BP神经网络算法java实现
bp使用方法

bp使用方法
BP(Back Propagation)是一种常用的神经网络训练算法,用于训练多层感知器(MLP)等神经网络。
以下是BP的用方法:
1.初始化神经网络:首先,需要初始化一个神经网络,包括输入层、隐藏层和输出层。
每个层包含一定数量的神经元,每个神经元都通过权重与其他神经元相连。
权重初始化为随机值。
2.前向传播:输入数据通过输入层进入神经网络,然后依次经过隐藏层和输出层,最终得到输出结果。
在前向传播过程中,每个神经元将输入值与其权重相乘,加上偏置项,然后通过激活函数得到输出值。
3.计算误差:根据实际标签和神经网络的输出结果,计算误差。
误差是实际标签与输出结果之间的差异,通常使用平方误差或交叉熵误差等函数计算。
4.反向传播:根据计算出的误差,通过反向传播算法更新神经网络的权重。
反向传播算法将误差从输出层逐层反向传播到输入层,并根据梯度下降法更新权重。
5.迭代训练:重复步骤2-4多次,直到神经网络的输出结果收敛或达到预设的训练轮数。
在每次迭代中,权重都会被更新以减小误差。
6.测试与预测:训练完成后,可以使用测试数据对神经网络进行测试或进行预测。
将测试数据输入神经网络,得到输出结果,并根据输出结果进行评估和比较。
BP算法是一种监督学习算法,需要使用已知标签的数据进行训练。
在训练过程中,需要注意选择合适的激活函数、学习率和迭代次数等参数,以获得最佳的训练效果。
同时,为了避免过拟合和欠拟合等问题,可以使用正则化、Dropout 等技术来优化神经网络的性能。
BP神经网络算法步骤

BP神经网络算法步骤
<br>一、概述
BP神经网络(Back Propagation Neural Network,BPNN)是一种经
典的人工神经网络,其发展始于上世纪80年代。
BP神经网络的原理是按
照误差反向传播算法,以及前馈神经网络的模型,利用反向传播方法来调
整网络各层的权值。
由于其具有自动学习和非线性特性,BP神经网络被
广泛应用在很多和人工智能、计算智能紧密相关的诸如计算机视觉、自然
语言处理、语音识别等领域。
<br>二、BP神经网络的结构
BP神经网络经常使用的是一种多层前馈结构,它可以由输入层,若
干隐藏层,以及输出层三部分组成。
其中,输入层是输入信号的正向传输
路径,将输入信号正向传送至隐藏层,在隐藏层中神经元以其中一种复杂
模式对输入信号进行处理,并将其正向传送至输出层,在输出层中将获得
的输出信号和设定的模式进行比较,以获得预期的输出结果。
<br>三、BP神经网络的学习过程
BP神经网络的学习过程包括正向传播和反向传播两个阶段。
其中,
正向传播是指从输入层到隐藏层和输出层,利用现有的训练数据,根据神
经网络结构,计算出网络每一层上各结点的的激活值,从而得到输出结果。
正向传播的过程是完全可以确定的。
BP算法代码实现

BP算法代码实现BP算法(Backpropagation Algorithm)是一种常用的神经网络训练算法,它主要用于监督式学习任务中的模型训练。
BP算法的核心思想是通过反向传播来更新神经网络的权重和偏差,以使得神经网络的输出逼近目标输出。
在反向传播的过程中,通过求解梯度来更新每个连接权重和偏置的值,从而最小化损失函数。
以下是BP算法的代码实现示例:```pythonimport numpy as npclass NeuralNetwork:def __init__(self, layers):yers = layersself.weights = []self.biases = []self.activations = []#初始化权重和偏置for i in range(1, len(layers)):self.weights.append(np.random.randn(layers[i], layers[i-1])) self.biases.append(np.random.randn(layers[i]))def sigmoid(self, z):return 1 / (1 + np.exp(-z))def sigmoid_derivative(self, z):return self.sigmoid(z) * (1 - self.sigmoid(z))def forward_propagate(self, X):self.activations = []activation = X#前向传播计算每一层的激活值for w, b in zip(self.weights, self.biases):z = np.dot(w, activation) + bactivation = self.sigmoid(z)self.activations.append(activation)return activationdef backward_propagate(self, X, y, output):deltas = [None] * len(yers)deltas[-1] = output - y#反向传播计算每一层的误差(梯度)for i in reversed(range(len(yers)-1)):delta = np.dot(self.weights[i].T, deltas[i+1]) * self.sigmoid_derivative(self.activations[i])deltas[i] = delta#更新权重和偏置for i in range(len(yers)-1):self.weights[i] -= 0.1 * np.dot(deltas[i+1],self.activations[i].T)self.biases[i] -= 0.1 * np.sum(deltas[i+1], axis=1)def train(self, X, y, epochs):for epoch in range(epochs):output = self.forward_propagate(X)self.backward_propagate(X, y, output)def predict(self, X):output = self.forward_propagate(X)return np.round(output)```上述代码使用numpy实现了一个简单的多层神经网络,支持任意层数和任意神经元个数的构建。
人工神经网络之BP模型算法实现

计算机与网络
人工袖经 网络 之 B 模型算法实坝 P
西 南林业 大 学 刘 鑫 赵 家刚( 讯作 者 ) 刘絮 子 通
[ 摘 要] P网络模型误差反 向传播 算法 , B 有效 的解 决 了 权值 调整 问题 , 也是 至今 为止应用最广泛的神经 网络。 因此 , 本文介绍 了B P 的网络模 型算法理论 , 并通过 c ≠ 言对该算法进行 实现 , ≠ 语 可根据不 同样本数据建立相应 的B 模 型 , 究具有一定的实用价值 。 P 本研 [ 关键词 ] 工神 经 网络 B 网络模 型 B 建模 模型训练 模 型预测 人 P P
0 引 言 .
人工神经 网络(rfi uanto sA N是 由大量简单 的处理 aic ler e r , N ) t an l w k i 单元互 相连接 而形成 的复杂并行 网络结构, 然各单元 只完成简单 的 虽 计算 功能, 但整个 网络可 以构成高度 复杂 的非 线性系统 。用人工 神经 网络进行数据分析处理, 能够得到更加接 近真实的拟合曲线 。
这种信 号正 向传播与误差反 向传播 的各层权值调整 过程是周而复始地 进行 的 。权值 不断调整 的过程 , 就是神 经网络 的学习训练 过程 。此 也 过程 一直进行到 网络输 出的误差 减少到可接受 的程度 或进行到预先设 定 的学 习次数 为止 。
1BP网络模型 .
采用 B 算法 的多层感 知器是至今为止 应用得最广泛 的神 经网络 , P 在 多层感 知器 的应 用 中 , 以图 1 示 的单隐层 网络 的应 用最 为普遍 。 所
所示 , 实现方法如下 : ( 在编写代码之前 , 1 ) 添加通用数据库引用 ui s m D t Oe b s g y e .a .l 。 nSt a D f为 “ 2 打开样本 数据库 ” ) 按钮添加 C c 事件 , lk i 实现将数 据库路 径存
神经网络中BP算法的原理与Python实现源码解析

