hadoop完全分布式的搭建步骤
hadoop的安装与配置(完全分布式)

hadoop的安装与配置(完全分布式)完全分布式模式: 前⾯已经说了本地模式和伪分布模式,这两种在hadoop的应⽤中并不⽤于实际,因为⼏乎没⼈会将整个hadoop集群搭建在⼀台服务器上(hadoop主要是围绕:分布式计算和分布式存储,如果以⼀台服务器做,那就完全违背了hadoop的核⼼⽅法)。
简单说,本地模式是hadoop的安装,伪分布模式是本地搭建hadoop的模拟环境。
(当然实际上并不是这个样⼦的,⼩博主有机会给⼤家说!)那么在hadoop的搭建,其实真正⽤于⽣产的就是完全分布式模式:思路简介域名解析ssh免密登陆java和hadoop环境配置hadoop⽂件复制主节点到其他节点格式化主节点hadoop搭建过程+简介在搭建完全分布式前⼤家需要了解以下内容,以便于⼤家更好的了解hadoop环境:1.hadoop的核⼼:分布式存储和分布式计算(⽤官⽅的说法就是HDFS和MapReduce)2.集群结构:1+1+n 集群结构(主节点+备⽤节点+多个从节点)3.域名解析:这⾥为了⽅便,我们选择修改/etc/hosts实现域名解析(hadoop会在.../etc/hadoop/salves下添加从节点,这⾥需要解析名,当然你也能直接输⼊ip地址,更简单)4.hadoop的命令发放,需要从ssh接⼝登录到其他服务器上,所以需要配置ssh免密登陆5.本⽂采取1+1+3 集群⽅式:域名为:s100(主),s10(备主),s1,s2,s3(从)⼀:配置域名解析主——s100:[root@localhost ~]# vim /etc/hosts1127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain42 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain63192.168.1.68 s1004192.168.1.108 s15192.168.1.104 s26192.168.1.198 s37192.168.1.197 s10将s100上的/etc/hosts拷贝到其他hadoop的集群服务器上。
hadoop完全分布式配置过程详解

hadoop完全分布式配置过程详解Hadoop全分布搭建⼀.今⽇任务hadoop完全分布式系统搭建⼆.任务内容1.准备软件hadoop-2.6.0-cdh5.7.0.tar.gzjdk-8u161-linux-x64.tar.gzCentos-6.5VirtualBox-5.2.18-124319-Win.exe1. 配置过程第⼀步:配置免密登录1. 新建虚拟机,设置静态ip地址,主机名master,ip以及主机名映射1. 配置免密登陆1. 启动ssh服务Service sshd start1. 配置免密登录,更新公钥第⼆步:复制虚拟机,更改ip主机名和ip映射,分别配置56.2 主机名master,56.3 主机名 slaver1,56.4 主机名slaver2第三步:上传jdk和hadoop到 hadoop⽤户⽬录使⽤sftp上传jdk和hadoop的压缩包到hadoop⽤户⽬录下第四步:jdk和hadoop配置1. 解压⽂件1. 配置环境变量1. 配置hadoop⽂件1. core-site.xml2.hdfs-site.Xml1. mapred-site.xml1. Yarn-site.xml1. Slaver1. 将jdk和hadoop⽂件分发到slaver1 和slaver21. 在master格式化hdfs的namenode 并且启动hdfs,使⽤jps验证启动三.遇到问题1.复制虚拟机后需要⼀个个更改ip包括映射等2.配置好之后启动 slaver1 和slaver2 均没有Java环境,但是jdk已配好四.处理⽅式Slaver1 和slaver2 配置成功环境变量但是启动时提⽰没有java环境的问题,解决⽅式是在master配置好之后,启动时显⽰6个进程,表⽰master主机hadoop⽂件已经全部配置,然后使⽤远程将 master配置好的 hadoop⽂件分发到slaver1和slaver2总结:1. 此处配置主机名和ip映射时,直接将所有的全部配置,以便复制虚拟机时不需要继续修改2. 配置java环境时,确保系统本⾝没有已经安装好的jdk安装包,有则删除3. 配置好环境变量,需要使⽤ source使其⽣效4. 分发⽂件时,最好是将master配置好的hadoop⽂件分发过去,避免出现其他问题5. 启动成功后,master有5个进程,slaver都只有2个进程。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop2.8和Spark2.1完全分布式搭建详解_光环大数据培训

为 了方便管理这里在主目录建了三个文件夹:Java,spark,hadoop. mkdir Java spark hadoop 现在将 jdk,hadoop,scala,spark 的安装包分别传到路径 basePath/Java,basePath/hadoop,basePah/spark 下,(scala 和 spark 的压缩包都 放在 spark 文件夹下)。
静态 IP 设置: 但是其中有部分问题, 不知道是 16.0 和 14.0 版本差异的问题 还是教程本身的问题,一个是网络重启之后 DNS 配置丢失的问题。每次重启之后会发现配 置的 DNS 文件恢复成了 127.0.0.1
光环大数据
光环大数据--大数据培训知名品牌
这个问题是由于 interface,networkManager 两种网络管理冲突造成的。 解决方法就是在编辑链接的时候将 DNS 也一起编辑。这样就不用再编辑 DNS 的配置文件。 如下图所示:
其他步骤按博文所说就可以完成静态 IP 的配置。
第五步:hosts 配置, 特别强调主机名称不要含有下划线"_",最好是纯英 文。 因为 hadoopXML 配置的时候部分 value 不能有下划线,会报错。 第六步:SSH 免密码登录:
光环大数据
光环大数据--大数据培训知名品牌
为什么大家选择光环大数据!
