如何运用Stata完成统计数据汇总工作论文.doc
stata结课论文==

stata结课论文==stata结课论文最重要的两个命令莫过于help和 search了。
即使是经常使用stata 的人也很难,也没必要记住常用命令的每一个细节,更不用说那些不常用到的了。
所以,在遇到困难又没有免费专家咨询时,使用stata自带的帮助文件就是最佳选择。
stata的帮助文件十分详尽,面面俱到,这既是好处也是麻烦。
当你看到长长的帮助文件时,是不是对迅速找到相关信息感到没有信心?闲话不说了。
help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。
如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。
回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。
如果你想知道在stata下做某个估计或某种计算,而不知道具体该如何实现,就需要用 search命令了。
使用的方法和help类似,只须把准确的命令名改成某个关键词。
回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。
在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。
耐心寻找,反复实验,通常可以较快地找到你需要的内容。
下面该正式处理数据了。
我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。
因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。
能够重复前面的工作是非常重要的。
有时因为一些细小的不同,你会发现无法复制原先的结果了。
这时如果有记录下以往工作的do文件将把你从地狱带到天堂。
因为你不必一遍又一遍地试图重现做过的工作。
在stata窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。
为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。
这里给出我使用的“头”和“尾”。
使用Stata进行经济学和统计分析

使用Stata进行经济学和统计分析在当今的经济学研究和数据分析领域,Stata 凭借其强大的功能和易用性,成为了众多学者和研究人员的得力工具。
Stata 是一款专门用于数据管理、统计分析和绘图的软件,它为我们解决各种经济和统计问题提供了高效而可靠的途径。
Stata 的一个显著优势在于其丰富的数据管理功能。
在进行经济研究时,我们常常需要处理大量的数据,这些数据可能来自不同的来源,格式也各不相同。
Stata 能够轻松地读取和导入各种常见的数据格式,如 Excel、CSV 等,并且可以对数据进行清理、转换和合并等操作。
例如,我们可以使用`drop` 命令删除不需要的变量,使用`generate`命令创建新的变量,使用`merge` 命令将多个数据集合并在一起。
通过这些操作,我们能够将原始数据整理成适合分析的形式,为后续的研究工作打下坚实的基础。
在统计分析方面,Stata 提供了广泛而全面的统计方法。
无论是描述性统计、推断统计,还是复杂的计量经济学模型,Stata 都能应对自如。
比如,我们可以使用`summarize` 命令快速获取数据的均值、标准差、最小值和最大值等描述性统计量,从而对数据的基本特征有一个直观的了解。
对于假设检验,Stata 提供了`ttest` 命令用于均值比较,`chi2test` 命令用于独立性检验等。
在计量经济学领域,Stata 支持线性回归、Logit 模型、Probit 模型、面板数据模型等多种模型的估计和检验。
以线性回归为例,我们可以使用`regress` 命令来估计回归方程,并通过查看输出结果中的系数估计值、标准误、t 值和 p 值等信息来评估模型的拟合效果和变量的显著性。
除了基本的统计分析,Stata 还在处理时间序列数据方面表现出色。
时间序列数据在经济学中非常常见,如股票价格、通货膨胀率等。
Stata 提供了一系列专门用于时间序列分析的命令和函数,如`arima` 命令用于拟合自回归移动平均模型(ARIMA),`forecast` 命令用于进行预测。
使用Stata进行数据处理和分析

使用Stata进行数据处理和分析第一章:Stata的介绍和安装Stata是一款统计软件,广泛应用于数据处理和分析领域。
本章将介绍Stata的基本功能和特点,并介绍如何安装Stata软件。
1.1 Stata的基本功能Stata具有数据管理、统计分析、图形绘制和模型拟合等功能。
数据管理功能包括数据输入、清理、转换和合并等操作;统计分析功能包括描述性统计、假设检验、回归分析和生存分析等方法;图形绘制功能可以用于可视化数据;而模型拟合功能可以进行回归、时间序列和面板数据等模型拟合。
1.2 Stata的特点Stata具有高度的统一性和完整性,适合处理小样本和大样本数据。
它提供了丰富的内置统计命令和扩展命令,可满足各种数据处理和分析的需求。
此外,Stata还具备灵活的数据处理能力和简洁的语法结构,方便用户进行数据操作和分析。
