数据挖掘教程
数据挖掘中的关联规则算法使用方法教程

数据挖掘中的关联规则算法使用方法教程数据挖掘是一门通过从大量数据中发现隐藏模式、关系和信息的技术。
关联规则算法是数据挖掘中的重要工具,用于发现数据集中的关联关系和规律。
本教程将介绍关联规则算法的基本概念、使用方法和常见问题。
一、关联规则算法概述关联规则算法主要用于发现数据集中的关联关系和规律,它可以帮助我们了解事物之间的相互关系,并通过这些关系进行预测和推断。
常见的应用场景包括购物篮分析、市场篮子分析、推荐系统等。
关联规则算法通过分析频繁项集和支持度,找到频繁项集之间的关联规则。
频繁项集是指在数据集中频繁出现的组合项集,支持度是指某个项集在数据集中出现的频率。
通过计算支持度和置信度,可以找到具有较高置信度的关联规则。
常用的关联规则算法包括Apriori算法、FP-Growth算法和Eclat算法。
接下来将逐一介绍这些算法的使用方法。
二、Apriori算法1. Apriori算法基本原理Apriori算法是关联规则算法中最常用的一种算法。
它通过迭代的方式逐步生成频繁项集,然后根据频繁项集生成关联规则。
Apriori算法的基本原理如下:- 生成频繁1项集;- 循环生成候选k项集,并计算支持度;- 剪枝:删除支持度低于阈值的项集,得到k频繁项集;- 生成关联规则,并计算置信度。
2. Apriori算法使用步骤使用Apriori算法进行关联规则挖掘的步骤如下:- 输入数据集:准备一份包含项集的数据集;- 设置支持度和置信度的阈值;- 生成频繁1项集;- 根据频繁1项集生成2频繁项集;- 通过剪枝操作得到k频繁项集;- 根据频繁项集生成关联规则,并计算置信度;- 输出频繁项集和关联规则。
三、FP-Growth算法1. FP-Growth算法基本原理FP-Growth算法是一种高效的关联规则挖掘算法,它通过构建频繁模式树来快速发现频繁项集和关联规则。
FP-Growth算法的基本原理如下:- 构建FP树:将数据集构造成FP树,每个节点表示一个项,每个路径表示一条事务;- 构建条件模式基:从FP树中抽取频繁1项集,并构建条件模式基;- 通过条件模式基递归构建FP树;- 根据FP树生成关联规则。
数据挖掘算法在电子商务中的使用教程

数据挖掘算法在电子商务中的使用教程随着互联网的快速发展,电子商务行业成为了全球经济的重要组成部分。
在这个竞争激烈的市场中,企业需要利用各种工具和技术来提高销售、预测市场趋势以及改进运营效率。
数据挖掘算法作为一种强大的工具,可以帮助电子商务企业挖掘潜在的商机,优化运营并提供个性化的用户体验。
本文将介绍几种常用的数据挖掘算法,并探讨它们在电子商务中的具体应用。
1. 关联规则算法关联规则算法是一种寻找数据集中项集之间的关联关系的方法。
它可以帮助企业发现隐藏在数据中的规律,并提供针对性的推荐。
在电子商务中,关联规则算法可以用于协同过滤推荐系统的构建。
通过分析用户购买历史或浏览记录,算法可以发现用户之间的相似性并推荐相关产品。
这种个性化推荐可以提高用户满意度和购买转化率。
2. 聚类算法聚类算法是将一组对象分成相似的子集的方法。
在电子商务中,聚类算法可以用于用户细分以及市场细分的研究。
通过对用户行为数据的分析,可以将用户划分成不同的群组,并了解他们的兴趣、需求和消费习惯。
这些信息可以帮助企业制定更加个性化和精准的营销策略,提高广告投放的效果和销售转化率。
3. 决策树算法决策树算法是一种用于分类和回归问题的监督学习方法。
在电子商务中,决策树算法可以用于构建精准的用户行为预测模型。
通过分析用户的历史浏览记录、购买记录和其他相关信息,算法可以预测用户的未来行为,例如是否会购买某个产品、对某个广告的反应等。
这些预测结果可以帮助企业优化广告投放和产品推荐策略,提高销售和盈利能力。
4. 神经网络算法神经网络算法是一种模拟人脑神经元工作原理的计算模型。
在电子商务中,神经网络算法可以用于构建用户情感分析模型。
通过分析用户在社交媒体、评论和评分等渠道的表达,算法可以了解用户的情感倾向,例如对产品的满意度、购买意愿等。
这些情感信息可以帮助企业更好地了解市场和用户需求,并及时调整产品策略。
5. 推荐算法推荐算法是一种根据用户兴趣和偏好向用户提供个性化推荐的方法。
数据仓库与数据挖掘教程(第2版)陈文伟版课后答案

第一章数据仓库与数据挖掘概述1.数据库与数据仓库的本质差别是什么?答:数据库用于事务处理,数据仓库用于决策分析;数据库保持事务处理的当前状态,数据仓库既保存过去的数据又保存当前的数据;数据仓库的数据是大量数据库的集成;对数据库的操作比较明确,操作数据量少,对数据仓库操作不明确,操作数据量大。
数据库是细节的、在存取时准确的、可更新的、一次操作数据量小、面向应用且支持管理;数据仓库是综合或提炼的、代表过去的数据、不更新、一次操作数据量大、面向分析且支持决策。
6.说明OLTP与OLAP的主要区别。
答:OLTP针对的是细节性数据、当前数据、经常更新、一次性处理的数据量小、对响应时间要求高且面向应用,事务驱动; OLAP针对的是综合性数据、历史数据、不更新,但周期性刷新、一次处理的数据量大、响应时间合理且面向分析,分析驱动。
8.元数据的定义是什么?答:元数据(metadata)定义为关于数据的数据(data about data),即元数据描述了数据仓库的数据和环境。
9.元数据与数据字典的关系什么?答:在数据仓库中引入了“元数据”的概念,它不仅仅是数据仓库的字典,而且还是数据仓库本身信息的数据。
18.说明统计学与数据挖掘的不同。
答:统计学主要是对数量数据(数值)或连续值数据(如年龄、工资等),进行数值计算(如初等运算)的定量分析,得到数量信息。
数据挖掘主要对离散数据(如职称、病症等)进行定性分析(覆盖、归纳等),得到规则知识。
19.说明数据仓库与数据挖掘的区别与联系。
答:数据仓库是一种存储技术,它能适应于不同用户对不同决策需要提供所需的数据和信;数据挖掘研究各种方法和技术,从大量的数据中挖掘出有用的信息和知识。
数据仓库与数据挖掘都是决策支持新技术。
但它们有着完全不同的辅助决策方式。
在数据仓库系统的前端的分析工具中,数据挖掘是其中重要工具之一。
它可以帮助决策用户挖掘数据仓库的数据中隐含的规律性。
数据仓库和数据挖掘的结合对支持决策会起更大的作用。
数据挖掘技术的使用教程与实战案例分析