大数据培训、 人工智能培训、 Python 培训、 大数据培训机构、 大数据培训班、 数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的 大数据领域知名讲师,确保教学的整体质量与教学水准。讲师团及时掌握时代潮 流技术,将前沿技能融入教学中,确保学生所学知识顺应时代所需。通过深入浅 出、通俗易懂的教学方式,指导学生更快的掌握技能知识,成就上万个高薪就业 学子。Hale Waihona Puke 2.辅助工具安装包:
hadoop2.2安装
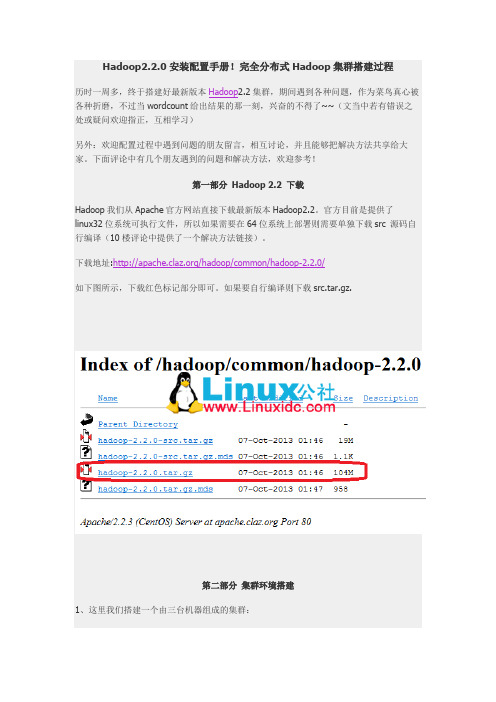
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
Hadoop完全分布式环境搭建

此处使用三个节点进行搭建集群环境,三个节点的IP分别为:192.168.170.128主机名为master192.168.170.129主机名为slave1192.168.170.130主机名为slave2一、修改主机名hostnameslave2。
二、修改主机--IP映射hosts文件左边是主机IP,右边是主机名.执行以下命令:修改每个节点/etc/hosts文件,加入以下内容:配置完后,需重启各节点使其生效。
三、安装SSH并配置各个节点间无密码登录SSh原理参考网址:/hujiapeng/p/5934711.html配置master节点无密码登录本机。
Ubuntu 默认已安装了SSH client,此外还需要安装SSH server:安装后,可以使用如下命令登陆本机:SSH首次登陆提示但这样登陆是需要每次输入密码的,我们需要配置成SSH无密码登陆比较方便。
再执行ssh localhost,就可以无密码登录本机。
同理,slave1、slave2节点都需要用上述步骤配置登录本机。
配置master与slave1无密码互登录:将master主机中的id_rsa.pub文件复制到slave1主机的id_rsa.pub.master文件(新生成的文将slave1主机的id_rsa.pub.master文件的内容追加到authorized_keys文件中验证master无密码登录slave1第一次登录时需要输入yes,然后无需输入密码即登录成功。
此后不需输入任何信息即可登录。
总之,想要在master上无密码登录slave1,只要将master的公钥追加到slave1的authorized_keys文件中即可。
如果想让master,slave1节点无密码互登录,需要在slave1中以同样的方式配置,即将slave1的公钥追加到master的authorized_keys文件中。
同理,需要配置master与slave2无密码互登录,slave1与slave2无密码互登录。
Hadoop2.7完全分布式搭建文档

Hadoop2.7 完全分布式搭建文档要想深入的学习hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,本文主要讲述如何搭建一套hadoop完全分布式集群环境。
环境配置:2台64位的redhat6.5 + 1台64位centos6.9 + Hadoop + java7一、先配置服务器的主机名Namenode节点对应的主机名为masterDatanode节点对应的主机名分别为node1、node21、在每一台服务器上执行vim /etc/hosts,先删除hosts里面的内容,然后追加以下内容:[html]view plaincopyprint?1.192.168.15.135 master2.172.30.25.165 node13.172.30.25.166 node22、在每一台服务器上执行vim /etc/sysconfig/network,修改红色部分的内容,对应上面所说的hostname,对于master节点那么hostname就为master[cpp]view plaincopyprint?WORKING=yes2.HOSTNAME= masterWORKING_IPV6=yes4.IPV6_AUTOCONF=no类似的,在node1服务器节点上应该为:[cpp]view plaincopyprint?WORKING=yes2.HOSTNAME= node1WORKING_IPV6=yes4.IPV6_AUTOCONF=no类似的,在node2服务器节点上应该为:[cpp]view plaincopyprint?WORKING=yes2.HOSTNAME= node2WORKING_IPV6=yes4.IPV6_AUTOCONF=no这两步的作用很关键,如果配置不成功,进行分布式计算的时候有可能找不到主机名二、安装SSH,并让master免验证登陆自身服务器、节点服务器1、执行下面命令,让master节点能够免验证登陆自身服务器[cpp]view plaincopyprint?1.ssh-keygen -t dsa -P'' -f ~/.ssh/id_dsa2.cat ~/.ssh/id_dsa.pub>> ~/.ssh/authorized_keys3.exportHADOOP\_PREFIX=/usr/local/hadoopHADOOP_PREFIX表示自己安装的hadoop路径2、让主结点(master)能通过SSH免密码登录两个子结点(slave)为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样当master就可以顺利安全地访问这两个slave结点了。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)

Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
CentOS7搭建hadoop2.7.3完全分布式(1)
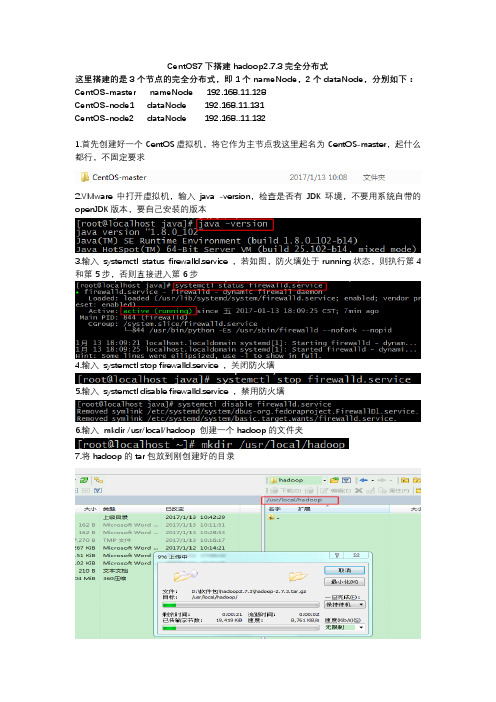