1.3 Stata的安装Stata支持Windows、Mac和Linux操作系统。
用户可以从Stata 官方网站购买软件并进行在线安装,或者通过光盘进行离线安装。
安装过程简单,用户只需按照安装向导的指示进行操作即可。
第二章:数据的导入和清洗本章将介绍如何使用Stata导入外部数据集并进行数据清洗。
2.1 数据导入Stata支持导入多种数据格式,如CSV、Excel和SPSS等。
用户可以使用命令“import”或点击菜单栏中的“File”-“Import”进行数据导入。
导入后,可以使用“describe”命令查看数据的基本信息。
2.2 数据清洗数据清洗是数据处理的重要环节,目的是提高数据的质量和可用性。
Stata提供了一系列数据清洗命令,如数据排序、缺失值处理和异常值检测等。
用户可以利用这些命令进行数据清洗,确保数据的准确性和完整性。
第三章:数据的转换和合并本章将介绍Stata中数据的转换和合并操作。
3.1 数据转换数据转换是将数据从一种形式转换为另一种形式的过程。
Stata 提供了多种数据转换命令,如变量生成、变量重编码和重塑数据等。
stata怎么归纳总结

stata怎么归纳总结Stata 怎么归纳总结Stata 是一种功能强大的统计分析软件,广泛应用于学术研究、数据分析等领域。
学会如何归纳总结 Stata 分析结果对于正确理解数据和有效沟通研究成果至关重要。
本文将介绍一些常用的方法和技巧,帮助读者在 Stata 中进行归纳总结。
一、可视化分析在归纳总结 Stata 分析结果时,可视化分析是一种常用且有效的方法。
Stata 提供了丰富的绘图函数和命令,可以生成各种类型的图形,如散点图、柱状图、线图等。
通过可视化分析,我们可以直观地观察数据的分布和趋势,并对关键变量之间的关系进行分析。
例如,我们可以使用 `scatter` 命令绘制散点图,以探索两个变量之间的相关性。
同时,我们可以通过添加颜色、标签等来增加图形的信息量,使得结果更加清晰明了。
此外, Stata 还支持批量生成图形、调整图形格式等功能,有助于提高分析效率。
二、统计描述除了可视化分析,统计描述也是一种常用的归纳总结方法。
Stata 提供了多种描述统计命令,用于计算数据集的基本统计量,如均值、标准差、中位数等。
通过对数据集进行统计描述,我们可以获得对数据整体特征的直观了解。
同时,我们也可以通过对不同子组进行统计描述,比较不同组别之间的差异和变化。
这些统计指标有助于我们了解数据的分布情况和异常点,为后续分析提供基础。
三、回归分析回归分析在社会科学和经济学等领域中得到广泛应用,用于探究变量之间的关系和影响。
Stata 提供了丰富的回归分析命令,如线性回归、逻辑回归等,可以帮助我们进行更深入的数据分析和归纳总结。
在进行回归分析时,我们可以通过`regress` 命令拟合线性回归模型,评估自变量对因变量的影响程度。
同时,我们还可以通过分析回归系数、拟合优度等指标,对回归模型的解释力和拟合效果进行评估。
四、报告撰写有效的归纳总结需要将分析结果以清晰、准确的方式进行呈现。
在Stata 中,我们可以通过报告撰写命令和导出功能来生成漂亮的报告和文档。
使用Stata进行统计分析的方法与实例

使用Stata进行统计分析的方法与实例第一章:导言统计分析是一种基于数据的科学方法,主要用于搜集、整理、分析和解释数据,以便更好地理解和描述现象、随机事件或人类行为。
Stata是一款功能强大且广泛应用于统计学和经济学领域的统计分析软件。
本文将介绍使用Stata进行统计分析的方法和实例,并按以下章节进行详细说明。
第二章:数据导入与清洗在使用Stata进行统计分析之前,首先需要导入和清洗数据。
Stata支持多种数据导入格式,如文本文件、Excel表格和数据库等。
通过使用Stata的数据管理命令,我们可以对数据进行清洗和预处理,包括删除缺失值、处理离群值和进行变量转换等。
第三章:描述性统计分析描述性统计分析是研究对象的基本特征和总体分布的方法。
在Stata中,我们可以使用各种命令来计算和展示数据的描述性统计量,如平均值、标准差、中位数和频数分布等。
此外,可以使用图表工具来可视化数据的分布和特征,如直方图、箱线图和散点图等。
第四章:推断统计分析推断统计分析是通过抽样来推断总体参数的方法。
Stata提供了一系列统计模型和命令,用于进行参数估计、假设检验和置信区间估计等推断统计分析。
常见的推断统计方法包括回归分析、方差分析和非参数检验等。
通过Stata的命令和函数,我们可以轻松地应用这些方法,从而得出关于总体的推断结论。
第五章:多元统计分析多元统计分析是研究多个变量之间关系的方法。
Stata提供了多元统计模型和命令,用于探索和解释多个变量之间的关系。
其中包括多元线性回归分析、主成分分析和因子分析等。
通过使用Stata的多元统计分析功能,我们可以深入研究变量之间的相关性和潜在结构等。
第六章:时间序列分析时间序列分析是研究时间变化规律的方法。
在Stata中,我们可以使用时间序列模型和命令,对时间序列数据进行建模和预测分析。
其中包括平稳性检验、自回归移动平均模型和差分自回归移动平均模型等。
通过利用Stata的时间序列分析功能,我们可以分析和预测各种经济和社会现象的发展趋势。
