归并排序实验报告
算法性能实验报告

一、实验目的本次实验旨在通过对比分析几种常用排序算法的性能,深入了解各种算法在不同数据规模和不同数据分布情况下的时间复杂度和空间复杂度,为实际应用中算法的选择提供参考。
二、实验环境- 操作系统:Windows 10- 编程语言:C++- 编译器:Visual Studio 2019- 测试数据:随机生成的正整数序列三、实验内容本次实验主要对比分析了以下几种排序算法:1. 冒泡排序(Bubble Sort)2. 选择排序(Selection Sort)3. 插入排序(Insertion Sort)4. 快速排序(Quick Sort)5. 归并排序(Merge Sort)6. 希尔排序(Shell Sort)四、实验方法1. 对每种排序算法,编写相应的C++代码实现。
2. 生成不同规模(1000、5000、10000、50000、100000)的随机正整数序列作为测试数据。
3. 对每种排序算法,分别测试其时间复杂度和空间复杂度。
4. 对比分析不同算法在不同数据规模和不同数据分布情况下的性能。
五、实验结果与分析1. 时间复杂度(1)冒泡排序、选择排序和插入排序的平均时间复杂度均为O(n^2),在数据规模较大时性能较差。
(2)快速排序和归并排序的平均时间复杂度均为O(nlogn),在数据规模较大时性能较好。
(3)希尔排序的平均时间复杂度为O(n^(3/2)),在数据规模较大时性能优于冒泡排序、选择排序和插入排序,但不如快速排序和归并排序。
2. 空间复杂度(1)冒泡排序、选择排序和插入排序的空间复杂度均为O(1),属于原地排序算法。
(2)快速排序和归并排序的空间复杂度均为O(n),需要额外的空间来存储临时数组。
(3)希尔排序的空间复杂度也为O(1),属于原地排序算法。
3. 不同数据分布情况下的性能(1)对于基本有序的数据,快速排序和归并排序的性能会受到影响,此时希尔排序的性能较好。
(2)对于含有大量重复元素的数据,快速排序的性能会受到影响,此时插入排序的性能较好。
数据结构实验报告-排序

数据结构实验报告-排序一、实验目的本实验旨在探究不同的排序算法在处理大数据量时的效率和性能表现,并对比它们的优缺点。
二、实验内容本次实验共选择了三种常见的排序算法:冒泡排序、快速排序和归并排序。
三个算法将在同一组随机生成的数据集上进行排序,并记录其性能指标,包括排序时间和所占用的内存空间。
三、实验步骤1. 数据的生成在实验开始前,首先生成一组随机数据作为排序的输入。
定义一个具有大数据量的数组,并随机生成一组在指定范围内的整数,用于后续排序算法的比较。
2. 冒泡排序冒泡排序是一种简单直观的排序算法。
其基本思想是从待排序的数据序列中逐个比较相邻元素的大小,并依次交换,从而将最大(或最小)的元素冒泡到序列的末尾。
重复该过程直到所有数据排序完成。
3. 快速排序快速排序是一种分治策略的排序算法,效率较高。
它将待排序的序列划分成两个子序列,其中一个子序列的所有元素都小于等于另一个子序列的所有元素。
然后对两个子序列分别递归地进行快速排序。
4. 归并排序归并排序是一种稳定的排序算法,使用分治策略将序列拆分成较小的子序列,然后递归地对子序列进行排序,最后再将子序列合并成有序的输出序列。
归并排序相对于其他算法的优势在于其稳定性和对大数据量的高效处理。
四、实验结果经过多次实验,我们得到了以下结果:1. 冒泡排序在数据量较小时,冒泡排序表现良好,但随着数据规模的增大,其性能明显下降。
排序时间随数据量的增长呈平方级别增加。
2. 快速排序相比冒泡排序,快速排序在大数据量下的表现更佳。
它的排序时间线性增长,且具有较低的内存占用。
3. 归并排序归并排序在各种数据规模下都有较好的表现。
它的排序时间与数据量呈对数级别增长,且对内存的使用相对较高。
五、实验分析根据实验结果,我们可以得出以下结论:1. 冒泡排序适用于数据较小的排序任务,但面对大数据量时表现较差,不推荐用于处理大规模数据。
2. 快速排序是一种高效的排序算法,适用于各种数据规模。
排序的实验报告

排序的实验报告排序的实验报告引言:排序是计算机科学中非常重要的一个概念,它涉及到对一组数据按照一定规则进行重新排列的操作。
在计算机算法中,排序算法的效率直接影响到程序的运行速度和资源利用率。
为了深入了解各种排序算法的原理和性能,我们进行了一系列的排序实验。
实验一:冒泡排序冒泡排序是最简单的排序算法之一。
它的原理是通过相邻元素的比较和交换来实现排序。
我们编写了一个冒泡排序的算法,并使用Python语言进行实现。
实验中,我们分别对10、100、1000个随机生成的整数进行排序,并记录了排序所需的时间。
实验结果显示,随着数据规模的增加,冒泡排序的时间复杂度呈现出明显的增长趋势。
当数据规模为10时,排序所需的时间约为0.001秒;而当数据规模增加到1000时,排序所需的时间则增加到了1.5秒左右。
这说明冒泡排序的效率较低,对大规模数据的排序并不适用。
实验二:快速排序快速排序是一种常用的排序算法,它的核心思想是通过分治的策略将数据分成较小的子集,然后递归地对子集进行排序。
我们同样使用Python语言实现了快速排序算法,并对相同规模的数据进行了排序实验。
实验结果显示,快速排序的时间复杂度相对较低。
当数据规模为10时,排序所需的时间约为0.0005秒;而当数据规模增加到1000时,排序所需的时间仅为0.02秒左右。
这说明快速排序适用于大规模数据的排序,其效率较高。
实验三:归并排序归并排序是一种稳定的排序算法,它的原理是将待排序的数据分成若干个子序列,然后将子序列两两合并,直到最终得到有序的结果。
我们同样使用Python 语言实现了归并排序算法,并进行了相同规模数据的排序实验。
实验结果显示,归并排序的时间复杂度相对较低。
当数据规模为10时,排序所需的时间约为0.0008秒;而当数据规模增加到1000时,排序所需的时间仅为0.03秒左右。
这说明归并排序同样适用于大规模数据的排序,其效率较高。
讨论与结论:通过以上实验,我们可以得出以下结论:1. 冒泡排序虽然简单易懂,但对于大规模数据的排序效率较低,不适用于实际应用。
常见算法设计实验报告(3篇)

