stata操作介绍之基础部分(一)讲述
Stata 简介及基本操作ppt课件

开另外一个数据集。
精选版课件ppt
14
2.变量的标签 在变量窗口,每个变量的“名字”(Name)旁边显示了
其“标签”(label)。但目前的标签过于简略,缺乏变量的 解 释信息。
如果想将变量“gov”的标签改为“government expenditures”,可进行如下操作。以鼠标的右键点击变量名 “gov”,然后选择“Edit variable label”,输入“government expenditures”即可。此时,再去看变量“gov”的标签,就已 经改为“government expenditures”。另外,在右上角的结果 窗口出现了以下一行命令:
打开Stata。此时可以看到,在最上方有一排菜单,即 “File Edit Data Graphics Statistics User Window Help”。 在此之下,有四个窗口,分别为:
左上“Review”(历史窗口):此窗口记录着自启 动Stata以来执行过的命令。
左下“Variables”(变量窗口):此窗口记录着目前 Stata 内存中的所有变量。
15
3.审视数据 一个数据集可能很大,而我们常希望看到数据的概貌。
想看数据集中的变量名单、标签等,可以在命令窗口输入: . describe
如果想给整个数据集加上一个标签,以说明这个数据 集来自“Wagner Law 1978-2009”,可输入命令: . label data "Wagner Law 1978-2009"
. summarize gov gcons gdp
Variable Obs gov 32 gcons 32 gdp 32
STATA基本操作入门PPT课件
6.2查看变量的统计特征
• 如果要查看满足q≥10000的子样本的统计指标。方法:输入summarize q if q >=10000 • 或者su q if q >=10000
第9页/共23页
6.3 查看变量的统计特征
• 如果要查看更多的统计指标 • 方法:输入 su q,detail • 显示了百分位数, 方差,偏度与峰度
第21页/共23页
9.6 图像合并展示
• 将线性拟合和二次拟合这两个图像在一起展示 • 方法:输入graph combine scatter1.gph scatter2.gph
第22页/共23页
谢谢您的观看!
第23页/共23页
第10页/共23页
6.4 查看变量的统计特征
• 如果summarize 后面不输入具体变量,则展示所有变量的统计指标 • 方法:输入summarize 或 su
第11页/共23页
7.经验累积分布函数
• 如果要查看q的经验累积分布函数 • 方法:tabulate q 或则 ta q
第12页/共23页
• 展示满足q>=10000的q的数据 • 方法:list q if q >=10000 • 展示满足q>=10000的q和tc的数据 • 方法:list q tc if q >=10000
第7页/共23页
6.1查看变量的统计特征
• 查看变量q的统计特征: • 方法:输入summarize q 或 su q • 展示变量q的样本容量,平均值,标准差,最小值,最大值
8.相关系数
• 如果要显示PL,PF两个变量的相关系数 • 方法:pwcorr pl pf
第13页/共23页
stata操作介绍之基础部分一讲述ppt课件

包含八项下拉菜单:文件、编辑、数据、绘图、统计分析、用户、窗口及帮助。
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
1.10 Stata文件格式
• Stata常用的文件格式:
文件类型
扩展名
数据文件
.dta
命令程序文件
.do
运行程序文件
.ado
帮助文件
.hlp
说明
stata使用的数据
一系列命令的集合
用于完成用户提交的数据处理与统 计分析任务的程序文件
与相应的.ado文件有相同的文件名, 形成一堆文件,并提供在线帮助
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
命令回顾 窗口
结果窗口
命令窗口
变量 名
窗口
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
1.4 Stata与其他软件的区别
“雪亮工程"是以区(县)、乡(镇) 、村( 社区) 三级综 治中心 为指挥 平台、 以综治 信息化 为支撑 、以网 格化管 理为基 础、以 公共安 全视频 监控联 网应用 为重点 的“群 众性治 安防控 工程” 。
STATA使用教程

STATA使用教程第一章:介绍 StataStata 是一款统计分析软件,广泛应用于经济学、社会科学、健康科学和医学研究等领域。
本章将介绍 Stata 软件的基本特点、适用范围和主要功能。
1.1 Stata 的特点Stata 是一款功能强大、易于使用的统计软件。
不同于其他统计软件,Stata 具有灵活性高、数据处理效率好的优点。
它支持多种数据文件格式,可以处理大规模的数据集,并且具有丰富的数据处理、统计分析和图形展示功能。
1.2 Stata 的适用范围Stata 软件适用于各类研究领域,涵盖了经济学、社会科学、医学、健康科学等多个领域。
它广泛应用于定量分析、回归分析、面板数据分析、时间序列分析等领域,可用于统计推断、数据可视化和模型建立等任务。
1.3 Stata 的主要功能Stata 软件提供了丰富的功能模块,包括数据导入导出、数据清洗、数据管理、描述性统计、推断统计、回归分析、面板数据分析、时间序列分析、图形展示等。
这些功能模块为用户提供了全面且灵活的数据分析工具。
第二章:Stata 数据处理数据处理是统计分析的前置工作,本章将介绍 Stata 软件的数据导入导出、数据清洗和数据管理等功能。
2.1 数据导入导出Stata 支持导入多种文件格式的数据,如文本文件、Excel 文件和 SAS 数据集等。
用户可以使用内置命令或者图形界面进行导入操作,导入后的数据可以存储为 Stata 数据文件(.dta 格式),方便后续的数据处理和分析。
2.2 数据清洗数据清洗是数据处理的重要环节,Stata 提供了多种数据清洗命令,如缺失值处理、异常值处理和数据类型转换等。
用户可以根据实际情况选择合适的数据清洗操作,确保数据的准确性和完整性。
2.3 数据管理数据管理是有效进行数据处理的关键,Stata 提供了许多数据管理命令,如数据排序、数据合并、数据分割和数据标记等。
这些命令可以帮助用户高效地对数据进行管理和组织,提高数据处理效率。
stata教程