数据挖掘技术的使用教程与实战案例分析在当今数字化时代,大量的数据被生成和积累,对这些数据进行有效利用成为了重要问题。
数据挖掘技术的出现为我们提供了一种强大的方法,通过挖掘数据中的模式、关联和趋势,从中提取有价值的信息来支持决策和预测未来。
本文将为读者提供一份数据挖掘技术的使用教程,并通过实战案例分析来展示其在不同领域的应用。
第一部分:数据挖掘技术的基本概念与流程1. 数据挖掘的定义和目标:详细介绍数据挖掘的概念和其在实际应用中的目标,包括发现隐藏在数据中的模式、关联和趋势。
2. 数据挖掘流程:介绍数据挖掘的基本流程,包括问题定义、数据收集与预处理、特征选择与转换、建模与评估以及结果解释。
3. 数据挖掘技术与算法:概述主要的数据挖掘技术和算法,如分类、聚类、关联规则、异常检测等,并介绍它们的原理和适用场景。
第二部分:数据挖掘实战案例分析1. 零售业销售数据分析:以某家零售商为例,介绍如何利用数据挖掘技术对销售数据进行分析,挖掘出热门产品、购买者行为模式等信息,从而提升销售和市场营销策略。
2. 银行业风险评估与欺诈检测:以银行业为背景,探讨如何利用数据挖掘技术对客户信用评估和欺诈检测进行分析,准确判断客户的信用评级和检测潜在的欺诈行为。
3. 医疗保险理赔数据分析:通过挖掘医疗保险理赔数据,展示如何利用数据挖掘技术识别高风险客户群体、预测保险索赔的情况,从而提高保险公司的风险管理水平。
4. 社交媒体用户行为分析:以社交媒体平台为背景,探讨如何利用数据挖掘技术分析用户的行为模式、兴趣爱好和社交关系,为社交媒体平台提供个性化推荐和社交网络分析的支持。
第三部分:数据挖掘技术的工具与资源1. 数据挖掘工具:介绍常见的数据挖掘工具,如WEKA、RapidMiner、Python的Scikit-learn等,以及它们的特点和应用范围。
2. 数据挖掘资源与学习平台:推荐一些在线学习平台和数据挖掘资源,包括Coursera、Kaggle等,以及一些优秀的数据挖掘书籍和文献。
数据仓库与数据挖掘教程(第2版)课后习题答案 第四章

第四章作业1.数据仓库的需求分析的任务是什么?P67需求分析的任务是通过详细调查现实世界要处理的对象(企业、部门用户等),充分了解源系统工作概况,明确用户的各种需求,为设计数据仓库服务。
概括地说,需求分析要明确用那些数据经过分析来实现用户的决策支持需求。
2.数据仓库系统需要确定的问题有哪些?P67、、(1)确定主题域a)明确对于决策分析最有价值的主题领域有哪些b)每个主题域的商业维度是那些?每个维度的粒度层次有哪些?c)制定决策的商业分区是什么?d)不同地区需要哪些信息来制定决策?e)对那个区域提供特定的商品和服务?(2)支持决策的数据来源a)那些源数据与商品的主题有关?b)在已有的报表和在线查询(OLTP)中得到什么样的信息?c)提供决策支持的细节程度是怎么样的?(3)数据仓库的成功标准和关键性指标a)衡量数据仓库成功的标准是什么?b)有哪些关键的性能指标?如何监控?c)对数据仓库的期望是什么?d)对数据仓库的预期用途有哪些?e)对计划中的数据仓库的考虑要点是什么?(4)数据量与更新频率a)数据仓库的总数据量有多少?b)决策支持所需的数据更新频率是多少?时间间隔是多长?c)每种决策分析与不同时间的标准对比如何?d)数据仓库中的信息需求的时间界限是什么?3.实现决策支持所需要的数据包括哪些内容?P68(1)源数据(2)数据转换(3)数据存储(4)决策分析4.概念:将需求分析过程中得到的用户需求抽象为计算机表示的信息结构,叫做概念模型。
特点:(1)能真实反映现实世界,能满足用户对数据的分析,达到决策支持的要求,它是现实世界的一个真实模型。
(2)易于理解,便利和用户交换意见,在用户的参与下,能有效地完成对数据仓库的成功设计。
(3)易于更改,当用户需求发生变化时,容易对概念模型修改和扩充。
(4)易于向数据仓库的数据模型(星型模型)转换。
5.用长方形表示实体,在数据仓库中就表示主题,椭圆形表示主题的属性,并用无向边把主题与其属性连接起来;用菱形表示主题之间的联系,用无向边把菱形分别与有关的主题连接;若主题之间的联系也具有属性,则把属性和菱形也用无向边连接上。
数据仓库与数据挖掘教程(第2版)陈文伟版课后习题答案(非常全)

