cache缓存淘汰算法--LRU算法
lru近似淘汰算法

lru近似淘汰算法1.引言1.1 概述近似淘汰算法是一种用于缓存管理的重要技术,其中最受欢迎和广泛使用的算法之一就是LRU(Least Recently Used)算法。
LRU算法的基本原理是根据最近使用的时间来决定何时淘汰掉缓存中的数据。
在计算机科学领域,缓存是一种用于存储临时数据的高速存储器。
由于其读写速度快、响应时间低等特点,缓存被广泛应用于各种系统中,如操作系统、数据库系统和网络应用等。
然而,缓存的大小是有限的,所以当缓存已满时,就需要采取一种淘汰策略来替换掉一部分旧的数据,以便为新的数据腾出空间。
LRU算法的思想是,当需要淘汰数据时,选择最近最久未使用的数据进行替换。
其基本操作是通过维护一个用于排序访问顺序的链表或者双向队列来实现的。
每当访问一个数据时,该数据就会被移动到链表的头部或者队列的头部,以表示这是最近被使用的数据。
当需要淘汰数据时,只需要将链表或者队列的尾部数据替换掉即可。
LRU近似淘汰算法相比于其他淘汰策略具有一些独特的优势。
首先,LRU算法能够充分利用最近的访问模式,因此能够相对准确地判断哪些数据是频繁访问的。
其次,LRU算法具有较高的缓存命中率,即能够更有效地将经常访问的数据保留在缓存中,从而提高系统的性能和响应速度。
另外,LRU算法的实现相对简单,容易理解和调试,因此广泛应用于实际系统中。
综上所述,本文将对LRU近似淘汰算法进行详细的介绍和探讨。
首先,将解释LRU算法的原理和基本操作。
然后,将探讨LRU近似淘汰算法相比其他淘汰策略的优势和适用性。
最后,将总结该算法的重要性和应用前景。
通过对LRU近似淘汰算法的深入理解,我们能够更好地应用该算法来提升系统的性能和效率。
文章结构部分的内容可以按照以下方式来撰写:1.2 文章结构本文将按照以下结构来展开介绍LRU近似淘汰算法:第一部分为引言,旨在概述本文的背景和目的。
首先,我们将对LRU 算法进行简要介绍,阐述其原理和应用场景。
Caffeine和CompleteFuture实际应用总结

Caffeine和CompleteFuture实际应⽤总结⽬录⼀.Caffeine 原理1.1 常见缓存淘汰算法FIFO:先进先出,在这种淘汰算法中,先进⼊缓存的会先被淘汰,会导致命中率很低。
LRU:最近最少使⽤算法,每次访问数据都会将其放在我们的队尾,如果需要淘汰数据,就只需要淘汰队⾸即可。
LFU:最近最少频率使⽤,利⽤额外的空间记录每个数据的使⽤频率,然后选出频率最低进⾏淘汰。
这样就避免了 LRU 不能处理时间段的问题。
1.2 LRU和LFU缺点:LRU 实现简单,在⼀般情况下能够表现出很好的命中率,是⼀个“性价⽐”很⾼的算法,平时也很常⽤。
虽然 LRU 对突发性的稀疏流量(sparse bursts)表现很好,但同时也会产⽣缓存污染,举例来说,如果偶然性的要对全量数据进⾏遍历,那么“历史访问记录”就会被刷⾛,造成污染。
如果数据的分布在⼀段时间内是固定的话,那么 LFU 可以达到最⾼的命中率。
但是 LFU 有两个缺点,第⼀,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨⼤的开销;第⼆,对突发性的稀疏流量⽆⼒,因为前期经常访问的记录已经占⽤了缓存,偶然的流量不太可能会被保留下来,⽽且过去的⼀些⼤量被访问的记录在将来也不⼀定会使。
1.3 W-TinyLFU 算法:TinyLFU 算法:解决第⼀个问题是采⽤了 Count–Min Sketch 算法。
为了解决 LFU 不便于处理随时间变化的热度变化问题,TinyLFU 采⽤了基于 “滑动时间窗” 的热度衰减算法,简单理解就是每隔⼀段时间,便会把计数器的数值减半,以此解决 “旧热点” 数据难以清除的问题。
W-TinyLFU算法:W-TinyLFU(Windows-TinyLFU):W-TinyLFU ⼜是 TinyLFU 的改进版本。
TinyLFU 在实现减少计数器维护频率的同时,也带来了⽆法很好地应对稀疏突发访问的问题,所谓稀疏突发访问是指有⼀些绝对频率较⼩,但突发访问频率很⾼的数据,此时 TinyLFU 就很难让这类元素通过 Sketch 的过滤,因为它们⽆法在运⾏期间积累到⾜够⾼的频率。
cache的lru 算法和plru算法

cache的lru 算法和plru算法LRU(Least Recently Used)算法和PLRU(Pseudo-Least Recently Used)算法是常用于缓存系统中的两种替换策略。
缓存是计算机系统中的重要组成部分,它用于临时存储常用数据,以提高系统的性能和响应速度。
LRU算法和PLRU算法能够有效地管理缓存中的数据,优化缓存的使用和替换,从而提高系统的效率。
LRU算法是一种基于时间局部性原理的替换策略。
它的基本思想是,当需要替换缓存中的数据时,选择最近最少使用的数据进行替换。
具体实现方式是通过维护一个访问时间的队列,每当数据被访问时,将其移动到队列的末尾。
当缓存满时,将队列头部的数据替换出去。
这样,最近最少使用的数据就会被优先替换,从而保证了缓存中的数据都是被频繁访问的。
然而,LRU算法的实现需要维护一个访问时间队列,当缓存的大小较大时,这个队列会占用较大的内存空间。
为了解决这个问题,PLRU算法应运而生。
PLRU算法是一种基于二叉树的替换策略,它通过使用多个位来表示缓存中数据的访问情况。
具体来说,PLRU 算法将缓存中的数据按照二叉树的形式组织起来,每个节点代表一个数据块。
当需要替换数据时,PLRU算法会根据节点的位状态来确定替换的路径,最终找到最久未被访问的数据进行替换。
相比于LRU算法,PLRU算法的优势在于它不需要维护一个访问时间队列,从而减少了内存开销。
而且,PLRU算法的查询和更新操作都可以在O(1)的时间复杂度内完成,具有较高的效率。
然而,PLRU算法的实现相对复杂,需要使用位运算等技术,对硬件的要求较高。
在实际应用中,选择LRU算法还是PLRU算法需要根据具体的场景和需求来决定。
如果缓存的大小较小,内存开销不是主要问题,那么可以选择LRU算法。
而如果缓存的大小较大,对内存的消耗比较敏感,那么可以选择PLRU算法。
另外,还可以根据实际情况结合两种算法的优点,设计出更加高效的替换策略。
Redis缓存的LRU与LFU算法实现与性能对比

Redis缓存的LRU与LFU算法实现与性能对比缓存是提升系统性能和响应速度的重要组成部分。
Redis是一个高性能的键值存储系统,常用于缓存数据。
在Redis中,LRU(最近最少使用)和LFU(最不经常使用)是两种常见的缓存淘汰算法,用于确定哪些数据应该被从缓存中移除。
本文将对Redis缓存的LRU和LFU算法进行实现和性能对比。
一、LRU算法的实现LRU(最近最少使用)算法是根据数据的访问时间进行淘汰的一种缓存淘汰算法。
实现LRU算法的一种常见方式是使用双向链表和哈希表的结合。
具体实现如下:```1. 设置一个双向链表用于存储缓存的键值对,链表头部为最近被访问的数据,尾部为最近最少被访问的数据。
2. 设置一个哈希表用于存储缓存的键和对应的节点在链表中的位置。
3. 当需要访问一个键值对时,按照以下步骤进行操作:- 如果键存在于哈希表中,则将对应的节点移到链表头部,并返回节点的值。
- 如果键不存在于哈希表中,则返回null。
4. 当需要插入一个键值对时,按照以下步骤进行操作:- 如果键存在于哈希表中,则将对应的节点移到链表头部,并更新节点的值。
- 如果键不存在于哈希表中,则进行以下操作:- 如果缓存已满,则删除链表尾部的节点,并从哈希表中删除对应的键。
- 创建一个新的节点,并将其添加到链表头部,同时将键值对存储到哈希表中。
```二、LFU算法的实现LFU(最不经常使用)算法是根据数据的访问频率进行淘汰的一种缓存淘汰算法。
实现LFU算法的一种常见方式是使用哈希表和最小堆的结合。
具体实现如下:```1. 设置一个哈希表用于存储缓存的键和对应的节点。
2. 设置一个最小堆用于存储缓存的节点,堆顶节点表示访问频率最低的数据。
