一种单片机不完整字库的生成和使用方法
利用CRT及8051单片机实现汉字的显示输出

文章编号:10082312X (2001)0320039202利用CRT 及8051单片机实现汉字的显示输出刘文江,富文军(济南交通高等专科学校,山东济南 250023)摘要:设计出了一种以8051单片机为主处理器,以CRT 为显示终端的智能汉字处理系统。
对字库的建立、汉字点阵的寻址、汉字的显示输出及8051与CRT 适配卡的接口进行了较详细地介绍。
实际应用表明,本系统实现了最佳的资源配置,具有极高的性能价格比。
关 键 词:CRT;8051;汉显系统中图分类号:TP391.12文献标识码:B 计算机的汉字信息处理主要解决中文信息在计算机上的输入、输出、汉字点阵的存贮、识别及读取等问题。
利用系统机来处理汉字,速度快、效率高、功能齐全,应用起来十分方便。
已基本能满足各行各业对汉字处理的需要,受到人们的普遍欢迎。
但在某些需要简单处理汉字显示的场合,应用系统机不经济,造成资源的浪费。
并且在大部分以单片机为核心构成的监控系统中,往往要求具有汉字显示的功能,以方便人机对话。
所以如何利用单片机的有限资源,探索一种简捷的汉字信息处理方法,不但具有一定的理论意义,并且具有很大的实用价值。
文中介绍的汉字处理系统是一个完整的单片机应用系统,以8051为主机,汉字点阵固化在片外EPROM 中,并作为片外RAM 读取,用CRT 实现汉字的显示。
本系统实现了最佳的资源配置,具有极高的性能价格比。
1 汉字库的建立计算机内部任何信息都是以数据形式表示的。
在需要汉字的计算机系统中,汉字作为计算机要处理的信息当然也不能例外。
这种计算机系统必须有一个用于产生直接存贮汉字字型和各种符号信息的存贮系统,称为汉字字型发生器或叫汉字库。
汉字库是由一批汉字的字型码或字型压缩码按一定的次序排列而成的。
它为汉字输出设备如显示器和打印机提供汉字的字型数据。
考虑到单片机资源有限,本系统的汉字库的汉字字型信息采用16×16点阵码,字库中包括全部国标G B2312中规定的一级和二级汉字。
HZK16应用示例

在C51中,HZK16汉字库的使用(mydows's Blog转载)定义如下:unsigned char str[]="我"在运行时str被初始化为2个字节长度,内容为“我”的GBK码,为:0xCE(区码),0xD2(位码)。
使用如下换算公式得到“我”在HZK16文件中的地址,从该位置开始的顺序32字节为“我”的字模。
ADD=【(区码-0xa1)×0x5e + (位码-0xa1)】×0x20按照上面的计算方法,“我”的字模地址:0x216E0 。
他的C语言字模为:0x04, 0x80,0x0E,0xA0,0x78,0x90,0x08,0x90,0x08,0x84,0xFF,0xFE,0x08,0x80,0x08,0x90,0x0A,0x90,0x0C,0x60,0x18,0x40,0x68,0xA0,0x09,0x20,0x0A,0x14,0x28,0x14,0x10,0x0CHZK16字库是符合GB2312标准的16×16点阵字库,HZK16的GB2312-80支持的汉字有6763个,符号682个。
其中一级汉字有3755个,按声序排列,二级汉字有3008个,按偏旁部首排列。
我们在一些应用场合根本用不到这么多汉字字模,所以在应用时就可以只提取部分字体作为己用。
HZK16字库里的16×16汉字一共需要256个点来显示,也就是说需要32个字节才能达到显示一个普通汉字的目的。
我们知道一个GB2312汉字是由两个字节编码的,范围为A1A1~FEFE。
A1-A9为符号区,B0到F7为汉字区。
每一个区有94个字符(注意:这只是编码的许可范围,不一定都有字型对应,比如符号区就有很多编码空白区域)。
下面以汉字“我”为例,介绍如何在HZK16文件中找到它对应的32个字节的字模数据。
前面说到一个汉字占两个字节,这两个中前一个字节为该汉字的区号,后一个字节为该字的位号。
菜鸟学习51单片机之12864液晶(无字库)

/* 选择屏幕来清屏 */
菜鸟学习 51 单片机
while(1)世界
void Lcd12864Clear(uint8 selet)
{
uint8 i,j;
Lcd12864SeletScreen(selet); //选择屏,分左屏和又屏,这个函数在程序中有
for(i = 0;i < 8 ;i++)
二.写入地址
void Lcd12864Point(uint8 page,uint8 x,uint8 y)
{
Lcd12864Write(CMD,0xb8 + page);
//确定页
Lcd12864Write(CMD,0xC0 + x);
//设定起始行
Lcd12864Write(CMD,0x40 + y);
菜鸟学习 51 单片机
while(1)世界
现在开始讲解如何使用,看这篇讲解前,请先到网盘去下载本教 程的仿真图和程序,结合起来更容易明白。
上图是仿真的结果。 在仿真软件中找出的 12864 液晶是没有字库的,对于仿真软件中 液晶的控制和平常的有点不同。一块液晶是由两块 64×64 的液晶显 示模块组合而成。下面是各管脚的介绍。
//有 8 页,循环 8 次
{
Lcd12864Point(i,0,0); //这个就是上面讲到的函数,确定位置
for(j = 0 ;j < 64;j++) //每一块液晶显示模块有 64 列
{
Lcd12864Write(DAT,0x00); //写入 0x00 来清屏
}
}
}
具体的使用如下:初始化函数中调用了清全屏 Lcd12864Clear(3); //清全屏
基于单片机的硬件字库设计

基于单片机的硬件字库设计作者:汤美玲陕西理工学院(物电学院)电子信息科学与技术专业2008级陕西汉中723000指导教师:刘东摘要:随着液晶显示技术的发展和应用,越来越多的开发人员希望在自己开发的仪器设备中使用液晶屏幕来显示汉字,通常的汉字显示方式是先根据所需要的汉字提取汉字点阵如16x16 点阵,将点阵文件存入ROM 形成新的汉字编码,而在使用时则需要先根据新的汉字编码组成语句再由MCU 根据新编码提取相应的点阵进行汉字显示,在这种显示方式中如果使用的汉字数量较大或语句较多时,利用汉字的新编码组成语句将是一件繁琐而枯燥的工作。
如果有新的汉字加入那么汉字库的维护也成问题,而我们日常生活的一些手持工具上如手机快译通等等它们可以任意输入汉字不仅灵活性大而且检索速度快,这其中的主要原因就是在这些设备中固化了硬件汉字库。
本设计就是通过keil软件编写c语言程序并生成HEX文件联合proteus电路设计仿真软件制作一个简单的硬件字库系统。
关键词:c语言, 单片机,硬件,字库一.任务设计并制作一个基于单片机的硬件字库系统.二.要求1.基本要求1.1可显示任何汉字字符.1.2可实现花样显示.2.发挥部分2.1不需要使用专门的字模软件提取固定汉字字模.2.2可人性化设置.三.说明3.1时间要求:11月12日到11月24日.3.2完成实际电路,总结报告.3.3本例将262KB的16x16点阵中文字库文件HZK16拆分为两个128KB文件,分别保存到两片24C1024中,多余6KB被删除,运行时,对于任意输入的汉字或中文标题符号,程序会直接从24C1024所保存的字库中提取点阵并转换为液晶格式,在12864液晶屏上显示。
四.硬件字库系统设计的基本原理及分析本系统在两块24C1024芯片中内置了16x16点阵汉字库文件HZK16,该文件共262KB (两块芯片各保存128KB ),多余的部分被删除。
本例运行时,程序根据汉字内码得到区位码,再根据区位码从硬件字库中提取汉字点阵,所提取的字库点阵进一步转换为本例液晶屏汉字显示所需要的格式后即可显示在液晶屏上。
Proteus中基于AT24C512的汉字库加载技术及显示仿真

Proteus中基于AT24C512的汉字库加载技术及显示仿真李建波【摘要】以往Proteus中利用LCD显示汉字,需要先用汉字取模软件取模、然后拷贝汉字点阵数据到程序,步骤繁琐,而且只能显示预备好的汉字,十分不方便.为解决这一问题,将汉字库HZK16以64 kB大小划分成4个区间,并分别加载到Proteus 的4个AT24C512存储器中,设计了数据读取电路,利用Proteus中的PG160128液晶模块实现了汉字显示.实验结果表明,采用AT24C512存储汉字库文件的方式可以方便地显示汉字,打破了只能显示固定汉字的模式,提高了开发效率.【期刊名称】《液晶与显示》【年(卷),期】2010(025)003【总页数】5页(P391-395)【关键词】Proteus;汉字库;加载技术;PG160液晶【作者】李建波【作者单位】华南理工大学,聚合物新型成型装备国家工程研究中心,广东,广州,510640;广东机电职业技术学院,计算机系,广东,广州,510515【正文语种】中文【中图分类】TP368.1;TN873.93Proteus是由英国Labcenter Electronics公司开发的EDA工具软件,可以仿真几十种单片机。
在Proteus软件中,可以将目标文件加载到单片机芯片,点击Play即可实现单片机仿真。
软件和硬件的结合,就是一个完整的单片机应用系统,能够进行单片机仿真,观察实践效果,对单片机开发和教学起到了极大的推动作用[1-4]。
