基于神经网络和聚类的预测算法
基于人工神经网络的聚类算法优化研究

基于人工神经网络的聚类算法优化研究随着科技的不断发展,人工智能成为了当今社会一个备受关注的热点话题。
其中,人工神经网络作为一种重要的技术,受到了越来越多的关注和研究。
而在人工神经网络应用领域中,聚类算法优化也成为了一个重要的研究课题。
那么,本文便将基于人工神经网络的聚类算法优化进行深入探讨。
一、人工神经网络基础人工神经网络是一种由多个神经元相互连接组成的网络,其结构与生物神经系统相似。
通过学习与训练,人工神经网络可以模拟人类的智能行为,并对大量数据进行分类、预测、识别等操作。
而人工神经网络训练过程中使用的算法和方法,则对于聚类算法优化而言尤为重要。
二、聚类算法优化研究聚类算法是机器学习中的一个重要领域,它主要通过对样本进行分组或分簇,对数据进行分类和分析。
聚类算法优化则是针对现有聚类算法进行改进和优化,提升其运行效率和准确性。
传统的聚类算法中,K-means算法是一种著名的聚类算法。
它通过计算样本之间的欧几里得距离,将样本依据距离远近分组。
但是,K-means算法具有计算量大,对初始值敏感以及易陷入局部最小值等问题。
为此,研究人员提出了一系列基于人工神经网络的聚类算法。
例如,自组织特征映射(SOM)算法、基于ART神经网络的聚类算法等。
这些算法的出现,旨在优化传统聚类算法的问题,并提高聚类效果和精度。
具体来说,这些新算法能够通过不同的神经元之间的相互作用,学习样本的非线性特征,并能够自适应地调整分组结果。
三、优化研究案例为了更好的说明基于人工神经网络的聚类算法优化的具体应用,我们举一个实际的例子。
研究人员曾对美国著名的湾流飞机的大量数据进行聚类分析,探讨其工作状态下性能和健康状况的影响因子。
在传统聚类算法下,所得到的聚类结果效果不佳。
于是,研究人员采用基于单层神经网络和基于ART神经网络的聚类算法,并将两种算法结果进行比较。
实验结果表明,采用基于ART神经网络的方法所得到的分组结果比传统K-means算法更优,能够更好地揭示湾流飞机性能和健康状况的关联因素。
基于相空间重构技术的EM聚类模糊神经网络预测模型及其应用

Fo e a tng M o e fEM —Cl s e r c si d lo u t r Fuz y Ne a t r z ur lNe wo k
的预测 方法 一直 是研究 领域 的热 点 和难点 。 随着 专 家 系统 、 工 智 能 和 机 器 学 习等 知 识 人 发现技 术 的发 展 , 工神 经 网 络 因 其 具 有 很 强 的 人 自适应 性 和 学 习能 力 、 线性 映射 能 力 和容 错 能 非 力 , 到 了 长 足 的 发 展 和广 泛 的 应 用 。模 糊 系统 得
一
、
引 言
现 实 经 济 系 统 中 , 策 者 经 常 会 遇 到 需要 考 决 虑 时间 未来行 为 的 问题 。 由于 经 济 系 统本 质 的非 线性 、 复杂性 、 息 的不 确 定 与所 涉 及 的 人类 活 动 信
有力工具 , 但一般不容易实现 自 适应的学 习。Tk a— a 等人 提 出 的 1 1 型 是 最 经 典 的模 糊 推 理 模 S模 型 … 。在 1 1 型 的基 础上 , 者对 于模 糊 系统 和 S模 学
则会 发生 “ 糊规 则组 合爆 炸 ” 模 的现 象 。这种 情 况 下神 经 网络 的结 构 就 显 得 特 别 臃 肿 , 至 于 无 法 以
摘
要 : 用相 空间重构技术对 时间序列进行 分割 , 应 将原序 列映射到 多维 的数 据 空间 中。将期 望最 大化 ( M) E
聚类算法和神 经网络相结合 , 出了一种基 于相 空间重构技术的 E 聚类模糊神经网络预测 模型。在股票 市场 提 M
人工智能十大算法总结

人工智能十大算法总结人工智能(Artificial Intelligence,简称AI)是一门涉及模拟和复制人类智能的科学和工程学科。
在人工智能的发展过程中,算法起着至关重要的作用。
算法是用来解决问题的一系列步骤和规则。
下面是人工智能领域中十大重要的算法总结。
一、回归算法回归算法用于预测数值型数据的结果。
常见的回归算法有线性回归、多项式回归、岭回归等。
这些算法通过建立数学模型来找到输入和输出之间的关系,从而进行预测。
二、决策树算法决策树算法是一种基于树形结构的模型,可用于分类和回归问题。
它将数据集拆分成决策节点和叶节点,并根据特征的属性进行分支。
决策树算法易于理解和解释,并且可以处理非线性关系。
三、支持向量机算法支持向量机算法用于分类和回归分析。
它通过在特征空间中构造一个超平面来将样本划分为不同的类别。
支持向量机算法具有高维特征空间的能力和较强的泛化能力。
四、聚类算法聚类算法用于将相似的数据点分组到一起。
常见的聚类算法有K均值聚类、层次聚类等。
聚类算法能够帮助我们发现数据中的模式和结构,从而对数据进行分析和处理。
五、人工神经网络算法人工神经网络是一种类似于生物神经系统的模型。
它由大量的节点和连接组成,可以模拟人脑的学习和推理过程。
人工神经网络算法可以用于分类、识别、预测等任务。
六、遗传算法遗传算法模拟生物进化的原理,通过模拟选择、交叉和变异等操作来寻找最优解。
遗传算法常用于求解复杂优化问题,如旅行商问题、背包问题等。
七、贝叶斯网络算法贝叶斯网络是一种概率图模型,用于表示变量之间的依赖关系。
贝叶斯网络算法可以用于推断和预测问题,如文本分类、诊断系统等。
它具有直观、可解释性强的特点。
八、深度学习算法深度学习是一种基于神经网络的算法,具有多层次的结构。
它可以通过无监督或监督学习来进行模型训练和参数优化。
深度学习算法在图像识别、语音识别等领域取得了显著的成果。
九、马尔科夫决策过程算法马尔科夫决策过程是一种基于状态转移的决策模型。
基于网络数据分析的违法犯罪行为预测研究