第一章作业1.数据库与数据仓库的本质差别是什么?书P2(1)数据库用于事务处理,数据仓库用于决策分析。
(2)数据库保持事物处理的当前状态,数据仓库即保存过去的数据又保存当前的数据。
(3)数据仓库的数据是大量数据库的集成。
(4)对数据库的操作比较明确,操作数量较小。
对数据仓库操作不明确,操作数据量大。
2.从数据库发展到数据仓库的原因是什么?书P1(1)数据库数据太多,信息贫乏。
如何将大量的数据转化为辅助决策信息成为了研究热点。
(2)异构环境数据的转换和共享。
随着各类数据库产品的增加,异构环境的数据也逐渐增加,如何实现这些异构环境数据的转换的共享也成了研究热点。
(3)利用数据进行事物处理转变为利用数据支持决策。
3.举例说明数据库与数据仓库的不同。
比如,银行中储蓄业务要建立储蓄数据库,信用卡要建立信用卡数据库,贷款业务要建立贷款数据库,这些数据库方便了银行的事务处理。
但是要对这些独立数据库进行决策分析就很复杂了。
因此可以把这些数据库中的数据存储转化到数据仓库中,方便进行决策。
4.OLTP(On Line Transaction Processing,联机事物处理)是在网络环境下的事务处理工作,以快速的响应和频繁的数据修改为特征,使用户利用数据库能够快速地处理具体的业务。
OLAP(On Line Analytical Processing,联机分析处理)是使用多维数据库和多维分析的方法,对多个关系数据库共同进行大量的综合计算来得到结果的方法。
5.OLTP是用户的数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。
6.OLTP OLAP细节性数据综合性数据当前数据历史数据经常更新不更新,但周期性刷新一次性处理的数据量小一次处理的数据量大对响应时间要求高响应时间合理面向应用,事务驱动面向分析,分析驱动7.包括数据项、数据结构、数据流、数据存储和处理过程五个部分。
8.定义为关于数据的数据,描述数据仓库中数据及其环境的数据。
数据仓库与数据挖掘教程(第2版)课后习题答案第七章

数据仓库与数据挖掘教程(第2版)课后习题答案第七章第七章作业1.信息论的基本原理是什么?一个传递信息的系统是由发送端(信源)和接收端(信宿)以及连接两者的通道(信道)组成的。
信息论把通信过程看做是在随机干扰的环境中传递信息的过程。
在这个通信模型中,信息源和干扰(噪声)都被理解为某种随机过程或随机序列。
在进行实际的通信之前,收信者(信宿)不可能确切了解信源究竟会发出什么样的具体信息,也不可能判断信源会处于什么样的状态。
这种情形就称为信宿对于信源状态具有不确定性,而且这种不确定性是存在于通信之前的,因而又叫做先验不确定性。
在通信后,信宿收到了信源发来的信息,这种先验不确定性才会被消除或者被减少。
如果干扰很小,不会对传递的信息产生任何可察觉的影响,信源发出的信息能够被信宿全部收到,在这种情况下,信宿的先验不确定性就会被完全消除。
但是,在一般情况下,干扰总会对信源发出的信息造成某种破坏,使信宿收到的信息不完全。
因此,先验不确定性不能全部被消除, 只能部分地消除。
换句话说,通信结束之后,信宿仍具有一定程度的不确定性。
这就是后验不确定性。
2.学习信道模型是什么?学习信道模型是信息模型应用于机器学习和数据挖掘的具体化。
学习信道模型的信源是实体的类别,采用简单“是”、“非”两类,令实体类别U 的值域为{u1,u2},U 取u1表示取“是”类中任一例子,取u2表示取“非”类中任一例子。
信宿是实体的特征(属性)取值。
实体中某个特征属性V ,他的值域为{v1,v2……vq}。
3.为什么机器学习和数据挖掘的分类问题可以利用信息论原理?信息论原理是数据挖掘的理论基础之一。
一般用于分类问题,即从大量数据中获取分类知识。
具体来说,就是在已知各实例的类别的数据中,找出确定类别的关键的条件属性。
求关键属性的方法,即先计算各条件属性的信息量,再从中选出信息量最大的属性,信息量的计算是利用信息论原理中的公式。
4自信息:单个消息ui 发出前的不确定性(随机性)称为自信息。
数据挖掘技术的使用教程及模型建立方法

数据挖掘技术的使用教程及模型建立方法数据挖掘技术是一种通过从大量的数据中挖掘出有价值的信息和模式的技术。
随着大数据时代的到来,数据挖掘技术越来越受到重视。
本文将介绍数据挖掘技术的使用教程及模型建立方法,帮助读者了解并应用这一重要的技术。
首先,我们需要明确数据挖掘技术的基本概念和步骤。
数据挖掘技术主要包括数据预处理、特征选择、模型选择和评估等步骤。
数据预处理是指对原始数据进行清洗和转换,以便后续的特征选择和模型建立。
特征选择是选择对目标变量有显著影响的特征,以减少模型的复杂性和计算成本。
模型选择是根据问题的类型和数据的特点选择适当的数据挖掘模型,如分类模型、聚类模型和关联规则模型。
模型评估是对建立的模型进行验证和评估,以确保其在未知数据上的泛化能力。
接下来,我们将逐步介绍数据挖掘技术的使用教程。
首先是数据预处理。
在数据预处理中,我们首先需要对原始数据进行清洗,去除重复值、缺失值和异常值。
然后,我们可以对数据进行转换,如标准化、归一化或离散化,以便后续处理。
最后,我们可以进行特征抽取和降维,选择对目标变量有重要影响的特征。
这些步骤可以使用Python编程语言中的一些开源库来实现,如pandas和scikit-learn。
特征选择是数据挖掘中非常重要的一步。
选择正确的特征可以提高模型的准确性和效率。
常用的特征选择方法包括过滤式方法、包裹式方法和嵌入式方法。
过滤式方法通过计算特征与目标变量之间的相关性来选择特征。
包裹式方法则通过建立模型,根据模型的性能选择特征。
嵌入式方法将特征选择嵌入到模型的训练过程中。
在实践中,我们可以尝试不同的特征选择方法,选择最适合的方法。
选择适当的数据挖掘模型是模型选择的关键步骤。
根据问题的类型和数据的特点,我们可以选择不同的数据挖掘模型。
对于分类问题,可以选择决策树、支持向量机或神经网络等模型;对于聚类问题,可以选择K均值聚类、层次聚类或高斯混合模型等模型;对于关联规则挖掘问题,可以选择Apriori 算法或FP-Growth算法等模型。
数据挖掘入门教程