利用Proteus对LCD的开发,可以缩短开发周期,节约开发成本。
但是,现在在汉字显示方面的开发力度尚嫌不足,尤其是汉字点阵获取方面。
开发者大多利用“汉字取模工具”,输入汉字,得到点阵数据,然后复制到编写的程序中[5-9]。
采用这种方式,每个汉字需要32个字节,如果显示汉字多的话数据将会非常庞大。
而且,这种方式只能显示固定汉字,如果需要显示其他汉字还要重新取模,非常不方便。
字库制作详细教程(精)

字库制作详细教程很多时候,我们会用到字库,平时用到字库一般是把用到的汉字用取模软件按照自己的取模方式得到汉字的编码数组,然后把这些编码放在单片机的Flash里,用时调用出来显示。
但是如果我们要用到很多的汉字时,这种方法就不可取了,占用太多的Flash空间,然后我们会想到把字库放在SD卡或者是U盘里,用到时再从存储介质里读出来,这样,我们就可以显示很多汉字。
下面是字库的制作方法,首先感谢一个人,就是本坛的章其波大虾,其实就是他的一个贴子里的方法,只是他那个太专业了,一般的人看得不是很懂,所以我把它整理成了这个图文并茂的,方便各大网友,也是方便自己查看。
1、首先,好比起房子,得有源材料,用到以下3个文件:(1 取点阵Mold.exe(2 ziku.txt(3 ziku.exe取点阵Mold.exe是“牧马字模0.84测试版”取模软件ziku.txt是按顺序写有8178个汉字和字符的txt文档ziku.exe是一个小程序,配合“牧马字模0.84测试版”生成bin文件2、打开“牧马字模0.84测试版”取模软件,其界面如下所示:3、在工具栏处点“打开”按钮,打开ziku.txt文件,然后根据自己的需要,设置想要的取模方式,然后点工具栏上的“输出”按钮并等待其完成,完成后会在取模软件所在路径生成了一个temp.txt文件,修改这个文件名,比如现在我是按照“宋体、点阵数为16、字重为4、取模为为16*16、对齐设置为左上、方向设置为横向取模,高位在左”的方式来取的字模,也就是我平时TFT常用的一种字模,改文件名为st16x16.txt 。
4、为了生成的方便,我们在D盘根目录下新建一个文件夹,名称就叫ziku吧,然后,把ziku.exe 和st16x16.txt复制一份到这个文件夹里。
5、打开命令窗口:“开始”->“运行”->“cmd”,如下图所示:然后用cd命令进入到我们刚刚建的ziku文件夹下,输入命令如下图所示:6、输入命令,生成字库文件,输入命令如下图所示:为什么输入这样的命令,如果大家对main函数参数argc和argv有所了解的话,即int main(int argc, char* argv[] 这一主函数,这是很容易理解的,第一个参数是命令行输入参数的个数,第二个参数则存储了所有的命令行参数,前面我们已经用cd命令进入到了ziku文件夹下,接着我们输入了两个参数:ziku.exe st16x16.txt则,argc的值是2,argv[0]是" ziku.exe ",argv[1]是" st16x16.txt "。
基于单片机控制的LED汉字显示.doc

分类号 TP 单位代码 11395 密级公开学号 0605230学生毕业设计(论文)题目LED汉字显示作者院 (系) 能源工程学院专业电气工程及自动化指导教师答辩日期2010年月日毕业设计(论文)诚信责任书本人郑重声明:所呈交的毕业设计(论文),是本人在导师的指导下独立进行研究所取得的成果。
毕业设计(论文)中凡引用他人已经发表或未发表的成果、数据、观点等,均已明确注明出处。
尽我所知,除文中已经注明引用的内容外,本论文不包含任何其他个人或集体已经公开发表或撰写过的研究成果。
对本文的研究做出重要贡献的个人和集体,均已在文中以明确方式标明。
本人毕业设计(论文)与资料若有不实,愿意承担一切相关的法律责任。
论文作者签名:年月日LED汉字显示摘要目前,作为方便、快捷的信息显示方式,LED汉字显示的应用非常广泛。
车站、银行、超市等大型公共场所的即时信息及广告的显示,无不应用LED汉字显示屏。
在能源日渐危机以及信息日渐重要的今天,具有低耗能、频更新、易维护的LED汉字显示屏必将受到广泛的应用,其具有非常的发展前景。
本文从LED的发展及单片机的简单原理开始,深入的研究了基于AT89C51单片机16×16 LED汉字滚动显示屏的设计并运用Proteus软件的仿真和实现。
主要介绍了LED汉字显示屏的硬件电路设计、汇编程序设计与调试、Proteus 软件仿真和实物制作等方面的内容,本显示屏的设计具有体积小、硬件少、电路结构简单及容易实现等优点。
能帮助广大电子爱好者了解汉字的点阵显示原理,认识单片机的基本结构、工作原理及应用方法,并提高单片机知识技术的运用能力。
关键词:单片机 LED 点阵 Proteus仿真ABSTRACTNow, as a convenient, quick, LED display mode of information that is very extensive application. Station, bank, supermarket and large public places of instant messaging and advertisement of the application of Chinese characters, LED display screen. In the energy crisis and information increasingly more important today, with low energy consumption, easy maintenance and update frequency of the Chinese character screen will be LED by the widespread application, it has very development prospects.In this paper, based on AT89C51 microcontroller 16 × 16LED scrolling display character design and the use of software in the simulation and realization of Proteus. Introduces the character LED display hardware design, assembly programming and debugging, Proteus software simulation and other aspects of physical production, the design of the screen is small, less hardware, the circuit structure is simple and easy to implement. Can help the fans understand the character of the lattice electronic display principle, understanding the basic structure of SCM, working principle and application of methods and technologies to improve knowledge and ability to use single chip.Keywords:microcontroller, LED dot matrix ,Proteus simulation.LED汉字显示目录摘要 (1)ABSTRACT (2)目录 (2)1 引言 (1)1.1 LED汉字显示研究背景及意义 (2)1.2本设计的研究内容及方法 (2)1.3 本设计的主要工作 (3)2 硬件电路组成及工作原理 (4)2.1 硬件电路组成 (4)2.1.1 A T89C51简介 .......................................................................................... (4)2.1.2 时钟电路设计 (7)2.1.3复位电路设计 (15)2.1.4 16×16LED点阵屏 (9)2.2 元器件选择 (10)2.3 硬件电路工作原理 (19)3 LED汉字显示原理及字库代码获取方法 (20)3.1 汉字的点阵显示原理 (20)3.2 字库代码获取方法 (20)3.3 LED屏的显示 (22)4 程序设计 (25)4.1 主程序 (25)4.2 显示子程序、延时子程序 (25)4.3 程序编译、仿真 (19)5 基于PROTEUS的电路仿真 (30)5.1用PROTEUS 绘制原理图 (30)5.2 PROTEUS 对单片机内核的仿真 (31)6 结束语 (33)参考文献 (35)致谢 (37)1 引 言1.1 LED 汉字显示研究背景及意义受到体育场馆用LED 显示屏需求快速增长的带动,近年来,中国 LED 显示屏应用逐步增多。
利用STC89C52单片机控制LCD1602