基于网络数据分析的违法犯罪行为预测研究一、引言近年来,随着网络技术与数据科学的快速发展,基于网络数据分析的违法犯罪行为预测研究也逐渐成为研究热点。
通过对网络数据进行分析,可以更加准确地预测犯罪行为的发生和发展趋势,有利于相关部门及时制定有效的措施预防犯罪,维护社会稳定。
本文将从数据的来源与收集、预测模型与算法、准确度与实时性等方面对基于网络数据分析的违法犯罪行为预测进行探讨。
二、网络数据来源与收集网络数据来源与收集是基于网络数据分析的违法犯罪行为预测的基础。
目前,网络数据来源主要有以下几种:1.社交媒体数据。
如微博、微信等,这些数据包含大量的人际交往信息,通过对这些数据进行分析可以了解人们的思想倾向、情感态度等,有助于预测犯罪行为的发生趋势。
2.网络搜索数据。
如百度、谷歌等搜索引擎,网络搜索数据广泛、实时,可以通过对用户的搜索行为进行分析,了解他们的兴趣爱好、需求等,为犯罪行为的预测提供支持。
3.在线交易数据。
如淘宝、京东等电商平台,这些平台通过大数据分析可以了解顾客的消费习惯,为犯罪行为的预测提供线索。
收集这些数据需要具备相关的技术手段,当前主要的技术手段有以下几种:1.网络爬虫。
通过程序自动访问网络,获取数据,并将数据转换为结构化的数据,以供分析。
2.API接口。
通过API接口获取特定网站或应用程序的数据,这种方法更加稳定,具有较好的数据准确度。
3.传感器技术。
通过安装传感器来收集不同类型的数据,这种方法在一些场景下效果很好,如物流配送、城市交通等领域。
三、预测模型与算法预测模型与算法是实现基于网络数据分析的违法犯罪行为预测的核心技术。
目前,犯罪行为的预测主要采用以下两种模型:1.监督学习模型。
监督学习模型通过训练样本和标签来建立模型,这些训练样本来自于以往已知的犯罪案件信息,标签表示样本是否发生了犯罪行为。
建立好的模型可以用于预测新样本的标签值,即是否存在犯罪行为。
2.无监督学习模型。
无监督学习模型不需要事先标注样本的标签,它通过对数据空间的聚类、降维、异常检测等技术,对数据空间进行分割和分类,以发现可能的犯罪行为。
聚类算法和分类算法总结

聚类算法和分类算法总结聚类算法总结原⽂:聚类算法的种类:基于划分聚类算法(partition clustering)k-means:是⼀种典型的划分聚类算法,它⽤⼀个聚类的中⼼来代表⼀个簇,即在迭代过程中选择的聚点不⼀定是聚类中的⼀个点,该算法只能处理数值型数据k-modes:K-Means算法的扩展,采⽤简单匹配⽅法来度量分类型数据的相似度k-prototypes:结合了K-Means和K-Modes两种算法,能够处理混合型数据k-medoids:在迭代过程中选择簇中的某点作为聚点,PAM是典型的k-medoids算法CLARA:CLARA算法在PAM的基础上采⽤了抽样技术,能够处理⼤规模数据CLARANS:CLARANS算法融合了PAM和CLARA两者的优点,是第⼀个⽤于空间数据库的聚类算法FocusedCLARAN:采⽤了空间索引技术提⾼了CLARANS算法的效率PCM:模糊集合理论引⼊聚类分析中并提出了PCM模糊聚类算法基于层次聚类算法:CURE:采⽤抽样技术先对数据集D随机抽取样本,再采⽤分区技术对样本进⾏分区,然后对每个分区局部聚类,最后对局部聚类进⾏全局聚类ROCK:也采⽤了随机抽样技术,该算法在计算两个对象的相似度时,同时考虑了周围对象的影响CHEMALOEN(变⾊龙算法):⾸先由数据集构造成⼀个K-最近邻图Gk ,再通过⼀个图的划分算法将图Gk 划分成⼤量的⼦图,每个⼦图代表⼀个初始⼦簇,最后⽤⼀个凝聚的层次聚类算法反复合并⼦簇,找到真正的结果簇SBAC:SBAC算法则在计算对象间相似度时,考虑了属性特征对于体现对象本质的重要程度,对于更能体现对象本质的属性赋予较⾼的权值BIRCH:BIRCH算法利⽤树结构对数据集进⾏处理,叶结点存储⼀个聚类,⽤中⼼和半径表⽰,顺序处理每⼀个对象,并把它划分到距离最近的结点,该算法也可以作为其他聚类算法的预处理过程BUBBLE:BUBBLE算法则把BIRCH算法的中⼼和半径概念推⼴到普通的距离空间BUBBLE-FM:BUBBLE-FM算法通过减少距离的计算次数,提⾼了BUBBLE算法的效率基于密度聚类算法:DBSCAN:DBSCAN算法是⼀种典型的基于密度的聚类算法,该算法采⽤空间索引技术来搜索对象的邻域,引⼊了“核⼼对象”和“密度可达”等概念,从核⼼对象出发,把所有密度可达的对象组成⼀个簇GDBSCAN:算法通过泛化DBSCAN算法中邻域的概念,以适应空间对象的特点DBLASD:OPTICS:OPTICS算法结合了聚类的⾃动性和交互性,先⽣成聚类的次序,可以对不同的聚类设置不同的参数,来得到⽤户满意的结果FDC:FDC算法通过构造k-d tree把整个数据空间划分成若⼲个矩形空间,当空间维数较少时可以⼤⼤提⾼DBSCAN的效率基于⽹格的聚类算法:STING:利⽤⽹格单元保存数据统计信息,从⽽实现多分辨率的聚类WaveCluster:在聚类分析中引⼊了⼩波变换的原理,主要应⽤于信号处理领域。
基于深度学习算法的聚类分析应用研究