stata教程Stata 是一种广泛应用于统计分析的软件,拥有强大的数据处理和建模能力。
本教程将介绍 Stata 的一些基础操作和常用命令,帮助您快速上手使用该软件。
1. 安装和启动 Stata在开始使用Stata 之前,您需要先安装该软件。
安装完成后,双击图标启动 Stata。
2. 导入数据使用 Stata 进行统计分析的第一步是导入数据。
可以通过命令 `use` 来加载已有的 Stata 数据集,或者使用 `import` 命令导入其它格式的数据文件。
3. 数据处理Stata 提供了许多数据处理的命令,比如 `drop` 可以删除某些变量或观察值,`rename` 可以修改变量名,`generate` 可以创建新变量等。
4. 描述性统计描述性统计是对数据的基本概况进行分析,可以使用命令`summarize` 来获取平均值、标准差等统计量,使用 `tabulate`命令生成频数表,还可以通过 `graph` 命令绘制直方图或散点图等图形。
5. 假设检验假设检验用于验证某个统计假设是否成立。
Stata 提供了多种假设检验的命令,比如 `ttest` 可以进行单样本或独立样本 t 检验,`anova` 可以进行方差分析等。
6. 回归分析回归分析是一种常用的建模方法,可以用于研究变量之间的关系。
在Stata 中,可以使用`regress` 命令进行简单线性回归,使用 `logit` 命令进行逻辑回归等。
7. 图形输出Stata 可以生成各种类型的图形输出,比如线图、散点图、柱状图等。
可以使用`graph export` 命令将图形导出为图片文件,方便在报告中使用。
8. 编写批处理脚本如果需要重复执行一组命令,可以将这些命令写入批处理脚本。
Stata 支持编写批处理脚本来自动化数据处理和分析的过程。
以上是关于 Stata 的基础教程,希望能帮助您快速入门并熟练使用该软件进行数据分析。
更多高级功能和命令,请参考Stata 官方文档或相关教程。
Stata入门介绍

Stata入门介绍Stata入门介绍转载,原作者不详。
(1) Stata要在使用中熟练的,大家应该多加练习。
(2) Stata的很多细节,这里不会涉及,只是选取相对重要的部分加以解释,大家在使用Stata过程中留心积累。
作为入门性质的介绍,本文只选取和中级计量经济学作业相关的内容和一些处理数据所使用的基本命令。
对于更高深的内容,请大家参看STATA manual.”界面当我们把stata装好以后,首先需要了解的是它的界面。
打开Stata后我们便可以看到它常用的四个窗口:Stata Results; Review; Variables; Stata Command。
我们所有的运行结果都会在Stata Results界面中显示;而命令的输入则在Stata Command窗口;Review窗口记录我们使用过的命令;最后Variables窗口显示存在于当前数据库中的所有变量的名称。
可以直接点击 Review窗口来重新输入已使用过的命令,我们所需变量可以通过点击Varaibles窗口来得到,这些都可以简便我们的操作。
Stata 命令Stata软件功能强大,体现在它提供了丰富的命令,可以实现许多功能。
每一个stata命令都相应的命令格式。
我们在这里介绍常用的一些命令的功能和相应的格式,大家在使用stata的过程中会不断积累命令的相关知识。
需要对命令的帮助时可以用help命令查询。
例如了解命令:“reg” ,就可以在Stata Command窗口输入“help reg” ,也可以在Help选项下content中查找我们需要的相关命令。
用help查询,则窗口会显示关于该命令的详尽说明。
更直接的办法是看Examples中的范例是如何使用该命令,阅读一些相关的说明并加以模仿。
重要习惯我们使用stata进行回归分析时,需要养成一些好的习惯。
在进行一些数据量很大,过程复杂的分析时尤其重要。
(1)使用日志(log)。
它可以帮助我们记录stata的运行结果。
STATA介绍和使用入门

STATA介绍和使用入门一、STATA的特点1.可靠性和稳定性:STATA是一个为数据分析和统计建模设计的软件,具有高度可靠性和稳定性,能够处理大规模的数据集,保证数据的准确性和一致性。
2.丰富的统计工具:STATA提供了丰富的统计工具,包括描述性统计、回归分析、方差分析、生存分析、面板数据分析等,涵盖了多种统计方法和模型,可以满足不同类型的数据分析需求。
3.强大的数据处理功能:STATA具有强大的数据处理功能,可以进行数据清洗、数据转换、数据合并等操作,同时也支持各种数据格式的导入和导出,方便与其他软件进行数据交互。
4.灵活的编程能力:STATA支持使用命令行进行数据操作和分析,同时也支持编写自定义的程序和脚本,可以灵活地扩展和自动化统计分析的过程。
二、STATA的安装和启动2.启动:完成安装后,可以通过找到安装目录下的STATA图标,双击打开软件。
启动后,会出现一个命令行窗口和一个结果窗口,我们可以在命令行窗口中输入命令进行数据操作和分析,结果会在结果窗口中显示。
三、STATA的基本操作1. 导入数据:使用命令"import"或者"insheet"可以将外部数据文件导入到STATA中进行分析。
例如,使用命令"import excel"可以导入Excel文件,命令"insheet"可以导入文本文件。
2. 数据查看:使用命令"browse"可以查看当前STATA中的数据集,可以浏览数据表格,观察数据的格式和内容。
3. 数据清洗:使用命令"drop"可以删除一些变量或者观测,使用命令"rename"可以修改变量名,使用命令"gen"可以根据已有变量生成新的变量,使用命令"replace"可以替换变量值,等等。
4. 描述性统计:使用命令"summarize"可以计算变量的均值、标准差、最小值、最大值等描述统计量,使用命令"tabulate"可以生成变量的频数表和交叉表,使用命令"graph"可以绘制直方图、散点图、折线图等图形。
stata基础命令

stata基础命令Stata基础命令Stata是一种功能强大的统计分析软件,广泛应用于学术研究和商业分析领域。
本文将介绍Stata的一些基础命令,帮助读者快速掌握Stata的使用方法。
1. 数据导入与查看命令在Stata中,可以使用"import"命令将外部数据导入到Stata的工作环境中。
例如,可以使用"import excel"命令导入Excel表格中的数据,或使用"import delimited"命令导入以逗号分隔的文本文件。
导入数据后,可以使用"browse"命令查看数据集的内容,或使用"describe"命令查看数据集的结构信息。
2. 数据清洗与变量处理命令在进行数据分析之前,通常需要对数据进行清洗和变量处理。
Stata 提供了一系列命令来完成这些任务。
例如,可以使用"drop"命令删除不需要的变量或观察值,使用"rename"命令修改变量名,使用"generate"命令创建新的变量,使用"recode"命令对变量进行重新编码等。
3. 描述性统计与绘图命令Stata提供了各种命令来计算和展示数据的描述性统计信息。
例如,可以使用"summarize"命令计算变量的均值、标准差和分位数等统计量,使用"tabulate"命令生成变量的频数表,使用"histogram"命令绘制变量的直方图,使用"scatter"命令绘制两个变量的散点图等。
4. 统计模型与假设检验命令在Stata中,可以使用各种命令来拟合统计模型和进行假设检验。
例如,可以使用"regress"命令拟合线性回归模型,使用"logit"命令拟合二元Logistic回归模型,使用"anova"命令进行方差分析,使用"ttest"命令进行两样本t检验等。
教你快速上手使用Stata进行数据处理和分析

