个页面、同类页面组的浏览分布情况,判断用户的兴趣点。
图3说明论坛用户主要对东南亚、日本比较感兴趣。
图3 该论坛国外旅游版的浏览比例(4)操作系统和浏览器比例。
方便网站更好的适应操作系统和浏览器。
图4显示用户使用的操作系统以windows为主;图5表明浏览器中IE占多半比例,Firefox和Chrome的用户量也比较大。
因此设计或改版时,需要重点满足windows模式,显示效果主要保证IE、Firefox和Chrome的兼容性。
基于Hadoop数据分析系统设计毕业论文

基于Hadoop数据分析系统设计毕业论文目录第一章某某企业数据分析系统设计需求分析 (1)第二章HADOOP简介 (2)第三章HADOOP单一部署 (5)3.1 H ADOOP集群部署拓扑图 (5)3.2 安装操作系统C ENTOS (6)3.3 H ADOOP基础配置 (12)3.4 SSH免密码登录 (16)3.5 安装JDK (17)3.6 安装H ADOOP (17)3.6.1安装32位Hadoop (18)3.6.2安装64位Hadoop (27)3.7 H ADOOP优化 (31)3.8 H IVE安装与配置 (32)3.8.1 Hive安装 (32)3.8.2 使用MySQL存储Metastore (32)3.8.3 Hive的使用 (35)3.9 H BASE安装与配置 (36)9.1 Hbase安装 (36)9.2 Hbase的使用 (38)3.10 集群监控工具G ANGLIA (41)第四章HADOOP批量部署 (47)4.1安装操作系统批量部署工具C OBBLER (47)4.2安装H ADOOP集群批量部署工具A MBARI (53)第五章使用HADOOP分析日志 (62)第六章总结 (66)第七章参考文献 (66)致谢 (67)第一章某某企业数据分析系统设计需求分析某某企业成立于1999年,其运营的门户每年产生大概2T的日志信息,为了分析的日志,部署了一套Oracle数据库系统,将所有的日志信息都导入Oracle 的表中。
随着时间的推移,存储在Oracle数据库中的日志系统越来越大,查询的速度变得越来越慢,并经常因为查询的数据量非常大而导致系统死机。
日志信息的分析成为了XX企业急需解决的问题,考虑到单机分析的扩展性与成本问题,且XX企业当前有一部分服务器处于闲置状态,最终决定在现有服务器的基础上部署一套分布式的系统来对当前大量的数据进行分析。
结合淘宝目前已经部署成功的数据雷达系统,同时由于XX企业预算有限,为了节约资金,决定采用开源的Hadoop来部署公司的数据分析系统。
ORACLE数据库调整归档日志空间大小

ORACLE数据库归档日志满后造成无法启动/连接的处理方法在\app\Administrator\diag\rdbms\orcl\orcl\trace(其中orcl根据具体的数据库实例名称而定)路径下的log中可以看到以下信息:ORA-19815: W ARNING: db_recovery_file_dest_size of 2147483648 bytes is 100.00% used, and has 0 remaining bytes available.Wed Jan 9 15:00:29 2013************************************************************************You have following choices to free up space from flash recovery area:1. Consider changing RMAN RETENTION POLICY. If you are using Data Guard,then consider changing RMAN ARCHIVELOG DELETION POLICY.2. Back up files to tertiary device such as tape using RMANBACKUP RECOVERY AREA command.3. Add disk space and increase db_recovery_file_dest_size parameter toreflect the new space.4. Delete unnecessary files using RMAN DELETE command. If an operatingsystem command was used to delete files, then use RMAN CROSSCHECK andDELETE EXPIRED commands.ORA-19815: W ARNING: db_recovery_file_dest_size of 2147483648 bytes is 100.00% used, and has 0 remaining bytes available.这句日志意思是db_recovery_file_dest_size已经满了,导致数据库无法启动。
浅谈民航AIMS系统设计与维护

浅谈民航AIMS系统设计与维护摘要:随着民航航空运输和通用航空的发展,运输总周转量持续增加,飞行动态信息越来越多,因此对于航管信息自动化处理能力的需求也越来越强烈。
该文通过对AIMS系统的设计思路进行分析,以期更好地满足空中交通发展的需要。
关键词:AIMS系统飞行流量控制设计思路引言近年来,航空交通的用途不断扩大,飞行流量不断增加,对航管信息管理方面也提出越来越高的要求。
民航以空管局和地区空管局为枢纽,联接各空管分局(站)、航站形成自动转报网络、帧中继网络、ATM网络、卫星通信网络,从而实现信息数据的交换和传输。
AIMS (航管信息自动化处理系统)正是基于以上资源实现的一种较为先进的信息自动化处理系统,该系统为空中交通管制提供飞行计划、飞行动态等信息,其在航空运行中的应用,势必会为空中交通管理提供更有利的支持。