3. 当需要访问一个键值对时,按照以下步骤进行操作:- 如果键存在于哈希表中,则更新节点的访问频率,并调整最小堆中节点的位置,并返回节点的值。
- 如果键不存在于哈希表中,则返回null。
LRU算法C语言实现

LRU算法C语言实现LRU(Least Recently Used)算法是一种常见的缓存替换算法,它根据数据最近被访问的时间进行缓存替换。
当缓存满时,LRU算法将替换最长时间未被访问的数据。
下面是使用C语言实现LRU算法的代码:```c#include <stdio.h>#include <stdlib.h>typedef struct nodeint key;int value;struct node *prev;struct node *next;} Node;typedef struct lru_cacheint capacity;int count;Node *head;Node *tail;Node **hashmap;} LRUCache;LRUCache *createCache(int capacity)LRUCache *cache = (LRUCache *)malloc(sizeof(LRUCache)); cache->capacity = capacity;cache->count = 0;cache->head = NULL;cache->tail = NULL;cache->hashmap = (Node **)malloc(sizeof(Node *) * capacity); // 初始化hashmap为NULLfor (int i = 0; i < capacity; i++)cache->hashmap[i] = NULL;}return cache;void addNodeToHead(LRUCache *cache, Node *node)//将节点添加到链表头部node->next = cache->head;node->prev = NULL;if (cache->head != NULL)cache->head->prev = node;}cache->head = node;if (cache->tail == NULL)cache->tail = node;}void removeNode(LRUCache *cache, Node *node) //移除节点if (node->prev != NULL)node->prev->next = node->next;} elsecache->head = node->next;}if (node->next != NULL)node->next->prev = node->prev;} elsecache->tail = node->prev;}void moveToHead(LRUCache *cache, Node *node)//将节点移动到链表头部removeNode(cache, node);addNodeToHead(cache, node);void removeTail(LRUCache *cache)//移除链表尾部的节点if (cache->tail != NULL)Node *node = cache->tail;cache->tail = node->prev;if (node->prev != NULL)node->prev->next = NULL;} elsecache->head = NULL;}free(node);}int get(LRUCache *cache, int key)//根据键值获取缓存值,并将节点移动到链表头部int hash = abs(key) % cache->capacity;Node *node = cache->hashmap[hash];while (node != NULL)if (node->key == key)moveToHead(cache, node);return node->value;}node = node->next;}//如果节点不存在,返回-1return -1;void put(LRUCache *cache, int key, int value)//添加或更新缓存键值对int hash = abs(key) % cache->capacity;Node *node = cache->hashmap[hash];//如果缓存中已存在该键值对,更新节点的值并移动到链表头部while (node != NULL)if (node->key == key)node->value = value;moveToHead(cache, node);return;}node = node->next;}// 如果缓存已满,移除链表尾部的节点,同时更新hashmap if (cache->count >= cache->capacity)int tailKey = cache->tail->key;removeTail(cache);cache->hashmap[abs(tailKey) % cache->capacity] = NULL; cache->count--;}// 创建新的节点,并添加到链表头部和hashmapNode *newNode = (Node *)malloc(sizeof(Node)); newNode->key = key;newNode->value = value;newNode->prev = NULL;newNode->next = NULL;addNodeToHead(cache, newNode);cache->hashmap[hash] = newNode;cache->count++;void destroyCache(LRUCache *cache)//销毁缓存Node *node = cache->head;while (node != NULL)Node *temp = node;node = node->next;free(temp);}free(cache->hashmap);free(cache);```上述代码中,我们定义了两个数据结构,`Node`表示缓存中的节点,`LRUCache`表示整个缓存。
LRU算法原理解析

LRU算法原理解析LRU是Least Recently Used的缩写,即最近最少使⽤,常⽤于页⾯置换算法,是为虚拟页式存储管理服务的。
现代操作系统提供了⼀种对主存的抽象概念虚拟内存,来对主存进⾏更好地管理。
他将主存看成是⼀个存储在磁盘上的地址空间的⾼速缓存,在主存中只保存活动区域,并根据需要在主存和磁盘之间来回传送数据。
虚拟内存被组织为存放在磁盘上的N个连续的字节组成的数组,每个字节都有唯⼀的虚拟地址,作为到数组的索引。
虚拟内存被分割为⼤⼩固定的数据块虚拟页(Virtual Page,VP),这些数据块作为主存和磁盘之间的传输单元。
类似地,物理内存被分割为物理页(Physical Page,PP)。
虚拟内存使⽤页表来记录和判断⼀个虚拟页是否缓存在物理内存中:如上图所⽰,当CPU访问虚拟页VP3时,发现VP3并未缓存在物理内存之中,这称之为缺页,现在需要将VP3从磁盘复制到物理内存中,但在此之前,为了保持原有空间的⼤⼩,需要在物理内存中选择⼀个牺牲页,将其复制到磁盘中,这称之为交换或者页⾯调度,图中的牺牲页为VP4。
把哪个页⾯调出去可以达到调动尽量少的⽬的?最好是每次调换出的页⾯是所有内存页⾯中最迟将被使⽤的——这可以最⼤限度的推迟页⾯调换,这种算法,被称为理想页⾯置换算法,但这种算法很难完美达到。
为了尽量减少与理想算法的差距,产⽣了各种精妙的算法,LRU算法便是其中⼀个。
LRU原理LRU 算法的设计原则是:如果⼀个数据在最近⼀段时间没有被访问到,那么在将来它被访问的可能性也很⼩。
也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。