基于深度学习算法的聚类分析应用研究随着互联网技术的日新月异,数据量的快速增长已经成为了当今社会的一个普遍现象。
为了更好地了解这些庞大的数据,我们可以通过数据分析的方式来寻找其中潜在的联系和规律。
其中的一个方法就是聚类分析。
聚类分析是一种数据分析方法,通过将数据划分成不同的群组,来挖掘出数据之间的内在联系。
这一方法也被广泛应用于人工智能领域之中。
基于深度学习算法的聚类分析,正是人工智能领域的一大创新。
一、深度学习算法的基本原理深度学习算法,是一种基于神经网络理论的学习方法。
其核心思想是借鉴生物神经系统中神经元之间信息传递的方式,构建出一个网络结构,利用输入数据与输出数据之间的关系,逐渐地训练出这个网络的参数,从而实现对于未知数据的预测。
在深度学习算法中,最为重要的是神经网络结构。
其中的主要构件是“神经元”,通过一定的权重间联系,形成了一个大规模的计算模型。
每一层的神经元都可以接受上一层的输入,并根据各自的函数进行计算,然后作为下一层神经元的输入进行传递。
而最后一层神经元的输出,则被认为是整个神经网络的预测结果。
二、深度学习算法在聚类分析中的应用深度学习算法因其优异的表现,被广泛应用于各种数据挖掘的应用场景之中。
其中包括了数据分类、目标检测、图像处理等领域。
而在聚类分析领域中,深度学习算法同样具有很大的优势。
基于深度学习算法的聚类分析,主要考虑到了数据内在的高阶规律性。
在网络训练的过程中,神经网络通过自适应策略来进行参数的调整,从而自动地发现数据内在的潜在联系。
相比于传统的聚类分析方法,这一方法所挖掘出的数据特征,更加准确、全面、以及具有实时性。
三、深度学习算法在聚类分析中的实例除了理论方面的研究外,深度学习算法在聚类分析领域中,也有着广泛的应用案例。
例如,在语音验证这一领域中,深度学习算法可以将许多声音特征归为一个群组。
这种方法可以帮助计算机提高对于语音信号的处理能力。
另一个实例,则是在图像处理方面的应用。
基于神经网络的数据分析与预测

基于神经网络的数据分析与预测随着互联网和物联网技术的不断发展,数据逐渐成为了企业决策和发展的重要依据。
随之而来的是数据分析和预测的需求,以便在未来做出正确的决策。
而神经网络正是一个有效的工具,可以对数据进行分析和预测。
一、神经网络的基本概念神经网络是一种模拟人类大脑神经元相互连接的计算模型,能够不断学习、改变和完善自身。
它的核心思想是通过层层处理,从中提取出更高层次的特征,从而对问题进行分类、识别或预测。
神经网络具有自学习和自适应的能力,能够在数据中自动学习模式和规律。
与传统的基于规则的机器学习模型不同,神经网络通过处理海量的数据,自动提取出其中的特征,并建立复杂的非线性关系式,从而进行分类、预测等任务。
二、神经网络在数据分析中的应用神经网络在数据分析中有广泛的应用,其中包括以下几个方面:1、分类神经网络可以对数据进行分类。
例如,在金融行业中,可以对客户进行风险评估,预测客户信用违约概率等。
在医疗行业中,可以对患者进行诊断,判断疾病类型和程度等。
2、聚类神经网络也可以进行数据聚类。
例如,在市场营销中,可以根据用户购买习惯将其分为不同的群体,从而提供个性化的推荐。
在航空航天领域中,可以根据飞机性能参数进行聚类,判断其是否需要检修等。
3、预测神经网络也可以用于数据预测。
例如,在交通运输领域中,可以预测交通拥堵情况、车辆行驶路线等。
在金融行业中,可以预测股票价格、汇率变化等。
三、神经网络在数据预测中的案例神经网络在数据预测中已经得到了广泛应用,以下是几个有代表性的案例:1、股票价格预测通过神经网络,可以对股票价格进行预测。
例如,可以将历史股票价格、公司财务数据和行业趋势等数据输入神经网络,进行训练和预测,从而找到合适的投资机会。
2、气象预测神经网络也可以用于气象预测。
例如,在预测飓风路径、暴雨洪水等自然灾害时,可以通过将多源数据输入神经网络,生成预报模型,提高预报准确率。
3、客户流失预测通过对客户购买历史、行为和态度等数据进行分析,可以预测客户未来的购买行为和流失率。
基于神经网络的聚类算法研究

基于神经网络的聚类算法研究近年来,随着人工智能技术的不断发展,基于神经网络的聚类算法也越来越受到研究者的关注。
此类算法能够根据数据的特征,将数据划分成不同的簇,从而方便后续的数据分析。
本文将探讨基于神经网络的聚类算法的研究现状、应用前景以及存在的问题。
一、研究现状随着数据量的不断增加,传统的聚类算法(例如k-means)已经不能满足现代数据的需求。
因此,基于神经网络的聚类算法应运而生。
这类算法结合了神经网络的非线性映射能力和聚类算法的分类能力,不仅能够处理大规模和高维的数据,还具有异构聚类的能力。
目前,基于神经网络的聚类算法主要可以分为两类:有监督学习和无监督学习。
有监督学习的算法需要先对数据标注,然后通过神经网络进行分类,这类算法的优点在于能够得到更准确的聚类结果。
无监督学习的算法则不需要数据标注,通常采用自组织映射网络(SOM)或高斯混合模型(GMM)进行计算,这类算法的优点在于不需要额外的标注信息。
二、应用前景基于神经网络的聚类算法在很多领域都有着广泛的应用前景。
其中,最为常见的应用领域就是图像分割和模式识别。
在图像分割领域,这类算法可以将一张图像分成若干个部分,每个部分代表一种物体或者纹理。
在模式识别领域,这类算法可以帮助我们检测文本和语言中的规律模式,从而方便我们进行分类和标注。
另外,基于神经网络的聚类算法还可以应用于网络安全领域。
例如,我们可以将用户的网络行为数据进行聚类,从而发现异常的网络行为,提供更加有效的安全防护。
三、存在的问题尽管基于神经网络的聚类算法具有许多优点,但也存在着一些问题和挑战。
首先,这类算法需要大量的计算资源才能进行有效的计算。
其次,由于神经网络模型的复杂性,这类算法可能存在过拟合的问题。
此外,由于神经网络的黑箱结构,这类算法可能难以解释计算的结果。
针对上述问题,目前研究者正在尝试寻找有效的解决方案。
例如,一些研究者提出了基于GPU加速的算法,可以显著减少计算时间。
基于神经网络的股票预测模型研究与实现