1 AIMS系统设计需求现代化航空交通管理正逐步趋向空地一体化、系统自动化、处理智能化等方向发展,以提升空中服务水平,对于AIMS系统的建设,在技术方面、运行方面、使用方面都提出了较高的要求,不仅要扩大用户容量,满足接入需求,同时还要提高业务处理效率,实现查询、播报一体化。
此外,还应当采取先进技术确保系统的可靠性,避免病毒入侵及木马攻击,以提升系统可靠性。
2 AIMS系统结构AIMS系统构建的目的是为了满足航空服务需求,并尽量降低恶意入侵事件发生率,从而提升航空服务水平。
AIMS系统整体架构图1如下所示。
(1)用户;AIMS系统中,用户模块主要用于前端信息的显示,通过在客户端屏幕上展示管制信息,能够为用户提供详细的服务信息,提升服务水平。
在这个模块中,系统主要采用统一化的用户界面,保证人性化,同时提升工作效率。
(2)服务:服务是AIMS系统中的一个重要模块,同时也是系统构建与运行的核心,对于服务模块的功能可以进行下一步的具体划分,包括数据接口层、数据处理层、数据管理层,实现安全管理与系统管理的垂直化服务。
Oracle导致Redo日志暴增的SQL语句排查

Oracle导致Redo⽇志暴增的SQL语句排查⼀、概述最近数据库频繁不定时的报出⼀些耗时长的SQL,甚⾄SQL执⾏时间过长,导致连接断开现象。
下⾯是⼀些排查思路。
⼆、查询⽇志的⼤⼩,⽇志组情况SELECT L.GROUP#,LF.MEMBER,L.ARCHIVED,L.BYTES /1024/1024 "SIZE(M)",L.MEMBERSFROM V$LOG L,V$LOGFILE LFWHERE L.GROUP# = LF.GROUP#;查询结果:从上图可以看出⽬前共分为10个⽇志组,每个⽇志组2个⽂件,每个⽂件⼤⼩为3G。
三、查询Oracle最近⼏天每⼩时归档⽇志产⽣数量SELECT SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) Day,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '00', 1, 0)) H00,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '01', 1, 0)) H01,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '02', 1, 0)) H02,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '03', 1, 0)) H03,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '04', 1, 0)) H04,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '05', 1, 0)) H05,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '06', 1, 0)) H06,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '07', 1, 0)) H07,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '08', 1, 0)) H08,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '09', 1, 0)) H09,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '10', 1, 0)) H10,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '11', 1, 0)) H11,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '12', 1, 0)) H12,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '13', 1, 0)) H13,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '14', 1, 0)) H14,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '15', 1, 0)) H15,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '16', 1, 0)) H16,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '17', 1, 0)) H17,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '18', 1, 0)) H18,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '19', 1, 0)) H19,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '20', 1, 0)) H20,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '21', 1, 0)) H21,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '22', 1, 0)) H22,SUM(DECODE(SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH24:MI:SS'), 10, 2), '23', 1, 0)) H23,COUNT(*) TOTALFROM v$log_history aWHERE first_time >= to_char(sysdate -10)GROUP BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5)ORDER BY SUBSTR(TO_CHAR(first_time, 'MM/DD/RR HH:MI:SS'), 1, 5) DESC;查询结果从上图可以看出业务⾼峰期每⼩时产⽣40个⽇志⽂件左右(⽬前设定的每个⽇志⽂件⼤⼩为3G),平均1.5分钟产⽣⼀个3G的⽇志⽂件。