神经⽹络中BP算法的原理与Python实现源码解析最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能⼒有限,若有明显错误,还请指正。
什么是梯度下降和链式求导法则假设我们有⼀个函数 J(w),如下图所⽰。
梯度下降⽰意图现在,我们要求当 w 等于什么的时候,J(w) 能够取到最⼩值。
从图中我们知道最⼩值在初始位置的左边,也就意味着如果想要使 J(w) 最⼩,w的值需要减⼩。
⽽初始位置的切线的斜率a > 0(也即该位置对应的导数⼤于0),w = w – a 就能够让 w 的值减⼩,循环求导更新w直到 J(w) 取得最⼩值。
如果函数J(w)包含多个变量,那么就要分别对不同变量求偏导来更新不同变量的值。
所谓的链式求导法则,就是求复合函数的导数:链式求导法则放个例题,会更加明⽩⼀点:链式求导的例⼦神经⽹络的结构神经⽹络由三部分组成,分别是最左边的输⼊层,隐藏层(实际应⽤中远远不⽌⼀层)和最右边的输出层。
层与层之间⽤线连接在⼀起,每条连接线都有⼀个对应的权重值 w,除了输⼊层,⼀般来说每个神经元还有对应的偏置 b。
神经⽹络的结构图除了输⼊层的神经元,每个神经元都会有加权求和得到的输⼊值 z 和将 z 通过 Sigmoid 函数(也即是激活函数)⾮线性转化后的输出值 a,他们之间的计算公式如下神经元输出值 a 的计算公式其中,公式⾥⾯的变量l和j表⽰的是第 l 层的第 j 个神经元,ij 则表⽰从第 i 个神经元到第 j 个神经元之间的连线,w 表⽰的是权重,b 表⽰的是偏置,后⾯这些符号的含义⼤体上与这⾥描述的相似,所以不会再说明。
下⾯的 Gif 动图可以更加清楚每个神经元输⼊输出值的计算⽅式(注意,这⾥的动图并没有加上偏置,但使⽤中都会加上)动图显⽰计算神经元输出值使⽤激活函数的原因是因为线性模型(⽆法处理线性不可分的情况)的表达能⼒不够,所以这⾥通常需要加⼊ Sigmoid 函数来加⼊⾮线性因素得到神经元的输出值。
bp算法原理

bp算法原理BP算法原理。
BP算法是一种常用的神经网络训练算法,它是基于梯度下降的反向传播算法。
BP算法的原理是通过不断地调整神经网络中的权重和偏置,使得网络的输出与期望输出之间的误差最小化。
在这篇文章中,我们将详细介绍BP算法的原理及其实现过程。
首先,我们需要了解神经网络的基本结构。
神经网络由输入层、隐藏层和输出层组成,其中隐藏层可以包含多层。
每个神经元都与下一层的所有神经元相连,每条连接都有一个权重。
神经元接收到来自上一层神经元的输入,通过加权求和后再经过激活函数得到输出。
BP算法的目标是通过训练数据,调整神经网络中的权重和偏置,使得网络的输出尽可能接近期望输出。
具体来说,BP算法包括前向传播和反向传播两个过程。
在前向传播过程中,输入样本通过神经网络,经过一系列的加权求和和激活函数处理后,得到网络的输出。
然后计算网络的输出与期望输出之间的误差,通常使用均方误差作为误差函数。
接下来是反向传播过程,通过误差函数对网络中的权重和偏置进行调整。
这里使用梯度下降算法,通过计算误差函数对权重和偏置的偏导数,来更新它们的取值。
具体来说,对于每个训练样本,首先计算输出层的误差,然后通过链式法则逐层向前计算隐藏层的误差,最后根据误差调整权重和偏置。
反复进行前向传播和反向传播,直到网络的输出与期望输出的误差达到要求的精度。
这样,神经网络就完成了训练过程,得到了合适的权重和偏置,可以用于对新的输入进行预测。
需要注意的是,BP算法的训练过程中可能存在过拟合和梯度消失等问题。
为了解决这些问题,可以采用正则化、dropout等技术,或者使用其他优化算法如Adam、RMSprop等。
总之,BP算法是一种有效的神经网络训练算法,通过不断地调整权重和偏置,使得网络的输出尽可能接近期望输出。
通过前向传播和反向传播过程,神经网络可以不断地优化自身,实现对复杂问题的建模和预测。
希望本文对您理解BP算法有所帮助。
神经网络的BP算法实验报告

