统计学_贾俊平第四版第八章课后答案(目前最全)
贾俊平《统计学》课后习题-第八章至第十四章(圣才出品)

量为 4.55。
2.一种元件,要求其使用寿命不得低于 700 小时。现从一批这种元件中随机抽取 36
件,测得其平均寿命为 680 小时。已知该元件寿命服从正态分布, =60 小时,试在显著
性水平 0.05 下确定这批元件是否合格。 解:建立假设:
圣才电子书 十万种考研考证电子书、题库视频学习平台
答:如果减小 错误,就会增大犯β错误的机会;若减小β错误,也会增大犯 错误的 机会。如果想使 和β同时变小,就只有增大样本量。
5.解释假设检验中的 P 值。 答:P 值就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。如果 P 值很小,说明这种情况发生的概率很小,而如果出现了,根据小概率原理,就有理由拒绝原 假设,P 值越小,拒绝原假设的理由就越充分。
H0 : 700 , H1 : 700
这是左侧检验,并且方差已知,检验统计量 Z 为:
3 / 152
圣才电子书
十万种考研考证电子书、题库视频学习平台
Z 680 700 2 60 / 36
而 Z0.05 1.645 2 ,因此拒绝原假设,即在显著性水平 0.05 下这批元件是不合
8.在单侧检验中原假设和备择假设的方向如何确定?
2 / 152
圣才电子书 十万种考研考证电子书、题库视频学习平台
答:单侧检验有两种情况:一种是所考察的数值越大越好,也就是左单侧检验,要求原
假设取 ,相应的备择假设取<;另一种是数值越小越好,也就是右单侧检验,要求原假设 取 ,相应的备择假设取>。
n
9
n
(xi x )2
统计学贾俊平_第四版课后习题答案第八章

姓名:潘方 学号:1106026 班级:金融一班8.2 解:根据题目的分析,本题采用左单侧检验:已知:μ0=700,x =680,σ=60, n=36,α=0.05则z α=1.645 其过程为: H 0:μ≥700 H 1:μ<700 x z ==-2 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明这批产品不合格。
因为2=Z ,且为左单侧检验,则()05.0022750132.0977249868.01=<=-=αP8.4 解:由excel 计算得:x =99.9778 S =1.21221H 0:μ=100 H 1:μ≠100 x t =-0.055 这是一个双侧检验,当α=0.05,自由度n -1=9时,得()29t α=2.262。
因为t <|2t α|,t 值位于接受区域,故接受原假设,说明打包机工作正常。
因为|Z|=0.055,且为双侧检验,由excel 得: P=0.95734>(α=0.05)8.9解:该题样本为,大样本,方差2σ已知、且不等,因此采用z 统计量 已知, 05.0=α、即96.12/=αZ ,811=n , 642=n ,σA=63*63 2σB=57*57 0:211≠-μμH 0:210=-μμH , ()()96.15.0645781630102010702222<≈+--=+---=BB A AB A B A n n x x Z σσμμ 因为|z|<|z α|,Z 值位于接受区域,故接受原假设,两厂生产材料抗压强度相同。
因为5.0=Z ,则()=-⨯=691462461.012P 0.617075078()05.0=>α8.13 解:此题为两个总体比例之差的假设H 0:π1≥π2;H 1:π1<π 2 α=0.05,即z α=1.6451100021==n n ,00945.0110001041==p ,01718.0110001892==pp p d z --=0.009450.017180--=-5 因为|z|>|z α|,Z 值位于拒绝域,故拒绝原假设,说明用阿司匹林可以降低心脏病发生率。
统计学贾俊平_第四版课后习题答案
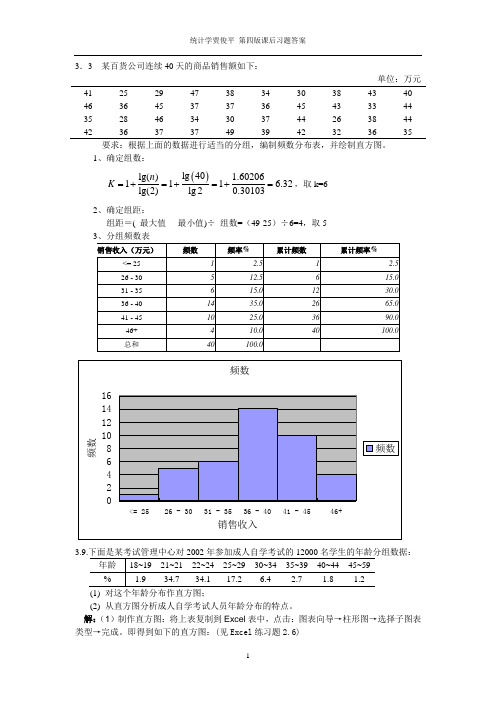
3.3 某百货公司连续40天的商品销售额如下:单位:万元41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42363737493942323635要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。
1、确定组数: ()l g 40l g () 1.60206111 6.32l g (2)l g 20.30103n K =+=+=+=,取k=62、确定组距:组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5(1) 对这个年龄分布作直方图;(2) 从直方图分析成人自学考试人员年龄分布的特点。
解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。
即得到如下的直方图:(见Excel 练习题2.6)(2)年龄分布的特点:自学考试人员年龄的分布为右偏。
解:(1)根据上面的数据,画出两个班考试成绩的对比条形图和环形图。
3.14 已知1995—2004年我国的国内生产总值数据如下(按当年价格计算):要求:(2)绘制第一、二、三产业国内生产总值的线图。
4.1 一家汽车零售店的10名销售人员5月份销售的汽车数量(单位:台)排序后如下:2 4 7 10 10 10 12 12 14 15要求:(1)计算汽车销售量的众数、中位数和平均数。