数据挖掘入门教程数据挖掘是一门利用统计学、机器学习和人工智能等方法,从大量数据中提取出有用信息的技术。
在当今信息爆炸的时代,数据挖掘技术成为了解决实际问题和做出决策的重要工具。
本文将介绍数据挖掘的基本概念、常用算法和实践技巧,帮助读者入门数据挖掘领域。
一、数据挖掘的基本概念数据挖掘是从大量数据中发现隐藏的模式、规律和知识的过程。
它可以帮助我们理解数据背后的规律,预测未来的趋势,并支持决策和问题解决。
数据挖掘的过程包括数据预处理、特征选择、模型构建和模型评估等步骤。
数据预处理是数据挖掘的第一步,它包括数据清洗、数据集成、数据转换和数据规约。
数据清洗是指处理数据中的噪声、缺失值和异常值,确保数据的质量。
数据集成是将来自不同数据源的数据进行整合,消除冗余和冲突。
数据转换是将原始数据转换为适合挖掘的格式,如将文本数据转换为数值型数据。
数据规约是减少数据集的规模,提高挖掘效率。
特征选择是从大量特征中选择出最相关的特征,以提高模型的准确性和可解释性。
常用的特征选择方法包括过滤式、包裹式和嵌入式方法。
过滤式方法通过统计指标或相关性分析选择特征,独立于具体的学习算法。
包裹式方法将特征选择看作是一个优化问题,通过搜索最优特征子集来选择特征。
嵌入式方法将特征选择与模型构建过程结合起来,通过学习算法自动选择特征。
模型构建是数据挖掘的核心步骤,它包括选择合适的算法、设置模型参数和训练模型。
常用的数据挖掘算法包括决策树、支持向量机、神经网络和聚类算法等。
不同的算法适用于不同的问题类型和数据特征。
在选择算法时,需要考虑算法的复杂度、准确性和可解释性等因素。
设置模型参数是调整算法的关键步骤,它会影响模型的性能和泛化能力。
训练模型是使用标记好的数据集来拟合模型,以学习模型的参数和结构。
模型评估是对构建好的模型进行性能评估,以选择最优的模型和调整模型参数。
常用的评估指标包括准确率、召回率、精确率和F1值等。
交叉验证是一种常用的评估方法,它将数据集划分为训练集和测试集,通过多次迭代来评估模型的性能。
数据仓库与数据挖掘教程(第2版)课后习题答案 第三章

第三章作业1.联机分析处理(OLAP)的简单定义是什么?它体现的特征是什么。
P40联机分析处理是共享多维信息的快速分析。
它体现在四个特征:(1)快速性(2)可分析性(3)多维性(4)信息性2.OLAP准则中的主要准则有哪些?P41(1)多维概念视图(2)透明性(3)可访问性(4)一直稳定的报表性能(5)客户/服务器体系结构(6)维的等同性(7)动态的系数矩阵处理(8)多用户支持能力(9)非限定的跨维操作(10)直观的数据操作(11)灵活的报表生成(12)不受限制的维和聚集层次3. 什么是维?关系数据库是二维数据吗?如何理解多维数据?P43维是人们观察数据的特定角度。
关系数据库不是二维数据,只是通过二维关系表示了数据的多维概念。
多维数据就是从多个特定角度来观察特定的变量。
4.MDDB(Multi Dimensional Database, 多维数据库)是以多维的方式组织数据,即以维作为坐标系,采用类似于数组的形式存储数据。
RDBMS(relational database management system,关系型数据库管理系统)通过数据、关系和对数据的约束三者组成的数据模型来存放和管理数据MDDB特点:1.数据库中的元素具有相同的数值2.多维数据库表达清晰,3.占用存储少RDBMS的特点:1.数据以表格的形式出现2.每行为各种记录名称3.每列为记录名称所对应的数据域4.许多的行和列组成一张表单5.若干的表单组成database5.1.数据存取速度ROLAP服务器需要将SQL语句转化为多维存储语句,临时“拼合”出多维数据立方体。
因此,ROLAP的响应时间较长。
MOLAP在数据存储速度上性能好,响应速度快。
2.数据存储的容量ROLAP使用的传统关系数据库的存储方法,在存储容量上基本没有限制。
MOLAP通常采用多平面叠加成立体的方式存放数据。
当数据量超过操作系统最大文件长度时,需要进行数据分割。
多维数据库的数据量级难以达到太大的字节级。
数据挖掘入门系列教程(十点五)之DNN介绍及公式推导
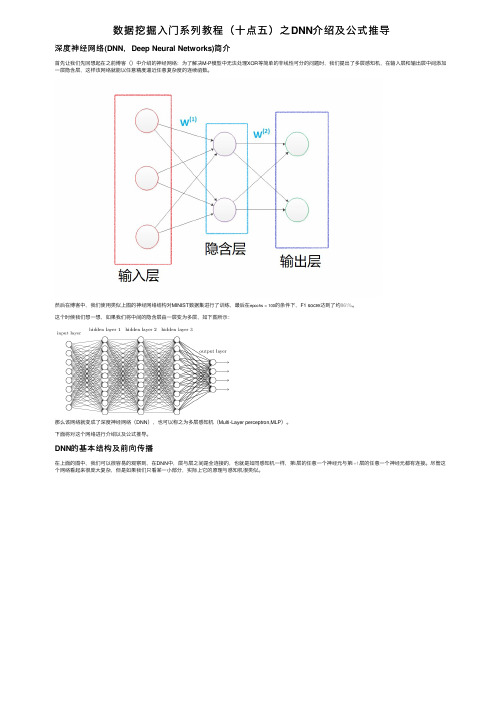
数据挖掘⼊门系列教程(⼗点五)之DNN介绍及公式推导深度神经⽹络(DNN,Deep Neural Networks)简介⾸先让我们先回想起在之前博客()中介绍的神经⽹络:为了解决M-P模型中⽆法处理XOR等简单的⾮线性可分的问题时,我们提出了多层感知机,在输⼊层和输出层中间添加⼀层隐含层,这样该⽹络就能以任意精度逼近任意复杂度的连续函数。
然后在博客中,我们使⽤类似上图的神经⽹络结构对MINIST数据集进⾏了训练,最后在epochs = 100的条件下,F1 socre达到了约86\%。
这个时候我们想⼀想,如果我们将中间的隐含层由⼀层变为多层,如下图所⽰:那么该⽹络就变成了深度神经⽹络(DNN),也可以称之为多层感知机(Multi-Layer perceptron,MLP)。
下⾯将对这个⽹络进⾏介绍以及公式推导。
DNN的基本结构及前向传播在上⾯的图中,我们可以很容易的观察到,在DNN中,层与层之间是全连接的,也就是如同感知机⼀样,第i层的任意⼀个神经元与第i+1层的任意⼀个神经元都有连接。
尽管这个⽹络看起来很庞⼤复杂,但是如果我们只看某⼀⼩部分,实际上它的原理与感知机很类似。
如同感知机,我们可以很简单的知道:对于LayerL_2的输出,可知:\begin{equation}\begin{aligned} &a_{1}^{2}=\sigma\left(z_{1}^{2}\right)=\sigma\left(w_{11}^{2} x_{1}+w_{12}^{2} x_{2}+w_{13}^{2} x_{3}+b_{1}^{2}\right)\\ &\begin{array}{l}a_{2}^{2}=\sigma\left(z_{2}^{2}\right)=\sigma\left(w_{21}^{2} x_{1}+w_{22}^{2} x_{2}+w_{23}^{2} x_{3}+b_{2}^{2}\right) \\a_{3}^{2}=\sigma\left(z_{3}^{2}\right)=\sigma\left(w_{31}^{2} x_{1}+w_{32}^{2} x_{2}+w_{33}^{2} x_{3}+b_{3}^{2}\right) \end{array} \end{aligned}\end{equation}对于w的参数上标下标解释,以下图为例:对于w_{24}^3,上标3代表w所在的层数,下标2对应的是第三层的索引2,下标4对应的是第⼆层的索引4。
高维数据挖掘中的聚类分析方法使用教程