计算智能基础实验报告实验名称:BP神经网络算法实验班级名称:341521班专业:探测制导与控制技术姓名:***学号:********一、 实验目的1)编程实现BP 神经网络算法;2)探究BP 算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、 实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差ε5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP 神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果 。
三、 实验原理1BP 神经网络算法的基本思想误差逆传播(back propagation, BP)算法是一种计算单个权值变化引起网络性能变化的较为简单的方法。
由于BP 算法过程包含从输出节点开始,反向地向第一隐含层(即最接近输入层的隐含层)传播由总误差引起的权值修正,所以称为“反向传播”。
BP 神经网络是有教师指导训练方式的多层前馈网络,其基本思想是:从网络输入节点输入的样本信号向前传播,经隐含层节点和输出层节点处的非线性函数作用后,从输出节点获得输出。
若在输出节点得不到样本的期望输出,则建立样本的网络输出与其期望输出的误差信号,并将此误差信号沿原连接路径逆向传播,去逐层修改网络的权值和节点处阈值,这种信号正向传播与误差信号逆向传播修改权值和阈值的过程反复进行,直训练样本集的网络输出误差满足一定精度要求为止。
2 BP 神经网络算法步骤和流程BP 神经网络步骤和流程如下:1) 初始化,给各连接权{},{}ij jt W V 及阈值{},{}j t θγ赋予(-1,1)间的随机值;2) 随机选取一学习模式对1212(,),(,,)k k k k k k k n k n A a a a Y y y y ==提供给网络;3) 计算隐含层各单元的输入、输出;1n j ij i j i s w a θ==⋅-∑,()1,2,,j j b f s j p ==4) 计算输出层各单元的输入、输出;1t t jt j t j l V b γ==⋅-∑,()1,2,,t t c f l t q ==5) 计算输出层各单元的一般化误差;()(1)1,2,,k k t t tt t t d y c c c t q =-⋅-=6) 计算中间层各单元的一般化误差;1[](1)1,2,,q kk jt jt j j t e d V b b j p ==⋅⋅-=∑7) 修正中间层至输出层连接权值和输出层各单元阈值;(1)()k jt jt t j V iter V iter d b α+=+⋅⋅(1)()k t t t iter iter d γγα+=+⋅8) 修正输入层至中间层连接权值和中间层各单元阈值;(1)()kk ij ij j i W iter W iter e a β+=+⋅⋅(1)()kj j j iter iter e θθβ+=+⋅9) 随机选取下一个学习模式对提供给网络,返回步骤3),直至全部m 个模式训练完毕;10) 重新从m 个学习模式对中随机选取一个模式对,返回步骤3),直至网络全局误差函数E 小于预先设定的一个极小值,即网络收敛;或者,当训练次数大于预先设定值,强制网络停止学习(网络可能无法收敛)。
bp神经网络算法步骤结合实例

bp神经网络算法步骤结合实例
BP神经网络算法步骤包括以下几个步骤:
1.输入层:将输入数据输入到神经网络中。
2.隐层:在输入层和输出层之间,通过一系列权值和偏置将输入数据进行处理,得到输出
数据。
3.输出层:将隐层的输出数据输出到输出层。
4.反向传播:通过反向传播算法来计算误差,并使用梯度下降法对权值和偏置进行调整,
以最小化误差。
5.训练:通过不断地进行输入、隐层处理、输出和反向传播的过程,来训练神经网络,使
其达到最优状态。
实例:
假设我们有一个BP神经网络,它的输入层有两个输入节点,隐层有三个节点,输出层有一个节点。
经过训练,我们得到了权值矩阵和偏置向量。
当我们给它输入一组数据时,它的工作流程如下:
1.输入层:将输入数据输入到神经网络中。
2.隐层:将输入数据与权值矩阵相乘,再加上偏置向量,得到输出数据。
3.输出层:将隐层的输出数据输出到输出层。
4.反向传播:使用反向传播算法计算误差,并使用梯度下降法调整权值和偏置向量,以最
小化误差。
5.训练:通过不断地输入、处理、输出和反向传播的过程,来训练神经网络,使其达到最
优状态。
这就是BP神经网络算法的基本流程。
在实际应用中,还需要考虑许多细节问题,如权值和偏置的初始值、学习率、激活函数等。
但是,上述流程是BP神经网络算法的基本框架。
BP神经网络代码

BP神经网络代码close all ;clear ;echo on ;clc ;% NEWFF——生成一个新的前向神经网络% TRAIN——对 BP 神经网络进行训练% SIM——对 BP 神经网络进行仿真%pause% 敲任意键开始clc% 定义训练样本% P 为输入矢量load bpdataa.mat;p1=bptrainx;% T 为目标矢量t1=bptrainy;p=p1;t=t1;%pauseclc% 创建一个新的前向神经网络net=newff(minmax(p),[12,5],{'tansig','logsig'},'trainlm'); %这些参数要自己设置% 当前输入层权值和阈值inputWeights=net.IW{1,1};inputbias=net.b{1} ;% 当前网络层权值和阈值layerWeights=net.LW{2,1} ;layerbias=net.b{2} ;%pauseclc% 设置训练参数也要自己设置net.trainParam.show = 50;net.trainParam.lr = 0.05;net.trainParam.mc = 0.9; % 附加动量因子net.trainParam.epochs =1000;net.trainParam.goal = 1e-4; %设置的目标%pauseclc% 调用 TRAINGDM 算法训练 BP 网络rand('state',0);[net,tr]=train(net,pn,t);%[net,tr]=train(net,pn,tn);%pauseclc% 对 BP 网络进行仿真%load filename netA=sim(net,pn);E=A-t;。
BP神经网络算法的C语言实现代码