(2)根据定义公式计算四分位数。
(3)计算销售量的标准差。
(4)说明汽车销售量分布的特征。
解:Statistics汽车销售数量N Valid 10Missing 0Mean 9.60Median 10.00Mode 10Std. Deviation 4.169Percentiles 25 6.2550 10.0075 12.50种是所有颐客都进入一个等待队列:另—种是顾客在三千业务窗口处列队3排等待。
统计学第四版课后答案

统计课后思考题答案第一章思考题什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
解释分类数据,顺序数据和数值型数据答案同举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计应用实例人口普查,商场的名意调查等。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1。
1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1。
2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1。
3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据.它也是有类别的,但这些类别是有序的.(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值. 统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的.实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据.时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1。
4解释分类数据,顺序数据和数值型数据答案同1.31。
5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1。
7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第四版答案(贾俊平)

请举出统计应用的几个例子:1、用统计识别作者:对于存在争议的论文,通过统计量推出作者2、用统计量得到一个重要发现:在不同海域鳗鱼脊椎骨数量变化不大,推断所有各个不同海域内的鳗鱼是由海洋中某公共场所繁殖的3、挑战者航天飞机失事预测请举出应用统计的几个领域:1、在企业发展战略中的应用2、在产品质量管理中的应用3、在市场研究中的应用④在财务分析中的应用⑤在经济预测中的应用你怎么理解统计的研究内容:1、统计学研究的基本内容包括统计对象、统计方法和统计规律。
2、统计对象就是统计研究的课题,称谓统计总体。
3、统计研究方法主要有大量观察法、数量分析法、抽样推断法、实验法等。
④统计规律就是通过大量观察和综合分析所揭示的用数量指标反映的客观现象的本质特征和发展规律。
举例说明分类变量、顺序变量和数值变量:分类变量:表现为不同类别的变量称为分类变量,如“性别”表现为“男”或“女”,“企业所属的行业”表现为“制造业”、“零售业”、“旅游业”等,“学生所在的学院”可能是“商学院”、“法学院”等顺序变量:如果类别有一定的顺序,这样的分类变量称为顺序变量,如考试成绩按等级分为优、良、中、及格、不及格,一个人对事物的态度分为赞成、中立、反对。
这里的“考试成绩等级”、“态度”等就是顺序变量。
数值变量:可以用数字记录其观察结果,这样的变量称为数值变量,如“企业销售额”、“生活费支出”、“掷一枚骰子出现的点数”。
定性数据和定量数据的图示方法各有哪些:1、定性数据的图示:条形图、帕累托图、饼图、环形图2、定量数据的图示:a、分组数据看分布:直方图b、未分组数据看分布:茎叶图、箱线图、垂线图、误差图c、两个变量间的关系:散点图d、比较多个样本的相似性:雷达图和轮廓图直方图与条形图有何区别:1、条形图中的每一个矩形表示一个类别,其宽度没有意义,而直方图的宽度则表示各组的组距。
2、由于分组数据具有连续性,直方图的各矩形通常是连续排列,而条形图则是分开排列。
统计学贾俊平课后习题答案完整版

统计学贾俊平课后习题答案HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】附录:教材各章习题答案第1章统计与统计数据1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5)分类数据。
1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”;(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。
1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。
1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者的月平均花费;(4)统计量;(5)推断统计方法。
1.5(略)。
1.6(略)。
第2章数据的图表展示2.1(1)属于顺序数据。
(2)频数分布表如下(4)帕累托图(略)。
