兰州大学操作系统实验五详细答案
操作系统教程第5版部分习题答案(1)

第一章:一、3、10、15、23、27、353.什么是操作系统?操作系统在计算机系统中的主要作用是什么?操作系统是管理系统资源、控制程序执行、改善人机界面、提供各种服务,并合理组织计算机工作流程和为用户有效地使用计算机提供良好运行环境的一种系统软件.主要作用(1)服务用户—操作系统作为用户接口和公共服务程序(2)进程交互—操作系统作为进程执行的控制者和协调者(3)系统实现—操作系统作为扩展机或虚拟机(4)资源管理—操作系统作为资源的管理者和控制者10.试述系统调用与函数(过程)调用之间的区别。
(1)调用形式和实现方式不同;(2)被调用的代码位置不同;(3)提供方式不同15.什么是多道程序设计?多道程序设计有什么特点?多道程序设计是指允许多个作业(程序)同时进入计算机系统内存并执行交替计算的方法。
从宏观上看是并行的,从微观上看是串行的。
(1)可以提高CPU、内存和设备的利用率;(2)可以提高系统的吞吐率,使单位时间内完成的作业数目增加;(3)可以充分发挥系统的并行性,使设备和设备之间,设备和CPU之间均可并行工作。
23.现代操作系统具有哪些基本功能?请简单叙述之。
(1)处理器管理;(2)存储管理;(3)设备管理;(4)文件管理;(5)联网与通信管理。
27.什么是操作系统的内核?内核是一组程序模块,作为可信软件来提供支持进程并发执行的基本功能和基本操作,通常驻留在内核空间,运行于内核态,具有直接访问计算机系统硬件设备和所有内存空间的权限,是仅有的能够执行特权指令的程序。
35.简述操作系统资源管理的资源复用技术。
系统中相应地有多个进程竞争使用资源,由于计算机系统的物理资源是宝贵和稀有的,操作系统让众多进程共享物理资源,这种共享称为资源复用。
(1)时分复用共享资源从时间上分割成更小的单位供进程使用;(2)空分复用共享资源从空间上分割成更小的单位供进程使用。
.二、2、52、答:画出两道程序并发执行图如下:(1)两道程序运行期间,CPU存在空闲等待,时间为100至150ms之间(见图中有色部分)。
兰州大学操作系统实验五进程管理题目和答案

实验五实验五实验名称:进程管理实验目的:1.进一步学习进程的属性2.学习进程管理的系统调用3.掌握使用系统调用获取进程的属性、创建进程、实现进程控制等4.掌握进程管理的基本原理实验时间pcb6学时预备知识:1.进程属性1.1 getpid(取得进程ID)表头文件#include<unistd.h>定义函数pid_t getpid(void);函数说明getpid()用来取得目前进程的进程ID,许多程序利用取到的此值来建立临时文件,以避免临时文件相同带来的问题。
返回值目前进程的进程ID范例1.2 getppid(取得父进程的进程ID)表头文件#include<unistd.h>定义函数pid_t getppid(void);函数说明getppid()用来取得目前进程的父进程ID。
返回值目前进程的父进程ID。
1.3 getegid(取得有效的组ID)/etc/shadow 存放用户口令信息,主人是root表头文件#include<unistd.h> 默认是只读,当然可以修改自己的这个权限#include<sys/types.h> 其他用户可以通过申请,修改自己的这些定义函数gid_t getegid(void); ls -l /usr/bin/passwd函数说明getegid()用来取得执行目前进程有效(effective)组ID。
有效的组ID用来决定进程执行时组的权限。
返回值返回有效的组ID。
Group 组1.4 geteuid(取得有效的用户ID)表头文件#include<unistd.h>#include<sys/types.h>定义函数uid_t geteuid(void)函数说明geteuid()用来取得执行目前进程有效的用户ID。
有效的用户ID用来决定进程执行的权限,借由此改变此值,进程可以获得额外的权限。
倘若执行文件的setID位已被设置,该文件执行时,其进程的euid值便会设成该文件所有者的uid。
计算机操作系统实验报告答案

《操作系统》实验报告专业年级:姓名:学号:提交日期:实验一:操作系统环境1.1 Windows 2000 系统管理(实验估计时间:60分钟)实验内容与步骤1、计算机管理2、事件查看器3、性能监视4、服务5、数据库(ODBC)为了帮助用户管理和监视系统,Windows 2000提供了多种系统管理工具,其中最主要的有计算机管理、事件查看器和性能监视等。
步骤1:登录进入Windows 2000 Professional。
步骤2:在“开始”菜单中单击“设置”-“控制面板”命令,双击“管理工具”图标。
在本地计算机“管理工具”组中,有哪些系统管理工具,基本功能是什么:1) 本地安全策略:查看和修改本地安全策略,如用户权限和审核策略。
2) 服务:启动和停止服务。
3) 计算机管理器:管理磁盘以及使用其他系统工具来管理本地或远程的计算机。
4) 事件查看器:显示来自于 Windows 和其他程序的监视与排错消息。
5) 数据源:添加、删除、以及配置 ODBC 数据源和驱动程序。
6) 性能:显示系统性能图表以及配置数据日志和警报。
7) 组件服务:配置和管理 COM+ 应用程序。