基于神经网络的股票预测模型研究与实现一、前言股票价格的波动一直以来都是金融领域研究的重点。
通过对股票价格变化趋势的研究,在一定程度上可以为投资者提供参考。
而神经网络技术在金融领域的应用也越来越多,因此本文将探讨基于神经网络的股票预测模型的研究与实现。
二、神经网络基础神经网络是一种人工智能技术,通常用于解决分类、聚类、回归等问题。
其基本结构是由节点和边组成的图形。
节点对应神经元,边对应神经元之间的连接,连接可以有权重。
整个网络的训练过程就是通过不断调整边的权重,使神经网络的输出结果与期望结果更加接近。
常见的神经网络有多层感知机、卷积神经网络、循环神经网络等。
其中,多层感知机常用于分类和回归等问题,而卷积神经网络常用于图像识别和语音识别等领域。
循环神经网络则常用于天气预测和自然语言处理等领域。
三、股票预测模型股票预测模型通常包括数据采集、预处理、特征提取以及模型建立等步骤。
其中,基于神经网络的股票预测模型主要包括以下三种模型:1. 多层感知机多层感知机是一种前馈神经网络模型,其结构包括输入层、若干个隐藏层和输出层。
在预测股票价格时,输入层通常将某一段时间内的开盘价、收盘价、最高价、最低价、交易量等作为输入,输出层则输出未来某一段时间的股票价格预测结果。
通过多次训练和优化神经网络模型,可以得到更加准确的预测结果。
2. 循环神经网络循环神经网络是一种有记忆的神经网络模型,其结构包括输入层、循环层和输出层。
在预测股票价格时,输入层和输出层的处理方式与多层感知机相同,而循环层则通过前一时刻的输出结果和当前输入结果计算得到当前时刻的输出结果。
循环神经网络模型可以考虑到时间序列信息,更加适合于股票价格预测。
3. 卷积神经网络卷积神经网络是一种特别擅长处理图像等空间信息的神经网络模型,通常被用于处理股票K线图等图片信息。
在预测股票价格时,输入层将股票K线图作为输入,输出层则输出某一段时间的股票价格预测结果。
卷积神经网络模型可以通过卷积操作提取K线图中的图案特征,更加精确地预测股票价格。
基于神经网络模型的聚类分析技术研究

维普资讯
第 2期
李大辉等 :基于神经 网络模 型的聚类分析技术研究
2 1 竞 争学 习神经 网络方 法 ( o e i eL a nn N ) . C mp ti e r i N t v g
竞争学习方法包含一个 由若干单元组成的层次结构… ,层与层之间的连接是有刺激 的,即一个给定层 上的单元接受来 自 低一层所有单元的输入 ,一个层上激活单元配置就构成了对高一层的输入模式.在一个 给定层上的聚类 中单元相互竞争 ,以响应来 自 低一层输 出的模式.层 内的连接是抑制的 ,以使得一个特定 聚类只有一个单元可被激活.获胜的单元调整与同一聚类 中其它单元 的连接,以使得之后可以对类似对象
反应更强烈.如果将一个权值定义为一个例证 ,那么新对象就赋给最近的例证.输入参数为聚类个数和每 个聚类的单元个数.在聚类过程结束时 , 每个簇被认为是一个新 的 “ 特征” 它检测对象 的某些规律.如此 ,
产生的结果簇可以看作一个低层特性向高层特性 的映射.
22 自组 织特征 图 S M 神 经 网络方 法 ( efOra in e tr p N ) . OF S l g nz gF aueMa sN — i
80年代初mchalski提出了概念聚类技术其要点是在划分对象时不仅考虑对象之间的距离还要求划分出的类具有某种内涵描述从而避免了传统技术的某些片面性聚类分析就是使用聚类算法来发现有意义的聚类它的主要依据是把相似的样本归为一类而把差异大的样本区分开来这样所生成的簇是一组数据对象的集合
维普资讯
在空间呈现这种结构 ,单元的组织形成一个特性映射 ,S F 被认 为类似于大脑的处理过程 ,对在二维或 OM 三维空间中可视化高维数据是很有用的. SF O M神经 网络结构是 由输入层和竞争层组成 , 输入层 由 个输入神经元组成,竞争层由 : X N个 输出神经元组成 ,且形成一个二维平面阵列.输入层各神经元与竞争层各神经元之间实现全互连接.该网 络根据其学习规则 ,通过对输入模式的反复学习 ,捕捉住各个输人模式 中所含的模式特征 ,并对其进行 自 组织 ,在竞争层将聚类结果表现出来 ,进行 自动聚类.竞争层的任何一个神经元都可以代表聚类结果. 2 引入可变学习速度的 S M神经网络训练算法 . 3 0F 设 网络 的输入 模 式 为 X , ,k …, ) k=l ,3 = , , ,2 ,… , P ;竞争 层 神 经 元 向量 为
神经网络预测法

Step2 • 利用样本计算网络输出,得到误差
Step3
• 利用误差反向计算每一层旳sensitivty, 更新权值和阈值。直到误差满足精度 要求。
BP网络学习算法旳改善
▪ BP算法缺陷小结
➢ 易形成局部极小而得不到全局最优; ➢ 训练次数多使得学习效率低,收敛速度慢; ➢ 隐节点旳选用缺乏理论指导; ➢ 训练时学习新样本有遗忘旧样本旳趋势。
w eight
af(W,p)
期望输出 t=1---苹果 t=0---香蕉
有导师旳学习
期望输出(向量)
训练样本:{ p 1 ,t 1 } { p 2 ,t 2 } { p Q , t Q }
输入(向量)
基本思想:
对样本对(输入和期望输出)进行学习;将样本旳输 入送至神经网络,计算得到实际输出;若实际输出与 期望输出之间旳误差不满足精度要求,则调整权值W
2、创建/训练BP神经网络: newff, train 创建前需要拟定网络旳构造:
隐层数
含一种隐层旳MLP网络能够以任意精度逼近任何有理函数。 在设计BP网络时,应优先考虑3层BP网络(即有1个隐层), 靠增长隐层节点数来取得较低旳误差。
隐层节点数 拟定隐层节点数旳最基本原则:在满足精度要求旳前提
BP神经网络旳Matlab工具箱函数
2、BP神经网络训练函数:
函数train用于训练已经创建好旳BP神经网络,其调 用格式为:
[net, tr, Y, E] = train(net, P, T)
训练前旳网络,
newff产生旳BP
网络
P:输入矩阵,每行相应于一种样本旳输入向量
T:输出矩阵,每行相应于该样本旳期望输出
下取尽量少旳隐层节点数。最佳隐层神经元个数可参照如下 公式:
aigc常用的算法