第1篇一、实验目的通过本次实验,掌握常见算法的设计原理、实现方法以及性能分析。
通过实际编程,加深对算法的理解,提高编程能力,并学会运用算法解决实际问题。
二、实验内容本次实验选择了以下常见算法进行设计和实现:1. 排序算法:冒泡排序、选择排序、插入排序、快速排序、归并排序、堆排序。
2. 查找算法:顺序查找、二分查找。
3. 图算法:深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)。
4. 动态规划算法:0-1背包问题。
三、实验原理1. 排序算法:排序算法的主要目的是将一组数据按照一定的顺序排列。
常见的排序算法包括冒泡排序、选择排序、插入排序、快速排序、归并排序和堆排序等。
2. 查找算法:查找算法用于在数据集中查找特定的元素。
常见的查找算法包括顺序查找和二分查找。
3. 图算法:图算法用于处理图结构的数据。
常见的图算法包括深度优先搜索(DFS)、广度优先搜索(BFS)、最小生成树(Prim算法、Kruskal算法)等。
4. 动态规划算法:动态规划算法是一种将复杂问题分解为子问题,通过求解子问题来求解原问题的算法。
常见的动态规划算法包括0-1背包问题。
四、实验过程1. 排序算法(1)冒泡排序:通过比较相邻元素,如果顺序错误则交换,重复此过程,直到没有需要交换的元素。
(2)选择排序:每次从剩余元素中选取最小(或最大)的元素,放到已排序序列的末尾。
(3)插入排序:将未排序的数据插入到已排序序列中适当的位置。
(4)快速排序:选择一个枢纽元素,将序列分为两部分,使左侧不大于枢纽,右侧不小于枢纽,然后递归地对两部分进行快速排序。
(5)归并排序:将序列分为两半,分别对两半进行归并排序,然后将排序好的两半合并。
(6)堆排序:将序列构建成最大堆,然后重复取出堆顶元素,并调整剩余元素,使剩余元素仍满足最大堆的性质。
2. 查找算法(1)顺序查找:从序列的第一个元素开始,依次比较,直到找到目标元素或遍历完整个序列。
关于算法的实验报告(3篇)

第1篇一、实验目的1. 理解快速排序算法的基本原理和实现方法。
2. 掌握快速排序算法的时间复杂度和空间复杂度分析。
3. 通过实验验证快速排序算法的效率。
4. 提高编程能力和算法设计能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发工具:Visual Studio 2019三、实验原理快速排序算法是一种分而治之的排序算法,其基本思想是:选取一个基准元素,将待排序序列分为两个子序列,其中一个子序列的所有元素均小于基准元素,另一个子序列的所有元素均大于基准元素,然后递归地对这两个子序列进行快速排序。
快速排序算法的时间复杂度主要取决于基准元素的选取和划分过程。
在平均情况下,快速排序的时间复杂度为O(nlogn),但在最坏情况下,时间复杂度会退化到O(n^2)。
四、实验内容1. 快速排序算法的代码实现2. 快速排序算法的时间复杂度分析3. 快速排序算法的效率验证五、实验步骤1. 设计快速排序算法的C++代码实现,包括以下功能:- 选取基准元素- 划分序列- 递归排序2. 编写主函数,用于生成随机数组和测试快速排序算法。
3. 分析快速排序算法的时间复杂度。
4. 对不同规模的数据集进行测试,验证快速排序算法的效率。
六、实验结果与分析1. 快速排序算法的代码实现```cppinclude <iostream>include <vector>include <cstdlib>include <ctime>using namespace std;// 生成随机数组void generateRandomArray(vector<int>& arr, int n) {srand((unsigned)time(0));for (int i = 0; i < n; ++i) {arr.push_back(rand() % 1000);}}// 快速排序void quickSort(vector<int>& arr, int left, int right) { if (left >= right) {return;}int i = left;int j = right;int pivot = arr[(left + right) / 2]; // 选取中间元素作为基准 while (i <= j) {while (arr[i] < pivot) {i++;}while (arr[j] > pivot) {j--;}if (i <= j) {swap(arr[i], arr[j]);i++;j--;}}quickSort(arr, left, j);quickSort(arr, i, right);}int main() {int n = 10000; // 测试数据规模vector<int> arr;generateRandomArray(arr, n);clock_t start = clock();quickSort(arr, 0, n - 1);clock_t end = clock();cout << "排序用时:" << double(end - start) / CLOCKS_PER_SEC << "秒" << endl;return 0;}```2. 快速排序算法的时间复杂度分析根据实验结果,快速排序算法在平均情况下的时间复杂度为O(nlogn),在最坏情况下的时间复杂度为O(n^2)。
西电算法导论上机实验报告