BP神经网络算法的C语言实现代码以下是一个BP神经网络的C语言实现代码,代码的详细说明可以帮助理解代码逻辑:```c#include <stdio.h>#include <stdlib.h>#include <math.h>#define INPUT_SIZE 2#define HIDDEN_SIZE 2#define OUTPUT_SIZE 1#define LEARNING_RATE 0.1//定义神经网络结构体typedef structdouble input[INPUT_SIZE];double hidden[HIDDEN_SIZE];double output[OUTPUT_SIZE];double weights_ih[INPUT_SIZE][HIDDEN_SIZE];double weights_ho[HIDDEN_SIZE][OUTPUT_SIZE];} NeuralNetwork;//激活函数double sigmoid(double x)return 1 / (1 + exp(-x));//创建神经网络NeuralNetwork* create_neural_networNeuralNetwork* nn =(NeuralNetwork*)malloc(sizeof(NeuralNetwork));//初始化权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] = (double)rand( / RAND_MAX * 2 - 1;}}return nn;//前向传播void forward(NeuralNetwork* nn)//计算隐藏层输出for (int i = 0; i < HIDDEN_SIZE; i++)double sum = 0;for (int j = 0; j < INPUT_SIZE; j++)sum += nn->input[j] * nn->weights_ih[j][i];}nn->hidden[i] = sigmoid(sum);}//计算输出层输出for (int i = 0; i < OUTPUT_SIZE; i++)double sum = 0;for (int j = 0; j < HIDDEN_SIZE; j++)sum += nn->hidden[j] * nn->weights_ho[j][i];}nn->output[i] = sigmoid(sum);}void backpropagation(NeuralNetwork* nn, double target)//计算输出层误差double output_error[OUTPUT_SIZE];for (int i = 0; i < OUTPUT_SIZE; i++)double delta = target - nn->output[i];output_error[i] = nn->output[i] * (1 - nn->output[i]) * delta;}//更新隐藏层到输出层权重for (int i = 0; i < HIDDEN_SIZE; i++)for (int j = 0; j < OUTPUT_SIZE; j++)nn->weights_ho[i][j] += LEARNING_RATE * nn->hidden[i] * output_error[j];}}//计算隐藏层误差double hidden_error[HIDDEN_SIZE];for (int i = 0; i < HIDDEN_SIZE; i++)double delta = 0;for (int j = 0; j < OUTPUT_SIZE; j++)delta += output_error[j] * nn->weights_ho[i][j];}hidden_error[i] = nn->hidden[i] * (1 - nn->hidden[i]) * delta;}//更新输入层到隐藏层权重for (int i = 0; i < INPUT_SIZE; i++)for (int j = 0; j < HIDDEN_SIZE; j++)nn->weights_ih[i][j] += LEARNING_RATE * nn->input[i] * hidden_error[j];}}void train(NeuralNetwork* nn, double input[][2], double target[], int num_examples)int iteration = 0;while (iteration < MAX_ITERATIONS)double error = 0;for (int i = 0; i < num_examples; i++)for (int j = 0; j < INPUT_SIZE; j++)nn->input[j] = input[i][j];}forward(nn);backpropagation(nn, target[i]);error += fabs(target[i] - nn->output[0]);}//判断误差是否已达到允许范围if (error < 0.01)break;}iteration++;}if (iteration == MAX_ITERATIONS)printf("Training failed! Error: %.8lf\n", error); }void predict(NeuralNetwork* nn, double input[]) for (int i = 0; i < INPUT_SIZE; i++)nn->input[i] = input[i];}forward(nn);printf("Prediction: %.8lf\n", nn->output[0]); int maiNeuralNetwork* nn = create_neural_network(; double input[4][2] ={0,0},{0,1},{1,0},{1,1}};double target[4] =0,1,1,};train(nn, input, target, 4);predict(nn, input[0]);predict(nn, input[1]);predict(nn, input[2]);predict(nn, input[3]);free(nn);return 0;```以上代码实现了一个简单的BP神经网络,该神经网络包含一个输入层、一个隐藏层和一个输出层。
研究实验2报告示范——单入单出BP人工神经网络及算法研究

研究实验2报告示范——单入单出BP 人工神经网络及算法研究一.研究问题描述:用BP 方法实现一个单输入单输出的函数的逼近。
假设转换函数的输出范围在0到1之间。
函数取以下3个:(),0.20.8x f x e x -=≤≤()0.50.3*sin ,01f x x x =+≤≤()0.50.3*sin(2*),01f x x x =+≤≤二.网络结构:1.三层前向神经网络根据逼近定理知,只含一个隐层的前向网络(即三层前向神经网络)是一个通用的逼近器,可以任意逼近函数f ,因此,在本题中选用三层前向神经网络,即输入层(x0,y0),一个隐层(x1,y1),输出层(x2,y2)。
2.网络结构由于要逼近的函数为单输入单输出函数,故输出层只有一个节点;输入层除了一个样本输入点外,还有一个阈值单元,因此可以看作是两个输入节点;隐层的节点个数p 可以在程序运行时进行选择,以适应和测试不同的逼近效果。
由输入层至隐层的权矩阵记为W0,由隐层到输出层的权矩阵记为W1。
整个网络的结构初步设计如下图所示:(略)三.算法实现本实验用C++程序实现该算法。
报告中所给出的实验数据均是运行C++程序所得的结果,然后将这些结果在matlab 中画出对应图形。
1.标准BP 算法(无动量项):根据公式:(α为学习率)-----⋅⋅-=∂∂⋅-=+Pl l l l l l j i l l j i l l j i k y k k w k w E k w k w 1,1,1,,1,,1,)()()()(/)()1(δαα编写程序,程序执行时允许选择:样本个数p ,隐层节点个数midnumber ,学习速率step ,训练过程结束条件(即训练结束时允许的最大误差)enderr 。
2.加动量项的BP 算法基本原理同上,仅在标准BP 算法的基础上,对权矩阵的修改添加动量项,程序执行时允许选择:样本个数p ,隐层节点个数midnumber ,学习速率step ,训练过程结束条件(即训练结束时允许的最大误差)enderr ,以及动量因子moti 。
BP神经网络算法实验报告

计算各层的输入和输出
es
计算输出层误差 E(q)
E(q)<ε
修正权值和阈值
结
束
图 2-2 BP 算法程序流程图
3、实验结果
任课教师: 何勇强
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 班号:131081 学号:13108117 姓名:韩垚 成绩:
任课教师: 何勇强
(2-7)
wki
输出层阈值调整公式:
(2-8)
ak
任课教师: 何勇强
E E netk E ok netk ak netk ak ok netk ak
(2-9)
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 隐含层权值调整公式: 班号:131081 学号:13108117 姓名:韩垚 成绩:
Ep
系统对 P 个训练样本的总误差准则函数为:
1 L (Tk ok ) 2 2 k 1
(2-5)
E
1 P L (Tkp okp )2 2 p 1 k 1
(2-6)
根据误差梯度下降法依次修正输出层权值的修正量 Δwki,输出层阈值的修正量 Δak,隐含层权 值的修正量 Δwij,隐含层阈值的修正量
日期: 2010 年 12 月 24 日
隐含层第 i 个节点的输出 yi:
M
yi (neti ) ( wij x j i )
j 1
(2-2)
输出层第 k 个节点的输入 netk:
q q M j 1
netk wki yi ak wki ( wij x j i ) ak
BP神经网络详细代码