论文写作中如何利用Stata进行数据处理与分析

论文写作中如何利用Stata进行数据处理与分析在论文写作中,数据处理与分析是非常重要的一步。
而Stata作为一款强大的统计软件,可以帮助研究者高效地处理和分析数据。
本文将探讨如何利用Stata进行数据处理与分析,并提供一些实用的技巧和方法。
一、数据准备在使用Stata进行数据处理与分析之前,首先需要将数据准备好。
数据准备包括数据清洗、变量选择和数据格式转换等步骤。
1. 数据清洗数据清洗是指对原始数据进行检查和筛选,去除无效数据和异常值,以保证数据的质量。
在Stata中,可以使用命令如"drop"、"keep"和"replace"等来删除或替换不符合要求的数据。
2. 变量选择在进行数据处理与分析时,需要根据研究目的选择合适的变量。
Stata提供了多种命令,如"keep"、"drop"、"rename"等,可以帮助研究者对变量进行选择和重命名。
3. 数据格式转换在Stata中,数据有多种格式,如数值型、字符型、日期型等。
在进行数据处理与分析之前,需要将数据格式转换成Stata可以识别的格式。
可以使用命令如"tostring"、"toint"和"todate"等来实现格式转换。
二、数据描述与探索在数据处理与分析之前,了解数据的基本情况是非常重要的。
Stata提供了多种命令,可以帮助研究者对数据进行描述和探索。
1. 描述统计描述统计是指对数据进行基本的统计分析,如计算均值、标准差、最大值、最小值等。
在Stata中,可以使用命令如"summarize"、"tabulate"和"histogram"等来进行描述统计分析。
2. 数据可视化数据可视化是一种直观地展示数据分布和关系的方法。
STATA命令应用及详细解释(汇总情况)

STATA命令应用及详细解释(汇总)调整变量格式:format x1 .3f ——将x1的列宽固定为10,小数点后取三位format x1 .3g ——将x1的列宽固定为10,有效数字取三位format x1 .3e ——将x1的列宽固定为10,采用科学计数法format x1 .3fc ——将x1的列宽固定为10,小数点后取三位,加入千分位分隔符format x1 .3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符format x1 %-10.3gc ——将x1的列宽固定为10,有效数字取三位,加入千分位分隔符,加入“-”表示左对齐合并数据:use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge using "C:\Documents and Settings\xks\桌面\1999.dta" ——将1999和2006的数据按照样本(observation)排列的自然顺序合并起来use "C:\Documents and Settings\xks\桌面\2006.dta", clear merge id using "C:\Documents and Settings\xks\桌面\1999.dta" ,unique sort——将1999和2006的数据按照唯一的(unique)变量id来合并,在合并时对id进行排序(sort)建议采用第一种方法。
对样本进行随机筛选:sample 50在观测案例中随机选取50%的样本,其余删除sample 50,count在观测案例中随机选取50个样本,其余删除查看与编辑数据:browse x1 x2 if x3>3 (按所列变量与条件打开数据查看器)edit x1 x2 if x3>3 (按所列变量与条件打开数据编辑器)数据合并(merge)与扩展(append)merge表示样本量不变,但增加了一些新变量;append表示样本总量增加了,但变量数目不变。
Stata面板数据的统计分析--资料

面板数据的统计分析(Stata)在写论文时经常碰见一些即是时间序列又是截面的数据,比如分析1999-2010的公司盈余管理影响因素,而影响盈余管理的因素有6个,那么会形成如下图的数和截面数据都是二维的,把面板数据当成时间序列数据或者截面数据来处理都是不合适的。
处理面板数据的软件较多,一般使用Eviews6.0、Stata等。
个人推荐使用Stata,因为Stata比较适合处理面板数据,且个性化强。
以下以Stata11.0为例来讲解怎么样处理面板数据。
由于面板数据的存储结构与我们通常使用的存储结构不太一样,所在统计分启动Stata11.0,Stata界面有4个组成部分,Review(在左上角)、Variables (左下角)、输出窗口(在右上角)、Command(右下角)。
首先定义变量,可以输入命令,也可以通过点击Data----Create new Variable or change variable。
特别注意,这里要定义的变量除了因素1、因素2、……因素6、盈余管理影响程度等,还要定义年份和公司名称两个变量,这两个变量的数据类型(Type)最好设置为int(整型),公司名称不要使用中文名称或者字母等,用数字代替。
定义好变量之后可以输入数据了。
数据可以直接导入(File-Import),也可以手工录入或者复制粘贴(Data-Data Edit(Browse)),手工录入数据和在excel中的操作一样。