1. 计算机管理使用“计算机管理”可通过一个合并的桌面工具来管理本地或远程计算机,它将几个Windows 2000管理实用程序合并到一个控制台目录树中,使管理员可以轻松地访问特定计算机的管理属性和工具。
步骤3:在“管理工具”窗口中,双击“计算机管理”图标。
“计算机管理”使用的窗口与“Windows资源管理器”相似。
在用于导航和工具选择的控制台目录树中有“系统工具”、“存储”及“服务和应用程序”等节点,窗口右侧“名称”窗格中显示了工具的名称、类型或可用的子工具等。
它们是:1)系统工具,填入表2-3中。
表2-3 实验记录2) 存储,填入表2-4中。
3) 服务和应用程序,填入表2-5中。
2. 事件查看器事件查看器不但可以记录各种应用程序错误、损坏的文件、丢失的数据以及其他问题,而且还可以把系统和网络的问题作为事件记录下来。
【最新精选】操作系统第5章作业答案
赵盈盈 2011210593 第五章作业1. 存储管理的功能及目的是什么?答:存储管理功能:内存分配与管理。
(1)记住每个存储区域的状态。
(2)实施分配。
分配方式有两种:静态分配与动态分配(3)回收。
内存共享。
共享的信息包括:代码共享(纯代码),数据共享存储保护。
存储保护内容有:保护系统程序区不受用户有意无意的侵犯;不允许用户程序写不属于自己地址空间的数据。
(1)以防止地址越界;(2)以防止操作越权“扩充”内存容量。
具体实现是在硬件支持下,软件硬件相互协作,将内存与外存结合起来统一使用。
地址映射。
也称作重定位。
将逻辑地址转换成物理地址。
有两种方法:静态地址映射,动态地址映射。
存储管理目的:充分利用内存,为多道程序并发执行提供存储基础;尽可能方便用户使用;解决程序空间比实际内存空间大的问题;程序在执行时可以动态伸缩;内存存取速度快;存储保护与安全;共享与通信;了解有关资源的使用状况;实现的性能和代价;2. 什么是逻辑地址?什么是物理地址?为什么要进行二者的转换工作?答:逻辑地址:就是cpu逻辑段管理内存而形成的地址。
物理地址:就是程序或数据在内存中的实际地址,即内存单元的地址,也就是被装入内存的内存地址寄存器的地址。
转换原因:当程序装入内存时,操作系统要为之分配一个合适的内存空间,由于程序逻辑地址与所分配到的内存物理地址编号不一致,而cpu执行指令时是按物理地址进行的,所以要进行地址转换。
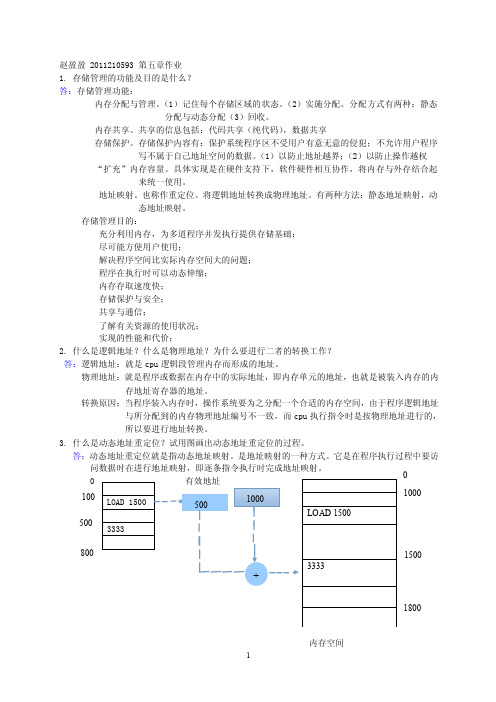
3. 什么是动态地址重定位?试用图画出动态地址重定位的过程。
答:动态地址重定位就是指动态地址映射。
是地址映射的一种方式。
它是在程序执行过程中要访内存空间4. 在分区分配方案中,回收一个分区时有几种不同的邻接情况,在各种情况下应如何处理? 答:有四种:上邻,下邻,上下相邻,上下不相邻。
(1)回收分区的上邻分区是空闲的,需要将两个相邻的空闲区合并成一个更大的空闲区,然后修改空闲区表。
(2)回收分区的下邻分区是空闲的,需要将两个相邻的空闲区合并成一个更大的空闲区,然后修改空闲区表。
操作系统教程课后习题参考答案

操作系统教程课后习题参考答案习题一习题二习题三习题四习题五习题六习题一1.设计操作系统的主要目的是什么?设计操作系统的目的是:(1)从系统管理人员的观点来看,设计操作系统是为了合理地去组织计算机工作流程,管理和分配计算机系统硬件及软件资源,使之能为多个用户所共享。
因此,操作系统是计算机资源的管理者。
(2)从用户的观点来看,设计操作系统是为了给用户使用计算机提供一个良好的界面,以使用户无需了解许多有关硬件和系统软件的细节,就能方便灵活地使用计算机。
2.操作系统的作用可表现在哪几个方面?(1) 方便用户使用:操作系统通过提供用户与计算机之间的友好界面来方便用户使用。
(2) 扩展机器功能:操作系统通过扩充硬件功能和提供新的服务来扩展机器功能。
(3) 管理系统资源:操作系统有效地管理系统中的所有硬件和软件资源,使之得到充分利用。
(4) 提高系统效率:操作系统合理组织计算机的工作流程,以改进系统性能和提高系统效率。
(5)构筑开放环境:操作系统遵循国际标准来设计和构造一个开放环境。
其含义主要是指:遵循有关国际工业标准和开放系统标准,支持体系结构的可伸缩性和可扩展性;支持应用程序在不同平台上的可移植性和互操作性。
3.试叙述脱机批处理和联机批处理工作过程(1)联机批处理工作过程用户上机前,需向机房的操作员提交程序、数据和一个作业说明书,后者提供了用户标识、用户想使用的编译程序以及所需的系统资源等基本信息。
这些资料必须变成穿孔信息,(例如穿成卡片的形式),操作员把各用户提交的一批作业装到输入设备上(若输入设备是读卡机,则该批作业是一叠卡片),然后由监督程序控制送到磁带上。
之后,监督程序自动输入第一个作业的说明记录,若系统资源能满足其要求,则将该作业的程序、数据调入主存,并从磁带上调入所需要的编译程序。
编译程序将用户源程序翻译成目标代码,然后由连接装配程序把编译后的目标代码及所需的子程序装配成一个可执行的程序,接着启动执行。
兰大18秋《操作系统课程作业_C(满分)

------------------------------------------------------------------------------------------------------------------------------ 单选题为了允许不同的用户可以使用相同的文件名,通常在文件系统中采用()。