根据所⽰,假定系统为某进程分配了3个物理块,进程运⾏时的页⾯⾛向为 7 0 1 2 0 3 0 4,开始时3个物理块均为空,那么LRU算法是如下⼯作的:基于哈希表和双向链表的LRU算法实现如果要⾃⼰实现⼀个LRU算法,可以⽤哈希表加双向链表实现:设计思路是,使⽤哈希表存储 key,值为链表中的节点,节点中存储值,双向链表来记录节点的顺序,头部为最近访问节点。
lru算法 java实现

lru算法 java实现LRU(LeastRecentlyUsed)算法是一种常用的缓存淘汰策略,它根据数据最近使用的频率来淘汰缓存中的数据。
在Java中,可以使用哈希表和双向链表来实现LRU算法。
一、实现思路1.创建一个哈希表来存储缓存数据,使用键值对的形式表示缓存中的数据和对应的访问时间。
2.创建一个双向链表,用于存储缓存数据的访问顺序。
最近使用的数据会放在链表的头部,最久未使用的数据会放在链表的尾部。
3.在访问缓存数据时,如果数据不存在于哈希表中,则需要将数据添加到哈希表中,并更新其访问时间。
如果数据已经存在于哈希表中,则需要更新其访问时间并移动到链表的头部。
4.在需要淘汰缓存数据时,可以遍历链表并依次删除头部节点,直到只剩下最后一个节点为止。
最后需要将最后一个节点所代表的数据从哈希表中删除。
二、代码实现下面是一个基于上述思路的LRU算法的Java实现示例:```javaimportjava.util.HashMap;importjava.util.Map;publicclassLRUCache{privateintcapacity;privateHashMap<Integer,Node>cacheMap;privateLinkedList<Integer>list;publicLRUCache(intcapacity){this.capacity=capacity;this.cacheMap=newHashMap<>();this.list=newLinkedList<>();}publicintget(intkey){if(!cacheMap.containsKey(key)){return-1;//缓存中不存在该键值对,返回-1表示失败}Nodenode=cacheMap.get(key);//获取该键值对的节点对象list.remove(node);//从链表中移除该节点list.addFirst(key);//将该节点移动到链表头部表示最近使用过returnnode.value;//返回该节点的值}publicvoidput(intkey,intvalue){if(cacheMap.containsKey(key)){//如果缓存中已经存在该键值对,更新其访问时间并移动到链表头部Nodenode=cacheMap.get(key);node.accessTime=System.currentTimeMillis();//更新访问时间并从链表中移除该节点list.remove(node);//从链表中移除该节点list.addFirst(node);//将该节点移动到链表头部表示最近使用过}else{//如果缓存中不存在该键值对,则需要添加新节点并更新其访问时间,同时将其放入链表头部表示最近使用过NodenewNode=newNode(key,System.currentTimeMillis(),value) ;//创建新节点对象cacheMap.put(key,newNode);//将新节点添加到哈希表中list.addFirst(newNode);//将新节点移动到链表头部表示最近使用过if(cacheMap.size()>capacity){//如果缓存已满,需要淘汰链表尾部的节点和对应的键值对数据NodetailNode=list.removeTail();//移除链表尾部的节点和对应的键值对数据并返回该节点对象(用于后续处理)cacheMap.remove(tailNode.key);//从哈希表中删除对应的键值对数据}}}}```其中,Node类表示一个缓存数据节点对象,包含键(key)、访问时间(accessTime)、值(value)等属性。
lru算法的实现过程,python

LRU算法是一种常用的缓存淘汰策略,LRU全称为Least Recently Used,即最近最少使用。
它的工作原理是根据数据的历史访问记录来淘汰最近最少使用的数据,以提高缓存命中率和性能。
在Python中,可以通过各种数据结构和算法来实现LRU算法,例如使用字典和双向链表来实现LRU缓存。
一、LRU算法的基本原理LRU算法是基于"最近最少使用"的原则来淘汰缓存中的数据,它维护一个按照访问时间排序的数据队列,当缓存空间不足时,会淘汰最近最少使用的数据。
LRU算法的基本原理可以用以下步骤来说明:1. 维护一个有序数据结构,用来存储缓存中的数据和访问时间。
2. 当数据被访问时,将其移动到数据结构的最前面,表示最近被使用过。
3. 当缓存空间不足时,淘汰数据结构最后面的数据,即最近最少使用的数据。
二、使用Python实现LRU算法在Python中,可以使用字典和双向链表来实现LRU算法。
其中,字典用来存储缓存数据,双向链表用来按照访问时间排序数据。
1. 使用字典存储缓存数据在Python中,可以使用字典来存储缓存数据,字典的键值对可以用来表示缓存的键和值。
例如:```cache = {}```2. 使用双向链表按照访问时间排序数据双向链表可以按照访问时间对数据进行排序,使得最近被访问过的数据在链表的最前面。
在Python中,可以使用collections模块中的OrderedDict来实现双向链表。
例如:```from collections import OrderedDict```3. 实现LRU算法的基本操作在Python中,可以通过对字典和双向链表进行操作来实现LRU算法的基本操作,包括缓存数据的存储、更新和淘汰。
以下是LRU算法的基本操作示例:(1)缓存数据的存储当缓存数据被访问时,可以将其存储到字典中,并更新双向链表的顺序。
例如:```def put(key, value):if len(cache) >= capacity:cache.popitem(last=False)cache[key] = value```(2)缓存数据的更新当缓存数据被再次访问时,可以更新其在双向链表中的顺序。
Redis缓存的LRU算法

Redis缓存的LRU算法Redis是一种基于内存的开源键值存储系统,常用于缓存、消息队列和数据库等场景。
其中一个重要的功能是提供高效的缓存机制,通过将数据存储在内存中,实现快速读取和写入,有效提升系统性能。
在Redis中,LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰策略,用于决定哪些数据应该被优先清除,以腾出空间存放新数据。
LRU算法基于一个假设,即最近被访问的数据更有可能在将来被再次访问。
因此,当缓存达到容量上限时,LRU算法会优先淘汰最近最少被访问的数据,以确保新数据能够被缓存。
下面我们将详细介绍Redis中LRU算法的实现机制。
1. Redis内部数据结构在Redis中,LRU算法的实现依赖于一个特殊的数据结构——LRU 链表。
该链表以访问数据的时间顺序来排列数据节点,最新访问的节点会被插入到链表头部,而最久未被访问的节点则位于链表尾部。
同时,Redis还使用一个字典来存储键和值的映射关系。
2. 数据访问过程当接收到一个读请求时,Redis会首先在LRU链表中查找对应的数据节点。
如果数据节点存在于链表中,说明该数据是热点数据,即最近被访问过,Redis会将该节点从原来的位置移动到链表头部,以表示其最新被访问。
然后,Redis会返回该节点所对应的值。
如果数据节点不存在于链表中,说明该数据是冷数据,即最近未被访问过。
此时,Redis会从缓存中查找对应的值,如果找到则返回;如果缓存中不存在该值,则需要从数据库中读取。
读取后,Redis会将该值缓存到LRU链表的头部,并更新字典中的映射关系。
3. 缓存淘汰策略LRU算法的核心是决定何时淘汰链表尾部的数据节点。
当缓存达到容量上限时,新的数据需要被缓存,而此时链表尾部的数据节点是最近最少被访问的,因此应该被淘汰。