2.2(1)频数分布表如下2.3频数分布表如下2.5(1)排序略。
(2)频数分布表如下2.6(3)食品重量的分布基本上是对称的。
2.72.8(1)属于数值型数据。
2.9(1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
2.10A 班分散,且平均成绩较A 班低。
2.11 (略)。
2.12 (略)。
2.13 (略)。
2.14 (略)。
2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量3.1(1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。
(3)2.4=s 。
(4)左偏分布。
3.2(1)190=M ;23=e M 。
(2)5.5=L Q ;12=U Q 。
(3)24=x ;65.6=s 。
(4)08.1=SK ;77.0=K 。
(5)略。
3.3 (1)略。
(2)7=x ;71.0=s 。
(3)102.01=v ;274.02=v 。
(4)选方法一,因为离散程度小。
3.4 (1)x =(万元);M e= 。
统计学课后题答案(袁卫庞皓曾五一贾俊平)

第1章绪论5.简要说明抽样误差和非抽样误差。
答:统计调查误差可分为非抽样误差和抽样误差。
非抽样误差是由于调查过程中各环节工作失误造成的,从理论上看,这类误差是可以避免的。
抽样误差是利用样本推断总体时所产生的误差,它是不可避免的,但可以控制的。
b5E2RGbCAP6.一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为 4.536 kg。
要求:p1EanqFDPw(1>描述总体;(2>描述研究变量;(3>描述样本;(4>描述推断。
答:(1>总体:最近的一个集装箱内的全部油漆;(2>研究变量:装满的油漆罐的质量;(3>样本:最近的一个集装箱内的50罐油漆;(4>推断:50罐油漆的质量应为4.536×50=226.8kg。
7.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝实验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝实验(即在品尝实验中,两个品牌不做外观标记>,请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:DXDiTa9E3d(1>描述总体;(2>描述研究变量;(3>描述样本;(4>描述推断。
答:(1>总体:市场上的“可口可乐”与“百事可乐”(2>研究变量:更好口味的品牌名称;(3>样本:1000名消费者品尝的两个品牌(4>推断:两个品牌中哪个口味更好。
第2章统计数据的描述思考题4. 一组数据的分布特征可以从哪几个方面进行测度?答:数据分布特征一般可从集中趋势、离散程度、偏态和峰度几方面来测度。
贾平凹统计学第四版第八章课后答案

贾平凹统计学第四版第⼋章课后答案8.01 已知某炼铁⼚的含碳量服从正态分布N(4.55, 0.108),现在测定了9炉铁⽔,其平均含碳量为4.484。
如果估计⽅差没有变化,可否认为现在⽣产的铁⽔平均含碳量为4.55 (a=0.05) 。
H0: = 4.55H1: 1 4.55= 0.05 n = 9临界值(s): -1.96,1.96 在-1.96~1.96之间接受;否则拒绝检验统计量: =(4.484-4.55)/(0.33/3 )= -0.6 -0.6∈(-1.96,1.96)决策:在 = 0.05的⽔平上接受H0结论: 有证据表明现在⽣产的铁⽔平均含碳量为4.558.02 ⼀种元件,要求其使⽤寿命不得低于700⼩时。
现从⼀批这种元件中随机抽取36件,测得其平均寿命为680⼩时。
已知该元件寿命服从正态分布,s=60⼩时,试在显著性⽔平a=0.05下确定这批元件是否合格。
H0: <700H1: ≥700= 0.05 n = 36临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(680-700)/(60/6)=-2 -2<1.645决策:在 = 0.05的⽔平上接受H0结论: 有证据表明元件不合格8.03 某地区⼩麦的⼀般⽣产⽔平为亩产250公⽄,其标准差为30公⽄。
现⽤⼀种化肥进⾏试验,从25个⼩区抽样结果,平均产量为270公⽄。
问这种化肥是否使⼩麦明显增产?(a=0.05) H0: ≤250H1: >250= 0.05 n = 25临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(270-250)/(30/5)=3.33 3.33>1.645决策:在 = 0.05的⽔平上拒绝H0结论: 有证据表明这种化肥使⼩麦明显增产8.04 糖⼚⽤⾃动打包机打包,每包标准重量是100公⽄。
每天开⼯后需要检验⼀次打包机⼯作是否正常。
某⽇开⼯后测得9包重量如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该⽇打包机⼯作是否正常?(a=0.05)H0: =100H1: ≠100= 0.05 n = 9 s=1.21 =99.98临界值(s): -2.31,2.31 在-2.31~2.231之间接受;否则拒绝检验统计量: =(99.98-100)/(1.21/3)=0.50 0.50∈(-2.31,2.31)决策:在 = 0.05的⽔平上接受H0结论: 有证据表明试检验该⽇打包机⼯作正常8.05 某种⼤量⽣产的袋装⾷品,按规定不得少于250克。