以上面说的为例,定义变量year、company、factor1、factor2、factor3、factor4、factor5、factor6、DA。
变量company 和year分别为截面变量和时间变量。
显然,通过这两个变量我们可以非常清楚地确定panel data 的数据存储格式。
因此,在使用STATA 估计模型之前,我们必须告诉它截面变量和时间变量分别是什么,所用的命令为tsset,命令为:tsset company year输出窗口将输出相应结果。
应用stata做统计分析

1)Describe 数据的简要描述d2)List 将所有数据列在result里面l3)Summarize 分析统计指标su4)correlate 统计各个变量之间的相关系数cor5)graph twoway connected math score,yaxis(1)||connected english score,yaxis(2) title(“”)横坐标表示score 左y轴表示数学右y轴表示英语6)browse chinese math if score>640只显示总分大于640的数学和语文的成绩7)edit math ability score 只显示数学基本能力和总分,可以进行编辑8)gen any=uniform() 新建一个随机变量,从0-19)list math chinese english in 60/70 列出其中60-70个观测值的数学语文和英语10)replace any=100*any 将ANY这个变量的值*100,然后取代原来的变量11)sample 10 仅剩下随即的10%,sample 30,count随机的剩下30个观测值12)gsort –math 按数学从高到低排序13)gsort name 将观测值的姓名顺序排序14)gsort –name 姓名逆序排序15)help gesort 排序的帮助16)tabulate math if score>600 在result窗口中显示总分600以上的数学得频数百分比及累计百分比17)edit math score 在编辑器窗口中只显示数学和总分18)list in 4在result窗口中只显示第4个观测值19)list in 10/20列出第10-20个观测值20)sum if score>660 只对总分大于660的观测值进行统计分析21)sun if place !=”canada”对字符串的除外统计22)sum if score>600&score<65023)list if score>620|(math>=140&english>=135)列出其中的总分大于620 或者数学大于140和英语大于135 的观测值24)help datafun寻找日期的命令25)help strfun字符串函数26)dispay 作为统计显示的计算器使用27)sum math ,display r(mean),gen mathdev=math-r(menn),sum math mathdev28)help egen生成函数的扩展29)tabulate class,gen (class) 在编辑窗口新生成16个变量,class26-41,并且以0-1 表示30)list class class10-class14 在result 中只显示10-14班的内容31)sum math if class!=28 对数学进行求统计量,然后排出28班32)replace score2=1 if score >=600&score<.主要针对缺失值的运算因为缺失值.被认为是非常大的数。
stata统计学运用与写作发表

stata统计学运用与写作发表近年来,随着数据分析技术的不断发展与普及,stata统计学软件在学术界和商业领域中的应用日益广泛。
stata软件作为一种专业的统计分析工具,提供了丰富的数据处理、统计分析和图表展示功能,为研究人员和决策者们提供了强大的支持。
本文将就stata统计学运用的基本原理、方法和写作发表进行深入探讨,希望能够帮助读者更好地理解stata统计学的应用和研究写作技巧。
一、stata统计学运用的基本原理1. 基本操作和数据输入:使用stata软件进行统计分析之前,需要了解stata的基本操作和数据输入方法。
在使用stata进行数据分析时,首先需要打开软件,然后读取或输入要分析的数据集。
stata可以处理各种类型的数据,包括文本数据、数字数据和日期数据等,用户可以在stata中使用命令进行数据导入和数据处理,以进行后续的统计分析。
2. 数据清洗和变量定义:在进行统计分析之前,需要对原始数据进行清洗和整理,以确保数据的完整性和准确性。
在stata中,用户可以使用命令对数据进行筛选、去重和缺失值处理等操作,同时还可以定义变量和创建新的变量,以满足具体的分析需求。
3. 统计分析和模型建立:一旦数据准备工作完成,就可以开始进行统计分析和模型建立。
stata提供了丰富的统计分析方法和模型技术,例如描述性统计分析、假设检验、回归分析和时间序列分析等,用户可以根据具体的研究目的和数据特点选择合适的分析方法,以获取准确的统计结果和科学的结论。