aigc常用的算法AIGC常用的算法一、引言在人工智能领域,AIGC(Artificial Intelligence and General Computing)是一种综合性的技术框架,集成了多种算法,用于解决各种问题。
本文将介绍AIGC常用的几种算法,包括神经网络、决策树、遗传算法和聚类算法。
二、神经网络算法神经网络算法是一种仿生学习算法,模拟了人脑神经元之间的连接。
它由多层神经元组成,每层神经元与上下层的神经元相连。
神经网络通过学习大量的样本数据,自动调整神经元之间的连接权重,以实现对输入数据的分类和预测。
神经网络算法在图像识别、语音识别和自然语言处理等领域取得了很大的成功。
三、决策树算法决策树算法是一种基于规则的分类算法,它通过一系列的决策节点和叶节点构成一棵树状结构。
每个决策节点表示一个特征,每个叶节点表示一个类别。
决策树算法通过学习样本数据,自动构建决策树,并根据输入特征的取值沿树结构进行分类。
决策树算法简单易懂,可解释性强,被广泛应用于数据挖掘和机器学习领域。
四、遗传算法遗传算法是一种模拟生物进化过程的优化算法。
它通过模拟遗传操作(交叉、变异和选择)来搜索最优解。
遗传算法首先随机生成一组初始解,然后通过遗传操作对解进行迭代优化,直到满足停止条件。
遗传算法适用于复杂的优化问题,如旅行商问题、机器调度和参数优化等。
五、聚类算法聚类算法是一种将相似对象归类到同一类别的算法。
聚类算法通过计算对象间的相似度,将相似的对象归为一类。
常用的聚类算法有K均值算法和层次聚类算法。
K均值算法将数据集划分为K个簇,层次聚类算法通过不断合并或分裂簇来构建聚类层次。
聚类算法在市场分析、社交网络分析和图像分割等领域有广泛应用。
六、总结本文介绍了AIGC常用的几种算法,包括神经网络、决策树、遗传算法和聚类算法。
这些算法在不同领域都有广泛的应用,可以用于解决分类、回归、优化和聚类等问题。
选择合适的算法对于解决具体问题非常重要,需要根据问题的特点和数据的特征来选择最合适的算法。
基于蚁群聚类算法的RBF神经网络交通流预测

(1 Taj yL b rtr f nel ec o uigadNoe ot r eh oo y Taj nv rt f eh oo y ini . i i Ke aoa yo t i neC mp t n v l f eT cn lg , i i U iesy o cn lg,Taj nn o I lg n S wa nn i T n
T31 P 9 文献 标 识码 A
中 图分 类 号
T a cF o F r c si gBa e n An ln u trn r f l w o e a t s d o t i n Co o y Cl se i g
Al o i m n g rt h a d RBF Ne r l t o k u a w r Ne
0 引言
随着社会 的进步 ,交通 事业也在 逐步 发展 ,但各种 交通 问题 也随之 产生 ,如交 通拥挤 、交通事故等 .而 交通 问题 的好坏 ,不仅影 响着人 民的 日常生活 ,也制约着 经济和 社会 的发展 .智能交通 系统 是近年来迅 速发 展 起来 的城 市道路 和 高速 公路控 制管 理新 技术 .它是 运用 高科 技手 段解 决当 今交通 运输 问题 ( 括运输 能 包
基于蚁群聚类算法的 R F神经 网络 交通流预测 B
林
育 部 重 点实 验 室 ,天 津 3 0 9 0 11)
鑫 ,王晓晔 ,王 卓 ,张德干
(1 .天津理工大学 天津市智能计算及软件新技术重点实验室,天津 30 9 ;2 天津理工大学 计算机视觉与系统省部共建教 011 .
基于模糊C均值聚类和样本加权卷积神经网络的日前光伏出力预测研究

精品文档供您编辑修改使用专业品质权威编制人:______________审核人:______________审批人:______________编制单位:____________编制时间:____________序言下载提示:该文档是本团队精心编制而成,希望大家下载或复制使用后,能够解决实际问题。
文档全文可编辑,以便您下载后可定制修改,请根据实际需要进行调整和使用,谢谢!同时,本团队为大家提供各种类型的经典资料,如办公资料、职场资料、生活资料、学习资料、课堂资料、阅读资料、知识资料、党建资料、教育资料、其他资料等等,想学习、参考、使用不同格式和写法的资料,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!And, this store provides various types of classic materials for everyone, such as office materials, workplace materials, lifestylematerials, learning materials, classroom materials, reading materials, knowledge materials, party building materials, educational materials, other materials, etc. If you want to learn about different data formats and writing methods, please pay attention!基于模糊C均值聚类和样本加权卷积神经网络的日前光伏出力猜测探究一、引言随着能源需求的不息增长和环境问题的凸显,太阳能光伏发电成为了备受探究关注的热点之一。
基于 SOM 算法的聚类分析研究