教你快速上手使用Stata进行数据处理和分析快速上手使用Stata进行数据处理和分析第一章:Stata软件的介绍和安装Stata是一款功能强大的统计分析软件,广泛应用于各个学科领域的数据处理和分析工作中。
它提供了强大的数据管理、数据处理和数据分析功能,能够帮助用户高效地完成各种统计任务。
1.1 Stata软件的特点和应用领域Stata具有易于使用的界面、丰富的数据处理和分析功能,可以满足不同用户对数据分析的需求。
它被广泛应用于社会科学、经济学、医学、生物学等领域的数据处理和分析工作中。
1.2 Stata软件的安装和系统要求Stata软件的安装非常简单,只需按照安装向导进行操作即可。
同时,为了保证软件的正常运行,用户需要满足一定的系统要求,比如合适的操作系统版本、足够的内存和硬盘空间等。
第二章:Stata基本命令和语法在使用Stata进行数据处理和分析之前,我们需要了解一些基本的命令和语法。
下面是一些常用的命令和语法:2.1 数据导入和导出命令Stata可以导入多种数据格式,如Excel、CSV、SPSS等,通过命令"import"和"export"可以实现数据的导入和导出。
2.2 数据的描述性统计和图表命令Stata提供了丰富的命令来计算和展示数据的描述性统计信息,比如平均值、标准差、频数等。
通过命令"summarize"和"graph"可以生成相应的统计表和图表。
2.3 数据的清洗和转换命令在实际的数据处理中,我们经常需要对数据进行清洗和转换。
Stata提供了一系列的命令来处理缺失值、异常值、重复值等问题,比如命令"drop"和"replace"等。
第三章:Stata高级数据处理和分析技巧除了基本的命令和语法,Stata还提供了一些高级的数据处理和分析技巧,可以帮助用户更加高效地完成工作。
STATA软件操作(一)基础数据处理

STATA数据库结构维护
频数的展开 expand命令 例: expand f
a
b
0 1
0 9 5
1 2 8
数据库结构的转换
频数的展开
f 9 5 2 8 a 0 0 1 1 b 0 1 0 1
expand f
ex9
ex8
no 1 2 3 4 5 6 7 8 9 10 11 12 h1 156.6 148.8 133.1 140.7 139.2 140.2 134.9 141.4 138.5 148.9 144.4 145.4 h2 142.3 134.4 150.3 141.9 143.5 138.1 142.9 140.9 134.7 141.2 135.5 140.2
STATA数据库的保留维护
保留变量或记录 keep in 10/20 /* 保留第10~20 个记录,其余记录删除 keep x1-x5 /* 保留数据库中介 于x1和x5间的所有变量(包括x1和x5),其 余变量删除 keep if x>0 /* 保留x>0的所有 记录,其余记录删除
STATA的函数: help functions
数学函数
abs(x),sqrt(x),exp(x),ln(x),log10(x)…… 统计函数 norm(u),invnorm(p),ttail(df,t),invttaill(df,p)…… 字符串函数 length(s),substr(s,n1,n2),string(x),real(s)…… 特殊函数 int(x),max(x1,x2,…),autocode(x,k,min,max)…… 随机数函数 uniform(seed),invnorm(uniform())
Stata操作讲义_经济学_高等教育_教育专区

Stata操作讲义第一讲Stata操作入门第一节概况Stata最初由美国计算机资源中心(Computer Resource Center)研制,现在为Stata公司的产品,其最新版本为7.0版。
它操作灵活、简单、易学易用,是一个非常有特色的统计分析软件,现在已越来越受到人们的重视和欢迎,并且和SAS、SPSS一起,被称为新的三大权威统计软件。
Stata最为突出的特点是短小精悍、功能强大,其最新的7.0版整个系统只有10M左右,但已经包含了全部的统计分析、数据管理和绘图等功能,尤其是他的统计分析功能极为全面,比起1G以上大小的SAS系统也毫不逊色。
另外,由于Stata在分析时是将数据全部读入内存,在计算全部完成后才和磁盘交换数据,因此运算速度极快。
由于Stata的用户群始终定位于专业统计分析人员,因此他的操作方式也别具一格,在Windows席卷天下的时代,他一直坚持使用命令行/程序操作方式,拒不推出菜单操作系统。
但是,Stata的命令语句极为简洁明快,而且在统计分析命令的设置上又非常有条理,它将相同类型的统计模型均归在同一个命令族下,而不同命令族又可以使用相同功能的选项,这使得用户学习时极易上手。
更为令人叹服的是,Stata语句在简洁的同时又拥有着极高的灵活性,用户可以充分发挥自己的聪明才智,熟练应用各种技巧,真正做到随心所欲。
除了操作方式简洁外,Stata的用户接口在其他方面也做得非常简洁,数据格式简单,分析结果输出简洁明快,易于阅读,这一切都使得Stata成为非常适合于进行统计教学的统计软件。
Stata的另一个特点是他的许多高级统计模块均是编程人员用其宏语言写成的程序文件(ADO文件),这些文件可以自行修改、添加和下载。
用户可随时到Stata网站寻找并下载最新的升级文件。
事实上,Stata的这一特点使得他始终处于统计分析方法发展的最前沿,用户几乎总是能很快找到最新统计算法的Stata程序版本,而这也使得Stata自身成了几大统计软件中升级最多、最频繁的一个。
stata操作指南