统计SQLSERVER表行数,以及每天数据变化的行数
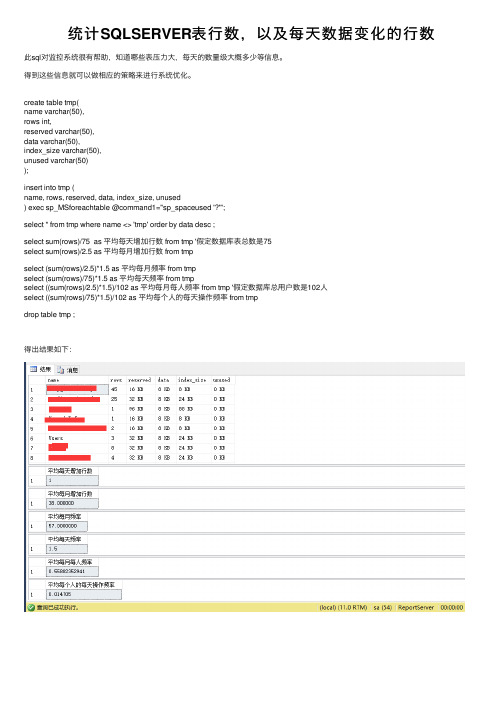
统计SQLSERVER表⾏数,以及每天数据变化的⾏数此sql对监控系统很有帮助,知道哪些表压⼒⼤,每天的数量级⼤概多少等信息。
得到这些信息就可以做相应的策略来进⾏系统优化。
create table tmp(name varchar(50),rows int,reserved varchar(50),data varchar(50),index_size varchar(50),unused varchar(50));insert into tmp (name, rows, reserved, data, index_size, unused) exec sp_MSforeachtable @command1="sp_spaceused '?'";select * from tmp where name <> 'tmp' order by data desc ;select sum(rows)/75 as 平均每天增加⾏数 from tmp '假定数据库表总数是75select sum(rows)/2.5 as 平均每⽉增加⾏数 from tmpselect (sum(rows)/2.5)*1.5 as 平均每⽉频率 from tmpselect (sum(rows)/75)*1.5 as 平均每天频率 from tmpselect ((sum(rows)/2.5)*1.5)/102 as 平均每⽉每⼈频率 from tmp '假定数据库总⽤户数是102⼈select ((sum(rows)/75)*1.5)/102 as 平均每个⼈的每天操作频率 from tmpdrop table tmp ;得出结果如下:。
OGG基础培训

• 磁盘
• OGG本身很小 • Trail文件的数量和大小,一般算法是存储空间=(每天的数据 库日志增量/3)*GoldenGate队列的的保留天数(一般建议保 留7天)
OGG安装环境的基本要求(2)
• 网络
• TCP/IP • 主要是OGG进程使用的端口、通讯用端口的开放 • 用于两个GoldenGate的Manager process之间通信(比如 Source的Manager process和Target的Manager process) • 本地GoldenGate进程间通信使用的端口范围:缺省的端口范围 从7840开始,或者可以定义一个从7840+256的端口 • 配置防火墙允许接受来自GoldenGate端口的请求 • 建议保存一份分配给GoldenGate的端口使用记录 • 如果可能的话,可以设置FTP端口用于GoldenGate传输数据、 参数和来自Source和Target的report
<Insert Picture Here>
<Insert Picture Here>
OGG104学习笔记
主要内容
• • • • • OGG安装 OGG的技术特点 Extract的配置 Replicat的配置 简单配置案例
版本V1.0
OGG的主要技术特点(1)
• 一个GoldenGate实例就是一个管理进程(Manager process),这个管理进程也是整个GoldenGate实例运 行时最主要的控制进程来自 OGG安装环境的基本要求(4)
• 对数据库的要求
• • • • 数据库处于归档模式下 打开补充日志 打开force logging 常用命令(Oracle) • SQL>alter database add supplemental log data • SQL>alter system switch log • SQL>shutdown immediate • SQL>startup mount • SQL>alter database ARCHIVELOG • SQL>startup open
SQL-数据库文件超级大而且增长速度过快的解决办法

SQL-数据库文件超级大而且增长速度过快的解决办法SQL 数据库文件超级大,而且增长速度过快!(2008-09-05 13:50:29)目前一客户的数据库文件(.MDF)占用空间超过有48G,切增长速度很快。
已经对日志文件进行了压缩。
在查询分析器中用exec sp_spaceused语句进行查询,输出结果如下:(头疼的问题)database_name database_size unallocated_space NSMIS48770.00M1370.97 MBreserved data index_size unused 48504160 KB7017272 KB270776KB41216112 KB--------------------------------------------------------------------------------------1、用BACKUP LOG database WITH NO_LOG清除日志把数据库属性中的故障还原模型改为“简单”可以大大减慢日志增长的速度。