A: 重名转换机制B: 存取控制方式C: 多级目录结构D: 标识符对照表单选题文件的存取方法依赖于()。
A: 文件的物理结构B: 存放文件的存储设备的特性C: A和BD: 文件的逻辑结构单选题磁盘与主机之间传递数据是以()为单位进行的。
A: 字节B: 字C: 数据块D: 文件单选题启动外设前必须组织好通道程序,通道程序是由若干()组成。
A: CCWB: CSWC: CAWD: PSW单选题在一单用户操作系统中,当用户编辑好一个程序要存放到磁盘上去的时候,他使用操作系统提供的()这一接口。
A: 键盘命令B: 作业控制命令C: 鼠标操作D: 原语单选题()是一种能由P和V操作所改变的整型变量。
A: 控制变量B: 锁C: 整型信号量D: 记录型信号量单选题LRU页面调度算法是选择()的页面先调出。
A: 最近才使用B: 最久未被使用C: 驻留时间最长D: 驻留时间最短------------------------------------------------------------------------------------------------------------------------------ 单选题为了使多个进程能有效地同时处理输入和输出,最好使用()。
A: 缓冲区B: 闭缓冲区环C: 多缓冲区D: 双缓冲区单选题下列()存储管理方式能使存储碎片尽可能少,而且使内存利用率较高。
A: 固定分区B: 可变分区C: 分页管理D: 段页式管理单选题如果允许不同用户的文件可以具有相同的文件名,通常采用()来保证按名存取的安全。
兰州大学智慧树知到“计算机科学与技术”《操作系统》网课测试题答案5

兰州大学智慧树知到“计算机科学与技术”《操作系统》网课测试题答案(图片大小可自由调整)第1卷一.综合考核(共15题)1.可实现虚拟存储器的存储管理方式有()。
A.固定分区B.段式C.页式D.段页式2.若中央处理机处于“管态”,可以执行的指令有()。
A.读系统时钟B.写系统时钟C.读用户内存自身数据D.写用户内存自身数据E.清除整个内存3.进程间的互斥是一种特殊的同步关系。
()A.正确B.错误4.程序在运行时需要很多系统资源,如内存、文件、设备等,因此操作系统以程序为单位分配系统资源。
()A.正确B.错误5.在文件系统中,()的逻辑文件中记录顺序与物理文件中占用物理块顺序一致。
A.Hash文件B.顺序文件C.索引文件D.链接文件6.若系统中有五个并发进程涉及某个相同的变量A,则变量A的相关临界区是由()临界区构成。
A.2个B.3个C.4个D.5个7.页表的作用是实现逻辑地址到物理地址的映射。
()A.正确B.错误8.任何两个并发进程之间存在着()的关系。
A.各自完全独立B.拥有共享变量C.必须互斥D.可能相互制约9.设备驱动程序具有哪些特点?10.按文件用途来分,编辑程序是()。
A.系统文件B.文档文件C.用户文件D.库文件11.进程和程序的一个本质区别是()。
A.前者分时使用CPU,后者独占CPUB.前者存储在内存,后者存储在外存C.前者在一个文件中,后者在多个文件中D.前者为动态的,后者为静态的12.某系统有同类资源m个,它们供n个进程共享。
若每个进程最多申请x个资源(1≤x≤m),问:各进程申请资源之和在什么范围内系统不会发生死锁?13.每一个进程都有一个从创建到消亡的生命周期,创建一个进程是指为一个程序分配一个工作区和建立一个进程控制块,因而,一个进程消亡时应删除它的程序、工作区和进程控制块。
()A.正确B.错误14.在进入线程的OS中,线程是资源分配和调度的基本单位。
()A.正确B.错误15.在多道程序系统,进程需要等待某种事件的发生时,进程一定进入阻塞状态。
操作系统教程第5版部分习题标准答案

第一章:一、3、10、15、23、27、353.什么是操作系统?操作系统在计算机系统中的主要作用是什么?操作系统是管理系统资源、控制程序执行、改善人机界面、提供各种服务,并合理组织计算机工作流程和为用户有效地使用计算机提供良好运行环境的一种系统软件.主要作用(1)服务用户—操作系统作为用户接口和公共服务程序(2)进程交互—操作系统作为进程执行的控制者和协调者(3)系统实现—操作系统作为扩展机或虚拟机(4)资源管理—操作系统作为资源的管理者和控制者10.试述系统调用与函数(过程)调用之间的区别。
(1)调用形式和实现方式不同;(2)被调用的代码位置不同;(3)提供方式不同15.什么是多道程序设计?多道程序设计有什么特点?多道程序设计是指允许多个作业(程序)同时进入计算机系统内存并执行交替计算的方法。
从宏观上看是并行的,从微观上看是串行的。
(1)可以提高CPU、内存和设备的利用率;(2)可以提高系统的吞吐率,使单位时间内完成的作业数目增加;(3)可以充分发挥系统的并行性,使设备和设备之间,设备和CPU之间均可并行工作。
23.现代操作系统具有哪些基本功能?请简单叙述之。
(1)处理器管理;(2)存储管理;(3)设备管理;(4)文件管理;(5)联网与通信管理。