stata操作指南计量经济学stata操作(实验课)第一章stata基本知识1、stata窗口介绍2、基本操作(1)窗口锁定:Edit-preferences-general preferences-windowing-lock splitter (2)数据导入(3)打开文件:use E:\example.dta,clear(4)日期数据导入:gen newvar=date(varname, “ymd”)format newvar %td 年度数据gen newvar=monthly(varname, “ym”)format newvar %tm 月度数据gen newvar=quarterly(varname, “yq”)format newvar %tq 季度数据(5)变量标签Label variable tc ` “total output” ’(6)审视数据describelist x1 x2list x1 x2 in 1/5list x1 x2 if q>=1000drop if q>=1000keep if q>=1000(6)考察变量的统计特征summarize x1su x1 if q>=10000su q,detailsutabulate x1correlate x1 x2 x3 x4 x5 x6(7)画图histogram x1, width(1000) frequency kdensity x1scatter x1 x2twoway (scatter x1 x2) (lfit x1 x2) twoway (scatter x1 x2) (qfit x1 x2) (8)生成新变量gen lnx1=log(x1)gen q2=q^2gen lnx1lnx2=lnx1*lnx2gen larg=(x1>=10000)rename larg largeg large=(q>=6000)replace large=(q>=6000)drop ln*(8)计算功能display log(2)(9)线性回归分析regress y1 x1 x2 x3 x4vce #显示估计系数的协方差矩阵reg y1 x1 x2 x3 x4,noc #不要常数项reg y1 x1 x2 x3 x4 if q>=6000reg y1 x1 x2 x3 x4 if largereg y1 x1 x2 x3 x4 if large==0reg y1 x1 x2 x3 x4 if ~large predict yhatpredict e1,residualdisplay 1/_b[x1]test x1=1 # F检验,变量x1的系数等于1test (x1=1) (x2+x3+x4=1) # F联合假设检验test x1 x2 #系数显著性的联合检验testnl _b[x1]= _b[x2]^2(10)约束回归constraint def 1 x1+x2+x3=1cnsreg y1 x1 x2 x3 x4,c(1)cons def 2 x4=1cnsreg y1 x1 x2 x3 x4,c(1-2)(11)stata的日志File-log-begin-输入文件名log off 暂时关闭log on 恢复使用log close 彻底退出(12)stata命令库更新Update allhelp command第二章有关大样本ols的stata命令及实例(1)ols估计的稳健标准差reg y x1 x2 x3,robust(2)实例use example.dta,clearreg y1 x1 x2 x3 x4test x1=1reg y1 x1 x2 x3 x4,rtestnl _b[x1]=_b[x2]^2第三章最大似然估计法的stata命令及实例(1)最大似然估计help ml(2)LR检验lrtest #对面板数据中的异方差进行检验(3)正态分布检验sysuse auto #调用系统数据集auto.dtahist mpg,normalkdensity mpg,normalqnorm mpg*手工计算JB统计量sum mpg,detaildi (r(N)/6)*((r(skewness)^2)+[(1/4)*(r(kurtosis)-3)^2]) di chi2tail(自由度,上一步计算值)*下载非官方程序ssc install jb6jb6 mpg*正态分布的三个检验sktest mpgswilk mpgsfrancia mpg*取对数后再检验gen lnmpg=log(mpg)kdensity lnmpg, normaljb6 lnmpgsktest lnmpg第四章处理异方差的stata命令及实例(1)画残差图rvfplotrvfplot varname*例题use example.dta,clearreg y x1 x2 x3 x4rvfplot # 与拟合值的散点图rvfplot x1 # 画残差与解释变量的散点图(2)怀特检验estat imtest,white*下载非官方软件ssc install whitetst(3)BP检验estat hettest #默认设置为使用拟合值estat hettest,rhs #使用方程右边的解释变量estat hettest [varlist] #指定使用某些解释变量estat hettest,iidestat hettest,rhs iidestat hettest [varlist],iid(4)WLSreg y x1 x2 x3 x4 [aw=1/var]*例题quietly reg y x1 x2 x3 x4predict e1,resgen e2=e1^2gen lne2=log(e2)reg lne2 x2,nocpredict lne2fgen e2f=exp(lne2f)reg y x1 x2 x3 x4 [aw=1/e2f](5)stata命令的批处理(写程序)Window-do-file editor-new do-file#WLS for examplelog using E:\wls_example.smcl,replaceset more offuse E:\example.dta,clearreg y x1 x2 x3 x4predict e1,resgen e2=e1^2g lne2=log(e2)reg lne2 x2,nocpredict lne2fg e2f=exp(lne2f)*wls regressionreg y x1 x2 x3 x4 [aw=1/e2f]log closeexit第五章处理自相关的stata命令及实例(1)滞后算子/差分算子tsset yearl.l2.D.D2.LD.(2)画残差图scatter e1 l.e1ac e1pac e1(3)BG检验estat bgodfrey(默认p=1)estat bgodfrey,lags(p)estat bgodfrey,nomiss0(使用不添加0的BG检验)(4)Ljung-Box Q检验reg y x1 x2 x3 x4predict e1,residwntestq e1wntestq e1,lags(p)* wntestq指的是“white noise test Q”,因为白噪声没有自相关(5)DW检验做完OLS回归后,使用estat dwatson(6)HAC稳健标准差newey y x1 x2 x3 x4,lag(p)reg y x1 x2 x3 x4,cluster(varname)(7)处理一阶自相关的FGLSprais y x1 x2 x3 x4 (使用默认的PW估计方法)prais y x1 x2 x3 x4,corc (使用CO估计法)(8)实例use icecream.dta, cleartsset timegraph twoway connect consumption temp100 time, msymbol(circle) msymbol(triangle) reg consumption temp price incomepredict e1, resg e2=l.e1twoway (scatter e1 e2) (lfit e1 e2)ac e1pac e1estat bgodfreywntestq e1estat dwatsonnewey consumption temp price income, lag (3)prais consumption temp price income, corcprais consumption temp price income, nologreg consumption temp l.temp price incomeestat bgodfreyestat dwatson第六章模型设定与数据问题(1)解释变量的选择reg y x1 x2 x3estat ic*例题use icecream.dta, clearreg consumption temp price incomeestat icreg consumption temp l.temp price incomeestat ic(2)对函数形式的检验(reset检验)reg y x1 x2 x3estat ovtest (使用被解释变量的2、3、4次方作为非线性项)estat ovtest, rhs (使用解释变量的幂作为非线性项,ovtest-omitted variable test)*例题use nerlove.dta, clearreg lntc lnq