如果把还原模型调到简单,这样就不支持时间点还原了,但是日志文件会很小,如果数据比较重要推荐还是把数据库的还原模型调为完全用BACKUP LOG database WITH NO_LOG命名后,会截断不活动日志,不减小物理日志文件的大小,但逻辑日志会减小,收缩数据库后会把不活动虚拟日志删除来释放空间,不会损坏数据。
如果日志被截断并收缩数据库后,就不能直接用最近的一个全库备份做时间点还原,建议立即备份数据库,以防万一。
2、sql server运行中,是否能删除主数据库事务日志文件步骤如下:(1)、分离数据库企业管理器--数据库--右击你要删除日志的数据库--所有任务--分离数据库(2)、然后删除日志文件(3)、然后再附加数据库企业管理器--数据库--右击数据库--所有任务--附加数据库这时候只附加。
实训一数据库和表的创建

实训一数据库和表的创建实训目的(1) 掌握数据库和表的基础知识。
(2) 掌握使用企业管理器和Transact-SQL语句创建数据库和表的方法。
(3) 掌握数据库和表的修改、查看、删除等基本操作方法。
实训内容和要求1 •数据库的创建、查看、修改和删除(1) 使用企业管理器创建数据库创建成绩管理数据库Grademanager,要求见表10-1。
(2)①在企业管理器中查看创建后的gradema nager数据库,查看gradema nager_data.md仁grademanager_log」df两个数据库文件所处的文件夹。
②使用企业管理器更改数据库。
更改的参数见表10-2。
(3)(4) 使用Transact-SQL命令创建上述要求的数据库(5) 使用Transact-SQL命令查看和修改上述要求的数据库⑹使用Transact-SQL命令删除该数据库2.表的创建、查看、修改和删除(1) 在Grademanager数据库中创建如表10-3、表10-4和表10- 5所示结构的表。
文档来源为:从网络收集整理.word版本可编辑•欢迎下载支持表10-3 Student表的表结构⑵向表10-3、表10-4和表10-5输入数据记录,见表10-6、表10-7和表10-8。
表10-6 学生关系表Student①向student表中增加“入学时间”列,其数据类型为日期时间型。
②将student表中的sdept字段长度改为20。
③将student表中的Speciality字段删除。
(4) 删除student 表。
思考题(1) SQL Server的数据库文件有几种?扩展名分别是什么?(2) SQL Server 2000中有哪几种整型数据类型?它们占用的存储空间分别是多少?取值范围分别是什么?(3) 在定义基本表语句时,NOT NULL参数的作用是什么?⑷主码可以建立在“值可以为NULL ”的列上吗?实训二单表查询实训目的(1) 掌握SELECT语句的基本用法。
ORACLE数据库DBA日常工作每日每周每月按天按周按月

ORACLE数据库DBA日常工作一、每天的工作(1).确认所有的INSTANCE状态正常登陆到所有数据库或例程,或者在服务器上检测ORACLE 进程:$ps –ef|grep ora_Sqlplus system/password@DBname(2). 检查文件系统的使用情况。
如果文件系统的剩余空间小于20%,需删除不用的文件以释放空间。
清理空间时请务必小心!$df –k重点关注根、Oracle数据库文件、Oracle软件、归档日志、备份文件所用文件系统的空间!如果使用了ASM,还应对ASM磁盘组的使用情况进行监控!(3). 检查日志文件和trace文件记录alert和trace 文件中的错误。
连接到每个需管理的系统对每个数据库,cd 到bdump目录,通常是ORACLE_BASE/<SID>/bdump使用 Unix tail 命令来查看alert_<SID>.log文件如果发现任何新的ORA- 错误,记录并解决(4). 检查表空间的使用情况SELECT tablespace_name, max_m, count_blocksfree_blk_cnt,sum_free_m,to_char(100*sum_free_m/sum_m, '99.99') || '%' AS pct_freeFROM ( SELECTtablespace_name,sum(bytes)/1024/1024 AS sum_m FROM dba_data_files GROUP BY tablespace_name),( SELECT tablespace_name AS fs_ts_name,max(bytes)/1024/1024 AS max_m, count(blocks) AS count_blocks, sum(bytes/1024/1024) AS sum_free_m FROM dba_free_space GROUP BY tablespace_name )WHERE tablespace_name = fs_ts_nameorder by pct_freeTABLESPACE_NAME MAX_M FREE_BLK_CNTSUM_FREE_M PCT_FRE------------ ----- ---------------- -----SYSTEM 54.5 5567.078125 22.36%TEMP 856.117188 162866.179688 84.59%RBS 557.992188 33683.992188 85.50%PERFSTAT 98.859375 198.859375 98.86%USERS 341.375 136482.242188 99.69%DRSYS 82.3046875 283.8046875 99.77%INDX 113.5 247434.242188 99.83%TOOLS 7.9921875 17.9921875 99.90%COMMUNITY 499.75 1 499.75 99.95%(5). 检查数据库当日备份的有效性。
Log4j每天生成日志文件和按文件大小生成日志文件