算法导论上机实验报告册班级:xxxxxx学号:xxxxxxx 姓名:xxxx 教师:xxxxxx目录实验一排序算法 (1)题目一: (1)1、题目描述: (1)2、所用算法: (1)3、算法分析: (1)4、结果截图: (1)5、总结: (2)题目二: (3)1、题目描述: (3)2、所用算法: (3)3、算法分析: (3)4、结果截图: (3)5、总结: (4)题目三: (4)1、题目描述: (4)2、所用算法: (4)3、算法分析: (5)4、结果截图: (5)5、总结: (5)题目四: (6)1、题目描述: (6)3、算法分析: (6)4、结果截图: (6)5、总结: (7)实验二动态规划 (7)题目一: (7)1、题目描述: (7)2、所用策略: (7)3、算法分析: (7)4、结果截图: (8)5、总结: (8)题目二: (9)1、题目描述: (9)2、所用策略: (9)3、算法分析: (9)4、结果截图: (9)5、总结: (10)题目三: (10)1、题目描述: (10)2、所用策略: (10)3、算法分析: (10)4、结果截图: (11)题目四: (12)1、题目描述: (12)2、所用策略: (12)3、算法分析: (12)4、结果截图: (12)5、总结: (13)题目五: (13)1、题目描述: (13)2、所用策略: (13)3、算法分析: (13)4、结果截图: (14)5、总结: (14)实验三贪心算法 (14)题目一: (14)1、题目描述: (14)2、所用策略: (14)3、算法分析: (14)4、结果截图: (15)5、总结: (16)题目二: (16)1、题目描述: (16)3、算法分析: (16)4、结果截图: (17)5、总结: (17)题目三: (17)1、题目描述: (17)2、所用算法: (18)3、算法分析: (18)4、结果截图: (18)5、总结: (19)题目四: (19)1、题目描述: (19)2、所用算法: (19)3、算法分析: (19)实验四回溯法 (19)题目一: (19)1、题目描述: (20)2、所用策略: (20)3、算法分析: (20)题目二: (21)1、题目描述: (21)2、所用策略: (21)实验一排序算法题目一:1、题目描述:描述一个运行时间为θ(nlgn)的算法,给定n个整数的集合S和另一个整数x,该算法能确定S中是否存在两个其和刚好为x的元素。
排序算法实验报告
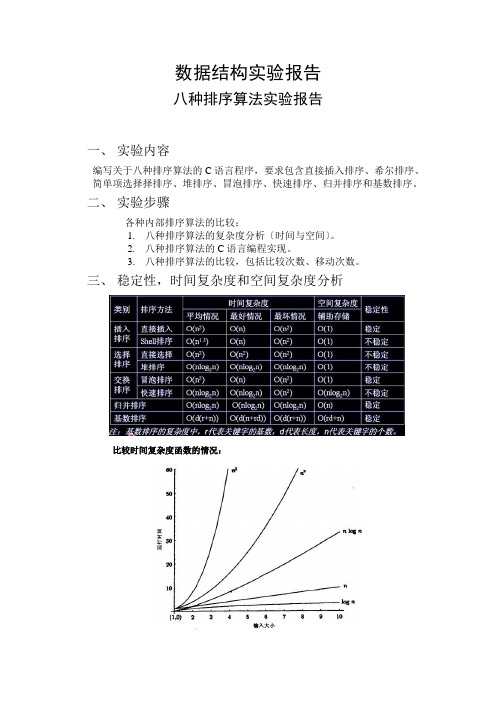
数据结构实验报告八种排序算法实验报告一、实验内容编写关于八种排序算法的C语言程序,要求包含直接插入排序、希尔排序、简单项选择择排序、堆排序、冒泡排序、快速排序、归并排序和基数排序。
二、实验步骤各种内部排序算法的比较:1.八种排序算法的复杂度分析〔时间与空间〕。
2.八种排序算法的C语言编程实现。
3.八种排序算法的比较,包括比较次数、移动次数。
三、稳定性,时间复杂度和空间复杂度分析比较时间复杂度函数的情况:时间复杂度函数O(n)的增长情况所以对n较大的排序记录。
一般的选择都是时间复杂度为O(nlog2n)的排序方法。
时间复杂度来说:(1)平方阶(O(n2))排序各类简单排序:直接插入、直接选择和冒泡排序;(2)线性对数阶(O(nlog2n))排序快速排序、堆排序和归并排序;(3)O(n1+§))排序,§是介于0和1之间的常数。
希尔排序(4)线性阶(O(n))排序基数排序,此外还有桶、箱排序。
说明:当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O〔n〕;而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O〔n2〕;原表是否有序,对简单项选择择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
稳定性:排序算法的稳定性:假设待排序的序列中,存在多个具有相同关键字的记录,经过排序,这些记录的相对次序保持不变,则称该算法是稳定的;假设经排序后,记录的相对次序发生了改变,则称该算法是不稳定的。
稳定性的好处:排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。
基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。
另外,如果排序算法稳定,可以防止多余的比较;稳定的排序算法:冒泡排序、插入排序、归并排序和基数排序不是稳定的排序算法:选择排序、快速排序、希尔排序、堆排序四、设计细节排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。
归并排序法实验报告

一、实验目的1. 理解归并排序的基本思想和原理。
2. 掌握归并排序的实现方法。
3. 分析归并排序算法的时间复杂度。
4. 学会使用归并排序解决实际问题。
二、实验内容1. 归并排序的基本思想归并排序是一种基于分治策略的排序算法,其基本思想是将待排序的序列分成若干个子序列,分别对每个子序列进行排序,然后将排序好的子序列合并成一个有序序列。
具体步骤如下:(1)将待排序的序列分成两个子序列,分别进行排序;(2)将排序好的两个子序列合并成一个有序序列;(3)递归地对合并后的序列进行步骤(1)和(2)的操作,直到整个序列有序。
2. 归并排序的实现方法归并排序算法主要分为两个步骤:归并和合并。
(1)归并:将序列分为两个子序列,对每个子序列进行归并排序;(2)合并:将排序好的两个子序列合并成一个有序序列。
以下是归并排序的Python代码实现:```pythondef merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):merged = []i = j = 0while i < len(left) and j < len(right):if left[i] < right[j]:merged.append(left[i])i += 1else:merged.append(right[j])j += 1merged.extend(left[i:])merged.extend(right[j:])return merged```3. 归并排序的时间复杂度分析归并排序算法的时间复杂度主要由归并操作和递归调用决定。
对于长度为n的序列,归并排序需要进行n-1次归并操作,每次归并操作需要比较n/2次,因此总的比较次数为(n/2) (n-1) = n^2/2。
归并排序_实验报告