//液晶显示中文-版本0.0//作者:pcdian//定义液晶的一些功能位//RS 为数据、指令寄存器选择位//RW 为读写选择位//E 为使能位RS BIT p2.5RW BIT P2.6E BIT P2.7ORG 0000HSJMP STARTORG 000BHLJMP Timer_ITORG 0030HSTART:MOV SP,#60HMOV TMOD,#01HMOV TH0,#0A6HMOV TL0,#00HSETB EASETB ET0CLR TR0MAIN:MOV P0,#01H //清屏ACALL ENABLEMOV P0,#38H //显示模式设置为16字*2行ACALL ENABLEMOV P0,#0CH //不显示光标ACALL ENABLEMOV P0,#06H //显示方向正向且屏不移动ACALL ENABLEDISPLAY:ACALL DISPLAY_C0//我MOV P0,#80HACALL ENABLEMOV P0,#00HACALL WRITEMOV P0,#81HACALL ENABLEMOV P0,#01HACALL WRITEMOV P0,#82HACALL ENABLEMOV P0,#02HACALL WRITEMOV P0,#0C0HACALL ENABLEMOV P0,#03HACALL WRITEMOV P0,#0C1HACALL ENABLEMOV P0,#04HACALL WRITEMOV P0,#0C2HACALL ENABLEMOV P0,#05HACALL WRITELCALL DELAY1SMOV P0,#01HACALL ENABLEACALL DISPLAY_C1//们MOV P0,#83HACALL ENABLEMOV P0,#00HACALL WRITEMOV P0,#84HACALL ENABLEMOV P0,#01HACALL WRITEMOV P0,#85HACALL ENABLEMOV P0,#02HACALL WRITEMOV P0,#0C3HACALL ENABLEMOV P0,#03HACALL WRITEMOV P0,#0C4HACALL ENABLEACALL WRITEMOV P0,#0C5HACALL ENABLEMOV P0,#05HACALL WRITELCALL DELAY1SMOV P0,#01HACALL ENABLEACALL DISPLAY_C2//的MOV P0,#86HACALL ENABLEMOV P0,#00HACALL WRITEMOV P0,#87HACALL ENABLEMOV P0,#01HACALL WRITEMOV P0,#88HACALL ENABLEMOV P0,#02HACALL WRITEMOV P0,#0C6HACALL ENABLEMOV P0,#03HACALL WRITEACALL ENABLEMOV P0,#04HACALL WRITEMOV P0,#0C8HACALL ENABLEMOV P0,#05HACALL WRITELCALL DELAY1SMOV P0,#01HACALL ENABLEACALL DISPLAY_C3//0MOV P0,#89HACALL ENABLEMOV P0,#00HACALL WRITEMOV P0,#8AHACALL ENABLEMOV P0,#01HACALL WRITEMOV P0,#0C9HACALL ENABLEMOV P0,#02HACALL WRITEMOV P0,#0CAHACALL ENABLEMOV P0,#03HLCALL DELAY1SMOV P0,#01HACALL ENABLEACALL DISPLAY_C4//7MOV P0,#8BHACALL ENABLEMOV P0,#00HACALL WRITEMOV P0,#8CHACALL ENABLEMOV P0,#01HACALL WRITEMOV P0,#0CBHACALL ENABLEMOV P0,#02HACALL WRITEMOV P0,#0CCHACALL ENABLEMOV P0,#03HACALL WRITE//3MOV P0,#8DHACALL ENABLEMOV P0,#04HACALL WRITEMOV P0,#8EHACALL ENABLEMOV P0,#05HACALL WRITEMOV P0,#0CDHACALL ENABLEMOV P0,#06HACALL WRITEMOV P0,#0CEHACALL ENABLEMOV P0,#07HACALL WRITELCALL DELAY1SMOV P0,#01HACALL ENABLELJMP DISPLAY DISPLAY_C0:MOV DPTR,#TAB0MOV R2,#48ACALL DISPLAY_CRET DISPLAY_C1:MOV DPTR,#TAB1MOV R2,#48ACALL DISPLAY_CRET DISPLAY_C2:MOV DPTR,#TAB2MOV R2,#48ACALL DISPLAY_CRET DISPLAY_C3:MOV DPTR,#TAB3MOV R2,#32ACALL DISPLAY_CRET DISPLAY_C4:MOV DPTR,#TAB4MOV R2,#64ACALL DISPLAY_CRETDISPLAY_C:MOV P0,#40HACALL ENABLEMOV R3,#0DISPLAY_CC:MOV A,R3MOVC A,@A+DPTRMOV P0,ALCALL WRITEINC R3DJNZ R2,DISPLAY_CCRETENABLE:CLR RSCLR RWCLR EACALL DELAYSETB ERETWRITE:SETB RSCLR RWCLR EACALL DELAYSETB ERETDELAY1S:SETB TR0CJNE R0,#20,DELAY1SCLR TR0MOV R0,#0RETDELAY:MOV R5,#08HL1:MOV R4,#0FAHL0:DJNZ R4,L0DJNZ R5,L1RETTimer_IT:MOV TH0,#0A6HMOV TL0,#00HINC R0RETITAB0: //我DB 0x00,0x07,0x01,0x01,0x01,0x1F,0x01,0x01 DB 0x19,0x01,0x01,0x01,0x01,0x1F,0x01,0x01 DB 0x00,0x08,0x04,0x04,0x00,0x1F,0x00,0x04 DB 0x01,0x07,0x19,0x01,0x01,0x01,0x05,0x02 DB 0x18,0x00,0x00,0x01,0x06,0x00,0x00,0x00 DB 0x14,0x18,0x10,0x08,0x09,0x05,0x03,0x01TAB1: //们DB 0x01,0x01,0x02,0x02,0x06,0x04,0x0c,0x14 DB 0x08,0x04,0x06,0x04,0x10,0x10,0x10,0x10 DB 0x00,0x00,0x1e,0x02,0x02,0x02,0x02,0x02 DB 0x04,0x04,0x04,0x04,0x04,0x04,0x04,0x00 DB 0x10,0x10,0x10,0x10,0x10,0x10,0x10,0x00 DB 0x02,0x02,0x02,0x02,0x02,0x0a,0x04,0x00TAB2: //的DB 0x02,0x02,0x04,0x0f,0x08,0x08,0x08,0x0f DB 0x02,0x02,0x02,0x13,0x14,0x14,0x18,0x12DB 0x00,0x00,0x00,0x1e,0x02,0x02,0x02,0x02DB 0x08,0x08,0x08,0x08,0x0f,0x08,0x08,0x00DB 0x11,0x11,0x10,0x10,0x10,0x10,0x00,0x00DB 0x02,0x12,0x12,0x02,0x02,0x14,0x08,0x00TAB3: //0DB 0x00,0x00,0x03,0x04,0x08,0x08,0x08,0x08DB 0x00,0x00,0x18,0x04,0x02,0x02,0x02,0X02DB 0x08,0x08,0x08,0x08,0x04,0x03,0x00,0x00DB 0x02,0x02,0x02,0x02,0x04,0x18,0x00,0x00TAB4: //7DB 0x00,0x00,0x0F,0x0F,0x00,0x00,0x00,0x00DB 0x00,0x00,0x1E,0x1E,0x06,0x06,0x06,0X06DB 0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00DB 0x06,0x06,0x06,0x06,0x06,0x06,0x00,0x00//3DB 0x00,0x00,0x0F,0x0F,0x00,0x00,0x00,0x0FDB 0x00,0x00,0x1E,0x1E,0x06,0x06,0x06,0X1EDB 0x0F,0x00,0x00,0x00,0x0F,0x0F,0x00,0x00DB 0x1E,0x06,0x06,0x06,0x1E,0x1E,0x00,0x00END四、总结:虽然LCD1602可以利用自建字符显示中文,但最多不能超过8个字符位。