一、按照一定时间产生日志文件,配置文件如下:# Setrootlogge r lev el to ERRO R and itsonlyappen der t o A1.log4j.ro otLog ger=E RROR,R# R is setto be a Da ilyRo lling FileA ppend er. log4j.appe nder.R=org.apac he.lo g4j.D ailyR ollin gFile Appen der log4j.app ender.R.Fi le=ba ckup.log log4j.appe nder.R.Dat ePatt ern = '.'y yyy-M M-ddlog4j.app ender.R.la yout=org.a pache.log4j.Pat ternL ayoutlog4j.ap pende r.R.l ayout.Conv ersio nPatt ern=%-d{yy yy-MM-dd H H:mm:ss} [%c]-[%p] %m%n 以上配置是每天产生一个备份文件。
其中备份文件的名字叫bac kup.l og。
具体的效果是这样:当天的日志信息记录在b ackup.log文件中,前一天的记录在名称为b ackup.log.yyyy-mm-dd的文件中。
类似的,如果需要每月产生一个文件可以修改上面的配置:将l og4j.appen der.R.Date Patte rn ='.'yy yy-MM-dd 改为l og4j.appen der.R.Date Patte rn ='.'yy yy-MM二、根据日志文件大小自动产生新日志文件配置文件内容如下:# Se t roo t log ger l evelto ER ROR a nd it s onl y app ender to A1.l og4j.rootL ogger=ERRO R,R # Ris se t tobe aRolli ngFil eAppe nder.log4j.ap pende r.R=o rg.ap ache.log4j.Roll ingFi leApp enderlo g4j.a ppend er.R.File=backu p.log#lo g4j.a ppend er.R.MaxFi leSiz e=100KB# Kee p one back up fi lel og4j.appen der.R.MaxB ackup Index=1l og4j.appen der.yo ut=or g.apa che.l og4j.Patte rnLay out log4j.appe ndery out.C onver sionP atter n=%-d{yyyy-MM-d d HH:mm:ss} [%c]-[%p] %m%n其中:#日志文件的大小log4j.appe nder.R.Max FileS ize=100KB# 保存一个备份文件lo g4j.a ppend er.R.MaxBa ckupI ndex=1 。
Oracle Mysql DM等数据库统计表数据量和条数

Mysql Oracle DM数据库统计表数据量和条数1MYSQL:select TABLE_SCHEMA, TABLE_NAME,CONCAT(round(DATA_LENGTH/1024/1024,2) ,'MB') as TABLE_VOLUME,TABLE_ROWSfrom information_schema.tableswhere TABLE_TYPE='BASE TABLE'2oracle:如果不含大字段直接user_tables /dba_tables,如果有大字段使用user_segments /dba_segments 通过块数计算数据量:to_char(round(s.blocks*8/1024,2),'fm990.0099')||'MB',可能不准,block大小可能会变data block :oracle 11g 标准块:8k,支持2-32k,有block header 、free space 、data 组成-- 如果是分区表, segment_type = 'TABLE PARTITION'通过字节数计算数据量:to_char(round(s.BYTES /1024/1024.0,2),'fm99999999990.00')select t.owner TABLE_SCHEMA,TABLE_NAME, num_rows||'' TABLE_ROWS,to_char(round(s.BYTES /1024/1024.0,2),'fm99999999990.00') TABLE_VOLUMEfrom dba_tables tleft join dba_segments son t.table_name=s.segment_namewhere s.segment_type like'TABLE%'3DM(达梦数据库):1、首先使用存储过程执行特定用户的表统计行数,否则NUM_ROWS为nullDBMS_STATS.GATHER_SCHEMA_STATS('ROOT',100,TRUE,'FOR ALL TABLE NUM_ROWS AUTO' );2、使用和oracle一样的sql统计行数和数据量select t.owner TABLE_SCHEMA,TABLE_NAME, num_rows||'' TABLE_ROWS,to_char(round(s.BYTES /1024/1024.0,2),'fm99999999990.00') TABLE_VOLUMEfrom dba_tables tleft join dba_segments son t.table_name=s.segment_namewhere s.segment_type like'TABLE%'and t.owner='ROOT'3、通过内置函数获取表数据量selectto_char(TABLE_USED_PAGES(t.owner,TABLE_NAME)*to_number(page())/1024/1 