运用BP神经网络进行预测代码如下:clcclear allclose all%bp神经网络预测%输入输出赋值p=[493 372 445;372 445 176;445 176 235;176 235 378;235 378 429;378 429 561;429 561 651;561 651 467;651 467 527;467 527 668;527 668 841; 668 841 526;841 526 480;526 480 567;480 567 685]';t=[176 235 378 429 561 651 467 527 668 841 526 480 567 685 507];%数据归一化[p1ps]=mapminmax(p);[t1ts]=mapminmax(t);%数据集分配[trainsample.pvalsample.ptestsample.p] =dividerand(p0.70.150.15);[alsample.ttestsample.t] =dividerand(t0.70.150.15);%建立BP神经网络TF1='tansig';TF2='purelin';net=newff(minmax(p)[101]{TF1 TF2}'traingdm');%网络参数的设置net.trainParam.epochs=10000;%训练次数设置net.trainParam.goal=1e-7;%训练目标设置net.trainParam.lr=0.01;%学习率设置net.trainParam.mc=0.9;%动量因子的设置net.trainParam.show=25;%显示的间隔次数% 指定训练参数net.trainFcn='trainlm';[nettr]=train(nettrainsample.ptrainsample.t);%计算仿真[normtrainoutputtrainPerf]=sim(nettrainsample.p[][]trainsample.t);%训练数据,经BP得到的结果[normvalidateoutputvalidatePerf]=sim(netvalsample.p[][]valsample.t);%验证数据,经BP得到的结果[normtestoutputtestPerf]=sim(nettestsample.p[][]testsample.t);%测试数据,经BP得到的结果%计算结果反归一化,得到拟合数据trainoutput=mapminmax('reverse'normtrainoutputts);validateoutput=mapminmax('reverse'normvalidateoutputts);testoutput=mapminmax('reverse'normtestoutputts);%输入数据反归一化,得到正式值trainvalue=mapminmax('reverse'trainsample.tts);%正式的训练数据validatevalue=mapminmax('reverse'valsample.tts);%正式的验证数据testvalue=mapminmax('reverse'testsample.tts);%正式的测试数据%输入要预测的数据pnewpnew=[313256239]';pnewn=mapminmax(pnew);anewn=sim(netpnewn);anew=mapminmax('reverse'anewnts);%绝对误差的计算errors=trainvalue-trainoutput;%plotregression拟合图figureplotregression(trainvaluetrainoutput)%误差变化图figureplot(1:length(errors)errors'-b')title('误差变化图')%误差值的正态性的检验figurehist(errors);%频数直方图figurenormplot(errors);%Q-Q图[muhatsigmahatmucisigmaci]=normfit(errors);%参数估计均值方差均值的0.95置信区间方差的0.95置信区间[h1sigci]= ttest(errorsmuhat);%假设检验figure ploterrcorr(errors);%绘制误差的自相关图figure parcorr(errors);%绘制偏相关图。
BP算法程序实现

BP算法程序实现BP算法(Back Propagation Algorithm,即反向传播算法)是一种用于训练神经网络的常用算法。
它的基本思想是通过不断地调整神经元之间的连接权值,使得网络的输出接近于期望的输出。
在实现BP算法时,需要进行以下几个步骤:1.初始化参数:首先,需要初始化神经网络的权值和偏置,通常可以使用随机的小数来初始化。
同时,需要设置好网络的学习率和最大迭代次数。
2.前向传播:通过前向传播过程,将输入数据输入到神经网络中,并计算出每个神经元的输出。
具体来说,对于第一层的神经元,它们的输出即为输入数据。
对于后续的层,可以使用如下公式计算输出:a[i] = sigmoid(z[i])其中,a[i]表示第i层的输出,z[i]为第i层的输入加权和,sigmoid为激活函数。
3.计算误差:根据网络的输出和期望的输出,可以计算出网络的误差。
一般来说,可以使用均方差作为误差的度量指标。
loss = 1/(2 * n) * Σ(y - a)^2其中,n为训练样本的数量,y为期望输出,a为网络的实际输出。
4.反向传播:通过反向传播算法,将误差从输出层向输入层逐层传播,更新权值和偏置。
具体来说,需要计算每一层神经元的误差,并使用如下公式更新权值和偏置:delta[i] = delta[i+1] * W[i+1]' * sigmoid_derivative(z[i])W[i] = W[i] + learning_rate * delta[i] * a[i-1]'b[i] = b[i] + learning_rate * delta[i]其中,delta[i]为第i层的误差,W[i]为第i层与i+1层之间的权值,b[i]为第i层的偏置,learning_rate为学习率,sigmoid_derivative为sigmoid函数的导数。
5.迭代更新:根据步骤4中的更新公式,不断迭代调整权值和偏置,直到达到最大迭代次数或误差小于一些阈值。
(完整版)bp神经网络算法
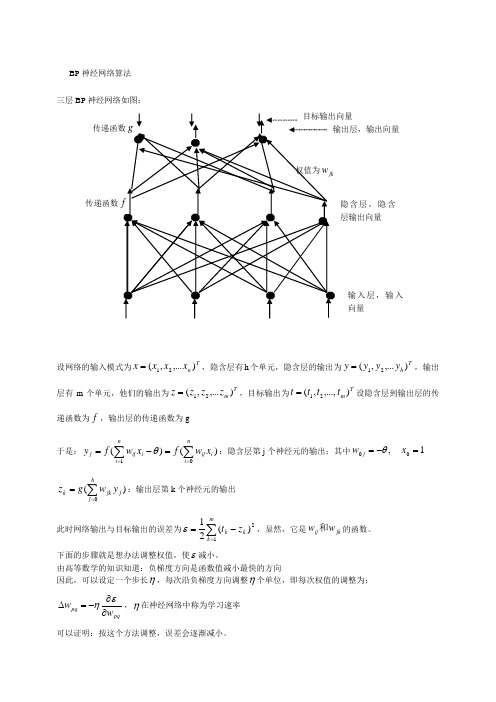
BP 神经网络算法 三层BP 神经网络如图:设网络的输入模式为Tn x x x x ),...,(21=,隐含层有h 个单元,隐含层的输出为Th y y y y ),...,(21=,输出层有m 个单元,他们的输出为Tm z z z z ),...,(21=,目标输出为Tm t t t t ),...,,(21=设隐含层到输出层的传递函数为f ,输出层的传递函数为g于是:)()(1∑∑===-=ni i ij ni iij j x w f xw f y θ:隐含层第j 个神经元的输出;其中1,00=-=x w j θ)(0∑==hj j jk k y w g z :输出层第k 个神经元的输出此时网络输出与目标输出的误差为∑=-=m k k k z t 12)(21ε,显然,它是jk ij w w 和的函数。
下面的步骤就是想办法调整权值,使ε减小。
由高等数学的知识知道:负梯度方向是函数值减小最快的方向因此,可以设定一个步长η,每次沿负梯度方向调整η个单位,即每次权值的调整为:pqpq w w ∂∂-=∆εη,η在神经网络中称为学习速率 可以证明:按这个方法调整,误差会逐渐减小。
隐含层,隐含层输出向量传递函数输入层,输入向量BP 神经网络(反向传播)的调整顺序为: 1)先调整隐含层到输出层的权值 设k v 为输出层第k 个神经元的输入∑==hj j jkk y wv 0-------复合函数偏导公式若取x e x f x g -+==11)()(,则)1()111(11)1()('2k k v v v v k z z ee e e u g kk k k -=+-+=+=---- 于是隐含层到输出层的权值调整迭代公式为: 2)从输入层到隐含层的权值调整迭代公式为: 其中j u 为隐含层第j 个神经元的输入:∑==ni i ijj x wu 0注意:隐含层第j 个神经元与输出层的各个神经元都有连接,即jy ∂∂ε涉及所有的权值ij w ,因此∑∑==--=∂∂∂∂∂-∂=∂∂m k jk k k k j k k k m k k k k j w u f z t y u u z z z t y 002)(')()(ε于是:因此从输入层到隐含层的权值调整迭代为公式为: 例:下表给出了某地区公路运力的历史统计数据,请建立相应的预测模型,并对给出的2010和2011年的数据,预测相应的公路客运量和货运量。
BP神经网络算法代码