统计学(第四版)贾俊平 第八章 方差分析与实验设计 练习题答案
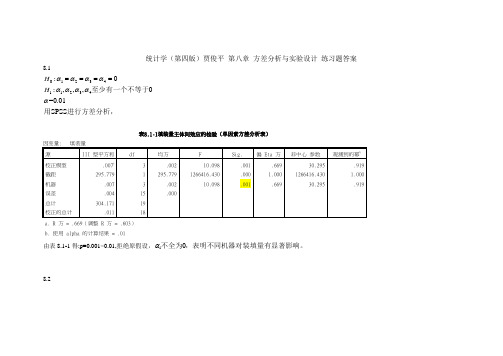
统计学(第四版)贾俊平 第八章 方差分析与实验设计 练习题答案8.10123411234:0:,,,0=0.01SPSS H H ααααααααα====至少有一个不等于用进行方差分析,表8.1-1填装量主体间效应的检验(单因素方差分析表)因变量: 填装量 源 III 型平方和df均方F Sig.偏 Eta 方非中心 参数观测到的幂b校正模型 .007a3 .002 10.098 .001 .669 30.295 .919 截距 295.7791 295.7791266416.430.000 1.000 1266416.4301.000 机器 .007 3 .002 10.098.001.66930.295.919误差 .004 15 .000总计 304.17119 校正的总计.01118a. R 方 = .669(调整 R 方 = .603)b. 使用 alpha 的计算结果 = .01由表8.1-1得:p=0.001<0.01,拒绝原假设,i 0α不全为,表明不同机器对装填量有显著影响。
8.201231123:0:,,0=0.05SPSS H H ααααααα===至少有一个不等于用进行方差分析,表8.2-1满意度评分主体间效应的检验(单因素方差分析表)因变量: 评分 源III 型平方和df 均方 F Sig.校正模型 29.610a2 14.805 11.756 .001 截距 975.156 1 975.156 774.324 .000 管理者 29.610 2 14.805 11.756.001误差 18.890 15 1.259总计 1061.000 18 校正的总计48.50017a. R 方 = .611(调整 R 方 = .559)由表8.2-1得:p=0.001<0.05,拒绝原假设,i 0α不全为,表明管理者水平不同会导致评分的显著差异。
8.301231123:0:,,0=0.05SPSS H H ααααααα===至少有一个不等于用进行方差分析,表8.3-1电池寿命主体间效应的检验(单因素方差分析表)因变量: 电池寿命 源III 型平方和df 均方 F Sig. 偏 Eta 方 非中心 参数 观测到的幂b校正模型 615.600a2 307.800 17.068 .000 .740 34.137 .997 截距 22815.000 1 22815.000 1265.157 .000 .991 1265.157 1.000 企业 615.600 2 307.800 17.068.000.74034.137.997误差 216.400 12 18.033总计 23647.000 15 校正的总计832.00014a. R 方 = .740(调整 R 方 = .697)b. 使用 alpha 的计算结果 = .05由表8.2-1得:p=0.001<0.05,拒绝原假设,i 0α不全为,表明3个企业生产的电池平均寿命之间存在显著差异。
贾平凹统计学第四版 第八章课后答案

8.01 已知某炼铁厂的含碳量服从正态分布N(4.55, 0.108),现在测定了9炉铁水,其平均含碳量为4.484。
如果估计方差没有变化,可否认为现在生产的铁水平均含碳量为4.55 (a=0.05) 。
H0: = 4.55H1: ¹ 4.55= 0.05 n = 9临界值(s): -1.96,1.96 在-1.96~1.96之间接受;否则拒绝检验统计量: =(4.484-4.55)/(0.33/3 )= -0.6 -0.6∈(-1.96,1.96)决策:在 = 0.05的水平上接受H0结论: 有证据表明现在生产的铁水平均含碳量为4.558.02 一种元件,要求其使用寿命不得低于700小时。
现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。
已知该元件寿命服从正态分布,s=60小时,试在显著性水平a=0.05下确定这批元件是否合格。
H0: <700H1: ≥700= 0.05 n = 36临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(680-700)/(60/6)=-2 -2<1.645决策:在 = 0.05的水平上接受H0结论: 有证据表明元件不合格8.03 某地区小麦的一般生产水平为亩产250公斤,其标准差为30公斤。
现用一种化肥进行试验,从25个小区抽样结果,平均产量为270公斤。
问这种化肥是否使小麦明显增产?(a=0.05) H0: ≤250H1: >250= 0.05 n = 25临界值(s):1.645 <1.645接受;否则拒绝检验统计量: =(270-250)/(30/5)=3.33 3.33>1.645决策:在 = 0.05的水平上拒绝H0结论: 有证据表明这种化肥使小麦明显增产8.04 糖厂用自动打包机打包,每包标准重量是100公斤。
每天开工后需要检验一次打包机工作是否正常。