CentOS7下搭建hadoop2.7.3完全分布式这里搭建的是3个节点的完全分布式,即1个nameNode,2个dataNode,分别如下:CentOS-master nameNode 192.168.11.128CentOS-node1 dataNode 192.168.11.131CentOS-node2 dataNode 192.168..11.1321.首先创建好一个CentOS虚拟机,将它作为主节点我这里起名为CentOS-master,起什么都行,不固定要求2.VMware中打开虚拟机,输入java -version,检查是否有JDK环境,不要用系统自带的openJDK版本,要自己安装的版本3.输入systemctl status firewalld.service ,若如图,防火墙处于running状态,则执行第4和第5步,否则直接进入第6步4.输入systemctl stop firewalld.service ,关闭防火墙5.输入systemctl disable firewalld.service ,禁用防火墙6.输入mkdir /usr/local/hadoop 创建一个hadoop的文件夹7.将hadoop的tar包放到刚创建好的目录8.进入hadoop目录,输入 tar -zxvf hadoop-2.7.3.tar.gz 解压tar包9.输入vi /etc/profile ,配置环境变量10.加入如下内容,保存并退出HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3/PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin11.输入 . /etc/profile ,使环境变量生效12.任意目录输入hado ,然后按Tab,如果自动补全为hadoop,则说明环境变量配的没问题,否则检查环境变量哪出错了13.创建3个之后要用到的文件夹,分别如下:mkdir /usr/local/hadoop/tmpmkdir -p /usr/local/hadoop/hdfs/namemkdir /usr/local/hadoop/hdfs/data14.进入hadoop解压后的 /etc/hadoop 目录,里面存放的是hadoop的配置文件,接下来要修改这里面一些配置文件15.有2个.sh文件,需要指定一下JAVA的目录,首先输入 vi hadoop-env.sh 修改配置文件16.将原有的JAVA_HOME注释掉,根据自己的JDK安装位置,精确配置JAVA_HOME如下,保存并退出export JAVA_HOME=/usr/local/java/jdk1.8.0_102/17.输入 vi yarn-env.sh 修改配置文件18.加入如下内容,指定JAVA_HOME,保存并退出export JAVA_HOME=/usr/local/java/jdk1.8.0_10219.输入 vi core-site.xml 修改配置文件20.在configuration标签中,添加如下内容,保存并退出,注意这里配置的hdfs:master:9000是不能在浏览器访问的<property><name> </name><value>hdfs://master:9000</value><description>指定HDFS的默认名称</description></property><property><name>fs.defaultFS</name><value>hdfs://master:9000</value><description>HDFS的URI</description></property><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop/tmp</value><description>节点上本地的hadoop临时文件夹</description> </property>21.输入 vi hdfs-site.xml 修改配置文件22.在configuration标签中,添加如下内容,保存并退出<property><name>.dir</name><value>file:/usr/local/hadoop/hdfs/name</value><description>namenode上存储hdfs名字空间元数据 </description></property><property><name>dfs.datanode.data.dir</name><value>file:/usr/local/hadoop/hdfs/data</value><description>datanode上数据块的物理存储位置</description></property><property><name>dfs.replication</name><value>1</value><description>副本个数,默认是3,应小于datanode机器数量</description></property>23.输入 cp mapred-site.xml.template mapred-site.xml 将mapred-site.xml.template 文件复制到当前目录,并重命名为mapred-site.xml24.输入 vi mapred-site.xml 修改配置文件25.在configuration标签中,添加如下内容,保存并退出<property><name>mapred.job.tracker</name><value>hadoop-master:9001</value><description>change your own hostname</description></property><property><name></name><value>yarn</value><description>指定mapreduce使用yarn框架</description></property>26.输入 vi yarn-site.xml 修改配置文件27.在configuration标签中,添加如下内容,保存并退出<property><name>yarn.resourcemanager.hostname</name><value>master</value><description>指定resourcemanager所在的hostname</description> </property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>NodeManager上运行的附属服务。