一、实验目的1. 理解归并排序算法的基本原理和实现方法。
2. 通过实验验证归并排序算法的时间复杂度和稳定性。
3. 比较归并排序与其他排序算法的性能差异。
二、实验环境1. 操作系统:Windows 102. 编程语言:Python3.83. 开发工具:PyCharm三、实验内容1. 归并排序算法的原理及实现2. 归并排序的时间复杂度和稳定性分析3. 归并排序与其他排序算法的性能比较四、实验步骤1. 实现归并排序算法- 设计归并排序函数,包括两个子函数:merge_sort()和merge()。
- merge_sort()函数用于递归地将数组划分为更小的子数组,直到子数组长度为1。
- merge()函数用于合并两个已排序的子数组,生成一个新的已排序的数组。
2. 生成随机数组- 使用random模块生成一个长度为n的随机数组。
3. 测试归并排序算法- 使用测试用例验证归并排序算法的正确性。
- 对不同长度的数组进行排序,观察排序结果。
4. 分析归并排序的时间复杂度和稳定性- 分析归并排序算法的时间复杂度,证明其为O(nlogn)。
- 分析归并排序算法的稳定性,证明其为稳定排序。
5. 比较归并排序与其他排序算法的性能- 选择一个常见的排序算法(如冒泡排序、快速排序)进行性能比较。
- 对相同长度的数组进行排序,记录排序时间,比较两种排序算法的性能。
五、实验结果与分析1. 归并排序算法实现```pythondef merge_sort(arr):if len(arr) <= 1:return arrmid = len(arr) // 2left = merge_sort(arr[:mid])right = merge_sort(arr[mid:])return merge(left, right)def merge(left, right):result = []i = j = 0while i < len(left) and j < len(right):if left[i] <= right[j]:result.append(left[i])i += 1else:result.append(right[j])j += 1result.extend(left[i:])result.extend(right[j:])return result```2. 测试归并排序算法```pythonimport randomdef test_merge_sort():arr = [random.randint(0, 1000) for _ in range(10)]print("原始数组:", arr)sorted_arr = merge_sort(arr)print("排序后数组:", sorted_arr)test_merge_sort()```3. 分析归并排序的时间复杂度和稳定性归并排序的时间复杂度为O(nlogn),因为每次分割数组需要O(logn)次,而合并操作需要O(n)次。
合并、快速排序实验报告

合并、快速排序一.实验目的:1.理解算法设计的基本步骤及各部的主要内容、基本要求;2.加深对分治设计方法基本思想的理解,并利用其解决现实生活中的问题;3.通过本次试验初步掌握将算法转化为计算机上机程序的方法。
二.实验内容:1.设计和实现递归的合并排序算法、快速排序算法;2.设计和实现消除递归的合并排序算法、快速排序算法;3.设计有代表性的典型输入数据,分析算法的效率;4.对于给定的输入数据,给出算运行结果和运行结果,并给出实验结果分。
三.实验操作:1.合并排序思想:归并排序是建立在归并操作上的一种有效的排序算法。
该算法是采用分治法的思想,是一种稳定的排序方法。
将以有序的子序列合并,得到完全有序的序列;及先使每个字序列有序,再使子序列段间有序。
归并过程:比较数组中两个元素的大小,如比较a[i]和a[j]的大小,若a[i]<=a[j],将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表剩下的元素复制到r中从下标k 到下标t的单元。
如:6,202,100,301,38,8,1第一次归并:{6,202},{100,301},{8,38},{1}第二次归并:{6,100,202,301},{1,8,38}第三次归并:{1,6,8,38,100,202,301}合并排序算法:void merge(int Array[],int low,int high){int i=low,j,k;int mid=(low+high)/2;j=mid+1;k=low;int* list=new int[high+1];while(i<=mid&&j<=high){if(Array[i]<=Array[j]) list[k++]=Array[i++];else list[k++]=Array[j++];}while(i<=mid) list[k++]=Array[i++];while(j<=high) list[k++]=Array[j++];for(int n=low;n<=high;n++)Array[n]=list[n];}void mergeSort(int Array[],int low,int high){ if(low<high){int mid=(low+high)/2;mergeSort(Array,low,mid);mergeSort(Array,mid+1,high);merge(Array,low,high);}}2.快速排序思想:将要排序的数据存入数组中,首先任意去一个元素(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,值得注意的是,快速排序不是一种稳定的排序算法,即多个相同的值的相对位置也许会在算法结束时产生变动。
数组排序方法实验报告