字库制作详细教程
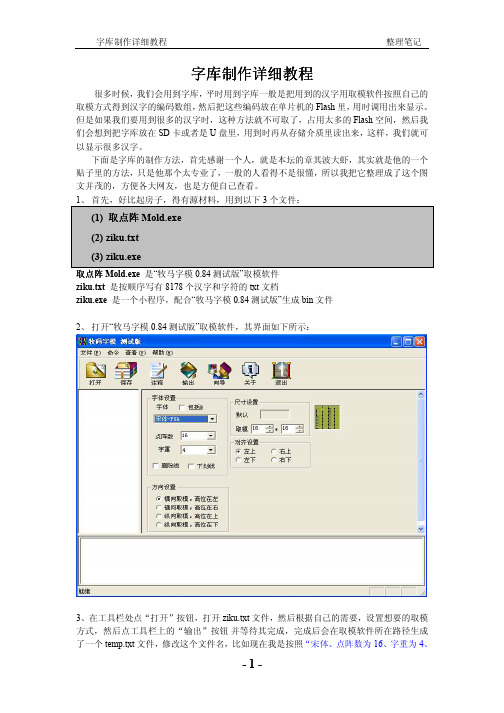
字库制作详细教程很多时候,我们会用到字库,平时用到字库一般是把用到的汉字用取模软件按照自己的取模方式得到汉字的编码数组,然后把这些编码放在单片机的Flash里,用时调用出来显示。
但是如果我们要用到很多的汉字时,这种方法就不可取了,占用太多的Flash空间,然后我们会想到把字库放在SD卡或者是U盘里,用到时再从存储介质里读出来,这样,我们就可以显示很多汉字。
下面是字库的制作方法,首先感谢一个人,就是本坛的章其波大虾,其实就是他的一个贴子里的方法,只是他那个太专业了,一般的人看得不是很懂,所以我把它整理成了这个图文并茂的,方便各大网友,也是方便自己查看。
1、首先,好比起房子,得有源材料,用到以下3个文件:(1) 取点阵Mold.exe(2) ziku.txt(3) ziku.exe取点阵Mold.exe是“牧马字模0.84测试版”取模软件ziku.txt是按顺序写有8178个汉字和字符的txt文档ziku.exe是一个小程序,配合“牧马字模0.84测试版”生成bin文件2、打开“牧马字模0.84测试版”取模软件,其界面如下所示:3、在工具栏处点“打开”按钮,打开ziku.txt文件,然后根据自己的需要,设置想要的取模方式,然后点工具栏上的“输出”按钮并等待其完成,完成后会在取模软件所在路径生成了一个temp.txt文件,修改这个文件名,比如现在我是按照“宋体、点阵数为16、字重为4、取模为为16*16、对齐设置为左上、方向设置为横向取模,高位在左”的方式来取的字模,也就是我平时TFT常用的一种字模,改文件名为st16x16.txt 。
4、为了生成的方便,我们在D盘根目录下新建一个文件夹,名称就叫ziku吧,然后,把ziku.exe 和st16x16.txt复制一份到这个文件夹里。
5、打开命令窗口:“开始”->“运行”->“cmd”,如下图所示:然后用cd命令进入到我们刚刚建的ziku文件夹下,输入命令如下图所示:6、输入命令,生成字库文件,输入命令如下图所示:为什么输入这样的命令,如果大家对main函数参数argc和argv有所了解的话,即int main(int argc, char* argv[]) 这一主函数,这是很容易理解的,第一个参数是命令行输入参数的个数,第二个参数则存储了所有的命令行参数,前面我们已经用cd命令进入到了ziku文件夹下,接着我们输入了两个参数:ziku.exe st16x16.txt则,argc的值是2,argv[0]是" ziku.exe ",argv[1]是" st16x16.txt "。
单片机系统中的汉字显示

单片机系统中的汉字显示摘要:需要显示的汉字较多时,单片机系统中的汉字编码非常繁琐。
本文介绍一种直接利用PC机的汉字内码作为单片机系统的汉字编码,以简化系统的设计。
关键词:单片机液晶显示器 29F040 汉字显示引言在现代工业控制和一些智能化仪器仪表中,越来越多的场所需要用点阵图形显示器显示汉字。
通常的汉字显示方式是先根据所需要的汉字提取汉字点阵(如16×16点阵),将点阵文件存入ROM,形成新的汉字编码;而在使用时刚需要先根据新的汉字编码组成语句,再由MCU根据新编码提取相应的点阵进行汉字显示。
在这种显示方式中,如果使用的流字数量较大或语句较多时,利用汉字的新编码组成语句将是一件十分繁琐而枯燥的工作。
针对这种情况,本文提出了一种十分简单的方式——直接利用PC机的汉字内码作为单片机系统的编码。
下面以8051单片机系统为例阐述如下:一、硬件组成本系统中采用香港精电公司的内置T6963控制器[1]的240128T点阵图形液晶显示器。
该显示器1行为240点,能容纳16×16点阵的汉字15个,总列数为128点,能显示8行汉字。
为了使用MCU操作可使用1片512KB的存储器(如本系统中的29F040)用来存储全部的国标16×16点阵汉辽、8×16的ASCII码点阵数据以及汉字语句编码数据。
为了降低成本和减小体积,对于速度要求不是很高的场合也可采用大容量的串行数据存储器,如AT45DB041B。
具体的硬件控制电路如图1所示(与汉字显示无关的电路略)。
由于29F040的容量为512KB,而5031微控制器只能管理64KB的数据间,所以可将29F040分成16页,每页32KB,占单片机系统数据空间的8000H~0FFFFH(剩余32KB为单片机系统的其他存储器和外设)。
页码由单片机的P1.0~P1.3选择。
液晶显示器的地址为7FF8H~7FF9H。
二、汉字显示原理及软件设计UCDOS软件中的文件HZK16和文件ASC16分别为16×16的国标汉字点阵文件和8×16的ASCII码点阵文件,以二进制格式存储。
建立单片机系统汉字库的一种通用方法

建立单片机系统汉字库的一种通用方法
寿建霞
【期刊名称】《微型电脑应用》
【年(卷),期】1999(015)002
【摘要】随着LCD显示器在单片机应用系统中的广泛使用,汉字显示越来越受欢迎,如何构造特定应用系统所需的汉字显示点阵字库,成为LCD汉字中首先必须解决的问题。
本文介绍一利用PC机中文操作系统的汉字库提取特定汉字显示点阵字库的实用方法,该方法具有很好的通用性,可为任何单片机应用系统建立所需的汉字显示点阵字库。
【总页数】3页(P60-62)
【作者】寿建霞
【作者单位】杭州电子工学院二分院
【正文语种】中文
【中图分类】TP391
【相关文献】
1.单片机应用系统专用汉字库的建立方法 [J], 原明亭;胡青
2.单片机系统中点阵汉字库的制作方法 [J], 陈爱萍;李朝健
3.单片机系统中标准汉字库的生成及应用 [J], 周军;蒋建军
4.在单片机系统中建立GBK汉字库 [J], 王晓宁
5.小型汉字库的一种建立方法 [J], 杨运峰
因版权原因,仅展示原文概要,查看原文内容请购买。
8039单片机P2.0—P2.3的使用方法

8039单片机P2.0—P2.3的使用方法
王攀峰
【期刊名称】《微型机与应用》
【年(卷),期】1990(000)010
【摘要】本文提出了扩展P2.0~P2.3作为I/O口的一种新方法。
P2.0~P2.3作为输入口使用时,不影响外部程序存贮器的高四位地址;作为输出口使用时,能输出稳定可靠的高电平或低电平。
【总页数】2页(P36-37)
【作者】王攀峰
【作者单位】无
【正文语种】中文
【中图分类】TP364.7
【相关文献】
1.8039单片机构成的可逆系统数字触发器 [J], 池孟平
2.STM8S103F3P单片机正交编码器接口的使用方法 [J], 时为
3.一种单片机不完整字库的生成和使用方法 [J], 刘先红
4.用8039单片机控制扬声器纸盘自动成型机 [J], 周志和
5.8039单片机在控制应用中的一些技巧 [J], 林而立;卢子明
因版权原因,仅展示原文概要,查看原文内容请购买。
点阵字库的生产原理

点阵字库∙·点阵字库的生产原理点阵字库的概述∙·在DOS程序中使用点阵字库的...∙·点阵字库和矢量字库的差别∙·如何使用Windows的系统字库...∙·Unicode中文点阵字库的生成...点阵字库的应用∙·标准点阵字库芯片∙·标准点阵字库芯片的种类和应用∙·51单片机的13×14点阵缩码汉卡∙·标准点阵汉字字库芯片点阵字库的生产原理所有的汉字或者英文都是下面的原理,由左至右,每8个点占用一个字节,最后不足8个字节的占用一个字节,而且从最高位向最低位排列。
生成的字库说明:(以12×12例子)一个汉字占用字节数:12÷8=1····4也就是占用了2×12=24个字节。
编码排序A0A0→A0FE A1A0→A2FE依次排列。
以12×12字库的“我”为例:“我”的编码为CED2,所以在汉字排在CEH-AOH=2EH区的D2H-A0H=32H个。
所以在12×12字库的起始位置就是[{FE-A0}*2EH+32H]*24=104976开始的24个字节就是我的点阵模。
其他的类推即可。
英文点阵也是如此推理。