lnpl lnpk lnpfestat ovtestg lnq2=lnq^2reg lntc lnq lnq2 lnpl lnpk lnpfestat ovtest(3)多重共线性estat vif*例题use nerlove.dta, clearreg lntc lnq lnpl lnpk lnpfestat vif(4)极端数据reg y x1 x2 x3predict lev, leverage (列出所有解释变量的lev值)gsort –levsum levlist lev in 1/3*例题use nerlove.dta, clearquietly reg lntc lnq lnpl lnpk lnpfpredict lev, leveragesum levgsort –levlist lev in 1/3(5)虚拟变量gen d=(year>=1978)tabulate province, generate (pr)reg y x1 x2 x3 pr2-pr30(6)经济结构变动的检验方法1:use consumption_china.dta, cleargraph twoway connect c y year, msymbol(circle) msymbol(triangle)reg c yreg c y if year<1992reg c y if year>=1992计算F统计量方法2:gen d=(year>1991)gen yd=y*dreg c y d ydtest d yd第七章工具变量法的stata命令及实例(1)2SLS的stata命令ivregress 2sls depvar [varlist1] (varlist2=instlist)如:ivregress 2sls y x1 (x2=z1 z2)ivregress 2sls y x1 (x2 x3=z1 z2 z3 z4) ,r firstestat firststage,all forcenonrobust (检验弱工具变量的命令)ivregress liml depvar [varlist 1] (varlist2=instlist)estat overid (过度识别检验的命令)*对解释变量内生性的检验(hausman test),缺点:不适合于异方差的情形reg y x1 x2estimates store olsivregress 2sls y x1 (x2=z1 z2)estimates store ivhausman iv ols, constant sigmamore*DWH检验estat endogenous*GMM的过度识别检验ivregress gmm y x1 (x2=z1 z2) (两步GMM)ivregress gmm y x1 (x2=z1 z2),igmm (迭代GMM)estat overid*使用异方差自相关稳健的标准差GMM命令ivregress gmm y x1 (x2=z1 z2), vce (hac nwest[#])(2)实例use grilic.dta,clearsumcorr iq sreg lw s expr tenure rns smsa,rreg lw s iq expr tenure rns smsa,rivregress 2sls lw s expr tenure rns smsa (iq=med kww mrt age),restat overidivregress 2sls lw s expr tenure rns smsa (iq=med kww),r first estat overidestat firststage, all forcenonrobust (检验工具变量与内生变量的相关性)ivregress liml lw s expr tenure rns smsa (iq=med kww),r *内生解释变量检验quietly reg lw s iq expr tenure rns smsaestimates store olsquietly ivregress 2sls lw s expr tenure rns smsa (iq=med kww) estimates store ivhausman iv ols, constant sigmamoreestat endogenous (存在异方差的情形)*存在异方差情形下,GMM比2sls更有效率ivregress gmm lw s expr tenure rns smsa (iq=med kww)estat overidivregress gmm lw s expr tenure rns smsa (iq=med kww),igmm*将各种估计方法的结果存储在一张表中quietly ivregress gmm lw s expr tenure rns smsa (iq=med kww)estimates store gmmquietly ivregress gmm lw s expr tenure rns smsa (iq=med kww),igmmestimates store igmmestimates table gmm igmm第八章短面板的stata命令及实例(1)面板数据的设定xtset panelvar timevarencode country,gen(cntry) (将字符型变量转化为数字型变量)xtdesxtsumxttab varnamextline varname,overlay*实例use traffic.dta,clearxtset state yearxtdesxtsum fatal beertax unrate state yearxtline fatal(2)混合回归reg y x1 x2 x3,vce(cluster id)如:reg fatal beertax unrate perinck,vce(cluster state)estimates store ols对比:reg fatal beertax unrate perinck(3)固定效应xtreg y x1 x2 x3,fe vce(cluster id)xi:reg y x1 x2 x3 i.id,vce(cluster id) (LSDV法)xtserial y x1 x2 x3,output (一阶差分法,同时报告面板一阶自相关)estimates store FD*双向固定效应模型tab year, gen (year)xtreg fatal beertax unrate perinck year2-year7, fe vce (cluster state)estimates store FE_TWtest year2 year3 year4 year5 year6 year7(4)随机效应xtreg y x1 x2 x3,re vce(cluster id) (随机效应FGLS)xtreg y x1 x2 x3,mle (随机效应MLE)xttest0 (在执行命令xtreg, re 后执行,进行LM检验)(5)组间估计量xtreg y x1 x2 x3,be(6)固定效应还是随机效应:hausman testxtreg y x1 x2 x3,feestimates store fextreg y x1 x2 x3,reestimates store rehausman fe re,constant sigmamore (若使用了vce(cluster id),则无法直接使用该命令,解决办法详见P163)estimates table ols fe_robust fe_tw re be, b se (将主要回归结果列表比较)第九章长面板与动态面板(1)仅解决组内自相关的FGLSxtpcse y x1 x2 x3 ,corr(ar1) (具有共同的自相关系数)xtpcse y x1 x2 x3 ,corr(psar1) (允许每个面板个体有自身的相关系数)例题:use mus08cigar.dta,cleartab state,gen(state)gen t=year-62reg lnc lnp lnpmin lny state2-state10 t,vce(cluster state)estimates store OLSxtpcse lnc lnp lnpmin lny state2-state10 t,corr(ar1) (考虑存在组内自相关,且各组回归系数相同)estimates store AR1xtpcse lnc lnp lnpmin lny state2-state10 t,corr(psar1) (考虑存在组内自相关,且各组回归系数不相同)estimates store PSAR1xtpcse lnc lnp lnpmin lny state2-state10 t, hetonly (仅考虑不同个体扰动性存在异方差,忽略自相关)estimates store HETONL Yestimates table OLS AR1 PSAR1 HETONL Y, b se(2)同时处理组内自相关与组间同期相关的FGLSxtgls y x1 x2 x3,panels (option/iid/het/cor) corr(option/ar1/psar1) igls注:执行上述xtpcse、xtgls命令时,如果没有个体虚拟变量,则为随机效应模型;如果加上个体虚拟变量,则为固定效应模型。
stata入门操作总结