024.0,'fm99999999990.00')||'MB',--TABLE_USED_SPACE占用页的数目要用to_number(page())否则有可能会报数据溢出to_char(TABLE_USED_PAGES(t.owner,TABLE_NAME)*to_number(page())/1024/1 024.0,'fm99999999990.00')||'MB'--TABLE_USED_PAGES实际使用页的数目from dual;--M为单位select t.owner TABLE_SCHEMA,TABLE_NAME,TABLE_USED_PAGES(t.owner,TABLE_NAME)*to_number(page())/1024/1024.0||'MB' SJ _TABLE_VOLUME ,--实际占用空间MBto_char(round(s.BYTES /1024/1024.0,2),'fm990.00')||'MB' TABLE_VOLUME--占用空间MBfrom dba_tables tleft join dba_segments s on t.table_name=s.segment_namewhere s.segment_type like'TABLE%'and t.owner='ROOT'4、通过自定义函数获取表的记录数创建获取表记录数的函数CREATE OR REPLACE FUNCTION ROOT.GET_TABLE_COUNT(SCHEMA_NAME IN VARCHAR(50),TABLE_NAME IN VARCHAR(50))RETURN INTASNUM_ROWS INT;V_SQL VARCHAR2(300);BEGINV_SQL := 'select count(*) from '||SCHEMA_NAME||'.'||TABLE_NAME;EXECUTE IMMEDIATE V_SQL INTO NUM_ROWS;RETURN NUM_ROWS;END;使用函数获取num_rows,注意用户可能没有使用TABLE_SCHEMA的权限,部分系统内置select t.owner TABLE_SCHEMA,TABLE_NAME, ROOT.GET_TABLE_COUNT(t.owner,TABLE _NAME) TABLE_ROWS,--自定义函数ROOT.GET_TABLE_COUNTto_char(round(s.BYTES /1024/1024.0,2),'fm990.00')||'MB' TABLE_VOLUME--占用空间MBfrom dba_tables tleft join dba_segments s on t.table_name=s.segment_namewhere s.segment_type like'TABLE%'。
网站流量日志分析(模块开发----统计分析实战)

⽹站流量⽇志分析(模块开发----统计分析实战)⼀、模块开发----统计分析数据仓库建设好以后,⽤户就可以编写Hive SQL语句对其进⾏访问并对其中数据进⾏分析。
在实际⽣产中,究竟需要哪些统计指标通常由数据需求相关部门⼈员提出,⽽且会不断有新的统计需求产⽣,以下为⽹站流量分析中的⼀些典型指标⽰例。
1.流量分析1.1.基础指标多维统计分析基础指标统计对于指标业务含义的解读是关键。
PageView 浏览次数(pv)select count(*) from ods_weblog_detail where datestr ="20181101" and valid = "true"; 排除静态资源Unique Visitor 独⽴访客(UV):select count(distinct remote_addr) as uvs from ods_weblog_detail where datestr ="20181101";访问次数(VV):select count(distinct session) as vvs from ods_click_stream_visit where datestr ="20181101";IP:select count(distinct remote_addr) as ips from ods_weblog_detail where datestr ="20181101";create table dw_webflow_basic_info(month string,day string,pv bigint,uv bigint ,ip bigint, vv bigint) partitioned by(datestr string);insert into table dw_webflow_basic_info partition(datestr="20181101")select '201811','01',a.,b. from(select count(*) as pv,count(distinct remote_addr) as uv,count(distinct remote_addr) as ipsfrom ods_weblog_detailwhere datestr ='20181101') a join(select count(distinct session) as vvs from ods_click_stream_visit where datestr ="20181101") b;多维统计分析按时间维度⽅式⼀:直接在ods_weblog_detail单表上进⾏查询--计算该处理批次(⼀天)中的各⼩时pvsdrop table dw_pvs_everyhour_oneday;create table dw_pvs_everyhour_oneday(month string,day string,hour string,pvs bigint) partitioned by(datestr