27.什么是操作系统的内核?内核是一组程序模块,作为可信软件来提供支持进程并发执行的基本功能和基本操作,通常驻留在内核空间,运行于内核态,具有直接访问计算机系统硬件设备和所有内存空间的权限,是仅有的能够执行特权指令的程序。
35.简述操作系统资源管理的资源复用技术。
系统中相应地有多个进程竞争使用资源,由于计算机系统的物理资源是宝贵和稀有的,操作系统让众多进程共享物理资源,这种共享称为资源复用。
(1)时分复用共享资源从时间上分割成更小的单位供进程使用;(2)空分复用共享资源从空间上分割成更小的单位供进程使用。
.二、2、52、答:画出两道程序并发执行图如下:(1)(见图中有色部分)。
(最新整理)操作系统第五章作业参考答案

(完整)操作系统第五章作业参考答案编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整)操作系统第五章作业参考答案)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整)操作系统第五章作业参考答案的全部内容。
第五章作业参考答案1. 旋转型设备上信息的优化分布能减少为若干个I/O服务的总时间.设磁鼓上分为20个区,每区存放一个记录,磁鼓旋转一周需20毫秒,读出每个记录平均需用1毫秒,读出后经2毫秒处理,再继续处理下一个记录。
在不知当前磁鼓位置的情况下:(1)顺序存放记录1、……,记录20时,试计算读出并处理20个记录的总时间;(2)给出优先分布20个记录的一种方案,使得所花的总处理时间减少,且计算出这个方案所花的总时间。
答:定位第1个记录需10ms。
读出第1个记录,处理花2ms,这时已到了第4个记录,再转过18个记录(花18ms)才能找到记录2,所以,读出并处理20个记录的总时间:10+3+(1+2+18)×19=13+21×19=412ms如果给出优先分布20个记录的方案为:1,8,15,2,9,16,3,10,17,4,11,18,5,12,19,6,13,20,7,14.当读出第1个记录,花2ms处理后,恰好就可以处理记录2,省去了寻找下一个记录的时间,读出并处理20个记录的总时间:10+3+3×19=13+247=260ms2。
现有如下请求队列:8,18,27,129,110,186,78,147,41,10,64,12;试用查找时间最短优先算法计算处理所有请求移动的总柱面数。
假设磁头当前位置下在磁道100.答:处理次序为:100—110-129-147—186-78-64-41—27-18-12—10—8.移动的总柱面数:264.4。
操作系统教程课后习题参考答案
操作系统教程课后习题参考答案习题一习题二习题三习题四习题五习题六习题一1.设计操作系统的主要目的是什么?设计操作系统的目的是:(1)从系统管理人员的观点来看,设计操作系统是为了合理地去组织计算机工作流程,管理和分配计算机系统硬件及软件资源,使之能为多个用户所共享。
因此,操作系统是计算机资源的管理者。
(2)从用户的观点来看,设计操作系统是为了给用户使用计算机提供一个良好的界面,以使用户无需了解许多有关硬件和系统软件的细节,就能方便灵活地使用计算机。
2.操作系统的作用可表现在哪几个方面?(1) 方便用户使用:操作系统通过提供用户与计算机之间的友好界面来方便用户使用。
(2) 扩展机器功能:操作系统通过扩充硬件功能和提供新的服务来扩展机器功能。
(3) 管理系统资源:操作系统有效地管理系统中的所有硬件和软件资源,使之得到充分利用。
(4) 提高系统效率:操作系统合理组织计算机的工作流程,以改进系统性能和提高系统效率。
(5)构筑开放环境:操作系统遵循国际标准来设计和构造一个开放环境。
其含义主要是指:遵循有关国际工业标准和开放系统标准,支持体系结构的可伸缩性和可扩展性;支持应用程序在不同平台上的可移植性和互操作性。
3.试叙述脱机批处理和联机批处理工作过程(1)联机批处理工作过程用户上机前,需向机房的操作员提交程序、数据和一个作业说明书,后者提供了用户标识、用户想使用的编译程序以及所需的系统资源等基本信息。
这些资料必须变成穿孔信息,(例如穿成卡片的形式),操作员把各用户提交的一批作业装到输入设备上(若输入设备是读卡机,则该批作业是一叠卡片),然后由监督程序控制送到磁带上。
之后,监督程序自动输入第一个作业的说明记录,若系统资源能满足其要求,则将该作业的程序、数据调入主存,并从磁带上调入所需要的编译程序。
编译程序将用户源程序翻译成目标代码,然后由连接装配程序把编译后的目标代码及所需的子程序装配成一个可执行的程序,接着启动执行。
兰大2019操作系统课程作业ABC

10.
(4 分)文件的存储管理实际上是对()的管理。
A. 内存空间
B. 外部存储空间
C. 逻辑存贮空间
D. 物理存储空间
得分: 4 知识点: 第六章 收起解析
答案 B 解析第六章 6.3 节文件存储管理实质
11.
(4 分)处理器执行的指令被分成两类,其中有一类称为特权指令,它只允许()使 用。
得分: 4 知识点: 第二章 收起解析
答案错误 解析第二章 2.3 节单道程序中的同步与互斥
8.
(4 分)多道程序的执行失去了封闭性和再现性,因此多道程序系统不需要封闭性和 再现性。
得分: 4 知识点: 第二章 收起解析
答案错误 解析第二章 2.1 节多道程序的执行
9.
(4 分)引入管程是为了让系统自动处理临机资源的互斥使用问题。