hadoop2.4.0完全分布式集群搭建-电脑资料

hadoop2.4.0完全分布式集群搭建-电脑资料新版本日志系统预计存储在TB级别,并且需要统计分析一些数据(离线统计,非即时),所以选择廉价linux服务器搭建一个hadoop集群,1个namenode,1个resourcemanager(mapreduce新框架yarn,去掉了原来的jobtracker和tasktracker,取而代之的是ResourceManager,ApplicationMaster与NodeManager),3个datanonde,1.配置hosts各linux版本hosts文件位置可能不同,我的是在/etc/hosts,在master上编辑之:172.17.0.1master172.17.0.2resorucemanager172.17.0.3datanode1172.17.0.4datanode2172.17.0.5datanode3然后copy到其余四台服务器,然后分别执行/bin/hostsnamehostsname例如:master上执行/bin/hostsnamemaster,使之生效。
2.配置ssha.创建hadoop用户注意:hadoop有两种运行模式,安全模式和非安全模式。
安装模式是以指定在健壮的,基于身份验证上运行的,如果无需运行在非安全模式下,可以直接使用root用户。
运行进程hdfs:hadoopNameNode,SecondaryNameNode,CheckpointNode,Bac kupNode,DataNodeyarn:hadoopResourceManager,NodeManagermapre d:hadoopMapReduceJobHistoryServer首先在master主机上创建用户hdfs,执行操作:groupaddhadoopuseradd-ghadoophdfs然后在其余四台服务器上创建用户yarn,执行操作:groupaddhadoopuseradd-ghadoopyarn最后在MapReduceJobHistory服务器上(我的为resourcemanager)创建用户mapredgroupaddhadoopuseradd-ghadoopmapredb.配置master无密码ssh各服务器在master执行操作:suhdfsssh-keygen-trsa,然后一直回车在/home/hdfs/.ssh/目录下生成了两个文件id_rsa和id_rsa.pubcatid_rsa.pub>./authorized_keys然后复制到其他服务器(若没有.ssh文件夹需要自行创建)scpauthorized_keysyarn@resourcemanager:/home/yarn/.ssh/scpauthorized_keysmapred@resourcemanager:/home/yarn/.ssh /scpauthorized_keysyarn@datanode1:/home/yarn/.ssh/scpauthorized_keysyarn@datanode2:/home/yarn/.ssh/scpauthorized_keysyarn@datanode3:/home/yarn/.ssh/验证能否无密码ssh,在master服务器上执行操作:sshhdfs@mastersshyarn@resourcemanagersshmapred@resourcemanagersshyarn@datanode1sshyarn@datanode2sshyarn@datanode3注意:第一次可能会提示输入yesorno,之后就可以直接ssh到其他主机上去了。
hadoop完全分布式搭建步骤

Hadoop是一个开源的分布式计算框架,它能够处理大规模数据的存储和处理。
本文将介绍如何搭建Hadoop完全分布式集群。
一、准备工作1. 安装Java环境:Hadoop需要Java环境的支持,因此需要先安装Java环境。
2. 下载Hadoop:从官网下载Hadoop的最新版本。
3. 配置SSH:Hadoop需要通过SSH进行节点之间的通信,因此需要配置SSH。
二、安装Hadoop1. 解压Hadoop:将下载好的Hadoop压缩包解压到指定目录下。
2. 配置Hadoop环境变量:将Hadoop的bin目录添加到系统的PATH环境变量中。
3. 修改Hadoop配置文件:进入Hadoop的conf目录,修改hadoop-env.sh文件和core-site.xml 文件。
4. 配置HDFS:修改hdfs-site.xml文件,设置NameNode和DataNode的存储路径。
5. 配置YARN:修改yarn-site.xml文件,设置ResourceManager和NodeManager的地址和端口号。
6. 配置MapReduce:修改mapred-site.xml文件,设置JobTracker和TaskTracker的地址和端口号。
7. 格式化HDFS:在NameNode所在的节点上执行格式化命令:hadoop namenode -format。
8. 启动Hadoop:在NameNode所在的节点上执行启动命令:start-all.sh。
三、验证Hadoop集群1. 查看Hadoop进程:在NameNode所在的节点上执行jps命令,查看Hadoop进程是否启动成功。
2. 查看Hadoop日志:在NameNode所在的节点上查看Hadoop的日志文件,确认是否有错误信息。