BP神经网络算法代码以下是一个简单实现的BP神经网络算法代码,实现了一个简单的二分类任务。
代码主要分为四个部分:数据准备、网络搭建、训练和预测。
```pythonimport numpy as np#数据准备def prepare_data(:X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]]) # 输入数据return X, y#网络搭建def build_network(X, y, hidden_dim):input_dim = X.shape[1] # 输入维度output_dim = y.shape[1] # 输出维度#初始化权重和偏置np.random.seed(0)W1 = np.random.randn(input_dim, hidden_dim) /np.sqrt(input_dim)b1 = np.zeros((1, hidden_dim))W2 = np.random.randn(hidden_dim, output_dim) / np.sqrt(hidden_dim)b2 = np.zeros((1, output_dim))return W1, b1, W2, b2#前向传播def forward_propagation(X, W1, b1, W2, b2):z1 = np.dot(X, W1) + b1a1 = sigmoid(z1)z2 = np.dot(a1, W2) + b2a2 = sigmoid(z2)return a1, a2#激活函数def sigmoid(x):return 1 / (1 + np.exp(-x))#反向传播def backward_propagation(X, y, a1, a2, W1, W2): m = X.shape[0] # 样本数量#计算损失loss = np.sum((a2-y)**2) / (2*m)#计算梯度delta2 = 1/m * (a2-y) * a2 * (1-a2)dW2 = np.dot(a1.T, delta2)db2 = np.sum(delta2, axis=0, keepdims=True)delta1 = np.dot(delta2, W2.T) * a1 * (1-a1)dW1 = np.dot(X.T, delta1)db1 = np.sum(delta1, axis=0)return loss, dW1, db1, dW2, db2#更新参数def update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate):W1 -= learning_rate * dW1b1 -= learning_rate * db1W2 -= learning_rate * dW2b2 -= learning_rate * db2return W1, b1, W2, b2#训练def train(X, y, hidden_dim, num_epochs, learning_rate):W1, b1, W2, b2 = build_network(X, y, hidden_dim)for epoch in range(num_epochs):a1, a2 = forward_propagation(X, W1, b1, W2, b2)loss, dW1, db1, dW2, db2 = backward_propagation(X, y, a1, a2, W1, W2)W1, b1, W2, b2 = update_parameters(W1, b1, W2, b2, dW1, db1, dW2, db2, learning_rate)if (epoch+1) % 100 == 0:print("Epoch {}: loss = {}".format(epoch+1, loss))return W1, b1, W2, b2#预测def predict(X, W1, b1, W2, b2):_, a2 = forward_propagation(X, W1, b1, W2, b2)predictions = (a2 > 0.5).astype(int)return predictions#主函数def main(:X, y = prepare_datahidden_dim = 3num_epochs = 1000learning_rate = 0.1W1, b1, W2, b2 = train(X, y, hidden_dim, num_epochs, learning_rate)predictions = predict(X, W1, b1, W2, b2)print("Predictions:", predictions)if __name__ == "__main__":main```注意:这段代码只是一个简单的实现,可能在复杂任务上效果不佳。
编程实现标准bp算法和累积bp算法

编程实现标准BP算法和累积BP算法1. 介绍在机器学习和神经网络中,BP算法是一种常用的反向传播算法,用于训练神经网络。
标准BP算法是最基本的反向传播算法,而累积BP算法则是对标准BP算法的改进。
本文将介绍如何编程实现这两种算法,并比较它们之间的差异和优劣。
2. 标准BP算法标准BP算法是基于梯度下降的优化算法,用于调整神经网络中的权重和偏置,使得网络的输出与实际值之间的误差最小化。
其主要步骤包括前向传播和反向传播两个过程。
在前向传播过程中,输入数据经过各层神经元的计算,得到网络的输出;在反向传播过程中,根据输出误差,通过链式求导法则计算各层权重和偏置的梯度,并进行参数更新。
标准BP算法简单易懂,但容易陷入局部最优解,收敛速度慢。
3. 累积BP算法累积BP算法是对标准BP算法的改进,主要是通过累积历史梯度来更新参数,以加速收敛速度。
其主要思想是在计算梯度时,不仅考虑当前的梯度值,还考虑历史时刻的梯度值,通过对梯度进行累积,可以减小参数更新的方差,从而提高收敛速度。
累积BP算法相对于标准BP算法收敛速度更快,但在处理非凸函数时可能会出现震荡的现象。
4. 编程实现我们需要实现神经网络的前向传播和反向传播过程。
在前向传播过程中,根据输入数据和当前的权重和偏置,逐层计算神经元的输出;在反向传播过程中,根据输出误差,计算各层权重和偏置的梯度,并更新参数。
在标准BP算法中,参数更新公式为: [w^{(t+1)} = w^{(t)} - ]在累积BP算法中,参数更新公式为: [w^{(t+1)} = w^{(t)} - _{i=1}^{T} ]其中,(w^{(t)})为第t次迭代时的参数值,()为学习率,(E)为误差函数,(T)为累积的历史时刻个数。
5. 比较与总结标准BP算法和累积BP算法各有优劣。