高维数据挖掘中的聚类分析方法使用教程聚类分析是一种重要的高维数据挖掘方法,可以帮助我们在大规模数据中发现相似的结构和模式。
在高维数据中进行聚类分析可以帮助我们挖掘数据中的深层次关联和规律,从而为决策和预测提供支持。
本文将介绍在高维数据挖掘中常用的聚类分析方法,并提供使用教程。
一、高维数据挖掘中的挑战高维数据挖掘涉及的数据集维度较高,通常包含大量的特征。
传统的聚类分析方法在高维数据中面临着一些挑战,如维度灾难和过拟合问题。
维度灾难指的是高维空间中样本密度稀疏,难以直观地对数据进行可视化和理解。
过拟合问题是指模型在训练集上表现良好,但在新数据集上的泛化能力较差。
因此,在高维数据挖掘中选择合适的聚类分析方法至关重要。
二、常用的高维数据聚类方法1. K-means聚类K-means聚类是一种常用的划分聚类方法,其原理是将数据划分成K个簇,使得同一簇内的样本相似度较高,不同簇之间的相似度较低。
K-means聚类算法首先随机选择K个中心点,然后迭代计算每个样本到各个中心点的距离,将样本划分到距离最近的中心点所在的簇中,然后更新中心点的位置,重复迭代直到簇的划分稳定。
K-means聚类适用于球形簇和欧氏距离度量,但对异常值和噪声数据敏感。
2. 均值漂移聚类均值漂移聚类是一种基于密度的聚类方法,其原理是通过计算样本点密度的梯度,将样本点向密度较高的区域漂移。
均值漂移聚类算法首先随机选择一个样本作为初始中心点,然后计算样本点密度的梯度向量,根据梯度向量的方向更新当前样本点的位置,重复迭代直到收敛。
均值漂移聚类相比K-means聚类具有更好的适应性,可以处理非球形簇和非线性距离度量,但在大规模数据集上计算复杂度较高。
3. 密度聚类方法密度聚类是一种基于样本点密度的聚类方法,其原理是将样本点密度较高的区域看作簇,样本点密度较低的区域看作噪声。
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是常用的密度聚类方法之一。
数据仓库与数据挖掘教程(第2版)课后习题答案 第八章

第七章作业说明等价关系、等价类以及划分的定义。
等价关系:对于∀a ∈A (A 中包含一个或多个属性),A ⊆R ,x ∈U ,y ∈U ,他们的属性值相同,即fa (x )=fb (y )成立,称对象x 和y 是对属性A 的等价关系。
等价类:在U 中,对属性集A 中具有相同等价关系的元素集合成为等价关系IND (A )的等价类。
划分:在U 中对属性A 的所有等价类形成的划分表示为A={Ei | Ei=[xi]a ,i=1,2,… } 说明集合X 的上、下近似关系定义。
下近似定义:任一一个子集X ⊆U ,属性A 的等价类Ei=[x]A ,有:A-(X )=U{Ei|Ei ∈A ∧Ei ⊆X} 或A-(X )={x|[x]A ⊆X} 表示等价类Ei=[x]A 中的元素x 都属于X ,即∀x ∈A-(X ),则x 一定属于X 。
上近似定义:任一一个子集X ⊆U ,属性A 的等价类Ei=[x]A ,有:A-(X )=U{Ei|Ei ∈A ∧Ei ∩X ≠∅} 或A-(X )={x|[x]A ∩X ≠∅} 表示等价类Ei=[x]A 中的元素x 可能属于X ,即∀x ∈A-(X ),则x 可能属于X ,也可能不属于X 。
说明正域、负域和边界的定义。
全集U 可以划分为三个不相交的区域,即正域(pos ),负域(neg )和边界(bnd ): POSA(X)= A-(X )NEGA(X)=U- A-(X )BNDA(X) = A-(X )-A-(X )4.粗糙集定义:若 ,即 , 即边界为空,称X 为A 的可定义集; 否则X 为A 不可定义的,即 ,称X 为A 的Rough 集(粗糙集)确定度定义:()A U A X A X X U α----=其中U 和A X A X ---分别表示集合U 、(AX AX ---)中的元素个数5.在信息表中根据等价关系,我们可以用等价类中的一个对象(元组)来代表整个等价类,这实际上是按纵方向约简了信息表中数据。
信息检索与数据挖掘技术教程

