模拟实现一个简单的可变分区存储管理系统
操作系统实验-可变分区存储管理

作业一实验一 :可变分区存储管理(一) 实验题目编写一个C 程序,用char *malloc(unsigned size)函数向系统申请一次内存空间(如size=1000,单位为字节),模拟可变分区内存管理,实现对该内存区的分配和释放管理。
(二) 实验目的1.加深对可变分区的存储管理的理解;2.提高用C 语言编制大型系统程序的能力,特别是掌握C 语言编程的难点:指针和指针作为函数参数;3.掌握用指针实现链表和在链表上的基本操作。
(三)程序代码 #include<malloc.h> #include<stdio.h> #include<string.h>#define new(type) (type *)malloc(sizeof(type))typedef struct _map {unsigned int size; char *address; struct _map *next; struct _map *prev;(a)(b)(c)(d)图2-9释放区与前后空闲区相邻的情况} map;typedef map *pmap;typedef struct _mem{unsigned int totalSize;char* space;pmap head;pmap cMap;} mem;typedef mem *pmem;pmem createMem(unsigned int to_size) //创建内存区域{pmem newMem=new(mem);pmap newHead=new(map);newMem->totalSize=to_size;newHead->size=to_size;newHead->address=newMem->space;newHead->next=newHead;newHead->prev=newHead;newMem->head=newHead;newMem->cMap=newHead;return newMem;}void freeMem(pmem m){pmap map,cMap;pmap head=m->head;free(map->address);for(map=head;map->next!=head;){cMap=map;map=cMap->next;free(cMap);}free(m);}char* lmalloc(pmem cMem,unsigned int size) //分配函数{if(size>1000){printf("内存容量超出范围!\n"); //当需要分配的内存空间已经大于实际空间时出错}else{pmap p=cMem->cMap;char* rAddr;if(size==0)return NULL;while(p->size<size){if(p->next==cMem->cMap)return NULL;p=p->next;}rAddr=p->address;p->size-=size;p->address+=size;if(p->size==0){p->prev->next=p->next;p->next->prev=p->prev;cMem->cMap=p->next;if(cMem->head==p)cMem->head=p->next;if(p->next!=cMem->head)free(p);}else{cMem->cMap=p;}return rAddr;}}void lfree(pmem m,unsigned int size,char* addr) //释放函数{pmap nextMap,prevMap,newMap;if(addr<m->space || addr>=m->space+m->totalSize){fprintf(stderr,"地址越界\n"); //释放空间时,大小输入出错return;}nextMap=m->head;while(nextMap->address<addr){nextMap=nextMap->next;if(nextMap==m->head)break;}prevMap=nextMap->prev;if(nextMap!=m->head && prevMap->address+prevMap->size==addr) //第一种情况{prevMap->size+=size;if(addr+size==nextMap->address) //第二种情况{prevMap->size+=nextMap->size;prevMap->next=nextMap->next;prevMap->next->prev=prevMap;if(nextMap==m->cMap){m->cMap=prevMap;}free(nextMap);nextMap=NULL;}}else{if(addr+size==nextMap->address) //第三种情况{nextMap->address-=size;nextMap->size+=size;}else //第四种情况{newMap=new(map);newMap->address=addr;newMap->size=size;prevMap->next=newMap;newMap->prev=prevMap;newMap->next=nextMap;nextMap->prev=newMap;if(nextMap==m->head)m->head=newMap;}}}void printMem(pmem m) //打印函数{pmap map=m->head;printf("\空闲内存空间:\n\-----------------------\n\大小起始地址\n");do{if(map==m->cMap)printf("-> ");elseprintf(" ");printf("%10u %10u\n",map->size,map->address);map=map->next;}while(map!=m->head);printf("-----------------------\n");}void main() //主函数{printf("--------------------------------------------------------\n");printf("请选择操作:分配内存(m) or 释放内存(f) or 打印内存表(p)\n");printf("--------------------------------------------------------\n");typedef enum{cmdMalloc,cmdFree,cmdPrint,cmdHelp,cmdQuit,cmdInvalid} cmdType; pmem m=createMem(1000);char cmd[20];char *addr;unsigned int size;cmdType type;while(1){scanf("%s",cmd);if(cmd[1]=='\0'){switch(cmd[0]){case 'm':case 'M':type=cmdMalloc;break;case 'f':case 'F':type=cmdFree;break;case 'p':case 'P':type=cmdPrint;break;}}else{if(!strcmp(cmd,"malloc"))type=cmdMalloc;else if(!strcmp(cmd,"free"))type=cmdFree;else if(!strcmp(cmd,"print"))type=cmdPrint;}switch(type){case cmdMalloc:scanf("%u",&size);lmalloc(m,size);printMem(m);break;case cmdFree:scanf("%u %u",&size,&addr);lfree(m,size,addr);printMem(m);break;case cmdPrint:printMem(m);break;return;}}}(四)程序结果。
3用C语言模拟实现可变式分区存储管理

3用C语言模拟实现可变式分区存储管理可变式分区存储管理是一种动态分配内存空间的方式,它能够根据进程的内存需求来动态地分配和回收内存空间,提高内存的利用率。
在C语言中,我们可以使用指针和数据结构来模拟实现可变式分区存储管理。
1.使用结构体来表示内存块首先,我们可以定义一个结构体来表示每个内存块的属性,包括起始地址、大小、以及是否被占用等信息。
```cstruct Blockint start_address;int size;int is_allocated; // 0代表未分配,1代表已分配};```2.初始化内存空间接下来,我们可以定义一个数组来表示整个内存空间,该数组的每个元素都是一个 Block 结构体,表示一个内存块。
在程序开始时,我们可以初始化一个 Block 数组,表示整个内存空间的初始状态。
```c#define TOTAL_SIZE 1024 // 内存总大小struct Block memory[TOTAL_SIZE];void init_memormemory[0].start_address = 0;memory[0].size = TOTAL_SIZE;memory[0].is_allocated = 0;```3.分配内存空间当进程需要分配内存空间时,可变式分区存储管理会选择一个合适的内存块来分配给该进程。
我们可以定义一个函数来实现分配内存的过程。
```cint allocate_memory(int size)int i;for (i = 0; i < TOTAL_SIZE; i++)if (!memory[i].is_allocated && memory[i].size >= size)//找到未分配且大小足够的内存块memory[i].is_allocated = 1;memory[i].size -= size;return memory[i].start_address;}}//没有找到合适的内存块return -1;```4.回收内存空间当进程释放已分配的内存空间时,我们需要回收这部分内存,使其变为未分配状态。
可变分区管理实验

实验三、可变分区内存管理实验环境:实验环境一:Windows平台实验时间:6小时实验目的:体会可变分区内存管理方案,掌握此方案的内存分配过程、内存回收过程和紧凑算法的实现。
实验目标:编制一个程序模拟实现可变分区内存管理。
实验时,假设系统内存容量为1000KB。
分配时使用malloc(pid, length)函数实现,作业释放内存时使用mfree(handle)函数实现,内存情况输出用mlist()函数实现。
实验步骤:1、编写主界面,界面上有三个选项:分配内存、回收内存、查看内存。
选择分配内存时,要求输入作业的进程号和作业长度,然后使用malloc函数分配内存,并报告内存分配结果。
回收内存时要求输入进程号,使用mfree函数实现回收。
查看内存时,使用mlist函数实现输出内存使用情况和空闲情况。
2、编写malloc(pid, length)函数,实现进程pid申请length KB内存,要求程序判断是否能分配,如果能分配,要把分配内存的首地址handle输出到屏幕上。
不能分配则输出字符串“NULL”。
要考虑不能简单分配时,是否符合紧凑的条件,如符合则采用紧凑技术,然后再分配。
分配时可在最佳适应算法、最差适应算法和首次适应算法中任选其一。
3、编写mfree(handle)函数,释放首地址为handle的内存块。
释放成功返回Success,否则返回Failure。
4、编写mlist()函数,要求输出内存使用情况和空闲情况。
输出的格式为:ID Address Length ProcessID 内存分区号Address 该分区的首地址Length 分区长度Process 如果使用,则为使用的进程号,否则为NULL实验结果:实验步骤2的实现过程是:实验步骤2中紧凑算法是如何实现的?实验步骤3中分别要考虑多少种情况?实验步骤3的实现过程是:实验步骤4的实现过程是:实验步骤4的结果是什么?实验报告:(1)完成实验结果中的问题。
模拟实现一个简单的固定(可变)分区存储管理系统

合肥学院计算机科学与技术系实验报告2009~2010学年第一学期课程操作系统原理实验名称模拟实现一个简单的固定(可变)分区存储管理系统学生姓名朱海燕、汪小白、秦月、程美玲专业班级07计本(1)班指导教师屠菁2009年12月1.实验目的通过本次课程设计,掌握了如何进行内存的分区管理,强化了对首次适应分配算法和分区回收算法的理解。