stata入门操作总结Stata是一种流行的统计分析软件,可以用于数据管理、统计分析和绘图。
以下是一些Stata入门操作的总结:1. 数据导入和导出:使用`use`命令导入Stata数据文件(.dta 文件),使用`import delimited`命令导入CSV或其他格式的数据文件。
使用`save`命令将数据保存为Stata数据文件,使用`export delimited`命令将数据保存为CSV或其他格式的数据文件。
2. 数据清理和转换:使用`drop`命令删除变量或观察值,使用`rename`命令重新命名变量,使用`generate`命令创建新变量,使用`egen`命令计算聚合统计量。
使用`sort`命令对数据进行排序,使用`replace`命令替换变量的值。
3. 描述统计:使用`summarize`命令计算变量的均值、标准偏差和其他描述统计量,使用`tabulate`命令制表并计算分组统计量,使用`histogram`命令绘制直方图,使用`scatter`命令绘制散点图。
4. 统计分析:使用`regress`命令进行线性回归分析,使用`logit`命令进行二元logistic回归分析,使用`probit`命令进行二元probit回归分析,使用`anova`命令进行方差分析。
使用`ttest`命令进行均值差异检验,使用`chi2`命令进行卡方检验。
5. 绘图:使用`graph`命令绘制各种图形,如折线图、柱状图、散点图和箱形图。
使用`twoway`命令绘制多元图形,如多个线条、散点和拟合线。
6. 循环和条件:使用`forvalues`命令进行循环操作,使用`if`命令进行条件筛选。
使用`foreach`命令在多个变量上执行相同的操作。
以上是Stata入门操作的一些总结,但这只是一个基本的概述。
Stata功能非常强大,可以进行更复杂的数据管理和统计分析操作。
要更全面地了解Stata的功能和用法,建议参考Stata的官方文档或参加Stata的培训课程。
stata第一章基本操作