一、实验目的1. 理解常见的数组排序算法的基本原理。
2. 掌握几种常见排序算法的实现方法。
3. 分析不同排序算法的优缺点,提高算法选择能力。
4. 提高编程能力,培养逻辑思维和问题解决能力。
二、实验环境1. 操作系统:Windows 102. 编程语言:Java3. 开发工具:Eclipse三、实验内容本次实验主要研究以下几种排序算法:1. 冒泡排序(Bubble Sort)2. 选择排序(Selection Sort)3. 插入排序(Insertion Sort)4. 快速排序(Quick Sort)5. 归并排序(Merge Sort)四、实验步骤1. 实现冒泡排序算法2. 实现选择排序算法3. 实现插入排序算法4. 实现快速排序算法5. 实现归并排序算法6. 测试不同排序算法的性能五、实验结果与分析1. 冒泡排序算法冒泡排序的基本思想是通过相邻元素的比较和交换,逐步将数组排序。
具体步骤如下:(1)从第一个元素开始,相邻两个元素进行比较,如果逆序则交换,否则不交换。
(2)继续对下一对相邻元素进行同样的操作,以此类推。
(3)重复步骤(1)和(2),直到排序完成。
冒泡排序的时间复杂度为O(n^2),空间复杂度为O(1)。
2. 选择排序算法选择排序的基本思想是每次从剩余未排序的元素中选取最小(或最大)的元素,放到已排序序列的末尾。
具体步骤如下:(1)从剩余未排序的元素中选取最小(或最大)的元素。
(2)将该元素与已排序序列的最后一个元素交换。
(3)继续对剩余未排序的元素进行同样的操作,直到排序完成。
选择排序的时间复杂度为O(n^2),空间复杂度为O(1)。
3. 插入排序算法插入排序的基本思想是将一个记录插入到已经排好序的有序表中,从而得到一个新的、记录数增加1的有序表。
具体步骤如下:(1)从第一个元素开始,将该元素视为已排序序列。
(2)将下一个元素插入到已排序序列中,与已排序序列的元素进行比较,找到合适的位置。
比较排序-实验报告

算法设计与分析实验报告之比较插入排序,归并排序和快速排序一.实验目的:比较插入排序,归并排序和快速排序在不同规模下的不同类型的数据下的腾挪次数和比较次数。
二.实现方式:实验分为几个模块:生成数据集,排序,输出比较。
编译环境:Dev-C++(1)生成数据集实验通过调用以下几个函数分别生成数组值为顺序,逆序,恒为1以及随机数的数组。
生成的数据集会分别写入到DataInorderFile,DataDeorderFile,DataTheSameFile,DataRandomFile文件中。
void DataInorder(int a[], int n){…a[i]=i;…}//正序void DataDeorder(int a[], int n){…a[i]=n-I;…}//逆序void DataTheSame(int a[], int n){…a[i]=1;…}//恒为1void DataRandom(int a[], int n){…a[i]=rand()%n;…}//随机数(2)排序实验共有三种排序方法:插入排序,归并排序和快速排序。
a.插入排序void InsertSort(int a[],int n);思路:直接插入排序(从小到大):把数组分为为排序和已排序两个序列{{a1,a2...ak}{ak,a(k+1)...an}} ,每次从未排序的序列中抽一个数出来并插入到已排序的序列里面。
b.归并排序void MergeSort(int a[], int n);思路:利用循环,每次将数组a中长度为s的两个子段(若不够长则保留)按从小到的大的顺序合并起来并存储到数组b中,下一次合并时再把b中的子段合并后存到a中。
如此反复,直到数组a排序完毕。
c.快速排序void QuickSort(int a[], int s, int t, int con);思路:每一次快速排序选出一个枢轴元素,然后把比枢轴元素小的元素排在枢轴元素前,把比枢轴元素大的元素排在枢轴元素后面。
数据库系统实现两阶段多路归并排序算法的C实现