4. 结果展示和报告输出:进行统计分析之后,需要将结果进行展示和报告输出。
在stata中,用户可以利用图表展示和数据表格等方式呈现统计分析结果,同时还可以导出报告文档和图表图片,以便于后续的研究写作和发表。
二、stata统计学运用的方法和技巧1. 命令的熟练应用:在使用stata进行统计分析时,熟练掌握各种命令和函数是非常重要的。
stata提供了丰富的命令和函数供用户调用,对于研究人员来说,掌握这些命令的使用方法和技巧,可以有效提高数据分析的效率和准确性。
如何运用Stata完成统计数据汇总工作论文.doc

本加总在一起,合并后样本变量数目不变,样本数增加,也就是数据文件变长了。
最常见的纵向合并情况是对一项调查在不同地区或者不同时间得来的数据进行合并。
Stata 纵向合并数据文件的命令为“append”.比如,我们将调查得到的包含北京市调查数据的数据文件“bj.dta”和包含天津市调查数据的数据文件“tj.dta”纵向合并的Stata命令为:use bj,clearappend using tj需要注意的是,在纵向合并两个数据文件前,两个文件中相同变量的变量名要一致,否则将会被当成两个变量处理,并产生无用的缺失值。
同时,相同变量的变量类型要一致。
汇总问卷调查结果问卷调查时效性较强,调查结果容易量化,便于统计处理与分析,是常用的统计调查方法。
问卷调查结果用Stata 进行汇总非常方便,使用“tabulate”命令,可方便的生成列联表,根据变量的频数分布可以得到问卷回答情况的汇总结果。
比如,对10000个样本企业开展问卷调查,涉及10 个问题,分别为:WT1,WT2, ……,WT10(每个问题的答案均为A、B、C、D 四个选项)。
汇总问题WT1 的回答情况时,只需输入命令:tabulateWT1,即可得到WT1 样本回答情况的频数(Freq)、百分比(Percent)及累计百分比(Cum)指标(Stata 输出结果见表1)。
从Freq 输出结果可见,样本企业对WT1 的回答情况为:选择答案A、B、C、D 的企业数量分别为1000、3000、4000 和2000 个。
Percent结果给出了选择答案1、2、3、4 的比重分别为10%,30%、40% 和20%.同时,“tabulate”命令还可以生成2 维列联表,比如,需要对问题WT1 做分省回答结果的汇总时,只需对省代码(sf)和WT1 执行“tabulate”汇总。
Stata 命令为:tabulate sf WT1,即可输出表 2 格式的汇总结果{ 假设调查只涉及北京市(代码11)、天津市(代码12)、河北省(代码13)}.类似的,可以对每一个问题的调查结果分行业、分登记注册类型、分控股情况等做交叉分组汇总。
stata论文

《应用stata做统计分析》论文论文名称ARIMA模型在预测未来的年底余额上的运用及ST AT A应用二○一二年十二月一日ARIMA模型在预测未来的年底余额上的运用及STA TA应用选题背景:中国城乡居民1990-2010年的人民币储蓄存款中年底余额做为研究对象10-3 城乡居民人民币储蓄存款单位:亿元年底余额年增加额年份总计定期活期总计定期活期1990 7119.6 5909.4 1210.2 1935.1 1700.9 234.21991 9244.9 7634.9 1610.0 2125.3 1725.5 399.8 1992 11757.3 9445.0 2312.3 2512.4 1810.1 702.3 1993 15203.5 12108.3 3095.2 3446.2 2663.3 782.9 1994 21518.8 16838.7 4680.1 6315.3 4730.4 1584.9 1995 29662.3 23778.3 5884.1 8143.5 6939.6 1203.91996 38520.8 30873.2 7647.6 8858.6 7095.0 1763.6 1997 46279.8 36226.7 10053.1 7759.0 5353.5 2405.4 1998 53407.5 41791.6 11615.9 7127.7 5564.8 1562.8 1999 59621.8 44955.1 14666.7 6214.4 3163.5 3050.8 2000 64332.4 46141.7 18190.7 4710.6 1186.6 3524.02001 73762.4 51434.9 22327.6 9430.1 5293.2 4136.9 2002 86910.7 58788.9 28121.7 13148.2 7354.1 5794.1 2003 103617.7 68498.7 35119.0 16707.0 9709.7 6997.3 2004 119555.4 78138.9 41416.5 15937.7 9640.2 6297.6 2005 141051.0 92263.5 48787.5 21495.6 14124.7 7370.92006 161587.3 103011.4 58575.9 20544.0 10777.3 9766.7 2007 172534.2 104934.5 67599.7 10946.9 1923.1 9023.8 2008 217885.4 139300.2 