标准BP算法简单易懂,但收敛速度较慢;累积BP算法收敛速度更快,但在处理非凸函数时可能会震荡。
在实际应用中,可以根据具体问题的特点选择合适的算法。
bp算法的设计与实现

bp算法的设计与实现一、BP算法的概述BP算法,全称为反向传播算法,是一种常用的人工神经网络学习算法。
其主要思想是通过不断地调整神经元之间的权重和阈值,使得网络输出与期望输出之间的误差最小化。
BP算法的核心在于误差反向传播,即将输出层的误差逐层向前传播至输入层,从而实现对权值和阈值的更新。
二、BP算法的设计1. 神经网络结构设计BP算法需要先确定神经网络的结构,包括输入层、隐藏层和输出层。
其中输入层负责接收外部输入数据,隐藏层通过变换将输入数据映射到高维空间中,并进行特征提取和抽象表示。
输出层则将隐藏层处理后的结果映射回原始空间中,并得出最终结果。
2. 激活函数设计激活函数用于计算神经元输出值,在BP算法中起到了非常重要的作用。
常见的激活函数有sigmoid函数、ReLU函数等。
其中sigmoid函数具有平滑性和可导性等优点,在训练过程中更加稳定。
3. 误差计算方法设计误差计算方法是决定BP算法效果好坏的关键因素之一。
常见的误差计算方法有均方误差法、交叉熵误差法等。
其中均方误差法是最常用的一种方法,其计算公式为:E = 1/2*(y - t)^2,其中y为网络输出值,t为期望输出值。
4. 权重和阈值调整方法设计权重和阈值调整方法是BP算法的核心所在。
常见的调整方法有梯度下降法、动量法、RMSprop等。
其中梯度下降法是最基础的一种方法,其核心思想是通过不断地迭代来更新权重和阈值。
三、BP算法的实现1. 数据预处理在使用BP算法进行训练前,需要对输入数据进行预处理。
常见的预处理方式包括归一化、标准化等。
2. 神经网络初始化神经网络初始化需要设置初始权重和阈值,并将其赋给神经元。
初始权重和阈值可以随机生成或者根据经验设置。
3. 前向传播前向传播过程中,输入数据从输入层开始逐层传递至输出层,并通过激活函数计算出每个神经元的输出值。
4. 反向传播反向传播过程中,先计算出输出层误差,并逐层向前传播至输入层。
人工智能实验报告-BP神经网络算法的简单实现

⼈⼯智能实验报告-BP神经⽹络算法的简单实现⼈⼯神经⽹络是⼀种模仿⼈脑结构及其功能的信息处理系统,能提⾼⼈们对信息处理的智能化⽔平。
它是⼀门新兴的边缘和交叉学科,它在理论、模型、算法等⽅⾯⽐起以前有了较⼤的发展,但⾄今⽆根本性的突破,还有很多空⽩点需要努⼒探索和研究。
1⼈⼯神经⽹络研究背景神经⽹络的研究包括神经⽹络基本理论、⽹络学习算法、⽹络模型以及⽹络应⽤等⽅⾯。
其中⽐较热门的⼀个课题就是神经⽹络学习算法的研究。
近年来⼰研究出许多与神经⽹络模型相对应的神经⽹络学习算法,这些算法⼤致可以分为三类:有监督学习、⽆监督学习和增强学习。
在理论上和实际应⽤中都⽐较成熟的算法有以下三种:(1) 误差反向传播算法(Back Propagation,简称BP 算法);(2) 模拟退⽕算法;(3) 竞争学习算法。
⽬前为⽌,在训练多层前向神经⽹络的算法中,BP 算法是最有影响的算法之⼀。
但这种算法存在不少缺点,诸如收敛速度⽐较慢,或者只求得了局部极⼩点等等。
因此,近年来,国外许多专家对⽹络算法进⾏深⼊研究,提出了许多改进的⽅法。
主要有:(1) 增加动量法:在⽹络权值的调整公式中增加⼀动量项,该动量项对某⼀时刻的调整起阻尼作⽤。
它可以在误差曲⾯出现骤然起伏时,减⼩振荡的趋势,提⾼⽹络训练速度;(2) ⾃适应调节学习率:在训练中⾃适应地改变学习率,使其该⼤时增⼤,该⼩时减⼩。
使⽤动态学习率,从⽽加快算法的收敛速度;(3) 引⼊陡度因⼦:为了提⾼BP 算法的收敛速度,在权值调整进⼊误差曲⾯的平坦区时,引⼊陡度因⼦,设法压缩神经元的净输⼊,使权值调整脱离平坦区。
此外,很多国内的学者也做了不少有关⽹络算法改进⽅⾯的研究,并把改进的算法运⽤到实际中,取得了⼀定的成果:(1) 王晓敏等提出了⼀种基于改进的差分进化算法,利⽤差分进化算法的全局寻优能⼒,能够快速地得到BP 神经⽹络的权值,提⾼算法的速度;(2) 董国君等提出了⼀种基于随机退⽕机制的竞争层神经⽹络学习算法,该算法将竞争层神经⽹络的串⾏迭代模式改为随机优化模式,通过采⽤退⽕技术避免⽹络收敛到能量函数的局部极⼩点,从⽽得到全局最优值;(3) 赵青提出⼀种分层遗传算法与BP 算法相结合的前馈神经⽹络学习算法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
BP神经网络算法java实现package backp;import java.*;import java.awt.*;import java.io.*;import java.util.Scanner;//by realmagicianimport org.omg.CORBA.portable.InputStream;public class backpro {public static void main(String args[]){String filename=new String("delta.in");try {FileInputStream fileInputStream=new FileInputStream(filename);Scanner sinScanner=new Scanner(fileInputStream);int attN,hidN,outN,samN;attN=sinScanner.nextInt();outN=sinScanner.nextInt();hidN=sinScanner.nextInt();samN=sinScanner.nextInt();//System.out.println(attN+" "+outN+" "+hidN+" "+samN);double samin[][]=new double[samN][attN];double samout[][]=new double[samN][outN];for(int i=0;i<samN;++i){for(int j=0;j<attN;++j){samin[i][j]=sinScanner.nextDouble();}for(int j=0;j<outN;++j){samout[i][j]=sinScanner.nextDouble();}}int times=10000;double rate=0.5;BP2 bp2=new BP2(attN,outN,hidN,samN,times,rate);bp2.train(samin, samout);for(int i=0;i<hidN;++i){for(int j=0;j<attN;++j)System.out.print(bp2.dw1[i][j]+" ");System.out.println();}for(int