得分: 4 知识点: 第一章 收起解析
答案错误 解析第一章 1.1 节操作系统的作用
7.
(4 分)操作系统对进程的管理和控制主要是通过控制原语言实现的。
得分: 4 知识点: 第二章 收起解析
答案正确 解析第二章 2.2 节进程的管理与控制
8.
(4 分)文件的存取方法可由用户根据文件的性质来选择。
交卷时间:2019-12-30 15:29:42
一、单选题
1.
(4 分)属共享型设备的是()。
A. 打印机
B. 磁带机
C. 磁盘机
D. 输入机
得分: 4 知识点: 第五章 收起解析
答案 C 解析第五章 5.1 节共享型设备
2.
(4 分)下列四个操作系统中,是分时系统的为()。
A. CP/W
[操作系统课后作业答案].doc
![[操作系统课后作业答案].doc](https://img.taocdn.com/s3/m/ca352b3b524de518974b7dcd.png)
操作系统课后作业答案step2:从执行设备5到ACstep5:取指300301 302CPU寄存器PC ACIR1.4 解:时钟周期:"只希⑸= 1.25X108 总线周期:T m =4xl.25xW 7 =5X 10'7(S)最大数据传输率:八磐^3.2X10*%)第一章1.1 解: 主存CPU 寄存器300 301 302 3005 5940 7006940 0002300―► 3005PC AC IRI/O B 56主存 300 301 302 3005 5940 7006 940 0002step3:取指300 301 302CPU 寄存器PC AC IR940 主存I/O 300 PC 「 00030003 ACv 」 3005 IRCPU 寄存器 I/O step4: AC+Add940—>AC主存300 3005 301 5940 302 7006 940 0002301 PC 0003 0005 AC v □5940 IRCPU 寄存器 I/O > 3+2=556stepl:取指300 3005302PC0003 5301 5940 ()005 AC ——> 0005 6 302 70067006 IR940 主存I/Ostep6: AC —设备 6主存 CPU 寄存器 I/O940 0002若将外部数据总线增加到32位则数据传输率为:V32肋5x10—76.4x1 ()7 (M/S)若将外部时钟频率增加到16MH乙则时钟周期为:厂=丄= 116x10°=6.25X10_8(S)总线周期为: 人「= 4x6.25x10" = 2.5x10-7 (S) 数据传输率为:八 2.5寫s"g/s)处理器速度将被降低的比率为:1-99.94% = 0.06%1.11 解:a. 1024x1024x8x0.001 = 8388.608(美分)= 83.88608(美元)b. 1024x1024x8x0.01 = 83886.08(美分)=838.8608(美元)c. 方法一:设有效访问吋间:T s =7^(l + 10%) = l.lxl00(nS) = 110nSTs =Hx/+(l —H)x(C +7;w)i00xH + (l —H)xl300方法二:利用书上39页公式1.3,仝二 ----------- 1―也可以解出兀 1 + (1-/7)仏Tc1.12 解:0.9x204-(1-0.9) x 0.6 x (20 + 60) + (1 - 0.9) x(l-0.6) x(12xl06+60 + 20) = 18 + 4.8 + 3.2 + 4.8x105«4.8X 105(M S)注:在(12X106+60 + 20)中由于(60+20)比起(12xl06)非常小可忽略不计第二章2.1 解:情况一:一个作业1.8 解: 型罟竺= 600(条/S)注:本题也可以将处理器速度化为每秒多少位來计算I600 一1x1(/1(/—600 ~~1(/--99.94%解出H : H =1300 —110~~1200-99.17%b :Nx-周转时间二NT 利用率=——二丄= 50%NT 2吞吐率=—!—NT情况二:2个作业a : 3T2TT 2NT + T /VT + - z 十'2周转时间=(N — 1) T + T + - = 2b T 3T 4T2T 2吞吐率二利用率 T 2NT + T NT + - z 十'2T TNT H ---- KJ rp 2 2 _ NTT NT + — 2NT + - 22N —-—X100%2N + 1周转时间=MT 吞吐率=需利用率= Nx-___ 2NT=r50%周转时间= NT +L2利用率=NT2NX100%吞吐率 NT + -情况三:四个作业4吞吐率二 -------T 4 NT + T 2NT + -如十'2b :T2T3T 4T周转时间= 2NT + -利用率=2NT 4N xlOOo/o22NT + -4W + 124 吞吐率= = 82NT + L 4NT + T2J2.3 解:丁"一1A ziz .