3. 访问Hadoop Web界面:在浏览器中输入NameNode的地址和端口号,访问HadoopWeb界面,确认Hadoop集群是否正常运行。
Hadoop完全分布式详细安装过程

Hadoop详细安装过程一、本文思路1、安装虚拟化PC工具VMware,用于支撑Linux系统。
2、在VMware上安装Ubuntu系统。
3、安装Hadoop前的准备工作:安装JDK和SSH服务。
4、配置Hadoop。
5、为了方便开发过程,需安装eclipse。
6、运行一个简单的Hadoop程序:WordCount.java注:在win7系统上,利用虚拟工具VMware建立若干个Linux系统,每个系统为一个节点,构建Hadoop集群。
先在一个虚拟机上将所有需要配置的东西全部完成,然后再利用VMware 的克隆功能,直接生成其他虚拟机,这样做的目的是简单。
二、所需软件1、VMware:VMware Workstation,直接百度下载(在百度软件中心下载即可)。
2、Ubuntu系统:ubuntu-15.04-desktop-amd64.iso,百度网盘:/s/1qWxfxso注:使用15.04版本的Ubuntu(其他版本也可以),是64位系统。
3、jdk:jdk-8u60-linux-x64.tar.gz,网址:/technetwork/java/javase/downloads/jdk8-downloads-2133151.html注:下载64位的Linux版本的jdk。
4、Hadoop:hadoop-1.2.1-bin.tar.gz,网址:/apache/hadoop/common/hadoop-1.2.1/注:选择1.2.1版本的Hadoop。
5、eclipse:eclipse-java-mars-1-linux-gtk-x86_64.tar.gz,网址:/downloads/?osType=linux注:要选择Linux版本的,64位,如下:6、hadoop-eclipse-plugin-1.2.1.jar,这是eclipse的一个插件,用于Hadoop的开发,直接百度下载即可。
三、安装过程1、安装VMware。
完全分布式和伪分布式

完全分布式和伪分布式
完全分布式和伪分布式是Hadoop集群的两种运行模式。
伪分布式集群、完全分布式搭建步骤详情:
1.伪分布式模式介绍:特点是在一台机器上安装,使用的是分布式思想,即分布式文件系统,非本地文件系统。
Hdfs 涉及到的相关守护进程都运行在一台机器上,都是独立的java进程。
用途比Standalone mode 多了代码调试功能,允许检查内存使用情况,以及其他的守护进程交互。
2.完全分布式介绍:完全分布式和伪分布式类似,区别在于伪分布式只有一个节点,然而完全分布式可以有多个节点,各节点的配置相同.完全分布式的部署如下更改数据持久物理层目录高可用namenode分散datanode格式化namenode启动集群验证进程启动WEB UI。
Hadoop2.7.3完全分布式集群搭建_光环大数据培训

Hadoop2.7.3完全分布式集群搭建_光环大数据培训光环大数据培训认为,集群如下:192.168.188.111 master192.168.188.112 slave1192.168.188.113 slave2一、环境配置1.修改hosts和hostname以master为例:修改hosts[[email protected] ~]# vim /etc/hosts192.168.188.111 master192.168.188.112 slave1192.168.188.113 slave2修改hostname[[email protected] ~]# vim /etc/hostname同样地,在slave1和slave2做相同的hostname操作,分别命名为slave1和slave2.然后分别把slave1和slave2的hosts文件更改为和master一样。
2.配免密登录次文章重点不在配免密登录,所有略,可以看其他博客。
3.配置环境变量[[email protected] ~]# vim /etc/profile#javaexport JAVA_HOME=/root/package/jdk1.8.0_121export PATH=$PATH:$JAVA_ HOME/bin#sparkexport SPARK_HOME=/root/package/spark-2.1.0-bin-hadoop2.7e xport PATH=$PATH:$SPARK_HOME/bin#ANACONDAexport ANACONDA=/root/anaconda2 export PATH=$PATH:$ANACONDA/bin#HADOOPexport HADOOP_HOME=/root/package/h adoop-2.7.3export HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HO ME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport YARN_HOME=$HAD OOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/nativeexpor t PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/binexport HADOOP_INSTALL=$HA DOOP_HOME输入source /etc/profile 使配置文件生效。
Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署

Hadoop2.7.3+Hbase-1.2.6完全分布式安装部署Hadoop安装部署基本步骤:1、安装jdk,配置环境变量。