在DOS程序中使用点阵字库的方法首先需要理解的是点阵字库是一个数据文件,在这个数据文件里面保存了所有文字的点阵数据.至于什么是点阵,我想我不讲大家都知道的,使用过"文曲星"之类的电子辞典吧,那个的液晶显示器上面显示的汉子就能够明显的看出"点阵"的痕迹.在 PC 机上也是如此,文字也是由点阵来组成了,不同的是,PC机显示器的显示分辨率更高,高到了我们肉眼无法区分的地步,因此"点阵"的痕迹也就不那么明显了.点阵、矩阵、位图这三个概念在本质上是有联系的,从某种程度上来讲,这三个就是同义词.点阵从本质上讲就是单色位图,他使用一个比特来表示一个点,如果这个比特为0,表示某个位置没有点,如果为1表示某个位置有点.矩阵和位图有着密不可分的联系,矩阵其实是位图的数学抽象,是一个二维的阵列.位图就是这种二维的阵列,这个阵列中的 (x,y) 位置上的数据代表的就是对原始图形进行采样量化后的颜色值.但是,另一方面,我们要面对的问题是,计算机中数据的存放都是一维的,线性的.因此,我们需要将二维的数据线性化到一维里面去.通常的做法就是将二维数据按行顺序的存放,这样就线性化到了一维.那么点阵字的数据存放细节到底是怎么样的呢.其实也十分的简单,举个例子最能说明问题.比如说16*16 的点阵,也就是说每一行有16个点,由于一个点使用一个比特来表示,如果这个比特的值为1,则表示这个位置有点,如果这个比特的值为0,则表示这个位置没有点,那么一行也就需要16个比特,而8个比特就是一个字节,也就是说,这个点阵中,一行的数据需要两个字节来存放.第一行的前八个点的数据存放在点阵数据的第一个字节里面,第一行的后面八个点的数据存放在点阵数据的第二个字节里面,第二行的前八个点的数据存放在点阵数据的第三个字节里面,…,然后后面的就以此类推了.这样我们可以计算出存放一个点阵总共需要32个字节.看看下面这个图形化的例子:| |1| | | | | | | | | | |1| | | || | |1|1| |1|1|1|1|1|1|1|1|1| | || | | |1| | | | | | | | |1| | | ||1| | | | | |1| | | | | |1| | | || |1|1| | | |1| | | | | |1| | | || | |1| | | |1| | | | |1| | | | || | | | |1| | |1| | | |1| | | | || | | |1| | | |1| | |1| | | | | || | |1| | | | | |1| |1| | | | | ||1|1|1| | | | | | |1| | | | | | || | |1| | | | | |1| |1| | | | | || | |1| | | | |1| | | |1| | | | || | |1| | | |1| | | | | |1| | | || | |1| | |1| | | | | | |1|1|1| || | | | |1| | | | | | | | |1| | || | | | | | | | | | | | | | | | |可以看出这是一个"汉"字的点阵,当然文本的方式效果不是很好.根据上面的原则,我们可以写出这个点阵的点阵数据:0x40,0x08,0x37,0xfc,0x10,0x08,…, 当然写这个确实很麻烦所以我不再继续下去.我这样做,也只是为了向你说明,在点阵字库中,每一个点阵的数据就是按照这种方式存放的.当然也存在着不规则的点阵,这里说的不规则,指的是点阵的宽度不是8的倍数,比如 12*12 的点阵,那么这样的点阵数据又是如何存放的呢?其实也很简单,每一行的前面8个点存放在一个字节里面,每一行的剩下的4点就使用一个字节来存放,也就是说剩下的4个点将占用一个字节的高4位,而这个字节的低4位没有使用,全部都默认的为零.这样做当然显得有点浪费,不过却能够便于我们进行存放和寻址.对于其他不规则的点阵,也是按照这个原则进行处理的.这样我们可以得出一个 m*n 的点阵所占用的字节数为(m+7)/8*n.在明白了以上所讲的以后,我们可以写出一个显示一个任意大小的点阵字模的函数,这个函数的功能是输出一个宽度为w,高度为h的字模到屏幕的 (x,y) 坐标出,文字的颜色为 color,文字的点阵数据为pdata 所指:/*输出字模的函数*/void _draw_model(char *pdata, int w, int h, int x, int y, int color){int i; /* 控制行 */int j; /* 控制一行中的8个点 */int k; /* 一行中的第几个"8个点"了 */int nc; /* 到点阵数据的第几个字节了 */int cols; /* 控制列 */BYTE static mask[8]={128, 64, 32, 16, 8, 4, 2, 1}; /* 位屏蔽字 */w = (w + 7) / 8 * 8; /* 重新计算w */nc = 0;for (i=0; i<h; i++){cols = 0;for (k=0; k<w/8; k++){for (j=0; j<8; j++){if (pdata[nc]&mask[j])putpixel(x+cols, y+i, color);cols++;}nc++;}}}代码很简单,不用怎么讲解就能看懂,代码可能不是最优化的,但是应该是最易读懂的.其中的putpixel 函数,使用的是TC提供的 Graphics 中的画点函数.使用这个函数就可以完成点阵任意大小的点阵字模的输出.接下来的问题就是如何在汉子库中寻址某个汉子的点阵数据了.要解决这个问题,首先需要了解汉字在计算机中是如何表示的.在计算机中英文可以使用 ASCII 码来表示,而汉字使用的是扩展 ASCII 码,并且使用两个扩展 ASCII 码来表示一个汉字.一个 ASCII 码使用一个字节表示,所谓扩展 ASCII 码,也就是ASCII 码的最高位是1的 ASCII 码,简单的说就是码值大于等于 128 的 ASCII 码.一个汉字由两个扩展ASCII 码组成,第一个扩展 ASCII 码用来存放区码,第二个扩展 ASCII 码用来存放位码.在 GB2312-80 标准中,将所有的汉字分为94个区,每个区有94个位可以存放94个汉字,形成了人们常说的区位码,这样总共就有 94*94=8836 个汉字.在点阵字库中,汉字点阵数据就是按照这个区位的顺序来存放的,也就是最先存放的是第一个区的汉字点阵数据,在每一个区中有是按照位的顺序来存放的.在汉字的内码中,汉字区位码的存放实在扩展 ASCII 基础上存放的,并且将区码和位码都加上了32,然后存放在两个扩展 ASCII 码中.具体的说就是:第一个扩展ASCII码 = 128+32 + 汉字区码第二个扩展ASCII吗 = 128+32 + 汉字位码如果用char hz[2]来表示一个汉字,那么我可以计算出这个汉字的区位码为:区码 = hz[0] - 128 - 32 = hz[0] - 160位码 = hz[1] - 128 - 32 = hz[1] - 160.这样,我们可以根据区位码在文件中进行殉职了,寻址公式如下:汉字点阵数据在字库文件中的偏移 = ((区码-1) * 94 + 位码) * 一个点阵字模占用的字节数在寻址以后,即可读取汉字的点阵数据到缓冲区进行显示了.以下是实现代码:/* 输出一个汉字的函数 */void _draw_hz(char hz[2], FILE *fp, int x, int y, int w, int h, int color){char fontbuf[128]; /* 足够大的缓冲区,也可以动态分配 */int ch0 = (BYTE)hz[0]-0xA0; /* 区码 */int ch1 = (BYTE)hz[1]-0xA0; /* 位码 *//* 计算偏移 */long offset = (long)pf->_hz_buf_size * ((ch0 - 1) * 94 + ch1 - 1);fseek(fp, offset, SEEK_SET); /* 进行寻址 */fread(fontbuf, 1, (w + 7) / 8 * h, fp); /* 读入点阵数据 */_draw_model(fontbuf, w, h, x, y, color); /* 绘制字模 */}以上介绍完了中文点阵字库的原理,当然还有英文点阵字库了.英文点阵字库中单个点阵字模数据的存放方式与中文是一模一样的,也就是对我们所写的 _draw_model 函数同样可以使用到英文字库中.唯一不同的是对点阵字库的寻址上.英文使用的就是 ASCII 码,其码值是0到127,寻址公式为:英文点阵数据在英文点阵字库中的偏移 = 英文的ASCII码 * 一个英文字模占用的字节数可以看到,区分中英文的关键就是,一个字符是 ASCII 码还是扩展 ASCII 码,如果是 ASCII 码,其范围是0到127,这样是使用的英文字库,如果是扩展 ASCII 码,则与其后的另一个扩展 ASCII 码组成汉字内码,使用中文字库进行显示.只要正确区分 ASCII 码的类型并进行分别的处理,也就能实现中英文字符串的混合输出了.点阵字库和矢量字库的差别我们都只知道,各种字符在电脑屏幕上都是以一些点来表示的,因此也叫点阵.最早的字库就是直接把这些点存储起来,就是点阵字库.常见的汉字点阵字库有 16x16, 24x24 等.点阵字库也有很多种,主要区别在于其中存储编码的方式不同.点阵字库的最大缺点就是它是固定分辨率的,也就是每种字库都有固定的大小尺寸,在原始尺寸下使用,效果很好,但如果将其放大或缩小使用,效果就很糟糕了,就会出现我们通常说的锯齿现象.因为需要的字体大小组合有无数种,我们也不可能为每种大小都定义一个点阵字库.于是就出现了矢量字库.矢量字库矢量字库是把每个字符的笔划分解成各种直线和曲线,然后记下这些直线和曲线的参数,在显示的时候,再根据具体的尺寸大小,画出这些线条,就还原了原来的字符.它的好处就是可以随意放大缩小而不失真.而且所需存储量和字符大小无关.矢量字库有很多种,区别在于他们采用的不同数学模型来描述组成字符的线条.常见的矢量字库有 Type1字库和Truetype字库.在点阵字库中,每个字符由一个位图表示(如图2.5所示),并把它用一个称为字符掩膜的矩阵来表示,其中的每个元素都是一位二进制数,如果该位为1表示字符的笔画经过此位,该像素置为字符颜色;如果该位为0,表示字符的笔画不经过此位,该像素置为背景颜色.