为了高效地删除链表尾部节点,Redis采用了一种优化的数据结构——LRU近似算法。
该算法通过周期性采样的方式,以概率的形式选择链表尾部的节点进行淘汰。
Java单链表实现LRU内存缓存淘汰算法

Java单链表实现LRU内存缓存淘汰算法⼀、什么是LRU 在了解什么是LRU算法时,得先清楚软件有哪些缓存,软件缓存分为: 1、内存缓存; 2、数据库缓存; 3、⽹络缓存; 速度依次减慢,缓存到内存中的数据,长时间可能会有⼀些⽆⽤的数据占⽤内存甚⾄导致内存雪崩的发⽣,为了解决这些,产⽣了LRU(Least Recently Used)算法。
LRU算法只是解决问题的其中⼀种,还有包括FIFO(First In, First Out),LFU(Least Frequently Used)算法。
这⾥我们只讲LRU算法的实现。
⼆、LRU算法内容 1、新数据插⼊到链表头部; 2、当缓存命中(即缓存数据被访问),数据要移到表头; 3、当链表满的时候,将链表尾部的数据丢弃⼆、LRU算法实现 根据描述,我们采⽤单链表的形式来实现该需求: (1)先实现单链表1//单链表2public class LinkedList<T> {34 Node list; //链表的头节点5int size; //链表有多少个节点67public LinkedList() {8 size = 0;9 }1011//添加节点12//在头部添加节点13public void put(T data) {14 Node head = list;15 Node curNode = new Node(data, list); //构建新节点,同时将该节点的下⼀个节点指向list16 list = curNode; //更新头节点为新节点17 size++;18 }1920//在链表的index 位置插⼊⼀个新的数据data21public void put(int index,T data) {22 checkPositionIndex(index);23 Node cur = list;24 Node head = list;25for(int i = 0; i < index; i++) {26 head = cur;27 cur = cur.next;28 }29 Node node = new Node(data, cur); //构建新节点,下⼀个节点指向原来的index节点30 head.next = node; //将index-1节点的下⼀个节点指向新构建的节点31 size++;3233 }3435//删除节点36//删除头部节点37public T remove() {38if (list != null) {39 Node node = list; //获取头节点40 list = list.next; //将头节点指向原本头节点的下⼀个节点41 node.next = null; // GC 回收将原本的头节点的下⼀个节点指向设为null42 size--;43return node.data;44 }45return null;46 }4748public T remove(int index) { //删除指定下标位置的节点49 checkPositionIndex(index);50 Node head = list;51 Node cur = list;52for(int i = 0; i < index; i++) {53 head = cur;54 cur = cur.next;55 }56 head.next = cur.next;57 cur.next = null;//GC58 size--;59return cur.data;60 }6162public T removeLast() { //删除最后⼀个节点63if (list != null) {64 Node node = list;65 Node cur = list;66while(cur.next != null) {67 node = cur;68 cur = cur.next;69 }70 node.next = null;71 size--;72return cur.data;7374 }75return null;76 }77//修改index位置的节点数据78public void set(int index,T newData) {79 checkPositionIndex(index);80 Node head = list;81for(int i = 0; i < index; i++) {82 head = head.next;83 }84 head.data = newData;85 }8687//查询节点88//get 头部节点89public T get() {90 Node node = list;91if (node != null) {92return node.data;93 } else {94return null;95 }96 }9798public T get(int index) { //获取下标index处的节点99 checkPositionIndex(index);100 Node node = list;101for(int i = 0; i < index; i++) {102 node = node.next;103 }104return node.data;105 }106107//检测index是否在链表范围以内108public void checkPositionIndex(int index) {109if(!(index >=0 && index <=size)) {110throw new IndexOutOfBoundsException("index: " + index + ", size: " + size); 111 }112113 }114115//节点的信息116class Node {117 T data;118 Node next;119120public Node(T data,Node node) {121this.data = data;122this.next = node;123 }124 }125 } (2)实现LRU缓存回收算法1public class LruLinkedList<T> extends LinkedList<T> {23int memory_size; // ⽤于限定内存空间⼤⼩,也就是缓存的⼤⼩,这⾥模拟⼤⼩ 4static final int DEFAULT_CAP = 5; //默认5个⼤⼩56public LruLinkedList() {7this(DEFAULT_CAP);8 }910public LruLinkedList(int default_memory_size) {11 memory_size = default_memory_size;12 }1314//LRU添加节点15public void lruPut(T data) {16if (size >= memory_size) {17 removeLast();18 put(data);19 } else {20 put(data);21 }22 }2324//LRU删除25public T lruRemove(){26return removeLast();27 }2829//LRU访问30public T lruGet(int index) {31 checkPositionIndex(index);32 Node node = list;33 Node pre = list;34for(int i = 0; i < index; i++) {35 pre = node;36 node = node.next;37 }38 T resultData = node.data;39//将访问的节点移到表头40 pre.next = node.next;41 Node head = list;42 node.next = head;43 list = node;44return resultData;45 }4647public static void main(String[] args) {48 LruLinkedList<Integer> lruLinkedList = new LruLinkedList<>(5);49for(int i = 0; i <4; i++) {50 lruLinkedList.lruPut(i);51 }52 lruLinkedList.lruGet(2)53 lruLinkedList.lruPut(12);54 lruLinkedList.lruPut(76);55 }56 } 到这⾥整个LRU算法就算模拟完成。