2.实验内容(1)建立相关的数据结构,作业控制块、已分配分区及未分配分区(2)实现一个分区分配算法,如最先适应算法、最优或最坏适应分配算法(3)实现一个分区回收算法(4)给定一个作业/进程,选择一个分配或回收算法,实现分区存储的模拟管理3.实验步骤首先,初始化函数initial()将分区表初始化并创建空闲分区列表,空闲区第一块的长度是30,以后的每个块长度比前一个的长度长20。
frees[0].length=30第二块的长度比第一块长20,第三块比第二块长30,以此类推。
frees[i].length=frees[i-1].length+20;下一块空闲区的首地址是上一块空闲区的首地址与上一块空闲区长度的和。
frees[i].front=frees[i-1].front+frees[i-1].length;分配区的首地址和长度都初始化为零occupys[i].front=0;occupys[i].length=0;显示函数show()是显示当前的空闲分区表和当前的已分配表的具体类容,分区的有起始地址、长度以及状态,利用for语句循环输出。
有一定的格式,使得输出比较美观好看。
assign()函数是运用首次适应分配算法进行分区,从链首开始顺序查找,直至找到一个大小能满足要求的空闲分区为止;然后再按照作业的大小,从该分区中划出一块内存空间分配给请求者,余下的空闲分区仍留在空闲链中。
若从链首直至链尾都不能找到一个能满足要求的分区,则此次内存分配失败,返回。
这个算法倾向于优先利用内存中低址部分被的空闲分区,从而保留了高址部分的的大空闲区。
可变分区存储管理的内存分配算法模拟实现----最佳适应算法

可变分区存储管理的内存分配算法模拟实现----最佳适应算法可变分区存储管理是一种内存管理技术,其通过将内存分割成不同大小的区域来存储进程。
每个进程被分配到与其大小最匹配的区域中。
内存分配算法的选择影响了系统的性能和资源利用率。
本文将介绍最佳适应算法,并模拟实现该算法。
一、什么是最佳适应算法?最佳适应算法是一种可变分区存储管理中的内存分配策略。
它的基本思想是在每次内存分配时选择最合适的空闲区域。
具体来说,它从可用的空闲区域中选择大小与需要分配给进程的内存最接近的区域。
二、算法实现思路最佳适应算法实现的关键是如何快速找到最合适的空闲区域。
下面给出一个模拟实现的思路:1. 初始化内存分区列表,首先将整个内存定义为一个大的空闲区域。
2. 当一个进程请求分配内存时,从列表中找到与所需内存最接近的空闲区域。
3. 将该空闲区域分割成两部分,一部分分配给进程,并将该部分标记为已分配,另一部分留作新的空闲区域。
4. 更新内存分区列表。
5. 当一个进程释放内存时,将其所占用的内存区域标记为空闲,然后尝试合并相邻的空闲区域。
三、算法模拟实现下面是一个简单的Python代码实现最佳适应算法:pythonclass MemoryPartition:def __init__(self, start_addr, end_addr, is_allocated=False): self.start_addr = start_addrself.end_addr = end_addrself.is_allocated = is_allocatedclass MemoryManager:def __init__(self, total_memory):self.total_memory = total_memoryself.partition_list = [MemoryPartition(0, total_memory)]def allocate_memory(self, process_size):best_fit_partition = Nonesmallest_size = float('inf')# 找到最佳适应的空闲区域for partition in self.partition_list:if not partition.is_allocated and partition.end_addr - partition.start_addr >= process_size:if partition.end_addr - partition.start_addr < smallest_size:best_fit_partition = partitionsmallest_size = partition.end_addr - partition.start_addrif best_fit_partition:# 将空闲区域分割,并标记为已分配new_partition =MemoryPartition(best_fit_partition.start_addr,best_fit_partition.start_addr + process_size, True)best_fit_partition.start_addr += process_sizeself.partition_list.append(new_partition)return new_partition.start_addr,new_partition.end_addrelse:return -1, -1def deallocate_memory(self, start_addr, end_addr):for partition in self.partition_list:if partition.start_addr == end_addr and not partition.is_allocated:# 标记空闲区域partition.is_allocated = False# 尝试合并相邻空闲区域for next_partition in self.partition_list:if not next_partition.is_allocated andnext_partition.start_addr == end_addr:end_addr = next_partition.end_addrself.partition_list.remove(next_partition)breakelse:breakdef print_partitions(self):for partition in self.partition_list:if partition.is_allocated:print(f"Allocated Partition: {partition.start_addr} - {partition.end_addr}")else:print(f"Free Partition: {partition.start_addr} - {partition.end_addr}")# 测试最佳适应算法if __name__ == "__main__":mm = MemoryManager(1024)start, end = mm.allocate_memory(256)print(f"Allocated memory: {start} - {end}")mm.print_partitions()mm.deallocate_memory(start, end)print("Memory deallocated:")mm.print_partitions()以上代码实现了一个简单的内存管理器类`MemoryManager`,它具有`allocate_memory`和`deallocate_memory`等方法。
模拟实现可变分区存储管理

《操作系统》课程设计说明书题目:模拟实现可变分区存储管理班级:学号:姓名:指导老师:1.目的和要求在熟练掌握计算机分区存储管理方式的原理的基础上,利用一种程序设计语言模拟实现操作系统的可变分区存储管理的功能,一方面加深对原理的理解,另一方面提高学生通过编程根据已有原理解决实际问题的能力,为学生将来进行系统软件开发和针对实际问题提出高效的软件解决方案打下基础。
2.设计内容设计合理的数据结构来描述存储空间:对于未分配出去的部分,可以用空闲分区队列或空闲分区链表来描述,对于已经分配出去的部分,由装入内存的作业占据,可以将作业组织成链表或数组。
实现分区存储管理的内存分配功能,实现两种适应算法:首次适应算法,最坏适应算法。
实现分区存储管理的内存回收算法:要求能够正确处理回收分区与空闲分区的四种邻接关系。
当碎片产生时,能够进行碎片的拼接。
3.设计环境Windows操作系统、DEV C++C语言4.程序概要(1)数据结构和全局变量int type = 0; //算法类型//空闲分区struct freelink {int len; //len为分区长度int address; //address为分区起始地址struct freelink *next;};//占用分区struct busylink {char name; //作业或进程名,name='S' 表示OS占用int len;int address;struct busylink *next;};struct freelink *free_head = NULL; //自由链队首指针struct busylink *busy_head = NULL, //占用区队首指针*busy_tail = NULL; //占用区队尾指针(2)功能模块划分大体上可以将整个程序的模块划分成如下几个部分:1)主模块:主要是初始化(设置物理内存的用户区的大小,选取适应算法)和界面,界面参考如下:2)内存分配算法(实现两种适应算法:最坏适应算法,首次适应算法)3)内存回收算法(考虑四种邻接情况,尤其是采用最佳(坏)适应算法时的分区合并)4)碎片拼接算法5)空闲分区队列显示6)占用分区队列显示(3)各函数调用关系(4)主要函数流程图allocateMemoByWF();//两种算法分配回收大致相同,在这里只列举一种compactMemo()freeMemoByWF()5. 源代码#include <stdio.h>#include <stdlib.h>#define MAX_SIZE 512 //系统能分配的最大内存#define FALSE 0#define TRUE 1int type = 0; //算法类型//空闲分区struct freelink {int len; //len为分区长度int address; //address为分区起始地址struct freelink *next;};//占用分区struct busylink {char name; //作业或进程名,name='S' 表示OS占用int len;int address;struct busylink *next;};struct freelink *free_head = NULL; //自由链队列(带头结点)队首指针struct busylink *busy_head = NULL, //占用区队列队(带头结点)首指针*busy_tail = NULL; //占用区队列队尾指针//初始化void init() {struct freelink *p;struct busylink *q;free_head = (struct freelink*)malloc(sizeof(struct freelink));free_head->next = NULL; // 创建自由链头结点busy_head = busy_tail = (struct busylink*)malloc(sizeof(struct busylink));busy_head->next = NULL; // 创建占用链头结点p = (struct freelink *)malloc(sizeof(struct freelink));p->address = 64;p->len = MAX_SIZE - 64; //(OS占用了64K)p->next = NULL;free_head->next = p;q = (struct busylink *)malloc(sizeof(struct busylink));q->name = 'S'; //S表示操作系统占用q->len = 64;q->address = 0;q->next = NULL;busy_head->next = q;busy_tail = q;}//紧凑struct freelink* compactMemo(int require) {int sum = 0;struct freelink *fNode = free_head->next;while (fNode != NULL) {sum += fNode->len;fNode = fNode->next;}printf("\n");if (sum < require) {return NULL;}//删除空闲区所有节点struct freelink *p = free_head->next; //让p一直指向第一个数据节点while (p != NULL) {free_head->next = p->next;free(p);p = free_head->next;}//创建新的分区struct freelink *node = (struct freelink*)malloc(sizeof(struct freelink));node->address = 0;node->len = MAX_SIZE;free_head->next = node;node->next = NULL;//修改占用区作业内存地址struct busylink *q = busy_head->next;while (q != NULL) {q->address = node->address;node->len -= q->len;node->address += q->len;q = q->next;}return node;}//最坏(佳)适应算法在分区合并和分割后需要调整分区位置int adjust(struct freelink *node) {struct freelink *p = free_head;//合并后链表中只剩一个分区if (p->next == NULL) {free_head->next = node;node->next = NULL;return TRUE;}while (p->next != NULL && node->len <= p->next->len) { p = p->next;}if (p->next == NULL) {p->next = node;node->next = NULL;}else {node->next = p->next;p->next = node;}return TRUE;}//最坏适应算法int allocateMemoByWF() {int require;printf("请输入作业所需内存大小:");scanf("%d", &require);//判断第一个空闲分区大小是否满足需求struct freelink *p = free_head->next;if (p->len < require) {printf("没有分区满足要求,正在尝试碎片拼接...\n");//判断所有分区容量总和是否满足要求if ((p = compactMemo(require)) == NULL) {return FALSE;}}//将第一个空闲分区切割require分配给该作业struct busylink *q = (struct busylink *)malloc(sizeof(struct busylink));printf("请输入作业名称:");getchar(); //输入require之后有一个换行符,用getchar吃掉scanf("%c", &q->name);//检查是否重名struct busylink *temp = busy_head->next;while (temp != NULL && temp->name != q->name) {temp = temp->next;}if (temp != NULL) {printf("该作业名已存在!\n");return FALSE;}q->len = require;q->address = p->address;q->next = NULL;//将作业按地址递增的顺序插入到作业队列中temp = busy_head;while(temp->next != NULL && q->address > temp->next->address) { temp = temp->next;}if (temp->next == NULL) {temp->next = q;q->next = NULL;}else {q->next = temp->next;temp->next = q;}//分割空闲分区if (p->len == require) {free(p);return TRUE;}else {p->address += require;p->len -= require;}//把第一个分区从空闲区中拿出来if (p->next != NULL) {free_head->next = p->next;}else return TRUE; //空闲队列中是否只存在一个节点//将分割后的分区放到合适的位置adjust(p);return TRUE;}//首次适应算法int allocateMemoByFF() {int require;printf("请输入作业所需内存大小:");scanf("%d", &require);struct freelink *p = free_head->next;struct freelink *pre = free_head;while (p != NULL && p->len < require) {pre = p;p = p->next;}if (p == NULL) {printf("没有分区满足要求,正在尝试碎片拼接...\n");//判断所有分区容量总和是否满足要求if ((p = compactMemo(require)) == NULL) {return FALSE;}}//将第一个满足条件的分区分割合适的内存分配给作业struct busylink *q = (struct busylink *)malloc(sizeof(struct busylink));printf("请输入作业名称:");getchar(); //输入require之后有一个换行符,用getchar吃掉scanf("%c", &q->name);//检查是否重名struct busylink *temp = busy_head->next;while (temp != NULL && temp->name != q->name) {temp = temp->next;}if (temp != NULL) {printf("该作业名已存在!\n");return FALSE;}q->len = require;q->address = p->address;q->next = NULL;//将作业按地址递增的顺序插入到作业队列中temp = busy_head;while(temp->next != NULL && q->address > temp->next->address) { temp = temp->next;}if (temp->next == NULL) {temp->next = q;q->next = NULL;}else {q->next = temp->next;temp->next = q;}//分割空闲分区if (p->len == require) {pre->next = p->next;free(p);return TRUE;}else {p->address += require;p->len -= require;return TRUE;}}//匹配节点并创建回收分区struct freelink* matchName(char name) {struct busylink *q = busy_head;struct freelink *node = (struct freelink *)malloc(sizeof(struct freelink));//找到匹配节点的前一个while (q->next != NULL && q->next->name != name) {q = q->next;}if (q->next == NULL) {printf("%c进程不存在\n",name);return NULL;}//接收匹配节点的内存信息node->len = q->next->len;node->address = q->next->address;//在占用分区中删除匹配的节点struct busylink *temp = q->next;if (q->next == busy_tail) {busy_tail = q;q->next = NULL;}else {q->next = q->next->next;}free(temp);return node;}int freeMemoByWF() {printf("请输入作业名称:");char name;getchar();scanf("%c", &name);printf("\n");//将内存(即node节点)放回空闲区struct freelink *node;if ((node = matchName(name)) == NULL) {return FALSE;}struct freelink *p = free_head->next;struct freelink *pre = free_head;//三种邻接情况(合并后需要重新根据大小排序)while (p != NULL) {//与下一分区邻接if (node->address + node->len == p->address) {//与上一分区邻接if (p->next != NULL&&p->next->address + p->next->len == node->address) {struct freelink* temp = p->next;temp->len = temp->len + p->len + node->len;free(node);pre->next = temp->next;free(p);adjust(temp);printf("回收成功!\n");return TRUE;}else {p->address = node->address;p->len += node->len;free(node);pre->next = p->next; //把合并后分区取出来adjust(p);printf("回收成功!\n");return TRUE;}}//与上一分区邻接if (p->address + p->len == node->address) {//同时与下一分区邻接if (p->next != NULL &&node->address + node->len == p->next->address) {p->len = p->len + node->len + p->next->len;pre->next = p->next->next;free(p->next);free(node);adjust(p);printf("回收成功!\n");return TRUE;}else {p->len += node->len;free(node);pre->next = p->next;adjust(p);printf("回收成功!\n");return TRUE;}}pre = p;p = p->next;}//不邻接adjust(node);printf("回收成功!\n");return TRUE;}int freeMemoByFF() {printf("请输入作业名称:");char name;getchar();scanf("%c", &name);printf("\n");//将内存(node节点)放回空闲区struct freelink *node;if ((node = matchName(name)) == FALSE) {return FALSE;}struct freelink *p = free_head->next;//三种邻接情况while (p != NULL) {//与下一分区邻接if (node->address + node->len == p->address) {p->address = node->address;p->len += node->len;free(node);printf("回收成功!\n");return TRUE;}//与上一分区邻接if (p->address + p->len == node->address) {//同时与下一分区邻接if (p->next != NULL &&node->address + node->len == p->next->address) {p->len = p->len + node->len + p->next->len;struct freelink* temp = p->next;p->next = p->next->next;free(temp);free(node);printf("回收成功!\n");return TRUE;}else {p->len += node->len;free(node);printf("回收成功!\n");return TRUE;}}p = p->next;}//不邻接p = free_head;while (p->next != NULL && node->address > p->next->address) { p = p->next;}if (p->next == NULL) {p->next = node;node->next = NULL;}/*回收分区是分区链中地址最大的一个*/else {node->next = p->next;p->next = node;}printf("回收成功!