jdk可以去⽹上⾃⾏下载,环境变量如下:编辑 vim /etc/profile ⽂件,添加如下内容:export JAVA_HOME=/opt/java_environment/jdk1.7.0_80(填写⾃⼰的jdk安装路径)export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jarexport PATH=$PATH:$JAVA_HOME/bin输⼊命令,source /etc/profile 使配置⽣效分别输⼊命令,java 、 javac 、 java -version,查看jdk环境变量是否配置成功2、linux环境下,⾄少需要3台机⼦,⼀台作为master,2台(以上)作为slave。
这⾥我以3台机器为例,linux⽤的是CentOS 6.5 x64为机器。
master 192.168.172.71slave1 192.168.172.72slave2 192.168.172.733、配置所有机器的hostname和hosts。
(1)更改hostname,可以编辑 vim /etc/sysconfig/network 更改master的HOSTNAME,这⾥改为HOSTNAME=master 其它slave为HOSTNAME=slave1、HOSTNAME=slave2 ,重启后⽣效。
或者直接输: hostname 名字,更改成功,这种⽅式⽆需重启即可⽣效, 但是重启系统后更改的名字会失效,仍是原来的名字 (2)更改host,可以编辑 vim /etc/hosts,增加如下内容: 192.168.172.71 master 192.168.172.72 slave1 192.168.172.73 slave2 hosts可以和hostname不⼀致,这⾥为了好记就写⼀致了。
Hadoop分布式文件系统的配置与使用教程

Hadoop分布式文件系统的配置与使用教程Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)是一种适用于大数据处理的可靠、安全且高扩展性的分布式文件系统。
它能够将大容量的数据分散存储在集群的多台计算机上,并提供高效的数据访问方式。
本文将为您提供关于Hadoop 分布式文件系统的配置和使用教程。
**1. 配置Hadoop集群**首先,我们需要准备一个Hadoop集群,该集群包括主节点和若干个从节点。
主节点负责协调和管理整个集群,而从节点则负责存储和处理数据。
2. 安装Hadoop在配置Hadoop集群之前,我们需要将Hadoop安装在每个节点上。
您可以从Hadoop官方网站下载最新版本的Hadoop。
下载完成后,解压缩文件并将其移动到您选择的安装目录。
3. 配置Hadoop集群文件在配置Hadoop集群之前,您需要对一些配置文件进行修改。
这些配置文件位于Hadoop的安装目录中的“etc/hadoop”文件夹中。
以下是一些需要注意的主要配置文件:- core-site.xml: 设置Hadoop核心属性,如HDFS的命名节点和文件系统的URI。
- hdfs-site.xml: 配置HDFS的属性,如数据块大小、副本数量等。
- mapred-site.xml:配置Hadoop MapReduce属性,如MapReduce框架的任务分配方式等。
- yarn-site.xml:配置Hadoop资源管理器(YARN)属性,如内存和CPU分配等。
配置完成后,将这些文件复制到Hadoop集群的每个节点。
4. 格式化文件系统在配置完成后,我们需要格式化HDFS文件系统以准备存储数据。
在主节点上, 打开终端并使用以下命令格式化文件系统:```hadoop namenode -format```5. 启动Hadoop集群在所有节点上启动Hadoop集群。
首先进入Hadoop的安装目录并输入以下命令:```start-dfs.sh```这个命令将启动HDFS服务。
Hadoop完全分布式搭建

Hadoop完全分布式搭建⼀、安装⼀台全新的Redhat 。
⼆、更改静态IP地址(1)获取本机IP地址,ifconfig -a(2) 更改hosts ⽂件vim /etc/hosts(3)更改hostnamevim /etc/sysconfig/network(4)配置静态IP地址vim /etc/sysconfig/network-scripts/ifcfg-ethx(5)重启⽹络服务使其⽣效service network restart三、安装JDK(1)查询Redhat本机jdkrpm -qa | grep jdkrpm -e --nodeps jdk(2)安装jdk通过此页⾯下载Linux版本jdk,并上传⾄虚拟机内tar -xzvf jdk 1.8.0(3)配置JDK环境在Linux 根⽬录下新建soft ⽂件夹,并将tar开的jdk剪切到soft ⽂件夹cd /mkdir softmv jdk /softln -s jdk-1.8 jdk配置/etc/profilevim /etc/profile--插⼊环境变量export JAVA_HOME=/soft/jdkexport PATH=$PATH:$JAVA_HOME/bin--使其⽴即⽣效source /etc/profile(4)检验 JDK是否安装成功四、克隆虚拟机配置从机IP地址使其IP互通通过master 克隆三台Redhat 机器,并修改其IP地址与hostname信息,其四台机器分别为master 、slave1 、slave2 、slave3。
直⾄四台机器IP互通为⽌。
因完全克隆导致三台从机slave可能本⾝⽹卡信息可能会与master⼀致,导致IP地址修改不成功,可以通过以下⽅法解决。
通过ifconfig -a 命令查询从机IP信息,master机器为eth0 ,⽽从机为eth1,在slave从机上,通过root ⽤户删除 /etc/sysconfig/network-scripts/ifcfg-eth0 ⽂件,复制ifconfig -a 中从机⽹卡的HWADDR字符串并复制ifcfg-lo⽂件,重命名为⽹卡ifcfg-eth1,编辑其内容将⽹络信息写⼊其中将HWADDR值加⼊进⼊后重启⽹络服务即可。
hadoop完全分布式搭建wp.