string);insert into table dw_pvs_everyhour_oneday partition(datestr='20130918')select a.month as month,a.day as day,a.hour as hour,count(*) as pvs from ods_weblog_detail awhere a.datestr='20130918' group by a.month,a.day,a.hour;--计算每天的pvsdrop table dw_pvs_everyday;create table dw_pvs_everyday(pvs bigint,month string,day string);insert into table dw_pvs_everydayselect count(*) as pvs,a.month as month,a.day as day from ods_weblog_detail agroup by a.month,a.day;⽅式⼆:与时间维表关联查询--维度:⽇drop table dw_pvs_everyday;create table dw_pvs_everyday(pvs bigint,month string,day string);insert into table dw_pvs_everydayselect count(*) as pvs,a.month as month,a.day as day from (select distinct month, day from t_dim_time) ajoin ods_weblog_detail bon a.month=b.month and a.day=b.daygroup by a.month,a.day;--维度:⽉drop table dw_pvs_everymonth;create table dw_pvs_everymonth (pvs bigint,month string);insert into table dw_pvs_everymonthselect count(*) as pvs,a.month from (select distinct month from t_dim_time) ajoin ods_weblog_detail b on a.month=b.month group by a.month;--另外,也可以直接利⽤之前的计算结果。
sqlserver数据以及日志文件的设置小结

sqlserver数据以及⽇志⽂件的设置⼩结1.1:增加次数据⽂件 从SQL SERVER 2005开始,数据库不默认⽣成NDF数据⽂件,⼀般情况下有⼀个主数据⽂件(MDF)就够了,但是有些⼤型的数据库,由于信息很多,⽽且查询频繁,所以为了提⾼查询速度,可以把⼀些表或者⼀些表中的部分记录分开存储在不同的数据⽂件⾥由于CPU和内存的速度远⼤于硬盘的读写速度,所以可以把不同的数据⽂件放在不同的物理硬盘⾥,这样执⾏查询的时候,就可以让多个硬盘同时进⾏查询,以充分利⽤CPU和内存的性能,提⾼查询速度。
在这⾥详细介绍⼀下其写⼊的原理,数据⽂件(MDF、NDF)和⽇志⽂件(LDF)的写⼊⽅式是不⼀样的: 数据⽂件:SQL Server按照同⼀个⽂件组⾥⾯的所有⽂件现有空闲空间的⼤⼩,按这个⽐例把新的数据分布到所有有空间的数据⽂件⾥,如果有三个数据⽂件A.MDF,B.NDF,C.NDF,空闲⼤⼩分别为200mb,100mb,和50mb,那么写⼊⼀个70mb的东西,他就会向ABC三个⽂件中⼀次写⼊40、20、10的数据,如果某个⽇志⽂件已满,就不会向其写⼊ ⽇志⽂件:⽇志⽂件是按照顺序写⼊的,⼀个写满,才会写⼊另外⼀个 由上可见,如果能增加其数据⽂件NDF,有利于⼤数据量的查询速度,但是增加⽇志⽂件却没什么⽤处。
1.2:设置⽂件⾃动增长(⼤数据量,⼩数据量⽆需设置) 在SQL Server 2005中,默认MDF⽂件初始⼤⼩为5MB,⾃增为1MB,不限增长,LDF初始为1MB,增长为10%,限制⽂件增长到⼀定的数⽬,⼀般设计中,使⽤SQL⾃带的设计即可,但是⼤型数据库设计中,最好亲⾃去设计其增长和初始⼤⼩,如果初始值太⼩,那么很快数据库就会写满,如果写满,在进⾏插⼊会是什么情况呢?当数据⽂件写满,进⾏某些操作时,SQL Server会让操作等待,直到⽂件⾃动增长结束了,原先的那个操作才能继续进⾏。
如果⾃增长⽤了很长时间,原先的操作会等不及就超时取消了(⼀般默认的阈值是15秒),不但这个操作会回滚,⽂件⾃动增长也会被取消。
SQL服务器的日志增长过快

SQL服务器的日志增长过快问题:在C盘空间不足的情况下, C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG 下的你每天增大,大量的占用C盘的空间。
在APACS OS 版本 6.1 中,ErrorLog 文件保存在c:/Program Files/Microsoft SQL Server/MSSQL$WINCC/LOG 文件夹中。
在APACS OS 版本7.0 中,ErrorLog 文件保存在c:/Program Files/Microsoft SQL Server/MSSQL.1/MSSQL/LOG 文件夹中。
原因分析:如果很少重起mssqlserver服务,那么服务器的日志会增长得很快(每天通过重启机器启动SQL服务,好像不起作用,目前没找到原因),而且打开和查看日志的速度也会很慢。
默认情况下,SQL Server 保存7 个ErrorLog 文件,名为:ErrorLogErrorLog.1ErrorLog.2ErrorLog.3ErrorLog.4ErrorLog.5ErrorLog.6ErrorLog 文件包含最新信息;ErrorLog.6 文件包含最老的信息。
每次重启动SQL Server 时,这些日志文件都如下循环:删除ErrorLog.6 文件中的所有数据,并创建一个新的ErrorLog 文件。