\n");return TRUE;}//输出空闲分区void printFreeLink() {struct freelink *p = free_head->next;printf("空闲分区:\n");while (p != NULL) {printf("分区起始地址:%d ", p->address);printf("分区大小:%d\n", p->len);p = p->next;}printf("\n");}//输出占用分区void printBusyLink() {struct busylink *q = busy_head->next;printf("占用分区:\n");while (q != NULL) {printf("进程名:%c ", q->name);printf("起始地址:%d ", q->address);printf("占用内存大小:%d\n", q->len);q = q->next;}printf("\n");}void WF() {while(1) {printf("----------------------------------------------------------------\n");printf("1. 初始化\n\n");printf("2. 作业进入内存\n\n");printf("3. 作业完成\n\n");printf("4. 显示当前自由分区\n\n");printf("5. 显示当前作业占用分区\n\n");printf("6. 退出\n");printf("----------------------------------------------------------------\n");int m;scanf("%d", &m);printf("\n");switch(m) {case 1: init(); break;case 2: allocateMemoByWF(); break;case 3: freeMemoByWF(); break;case 4: printFreeLink(); break;case 5: printBusyLink(); break;case 6: return;}}}void FF() {while(1) {printf("----------------------------------------------------------------\n");printf("1. 初始化\n\n");printf("2. 作业进入内存\n\n");printf("3. 作业完成\n\n");printf("4. 显示当前自由分区\n\n");printf("5. 显示当前作业占用分区\n\n");printf("6. 退出\n");printf("----------------------------------------------------------------\n");int m;scanf("%d", &m);printf("\n");switch(m) {case 1: init(); break;case 2: allocateMemoByFF(); break;case 3: freeMemoByFF(); break;case 4: printFreeLink(); break;case 5: printBusyLink(); break;case 6: return;}}}int main() {while(1) {printf("----------------------------------------------------------------\n");printf("1. 首次适应算法\n\n");printf("2. 最坏适应算法\n\n");printf("3. 退出\n");printf("----------------------------------------------------------------\n");int m;scanf("%d", &m);printf("\n");switch(m) {case 1: FF(); break;case 2: WF(); break;case 3: exit(0);}}}6. 实验结果:1.最坏适应算法:A(16), B(32), C(64), D(128)分配(成功):分配失败(重名):当前空闲区和占用区情况:free(A)//不邻接回收成功:回收失败(不存在该进程):当前空闲区和占用区情况:free(C)当前空闲区情况:free(B)//与上下分区邻接当前空闲区情况:E(100)当前空闲区情况:F(200)没有分区满足时尝试碎片拼接当前空闲区和占用区情况:最坏适应算法有一种情况:A(40), B(50), C(60), D(50)free(A), free(C)与首次适应分配不同,最坏适应算法可能高地址在低地址前free(B)2. 首次适应算法:A(16), B(32), C(64), D(128),E(10),F(5),free(F)free(A), free(C)free(B)G(200)在分配内存过程中,将作业加入到占用队列时是按地址递增的顺序排列,保证了拼凑算法后各作业的相对位置不变化7. 实验总结:a)以前对链表操作有一些误操作,比如排序时,一般使用冒泡法。
实验2可变分区管理及存储管理

实验2 可变分区管理一、存储管理背景知识1. 分页过程2. 内存共享3. 未分页合并内存与分页合并内存4. 提高分页性能耗尽内存是Windows系统中最常见的问题之一。
当系统耗尽内存时,所有进程对内存的总需求超出了系统的物理内存总量。
随后,Windows必须借助它的虚拟内存来维持系统和进程的运行。
虚拟内存机制是Windows操作系统的重要组成部分,但它的速度比物理内存慢得多,因此,应该尽量避免耗尽物理内存资源,以免导致性能下降。
解决内存不足问题的一个有效的方法就是添加更多的内存。
但是,一旦提供了更多的内存,Windows很可以会立即“吞食”。
而事实上,添加更多的内存并非总是可行的,也可能只是推迟了实际问题的发生。
因此,应该相信,优化所拥有的内存是非常关键的。
1. 分页过程当Windows求助于硬盘以获得虚拟内存时,这个过程被称为分页(paging) 。
分页就是将信息从主内存移动到磁盘进行临时存储的过程。
应用程序将物理内存和虚拟内存视为一个独立的实体,甚至不知道Windows使用了两种内存方案,而认为系统拥有比实际内存更多的内存。
例如,系统的内存数量可能只有16MB,但每一个应用程序仍然认为有4GB内存可供使用。
使用分页方案带来了很多好处,不过这是有代价的。
当进程需要已经交换到硬盘上的代码或数据时,系统要将数据送回物理内存,并在必要时将其他信息传输到硬盘上,而硬盘与物理内存在性能上的差异极大。
例如,硬盘的访问时间通常大约为4-10毫秒,而物理内存的访问时间为60 us,甚至更快。
2. 内存共享应用程序经常需要彼此通信和共享信息。
为了提供这种能力,Windows必须允许访问某些内存空间而不危及它和其他应用程序的安全性和完整性。
从性能的角度来看,共享内存的能力大大减少了应用程序使用的内存数量。
运行一个应用程序的多个副本时,每一个实例都可以使用相同的代码和数据,这意味着不必维护所加载应用程序代码的单独副本并使用相同的内存资源。
模拟实现一个简单的可变分区存储管理系统资料

合肥学院计算机科学与技术系实验报告2013 ~2014 学年第一学期课程操作系统原理实验名称模拟实现一个简单的可变分区存储管理系统学生姓名专业班级指导教师谢雪胜2013 年12 月1.实验目的模拟实现一个简单的固定(或可变)分区存储管理系统2.实验内容本实验要求完成如下任务:(1)建立相关的数据结构,作业控制块、已分配分区及未分配分区(2)实现一个分区分配算法,如最先适应分配算法、最优或最坏适应分配算法(3)实现一个分区回收算法(4)给定一批作业/进程,选择一个分配或回收算法,实现分区存储的模拟管理。
3.实验步骤(1)任务分析本实验要实现的功能是模拟分区管理系统,即输入一个批作业,由程序根据各个作业的大小为批作业分配分区。
如果能找到满足条件的分区,则分配成功,否则分配失败。
对于程序的输入,输入用户程序所要请求的分区大小,-1表示输入完成。
程序输入分配分区后各个分区的使用情况,然后回收分区,程序输出回收分区后各个分区的使用情况。
(2)概要设计对于分区的定义,定义的数据结构如下所示typedef struct{int no; //定义分区编号int size; //定义大小int start; //定义分区起始位置int state; //定义分区状态,已分配或未分配}fenqubiao;fenqubiao arr[50];其中,no表示分区的编号,size表示当前分区块的大小,start表示当前分区的起始位置,state表示当前分区的状态,已分配或空闲。
Arr[50]表示当前系统所有分区情况。
主程序的流程图如下:开始初始化分区输出分区表输入分区请求N 是否输入完Y输出分区表输入回收分区编号N 是否输入完Y结束(3)详细设计一、初始化分区Fenqubiao arr[50]={{1,10,0,0},{2,20,10,1},{3,10,30,0},{4,12,40,0},{5,30,52,1},{6,25,82,0},{7,20,107,0},{8,5,127,1},{9,64,132,0},{10,32,196,0}};二、分区分配函数采用的分区分配函数是最先适应法,每次从地址部分开始遍历。
实验4:可变分区存储管理

沈阳工程学院
学生实验报告
(课程名称:操作系统)实验题目:可变分区存储管理
班级学号姓名
地点f612 指导教师
实验日期:
{
case 0:printf("感谢您的使用!再见!\n");exit(0);
case 1:view();break;
case 2:earliest();break;
case 3:excellent();break;
case 4:worst();break;
}
system("cls");
}
}
①建立文件以adc为名字的文件输入如图1所示
图
1 建立文件adc
②建立3个空闲分区起始地址和行实现如图2所示
图2 建立起始地址③显示空闲表和分配表实现如图3所示
图3 显示空闲表和分配表
④执行首次算法后,建立的空闲表长度分别为3 8 10,申请一个名为a长度为5的作业故首次适应算法从第二个空闲表首地址为3开始,运行实现如图4所示
图4 首次适应算法
⑤最佳适应算法,执行首次算法后,建立的空闲表长度分别为3 8 10,申请一个名为a长度为9的作业故首次适应算法从第二个空闲表首地址为11开始,运行实现如图5所示
图5 最佳适应算法
⑥最坏适应算法,执行首次算法后,建立的空闲表长度分别为3 8 10,申请一个名为a长度为3的作业故首次适应算法从第二个空闲表首地址为11开始,运行实现如图6所示
图6 最坏适应算法⑦生成文件abc如图7所示
图7 生成a文件。
可变分区存储管理实验报告

可变分区存储管理实验报告一、实验目的了解可变分区存储管理的原理和方法,掌握可变分区分配和回收的算法。
二、实验内容使用C语言编写一个模拟的存储管理系统,实现可变分区存储管理的算法。
三、实验原理首次适应算法是指分配分区时,从第一个空闲分区开始查找,找到第一个能够满足要求的分区进行分配。
最佳适应算法是指分配分区时,从所有空闲分区中找到最小且大于等于要求的分区进行分配。
最坏适应算法则是指分配分区时,从所有空闲分区中找到最大的分区进行分配。
分配分区时,需要考虑一些问题,如分区大小是否满足要求,是否有足够的空闲分区,以及如何更新空闲分区表等。
回收分区时,需要考虑将回收的分区加入空闲分区表,并且可能需要合并相邻的空闲分区,以获得更大的空闲分区。
四、实验步骤1.定义作业结构体,包含作业名、作业大小等字段。
2.定义分区结构体,包含分区号、分区大小等字段。
3.初始化空闲分区表,将整个内存作为一个空闲分区,插入空闲分区表中。
4.进入循环,接受用户输入的指令,包括分配作业、回收作业和退出程序。
5.根据用户指令进行相应的操作,包括按首次适应、最佳适应或最坏适应算法进行分配作业,将分配和回收的分区加入空闲分区表。
6.根据用户指令输出当前空闲分区表和已分配的作业表。
7.重复步骤4-6,直到用户输入退出指令。
五、实验结果与分析经过多次测试,可变分区存储管理系统能够成功实现各种分区算法的分配和回收。
根据实验结果可以看出,首次适应算法的分配速度较快,但可能会产生较多的碎片。
最佳适应算法能够较好地利用空闲分区,但分配时间较长。