小 Z1M -1W 1m-\z xo 厂、— --- x A + (1 ---- ) --- x (A + B) + (1 ---- )(1 ---- ) x (A + 3 + C)n n m n m = --- x A + —x ---- x(A + B) + — x — x(A + B + C) n n m n m第三章3」答:进程管理的活动和产生原因有:没有—A 新建进程:新的批作业的到来,交互登陆,由于操作系统提供一项服务而创建,由现有 进程生成 新建进程一►就绪:当就绪队列能够接纳新的进程时 就绪—A 执行:当进程调度程序为其分配了处理机执行—> 终止:如果进程已经完成或发生某事件(地址越界、非法指令等错误而被异常结束时) 执行_>就绪:时间片用完;在抢占调度方式中,一个优先权高的进程到来后可以抢占一个正在 执行的低优先权的进程的处理机,这时低优先权将由执彳―就绪执行—> 阻塞:请求访问临界资源,而该资源正被其它进程访问;进程间通信时,当一个进程正 在等待另一进程提供输入或等待从另外的进程传来消息阻塞—> 就绪:I/O 完成;等待的事件已发生 就绪_>终止:父进程的结束引起所有子进程的结束3.2答:挂起引入的原因:1)终端用户的需耍:用户在程序运行期间发现可疑问题希望暂停4TT 2T 3T 周转时间= 2NT + -2利用率二為二船曲22)父进程的需求:父进程考查修改子进程或协调各子进程的活动3)OS的需求:OS挂起一些进程,检查运行中资源的使用情况及记帐,以改善运行的性能4)对换的需要:为缓和内存紧张情况5)负荷调节的需要:当实时系统屮的工作负荷较重,可能影响到对实时任务的控制时,可由系统把一些不重要或不紧迫的进程挂起,以保证系统正常运行无论“挂起”或“阻塞”都是处于一种暂停执行的状态,都提高了系统资源的利用率。
操作系统 第五章作业参考答案

第五章作业参考答案1.旋转型设备上信息的优化分布能减少为若干个I/O服务的总时间。
设磁鼓上分为20个区,每区存放一个记录,磁鼓旋转一周需20毫秒,读出每个记录平均需用1毫秒,读出后经2毫秒处理,再继续处理下一个记录。
在不知当前磁鼓位置的情况下:(1)顺序存放记录1、……,记录20时,试计算读出并处理20个记录的总时间;(2)给出优先分布20个记录的一种方案,使得所花的总处理时间减少,且计算出这个方案所花的总时间。
答:定位第1个记录需10ms。
读出第1个记录,处理花2ms,这时已到了第4个记录,再转过18个记录(花18ms)才能找到记录2,所以,读出并处理20个记录的总时间:10+3+(1+2+18)×19=13+21×19=412ms如果给出优先分布20个记录的方案为:1,8,15,2,9,16,3,10,17,4,11,18,5,12,19,6,13,20,7,14。
当读出第1个记录,花2ms 处理后,恰好就可以处理记录2,省去了寻找下一个记录的时间,读出并处理20个记录的总时间:10+3+3×19=13+247=260ms2.现有如下请求队列:8,18,27,129,110,186,78,147,41,10,64,12;试用查找时间最短优先算法计算处理所有请求移动的总柱面数。
假设磁头当前位置下在磁道100。
答:处理次序为:100-110-129-147-186-78-64-41-27-18-12-10-8。
移动的总柱面数:264。
4.某文件为连接文件,由5个逻辑记录组成,每个逻辑记录的大小与磁盘块大小相等,均为512字节,并依次存放在50、121、75、80、63号磁盘块上。
现要读出文件的1569字节,问访问哪一个磁盘块?答:80号磁盘块7.假定磁盘有200个柱面,编号0~199,当前存取臂的位置在143号柱面上,并刚刚完成了125号柱面的服务请求,如果请求队列的先后顺序是:86,147,91,177,94,150,102,175,130;试问:为完成上述请求,下列算法存取臂移动的总量是多少?并算出存取臂移动的顺序。
操作系统教程第5版课后答案解析

操作系统教程第5版课后答案解析专业整理操作系统教程第 5 版课后答案费祥林、骆斌编著第⼀章操作系统概论习题⼀⼀、思考题1.简述现代计算机系统的组成及层次结构。
答:现代计算机系统由硬件和软件两个部分组成。
是硬件和软件相互交织形成的集合体,构成⼀个解决计算问题的⼯具。
硬件层提供基本可计算的资源,包括处设备。
软件层由包括系统软件、⽀撑软件和应I/O 理器、寄存器、内存、外存及⽤软件。
其中系统软件是最靠近硬件的。
2、计算机系统的资源可分成哪⼏类?试举例说明。
设备、存答:包括两⼤类,硬件资源和信息资源。
硬件资源分为处理器、I/O 储器等;信息资源分为程序和数据等。
什么是操作系统?操作系统在计算机系统中的主要作⽤是什么?3.答:操作系统是⼀组控制和管理计算机硬件和软件资源,合理地对各类作业进⾏调度,以及⽅便⽤户使⽤的程序的集合。
操作系统在计算机系统中主要起 4 个⽅⾯的作⽤。
服务⽤户观点——操作系统提供⽤户接⼝和公共服务程序1()(2)进程交互观点——操作系统是进程执⾏的控制者和协调者系统实现观点——操作系统作为扩展机或虚拟机)(3资源管理观点——操作系统作为资源的管理者和控制者(4) 4.操作系统如何实现计算与操作过程的⾃动化?批处理操作系统、分时操作系统、实答:⼤致可以把操作系统分为以下⼏类:其中批处理操作系统能按照⽤户预时操作系统、⽹络操作系统和分布式操作系统。
⼜可分为批处理单道实现计算机操作的⾃动化。
先规定好的步骤控制作业的执⾏,单道系统每次只有⼀个作业装⼊计算机系统的主存储器运系统和批处理多道系统。
批处理多道系统则允许多个作业同时装⾏,多个作业可⾃动、顺序地被装⼊运⾏。