点阵字符的显示分为两步:首先从字库中将它的位图检索出来,然后将检索到的位图写到帧缓冲器中.在实际应用中,同一个字符有多种字体(如宋体、楷体等),每种字体又有多种大小型号,因此字库的存储空间十分庞大.为了减少存储空间,一般采用压缩技术.矢量字符记录字符的笔画信息而不是整个位图,具有存储空间小,美观、变换方便等优点.例如:在AutoCAD中使用图形实体-形(Shape)-来定义矢量字符,其中,采用了直线和圆弧作为基本的笔画来对矢量字符进行描述. 对于字符的旋转、放大、缩小等几何变换,点阵字符需要对其位图中的每个象素进行变换,而矢量字符则只需要对其几何图素进行变换就可以了,例如:对直线笔画的两个端点进行变换,对圆弧的起点、终点、半径和圆心进行变换等等.矢量字符的显示也分为两步.首先从字库中将它的字符信息.然后取出端点坐标,对其进行适当的几何变换,再根据各端点的标志显示出字符.轮廓字形法是当今国际上最流行的一种字符表示方法,其压缩比大,且能保证字符质量.轮廓字形法采用直线、B样条/Bezier曲线的集合来描述一个字符的轮廓线.轮廓线构成一个或若干个封闭的平面区域.轮廓线定义加上一些指示横宽、竖宽、基点、基线等等控制信息就构成了字符的压缩数据.如何使用Windows的系统字库生成点阵字库?我的程序现在只能预览一个汉字的不同字体的点阵表达.界面很简单: 一个输出点阵大小的选择列表(8x8,16x16,24x24等),一个系统中已有的字体名称列表,一个预览按钮,一块画图显示区域.得到字体列表的方法:(作者称这一段是用来取回系统的字体,然后添加到下拉框中)//取字体名称列表的回调函数,使用前要声明一下该方法int CALLBACK MyEnumFontProc(ENUMLOGFONTEX* lpelf,NEWTEXTMETRICEX* lpntm,DWORD nFontType,long lParam){CFontPeekerDlg* pWnd=(CFontPeekerDlg*) lParam;if(pWnd){if( pWnd->m_combo_sfont.FindString(0, lpelf->elfLogFont.lfFaceName) <0 )pWnd->m_combo_sfont.AddString(lpelf->elfLogFont.lfFaceName);return 1;}return 0;}//说明:CFontPeekerDlg 是我的dialog的类名, m_combo_sfont是列表名称下拉combobox关联的control变量//调用的地方 (******问题1:下面那个&lf怎么得到呢……){::EnumFontFamiliesEx((HDC) dc,&lf, (FONTENUMPROC)MyEnumFontProc,(LPARAM) this,0);m_combo_sfont.SetCurSel(0);}字体预览:如果点阵大小选择16,显示的时候就画出16x16个方格.自定义一个类CMyStatic继承自CStatic,用来画图.在CMyStatic的OnPaint()函数中计算并显示.取得字体:常用的方法:用CreateFont创建字体,把字TextOut再用GetPixel()取点存入数组. 缺点:必须把字TextOut出来,能在屏幕上看见,不爽.我的方法,用这个函数:GetGlyphOutline(),可以得到一个字的轮廓矢量或者位图.可以不用textout到屏幕,直接取得字模信息函数原型如下:DWORD GetGlyphOutline(HDC hdc, //画图设备句柄UINT uChar, //将要读取的字符/汉字UINT uFormat, //返回数据的格式(字的外形轮廓还是字的位图)LPGLYPHMETRICS lpgm, // GLYPHMETRICS结构地址,输出参数DWORD cbBuffer, //输出数据缓冲区的大小LPVOID lpvBuffer, //输出数据缓冲区的地址CONST MAT2 *lpmat2 //转置矩阵的地址);说明:uChar字符需要判断是否是汉字还是英文字符.中文占2个字节长度.lpgm是输出函数,调用GetGlyphOutline()是无须给lpgm 赋值.lpmat2如果不需要转置,将 eM11.value=1; eM22.value=1; 即可.cbBuffer缓冲区的大小,可以先通过调用GetGlyphOutline(……lpgm, 0, NULL, mat); 来取得,然后动态分配lpvBuffer,再一次调用GetGlyphOutline,将信息存到lpvBuffer. 使用完毕后再释放lpvBuffer.程序示例:(***问题2:用这段程序,我获取的字符点阵总都是一样的,不管什么字……)……前面部分省略……GLYPHMETRICS glyph;MAT2 m2;memset(&m2, 0, sizeof(MAT2));m2.eM11.value = 1;m2.eM22.value = 1;//取得buffer的大小DWORD cbBuf = dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph, 0L, NULL, &m2);BYTE* pBuf=NULL;//返回GDI_ERROR表示失败.if( cbBuf != GDI_ERROR ){pBuf = new BYTE[cbBuf];//输出位图GGO_BITMAP 的信息.输出信息4字节(DWORD)对齐dc.GetGlyphOutline( nChar, GGO_BITMAP, &glyph, cbBuf, pBuf, &m2);}else{if(m_pFont!=NULL)delete m_pFont;return;}编程中遇到问题:一开始,GetGlyphOutline总是返回-1,getLastError显示是"无法完成的功能",后来发现是因为调用之前没有给hdc设置Font.后来能取得pBuf信息后,又开始郁闷,因为不太明白bitmap的结果是按什么排列的.后来跟踪汉字"一"来调试(这个字简单),注意到了glyph.gmBlackBoxX 其实就是输出位图的宽度,glyph.gmBlackBoxY就是高度.如果gmBlackBoxX=15,glyph.gmBlackBoxY=2,表示输出的pBuf中有这些信息:位图有2行信息,每一行使用15 bit来存储信息.例如:我读取"一":glyph.gmBlackBoxX = 0x0e,glyph.gmBlackBoxY=0x2; pBuf长度cbBuf=8 字节pBuf信息: 00 08 00 00 ff fc 00 00字符宽度 0x0e=14 则第一行信息为: 0000 0000 0000 100 (只取到前14位)第二行根据4字节对齐的规则,从0xff开始 1111 1111 1111 110看出"一"字了吗?呵呵直到他的存储之后就可以动手解析输出的信息了.我定义了一个宏#define BIT(n) (1<<(n)) 用来比较每一个位信息时使用后来又遇到了一个问题,就是小头和大头的问题了.在我的机器上是little endian的形式,如果我用unsigned long *lptr = (unsigned long*)pBuf;//j from 0 to 15if( *lptr & BIT(j) ){//这时候如果想用j来表示写1的位数,就错了}因为从字节数组中转化成unsigned long型的时候,数值已经经过转化了,像上例中,实际上是0x0800 在同BIT(j)比较.不多说了,比较之前转化一下就可以了if( htonl(*lptr) & BIT(j) )Unicode中文点阵字库的生成与使用点阵字库包含两部分信息.首先是点阵字库文件头信息,它包含点阵字库文字的字号、多少位表示一个像素,英文字母与符号的size、起始和结束unicode编码、在文件中的起始偏移,汉字的size、起始和结束unicode编码、在文件中的起始偏移.然后是真实的点阵数据,即一段段二进制串,每一串表示一个字母、符号或汉字的点阵信息.要生成点阵字库必须有文字图形的来源,我的方法是使用ttf字体.ttf字体的显示采用的是SDL_ttf 库,这是开源图形库SDL的一个扩展库,它使用的是libfreetype以读取和绘制ttf字体.它提供了一个函数,通过传入一个Unicode编码便能输出相应的文字的带有alpha通道的位图.那么我们可以扫描这个位图以得到相应文字的点阵信息.由于带有alpha通道,我们可以在点阵信息中也加入权值,使得点阵字库也有反走样效果.我采用两位来表示一个点,这样会有三级灰度(还有一个表示透明).点阵字库的显示首先需要将文件头信息读取出来,然后根据unicode编码判断在哪个区间内,然后用unicode编码减去此区间的起始unicode编码,算出相对偏移,并加上此区间的文件起始偏移得到文件的绝对偏移,然后读出相应位数的数据,最后通过扫描这段二进制串,在屏幕的相应位置输出点阵字型.显示点阵字体需要频繁读取文件,因此最好做一个固定大小的缓存,采用LRU置换算法维护此缓存,以减少磁盘读取.标准点阵字库芯片标准点阵字库芯片的特点:1.内涵全国信标委授权的标准点阵字型数据、2.支持国标字符集GB2312(6,763汉字),GB18030(27,484汉字).3.