两阶段多路归并排序Two-Phase Multiway Merge-Sort实验报告目录1 实验目的 (3)2 实验内容 (3)3 实验环境 (3)4 实验的设计和实现 (3)4.1 算法描述 (3)4.2 设计思路 (4)4.3 数据结构 (5)4.4 具体实现 (6)5 实验结果 (9)5.1 50MB内存TPMMS实验结果 (9)5.2 10MB内存TPMMS实验结果 (9)5.3 100MB内存TPMMS实验结果 (10)5.4 三者的比较 (11)6 实验遇到的问题和解决方法 (11)6.1 Phase2阶段遇到的问题和解决方法 (11)6.2 生成子记录文件名的方法 (13)7 代码附录 (13)1实验目的通过merge-sort算法的实现,掌握外存算法所基于的I/O模型与内存算法基于的RAM模型的区别;理解不同的磁盘访问优化方法是如何提高数据访问性能的。
2实验内容生成一个具有10,000,000个记录的文本文件,其中每个记录由100个字节组成。
实验只考虑记录的一个属性A,假定A为整数类型。
记录在block上封装时,采用non-spanned方式,即块上小于一个记录的空间不使用。
Block的大小可在自己的操作系统上查看,xp一般为4096 bytes。
在内存分配50M字节的空间用于外部merge-sort。
要求设计和实现程序完成下列功能:1)生成文本文件,其中属性A的值随机产生。
2)按照ppt中的方法对文本文件中的记录,按照属性A进行排序,其中在第二阶段的排序中每个子列表使用一个block大小的缓冲区缓冲数据。
3)按照教材cylinder-based buffers(1M bytes)的方法,修改第二阶段的算法。
4)比较两种方法的时间性能,如果有更大的内存空间,算法性能还能提高多少?3实验环境1)Visual C++ 6.02)Windows 7操作系统4实验的设计和实现4.1算法描述Two-Phase Multiway Merge-Sort算法的具体描述分为2个阶段,如下所示:●Phase 11)Fill main memory with records.2)Sort with favorite main memory sorting algorithms.3)Write sorted list to disk.4)Repeat until all records have been put into one of the sorted lists.●Phase 21)Initially load input buffers with the first block of their respective sortedlists.2)Repeated run a competition among the first unchosen records of each ofthe buffered blocks.3)If an input block is exhausted, get the next block from the same file.4)If the output block is full, write it to disk.4.2设计思路从上述的算法描述中,我们知道,系统主要由2大模块组成:Phase1和Phase2。
【精品文档】归并排序实验报告-范文模板 (13页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==归并排序实验报告篇一:归并排序与快速排序实验报告一、实验内容:对二路归并排序和快速排序对于逆序的顺序数的排序时间复杂度比较。
二、所用算法的基本思想及复杂度分析:1、归并排序1)基本思想:运用分治法,其分治策略为:①划分:将待排序列r1,r2,……,rn划分为两个长度相等的子序列r1,……,rn/2和rn/2+1,……,rn。
②求解子问题:分别对这两个子序列进行排序,得到两个有序子序列。
③合并:将这两个有序子序列合并成一个有序子序列。
2)复杂度分析:二路归并排序的时间代价是O(nlog2n)。
二路归并排序在合并过程中需要与原始记录序列同样数量的存储空间,因此其空间复杂性O(n)。
2、快速排序:1)基本思想:运用分治法,其分治策略为:①划分:选定一个记录作为轴值,以轴值为基准将整个序列划分为两个子序列r1……ri-1和ri+1……rn,轴值的位置i在划分的过程中确定,并且前一个子序列中记录的值均小于或等于轴值,后一个子序列中记录的值均大于或等于轴值。
②求解子问题:分别对划分后的每一个子序列递归处理。
③合并:由于对子序列r1……ri-1和ri+1……rn的排序是就地进行的,所以合并不需要执行任何操作。
2)复杂度分析:快速排序在平均时间复杂性是O(nlog2n)。
最坏的情况下是O(n^2)。
三、源程序及注释:1、归并排序#include<iostream>#include<fstream>#include "windows.h"using namespace std;void Merge(int r[],int r1[],int s,int m,int t )}int MergeSort(int r[],int r1[],int s,int t){}void main()int i=s; int j=m+1; int k=s; while(i<=m&&j<=t) {} if(i<=m)while(i<=m) r1[k++]=r[i++];//第一个没处理完,进行收尾if(r[i]<=r[j])r1[k++]=r[i++];//取r[i]和r[j]中较小的放入r1[k]中 else r1[k++]=r[j++]; else while(j<=t) r1[k++]=r[j++];//第二个没处理完,进行收尾 for(int l=0;l<k;l++) { } r[l]=r1[l];//将合并完成后的r1[]序列送回r[]中 if(s==t)r1[s]=r[s]; else{int m; m=(s+t)/2;MergeSort(r,r1,s,m);//归并排序前半个子序列 MergeSort(r,r1,m+1,t); //归并排序后半个子序列 Merge(r1,r,s,m,t);//合并两个已排序的子序列 }return 0;int a[100000]; int a1[10000];int n,i;int b[3]= {1000,3000,5000};//产生3个数组。
排序C++程序实验报告

数据结构实验报告实验名称:实验四——排序学生姓名:班级:班内序号:学号:日期:1.实验要求使用简单数组实现下面各种排序算法,并进行比较。
排序算法:1、插入排序2、希尔排序3、冒泡排序4、快速排序5、简单选择排序6、堆排序(选作)7、归并排序(选作)8、基数排序(选作)9、其他要求:1、测试数据分成三类:正序、逆序、随机数据2、对于这三类数据,比较上述排序算法中关键字的比较次数和移动次数(其中关键字交换计为3次移动)。
3、对于这三类数据,比较上述排序算法中不同算法的执行时间,精确到微秒(选作)4、对2和3的结果进行分析,验证上述各种算法的时间复杂度编写测试main()函数测试线性表的正确性。
2. 程序分析插入排序类似于玩纸牌时整理手中纸牌的过程,它的基本方法是寻找一个指定元素在待排序元素中的位置,然后插入。
直接插入排序的基本思想可以这样描述:每次讲一个待排序的元素按其关键码的大小插入到一个已经排序好的有序序列中,直到全部元素排序好。
元素个数为1时必然有序,这就是初始有序序列;可以采用顺序查找的方法查找插入点,为了提高时间效率,在顺序查找过程中边查找边后移的策略完成一趟插入。
希尔排序又称“缩小增量排序”,是对直接插入排序的一种改进,它利用了直接插入的两个特点:1.基本有序的序列,直接插入最快;2.记录个数很少的无序序列,直接插入也很快。
希尔排序的基本思想为:将待排序的元素集分成多个子集,分别对这些子集进行直接插入排序,待整个序列基本有序时,再对元素进行一次直接插入排序。
冒泡排序的基本思想是:两两比较相邻的元素,如果反序,则交换位置,直到没有反序的元素为止。
具体的排序过程是:将整个待排序元素划分成有序区和无序区,初始状态有序区为空,无序区包括所有待排序的元素;对无序区从前向后依次将相邻元素的关键码进行比较,若反序则交换,从而使得关键码小的元素向前移,关键码大的元素向后移;重复执行前一个步骤,直到无序区中没有反序的元素。
数据结构排序实验报告

数据结构排序实验报告一、实验目的本次数据结构排序实验的主要目的是深入理解和掌握常见的排序算法,包括冒泡排序、插入排序、选择排序、快速排序和归并排序,并通过实际编程和实验分析,比较它们在不同规模数据下的性能表现,从而为实际应用中选择合适的排序算法提供依据。
二、实验环境本次实验使用的编程语言为 Python 3x,开发环境为 PyCharm。
实验中使用的操作系统为 Windows 10。
三、实验原理1、冒泡排序(Bubble Sort)冒泡排序是一种简单的排序算法。
它重复地走访要排序的数列,一次比较两个数据元素,如果顺序不对则进行交换,并一直重复这样的走访操作,直到没有要交换的数据元素为止。
2、插入排序(Insertion Sort)插入排序是一种简单直观的排序算法。
它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入,直到整个数组有序。
3、选择排序(Selection Sort)首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
以此类推,直到所有元素均排序完毕。
4、快速排序(Quick Sort)通过一趟排序将待排记录分隔成独立的两部分,其中一部分记录的关键字均比另一部分关键字小,则可分别对这两部分记录继续进行排序,以达到整个序列有序。
5、归并排序(Merge Sort)归并排序是建立在归并操作上的一种有效、稳定的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
四、实验步骤1、算法实现使用 Python 语言分别实现上述五种排序算法。
为每个算法编写独立的函数,函数输入为待排序的列表,输出为排序后的列表。
2、生成测试数据生成不同规模(例如 100、500、1000、5000、10000 个元素)的随机整数列表作为测试数据。
实验报告