各个作业可以同时使⽤各⾃所需的⼊主存储器,中央处理器轮流地执⾏各个作业,提⾼系统的吞缩短作业时间,外围设备,这样可以充分利⽤计算机系统的资源,吐率.操作系统要为⽤户提供哪些基本的和共性的服务?5)4)通信服务;(和信息存取;(1答:()创建程序和执⾏程序;(2)数据I/O 3使得多个应⽤程序能够有效的差错检测和处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验五实验名称:进程管理实验报告:实验要求: cat /etc/group (查看组信息)1.编写一个程序,打印进程的如下信息:进程标识符,父进程标识符,真实用户ID,有效用户ID,真实用户组ID,有效用户组ID。
并分析真实用户ID和有效用户ID的区别。
代码如下:#include<unistd.h>#include<stdio.h>int main(){printf("***********\n");printf("This is the process\n");printf(" pid=%d\n",getpid());printf("ppid=%d\n",getppid());printf(" uid=%d\n",getuid());printf("euid=%d\n",geteuid());printf(" gid=%d\n",getgid());printf("egid=%d\n",getegid());}真实用户ID和有效用户ID的区别:真实用户ID:这个ID就是我们登陆unix系统时的身份ID。
有效用户ID:定义了操作者的权限。
有效用户ID是进程的属性,决定了该进程对文件的访问权限.2.阅读如下程序:/*process using time */#include<stdio.h>#include<stdlib.h>#include<sys/times.h>#include<time.h>#include<unistd.h>void time_print(char *,clock_t);int main(void){clock_t start,end;struct tms t_start,t_end;start = times(&t_start);system(“grep the /usr/doc/*/*> /dev/null2> /dev/null”); // > 将信息放到该文件null中end=times(&t_end); //0 1 2 标准输入标准输出错误输出time_ print(“elapsed”,end-start);puts(“parent times”);time _print(“\tuser CPU”,t_end.tms _utime);time_ print(“\tsys CPU”,t_end.tms_stime);//获得执行system()的子进程IDputs(“child times”);time_print(“\tuser CPU”,t_end.tms_cutime);time_print(“\tsys CPU”,t_end.tms_cstime);exit(EXIT_SUCCESS);}void time_print(char *str, clock_t time){long tps = sysconf(_SC_CLK_TCK);/*函数sysconf()的作用为将时钟滴答数转化为秒数,_SC_CLK_TCK 为定义每秒钟有多少个滴答的宏*/printf(“%s: %6.2f secs\n”,str,(float)time/tps);}编译并运行,分析进程执行过程的时间消耗(总共消耗的时间和CPU消耗的时间),并解释执行结果。
再编写一个计算密集型的程序替代grep,比较两次时间的花销。
注释程序主要语句。
因为该程序计算量很小,故消耗的时间比较少,均为0.00secs 不奇怪。
而更改为计算密集型的之后就较容易观察出消耗时间的差异,如图所示。
3.阅读下列程序:/* fork usage */#include<unistd.h>#include<stdio.h>#include<stdlib.h>int main(void){pid_t child;if((child=fork())==-1{perror(“fork”);exit(EXIT_FAILURE);}else if(child==0){puts(“in child”);printf(“\tchild pid = %d\n”,getpid()); //取得目前进程的进程IDprintf(“\tchild ppid = %d\n”,getppid());//取得目前进程的父进程IDexit(EXIT_SUCCESS);}else{puts(“in parent”);printf(“\tparent pid = %d\n”,getpid());printf(“\tparent ppid = %d\n”,getppid());}exit(EXIT_SUCCESS);}编译并多次运行,观察执行输出次序,说明次序相同(或不同)的原因;观察进程ID,分析进程ID的分配规律。
总结fork()的使用方法。
注释程序主要语句。
创建进程ID开始时一般随机分配,但若多次运行,或创建子进程时,会顺序分配内存。