lru算法堆栈类算法 -回复

lru算法堆栈类算法-回复什么是LRU算法?LRU算法,全称为“最近最少使用”(Least Recently Used)算法,是一种常用的缓存算法。
LRU算法的核心思想是,如果一个数据最近被访问或使用过,那么它以后也有很高的概率会被再次访问或使用,因此应该优先保留在缓存中。
与其他缓存算法不同,LRU算法会从缓存中淘汰最近最少被访问的数据,以便为新的数据腾出空间。
LRU算法的目的是提高缓存的命中率,从而提高系统性能。
LRU算法的实现原理是通过一个数据结构来记录缓存中数据项的访问顺序。
一般使用一个双向链表来实现,链表头表示最近使用的数据项,链表尾表示最久未使用的数据项。
每当一个数据项被访问时,它会被移到链表头,而当缓存满时,链表尾的数据项会被淘汰。
这样做的好处是,链表的头部是最热门的数据项,被频繁访问的几率较高,而链表的尾部是最冷门的数据项,被访问的几率较低。
下面一步一步来介绍LRU算法的实现过程。
步骤一:创建一个双向链表的节点类首先,我们需要创建一个双向链表的节点类,该节点类包含一个值域和两个指针,分别指向前一个节点和后一个节点。
该节点类的定义如下:javaclass Node{int key;int value;Node prev;Node next;}步骤二:创建一个哈希表来存储缓存的键值对为了使LRU算法的查找效率更高,我们需要使用一个哈希表来存储缓存的键值对。
哈希表的键用来进行快速查找,对应的值是指向双向链表节点的指针。
在Java中,我们可以使用HashMap来实现哈希表。
具体的代码如下:javaimport java.util.HashMap;class LRUCache {int capacity;HashMap<Integer, Node> map;Node head;Node tail;public LRUCache(int capacity) {this.capacity = capacity;map = new HashMap<>();head = new Node();tail = new Node();head.next = tail;tail.prev = head;}}步骤三:实现LRU算法的get操作当进行get操作时,首先需要在哈希表中查找对应的节点。
LRU算法详解

LRU算法详解⼀、什么是 LRU 算法就是⼀种缓存淘汰策略。
计算机的缓存容量有限,如果缓存满了就要删除⼀些内容,给新内容腾位置。
但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么⽤的缓存,⽽把有⽤的数据继续留在缓存⾥,⽅便之后继续使⽤。
那么,什么样的数据,我们判定为「有⽤的」的数据呢?LRU 缓存淘汰算法就是⼀种常⽤策略。
LRU 的全称是 Least Recently Used,也就是说我们认为最近使⽤过的数据应该是是「有⽤的」,很久都没⽤过的数据应该是⽆⽤的,内存满了就优先删那些很久没⽤过的数据。
举个简单的例⼦,安卓⼿机都可以把软件放到后台运⾏,⽐如我先后打开了「设置」「⼿机管家」「⽇历」,那么现在他们在后台排列的顺序是这样的:但是这时候如果我访问了⼀下「设置」界⾯,那么「设置」就会被提前到第⼀个,变成这样:假设我的⼿机只允许我同时开 3 个应⽤程序,现在已经满了。
那么如果我新开了⼀个应⽤「时钟」,就必须关闭⼀个应⽤为「时钟」腾出⼀个位置,关那个呢?按照 LRU 的策略,就关最底下的「⼿机管家」,因为那是最久未使⽤的,然后把新开的应⽤放到最上⾯:现在你应该理解 LRU(Least Recently Used)策略了。
当然还有其他缓存淘汰策略,⽐如不要按访问的时序来淘汰,⽽是按访问频率(LFU 策略)来淘汰等等,各有应⽤场景。
本⽂讲解 LRU 算法策略。
⼆、LRU 算法描述LRU 算法实际上是让你设计数据结构:⾸先要接收⼀个 capacity 参数作为缓存的最⼤容量,然后实现两个 API,⼀个是 put(key, val) ⽅法存⼊键值对,另⼀个是 get(key) ⽅法获取 key 对应的 val,如果 key 不存在则返回 -1。
注意哦,get 和 put ⽅法必须都是O(1)的时间复杂度,我们举个具体例⼦来看看 LRU 算法怎么⼯作。
/* 缓存容量为 2 */LRUCache cache = new LRUCache(2);// 你可以把 cache 理解成⼀个队列// 假设左边是队头,右边是队尾// 最近使⽤的排在队头,久未使⽤的排在队尾// 圆括号表⽰键值对 (key, val)cache.put(1, 1);// cache = [(1, 1)]cache.put(2, 2);// cache = [(2, 2), (1, 1)]cache.get(1); // 返回 1// cache = [(1, 1), (2, 2)]// 解释:因为最近访问了键 1,所以提前⾄队头// 返回键 1 对应的值 1cache.put(3, 3);// cache = [(3, 3), (1, 1)]// 解释:缓存容量已满,需要删除内容空出位置// 优先删除久未使⽤的数据,也就是队尾的数据// 然后把新的数据插⼊队头cache.get(2); // 返回 -1 (未找到)// cache = [(3, 3), (1, 1)]// 解释:cache 中不存在键为 2 的数据cache.put(1, 4);// cache = [(1, 4), (3, 3)]// 解释:键 1 已存在,把原始值 1 覆盖为 4// 不要忘了也要将键值对提前到队头三、LRU 算法设计分析上⾯的操作过程,要让 put 和 get ⽅法的时间复杂度为 O(1),我们可以总结出 cache 这个数据结构必要的条件:查找快,插⼊快,删除快,有顺序之分。
lrucache原理

lrucache原理
LRU Cache(最近最少使用缓存)是一种常见的缓存淘汰算法,用于解决访问模式具有时间局部性的场景下的缓存效率问题。
LRU Cache的原理是基于“最近最少使用”策略。
当缓存被访问时,如果缓存中已存在要访问的数据,则该数据被移到缓存的最前面;如果缓存中不存在要访问的数据,则将其放入缓存的最前面。
同时,如果缓存已满,那么在放入新数据之前,需要将缓存中最久未使用的数据从缓存中淘汰出去。
具体实现LRU Cache可以使用哈希表和双向链表的结合来完成。
哈希表用于存储缓存数据,双向链表用于维护数据的访问顺序。
每个节点包含一个key和一个value,以及指向前向和
后向节点的指针。
当数据被访问时,首先查询哈希表,如果存在则将对应的节点移动到链表头部。
如果不存在,则将数据放入链表头部,并在哈希表中添加对应的键值对。
同时,如果缓存已满,需要将链表尾部的节点从链表和哈希表中删除。
这样,LRU Cache可以通过双向链表维护数据的访问顺序,每次访问时将最新的数据移动到链表头部,最久未使用的数据位于链表尾部。
当缓存满时,淘汰链表尾部的数据,保证缓存的容量始终在限制范围内。
通过LRU Cache,可以在时间复杂度为O(1)的情况下实现数
据的快速访问和更新,避免了频繁从磁盘或数据库中读取数据,并提升了系统的性能。
缓存算法之LRU与LFU

缓存算法之LRU与LFU1. LRU算法1.1 背景⽬前尽量由于摩尔定律,但是在存储硬件⽅⾯始终存在着差异,并且这种差异是不在同⼀数量级别的区别,例如在容量⽅⾯,内存<<外存;⽽在硬件成本与访问效率⽅⾯,内存>>外存。