支持多种点阵字型,包括11×12点,15×16点,24×24点,32×32点.4.免除了字库烧录和测试工序,并节省了2%以上的烧录损耗.5.价格相当于空白FLASH价格标准点阵字库芯片的种类和应用51单片机的13×14点阵缩码汉卡我们历时数载,开发成"51单片机13×14点阵缩码汉卡",适用于目前国内外应用最为广泛的MCSX-51及其兼容系列单片机.与此同时,还开发了13×14点阵汉字字模.13×14点阵字模,可完全与目前通用的16×16点阵汉字字模媲美,其在单片机和嵌入式系统的汉字显示应用中也具有明显的经济价值和实用意义.1.单片机目前的汉字显示信息交流的最主要方式之一即文字交流,但由于我国方块汉字数量繁多,构形迥异,使汉字显示一直是我国计算机普及的障碍.随着计算机技术的迅速发展,PC机的汉字显示已不成问题.但对于成本低、体积小、应用灵活且用量极为巨大的单片机而言,因其结构简单,硬件资源十分有限,其汉字显示仍面对着捉襟见肘,力不从心的窘境.目前单片机的汉字显示有三种基本方法.①采用标准字库法.即将国标汉字库固人ROM中,将单片机的硬件和软件进行特别扩展后以显示汉字.众所周知,即使是16×16点阵标准字库,也须占用200KB以上的单元内存,而就目前主流5l系列单片机而言,最大寻址范围仅64KB,即使程序区与数据区合起来也仅128KB内存.因此,若不加特别的扩展设计,不要说检字程序和用户空间,仅字库都装不下.这种方法虽然可以方便地使用现成标准字库,但却需占用大量的硬件和软件资源,增加很大一部分成本和设计难度,所以不经常使用.②字模直接固化法.即将所显示的汉字,依先后顺序将其字模一一从标准字库中提取后,重新固化,予以显示.此法虽为简捷,但只适于显示少量汉字,且字模的制取繁琐,软件的修改维护都很困难.③带索引小字库法.即将欲显示文件中的汉字字模,从标准字库中逐一提取固化,制成小型字库,并按其在小字库中的位置制成索引表,显示时从索引表查出其新的字模取码地址,取码显示.此方法虽比较灵活,可显示较多的汉字,但仍然局限于只能显示固定文件内容,且字模制取同样麻烦.一种较新的单片机"汉字动态编码与显示方案"(见《单片机与嵌入式系统应用》杂志2003年第1期和第9期),实际上也是一种动态的"小字库"法,只是字库的制取,索引的编写及文件的改码皆由PC机自动完成,免去了繁琐的人工处理.由上可见,目前单片机各种汉字显示方案均不理想.标准字库法,单片机不堪重负;而其它方法最大且又无法克服的缺点是,所显示文字皆有局限.显示内容也皆须专业人员设计而定,用户难于更改.这便极大地限制了单片机在各个领域的开拓和应用.究其原因,皆为单片机本身无汉卡,而这也正是我们致力于"51汉卡"开发的初衷.2.13×14点阵汉字字模为垫定"5l汉卡"的字型基础,首先开发成了l3×14点阵汉字字模.在目前通用的汉字字模中,最简单的是16×16点阵字模.在微型打字机中,也偶见有12×12点阵字模,但实用中不多见.字模点阵数直接决定着每一汉字所占单元内存值,能否在保证字模准确、美观的基础上,寻找一种较少的点阵字模呢?这便是我们最初的想法.于是我们经过反复选择比较,终于在国内首个推出了13×14点阵字模.此设计,一是基于我国汉字为方块字,故其行、列值需相近;二是汉字多有对称1生,故其列值宜奇不宜偶.设计实际表明,若行、列值很少,则难保证字模的准确性和美观性.?13×14点阵字模,是以我国现行简化字为准,并在此基础上设计而成.与目前通用的汉字16×l6点阵字模相比,其准确性和美观性并不逊色.然而其单字所占内存却由32个单元降至26个单元;另外使得每个单字显示由原来的256个像素降至l82个像素,使显示成本和空间均减少近三分之一.100×200点阵LED字屏,可显示16×l6点阵汉字72个,而l3×14点阵汉字便可显示l05个,且显示效果并无太大差异.这无疑对单片机和嵌入式系统汉字显示产品的开发和应用,具有明显的经济价值和实用意义.3.51单片机13×14点阵缩码汉卡"51汉卡"依据我国的汉字特点和单片机的快速构字功能,在13×14点阵字模基础上,以缩码形式开发而成单片机汉卡的开发,应以目前通用的主流单片机为研发对象,还应在囊括国标一、二级汉字及常用字符的前提下,使内存占用必须降至主流单片机可寻址范围内,且需留有足够的检字程序和用户应用空间.另外,字模设计必须准确、美观.字模提取速度也必须满足实用要求."51汉卡"的开发正是依据原则,并达到了以上各项要求.顾名思义,"51汉卡,即以MCS-51系列及其兼容单片机为研发对象.以51系列为代表的8位单片机,在过去、现在以及可以予见的将来,都将是嵌入式系统低端应用的主流机型.此乃业界专家的共识."51汉卡"囊括了"GB2312-80"国标字库的全部一、二级汉字,并增补汉字86个;同时包括了大、小英文字母、阿拉伯数字等160个常用字符和不到4KB的构字程序,却仅总共占用了不足66KB的内存.每字平均约占9.8个单元,相对于16×16点阵每字占32单兀内存而言,尚不到其三分之一.这对于具有相互独立的64KB 程序区和64KB数据区的51系列单片机而言,若适当配置内存,可为检字程序和用户留出90%以上的程序空间及相当数量的数据空间,对于一般用户的应用,都将绰绰有余.另外,为使"51汉卡''更便于使用和进一步节省内存,在上述基础上又开发成一套简化版本,删去了部分较偏僻的二级汉字.简化版本包括约5580个汉字,共占用内存58KB.实际上,按有关权威部门的统计,一般文本99%的文字是由2400个字写成的,因此使用简化版本,并配以简单的造字程序,一般亦可满足我们的使用要求."51汉卡"所用字模,即我们开发的完全可与16×16点阵字模媲美的I3×14点阵汉字字模.字模提取速度是我们最为关心的问题之一.经测试及实际使用表明,"51汉卡''的提模速度完全可满足单片机汉字显示的实用要求.我们使用INTEL公司MCS-51经典系列87C51单片机在24MHz频率下测试,平均字模提取速度为2.1ms/字.因人的视觉暂留时间为0.1s,无论理论还是实际使用都表明,50字字模提取并显示,并无迟滞和待机之感.即使在1?2MHz频率下,20字取模,即点即出,在一般拼音检字和少量汉字显示中,完全可满足使用要求.随着单片机技术的迅速发展,目前,INTEL公司、Atmel公司、philips公司、我国台湾华邦等公司生产的MCS-51兼容单片机时钟频率可达33MHz,增强型可达40MHz,以至达60MHz;现市售的"STC89LE"系列单片机,最高频率可达90MHz.这些芯片都完全能与MCS-51芯片兼容,对于更高需求的场合,更新升级也十分简便.另外,在单片机和嵌入式系统中,文字显示速度要求并不高,只要满足换屏时的视觉要求即可.其汉字显示字数,一般也不太多.如用LCD显示屏,128×64点阵,才显示32个字;192×64点阵才显48个字;即使使用l3×14点阵字模,满屏也才56个汉字.4."51汉卡"设计依据及说明"51汉卡"设计依据是,我国汉字虽然数量繁多,字型各异,但其中复合结构者占大部分,并素有"偏旁取义,正字取音"之说.如"寸"字与不同偏旁可组成"村"、"付"、"讨"、"守"、"过"等字.因此"51汉卡"除单结构字基本以全码设计外,复台结构字多用相应的单体字及其偏旁,以结构代码写成.利用单片机快速的单元积木式构字程序,便可迅速生成字模代码.这既保证了提码速度,又节省了大量的汉卡内存.有关"51汉卡"的几点说明如下:①凡汉字库中简、繁体字都有的用简体.如"後"以"后"代,"馀"以"余"代等;②《新华字典》未收入字,多未收入,如"酏"、"鼽"等字,但"婧"、"弪"等字仍收入;③对于多体字,一般以常用字代,如"摺"以"折"代,"镟"以"旋,代等,但"吒"不以"咤"代,"雠"不以"仇"代等;④对通常已由其它字取代的字,都以这些字代替,如"岽"以"东"代,"肛''以"船"代等;⑤二级汉字中,不单独构成汉字的偏旁未收入;⑥依据名篇名著,生活用语等,增补汉字86个;⑦收编大、小写英文字母、阿拉伯数字、标点符号等各种常用字符160个.5."51单片机汉卡"应用举例利用"51单片机汉卡",将使51系列单片机的汉字显示轻而易举,并可大为降低成本、体积和设计开发的难度,为单片机在生产控制、信息通信、文化教育和日常生活等领域,特别是计算机终端和手持产品的开发提供极大的便利和支持.?我们现已初步开发成"51汉卡"的"区位码输入法"和"拼音输入法,检字程序,并利用"51汉卡"成功地开发了带有廉价单片机控制器的LED汉字显示屏.这不仅大幅度降低了成本费用.而且用户可以通过单片机控制器,随心所欲地改变显示内容.51硬件设计CPU--87C51、12MHz晶振.。
基于ARM9的LCD非完整字库汉字显示电路的设计与实现

基于ARM9的LCD非完整字库汉字显示电路的设计与实现张玉茹;陈德龙;李彬彬
【期刊名称】《中国电子商务》
【年(卷),期】2011(000)005
【摘要】针对自带字库的液晶模块价格较贵的特点,在ARM 9硬件平台上,通过字模提取软件将汉字转化成可以在TFT_LCD屏上显示的汉字代码——字模,并将汉字代码以数组的形式保存在应用程序当中,从而实现了TFT_LCD的非完整字库汉字显示.介绍了TFT_LCD的工作原理和如何在 ARM9中加载非完整汉字库的过程,并给出了应用程序代码.