此外,当父进程结束时,子进程尚未结束,则子进程的父进程ID变为1,即init fork()的使用方法:fork()会产生一个新的子进程,其子进程会复制父进程的数据与堆栈空间,如果fork()成功则在父进程会返回新建立的子进程代码(PID),而在新建立的子进程中则返回0。
如果fork 失败则直接返回-1,失败原因存于errno中。
在父进程中用fork()创建子进程,通过返回值if语句判断来进行父子进程代码执行。
4.阅读下列程序:/* usage of kill,signal,wait */#include<unistd.h>#include<stdio.h>#include<sys/types.h>#include<signal.h>int flag;void stop(); //该函数是自定义的一个single()触发的自定义函数int main(void){int pid1,pid2; //定义了两个进程号参数signal(3,stop); //signal() 触发软中断while((pid1=fork()) ==-1); //程序等待成功创建子进程事件的发生if(pid1>0){while((pid2=fork()) ==-1);if(pid2>0){ //当前进程为父进程,父进程发出两个中断信号Kill子进程flag=1;sleep(5);kill(pid1,16);kill(pid2,17);wait(0); //等待子进程死信号wait(0);printf(“\n parent is killed\n”); //接收到子进程死信号后,杀死父进程exit(EXIT_SUCCESS);}else{ //当前进程为子进程,则发送子进程Kill信号,杀死该子进程2 flag=1;signal(17,stop);printf(“\n child2 is killed by parent\n”);exit(EXIT_SUCCESS);}}else{ //当前进程为子进程,则发送子进程Kill信号,杀死该子进程1 flag=1;signal(16,stop);printf(“\n child1 is killed by parent\n”);exit(EXIT_SUCCESS);}}void stop(){ //自定义函数,供signal()调用flag = 0;}编译并运行,等待或者按^C,分别观察执行结果并分析,注释程序主要语句。
flag有什么作用?通过实验说明。
每个进程(父进程,子进程)都有一个flag,起状态标志作用,flag=1时,表示进程在运行,flag=0,表示进程结束。
5.编写程序,要求父进程创建一个子进程,使父进程和子进程各自在屏幕上输出一些信息,但父进程的信息总在子进程的信息之后出现。
(分别通过一个程序和两个程序实现)代码如下:Ptest.c ---------------一个程序实现方案(fork())#include<unistd.h>#include<stdio.h>#include<stdlib.h>main(){while((p=fork())==-1);//创建子进程直至成功if(p>0){wait(0);printf("***\n");printf("The parent process!\n");printf("***\n");exit(0);}else{printf("***\n");printf("The child process!\n");printf("***\n");sleep(3);exit(0);}}/////////////////////////////////////////////////////////////////////////////////////Ptest2.c ------------------两个程序实现方案(execl())#include<stdio.h>#include<unistd.h>#include<stdlib.h>int main(int argc,char *argv[]){int p,i;while((p=fork())==-1);//创建子进程直至成功if(p>0){wait(0);printf("***\n");printf("The parent process!\n");printf("***\n");exit(0);}else{printf("***\n");printf("The child process!\n");execl("/home/xingkong/ptest22",argv[1],(char*)0);printf("***\n");sleep(3);exit(0);}}#include<stdio.h>#include<unistd.h>int main(int argc,char *argv[]){int i;printf("*****\nThis is two process\n*****\n");for(i=0;i<argc;i++){printf("parameter %d is:%s\n",i,argv[i]);}return 0;}6.编写程序,要求父进程创建一个子进程,子进程执行shell命令find / -name hda* 的功能,子进程结束时由父进程打印子进程结束的信息。