最坏适应算法分配时间最长,但可以减少碎片的产生。
六、实验总结通过本次实验,我了解了可变分区存储管理的原理和方法,掌握了可变分区分配和回收的算法。
在实践中,我发现不同的分区算法适用于不同的场景,需要根据实际情况进行选择。
此外,对于空闲分区的合并也是提高存储利用率的重要步骤,需要重视。
最后,通过本次实验,我对存储管理的概念和原理有了更深入的理解,并且掌握了实现可变分区存储管理的方法和技巧。
操作系统课程设计可变分区存储管理

工程技术学院电气信息系操作系统课程设计报告专业:模拟实现可变分区存储管理一、设计目地在熟练掌握计算机分区存储管理方式地原理地基础上,利用C程序设计语言在windows操作系统下模拟实现操作系统地可变分区存储管理地功能,一方面加深对原理地理解,另一方面提高根据已有原理通过编程解决实际问题地能力,为进行系统软件开发和针对实际问题提出高效地软件解决方案打下基础.二、各功能模块分析实现1.设计合理地数据结构来描述存储空间:1)对于未分配出去地部分,用空闲分区链表来描述.struct freeList{int startAddress; /* 分区起始地址*/int size; /* 分区大小*/struct freeList *next; /* 分区链表指针*/}2)对于已经分配出去地部分,由装入内存地作业占据.struct usedList{int startAddress; /* 分区起始地址*/int jobID; /* 分区中存放作业ID */struct usedList *next; /* 分区链表指针*/}3)将作业组织成链表.struct jobList{int id; /* 作业ID */int size; /* 作业大小(需要地存储空间大小)*/int status; /* 作业状态0 : new job ,1 : in the memory , 2 : finished . */struct jobList *next; /* 作业链表指针*/}以上将存储空间分为空闲可占用两部分,在usedlist中设jobID而不设size,可以在不增加空间复杂度(与freelist相比)地同时更方便地实现可变分区存储管理(从后面地一些函数地实现上可以得出这个结论).尽管设置joblist增加了空间复杂度,但它地存在,使得该程序可以方便地直接利用C盘中地Job.txt文件.该文件可以认为是一个和其他进程共享地资源.通过这个文件,其他进程写入数据供读取.这中思想在操作系统设计中体现地很多.2.实现分区存储管理地内存分配功能,选择适应算法(首次适应算法,最佳适应算法,最后适应算法,最坏适应算法).基本原理分析:1)Best fit :将空闲分区按大小从小到大排序,从头找到大小合适地分区.2)Worst fit:将空闲分区按大小从大到小排序,从头找到大小合适地分区.3)First fit :将空闲分区按起始地址大小从小到大排序,……4)Last fit :将空闲分区按起始地址大小从大到小排序,……由此,可将空闲分区先做合适地排序后用对应地适应算法给作业分配存储空间.排序函数order(bySize为零则按分区大小排序,否则按分区起始地址;inc为零从小到大排序,否则从大到小排序;通过empty指针返回结果).void order(struct freeList **empty,int bySize,int inc){struct freeList *p,*q,*temp;int startAddress,size;for(p = (*empty) -> next;p;p = p -> next){ /* 按bySize和inc两个参数寻找合适地节点,用temp指向它*/ for(temp = q = p;q;q = q -> next){switch(bySize){case 0 : switch(inc){case 0:if(q->size < temp->size)temp = q;break;default:if(q->size > temp->size)temp = q;break;} break;default: switch(inc){case 0:if(q->startAddress < temp->startAddress)temp = q;break;default:if(q->startAddress > temp->startAddress)temp = q;break;} break;}} /* 交换节点地成员值*/if(temp != p){startAddress = p->startAddress;size = p->size;p->startAddress = temp->startAddress;p->size = temp->size;temp->startAddress = startAddress;temp->size = size;}}}3.实现分区存储管理地内存回收算法:void insertFreeNode(struct freeList **empty,int startAddress,int size)插入回收地空节点分区,处理回收分区与空闲分区地四种邻接关系.{struct freeList *p,*q,*r;for(p = *empty;p -> next;p = p -> next) ; /* 处理链表尾部地邻接情况*/ if(p == *empty || p -> startAddress + p -> size < startAddress)/* 与尾部不相邻*/ {makeFreeNode(&r,startAddress,size); /* 通过r指针返回创建地空闲节点*/r -> next = p -> next; /* 插入独立地空闲节点*/p -> next = r;return ;}if(p -> startAddress + p -> size == startAddress) /* 与尾部上邻*/ {p -> size += size; /* 合并尾部节点*/return ;}q = (*empty) -> next; /* 处理链表首节点地邻接情况*/ if(startAddress + size == q -> startAddress) /* 与首节点下邻*/ {q -> startAddress = startAddress; /* 合并首节点*/q -> size += size;}else if(startAddress + size < q -> startAddress) /* 与首节点不相邻*/ {makeFreeNode(&r,startAddress,size);r -> next = (*empty) -> next;(*empty) -> next = r;}else{ /* 处理链表中间地邻接情况*/ while(q -> next && q -> startAddress < startAddress){p = q;q = q -> next;}if(p -> startAddress + p -> size == startAddress &&\q -> startAddress == startAddress + size) /* 上下邻,合并节点*/ {p -> size += size + q -> size;p -> next = q -> next;free(q); /* 删除多余节点*/ }else if(p -> startAddress + p -> size == startAddress &&\q -> startAddress != startAddress + size) /*上邻,增加节点地大小*/ {p -> size += size;}else if(p -> startAddress + p -> size != startAddress &&\q -> startAddress == startAddress + size) /* 下邻*/ {q -> startAddress = startAddress; /* 修改节点起始地址*/q -> size += size; /* 修改节点地大小*/ }else{ /* 上下不相邻*/ makeFreeNode(&r,startAddress,size);r -> next = p -> next;p -> next = r;}}}4.当碎片产生时,进行碎片地拼接.void moveFragment(struct jobList *jobs,struct freeList **empty,struct usedList **used){int size,status;struct usedList *p;int address = memoryStartAddress; /*全局变量,初始化时分配存储空间始址*/ if((*empty)->next == NULL) /* 空闲分区链表为空,提示并返回*/ {printf("\nThe memory was used out at all.\nMay be you should finish some jobs first or press any key to try again !");getch();return;}for(p = (*used) -> next;p;p = p-> next) /* 循环地修改占用分区地始址*/ {p -> startAddress = address;getJobInfo(jobs,p -> jobID,&size,&status); /* 由作业ID获得作业大小*/address += size;}(*empty)->next->startAddress = address;/*修改空闲分区地首节点始址、大小*/ (*empty) -> next -> size = memorySize - (address - memoryStartAddress);(*empty) -> next -> next = NULL; /* 删除首节点后地所有节点*/ }5.空闲分区队列显示:int showFreeList(struct freeList *empty)6.作业占用链表显示:int showUsedList(struct jobList *jobs,struct usedList *used) 从头到尾显示used链,同时通过其中地作业ID在jobs中查对应地大小.7.从键盘输入作业到D盘地JOB文件:void inputJob(void)8.从JOB文件中读出作业并创建作业链表:i nt makeJobList(struct jobList **jobs)9.显示作业链表:int showJobList(struct jobList *jobs)10.更新作业链表中作业地状态:int updateJobFile(struct jobList *jobs)11.根据作业链表更新JOB文件:int updateJobFile(struct jobList *jobs)12.为作业分配存储空间、状态必须为0:int allocate(struct freeList **empty,int size)13.结束一个作业号为id地作业,释放存储空间(由*startAddress返回空间地起始地址):int finishJob(struct usedList **used,int id,int *startAddress)14.插入释放地空间到used链表中(作业号为id,startAddress由函数13返回):void insertUsedNode(struct usedList **used,int id,int startAddress)15.获取作业地信息:void getJobInfo(struct jobList *jobs,int id,int *size,int *status)16.初始化存储空间起始地址、大小:void iniMemory(void)17.选择适应算法:char selectFitMethod(void)18.根据参数startAddress、size创建空闲节点,由empty指针返回:void makeFreeNode(struct freeList **empty,int startAddress,int size)19.以要求地方式打开文件:void openFile(FILE **fp,char *filename,char *mode)20.出现严重错误时显示信息并结束程序;void errorMessage(void)三、总体界面与程序流程分析Dynamic Zonal Memory Management其中1、Initializiation.