某日开工后测得9包重量如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该日打包机工作是否正常?(a=0.05)H0: =100H1: ≠100= 0.05 n = 9 s=1.21 =99.98临界值(s): -2.31,2.31 在-2.31~2.231之间接受;否则拒绝检验统计量: =(99.98-100)/(1.21/3)=0.50 0.50∈(-2.31,2.31)决策:在 = 0.05的水平上接受H0结论: 有证据表明试检验该日打包机工作正常8.05 某种大量生产的袋装食品,按规定不得少于250克。
[管理]统计学第四版(贾俊平)课后思考题答案
![[管理]统计学第四版(贾俊平)课后思考题答案](https://img.taocdn.com/s3/m/2c76c32530126edb6f1aff00bed5b9f3f90f72c4.png)
统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学第四版(贾俊平)课后思考题答案

统计课后思考题答案第一章思考题1.1什么是统计学统计学是关于数据的一门学科,它收集,处理,分析,解释来自各个领域的数据并从中得出结论。
1.2解释描述统计和推断统计描述统计;它研究的是数据收集,处理,汇总,图表描述,概括与分析等统计方法。
推断统计;它是研究如何利用样本数据来推断总体特征的统计方法。
1.3统计学的类型和不同类型的特点统计数据;按所采用的计量尺度不同分;(定性数据)分类数据:只能归于某一类别的非数字型数据,它是对事物进行分类的结果,数据表现为类别,用文字来表述;(定性数据)顺序数据:只能归于某一有序类别的非数字型数据。
它也是有类别的,但这些类别是有序的。
(定量数据)数值型数据:按数字尺度测量的观察值,其结果表现为具体的数值。
统计数据;按统计数据都收集方法分;观测数据:是通过调查或观测而收集到的数据,这类数据是在没有对事物人为控制的条件下得到的。
实验数据:在实验中控制实验对象而收集到的数据。
统计数据;按被描述的现象与实践的关系分;截面数据:在相同或相似的时间点收集到的数据,也叫静态数据。
时间序列数据:按时间顺序收集到的,用于描述现象随时间变化的情况,也叫动态数据。
1.4解释分类数据,顺序数据和数值型数据答案同1.31.5举例说明总体,样本,参数,统计量,变量这几个概念对一千灯泡进行寿命测试,那么这千个灯泡就是总体,从中抽取一百个进行检测,这一百个灯泡的集合就是样本,这一千个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是参数,这一百个灯泡的寿命的平均值和标准差还有合格率等描述特征的数值就是统计量,变量就是说明现象某种特征的概念,比如说灯泡的寿命。
1.6变量的分类变量可以分为分类变量,顺序变量,数值型变量。
变量也可以分为随机变量和非随机变量。
经验变量和理论变量。
1.7举例说明离散型变量和连续性变量离散型变量,只能取有限个值,取值以整数位断开,比如“企业数”连续型变量,取之连续不断,不能一一列举,比如“温度”。
统计学 - 贾俊平第四版第八章课后答案(目前最全)

统计学 - 贾俊平第四版第八章课后答案(目前最全)8.2 一种元件,要求其使用寿命不得低于700小时。
现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。
已知该元件寿命服从正态分布,?=60小时,试在显著性水平0.05下确定这批元件是否合格。
解:H0:μ≥700;H1:μ<700已知:x=680 ?=60由于n=36>30,大样本,因此检验统计量:z?x??0sn=680?700=-26036当α=0.05,查表得z?=1.645。
因为z<-z?,故拒绝原假设,接受备择假设,说明这批产品不合格。
8.38.4 糖厂用自动打包机打包,每包标准重量是100千克。
每天开工后需要检验一次打包机工作是否正常。
某日开工后测得9包重量(单位:千克)如下:99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该日打包机工作是否正常(a=0.05)? 解:H0:μ=100;H1:μ≠100经计算得:x=99.9778 S=1.21221 检验统计量:t?x??0sn=99.9778?100=-0.0551.2122192当α=0.05,自由度n-1=9时,查表得t??9?=2.262。
因为t<t?2,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明打包机工作正常。
8.5 某种大量生产的袋装食品,按规定不得少于250克。
今从一批该食品中任意抽取50袋,发现有6袋低于250克。
若规定不符合标准的比例超过5%就不得出厂,问该批食品能否出厂(a=0.05)? 解:解:H0:π≤0.05;H1:π>0.05已知: p=6/50=0.12 检验统计量:Z?p??0?0?1??0?n=0.12?0.050.05??1?0.05?50=2.271当α=0.05,查表得z?=1.645。
因为z>z?,样本统计量落在拒绝区域,故拒绝原假设,接受备择假设,说明该批食品不能出厂。
贾俊平统计学(四版)课后习题答案

第1章绪论1.什么是统计学?怎样理解统计学与统计数据的关系?2.试举出日常生活或工作中统计数据及其规律性的例子。
3..一家大型油漆零售商收到了客户关于油漆罐分量不足的许多抱怨。
因此,他们开始检查供货商的集装箱,有问题的将其退回。