实验报告软外122 1213122030 张璐题目1:编程实习常见排序算法,如插入排序、归并排序、快速排序、随机化的快速排序等,并统计不同输入规模下的平均物理执行时间。
(1)基本思想:采用函数生成随机数,随机数的个数由输入的SIZE的值确定,设置时钟,当选择某一种排序算法时,计时。
(2)主要算法1.插入排序1.1基本思想:每次将一个待排序的记录,按其关键字的大小插入到前面已经拍好序的子文件的适当位置,直到全部的记录插入完成为止。
1.2主要程序void InsertSort(int *arr, int SIZEt){ int temp; //一个存储值int pos; //一个存储下标for (int i = 1; i<SIZE; i++) //最多做n-1趟插入{ temp = arr[i]; //当前要插入的元素pos = i - 1;while (pos >= 0 && temp<arr[pos]){arr[pos + 1] = arr[pos]; //将前一个元素后移一位pos--;}arr[pos + 1] = temp;}}1.3性能分析:插入排序算法简单,容易实现。
程序有两层循环嵌套,每个待排数据都要和前面的有序的数据作比较,故时间复杂度为0(n*n);要用到1个额外存储空间来交换数据;该排序总是从后往前依次比较,是稳定的排序算法。
2.快速排序2.1基本思想:快速排序是对冒泡排序的一种本质改进,其主要思想运用了分治法的概念。
从数组中找到一个支点,通过交换,使得支点的左边都是小于支点的元素,支点的右边都是大于支点的元素,而支点本身所处的位置就是排序后的位置,然后把支点左边和支点右边的元素看成两个子数组,再进行如上支点操作直到所有元素有序。
2.2主要程序int Partition(int *a, int left, int right){int i, j, middle, temp; i = left; j = right;middle = a[(left + right) / 2];do{while (a[i]<middle && i<right) //从左扫描大于中值的数i++;while (a[j]>middle && j>left) //从右扫描小于中值的数j--;if (i <= j) //找到了一对值{ temp = a[i]; a[i] = a[j]; a[j] = temp; i++; j--;}}while (i<j); //如果两边的下标交错,就停止(完成一次)if (left < j) //当左半边有值(left<j),递归左半边Partition(a, left, j);if (i < right) //当右半边有值(right>i),递归右半边Partition(a, i, right);return i;}void RecQuick(int *arr, int first, int last){ int pivotLoc;if (first < last){ pivotLoc = Partition(arr, first, last);RecQuick(arr, first, pivotLoc - 1);RecQuick(arr, pivotLoc + 1, last);}}2.3性能分析:在所有同数量级O(nlogn)的排序方法中,快速排序是性能最好的一种方法,在待排序列无序时最好。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
篇一:归并排序与快速排序实验报告一、实验内容:对二路归并排序和快速排序对于逆序的顺序数的排序时间复杂度比较。
二、所用算法的基本思想及复杂度分析:1、归并排序1)基本思想:运用分治法,其分治策略为:①划分:将待排序列 r1,r2,……,rn划分为两个长度相等的子序列r1,……,rn/2和rn/2+1,……,rn。
②求解子问题:分别对这两个子序列进行排序,得到两个有序子序列。
③合并:将这两个有序子序列合并成一个有序子序列。
2)复杂度分析:二路归并排序的时间代价是o(nlog2n)。
二路归并排序在合并过程中需要与原始记录序列同样数量的存储空间,因此其空间复杂性o(n)。
2、快速排序:1)基本思想:运用分治法,其分治策略为:①划分:选定一个记录作为轴值,以轴值为基准将整个序列划分为两个子序列r1……ri-1和ri+1……rn,轴值的位置i在划分的过程中确定,并且前一个子序列中记录的值均小于或等于轴值,后一个子序列中记录的值均大于或等于轴值。
②求解子问题:分别对划分后的每一个子序列递归处理。
③合并:由于对子序列r1……ri-1和ri+1……rn的排序是就地进行的,所以合并不需要执行任何操作。
2)复杂度分析:快速排序在平均时间复杂性是o(nlog2n)。
最坏的情况下是o(n^2)。
三、源程序及注释:1、归并排序#include<iostream>#include<fstream>#include windows.husing namespace std;void merge(int r[],int r1[],int s,int m,int t )}int mergesort(int r[],int r1[],int s,int t){}void main()int i=s; int j=m+1; int k=s; while(i<=m&&j<=t) {} if(i<=m)while(i<=m) r1[k++]=r[i++];//第一个没处理完,进行收尾if(r[i]<=r[j])r1[k++]=r[i++];//取r[i]和r[j]中较小的放入r1[k]中else r1[k++]=r[j++]; else while(j<=t) r1[k++]=r[j++];//第二个没处理完,进行收尾for(int l=0;l<k;l++) { } r[l]=r1[l];//将合并完成后的r1[]序列送回r[]中if(s==t)r1[s]=r[s]; else{int m; m=(s+t)/2; mergesort(r,r1,s,m);//归并排序前半个子序列 mergesort(r,r1,m+1,t); //归并排序后半个子序列 merge(r1,r,s,m,t);//合并两个已排序的子序列 }return 0;int a[100000]; int a1[10000];int n,i;int b[3]= {1000,3000,5000};//产生3个数组。