基于 SOM 算法的聚类分析研究聚类分析是数据挖掘和机器学习领域中的一个重要研究方向,而SOM算法是其中一种经典的聚类方法。
本文我们将从SOM算法的基本原理、应用场景和研究成果等方面,深入探讨SOM算法在聚类分析中的应用。
一、基本原理SOM算法全称为自组织映射(Self-Organizing Map),是由芬兰赫尔辛基理工大学教授Teuvo Kohonen于1980年提出的一种基于无监督学习的神经网络算法。
SOM算法基本思想是将一组高维数据映射到一个低维或二维的输出空间中,使得距离接近的数据点映射到相邻的输出单元中。
SOM算法由输入层、竞争层和输出层构成,其中输入层来自数据集的特征向量,而竞争层和输出层均为拓扑结构,其在输出空间中形成了一个格点。
竞争层中的神经元互相竞争输入向量,最终输出与输入向量最相近的神经元。
在训练过程中,每个输入向量通过与竞争层中神经元的权重进行点乘,得到该神经元对应的输出向量。
竞争过程中,SOM算法中最常用的竞争函数是欧氏距离公式,它的计算公式如下:$\sqrt{\sum_{i=1}^n(w_{i}-x_{i})^2}$其中,w和x分别是竞争层神经元的权重和训练集的输入向量,n是输入向量的维度。
竞争函数的结果越小,则一定程度上说明该输入向量与对应的神经元越相似。
竞争完毕后,输出层将竞争成功的神经元按照拓扑结构重新排列,以此形成一个无监督的聚类分布。
二、应用场景SOM算法被广泛应用于自然语言处理、生物信息学、物联网、图像识别等领域。
具体例子如下:1. 自然语言处理方面,SOM算法已被应用于文本聚类、语音识别等方面。
在文本聚类中,SOM可将文本数据聚类为若干个主题,是一种趋势分析和舆情分析的常用工具。
2. 生物信息学方面,SOM算法已被应用于基因表达数据的聚类分析,帮助生命科学研究者挖掘基因表达的深层次特征。
3. 物联网方面,SOM算法已被应用于传感器数据的聚类,为物联网应用提供更好的数据分析支持。
基于k-means聚类算法和BP神经网络的物资消耗预测模型的构建与测试
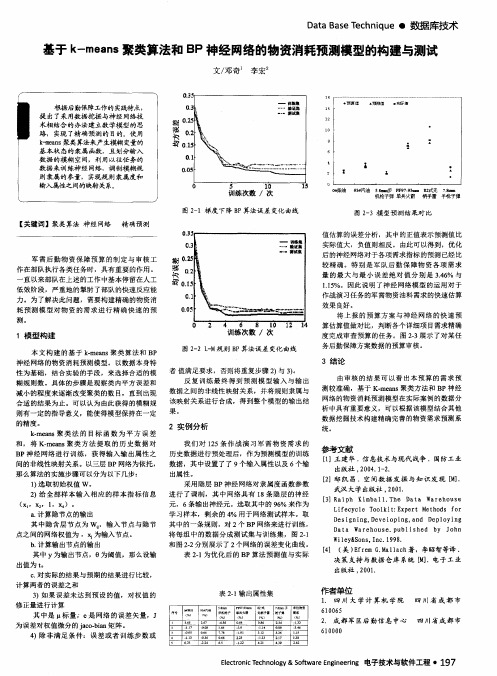
b . 计算输 出节 点的输 出 和 图2 — 2分别展示 了2个网络的误差变化 曲线。 其 中 Y为输 出节点,0为 阈值 ,那么设输 表2 . 1 为优 化后 的 B P算法 预测值与实 际 出值为 t 。 C . 对实际的结果与预期的结果进行 比较 , 计 算 两 者 的误 差 之 和 3 ) 如 果误差未 达到预 设的值,对权值 的 修正量进行计算 其 中是 标 量 e 是 网络 的误差矢 量,J 为误差对权值微分 的 i a c o . b i a n矩阵 。 4 )除非满 足条 件 :误 差或 者训练 步数 或 表2 - 1 输 出属性集
低效阶段 ,严重地 的掣肘了部队的快速反应能 力 。为 了解 决此 问题,需要构建精确的物资消 耗 预测模 型对 物 资 的需求进 行精 确快 速 的预
测。
作 战演 习任务 的军需物 资油料需求的快速 估算
效果良好 。 将 上报 的预 算方案 与神 经 网络 的快速 预 算估算值做对 比,判断各个详细项 目需求精确 度完成 审查预算的任务 。图 2 — 3展示 了对某任 务后勤保障方案数据 的预算审核。
a . Байду номын сангаас算 隐节点 的输 出 其 中隐含层 节点为 W , ,输 入节 点与隐节 点之 间的网络权值 为 , 为输入节点。
D es i g ni n g ,D e ve 1 o pi n g , an d D e p1 o yi n g D at a Wa re ho uS e .p ub1 i S hed b Y Jo hn
由审核 的结果 可 以看 出本 预算 的 需求预 测较准确 ,基 于 K. me a n s聚类方法和 B P神经 网络 的物 资消耗预测模 型在实 际案例 的数据分 析 中具有重要意义 ,可 以根据该模型结合其他 数据挖掘技术构建精确完善 的物资需求预测系
基于聚类分析和PSO优化的神经网络短期负荷预测研究

V o 1 . 1 6 N o . 2
象根 据其 与各 个簇 中心 的距 离 , 将 它赋予 给最 近 的
天最 高温度 ( ) 。相 应 的输 出量 为预测 日时刻 的预
簇, 并使 目标 数
=
m
i n
i 1 1 j E 11. 2 Z. 。 … } … }
l } 啦 一 l l 值减小。然
等 。然而 , 由于影 响短期 电力负 荷 的 因素大 都具 有 很 强 的非 线性 , 传 统 的拟线 性预 测 方法存 在 着 局 限
性, 一 些智 能 算法 凸显 出 了一定 的 优势 。但 同时 由 于大 量影 响负 荷 的随机 因素存 在 , 使得 负荷 波 动性
1 K — me a n s 聚 类算 法
想是 随 机选 择 k ( 聚 类 个数 ) 个对 象 , 每个 对 象 初始 地 代表 了一 个簇 的平 均值 或 中心 , 对剩 余 的每个 对
方 向为 电力 企 业 战 略 案 例 、 电 力市 场 技 术 、 技 术创 新理 论 。
;
2
基 于 聚类 分析 和P S O 优化 的神 经 网络短期 负荷 预测研究
未 来2 4 h 至 几 天 内的 电力负荷 需 求情 况 。短 期 负荷 预测 特别 是 日负荷 预测 曲线 为地 区 电力 余 缺调 度 、
度。 一些 新 的预i 贝 4 方法 也 显现 出不 足 。[ 1 - 4 ]
传 统 的短 期 负荷 预 测 方法 大 部 分 是针 对 未 来
S t u d y o n S h o r t - t e r m L o a d F o r e c a s t i n g Ba s e d o n Cl u s t e r i n g An a l y s i s a n d Op t i mi z e d N e u r a l Ne t wo r k b y P S O
基于蚁群聚类-Elman神经网络模型的短期电力负荷预测