信息检索与数据挖掘技术教程第一章:引言信息检索与数据挖掘技术是当今信息时代中应用广泛的领域。
信息检索是指从大量文本、图像或其他形式的数据中,根据用户的需求寻找并提供相关信息的过程。
数据挖掘则是从大量数据中自动发现潜在的模式、规律和知识。
本教程将介绍信息检索与数据挖掘的基本概念、技术方法以及应用领域。
第二章:信息检索技术2.1 检索模型2.1.1 布尔模型2.1.2 向量空间模型2.1.3 概率检索模型2.2 检索评价指标2.2.1 查准率和查全率2.2.2 准确率和召回率2.2.3 F1值2.3 查询扩展技术2.3.1 同义词扩展2.3.2 相关词扩展2.3.3 查询改写2.4 高级检索技术2.4.1 基于用户反馈的检索2.4.2 个性化检索2.4.3 语言模型检索2.5 图像检索技术2.5.1 基于内容的图像检索2.5.2 基于标签的图像检索2.5.3 基于深度学习的图像检索第三章:数据挖掘技术3.1 数据预处理3.1.1 数据清洗3.1.2 数据集成3.1.3 数据变换3.2 数据挖掘任务3.2.1 分类3.2.2 聚类3.2.3 关联规则挖掘3.2.4 时序模式挖掘3.3 数据挖掘算法3.3.1 决策树3.3.2 支持向量机3.3.3 神经网络3.3.4 K近邻算法3.4 特征选择与降维3.4.1 特征选择3.4.2 主成分分析3.4.3 线性判别分析3.5 数据挖掘工具与软件3.5.1 Weka3.5.2 RapidMiner3.5.3 Python数据挖掘库第四章:信息检索与数据挖掘应用4.1 互联网搜索引擎4.1.1 Google4.1.2 百度4.1.3 Bing4.2 社交媒体数据分析4.2.1 舆情监测与分析4.2.2 用户兴趣建模4.2.3 社交网络分析4.3 电子商务推荐系统4.3.1 商品推荐4.3.2 用户画像构建4.3.3 数据分析与精准营销4.4 医疗大数据应用4.4.1 疾病诊断与预测4.4.2 基因组学数据分析4.4.3 医药知识发现4.5 金融领域数据挖掘4.5.1 信用评分模型4.5.2 股市预测与交易策略4.5.3 欺诈检测第五章:未来发展趋势信息检索与数据挖掘技术在不断发展,随着新的技术和方法的出现,它们在各个领域中的应用将愈发广泛和深入。
数据挖掘开源工具weka简明教程

基于概率模型的分类方法,如Naive Bayes,适用于特征之间独立性较强的数据集。
贝叶斯
基于规则的分类方法,如JRip、OneR等,适用于可解释性要求较高的场景。
规则学习
支持多类别的分类问题,如SVM、Logistic回归等。
多类分类
分类算法
经典的聚类算法,将数据划分为K个簇,使每个数据点与其所在簇的中心点距离之和最小。
与Java集成
Weka是用Java编写的,因此可以方便地与Java集成,用户可以通过Java调用Weka的功能,或使用Weka提供的Java API进行二次开发。
与Excel集成
05
CHAPTER
实践案例
通过使用Weka的分类算法,可以有效地识别出信用卡交易中的欺诈行为,提高银行的风险管理能力。
总结词
客户细分是市场营销中的重要环节,能够帮助企业更好地了解客户需求和行为特征。Weka提供了多种聚类算法,如K-means、层次聚类等,可以对客户数据进行聚类分析,将客户群体划分为不同的细分市场。企业可以根据这些细分市场的特点和需求,制定更有针对性的市场策略,提高客户满意度和忠诚度。
详细描述
总结词
使用Weka进行股票价格预测
THANKS
感谢您的观看。
通过使用Weka的时间序列预测算法,可以对股票价格进行短期预测,帮助投资者做出更明智的投资决策。
详细描述
股票价格预测是投资者关注的焦点之一,但由于市场复杂性和不确定性,预测难度较大。Weka提供了多种时间序列预测算法,如ARIMA、指数平滑等,可以对历史股票价格数据进行学习和预测,为投资者提供参考。当然,股票价格预测存在风险,投资者需要结合其他因素和市场情况做出决策。
使用Weka进行数据挖掘
数据挖掘中聚类分析的使用教程