上个ErrorLog 文件中的所有数据被写入到ErrorLog.1 文件中。
上个ErrorLog.1 文件中的所有数据被写入到ErrorLog.2 文件中。
上个ErrorLog.2 文件中的所有数据被写入到ErrorLog.3 文件中。
上个ErrorLog.3 文件中的所有数据被写入到ErrorLog.4 文件中。
上个ErrorLog.4 文件中的所有数据被写入到ErrorLog.5 文件中。
上个ErrorLog.5 文件中的所有数据被写入到ErrorLog.6 文件中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
CREATE TABLE[dbo].[db_size](
Id int identity,
[vtime][datetime]NULL,
[database_size][nvarchar](50)NULL,
[database_sizeZ][nvarchar](50)NULL,
[database_sizeB][nvarchar](50)NULL,
[free_size][nvarchar](50)NULL,
[free_sizeZ][nvarchar](50)NULL,
[free_sizeB][nvarchar](50)NULL
)
GO
CREATE PROCEDURE[dbo].[get_db_size]
AS
BEGIN
SET NOCOUNT ON;
declare
@pages bigint
,@dbsize bigint
,@logsize bigint
,@reservedpages bigint
,@usedpages bigint
,@dbsizePre decimal(18,4)
,@logsizePre decimal(18,4)
,@dbsizeB decimal(18,4)
,@logsizeB decimal(18,4)
,@dbsizeZ decimal(18,4)
,@logsizeZ decimal(18,4)
,@dbsizeBF decimal(18,4)
,@logsizeBF decimal(18,4)
select@dbsize=sum(convert(bigint,case when status&64 =0 then size else 0 end))
,@logsize=sum(convert(bigint,case when status&64 <>0 then size else 0 end))
from dbo.sysfiles
select@reservedpages=sum(a.total_pages),
@usedpages=sum(ed_pages),
@pages=sum(
CASE
When it.internal_type IN(202,204)Then 0
When a.type<> 1 Then ed_pages
When p.index_id< 2 Then a.data_pages
Else 0
END
)
from sys.partitions p join sys.allocation_units a on p.partition_id= a.container_id
left join sys.internal_tables it on p.object_id=it.object_id
select top 1
@dbsizePre=CONVERT(decimal,database_size),@logsizePre=CONVERT(decimal,fr ee_size)from db_size order by id desc
set@dbsizeB=CONVERT(decimal,ltrim(str((convert(dec (15,2),@dbsize)+ convert(dec (15,2),@logsize))* 8192 / 1048576,15,2)))
set@logsizeB=CONVERT(decimal,ltrim(str((case when@dbsize>=
@reservedpages then (convert(dec (15,2),@dbsize)-convert(dec (15,2),@reservedpages))* 8192 / 1048576 else 0 end),15,2)))
set@dbsizeZ=@dbsizeB-@dbsizePre
set@logsizeZ=@logsizeB-@logsizePre
set@dbsizeBF=(@dbsizeZ/@dbsizePre)*100
set@logsizeBF=(@logsizeZ/@logsizePre)*100
INSERT INTO db_size(
[vtime]
,[database_size]
,[database_sizeZ]
,[database_sizeB]
,[free_size]
,[free_sizeZ]
,[free_sizeB])
select
vtime=getdate(),
@dbsizeB,
@dbsizeZ,
@dbsizeBF,
@logsizeB,
@logsizeZ,
@logsizeBF
END
GO
--放到每天作业里调用即可。
--exec [get_db_size]
--检查大小:
--select * from db_size
select*from db_size
truncate table db_size
update db_size set database_size=530,free_size=7 where id=7
select top1 CONVERT(bigint,database_size),CONVERT(bigint,free_size)from db_size order by id desc。