insheet using "D:\Teach课件\STATA\data\corgov0110.csv ",clear
append using "D:\Teach课件\STATA\data\corgov99-00.dta "
keep year topone,删除其它变量,只保留year和topone这 两个变量
keep if year==2010,删除其它年度变量,只保留2010年的 变量
rename,编辑变量名称
rename topone top1
label ,为变量名贴标签,以更容易理解
label var top1 "第一大股东持股比例"
save "D:\Teach课件\STATA\data\corgov9910.dta",replace
br
merge命令
数据表之间横向合并,追加新的变量
insheet using "D:\Teach课件\STATA\data\corgov.csv",clear sort stkcd year save "D:\Teach课件\STATA\data\corgov.dta",replace insheet using "D:\Teach课件\STATA\data\earning.csv",clear sort stkcd year merge stkcd year using "D:\Teach课件\STATA\data\corgov.dta" tab _merge(数值为1表示表一有,表二没有;2表示表二有表一没有;
stata入门中文讲义

及数据处理目录第一章基础的使用有两种方式,即菜单驱动和命令驱动。
菜单驱动比较适合于初学者,容易入学,而命令驱动更有效率,适合于高级用户。
我们主要着眼于经验分析,因而重点介绍命令驱动模式。
图的基本界面关于的使用,可以参考手册,特别是[] ,尤其是第1章和第2章。
有关使用的资料非常多,其中官方的有手册,比如对于初学者,[]是有用的起点,最有用的手册可能是[] ’ 。
除此之外,还有很多的其他相关手册,相关介绍参见用户手册[] —。
() 和 () 是的官方期刊,里面介绍一些没有包括在当前安装里的例子和程序。
其中,是的前身,自年起,改为。
另外,的网站上有很多有用的信息软件本身也提供很多有用的帮助命令,其中使用最多的可能是命令,比如当你忘记命令的使用方法时,可以在命令窗口输入,从而调出的窗口,提供命令的使用方法。
有时,你如果不知道具体的命令,也可以使用命令获得帮助,比如想了解特征的函数命令,但有忘记了,可以使用调出所有的函数。
另外,还提供、、等搜索命令。
会在官方帮助文件、、例子、、等搜索关键词,但不会搜索网络。
会在网络(包括)上搜索可安装的程序。
会进行更广范围的搜索,包括本机和网络信息,并且关键词不必完整。
会在本机上搜索所有的帮助文件(扩展名为或的文件),包括官方命令和用户写的命令。
1.1命令格式所有命令基本具有下列模式[:] [] [ ][][][][ ][, ]方括号表示可选项,打字机体是直接输入,斜体需要用户替代,其中表示前缀,是相应的命令,是变量列表,是表达式,是文件名,表示适用于该命令的一个或多个可选项。
比如,简单统计命令的命令格式为[] [] [] [] [, ]下划线表示该命令也可缩写为。
以系统自带数据为例,看一下命令的使用。
. sysuse auto(1978 Automobile Data). summarizeVariable Obs Mean Std. Dev. Min Maxmake 0price 74 6165.257 2949.496 3291 15906mpg 74 21.2973 5.785503 12 41rep78 69 3.405797 .9899323 1 5headroom 74 2.993243 .8459948 1.5 5trunk 74 13.75676 4.277404 5 23weight 74 3019.459 777.1936 1760 4840length 74 187.9324 22.26634 142 233turn 74 39.64865 4.399354 31 51displacement 74 197.2973 91.83722 79 425gear_ratio 74 3.014865 .4562871 2.19 3.89foreign 74 .2972973 .4601885 0 1可以利用查看它的可选项,比如用可选项,还可以把变量的偏度和峰度显示出来。
stata 教程

stata 教程Stata是一种强大的统计分析软件,广泛应用于经济学、社会科学、生物统计学等领域。
本教程将介绍Stata的基本操作和常用功能,帮助您快速入门。
1. Stata的界面和基本操作- 打开Stata软件后,会出现一个命令行界面。
您可以直接在命令行输入Stata命令进行操作。
- 菜单栏提供了常用的功能选项,包括打开数据文件、保存结果、运行程序等。
- 数据编辑窗口可以对数据进行编辑和处理。
- 结果窗口会显示Stata命令的执行结果和输出信息。
2. 导入和导出数据- 使用`import`命令可以导入各种格式的数据文件,如CSV、Excel、SPSS等。
- 使用`export`命令可以将Stata数据文件保存为其他格式的文件。
3. 数据的描述性统计- 使用`summarize`命令可以计算数据的基本统计量,如均值、中位数、标准差等。
- 使用`tabulate`命令可以制作数据的列联表和交叉报表。
- 使用`graph`命令可以绘制数据的直方图、散点图等。
4. 数据的清洗和处理- 使用`drop`命令可以删除数据中的变量或观察。
- 使用`rename`命令可以修改变量的名称。
- 使用`generate`命令可以生成新的变量,并进行数值计算和逻辑判断。
5. 统计分析- 使用`regress`命令可以进行回归分析。
- 使用`ttest`命令可以进行单样本或双样本t检验。
- 使用`correlate`命令可以计算变量之间的相关系数。
6. 编写和运行程序- 使用`do`命令可以运行存储在.do文件中的Stata程序。
- 使用`foreach`和`forvalues`命令可以进行循环操作。
- 使用`if`和`else`命令可以进行条件判断。
这些是Stata的基本操作和常用功能,希望对您的学习和使用有所帮助。
通过实践和深入了解Stata的不同命令和功能,您将能够灵活地进行数据处理和统计分析。
stata 第一章 基本操作