按顺序利用了openFile()、iniMemory()、makeFreeNode()、inputJob()(选择利用C盘JOB文件时提供作业信息)、makeJobList()、allocate()、insertUsedNode()(选择利用C盘JOB文件时先将状态为1地作业放到存储空间中,以恢复上次地模拟实验,或使本次模拟时不出错)selectFitMethod()等自编函数.2、Put job into memory(allocate memory)按顺序利用了showJobList()(选手动逐个为作业分配存储空间时)、openFile()、order()、allocate()、errorMessage()、insertUsedNode()、updateJobStatus()updateJobFile()函数(自动为如上作业分配存储后状态地变化——>)3、Finish job(reuse memory)按顺序利用了openFile()、showUsedList()、getJobInfo()、insertFreeNode()、updateJobStatus()、updateJobFile()、errorMessage()等自编函数.(完成部分作业后作业——>)4、Show current free list按顺序利用了openFile()、showFreeList()函数. (如下图为当前空闲分区)5、Show current memory used by jobs按顺序利用了openFile()、showUsedList()函数. (如下图为当前作业占用地分区)6、Move fragment together 按顺序利用了openFile()、moveFragment()函数.整理7、Exit 按顺序利用了openFile()、exit(0)函数.四、主程序流程图step=’1’ step=’2’ step=’6’ step=’3’step=’4’step=’5’step=’7’五、结果分析与总结程序中创建地两个文件创建分区头节点删除上次地结果文件键盘输入字符step 字符step 为? Exit Put job into memoryFinish job Show current free listShow current memory used by jobs Move fragment together Initializiation1)Best fit算法验证:如下图分配大小为50地8号作业,恰好占用大小为50地空闲而非大小为240地.2)Worst fit算法验证:如下图分配大小为50地8号作业,占用大小为100空闲而非大小为70地.3)First fit算法验证:如下图分配大小为50地8号作业,占用起始地址为110空闲而非350地.4)Last fit算法验证:如下图分配大小为50地8号作业,占用起始地址为350空闲而非110地.总结:通过这次课程设计我练习了用C语言写系统软件,对OS中可变分区存储管理有了更深刻地了解.在写程序地时候也遇到了一些困难.比如在设计数据结构时特别犹豫,总想找一个很合适地.但是,后来才知道,关键要多尝试,而空想是没有用地.最后我证实了自己地设计地合理性.还有为了使程序更健壮,我尝试着将程序中地输入部分全部改为字符(串).成功地避免了接受整型数据时输入字符后引起地错误,使程序能接受任何输入而正常结束.很遗憾地是因为时间问题,没有把这个模拟程序写成动画形式,还可以加几句代码后实现动态地增加作业.。
操作系统可变分区存储管理模拟

操作系统实验(三)可变分区存储管理模拟实验作者:顾熙杰准考证号:4报到号:177实验地点:浙工大计算机中心1)实验目的理解操作系统中可变分区管理的算法,掌握分配和回收算法掌握空闲分区的合并方法掌握不同的适应算法2)实验内容建立数据结构建立空闲分区队列根据不同的适应算法建立队列编写分配算法编写回收算法3)数据结构'分区首地址'分区长度'分区状态-1表示不存在,0表示空闲分区,1表示已经分配的分区'该分区正在活动的进程代号4)程序流程图面向对象程序设计由事件驱动,画流程图比较困难。
(1)分配新的分区最先适应按地址找最优适应,找最小可以满足的最坏适应,找最大可以满足的(2)分区回收既无上邻又无下邻既有上邻又有下邻只有上邻只有下邻5)实验中需要改进的地方由于没有使用链表,程序结构比较混乱,需要大大改进,提高可阅读性。
6)程序代码()"32" "" ( , , , , , )'表示内存分区的结构信息类型的变量类型'分区首地址'分区长度'分区状态-1表示不存在,0表示空闲分区,1表示已经分配的分区'该分区正在活动的进程代号'定义最多640个,总共640K内存数组(1 640)'表示可以使用的进程代号(1 640)'0表示该进程号可以使用'.>=1表示该进程号不可以使用'表示分配方法'0=最先分配'1=最优分配'2=最坏分配()'取可以使用的进程号ii = 1 640(i) = 0(i) = 1= i= 0()'取可以使用的为了表示分区的存储空间,模拟c语言的指针ii = 1 640(i) = -1= i= 0( )i,'分配新的分区0 '最先适应按地址找i = 1 640(i) = 0(i) >== ii1 '最优适应,找最小可以满足的= 10000i = 1 640(i) = 0(i) >=(i) <= (i)= ii= 0("内存不足!", )=2 '最坏适应,找最大可以满足的= 10000i = 1 640(i) = 0(i) >=(i) >= (i)= ii= 0("内存不足!", )=("内存不足!", ) ()ijL'新的进程进入= ()= ()i = ()(i) = 1L = (i) -(i) =(i) =L > 0= ()() = 0() = L() = (i) +()i = ((1) * 6 + 1)= (i):"请在文本框内输入正确的数字"()'刷新显示ij, ki = 1 640(i) <> -1(i) = 1(i 2) = 1= 4= 5= 6= (i)= (i)= (i)j = + 1(i) = 1(j, 1) = (i)(j, 2) = ((i)) + "K"(j, 3) = ((i)) + "K"(j, 4) = ((i)) + "已分配"(j, 5) = () + "号进程"(i) = 0(j, 1) = (i)(j, 2) = ((i)) + "K"(j, 3) = ((i)) + "K"(j, 4) = ((i)) + "未分配"(j, 5) = ""k = 1 5= kj = + 1 += j=j <> + 1(, ) = ""jk()ip, nj'回收进程的内存和合并空闲分区= ()i = 1 640(i) ='既无上邻又无下邻(i) = 0(i) = 0() = 0i = 1n = 0'找下一个相连的分区j = 1 640(i) + (i) = (j)(j) = 0n = jjn <> 0'有下邻(i) = (i) + (n)(n) = -1i = 640p = 0'找上一个相连的分区j = 1 640(j) + (j) = (i)(j) = 0p = jjp <> 0''有上邻(p) = (p) + (i)(i) = -1p = 0n = 0'找上一个相连的分区j = 1 640(j) + (j) = (i)(j) = 0p = jj'找下一个相连的分区j = 1 640(i) + (i) = (j)(j) = 0n = jjp <> 0 n <> 0'既有上邻又有下邻(p) = (p) + (i) + (n)(i) = -1(n) = -1p <> 0''只有上邻(p) = (p) + (i)(i) = -1n <> 0'只有下邻(i) = (i) + (n)(n) = -1("不存在这个进程!", ):("不存在这个进程!", )()i(1) = 1800(2) = 1800(3) = 1800(4) = 1800(5) = 1800(0, 0) = "内存地址" (0, 1) = "分区号"(0, 2) = "分区首址" (0, 3) = "分区长度" (0, 4) = "分配状态" (0, 5) = "活动进程"= 0= 0i = 0 639(i + 1, 0) = (i) + "K"i = 1 640(i) = -1(1) = 0(1) = 640(1) = 0(1) = 0= "存储管理器"( i )'延迟i秒t1, t2t1 = ()t2 = t1(t2 - t1 < i)t2 = ()()("")()("作者:顾熙杰" + + "考客主页:", 48) ()()( + "\")( )i'外浏览器访问网页i = (0&, , , , , )' i'返回10767正确'返回2,文件不存在i = 2("文件不存在", 48):$1()= 02()= 13()= 2( b )'寻找上邻区ii = b - 1 1 -1(i) <> -1= i( b )'寻找下邻区ii = b + 1 640(i) <> -1= i7)运行结果用户区分配前分配了5个进程一个进程退出以后。
可变分区存储管理实验报告
实验三可变分区存储管理
一、实验目的
通过编写可变分区存储模拟系统,掌握可变分区存储管理的基本原理,分区的分配与回收过程。
二、实验内容与步骤
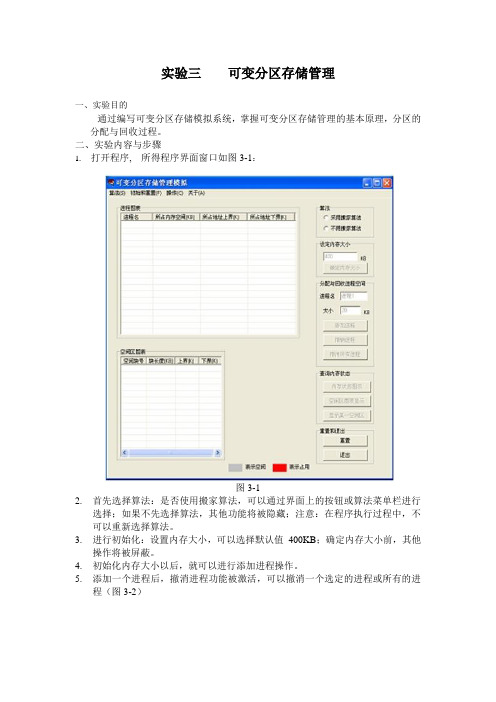
1.打开程序,所得程序界面窗口如图3-1:
图3-1
2.首先选择算法:是否使用搬家算法,可以通过界面上的按钮或算法菜单栏进行
选择;如果不先选择算法,其他功能将被隐藏;注意:在程序执行过程中,不可以重新选择算法。
3.进行初始化:设置内存大小,可以选择默认值400KB;确定内存大小前,其他
操作将被屏蔽。
4.初始化内存大小以后,就可以进行添加进程操作。
5.添加一个进程后,撤消进程功能被激活,可以撤消一个选定的进程或所有的进
程(图3-2)
图3-2
6.查询功能:可以通过按钮或菜单栏显示内存状态图形、空闲区图表,还可以在内存状态条里闪烁显示某一在空闲区图表选中的空闲区。
7.内存不足但经过搬家算法可以分配内存空间给进程,将有如下(图3-3)提示:
图3-3
8.内存空间不足也有相应提示。
9.重置或退出。
三、实验结果
第一至四组数据测试采用搬家算法,第二至八组数据测试不采用搬家算法。
第一组测试数据:(测试内存错误输入) 选择搬家算法,内存大小:0KB/-50KB/空
第二组测试数据:(测试内存空间不够)选择搬家算法,内存大小:400KB
第三组测试数据:(测试是否采用最佳适应法)选择搬家算法,内存大小:200KB 第四组数据:(测试搬家算法)选择搬家算法,内存大小:400KB
第五组数据至第八组数据:不采用搬家算法,内存大小:分别与第一至第四组数据相同,操作过程:分别与第一至第四组数据相同。
可变分区存储管理的内存分配算法模拟实现----最佳适应算法 -回复

可变分区存储管理的内存分配算法模拟实现----最佳适应算法-回复可变分区存储管理是一种常用的内存分配算法,用于管理计算机系统中的内存空间。
其中,最佳适应算法是其中一种经典的实现方式。
本文将围绕最佳适应算法展开,详细介绍其原理、实现方法以及优缺点。
首先,我们需要明确什么是可变分区存储管理。
在计算机系统中,内存是被划分为多个可用的分区,每个分区有不同的大小。
当一个程序需要内存时,系统会选择一个适合该程序大小的分区进行分配。
使用可变分区存储管理算法,系统可以灵活地分配和回收内存,并提高内存的利用率。
最佳适应算法是可变分区存储管理中的一种常用算法。
其核心思想是始终选择最小但足够容纳所需内存的分区进行分配。
这样可以最大程度地减少内存碎片的产生,提高系统内存利用率。
下面我们将一步一步来模拟实现最佳适应算法。
首先,我们需要创建一个数据结构来表示内存分区。
我们可以使用一个链表来存储每个分区的信息,每个节点包含分区的起始地址、结束地址和大小。
初始时,整个内存空间被视为一个大的可用分区。
接下来,当一个程序需要内存时,我们需要遍历整个分区链表,找到一个大小不小于所需内存的最小分区。
我们可以使用一个变量来记录当前找到的最小分区的大小,以及一个指针来指向该分区节点。
在遍历过程中,如果找到一个分区的大小恰好等于所需内存,那么直接分配给程序,并将该节点从链表中删除即可。
如果找到的分区的大小大于所需内存,我们需要进行分割操作。
即将该分区分成两个部分,一个部分分配给程序,另一个部分保留未分配状态,并将其添加到链表中。
同时,我们需要更新原有分区节点的起始地址和大小。
最后,当一个程序终止并释放内存时,我们需要将该内存块归还给系统,并进行合并操作。
即将释放的内存块与相邻的空闲内存块进行合并,以减少内存碎片。
通过以上步骤,我们可以实现最佳适应算法来管理内存分配。
但是,最佳适应算法也有其优缺点。
首先,最佳适应算法相对于其他算法来说,可以更好地减少内存碎片的产生。
3用C语言模拟实现可变式分区存储管理

试验三:用C语言模拟实现可变式分区存储管理一、試驗目标:1、通过编写可变式分区存储管理的C语言程序,使学生加强对可变式分区存储管理的认识。