最近的一个集装箱装的是2 440加仑的油漆罐。
这家零售商抽查了50罐油漆,每一罐的质量精确到4位小数。
装满的油漆罐应为4.536 kg。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)描述推断。
答:(1)总体:最近的一个集装箱内的全部油漆;(2)研究变量:装满的油漆罐的质量;(3)样本:最近的一个集装箱内的50罐油漆;(4)推断:50罐油漆的质量应为4.536×50=226.8 kg。
4.“可乐战”是描述市场上“可口可乐”与“百事可乐”激烈竞争的一个流行术语。
这场战役因影视明星、运动员的参与以及消费者对品尝试验优先权的抱怨而颇具特色。
假定作为百事可乐营销战役的一部分,选择了1000名消费者进行匿名性质的品尝试验(即在品尝试验中,两个品牌不做外观标记),请每一名被测试者说出A品牌或B品牌中哪个口味更好。
要求:(1)描述总体;(2)描述研究变量;(3)描述样本;(4)一描述推断。
答:(1)总体:市场上的“可口可乐”与“百事可乐”(2)研究变量:更好口味的品牌名称;(3)样本:1000名消费者品尝的两个品牌(4)推断:两个品牌中哪个口味更好。
第2章统计数据的描述——练习题●1.为评价家电行业售后服务的质量,随机抽取了由100家庭构成的一个样本。
服务质量的等级分别表示为:A.好;B.较好;C.一般;D.差;E.较差。
调查结果如下:B EC C AD C B A ED A C B C DE C E EA DBC C A ED C BB ACDE A B D D CC B C ED B C C B CD A C B C DE C E BB EC C AD C B A EB ACDE A B D D CA DBC C A ED C BC B C ED B C C B C(1) 指出上面的数据属于什么类型;(2)用Excel制作一张频数分布表;(3) 绘制一张条形图,反映评价等级的分布。
统计学贾俊平课后习题答案

附录:教材各章习题答案第1章统计与统计数据1.1(1)数值型数据;(2分类数据;(3)数值型数据;(4)顺序数据;(5)分类数据。
1.2(1)总体是该城市所有的职工家庭”样本是抽取的2000个职工家庭”(2)城市所有职工家庭的年人均收入,抽取的“ 200个家庭计算出的年人均收入。
1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。
1.4(1)总体是所有的网上购物者”(2)分类变量;(3)所有的网上购物者的月平均花费;(4)统计量;(5)推断统计方法。
1.5(略)。
1.6(略)。
第2章数据的图表展示2.1(1)属于顺序数据。
(2)频数分布表如下服务质量等级评价的频数分布(3)条形图(略)(4)帕累托图(略)。
2.2(1)频数分布表如下40个企业按产品销售收入分组表(2)某管理局下属40个企分组表2.3 频数分布表如下某百货公司日商品销售额分组表直方图(略)。
2.4 茎叶图如下箱线图(略)。
2.5(1)排序略。
(2)频数分布表如下100只灯泡使用寿命非频数分布690~700 700~710 710~720 720~730 730~740 261813103261813103合计100 100(3)直方图(略)(4)茎叶图如下茎叶65 1 866 1 4 5 6 867 1 3 4 6 7 968 1 1 2 3 3 3 4 5 5 5 8 8 9 969 0 0 1 1 1 1 2 2 2 3 3 4 4 5 5 6 6 6 7 7 8 8 8 8 9 970 0 0 1 1 2 2 3 4 5 6 6 6 7 7 8 8 8 971 0 0 2 2 3 3 5 6 7 7 8 8 972 0 1 2 2 5 6 7 8 9 973 3 5 674 1 4 7(1)频数分布表如下按重量分组频率/包40 〜42 242 〜44 344 〜46 746 〜48 1648 〜50 1752 〜52 1052 〜54 202.62.7 2.854 〜56 856 〜58 1058 〜60 460 〜62 3合计100(2)直方图(略)。
贾俊平_统计学(第四版)最完整的答案(用一次就知道是我想要的)
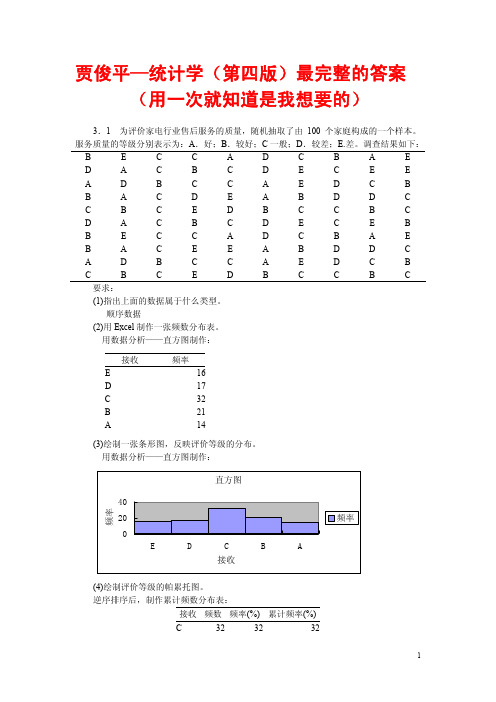
3.6一 种 袋 装 食 品 用 生 产 线 自 动 装 填 ,每 袋 重 量 大 约 为 50g,但 由 于 某 些 原 因 , 每 袋 重 量 不 会 恰 好 是 50g 。 下 面 是 随 机 抽 取 的 100 袋 食 品 , 测 得 的 重 量 数 据 如 下: 单位:g 57 46 49 54 55 58 49 61 51 49 51 60 52 54 51 55 60 56 47 47
直方图:
6
组距3,小于
30
20
Frequency
10
Mean =5.22 Std. Dev. =1.508 N =100 0 0 2 4 6 8 10
组距3,小于
组距 4,上限为小于等于 频数 有效 <= 40.00 41.00 - 44.00 45.00 - 48.00 49.00 - 52.00 53.00 - 56.00 57.00 - 60.00 61.00+ 合计 1 7 28 28 22 13 1 100 百分比 1.0 7.0 28.0 28.0 22.0 13.0 1.0 100.0 累计频数 1 8 36 64 86 99 100 累积百分比 1.0 8.0 36.0 64.0 86.0 99.0 100.0