⽽⽬前互联⽹服务平台存在的特点:a. 读多写少,快速ms级响应,因此需要把数据搁在内存上;b. 数据规模巨⼤,长尾效应,由于数据规模巨⼤,只能把全量数据搁在外存上。
正是由于服务场景需求与存储硬件特征之间的本⾝⽭盾,缓存及相应的淘汰算法由此产⽣了:⼀个在线服务平台其读取数据的过程:总是优先去离CPU最近的地⽅内存中读取数据,当有限的内存容量空间读取命中为空被击穿时,则会去外存的数据库或⽂件系统中读取;⽽当有限的缓存空间⾥“⼈满为患”时,⽽⼜有新的热点成员需要加⼊时,⾃然需要⼀定的淘汰机制。
本能的基础淘汰算法:最后访问时间最久的成员最先会被淘汰(LRU)。
1.2 基本原理由于队列具有先进先出的操作特点,所以通常⽤队列实现LRU,按最后访问的时间先进先出。
a. 利⽤队列类型对象,记录最近操作的元素,总是放在队⾸,这样最久未操作的元素⾃然被相对移动到队尾;同时,当元素总数达到上限值时,优先移除与淘汰队尾元素。
b. 利⽤HashMap辅助对象,快速检索队列中存在的元素。
1.3 操作a. 写⼊操作:新建⼀个元素,把元素插⼊队列⾸,当元素总和达到上限值时,同时删除队尾元素。
b. 读取操作:利⽤map快速检索,队列相关联的元素。
1.4 实现源码a. ⾃定义链表⽅式1// A simple LRU cache written in C++2// Hash map + doubly linked list3 #include <iostream>4 #include <vector>5 #include <ext/hash_map>6using namespace std;7using namespace __gnu_cxx;89 template <class K, class T>10struct Node{11 K key;12 T data;13 Node *prev, *next;14 };1516 template <class K, class T>17class LRUCache{18public:19 LRUCache(size_t size){20 entries_ = new Node<K,T>[size];21for(int i=0; i<size; ++i)// 存储可⽤结点的地址22 free_entries_.push_back(entries_+i);23 head_ = new Node<K,T>;24 tail_ = new Node<K,T>;25 head_->prev = NULL;26 head_->next = tail_;27 tail_->prev = head_;28 tail_->next = NULL;29 }30 ~LRUCache(){31delete head_;32delete tail_;33delete[] entries_;34 }35void Put(K key, T data){36 Node<K,T> *node = hashmap_[key];37if(node){ // node exists38 detach(node);39 node->data = data;40 attach(node);41 }42else43 {44if(free_entries_.empty())45 {// 可⽤结点为空,即cache已满46 node = tail_->prev;47 detach(node);48 hashmap_.erase(node->key);49 }50else{51 node = free_entries_.back();52 free_entries_.pop_back();53 }54 node->key = key;55 node->data = data;56 hashmap_[key] = node;57 attach(node);58 }59 }6061 T Get(K key){62 Node<K,T> *node = hashmap_[key];63if(node){64 detach(node);65 attach(node);66return node->data;67 }68else{// 如果cache中没有,返回T的默认值。
cache缓存淘汰算法--LRU算法
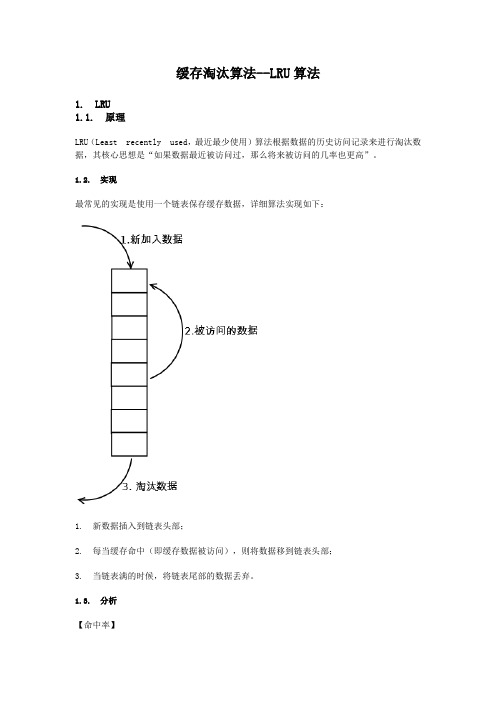
缓存淘汰算法--LRU算法1. LRU1.1. 原理LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:1. 新数据插入到链表头部;2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析【命中率】当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】实现简单。
【代价】命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K2.1. 原理LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
只有当数据的访问次数达到K次的时候,才将数据放入缓存。
当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
详细实现如下:1. 数据第一次被访问,加入到访问历史列表;2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;4. 缓存数据队列中被再次访问后,重新排序;5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
lru应用场景

lru应用场景LRU(Least Recently Used,最近最少使用)是常见的一种缓存算法,它的核心思想是在缓存满时,优先淘汰最近最少用的缓存项。
LRU广泛应用于电子商务、科技、金融和社交等行业,以下是几个应用场景。
一、网站页面缓存LRU算法被广泛应用于网站的页面缓存中,例如针对流量较大的电商品牌网站。
对于这类网站,用户访问频率高,缓存需要经常刷新且占用大量的内存空间。
使用LRU可以确保在内存空间不够时,优先保留最活跃、最常用的缓存页面,便于快速响应用户请求。
通过LRU算法可以减少服务器负载,并加速页面加载速度。
同时,它还可以优化用户体验,使用户感受到更流畅的页面浏览。
二、图片缓存随着智能手机的普及,图片在移动应用中扮演越来越重要的角色。
然而,图片占用内存大,因此需要尽可能压缩图片的内存占用。
通过LRU算法,可以在内存不够用时,快速清除内存占用率高的图片,并将最近最少使用的图片替换掉。
当用户下次打开应用时,缓存中已经过期的图片将重新从服务器加载,就不需要再次从内存加载,减少了内存使用。
三、数据结构缓存对于大多数企业级应用,基于内存的缓存是必不可少的。
数据结构缓存通过将数据保存在内存中,提高了应用程序的响应速度。
LRU算法可以在实现数据结构缓存时使用,保证最近最常用的数据被保留在内存中,以便快速访问。
同时使用LRU算法可以有效减少内存使用并提高程序的运行效率。
四、数据库缓存数据库查询是企业级应用程序中常见而重要的部分。
在处理高并发的请求时,常常是使用缓存来优化性能。
通过LRU算法的数据库缓存,可以快速定位查询中经常使用的数据,并将它们添加到缓存中。
缓存中存储的数据将被频繁使用,避免了重复查询,减少了数据库服务器的负载。
总之,LRU算法在众多应用场景中起到了重要的作用。
它可以确保增加系统的性能,减少内存使用,并改进用户的体验。
虽然它可能存在一些限制,例如对于不断更新的数据缓存效果较差,但对于需要快速响应的数据查询和访问,LRU算法是一项不可或缺的技术。
lru算法

LRU算法1. 简介LRU(Least Recently Used,最近最少使用)算法是一种常用的缓存淘汰算法。
该算法根据数据的访问顺序来进行缓存淘汰,优先淘汰最近最少使用的数据,以保证缓存中始终保存着最常用的数据。