练习1.3
用stata打开corgov文件 看看一共有多少家样本 看看2010年一共有多少家样本
keep year topone,删除其它变量,只保留year和topone这 两个变量
keep if year==2010,删除其它年度变量,只保留2010年的 变量
rename,编辑变量名称
rename topone top1
label ,为变量名贴标签,以更容易理解
lab;
数据
试试browse,list,edit三个命令,看看三者的区别 注意:上述命令也可以通过菜单的方式实现。
--
保存数据
菜单窗口
File/save File/save as(另存为)
命令窗口
save "D:\Teach课件\STATA\data\corgov.dta " save "D:\Teach课件\STATA\data\corgov.dta
--
Insheet:导入数据
通常数据来源于数据库下载,而不是手工录入 导入格式
Stata不能直接支持很多格式(Excel files, SAS files) 可以先保存为csv格式后再导入stata
准备工作:将Excel文件另存为csv格式,然后导入 csv文 件。
菜单窗口
File/import/ASCII data created by spreadsheet /browse file name
",replace
replace的作用是,如果文件已存在,则替换 注意stata格式文件的后缀为.dta
--
练习1.1
导入表名为earning的Excel格式数据 检查数据 保存数据为stata数据格式
STATA基本操作入门

STATA基本操作入门1.数据导入在STATA中,可以导入多种格式的数据文件,如Excel、CSV和文本文件。
最常用的命令是"import excel"和"import delimited"。
例如,要导入名为"data.xlsx"的Excel文件,可以使用以下命令:```import excel using "data.xlsx", sheet("Sheet1") firstrow clear```这里,"using"指定了文件路径和文件名,"sheet"指定了工作表名称(如果有多个工作表),"firstrow"表示第一行是变量名。
2.数据清洗在导入数据后,通常需要进行数据清洗,包括处理缺失值、异常值和重复值等。
STATA提供了一些常用的命令来处理这些问题。
- 缺失值处理:使用"drop"命令删除带有缺失值的观测值,使用"egen"命令创建新变量来表示缺失值。
- 异常值处理:可以使用描述性统计命令(如"summarize")来查找异常值,并使用"drop"命令删除异常值所对应的观测值。
- 重复值处理:使用"deduplicate"命令删除重复的观测值,或使用"egen"命令创建新变量来表示重复值。
3.变量操作在STATA中,可以对变量进行各种操作,如创建变量、重命名变量、计算变量和合并变量等。
- 创建变量:可以使用"generate"命令创建新变量,并赋予其数值或字符值。
- 重命名变量:使用"rename"命令将变量重命名为新的名称。
- 计算变量:使用"egen"命令计算新变量,例如,可以使用"egen mean_var = mean(var)"计算变量"var"的均值,并将结果赋值给新的变量"mean_var"。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.1 变量与变量值
• Stata变量的命名原则:
. 变量名中字符的组成部分为A~Z,a~z、0~9与下划线“ _ ” ,这些字符以外的其他符号不能出现在变量名当中; . 变量名不能以数字作为开始符号; . 变量名区分大小写字母,而且不能识别汉字;
• 变量的取值类型: 1、字符型变量:由特定的字符串构成,用来分辨不同的类型; 2、数值型变量:数值变量的取值由数字构成,参与数字运算; 3、日期型变量:在Stata中,1960 年1 月1 日被认为是第0 天, 因此1959 年12 月31 日为第-1天,表示形式为:jan/10/2001或者 10jan2001; 4、缺失值:STATA 默认的缺失值用“.”来表示;
• 网络帮助: 如 . net from (连接stata官网)
二、Stata使用基础
2.1 Stata命令结构
• Stata的通用命令结构如下:
[ prefix : ] command [ varlist ] [= exp.] [ if exp. ] [ using filename ] [ in range ] [ weight = ] [ , options ]
术语 prefix command 含义 命令前缀 命令 术语 using filename in range 含义 使用的文件 观察个案范围
varlist
= exp.
变量串
表达式 条件表达式
weight
权重
选项
options
if exp.
• Stata常用命令及其缩写
命令或选项 list describe display summarize tabulate lable li des di, dis sum ta, tab lab 缩写 含义 列出变量 描述分析 展示变量 统计摘要 列表显示 标签 命令或选项 rename generate graph regress variable column ren gen, g gr reg var col 缩写 含义 重命名 新建变量 绘图 回归 变量 列
6、最后软件安装完成。
7、接下来对软件进行破解,在桌面打开Stata14快捷方式,会弹 出如下对话框。将序列号,授权码,激活码输入到对应框中即可。 序列号:(Seri)10699393 授权码:(Code)4gpp mkha 3yqe 3o9v g1m7 iu6j ou5j 激活码:(Auth)tsrk
2.2 输入、输出与存储
• 数据的输入包括三种方法:
1.直接从键盘输入
2.打开已有数据文件 3.拷贝、粘贴方式交互数据
1.直接键盘输入
在Stata中可以使用命令行方式直接建立数据集,首先使用input命令制定相
应的变量名称,然后一次录入数据,最后使用end语句表明数据录入结束。
建立两个变量x、y
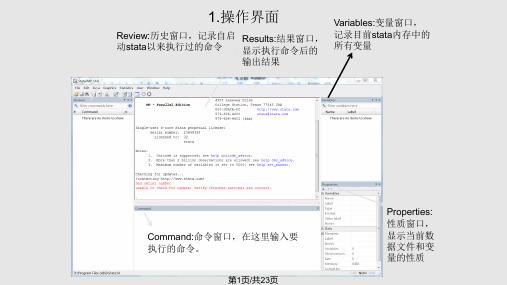
• 命令回顾窗口:即 review 窗口,位于界面左上方,所有执行过的 命令会依 次在该窗口中列出,选中某一行单击后命令即被自动拷 贝到命令窗口中;如果需 要重复执行,用鼠标双击相应的命令行 即可。
• 变量名窗口:位于界面左下方,列出当前数据集中的所有变量名 称,。 除以上四个默认打开的窗口外,在 Stata 中还有数据编辑 窗口、程序文件编 辑窗口、帮助窗口、绘图窗口、Log 窗口等, 如果需要使用,可以用 Window 或 Help 菜单将其打开。
• 数据文件的存储: 1、存储在当前工作目录的命令输出格式: save filename [ ,replace] 2、更改工作目录的命令输出格式: save d:\data\undp\ filename
2.3 添加数据标签
• 添加标签包括给文件和变量添加标签,命令格式如下: . label data " label " . label variable varname " label "1.6 Stata软件分享(网盘)1.stata14版
• 提取密码:fsqn
2.Stata文档教程
• 提取密码:9x1n
3.Stata视频教程
• 提取密码:ytwm
1.7 Stata安装
1、首先下载文件然后解压。解压完成后双击 “SetupStata14.exe”进行安装。点击“Next”继续。如下图:
1.2 Stata功能
Stata主要功能: 1、数据管理功能 2、统计分析功能
• 统计分析:概要统计、交互表 • 回归分析: OLS, 2SLS, Logit, Probit, Tobit, Heckman, GMM Panel data, Time series, Survey data • 多变量分析: Cluster analysis • 抽样和模拟: Bootstrap, Monte Carlo Simulation
Stata 菜单栏简介
包含八项下拉菜单:文件、编辑、数据、绘图、统计分析、用户、窗口及帮助。
1.9 Stata命令输入
• Stata的命令输入方式: 1、点击菜单栏输入命令; 2、在命令窗口输入命令; 3、运行命令程序(利用.do文件);
1.10 Stata文件格式
• Stata常用的文件格式:
• 命令包内容图例:
• 用法如下: findit var_2 (search var_2 )
1.12 Stata帮助
• 三种主要途径可获得Stata 帮助: Stata手册; Stata自带帮助; 网络帮助;
• Stata手册:
Stata手册(英文版)默F,可通过stata手册查阅相关帮助。
• Stata自带帮助:
1、直接在命令窗口中输入 help var_1
如 . help summarize 2、通过菜单窗口的点选方式获得帮助: 如 . help>>stata command 在弹出的 对话框中输入:summarize 然后回车,得到与 help summarize,同样的结 果。
文件类型 数据文件 命令程序文件 扩展名 .dta .do 说明 stata使用的数据 一系列命令的集合
运行程序文件
帮助文件
.ado
.hlp
用于完成用户提交的数的文件名, 形成一堆文件,并提供在线帮助
1.11 Stata命令包安装
利用Stata做统计分析时,官方提供的命令包并不一定能满足需 求,因此许多研究者编写了大量的非官方命令包(包括.do文件、 .ado文件和帮助文件),使用此类非官方命令包之前需要对其进行 安装。 Stata中有两个命令对于用户寻找与安装命令包相当有用:search 和findit。 通过这两个命令可以找到相关搜索内容中有哪些额外的命令,点 击链接后安装即可。
数据处理与运算
三、Stata数据处理与运算
本部分讨论的主要对象是数据内部的变量,具体内容就是介绍 Stata处理数据的基础知识与基础技术,其中包括: 变量的名称给定、变量与变量取值标签的设定、变量变量的类 型与储存格式的给定与更改、变量的运算、生成新变量、使用运算 函数等等。此外,Stata还可以用来选择数据中特定的观察个案与变 量。
有点stata数据编辑器第一格即可复制全部数据。复制会问你是否把第一行作为变量。
方法二:导入的方式 先做好excel数据文件,并以“xml 表格(*.xml)”的形式保存,注意不能以“xml 数据(*.xml)”的形 式保存。而且注意,保存时不能在第一行中输入变量名,只能全部为数据。
• 数据的输出可通过命令直接输出和使用菜单栏输出: 1、命令输出格式 outsheet [ varlist ] using filename [ if ] [ in ] [ ,opt ] 2、使用菜单栏输出 File>>Export>>Excel spreadsheet(*.xls,*xlsx)>>选中要输出的,设 置文件名,再点击确认即可(也可以选择其它输出格式)。
在第一列输入数据后,Stata
第一列自动命名为var1(x); 在第二列输入数据后,第二列
数据编辑器
自动命名为var2(y)„„依次
类推。在输入数据后,双击纵 格顶端的变量名栏,可以更改
变量名,并可以在label栏中
注释变量名的含义,点击OK确 认。 数据输入完毕后,单击 preserve键确认所输数据,按 关闭键即可退出编辑器。
1.8 Stata窗口介绍
• Stata 的界面主要是由四个窗口构成: 1、结果窗口 2、命令窗口 3、命令回顾窗口 4、变量名窗口 除以上四个默认打开的窗口外,在 Stata 中还有数据编辑窗口、 程序文件编 辑窗口、帮助窗口、绘图窗口、Log 窗口等,如果需要 使用,可以用 Window 或 Help 菜单将其打开。
3、绘图功能 4、编程和矩阵运算功能
1.3 Stata工作界面
1.4 Stata与其他软件的区别
1.5 工具书、论坛推荐
• Stata工具书: 1、Stata实用教程——王天夫、李博柏著(基础教程) 2、应用Stata做统计分析——汉密尔顿著;郭志刚等译(最全教程) • Stata学习相关资料 1、经管之家论坛:/forum-67-1.html 2、Stata官方论坛:/links/resources.html
注意:
1.如果为某一变量输入的第一个值是一个数字,比如对人口、失业率和预 期寿命这些变量,那么stata便会认为这一列是一个“数值变量”,从此
以后只允许数字作为取值。
2.如果为某一变量第一次输入的是非数值字符,比如像地名的输入(或者 输入了带逗号的数字),那么stata会判断此列是字符串或文本变量。 3.在数据编辑器或数据浏览器中,字符串变量值显示为红色,这将其与数 值变量(黑色)或加标签的数值变量(蓝色)区分开来。
录入相应的数值
2.用STATA的数据编辑器 ①进入数据编辑器 进入stata界面,在命令栏键入edit或在stata的window下拉菜单中单击data editor 编辑图标 (注意: 是浏览图标,点击后只能浏览,不能编辑)即可进入 stata数据编辑器。 ②数据编辑 stata 数据编辑器界面:此时进入了数据全屏幕编辑状态。