数据挖掘中聚类分析的使用教程数据挖掘是一个广泛应用于计算机科学和统计学的领域,它旨在从大量的数据中发现隐藏的模式和关联。
聚类分析是数据挖掘中最常用的技术之一,它可以将相似的数据点归类到同一个群组中。
本文将介绍聚类分析的基本概念、常用算法以及如何在实际应用中使用。
一、什么是聚类分析?聚类分析是一种无监督学习方法,它通过计算数据点之间的相似性来将它们划分为不同的群组。
聚类分析的目标是使同一群组内的数据点尽可能相似,而不同群组之间的数据点尽可能不同。
聚类分析可以帮助我们发现数据中的潜在模式、结构和关联。
二、常用的聚类算法1. K-means算法K-means算法是最常用的聚类算法之一,它将数据点划分为预先设定的K个簇。
算法的基本思想是通过计算数据点与簇中心的距离,将每个数据点分配到距离最近的簇中心。
然后,重新计算每个簇的中心点,并重复此过程直到簇心不再发生变化或达到预定的迭代次数。
2. 层次聚类算法层次聚类算法是一种自底向上或自顶向下的递归分割方法。
它的特点是不需要预先设定聚类簇的个数,而是通过计算数据点之间的距离或相似性,逐步合并或分割簇。
层次聚类可以生成一棵树形结构,称为聚类树或谱系树,通过对树进行剪枝可以得到不同个数的簇。
3. 密度聚类算法密度聚类算法基于数据点之间的密度来识别具有高密度的区域。
算法的核心思想是计算每个数据点的密度,并将高密度区域作为簇的中心进行扩展。
最常用的密度聚类算法是DBSCAN,它使用一个邻域半径和最小密度来定义一个核心点,从而将数据点划分为核心点、边界点和噪声点。
三、如何使用聚类分析1. 准备数据在使用聚类分析前,首先需要准备好适合进行聚类的数据。
这些数据可以是数字、文本或图像等形式,但需要将其转化为计算机能够处理的格式。
同时,数据应该经过预处理,例如去除噪声、处理缺失值和标准化等。
2. 选择适当的聚类算法根据数据的特点和问题的需求,选择合适的聚类算法。
例如,如果数据点的分布呈现明显的球状或椭球状,可以选择K-means算法;如果数据点的分布具有一定的层次结构,可以选择层次聚类算法;如果数据点的分布具有不同的密度区域,可以选择密度聚类算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
摘要:顾名思义, 数据挖掘就是从大量的数据中挖掘出有用的信息。
它是根据人们的特定要求,从浩如烟海的数据中找出所需的信息来,供人们的特定需求使用。
2000年7 月,IDC发布了有关信息存取工具市场的报告。
1999年,数据挖掘市场大概约为7.5亿美元,估计在下个5年内市场的年增长率为32.4%,其中亚太地 区为26.6%。
到2002年,该市场会发展到22亿美元。
据国外专家预测,随着数据量的日益积累和计算机的广泛应用,在今后的5—10年内,数据挖掘将 在中国形成一个新型的产业。
为了帮助大家了解数据挖掘的基本理论和方法,我们从“数据挖掘讨论组”网站上整理加工了一组有关该概念的基本知识,省却了纷繁的技术方法,供读者学习参考。
第一课 数据挖掘技术的由来第二课 数据挖掘的定义第三课 数据挖掘的研究历史和现状第四课 数据挖掘研究内容和本质第五课 数据挖掘的功能第六课 数据挖掘常用技术第七课 数据挖掘的流程第八课 数据挖掘未来研究方向及热点第九课 数据挖掘应用第十课 实施数据挖掘项目考虑的问题URL:h ttp:///learning/lesson/xinxi/20021125/lesson.asp第一课数据挖掘技术的由来1.1 网络之后的下一个技术热点1.2 数据爆炸但知识贫乏1.3 支持数据挖掘技术的基础1.4 从商业数据到商业信息的进化1.5 数据挖掘逐渐演变的过程1.1网络之后的下一个技术热点我们现在已经生活在一个网络化的时代,通信、计算机和网络技术正改变着整个人类和社会。
如果用芯片集成度来衡量微电子技术,用CPU处理速度来衡量计 算机技术,用信道传输速率来衡量通信技术,那么摩尔定律告诉我们,它们都是以每18个月翻一番的速度在增长,这一势头已经维持了十多年。
在美国,广播达到 5000万户用了38年;电视用了13年;Internet拨号上网达到5000万户仅用了4年。
全球IP网发展速度达到每6个月翻一番,国内情况亦然。
1999年初,中国上网用户为210万,现在已经达到600万。
网络的发展导致经济全球化,在1998年全球产值排序前100名中,跨国企业占了51个, 国家只占49个。
有人提出,对待一个跨国企业也许比对待一个国家还要重要。
在新世纪钟声刚刚敲响的时候,回顾往昔,人们不仅要问:就推动人类社会进步而 言,历史上能与网络技术相比拟的是什么技术呢?有人甚至提出要把网络技术与火的发明相比拟。
火的发明区别了动物和人,种种科学技术的重大发现扩展了自然人 的体能、技能和智能,而网络技术则大大提高了人的生存质量和人的素质,使人成为社会人、全球人。
现在的问题是:网络之后的下一个技术热点是什么?让我们来看一些身边俯拾即是的现象:《纽约时报》由60年代的10~20版扩张至现在的 100~200版,最高曾达1572版;《北京青年报》也已是16~40版;市场营销报已达100版。
然而在现实社会中,人均日阅读时间通常为30~45 分钟,只能浏览一份24版的报纸。
大量信息在给人们带来方便的同时也带来了一大堆问题:第一是信息过量,难以消化;第二是信息真假难以辨识;第三是信息安 全难以保证;第四是信息形式不一致,难以统一处理。
人们开始提出一个新的口号:“要学会抛弃信息”。
人们开始考虑:“如何才能不被信息淹没,而是从中及时 发现有用的知识、提高信息利用率?”面对这一挑战,数据开采和知识发现(DMKD)技术应运而生,并显示出强大的生命力。
1.2 数据爆炸但知识贫乏另一方面,随着数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越多。
激增的数据背后隐藏着许多重要的信息,人们希望能够对其 进行更高层次的分析,以便更好地利用这些数据。
目前的数据库系统可以高效地实现数据的录入、查询、统计等功能,但无法发现数据中存在的关系和规则,无法根 据现有的数据预测未来的发展趋势。
缺乏挖掘数据背后隐藏的知识的手段,导致了“数据爆炸但知识贫乏”的现象。
1.3 支持数据挖掘技术的基础数据挖掘技术是人们长期对数据库技术进行研究和开发的结果。
起初各种商业数据是存储在计算机的数据库中的,然后发展到可对数据库进行查询和访问,进而 发展到对数据库的即时遍历。