78585.2 45351.2 34365.7 10985.5 2009 260771.7 160230.4 100541.3 42886.3 20930.2 21956.1 2010 303302.5 178413.9 124888.6 42530.8 18183.5 24347.3截取得下图城乡居民人民币储蓄存款单位:亿元时间年底余额1990 7119.61991 9244.91992 11757.31993 15203.51994 21518.81995 29662.31996 38520.81997 46279.81998 53407.51999 59621.82000 64332.42001 73762.42002 86910.72003 1036182004 1195552005 1410512006 1615872007 1725342008 2178852009 2607722010 303303[摘要]通过stata软件对成交量建立一个ARIMA模型,观察年底余额的变化情况和未来走势。
stata论文
国民消费需求与GDP、人均GDP的相关研究分析摘要:GDP是体现国民经济增长状况和人民群众客观生活质量的重要指标。
当今我国的GDP总额排名已经跃居世界第二,仅次于美国之后,经过这些年经济的快速发展已经超过了日本、德国等一众经济强国,而中国的这个第二名是仅根据GDP,即国内生产总值来判定的。
GDP是宏观经济中最受关注的经济统计数字,因为它被认为是衡量国民经济发展情况最重要的一个指标。
而国民消费需求则影响着宏观经济的均衡发展。
本文利用stata软件研究了影响国民消费的因素以及利用1994年至2008年这15年的相关数据针对与GDP有关的因素进行分析说明,判定哪些社会指标、经济指标与GDP存在相关性,并对模型的分析结果进行了经济意义检验,以及统计推断检验。
关键词:GDP、国民经济发展、国民消费需求、stata软件、相关性引言:按照经济学的分析,社会需求包括消费需求,投资需求和净出口。
消费需求作为其中很重要的一部分,对总需求具有很重要的影响,进而对总需求政策的制定也有明显的影响,它影响着宏观经济的均衡发展。
如果说GDP、GNP、人均GDP、人均GNP是衡量国强、民富的重要指标,那么,国民消费需求指数则是衡量国稳、民福的重要指标。
GDP并不是评价一国社会发展的唯一标准,它不能提供大众福利状况的全部真实信息,不能反映民生状况,甚至可能以GDP增长的强势掩盖一个国家发展及社会变革方面的劣势。
我国处于居民消费结构优化升级的发展阶段,较高的国民储蓄率和巨大的国内市场潜力为拉动需求增长提供了物质条件。
相对于GDP,以国民消费需求指数作为衡量经济福利的指标,最大的优点在于引导政府的公共政策应当从追求经济总量的增长,转到追求建立并维系一个健康、公平、正义的宏观制度安排。
虽然中国的经济总量不断扩大,但仍存在发展方式粗放、人均国民收入不高等问题,需要冷静客观地对待。
”所以说,我们应当更客观更理性地根据我国的GDP水平和国民消费指数来评价我国的综合经济实力。
统计学小论文stata
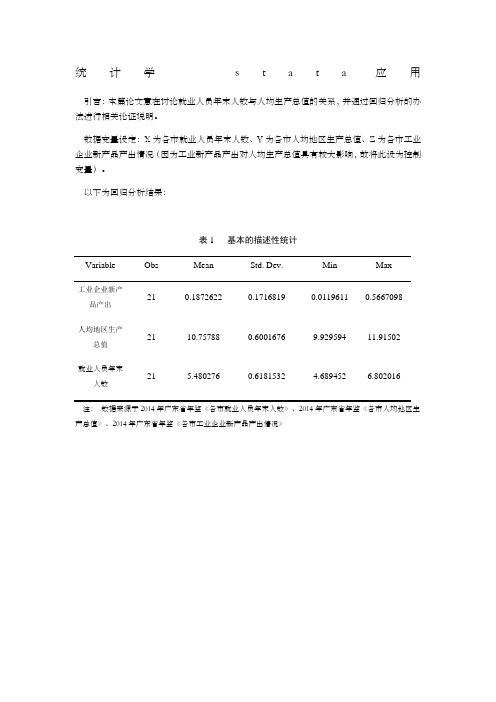
统计学s t a t a应用引言:本篇论文意在讨论就业人员年末人数与人均生产总值的关系,并通过回归分析的办法进行相关论证说明。
数据变量设定:X为各市就业人员年末人数、Y为各市人均地区生产总值、Z为各市工业企业新产品产出情况(因为工业新产品产出对人均生产总值具有较大影响,故将此设为控制变量)。
以下为回归分析结果:表1 基本的描述性统计Variable Obs Mean Std. Dev. Min Max工业企业新产21 0.1872622 0.1716819 0.0119611 0.5667098品产出人均地区生产21 10.75788 0.6001676 9.929594 11.91502总值就业人员年末21 5.480276 0.6181532 4.689452 6.802016人数注:数据来源于2014年广东省年鉴《各市就业人员年末人数》、2014年广东省年鉴《各市人均地区生产总值》、2014年广东省年鉴《各市工业企业新产品产出情况》图1 各市就业人员年末人数与各市人均GDP从图1可知,x与y是正相关表2 基本的回归模型(1) (2)人均地区生产总值人均地区生产总值就业人员年末人数0.562*** 0.360*(2.96) (2.01)工业企业新产品产出2.122***(3.14)_cons 7.676*** 8.390***(7.06)(9.11)N 21 21r2 0.336 0.66注:括号内为t统计量。
***表示在1%的水平上显著、**表示在5%的水平上显著、*表示在10%的水平上显著从表2中我们可以得知,在(1)中,x变动一个单位,y变动0.562个单位,即弹性为0.562(在1%的水平上显著);在(2)中,弹性为0.360。
R2为0.66时拟合优度较佳。
综上所述:各市就业人员年末人数与各市人均地区生产总值正相关。
对政府具有一定的启示作用:政府可以增加就业岗位,减少失业人数,增加就业人数,从而能使地区经济得到一定的发展。
统计描述的Stata实现

为制作频数表,键入 Stata 命令:
.gen f=int((x-160)/2)*2+160 .tab f 产生用以作频数表的新变量“f” 对变量“f”作频数表
“gen”命令产生新变量“f”,将各观察值转换成相应该组的下限值。 int 为取整函数,结果为括号内函数值的整数部分,如 int(3.24)=3。“160”为第 一 组 的 下 限 , “ 2 ” 为 组 距 。 以 第 一 例 观 察 值 160.1cm 为 例 , f=int((160.1-160)/2)*2+160=160,则它应归入“160~”组。 结果如下:
49 28 14 12 10 8 5 3 230
21.30 12.17 6.09 5.22 4.35 3.48 2.17 1.30
100.00
150 178 192 204 214 222 227 230 —
65.2 77.4 83.5 88.7 93.0 96.5 98.7 100.0 —
Stata 数据格式如下: x 1 2 3 4 5 6 7 8 9 10
数据格式如下:
x 1 2 3 4 5 6 7 8
164.4 175.5 171.7 171.8 172.2 176.4 164.3 169.9
9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51
结果如下:
.1 Density .02 0
160
.04
.06
.08
165
170 f
175
如何使用Stata进行统计分析和数据管理

如何使用Stata进行统计分析和数据管理第一章:Stata软件介绍Stata是一款功能强大的统计分析和数据管理软件,被广泛应用于学术研究、商业分析和政府决策等领域。
它提供了丰富的统计分析工具和数据操作功能,可以帮助用户进行各种数据处理、可视化和模型建立等工作。
第二章:数据导入和管理在使用Stata进行统计分析之前,首先需要将数据导入到软件中进行管理。
Stata支持多种数据格式的导入,比如Excel、CSV、SPSS等。
用户可以使用import命令将外部数据导入到Stata的数据集中,并可以使用rename、label等命令对数据集进行重命名和备注,提高数据管理的效率和准确性。
第三章:数据清洗和变量转换在进行统计分析之前,常常需要对原始数据进行清洗和变量转换。
Stata提供了丰富的数据清洗命令,如drop、replace、gen等,可以帮助用户处理缺失值、异常值和重复观测等问题。
同时,Stata还支持对变量进行变换,如计算新变量、重编码变量和生成虚拟变量等,以满足不同的分析需求。
第四章:描述性统计分析描述性统计是了解数据特征和总体情况的基本手段,Stata提供了多种描述性统计命令,如mean、median、sum、tab等。
这些命令可以计算数据的均值、中位数、总和、频数等统计量,并可以按照变量和组别进行分析,帮助用户发现数据的分布、集中趋势和离散程度等信息。
第五章:推断性统计分析推断性统计分析是基于样本数据对总体进行推断的方法,Stata 提供了丰富的推断性统计命令,如ttest、regress、anova等。
这些命令可以进行单样本和双样本假设检验、回归分析、方差分析等统计计算,从而帮助用户验证研究假设、探究变量之间的关系和差异。
第六章:多元统计分析多元统计分析是研究多个变量之间的关系和模式的方法,Stata 提供了多种多元统计分析命令,如因子分析、聚类分析和多元回归等。
用户可以使用这些命令对数据进行降维、分类、预测和解释,挖掘变量之间的潜在结构和相互作用关系,为研究提供更深入的认识和解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
本加总在一起,合并后样本变量数目不变,样本数增加,也就是数据文件变长了。
最常见的纵向合并情况是对一项调查在不同地区或者不同时间得来的数据进行合并。
Stata 纵向合并数据文件的命令为“append”.比如,我们将调查得到的包含北京市调查数据的数据文件“bj.dta”和包含天津市调查数据的数据文件“tj.dta”纵向合并的Stata命
令为:
use bj,clear
append using tj
需要注意的是,在纵向合并两个数据文件前,两个文件中相同变量的变量名要一致,否则将会被当成两个变量处理,并产生无用的缺失值。
同时,相同变量的变量类型要一致。
汇总问卷调查结果
问卷调查时效性较强,调查结果容易量化,便于统计处理与分析,是常用的统计调查方法。
问卷调查结果用Stata 进行汇总非常方便,使用“tabulate”命令,可方便的生成列联表,根据变量的频数分布可以得到问卷回答情况的汇总结果。
比如,对10000个样本企业开展问卷调查,涉及10 个问题,分别为:
WT1,WT2, ……,WT10(每个问题的答案均为A、B、C、D 四个选项)。
汇总问题WT1 的回答情况时,只需输入命令:tabulateWT1,即可得到WT1 样本回答情况的频数(Freq)、百分比(Percent)及累计百分比(Cum)指标(Stata 输出结果见表1)。
从Freq 输出结果可见,样本企业对WT1 的回答情况为:选择答案A、B、C、D 的企业数量分别为1000、3000、4000 和2000 个。
Percent结果给出了选择答案1、2、3、4 的比重分别为10%,30%、40% 和20%.