2、掌握操作系统设计的根本原理、方法和一般步骤。
二、試驗容:用C語言編寫一個实现可变式的分区管理的模擬程序。
*复习相关的知识:1、分区管理的原理:将存储器划分成假设干段大小固定的区域,一个区域里只能运行一个程序,程序只能在其自身所在的分区中活动。
2、固定式分区管理的原理:区域大小及起始地址是固定的。
一个分区只能存放一个程序。
需要设置一个分区说明表来标明存的使用状态。
根据分区说明表来给程序分配相应的区域。
由于程序不可能刚刚占有一个分区的大小,这样就会在一个分区之中留下零头,造成了极大的浪费。
3、可变式分区管理的原理:区域的大小及起始地址是可变的,根据程序装入时的大小动态地分配一个区域。
保证每个区域之中刚好放一个程序。
这样可以充分地利用存储空间,提高存的使用效率。
如果一个程序运行完毕,就要释放出它所占有的分区,使之变成空闲区。
这样就会出现空闲区与占用区相互交织的情况。
这样就需要P表,F表来分别表示存的占用区状态与空闲区的状态。
*确定该系统所使用的数据构造:我们可以把存表示为一个数组的形式。
这个数组中的每一个单元都是一个无符号的字符型的数据类型。
这样一个单元刚好占用一个字节的大小。
这一个字节的地址可以用它在此数组中的下标来表示。
如果一个程序占用了一定的区域,则这个区域的大小就可以用它占有的字节数的个数来表示。
用C语言可以表述如下:unsigned char memory[1024]它就可以表示一个1K的存空间。
为了实现可变式的分区管理,还需要设立两个表,一个是P表,一个是F表,它们分别表示存的占用区状态。
由于在该程序运行的过程之中需要不断地修改P表和F表,所以这两个表不适合于用数组的形式来表示;而应该使用单链表的形式。
这样就要给单链表中的结点确立一个数据构造。
很显然,P表中的每一个结点至少要包括以下的几项:占用的程序名、占用区的起始地址、占用区的大小、指向下一个结点的指针。
实验、可变分区存储管理系统模拟——最先适应分配算法

实验、可变分区存储管理系统模拟——最先适应分配算法1. 实验⽬的可变分区分配是⼀种重要的存储管理思想,⽬前流⾏的操作系统采⽤的分段存储管理的基本思想就源⾃该⽅法。
本实验的⽬的是通过编程来模拟⼀个简单的可变分区分配存储管理系统,利⽤最先适应分配算法实现。
经过实验者亲⾃动⼿编写管理程序,可以进⼀步加深对可变分区分配存储管理⽅案设计思想的理解。
2. 实验原理固定分区分配按操作系统初始化时划定的分区⽅案为作业分配内存,由于各分区的位置和⼤⼩固定,因此作业所需的内存⼤⼩通常⼩于分到的实际内存的⼤⼩,造成存储空间的浪费。
可变分区分配对此作了改进,它总是根据作业的实际需要分配刚好够⽤的连续存储空间,保证分配给作业的存储空间都是有⽤的,避免了零头的产⽣。
(1)可变分区中的数据结构建⽴描述作业的数据结构作业控制块,⾄少应包括:作业名称作业需要执⾏时间作业的内存需求作业调⼊主存时间作业执⾏结束时间作业所在分区的起始地址建⽴描述内存已分配分区的数据结构;建⽴描述内存未分配的空闲分区的数据结构;空闲分区和已分配分区的信息可以使⽤分区表来描述。
系统中所有空闲分区构成分区表,所有已分配分区构成分配分区表。
出于效率的考虑,也可使⽤分区链来记录分区信息。
分区链是⼀种双向链表,链表的每个结点描述⼀个分区的信息。
系统中所有空闲分区构成空闲分区链,所有已分配分区构成分配分区链。
分配和回收分区时,需要在这两个链表中进⾏结点的查找和插⼊、删除与修改操作。
为改进算法的执⾏效率,可以将分区链按特定的顺序排序。
分区链结点的数据结构为:Struct Section {Section *pPre; //前向指针,指向链表的前⼀个结点int nSart; //分区的起始地址int nSize; //分区的尺⼨Section *pSuf; //后向指针,指向链表的后⼀个结点};可变分区分配算法——最先适应分配算法最先适应分配算法要求空闲分区按地址递增的顺序排列,在进⾏内存分配时,从低地址部分向⾼地址部分查找,直到找到⼀个能满⾜要求的空闲分区为⽌。
实验上机02-可变分区存储管理程序模拟的实现

实验题目可变分区存储管理的程序模拟一、可变分区存储管理的基本策略1)不预先划分几个固定分区,分区的建立是在作业的处理过程中进行的,各分区的大小由作业的空间需求量决定。
2)采用指针方式将各个空闲分区链接而成的链表,用以记录主存分配现状。
3)分配与回收算法按空闲分区链接方式的不同分类,有最佳、最坏、首次和下次适应四种算法。
二、程序模拟的设计1、基本思想采用事件驱动模型。
事件有:1)申请主存事件,表示一个作业创建时提出的主存资源要求;2)释放主存事件,表示一个作业结束时其占用主存被回收。
2、数据结构设计1)程序使用的常值和工作变量的说明作业表所含表项的最大数量 MaxAmountOfJobTableItems 10处理的作业的最大数量 MaxAmountOfJobs 20主存空间的最大尺寸 MaxSizeOfMemorySpace 1000作业申请主存的最大尺寸 MaxSizeOfMemoryForAsk 500时间单位的最大值 MaxSizeOfTimeUnit 100占用主存时间单位的最大值 MaxSizeOfOccupyTimeUnit 300占用标志 BUSY 1空闲标志 FREE 0申请标志 ASK 1释放标志 RELEASE 0逻辑是标志 TRUE 1逻辑否标志 FALSE 0尾标志 END -1当前时间 CurrentTime作业计数器 CounterOfJobs作业命名序列字符 SerialCharOfJobName2)事件与事件表typedef struct Event_DataType{ 事件数据类型的定义int EventType; 事件的类型申请ASK或释放RELEASEint OccurTime; 事件发生的时间char JobName; 申请主存或被回收主存的作业名int JobId; 进入系统的作业在作业表中相应表项的编号int SizeOfMemoryForAsk; 作业申请占用主存的尺寸int OccupyTimeOfMemoryForAsk; 作业申请占用主存的时间长度int WaitFlag; 该事件是否等待过TRUE或FALSEint AdmitTime; 申请事件的提交时间或释放事件的处理时间struct Event_DataType *Next; 下一事件的指示信息} Event_DataType;设立3个事件表事件表TableOfEvents等待事件表TableOfWaitEvents 用于存放未能及时处理的主存申请事件统计事件表TableOfSumEvents 用于备份事件表3)字单元与主存空间typedef struct Word_DataType{ 主存物理单元数据类型定义int State; 所在分区的状态 FREE或BUSYint Size; 所在分区的大小char JobName; 占用分区的作业名int Next; 相邻分区的指示信息(前相邻或后相邻)} Word_DataType;主存空间是字单元的数组MemorySpace[MaxSizeOfMemory]4)作业表项与作业表typedef struct JobTableItem_DataType{ 作业表项的数据类型定义int State; 表项的状态FREE或BUSYchar JobName; 占用的作业名int MemoryLocation; 作业的主存位置int OccupyTimeOfMemory; 作业占用主存的时间长度int Next; 下一个空闲表项} JobTableItem_DataType;作业表是作业表项的数组TableOfJobs[MaxAmountOfJobTableItems] 5)核心数据结构typedef struct KernalDataStructure_DataType{ 核心数据结构数据类型定义JobTableItem_DataType TableOfJobs[MaxAmountOfJobTableItems];一张作业表int AmountOfFreeItems; 空闲表项的数量int FirstFreeItem; 第一个空闲表项int AmountOfFreeAreas; 空闲分区的数量int FirstFreeArea; 第一个空闲分区int SizeOfFreeMemory; 空闲主存的尺寸} KernalDataStructure_DataType;3、处理流程设计参数说明:形、变参数的区分按参数的逻辑意义认定。
实验一+可变分区存储管理

实验一 可变分区存储管理(一) 实验题目编写一个C 程序,用char *malloc(unsigned size)函数向系统申请一次内存空间(如size=1000,单位为字节),模拟可变分区内存管理,实现对该内存区的分配和释放管理。
(二) 实验目的1.加深对可变分区的存储管理的理解;2.提高用C 语言编制大型系统程序的能力,特别是掌握C 语言编程的难点:指针和指针作为函数参数;一) 实验题目编写一个C 程序,用char *malloc(unsigned size)函数向系统申请一次内存空间(如size=1000,单位为字节),用循环首次适应法addr = (char *)lmalloc(unsigned size) 和lfree(unsigned size,char * addr)模拟可变分区内存管理,实现对该内存区的分配和释放管理。
(二) 实验目的1.加深对可变分区的存储管理的理解;2.提高用C 语言编制大型系统程序的能力,特别是掌握C 语言编程的难点:指针和指针作为函数参数;3.掌握用指针实现链表和在链表上的基本操作。
(三) 实验要求(a)(b)(c)(d)图2-9释放区与前后空闲区相邻的情况要分配函数lmalloc的参数size和释放函数lfree的参数size、addr以键盘命令的形式输入,每次分配和释放后显示自己的空闲存储区表。
空闲存储区表可采用结构数组的形式(基本要求),或双向链接表的形式(提高一步),建议采用的数据结构为:结构数组的形式:struct map {unsigned m_size;char * m_addr;};struct map coremap[N];或双向链接表的形式:struct map {unsigned m_size;char *m_addr;struct map *next, *prior;};struct map *coremap;整个系统的基本框架为:程序结束前将整个存储区归还给系统。
实验五 动态分区存储管理系统模拟

实验五动态分区存储管理模拟一、实验目的深入了解可变分区存储管理方式主存分配回收的实现。
二、实验预备知识可变分区存储管理方式不预先将主存划分成几个区域,而把主存除操作系统占用区域外的空间看作一个大的空闲区。
当进程要求装入主存时,根据进程需要主存空间的大小查询主存内各个空闲区,当从主存空间找到一个大于或等于该进程大小要求的主存空闲区时,选择其中一个空闲区,按进程需求量划出一个分区装入该进程。
进程执行完后,它所占的主存分区被回收,成为一个空闲区。
如果该空闲区的相邻分区也是空闲区,则需要将相邻空闲区合并成一个空闲区。
这个实验主要需要考虑三个问题:(1)设计记录主存使用情况的数据表格,用来记录空闲区和进程占用的区域;(2)在设计的数据表格基础上设计主存分配算法;(3)在设计的数据表格基础上设计主存回收算法。
首先,考虑第一个问题:设计记录主存使用情况的数据表格,用来记录空闲区和进程占用的区域。
由于可变分区的大小是由进程需求量决定的,故分区的长度是预先不固定的,且分区的个数也随主存分配和回收而变动。
总之,所有分区情况随时可能发生变化,数据表格的设计必须和这个特点相适应。
由于分区长度不同,因此设计的表格应该包括分区在主存中的起始地址和长度。
由于分配时空闲区有时会变成两个分区:空闲区和已分分区,回收主存分区时,可能会合并空闲分区,这样如果整个主存采用一张表格记录已分分区和空闲区,就会使表格操作繁琐。
主存分配时查找空闲区进行分配,然后填写已分分区表,主要操作在空闲区;某个进程执行完成后,将该分区变成空闲区,并将其与相邻空闲区合并,主要操作也在空闲区。
由此可见,主存分配和回收主要是对空闲区的操作。
这样,为了便于对主存空间的分配和回收,就建立两张分区表记录主存使用情况,一张表格记录进程占用分区的“已分分区表”;一张是记录空闲区的“空闲区表”。
这两张表的实现方法一般有两种,一种是链表形式,一种是顺序表形式。
在实验中,采用顺序表形式,用数组模拟。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
合肥学院计算机科学与技术系实验报告2013 ~2014 学年第一学期课程操作系统原理实验名称模拟实现一个简单的可变分区存储管理系统学生姓名专业班级指导教师谢雪胜2013 年12 月1.实验目的模拟实现一个简单的固定(或可变)分区存储管理系统2.实验内容本实验要求完成如下任务:(1)建立相关的数据结构,作业控制块、已分配分区及未分配分区(2)实现一个分区分配算法,如最先适应分配算法、最优或最坏适应分配算法(3)实现一个分区回收算法(4)给定一批作业/进程,选择一个分配或回收算法,实现分区存储的模拟管理。