2. 算法原理LRU算法的原理很简单,在数据插入或访问时,首先查看缓存中是否存在该数据,如果存在,则将该数据移动到链表的头部;如果不存在,则将该数据插入到链表的头部。
当缓存达到容量上限时,需要淘汰最近最少使用的数据,即将链表尾部的数据删除。
基本的数据结构是双向链表,链表的头部存储的是最近访问的数据,链表的尾部存储的是最久未访问的数据。
3. 算法实现下面是一个简单的实现LRU算法的伪代码:class LRUCache:def__init__(self, capacity: int):self.capacity = capacityself.cache = {}self.count =0self.head = DoubleNode(0, 0)self.tail = DoubleNode(0, 0)self.head.next =self.tailself.tail.prev =self.headdef get(self, key: int) -> int:if key in self.cache:node =self.cache[key]self._remove(node)self._add(node)return node.valreturn-1def put(self, key: int, value: int) ->None: if key in self.cache:node =self.cache[key]self._remove(node)self.count -=1node = DoubleNode(key, value)self.cache[key] = nodeself._add(node)self.count +=1if self.count >self.capacity:node =self.tail.prevself._remove(node)self.count -=1def _add(self, node: DoubleNode) ->None:next_node =self.head.nextself.head.next = nodenode.prev =self.headnode.next = next_nodenext_node.prev = nodedef _remove(self, node: DoubleNode) ->None:prev_node = node.prevnext_node = node.nextprev_node.next = next_nodenext_node.prev = prev_nodeclass DoubleNode:def__init__(self, key: int, val: int):self.key = keyself.val = valself.prev =Noneself.next =None4. 使用示例cache = LRUCache(2) # 创建一个容量为2的缓存cache.put(1, 1) # 缓存中插入数据 (1,1)cache.put(2, 2) # 缓存中插入数据 (2,2)cache.get(1) # 返回 1cache.put(3, 3) # 缓存中插入数据 (3,3),因为缓存容量已满,所以需要淘汰 (2,2)cache.get(2) # 返回 -1,因为该数据已被淘汰cache.put(4, 4) # 缓存中插入数据 (4,4),因为缓存容量已满,所以需要淘汰 (1,1)cache.get(1) # 返回 -1,因为该数据已被淘汰cache.get(3) # 返回 3cache.get(4) # 返回 45. 算法分析•时间复杂度:LRU算法的时间复杂度是O(1),由于使用哈希表存储数据和双向链表维护数据顺序,所以对于插入、查找、删除等操作都是常数时间复杂度。
LRU算法总结

LRU算法总结LRU算法总结⽆论是哪⼀层次的缓存都⾯临⼀个同样的问题:当容量有限的缓存的空闲空间全部⽤完后,⼜有新的内容需要添加进缓存时,如何挑选并舍弃原有的部分内容,从⽽腾出空间放⼊这些新的内容。
解决这个问题的算法有⼏种,如最近使⽤算法(LRU)、先进先出算法(FIFO)、最近最少使⽤算法(LFU)、⾮最近使⽤算法(NMRU)等,这些算法在不同层次的缓存上执⾏时拥有不同的效率和代价,需根据具体场合选择最合适的⼀种。
最近使⽤算法,顾名思义,可以将其理解为如果数据最近被访问过,那么将来被访问的⼏率也很⾼。
它的实现有多种⽅式,⽐如LRU、LRU-K、Two queues、Mutiple queues等。
LRU常⽤的实现是使⽤下图中的⽅式,往头部加⼊新的数据,如果该数据存在则将其放到头部,如果加⼊时已满,则从底部淘汰掉数据。
这种⽅式虽然简单,在频繁访问热点数据的时候效率⾼,但是它的缺点在于如果是偶尔的批量访问不同的数据时其命中率就会很低。
⽐如我频繁的访问A,接着访问不同的数据直到A被淘汰,此时我再访问A,则不得不⼜再次把A加⼊到Cache中,显然这种⽅式是不合时宜的,因为A已经访问了很多次了,不应该将其淘汰⽽把⼀堆只访问⼀次的数据加⼊到Cache中。
LRU-K上⾯的LRU只会将最近使⽤的⼀次加⼊到缓存,因此需要将其进⾏优化,变成缓存k次的才加⼊到缓存中,于是我们需要维护⼀个历史队列,纪录其数据对应的访问次数,其根据访问次数来进⾏淘汰,如果访问次数达到了k次才从历史队列中删除加⼊到缓存中,缓存按照LRU的规则来淘汰数据。
它的命中率要⽐LRU要⾼,但是因为需要维护⼀个历史队列,因此内存消耗会⽐LRU多。
实际应⽤中LRU-2是综合各种因素后最优的选择,LRU-3或者更⼤的K值命中率会⾼,但适应性差,需要⼤量的数据访问才能将历史访问记录清除掉。
Two queues(2Q)和LRU-k类似,但不同的是,其有两个缓存队列,⼀个是FIFO队列,⼀个是LRU队列。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
缓存淘汰算法--LRU算法1. LRU1.1. 原理LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
1.2. 实现最常见的实现是使用一个链表保存缓存数据,详细算法实现如下:1. 新数据插入到链表头部;2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;3. 当链表满的时候,将链表尾部的数据丢弃。
1.3. 分析【命中率】当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。
【复杂度】实现简单。
【代价】命中时需要遍历链表,找到命中的数据块索引,然后需要将数据移到头部。
2. LRU-K2.1. 原理LRU-K中的K代表最近使用的次数,因此LRU可以认为是LRU-1。
LRU-K的主要目的是为了解决LRU算法“缓存污染”的问题,其核心思想是将“最近使用过1次”的判断标准扩展为“最近使用过K次”。
2.2. 实现相比LRU,LRU-K需要多维护一个队列,用于记录所有缓存数据被访问的历史。
只有当数据的访问次数达到K次的时候,才将数据放入缓存。
当需要淘汰数据时,LRU-K会淘汰第K次访问时间距当前时间最大的数据。
详细实现如下:1. 数据第一次被访问,加入到访问历史列表;2. 如果数据在访问历史列表里后没有达到K次访问,则按照一定规则(FIFO,LRU)淘汰;3. 当访问历史队列中的数据访问次数达到K次后,将数据索引从历史队列删除,将数据移到缓存队列中,并缓存此数据,缓存队列重新按照时间排序;4. 缓存数据队列中被再次访问后,重新排序;5. 需要淘汰数据时,淘汰缓存队列中排在末尾的数据,即:淘汰“倒数第K次访问离现在最久”的数据。
LRU-K具有LRU的优点,同时能够避免LRU的缺点,实际应用中LRU-2是综合各种因素后最优的选择,LRU-3或者更大的K值命中率会高,但适应性差,需要大量的数据访问才能将历史访问记录清除掉。
2.3. 分析【命中率】LRU-K降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】LRU-K队列是一个优先级队列,算法复杂度和代价比较高。