切 比 雪 夫 距 离 等 ) 算 任 意 2个 样 本 之 间 的 距 离 , 计 本 文 以加权 欧 氏距 离为例计 算 , 式 ( ) 如 1:
厂 ———————一
此 外 , 荷 历 史 数 据 的 海 量 问 题 极 大 增 加 了 网 络 训 负
练 的 负 担 。 因 此 , 文 提 出 蚁 群 聚 类 预 处 理 负 荷 数 本
荷 预 测 样 本 代 表 性 问 题 ,建 立 了基 于 蚁 群 聚 类 的 Em n神 经 网络 预测 模 型 。对 负 荷 历史 数据 进 行 蚁 群 聚 类 la 预 处 理 ,将 聚 类 后 的数 据 作 为 神经 网络 的训 练样 本 。其 目的是 使 输 入样 本 具 有 代 表性 ,改 善 网络 训 练 时 间和 收 敛 速度 ,有 效 提 高 预测 精 度 。 通过 某 发 电 厂 负荷 数 据 的 验证 ,该 模 型 的 预测 结 果 精度 较 好 。 关 键 词 :负 荷 预测 ;蚁 群 ;聚 类 ;Ema 经 网 络 l n神
据 的方 法 。
dI( ) , ) IX 、∑p( z : P /
=
1
() 1
式 中 : ( , z … , 为 权 因 子 。 p・ , P ) P
( 用式 () 算 各路 径上 的信 息量 : 3) 2计
1 数据预处 理—— 蚁群聚类
11 蚁 群聚 类原 理 .
知 识 处 理 系统 , 立 在 实 例 学 习 的 基 础 上 , 用 并 行 建 采
聚 类 半 径 r 预 设 的 允 许 误 差 值 £ , 示 蚂 蚁 在 运 动 , 。表 过 程 中 所 积 累 的 信 息 及 启 发 因 子 在 蚂 蚁 选 择 路 径 中 所 起 的 不 同 作 用 的 参 数 、 , 参 考 概 率 值 P 和 M 。 值 ( 是 根 据 经 验 或 随 机 选 择 的 代 表 点 数 目 ) 。
基于图卷积神经网络的多视角聚类