hadoop完全分布式搭建详解前期准备:准备需要的软件(环境)。
hadoop-1.0.4为最稳定版本之一,利于学习时使用。
hadoop由java语言开发需要java环境,必须安装jdk。
使用redHat与vmwareWorkStation搭建虚拟机环境。
使用scrt71-x64多客户端远程登陆服务器。
winscp424可视化界面windows与linux的文件操作。
配置虚拟机:解压安装redHat与vmwareWorkStation。
使用Mware打开redHat,选择对应目录的文件,如下图:启动虚拟机,如下图:虚拟机基础配置修改Network为NAT方式登录虚拟机,防止ip动态变化。
配置网卡信息,使用eth0为我们的第一张网卡。
删除原来的eth0,修改下面的eth1为eth0,复制下面椭圆中的mac地址,配置ip时使用。
配置静态ip,重启虚拟机时ip不变动。
注意:根据对应的ip网段修改红框里面信息(我的是.168.248.0),HWADDR为我们刚才复制的mac重启网络服务查看ip与网卡,我们发现网卡还是eth1,但是ip地址发生了改变。
更新网卡信息,使用reboot。
我们这里就不给大家截图了,网卡肯定是变成eth0了。
先关闭当前系统防火墙,使用root才行。
配置完全关闭防火墙,重启不开启。
查看防火墙信息,现在是init 5,启动时全部关掉吧设置防火墙开机为自动关闭。
安装jdk、hadoop并配置环境变量。
使用winscp在/usr目录下创建hadoop目录并导入,下图两个文件这里注意说明一点,请选择二进制形式传文件,查看文件,注意配置权限,否则执行不了。
开始解压复制此目录准备配置环境变量配置如下图红框内,后面的为hadoop的环境变量,注意:等于windows下的;验证配置成功,注意需要source激活环境变量解压hadoop,环境变量已经配置成功1. 创建主机名、hadoop账号和无密钥ssh登陆。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop完全分布式的搭建步骤
步骤目录:
第一步:安装虚拟机
第二步:Linux的环境配置
第三步:安装jdk并配置环境变量
第四步:建立专门运行Hadoop的专有用户abc 第五步:ssh免密码登录配置
第六步:Hadoop的安装与配置
第七步:格式化hdfs和启动守护进程
详细步骤如下
第一步:安装虚拟机
第二步:Linux的环境配置
1.修改IP(桥接模式)
vim /etc/sysconfig/network-scriptps/ifcfg-eth0
(推荐使用手动的方法设置)
2.修改主机名
vim /etc/sysconfig/network
3.修改主机名和IP的映射关系
vim /etc/hosts
192.168.6.115 hadoop01
192.168.6.116 hadoop02
192.168.6.117 hadoop03
4.关闭防火墙
service iptables status//查看状态
service iptables stop//关闭防火墙
chkconfig iptables --list //查看防火墙是否开机自启
chkconfig iptables off//关闭防火墙开机自启
5.重启系统
reboot
6.查看主机名:hostname
查看IP:ifconfig
查看防火墙状态:service iptables status
7.查看各个主机之间是否能通信:互相ping IP地址
第三步:安装jdk并配置环境变量
1.上传jdk到根目录
2.创建目录mkdir /usr/java
3.解压jdk
tar –zxvf jdk-7u76-linux-i586.tar.gz –C /usr/java
cd /usr/java
ls
4.将Java添加到环境变量(使得在任何目录下均可使用Java)
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_76
export PATH=$PATH:$JAVA_HOME/bin
Esc+shift+zz//保存并退出
source /etc/profile//刷新
java –version//在任何目录查看Java版本信息
注意:配置好后一定要删除Linux系统先前自带的jdk,具体步骤如下:
安装好的CentOS会自带OpenJdk,用命令 java -version ,会有下面的信息:
java version "1.6.0"
OpenJDK Runtime Environment (build 1.6.0-b09)
OpenJDK 64-Bit Server VM (build 1.6.0-b09, mixed mode) (最好还是先卸载掉openjdk,在安装sun公司的jdk.)