【代价】由于LRU-K还需要记录那些被访问过、但还没有放入缓存的对象,因此内存消耗会比LRU 要多;当数据量很大的时候,内存消耗会比较可观。
LRU-K需要基于时间进行排序(可以需要淘汰时再排序,也可以即时排序),CPU消耗比LRU 要高。
3. Two queues(2Q)3.1. 原理Two queues(以下使用2Q代替)算法类似于LRU-2,不同点在于2Q将LRU-2算法中的访问历史队列(注意这不是缓存数据的)改为一个FIFO缓存队列,即:2Q算法有两个缓存队列,一个是FIFO队列,一个是LRU队列。
3.2. 实现当数据第一次访问时,2Q算法将数据缓存在FIFO队列里面,当数据第二次被访问时,则将数据从FIFO队列移到LRU队列里面,两个队列各自按照自己的方法淘汰数据。
详细实现如下:1. 新访问的数据插入到FIFO队列;2. 如果数据在FIFO队列中一直没有被再次访问,则最终按照FIFO规则淘汰;3. 如果数据在FIFO队列中被再次访问,则将数据移到LRU队列头部;4. 如果数据在LRU队列再次被访问,则将数据移到LRU队列头部;5. LRU队列淘汰末尾的数据。
注:上图中FIFO队列比LRU队列短,但并不代表这是算法要求,实际应用中两者比例没有硬性规定。
3.3. 分析【命中率】2Q算法的命中率要高于LRU。
【复杂度】需要两个队列,但两个队列本身都比较简单。
【代价】FIFO和LRU的代价之和。
2Q算法和LRU-2算法命中率类似,内存消耗也比较接近,但对于最后缓存的数据来说,2Q 会减少一次从原始存储读取数据或者计算数据的操作。
4. Multi Queue(MQ)4.1. 原理MQ算法根据访问频率将数据划分为多个队列,不同的队列具有不同的访问优先级,其核心思想是:优先缓存访问次数多的数据。
4.2. 实现MQ算法将缓存划分为多个LRU队列,每个队列对应不同的访问优先级。
访问优先级是根据访问次数计算出来的,例如详细的算法结构图如下,Q0,Q1....Qk代表不同的优先级队列,Q-history代表从缓存中淘汰数据,但记录了数据的索引和引用次数的队列:如上图,算法详细描述如下:1. 新插入的数据放入Q0;2. 每个队列按照LRU管理数据;3. 当数据的访问次数达到一定次数,需要提升优先级时,将数据从当前队列删除,加入到高一级队列的头部;4. 为了防止高优先级数据永远不被淘汰,当数据在指定的时间里访问没有被访问时,需要降低优先级,将数据从当前队列删除,加入到低一级的队列头部;5. 需要淘汰数据时,从最低一级队列开始按照LRU淘汰;每个队列淘汰数据时,将数据从缓存中删除,将数据索引加入Q-history头部;6. 如果数据在Q-history中被重新访问,则重新计算其优先级,移到目标队列的头部;7. Q-history按照LRU淘汰数据的索引。
4.3. 分析【命中率】MQ降低了“缓存污染”带来的问题,命中率比LRU要高。
【复杂度】MQ需要维护多个队列,且需要维护每个数据的访问时间,复杂度比LRU高。
【代价】MQ需要记录每个数据的访问时间,需要定时扫描所有队列,代价比LRU要高。
注:虽然MQ的队列看起来数量比较多,但由于所有队列之和受限于缓存容量的大小,因此这里多个队列长度之和和一个LRU队列是一样的,因此队列扫描性能也相近。
5. LRU类算法对比由于不同的访问模型导致命中率变化较大,此处对比仅基于理论定性分析,不做定量分析。
实际应用中需要根据业务的需求和对数据的访问情况进行选择,并不是命中率越高越好。
例如:虽然LRU看起来命中率会低一些,且存在”缓存污染“的问题,但由于其简单和代价小,实际应用中反而应用更多。
java中最简单的LRU算法实现,就是利用jdk的LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可如果你去看LinkedHashMap的源码可知,LRU算法是通过双向链表来实现,当某个位置被命中,通过调整链表的指向将该位置调整到头位置,新加入的内容直接放在链表头,如此一来,最近被命中的内容就向链表头移动,需要替换时,链表最后的位置就是最近最少使用的位置。
1 2 3 4 5 6 7 8 91011121314151617181920212223 import java.util.ArrayList;import java.util.Collection;import java.util.LinkedHashMap;import java.util.concurrent.locks.Lock;import java.util.concurrent.locks.ReentrantLock;import java.util.Map;/*** 类说明:利用LinkedHashMap实现简单的缓存,必须实现removeEldestEntry方法,具** @author dennis** @param <K>* @param <V>*/public class LRULinkedHashMap<K, V> extends LinkedHashMap<K, V> { private final int maxCapacity;private static final float DEFAULT_LOAD_FACTOR = 0.75f;private final Lock lock = new ReentrantLock();2425262728293031323334353637383940414243444546474849505152535455565758596061626364656667 public LRULinkedHashMap(int maxCapacity) {super(maxCapacity, DEFAULT_LOAD_FACTOR, true);this.maxCapacity = maxCapacity;}@Overrideprotected boolean removeEldestEntry(java.util.Map.Entry<K, V> eldest) return size() > maxCapacity;}@Overridepublic boolean containsKey(Object key) {try {lock.lock();return super.containsKey(key);} finally {lock.unlock();}}@Overridepublic V get(Object key) {try {lock.lock();return super.get(key);} finally {lock.unlock();}}@Overridepublic V put(K key, V value) {try {lock.lock();return super.put(key, value);} finally {lock.unlock();}}public int size() {try {lock.lock();return super.size();686970717273747576777879808182838485868788899091} finally {lock.unlock();}}public void clear() {try {lock.lock();super.clear();} finally {lock.unlock();}}public Collection<Map.Entry<K, V>> getAll() {try {lock.lock();return new ArrayList<Map.Entry<K, V>>(super.entrySet() } finally {lock.unlock();}}}基于双链表的LRU实现:传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。
它的弊端很明显,如果Cache的数量少,问题不会很大,但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。