i=0;i<outN;++i){for(int j=0;j<hidN;++j)System.out.print(bp2.dw2[i][j]+" ");System.out.println();}while(true){double testout[]=new double[outN];double testin[]=new double[attN];Scanner testinScanner=new Scanner(System.in);for(int i=0;i<attN;++i){testin[i]=testinScanner.nextDouble();}testout=bp2.getResault(testin);for(int i=0;i<outN;++i)System.out.print(testout[i]+" ");System.out.println(outN);}} catch (IOException e) {// TODO: handle exception}System.out.println("End");}}class BP2//包含一个隐含层的神经网络{double dw1[][],dw2[][];int hidN;//隐含层单元个数int samN;//学习样例个数int attN;//输入单元个数int outN;//输出单元个数int times;//迭代次数double rate;//学习速率boolean trained=false;//保证在得结果前,先训练BP2(int attN,int outN,int hidN,int samN,int times,double rate) {this.attN=attN;this.outN=outN;this.hidN=hidN;this.samN=samN;dw1=new double[hidN][attN+1];//每行最后一个是阈值w0for(int i=0;i<hidN;++i)//每行代表所有输入到i隐藏单元的权值{for(int j=0;j<=attN;++j)dw1[i][j]=Math.random()/2;}dw2=new double[outN][hidN+1];//输出层权值,每行最后一个是阈值w0 for(int i=0;i<outN;++i)//每行代表所有隐藏单元到i输出单元的权值{for(int j=0;j<=hidN;++j)dw2[i][j]=Math.random()/2;}this.times=times;this.rate=rate;}public void train(double samin[][],double samout[][]){double dis=0;//总体误差int count=times;double temphid[]=new double[hidN];double tempout[]=new double[outN];double wcout[]=new double[outN];double wchid[]=new double[hidN];while((count--)>0)//迭代训练{dis=0;for(int i=0;i<samN;++i)//遍历每个样例samin[i]{for(int j=0;j<hidN;++j)//计算每个隐含层单元的结果{temphid[j]=0;for(int k=0;k<attN;++k)temphid[j]+=dw1[j][k]*samin[i][k];temphid[j]+=dw1[j][attN];//计算阈值产生的隐含层结果temphid[j]=1.0/(1+Math.exp(-temphid[j] ));}for(int j=0;j<outN;++j)//计算每个输出层单元的结果{tempout[j]=0;for(int k=0;k<hidN;++k)tempout[j]+=dw2[j][k]*temphid[k];tempout[j]+=dw2[j][hidN];//计算阈值产生的输出结果tempout[j]=1.0/(1+Math.exp( -tempout[j] ));}//计算每个输出单元的误差项for(int j=0;j<outN;++j){wcout[j]=tempout[j]*(1-tempout[j])*(samout[i][j]-tempout[j]);dis+=Math.pow((samout[i][j]-tempout[j]),2);}//计算每个隐藏单元的误差项for(int j=0;j<hidN;++j){double wche=0;for(int k=0;k<outN;++k)//计算输出项误差和{wche+=wcout[k]*dw2[k][j];}wchid[j]=temphid[j]*(1-temphid[j])*wche;}//改变输出层的权值for(int j=0;j<outN;++j){for(int k=0;k<hidN;++k){dw2[j][k]+=rate*wcout[j]*temphid[k];}dw2[j][hidN]=rate*wcout[j];}//改变隐含层的权值for(int j=0;j<hidN;++j){for(int k=0;k<attN;++k){dw1[j][k]+=rate*wchid[j]*samin[i][k];}dw1[j][attN]=rate*wchid[j];}}if(dis<0.003)break;}trained=true;}public double[] getResault(double samin[]){double temphid[]=new double[hidN];double tempout[]=new double[outN];if(trained==false)return null;for(int j=0;j<hidN;++j)//计算每个隐含层单元的结果{temphid[j]=0;for(int k=0;k<attN;++k)temphid[j]+=dw1[j][k]*samin[k];temphid[j]+=dw1[j][attN];//计算阈值产生的隐含层结果temphid[j]=1.0/(1+Math.exp(-temphid[j] ));}for(int j=0;j<outN;++j)//计算每个输出层单元的结果{tempout[j]=0;for(int k=0;k<hidN;++k)tempout[j]+=dw2[j][k]*temphid[k];tempout[j]+=dw2[j][hidN];//计算阈值产生的输出结果tempout[j]=1.0/(1+Math.exp( -tempout[j]));//System.out.print(tempout[j]+" ");}return tempout;}}。