【总页数】2页(P60-61)
【作者】张玉茹;陈德龙;李彬彬
【作者单位】哈尔滨商业大学计算机与信息工程学院,黑龙江,哈尔滨,150028;哈尔滨商业大学计算机与信息工程学院,黑龙江,哈尔滨,150028;哈尔滨商业大学计算机与信息工程学院,黑龙江,哈尔滨,150028
【正文语种】中文
【中图分类】TN4
【相关文献】
1.基于程序框架Qt的嵌入式系统汉字库设计与实现 [J], 殷知磊;张钟澍;肖跃先;薛松
2.在LCD上应用标准汉字点阵字库的方法 [J], 郭劲松
3.基于ARM和TFT-LCD的汉字库加载与显示 [J], 陈军;王彬;林振衡
4.利用LCD1602的自定义字库显示汉字 [J], 赵秋
5.基于不带字库的图形LCD模块汉字显示解决方案 [J], 刘红; 覃光华; 汪道辉因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一种单片机不完整字库的生成和使用方法
作者:刘先红
来源:《价值工程》2012年第28期
摘要:针对小型单片机系统LCD显示程序中字模的特点,提出了一种高效的不完整字库的生成方法,可自动完成字模提取和字符串的重新编码,并生成C语言代码,有效的提高了开发效率。
Abstract: According to the features of character in LCD display program of small SCM,an efficient method of building incomplete fonts is proposed in the paper. By acquiring Chinese matrix automatically and recoding character string,the exploit efficiency is increased.
关键词:字库;重新编码;单片机
Key words: matrix fonts;character string recode;SCM
中图分类号:TN873.93 文献标识码:A 文章编号:1006—4311(2012)28—0192—02
0 引言
在嵌入式系统软件设计中,尤其是基于小型单片机的LCD显示仪器仪表软件,汉字字库和一些特殊符号字库是必备要素。
虽然市场上有很多带字库的LCD,但字库会超出普遍使用的单片机的寻址范围,成本也较不含字库的高。
在很多LCD显示仪器仪表中,软件中用到的字符数一般有限,甚至只有十几个;若将完整的汉字字库存入到单片机ROM中,往往ROM 容量不够,而若只存储使用到的字符字模,需要建立每个汉字内码及其字模首地址的映射表,当显示某个字时,需首先查找这个表找到对应的字模首地址,但查找效率随着字符数的增多越来越低,而且需要把所有用到的字符输入到字模提取软件中提取字模。
因此,本文提出一种高效的单片机不完整字库的生成和使用方法,适用于绝大部分小型单片机的软件设计。
1 不完整字库生成方法
不完整字库的生成基于这样的方法:程序员首先将显示程序中用到的汉字字符串和特殊符号字符存入到一个文本文件中,采用[英文字符串]{中文字符串}格式,其中作为后续程序中访问字符串的标识,[英文字符串]作为{中文字符串}的对应的英文翻译,如“[Main Menu]{主菜单}”。
在程序设计中,可以顺序按行添加字符串。
采用Microsoft Visual C++ 6.0编程,程序流程图如图1所示,首先读入文本文件,并对文件中所有{}内的汉字进行扫描,根据汉字内码大小顺序存储所有汉字,如“[Main Menu]{主菜单}”中的汉字存储为“单菜主”,重复汉字只存储一次,这样就找到了程序中用到的所有汉字。
其次,提取找到的汉字字模并按顺序生成C语言数组,如“单菜主”生成的16×16的字模数组为:
const unsigned char ucGB16x16Dot[] =
{
0x08,0x20,0x06,0x30,0x04,0x40,0x3f,0xf8,0x21,0x08,
0x3f,0xf8,0x21,0x08,0x21,0x08,
0x3f,0xf8,0x21,0x08,0x01,0x00,0xff,0xfe,0x01,0x00,0x01,
0x00,0x01,0x00,0x01,0x00, /* —单—*/
0x04,0x40,0xff,0xfe,0x04,0x40,0x04,0x40,0x3f,0xf8,0x22,
0x08,0x11,0x10,0x08,0x20,
0x01,0x00,0x7f,0xfe,0x03,0x80,0x05,0x40,0x09,
0x30,0x11,0x1c,0x61,0x08,0x01,0x00, /* —菜—*/
0x02,0x00,0x01,0x80,0x01,0x00,0x00,0x08,0x3f,0xfc,0x01,0x00,0x01,0x00,0x01,0x08,
0x3f,0xfc,0x01,0x00,0x01,0x00,0x01,0x00,0x01,0x04,0x7f,0xfe,0x00,0x00,0x00,0x00, /* —主—*/
}
由于包括英文字母的ASCII码只有127个,字模占的空间很小,所以每次字库生成之后首先生成常用ASCII码的字模。
当所有的字模提取完成后,重新扫描文本文件中的字符串,对字符串的字符重新编码,编码规则如下:
①占一个字节的ASCII码和占两个字节的汉字或特殊字符编码均以两字节编码,ASCII码的编码最高位为1,非ASCII码最高位为0,低15位为字符字模在字模数组中的位置;
②每个字符串以0xffff为结束符。
如“{主菜单}”的编码为:
const unsigned short strings[] =
{
0x804d,0x8061,0x8069,0x806e,0x8020,0x804d,0x8065,0x806e,0x8075,
0xffff, /* Main Menu */0x0002,0x0001,0x0000,0xffff, /* 主菜单 */
}
在生成重新编码的数组同时,以字符串标识生成每个字符串在数组位置的宏定义,如
TID_MAINMENU_E 0
TID_MAINMENU_C 10
2 不完整字库使用方法
当显示程序中所有字符串均重新编码后,显示程序即可方便地显示这些字符串,显示程序的流程如图2所示。
首先根据宏定义找到重新编码的字符串在字符串编码数组中的位置,其次读取每个字符的16位编码,根据每个编码的最高位和低15位确定字符在字模数组中位置并显示。
当读取到0xffff时显示结束。
3 结论
将不完整字库的生成程序作为嵌入式软件资源生成工具,无需使用字模提取软件提取程序中用到的每一个字符的字模,自动完成字模提取和字符串的重新编码,显示程序无需查找,可以直接定位字模位置,由于使用宏定义,不会降低程序的可读性和可维护性。
同时,目标代码中不包含任何字符串,增加了程序被反汇编的难度。
目前,该方法已成功应用于LPC2000系列和STM32F系列单片机显示程序的开发中,提高了开发效率。
参考文献:
[1]黄海宏,王海欣.液晶显示汉字的字模提取新方法[J].液晶与显示,2005,20(4):346~349.
[2]国家技术监督局.汉字内码扩展规范[S].1995.。