贾俊平—统计学(第四版)最完整的答案 (用一次就知道是我想要的)
3.1 为评价家电行业售后服务的质量,随机抽取了由 100 个家庭构成的一个样本。 服务质量的等级分别表示为:A.好;B.较好;C 一般;D.较差;E.差。调查结果如下: B D A B C D B B A C E A D A B A E A D B C C B C C C C C B C C B C D E B C E C E A C C E D C A E C D D D A A B D D A A B C E E B C E C B E C B C D D C C B D D C A E C D B E A D C B E E B C C B E C B C
统计学(第四版)贾俊平 第八章 方差分析与实验设计 练习题答案
统计学(第四版)贾俊平 第八章 方差分析与实验设计 练习题答案8.10123411234:0:,,,0=0.01SPSS H H ααααααααα====至少有一个不等于用进行方差分析,表8.1-1填装量主体间效应的检验(单因素方差分析表)因变量: 填装量 源 III 型平方和df均方F Sig.偏 Eta 方非中心 参数观测到的幂b校正模型 .007a3 .002 10.098 .001 .669 30.295 .919 截距 295.7791 295.7791266416.430.000 1.000 1266416.4301.000 机器 .007 3 .002 10.098.001.66930.295.919误差 .004 15 .000总计 304.17119 校正的总计.01118a. R 方 = .669(调整 R 方 = .603)b. 使用 alpha 的计算结果 = .01由表8.1-1得:p=0.001<0.01,拒绝原假设,i 0α不全为,表明不同机器对装填量有显著影响。
8.201231123:0:,,0=0.05SPSS H H ααααααα===至少有一个不等于用进行方差分析,表8.2-1满意度评分主体间效应的检验(单因素方差分析表)因变量: 评分 源III 型平方和df 均方 F Sig.校正模型 29.610a2 14.805 11.756 .001 截距 975.156 1 975.156 774.324 .000 管理者 29.610 2 14.805 11.756.001误差 18.890 15 1.259总计 1061.000 18 校正的总计48.50017a. R 方 = .611(调整 R 方 = .559)由表8.2-1得:p=0.001<0.05,拒绝原假设,i 0α不全为,表明管理者水平不同会导致评分的显著差异。
8.301231123:0:,,0=0.05SPSS H H ααααααα===至少有一个不等于用进行方差分析,表8.3-1电池寿命主体间效应的检验(单因素方差分析表)因变量: 电池寿命 源III 型平方和df 均方 F Sig. 偏 Eta 方 非中心 参数 观测到的幂b校正模型 615.600a2 307.800 17.068 .000 .740 34.137 .997 截距 22815.000 1 22815.000 1265.157 .000 .991 1265.157 1.000 企业 615.600 2 307.800 17.068.000.74034.137.997误差 216.400 12 18.033总计 23647.000 15 校正的总计832.00014a. R 方 = .740(调整 R 方 = .697)b. 使用 alpha 的计算结果 = .05由表8.2-1得:p=0.001<0.05,拒绝原假设,i 0α不全为,表明3个企业生产的电池平均寿命之间存在显著差异。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
8.2 一种元件,要求其使用寿命不得低于700小时。
现从一批这种元件中随机抽取36件,测得其平均寿命为680小时。
已知该元件寿命服从正态分布,=60小时,试在显著性水平0.05下确定这批元件是否合格。
解:H0:μ≥700;H1:μ<700
已知:=680 =60
由于n=36>30,大样本,因此检验统计量:
==-2
当α=0.05,查表得=1.645。
因为z<-,故拒绝原假设,接受备择假设,说明这批产品不合格。
8.3
8.4 糖厂用自动打包机打包,每包标准重量是100千克。
每天开工后需要检验一次打包机工作是否正常。
某日开工后测得9包重量(单位:千克)如下:
99.3 98.7 100.5 101.2 98.3 99.7 99.5 102.1 100.5已知包重服从正态分布,试检验该日打包机工作是否正常(a=0.05)?
解:H0:μ=100;H1:μ≠100
经计算得:=99.9778 S=1.21221
检验统计量:
==-0.055
当α=0.05,自由度n-1=9时,查表得=2.262。
因为<,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明打包机工作正常。
8.5 某种大量生产的袋装食品,按规定不得少于250克。
今从一批该食品中任意抽取50袋,发现有6袋低于250克。
若规定不符合标准的比例超过5%就不得出厂,问该批食品能否出厂(a=0.05)?