2021575随着信息技术的飞速发展以及互联网应用的日益丰富,可用数据规模越来越大,数据的表现形式也越来越多样。
例如,网页可以由网页中出现的图片、文字以及超级链接进行表达,又比如文本可以由词频、词向量等多种描述算子进行刻画。
这种描述相同语义的不同特征表达称之为多视角数据。
一般来说,多视角数据描述相同的语义又相互补充,表现为互补与一致特性。
多视角聚类通过挖掘上述特性获得了相比于单视角聚类的有效性能提升,并在数据挖掘、模式识别、信息检索等领域产生广泛的应用[1]。
近些年来,研究者提出了大量的多视角聚类算法并取得了优异的聚类性能。
一般来说,典型多视角聚类算法包含亲和矩阵/图学习算法[2]、子空间学习算法[3]、协同训练算法[4]以及后融合算法[5]。
例如,Chaudhuri等人[6]采用典型相关分析算法实现两视角数据最大相关性挖掘。
Kumar等人[7]基于谱分解技术提出学习不同视角相似或一致的子空间嵌入,进而实现多视角嵌入学习。
Zhao等人[8]引入层次学习思想,提出多视角深度矩阵分基于图卷积神经网络的多视角聚类李勇振1,2,廖湖声11.北京工业大学信息学部,北京1001242.北京建筑大学电气与信息工程学院,北京100044摘要:针对多视角数据间互补与一致特性难以刻画问题,提出一种基于图卷积神经网络的多视角聚类方法。
通过对样本不同视角间相同邻接子图基于图卷积神经网络学习到的表达进行约束,有效挖掘了多视角数据间的一致特性。
通过共享图卷积神经网络参数、学习不同视角完整邻接图嵌入表达并串接得到多视角表达,有效挖掘了多视角数据间的互补特性。
对上述多视角表达增加相对熵约束,使得最终学习到的多视角表达得以提升并符合聚类特性。
在五个数据集上均取得了最好的聚类效果,说明所提出的基于图卷积神经网络的聚类方法可以有效挖掘视角间互补与一致特性并提升聚类性能。
关键词:多视角聚类;图卷积神经网络;相对熵文献标志码:A中图分类号:TP18doi:10.3778/j.issn.1002-8331.2010-0274Multi-view Clustering via Graph Convolutional Neural NetworkLI Yongzhen1,2,LIAO Husheng1rmation Department,Beijing University of Technology,Beijing100124,China2.School of Electrical and Information Engineering,Beijing University of Civil Engineering and Architecture,Beijing100044,ChinaAbstract:Aiming at discovering complementarity and consistency among multi-view data,a multi-view clustering based on Graph Convolutional neural Network(GCN)is proposed.By adding pairwise constraints on embeddings learned via the GCN on common sub-graphs of multiple views,consistency can be effectively measured.Through sharing the parameters of GCN,generating embeddings of each view based on their complete graphs,and concatenating those embeddings for multi-view embedding,complementarity will be explored.Besides,a Kullback-Leibler(KL)divergence based objective is designed to constrain the above embedding,leading to clustering oriented embedding learned.Experiments are conducted on five widely used datasets,achieving best clustering results,which clarifies the effectiveness of the method for exploring complementarity and consistency among multi-view data.Key words:multi-view clustering;graph convolutional neural network;Kullback-Leibler divergence基金项目:北京建筑大学优秀主讲教师培育计划(21082717046);北京建筑大学基金(00331615029)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
网络构建:输入为特征,期望输出为类别:0.1或0.9 网络的训练及检验: 在已知类别序列1~20中,取A类前7个序列(1~7) 和B类前7个序列(11~17)作为训练集P_train,序列 8~10、18~20作为测试集P_test.对BP/RBF/PNN 网络进行训练,给定样本总体误差标准为10^(-5).当 网络学习收敛于给定的标准后,用测试集进行分类检 验,考察这三种网络性能优劣,选择性能最好的网络 进行分类。 网络进行分类 将标号21~40的特征输入训练好的网络,输出 即为类别
信号前向传播+误差反向传播
二、BP网络的学习
1、信号前向传播
p
BP神经网络
a
a f (W , p)
Forward Propagation
a = p a
m+1 0 m+ 1 m+1 m m+ 1
=f
W
a +b
m = 0 2 M – 1
a = aM
2、误差反向传播
训练样本: { p1, t 1} { p2, t 2}
神经元模型
连接权值w对应于突触
完成输入-输出的非线性映射,有三个关键
连接权值
x1
求和单元
激活函数
激活函数
w1 权值
w2
n
阈值
多输入
x2
f
a
wn xn
净输入 n 输入-输出关系
T w x w x ii i 1 n
单输出
w1 w2 w 其中, wn 1 x1 x2 x xn
2 2 a2 2
n f
3 2
2 3 a2 2
w23
wR 1
wR 2
1 n1 s1 f s
1
a1 s1
n f
2 s2
2 2 as 2 s2
n f
3 s3
2 3 as 2 s3
wR 3
xR
输入层
隐含层
输入-输出关系:
a f W , p
隐含层
输出层
人工神经网络
一、网络结构
1、输入神经元数,输出神经元个数 2、隐层数,每个隐层中神经元个数 3、每个神经元的激活函数f
3、理论上,具有一个隐含层的BP网络可以以任意精度
逼近任意非线性函数。
二、BP网络的学习算法
} { p2, t 2 } {pQ,tQ } 训练样本 { p1, t 1 BP网络的学习算法是典型的有导师学习算法: 将样本输入神经网络,得到网络的实际输出,若 输出值与期望输出之间的误差不满足精度要求, 则从输出层反向传播该误差,从而调整权值及阈 值,使得网络的输出和期望输出间的误差逐渐减 小,直至满足精度要求。 学习过程:
已知的人工序列
1.aggcacggaaaaacgggaataacggaggaggacttggca cggcattacacggaggacgaggtaaaggaggcttgtctacgg ccggaagtgaagggggatatgaccgcttgg 2.cggaggacaaacgggatggcggtattggaggtggcggact gttcggggaattattcggtttaaacgggacaaggaaggcggctg gaacaaccggacggtggcagcaaagga 。。。。。。。。 attagggtttatttacctgtttattttttcccgagaccttaggttt accgtactttttaacggtttacctttgaaatttttggactagcttaccct ggatttaacggccagttt
均方误差(单输出)
{pQ,tQ }
均方误差(多输出)
2
F x = E e = E t – a
2
F x= Ee e = E t – a t – a
T
T
F w(k 1) w(k ) w
梯度下降法:权值阈值的调整沿着误差函数下降 最快的方向——负梯度方向
(n M )(t a)
m = M – 1 2 1
s
m
F
M
(n ) W
m
m 1 T
s m1
BP学习过程
Step1 • 选定样本,p=1,…,P, 随机确定初始权矩阵 W( 0 ) • 利用样本计算网络输出,得到误差
Step2 Step3
• 利用误差反向计算每一层的 sensitivty , 更新权值和阈值。直到误差满足精度 要求。
BP网络的学习算法(梯度下降法)
F w(k 1) w(k ) w
Weight Update 第m 层的灵 敏度
W k + 1 = W k – s a
m
m
m
m–1 T
b k + 1 = b k – s
m
m
m
误差反向传播
s
M
2 F
M
输入-输出关系
p a
神经网络
a f (W , p)
二、前馈神经网络的学习
这类网络模型 怎样实现分类、识别、 预测等智能行为?
通过学习!改变连接权值W!
通过样本更新权值和阈值
以识别苹果和香蕉为例
期望输出
} { p2, t 2 } {pQ,tQ } 训练样本:{ p1, t 1
输入
关键:调整权值
p
a
神经网络
输入:苹果或香蕉
a f (W , p)
期望输出
t=1---苹果 t=0---香蕉
shape p = te xture w eight
有导师的学习
期望输出(向量)
训练样本:{ p1, t 1} { p2, t 2} {pQ,tQ }
输入(向量)
基本思想:
x1 x2 x xn
单层前馈神经网络
p1 w11 w12 w13
p2 w21
n1 f 1 n2 f 2
a1
w22
a2
输入-输出关系: R ai f i w p ij j j 1
w23
wR 1
练习
1、现给出一药品商店两年当中24个月的药 品销售量(单位:箱)如下: 1856 1995 2220 2056 1123 1775 1900 1389 1609 1424 2276 1332 2056 2395 2600 2298 1634 1600 1873 1487 1900 1500 2046 1556 要求用当前的所有数据预测下一个月的药品 销售量。
神经网络的结构
前馈神经网络
输入--输出关系?
递归神经网络
特点:神经元之间 有反馈连接
单个神经元
x1
w1 权值
w2
n
x2
多输入
f
a
单输出
wn xn
净输入 n 输入-输出关系
T w x w x ii i 1 n
a f (n) f ( wT x)
w1 w2 w 其中, wn 1
一、结构
1、多层前馈网络:
前、后层之间各神经元 实现全联接;同一层的 神经元之间无联接。
x1 x2 xn
j
误差反向传播(学习算法) i k +
输入层
M wij
2、输入输出关系: a f W , x
隐含层 信息流
q
wki
输出层
L
激活函数通常采用 S 形函数,如 logsig,tansig函数;输出 层激活函数多采用purelin函数。
a f (n) f ( wT x)
常见的几类激活函数
这些非线性函数具有两个显著的特征,一是 突变性,二是饱和性,这正是为了模拟神经 细胞兴奋过程中所产生的神经冲动以及疲劳 等特性
人工神经网络
人工神经网络=神经元+连接
连接
神经元 神经元
神经网络分类 •无反馈网络:前馈神经网络 •有反馈网络:递归神经网络
ni wij p j
j 1
R
wR 2
ns f s
as
a f W p
T
wR 3
pR
权值, 求和,激活函数
多层前馈神经网络
x1 w11 w12 w13
x2
n f
1 1
1 1 a1 1
n f n f
2 2
2 1
2 a12 1
n
3 1
3 a12 f1
w21
w22
n f
1 2
1 a1 2 2
2、 2000年全国竞赛A题
人类基因组计划中DNA全序列草图是由4个字符A,T,C,G按一定顺序排成 的长约30亿的字符序列,其中没有“断句”也没有标点符号.虽然人类对它知 之甚少,但也发现了其中的一些规律性和结构.例如,在全序列中有一些是用 于编码蛋白质的序列片段,即由这4个字符组成的64种不同的3字符串,其中大 多数用于编码构成蛋白质的20种氨基酸.又例如,在不用于编码蛋白质的序列 片段中,A和T的含量特别多些,于是以某些碱基特别丰富作为特征去研究DNA 序列的结构也取得了一些结果.此外,利用统计的方法还发现序列的某些片段 之间具有相关性,等等.这些发现让人们相信,DNA序列中存在着局部的和全 局性的结构,充分发掘序列的结构对理解DNA全序列是十分有意义的.目前在 这项研究中最普通的思想是省略序列的某些细节,突出特征,然后将其表示成 适当的数学对象.作为研究DNA序列的结构的尝试,提出以下对序列集合进行 分类的问题: 1)请从20个已知类别的人工制造的序列(其中序列标号1~10 为A类,11~20 为B类)中提取特征,构造分类方法,并用这些已知类别的序列,衡量你的方 法是否足够好.然后用你认为满意的方法,对另外20个未标明类别的人工序列 (标号21~40)进行分类,把结果用序号(按从小到大的顺序)标明他们的类 别(无法分类的不写入) 2)同样方法对182个自然DNA序列(他们都较长)进行分类,像1)一样地给出分 类结果.