3.实验步骤(1)任务分析本实验要实现的功能是模拟分区管理系统,即输入一个批作业,由程序根据各个作业的大小为批作业分配分区。
如果能找到满足条件的分区,则分配成功,否则分配失败。
对于程序的输入,输入用户程序所要请求的分区大小,-1表示输入完成。
程序输入分配分区后各个分区的使用情况,然后回收分区,程序输出回收分区后各个分区的使用情况。
(2)概要设计对于分区的定义,定义的数据结构如下所示typedef struct{int no; //定义分区编号int size; //定义大小int start; //定义分区起始位置int state; //定义分区状态,已分配或未分配}fenqubiao;fenqubiao arr[50];其中,no表示分区的编号,size表示当前分区块的大小,start表示当前分区的起始位置,state表示当前分区的状态,已分配或空闲。
Arr[50]表示当前系统所有分区情况。
主程序的流程图如下:(3)详细设计一、初始化分区Fenqubiao arr[50]={{1,10,0,0},{2,20,10,1},{3,10,30,0},{4,12,40,0},{5,30,52,1},{6,25,82,0},{7,20,107,0},{8,5,127,1},{9,64,132,0},{10,32,196,0}};二、分区分配函数采用的分区分配函数是最先适应法,每次从地址部分开始遍历。
本程序用的是编号作为遍历的关键字,方便处理。
如果当前分区的大小大于所请求的大小,并且分区处于空闲状态,则进行分区,划出满足请求大小的分区,并修改状态为已分配。
如果所划分分区所剩空间不为0,则修改其首址,设定其大小,添加到分区表中。
如果当前分区不满足请求,则继续查找,直至所有分区遍历完成。
然后返回分配失败给请求者。
具体代码如下:int fun_allocate(int x,int *num,fenqubiao *arr){int i=0,p;fenqubiao t={0,0,0,0};for(i=0;i<*num;i++){if(arr[i].size>=x && arr[i].state==0) break;0 10 30 40 52 82 107 127 132 196 228if(i==*num)return 0;p=i;t.no=arr[i].no+1;t.size=arr[i].size-x;t.start=arr[i].start+x;t.state=0;arr[i].size=x;arr[i].state=1;if(t.size!=0){for(i=*num;i>p;i--){arr[i]=arr[i-1];arr[i].no=arr[i].no+1;}arr[p+1]=t;*num=*num+1;}return *num;}三、输出分区使用情况对分区表进行遍历,输出各个分区的信息(编号,大小,起始,状态)。
其中为了简单易懂,若状态为0则输出空闲,否则输出已分配。
void fun_print(fenqubiao *arr,int num){int i=0;printf("编号大小起始状态\n");for(i=0;i<num;i++)printf("%2d%7d%7d",arr[i].no,arr[i].size,arr[i].start);if(arr[i].state==1)printf(" 已分配\n");elseprintf(" 空闲\n");}}四、回收分区对所要回收的分区,则有四种情况。
1、上临空闲,下临空闲:修改上一个分区大小为三个分区大小之和,下临区之后的分区改变其分区编号,往前移两个。
2、上临空闲:修改上一个分区大小为两个分区大小之和,下临区之后的分区上移一个单位。
3、下临空闲:修改当前分区大小为两个分区大小之和,修改状态为未分配。
然后下临区之后的分区上移一个单位。
4、上下均无空闲:直接修改状态为未分配。
如果具体代码如下:void fun_huishou(int no,int *num,fenqubiao *arr){int i=0;int p=0;for(i=1;i<=*num;i++){if(arr[i].no==no){p=i;break;}}if(arr[p-1].state==0 && arr[p+1].state==0)//上下临区arr[p-1].size=arr[p-1].size+arr[p].size+arr[p+1].size;for(i=p;i<*num-1;i++){arr[i]=arr[i+2];arr[i].no=arr[i].no-2;}*num=*num-2;}else if(arr[p+1].state==0)//下临区{arr[p].size=arr[p].size+arr[p+1].size;arr[p].state=0;for(i=p+1;i<*num;i++){arr[i]=arr[i+1];arr[i].no=arr[i].no-1;}*num=*num-1;}else if(arr[p-1].state==0) //上临区{arr[p-1].size=arr[p-1].size+arr[p].size;for(i=p;i<*num;i++){arr[i]=arr[i+1];arr[i].no=arr[i].no-1;}*num=*num-1;}else //无相邻分区{arr[p].state=0;}}(4)调试分析实验结果截图如下:4.实验总结首次适应算法,分配时,当进程申请大小为SIZE的内存时,系统从空闲区表的第一个表目开始查询,直到首次找到等于或大于SIZE的空闲区。
从该区中划出大小为SIZE的分区分配给进程,余下的部分仍作为一个空闲区留在空闲区表中,但要修改其首址和大小。
回收时,按释放区的首址,查询空闲区表,若有与释放区相邻的空闲区,则合并到相邻的空闲区中,并修改该区的大小和首址,否则,把释放区作为一个空闲区,将其大小和首址按照首地址大小递增的顺序插入到空闲区表的适当位置。
这里,采用数组的方式,模拟内存分配首次适应算法,动态的为作业分配内存块。
可以根据作业名称回收已分配的内存块,当空闲内存块相邻时,则合并,不相邻是,直接插入。
通过此次的实验,让我对内存分配中首次适应算法更加熟悉,还通过这次实验了解了分配空间的另外两种方法:最佳和最坏算法。
通过编程模拟实现操作系统的可变分区存储管理的功能,一方面加深对原理的理解,另一方面提高根据已有原理通过编程解决实际问题的能力,为进行系统软件开发和针对实际问题提出高效的软件解决方案打下基础。
5.附录程序源代码#include <stdio.h>typedef struct{int no; //定义分区编号int size; //定义大小int start; //定义分区起始位置int state; //定义分区状态,已分配或未分配}fenqubiao;int fun_allocate(int x,int *num,fenqubiao *arr);//分区算法,分配成功返回分区数,否则返回0void fun_print(fenqubiao *arr,int num); //输出当前分区表状态void fun_huishou(int no,int *num,fenqubiao *arr);int main(){fenqubiaoarr[50]={{1,10,0,0},{2,20,10,1},{3,10,30,0},{4,12,40,0},{5,30,52,1}, {6,25,82,0},{7,20,107,0},{8,5,127,1},{9,64,132,0},{10,32,196,0}};int num=10; //用于统计分区个数int i=0,x,t;puts("||====================操作系统大实验==================||");puts("|| ||");puts("|| 题目:模拟实现一个可变分区存储管理系统 ||");puts("|| ||");puts("|| ||");puts("|| 制作者信息: ||");puts("|| ||");puts("|| 姓名学号 ||");puts("|| 万定国 1104032034 ||");puts("|| 刘国庆 1104032035 ||");puts("|| 许成谦 1104032036 ||");puts("|| 祁益祥 1104032037 ||");puts("|| 朱旭 1104032038 ||");puts("|| ||");puts("||====================================================||");system("pause");system("cls");printf("初始分区情况:\n");printf("编号大小起始状态\n");for(i=0;i<10;i++){printf("%2d%7d%7d",arr[i].no,arr[i].size,arr[i].start);if(arr[i].state==1)printf(" 已分配\n");elseprintf(" 空闲\n");}printf("====请求资源====\n");printf("输入请求大小(-1结束):\n");while(scanf("%d",&x) && x!=-1){t=fun_allocate(x,&num,arr);if(t==0)printf("分配失败!\n");else{num=t;fun_print(arr,num);}}printf("====回收资源=====\n");printf("请输入回收分区的编号(-1结束):\n");while(scanf("%d",&x) && x!=-1){fun_huishou(x,&num,arr);fun_print(arr,num);}}int fun_allocate(int x,int *num,fenqubiao *arr) {int i=0,p;fenqubiao t={0,0,0,0};for(i=0;i<*num;i++){if(arr[i].size>=x && arr[i].state==0)break;}if(i==*num)return 0;p=i;t.no=arr[i].no+1;t.size=arr[i].size-x;t.start=arr[i].start+x;t.state=0;arr[i].size=x;arr[i].state=1;if(t.size!=0){for(i=*num;i>p;i--){arr[i]=arr[i-1];arr[i].no=arr[i].no+1;}arr[p+1]=t;*num=*num+1;}return *num;}void fun_print(fenqubiao *arr,int num){int i=0;printf("编号大小起始状态\n");for(i=0;i<num;i++){printf("%2d%7d%7d",arr[i].no,arr[i].size,arr[i].start);if(arr[i].state==1)printf(" 已分配\n");elseprintf(" 空闲\n");}}void fun_huishou(int no,int *num,fenqubiao *arr){int i=0;int p=0;for(i=1;i<=*num;i++){if(arr[i].no==no){p=i;break;}}if(arr[p-1].state==0 && arr[p+1].state==0)//上下临区{arr[p-1].size=arr[p-1].size+arr[p].size+arr[p+1].size;for(i=p;i<*num-1;i++){arr[i]=arr[i+2];arr[i].no=arr[i].no-2;}*num=*num-2;}else if(arr[p+1].state==0)//下临区{arr[p].size=arr[p].size+arr[p+1].size;arr[p].state=0;for(i=p+1;i<*num;i++){arr[i]=arr[i+1];arr[i].no=arr[i].no-1;}*num=*num-1;}else if(arr[p-1].state==0) //上临区{arr[p-1].size=arr[p-1].size+arr[p].size;for(i=p;i<*num;i++){arr[i]=arr[i+1];arr[i].no=arr[i].no-1;}*num=*num-1;}else //无相邻分区{arr[p].state=0;}}。