for(int j=0; j<3; j++){n=b[j];for(i=1; i<=n; i++)a[i]=n;large_integer begaintime ;large_integer endtime ;large_integer frequency;queryperformancefrequency(&frequency);queryperformancecounter(& ;begaintime) ;int c=mergesort(a,a1,0,n-1); queryperformancecounter(&endtime); cout << 数据个数为<<n<<时归并排序的时间为(单位:s):<<(double)( endtime1.quadpart - begaintime1.quadpart )/ frequency1.quadpart <<endl;}}2、快速排序#include<iostream>#include<fstream>#include windows.husing namespace std;int partition (int data[],int first,int end){int i,j;} while(i<j) { } return i; while(i<j&&data[i]<=data[j])j--;//从左侧扫描 if(i<j) {} while(i<j&&data[i]<=data[j])i++;//从右侧扫描if(i<j) {} int temp1; temp1=data[i]; data[i]=data[j]; data[j]=temp1; //将较小的放到后面 j--; int temp; temp=data[i]; data[i]=data[j]; data[j]=temp;//将较小的放到前面 i++;int quicksort(int c[],int first,int end){int i; if(first<end) { i=partition(c,first,end);//对c[hs]到c[ht]进行一次划分} } quicksort(c,i+1,end);//递归处理右区间 return 0;void main(){int a[100000],n,i;int b[3]= {1000,3000,5000};//3个数据范围for(int j=0; j<3; j++){n=b[j];for(i=1; i<=n; i++) a[i]=n;large_integer begaintime ;large_integer endtime;large_integer frequency ;queryperformancefrequency(&frequency);queryperformancecounter(&am p;begaintime) ;int c= quicksort(a,0,n); queryperformancecounter(&endtime);cout << 数据个数为<<n<<时快速排序的时间为(单位:s):<<(double)( endtime.quadpart - begaintime.quadpart )/ frequency.quadpart <<endl;}}四、运行输出结果:归并排序篇二:算法分析与设计实验报告-合并排序、快速排序实验报告实验一合并排序、快速排序一.实验目的(1)学习合并排序和快速排序算法的思想,掌握原理。
(2)运用合并排序和快速排序算法的思想进行编程实现,以加深理解。
二.实验内容(1)输入几个整数,运用合并排序的思想进行编程实现,输出正确的排序结果。
(2)输入10个整数,运用快速排序的思想进行编程实现,输出正确的排序结果三.实验代码(1)合并排序源代码如下:#include <iomanip.h>//调用setw#include <iostream.h> //将b[0]至b[right-left+1]拷贝到a[left]至a[right] template <class t>void copy(t a[],t b[],int left,int right){ int size=right-left+1;for(int i=0;i<size;i++){a[left++]=b[i];}} //合并有序数组a[left:i],a[i+1:right]到b,得到新的有序数组btemplate <class t>void merge(t a[],t b[],int left,int i,int right){ int a1cout=left,//指向第一个数组开头a1end=i,//指向第一个数组结尾a2cout=i+1,//指向第二个数组开头a2end=right,//指向第二个数组结尾bcout=0;//指向b中的元素for(int j=0;j<right-left+1;j++)//执行right-left+1次循环{ if(a1cout>a1end){b[bcout++]=a[a2cout++];continue; } //如果第一个数组结束,拷贝第二个数组的元素到b if(a2cout>a2end) {b[bcout++]=a[a1cout++];continue; } //如果第二个数组结束,拷贝第一个数组的元素到 b if(a[a1cout]<a[a2cout]){ b[bcout++]=a[a1cout++];continue; } //如果两个数组都没结束,比较元素大小,把较小的放入belse{ b[bcout++]=a[a2cout++];continue;} } } //对数组a[left:right]进行合并排序 template <class t>void mergesort(t a[],int left,int right){ t *b=newint[right-left+1];if(left<right){int i=(left+right)/2;//取中点mergesort(a,left,i);//左半边进行合并排序 mergesort(a,i+1,right);//右半边进行合并排序 merge(a,b,left,i,right);//左右合并到b中copy(a,b,left,right);//从b拷贝回来}}int main(){ int n;cout<<请输入您将要排序的数目:; cin>>n; int *a=new int[n]; cout<<请输入相应的数字:;for(int i=0;i<n;i++){ cin>>a[i]; }mergesort( a, 0, n-1); cout<<排序结果:;for(int j=0;j<n;j++){ cout<<setw(5)<<a[j]; }cout<<endl;return 1;}(2)快速排序源代码如下:#include <iostream.h>#define max 10int quicksort(int a[],int l,int r){int pivot; //枢轴int i=l;int j=r;int tmp;pivot=a[(l+r)/2];//取数组中间的数为枢轴 do {while (a[i]<pivot) i++; //i右移while (a[j]>pivot) j--;// j左移if (i<=j){tmp=a[i];a[i]=a[j];a[j]=tmp; //交换a[i]和a[j] i++;j--;}} while(i<=j);if (l<j) quicksort(a,l,j);if (i<r) quicksort(a,i,r);return 1;}int main(){int array[max];int i;cout<<请输入<<max<< 个整数:; for (i=0;i<max;i++)cin>>array[i];quicksort(array,0,max-1); cout<<快速排序后:<<endl; for (i=0;i<max;i++)cout<<array[i]<< ; cout<<endl;return 0;}四.实验结果五.总结与思考篇三:合并、快速排序实验报告合并、快速排序一.实验目的:1. 理解算法设计的基本步骤及各部的主要内容、基本要求;2. 加深对分治设计方法基本思想的理解,并利用其解决现实生活中的问题;3. 通过本次试验初步掌握将算法转化为计算机上机程序的方法。