数据挖掘使数据库技术进入了一个更高级的阶段,它不仅能对过去的数据进行查询和遍历,并且能够找出过去数据之间的潜在联系,从 而促进信息的传递。
现在数据挖掘技术在商业应用中已经可以马上投入使用,因为对这种技术进行支持的三种基础技术已经发展成熟,他们是: - - 海量数据搜集- - 强大的多处理器计算机- - 数据挖掘算法Friedman[1997]列举了四个主要的技术理由激发了数据挖掘的开发、应用和研究的兴趣:- - 超大规模数据库的出现,例如商业数据仓库和计算机自动收集的数据记录;- - 先进的计算机技术,例如更快和更大的计算能力和并行体系结构;- - 对巨大量数据的快速访问;- - 对这些数据应用精深的统计方法计算的能力。
商业数据库现在正在以一个空前的速度增长,并且数据仓库正在广泛地应用于各种行业;对计算机硬件性能越来越高的要求,也可以用现在已经成熟的并行多处 理机的技术来满足;另外数据挖掘算法经过了这10多年的发展也已经成为一种成熟,稳定,且易于理解和操作的技术。
1.4 从商业数据到商业信息的进化从商业数据到商业信息的进化过程中,每一步前进都是建立在上一步的基础上的。
见下表。
表中我们可以看到,第四步进化是革命性的,因为从用户的角度来看,这一阶段的数据库技术已经可以快速地回答商业上的很多问题了。
进化阶段商业问题支持技术产品厂家产品特点数据搜集(60年代)“过去五年中我的总收入是多少?”计算机、磁带和磁盘IBM,CDC提供历史性的、静态的数据信息数据访问(80年代)“在新英格兰的分部去年三月的销售额是多少?”关系数据库(RDBMS),结构化查询语言(SQL),ODBCOracle、Sybase、Informix、IBM、MicrosoftOracle、Sybase、Informix、IBM、Microsoft在记录级提供历史性的、动态数据信息数据仓库;决策支持(90年代)“在新英格兰的分部去年三月的销售额是多少?波士顿据此可得出什么结论?”联机分析处理(OLAP)、多维数据库、数据仓库Pilot、Comshare、Arbor、Cognos、Microstrategy在各种层次上提供回溯的、动态的数据信息数据挖掘(正在流行)“下个月波士顿的销售会怎么样?为什么?”高级算法、多处理器计算机、海量数据库Pilot、Lockheed、IBM、SGI、其他初创公司提供预测性的信息表一、数据挖掘的进化历程。
数据挖掘的核心模块技术历经了数十年的发展,其中包括数理统计、人工智能、机器学习。
今天,这些成熟的技术,加上高性能的关系数据库引擎以及广泛的数据集成,让数据挖掘技术在当前的数据仓库环境中进入了实用的阶段。
1.5 数据挖掘逐渐演变的过程数据挖掘其实是一个逐渐演变的过程,电子数据处理的初期,人们就试图通过某些方法来实现自动决策支持,当时机器学习成为人们关心的焦点.机器学习的过 程就是将一些已知的并已被成功解决的问题作为范例输入计算机,机器通过学习这些范例总结并生成相应的规则,这些规则具有通用性,使用它们可以解决某一类的 问题.随后,随着神经网络技术的形成和发展,人们的注意力转向知识工程,知识工程不同于机器学习那样给计算机输入范例,让它生成出规则,而是直接给计算机 输入已被代码化的规则,而计算机是通过使用这些规则来解决某些问题。
专家系统就是这种方法所得到的成果,但它有投资大、效果不甚理想等不足。
80年代人们 又在新的神经网络理论的指导下,重新回到机器学习的方法上,并将其成果应用于处理大型商业数据库。
随着在80年代末一个新的术语,它就是数据库中的知识发 现,简称KDD(Knowledge discovery in database).它泛指所有从源数据中发掘模式或联系的方法,人们接受了这个术语,并用KDD 来描述整个数据发掘的过程,包括最开始的制定业务目标到 最终的结果分析,而用数据挖掘(data mining)来描述使用挖掘算法进行数据挖掘的子过程。
但最近人们却逐渐开始使用数据挖掘中有许多工作可以由统计方法来完成,并认为最好的策略是将统计 方法与数据挖掘有机的结合起来。
数据仓库技术的发展与数据挖掘有着密切的关系。
数据仓库的发展是促进数据挖掘越来越热的原因之一。
但是,数据仓库并不是数据挖掘的先决条件,因为有很多数据挖掘可直接从操作数据源中挖掘信息。
第二课数据挖掘的定义2.1 技术上的定义及含义2.2 商业角度的定义2.3 数据挖掘与传统分析方法的区别2.4 数据挖掘和数据仓库2.5 数据挖掘和在线分析处理(OLAP)2.6 数据挖掘,机器学习和统计2.7 软硬件发展对数据挖掘的影响2.1 技术上的定义及含义数据挖掘(Data Mining)就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
与 数据挖掘相近的同义词有数据融合、数据分析和决策支持等。
这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知 识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。
----何为知识?从广义上理解,数据、信息也是知识的表现形式,但是人们更把概念、规则、模式、规律和约束等看作知识。
人们把数据看作是形成知识的 源泉,好像从矿石中采矿或淘金一样。
原始数据可以是结构化的,如关系数据库中的数据;也可以是半结构化的,如文本、图形和图像数据;甚至是分布在网络上的 异构型数据。
发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。
发现的知识可以被用于信息管理,查询优化,决策支持和过程控 制等,还可以用于数据自身的维护。
因此,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。
在这 种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术、数理统计、可视化技术、并行计算等方面的学者和工程技术人员,投身到数据挖掘这 一新兴的研究领域,形成新的技术热点。
这里所说的知识发现,不是要求发现放之四海而皆准的真理,也不是要去发现崭新的自然科学定理和纯数学公式,更不是什么机器定理证明。
实际上,所有发现 的知识都是相对的,是有特定前提和约束条件,面向特定领域的,同时还要能够易于被用户理解。
最好能用自然语言表达所发现的结果。
2.2 商业角度的定义数据挖掘是一种新的商业信息处理技术,其主要特点是对商业数据库中的大量业务数据进行抽取、转换、分析和其他模型化处理,从中提取辅助商业决策的关键性数据。