解:解:H0:π≤0.05;H1:π>0.05
已知:p=6/50=0.12
检验统计量:
==2.271
当α=0.05,查表得=1.645。
因为>,样本统计量落在拒绝区域,故拒绝原假设,接受备择假设,说明该批食品不能出厂。
8.6
8.7 某种电子元件的寿命x(单位:小时)服从正态分布。
现测得16只元件的寿命如下:
159 280 101 212 224 379 179 264
222 362 168 250 149 260 485 170
问是否有理由认为元件的平均寿命显著地大于225小时(a=0.05)?
解:H0:μ≤225;H1:μ>225
经计算知:=241.5 s=98.726
检验统计量:
==0.669
当α=0.05,自由度n-1=15时,查表得=1.753。
因为t<,样本统计量落在接受区域,故接受原假设,拒绝备择假设,说明元件寿命没有显著大于225小时。
8.8
8.9
8.10 装配一个部件时可以采用不同的方法,所关心的问题是哪一个方法的效率更高。
劳动效率可以用平均装配时间反映。
现从不同的装配方法中各抽取12件产品,记录各自的装配时间(单位:分钟)如
下:
甲方法:31 34 29 32 35 38 34 30 29 32 31 26
乙方法:26 24 28 29 30 29 32 26 31 29 32 28
两总体为正态总体,且方差相同。
问两种方法的装配时间有无显著
不同 (a=0.05)?
解:建立假设
H0:μ1-μ2=0 H1:μ1-μ2≠0
总体正态,小样本抽样,方差未知,方差相等,检验统计量
根据样本数据计算,得=12,=12,=31.75,=3.19446,=
28.6667,=2.46183。
==8.1326
=2.648
α=0.05时,临界点为==2.074,此题中>,故拒绝原假设,认为两种方法的装配时间有显著差异。
8.11 调查了339名50岁以上的人,其中205名吸烟者中有43个患慢性气管炎,在134名不吸烟者中有13人患慢性气管炎。
调查数据能否支
持“吸烟者容易患慢性气管炎”这种观点(a=0.05)?
解:建立假设
H0:π1≤π2;H1:π1>π2
p1=43/205=0.2097 n1=205 p2=13/134=0.097 n2=134检验统计量
=
=3
当α=0.05,查表得=1.645。
因为>,拒绝原假设,说明吸烟者容易患慢性气管炎。
8.12 为了控制贷款规模,某商业银行有个内部要求,平均每项贷款数额不能超过60万元。
随着经济的发展,贷款规模有增大的趋势。
银行经理想了解在同样项目条件下,贷款的平均规模是否明显地超过60万元,故一个n=144的随机样本被抽出,测得=68.1万元,
s=45。
用a=0.01的显著性水平,采用p值进行检验。
解:H0:μ≤60;H1:μ>60
已知:=68.1 s=45
由于n=144>30,大样本,因此检验统计量:
==2.16
由于>μ,因此P值=P(z≥2.16)=1-,查表的=0.9846,P值=0.0154
由于P>α=0.01,故不能拒绝原假设,说明贷款的平均规模没有明显地超过60万元。
8.13 有一种理论认为服用阿司匹林有助于减少心脏病的发生,为了进行验证,研究人员把自愿参与实验的22 000人随机平均分成两组,一组人员每星期服用三次阿司匹林(样本1),另一组人员在相同的时间服用安慰剂(样本2)持续3年之后进行检测,样本1中有104人患心
脏病,样本2中有189人患心脏病。
以a=0.05的显著性水平检验服用阿司匹林是否可以降低心脏病发生率。
解:建立假设
H0:π1≥π2;H1:π1<π2
p1=104/11000=0.00945 n1=11000 p2=189/11000=0.01718
n2=11000
检验统计量
=
=-5
当α=0.05,查表得=1.645。
因为<-,拒绝原假设,说明用阿司匹林可以降低心脏病发生率。
8.14
8.15 有人说在大学中男生的学习成绩比女生的学习成绩好。
现从一个学校中随机抽取了25名男生和16名女生,对他们进行了同样题目的测试。
测试结果表明,男生的平均成绩为82分,方差为56分,女生的平均成绩为78分,方差为49分。
假设显著性水平α=0.02,从上
述数据中能得到什么结论?
解:首先进行方差是否相等的检验:
建立假设
H0:=;H1:≠
n1=25,=56,n2=16,=49
==1.143
当α=0.02时,=3.294,=0.346。
由于<F<,检验统计量的值落在接受域中,所以接受原假设,说明总体方差无显著差异。
检验均值差:
建立假设
H0:μ1-μ2≤0 H1:μ1-μ2>0
总体正态,小样本抽样,方差未知,方差相等,检验统计量
根据样本数据计算,得=25,=16,=82,=56,=78,=49
=53.308
=1.711
=0.02时,临界点为==2.125,t<,故不能拒绝原假设,不能认为大学中男生的学习成绩比女生的学习成绩好。