先查看 rpm -qa | grep java
显示如下信息:
java-1.4.2-gcj-compat-1.4.2.0-40jpp.115
java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5
卸载:
rpm -e --nodeps java-1.4.2-gcj-compat-1.4.2.0-
40jpp.115
rpm -e --nodeps java-1.6.0-openjdk-1.6.0.0-1.7.b09.el5 还有一些其他的命令
rpm -qa | grep gcj
rpm -qa | grep jdk
如果出现找不到openjdk source的话,那么还可以这样卸载yum –y remove java java-1.4.2-gcj-compat-1.4.2.0-
40jpp.115
yum –y remove java java-1.6.0-openjdk-1.6.0.0-
1.7.b09.el5
第四步:建立专门运行Hadoop的专有用户abc
useradd abc
passwd abc//给用户abc加密
第五步:ssh免密码登录配置
注意:每个节点都用abc用户登录,在abc用户的目录下进行操作,每个节点做以下相同操作。
ssh-keygen –t rsa//连续三次回车,选择默认的保存路径
cd .ssh/
cp id_rsa.pub authorized_keys
scp .ssh/authorized_keys abc@hadoop02:~/.ssh//把各个节点的authorized_keys的内容互相拷贝加入到对方的此文件中
cat id_rsa.pub >> ~/.ssh/ authorized_keys
chmod 644 .ssh/ authorized_keys//给authorized_keys文件的所有者赋予读和写的权限
ssh hadoop01//免密码登录自己
第六步:Hadoop的安装与配置
1.注意一定要用hadoop01的abc用户登录Filezilla把hadoop-
2.2.0压缩包上传到该用户目录下(/home/abc)
2.解压 tar –zxvf hadoop-2.2.0.tar.gz
3.将hadoop添加到环境变量,使得在任何目录下均可运行hadoop
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_76
export HADOOP_HOME=/home/abc/hadoop-2.2.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
source /etc/profile//刷新
4.修改hadoop-env.sh文件
export JAVA_HOME=/usr/java/jdk1.7.0_76(第27行插入)
5.修改core-site.xml文件
6.修改hdfs-site.xml文件
7.修改mapred-site.xml文件(先前没有该文件,要把mapred-site.xml.template修改为mapred-site.xml。
命令是mv mapred-site.xml.template mapred-site.xml)
8.修改yarn-site.xml文件
9.修改slaves文件(记录datanode)
hadoop02
hadoop03
10.修改masters文件(记录namenode)
Hadoop01
11.配置好Hadoop之后,将Hadoop整个安装文件夹通过scp命令分别拷贝到hadoop02和hadoop03主机上面去,设置都不需要更改。
执行以下命令:
scp –r ./hadoop-2.2.0 abc@hadoop02:/home/abc
scp –r ./hadoop-2.2.0 abc@hadoop03:/home/abc
第七步:格式化分布式文件系统(HDFS)和启动守护进程(用namenode节点进行操作)
1.格式化hdfs命令:bin/hadoop namenode –format
2.启动hdfs命令:cd hadoop-2.2.0/sbin
./start-all.sh
3.在namenode终端下执行jps如果有namenode和resourcemanager进程,则hadoop01就安装好了。
在hadoop02和hadoop03终端下执行jps,如果有datanode和nodemanager进程,则hadoo02和hadoop03就安装好了。
4.一些常用的hdfs命令:
上传文件到hdfs:hadoop fs –put /root/jdk7u76-linux-i586.tar.gz hdfs://hadoop01:9000/jdk
查看已上传的文件:hadoop fs –ls hdfs://hadoop01:9000/ 下载已上传的文件:hadoop fs –get hdfs://hadoop01:900/jdk /home/jdk1.7
查看集群状态:bin/hdfs dfsadmin –report
查看文件块组成:bin/hdfs fsck / -files –blocks
查看HDFS的管理界面:http://192.168.5.115:50070
查看yarn管理界面:http://192.168.5.115:8088
查看namenode的端口监听情况:netstat –an | grep 9000 查看namenode是否处于安全模式:hadoop dfsadmin –safemode get
使得namenode进入安全模式:hadoop dfsadmin –safemode enter
使得namenode离开安全模式:hadoop dfsadmin –safemode leave。