同时,“tabulate”命令还可以生成2 维列联表,比如,需要对问题WT1 做分省回答结果的汇总时,只需对省代码(sf)和WT1 执行“tabulate”汇总。
Stata 命令为:tabulate sf WT1,即可输出表 2 格式的汇总结果{ 假设调查只涉及北京市(代码11)、天津市(代码12)、河北省(代码13)}.
类似的,可以对每一个问题的调查结果分行业、分登记注册类型、分控股情况等做交叉分组汇总。
汇总生产经营情况调查结果
现行的统计报表制度更多的是对调查单位的生产经营情况开展年度、季度或者是月度调查。
日常的数据汇总工作更多的是对生产经营指标做各种交叉分组汇总。
与问卷调查结果不同,生产经营情况的调查结果需要对调查指标数据加总或者通过计算生成新的指标,因此,我们首先要生成新的变量,来记录相应指标的汇总结果。
Stata 生成新变量的命令为“generate”及其扩展命令“egen”.“generate”用来生
成一般变量,“egen”可以生成包含函数表达式的变量。
比如,我们对规模以上服务业企业“财务状况(F103 表)”中“营业收入”指标的本年(yysr1)和上年同期(yysr2)数据进行汇总,并计算两年的同比增速(d),用到的Stata 语句为:
egen a=sum(yysr1)
egen b=sum(yysr2)
gen d=(a/b)*100-100
其中:“sum()”为求和函数,变量a 用来记录“营业收入”本年的合计数,变量 b 用来记录“营业收入”上年同期的合计数,变量d用来记录“营业收入”的同比增速。
统计调查表中通常包含多个指标,我们可以使用Stata 的循环语句“forvalues”同时对多个指标汇总。
比如,我们对规模以上服务业企业“财务状况(F103 表)”涉及的31 个财务指标汇总。
31 个指标的本年和上年同期数据我们分别用ai 和bi (i=1,2,…,31)表示。
汇总语句为:
forvalues i=1/31{
egen suma`i =sum(a`i‘)
egen sumb`i =sum(b`i’)
gen d`i =(suma`i /sumb`i‘)*100-100}
31 个指标的本年和上年同期汇总数据分别记录于sumai 和sumbi 变量,di 为同比增速(i=1,2,…,31)。
我们还可以用“by+ 变量名”实现各种交叉分组汇总。
比如,分省汇总“营业收入”本年(yysr1)和上年同期数(yysr2)指标的Stata 语句为:
by sf,sort:egen a=sum(yysr1)
by sf,sort:egen b =sum(yysr2)
其中:“sort”命令为排序命令,对省代码(sf)变量按照从小到大排序。
在用“by”命令对变量进行分类汇总前,必须要对分类变量进行排序。
运用“by+变量名”我们还可以进一步实现分行业分指标、分登记注册类型分指标及分省分行业等交叉汇总工作。
比如,分省分行业大类汇总“营业收入”指标的语句为:
sort sf hydl :egen suma=sum(yysr1)
sort sf hydl :egen sumb=sum(yysr2)
综上可见,运用Stata 语句,可以快速、灵活的完成统计数据的各种交叉汇总工作,为数据的审核及后续的分析研究工作带来便利。
同时,Stata的数据汇总结果既可以以文本格式直接粘贴进Word 等文字编辑器,也可以以表格的形式粘贴进Excel 等数据表格处理器,便于存储和使用。